

Abstract
BACKGROUND:
Cardiovascular (CV) risk tools have been developed both nationally and internationally to identify patients at risk for developing CV disease or experiencing a CV event. However, these tools vary widely in the definitions of endpoints, the time at which the endpoints are measured, patient populations, and their validity. The primary limitation of some of the most commonly utilized tools is the lack of specificity for a type 2 diabetes (T2D) population and/or among older patients.
OBJECTIVE:
To develop a predictive model within an older population of patients with T2D to identify patients at risk for CV events.
METHODS:
This retrospective cohort study used claims, laboratory, and enrollment data during the 2011-2018 study period. Patients with T2D were identified based on diagnoses and/or medications from 2012-2013. The patient cohort was split into 3 different datasets. The holdout dataset included only those patients residing in the northeastern United States. The rest of the sample was then randomly split: 70% for the training dataset, which were used to fit the predictive model, and 30% for the test dataset to assess internal validity. The primary outcome was the first composite CV event defined as at least 1 of the following: inpatient hospitalization for myocardial infarction, ischemic stroke, unstable angina, or heart failure; or any evidence of revascularization. A survival model for the composite outcome was fitted with baseline demographic and clinical characteristics prognostic for the dependent variable utilizing augmented backwards elimination. For assessing model performance, accuracy, sensitivity, specificity, and the c-statistic were used. Patients were ranked as having a low, moderate, or high probability of a future CV event.
RESULTS:
A total of 362,791 patients were identified. The holdout dataset included only those patients residing in the northeastern United States (n = 8,303). There were 248,142 patients included in the training dataset and 106,346 patients in the test dataset. The proportion with at least 1 observed composite CV event was 20.9%. The final model included 42 variables. The c-statistic was 0.68, and the accuracy, sensitivity, and specificity were approximately 63%. Results were consistent across the training, test, and holdout samples. The optimal cut points minimizing the difference in sensitivity and specificity for low-, moderate-, and high-risk future CV events were determined to be less than 0.18, 0.18-0.63, and greater than 0.63, respectively, in the training dataset at 5 years. The 5-year observed event risk was 11%, 27%, and 51% for patients classified as low, moderate, and high risk of a future CV event, respectively.
CONCLUSIONS:
A model predicting CV events among older patients with T2D using administrative claims to identify those at risk may be used for focusing interventions to prevent future events.
What is already known about this subject
Tools identifying patients at risk for cardiovascular (CV) events vary in the definitions of endpoints, the time at which the endpoints are measured, patient populations, and their validity.
While currently available models may provide some utility in predicting CV risk among older patients with type 2 diabetes (T2D), those models were not developed or trained specifically in that patient population and may have limitations for use.
Utilizing established predictive models from a health plan perspective may not be feasible to identify patients at risk who may benefit from interventions, as specific clinical inputs (eg, laboratory values, duration of diabetes) are not always available for assessment.
What this study adds
The CV risk prediction model used in this study, specifically developed and trained in a Medicare population with T2D using administrative claims, fills a gap in the current literature by providing a model that identifies risk of disease in this population, which is much different from the general at-risk population.
The model was able to be used to identify stratifications of low-, moderate-, and high-risk patients for a CV event.
A model predicting CV events among older patients with T2D using administrative claims to identify those at risk may be used for focusing interventions to prevent future events.
Diabetes increases the risk of developing cardiovascular (CV) disease and nearly doubles the risk of death from heart disease or stroke.1 More than 344 million individuals in the United States in 2018 were estimated to have diabetes (diagnosed and undiagnosed), with approximately 95% of those individuals having type 2 diabetes (T2D).2 An estimated 21.4% of individuals aged at least 65 years have a diagnosis of diabetes, a higher proportion than those individuals in younger-aged groups.2 Given the higher prevalence of T2D in this older population, identification of individuals in this age group who are at risk for complications from diabetes such as CV disease and CV events may help in developing tailored interventions preventing additional morbidity and early mortality.3
CV risk tools have been developed both nationally and internationally to identify patients at risk for developing CV disease or experiencing a CV event (eg, myocardial infarction [MI], stroke). However, these tools vary widely in the definitions of endpoints, the time at which the endpoints are measured, patient populations, and their validity.4-6 The variability of these tools limits the generalizability and usability of any 1 tool, as highlighted in the 2013 American College of Cardiology/American Heart Association (ACC/AHA) Guideline on the Assessment of Cardiovascular Risk.6 The primary limitation of some of the most commonly utilized tools is the lack of specificity for a T2D population. While diabetes is included as a risk factor in these calculators, the development of such algorithms was conducted with varied populations, thus potentially limiting the utility in specific high-risk populations, such as those with T2D. For example, the Framingham CV risk estimates have been cited as potentially unreliable in a T2D population and may underestimate the risk.7
While the Framingham population was diverse in age (30-74 years), it is not generalizable to an older patient population in which specific risk scores are lacking; the population was limited in racial and geographic diversity, and the risk score represented risk over a long time period (ie, ≥ 10 years).6 While calculating CV risk with other available algorithms, such as the ACC/AHA atherosclerotic CV disease (ASCVD) risk calculator, is suggested by the American Diabetes Association guidelines to be potentially useful, there is similar cited concern that the calculator may have varying utility in patients with diabetes and in specific populations (eg, individuals aged ≥ 65 years).8
The UK Prospective Diabetes Study (UKPDS) Risk Engine is 1 of the most widely recognized diabetes-specific risk tools based upon the UKPDS study population.9,10 While this is specific to a diabetes population, there are limitations with this risk calculator as well. The data from which the risk predictor was built are not contemporary; in addition, risk is evaluated over at least a 10-year time frame, and the risk calculation is limited to patients without known heart disease. Recent studies have suggested that the UKPDS risk engine requires updates as the discrimination was moderate to poor for coronary heart disease and CV disease, and such risks were overestimated.4,11
Developing a predictive model to identify patients at risk for CV outcomes is of value for use in patients with diabetes aged over 65 years, regardless of baseline heart disease. There is a paucity of evidence supporting risk model use in developing patient-focused interventions aimed to address modifiable CV risk factors (ie, hypertension, high cholesterol, obesity, smoking, and an inactive lifestyle).4,6
The purpose of this study was to develop a predictive model and appropriate risk stratification to identify a patient population aged at least 65 years with T2D at risk for a CV event.
