

Abstract
Stepped wedge trials are increasingly adopted because practical constraints necessitate staggered roll-out. While a complete design requires clusters to collect data in all periods, resource and patient-centered considerations may call for an incomplete stepped wedge design to minimize data collection burden. To study incomplete designs, we expand the metric of information content to discrete outcomes. We operate under a marginal model with general link and variance functions, and derive information content expressions when data elements (cells, sequences, periods) are omitted. We show that the centrosymmetric patterns of information content can hold for discrete outcomes with the variance-stabilizing link function. We perform numerical studies under the canonical link function, and find that while the patterns of information content for cells are approximately centrosymmetric for all examined underlying secular trends, the patterns of information content for sequences or periods are more sensitive to the secular trend, and may be far from centrosymmetric.
Keywords: centrosymmetry, cluster randomized trials, generalized estimating equations, symmetric block correlation structure, variance-stabilizing link function
1 |. INTRODUCTION
The stepped wedge design is a unidirectional crossover design where all clusters start out in the control condition and switch to active treatment at randomly assigned time points. This design has become popular in pragmatic cluster randomized trials to evaluate health care interventions, because practical constraints necessitate staggered roll-out, or there is a need to eventually implement the intervention in all clusters (Hemming & Taljaard, 2020; Li & Wang, 2022; Ouyang et al., 2022). While a complete stepped wedge design requires all clusters to collect outcome data in all periods, resource and patient-centered considerations may call for an incomplete stepped wedge design (Hemming et al., 2015). Incomplete designs may be chosen when resource constraints place a cap on the total number of cluster-periods and study participants, or when logistical considerations dictate deviations from all clusters commencing simultaneously. This leaves many potential incomplete design variants for consideration. For example, the AFFIRM trial (Heazell et al., 2017) is a stepped wedge cluster randomized trial implementing a new package of care to increase women’s awareness of the need for prompt reporting of reduced fetal movements and standardized management to identify fetal compromise and reduce the rate of stillbirth. The study considered a design akin to Figure 1a where a transition period to allow implementation of the intervention is incorporated when clusters transition from the control to the intervention condition. No data is collected during the transition/implementation period. Alternatively, the staggered enrollment of clusters may also give rise to an incomplete stepped wedge design similar to Figure 1b. This is similar to a pregnancy trial described by Kenyon et al. (2017), where outcome data were only collected near the treatment switch (and which, in practice, had an additional implementation phase to fully roll out the intervention). Due to these emerging incomplete stepped wedge designs, there has been an increasing amount of interest in identifying cluster-period cells, treatment sequences and periods that contribute the least information to the estimation of the treatment effect and that could be preferentially omitted with minimal loss of power. To this end, methods are needed to better understand the trade-offs involved when using incomplete stepped wedge designs.
