

Abstract
Gaussian processes are widely employed as versatile modelling and predictive tools in spatial statistics, functional data analysis, computer modelling and diverse applications of machine learning. They have been widely studied over Euclidean spaces, where they are specified using covariance functions or covariograms for modelling complex dependencies. There is a growing literature on Gaussian processes over Riemannian manifolds in order to develop richer and more flexible inferential frameworks for non-Euclidean data. While numerical approximations through graph representations have been well studied for the Matérn covariogram and heat kernel, the behaviour of asymptotic inference on the parameters of the covariogram has received relatively scant attention. We focus on asymptotic behaviour for Gaussian processes constructed over compact Riemannian manifolds. Building upon a recently introduced Matérn covariogram on a compact Riemannian manifold, we employ formal notions and conditions for the equivalence of two Matérn Gaussian random measures on compact manifolds to derive the parameter that is identifiable, also known as the microergodic parameter, and formally establish the consistency of the maximum likelihood estimate and the asymptotic optimality of the best linear unbiased predictor. The circle is studied as a specific example of compact Riemannian manifolds with numerical experiments to illustrate and corroborate the theory.
Keywords: Equivalence of Gaussian measures, Identifiability and consistency, Laplace-Beltrami operator, Microergodic parameters
1. Introduction
Gaussian processes are pervasive in spatial statistics, functional data analysis, computer modelling and machine learning applications because of the flexibility and richness they allow in modelling complex dependencies (Rasmussen and Williams, 2006; Stein, 1999; Gelfand et al., 2010; Cressie and Wikle, 2011; Banerjee et al., 2015). For example, in spatial statistics Gaussian processes are widely used to model spatial dependencies in geostatistical models and perform spatial prediction or interpolation (“kriging”) (Matheron, 1963). In non-parametric regression models Gaussian processes are used to model unknown functions and, specifically in Bayesian contexts, act as priors over functions (Ghosal and van der Vaart, 2017). A typical modelling framework assumes for inputs (e.g., spatial coordinates; functional inputs) over a domain , where is a dependent variable of interest, is a mean function, is a zero-mean Gaussian process and is a noise process1. These frameworks can also be adapted to deal with discrete outcomes and applied to classification problems (Neal, 1999). Gaussian processes are also being increasingly employed in deep learning and reinforcement learning (Damianou and Lawrence, 2013; Deisenroth et al., 2013). The current manuscript focuses upon inferential properties of when is not necessarily Euclidean but a compact Riemannian manifold.
A Gaussian process is determined by its covariogram, also known as the covariance function. In Euclidean space, the Matérn covariogram (Matérn, 1986) is especially popular in spatial statistics and machine learning (see, e.g., Stein, 1999, for an extensive discussion on the theoretical properties of the Matérn covariogram). A key attraction of the Matérn covariogram is the availability of a smoothness parameter for the process. Several simpler covariograms, such as the exponential, arise as special cases of the Matérn.
This article is motivated by the emergence of non-Euclidean data, especially manifold data, in a variety of scientific fields over the last decade. As a consequence, inference for Gaussian processes on manifolds have been attracting attention in spatial statistics and machine learning in settings where the data generating process is more appropriately mod-elled over non-Euclidean spaces. Taking climate science as an example, geographic data involving geopotential height, temperature and humidity are measured at global scales and are more appropriately treated as (partial) realisations of a spatial process over a sphere (see, e.g., Banerjee, 2005; Jun and Stein, 2008; Jeong and Jun, 2015a). Data arising over domains with irregular shapes or examples in biomedical imaging where the domain is a three-dimensional shape of an organ comprise other examples where inference for Gaussian processes over manifolds will be relevant (see, e.g., Gao et al., 2019, and references therein). Motivated by isotropic covariograms in Euclidean space, it is natural to replace Euclidean distance by an appropriate geodesic distance to define a “Matérn” covariogram on Riemannian manifolds. However, this formal generalisation is not valid for the squared exponential covariogram, or Matérn with (Feragen et al., 2015), unless the manifold is flat. For Matérn with , this naive generalisation is not even valid on the sphere (Gneiting, 2013). Recently, valid covariograms for smooth Gaussian processes on general Riemannian manifolds have been constructed based upon heat equations, Brownian motion and diffusion models on manifolds (Castillo et al., 2014; Niu et al., 2019; Dunson et al., 2020). However, these covariograms lack flexibility, especially in terms of modelling smoothness.
Whittle (1963) proposed a new representation of GP by stochastic partial differential equations. Following this path, Lindgren et al. (2011) introduced a “Matérn” family on generic compact Riemannian manifolds with three parameters involved in the covariogram. Since such Matérn covariograms involve the spectrum of the Laplace-Beltrami operator, a numerical approximation to the covariogram is needed for most nontrivial manifolds. There is a rich literature focusing on approximations to the covariogram using tools from harmonic analysis, graph Laplacians, and stochastic partial differential equations (Sanz-Alonso and Yang, 2022a b). However, the study of statistical inference for the parameters in the Matérn covariogram remains relatively sparse.
In Euclidean domains with , while not all parameters in the Matérn covariogram are consistently estimable within the paradigm of “fixed-domain” or “in-fill” asymptotic inference (see, e.g. Stein, 1999; Zhang, 2004), certain parameters, customarily referred to as microergodic parameters, which can identify Gaussian processes specified by Matérn covariograms are consistently estimable (see Section 2). Furthermore, the maximum likelihood estimator of the spatial variance under any misspecified decay parameter is consistently and asymptotically normally distributed (Du et al., 2009; Kaufman et al., 2008; Wang and Loh, 2011), while predictive inference is also asymptotically optimal using maximum likelihood estimators (Kaufman and Shaby, 2013). Recently, Bevilacqua et al. (2019) and Ma and Bhadra (2022) considered more general classes of covariance functions outside of the Matérn family and studied the consistency and asymptotic normality of the maximum likelihood estimator for the corresponding microergodic parameters.
Our current contribution develops asymptotic inference for a flexible and rich Matérn-type covariogram on compact Riemannian manifolds. We review the Matérn covariogram (Section 3.1) on general compact Riemannian manifolds from the perspective of stochastic partial differential equations with reasonably tractable covariograms and spectral densities (Borovitskiy et al., 2020). Our specific results emanate from a sufficient and necessary condition for the equivalence of two Gaussian random measures on compact Riemannian manifolds with Matérn or squared exponential covariograms (Section 3.2). We subsequently establish (Section 3.3) that for Gaussian measures with Matérn covariograms the smoothness parameter is identifiable, while the spatial variance and decay parameters are not identifiable when , where is the dimension of the manifold. For , all three parameters are identifiable. For squared exponential covariograms on manifolds with arbitrary dimension, we show that both parameters are identifiable. Again, this problem is still open in Euclidean spaces. For Matérn covariograms on manifolds with , we formally establish that the maximum likelihood estimate of the spatial variance with a misspecified decay parameter is still consistent. Next, we turn to predictive inference (Section 3.4) and show that for any misspecified decay parameter in the Matérn covariogram, the best linear unbiased predictor derived from the maximum likelihood estimate is asymptotically optimal. Finally, for spheres with dimension less than 4, we explicitly study the Matérn covariogram, the microergodic parameter, the consistency of the maximum likelihood estimate and the optimality of the best linear unbiased predictor (Section 4). Proofs and mathematical details surrounding our main results are provided in the Appendix.
