

Abstract
Aim:
Psychotic symptoms are typically measured using clinical ratings, but more objective and sensitive metrics are needed. Hence, we will assess thought disorder using the Research Domain Criteria (RDoC) heuristic for language production, and its recommended paradigm of “linguistic corpus-based analyses of language output”. Positive thought disorder (e.g., tangentiality and derailment) can be assessed using word-embedding approaches that assess semantic coherence, whereas negative thought disorder (e.g., concreteness, poverty of speech) can be assessed using part-of-speech (POS) tagging to assess syntactic complexity. We aim to establish convergent validity of automated linguistic metrics with clinical ratings, assess normative demographic variance, determine cognitive and functional correlates, and replicate their predictive power for psychosis transition among at-risk youths.
Methods:
This study will assess language production in 450 English-speaking individuals in Australia and Canada, who have recent onset psychosis, are at clinical high risk (CHR) for psychosis, or who are healthy volunteers, all well-characterized for cognition, function and symptoms. Speech will be elicited using open-ended interviews. Audio files will be transcribed and preprocessed for automated natural language processing (NLP) analyses of coherence and complexity. Data analyses include canonical correlation, multivariate linear regression with regularization, and machine-learning classification of group status and psychosis outcome.
Conclusions:
This prospective study aims to characterize language disturbance across stages of psychosis using computational approaches, including psychometric properties, normative variance and clinical correlates, important for biomarker development. SPEAK will create a large archive of language data available to other investigators, a rich resource for the field.
Keywords: Thought disorder, Ultra/clinical high risk, Natural language processing, Psychosis, Latent semantic analysis, Part-of-speech-tagging
1. Introduction
Speech and language reflect the coherence, complexity, emotional focus and content of human thinking and reasoning, and provide access to an individual’s cognitive and mental state. The rich source of data that can be obtained from this “window into the mind” has therefore been a primary source of information for psychiatrists and psychologists to diagnose and monitor treatment of mental disorders. The use of the analysis of speech as a proxy for mental states/processes is particularly suitable for clinical settings, as speech data are easy to acquire as it can be recorded during a clinical interview, reducing the need for questionnaires and decreasing participant burden. In addition, Large quantities of speech data can be obtained, which may maximize accuracy of (diagnostic or predictive) inferences from the data.
1.1. Speech patterns in schizophrenia
Disturbances in speech and language have been recognized as characteristic of schizophrenia for more than a century (Bleuler, 1950; Kraepelin, 2010). Among the abnormalities in language patterns identified in psychotic disorders are decreases in semantic or discourse coherence (e.g., tangentiality, derailment, and circumstantiality) and poverty of speech and content (Andreasen, 1979a). The systematic study of these two constructs continued in the 1970’s and they were labelled respectively as positive and negative thought disorder (TD) by Andreasen, who noted that in psychotic disorders, an individual “violates the syntactical and semantic conventions which govern language usage” (Andreasen, 1986).
1.2. Early analysis of the “psychotic mind” using speech-based methods
In line with the assumption that an individual’s mental state can be inferred from their spoken language, Andreasen’s observations led to the development of the Scale for the Assessment of Thought, Language and Communication (TLC) (Andreasen, 1979a), based on assessing a “patient’s [natural] speech and language behavior […] without complicated experimental procedure” (Andreasen and Grove, 1986). Andreasen was also among the first to address the specificity and sensitivity of these concepts, noting that positive TD could be found among individuals with different diagnoses, such as depression, mania, and schizophrenia, whereas negative TD was more prevalent in schizophrenia than in mood disorders (Andreasen, 1979b). The specificity of poverty of speech to schizophrenia cohorts compared to the presence of disturbance of speech coherence across psychotic and mood disorders was confirmed in a later meta-analysis (Yalincetin et al., 2017).
1.3. Early studies of language disturbance in clinical high risk for psychosis
Beyond investigating associations of speech patterns in psychotic disorders such as schizophrenia, efforts have also been made to use language to forecast the onset of threshold psychotic disorders in individuals who are at risk but do not yet meet threshold diagnostic criteria (Yung et al., 2003). Those efforts are motivated by the morbidity associated with psychotic disorders, especially their impact on basic social, educational and occupational role function (Marggraf et al., 2020; Racenstein et al., 1999) and the fact that languages disturbances identified in psychotic disorders are related to this functional disability and to worse outcomes (Roche et al., 2015).
For example, among children (~ages 9–10) who had parents with serious mental illness, including schizophrenia and mood disorders, their TLC ratings of positive and negative thought disorder (TD), based on their spoken language, were highly predictive of later schizophrenia onset during early adulthood, with accuracy as high as 94 % (Gooding et al., 2013). While behavior-based coding strategies have considerable utility, they are limited when used alone: they are ordinal-based with a limited response set and depend on clinical judgment. Beyond the TLC, therefore, speech patterns in TD have also been assessed using manual linguistic methods that operationalize language abnormalities and assess their frequency via speech transcripts. The application of manual linguistic analysis to speech transcripts of clinical high risk for psychosis (CHR) individuals (Bearden et al., 2011) showed that later transition to psychosis was predicted by increased frequency of semantic features such as illogical thinking in brief free speech, with accuracy of 71 %, compared with 35 % for clinical ratings. Poverty of content and decreased referential cohesion, both indices of syntactic complexity, also predicted psychosis onset in this CHR sample.
While these studies demonstrate the advantages of an operationalized manual linguistic approach in predicting onset of psychosis in CHR individuals over subjective clinical ratings and coding, they are nonetheless laborious and time-consuming, require highly trained raters and are impractical to implement in larger studies, and eventually in the clinic. Moreover, they depend upon predefined measures that might not fully capture critical deficits (Corcoran and Cecchi, 2020).