Methods
STUDY DESIGN
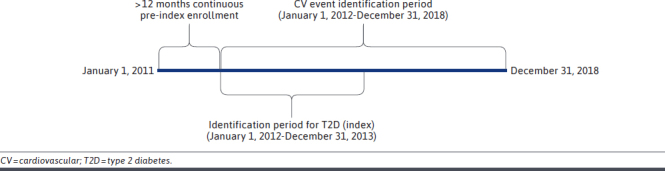
This non-interventional, retrospective cohort study utilized administrative claims data (medical, pharmacy), laboratory data, and health plan enrollment files from the Humana Research Database during the study period (January 1, 2011, to December 31, 2018). Patients with T2D were identified between 2012 and 2013 and followed until disenrollment in their health plan, date of study outcome, or the end of the study period (Figure 1).
FIGURE 1.
Study Design
PATIENT POPULATION
Patients with T2D aged 65 through 89 years enrolled in a Medicare Advantage Prescription Drug (MAPD) plan were identified based on diagnosis and/or evidence of use of antihyperglycemic medications: at least 2 outpatient (nonacute) diagnoses of T2D in any diagnostic position on separate days or at least 1 inpatient or acute (emergency department [ED]) diagnosis of T2D in any diagnostic position or at least 1 outpatient claim in any diagnostic position and at least 1 prescription claim for a T2D medication. The date of the first T2D diagnosis and/or medication in the identification period (January 1, 2012, to December 31, 2013) was defined as the index date. Patients with a diagnosis of type 1 diabetes, secondary causes of T2D, gestational diabetes, or those with the outcome on the same day as the index date were excluded. Patients were required to have at least 12 months of pre-index continuous enrollment. The post-index (follow-up) period was defined as the end date of continuous enrollment in an MAPD health plan, date of study outcome, or end of study period (December 31, 2018).
MEASURES
Primary Outcome Measure.
The primary outcome was the first composite CV event defined as at least 1 of the following: MI, ischemic stroke, unstable angina, or heart failure as the principal diagnosis on at least 1 inpatient claim; or revascularization (eg, percutaneous coronary intervention, coronary artery bypass graft) diagnosis or procedure on any claim type in any claim position (Supplementary Table 1 (522.9KB, pdf) , available in online article). For each inpatient admission, a principal diagnosis was identified using the primary diagnosis code on the principal facility (room and board) record during the hospital stay, which was considered the cause of hospitalization.12
Covariates and Other Measures.
Baseline demographic, socioeconomic, and clinical covariates were entered as candidate covariates into the predictive model. These included age, sex, race, geographic location, population density,13,14 comorbidity scores and components (Deyo-Charlson Comorbidity Index,15-17 Diabetes Complications and Severity Index [DCSI]), body mass index/obesity, the number of unique total medications, antihyperglycemic and CV medication utilization, smoking status, vital and laboratory values of interest if not missing more than 50% in all observations (hemoglobin A1c [HbA1c], low-density lipoprotein cholesterol, high-density lipoprotein cholesterol [HDL-C], triglycerides, total cholesterol, serum creatinine [for calculation of estimated glomerular filtration rate (eGFR)], and blood pressure), inpatient hospitalizations, and ED and outpatient visits.
STATISTICAL METHODS
Any demographic variable with missing values and any laboratory values with at least 50% of results available were considered for imputation.18 These variables included race, population density, and serum creatinine (for calculation of eGFR). Three imputations were conducted across each of the variables and compared with the complete case values.19-21 Each of the imputations was similar to each other and to the complete case values; thus, one imputation was randomly selected to be used in the predictive model (Supplementary Table 2 (522.9KB, pdf) , available in online article). This dataset was used for all analyses.
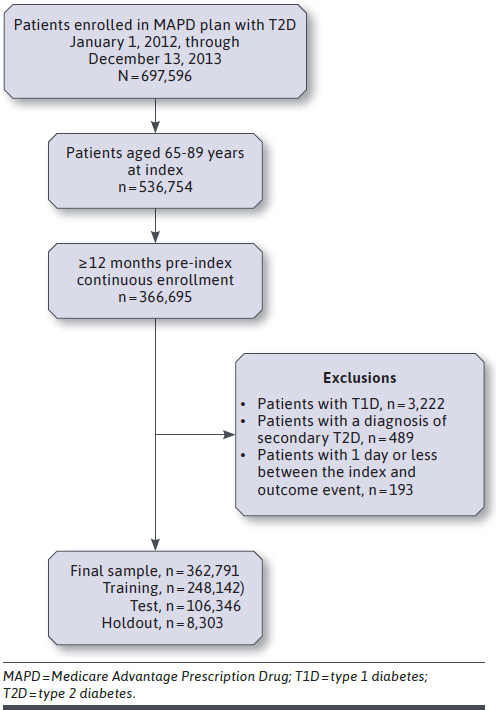
A holdout sample is a predefined, nonrandom subsample of the entire database, usually defined by a baseline characteristic (eg, geographic region) to test external validity. It was decided a priori that the holdout sample would comprise patients from a different US geographical region (type 2b, nonrandom split sample as described by transparent reporting of a multivariable prediction model for individual prognosis or diagnosis guidelines).22,23 Based on the distribution of geographic region in the patient cohort, the holdout dataset included only those patients residing in the northeastern United States (n = 8,303). The rest of the sample (n = 354,488) was then randomly split: 70% for the training dataset (n = 248,142), which was used to fit the predictive model, and 30% for the test dataset (n = 106,346) to assess internal validity. Patients in the test dataset and the holdout dataset were compared to determine representativeness and generalizability of the specifically selected holdout sample (Supplementary Table 3 (522.9KB, pdf) , available in online article).
Aside from differences in race and population density, which are likely a function of the geographic region, the characteristics of the populations were generally similar. In addition, the composite CV event rate was examined in the test and holdout sample to determine if region might be a predictor for CV events and thus not appropriate for selection as a holdout sample. It was determined that the CV event rate was the same for the test and holdout datasets (20.9% vs 20.9%), thus suggesting that region was not predictive of the CV event and an appropriate choice for a holdout sample.
The training data sample was used to fit and tune the predictive model fitted with baseline demographic and clinical variables that were identified as predictive for the outcome utilizing augmented backwards elimination.24 Multicollinearity that may arise due to correlation between covariates was assessed examining variance inflation factor (VIF) and correlations. Covariates were excluded with VIF greater than 10 or correlations greater than plus or minus 0.7 (ie, strong correlations). Applying both the VIF and correlation thresholds was felt to sufficiently address any multicollinearity and the thresholds acceptable for large sample sizes.25 The final best model was created using only the training data sample.