FIGURE 1.
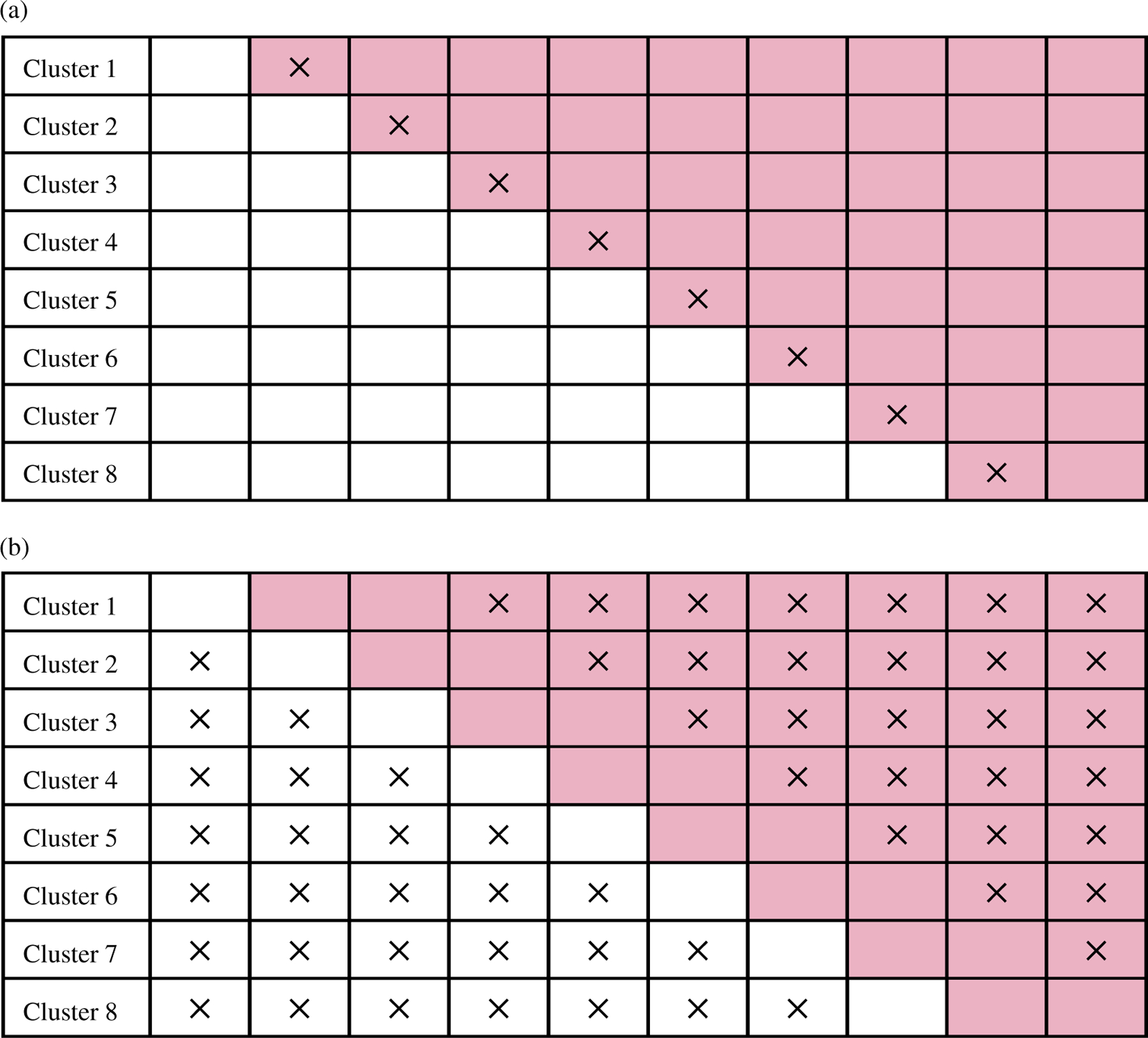
Two examples of incomplete stepped wedge CRTs with I = 8 clusters and J = 10 calendar periods. A white cell indicates a cluster-period under usual care and outcome data collection, a colored cell indicates a cluster-period under treatment and outcome data collection, a cell with ‘×’ indicates a cluster-period without any outcome data collection. (a) A schematic of a incomplete stepped wedge design with I = 8 clusters and J = 10 calendar periods and one transition period. (b) A schematic of a incomplete stepped wedge design with I = 8 clusters and J = 10 calendar periods, one before and two after measurements [Colour figure can be viewed at wileyonlinelibrary.com]
Assuming a Gaussian linear mixed model with a continuous outcome, Kasza and Forbes (2019b) defined the metric of information content of cluster-period cells, entire treatment sequences and entire periods as the relative variance inflation of the treatment effect estimator, when the corresponding data elements are omitted. They found that cells closest to the treatment switch points are most information-rich for estimating the treatment effect. Under a class of centrosymmetric intraclass correlation structures, it has been shown that the information content of cells, treatment sequences and periods also exhibits a centrosymmetric structure. Here, a centrosymmetric intraclass correlation structure is one such that the matrix element is symmetric about its center and hence one that is invariant to joint row and column reverse operation, and the information content of a stepped wedge design is centrosymmetric when the information content values are symmetric about the center of the design diagram. More precise mathematical definitions are provided in Section 3.1. Furthermore, if the three-parameter block exchangeable correlation structure for closed cohort designs (Li et al., 2020) is considered, certain cells have null information content and can be preferentially omitted with no variance inflation (Kasza & Forbes, 2019b). This result also applies to special cases including the simple exchangeable (Hussey & Hughes, 2007) and two-parameter nested correlation structure (Li et al., 2018b) for cross-sectional designs, both of which were referred to as “block exchangeable” in Kasza and Forbes (2019b). Based on the linear mixed model, Kasza et al. (2019b) further studied the information content in the presence of implementation periods as well as treatment effect heterogeneity across clusters. While the cells closest to treatment switch points remain information-rich, the presence of implementation periods elevates the information content of cells around the treatment switch points, due to fewer periods permitting direct within-cluster comparisons. On the other hand, including treatment effect heterogeneity in the outcome model reduces the differences between the information content of treatment sequences. These findings provide important insights to guide the design of incomplete stepped wedge trials with continuous outcomes, where some cluster-period cells are intentionally omitted to minimize data collection burden.