1.4. Natural language processing (NLP)
Recent developments in artificial intelligence have led to the development of objective and sensitive automated methods of “natural language processing” (NLP), which can provide deep and comprehensive analysis of speech and language data. These methods are based in machine learning algorithms that have been trained on a large corpus of text obtained from the internet, resulting in probabilistic representations of grammar (syntax) and vocabulary (semantics) of human speech. As a result, NLP allows for a data-driven, objective, and automated analysis of human speech. Of note, the NLP approach is also in line with the Research Domain Criteria (RDoC) approach, which promotes the adoption of operationalized, objective and individualized diagnostics and treatment standards based on symptoms and units of mental (ill) health (Insel, 2017). The NLP approach aligns with the RDoC “linguistic corpus-based” paradigm for studying the construct of language production, both for the study of semantics and syntax.
1.5. NLP methods to study language
Automated methods for deep language analysis are already widely used in industry and are only beginning to be applied to clinical/research datasets in psychiatry. We posit that speech alterations such as reduced syntactic complexity (shorter sentences, fewer dependent clauses) can be assayed with POS tagging (Santorini, 1990) and speech graphs (Mota et al., 2012) while reduced semantic coherence can be measured via word embedding approaches such as latent semantic analysis (LSA) (Landauer et al., 1998), and secondarily bizarreness (or perplexity) (Chen et al., 1998; Vail et al., 2018) and metaphoricity (Gutíerrez et al., 2017). These concepts will be outlined in more detail in the following paragraphs. Of note, analyses of both semantic coherence (e.g., word embeddings such as latent semantic analysis) and syntactic complexity (e.g., part-of-speech tagging) can be done using open-source software available through the Natural Language Tool Kit website (nltk.org).
1.6. Word embedding analyses of coherence: LSA
Automated latent semantic analysis (LSA) provides an objective, sensitive and intrinsically reliable computational approach for quantifying the flow of ideas, including the disjointed flow that can be present in patients with schizophrenia. In doing so, it overcomes the subjectivity of clinical ratings and limitations of simple but labor-intensive manual methods. The method is based on creating a high dimensional representation (300–400 dimensional vectors) of the sematic proximity of words in the lexicon, which is obtained by training machine learning algorithms on large corpuses of text (e.g., from the internet). Information-obtained word similarity is stored in a probability distribution that describes the frequencies of co-occurrence for each word with every other word in the lexicon, across contexts. For example, “happy” and “cheerful” would be rated as highly similar, due to their high co-occurrence. Formally, the semantic similarity between words is indexed by the cosine of the angle between word vectors (or word embeddings), a measure that ranges from −1.0 to 1.0. Of note, the field of semantic speech analysis constantly evolves and is in flux, such that new methods of constructing word embeddings beyond LSA have been created, including Word2Vec (Mikolov et al., 2013), GloVe (Pennington et al., 2014) and more recently BERT (Devlin et al., 2019).
1.7. Word embedding approaches to study semantic coherence in psychosis
LSA has been used since the early 2000s to study language alterations in schizophrenia. One of the first applications of LSA to speech data from schizophrenia patients was conducted by Elvevåg, who found that LSA semantic coherence measures were able to differentiate language patterns of individuals with schizophrenia from those of healthy controls (82 % accuracy; Elvevåg et al., 2007) and from their unaffected adult siblings (86 % accuracy; Elvevåg et al., 2010). Decreased LSA semantic coherence has convergent validity in that is correlated with clinical ratings of thought disorder in both schizophrenia (Elvevåg et al., 2007, 2010) and among clinical high risk (CHR) individuals (Bilgrami et al., 2022), demonstrating construct validity. Further, these NLP metrics are clinically relevant, as decreased LSA semantic coherence has been associated with poorer functioning, including in older schizophrenia patients (Holshausen et al., 2014), independent of demographics and other symptoms.
1.8. Part-of-speech (POS) tagging approaches to study syntactic complexity
Part-of-speech tagging allows for the assessment of syntactic complexity in language and may be used to indicate poverty of speech in schizophrenia. It involves “tagging” each word in a transcript with respect to its grammatical function (Bird, 2009; Santorini, 1990). Similar to word embedding approaches such as LSA, POS tagging is linguistic corpus-based in that it relies on the scanning of large corpuses of text. The grammatical function of words can be identified using the University of Pennsylvania (Penn) Treebank Tag-set (Santorini, 1990), comprising thirty-six “part-of-speech” tags, including nouns, verbs, prepositions, and other parts of speech. Syntactic complexity can be determined in that POS tagging leads to the determination of sentence length, and that rates of usage of parts of speech can be calculated, such as complementizer words (such as ‘that’ and ‘which’), that introduce dependent clauses. By contrast to LSA analyses of coherence, there have been only a few studies (Bedi et al., 2015; Corcoran et al., 2018) using POS tagging to analyze syntactic complexity in psychiatry, specifically risk for schizophrenia.
1.9. Analyses of coherence and complexity in clinical high risk (CHR) states for psychosis
Given the presence of reductions in both semantic coherence (positive TD) and syntactic complexity (negative TD) in schizophrenia, we plan to use both LSA and POS tagging in combination to study speech disturbances in CHR. The focus of most studies so far has been on the predictive value of language patterns for transition to psychosis. In an early small study, Bedi et al. (Bedi et al., 2015) showed that reductions in complexity and coherence were predictive of psychosis onset and were correlated with symptom severity in CHR individuals, with a machine classifier based on these metrics outperforming symptom ratings in predictive accuracy. Of note, this linguistic classifier was also able to distinguish among Portuguese-speaking schizophrenia patients and healthy comparison subjects in Brazil, who were previously studied by Mota (Mota et al., 2012), with their transcripts translated to English using Google Translate (unpublished data). In a subsequent study of linguistic predictors of later psychosis onset among CHR individuals, Corcoran and Cecchi (Corcoran et al., 2018) applied a combination of LSA and POS to speech transcripts from Bearden’s manual linguistic study (Bearden et al., 2011), cited above, finding a highly accurate machine learning linguistic classifier that could predict psychosis onset in two independent CHR cohorts, thereby showing cross-validation. The classifier was also highly correlated with the manual ratings of illogical thinking and poverty of content, demonstrating convergent validity of the NLP features with “ground truth” manual ratings.
