

Abstract
A recent surge of patent applications among public hospitals in China has aroused significant research interest. A country’s healthcare innovation capacity can be measured by its number of patents. This paper explores the link between the number of patents and ten independent variables. Multicollinearity was carefully detected and removed by using the variable selection method and LASSO regression, respectively. The Poisson model and the negative binomial model were proposed to analyze the patent data. Three goodness of fit tests, the Pearson test, the deviance test, and the DHARMa non-parametric dispersion test, were conducted to investigate if the model has a good fit. After discovering four clusters by conducting agglomerative hierarchical clustering, these two models were replaced by the negative binomial mixed model. The likelihood ratio test was used to determine which model is more appropriate and the results reveal that the negative binomial mixed model outperforms both the Poisson model and the negative binomial model. Three variables, number of health technicians per 10,000 people, financial expenditure on science and technology as well as number of patent applications per 10,000 health personnel, have a significantly positive relationship with the number of patents in Chinese tertiary public hospitals.
Subject terms: Mathematics and computing, Statistics
Introduction
Over the past ten years, the number of patents application in China has been skyrocketing. China has surpassed all other countries worldwide in terms of patent application filings since 20111. The number of applications for invention patents climbed from 526,412 in 2011 to 1,586,000 in 2021, with an average annual growth rate of 11.7%, according to the National Bureau of Statistics of China. Healthcare patents, one of the most important areas of the patent, provide important protections for intellectual property in the medical arena, which can further innovations that benefit everyone. Medical patents are defined broadly to include patents that relate to pharmaceuticals; methods of making and using them; medical treatment regimens; surgical procedures; medical devices; health care information technology for hospital and health care management systems; and combinations of them2.
Medical patents holders are mainly tertiary public hospitals in China. In China, hospitals are organized in a three-tiered hierarchy, with primary hospitals providing general healthcare and preventive care to the population. Secondary hospitals provide complete health care to a region, accept referrals from primary hospitals, and are also responsible for teaching and research. Lastly, tertiary hospitals, often located in urban areas, are responsible for specialty care and act as medical centres for several regions3–6. This system is motivated by the expectation that tertiary hospitals can focus more on research and lead Chinese medical innovation to a higher level. As for the evaluation, patents are vital to measure hospitals’ achievement. The number of applied patents can be related to many factors. For example, based on the scale of a region, the investment or the population size can be considered.
Following the acquisition of data on the number of patents, a linear regression model will be considered first to fit. However, we would only consider the linear regression process, the least absolute shrinkage and selection operator (LASSO) regression model, in the step of variable selection7. The number of patents is a counting value over a fixed period of time. In other words, we are counting the occurrences of the event that a patent application is submitted during a certain time interval. We are assuming that the event happens completely randomly and independently. Thus, the number of patents no longer follows a normal distribution, and hence a simple linear regression model will be dismissed under our assumption.
To overcome the problem of the non-normal distribution of dependent variables, generalized linear models like the Poisson regression model will be introduced8. A count variable is a variable that reflects the number of occurrences of an interested event in a fixed period of time8. Linear regression model is not appropriate for a count variable as a dependent variable and problems like biased standard errors will occur9. Poisson regression model offers an alternative analysis for count data. It can also be used for summarizing relative risk across strata of a covariate and for evaluating interactions between covariates10. The Poisson regression model is an example of generalized linear models (GLM). There are three components in a GLM: a random component, a systematic component and a link function. Random component is the probability distribution of the dependent variable, for example, Poisson distribution for response variable in the Poisson regression. Systematic component refers to the independent variables as a combination of linear predictors and link function specifies the link between random and systematic components11–13. Poisson regression with overdispersion can be replaced with the negative binomial model if the assumption must be met for the model to be valid14. Besides, this paper also proposed a mixed model, which is a combination of regression with clustering15–17. The summary of results is provided in the last part.
Materials and methods
Data description
Patent number data from the effective patents for tertiary public hospitals in China was used as the dependent variable in this paper. The Baiten database (www.baiten.cn) was thoroughly searched for patent numbers in tertiary public hospitals. Since a time lag exists between the application time and publication time in patent authorization period18, we select the year of application to conduct our count procedure. A total number of 165,262 patent was collected in 2243 tertiary public hospitals from year 2016 to year 2021. The independent variables, population, GDP, number of health technicians per 10,000 people, R &D, number of health personnel, financial expenditure on education, financial expenditure on science and technology, financial health care expenditure, health industry income per capita and number of patent applications per 10,000 health personnel, were obtained from the National Bureau of Statistics (NBS) website.