Thus far, the work to derive the information content has been limited to the linear mixed model with Gaussian random effects and error structures. However, binary and count outcomes are also common in stepped wedge designs (Barker et al., 2016; Scott et al., 2017), and it remains unknown whether the patterns of information content with Gaussian linear mixed models hold for a larger class of outcome types and models. In this article, we generalize the metric of information content to outcomes with an arbitrary mean–variance relationship and link functions. Rather than using a conditional framework with a mixed model, we operate under a marginal modeling framework with specified link and variance functions, and derive analytical expressions of the information content when certain data elements, including cluster-period cells, treatment sequences and periods, are omitted. The marginal models separately specify the mean and intraclass correlation structures, and have a population-averaged interpretation of the intervention effect (Li et al., 2018b; Li et al., 2019; Preisser et al., 2003). When the marginal variance function is independent of the marginal mean or the variance-stabilizing link function (Bartlett, 1947) is specified according to the marginal variance function, we show that the patterns of information content in Kasza and Forbes (2019b) hold beyond the linear mixed model setup. While existing information content results do not hold exactly under other link functions, we discuss approximate conditions when the information content profiles remain approximately centrosymmetric, and numerically explore cells that contribute negligible information for estimating the intervention effect. Our findings expand previous investigations to a broader class of outcomes and models, and serve to strengthen the theoretical underpinnings for incomplete stepped wedge designs.
2 |. INFORMATION CONTENT BASED ON MARGINAL MODELS
2.1 |. Marginal model and variance of the treatment effect estimator
We first consider a complete stepped wedge design with I clusters and T periods, where each cluster corresponds to a unique treatment sequence, or equivalently T = I + 1. Although we focus on this basic design, our results still apply when a constant (≥ 2) number of clusters are assigned to each sequence once we redefine the information content for the entire sequence or the sequence-period cells. Let Yijl be the outcome for participant l = 1,…, N from cluster i = 1,…, I in period j = 1,…, T. We assume the following marginal mean model with a known link function g
| (1) |
where μij is the marginal mean outcome in each cluster-period, βj refers to the categorical secular trend in the absence of intervention, Xij is the treatment indicator (e.g., Xij = 0 or 1 depending on whether cluster i receives the intervention at period j), and δ is the treatment effect parameter of interest on the link function scale. We write θ = (β1,…, βT, δ)′, denote h(μij) as the variance function, and ϕ as the common dispersion parameter; thus the marginal variance of Yijl is ϕh(μij).