1.10. Other NLP approaches for evaluating language in psychosis and its risk states
1.10.1. Metaphoricity and perplexity to study semantic coherence
Other NLP approaches have been considered for analysis in this project, including perplexity (i.e., bizarreness) and metaphor usage as indices of positive thought disorder. Early manual linguistic studies have shown that while schizophrenia patients and healthy controls have equivalent rates of coherent metaphor production, schizophrenia patients use deviant and bizarre metaphors at significantly higher rates (Billow et al., 1997). Now, automated NLP methods have been developed that identify and tag words used in metaphoric constructions (Gutíerrez et al., 2017), finding increased use in a small cohort of clinical high-risk individuals, as compared to healthy controls. Perplexity is an NLP metric that estimates infrequency of word use in a specific text as compared to a very large corpus (Chen et al., 1998): small studies show increase in NLP perplexity (e.g., bizarreness) among schizophrenia patients (Vail et al., 2018).
1.10.2. Speech graphs to study syntactic complexity
Another approach for studying language patterns in schizophrenia and its risk states is speech graph analysis (see Fig. 1), as speech can be represented as a graph or network with nodes (words) connected by edges (semantic and grammatical relationships; Mota et al., 2012). Mota and colleagues have shown that speech in patients with manic symptoms shows significantly more total nodes and edges, with more connectivity and recurrence, as compared with the sparser speech patterns of patients with schizophrenia, consistent with studies that show more negative TD (poverty of content and output) in schizophrenia (Andreasen, 1979b; Marggraf et al., 2020; Yalincetin et al., 2017). In a more recent study, Spencer and colleagues (Spencer et al., 2021) found in a small study that “speech graph” connectedness measures were lower in individuals with first episode psychosis (FEP), as compared to CHR individuals and healthy controls, and that lower speech connectedness was predictive of transition to psychosis in CHR individuals. Further exploratory studies will evaluate the emotional content of words spoken, or sentiment, which can also be tagged using a similar linguistic corpus-based approach, with each word tagged as positive, neutral or negative.
Fig. 1.
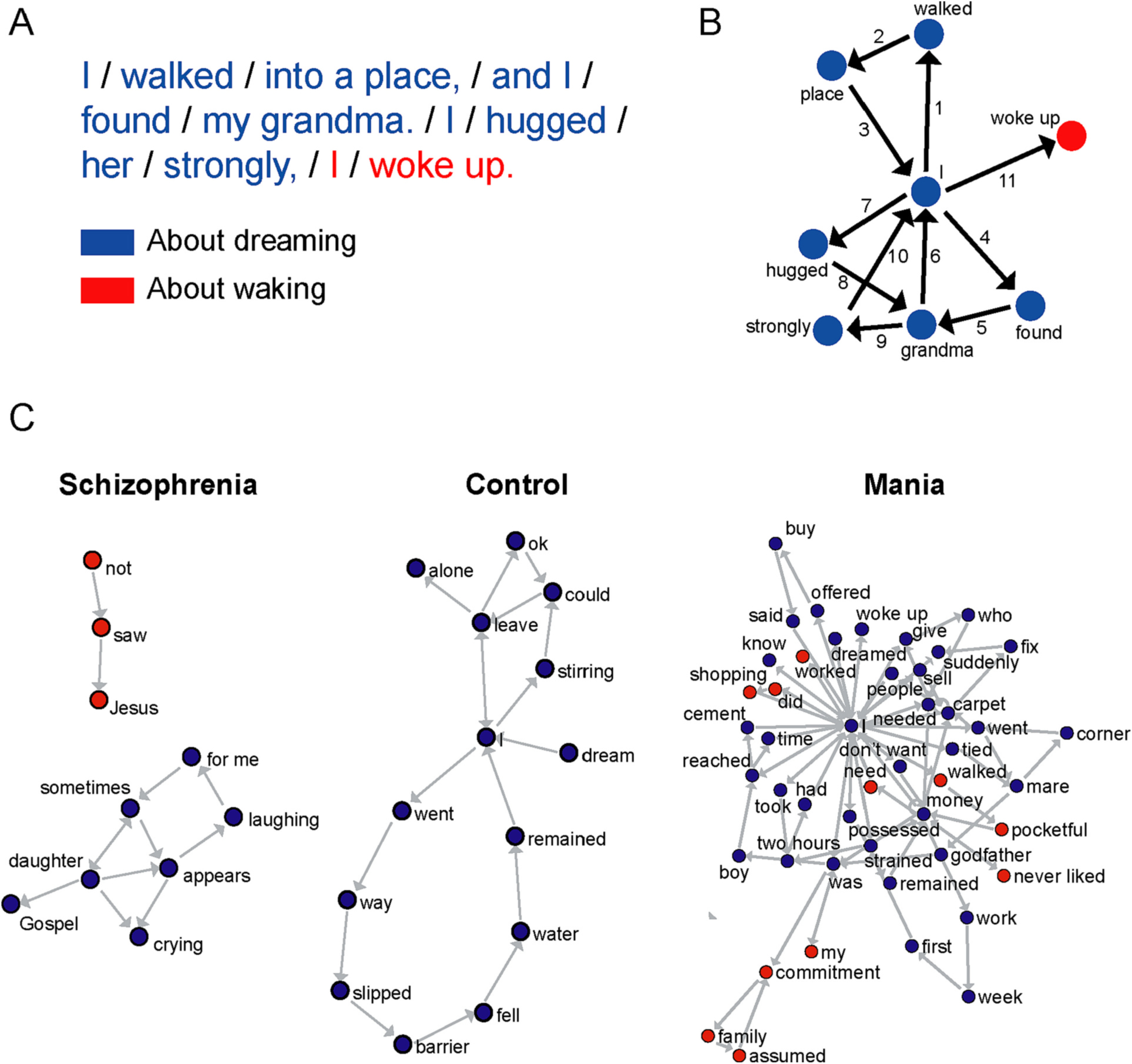
Speech graph analysis by Mota et al. (2012). (A). Parsing of words into canonical elements (separated by slashes) from reposting a dream. (B) Speech graph from example in (A). (C) speech graph patterns representative for individuals with schizophrenia, control, and, mania. For full analysis see Mota et al. (2012) adapted from Mota et al. (2012) with permission.