Summary statistics regarding variables in our data are shown in Table 1. Table 2 and Fig. 1show the number of patents from the year 2016 to the year 2021. The sharp increase in the number of patents in 2018 was due to the regulation announcement that tertiary public hospitals began assessing patents in 2018. The reason why only a half number of patents in 2021 compared with the year 2020 is that China carried out intellectual property quality improvement projects.
Table 1.
Variable description.
| Abbreviations | Description | Mean | SD | Min. | Max. |
|---|---|---|---|---|---|
| NumPat | Number of patents | 888.51 | 1446.50 | 0.00 | 9,951.00 |
| Pop | Population | 4526.72 | 2975.69 | 340.00 | 12,684.00 |
| GDP | Gross domestic product | 30,253.57 | 24,993.020 | 124,369.70 | 1173.00 |
| NumHeaTec | Number of health technicians per 10,000 people | 71.05 | 12.98 | 45.00 | 126.00 |
| R &D | Research and development | 99,422.66 | 144,492.69 | 190.00 | 700,017.00 |
| NumHeaPer | Number of health personnel | 40.37 | 25.34 | 2.92 | 102.79 |
| FinEdu | Financial expenditure on education | 1000.06 | 616.57 | 152.57 | 3,510.56 |
| FinSci | Financial expenditure on science and technology | 166.32 | 201.56 | 4.81 | 1168.79 |
| FinHea | Financial health care expenditure | 510.84 | 300.43 | 69.97 | 1772.99 |
| HeaInc | Health industry income per capita | 99,681.45 | 31,336.74 | 51,135.00 | 208,481.00 |
| NumPatHeaPer | Number of patent applications per 10,000 health personnel | 17.99 | 22.05 | 0.00 | 120.87 |
| Pro | Province | categorical | categorical | categorical | categorical |
Table 2.
The number of patents from 2016 to 2021.
| Year | Number of patents |
|---|---|
| 2016 | 3325 |
| 2017 | 6613 |
| 2018 | 14,509 |
| 2019 | 39,131 |
| 2020 | 63,737 |
| 2021 | 37,947 |
Figure 1.
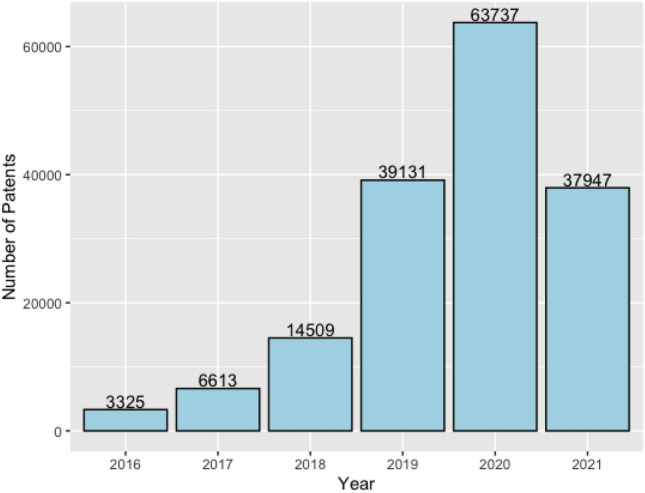
Bar plot of the number of patents every year between 2016 and 2021.
Variable selection
Multicollinearity appears when independent variables (NumPat, Pop, GDP, NumHeaTec, R &D, NumHeaPer, FinEdu, FinSci, FinHea, HeaInc and NumPatHeaPer) in the regression model are highly correlated to each other. It generates high variance of the estimated coefficients and hence, the coefficient estimates corresponding to those interrelated explanatory variables will lead to wrong results. To detect multicollinearity, the correlation matrix is plotted. Variable selection and LASSO regression can be utilized to eliminate the problem of multicollinearity.
Variable selection via variance inflation factor
One of the two methods we applied here is variable selection method using variance inflation factor (VIF).
VIF is used to measure the multicollinearity among the our ten independent variables. When there is high correlation among the predictor variables, the standard errors of predictors coefficients will increase, then the variance of their coefficients will be inflated.
The VIF on NumPat, Pop, GDP, NumHeaTec, R &D, NumHeaPer, FinEdu, FinSci, FinHea, HeaInc, NumPatHeaPer is defined as
| 1 |
where is the coefficient determination for the regression of on the remaining variables19. For example, to calculate , we regress NumPat against all other independent variables and then we can obtain , thus, VIF of NumPat can be derived. Normally, for VIF, a value of 10 and above indicates multicollinearity20.