2. Gaussian Processes in Euclidean spaces
Let be a zero-mean Gaussian process on a bounded domain . The process is characterised by its covariogram so that for any finite collection of points, say , we have , where is the covariance matrix with -th entry . The Matérn process is a zero-mean stationary Gaussian process specified by the covariogram2,
| (1) |
where is called the partial sill or spatial variance, is the scale or decay parameter, is a smoothness parameter, is the Gamma function, and is the modified Bessel function of the second kind of order (Abramowitz and Stegun, 1965, Section 10). The Matérn covariogram in (1) is isotropic and its spectral density (also known as the Hankel-Fourier transform, Genton (2002)) is given by
2.1. Identifiability
Let and be Gaussian measures corresponding to Matérn parameters and , respectively. Two measures are said to be equivalent, denoted by , if they are absolutely continuous with respect to each other. Two equivalent measures cannot be distinguished no matter how dense the observations are. Zhang (2004) showed that when is equivalent to if and only if . Hence, and do not admit asymptotically consistent estimators, while , also known as a microergodic parameter, is consistently estimable. For , Anderes (2010) proved that both and are consistently estimable. The case for remains unresolved. The integral test offers a sufficient (but not necessary) condition on the spectral densities to determine whether two measures are equivalent. While unidentifiable parameters are never consistently estimable, identifiable parameters may be consistently estimable. However, deriving an explicit construction for such a consistent estimator is often challenging and is beyond the scope of the current manuscript; we identify this as an area of future research.
2.2. Parameter estimation
In practice, the maximum likelihood estimate is customarily used to estimate unknown parameters in the covariogram. Let be the likelihood function:
| (2) |
where and is independent of . Given , the maximum likelihood estimation of is given by (Stein, 1999)
Let be the data generating parameters with observations . For any misspecified , if is the maximum likelihood estimation of , then as with probability 1 under when is bounded and infinite (Zhang, 2004; Kaufman et al., 2008). Moreover, as (Du et al., 2009; Wang and Loh, 2011; Kaufman and Shaby, 2013). As a result, even if we do not know the true parameters , we can choose an arbitrary, possibly misspecified, decay parameter and find the maximum likelihood estimate of the spatial variance . The resulting Gaussian measure is asymptotically equivalent to the Gaussian measure corresponding to the true parameter.
2.3. Prediction and kriging
Gaussian processes are widely deployed in spatial or nonparametric regression models to carry out model-based predictive inference. Given a new location , the best linear unbiased predictor (BLUP) for is given by
where . Then
where is the expectation with respect to the measure characterised by the parameter or spectral density (see Section 3) in the subscript. As a result, any misspecified still yields an asymptotically optimal BLUP as long as is replaced by its maximum likelihood estimate (Stein, 1993; Kaufman and Shaby, 2013). In the current manuscript, we develop parallel results for the dimensional compact Riemannian manifold .
3. Gaussian processes on compact Riemannian manifold
Henceforth, we assume that our domain of interest is a -dimensional compact Riemannian manifold equipped with a Riemannian metric . We denote the Laplace–Beltrami operator on by– with eigenvalues and eigenfunctions , the volume form by and the volume of by (see, e.g., Kobayashi and Nomizu, 1963; Lee, 2018; do Carmo, 1992, for further details on operators and spectral theory on Riemannian manifolds).
3.1. Matérn covariogram on compact Riemannian manifolds
On a Riemannian manifold, where the linear structure of is missing, the standard definition of the Matérn covariogram is no longer valid. A natural extension of the Matérn covariogram to manifolds will consider replacing the Euclidean norm in (1) by the geodesic distance . Unfortunately, this naive generalisation is not valid for (Feragen et al., 2015), unless the manifold is flat. If we restrict ourselves to spheres, Matérn with is still invalid (Gneiting, 2013). Instead, some Matérn-like covariograms including chordal, circular and Legendre Matérn covariograms and other families of covariograms have been studied (Jeong and Jun, 2015b; Porcu et al., 2016; Guinness and Fuentes, 2016; Guella et al., 2018; Clarke De la Cerda et al., 2018; Alegría et al., 2021). However, these covariograms are constructed specifically with respect to the geometry of the sphere and do not generalise to generic compact Riemannian manifolds.
Whittle (1963) showed that the Matérn covariogram in Euclidean space admits a representation through a stochastic partial differential equation involving white noise and the Laplace operator . Lindgren et al. (2011) built on this stochastic partial differential equation approach to define the Matérn covariogram on manifolds involving the Laplace-Beltrami operator . This idea was further developed, both theoretically and practically, by several scholars (see, e.g., Bolin and Lindgren, 2011; Lang and Schwab, 2015; Herrmann et al., 2020; Borovitskiy et al., 2020, 2021, among others). We state the definition of the Matérn covariogram in the stochastic partial differential equation sense, which is a valid positive definite function for any on any compact Riemannian manifold .
Definition 1 Let be the orthonormal eigenfunctions of - and be the corresponding eigenvalues in ascending order. The Matérn covariogram is defined by
where is a constant such that the average variance is . The corresponding spectral density is
Similarly, the squared exponential covariogram is
where is a constant such that the average variance is .
The corresponding spectral density is
Remark 2 There are several commonly used parametric representations of the Matérn covariogram. In particular, this article adopts the same parametric representation as the one in Zhang (2004), but different from Borovitskiy et al. (2021).
If is a sphere, the covariograms defined above coincide with the Matérn-like covariograms on spheres provided by Guinness and Fuentes (2016) and Kirchner and Bolin (2022). As a result, we focus on a non-trivial generalisation to generic compact Riemannian manifolds. The relation between the three parameters in the above definition and the coefficients in the stochastic partial differential equation representation is not straightforward (see Lindgren et al., 2011, for details). Note that for any , the covariogram shares the same eigenbasis with the Laplace-Beltrami operator . This property is not deemed restrictive for our ensuing development since we primarily focus on the Matérn and squared exponential covariograms. Furthermore, this property offers crucial analytic tractability for several results developed subsequently. Hence, we refer to the Matérn and squared exponential covariograms as in Definition 1 in the following sections.