Depending on the nature of the intervention and outcome variable, stepped wedge trials may employ a cross-sectional design, where different sets of participants are recruited during each period, or a closed-cohort design, where the same set of participants are followed up longitudinally over time (Copas et al., 2015). These two different designs require different assumptions on the intraclass correlation structure for the outcomes. Define and as the collection of outcomes in cluster i. Typical intraclass correlation structures considered in stepped wedge designs are special cases of a symmetric block structure (also see Appendix A of Data S1 for more explicit matrix representations)
| (2) |
where IN is the N × N identity matrix, JN is the N × N matrix of ones, and the symmetric but otherwise unstructured T × T basis matrices are
For two different participants in cluster i, rijj is the correlation between their responses if they are both measured in the jth period, and rijt is the correlation if one response is measured in period j and the other is measured in period t. For repeated responses on the same participant (applicable in a closed-cohort design), is the correlation between responses in periods j and t, (and by definition). If rijj = α0 for all j, t, and for |j − t| ≥ 1, Ri = (1 – α0)ITN + α0 JTN is the simple exchangeable correlation structure as implied from the linear random intercept model in Hussey and Hughes (2007). Setting rijj = α0 for all j, and for all |j − t| ≥ 1 induces the nested exchangeable correlation structure as implied by the random cluster-by-time interaction model in Hooper et al. (2016) and Girling and Hemming (2016). The exponential decay correlation structure is implied by setting rijj = α0 for all j and for all |j – t| ≥ 1 (Kasza, Hemming, et al., 2019; Li et al., 2021). While the above three examples are mainly applicable to cross-sectional designs, Ri also accommodates correlation structures under closed-cohort designs. For example, the three-parameter block exchangeable correlation structure is obtained with rijj = α0 for all j, rijt = α1 and for all |j − t| ≥ 1 (Li et al., 2018a; Li et al., 2018b); the proportional decay structure (Li, 2020) is obtained with j, rijj = α0 for all and for all |j − t| ≥ 1. Further elaborations of Ri are provided in Appendix A of Data S1.
With a suitable working correlation model, estimation of treatment effect δ can proceed with paired generalized estimating equations (GEEs) as in Preisser et al. (2008) and Li et al. (2018b). Assuming that the working correlation structure is correctly specified, the variance of the GEE treatment effect estimator, var(), in a complete design can be obtained as the (T + 1,T + 1)th element of the model-based variance for θ. Specifically, define the design matrix for cluster i as , where Zi = (IT, Xi), and Xi = (Xi1,…, XiT)′ is the vector of treatment indicators common across participants in cluster i. Defining and , the estimation of θ can be operationalized by iteratively reweighted least squares through regression of the working outcome vector with a cluster-specific precision matrix , where
| (3) |
is the variance of the working outcome, and (Preisser & Qaqish, 1996). By this formulation, the asymptotic variance of the GEE treatment effect estimator can be obtained as
with and . With an identity link function and the Gaussian variance function hij = 1, var() can be further simplified to a scalar expression under the simple exchangeable (Hussey & Hughes, 2007), block exchangeable (Li et al., 2018b) and the proportional decay (Li, 2020) correlation structures. On the other hand, when the link function is nonidentity or the marginal variance function depends on the marginal mean, var() generally does not have a simple analytical expression, even when the correlation matrix Ri has a simple closed-form inverse. To proceed, the following Lemma provides a simpler expression of var() by collapsing the working outcomes by each cluster-period.
Lemma 1. The asymptotic variance of the GEE treatment effect estimator is
where Xi is the treatment sequence indicator of cluster i and is the variance matrix for the cluster-period means of the working outcome vector, defined as .
The proof of Lemma 1 boils down to a key identity, for each cluster i, which we show in Appendix B of Data S1 by block matrix inversion. Under a constant variance, hij = 1, and identity link such that Di = IT, Lemma 1 is similar to the result in Grantham et al. (2019) based on a linear mixed model, but does not require the full Gaussian distributional assumption. Lemma 1 also extends the result of Li et al. (2021) to a broader class of correlation models with the incorporation of the auto-correlation parameters , albeit under the assumption of equal cluster-period sizes. In addition, Lemma 1 expands the result of Davis-Plourde et al. (2021) developed for generalized linear mixed models to GEE. Intuitively, Lemma 1 implies that the GEE treatment effect estimator with participant-level data has the same asymptotic variance as that with cluster-period means in stepped wedge designs. This intermediate step allows us to conveniently represent the information content of each cluster-period.
