

ABSTRACT
Primatologists, psychologists and neuroscientists have long hypothesized that primate behavior is highly structured. However, delineating that structure has been impossible due to the difficulties of precision behavioral tracking. Here we analyzed a data set consisting of continuous measures of the 3D position of two male rhesus macaques (Macaca mulatta) performing three different tasks in a large unrestrained environment over several hours. Using an unsupervised embedding approach on the tracked joints, we identified commonly repeated pose patterns, which we call postures. We found that macaques' behavior is characterized by 49 distinct postures, lasting an average of 0.6 seconds. We found evidence that behavior is hierarchically organized, in that transitions between poses tend to occur within larger modules, which correspond to identifiable actions; these actions are further organized hierarchically. Our behavioral decomposition allows us to identify universal (cross-individual and cross-task) and unique (specific to each individual and task) principles of behavior. These results demonstrate the hierarchical nature of primate behavior, provide a method for the automated ethogramming of primate behavior and provide important constraints on neural models of pose generation.
Keywords: pose, ethogramming, behavioral hierarchy
INTRODUCTION
Understanding the principles behind the organization of behavior has long been an important problem to ethology, psychology and neuroscience [1–7]. Macaques are especially important in this regard because of their pivotal role as a model organism for biomedical research [8, 9]. Indeed, a great deal of research has benefited from the rudimentary tracking and identification of behavior in laboratory tasks in macaques. However, precise measurement of behavior has generally been limited to a single motor modality (typically the eyes or arm) under conditions of bodily constraint. As a result, we have an impoverished understanding of behavior in the natural context, involving the free movement of full bodies in three-dimensional space [10].
Recent years have seen a great deal of success in the development of camera-based systems for tracking the behavior of small animals, including worms, flies and mice [6, 11–16]. There is now growing interest in larger species, including primates [17–22]. These tracking systems have allowed for the automated identification of specific meaningful behavioral units (‘ethogramming’) in these species [17, 23–25]. Results of these analyses have shown that behavior in these organisms consists of simple motifs that are repeated and are organized into a hierarchical structure [18, 23]. These methods are important because they can provide quantitative answers to longstanding questions at the core of behavioral science.
Our laboratory has developed a system that can perform detailed three-dimensional behavioral tracking in rhesus macaques with high spatial and temporal precision [26, 27]. Our system uses 62 cameras positioned around a specially designed open field environment (2.45 × 2.45 × 2.75 m) in which macaque subjects can move freely in three dimensions and interact with computerized feeders (see also haydenlab.com/tracking). We used this system to track the position of 15 joints at high temporal and spatial resolution as our subjects performed three different behavioral tasks. The data collected by this system open up the possibility of automated behavioral identification and analysis in macaques.
Previous unsupervised approaches to quantifying behavior were centered on actions [23, 24]. In contrast, our approach starts with the configuration of landmarks (‘postures’) as the fundamental unit of behavior. Specifically, we generated 23 variables corresponding to the angles between all major joint pairs and the velocity of the subject in three dimensions. We then performed dimensionality reduction to identify postures and graph theoretic methods to identify extended actions. We find that behavior clusters into 49 distinct postures. Further graph-theoretic analyses show that postures are organized into specific actions. These actions correspond to nameable, intuitive behaviors and are further organized into higher categories. Together, these results confirm that monkey behavior obeys hierarchical organizational principles. These results also indicate that our pipeline can overcome the daunting problems faced by patterns of movement in monkeys.
We examined behavior of two macaque subjects performing one of two different tasks, or, in a third condition, no task. This design allowed us to examine the effect of task and of individual on the organization of behavior. We found prominent cross-individual differences and only modest cross-task differences. Having said that, with only two subjects in our sample, the generality of this cross-individual claim is severely limited. We also found that the composition of behavior (as inferred by adjusted mutual information) is more stable during task performance than during task-free behavior. This finding demonstrates changes in the way behavioral repertoires are selected on the basis of behavioral context. Overall, these findings demonstrate that it is possible to obtain automatic behavioral ethograms in macaque monkeys and delineate the organization of behavior across contexts.
RESULTS
We studied the behavior of two rhesus macaques under three different experimental conditions (see Methods) in a large open cage that allowed for free unimpeded movement (a 2.45 × 2.45 × 2.75 m cage with barrels, Fig. 1A, [26]). Each subject performed under one of three possible task conditions per day (see below and Methods). Each daily session took about two hours. Each task condition was repeated three times over three different days (fully randomized and interleaved order). Our data set therefore consists of 18 sessions (9 for each subject; divided into two different task conditions, 6 task-OFF, 12 task-ON) for a total of 31.4 hours, or about 3.3 million frames. Behavior was tracked with 62 high-resolution machine vision video cameras, and pose (3D position of 15 cardinal landmarks, see Methods) of each macaque was determined using OpenMonkeyStudio ([26], Fig. 1B) with secondary landmark augmentation [27].
Figure 1.

Identification of postures in an open-field environment. (A) Depiction of the cage environment. Sixty-two cameras were mounted on an exoskeleton, facing inwards. (B) Reconstructed pose was defined by 15 landmarks. (C) Outline of general methodological approach. See methods for details. (D) The heatmap denotes the density of embedded samples. Select postures are visualized here, both as the mean posture within clusters (monkey stick figures) and example reprojections onto the raw data.
Embedding of macaque posture results in semantically meaningful clusters
We developed a novel pipeline to characterize behavioral states based on tracked poses. Our pipeline is a variation of one developed by Berman and colleagues to characterize the behavior of flies (Methods, Fig. 1C, [23, 28]. The major difference is with the way that pose data were structured at the beginning of the pipeline. Briefly, poses were translated using the neck as the reference. Then, the pose of the subject in each individual frame was rotated to face a common direction (see Methods). This rotation was defined via two vectors corresponding to the spine and shoulders. Next, poses were size-scaled (with size defined as hip to neck distance) so that subjects matched. This process produced normalized postural orientations. Finally, to further reduce individual variation in poses, we aligned poses of individual subjects via a variation of the Mutual Nearest Neighbors approach (a local alignment procedure; see Methods and [29]).
After normalization, we embedded poses using all collected data to generate a single overall postural embedding. To mitigate possible effects of noise, we first applied a principal component analysis (PCA) and extracted the first 16 PCs (which accounted for 95% of the explained variance). Projections onto these PCs served as the features that were then used in subsequent embedding and clustering. Alignment is required to ensure that idiosyncratic variability in behavior does not bias the embedding process. This alignment serves the function of correcting for idiosyncratic day to day measurement effects, such as the distribution of poses and transitions present in daily measurements. These effects, while small, can wind up having very large spurious effects on the resulting clustering.