3.2. Identifiability
In Euclidean domains, the integral test (Yadrenko, 1983; Stein, 1999) is a powerful tool to determine the equivalence of two Gaussian measures. However, such tests do not carry through to non-Euclidean domains as the spectrum on such manifolds is discrete. Alegría et al. (2021) studied the so called -family of covariograms on spheres and numerically deduced, without proof, the consistency of the maximum likelihood estimate of some parameters for this family. Arafat et al. (2018) derived the equivalence of Gaussian measures on spheres and derived microergodic parameters of some covariograms excluding the Matérn. All of the above results are built upon the Feldman-Hájek Theorem (Da Prato and Zabczyk, 2014), which is valid for any metric space and, hence, applicable to compact Riemannian manifolds. Here, we generalise the above results to a Gaussian process with Matérn and squared exponential covariograms on arbitrary compact Riemannian manifolds, also motivated by the Feldman-Hájek theorem. Therefore, we can still study the identifiability of these parameters by finding the microergodic parameters.
Lemma 3 Let be mean zero Matérn/squared exponential Gaussian random measures with spectral densities . Then, if and only if
Proof See Appendix A. ■
From Definition 1, is strictly positive so the denominator is always non-zero. The series test is a sufficient and necessary condition. This is a significant enhancement over the integral test in Euclidean spaces, which offers only a sufficient condition. Its importance to us will become clear after Theorem 4. Subsequently, we consider microergodic parameters of Gaussian processes on a manifold with the Matérn covariogram. This is analogous to Theorem 2 in Zhang (2004) for compact Riemannian manifolds.
Theorem 4 Let , denote two Gaussian measures with the Matérn covariogram parametrized by . Then the following results hold.
If , then if and only if .
If , then if and only if and .
Proof See Appendix B. ■
Part (A) of Theorem 4 implies that if , then neither nor are identifiable or consistently estimable, while is identifiable. Part (B) implies that when , all three parameters - and -are identifiable. In Euclidean space, the smoothness parameter is typically assumed to be known and fixed when discussing fixed-domain asymptotic inference. In this specific Euclidean setting, assuming , (A) still holds while (B) holds for is still an unresolved problem in Euclidean space unless the domain is assumed to be bounded (Bolin and Kirchner, 2021). This difference in behaviour between (A) and (B) can be attributed to the integral test being a sufficient condition in Euclidean spaces, which ensures only the equivalence of measures when ; (see Zhang, 2004, for details). In , Anderes (2010) estimated the principal irregular term without the integral test and constructed consistent estimators for and directly. However, this construction does not hold for .
In contrast, the series test in Lemma 3 is a sufficient and necessary condition so that we can provide a condition for the equivalence of two measures with Matérn covariograms over any dimension. The dimension also plays an important role in the manifold setting due to Weyl’s Law (Li, 1987; Canzani, 2013). That is, the growth of the eigenvalues and their multiplicities are intertwined with the dimension ; further details are provided within the proof in Appendix B. Another benefit of the sufficient and necessary condition is that the series test can be applied to the squared exponential covariogram, also known as the radial basis function, which can be viewed as a limiting case of the Matérn covariogram when , as introduced in Definition 1. Since the spectral density is not a polynomial, the integral test over Euclidean domains is invalid and the conditions for the equivalence of two squared exponential covariograms are intractable. In contrast, the following theorem resolves the equivalence of squared exponential covariograms on a compact manifold .
Theorem 5 Let , for , be Gaussian measures with squared exponential covariograms parametrised by . Then if and only if and .
Proof See Appendix C. ■
Theorem 5 shows that it is possible to have consistent estimators for both and . So far we have developed formal results on the identifiability of parameters in the covariogram on a compact Riemannian manifold. Inference for identifiable parameters will proceed in customary fashion so we turn our attention to non-identifiable settings, i.e., the Matérn covariogram with known on manifolds with dimension .
3.3. Consistency of maximum likelihood estimation
Since is compact, there is no increasing-domain asymptotic framework and is always bounded. In the remaining sections, we assume that is infinite, which is the standard assumption also known as the increasing sequence assumption (also see Stein, 1999; Zhang, 2004; Kaufman and Shaby, 2013). Let be the data generating parameter (oracle) and let be the maximum likelihood estimate of obtained by maximising with a misspecified . The following theorem is analogous to Theorem 3 in Zhang (2004) for compact Riemannian manifolds.
Theorem 6 Under the setting of Theorem 4, assuming is infinite, we obtain
Proof See Appendix D. ■
In Euclidean space, is asymptotically Gaussian. We conjecture that this asymptotic normality still holds on Riemannian manifolds. However, this result relies on specific constructions in Euclidean space (Wang, 2010), which become invalid for manifolds. A formal proof is beyond the scope of the current manuscript and we intend to pursue this development in future investigations. In Section 4 we present a numerical simulation experiment to demonstrate the asymptotic (normal) behaviour of this parameter on spheres.
3.4. Prediction
Given a new location , the best linear unbiased predictor for under a covariance function characterised by its spectral density is given by
where and .
Kirchner and Bolin (2022) and Bolin and Kirchner (2021) generalise the results of asymptotic optimality of the BLUP based on a misspecified scale parameter in Euclidean spaces (Stein, 1993) to metric spaces. That is, the prediction error of the BLUP under a misspecified scale parameter is asymptotically the same as the error of the BLUP under the true parameter. If the domain is a compact Riemannian manifold and the covariograms are Matérn, then two covariance operators share the same eigenbasis; this is the setting described in Section 5.1 of Kirchner and Bolin (2022) as a special case of Theorem 3.1 therein. We rephrase it in the following lemma with some modifications to fit the Matérn covariograms on a compact Riemannian manifold with a different and simpler proof.
Lemma 7 Let be the spectral densities of two Gaussian measures on with Matérn covariograms. Given , let be the best linear unbiased predictor of based on observations with being infinite and having as an accumulation point, where is the spectral density of . If there exists a real number such that , then:
Proof See Appendix E. ■
Focusing on the parameters in a Matérn covariogram, let be the maximum likelihood estimate of and be the spectral density of the Matérn covariogram with decay parameter .
Theorem 8 Under the same conditions as in Theorem & and Lemma 7, let , then
Proof See Appendix F. ■
Note that Lemma 7 and Theorem 8 offer the manifold versions of Theorems 3 and 4 in Kaufman and Shaby (2013).
4. Matérn on spheres
We now consider Gaussian processes with the Matérn covariogram on the -dimensional sphere , including two popular manifolds in spatial statistics: the circle and sphere . We show that all theorems in the previous sections hold for with . As earlier, we assume that , are two Gaussian measures on with Matérn covariogram parameters .
Theorem 9 For spheres with dimension , the following results are true:
if and only if , so neither nor can be consistently estimated.
- Let the data generating parameters be and be the maximum likelihood estimation of with misspecified based on increasing sequence . Then,
- Given , let be the best linear unbiased predictor of based on observations with being infinite, then
Proof See Appendix G. ■
Next, we consider two concrete examples: the circle and the sphere .
