

Abstract
When effect modifiers influence the decision to participate in randomized trials, generalizing causal effect estimates to an external target population requires the knowledge of two scores – the propensity score for receiving treatment and the sampling score for trial participation. While the former score is known due to randomization, the latter score is usually unknown and estimated from data. Under unconfounded trial participation, we characterize the asymptotic efficiency bounds for estimating two causal estimands – the population average treatment effect and the average treatment effect among the non-participants – and examine the role of the scores. We also study semiparametric efficient estimators that directly balance the weighted trial sample toward the target population, and illustrate their operating characteristics via simulations.
Keywords: Causal inference, external validity, empirical likelihood, propensity score, sampling score, semiparametric efficiency bound
1. Introduction
While randomized trials ensure the optimal internal validity for treatment comparisons, they may not provide valid effect estimates for external target populations when effect modifiers also influence trial participation (Cole and Stuart 2010; Stuart et al. 2011). Generalizing causal inferences from potentially unrepresentative randomized trials to populations requires an understanding of the sampling mechanism, by which individuals are selected to participate in the trial. In a randomized trial, the propensity score for receiving treatment is usually known by design (Rosenbaum and Rubin 1983). However, the sampling score, which is the conditional probability of trial participation given the covariates, is usually unknown and must be estimated. Assuming no unmeasured effect modifiers and a correct sampling model, the inverse probability of sampling weights can be constructed to provide an unbiased estimate of the average causal effects in the target population and has received considerable attention (Cole and Stuart 2010; Stuart, Bradshaw, and Leaf 2015; Buchanan et al. 2018). These weights are often estimated from a parametric regression model using maximum likelihood, without a formal mechanism to ensure balance of effect modifiers between the weighted trial population and the target population in finite samples. In addition, even if the model for the weights is correctly specified, inverse weighting alone may not be statistically efficient (Robins, Rotnitzky, and Zhao 1994) and could exhibit excessive variability in the effect estimates when the sampling score is estimated to be close to zero (Cole and Hernán 2008; Crump et al. 2009; Li, Thomas, and Li 2019).
In this note, we consider semiparametric efficient approaches for generalizing causal effects from randomized trials to target populations. We first obtain explicit forms of the semiparametric efficiency bounds with regard to the estimation of two population-level causal estimands – the population average treatment effect including the trial participants and the average treatment effect among non-participants. The estimation of the latter is also closely connected to the concept of causal transportability (Westreich et al. 2017). The efficiency bounds parallel those developed in Hahn (1998) and Hirano, Imbens, and Ridder (2003), where the primary interests are unconfounded treatment comparisons in observational studies. The asymptotic variance bounds provide an efficiency perspective to the role of propensity score and sampling score. We show that the propensity score is ancillary for estimation of the aforementioned two estimands while the sampling score is only ancillary for estimation of the population average treatment effect.
To improve the robustness and efficiency of the generalizability estimator, Dahabreh et al. (2019) discussed doubly robust estimators that combine the inverse probability of sampling weights and outcome regression; their estimators are consistent when either the sampling score or the outcome model is correct but not necessarily both. When both models are correct, their estimators are considered more efficient than inverse weighting by sampling scores alone. However, because their doubly robust estimator is a plug-in estimator based on the efficient influence function, it could still be subject to large variability in the presence of extreme sampling scores, which arises, for example, when there is a strong selection effect based on effect modifiers. Besides, the parametric doubly robust approaches does not guarantee adequate balance of the effect modifiers between the weighted trial population and the target population in finite samples. To overcome these potential limitations, we provide robust and semiparametric efficient empirical likelihood estimators that solve the weights from a set of balancing conditions. Since finite-sample covariate balance is enforced by these conditions, our estimators could provide greater efficiency by eliminating residual bias and maintain robustness against model misspecification. Estimating weights that exploit covariate-balancing conditions originates from the survey sampling literature (Deville and Särndal 1992), and has been increasingly used to address confounding bias in observational studies; see, for example, Qin and Zhang (2007); Hainmueller (2012); Imai and Ratkovic (2014); Zubizarreta (2015); and Zhao (2019). Our empirical likelihood estimators extend these earlier results to causal generalizability with new insights. We show that by carefully selecting the balancing conditions, one may tailor the estimator to achieve double robustness and efficiency with respect to different asymptotic variance bounds.
2. Basic setup and efficiency bounds
We consider a single randomized trial with n1 participants nested within a population of trial-eligible individuals of size n. For each participant i = 1, …, n1, the outcome Yi, a binary treatment Ai ∈ {0, 1}, and a set of pretreatment covariates Xi are recorded. We define for each participant two potential outcomes, , mapped to each level of treatment. Under the Stable Unit Treatment Value Assumption (SUTVA) (Rubin 1980), the observed outcome is . Define n0 = n − n1, then for each non-participant i = n1 + 1, …, n, we assume the same set of observable covariates Xi but do not have information on treatment or outcome. We define Si = 1 if individual i participates in the trial and Si = 0 otherwise. We also write ω = pr(Ai = 1|Si = 1) and π = pr(Si = 1) as two proportions in the population. Generalizing trial findings could focus on two estimands: the population average treatment effect
and the average treatment effect among the non-participants
In the nested trial design (where the trial is a true subset of the entire target population), μ is of policy interest as it measures the average change in outcome when the intervention is rolled out to the entire population, while τ remains relevant for comparing the effect estimates among trial participants and non-participants. Although we focus on the nested trial design, the estimation of τ is akin to those for transporting inferences from a trial to an external target population, due to similarity in the identification conditions (Westreich et al. 2017). To proceed, we assume the following two identification conditions.
Assumption 2.1. (Strongly Ignorable Assignment)
Assignment to treatment is unconfounded given pretreatment covariates Xi among trial participants, that is, .
The treatment propensity score e(Xi) = pr(Ai = 1|Xi, S = 1) is strictly bounded between zero and one for all values of Xi with a positive density.
Assumption 2.1 holds by randomization within the trial sample, and suffices to identify the within-trial causal estimand, . This quantity typically differs from μ and τ, especially when Xi includes important effect modifiers that influence trial participation. Assumption 2.1 is also comparable to the strongly ignorable assumption in Rosenbaum and Rubin (1983) for observational studies, where the treatment is assumed to be conditionally randomized based on a set of measured covariates Xi.
Assumption 2.2. (Strongly Ignorable Participation)
Trial participation is conditional independent of potential outcomes, that is, .
The sampling score, defined as the conditional probability of participation given the covariates, p(Xi) = pr(Si = 1|Xi), is strictly bounded between zero and one for all values of Xi with a positive density.