The test sample (30% random split) was created to test internal validity and assess misclassification error (percentage of false-positives and false-negatives) in a sample generalizable to those data that were used for training. The performance of the model on the training vs the testing data was also used to assess if the final model was overfit to the training data. The holdout sample was used to assess misclassification error in a sample somewhat different to those data that were used for training to reflect how the model may perform in a different population.
The distribution of the time-dependent predicted probabilities of occurrence of a composite CV event were examined for optimal decision thresholds. Optimal decision threshold was based on receiver operator characteristic curves, and the threshold was chosen with the intent to have best possible balance between sensitivity and specificity for the predictive model (ie, difference between sensitivity and specificity minimized). Based on this threshold and the distribution of the predicted probability, patients were stratified into 3 categories: high, moderate, and low risk. The patients with probabilities below or equal to the optimal cut point were categorized as low risk, probabilities between the optimal cut point and 99th percentile of the distribution were categorized as moderate risk, and those with probabilities greater than the 99th percentile of the distribution were categorized as high risk. The probability of CV events occurring up to 5 years after the index date within each risk category was assessed and compared with the percentage of patients actually experiencing the event within these time periods. SAS Enterprise Guide 7.11 (platform version 9.4.3) was used for all analyses.26
Prior to study initiation, the research protocol was reviewed and approved by an independent institutional review board.
Results
A total of 362,791 unique patients were identified based on the inclusion and exclusion criteria, 20.9% having at least 1 composite CV event during the mean follow-up of 4.1 years (Figure 2). The overall cohort was on average aged 73 years at index. The cohort with evidence of a CV event was predominantly male (55%), White (82%), and had more patients residing in the South and fewer in the western United States (Table 1). There was a higher comorbidity burden among patients in the CV cohort as evidenced by the mean Deyo-Charlson and DCSI scores compared with the cohort without evidence of CV. A higher proportion of patients in the CV cohort were being treated with sulfonylureas (34.2%) and insulin (23.3%). Additionally, across almost all of the CV medication classes, a higher proportion of patients with a composite CV event were utilizing those medications as compared with the no-CV cohort. Among those patients with laboratory values to report, the CV cohort had higher HbA1c (mean [SD], 7.1 [1.40] mg/dL vs 6.8 [1.17] mg/dL) and triglyceride (159.2 [104.68] mg/dL vs 146.6 [85.66] mg/dL) values, and lower HDL (46.2 [13.86] mg/dL vs 49.7 [14.71] mg/dL) and eGFR (61.7 [22.16] ml/min/1.73m2 vs 68.0 [21.10] ml/min/1.73m2) values compared with the no-CV cohort. Patients in the CV cohort had greater utilization of all health care resources as compared with the no-CV cohort.
FIGURE 2.
Attrition Flow Diagram
TABLE 1.
Demographics
| Characteristics in the 12-month pre-index period | Study population with T2D | ||
|---|---|---|---|
| Overall N = 362,791 | With no CV event n = 286,896 | With CV event n = 75,895 | |
| Age in years, mean (SD) | 74.1 (± 5.99) | 73.9 (± 5.96) | 74.6 (± 6.10) |
| Median (IQR) | 73 (69-78) | 73 (69-78) | 74 (70-79) |
| Min, Max | 65, 89 | 65, 89 | 65, 89 |
| Age category in years, n (%) | |||
| 65-69 | 100,013 (27.6) | 81,359 (28.4) | 18,654 (24.6) |
| 70-74 | 112,110 (30.9) | 89,583 (31.2) | 22,527 (29.7) |
| 75-79 | 76,665 (21.1) | 59,594 (20.8) | 17,071 (22.5) |
| 80-84 | 49,222 (13.6) | 37,494 (13.1) | 11,728 (15.5) |
| 85-89 | 24,781 (6.8) | 18,866 (6.6) | 5,915 (7.8) |
| Female, n (%) | 185,823 (51.2) | 151,770 (52.9) | 34,053 (44.9) |
| Race/ethnicity, n (%) | |||
| White | 288,384 (79.5) | 226,212 (78.8) | 62,172 (81.9) |
| Black | 54,757 (15.1) | 44,253 (15.4) | 10,504 (13.8) |
| Other | 17,660 (4.9) | 14,735 (5.1) | 2,925 (3.9) |
| Unknown/missing | 1,990 (0.5) | 1,696 (0.6) | 294 (0.4) |
| Geographic region, n (%) | |||
| Northeast | 8,303 (2.3) | 6,566 (2.3) | 1,737 (2.3) |
| Midwest | 85,296 (23.5) | 66,701 (23.2) | 18,595 (24.5) |
| South | 234,825 (64.7) | 184,678 (64.4) | 50,147 (66.1) |
| West | 34,367 (9.5) | 28,951 (10.1) | 5,416 (7.1) |
| Population density (member residence), n (%) | |||
| Urban | 40,671 (11.2) | 32,004 (11.2) | 8,667 (11.4) |
| Suburban | 88,991 (24.5) | 69,359 (24.2) | 19,632 (25.9) |
| Rural | 224,359 (61.8) | 178,710 (62.3) | 45,649 (60.1) |
| Unknown/missing | 8,770 (2.4) | 6,823 (2.4) | 1,947 (2.6) |
| Low-income/dual status, n (%) | |||
| Low-income subsidy only | 23,303 (6.4) | 17,871 (6.2) | 5,432 (7.2) |
| Dual eligibility only | 2,993 (0.8) | 2,306 (0.8) | 687 (0.9) |
| Low-income subsidy and dual eligibility | 49,816 (13.7) | 38,666 (13.5) | 11,150 (14.7) |
| Baseline clinical characteristics | |||
| Deyo-Charlson score, mean (SD) | 1.2 (± 1.77) | 1.1 (± 1.72) | 1.6 (± 1.93) |