4.1. Matérn covariogram on circle
First, we recall the simplified form of the Matérn covariogram on (Borovitskiy et al., 2020):
Lemma 10 When and , the Matérm covariogram is given by
| (3) |
where is chosen so that is cosh when is even and sinh when is odd, are constants depending on and ; see Borovitskiy et al. (2020) for details.
Note that for and . Therefore, the Matérn covariogram is “stationary” with respect to this group addition instead of the standard addition in Euclidean space. The corresponding spectral density is given by
| (4) |
In particular, when , the covariogram and spectral densities admit simple forms:
Figure 1(a) depicts a covariogram with , and . Note that means that and are antipodal points so the correlation attains a minimum. Figure 1(b) shows a set of simulated ‘s with different values of . It is clear that the smaller values of generate smoother random fields as the correlation grows larger.
Figure 1:
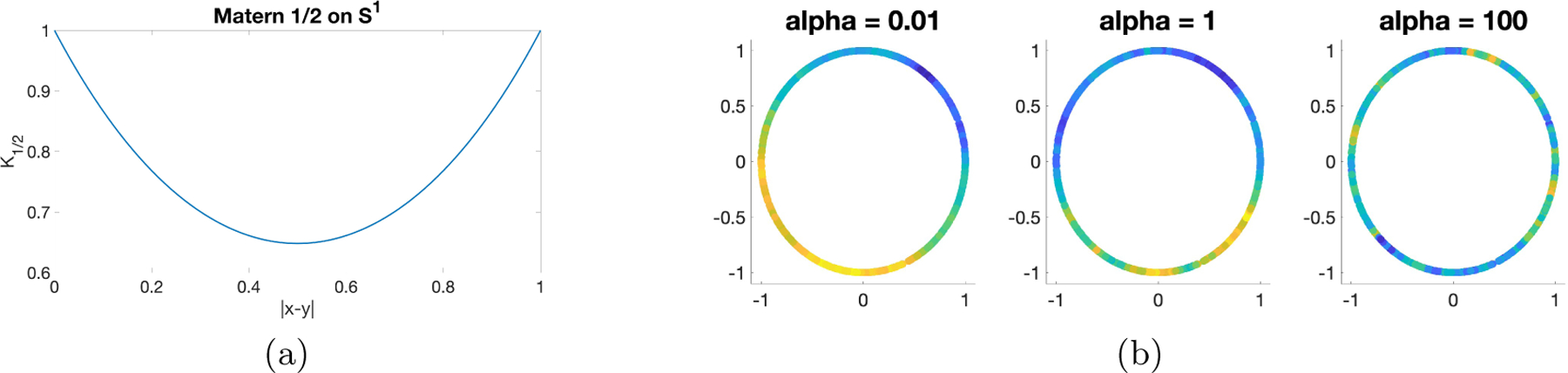
(a) Covariogram of Matérn 1/2 on ; (b): Sample fields with .
Corollary 11 Let , then if and only if , so neither nor can be consistently estimated.
For a general , the normalising constant is
We point out that this is different from the in Definition 1 when . Although we cannot express as an elementary function, we can still find the microergodic parameter for any :
Corollary 12 Let , then if and only if , so neither nor can be consistently estimated.
Figure 2 shows that as shown by the horizontal line and the empirical distribution of is , for . Panel (a) supports Theorem 9 empirically. That is, although are not consistently estimable, the microergodic parameter is consistently estimable. Panel (b) supports our conjecture after Theorem 6 empirically.
Figure 2:
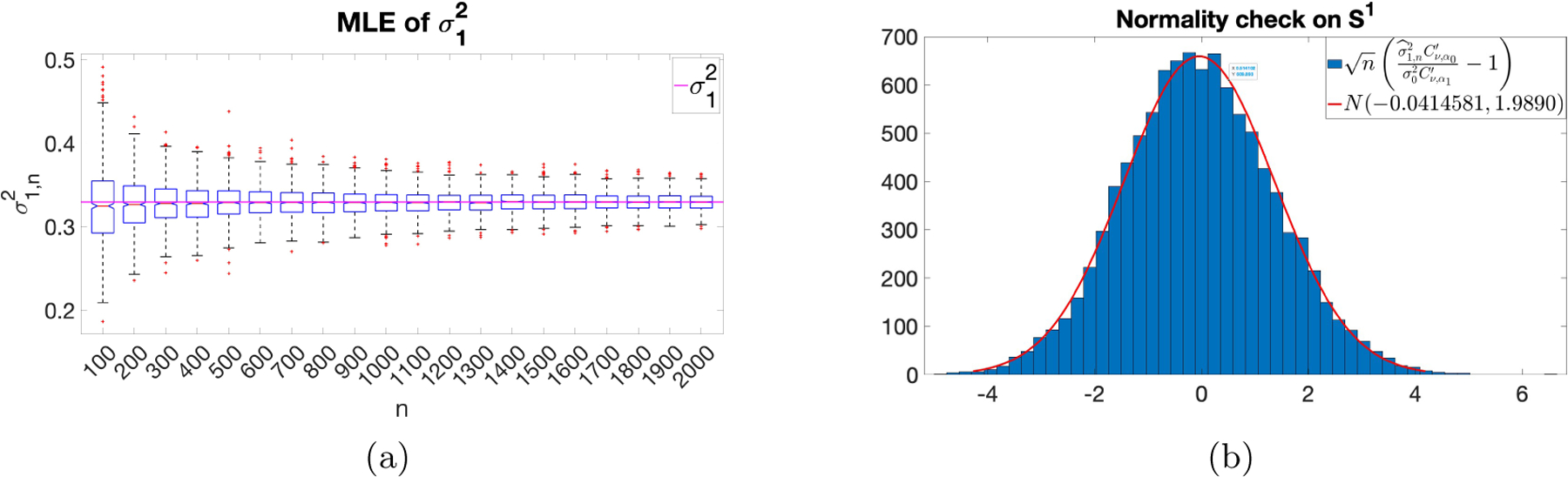
(a) v.s. ; (b): Distribution of .
4.2. Matérn covariogram on the sphere
On a sphere , the Mateŕn covariogram is more complicated (Borovitskiy et al., 2020):
Lemma 13 The Matérn covariogram on with is
and its spectral density is given by
where is the geodesic distance on is the Legendre polynomial of degree l:
Remark 14 The index in the above covariance function is different from the index in Definition 1. In fact, each Legendre polynomial corresponds to multiple spherical harmonics, so the spectral density does not contain the constants anymore.
Unlike Lemma 10, where is required to be a half-integer, here can be any positive number. However, the covariogram now involves an infinite series, which needs to be approximated when . Approximating a function on is known as the “scatter data interpolation problem” (Narcowich et al., 1998) and preserving the positive definiteness is known as the stability problem (Kunis, 2009). For the Matérn covargioram considered in this manuscript, we adopt a natural and simple approximation using the partial sum of an infinite series. The following theorem controls the approximation error and ensures the positive definiteness of the approximated covariogram.