Assumption 2.2 requires the absence of unmeasured treatment effect modifiers and its plausibility may only be indirectly assessed (Stuart et al. 2011). Even though weaker conditions such as mean generalizability and mean transportability (Dahabreh et al. 2020) are sufficient for point identification, we maintain Assumption 2.2 as it is required to obtain the expression of efficiency bounds. Part (ii) of Assumption 2.2 is often referred to as the positivity assumption, and critically depends on the definition of the target population. In settings where some individuals in the external population would never participate in the trial, the target population could be redefined to avoid extrapolation (Tipton 2013). Assumptions 2.1 and 2.2 permit the calculation of the semiparametric asymptotic variance bounds for estimation of μ and τ; in other words, there does not exist any sequence of regular estimators that has a smaller asymptotic variance. The bounds are introduced in Theorems 2.3 and 2.4, with derivations provided in the Appendices A and B.
Theorem 2.3. Assuming the sampling score p(Xi) is unknown, the efficient influence function for estimating μ and τ are
Therefore, the semiparametric efficiency bounds for μ and τ are
and
where , , , and .
Theorem 2.4. Assume the sampling score p(Xi) is known, the efficient influence function for estimating μ and τ are and
Therefore, the semiparametric efficiency bounds for μ and τ are
and
The derivations in the Appendices A and B indicate that the efficiency bounds for μ and τ remain the same regardless of the knowledge of propensity score e(Xi). Therefore, e(Xi) is ancillary to the estimation of both μ and τ, without respect to the knowledge of sampling score. Interestingly, this suggests that the form of the efficiency bounds do not change whether the causal generalization is from a randomized experiment or an observational study, as long as Assumption 2.1 holds.
On the other hand, even if the trial participants are selected according to a well-planned survey with known sampling score, this knowledge of the sampling score does not reduce the efficiency bound for estimation of μ, because ; thus p(Xi) is ancillary to the estimation of population average treatment effect. However, the knowledge of the sampling score p(Xi) reduces the efficiency bound for estimating τ, by the amount of
This value quantifies the marginal information content of the sampling score for the estimation of τ, in parallel to the estimation of the average treatment effect among the treated in observational studies (Hahn 1998). In particular, when there is no effect modification by Xi, or τ(Xi) = τ, among non-participants.
3. Semiparametric efficient generalizability estimators
3.1. Estimation of the population average treatment effect
We study several semiparametric efficient estimators that achieve the above variance lower bounds under certain conditions. The empirical likelihood approach is used to directly balance the covariates between the trial sample and the target population (Owen 2001). Write the set of trial participants receiving treatment by 𝒯 and those receiving control by 𝒞. We further define the set of non-participants by 𝒩, and the entire population 𝒫 = 𝒯 ∪ 𝒞 ∪ 𝒩. The sample proportion of trial participants and that of treated are and . Suppose and are propensity score and sampling score estimated via “working” parametric models using maximum likelihood. We then estimate μ1 by , where the empirical weights are obtained by maximizing log qi subject to the following three constraints:
| (1) |
| (2) |
| (3) |
The first constraint ensures validity of the empirical weights so that they sum to unity. The second constraint ensures that the product of the estimated propensity score and sampling score among the treated are balanced toward the population mean, while the last constraint directly balances a k1-vector of effect modifiers or functions of them, denoted by , toward the respective population means. Similarly, we estimate μ0 by , where the empirical weights maximize log qi and are subject to the following constraints:
| (4) |
| (5) |
| (6) |
where is a k0-vector of effect modifiers one wishes to balance through weighting. Then the population average treatment effect μ is estimated by . The solutions to the empirical weights {qi : i ∈ 𝒯} and {qi : i ∈ 𝒞} can be obtained via the iterative algorithm suggested by Chen, Sitter, and Wu (2002). It is evident from the last constraint in Equations (3) and (6) that the weights are constructed to directly achieve balance on the effect modifiers and so avoids the iterative fitting-checking procedure when using the inverse probability of sampling weights (Stuart et al. 2011). In addition to balancing the effect modifiers, the inclusion of the second constraint in Equations (2) and (5) ensures the double robustness property of , as explained in Theorem 3.1.
Theorem 3.1. Assuming that and are maximum likelihood estimators of the regression coefficient in the propensity score and sampling score models, we have . The influence function is expanded as
where β*, α* are probability limits of , , , , B1, B0, G1, G0, t1(·), t0(·) are defined in the Appendix C, and Δμ, i(β*, α*) is a residual term arising from estimating β and α through maximum likelihood. The following properties hold for :
when the propensity score and sampling score models are correct, ;
when the implied outcome model is correct such that , , the estimator remains consistent and ; therefore is doubly robust;
when all models are correct, , namely is efficient with respect to the efficiency bound Σμ.
In fact, the same robustness and efficiency property can be achieved by enforcing an alternative set of constraints. Specifically, one could define a new estimator by replacing the second constraints in Equations (2) and (5) with
| (7) |
| (8) |
where is the average of the estimated sampling scores. Intuitively, had one known the true sampling score model, is a potentially more efficient estimator for π than . But Theorem 2.4 suggests knowledge of the true sampling score does not reduce the asymptotic variance bound for μ, and correspondingly, we could show that both and are semiparametric efficient with respect to the same efficiency bound Σμ. However, because the right hand sides of Equations (7) and (8) will only be consistent to pr[S = 1, A = 1] and pr[S = 1, A = 0] when p(X) is correctly specified, the general asymptotic expansion of is unavailable under misspecified p(X).
3.2. Estimation of the average treatment effect among non-participants
Robust and efficient estimation of τ can proceed with a similar strategy, by instead weighting the trial sample toward the population of non-participants. Specifically, τ1 is estimated by , where the empirical weights are obtained by maximizing log qi subject to
| (9) |
| (10) |
| (11) |
Likewise, τ0 is estimated by , where the empirical weights maximize log qi and are subject to
| (12) |
| (13) |
| (14) |
where a(X), b(X) are again sets of effect modifiers defined in Section 3.1. Similar to , is also a doubly robust construction, as summarized in Theorem 3.2.
Theorem 3.2. Assuming that and are maximum likelihood estimators of the regression coefficient in the propensity score and sampling score models, we have . The influence function is expanded as
where β*, α* are probability limits of , , , , J1, J0, K1, K0, η1(·), η0(·) are defined in the Appendix D, and Δτ, i(β*, α*) is a residual term arising from estimating β and α through maximum likelihood. The following property holds for :
when the propensity score and sampling score models are correct, ;
when the implied outcome model is correct such that , , the estimator remains consistent and ; therefore is doubly robust;
when all models are correct, , namely is semiparametric efficient with respect to the efficiency bound Στ.