| Median (IQR) | 0 (0-2) | 0 (0-2) | 1 (0-3) |
| Min, Max | 0, 18 | 0, 18 | 0, 16 |
| Baseline clinical characteristics | |||
| Deyo-Charlson categories, n (%) | |||
| Myocardial infarction | 19,178 (5.3) | 11,721 (4.1) | 7,457 (9.8) |
| Congestive heart failure | 43,149 (11.9) | 26,517 (9.2) | 16,632 (21.9) |
| Peripheral vascular disease | 48,773 (13.4) | 34,307 (12.0) | 14,466 (19.1) |
| Cerebrovascular disease | 30,484 (8.4) | 20,792 (7.2) | 9,692 (12.8) |
| Dementia | 6,096 (1.7) | 5,081 (1.8) | 1,015 (1.3) |
| Chronic obstructive pulmonary disease | 61,197 (16.9) | 44,570 (15.5) | 16,627 (21.9) |
| Connective tissue disease | 7,741 (2.1) | 5,932 (2.1) | 1,809 (2.4) |
| Peptic ulcer disease | 2,768 (0.8) | 2,042 (0.7) | 726 (1.0) |
| Mild liver disease | 7,325 (2.0) | 5,744 (2.0) | 1,581 (2.1) |
| Para- or hemiplegia | 2,675 (0.7) | 2,007 (0.7) | 668 (0.9) |
| Renal disease | 66,772 (18.4) | 48,061 (16.8) | 18,711 (24.7) |
| Cancer | 29,981 (8.3) | 24,045 (8.4) | 5,936 (7.8) |
| Moderate or severe liver disease | 946 (0.3) | 772 (0.3) | 174 (0.2) |
| Metastatic carcinoma | 2,978 (0.8) | 2,592 (0.9) | 386 (0.5) |
| HIV/AIDS | 158 (0.0) | 126 (0.0) | 32 (0.0) |
| Diabetes complications and severity index score, mean (SD) | 1.7 (± 1.79) | 1.5 (± 1.69) | 2.3 (± 2.00) |
| Median (IQR) | 1 (0-3) | 1 (0-2) | 2 (1-4) |
| Min, Max | 0, 13 | 0, 13 | 0, 12 |
| Diabetes complications and severity index categories, n (%) | |||
| Retinopathy | 20,487 (5.6) | 14,770 (5.1) | 5,717 (7.5) |
| Nephropathy | 156,324 (43.1) | 118,751 (41.4) | 37,573 (49.5) |
| Neuropathy | 56,449 (15.6) | 42,213 (14.7) | 14,236 (18.8) |
| Cardiovascular | 125,372 (34.6) | 85,918 (29.9) | 39,454 (52.0) |
| Cerebrovascular | 23,916 (6.6) | 15,982 (5.6) | 7,934 (10.5) |
| Peripheral vascular disease | 40,773 (11.2) | 28,239 (9.8) | 12,534 (16.5) |
| Metabolic | 1,213 (0.3) | 872 (0.3) | 341 (0.4) |
| Body mass index in kg/m2, n (%) | |||
| < 19 | 948 (0.3) | 804 (0.3) | 144 (0.2) |
| 19-24 | 7,136 (2.0) | 5,883 (2.1) | 1,253 (1.7) |
| 25-29 | 16,173 (4.5) | 13,085 (4.6) | 3,088 (4.1) |
| 30-39 | 19,428 (5.4) | 15,459 (5.4) | 3,969 (5.2) |
| ≥ 40 | 7,340 (2.0) | 5,501 (1.9) | 1,839 (2.4) |
| Unknown/missing | 311,766 (85.9) | 246,164 (85.8) | 65,602 (86.4) |
| Obesity, n (%) | 60,071 (16.6) | 46,324 (16.1) | 13,747 (18.1) |
| Medications of interest | |||
| Number of unique medications, mean (SD) | 10.4 (± 6.44) | 10.1 (± 6.24) | 11.8 (± 7.00) |
| Median [IQR] | 10 [6-14] | 9 [6-14] | 11 [7-16] |
| Min, Max | 0, 57 | 0, 57 | 0, 56 |
| Antihyperglycemic medications, n (%) | |||
| Biguanides | 156,972 (43.3) | 126,074 (43.9) | 30,898 (40.7) |
| Sulfonylureas | 111,247 (30.7) | 85,277 (29.7) | 25,970 (34.2) |
| Thiazolidinediones | 25,430 (7.0) | 20,555 (7.2) | 4,875 (6.4) |
| Dipeptidyl peptidase-4 inhibitors | 2,042 (0.6) | 1,595 (0.6) | 447 (0.6) |
| Sodium-glucose cotransporter-2 inhibitors | 3,105 (0.9) | 2,484 (0.9) | 621 (0.8) |
| Glucagon-like peptide 1 receptor agonists | 0 (0.0) | 0 (0.0) | 0 (0.0) |
| Insulin | 58,939 (16.2) | 41,284 (14.4) | 17,655 (23.3) |
| Fixed-dose combinations | 17,280 (4.8) | 13,836 (4.8) | 3,444 (4.5) |
| Other (amylin agonists, meglitinides, alpha-glucosidase inhibitors) | 3,406 (0.9) | 2,508 (0.9) | 898 (1.2) |
| Cardiovascular medications, n (%) | |||
| Angiotensin-converting enzyme inhibitors, angiotensin receptor blocking agents, renin inhibitors | 188,933 (52.1) | 145,770 (50.8) | 43,163 (56.9) |
| Antianginal agents | 32,577 (9.0) | 19,939 (7.0) | 12,638 (16.7) |
| Antiarrhythmics | 8,702 (2.4) | 5,659 (2.0) | 3,043 (4.0) |
| Anticoagulants | 34,816 (9.6) | 24,434 (8.5) | 10,382 (13.7) |
| Antihyperlipidemics (eg, statins, fibrates) | 239,746 (66.1) | 188,060 (65.6) | 51,686 (68.1) |
| Beta blockers | 151,691 (41.8) | 110,331 (38.5) | 41,360 (54.5) |
| Calcium channel blockers | 109,857 (30.3) | 83,197 (29.0) | 26,660 (35.1) |
| Cardiotonics | 13,701 (3.8) | 8,954 (3.1) | 4,747 (6.3) |
| Diuretics | 134,783 (37.2) | 99,588 (34.7) | 35,195 (46.4) |
| Other antihypertensives | 98,143 (27.1) | 76,399 (26.6) | 21,744 (28.7) |
| Vasopressors | 1,444 (0.4) | 1,107 (0.4) | 337 (0.4) |
| Cardiovascular agents–miscellaneous | 7,934 (2.2) | 6,285 (2.2) | 1,649 (2.2) |
| Baseline lifestyle characteristics and laboratory values | |||
| Smoking, n (%) | 34,821 (9.6) | 25,796 (9.0) | 9,025 (11.9) |
| Laboratory values of interest, n (%)a | |||
| Hemoglobin A1c, n (%) | 168,002 (46.3) | 133,845 (46.7) | 34,157 (45.0) |
| Low-density lipoprotein cholesterol, n (%) | 172,421 (47.5) | 137,718 (48.0) | 34,703 (45.7) |
| High-density lipoprotein cholesterol, n (%) | 172,530 (47.6) | 137,502 (47.9) | 35,028 (46.2) |
| Triglycerides, n (%) | 171,606 (47.3) | 136,685 (47.6) | 34,921 (46.0) |
| Total cholesterol, n (%) | 173,365 (47.8) | 138,164 (48.2) | 35,201 (46.4) |
| Estimated glomerular filtration rate, n (%) | 193,213 (53.3) | 152,936 (53.3) | 40,277 (53.1) |
| Systolic blood pressure, n (%) | 412 (0.1) | 320 (0.1) | 92 (0.1) |
| Diastolic blood pressure, n (%) | 412 (0.1) | 320 (0.1) | 92 (0.1) |
| Baseline lifestyle characteristics | |||
| Laboratory values of interest, mean (SD)b | |||
| Hemoglobin A1c, mean (SD) | 6.9 (± 1.2) | 6.8 (± 1.2) | 7.1 (± 1.4) |
| Low-density lipoprotein cholesterol, mean (SD) | 91.4 (± 33.0) | 91.3 (± 32.6) | 91.8 (± 34.8) |