Theorem 15 For the partial sum
the approximation error is controlled by
Given observations with minimal separation , the approximated covariance matrix is positive definite for any
where is a constant depending on the spectral density and minimal separation q; see the proof for more details.
Proof See Appendix H. ■
The above result implies that the computational cost is of order as . Larger values of imply smoother random fields that require smaller values of to approximate the covariogram. In practice, we can first calculate , which is computationally practicable because of the closed-form representation (see Appendix H for details), and then choose .
Figure 3(a) presents the covariogram with , and . Note that means that and are antipodal points so the correlation reaches the minimum. Figure 3(b) shows some simulated ’s with different ’s. Similar to , smaller values of lead to smoother random fields.
Figure 3:
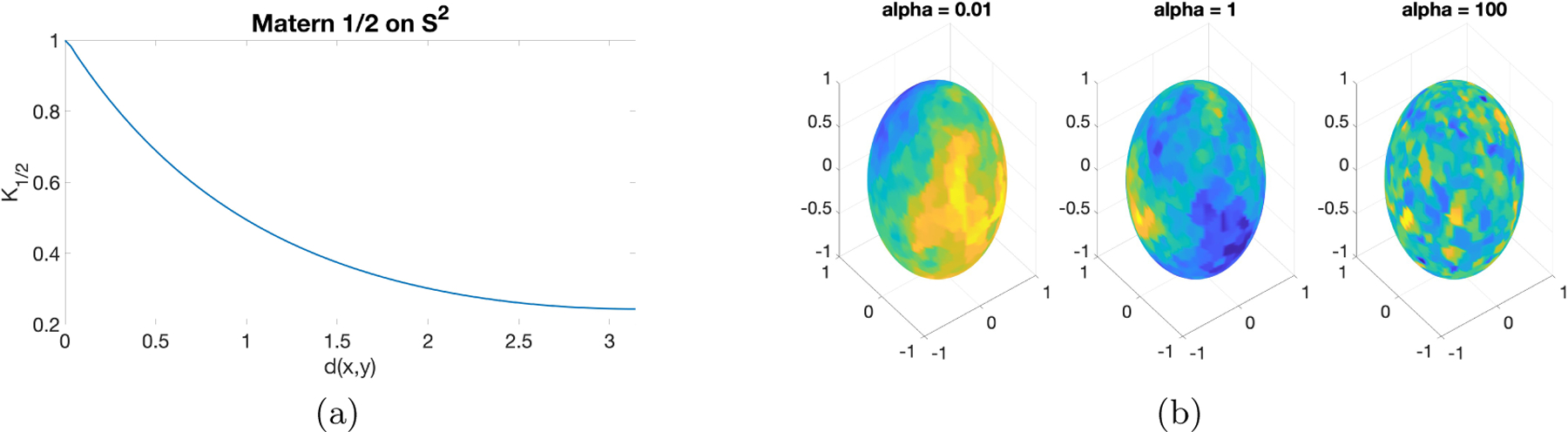
(a) Covariogram of Matérn 1/2 on ; (b): Sample fields with .
However, due to the bias introduced by the partial sum, we do not have access to the ground truth covariogram, so the analogue of Figure 2 is not available anymore. Similar issues arise in approximations to the Matérn on a compact manifold (Sanz-Alonso and Yang, 2022a). Instead, we show the theoretical results on microergodic parameters analogous to Corollary 12:
Corollary 16 if and only if , so neither nor can be consistently estimated.
5. Discussion
This article has formally developed some theoretical results on statistical inference for Gaussian processes with Matérn covariograms on compact Riemannian manifolds. Our focus has primarily been on the identifiability and consistency (or lack thereof) of the covariogram parameters and of spatial predictions. For the Matérn and squared exponential covariograms, we provide a sufficient and necessary condition for the equivalence of two Gaussian random measures through a series test and derive identifiable and consistently estimable microergodic parameters for an arbitrary dimension . Specifically for , we formally establish the consistency of maximum likelihood estimates of the parameters and the asymptotic normality of the best linear unbiased predictor under a misspecified decay parameter. The circle and sphere are analysed as two examples with corroborative numerical experiments.
We anticipate that the results developed here will generate substantial future work in this domain. For example, as we have alluded to earlier in the article, in Euclidean spaces we know that the maximum likelihood estimate of is asymptotically normal: . While our numerical experiments lead us to conjecture that an analogous result holds for compact Riemannian manifolds, a formal proof may well require substantial new machinery that we intend to explore further. Next, we conjecture that two measures with the Matérn covariogram are equivalent on if and only if they have the same decay and spatial variance parameters. We know this result holds for manifolds with , but a formal proof for has not yet been established. Based upon similar reasonings we conjecture that two measures with squared exponential covariograms are equivalent on Euclidean spaces if and only if they have the same decay and spatial variance parameters.
Another future generalisation is to consider covariograms on compact Riemannian manifolds that are not simultaneously diagonalisable, whose asymptotically optimal linear predictor has been studied in Kirchner and Bolin (2022). Nevertheless, issues pertaining to the equivalence of measures, derivation of microergodic parameters and consistency of maximum likelihood estimates remain unresolved. Furthermore, covariograms that offer scientific interpretation in practical inference need to be explored. In this regard, it is worth remarking that although our results are primarily concerned with maximum likelihood estimates, they will provide useful insights into Bayesian learning on manifolds. For example, the failure to consistently estimate certain (non-microergodic) parameters will inform Bayesian modellers that inference for such parameters will always be sensitive to their prior specifications. This will open up new avenues of research in specifying prior distributions for microergodic parameters. Formal investigations into the consistency of the posterior distributions of Matérn covariogram parameters on manifolds are of inferential interest and may benefit from some of our developments in the current manuscript.
Other avenues for future developments will relate to computational efficiency of Gaussian processes on manifolds. Here, a natural candidate for explorations is the tapered covariogram on manifold to introduce sparsity in the covariance matrix (Furrer et al., 2006). Since our domain in the current manuscript is compact, unlike in Euclidean domains, further compact truncation is redundant. One can explore the development of new “tapered” covariograms that achieve positive-definiteness and sparsity. Other approaches that induce dimension reduction based on conditional expectations, such as Gaussian predictive processes (Banerjee et al., 2008), may be explored on compact Riemannian manifolds since these low-dimensional processes are induced by any valid probability measure, although the choice of inputs to define the lower dimensional subspace will need to be addressed. On the other hand, sparse processes resulting from approximations using directed acyclic graphs (Datta et al., 2016b) are less natural for modelling data on manifolds since they depend on well-defined neighbours of inputs, which are less obvious to define outside of Euclidean spaces. Nevertheless, Datta et al. (2016a) developed adaptive Nearest-Neighbour Gaussian processes for massive space-time data sets on Euclidean spaces that selected neighbours using the covariance kernel as a metric for proximity. Such an approach holds promise in modelling massive data sets on manifolds.