We realize that the doubly robust estimator is semiparametric efficient with respect to the efficiency bound without the knowledge of the sampling score. As Theorem 2.4 suggests that the knowledge of the sampling score in fact further reduces the bound, there should exist a more efficient estimator than perhaps by trading off some of its robustness property. Intuitively, had one known the true sampling score, not only is a more efficient estimator than , but also and could be more efficient estimators for , than and , which are simple averages. This observation motivates us to employ constraints that exploit more information from the data and possibly arrive at an estimator for τ with higher asymptotic efficiency. Specifically, we could estimate τ1 by , where the empirical weights are obtained by maximizing log qi subject to
| (15) |
| (16) |
| (17) |
and estimate τ0 by , where the empirical weights are obtained by maximizing log qi subject to
| (18) |
| (19) |
| (20) |
The contrast between and exemplifies the bias-variance tradeoff. Because the right hand side of the last constraint in Equations (17) and (20) only converges in probability to the average values of the effect modifiers among the non-participants when the sampling score is correctly estimated, the consistency of to τ necessitates the correct specification of p(X) and hence is only “singly” robust. In other words, is singly robust in a sense that it is consistent for τ if and only if the sampling score model for p(X) is correctly specified, regardless of the specification of a(X), b(X). But as we encode more information in the constraints, achieves a lower efficiency bound in large samples compared to , as elucidated in the following results.
Theorem 3.3. Assuming both the sampling score model is correctly specified, and that , are maximum likelihood estimators of the regression coefficient in the propensity score and sampling score models, we have . The influence function is expanded as
where β0, α0 are true values of , , , , J1, J0, K1, K0, , are defined in the Appendix E, and is a residual term arising from estimating β and α through maximum likelihood. The following properties hold for :
since , is a consistent estimator, ;
when the implied outcome model is correct such that , , the large-sample variance , therefore is semiparametric efficient with respect to the efficiency bound .
The asymptotic analysis of the empirical likelihood estimators for μ and τ exemplifies the role of the sampling score for causal generalization. When all models are correctly specified, encodes the knowledge of the sampling score but still has the same asymptotic variance as ; this illustrates that the sampling score is ancillary for the estimation of μ. By contrast, when all models are correctly specified, encodes the knowledge of the sampling score and achieves a lower asymptotic variance than ; this illustrates that the sampling score is not ancillary for the estimation of τ. Therefore, the insights obtained from deriving the efficiency bounds provide an interesting perspective on the properties of different empirical likelihood estimators.
Although the true propensity score is known in randomized trials, the constraints we imposed involve an estimated propensity score . In this regard, the above estimators apply even when the generalization is from a non-randomized, observational study, providing the ignorability condition in Assumption 2.1 holds. In fact, the way how the estimated propensity score is utilized in the constraints could also exemplify the role of the propensity score. One could replace with a potentially more efficient estimator to re-construct all the above empirical likelihood estimators without modifying their semiparametric efficiency properties; such results then exemplify that the propensity score is ancillary for the estimation of both μ and τ.
4. Numerical studies
We study the finite-sample performance of the empirical likelihood estimators and compare with the classical augmented inverse probability weighting (AIPW) estimators. The AIPW estimator for estimating μ can be obtained as the solution to the estimating equations with estimated propensity scores, sampling scores as well as predicted potential outcomes. This estimator is discussed in Dahabreh et al. (2019) and has the form
where , are estimated values of and , for example, through linear regression with finite-dimensional parameters γ1 and γ0. Similar to the two types of the empirical likelihood estimators introduced in Section 3.2, the two types of AIPW estimators for estimating τ can be obtained as the solutions to the estimating equations and and are expressed by
where , are estimated values of and , for example, through linear regression with finite-dimensional parameters γ1 and γ0. Among them, is a doubly robust estimator whose consistency only requires the correct specification of either the sampling score model or the outcome model (Dahabreh et al. 2020), while is only singly robust, in parallel to the empirical likelihood estimators and . In the following simulation studies, the outcome models in the AIPW procedures are all estimated by least-squares regression using the trial sample.
4.1. Simulation study I
To compare the empirical likelihood estimators with the classical AIPW estimators, we first consider the following data generating mechanisms. The covariates are generated from X1 ~ N(0, 1), , X3 ~ unif(−2, 2) and X4 = I(X3 > 0), with the true sampling score model
We fix the trial sample size n1 = 500, and consider three values of β0 so that the proportion of the trial sample is 50%, 10%, and 5%, corresponding to target population sizes n = 1000, n = 5000 and n = 10,000. Overall, the data generating processes represent moderate to strong selection effect based on the effect modifiers. Specifically, as the proportion of trial sample decreases, there is an increasing chance of occurrence of extremely small sampling scores p(X) for specific combination of covariate points. The distributions of the true sampling scores in the population are provided in Figure 1. Such specific data generating processes were chosen to challenge the inferential procedures when there is limited overlap between the trial participants and non-participants.
Figure 1.

Distributions of true sampling scores in the population when the proportion of trial participation is (a) 50%, (b) 10%, and (c) 5%, in the first simulation study. The trial sample size is fixed at n1 = 500, while the population size corresponding to each panel is (a) n = 1000, (b) n = 5000, and (c) n = 10,000.
The potential outcomes are generated from
The true values of μ and τ are estimated using Monte Carlo integration. For each estimator, we use the first letter to label whether the fitted sampling score model is correct (C) or misspecified (M). The misspecified model omits X2, X4 in the logistic model. We similarly use a second letter to label whether the outcome model is correct (C) or misspecified (M), with the misspecified outcome model omitting X2, X4 (for the empirical likelihood estimators, the misspecification refers to omitting X2, X4 in the covariate-balancing constraints). For simplicity, the treatment propensity score is estimated based on X1 and X3 for all methods. In theory, the influence functions in Theorems 3.1 and 3.2 could suggest a plug-in variance estimator for and . However, as one does not known whether the sampling score model or the implied outcome model is correct, all terms in the influence functions must be calculated even though certain terms are actually zero. Because the implementation of the plug-in variance is quite complex and would propagate a substantial amount of estimation error, we bootstrapped 200 samples to estimate variance and construct percentile-based confidence intervals. For the estimation of μ, we report bias, root mean squared error (RMSE) and 95% coverage of all estimators over 1000 Monte Carlo replications in Table 1. Corresponding results for the estimation of τ can be found in Table 2.
Table 1.