| High-density lipoprotein cholesterol, mean (SD) | 49.0 (± 14.6) | 49.7 (± 14.7) | 46.2 (± 13.9) |
| Triglycerides, mean (SD) | 149.2 (± 90.0) | 146.6 (± 85.7) | 159.2 (± 104.7) |
| Total cholesterol, mean (SD) | 169.9 (± 40.2) | 170.0 (± 39.5) | 169.3 (± 43.0) |
| Estimated glomerular filtration rate, mean (SD) | 66.7 (± 21.5) | 68.0 (± 21.1) | 61.7 (± 22.7) |
| Systolic blood pressure, mean (SD) | 133.2 (± 19.1) | 133.9 (± 19.6) | 130.9 (± 17.0) |
| Diastolic blood pressure, mean (SD) | 73.5 (± 12.0) | 73.7 (± 11.7) | 73.0 (± 12.8) |
| All-cause health care resource utilization | |||
| Inpatient hospitalization, n (%) | 67,324 (18.6) | 47,256 (16.5) | 20,068 (26.4) |
| Inpatient hospitalization | |||
| Mean (SD) | 0.3 (± 0.75) | 0.2 (± 0.68) | 0.4 (± 0.95) |
| Median [IQR] | 0 [0-0] | 0 [0-0] | 0 [0-1] |
| Min, Max | 0, 27 | 0, 18 | 0, 27 |
| Emergency department visits | |||
| Mean (SD) | 0.7 (± 1.57) | 0.6 (± 1.45) | 0.9 (± 1.96) |
| Median [IQR] | 0 [0-1] | 0 [0-1] | 0 [0-1] |
| Min, Max | 0, 85 | 0, 85 | 0, 81 |
| Physician encounters | |||
| Mean (SD) | 8.5 (± 6.88) | 8.1 (± 6.66) | 9.6 (± 7.54) |
| Median [IQR] | 7 [4-11] | 7 [4-11] | 8 [4-13] |
| Min, Max | 0, 212 | 0, 207 | 0, 212 |
| Outpatient visits | |||
| Mean (SD) | 15.4 (± 14.01) | 14.8 (± 13.43) | 17.7 (± 15.82) |
| Median [IQR] | 12 [6-20] | 11 [6-19] | 14 [7-23] |
| Min, Max | 0, 364 | 0, 363 | 0, 364 |
aClosest diagnosis or laboratory value to the index date.
bDenominator includes only those participants who had the laboratory test.
CV = cardiovascular; IQR = interquartile range; Min = minimum; Max = maximum; T2D = type 2 diabetes.
The training dataset (n = 248,142) was used to fit the predictive model. There were 42 variables that were prognostic for the composite CV event and included in the Cox model (Table 2). The c-statistic was 0.68. Additional model performance statistics in the training, test, and holdout datasets (Supplementary Table 4 (522.9KB, pdf) , available in online article) were assessed at the chosen optimal decision threshold (cut point) that minimized the difference between sensitivity and specificity (ie, created balance between the two). The optimal cut point in all available training data was 0.18. The misclassification using this cut point was 37%, and the sensitivity and specificity were both approximately 63%. These results were consistent across the training, test, and holdout data, suggesting model stability.
TABLE 2.
Composite Event Hazards: Training Dataset
| Variable | Adjusted HRa | 95% CI | P value |
|---|---|---|---|
| CV event (composite outcome) | |||
| Demographics | |||
| Female | 0.769 | (0.754-0.784) | < 0.0001 |
| Age | 1.017 | (1.016-1.019) | < 0.0001 |
| Race–White | 1.183 | (1.155-1.212) | < 0.0001 |
| Low-income subsidy | 1.180 | (1.141-1.221) | < 0.0001 |
| Dual eligibility | 1.229 | (1.123-1.346) | < 0.0001 |
| Suburban residence | 1.079 | (1.058-1.101) | < 0.0001 |
| Diabetes comorbidity index categories | |||
| No cardiovascular abnormality | 0.697 | (0.675-0.720) | < 0.0001 |
| Severe cerebrovascular abnormality | 1.360 | (1.318-1.403) | < 0.0001 |
| No peripheral vascular disease | 0.803 | (0.778-0.828) | < 0.0001 |
| No nephropathy abnormality | 0.910 | (0.888-0.933) | < 0.0001 |
| Some retinopathy abnormality | 1.113 | (1.073-1.155) | < 0.0001 |
| Some cardiovascular abnormality | 1.080 | (1.043-1.118) | < 0.0001 |
| Some nephropathy abnormality | 0.959 | (0.935-0.984) | 0.0012 |
| Deyo-Charlson Comorbidity Index categories | |||
| Congestive heart failure | 1.453 | (1.410-1.498) | < 0.0001 |
| Dementia | 0.782 | (0.725-0.844) | < 0.0001 |
| Myocardial infarction | 1.205 | (1.165-1.248) | < 0.0001 |
| Cancer | 0.909 | (0.880-0.940) | < 0.0001 |
| Para/hemiplegia | 0.904 | (0.822-0.994) | 0.0379 |
| Mild liver disease | 0.910 | (0.856-0.967) | 0.0024 |
| Chronic obstructive pulmonary disease | 1.138 | (1.112-1.165) | < 0.0001 |
| Peripheral vascular disease | 0.963 | (0.933-0.993) | 0.0162 |
| Diabetes without complications | 0.901 | (0.882-0.921) | < 0.0001 |
| Medications | |||
| Unique number of medications | 1.003 | (1.001-1.005) | 0.0034 |
| Antianginal agents | 1.437 | (1.401-1.474) | < 0.0001 |
| Insulin | 1.447 | (1.414-1.480) | < 0.0001 |
| Beta blockers | 1.247 | (1.222-1.272) | < 0.0001 |
| Diuretics | 1.151 | (1.128-1.174) | < 0.0001 |
| Sulfonylureas | 1.120 | (1.098-1.142) | < 0.0001 |
| Antihyperlipidemics | 0.820 | (0.804-0.837) | < 0.0001 |
| Calcium channel blockers | 1.090 | (1.069-1.111) | < 0.0001 |
| Cardiotonics | 1.213 | (1.167-1.260) | < 0.0001 |
| Other antihypertensives | 1.026 | (1.006-1.047) | 0.0094 |
| Thiazolidinediones | 0.913 | (0.881-0.946) | < 0.0001 |
| Biguanides | 0.933 | (0.915-0.952) | < 0.0001 |
| Anticoagulants | 0.959 | (0.931-0.988) | 0.0053 |
| Laboratory | |||
| Creatinine value | 1.110 | (1.092-1.129) | < 0.0001 |
| Estimated glomerular filtration rate | 0.999 | (0.998-0.999) | < 0.0001 |
| Low-density lipoprotein cholesterol measured | 0.800 | (0.784-0.817) | < 0.0001 |
| Other | |||
| Inpatient hospitalization | 1.116 | (1.089-1.144) | < 0.0001 |
| Body mass index > 40 kg/m2 | 1.175 | (1.105-1.250) | < 0.0001 |
| Body mass index-unknown | 1.246 | (1.210-1.283) | < 0.0001 |
| Tobacco use | 1.123 | (1.092-1.155) | < 0.0001 |
aHazard ratios are adjusted for variables listed.