We used a dimensionality reduction technique known as uniform manifold approximation and projection (UMAP, [30]). This process results in a reprojection onto two dimensions in which similar poses are adjacent in the resulting low-dimensional space. We then performed a kernel density estimation to approximate the probability density of embedded poses at equally interspersed points. The color in the resulting plot reflects the probability of each pose in our data set (Fig. 1C and D).
The clusters have a clear organization. Each cluster reflects a set of similar poses that are relatively distinct from other sets of poses. To formally identify these clusters, we used the watershed algorithm on the inverse of the density map [28]. This algorithm treats each peak as a sink and draws boundaries along lines that separate distinct basins. We found that the resulting embedding space contains 49 distinct clusters. These clusters correspond to sets of closely related poses (Fig. 1D). We verified that the embedding space captures differences in poses by correlating the euclidean distance of pose features with that of embedded points (bootstrap test, mean Pearson r = 0.45, p < 0.001). We refer to the clusters of poses as postures. Visual inspection reveals that these postural states are semantically meaningful in the sense that they correspond to recognizable postures, such as left or right stride, sitting, hanging, etc. Each posture lasted on average 0.612 ± 0.0015 seconds (s.e.m.). The clustered nature of this embedding space confirms that, at least within our sample of two subjects, macaque behavior is composed of stereotypical postures.
Directed graph analysis of posture transitions reveals behavioral modularity
We next sought to understand how postures combine to form recognizable behaviors. To do this, we identified sets of postures with a high probability of occurring in sequence. We therefore computed transition probability matrices for the specific postures identified above. Any organization in sequences of postures will show up in the form of increased likelihood of specific transitions between the postures within the sequence. Our goal, then, is to discover sets of postures that have a high probability of transitioning between one another, but not other sets of postures.
The transition probability matrix, in graph theoretic terms, is a directed graph. In this framework, nodes that form strong links between each other are referred to as modules or communities. Because of this, we refer to sets of postures that have a high probability of co-transition as ‘behavioral modules’. These modules are roughly equivalent to what are sometimes called actions [1]. The identification of these modules allows us to re-sort the transition probability matrix, such that there are blocks on the diagonal; these blocks correspond to the behavioral modules.
To formally identify behavioral modules in the transition matrix, we used a recently-developed algorithm named Paris [31]. This algorithm performs hierarchical clustering on the graph derived from the transition matrix and returns a tree describing the distance between poses and their composing modules (we will return to examine the hierarchical structure of behavior below). Next, to determine the optimal number of behavioral modules, we proceed to cut the tree at a series of hierarchical levels and compute a modularity score for each cut tree. We then choose the cut that corresponds to the tree with the maximal modularity score. The modules that result from this cut give the highest average within-module posture–transition probability and the lowest average across-module posture–transition probability. Formally speaking, they maximize the difference between these two measures. From this process, we can identify the most likely behavioral modules.
A transition matrix from an example task-OFF session is depicted in Figure 2Ai. For this session, the number of modules that maximizes the modularity score is 5, indicating that the best fitting classification has five discrete behavioral modules (Figure 2Aii). As illustrated in the figure, these behavioral modules hew closely to nameable actions (Fig. 2B) such as walking (Video 1), swaying (Video 2), climbing (Video 3), jumping (Video 4) and idling (Video 5). The modular nature of the behaviors in this session is clearly visible in the sorted transition matrix (Figure 2Aiii).
Figure 2.

Postures are organized into behavioral modules. (A) Example of modularity in one data set. (i) The original transition probability matrix. (ii) The modularity score for multiple different cutoffs of the dendrogram. (iii) Same as (i) but sorted according to the results of (ii). Now, it is evident that transitions between poses occur within modules (highlighted with black squares). (B) All modules in this example. These correspond to semantically meaningful sequences of poses. (C) Histogram of the maximal modularity score, both for observed (dark) and randomized (light) transition matrices. Modularity is higher than expected by chance.
We tested for modularity by computing the modularity score. All 18 of the individual data sets we collected individually showed statistically significant evidence of modularity (randomization test, p < 0.001, Fig. 3C). The average number of unique behavioral modules in each session was 3.8 ± 0.15 (s.e.m.), and each behavioral module lasted 2.73 ± 0.0327 seconds. Across all sessions, the duration of modules ranged from 0.47 to 16.8 seconds. Together, these results indicate that subjects' behavior is organized into discrete behavioral actions that consist of stereotyped patterns of postures.
Figure 3.

Pose transitions are hierarchically organized. (A) Dendrograms for two example sessions from the same individual, for a task OFF (left) and task ON (right) condition. (B) Dasgupta score, measuring hierarchical organization, from transition matrices derived from observed (dark) and randomized (light) transitions.
Transitions are hierarchically organized
Our next analysis investigated the hierarchical organization of behavior (Fig. 3). Dendrograms in this figure show the hierarchical organization of postures according to their transition probabilities. Higher-level connections in this dendrogram show how different sets of poses are related. Not only are different behavioral modules recognizable actions (see above), but their relationship in the tree reveals this subject’s idiosyncrasies; for example, idling before climbing (Fig. 3A). Moreover, across sessions, similar behavioral modules were composed of similar postures, highlighting the stable behavioral repertoire of one subject (more on this below). To quantify the degree of hierarchical organization, we calculated the Dasgupta score on these dendrograms, which quantifies the quality of hierarchical clustering on a graph [32]. A Dasgupta score above chance indicates that the observed tree indeed has connected components that are related to one another [32]. The Dasgupta score was significantly above chance for all 18 data sets (Fig. 3B; randomization test, P < 0.001).
Behavioral organization is evident for lagged transitions
The previous sections indicate that at short timescales, behavior is modular and hierarchical. We next investigated the possibility of levels of organization defined by even longer timescales. To this end, we performed the same modularity analysis as above, but constructed the transition probability matrix with lags of up to 1000 transitions. Thus, if there are long timescale drivers of behavior, this should again be evident as above-chance behavioral modularity.