1.11. SPEAK will result in a large language archive in CHR
The cohort created by the present study will provide a rich archive of language data across stages of psychosis that will be available to other investigators, who may employ other NLP metrics to test for correlations with demographics, clinical features and cognition, as well as identify group differences and predict psychosis and other outcomes among CHR participants. For example, other investigators have found that other NLP metrics of language disturbance can predict psychosis among CHR individuals, including semantic content (e.g., using words related to “hearing”), and semantic density (the richness of ideas within phrases and sentences, Rezaii et al., 2019) using a skip-gram version of Word2Vec.
Unlike the previous studies cited, the current study will involve hundreds of participants, from whom language will be elicited using naturalistic open-ended interview. Prior studies suggest that NLP can identify abnormal language patterns across stages of psychosis that may have predictive value. Here, to better understand the linguistic underpinnings of language disturbance in psychosis and its risk states, the current study (SPEAK) will assess these features dimensionally with respect to demographics, clinical ratings of positive and negative thought disorder, cognition and functional capacity, in a large cohort that captures the range from normal/subtle to overt across stages of psychosis, in comparison with healthy individuals. Due to the large coverage of clinical symptoms and the specificity of some of our measures, we expect large variance in the NLP metrics, with many CHR individuals appearing to have normal language (and lack of thought disorder), similar to other features (e.g. relatively intact cognition in many CHR individuals). The longitudinal follow-up will enable an assessment of the stability of these linguistic features over time (e.g., test-retest reliability), as prior studies show that clinical ratings of language disturbance in CHR remain stable over time, and do not worsen with psychosis onset (DeVylder et al., 2014), as well as their predictive value for clinical outcome.
2. Study rationale
The main goal of this study is to refine our understanding of language disturbance in psychosis and its risk states, in the context of normal population variance, which may inform prediction and intervention strategies. The study aims to address NIMH “concept clearances” for biomarker development and validation, as it comprises tests of validity and reliability, and identification of sources of variability. Specifically, this includes cross-site validation and estimates of convergent validity with clinical ratings (e.g., “ground truth”), test-retest reliability, and variability (by age, sex, and ethnicity). This protocol aims to also identify clinical relevance, in terms of concurrent association with and prediction of function and symptoms, as well as explore potential mechanisms, in respect to associations with processing speed, working memory and other cognitive domains.
3. Aims and hypotheses
3.1. Aim 1
We will apply latent semantic analysis (Landauer et al., 1998) to measure semantic coherence in language production and examine its association with positive TD and functional impairment in CHR and FEP participants. We will use complementary semantic measures of metaphoricity (Gutíerrez et al., 2017) and perplexity (i.e., bizarreness; Chen et al., 1998; Vail et al., 2018) to see if these strengthen these associations.
Hypothesis 1. Reduced semantic coherence will be correlated with positive TD and functional impairment in both the CHR and FEP groups.
3.2. Aim 2
We will apply POS tagging (Santorini, 1990) to measure syntactic complexity in language production and examine its association with negative TD and functional impairment in CHR and FEP participants. We will use complementary speech graph methods (Mota et al., 2012) to see if these strengthen these associations.
Hypothesis 2. Reduced syntactic complexity (from POS tagging and speech graphs) will be correlated with negative TD and functional impairment in the CHR and FEP groups.
3.3. Aim 3
We will investigate whether measures of semantic coherence and syntactic complexity predict onset of psychotic disorder and functional impairment in CHR participants.
Hypothesis 3. Reduced semantic coherence and reduced syntactic complexity will together constitute a classifier that predicts later psychosis onset in the CHR cohort.
3.4. Aim 4
This large archive of language data will be available for analysis to determine correlates of TD, both semantic and syntactic. We will make the language dataset available for future analyses.
4. Methods
4.1. Study setting
The study is an international, multi-site study led by The Icahn School of Medicine at Mt. Sinai. Participants are recruited from: 1) Orygen Specialist Program and four headspace centers in Melbourne, Australia; 2) The Centre for Addiction and Mental Health (CAMH) in Toronto, Canada. These two sites were chosen because they have well established early psychosis and CHR clinical research programs with clinical researchers interested specifically in language disturbances and their associations with thought disorder. Orygen is a government funded mental health program for young people in Melbourne. The four headspace centers, provide universal access under a federally funded model of enhanced primary care to a broad array of mental health and welfare services. CAMH is a psychiatric teaching hospital with 90 distinct clinical services across inpatient, outpatient, day treatment, and partial hospitalization models. The study’s onset is contingent upon receipt of all appropriate ethical approvals and meeting all regulatory requirements of local competent authorities.
4.2. Participants
Participants will include individuals identified as being at Clinical High Risk (CHR) for psychosis (N = 150), experiencing recent-onset psychosis (<2 years’ duration) (N = 150), and healthy individuals (N = 150) ascertained from the same source population. Individuals who are at CHR for psychosis have attenuated or subthreshold psychotic symptoms that are clinically relevant; among CHR individuals, transition rates to psychosis are 36 % within three years (Fusar-Poli et al., 2012). CHR and recent-onset psychosis participants will be recruited from clinics and healthy controls were recruited from the community through social media advertising. Inclusion and exclusion criteria are listed in Table 2.
Table 2.