CV = cardiovascular; HR = hazard ratio.
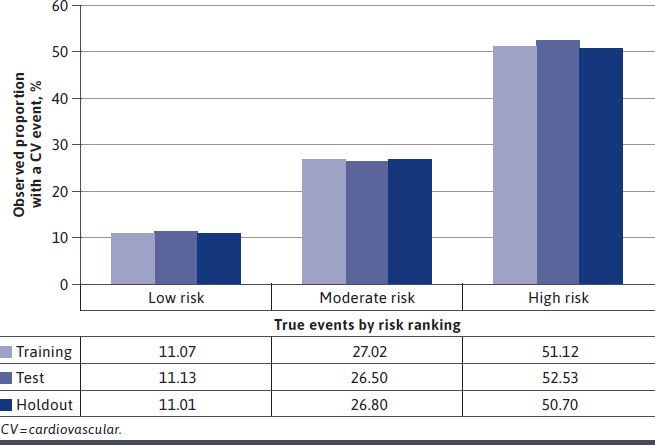
Patients were classified as low, moderate, or high risk of having the event up to 5 years after identification based on the predictive model and cut points. The optimal cut points minimizing the difference in sensitivity and specificity for low, moderate, and high risk were determined to be less than 0.18, 0.18 through 0.63, and greater than 0.63, respectively, in the training data at 5 years. The results were consistent across the 3 subgroups. When looking at the observed event risk for up to 5 years among those that had the event during the follow-up period, there were approximately 11% of patients in the low-risk group who had an event, 27% in the moderate-risk group who had an event, and 51% in the high-risk group who had an event. These results were generally consistent across the training, test, and holdout datasets (Figure 3). The Kaplan-Meier plot (Supplementary Figure 1 (522.9KB, pdf) , available in online article) displays the survival curve for CV events occurring within 5 years for each risk group. The low-risk group had the lowest CV event risk over the 5 years, and the high-risk group had the highest CV event risk over the period as expected.
FIGURE 3.
Observed Event Proportion by Risk Group Up to 5 Years
Discussion
The primary goal of this study was to develop a predictive model to identify patients at risk for a composite CV event in a population of older patients diagnosed with T2D utilizing administrative claims. The model minimizing the difference, thereby creating balance between sensitivity and specificity, had an accuracy of 62% vs 63% in the test and holdout datasets, respectively. When classifying patients as low, moderate, or high risk of a composite CV event at 5 years, a stair-step pattern was noted across risk categories, with approximately 11% of patients in the lowest risk category having an event, and more than 50% of patients in the highest risk group having an event. The model, built with main effects variables alone, was shown to be generalizable and not overfit.
While there are numerous risk models currently in existence with varying populations, outcomes, and follow-up periods, some of the most recognized include those developed utilizing the Framingham Heart Study cohort as well as the UKPDS participants.9,27 In addition, the ACC, in conjunction with the AHA, more recently organized a Risk Assessment Work Group to develop a quantitative approach to ASCVD risk assessment.6
Multiple risk models using the Framingham Heart Study cohort have been developed and have evolved over time.27-29 One of the more contemporary models evaluated the 5-year probability of coronary heart disease (CHD) risk (coronary death or MI) in 2,439 men and 2,812 women aged 30-74 years in the Framingham cohort free of CHD at the outset, with separate models developed by sex and race/ethnicity.27 The event rates for this composite outcome were 3.7% for men and 1.4% for women at 5 years. The event rate in our study was greater than 20%; however, our study included more outcomes, such as procedures, thus potentially explaining 1 of the reasons behind the differences in these rates between the studies.
Additionally, in contrast to our study, the Framingham models included relatively few variables, including, but not limited to, age, sex, blood pressure, total cholesterol, HDL-C, diabetes, and current smoking status. The c-statistics were dependent on sex- and race-/ethnicity-specific models and ranged from 0.63 to 0.83. Also, the Framingham cohort of patients was on average younger in comparison with our cohort. Furthermore, the Framingham Heart Study captured death and a specific cause of death for the outcome, which was included in the model. Additionally, the model was only developed in incident patients, in contrast to the model presented in this work, which included additional outcomes and a more heterogeneous population. However, the Framingham-based model was not developed specifically in patients with diabetes, thus making the applicability of that model to that high-risk population questionable, particularly due to the low proportion of patients with diabetes in that cohort. Coleman et al reported that the Framingham risk scores underestimated CHD (MI or sudden death) and fatal CVD (MI, sudden death, stroke, peripheral vascular disease) in patients with T2D.7 A recent systematic review and meta-analysis indicated c-statistics across studies validating the Framingham models (originally developed in a general population) in a diabetes population were 0.64 to 0.67 overall.30 Thus, while the risk equations developed from the Framingham cohort may prove to have utility in some populations and circumstances, the applicability to an older, heterogeneous population of patients with T2D and the utility for use across health plans, where specific clinical data may not be readily available, may be limited.