For the same task OFF example data set as above, the modularity score decreases as a function of transition lag, before plateauing close to (but greater than) zero around a lag of about 100 transitions (Figure 4Ai). This result demonstrates that behavior is non-stochastic even on very long timescales, but that its organization decreases with timescale in a systematic and lawful way. This modularity is also reflected in the transition matrices for shorter, rather than longer, lags (Figure 4Aii). Across all 18 data sets, the average modularity shows steady decay up to ~100 transitions into the future (~60 seconds), before plateauing close to chance levels (Fig. 4B). This pattern suggests that not only do poses tend to co-occur in distinct behavioral modules, but that this organization is evident even when considering longer timescales.
Figure 4.

Modular and hierarchical organization of behavior is evident for long timescales. (A) Example transition matrices and associated modularity, (i) transition matrices with lag 1, 10, 100, 1000. Note that states have been reordered according to module classification. (ii) modularity as a function of transition lag. Black circles correspond to transition matrices in (i). (B) Mean modularity across all data sets, for observed (red) and randomized (gray) transition matrices. (C) Mean module stability (adjusted mutual information score) of module assignments between consecutive transition lags, for observed (red) and randomized (gray) transition matrices.
Because modules are computed independently for each transition matrix of different lags, a critical question is whether the extracted behavioral modules are consistent across transition lags. We assessed this by comparing module assignments using the adjusted Mutual Information Score (AMI; [33]; see Methods) between modules derived from transition matrices of consecutive lags. We found that cluster assignment was stable across transition lags (Fig. 4C), up to ~100 transitions into the future (P < 0.05, multiple comparison corrected). This finding is reassuring; it suggests that behavioral modules are composed of similar poses for as long as 100 transitions into the future. Taken together, these results indicate that current states hold information about states up to at least 100 transitions into the future.
Variability in behavioral repertoire is driven by individual and task differences
Up to this point, we have considered the organization of behavior across all individuals and data sets, leaving open the question of how individual and task variability affects behavioral organization. To this end, we first determined if behavioral modularity—derived from transition probabilities with a lag of 1—was affected by task and individual. We found that the modularity score varied as a function of individual (two-way ANOVA; F = 8.08, p = 0.013), but not task (F = 0.14, P = 0.87). Similarly, the Dasgupta score varied by individual (two-way ANOVA; F = 5.2, P = 0.039) but not task (F = 0.1, P = 0.90). Taken together, these results suggest that the degree of behavioral organization at the shortest timescale is driven by individuals but not environmental constraints. Note that this analysis assumes that each session is independent of each other. We make this assumption out of necessity (because our number of subjects is low), and it is a limitation of the present work. Due to the limited number of sessions and animals, our study cannot capture individual differences or model our findings in a mixed effects approach. We hope that over time our sample size will increase to specifically address these shortcomings.
While the degree of organization may not vary by task or individual, it is still possible that the composition of behavior differs. To this end, we compared module stability between individuals and tasks (Fig. 5). We computed the AMI between all pairs of data sets and asked if stability between pairs differed as a function of subject or task. We found that both individual and task influenced the degree of stability between pairs of data sets (Fig. 5A; two-way ANOVA; F(individual) = 43.7, P < 0.0001; F(task) = 7.14, P = 0.001). All individual/task combinations were also more stable than chance level (Fig. 5A; randomization test, P < 0.001). We also found that within-subject stability was higher than between subject stability (Fig. 5B; unpaired t test, T = 9.4, P < 0.001), indicating that while there is a significant amount of overlap in behavioral modules, subjects still tend to perform specific actions in idiosyncratic ways.
Figure 5.

Behavioral modularity is both shared and unique. (A) Mean module similarity (quantified via the AMI score) across data sets with the same or different subjects, and same or different task demands. White dots denote significant cells (randomization test, P < 0.05, multiple comparison corrected). There is significant module overlap both between data sets of the same subject, and that of different subjects. (B) Comparison of module stability either within the same individuals (green) or across different individuals (between), where the effect of task has been partialled out. (C) Same as (B) but comparing module stability across different tasks, either task OFF–OFF (orange) or task ON–ON (blue) comparisons. The effect of individuals has been partialled out. (D) Mean + SEM of module stability comparing task ON–ON (blue) or task OFF–OFF (orange) pairs, after partialling out the effect of individual. Black lines and dots denote significant differences (multiple comparisons corrected). The mean cutoff that maximized modularity is depicted in red.
We next asked if module stability varied as a function of task (Fig. 5C). We found that sessions with a task were more similar to one another, rather than sessions with no task (unpaired t test, T = 4.16, P < 0.001). This suggests that task demands are a strong constraint on the expression of behavior.
We further explored the effect of task on behavioral expression by quantifying stability for different cuts of the dendrograms associated with each data set (Fig. 5D). We found that task ON pairs showed more stable behavioral expression than task OFF pairs, and this was generally significant for lower and higher dendrogram cuts (unpaired t test, multiple comparison corrected, P < 0.05). Thus, environmental context constrains behavioral expressivity whether the span of individual behaviors is large or small.
Timescale of behavioral organization is driven by individual, but not task, variation
We next asked if the timescales of behavioral organization differed by task and individual. We operationalized the notion of how many transitions into the future exhibited modular organization as the half-life of the function that relates modularity to transition lag (the modularity curve). Specifically, we fit an exponential model to the individual modularity curves, and determined the half-life associated with the exponent term (see Methods). We found that modularity curves are well fit by the model (Fig. 6A inset; mean adjusted R2 = 0.95 + 0.005). Half-lives varied significantly as a function of individual but not task (Fig. 6A; two-way ANOVA, F(individual) = 26.8, P < 0.001; F(task) = 2.87, P = 0.11). In other words, individuals varied in the extent of the temporal horizon of modular behavioral organization.
Figure 6.

Timescale of behavioral organization varies as a function of individual, but not task. (A) Mean and standard error of half-life associated with fitted modularity curves. Fitted modularity curves are visualized in the inset, and plotted as a function of transition lags. Orange (blue) is for task OFF (ON) sessions, and solid (dotted) lines are for subject C (Y). The half-life of each curve is depicted as a solid circle (triangle), for subject C (Y). Mean half-life varies as a function of individual, but not task. (B) Same as (A) but calculated for AMI (i.e. module stability) curves. Mean half-life varies as a function of individual, but not task.