Summary of results in the first simulation study based on 1000 Monte Carlo replications for estimating μ; all values have been multiplied by 100.
| n = 1000 | n = 5000 | n = 10,000 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Coverage | Bias | RMSE | Coverage | Bias | RMSE | Coverage | |
| 4 | 26 | 94 | 4 | 20 | 94 | 3 | 19 | 94 | |
| 3 | 35 | 95 | 4 | 54 | 93 | 2 | 66 | 93 | |
| 4 | 26 | 95 | 4 | 33 | 96 | 1 | 59 | 96 | |
| 46 | 98 | 89 | 284 | 805 | 85 | 553 | 2284 | 83 | |
| 4 | 26 | 94 | 4 | 22 | 93 | 4 | 21 | 95 | |
| 4 | 29 | 95 | 3 | 30 | 93 | 2 | 32 | 94 | |
| 4 | 26 | 95 | 4 | 23 | 95 | 4 | 23 | 95 | |
| 23 | 44 | 92 | 21 | 41 | 89 | 15 | 38 | 93 | |
| 4 | 26 | 94 | 4 | 22 | 93 | 4 | 21 | 95 | |
| 4 | 29 | 95 | 3 | 30 | 94 | 2 | 32 | 94 | |
| 4 | 26 | 95 | 4 | 23 | 94 | 4 | 23 | 95 | |
| 23 | 44 | 92 | 21 | 41 | 89 | 15 | 38 | 92 | |
Table 2.
Summary of results in the first simulation study based on 1000 Monte Carlo replications for estimating τ; all values have been multiplied by 100.
| n = 1000 | n = 5000 | n = 10,000 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Coverage | Bias | RMSE | Coverage | Bias | RMSE | Coverage | |
| 6 | 35 | 94 | 2 | 21 | 94 | 3 | 20 | 94 | |
| 5 | 47 | 95 | 3 | 59 | 94 | 2 | 69 | 93 | |
| 6 | 36 | 94 | 3 | 36 | 96 | 1 | 62 | 96 | |
| 90 | 183 | 87 | 314 | 893 | 84 | 581 | 2401 | 83 | |
| 6 | 35 | 94 | 2 | 21 | 94 | 3 | 20 | 94 | |
| 5 | 47 | 95 | 3 | 59 | 94 | 2 | 69 | 93 | |
| 21 | 41 | 91 | 6 | 37 | 95 | 3 | 62 | 95 | |
| 90 | 183 | 87 | 314 | 893 | 84 | 581 | 2401 | 83 | |
| 6 | 35 | 95 | 2 | 23 | 94 | 3 | 22 | 95 | |
| 6 | 38 | 95 | 1 | 32 | 94 | 2 | 34 | 94 | |
| 6 | 37 | 95 | 2 | 25 | 93 | 4 | 24 | 94 | |
| 38 | 58 | 88 | 20 | 41 | 90 | 14 | 39 | 93 | |
| 6 | 35 | 95 | 2 | 23 | 93 | 3 | 22 | 94 | |
| 6 | 38 | 95 | 1 | 32 | 94 | 2 | 34 | 95 | |
| 21 | 41 | 92 | 6 | 25 | 93 | 6 | 24 | 94 | |
| 38 | 58 | 88 | 20 | 41 | 90 | 14 | 39 | 93 | |
Overall, the simulation results demonstrate the double robustness properties of both the AIPW and the empirical likelihood estimators. While the empirical likelihood and the AIPW estimators perform similarly when all models are correct, the empirical likelihood estimators provide notably greater efficiency when the outcome model is misspecified. For instance, the RMSE of is 60 times larger than that of or when all models are misspecified. Besides, when at least one model is misspecified, the variability of AIPW estimators sharply increases with decreasing proportion of trial participation, but the variability of empirical likelihood estimators remains relatively stable across scenarios. For the estimation of the population average treatment effect μ, the two empirical likelihood estimators, and , have almost identical performance, matching our theoretical discussion in Section 3.1.
For the estimation of τ, when all models are correct, there seems to be negligible difference between the variance for and in finite samples, even though the latter theoretically achieves a lower efficiency bound. This observation suggests that the marginal information content of the sampling score is usually a small positive quantity relative to the population size n. For this reason, appears to be superior over because is doubly robust while is only singly robust.
4.2. Simulation study II
To further compare the empirical likelihood estimators with the AIPW estimators, we consider an additional data generating mechanisms with more covariates and even higher degree of selection bias, leading to high degree of positivity violation. We consider seven covariates generated from X1 ~ N(0, 1), , X3 ~ unif(−2, 2), X4 = I(X3 > 0), X5 ~ N(0, 1), X6 ~ unif(−1, 1) and X7 = X5X6. The true sampling score model is given by
Similar to the first simulation study, we fix the trial sample size n1 = 500, and consider three values of β0 so that the proportion of the trial sample is 50%, 10% and 5%, corresponding to target population sizes n = 1000, n = 5000 and n = 10,000. Overall, the data generating processes represent very strong selection effect, giving rise to extremely small sampling scores p(X) for a substantial proportion of the population. For example, 28% and 55% of the non-participants have true sample score p(X) smaller than 0.01 when n = 5000 and n = 10,000. The distributions of the true sampling scores in the population are visualized in Figure 2, which clearly shows separation between the trial participants and non-participants.
Figure 2.
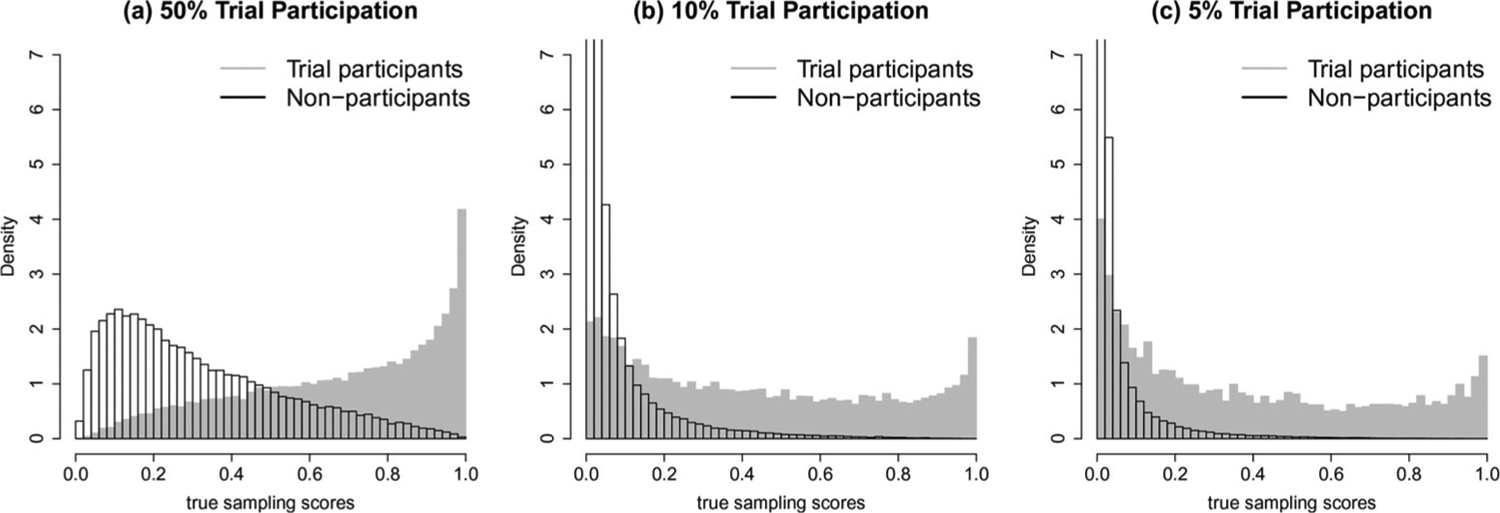
Distributions of true sampling scores in the population when the proportion of trial participation is (a) 50%, (b) 10%, and (c) 5%, in the second simulation study with high degree of positivity violation. The trial sample size is fixed at n1 = 500, while the population size corresponding to each panel is (a) n = 1000, (b) n = 5000, and (c) n = 10,000.