2.2 |. Variance of the treatment effect estimator when omitting one cell
Following Kasza and Forbes (2019b), we use to denote the variance of the GEE estimator when the observations in the design cell corresponding to cluster i and period j are omitted. As we operate under the basic stepped wedge design with T = I + 1 periods, each design cell in fact corresponds to a sequence-period, which is identical to a cluster-period with one cluster per sequence. Without ambiguity, below we will use a cluster-period and a sequence-period interchangeably (a cluster therefore also corresponds to a treatment sequence). Specifically, the information content of each cluster-period is defined as
which measures the relative asymptotic variance inflation when design cell (i, j) is omitted, and var()is given in Lemma 1. To obtain an expression for , we first rearrange the IT × 1 cell means of the working outcome, such that the summary statistic corresponding to the omitted cell is the first element, followed by the remaining observations from the same cluster, and then the observations from other clusters; the rows and columns of cov() are also correspondingly rearranged such that variance of the summary statistic of the omitted cell is the upper left element. We write the IT × IT covariance matrix of the rearranged cluster-period means as
where is the variance of the jth element of , and is the (IT − 1) × 1 column vector with (k,t)th element given by cov(), with (k, t) ≠ (i, j). Due to independence of observations between clusters, we can write , where 0s is the s-vector of zeros. Furthermore, is a (IT − 1) × (IT − 1) block diagonal structure, with the first block given by the (T − 1) × (T − 1) matrix , the covariance matrix of cluster-period mean working outcomes in cluster i with the jth row and column removed, and the remaining blocks given by cov() for k ≠ i. We further define ej as the T-vector with its jth element as 1 and 0 elsewhere. By deriving the expression of , the following Theorem provides an analytical expression of the information content for the GEE treatment effect estimator when the (i,j)th cell is excluded. The detailed proof can be found in Appendix C in Data S1.
Theorem 1. The information content of design cell (i, j) is
where , is the (T − 1) × T matrix obtained by removing the jth row from IT, and , Xi[j] is obtained by omitting Xij from Xi.
Several remarks are in order based on Theorem 1. First, as we show in Appendix C in Data S1, the information content of each cluster-period is at least 1, namely IC(i, j) ≥ 1 for all i, j. Second, when , such as when Yijl follows a Gaussian or Laplace distribution, the marginal variance of the outcome is invariant to its marginal mean. Assuming Ri is identical across clusters (e.g., when treatment has no effect on the intraclass correlation structures), our information content expression simplifies to the expression obtained in Kasza and Forbes (2019b) based on a linear mixed model. Our expression, however, is more general as we allow h(μij) ≥ 0 to be an arbitrary function of the mean, and accommodate scenarios even when the intraclass correlation structure Ri differs across clusters. Finally, because the information content expression is derived without restrictions on the treatment indicator Xij, Theorem 1 is actually more general than for stepped wedge designs and holds for any complete longitudinal cluster randomized design. For example, to obtain IC(i, j) for a parallel-arm longitudinal cluster randomized trial with baseline randomization, one can consider Xi = 1T for half of the clusters and Xi = 0T for the remaining half. As a second example, if Xij represents the number of periods elapsed since treatment initiation, model (1) is referred as the linear time-on-treatment effect model (Hughes et al., 2015), and Theorem 1 can be used to explore the information patterns with increasing or decreasing treatment effect over time in stepped wedge trials.
2.3 |. Information content when omitting a sequence or period
Following a similar strategy, we can define as the asymptotic variance of the treatment effect estimator when an entire treatment sequence i is omitted, and as the asymptotic variance of the treatment effect estimator when an entire period j is omitted. We then similarly define the relevant information content to understand which treatment sequence or period contributes the most information for estimating δ, and therefore can potentially inform the decision to randomize in earlier or later sequences for maximizing power, or the decision to omit data collection in earlier or later time periods. In Appendix D in Data S1, we establish the following information content expressions for the GEE estimator.
Theorem 2. Define and . Then the information content for each treatment sequence i is given by
| (4) |
Denote the cell means from period j across all clusters as and then re-arrange the collection of all cell means such that . Define , , and . Further define , and , where Z[j] is Zj with jth row omitted. Then the information content for each time period j is given by
| (5) |
where , and “+” denotes the Moore-Penrose generalized inverse.