As noted above, modularity at different lags does not guarantee similar module composition. Thus, we repeated the same analysis as above, but fitting module stability curves (AMI as a function of transition lag) and extracted their half-lives (instead of from the modularity curves as before). Stability curves were well fitted by the exponential model (Fig. 6B inset; mean adj. R2 = 0.68 + 0.02). Half-lives varied by individual, but not task (Fig. 6B; ANOVA, F(individual) = 18.3, P < 0.001; F(task) = 0.044, P = 0.84).
DISCUSSION
Here we provide the first analyses of macaque behavior derived from quantitative 3D pose data. Our ability to perform these analyses relies on our recently developed OpenMonkeyStudio system, which allows for the tracking of major body landmarks as macaques move freely in a large space in three dimensions [26, 27]. We find that, within the context of three different task conditions (including a no task condition), macaque behavior can be classified into 49 different postures, such as left and right strides, sitting and hanging. We find that these postures in turn can be clustered into behavioral modules, such as walking, climbing and swaying; these can in turn be organized into even higher-level structures. Thus, our method provides a hierarchical description of behavior that spans low-level postures and higher-level extended action sequences.
We find that these hierarchies vary both across individuals and task. Behavioral modules were more stable within the same individual than across the two individuals. In addition, the presence of a task resulted in more stable behavior composition as compared to when no task was present. Finally, we found that the timescale over which behavior was detectably organized varied strongly as a function of individual, but not task (although the small number of individuals, n = 2, limits the generality of this conclusion). Taken together, these results highlight the importance of both task demand and individual identity in determining the makeup of the hierarchy of actions, while also demonstrating that actions can have consistent cross-individual and cross-task properties. Our results also raise important lines of inquiry, including what factors may alter the timescale of structures behavior other than individual identity, identifying the extent to which the timescale of structured behavior depends on internally defined or externally imposed timescales and identifying variation in individual actions that are relevant for task goals.
Multiple approaches exist to identify relevant behaviors based on pose data. These can, like our methods, rely on embedding pose features to discover low-level behaviors [23, 24], on fitting pose time series using Hidden Markov Models [12, 25] or on pre-trained, supervised neural network architectures [16, 21]. Regardless of the method used, there are three important principles to consider that determine what inferences can be made to determine the structure of behavior. First, the timescale over which features are calculated determines the nature of the lowest level of behavior identified. In our case, because our model inputs correspond to instantaneous joint positions and speeds, our elementary unit of behavior is posture. Second, it is important to consider the way in which low-level behaviors are combined to form high-level actions. In our case, we do this solely on the basis of subsequent transitions, which allows for the discovery of actions with no strong a priori guess about their duration. Third, it can be constrained by previously identified behaviors, meaning that learning is semi-supervised (e.g. [24]) or fully supervised (e.g. [16, 17, 21]); we used an unsupervised method to identify behaviors. The unsupervised nature means our system can identify a much wider range of possible behaviors, including new ones not anticipated by existing theories.
The repertoire of behavior was more stable with an externally imposed task, suggesting that environmental demands may provide a force for behavioral stabilization. Stabilization can occur in one of two (not mutually exclusive) ways: either the repertoire of actions significantly shrinks during task, or actions themselves become less variable during task performance. Our data suggest the latter, as modules were stable even when we considered relatively high cutoffs of the dendrogram (which is to say, for larger and more-encompassing behavioral modules, Fig. 5D). This is reminiscent of hunting behavior observed in zebra-fish placed in a prey-rich or prey-poor environment [34]. In that study, animals exhibited behavioral motifs associated with exploitation and exploration, regardless of the environment. An intriguing future possibility direction would be to dissociate the sources of variation underlying variation in actions themselves, or which actions are expressed, on the basis of task demands.
One major limitation of the present work is that we only recorded data in two subjects. As such we cannot make strong claims about individual differences. Indeed, in our statistical analyses, we use the behavioral session, not the subject, as the unit of analysis. This approach risks reducing statistical power because it treats variance between subjects as no different from variance within. Another result of this limitation is that we have likely failed to explore the full range of possible behaviors and the diversity of behavioral organizations. As such, our general claims must be taken as preliminary. We believe that future work will mitigate some of these problems by including larger numbers of research subjects.
One of the greatest potential benefits for statistical analysis of highly quantified behavior is in the prospect of automated ethogramming [1, 6, 20]. By ‘ethogramming’, we mean the classification of pose sequences into specific behavior into ethologically meaningful categories, such as walking, foraging, grooming and sleeping [20]. Currently, constructing an ethogram requires the delineation of ethogrammatical category involves the time-consuming and careful annotation of behavior by highly trained human observers. Human-led ethogramming is slow, extremely costly, error-prone, and susceptible to characteristic biases [1, 35, 36, 37]. For these reasons, it is simply impractical for even moderately large data sets, collected either in an open environment or the home cage [38, 39]. These kinds of data sets require automated alternatives. Automated ethogramming requires both high quality behavioral tracking and novel methods applied to tracked data that result in detection of meaningful categories. Such techniques have not, until recently, existed for primates. Our methods take the raw information needed for ethogramming—pose data—and infer posture and higher-level categories from it. As such, they provide the first step toward automated ethogramming in primates. We are particularly optimistic about the potential benefits of ethogramming for systems neuroscience. Relating behavior to neural circuits and networks is an important goal in the field, so being able to quantify behavior more rigorously—without sacrificing freedom of movement or naturalness—is likely to be invaluable for future studies [40–42].
METHODS
Animal care
All research and animal care procedures were conducted in accordance with University of Minnesota Institutional Animal Care and Use Committee approval and in accord with National Institutes of Health standards for the care and use of non-human primates. Two male rhesus macaques served as subjects for the experiment. One of the subjects (C) had previously served as subjects on standard neuroeconomic tasks, including a set shifting task, a diet selection task, intertemporal choice tasks, and a gambling task [43–47]. This subject also participated in a study of foraging decision-making in the same environment as the current study [48–50]. The second subject (Y) was naïve to all laboratory tasks before training for this study. Both subjects were fed ad libitum and pair-housed with conspecifics within a light and temperature-controlled colony room.
Behavioral training and tasks
Subjects were tested in a large cage (2.45 × 2.45 × 2.75 m) made from framed panels consisting of 5 cm wire mesh [26]. Subjects were allowed to move freely within the cage in three dimensions. The wire mesh allowed them to climb the walls and ceiling, which they often did. Five 208-L drum barrels, weighted with sand, were placed within the cage to serve as perches for the subjects to climb and sit on. There was also a small, swinging tire hung from the center of the ceiling of the cage. In sessions with a task, four juice feeders were placed on the wire mesh walls at each of the four corners of the cage. Feeders were placed at various heights, including atop barrels. The juice feeders consisted of a 16 × 16 LED screen, a lever, buzzer, a solenoid valve (Parker Instruments) and were controlled by an Arduino Uno microcontroller. Each feeder ran (the same) custom Arduino code.