The variable selection procedure is done by removing the variable that has the highest VIF value. Then correlation matrix and VIF were calculated again to remove next variable that has the highest VIF value. The procedure was stopped when there is no VIF value larger than 1021.
LASSO regression
Though variable selection via VIF can perform feature selection and make parsimonious models, with advancements in machine learning, Least Absolute Shrinkage and Selection Operator, known as LASSO, provides a good alternative as it gives much better output, requiring fewer tuning parameters and being automated to a large extend22.
LASSO was proposed by Tibshirani (1996) for subset selection based in regression process. It puts a constraint on the sum of the absolute values of the model parameters. In other words, it apply a shrinking or regularization process where it penalizes the coefficients of the regression variables, shrinking some of them to zero.
LASSO solves the -penalized regression problem of finding to minimize
| 2 |
where are the standardized NumPat, Pop, GDP, NumHeaTec, R &D, NumHeaPer, FinEdu, FinSci, FinHea, HeaInc, NumPatHeaPer and is the NumPat. The method of K-fold cross-validation is performed to tuning parameter values and we used ten-fold. This procedure begins with splitting the data into “folds.” Then the prediction performance of each model is evaluated across the “left-out” fold using a sequence of tuning parameter settings. This procedure is done until every fold has been calculated as test data. Typically, the tuning parameter is set to the sequence value with the smallest cross-validation error23.
Methods
The Poisson regression model was utilized to analyze the relationship between count data and the independent variables. In Poisson regression, the response variable is assumed to follow a Poisson distribution , and hence the regression formula is defined as
| 3 |
or written as
| 4 |
where is the expected value or mean of the NumPat, is a matrix of the NumPat, Pop, GDP, NumHeaTec, R &D, NumHeaPer, FinEdu, FinSci, FinHea, HeaInc, NumPatHeaPer and , and is the set of regression coefficients to be estimated.
Different from linear regression models, the Poisson regression model uses Maximum Likelihood Estimation (MLE) method instead of OLS estimation. Since we have assumed that , the probability density function (pdf) of (NumPat) is
| 5 |
then the likelihood function takes the form
| 6 |
given N vectors with along with a set of N values . Hence the log-likelihood is derived as
| 7 |
and finally some calculation methods would be taken to maximize the log-likelihood, selecting the best values of .
The interpretation of is that, in particular, given one unit change of the independent variable, the difference in the natural logarithm of expected counts is expected to change by the respective regression coefficient, with other independent variables in the model constant.
We should recognize that models can only approximate complete information or reality. Thus, we tried to find the model that minimize the loss of information. A useful criterion in model selection named Akaike’s information criterion (AIC) is defined as
| 8 |
where is the log-likelihood function of the candidate model evaluated under by using observations and k is the number of unknown parameters. Then, the resulting model is subjected to the log-likelihood value where is log-likelihood at convergence.
A basic assumption of the Poisson distribution is that, for the count data, the mean equals the variance. However, this assumption is not always satisfied. Real data often does not show this specific pattern and the variance tends to be larger than the mean for most of the data. This is known as overdispersion problem in statistics24.
We have discussed that it is unrealistic to assume for most cases, hence a more flexible relationship between the variance and the mean should be considered25. As a result, the negative binomial model is proposed.
In the negative binomial model, the number of patents was assumed to follow the negative binomial distribution, that is, with , whose pdf is
| 9 |
where is the mean and is the dispersion parameter that controls the amount of overdispersion. Thus, the variance and the mean of can be derived as
| 10 |
| 11 |
As the above formula shows, the variance and the mean are not the same thing in the negative binomial regression assumption. This is not the case with the Poisson regression. Instead, the model assumes a quadratic relationship between the mean and the variance. The negative binomial model can be used for overdispersed count data and it can be considered as a generalization of Poisson regression since it has the same mean structure as Poisson regression and it has an extra parameter to model the overdispersion.
The MLE of parameters in the negative binomial model is straightforward25. Lawless has discussed about the efficiency and robustness properties of the inference procedure26.