Importantly, when an entire period j is omitted, the period effect βj becomes unestimable, and therefore we use the Moore–Penrose generalized inverse to represent the asymptotic variance of the GEE estimator , so that we can connect with var() through a modified Woodbury matrix identity for rank-deficient matrices (Deng, 2011). Additional variance expressions when an arbitrary set of cluster-periods are omitted are more complicated and are pursued in Appendix D in Data S1. Finally, while we assume a standard design with one cluster per sequence for brevity of exposition, when multiple clusters of the same size are assigned to the same treatment sequence, we naturally have IC(i, •) = IC(k, •) for clusters i and k receiving the same sequence. This implies that our general formulas should directly apply for an equal number of clusters in each sequence.
3 |. PROPERTIES AND EXAMPLES OF INFORMATION CONTENT IN STEPPED WEDGE DESIGNS
3.1 |. Information content with variance-stabilizing link functions
The information content expressions derived in Theorems 1 and 3 are fairly general with an arbitrary link function and variance function. To get some further insights on these expressions, we first discuss one special case where the results can be further simplified. For a given variance function, h(μij), we first tailor the choice of link function in model (1) to simplify the information content expressions. Even when the intraclass correlation model (2) is common across all clusters, both variance expressions Vi and can be cluster-dependent through matrices Di and Ai. In the special case of an identity link, g(μij) = μij, and constant variance function , it is apparent that , in which case is common to all clusters, therefore allowing the results in Kasza and Forbes (2019b) to apply. When the variance function explicitly depends on the marginal mean, such as for binary or count outcomes, one can still ensure a common variance , as long as the link function g(μij) in model (1) is chosen from the class of variance-stabilizing link functions, whose definition is given below.
Definition 1. If for constants a ≠ 0 and , then g(x) defines a class of variance-stabilizing link functions.
The concept of a variance-stabilizing link is closely connected with the variance-stabilizing transformation techniques to achieve approximately constant variance for nonnormal data (Anscombe, 1948; Bartlett, 1947). However, the motivation here is to ensure the variance of the working outcome vector (3) is no longer cluster-dependent, which requires and the link function to satisfy the following ordinary differential equation for any i and j:
| (6) |
It is then evident that the class of link functions in Definition 1 satisfies condition (6) and stablilizes the variance of the working outcome vector such that . Table 1 provides explicit examples of variance-stabilizing link functions (up to an affine transformation) for common data types. For example, the angular link function, arcsin () can be used for binary outcomes, while the square-root link function, can be used for Poisson count outcomes, among others. Except for the Gaussian variance function, the variance-stabilizing link functions generally do not coincide with the canonical link functions. With the use of variance-stabilizing link functions, we have and , the information content expression in
TABLE 1.
Common data types, canonical link, and typical variance-stabilizing link functions (up to an affine transformation) for each marginal variance function
| Family | Mean-variance | Canonical link | Variance-stabilizing link |
|---|---|---|---|
| Gaussian | |||
| Binomial | |||
| Negative binomial | |||
| Poisson | |||
| Gamma | |||
| Inverse Gaussian |
Theorem 1 thus simplifies to
| (7) |
with , which coincides with that obtained in Kasza and Forbes (2019b) but now applies more generally to discrete outcomes.
The variance-stabilizing link function also allows us to simplify expressions of IC(i, •) and IC(•, j) (for the information content for sequences and periods, respectively), without assuming variance function . These simplified expressions coincide with those derived in Kasza and Forbes (2019b) under the linear mixed model assumption, and lead to the following analytical results. To state the results, we follow Kasza and Forbes (2019b) and Bowden et al. (2021) to define a variance matrix to be centrosymmetric as long as the permutation matrix that reverses the order of the rows of satisfies . For example, the variance matrix obtained under the block exchangeable correlation structure and the proportional decay structure along with other special cases in Section 2.1 are all centrosymmetric (assuming a variance-stabilizing link function); for these structures, the information content profiles are also centrosymmetric.