Correspondingly, the potential outcomes of each unit are generated from
The true values of μ and τ are estimated using Monte Carlo integration. For each estimator, we also use the first letter to label whether the fitted sampling score model is correct (C) or misspecified (M). The misspecified model omits X2, X4, and X7 in the logistic model. We similarly use a second letter to label whether the outcome model is correct (C) or misspecified (M), with the misspecified outcome model omitting X2, X4, and X7 in the covariate-balancing constraints. For simplicity, the treatment propensity score is estimated based on X1, X3, X4, and X5 for all methods. For the estimation of μ and τ, we report bias, root mean squared error (RMSE) and 95% coverage of all estimators over 1000 Monte Carlo replications in Tables 3 and 4.
Table 3.
Summary of results in the second simulation study with high degree of positivity violation based on 1000 Monte Carlo replications for estimating μ; all values have been multiplied by 100.
| n = 1000 | n = 5000 | n = 10,000 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Coverage | Bias | RMSE | Coverage | Bias | RMSE | Coverage | |
| 3 | 28 | 92 | 4 | 31 | 92 | 5 | 41 | 91 | |
| 5 | 42 | 93 | 8 | 111 | 91 | 1 | 165 | 91 | |
| 3 | 29 | 93 | −8 | 549 | 94 | −74 | 3482 | 94 | |
| 58 | 171 | 89 | 2651 | 14,295 | 80 | 18,648 | 133,237 | 81 | |
| 3 | 27 | 93 | 2 | 49 | 98 | −7 | 82 | 93 | |
| 3 | 33 | 93 | 2 | 63 | 91 | 8 | 82 | 93 | |
| 3 | 27 | 92 | 2 | 54 | 95 | −8 | 89 | 92 | |
| 23 | 51 | 90 | 33 | 99 | 88 | 23 | 119 | 92 | |
| 3 | 27 | 93 | 2 | 49 | 96 | −7 | 82 | 93 | |
| 3 | 33 | 93 | 2 | 63 | 91 | 8 | 82 | 93 | |
| 3 | 28 | 92 | 2 | 54 | 95 | −8 | 89 | 92 | |
| 23 | 51 | 90 | 33 | 99 | 88 | 23 | 119 | 92 | |
Table 4.
Summary of results in the second simulation study with high degree of positivity violation based on 1000 Monte Carlo replications for estimating τ; all values have been multiplied by 100.
| n = 1000 | n = 5000 | n = 10,000 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Coverage | Bias | RMSE | Coverage | Bias | RMSE | Coverage | |
| 0 | 39 | 93 | 3 | 34 | 92 | 4 | 42 | 91 | |
| 3 | 64 | 92 | 8 | 122 | 91 | 0 | 174 | 91 | |
| −1 | 43 | 92 | −10 | 608 | 94 | −78 | 3661 | 94 | |
| 110 | 333 | 88 | 2940 | 15,853 | 81 | 19631 | 140,198 | 81 | |
| 0 | 39 | 93 | 3 | 34 | 92 | 4 | 42 | 91 | |
| 3 | 64 | 92 | 8 | 122 | 91 | 0 | 174 | 91 | |
| 8 | 43 | 92 | −7 | 608 | 94 | −76 | 3661 | 94 | |
| 110 | 333 | 88 | 2940 | 15,853 | 81 | 19,631 | 140,198 | 81 | |
| 0 | 40 | 93 | 2 | 47 | 95 | −7 | 80 | 93 | |
| −4 | 48 | 92 | 1 | 71 | 92 | 8 | 87 | 93 | |
| 0 | 44 | 94 | 1 | 55 | 95 | −9 | 86 | 91 | |
| 34 | 71 | 88 | 33 | 107 | 89 | 22 | 124 | 92 | |
| 0 | 40 | 93 | 2 | 47 | 95 | −7 | 80 | 93 | |
| −4 | 48 | 92 | 1 | 71 | 92 | 8 | 87 | 93 | |
| 9 | 41 | 92 | 6 | 50 | 95 | −5 | 79 | 93 | |
| 34 | 71 | 88 | 33 | 107 | 89 | 22 | 124 | 92 | |
The simulation results under high degree of positivity violation are largely consistent with those in Section 4.1. When n = 1000 and n = 5000 and both models are correctly specified, the empirical likelihood estimators have slightly larger RMSE compared to the AIPW estimators. However, when at least one model is misspecified, the empirical likelihood estimators demonstrate substantially smaller bias, RMSE and closer to nominal coverage for estimating both μ and τ, compared to the AIPW estimators. As a typical example, when the outcome model is misspecified, both empirical likelihood estimators and , are 10 times more efficient than . When both models are misspecified, and , are then 142 times more efficient than . In the most challenging scenario with n = 10,000 and severe positivity violation (over half of the non-participants have true sampling score < 0.01), the robustness of empirical likelihood estimators appears more evident under model misspecification, even though they can be slightly less efficient compared to AIPW estimators in the absence of model misspecification. Finally, this second simulation also indicates that there is general little difference between and , and between and in finite samples, a finding that is consistent to that shown in Tables 1 and 2.