Hierarchical clustering, one of the most popular unsupervised learning methods, was conducted to find if there exists correlation in the data. In other words, within-cluster observations have high similarity in comparison to others. There are two approaches, agglomerative hierarchical clustering and divisive hierarchical clustering. Agglomerative hierarchical clustering is a bottom up approach that each observation starts from its own cluster, and then clusters are grouped as observations move up the hierarchy. Divisive hierarchical cluserting is a top down approach that observations start from one cluster, and then split as observations moving down the hierarchy. However, the complexity of divisive clustering is , which makes it too slow for large data sets. Moreover, no provision can be made for a relocation of observations that may have been ’incorrectly’ grouped at an early stage in divisive hierarchical cluserting27. Therefore, the agglomerative clustering was used to group data into clusters based on their similarity in this paper.
Euclidean distance matrix was used for hierarchical clustering and the linkage criterion determines the distance between sets of observations as a function of the pairwise distances between observations. Ward’s method is based on the objective of minimizing the deterioration in the overall within sum of squares. The latter is the sum of squared deviations between the data in a cluster and the centroid:
| 12 |
with is a data point and as the centroid of cluster C. Since any merger of two existing clusters results in an overall WSS decline, Ward’s method is intended to minimize this decline. In other words, it is utilized to minimize the difference between the new WSS in the merged cluster and the total WSS of the merged components.
Dendrogram is widely used in visualizing a clustering hierarchy and it is simple to interpret similarity and clustering. The horizontal axis of the dendrogram indicates the dissimilarity or distance between clusters, while the vertical axis represents the objects and clusters.
The Poisson mixed effects model can be an appropriate choice for clustered patent count data. However, it still suffers from the overdispersion problem. Therefore, the negative binomial mixed model was proposed based on the negative binomial model, to analyze the clustered count data, where the observations are no longer considered as independent with each other but are correlated on the counts. Observations are divided into several clusters. These clusters are also called “subjects” and observations in each cluster are seen as repeated measurements over a period of time, hence they have correlation, while observations from different clusters or subjects are independent. To be more specific, is the value of the patent count variable for subject at time point.
Compared with the negative binomial model, the only change in the negative binomial mixed model is that, in order to take the influence of within-cluster correlation into account, we add subject-specific random effects into the linear predictor. The mean of subject is related to the host variables via the logarithm link function written in matrix notation:
| 13 |
where is the vector of fixed effects for the independent variables (NumPat, Pop, GDP, NumHeaTec, R &D, NumHeaPer, FinEdu, FinSci, FinHea, HeaInc, NumPatHeaPer), cluster is the vector of random effects and is the random errors. The random effects are utilized to partition the multiple sources of variation, and thus to avoid biased inference on the effects of the NumPat, Pop, GDP, NumHeaTec, R &D, NumHeaPer, FinEdu, FinSci, FinHea, HeaInc and NumPatHeaPer. The vector of the random effects is usually assumed to follow the multivariate normal distribution and is a positive-definite variance-covariance matrix that determines the form and complexity of random effects b.
Results
Variable selection
The correlation matrix plot was plotted to detect if multicollinearity exists. According to the heat map in Fig. 2, obviously there is severe collinearity among the predictor variables. Thus, before fitting models, some measures may need to be taken to avoid this problem, otherwise we might have irrelevant variables in our model, influencing the significance of coefficients.
Figure 2.
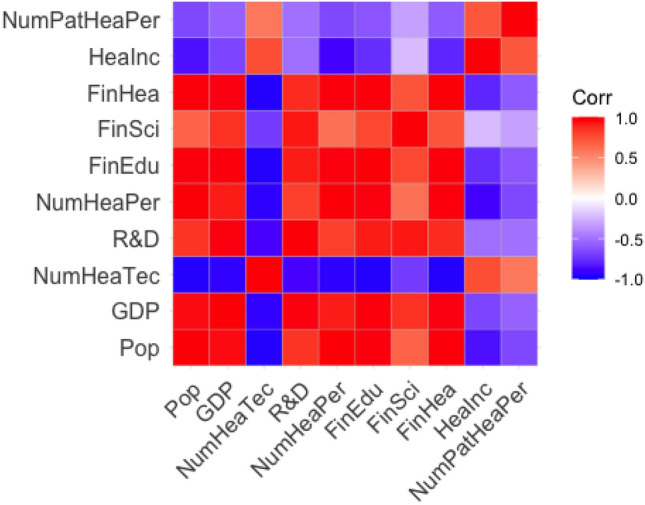
Correlation matrix heatmap for measuring of dispersion.