In addition, asymptotic properties of estimates under tapering are of interest and have, hitherto, been explored only in Euclidean domains (Kaufman et al., 2008; Du et al., 2009) and without the presence of measurement error processes (“nuggets”). Inference for Gaussian process models with measurement errors (nuggets) on compact manifolds also present novel challenges and can constitute future work. Identifiability and consistency of the nugget in Euclidean spaces have only recently started receiving attention (Tang et al., 2021). However, the developments for Euclidean spaces do not easily apply to compact Riemannian manifolds; hence new tools will need to be developed. On complex or unknown domains, the eigenvalues and eigenfunctions of the Laplacian operator need to be estimated (Belkin and Niyogi, 2007). Asymptotic analysis of estimation in the spectral domain should be closely related to the frequency domain. Finally, since compact manifolds are distinct from non-compact manifolds, both geometrically and topologically, generalisation to non-compact Riemannian manifolds is of interest, where the spectrum is not discrete. Analytic tools on non-compact manifolds will need to be developed.
Acknowledgments
DL would like to thank Viacheslav Borovitskiy, Yidan Xu and Aritra Halder for helpful discussions. DL was supported by NIH/NCATS award UL1 TR002489, NIH/NHLBI award R01 HL149683 and NIH/NIEHS award P30 ES010126. DL and SB were supported by NSF awards DMS-1916349, IIS-1562303, and NIH/NIEHS award R01ES027027. WT acknowledges support from NSF awards DMS-2113779 and DMS-2206038, and from a startup grant at Columbia University.
Appendix A. Proof of Lemma 3
Before proving Lemma 3, we recall the following lemma (Proposition B, Chapter III Yadrenko, 1983), also known as the Feldman-Hájek theorem:
Lemma 17 if and only if
Operator is Hilbert-Schmidt;
Eigenvalues of are strictly greater than −1,
where is the correlation operator of defined by:
Proof of Lemma 3. By Lemma 17, it suffices to check conditions 1 and 2. Let be the eigenvalue of and be the eigenvalue of . Observe that is an eigenfunction of with eigenvalue :
where is the Kronecker delta and is the inner product on with being orthonormal basis.
Since ’s share the same eigenfunctions and hence commute, we have , so condition 2 holds by the definition of . For condition 1, observe that , so
■
Appendix B. Proof of Theorem 4
Proof We start with (A). First assume that and , then observe
Note that as , then when is sufficiently large so that ,
As a result,
By Weyl’s law (equation (4.1) in Grebenkov and Nguyen (2013)), , so we have hence when . By the series test in Lemma .
For the other direction, observe that
As a result, if so by the series test.
Then assume and . Let , then
so and define two equivalent measures, denoted by and . Observe that
then the corresponding spectral densities and only differ by a multiplicative scalar so . So by Lemma is orthogonal to , so is , which is equivalent to . Now we conclude that if and only if and .
Then we show (B). As proved in (A), if so we assume . Recall that , so when is sufficiently large, , then
| (5) |
When or , the constant term and the linear coefficient in Equation (5) do not vanish at the same time hence . Then
since . By the series test, . When and so , which finises the proof of (B). ■
Appendix C. Proof of Theorem 5
Proof First assume , or without loss of generality, then
since . As a result,
Then assume but , similarly,
Then the series test applies. ■
Appendix D. Proof of Theorem 6
Proof Let so by Theorem 4. It suffices to show a.s. Recall that and under , where . As a result, a.s., as . ■
Appendix E. Proof of Lemma 7
Proof The logic of the proof is similar to the proof of Theorem 1 and 2 in Stein (1993). However, these two theorems are not directly applicable due to the discreteness of spectrum in our case. To be more specific, the key construction in the proof of Stein (1993) is the following. By the assumption, for any , there exists such that . We define
That is, differs from only on a bounded subset of . Note that in Stein (1993), the key step is to show , and the rest of the proof will not rely on any special structure of the Euclidean domain anymore. That is, it suffices to show , which is a direct consequence of the series test in Lemma 3. The rest of the proof of (i) naturally follows the proof of Theorem 1 in Stein (1993) while the proof of (ii) follows the proof of Theorem 2 in Stein (1993), where in Stein (1993) corresponds to in our paper. ■
Appendix F. Proof of Theorem 8
Proof For , let and be the spectral density of the Gaussian process parametrised by and hence . Then by (ii) in Lemma 7,
Observe that
| (6) |
The second term in Equation (6) tends to 1. For the first term, by the definition of , we obtain
Hence, the first term in Equation (6) is . Similar to the proof of Theorem a.s. By Theorem 4, , so the left hand side of Equation (6) tends to 1, a.s. ■
Appendix G. Proof of Theorem 9
Proof -dimensional spheres are compact Riemannian manifolds. The eigenfunctions of the Laplace operator on are known as spherical harmonics, denoted by . The corresponding eigenvalues are with multiplicity (Müller, 1966; Efthimiou and Frye, 2014)
So 1, 2, 3 follow directly from Theorem 4,6 and 8 respectively. ■
Appendix H. Proof of Theorem 15
Proof First we reformulate the covariogram as
where and
Observe that . Therefore,
As a result,
That is, if the target approximation error is , then we can truncate the infinite sum at
To prove positive definiteness, we first find the lower bound of the minimal eigenvalue of the covariance matrix , denoted by . By Theorem 2.8 (i) in Narcowich et al. (1998),
where
and is determined by the spectral density and the B-spline, see Equation (2.41) in Narcowich et al. (1998) for further details (where in our setting). Let the truncated covariance function be with minimal eigenvalue , then by the first half of the proof,
The second inequality follows from a matrix norm equivalence: for any matrix . The first inequality relies on the fact that for symmetric matrices and . Note that and let be the eigenvector of associated with the smallest eigenvalue, that is, . By the same observation, . Then,
For the last term, since , we have , hence as desired. Let , we have
Footnotes
This article does not consider the noise process, which introduces additional difficulties that are beyond the scope of the current manusript; see Tang et al. (2021) for related developments in Euclidean space.
Solin and Kok (2019) provides an alternative definition based on PDEs with boundary conditions.
Contributor Information
Didong Li, Department of Biostatistics, University of North Carolina at Chapel Hill, Chapel Hill, NC 27599, USA.
Wenpin Tang, Department of Industrial Engineering and Operations Research, Columbia University, New York, NY 10027, USA.
Sudipto Banerjee, Department of Biostatistics, University of California, Los Angeles, Los Angeles, CA 90095 USA.