We first introduced subjects to the large cage environment and allowed them to become comfortable in it. This process consisted of placing them within the large cage for progressively longer periods of time over the course of about five weeks. We monitored their behavior for signs of stress or anxiety. Notably, we did not observe these symptoms; indeed, subjects appeared to be eager to begin their sessions in the large cage, and somewhat reluctant to terminate them. Nonetheless, to ensure that the cage environment had positive associations, we provisioned the subjects with copious food rewards (chopped fruit and vegetables) placed throughout the environment. We then trained subjects to use the specially designed juice dispenser. We defined acquisition of task understanding as obtaining juice rewards in excess of their daily water minimum. For both subjects, acquisition of reliable lever pressing took about 3 weeks.
On any given day, animals performed one of three task conditions: [1] a ‘controlled depletion task’, [43] ‘a random depletion task’ and [17] ‘no task’ (the same tasks were used in [48]). In the no task condition, animals were free to explore the environment but no juice feeders were available. For both the controlled and random depletion tasks, each feeder was programmed to deliver a specific reward size on pressing of a lever; it started high and decreased by a specified amount. In the controlled condition each feeder delivered, a base reward consisting of an initial 2 mL of juice that decreased by 0.125 mL with each subsequent delivery (turn). In the random condition, feeder depletion rates were the same as the controlled depletion condition. However, feeders randomly increased or decreased the juice delivery amount by 1 mL in addition to the base reward schedule at a probability of 50%. Both feeder types delivered rewards following their respective schedules until reaching the base value of 0, at which point the patch was depleted, and no more rewards were delivered.
Data acquisition
Images were captured with 62 cameras (Blackfly, FLIR), synchronized via a high-precision pulse generator (Aligent 33120A) at a rate of 30 Hz. The cameras were positioned to ensure coverage of the entire arena, and specifically, so that at least 10 cameras captured the subject with high-enough resolution for subsequent pose reconstruction, regardless of the subject's position and pose. Images were streamed to one of 6 dedicated Linux machines. The entire system produced about six TB of data for a 2-hour session. After data acquisition, the data were copied to an external drive for processing on a dedicated Linux server (Lambda Labs).
To calibrate the camera's geometries for pose reconstruction, a standard recording session began with a camera calibration procedure. A facade of complex and non-repeating visual patterns (mixed art works and comic strips) was wrapped around two columns of barrels placed at the center of the room, and images of this calibration scene were taken from all 62 cameras. These images were used to calibrate the camera geometry (see below). This setup was then taken down, and the experiment began.
Pose reconstruction
We first extracted parameters relating to the cameras' geometry for the session. To this end, we used a standard structure-from-motion algorithm (‘colmap’) to reconstruct the space containing the 3D calibration object and 62 cameras from the calibration images, as well as determine intrinsic and extrinsic camera parameters. We first prepared images by subtracting the background from each image in order to isolate the subject's body. Then, 3D center-of-mass trajectories were determined via random sample consensus (RANSAC). Finally, the 3D movement and subtracted images were used to select and generate a set of maximally informative cropped images, such that the subject's entire body was encompassed. To reduce the chance that the tire swing would bias pose estimation, we defined a mask of pixels to ignore that encompassed the tire's swinging radius.
Next, we inferred 3D joint positions using a trained convolutional pose machine (CPM; [26]). We used a loss function that incorporated physical constraints (such as preserving limb length and temporal smoothness) to refine joint localization. We found residual variability in limb length across subjects after reconstruction, between subjects, particularly for the arm, resulting in poses that were highly specific to individual subjects. To prevent subject-specific limb lengths from biasing subsequent behavior identification, we augmented the original 13 inferred landmarks to include two new ones (positions of left and right elbows) using a supplementary trained CPM model (method described in [27]). Thus, the augmented reconstruction resulted in 15 annotated landmarks for each image.
Pose preprocessing
To discover poses, we applied a number of smoothing and transformation steps to the 3D pose data. First, we transformed the reconstructed space to a reference space that was measured using the Optitrack system [26]. Then, we ignored any frame where a limb was outside the bounds of the cage due to poor reconstruction, or residual frames where subject poses were still subject to collapse (defined as where the mean limb length < 10 cm). Next, we interpolated over any segments of missing data (lasting at most 10 frames, or 0.33 seconds) using a piecewise cubic interpolation. Note that only a small number of frames were removed after this procedure; specifically, 0.64% of frames on average were ignored.
We next normalized the orientation of poses on individual frames. To this end, we translated the 3D joints to a common reference point by subtracting the position of the neck landmark. Next, we scaled poses to all have the same size, so that the spine was of length 1.0 (arbitrary units). Finally, we rotated poses to face a common direction. To do this rotation, we first defined two vectors, one corresponding to the spine (neck to hip landmarks), and the other to the expanse of the shoulders (left and right shoulder landmarks, which was then centered on the neck landmark). Poses were then rotated such that the plane defined by these vectors faced the same direction (in essence, so that the torso faced the same direction).
We next aligned individual data sets, inspired by the ‘mutual nearest neighbors’ procedure developed for correcting for batch effects in genomics data [29]. Broadly speaking, this algorithm first seeks similar poses between data sets, and then applies a locally linear correction to align similar poses. Specifically, for two data sets X1 and X2, we first performed two K-nearest neighbor (KNN) searches (for samples x2 in X1, and x1 in X2) using a euclidean distance and searching for K = 100 samples. On the basis of this search, for each sample, we defined a ‘mutual nearest neighbors’ set, namely, samples from each data set that were within each other's nearest neighbor set. We then computed a correction vector c for each sample in X2 as the mean of the difference between the sample and its mutual nearest neighbors, weighted by their distance. Samples that had no mutual nearest neighbors did not have a correction vector computed. As poses vary continuously in time, we then used a median filter (15th order) to smooth out the correction vectors in time, obtaining a correction matric C. The aligned data set X2' was defined:
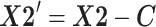 |
Feature engineering
To label pose samples, we first defined a set of 23 features derived from the preprocessed pose data. The first 19 features were the angles at each joint (i.e. the vertex of each triplet of adjacent landmarks). The other four features were [1] the overall speed of the subject (calculated from the center-of-mass) and [17, 26, 38] the speed of the subject in the three canonical dimensions (X, Y and Z). To prevent feature bias due to differences in scale during embedding, we normalized each set of features (joint angles, COM velocity and planar velocities) to the range [0 1]. This was performed independently for each subject.