A more formal way to test multicollinearity is the Variance Inflation Factor. The multicollinearity arises when VIF is larger than 10 and the detailed VIF results are shown in Table 3. A variable selection procedure was conducted to get rid of the high multicollinearity problem. It is done by removing the variable that has the highest VIF value, which is variable Population. Then the correlation matrix and VIF were calculated again to remove the next variable that has the highest VIF value. The procedure was stopped when there was no VIF value larger than 10. At the end of our procedure, the number of health technicians per 10,000 people, R &D, number of health personnel, financial expenditure on science and technology, health industry income per capita and number of patents applications per 10,000 people can be used with a further regression model, and the VIF values of these variables are shown in Table 4.
Table 3.
VIF with all variables.
| Variable | VIF | Detection |
|---|---|---|
| Pop | 107.34 | Collinearity |
| GDP | 28.96 | Collinearity |
| NumHeaTec | 4.33 | No collinearity |
| R &D | 13.58 | Collinearity |
| NumHeaPer | 94.16 | Collinearity |
| FinEdu | 43.29 | Collinearity |
| FinSci | 12.85 | Collinearity |
| FinHea | 32.37 | Collinearity |
| HeaInc | 3.76 | No collinearity |
| NumPatHeaPer | 2.63 | No collinearity |
Table 4.
VIF with selected variables.
| Variable | VIF |
|---|---|
| NumHeaTec | 1.78 |
| R &D | 5.58 |
| NumHeaPer | 2.55 |
| FinSci | 5.98 |
| HeaInc | 3.40 |
| NumPatHeaPer | 1.98 |
In LASSO regression, 5-fold cross-validation is performed to find an optimal lambda value, which equals 0.01. After using this optimal lambda value for LASSO regression, we have the coefficients of population, GDP, financial expenditure on education and Financial health care expenditure constrained to 0, leaving number of health technicians per 10,000 people, R &D, number of health personnel, financial expenditure on science and technology, health industry income per capita and number of patents applications per 10,000 health personnel. It is the same result when we use the variable selection method via the VIF.
Poisson regression model and negative binomial model
After backward selection based on the AIC used, the number of health personnel was dropped and we used left variables to generate our Poisson regression model, negative binomial model and negative binomial mixed model. Goodness of fit tests are performed to check if the model is correct given the data. First, the Pearson and deviance goodness of fit tests were utilized to test the goodness of fit of the Poisson regression model. The p-values of both these two tests are close to 0. Thus, we don’t have enough evidence to show our model is good. Moreover, Kolmogorov-Smirnov test were used to test the goodness of fitness. The p-value of KS test is close to 0 and the residuals of the Poisson model didn’t follow a uniform distribution.
DHARMa non-parametric dispersion has a very nice test for dispersion and the result showed that the observed value was much larger than what we could expect under the model. Thus, the Poisson regression model suffers from overdispersion.
In order to deal with the overdispersion problem, a negative binomial model was used. As we can see from the Fig. 3, the p-value of the Kolmogorov-Smirnov test showed the residuals of the negative binomial model follow the uniform distribution and the DHARMa nonparametric dispersion test showed the overdispersion problem no longer exists.
Figure 3.

Goodness of fit for negative binomial model. Left: the Kolmogorov-Smirnov test indicates that the residuals of the negative binomial model follow a uniform distribution; Right:the DHARMa nonparametric dispersion test shows that the overdispersion problem no longer exists in the negative binomial model.
Hierarchical clustering
To detect if there are correlations or clusters among the 31 provinces in China, the data of the year 2021 was selected to conduct the hierarchical clustering method. After plotting the dendrogram in Fig. 4, four clusters can be summarized from the dendrogram plot. After doing agglomerative hierarchical clustering among the 31 provinces, and the detailed provinces in the four clusters are shown in Table 5.
Figure 4.

Dendrogram of a hierarchical clustering using agglomerative clustering.
Table 5.
Clustering results.
| Cluster | Province |
|---|---|
| Cluster 1 | Jiangsu, Zhejiang, Guangdong |
| Cluster 2 | Tianjin, Shanxi, Neimenggu, Liaoning, Jilin, Heilongjiang, Hainan, Xizang, Shanxi, Gansu, Qinghai, Ningxia, Xinjiang |
| Cluster 3 | Beijing, Shanghai |
| Cluster 4 | Hebei, Anhui, Fujian, Jiangxi, Shandong, Henan, Hubei, Hunan, Guangxi, Chongqing, Sichuan, Guizhou, Yunnan |
Negative binomial mixed model
Taking the clustering and the overdispersion problem into account, a negative binomial mixed model was conducted in this paper. The results of the coefficient estimator and p-values of Poisson model, negative binomial model (abbreviated as NBM) and negative binomial mixed model’s fix effect (abbreviated as NBMM FE) are shown in Table 6.