5. Discussion
The asymptotic results on efficiency bounds in this note could be extended to generalizing results in randomized trials with multiple arms, where the treatment variable Ai ∈ {0, 1, …, J}. Extending the steps outlined in Cattaneo (2010), one could obtain the asymptotic covariance bounds for estimating μ = (μ0, μ1, …, μJ)T and τ = (τ0, τ1, …, τJ)T, where and . By replacing the estimated propensity scores with the estimated generalized propensity scores (Imbens 2000) in the balancing constraints, one could also derive the corresponding empirical likelihood estimators to provide semiparametric efficient inference for μ and τ. On the other hand, the sharp covariate-balancing constraints imposed by the empirical likelihood approach may come with a cost. In practice where the number of covariates is large and the sample size is small, the search algorithm may fail to identify a solution that ensures exact balance of the effect modifiers. Our future work will include relaxing the exact covariate-balancing conditions to tolerate a small amount of imbalance, such as along the lines of Fong, Hazlett, and Imai (2018) and Wang and Zubizarreta (2020).
Acknowledgement
The authors thank Can Meng for computational assistance with the simulations in Section 4.2, and are grateful to the Editor and anonymous reviewer for providing constructive comments, which improved the exposition of this work.
Funding
The research of Fan Li is partially supported by CTSA Grant Number UL1 TR001863 from the National Center for Advancing Translational Science (NCATS), a component of the National Institutes of Health (NIH). The statements presented in this article are solely the responsibility of the authors and do not necessarily represent the views of the National Institutes of Health.
Appendix A. Proof of Theorem 2.3
The calculation of efficiency bounds follow the general approach outlined in Bickel et al. (1993) and Hahn (1998) and includes the following three steps: characterization of tangent space, verification of pathwise differentiability in the parameter and computation of the asymptotic variance bound. By Assumptions 1 and 2, the density of the observed data (Y, S, A, X) is
where f1(y|x) = dF1(y|x) and f0(y|x) = dF0(y|x) are densities of Y1 and Y0 given X = x.
Consider a regular parametric submodel for the joint distribution of (Y, S, A, X)
which equals f(y, s, a, x) when θ = θ0, the true value. Define the score to be H(y, s, a, x; θ0) = Hy(y, s, a, x) + Hp(s, x) + Hx(x), where
Let 𝓛2(F) be the usual Hilbert space of mean-zero and square-integrable measurable functions with respect to distribution F. The tangent space is then characterized by 𝓗y + 𝓗p + 𝓗x, with 𝓗y = {Hy(Y, S, A, X) : ha(Y, X) ∈ 𝓛2(Fa), a = 0, 1}, 𝓗p = {Hp(S, X) : Hp(S, X) ∈ 𝓛2(FS|X)} and 𝓗x = {Hx(X) : Hx(X) ∈ 𝓛2 (FX)}.
The moment function for μ based on the potential outcomes is m(Y1, Y0; μ) = m(μ) = (Y1 − Y0) – μ, where . Interchanging differentiation and integration, we have . Since , we obtain
| (A1) |
The mapping μ(θ) is pathwise differentiable if there exists a function Ψμ(Y, S, A, X) ∈ 𝓗 such that for all regular parametric submodels. We can verify that the efficient score
| (A2) |
is an element in 𝓗 and satisfies the above condition, because
and .
The moment function for τ is m(Y1, Y0; τ) = m(τ) = (Y1 - Y0) – τ, where . Differentiating under the integral sign, we have
| (A3) |
The mapping τ(θ) is pathwise differentiable if there exists a function Ψτ(Y, S, A, X) ∈ 𝓗 such that for all regular parametric submodels. We can verify that the function
| (A4) |
is an element in 𝓗 and satisfies the above condition, because
| (A5) |
| (A6) |
and . By Theorem 2 in Section 3.3 of Bickel et al. (1993), the asymptotic variance bounds are the expected square of the projection of Ψμ and Ψτ onto 𝓗. But Ψμ, Ψτ ∈ 𝓗, and therefore , . The explicit forms of Σμ and Στ are given in Theorem 2.3.
The above calculation assumes the knowledge of the propensity score e(X), but the results remain virtually the same even if e(X) is unknown, as when the generalization is based on an observational study. To see why, notice that with e(X) unknown, the score becomes 𝓗(y, s, a, x; θ0) = Hy(y, s, a, x) + He(s, a, x) + Hp(s, x) + Hx(x), with
and the tangent space is characterized by 𝓗y + 𝓗e + 𝓗p + 𝓗x, where 𝓗e = {He(S, A, X) : He(S, A, X) ∈ 𝓛2(FA|X, S=1)}. This change in tangent space, however, does not affect Equations (A1) and (A3). Further because , we can show that the efficiency bounds for estimating μ and τ are still Σμ and Στ. This proves that e(X) is ancillary for the estimation of μ and τ, when p(X) is unknown.
Appendix B. Proof of Theorem 2.4
If the sampling score p(X) is known, then the score becomes H(y, s, a, x; θ0) = Hy(y, s, a, x) + Hx(x), and the tangent space is characterized by 𝓗y + 𝓗x. However, one can verify that this change in tangent space does not change Equation (A1). Further, μ(θ) is pathwise differentiable since for all regular parametric submodels. This indicates that the efficiency bound for estimation of μ is the same as that when p(X) is unknown. In other words, p(X) is ancillary for the estimation of μ.
For estimation of τ, we obtain
Define
| (B1) |
which is an element in the tangent space 𝓗. We can show that for all regular parametric submodels, , because of Equations (A5) (A6), and
This verifies that τ(θ) is pathwise differentiable and therefore , whose explicit expression is given in Theorem 2.4. This also shows that p(X) is not ancillary for the estimation of τ.
Finally, under the assumption that the sampling score p(X) is known, the ancillarity of e(X) to the estimation of μ and τ follows the same reasoning as in the last paragraph of Appendix A.
Appendix C. Proof of Theorem 3.1
Define , , and , we have and , . From Qin and Lawless (1994) and Owen (2001), the empirical probabilities for estimating μ1 are written as
where satisfy
Following the results in Qin (1993, Section 2), the Lagrange multiplier converges in probability to a non-zero limit, therefore a centralization step is required to re-parameterize the above estimating equations. Define , , and
it follows that we could re-write the empirical probabilities as
with the centralized converging in probability to zero and satisfying
We define β*, α* as the probability limits of and . According to the results of White (1982), β* and α* are the least favorable values minimizing the Kullback-Leibler distance between the distributions implied from the assumed models and those from the true data generating processes. When the propensity model and the sampling score model are both correct, the probability limits equals the true values β* = β0 and α* = α0. Notice that in randomized trials, the propensity score is known and so α* = α0, while this may not be the case in observational studies. Here we allow the more general case where α* can differ from α0 since α* = α0 could just be included as a special case. For the sampling score model, we have , where
, and z⊗2 = zzT. Similarly for the propensity score model, , where
where .