As an alternative to the Framingham risk score, and in comparison to the model presented in this study, the ACC/AHA Risk Assessment Workgroup (2013) developed risk equations for the prediction of 10-year risk of development of ASCVD in individuals aged 40-79 years.6 Population-based cohort studies funded by the National Heart, Lung, and Blood Institute were pooled and used to derive these models. These models were developed using data derived from patients without ASCVD, and the composite outcome was a nonfatal MI, CHD death, and nonfatal or fatal stroke. The variables included in the models were age, systolic blood pressure, total cholesterol, HDL, current smoking status, and history of diabetes. The c-statistics varied by sex and race but ranged from 0.713 to 0.818. These ACC/AHA risk equation models apply to more contemporary and diverse datasets than found in the Framingham cohort. While the risk prediction of the estimator has been cited to not differ based on diabetes status, it was not developed in a diabetes-specific cohort.
Another existing model of interest is the UKPDS risk engine, which is 1 of the more widely known models predicting CHD events (fatal or nonfatal MI or sudden death) in patients with newly diagnosed T2D.9 While this model includes age, sex, race, smoking status, systolic blood pressure, and the ratio of total cholesterol to HDL cholesterol, it also includes HbA1c and duration of diagnosed diabetes. The UKPDS population has also been used to develop a stroke-specific model that includes the factors listed above, with the exception of HbA1c and race (nonsignificant), and the addition of atrial fibrillation.10 While the UKPDS has the benefit over the aforementioned models since it is specific to the T2D population, external validation studies have found that the UKPDS may also not be accurate for risk assessment.4,11 For example, 1 validation study evaluating outcomes in shorter time periods (ie, 4, 5, 6, and 8 years) as compared with over 10 years in the UKPDS study and within specific subgroups (eg, duration of T2D < 10 years) found that CHD and CVD risks were overestimated.4 Another validation study also found consistent overestimation of CHD risk in patients with newly diagnosed T2D.11 The UPKDS has been the most externally validated diabetes-specific CV risk model, with external validation studies reporting pooled c-statistics of 0.68.30
While established risk models are more parsimonious than our model, given the lack of specific clinical information, particularly laboratory values and diabetes-related factors (eg, duration of diabetes), our model had to utilize additional factors available in administrative claims as potential proxies. Utilizing established predictive models, from a health plan perspective, may not be feasible to identify patients at risk who may benefit from interventions, as those clinical values are not always available for assessment. Thus, our model and method may be leveraged with similar claims-based sources that may not have specific clinical data that may only be in medical charts or electronic health records. A predictive model such as this could be used in conjunction with other models or methods to identify patients within health plans appropriate for engagement in clinical programs (eg, diabetes disease management,) or for referral to resources to reduce future risk (eg, nurse or case management, transition support).
In addition, longer-term risk assessment (ie, 10 years) across a large number of individuals may not be useful as only those with the highest or most imminent risk may be able to be included in outreach for risk reduction. Thus, leveraging existing data to identify patients who potentially are at highest risk over shorter periods may prove to have utility in a health plan setting. While the sensitivity and specificity did not show optimal performance, the model c-statistic was 0.68, similar to the validity of other published models specific to patients with T2D or validated in patients with T2D while being generalizable to a large, older US population of patients.
LIMITATIONS
Limitations common to studies using administrative claims data apply to this study. These limitations include lack of certain information in the database (eg, full clinical and laboratory data, personal and family histories) and errors in claims coding. While predictive models based on administrative claims may not have as robust clinical data as predictive models built on years of detailed and specific clinical data (eg, Framingham), they may have higher utility as they use real-world data available on a large number of individuals to identify patients in real-time practice. Some clinical data, such as laboratory values, were available for this study, though only in a portion of patients. As such, imputation techniques were used in an attempt to mitigate missing data to the extent feasible.
This study used data with a Medicare Advantage member population, so the results may not be generalizable, particularly for younger patients in commercial health insurance plans. Relationships were established based on statistical associations and temporal relationships; as such, causal inference may not be directly determined.
This study also used a composite CV event outcome inclusive of events that are thrombotic or embolic in nature (eg, MI, stroke) or a hospitalization for heart failure. While there may be similarities and overlap in predictors for these events, the model may have been able to be better fit with outcomes focused either on acute events, such as MI or stroke, or events due to an underlying chronic condition, such as hospitalization for heart failure. Additionally, coronary artery bypass graft and percutaneous coronary intervention procedures of importance for patients, providers, and health systems were included in the composite, increasing the event rate as compared with other studies.
Also, the outcome did not include mortality in the composite. Models currently in existence have typically included cause-specific mortality, which is unable to be accurately determined utilizing claims data alone. Furthermore, the only laboratory measures that were considered for imputation and included in the predictive model were ones with missing values greater than 50%. Only 1 laboratory value, serum creatinine used to calculate eGFR, met that criterion. Other laboratory values with potential prognostic importance, such as HbA1c or cholesterol, were not included.
This was a main effects model with no interactions; inclusion of higher-order terms or variable transformations would have reduced the explanatory capacity of the model but may have enhanced the predictive power. In addition, only 1 modeling technique, a survival model, was utilized. Other modeling considerations, including machine learning or ensemble methods, may have also provided a more predictive and robust model.
To create a model that was generalizable, there were few exclusions on the patient sample. For example, patients with incident or prevalent CV events were included, as were patients with possible kidney failure. As such, a model focusing on a narrower cohort of patients may have reduced some bias and provided a model with enhanced predictive capabilities.
Conclusions
A model predicting the risk of composite CV events developed using administrative claims may be useful for focusing interventions for a large population of older patients diagnosed with T2D. Further recalibration and validation of the model may be warranted to achieve optimal performance and utility across other populations for future application.