We then concatenated data from all 18 data sets. To mitigate possible effects of noise, we applied a Principal Component Analysis (PCA), and extracted the first 16 PCs (which accounted for 95% of the explained variance). Initial PCA dimensionality reduction was performed to reduce noise, as well as to sparsen the data, which greatly increases computational efficiency. The PCA procedure serves to sparsen the data and reduce noise; the UMAP serves to implement the high dimensional clustering. Projections onto these PCs served as the features that were then used in subsequent embedding and clustering. Alignment is required to ensure that idiosyncratic variability in behavior does not bias the embedding process. This alignment serves the function of correcting for idiosyncratic day to day measurement effects, such as the distribution of poses and transitions present in daily measurements.
Posture identification via embedding and clustering
We created behavioral maps by embedding the extracted pose features into two dimensions using UMAP [30], using a euclidean distance metric. We set the parameters min_dist = 0.001 and n_neighbors = 20, which we found to be a good balance between separating dissimilar poses, while combining similar ones.
To define behavioral clusters, we first estimated the probability density at 200 equally interspersed points both in the first and second UMAP dimensions. This produced a smoothed map of the pose embeddings, with clearly visible peaks. We then employed the watershed algorithm on the inverse of this smoothed map [28]. This algorithm defines borders between separate valleys in the (inverse of) the embedding space. Thus, the algorithm determines sections of the embedding space with clearly delineated boundaries (i.e. clusters). Samples were then assigned a posture label according to where they fell within these borders.
Transition probabilities
We defined transition matrices between postures. Specifically, the transition matrix M for a transition lag of T was defined as:
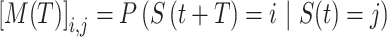 |
which describes the probability that the subject would go to posture S = i given posture S = j at time t after T transitions. Note that we did this for transitions between different postures (thus, for a transition lag T = 1, it is impossible for a posture to transition to itself). We performed this for each data set individually. The resulting transition probability matrix is a directed graph, where nodes are the individual postures, and the probabilities are the weights on the edges between nodes. This formalization allows us to leverage tools from graph theoretic work.
Measures of behavioral organization
To discover how postures are organized, we employed a hierarchical clustering algorithm named Paris [31], using the ‘sknetwork’ library (https://scikit-network.readthedocs.io/). This algorithm employs a distance metric based on the probability of sampling node pairs and performs agglomerative clustering. Paris requires no user-defined parameters (as opposed to another popular graph clustering algorithm, Louvain, which can perform hierarchical clustering according to a user-supplied resolution parameter). It is equivalent to a multi-resolution version of the Louvain algorithm [31]. The result of this algorithm is a dendrogram describing the relation between different posture transitions (which we will refer to as the behavioral dendrogram). To segment pose transitions into modules, we determined the ‘modularity score’ (see below) for different cuts of each dendrogram (space equally from 0.4 to 1.4). We then determined module assignment by cutting the behavioral dendrogram where the modularity score was maximized.
We leveraged three important graph-theoretic metrics to assess behavioral composition:
‘modularity score’: The modularity score describes the degree to which postures transition within, rather than between, modules. Transition probability matrices with high modularity scores exhibit a high probability of transitions within modules, but not between modules. Modularity was calculated with the MATLAB function ‘modularity.m’.
‘Dasgputa score’: To assess whether the graph defined by posture transitions truly reflected hierarchical organization, we calculated the ‘Dasgputa score’ [32]. The Dasgupta score is a normalized version of the Dasgupta cost, which defines the cost of constructing a particular dendrogram, given distances between nodes. The Dasgupta score thus provides quantification of the quality of the hierarchical clustering. We calculated this score using the function ‘Dasgupta_score’ in the ‘sknetwork’ library.
‘adjusted mutual information score’: We assessed whether modules were composed of similar poses using the adjusted mutual information score (AMI) [33]). This measure assesses the information (in bits) about one set of cluster assignments given knowledge of another. It is ‘adjusted’ because given two random clusterings, the mutual information score is biased by the number of clusters; the adjustment thus corrects for this bias. AMI was computed using the Matlab function ‘ami.m’.
We further leveraged these measures to determine the timescale of behavioral organization, and make subsequent comparisons between data sets. Specifically, we extracted the half-life associated with the various measures as a function of transition lag. As a concrete example, we extracted the modularity score using transition matrices at different lags. We then fit an exponential model of the form:
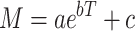 |
where M is the modularity score at transition lag T. From this, we can determine the half-life of the curve H as:
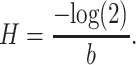 |
We repeated this analysis using AMI scores between consecutive lags.
Statistical testing
For the present study, we sought to delineate how the structure of behavior changes with externally imposed task demands. Thus, we grouped sessions into task ‘ON (controlled depletion task or random depletion task) or a task OFF (no task sessions)’.
Hierarchical and modular organization
To determine statistical significance of modular and hierarchical organization of behavior for any one data set, we compared modularity and hierarchy to a transition matrix defined by random transitions. To this end, for each data set, we (1) shuffled the pose labels across the whole session, (2) re-built the transition matrix, (3) applied hierarchical clustering and then (4) recomputed the modularity and Dasgupta scores. This was performed 100 times. The P value was computed by comparing the random distribution to that of the observed, for each data set individually. We repeated this analysis for transition matrices defined by different lags.
Module stability across transition lags
To determine if behavioral modules were similar across behavioral trees constructed from different transition lags, we compared module clusterings of consecutive lags (i.e. at lag t + T and t + T + 1). To assess statistical significance, we again used a randomization approach. We randomized module labels, and then recomputed the AMI. This was performed 100 times, from which we determined the P value.
Comparison of hierarchical and modular organization as a function of task and individual
To compare modularity as a function of task and individual, we performed a two-way ANOVA on modularity scores obtained from transition matrices of lag = 1. We performed the same analysis for Dasgupta scores in order to compare hierarchical organization.
Module stability between data sets as a function of task and individual
We compared the composition of postures into modules across data sets, as a function of task and individual. To this end, we computed the AMI between module assignments (determined from a transition matrix of lag T = 1) of all (unique) pairs of data sets.