Inclusion and exclusion criteria.
| Inclusion criteria |
|
| Exclusion criteria |
|
4.3. Study duration
Recruitment will occur over four years. CHR participants will be followed at 12 months post-baseline to determine functional outcome and rate of psychosis onset, as well as stability in language variables.
4.4. Visits and assessments
The schedule of assessments and measures used to determine eligibility, demographics, medical and psychiatric history, medication exposures, psychiatric symptoms, diagnosis, substance use and psychosocial functioning (Table 1). All participants will be assessed at baseline with CHR participants being re-assessed with a subset of measures at 12 months follow up. All scoring of clinical assessments and measurements will be done by trained raters at the specific site and collated to a final data base, except for the TLC, which will entirely be scored by trained raters at the New York Site. TLC raters will be blind to group status.
Table 1.
Schedule of assessments and measures.
| Visit number | 1 | 2 | 3 |
|---|---|---|---|
| Assessments | Screening interview and medical file review | Baseline | Month 12 end of study (only for CHR) |
| X | |||
| Inclusion/exclusion criteria | X | ||
| Demographics | X | ||
| Medical and psychiatric history | X | ||
| Treatment log | X | X | X |
| Speech elicitation and transcription | X | X | |
| Clinical assessments | |||
| SCID-5 | X | X | |
| CAARMS (Australia) or SIPS (Canada)a | X | X | |
| PANSSb | X | X | |
| Neurocognition | |||
| WASI (IQ) | X | ||
| MATRICS | X | ||
| SOFAS | X | X | |
| GF: social and role | X | X |
SIPS(Woods et al., 2019): Structured Interview for Psychosis-Risk Syndromes. CAARMS(Yung et al., 2005): The Comprehensive Assessment of At-Risk Mental States. SCID-5(First et al., 1993): The Structured Clinical Interview for DSM disorders. PANSS(Kay and Opler, 1987): Positive and Negative Syndrome Scale. ASSIST: Alcohol, Smoking and Substance Involvement Screening Test. SOFAS(Morosini et al., 2000): Social and Occupational Functioning Scale. GF:S(Cornblatt et al., 2007): Global Functioning Social Scales. GF:R(Cornblatt et al., 2007.):Global Functioning Role Scales. WASI(Wechsler, 1999): IQ measure. MATRICS(Stone et al., 2016): includes domains for processing speed, attention/vigilance, working memory, verbal learning, visual learning, and reasoning/problem-solving.
Not in recent-onset psychosis participants.
Only in recent-onset psychosis participants.
4.5. Speech elicitation and transcription
All participants will have an open-ended audiotaped narrative interview of 30 to 45 min to elicit free natural speech, following methods applied previously by our group (Bedi et al., 2015; Ben-David et al., 2014). Interviewers at each site will be trained in qualitative interviewing methods based in phenomenological methods (Davidson, 1994) that aim to elicit description of subjective experience. Prompts include perceived changes over time and their impact, and expectations for the future. Interviewers will be trained to minimize interruption, and use clarifying questions to promote speech production. Interview audio files will be sent to New York, where they will be transcribed and manually de-identified (substitution of proper names with pronoun or role). These de-identified transcripts will be used for both clinical analyses using the Thought, Language and Communication (TLC) scale (Andreasen, 1986) and automated linguistic corpus-based analyses.
4.5.1. Clinical ratings of thought disorder
Speech transcripts will be rated for negative and positive TD using the Scale for the Assessment of Thought, Language and Communication (TLC; Andreasen, 1986) by research assistants based at the New York site trained to reliability, consistent with previous work conducted by the New York site. Additional ratings of TD include the Positive and Negative Symptom Scale (PANSS; Kay and Opler, 1987) Disorganization factor and the SIPS (Woods et al., 2019) and CAARMS (Yung et al., 2005) Disorganized Communication items.
4.6. Data analysis
4.6.1. Automated linguistic corpus-based analyses of speech
Speech preprocessing will be done using the open access software of the Natural Language Toolkit (www.nltk.org) and will include discarding punctuation and conversion of words to roots from which they are inflected (NLTK WordNet lemmatizer). POS tagging (Santorini, 1990) will be done using Treebank tagger in NLTK for determination of sentence boundaries and estimate of usage of grammatical functions. Preprocessed data will also undergo Latent Semantic Analysis (LSA; Landauer et al., 1998) trained on TASA Corpus, to generate semantic coherence parameters, with a focus on sentence-level semantic coherence (Bedi et al., 2015). Speech graph analysis (Mota et al., 2012) will also be used to supplement POS tagging to assess syntactic complexity and negative TD. In speech graph analysis, nodes denote individual words or “backbone speech elements” that correspond to subject, verb and object; and edges are temporal links between them (e.g., they occur in succession). Finally, we will also use NLP tagging of metaphoric constructions (Gutíerrez et al., 2017) and perplexity (i.e., bizarreness; Vail et al., 2018) to supplement LSA coherence analyses in assessing positive TD. Overall, speech features will be assessed for correlations with clinical ratings of thought disorder and function, as well as demographics and cognitive capacity.
4.6.2. Hypothesis 1: semantic coherence will be correlated with positive TD and functional impairment
This analysis will be implemented using canonical correlation, which finds the linear combination of features in one space that is most correlated with features in a second space. We will use an extended set of semantic coherence features, including statistical properties of phrase-to-phrase semantic alignment (minimum, standard deviation, kurtosis, etc.), and usage of bizarreness-tagged words and metaphoric constructions in respect to clinical ratings and function. We will also implement machine learning techniques to identify semantic-TD+ correlations, including L1/L2 regularized multivariate linear and logistic regression, and regularized inverse covariance. An alternative approach is to consider the relation between semantic and clinical variables (symptoms, function) as a causal one, measuring this with the inverse covariance (Prill et al., 2015).