Table 6.
Model Estimated Cficients.
| Variable | Poisson | NBM | NBMM FE | |||
|---|---|---|---|---|---|---|
| ES (95% CI) | p-value | ES (95% CI) | p-value | ES (95% CI) | p-value | |
| NumHeaTec | 0.20 (0.20,0.21) | < 0.001 | 0.35 (0.16,0.55) | < 0.001 | 0.72 (0.54,0.92) | < 0.001 |
| R &D | 0.06 (0.05,0.06) | < 0.001 | 0.39 (0.06,0.72) | < 0.01 | 0.34 (− 0.08,0.76) | 0.11 |
| FinSci | 0.34 (0.33,0.35) | < 0.001 | 0.20 (− 0.14,0.56) | 0.2 | 0.36 (0.03,0.70) | < 0.05 |
| HeaInc | − 0.32 (− 0.33, − 0.31) | < 0.001 | − 0.41 (− 0.64,-0.17) | < 0.001 | − 0.38 (− 0.57,-0.18) | < 0.001 |
| NumPatHeaPer | 0.64 (0.64,0.65) | < 0.001 | 1.31 (1.09,1.55) | < 0.001 | 1.12 (0.92,1.32) | < 0.001 |
A likelihood ratio test was used to determine if the negative binomial model is more appropriate statistically than the Poisson model, and the results <0.001 suggest that the negative binomial model is a better fit. The same conclusion can be drawn from the Pearson goodness of fit test (p-value = 0.98), deviance goodness of fit test (p-value = 0.05) and the DHARMa non-parametric dispersion test (p-value = 0.32) in the negative binomial model. The likelihood ratio test between the negative binomial model and the negative binomial mixed model suggests that the multilevel model provides a better fit. The variance of the random effects equals 0.2908, which is not too close to 0 and thus, we cannot assume all provinces are independent of each other and the clustering needs to be considered in this data.
The AIC of three models, Poisson model, negative binomial model and negative binomial mixed model, are 71270, 2588.1 and 2533.6, respectively. It is also proved that negative binomial mixed model outperformed than these two models in our data.
Discussion
Regarding to the count variable, number of patents, Poisson regression model is a commonly used analysis. The Poisson regression is performed based on the assumption that the mean and the variance of the dependent variable are the same. Overdispersion appears when there is more variability around the variance than the mean28. Therefore, the negative binomial model is better than the Poisson model when the data shows evidence of overdisperson29,30. After conducting the agglomerative hierarchical clustering, four clusters among the 31 provinces were demonstrated in Table 5 and Fig. 4. Therefore, we have solid evidence to take the clustering into account and use multilevel model in this data. The R &Ds of Jiangsu, Zhejiang and Guangdong provinces are almost 10 times larger than other provinces which is the primary reason that these three provinces are grouped. It means that Jiangsu, Zhejiang and Guangdong have a relatively high economy and undertake to innovate and introduce new products and services. Beijing and Shanghai are the two major and most well-known provinces in China. They have the similar economic status, policies and wealth structures. According to our data, all of variables are similar between Beijing and Shanghai and it is reasonable to group them together. Another two clusters can be summarized by saying that they are separated by region—most of the provinces in cluster 2 are from northern China and most of the provinces in cluster 4 are from southern China.
Considering both the clustering and the overdispersion problem, a negative binomial mixed model was proposed. The comparison among estimated coefficients with confidence intervals and p-values of the Poisson model, negative binomial model and negative binomial mixed model’s fix effect are shown in Table 6. From the results of negative binomial model, three variables, number of health technicians per 10,000 people, financial expenditure on science and technology as well as number of patents applications per 10,000 health personnel, have significantly positive relationship with the number of patents in Chinese tertiary public hospitals. To be specific, holding all other variables constant in the negative binomial mixed model , by increasing the number of patents applications per 10,000 health personnel by 1 unit, the number of patents will increase more than two times . The variable, health industry income per capita, has a significantly negative relationship with the patent number and when it increases by 1 unit, the number of patents decreases by 32%. Moreover, the likelihood ratio test and AIC are used to compare two models based on the ratio of the likelihoods31,32. The results of likelihood ratio test revealed that negative binomial mixed model outperformed both the Poisson model and the negative binomial model in the data. The variance of the random effects in the negative binomial model is not close to 0 and it also proved that there were associations among the provinces.