Theorem 3. Assuming g is chosen as a variance-stabilizing link function, when all clusters have a common variance structure Ri = R that leads to a centrosymmetric variance , in a standard stepped wedge design, the information content profiles are also centrosymmetric, namely, IC(i, j) = IC(I + 1 − i, T + 1 − j), IC(i, •) = IC(I + 1 − i, •) and IC(•, j) = IC(•, T + 1 − j),
Under a variance-stabilizing link function, the expressions for IC(i, j), IC(i, •) and IC(•, j) are identical to those in Kasza and Forbes (2019b), and therefore the same arguments can be used to establish Theorem 3. However, with the application of a suitable variance-stabilizing link function, Theorem 3 extends the findings for linear mixed models to a larger class of outcome types. Intuitively, Theorem 3 suggests that omitting data from cluster-period (i, j) leads to the same variance inflation as omitting its centrosymmetric counterpart, cluster-period (I + 1 − i, T + 1 − j). Further, omitting treatment sequence i or period j can lead to the same variance inflation as omitting treatment sequence I + 1 − i or period T + 1 − j, respectively. In addition to the centrosymmetry results in Theorem 3, certain information content may be expressed more explicitly when the variance admits a closed-form inverse. This is the case when Ri = R exhibits a block exchangeable (Li et al., 2018b) and proportional decay (Li, 2020) structure, which we elaborate as two specific examples below, with details of their correlation structure components in Appendix A in Data S1.
Example 1 (Block exchangeable correlation structure). When the correlation structure (2) is block exchangeable such that rijj = α0 for all i, j, rijt = α1 and for all i and |j − t| ≥ 1, we have , with basis matrices
where λ1 = 1 − α0 + α1 − α2, λ2 = 1 − α0 − (T − 1)(α1 − α2), λ3 = 1 + (N − 1)(α0 − α1) − α2 and λ4 = 1 + (N − 1)α0 + (T − 1)(N − 1)α1 + (T − 1)α2 are four distinct eigenvalues of Ri (Li et al., 2018b). This correlation structure includes the nested exchangeable and simple exchangeable correlation structures as two special cases by equating, α1 = α2, and α0 = α1 = α2, respectively. Under the block exchangeable correlation structure, the variance matrix of the cluster-period means, , is not only centrosymmetric, but also order-invariant. Specifically, an order-invariant matrix satisfies for any permutation matrix P. In this case, when the variance-stabilizing link function is used, the analytical insights established with the linear mixed model can be generalized to binary and count outcomes such that IC(J/2, 1) = IC(J/2, J) = 1 (Matthews & Forbes, 2017). That is, in a standard stepped wedge design with an even number of periods and hence an odd number of sequences, observations from the first and last period in the cluster receiving the same number of treatment and control periods (namely the middle cluster in a cluster-by-period diagram) contain no information for estimating the treatment effect. Omitting these cells thus yields no increase in the asymptotic variance of the GEE treatment effect estimator.
Because a closed-form inverse is available for the block exchangeable correlation structure, we can provide a more explicit information content expression for each sequence defined in (4). Assuming the variance-stabilizing link function, we show in Appendix E in Data S1 that
where and are design constants in a standard stepped wedge design. Evidently, IC(i, •) is an increasing function in the quadratic term i(i − T), and will be maximized when i(i − T) is maximized. That is, the outer sequences closer to the edges of the design have larger information content and contain more information for estimating δ, which echoes the optimal allocation of sequences derived in Lawrie et al. (2015); Li et al. (2018a) and Matthews (2020).