4.6.3. Hypothesis 2: measures of syntactic complexity (from POS and speech graphs) will be correlated with negative TD and functional impairment
POS tagging and speech graph analyses will be done to examine syntactic complexity. We will use tag labels to define features based on their frequency of occurrence, and the parsing trees to define measures of complexity based on the depth and connectivity of the trees. As in specific aim 1, canonical correlation methods will be applied to find the linear combination of syntactic features that is most correlated with negative TD. Besides using regularization approaches, we will also implement a cross-validated approach to enforce statistical significance, including a leave-subject out approach. Exploratory analyses will include canonical correlation with both semantic and syntactic features together, and convex hull analyses.
4.6.4. Hypothesis 3: reduced semantic coherence and reduced syntactic complexity will together constitute a classifier that predicted later psychosis onset in the CHR cohort
Speech features will be fed into a convex hull classification algorithm with leave-one-subject-out cross-validation to assess their predictive value for psychosis outcome (transition to first episode psychosis) in the CHR participants. Repeated-measures ANOVA and linear regression will be used for prediction of functional outcome.
4.6.5. Potential covariates and relevant biological variables
Potential covariates will be considered in analyses, including demographics (age, gender, educational status, ethnicity, SES, site), cognition (IQ, verbal fluency, processing speed, working memory), and use of medications (antipsychotics yes/no) and drugs of abuse (tobacco yes/no, cannabis yes/no). While we have not yet found sex effects on language production thus far, our studies were small. Language production will be assessed across development, from early adolescence to adulthood, indicating the need to covary for age.
4.6.6. Sample size and power
For Aims 1 and 2, the primary analyses are canonical correlations, which generally require a sample size that is −20× greater than the number of variables (−20 per analysis), and an N > 200 to detect R < 0.328. Attrition in this study is expected to be <5 % (cancellation, lost or unusable data), but even if 10 %, N − 400 provides sufficient power not only for canonical correlation analyses of semantic and syntactic variables with positive and negative TD, and with functional impairment, but also for machine learning SVM classification with convex hull and logistic modeling for categorical variables (e.g. sex) (Figueroa et al., 2012) to study biological variables, cross-site validation for reproducibility, and for estimates of developmental trajectories, including linear and non-linear models.. This estimation is based on the aim to provide sufficient power to perform a reliable detection and prediction of an25–30 % converter rate to psychosis with an Area Under the Curve Sensitivity/Specificity of 0.7–0.75 within a binary classification scheme (Mason and Graham, 2002).
4.6.7. Rigor and reproducibility
The inclusion of two sites offers the opportunity to cross-validate findings of associations with TD and function across the two sites, as we have done for psychosis prediction.
5. Summary
This paper presents the rationale and methodology of the SPEAK study, which is being conducted to examine disturbances in language production and use as an objective biomarker of thought disorder across stages of psychosis, its association with symptoms and functioning, and its predictive utility in heterogeneous cohorts of CHR patients. Automated linguistic corpus-based analysis of semantics and syntax is a promising new paradigmatic approach to the characterization of thought disorder and language disturbance across development, both dimensionally and trans-diagnostically. This study will generate a large international rich archive of language data (in English) across stages of psychosis, in participants who are well-characterized for symptoms, function and key covariates.
Acknowledgements
The resaerch for this paper was funded by the grant Using the RDoC Approach to Understand Thought Disorder: A Linguistic Corpus-Based Approach (R01 MH115332)
Footnotes
CRediT authorship contribution statement
J. M. M. B. contributed to writing of the original draft, review & editing of following drafts, visualization and literature review.
J. S. contributed project supervision and administration.
M. K. contributed to project supervision and administration.
M.F. contributed project supervision and administration.
K. G. contributed to data collection.
A. S. contributed to data analysis, study design and manuscript review.
A.S: contributed to data analysis.
M.C. contributed to project supervision.
J. H. contributed to supervision.
A P. contributed to project administration and supervision.
Z. R. B. contributed to study design, literature review and data analysis, manuscript review and project administration.
C. S. contributed to study design, literature review and data analysis, manuscript review and project administration.
A. L. contributed to literature review, manuscript review, project administration.
A. R. Y: contributed to manuscript review and editing.
A. McG. contributed to literature review, manuscript review, project administration.
P. McG: contributed to obtaining funding and study design.
J. L. S. contributed to manuscript review and editing.
G. A. contributed to study design.
R. M. contributed to review & editing, supervision and project administration.
B. N. contributed to review & editing, supervision, project administration and funding acquisition.
C. M. C: contributed to review & editing, supervision, project administration and funding acquisition.
Declaration of competing interest
The authors declare no real or potential conflict of interest. All authors have reviewed and approved the manuscript before submission.