The reason why R &D is not significant in the negative binomial mixed model is that we add the province as a random effect in this model. This result is consistent with the finding that R &D is very imprecisely estimated when comparing France and the USA33. It may be because the R &D is a significant variable when we group the provinces, but after we clustered, each group had close R &D and thus, the p-value of R &D is not significant after we grouped.
We suggest that each province should adjust the proportion of financial investment and health technicians in different regions according to the local conditions. For example, relatively wealthy provinces can devote more resources to increase the number of health technicians and the protection and supervision of the patent exchange market, while less wealthy provinces should invest more finance in medical science and technology to increase their research and development ability.
The literature on comparison in terms of the traditional variable selection method and the LASSO regression remains scarce. In our study, we compared these methods in the selection of the feature. Moreover, to the best of our knowledge, this paper is the first work to use hierarchical clustering before conducting the multilevel model. One potential limitation of our negative binomial mixed model is that it is not designed to explicitly detect the association between the number of patents and one specific independent variable. The variance function versus the observed variance in our negative binomial mixed model needs to be further investigated and if the variance is wrong, the random effects need to be fixed since it models the variance and covariance structure.
Author contributions
Conceptualization and methodology, S.Q. and Y.Z; Formal analysis, S.Q. and Y.Z; Data collection, H.L.; Supervision, Y.G. and H.G.; Writing-original draft preparation, S.Q.; Writing-review and editing, F.Z., Q.Z. and M.G.. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Zhejiang Province Pointer Leader Plan Major Social Welfare Project grant number 2022C03124 and Zhejiang Province Soft Science Key Project grant number 2020C25002.
Data availability
The datasets generated during and analysed during the current study are available from the corresponding author on reasonable request.
Competing interersts
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Qifeng Zhang, Email: kjzx@zjwjw.gov.cn.
Yanchao Gao, Email: kjzxgyc@163.com.
References
- 1.Chen Z, Zhang J. Types of patents and driving forces behind the patent growth in China. Econ. Modell. 2019;80:294–302. doi: 10.1016/j.econmod.2018.11.015. [DOI] [Google Scholar]
- 2.Mayfield DL. Medical patents and how new instruments or medications might be patented. Missouri Med. 2016;113(6):456. [PMC free article] [PubMed] [Google Scholar]
- 3.Feng XL, et al. Extending access to essential services against constraints: The three-tier health service delivery system in rural china (1949–1980) Int. J. Equity Heal. 2017;16:1–18. doi: 10.1186/s12939-017-0541-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Tu J, Wang C, Wu S. The internet hospital: An emerging innovation in china. Lancet Glob. Health. 2015;3:e445–e446. doi: 10.1016/S2214-109X(15)00042-X. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.YE, T. et al. A reflection on the continuity of the three-tier healthcare network in rural china. Chin. J. Hosp. Adm. 184–187 (2011).
- 6.Yip WC-M, Hsiao W, Meng Q, Chen W, Sun X. Realignment of incentives for health-care providers in china. The Lancet. 2010;375:1120–1130. doi: 10.1016/S0140-6736(10)60063-3. [DOI] [PubMed] [Google Scholar]
- 7.Tibshirani R. Regression shrinkage and selection via the lasso: A retrospective. J. R. Stat. Soc. Ser. B. 2011;73:273–282. doi: 10.1111/j.1467-9868.2011.00771.x. [DOI] [Google Scholar]
- 8.Coxe S, West SG, Aiken LS. The analysis of count data: A gentle introduction to poisson regression and its alternatives. J. Pers. Assess. 2009;91:121–136. doi: 10.1080/00223890802634175. [DOI] [PubMed] [Google Scholar]
- 9.Gardner W, Mulvey EP, Shaw EC. Regression analyses of counts and rates: Poisson, overdispersed poisson, and negative binomial models. Psychol. Bull. 1995;118:392. doi: 10.1037/0033-2909.118.3.392. [DOI] [PubMed] [Google Scholar]