Define , ,
We expand around the limiting values of its arguments as
where
Therefore
| (C1) |
It follows that
| (C2) |
where
Inserting Equation (C1) into Equation (C2) leads to , where
We next show that is doubly robust. When models for p(X) and e(X) are correctly specified, β* = β0 and α* = α0 (the latter usually holds automatically in randomized trials), it is easy to see that , and
by the ignorability conditions in Assumptions 2.1 and 2.2. In addition, D1 = 1 and so
which has zero expectation. Therefore and .
We now show consistency under a correct outcome model implied from the constraints. Write
where
Observe that , . When the “outcome model” is correct in the sense that , the conditional expectation, , lies in the linear space spanned by {a(Xi) - a0}. Because
for all functions L(Xi) and g1(Xi; β*, α*, π, ω, a) only involves Xi, we have
Therefore . Further since
we obtain
Similar projection-based arguments lead to . Therefore
When all models are correctly specified, it is easy to verify that becomes the efficient influence function for estimating μ1, i.e.,
The asymptotic analysis for follows the exact same fashion, except that we will now replace Ai by 1 − Ai, and the propensity score e(Xi; β) by its complement 1 – e(Xi; β). We will omit the details for brevity, but note that the influence function of is
where and
The last quantities in Theorem 3.1 are thus defined as . Finally, when all models are correct, we could verify that the efficient score in (A2), . Therefore, is semiparametric efficient with respect to the variance bound Σμ.
Appendix D. Proof of Theorem 3.2
Define , , and , we must have and , . Denote m1(Xi; β, α) = p(Xi; β)e(Xi; α)/(1 – p(Xi; β)), the empirical probabilities for estimating τ1 are written as
where satisfy
Similar to Appendix C, the Lagrange multiplier now converges in probability to a non-zero limit due to biased sampling, therefore a centralization step is required to re-parameterize the above estimating equations (Qin 1993, Section 2). Define , , and
it follows that we could re-write the empirical probabilities as
with the centralized converging in probability to zero and satisfying
Write β*, α* as the probability limits of and as in Appendix C, and now define ,
We expand around the limiting values of its arguments as
where
Therefore
| (D1) |
It follows that
| (D2) |
where
Inserting Equation (D1) into Equation (D2) gives , where
We now show that is also doubly robust. When models for p(X) and e(X) are correctly specified, β* = β0 and α* = α0 (the latter holds automatically in randomized trials), it is easy to verify that
by the Law of Iterated Expectations. In addition, D1 = 1 and so
which has zero expectation. Because , we have and .
To show the consistency under a correct outcome model implied from constraints, we write
where
Observe that , . When the “outcome model” is correct in the sense that , the conditional expectation, , lies in the linear space spanned by {a(Xi) − a}. Because
for all functions L(Xi) and g1(Xi; β*, α*, π, ω, a) only involves Xi, we have
Therefore . Further because
and we obtain
Similar projection-based arguments lead to . Therefore
and .
Finally when all models are correct, it is easy to verify that becomes the efficient influence function for estimating τ1 in Theorem 1, i.e.,
The asymptotic analysis for follows the same way, except that we will now replace Ai by 1 − Ai, and the propensity score e(Xi; β) by its complement 1 – e(Xi; β). The details are omitted for brevity, but we note that the influence function of is
where , m0(Xi; β, α) = p(Xi; β)(1 - e(Xi; α))/(1 - p(Xi; β)) and
The residual quantities in Theorem 3.2 are thus defined as . Finally, when all models are correct, we could verify that the efficient score in Equation (A4), . Therefore, is semiparametric efficient with respect to Στ, the bound without the knowledge of the sampling score.
Appendix E. Proof of Theorem 3.3
Although , the consistency of and to π = pr(Si = 1) and relies on the correct specification of the sampling score model. Because of this, the general asymptotic expansion of cannot be obtained. This challenge is due to the fact that the probability limits for the Lagrange multipliers will change depending on whether p(Xi) is correctly estimated. We shall focus on the case when both the sampling score and propensity score are correctly estimated, and therefore β* = β0, α* = α0. Denote m1(Xi; β, α) = p(Xi; β)e(Xi; α)/(1 – p(Xi; β)), the empirical probabilities for estimating τ1 are written as
where, and satisfy
Since we assume sampling scores are correctly estimated, the probability limits of the Lagrange multipliers are the same as those in Appendix D, and therefore we can employ a similar centralization step to re-parameterize the above estimating equations. Define , , and
it follows that we could re-write the empirical probabilities as
with the centralized converging in probability to zero and satisfying
Define , , we have
and
where the last equation results from the fact that
Now define
We expand around the limiting values of its arguments as
where and
Therefore
| (E1) |
It follows that
| (E2) |
where
Inserting Equation (E1) into Equation (E2) gives , where
The estimator is only singly robust since the above derivation rests on correct specification of the sampling score (regardless of the implied outcome model). It is easy to see that in this case because
In addition, we can write
where
Observe that , . When the “outcome model” is correct in the sense that , the conditional expectation, , lies in the linear space spanned by {a(Xi) – a}. Similar projection-based arguments to those in Appendix D lead to
Therefore we obtain
Repeating the projection-based arguments, we also get . This proves that when all models are correctly specified, in fact becomes the efficient influence function for estimating τ1 in Theorem 2.4, i.e.,
The asymptotic analysis for follows the same fashion. The details are omitted for brevity, but we note that with a correctly specified sampling score, the influence function of is
where , m0(Xi; β, α) = p(Xi; β)(1 - e(Xi; α))=(1 - p(Xi; β)) and
The residual quantities in Theorem 3.3 are thus defined as . Finally, when all models are correct, we could verify that the efficient score in Equation (B1), . Therefore, is semiparametric efficient with respect to , the lower variance bound assuming the knowledge of the sampling score.