To determine if a particular combination of task/individual exhibited stable module assignments, we employed a randomization procedure. Namely, we randomized the module labels for any one data set, recomputed the AMI and repeated this 100 times in order to get a random distribution. P values were determined by comparing the observed AMI to the random distribution.
To determine if task/individual affected stability between paired data sets, we used a two-way ANOVA. The first factor had three levels corresponding to individual pairings (subject C–Y, C–C and Y–Y). The second factor also had three levels (task OFF–OFF, ON–ON and OFF–ON).
To determine if within-subject modules were more stable than between-subject modules, we first collapsed data set pairs into within-subject (subjects C–C and Y–Y) and across-subject (subjects C–Y) groups. Then, because we found AMI varied by task and individual, we partialed out the effect of task by subtracting the mean AMI associated with each task pair. Significance was assessed with an unpaired t test.
We used a similar procedure to compare the effect of environmental demands. Namely, we considered two groups of data set pairs, either task OFF–OFF or task ON–ON, and partialed out the effect of individuals by subtracting the mean AMI associated with individuals. Significance was assessed with an unpaired t test.
Comparison of behavioral organization timescales as a function of task and individual
To compare the timescale across which behavior is organized, we compared the half-lives of modularity and AMI curves (i.e. either of these measures as a function of transition lag). We then performed a two-way ANOVA on the half-lives, with individual and task as the factors.
STUDY FUNDING
This research was supported by a National Institute on Mental Health grant R01 to B.Y.H. (125377), an NSF award to H.S.P., B.Y.H. and J.Z., and a UMN AIRP award to B.Y.H. and J.Z.
CONFLICT OF INTEREST STATEMENT
The authors report no conflicts of interest.
Supplementary Material
ACKNOWLEDGEMENTS
We thank the Hayden/Zimmermann lab for valuable discussions.
Contributor Information
Benjamin Voloh, Department of Neuroscience, Center for Magnetic Resonance Research, Center for Neuroengineering, 1 Baylor Plaza, Houston, TX 77030.
Benjamin R Eisenreich, Department of Neuroscience, Center for Magnetic Resonance Research, Center for Neuroengineering, 1 Baylor Plaza, Houston, TX 77030.
David J-N Maisson, Department of Neuroscience, Center for Magnetic Resonance Research, Center for Neuroengineering, 1 Baylor Plaza, Houston, TX 77030.
R Becket Ebitz, Department of Neuroscience, Center for Magnetic Resonance Research, Center for Neuroengineering, 1 Baylor Plaza, Houston, TX 77030.
Hyun Soo Park, Department of Computer Science and Engineering, University of Minnesota, 40 Church St, Minneapolis, MN 55455, USA.
Benjamin Y Hayden, Department of Neuroscience, Center for Magnetic Resonance Research, Center for Neuroengineering, 1 Baylor Plaza, Houston, TX 77030.
Jan Zimmermann, Department of Neuroscience, Center for Magnetic Resonance Research, Center for Neuroengineering, 1 Baylor Plaza, Houston, TX 77030.
AUTHOR CONTRIBUTIONS
Designed the experiment, collected data: B.V., B.R.E., D.J.N.M., B.Y.H., J.Z.
Led the analysis: B.V.
Contributed to the analysis: H.S.P., R.B.E., B.Y.H., J.Z.
SUPPLEMENTARY MATERIAL
Supplementary data is available at Oxford Open Neuroscience Journal online.
REFERENCES
- 1.Anderson DJ, Perona P. Toward a science of computational ethology. Neuron 2014;84:18–31 [DOI] [PubMed] [Google Scholar]
- 2.Calhoun A, El Hady A. What is behavior? No seriously, what is it? bioRxiv, 2021-07 [Google Scholar]
- 3.Gallistel CR The Organization of Action: A New Synthesis. Psychology Press, 2013 [Google Scholar]
- 4.Krakauer JW, Ghazanfar AA, Gomez-Marin Aet al. . Neuroscience needs behavior: correcting a reductionist bias. Neuron 2017;93:480–90 [DOI] [PubMed] [Google Scholar]
- 5.Ölveczky BP. Motoring ahead with rodents. Curr Opin Neurobiol 2011;21:571–8 [DOI] [PubMed] [Google Scholar]
- 6.Pereira TD, Shaevitz JW, Murthy M. Quantifying behavior to understand the brain. Nat Neurosci 2020;23:1537–49 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Tinbergen N. Ethology: the objective study of behaviour. In Tinbergen N (ed.), The Study of Instinct. Oxford, UK: Clarendon Press/Oxford University Press, 1951 [Google Scholar]
- 8.Buffalo EA, Movshon JA, Wurtz RH. From basic brain research to treating human brain disorders. Proc Natl Acad Sci 2019;116:26167–72 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Rudebeck PH, Rich EL, Mayberg HS. From bed to bench side: reverse translation to optimize neuromodulation for mood disorders. Proc Natl Acad Sci 2019;116:26288–96 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Hayden BY, Niv Y. The case against economic values in the orbitofrontal cortex (or anywhere else in the brain). Behav Neurosci 2021;135:192–201 [DOI] [PubMed] [Google Scholar]
- 11.Bohnslav JP, Wimalasena NK, Clausing KJet al. . DeepEthogram, a machine learning pipeline for supervised behavior classification from raw pixels. elife 2021;10:e63377 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Calhoun AJ, Pillow JW, Murthy M. Unsupervised identification of the internal states that shape natural behavior. Nat Neurosci 2019;22:2040–9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Hsu AI, Yttri EA. B-SOiD: an open source unsupervised algorithm for discovery of spontaneous behaviors. BioRXiv 2020;770271 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Luxem K, Sun JJ, Bradley SPet al. . Open-source tools for behavioral video analysis: setup, methods, and best practices. elife 2023;12:e79305 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Mathis MW, Mathis A. Deep learning tools for the measurement of animal behavior in neuroscience. Curr Opin Neurobiol 2020;60:1–11 [DOI] [PubMed] [Google Scholar]
- 16.Sturman O, von Ziegler L, Schläppi Cet al. . Deep learning-based behavioral analysis reaches human accuracy and is capable of outperforming commercial solutions. Neuropsychopharmacology 2020;45:1942–52 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Bain M, Nagrani A, Schofield Det al. . Automated audiovisual behavior recognition in wild primates. Sci Adv 2021;7:eabi4883. 10.1126/sciadv.abi4883 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Dunn TW, Marshall JD, Severson KSet al. . Geometric deep learning enables 3D kinematic profiling across species and environments. Nat Methods 2021;18:564–73 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Grund C, Badihi G, Graham KEet al. . GesturalOrigins: a bottom-up framework for establishing systematic gesture data across ape species. Behav Res Methods 2023;1–16 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hayden BY, Park HS, Zimmermann J. Automated pose estimation in primates. Am J Primatol 2022;84:e23348 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Marks M, Qiuhan J, Sturman Oet al. . Deep-learning based identification, pose estimation and end-to-end behavior classification for interacting primates and mice in complex environments. bioRxiv 2021;2020–10 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Wiltshire C, Lewis-Cheetham J, Komedová Vet al. . DeepWild: application of the pose estimation tool DeepLabCut for behaviour tracking in wild chimpanzees and bonobos. J Anim Ecol 2023; [DOI] [PubMed] [Google Scholar]
- 23.Berman GJ, Bialek W, Shaevitz JW. Predictability and hierarchy in drosophila behavior. Proc Natl Acad Sci 2016;113:11943–8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Marshall JD, Aldarondo DE, Dunn TWet al. . Continuous whole-body 3D kinematic recordings across the rodent behavioral repertoire. Neuron 2021;109:420–437.e8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Wiltschko AB, Johnson MJ, Iurilli Get al. . Mapping sub-second structure in mouse behavior. Neuron 2015;88:1121–35 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Bala PC, Eisenreich BR, Yoo SBMet al. . Automated markerless pose estimation in freely moving macaques with OpenMonkeyStudio. Nat Commun 2020;11:1–12 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Bala PC, Zimmermann J, Park HSet al. . Self-supervised secondary landmark detection via 3D representation learning. Int J Comput Vis 2021;1–15.