References
- Abramowitz M and Stegun A. Handbook of Mathematical Functions: with Formulas, Graphs, and Mathematical Tables. Dover, 1965. [Google Scholar]
- Alegría A, Cuevas-Pacheco F, Diggle P, and Porcu E. The -family of covariance functions: a Matérn analogue for modeling random fields on spheres. Spat. Stat, 43:Paper No. 100512, 25, 2021. [Google Scholar]
- Anderes Ethan. On the consistent separation of scale and variance for Gaussian random fields. Annals of Statistics, 38(2):870–893, 2010. [Google Scholar]
- Arafat Ahmed, Porcu Emilio, Bevilacqua Moreno, and Mateu Jorge. Equivalence and orthogonality of Gaussian measures on spheres. Journal of Multivariate Analysis, 167: 306–318, 2018. [Google Scholar]
- Banerjee Sudipto. On geodetic distance computations in spatial modeling. Biometrics, 61 (2):617–625, 2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Banerjee Sudipto, Gelfand Alan E., Finley Andrew O., and Sang Huiyan. Gaussian predictive process models for large spatial data sets. Journal of the Royal Statistical Society: Series B (Methodology), 70(4):825–848, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Banerjee Sudipto, Carlin Bradley P., and Gelfand Alan E.. Hierarchical modeling and analysis for spatial data, volume 135 of Monographs on Statistics and Applied Probability. CRC Press, Boca Raton, FL, second edition, 2015. [Google Scholar]
- Belkin Mikhail and Niyogi Partha. Convergence of Laplacian eigenmaps. In NIPS, pages 129–136, 2007. [Google Scholar]
- Bevilacqua Moreno, Faouzi Tarik, Furrer Reinhard, and Porcu Emilio. Estimation and prediction using generalized Wendland covariance functions under fixed domain asymptotics. Annals of Statistics, 47(2):828–856, 2019. [Google Scholar]
- Bolin David and Kirchner Kristin. Equivalence of measures and asymptotically optimal linear prediction for Gaussian random fields with fractional-order covariance operators. arXiv, 2021. arXiv:2101.07860. [Google Scholar]
- Bolin David and Lindgren Finn. Spatial models generated by nested stochastic partial differential equations, with an application to global ozone mapping. Annals of Applied Statistics, 5(1):523–550, 2011. [Google Scholar]
- Borovitskiy Viacheslav, Terenin Alexander, Mostowsky Peter, and Deisenroth Marc. Matérn Gaussian processes on Riemannian manifolds. In NIPS, pages 12426–12437, 2020. [Google Scholar]
- Borovitskiy Viacheslav, Azangulov Iskander, Terenin Alexander, Mostowsky Peter, Deisenroth Marc, and Durrande Nicolas. Matérn Gaussian processes on graphs. In AISTATS, pages 2593–2601, 2021. [Google Scholar]
- Canzani Yaiza. Analysis on manifolds via the Laplacian, 2013. URL https://www.math.mcgill.ca/toth/spectral%20geometry.pdf.
- Castillo Ismaël, Kerkyacharian Gérard, and Picard Dominique. Thomas Bayes’ walk on manifolds. Probab. Theory Related Fields, 158(3–4):665–710, 2014. [Google Scholar]
- De la Cerda Jorge Clarke, Alegría Alfredo, and Porcu Emilio. Regularity properties and simulations of Gaussian random fields on the sphere cross time. Electronic Journal of Statistics, 12(1):399–426, 2018. [Google Scholar]
- Cressie Noel and Wikle Christopher K.. Statistics for spatio-temporal data. Wiley Series in Probability and Statistics. John Wiley & Sons, Inc., Hoboken, NJ, 2011. [Google Scholar]
- Da Prato Giuseppe and Zabczyk Jerzy. Stochastic equations in infinite dimensions, volume 152 of Encyclopedia of Mathematics and its Applications. Cambridge University Press, Cambridge, second edition, 2014. [Google Scholar]
- Damianou Andreas and Lawrence Neil D. Deep Gaussian processes. In AISTATS, pages 207–215, 2013. [Google Scholar]
- Datta A, Banerjee S, Finley AO, Hamm NAS, and Schaap M. Non-separable dynamic nearest-neighbor gaussian process models for large spatio-temporal data with an application to particulate matter analysis. Annals of Applied Statistics, 10:1286–1316, 2016a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Datta Abhirup, Banerjee Sudipto, Finley Andrew O., and Gelfand Alan E.. Hierarchical nearest-neighbor Gaussian process models for large geostatistical datasets. Journal of the American Statistical Association, 111(514):800–812, 2016b. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deisenroth Marc Peter, Fox Dieter, and Rasmussen Carl Edward. Gaussian processes for data-efficient learning in robotics and control. IEEE Transactions in Pattern Analysis and Machine Intelligence, 37(2):408–423, 2013. [DOI] [PubMed] [Google Scholar]
- do Carmo Manfredo Perdigão. Riemannian geometry. Mathematics: Theory & Applications. Birkhäuser Boston, Inc., Boston, MA, 1992. [Google Scholar]
- Du Juan, Zhang Hao, and Mandrekar VS. Fixed-domain asymptotic properties of tapered maximum likelihood estimators. Annals of Statistics, 37(6A):3330–3361, 2009. [Google Scholar]
- Dunson David B., Wu Hau-Tieng, and Wu Nan. Diffusion based Gaussian processes on restricted domains. arXiv, 2020. arXiv:2010.07242. [Google Scholar]
- Efthimiou Costas and Frye Christopher. Spherical harmonics in p dimensions. World Scientific Publishing Co. Pte. Ltd., Hackensack, NJ, 2014. [Google Scholar]
- Feragen Aasa, Lauze François, and Hauberg Søren. Geodesic exponential kernels: When curvature and linearity conflict. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3032–3042, 2015. doi: 10.1109/CVPR.2015.7298922. [DOI] [Google Scholar]
- Furrer Reinhard, Genton Marc G., and Nychka Douglas. Covariance tapering for interpolation of large spatial datasets. Journal of Computational and Graphical Statistics, 15(3): 502–523, 2006. [Google Scholar]
- Gao Tingran, Kovalsky Shahar Z, and Daubechies Ingrid. Gaussian process landmarking on manifolds. SIAM Journal of Mathematics of Data Science, 1(1):208–236, 2019. [Google Scholar]
- Gelfand Alan E., Diggle Peter J., Fuentes Montserrat, and Guttorp Peter, editors. Handbook of spatial statistics. Chapman & Hall/CRC Handbooks of Modern Statistical Methods. CRC Press, Boca Raton, FL, 2010. [Google Scholar]
- Genton Marc G.. Classes of kernels for machine learning: a statistics perspective. Journal of Machine Learning Research, 2(2):293–312, 2002. [Google Scholar]
- Ghosal Subhashis and van der Vaart Aad. Fundamentals of nonparametric Bayesian inference, volume 44 of Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge, 2017. [Google Scholar]
- Gneiting Tilmann. Strictly and non-strictly positive definite functions on spheres. Bernoulli, 19(4):1327–1349, 2013. [Google Scholar]
- Grebenkov Denis S and Nguyen B-T. Geometrical structure of laplacian eigenfunctions. SIAM Review, 55(4):601–667, 2013. [Google Scholar]