Footnotes
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Bickel CA, Klaassen J, Ritov Y, and Wellner JA. 1993. Efficient and adaptive estimation for semiparametric models. New York: Springer. [Google Scholar]
- Buchanan AL, Hudgens MG, Cole SR, Mollan KR, Sax PE, Daar ES, Adimora AA, Eron JJ, and Mugavero MJ. 2018. Generalizing evidence from randomized trials using inverse probability of sampling weights. Journal of the Royal Statistical Society: Series A (Statistics in Society) 181 (4):1193–209. doi: 10.1111/rssa.12357. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cattaneo MD 2010. Efficient semiparametric estimation of multi-valued treatment effects under ignorability. Journal of Econometrics 155 (2):138–54. doi: 10.1016/j.jeconom.2009.09.023. [DOI] [Google Scholar]
- Chen J, Sitter RR, and Wu C. 2002. Using empirical likelihood methods to obtain range restricted weights in regression estimators for surveys. Biometrika 89 (1):230–7. doi: 10.1093/biomet/89.1.230. [DOI] [Google Scholar]
- Cole SR, and Hernán MA. 2008. Constructing inverse probability weights for marginal structural models. American Journal of Epidemiology 168 (6):656–64. doi: 10.1093/aje/kwn164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cole SR, and Stuart EA. 2010. Generalizing evidence from randomized clinical trials to target populations: The ACTG 320 trial. American Journal of Epidemiology 172 (1):107–15. doi: 10.1093/aje/kwq084. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Crump RK, Hotz VJ, Imbens GW, and Mitnik OA. 2009. Dealing with limited overlap in estimation of average treatment effects. Biometrika 96 (1):187–99. doi: 10.1093/biomet/asn055. [DOI] [Google Scholar]
- Dahabreh IJ, Robertson SE, Steingrimsson JA, Stuart EA, and Hernán MA. 2020. Extending inferences from a randomized trial to a new target population. Statistics in Medicine 39 (14):1999–2014. doi: 10.1002/sim.8426. [DOI] [PubMed] [Google Scholar]
- Dahabreh IJ, Robertson SE, Tchetgen Tchetgen EJ, Stuart EA, and Hernán MA. 2019. Generalizing causal inferences from individuals in randomized trials to all trial-eligible individuals. Biometrics 75 (2):685–12. doi: 10.1111/biom.13009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deville JC, and Särndal CE. 1992. Calibration estimators in survey sampling. Journal of the American Statistical Association 87 (418):376–82. doi: 10.1080/01621459.1992.10475217. [DOI] [Google Scholar]
- Fong C, Hazlett C, and Imai K. 2018. Covariate balancing propensity score for a continuous treatment: Application to the efficacy of political advertisements. The Annals of Applied Statistics 12 (1):156–77. doi: 10.1214/17-AOAS1101. [DOI] [Google Scholar]
- Hahn J 1998. On the role of the propensity score in efficient semiparametric estimation of average treatment effects. Econometrica 66 (2):315. doi: 10.2307/2998560. [DOI] [Google Scholar]
- Hainmueller J 2012. Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies. Political Analysis 20 (1):25–46. doi: 10.1093/pan/mpr025. [DOI] [Google Scholar]
- Hirano K, Imbens GW, and Ridder G. 2003. Efficient estimation of average treatment effects using the estimated propensity score. Econometrica 71 (4):1161–89. doi: 10.1111/1468-0262.00442. [DOI] [Google Scholar]
- Imai K, and Ratkovic M. 2014. Covariate balancing propensity score. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 76 (1):243–63. doi: 10.1111/rssb.12027. [DOI] [Google Scholar]
- Imbens GW 2000. The role of the propensity score in estimating dose-response functions. Biometrika 87 (3):706–10. doi: 10.1093/biomet/87.3.706. [DOI] [Google Scholar]
- Li F, Thomas LE, and Li F. 2019. Addressing extreme propensity scores via the overlap weights. American Journal of Epidemiology 188 (1):250–7. [DOI] [PubMed] [Google Scholar]
- Owen A 2001. Empirical likelihood. New York: Chapman & Hall/CRC Press. [Google Scholar]
- Qin J 1993. Empirical likelihood in biased sample problems. The Annals of Statistics 21 (3): 1182–96. doi: 10.1214/aos/1176349257. [DOI] [Google Scholar]
- Qin J, and Lawless J. 1994. Empirical likelihood and general estimating equations. The Annals of Statistics 22 (1):300–25. doi: 10.1214/aos/1176325370. [DOI] [Google Scholar]
- Qin J, and Zhang B. 2007. Empirical-likelihood-based inference in missing response problems and its application in observational studies. Journal of the Royal Statistical Society, Series B 69 (1):101–22. [Google Scholar]
- Robins JM, Rotnitzky A, and Zhao LP. 1994. Estimation of regression-coefficients when some regressors are not always observed. Journal of the American Statistical Association 89 (427):846–66. doi: 10.1080/01621459.1994.10476818. [DOI] [Google Scholar]
- Rosenbaum PR, and Rubin DB. 1983. The central role of the propensity score in observational studies for causal effects. Biometrika 70 (1):41–55. doi: 10.1093/biomet/70.1.41. [DOI] [Google Scholar]
- Rubin DB 1980. Comment on ‘Randomization analysis of experimental data: The fisher randomization test’ by D. Basu. Journal of the American Statistical Association 75 (371):591–3. doi: 10.2307/2287653. [DOI] [Google Scholar]
- Stuart EA, Bradshaw CP, and Leaf PJ. 2015. Assessing the generalizability of randomized trial results to target populations. Prevention Science: The Official Journal of the Society for Prevention Research 16 (3):475–85. doi: 10.1007/s11121-014-0513-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stuart EA, Cole SR, Bradshaw CP, and Leaf PJ. 2011. The use of propensity scores to assess the generalizability of results from randomized trials. Journal of the Royal Statistical Society: Series A (Statistics in Society) 174 (2):369–86. doi: 10.1111/j.1467-985X.2010.00673.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tipton E 2013. Improving generalizations from experiments using propensity score subclassification: Assumptions, properties, and contexts. Journal of Educational and Behavioral Statistics 38 (3):239–66. doi: 10.3102/1076998612441947. [DOI] [Google Scholar]
- Wang Y, and Zubizarreta JR. 2020. Minimal dispersion approximately balancing weights: Asymptotic properties and practical considerations. Biometrika 107 (1):93–105. [Google Scholar]
- Westreich D, Edwards JK, Lesko CR, Stuart E, and Cole SR. 2017. Transportability of trial results using inverse odds of sampling weights. American Journal of Epidemiology 186 (8): 1010–4. doi: 10.1093/aje/kwx164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- White H 1982. Maximul likelihood estimation of misspecified models. Econometrica 50 (1):1–25. doi: 10.2307/1912526. [DOI] [Google Scholar]
- Zhao Q 2019. Covariate balancing propensity score by tailored loss functions. Annals of Statistics 47 (2):965–93. [Google Scholar]
- Zubizarreta JR 2015. Stable weights that balance covariates for estimation with incomplete outcome data. Journal of the American Statistical Association 110 (511):910–22. doi: 10.1080/01621459.2015.1023805. [DOI] [Google Scholar]