- 28.Berman GJ, Choi DM, Bialek Wet al. . Mapping the stereotyped behaviour of freely moving fruit flies. J R Soc Interface 2014;11:20140672. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Haghverdi L, Lun AT, Morgan MDet al. . Batch effects in single-cell RNA-sequencing data are corrected by matching mutual nearest neighbors. Nat Biotechnol 2018;36:421–7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.McInnes L, Healy J, Melville J. UMAP: uniform manifold approximation and projection for dimension reduction. 2018; arXiv preprint arXiv:1802.03426
- 31.Bonald T, Charpentier B, Galland Aet al. . Hierarchical graph clustering using node pair sampling. 2018; arXiv. preprint arXiv:1806.01664
- 32.Dasgupta S. A cost function for similarity-based hierarchical clustering. Proceedings of the forty-eighth annual ACM symposium on Theory of Computing 2016;118–27 [Google Scholar]
- 33.Vinh NX, Epps J, Bailey J. Information theoretic measures for clusterings comparison: variants, properties, normalization and correction for chance. J Mac Learn Res 2010;11:2837–54 [Google Scholar]
- 34.Marques JC, Li M, Schaak Det al. . Internal state dynamics shape brainwide activity and foraging behaviour. Nature 2020;577:239–43 [DOI] [PubMed] [Google Scholar]
- 35.Holman L, Head ML, Lanfear Ret al. . Evidence of experimental bias in the life sciences: why we need blind data recording. PLoS Biol 2015;13:e1002190 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Tuyttens FAM, de Graaf S, Heerkens JLet al. . Observer bias in animal behaviour research: can we believe what we score, if we score what we believe? Anim Behav 2014;90:273–80 [Google Scholar]
- 37.Kardish MR, Mueller UG, Amador-Vargas Set al. . Blind trust in unblinded observation in ecology, evolution, and behavior. Front Ecol Evol 2015;3:51 [Google Scholar]
- 38.Womelsdorf T, Thomas C, Neumann Aet al. . A kiosk station for the assessment of multiple cognitive domains and cognitive enrichment of monkeys. Front Behav Neurosci 2021;15: [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Jhuang H, Garrote E, Yu Xet al. . Automated home-cage behavioural phenotyping of mice. Nat Commun 2010;1:1–10 [DOI] [PubMed] [Google Scholar]
- 40.Pearson JM, Watson KK, Platt ML. Decision making: the neuroethological turn. Neuron 2014;82:950–65 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Yoo SBM, Hayden BY, Pearson JM. Continuous decisions. Philos Trans R Soc B 2021;376:20190664. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Yoo SBM, Tu JC, Piantadosi STet al. . The neural basis of predictive pursuit. Nat Neurosci 2020;23:252–9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Azab H, Hayden BY. Correlates of economic decisions in the dorsal and subgenual anterior cingulate cortices. Eur J Neurosci 2018;47:979–93 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Blanchard TC, Pearson JM, Hayden BY. Postreward delays and systematic biases in measures of animal temporal discounting. Proc Natl Acad Sci 2013;110:15491–6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Blanchard TC, Wolfe LS, Vlaev Iet al. . Biases in preferences for sequences of outcomes in monkeys. Cognition 2014;130:289–99 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Ebitz RB, Sleezer BJ, Jedema HPet al. . Tonic exploration governs both flexibility and lapses. PLoS Comput Biol 2019;15:e1007475 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Farashahi S, Donahue CH, Hayden BYet al. . Flexible combination of reward information across primates. Nat Hum Behav 2019;3:1215–24 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Eisenreich BR, Hayden BY, Zimmermann J. Macaques are risk-averse in a freely moving foraging task. Sci Rep 2019;9:1–12 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Blanchard TC, Strait CE, Hayden BY. Ramping ensemble activity in dorsal anterior cingulate neurons during persistent commitment to a decision. J Neurophysiol 2015;114:2439–49 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Hayden BY, Moreno-Bote R. A neuronal theory of sequential economic choice. Brain and Neuroscience Advances 2018;2:239821281876667 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Hayden BY. Why has evolution not selected for perfect self-control? Philos Trans R Soc B 2019;374:20180139 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Smith EH, Horga G, Yates MJet al. . Widespread temporal coding of cognitive control in the human prefrontal cortex. Nat Neurosci 2019;22:1883–91 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Wang MZ, Hayden BY. Monkeys are curious about counterfactual outcomes. Cognition 2019;189:1–10 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Widge AS, Heilbronner SR, Hayden BY. Prefrontal cortex and cognitive control: new insights from human electrophysiology. 2019;8:8. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.