References
- Andreasen NC, 1979a. Thought, language, and communication disorders: I. Clinical assessment, definition of terms, and evaluation of their reliability. Arch. Gen. Psychiatry 10.1001/archpsyc.1979.01780120045006. [DOI] [PubMed] [Google Scholar]
- Andreasen NC, 1979. Thought, language, and communication disorders: II. Diagnostic significance. Arch. Gen. Psychiatry 10.1001/archpsyc.1979.01780120055007. [DOI] [PubMed] [Google Scholar]
- Andreasen NC, 1986. Scale for the assessment of thought, language, and communication (TLC). Schizophr. Bull 10.1093/schbul/12.3.473. [DOI] [PubMed] [Google Scholar]
- Andreasen NC, Grove WM, 1986. Thought, language, and communication in schizophrenia: diagnosis and prognosis. Schizophr. Bull 12 10.1093/schbul/12.3.348. [DOI] [PubMed] [Google Scholar]
- Bearden CE, Wu KN, Caplan R, Cannon TD, 2011. Thought disorder and communication deviance as predictors of outcome in youth at clinical high risk for psychosis. J. Am. Acad. Child Adolesc. Psychiatry 10.1016/j.jaac.2011.03.021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bedi G, Carrillo F, Cecchi GA, Slezak DF, Sigman M, Mota NB, Ribeiro S, Javitt DC, Copelli M, Corcoran CM, 2015. Automated analysis of free speech predicts psychosis onset in high-risk youths. NPJ Schizophr 1 10.1038/npjschz.2015.30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ben-David S, Birnbaum ML, Eilenberg ME, DeVylder JE, Gill KE, Schienle J, Azimov N, Lukens EP, Davidson L, Corcoran CM, 2014. The subjective experience of youths at clinically high risk of psychosis: a qualitative study. Psychiatr. Serv 65 10.1176/appi.ps.201300527. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bilgrami ZR, Sarac C, Srivastava A, Herrera SN, Azis M, Haas SS, Shaik RB, Parvaz MA, Mittal VA, Cecchi G, Corcoran CM, 2022. Construct validity for computational linguistic metrics in individuals at clinical risk for psychosis: associations with clinical ratings. Schizophr. Res 10.1016/j.schres.2022.01.019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Billow RM, Rossman J, Lewis N, Goldman D, Raps C, 1997. Observing expressive and deviant language in schizophrenia. Metaphor. Symb 10.1207/s15327868ms1203_3. [DOI] [Google Scholar]
- Bird S, 2009. Natural language processing and linguistic fieldwork. Comput.Linguist 10.1162/coli.35.3.469. [DOI] [Google Scholar]
- Bleuler E, 1950. Dementia praecox or the group of schizophrenias (Zinkin J, trans.). In: Dementia Praecox Or the Group of Schizophrenias (J. Zinkin, trans.). [PubMed] [Google Scholar]
- Chen S, Beeferman D, Rosenfeld R, 1998. Evaluation metrics for language models. In: Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop. [Google Scholar]
- Corcoran CM, Cecchi GA, 2020. Using language processing and speech analysis for the identification of psychosis and other disorders. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 10.1016/j.bpsc.2020.06.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Corcoran CM, Carrillo F, Fernández-Slezak D, Bedi G, Klim C, Javitt DC, Bearden CE, Cecchi GA, 2018. Prediction of psychosis across protocols and risk cohorts using automated language analysis. World Psychiatry 17. 10.1002/wps.20491. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cornblatt BA, Auther AM, Niendam T, Smith CW, Zinberg J, Bearden CE, Cannon TD, 2007. Preliminary findings for two new measures of social and role functioning in the prodromal phase of schizophrenia. 10.1093/schbul/sbm029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davidson L, 1994. Phenomenological research in schizophrenia: from philosophical anthropology to empirical science. J. Phenomenol. Psychol 10.1163/156916294X00133. [DOI] [Google Scholar]
- Devlin J, Chang MW, Lee K, Toutanova K, 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In: NAACL HLT 2019 – 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies - Proceedings of the Conference, 1, pp. 4171–4186. [Google Scholar]
- DeVylder JE, Muchomba FM, Gill KE, Ben-David S, Walder DJ, Malaspina D, Corcoran CM, 2014. Symptom trajectories and psychosis onset in a clinical high-risk cohort: the relevance of subthreshold thought disorder. Schizophr. Res 159 10.1016/j.schres.2014.08.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elvevåg B, Foltz PW, Weinberger DR, Goldberg TE, 2007. Quantifying incoherence in speech: an automated methodology and novel application to schizophrenia. Schizophr. Res 10.1016/j.schres.2007.03.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elvevåg B, Foltz PW, Rosenstein M, DeLisi LE, 2010. An automated method to analyze language use in patients with schizophrenia and their first-degree relatives. J. Neurolinguistics 10.1016/j.jneuroling.2009.05.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Figueroa RL, Zeng-Treitler Q, Kandula S, Ngo LH, 2012. Predicting sample size required for classification performance. BMC Med. Inform. Decis. Mak 12 10.1186/1472-6947-12-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- First MB, Opler LA, Hamilton RM, Linder J, Linfield LS, Silver JM, Toshav NL, Kahn D, Williams JBW, Spitzer RL, 1993. Evaluation in an inpatient setting of DTREE, a computer-assisted diagnostic assessment procedure. Compr. Psychiatry 34. 10.1016/0010-440X(93)90043-4. [DOI] [PubMed] [Google Scholar]
- Fusar-Poli P, Bonoldi I, Yung AR, Borgwardt S, Kempton MJ, Valmaggia L, Barale F, Caverzasi Edgardo, Mcguire P, 2012. Predicting psychosis meta-analysis of transition outcomes in individuals at high clinical risk. 10.1001/archgenpsychiatry.2011.1472. [DOI] [PubMed] [Google Scholar]
- Gooding DC, Ott SL, Roberts SA, Erlenmeyer-Kimling L, 2013. Thought disorder in mid-childhood as a predictor of adulthood diagnostic outcome: findings from the New York High-risk Project. Psychol. Med 10.1017/S0033291712001791. [DOI] [PubMed] [Google Scholar]