REFERENCES
- 1.American Diabetes Association. 14. Diabetes care in the hospital: standards of medical care in diabetes—2018. Diabetes Care. 2018;41(suppl 1):S144-S151. [DOI] [PubMed] [Google Scholar]
- 2.Centers for Disease Control and Prevention. National diabetes statistics report, 2020. Accessed May 19, 2021. https://www.cdc.gov/diabetes/pdfs/data/statistics/national-diabetes-statistics-report.pdf
- 3.He W, Goodkind D, Kowal PR. An aging world: 2015. International Population Reports, P95/16-1. US Census Bureau. 2016. Accessed May 19, 2021. https://www.census.gov/content/dam/Census/library/publications/2016/demo/p95-16-1.pdf
- 4.van Dieren S, Beulens JWJ, Kengne AP, et al. Prediction models for the risk of cardiovascular disease in patients with type 2 diabetes: a systematic review. Heart. 2012;98(5):360-369. [DOI] [PubMed] [Google Scholar]
- 5.Echouffo-Tcheugui JB, Kengne AP. On the importance of global cardiovascular risk assessment in people with type 2 diabetes. Primary Care Diabetes. 2013;7(2):95-102. [DOI] [PubMed] [Google Scholar]
- 6.Goff DC Jr, Lloyd-Jones DM, Bennett G, et al. 2013 ACC/AHA guideline on the assessment of cardiovascular risk: a report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines. Circulation. 2014;129(25 suppl 2):S49-73. [DOI] [PubMed] [Google Scholar]
- 7.Coleman RL, Stevens RJ, Retnakaran R, Holman RR. Framingham, SCORE, and DECODE risk equations do not provide reliable cardiovascular risk estimates in type 2 diabetes. Diabetes Care. 2007;30(5):1292-1293. [DOI] [PubMed] [Google Scholar]
- 8.American Diabetes Association. 9. Cardiovascular disease and risk management: standards of medical care in diabetes—2018. Diabetes Care. 2018;41(suppl 1):S86-S104. [DOI] [PubMed] [Google Scholar]
- 9.Stevens R, Kothari V, Adler A, Stratton I, Holman R. The UKPDS risk engine: a model for the risk of coronary heart disease in type II diabetes (UKPDS 56) Clin Sci. 2001;101(6):671-679. [PubMed] [Google Scholar]
- 10.Kothari V, Stevens R, Adler A, et al. UKPDS 60 risk of stroke in type 2 diabetes estimated by the UK Prospective Diabetes Study Risk Engine. Stroke. 2002;33:1776-1781. [DOI] [PubMed] [Google Scholar]
- 11.Bannister CA, Poole CD, Jenkins-Jones S, et al. External validation of the UKPDS risk engine in incident type 2 diabetes: a need for new type 2 diabetes-specific risk equations. Diabetes Care. 2014;37(2):537-545. [DOI] [PubMed] [Google Scholar]
- 12.National Center for Health Statistics. Official ICD-9-CM guidelines for coding and reporting. October 1, 2011. Accessed May 19, 2021. https://www.cdc.gov/nchs/data/icd/icd9cm_guidelines_2011.pdf
- 13.Hart LG, Larson EH, Lishner DM. Rural definitions for health policy and research. Am J Public Health. 2005;95(7):1149-1155. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.West AN, Weeks WB, Wallace AE. Rural veterans and access to high-quality care for high-risk surgeries. Health Serv Res. 2008;43(5 Pt 1):1737-1751. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Deyo RA, Cherkin DC, Ciol MA. Adapting a clinical comorbidity index for use with ICD-9-CM administrative databases. J Clin Epidemiol. 1992;45(6):613-619. [DOI] [PubMed] [Google Scholar]
- 16.Quan H, Sundararajan V, Halfon P, et al. Coding algorithms for defining comorbidities in ICD-9-CM and ICD-10 administrative data. Medical Care. 2005;43(11):1130-1139. [DOI] [PubMed] [Google Scholar]
- 17.Klabunde CN, Potosky AL, Legler JM, Warren JL. Development of a comorbidity index using physician claims data. J Clin Epidemiol. 2000;53(12):1258-1267. [DOI] [PubMed] [Google Scholar]
- 18.Steyerberg EW. Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating. Springer; 2009. [Google Scholar]
- 19.Berglund, P. Multiple imputation using the fully conditional specification method: a comparison of SAS®, Stata, IVEware, and R. 2015. SAS Global Forum 2015 Proceedings. April 26-29, 2015. Dallas, TX. Accessed May 19, 2021. https://support.sas.com/resources/papers/proceedings15/ [Google Scholar]
- 20.Berglund P, Heeringa S. Multiple Imputation of Missing Data Using SAS. SAS Institute Inc; 2014. [Google Scholar]
- 21.Marshall A, Altman DG, Holder RL, Royston P. Combining estimates of interest in prognostic modelling studies after multiple imputation: current practice and guidelines. BMC Med Res Methodol. 2009;9:57. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. Ann Intern Med. 2015;162(1):55-63. [DOI] [PubMed] [Google Scholar]
- 23.Moons KG, Altman DG, Reitsma JB, et al. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): explanation and elaboration. Ann Intern Med. 2015;162(1):W1-73. [DOI] [PubMed] [Google Scholar]
- 24.Dunkler D, Plischke M, Leffondre K, Heinze G. Augmented backward elimination: a pragmatic and purposeful way to develop statistical models. PLoS One. 2014;9(11):e113677. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.de Jongh PJ, de Jongh E, Pienaar M, Gordon-Grant H, Oberholzer M, Santana L. The impact of pre-selected variance in ation factor thresholds on the stability and predictive power of logistic regression models in credit scoring. ORiON. 2015;31(1):17-37. [Google Scholar]
- 26.SAS Institute. SAS Enterprise. Cary, NC. 2015. [Google Scholar]
- 27.D’Agostino RB Sr, Grundy S, Sullivan LM, Wilson P, Group CHDRP. Validation of the Framingham coronary heart disease prediction scores: results of a multiple ethnic groups investigation. JAMA. 2001;286(2):180-187. [DOI] [PubMed] [Google Scholar]
- 28.Anderson KM, Wilson PW, Odell PM, Kannel WB. An updated coronary risk profile. A statement for health professionals. Circulation. 1991;83(1):356-362. [DOI] [PubMed] [Google Scholar]
- 29.Wilson PW, D’Agostino RB, Levy D, Belanger AM, Silbershatz H, Kannel WB. Prediction of coronary heart disease using risk factor categories. Circulation. 1998;97(18):1837-1847. [DOI] [PubMed] [Google Scholar]
- 30.Chowdhury MZI, Yeasmin F, Rabi DM, Ronksley PE, Turin TC. Prognostic tools for cardiovascular disease in patients with type 2 diabetes: a systematic review and meta-analysis of c-statistics. J Diabetes Complications. 2019;33(1):98-111. [DOI] [PubMed] [Google Scholar]