- Carlo Guella Jean, Antonio Menegatto Valdir, and Porcu Emilio. Strictly positive definite multivariate covariance functions on spheres. Journal of Multivariate Analysis, 166:150159,2018. [Google Scholar]
- Guinness Joseph and Fuentes Montserrat. Isotropic covariance functions on spheres: some properties and modeling considerations. Journal of Multivariate Analysis, 143:143–152, 2016. [Google Scholar]
- Herrmann Lukas, Kirchner Kristin, and Schwab Christoph. Multilevel approximation of Gaussian random fields: Fast simulation. Mathematical Models and Methods in Applied Sciences, 30(01):181–223, 2020. [Google Scholar]
- Jeong Jaehong and Jun Mikyoung. A class of Matérn-like covariance functions for smooth processes on a sphere. Spatial Statistics, 11:1–18, 2015a. [Google Scholar]
- Jeong Jaehong and Jun Mikyoung. Covariance models on the surface of a sphere: when does it matter? Stat, 4(1):167–182, 2015b. [Google Scholar]
- Jun Mikyoung and Stein Michael L.. Nonstationary covariance models for global data. Annals of Applied Statistics, 2(4):1271–1289, 2008. [Google Scholar]
- Kaufman CG and Shaby BA. The role of the range parameter for estimation and prediction in geostatistics. Biometrika, 100(2):473–484, 2013. [Google Scholar]
- Kaufman Cari G., Schervish Mark J., and Nychka Douglas W.. Covariance tapering for likelihood-based estimation in large spatial data sets. Journal of the American Statistical Association, 103(484):1545–1555, 2008. [Google Scholar]
- Kirchner Kristin and Bolin David. Necessary and sufficient conditions for asymptotically optimal linear prediction of random fields on compact metric spaces. Annals of Statistics, 50(2):1038–1065, 2022. [Google Scholar]
- Kobayashi Shoshichi and Nomizu Katsumi. Foundations of differential geometry. Vol I. Interscience Publishers, New York-London, 1963. [Google Scholar]
- Kunis Stefan. A note on stability results for scattered data interpolation on euclidean spheres. Advances in Computational Mathematics, 30(4):303–314, 2009. [Google Scholar]
- Lang Annika and Schwab Christoph. Isotropic Gaussian random fields on the sphere: regularity, fast simulation and stochastic partial differential equations. Annals of Applied Probability, 25(6):3047–3094, 2015. [Google Scholar]
- Lee John M.. Introduction to Riemannian manifolds, volume 176 of Graduate Texts in Mathematics. Springer, Cham, 2018. [Google Scholar]
- Li Peter. Book Review: Eigenvalues in Riemannian geometry. Bulletin of the American Mathematical Society (N.S.), 16(2):324–325, 1987. [Google Scholar]
- Lindgren Finn, Rue Hå vard, and Lindström Johan. An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach. Journal of the Royal Statistical Society: Series B (Methodology), 73(4):423–498, 2011. [Google Scholar]
- Ma Pulong and Bhadra Anindya. Beyond matérn: On a class of interpretable confluent hypergeometric covariance functions. Journal of the American Statistical Association, 0 (0):1–14, 2022. doi: 10.1080/01621459.2022.2027775. [DOI] [Google Scholar]
- Matérn Bertil. Spatial variation, volume 36 of Lecture Notes in Statistics. Springer-Verlag, Berlin, second edition, 1986. [Google Scholar]
- Matheron Georges. Principles of geostatistics. Econ. Geol, 58(8):1246–1266, 1963. [Google Scholar]
- Müller Claus. Spherical harmonics, volume 17 of Lecture Notes in Mathematics. Springer-Verlag, Berlin-New York, 1966. [Google Scholar]
- Narcowich Francis J., Sivakumar N, and Ward Joseph D.. Stability results for scattereddata interpolation on euclidean spheres. Advances in Computational Mathematics, 8(3): 137–163, 1998. [Google Scholar]
- Neal Radford M.. Regression and classification using Gaussian process priors. In Bayesian Statistics, 6 (Alcoceber, 1998), pages 475–501. Oxford Univ. Press, New York, 1999. [Google Scholar]
- Niu Mu, Cheung Pokman, Lin Lizhen, Dai Zhenwen, Lawrence Neil, and Dunson David. Intrinsic Gaussian processes on complex constrained domains. Journal of the Royal Statistical Society: Series B (Methodology), 81(3):603–627, 2019. [Google Scholar]
- Porcu Emilio, Bevilacqua Moreno, and Genton Marc G.. Spatio-temporal covariance and cross-covariance functions of the great circle distance on a sphere. Journal of the American Statistical Association, 111(514):888–898, 2016. [Google Scholar]
- Rasmussen Carl Edward and Williams Christopher K. I.. Gaussian processes for machine learning. Adaptive Computation and Machine Learning. MIT Press, Cambridge, MA, 2006. [Google Scholar]
- Sanz-Alonso Daniel and Yang Ruiyi. The SPDE Approach to Matérn Fields: Graph Representations. Statist. Sci, 37(4):519–540, 2022a. [Google Scholar]
- Sanz-Alonso Daniel and Yang Ruiyi. Finite Element Representations of Gaussian Processes: Balancing Numerical and Statistical Accuracy. SIAM/ASA Journal of Uncertainty Quantification, 10(4):1323–1349, 2022b. [Google Scholar]
- Solin Arno and Kok Manon. Know your boundaries: Constraining Gaussian processes by variational harmonic features. In AISTATS, pages 2193–2202, 2019. [Google Scholar]
- Stein Michael L.. A simple condition for asymptotic optimality of linear predictions of random fields. Statistics and Probability Letters, 17(5):399–404, 1993. [Google Scholar]
- Stein Michael L.. Interpolation of spatial data. Springer Series in Statistics. Springer-Verlag, New York, 1999. Some theory for Kriging. [Google Scholar]
- Tang Wenpin, Zhang Lu, and Banerjee Sudipto. On identifiability and consistency of the nugget in Gaussian spatial process models. Journal of the Royal Statistical Society: Series B (Methodology), 83(5):1044–1070, 2021. [Google Scholar]
- Wang Daqing. Fixed domain asymptotics and consistent estimation for Gaussian random field models in spatial statistics and computer experiments. Technical Report: National University of Singapore, 2010. [Google Scholar]
- Wang Daqing and Loh Wei-Liem. On fixed-domain asymptotics and covariance tapering in Gaussian random field models. Electronic Journal of Statistics, 5:238–269, 2011. [Google Scholar]
- Whittle P. Stochastic processes in several dimensions. Bulletin of the International Statistical Institute, 40:974–994, 1963. [Google Scholar]
- Yadrenko MI. Spectral theory of random fields. Optimization Software, Inc., Publications Division, New York, 1983. [Google Scholar]
- Zhang Hao. Inconsistent estimation and asymptotically equal interpolations in model-based geostatistics. Journal of the American Statistical Association, 99(465):250–261, 2004. [Google Scholar]