- Gutíerrez ED, Corlett PR, Corcoran CM, Cecchi GA, 2017. Using automated metaphor identification to aid in detection and prediction of first-episode schizophrenia. In: EMNLP 2017 - Conference on Empirical Methods in Natural Language Processing, Proceedings. 10.18653/v1/d17-1316. [DOI] [Google Scholar]
- Holshausen K, Harvey PD, Elvevåg B, Foltz PW, Bowie CR, 2014. Latent semantic variables are associated with formal thought disorder and adaptive behavior in older inpatients with schizophrenia. Cortex. 10.1016/j.cortex.2013.02.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Insel TR, 2017. Digital phenotyping: technology for a new science of behavior. JAMA. 10.1001/jama.2017.11295. [DOI] [PubMed] [Google Scholar]
- Kay SR, Opler LA, 1987. The positive-negative dimension in schizophrenia: its validity and significance. Psychiatr. Dev 5 (2), 79–103. [PubMed] [Google Scholar]
- Kraepelin E, 2010. [100 years of psychiatry]. Vertex 21 (91), 317–320. [PubMed] [Google Scholar]
- Landauer TK, Foltz PW, Laham D, 1998. An introduction to latent semantic analysis. Discourse Process. 10.1080/01638539809545028. [DOI] [Google Scholar]
- Marggraf MP, Lysaker PH, Salyers MP, Minor KS, 2020. The link between formal thought disorder and social functioning in schizophrenia: a meta-analysis. Eur. Psychiatry 63. 10.1192/j.eurpsy.2020.30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mason Simon J., Graham Nicholas E., 2002. Areas beneath the relative operating characteristics (ROC) and relative operating levels (ROL) curves: statistical significance and interpretation. Q.J.R.Meteorol.Soc 128, 2145–2166. [Google Scholar]
- Mikolov T, Sutskever I, Chen K, Corrado G, Dean J, 2013. Distributed representations of words and phrases and their compositionality. In: Advances in Neural Information Processing Systems. [Google Scholar]
- Morosini PL, Magliano L, Brambilla L, Ugolini S, Pioli R, 2000. Development, reliability and acceptability of a new version of the DSM- IV Social Occupational Functioning Assessment Scale (SOFAS) to assess routine social functioning. Acta Psychiatr. Scand 101 10.1034/j.1600-0447.2000.101004323.x. [DOI] [PubMed] [Google Scholar]
- Mota NB, Vasconcelos NAP, Lemos N, Pieretti AC, Kinouchi O, Cecchi GA, Copelli M, Ribeiro S, 2012. Speech graphs provide a quantitative measure of thought disorder in psychosis. PLoS One. 10.1371/journal.pone.0034928. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pennington J, Socher R, Manning CD, 2014. GloVe: global vectors for word representation. In: EMNLP 2014 – 2014 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference. 10.3115/v1/d14-1162. [DOI] [Google Scholar]
- Prill RJ, Vogel R, Cecchi GA, Altan-Bonnet G, Stolovitzky G, 2015. Noise-driven causal inference in biomolecular networks. PLoS One 10. 10.1371/journal.pone.0125777. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Racenstein JM, Penn D, Harrow M, Schleser R, 1999. Thought disorder and psychosocial functioning in schizophrenia: the concurrent and predictive relationships. J. Nerv. Ment. Dis 187 10.1097/00005053-199905000-00003. [DOI] [PubMed] [Google Scholar]
- Rezaii N, Walker E, Wolff P, 2019. A machine learning approach to predicting psychosis using semantic density and latent content analysis. NPJ Schizophr. 10.1038/s41537-019-0077-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roche E, Creed L, Macmahon D, Brennan D, Clarke M, 2015. The epidemiology and associated phenomenology of formal thought disorder: a systematic review. Schizophr. Bull 10.1093/schbul/sbu129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Santorini B, 1990. Part-of-Speech Tagging Guidelines for the Penn Treebank Project (3rd Revision). University of Pennsylvania. 10.1017/CBO9781107415324.004, 3rd Revision 2nd Printing. [DOI] [Google Scholar]
- Spencer TJ, Thompson B, Oliver D, Diederen K, Demjaha A, Weinstein S, McGuire P, 2021. Lower speech connectedness linked to incidence of psychosis in people at clinical high risk. Schizophr. Res 228 10.1016/j.schres.2020.09.002. [DOI] [PubMed] [Google Scholar]
- Stone WS, Mesholam-Gately RI, Giuliano AJ, Woodberry KA, Addington J, Bearden CE, Cadenhead KS, Cannon TD, Cornblatt BA, Mathalon DH, McGlashan TH, Perkins DO, Tsuang MT, Walker EF, Woods SW, McCarley RW, Heinssen R, Green MF, Nuechterlein K, Seidman LJ, 2016. Healthy adolescent performance on the MATRICS Consensus Cognitive Battery (MCCB): developmental data from two samples of volunteers. Schizophr. Res 10.1016/j.schres.2016.02.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vail AK, Baker JT, Liebson E, Morency LP, 2018. Toward objective, multifaceted characterization of psychotic disorders: lexical, structural, and disfluency markers of spoken language. In: ICMI 2018 - Proceedings of the 2018 International Conference on Multimodal Interaction. 10.1145/3242969.3243020. [DOI] [Google Scholar]
- Wechsler D, 1999. Manual for the Wechsler Abbreviated Intelligence Scale (WASI). WASI. [Google Scholar]
- Woods SW, Walsh BC, Powers AR, McGlashan TH, 2019. Reliability, validity, epidemiology, and cultural variation of the Structured Interview for Psychosis-risk Syndromes (SIPS) and the Scale of Psychosis-risk Symptoms (SOPS). In: Handbook of Attenuated Psychosis Syndrome Across Cultures. 10.1007/978-3-030-17336-4_5. [DOI] [Google Scholar]
- Yalincetin B, Bora E, Binbay T, Ulas H, Akdede BB, Alptekin K, 2017. Formal thought disorder in schizophrenia and bipolar disorder: a systematic review and meta-analysis. Schizophr. Res 10.1016/j.schres.2016.12.015. [DOI] [PubMed] [Google Scholar]
- Yung AR, Phillips LJ, Yuen HP, Francey SM, McFarlane CA, Hallgren M, et al. , 2003. Psychosis prediction: 12-month follow up of a high-risk (“prodromal”) group. Schizophr. Res 60. [DOI] [PubMed] [Google Scholar]
- Yung AR, Yuen HP, McGorry PD, Phillips LJ, Kelly D, Dell’Olio M, Francey SM, Cosgrave EM, Killackey E, Stanford C, Godfrey K, Buckby J, 2005. Mapping the onset of psychosis: the comprehensive assessment of at-risk mental states. Aust. N. Z. J. Psychiatry 10.1111/j.1440-1614.2005.01714.x. [DOI] [PubMed] [Google Scholar]