- 10.Frome EL, Checkoway H. Use of poisson regression models in estimating incidence rates and ratios. Am. J. Epidemiol. 1985;121:309–323. doi: 10.1093/oxfordjournals.aje.a114001. [DOI] [PubMed] [Google Scholar]
- 11.Dobson AJ, Barnett AG. An Introduction to Generalized Linear Models. Chapman and Hall/CRC; 2018. [Google Scholar]
- 12.Faraway JJ. Extending the Linear Model with R: Generalized Linear, Mixed Effects and Nonparametric Regression Models. Chapman and Hall/CRC; 2016. [Google Scholar]
- 13.Jiang J, Nguyen T. Linear and Generalized Linear Mixed Models and Their Applications. Springer; 2017. [Google Scholar]
- 14.Hinde J, Demétrio CG. Overdispersion: Models and estimation. Comput. Stat. Data Anal. 1998;27:151–170. doi: 10.1016/S0167-9473(98)00007-3. [DOI] [Google Scholar]
- 15.Yirga AA, Melesse SF, Mwambi HG, Ayele DG. Negative binomial mixed models for analyzing longitudinal cd4 count data. Sci. Rep. 2020;10:1–15. doi: 10.1038/s41598-020-73883-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Zhang X, et al. Negative binomial mixed models for analyzing longitudinal microbiome data. Front. Microbiol. 2018;9:1683. doi: 10.3389/fmicb.2018.01683. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Zhang X, et al. Negative binomial mixed models for analyzing microbiome count data. BMC Bioinform. 2017;18:1–10. doi: 10.1186/s12859-016-1441-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Dang J, Motohashi K. Patent statistics: A good indicator for innovation in china? patent subsidy program impacts on patent quality. China Econ. Rev. 2015;35:137–155. doi: 10.1016/j.chieco.2015.03.012. [DOI] [Google Scholar]
- 19.Chan JY-L, et al. Mitigating the multicollinearity problem and its machine learning approach: A review. Mathematics. 2022;10:1283. doi: 10.3390/math10081283. [DOI] [Google Scholar]
- 20.Daoud JI. Multicollinearity and regression analysis. J. Phys: Conf. Ser. 2017;949:012009. [Google Scholar]
- 21.Prahutama, A., Ispriyanti, D. & Warsito, B. Modelling generalized poisson regression in the number of dengue hemorrhagic fever (DHF) in east nusa tenggara. In E3S Web of Conferences, vol. 202, 12017 (EDP Sciences, 2020).
- 22.Muthukrishnan, R. & Rohini, R. Lasso: A feature selection technique in predictive modeling for machine learning. In 2016 IEEE International Conference on Advances in Computer Applications (ICACA), 18–20 (2016).
- 23.Roberts S, Nowak G. Stabilizing the lasso against cross-validation variability. Comput. Stat. Data Anal. 2014;70:198–211. doi: 10.1016/j.csda.2013.09.008. [DOI] [Google Scholar]
- 24.Moksony F, Hegedűs R. The use of Poisson regression in the sociological study of suicide. Corvinus J. Sociol. Soc. Policy. 2014;5:97. doi: 10.14267/cjssp.2014.02.04. [DOI] [Google Scholar]
- 25.Greene W. Functional forms for the negative binomial model for count data. Econ. Lett. 2008;99:585–590. doi: 10.1016/j.econlet.2007.10.015. [DOI] [Google Scholar]
- 26.Lawless JF. Negative binomial and mixed Poisson regression. Can. J. Stat. 1987;15:209–225. doi: 10.2307/3314912. [DOI] [Google Scholar]
- 27.Day WH, Edelsbrunner H. Efficient algorithms for agglomerative hierarchical clustering methods. J. Classif. 1984;1:7–24. doi: 10.1007/BF01890115. [DOI] [Google Scholar]
- 28.Nelder JA, Wedderburn RW. Generalized linear models. J. R. Stat. Soc. Ser. A (General) 1972;135:370–384. doi: 10.2307/2344614. [DOI] [Google Scholar]
- 29.Hilbe JM. Negative Binomial Regression. Cambridge University Press; 2011. [Google Scholar]
- 30.Paternoster R, Brame R. Multiple routes to delinquency? A test of developmental and general theories of crime. Criminology. 1997;35:49–84. doi: 10.1111/j.1745-9125.1997.tb00870.x. [DOI] [Google Scholar]
- 31.Lewis F, Butler A, Gilbert L. A unified approach to model selection using the likelihood ratio test. Methods Ecol. Evol. 2011;2:155–162. doi: 10.1111/j.2041-210X.2010.00063.x. [DOI] [Google Scholar]
- 32.Vuong QH. Likelihood ratio tests for model selection and non-nested hypotheses. Econom. J. Econ. Soc. 1989;57:307–333. [Google Scholar]
- 33.Hall BH, Mairesse J. Exploring the relationship between r &d and productivity in French manufacturing firms. J. Econ. 1995;65:263–293. doi: 10.1016/0304-4076(94)01604-X. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets generated during and analysed during the current study are available from the corresponding author on reasonable request.