Example 2 (Proportional decay correlation structure). A second example where Ri has a closed-form inverse is the proportional decay structure introduced in Li et al. (2020). In this model, the within-period correlation rijj = α0 for all i, j, and the between-period correlations are allowed to decay exponentially with the same rate ρ over time, namely, and for all i and |j – t| ≥ 1. The correlation matrix is given by , with , and is the T × T first-order autoregressive correlation matrix. It is straight-forward to verify that is centrosymmetric but, as expected, not order-invariant. Under this structure, while the information content profiles are also centrosymmetric as in Theorem 3, different from the block exchangeable correlation structure, there does not exist a cluster-period cell that contributes no information to the treatment effect estimator, that is, has null information content such that IC(i, j) = 1. Furthermore, assuming a variance-stabilizing link function, we show in Appendix E in Data S1 that Equation (4) for the information content of sequence i has a more explicit expression
where . Similar to Example 1, IC(i, •) obtained under the proportional decay structure is also an increasing function in i(i − T), and will be maximized when the quadratic term i(i − T) is maximized. That is, the outer sequences closer to the edges of the design still contain more information for estimating δ.
3.2 |. Information content with general link functions
If g is no longer a variance-stabilizing link function, the information content is generally not centrosymmetric under a nonconstant mean–variance relationship, except for the trivial case of null secular trend and treatment effect. Specifically, when βj = 0 for all j ≥ 2 and δ = 0, the marginal mean and hence the variance function is no longer cluster-dependent, allowing for the results in Section 3.1 to apply. Alternatively, when there is minimal secular trend and a small treatment effect on the link function scale, the marginal variance function will have negligible differences across clusters and periods, and we can expect the information content profiles to be approximately centrosymmetric. Beyond these simple cases, we can still regard the results in Section 3.1 as a benchmark, and consider the difference between the specified link function and variance-stabilizing link function within the common parameter space (for cluster-period means) to quantify the lack of centrosymmetry. Intuitively, if we write gvs(x) and g(x) as the variance-stabilizing link function and the specified link function, then the degree of lack of centrosymmetry can depend on any discrepancy measure between gvs(x) and g(x) evaluated at the outcome trajectories. For example, one possible discrepancy measure is given by the set of differences , for anticipated nonnull secular trend and treatment effect (by definition and corresponds to centrosymmetric patterns). Because the exact patterns under this general case are challenging to quantify analytically, in Section 4 we explore the patterns of information content numerically under the canonical link functions for binary and count outcomes, both which are common in stepped wedge trials.
4 |. NUMERICAL STUDIES OF INFORMATION CONTENT
To numerically illustrate the patterns of information content of design cells, sequences and periods under canonical link functions with binary and count outcomes, we consider one particular stepped wedge design with I = 9 clusters and T = 10 periods, with cluster-period size N = 100. We focus on the simple exchangeable correlation model with a common correlation , as well as the exponential decay correlation model with rijj = α0 = 0.05 and a 5% decay per period (or equivalently ρ = 0.95). With a binary outcome and a logistic link function, we consider , corresponding to low, medium, and high levels of baseline prevalence. For each baseline prevalence, we consider the null secular trend (), the increasing secular trend ( and ), and the decreasing secular trend ( and ). We assume the true treatment effect in log odds ratio as δ = log(1.5), and omit the results for δ = −log(1.5) due to symmetry. The compatibility of marginal mean and correlation parameters is ensured by verifying natural constraints (Qaqish, 2003).
For a count outcome with a log link, we fix the baseline event rate as , and similarly consider the null secular trend (), increasing secular trend ( and ), and decreasing secular trend ( and ). We also vary the treatment effect in log rate ratio as . We assume the Poisson variance function such that the marginal variance equals the marginal mean. Although we have focused on the above set of parameter choices, results under alternative parameter choices can be investigated in our R Shiny App at https://information-content-binary-count.shinyapps.io/code_for_paper/. In addition, Figure S1 presents the information content patterns under each correlation model assuming a variance-stabilizing link function. As expected from Theorem 3, the information content patterns are centrosymmetric regardless of the outcome type and the underlying secular trend. Such results serve as a benchmark for our evaluation under the canonical link functions.
4.1 |. Binary outcome with a logistic link
Figures 2, S2 and S3 present the information content of cells for three values of baseline prevalence. Within each figure, results under two correlation models and three secular trends are presented. Overall, the information content of cells under the logistic link function remains approximately centrosymmetric and does not appear to be substantially different than the benchmark patterns in Figure S1, especially when the overall prevalence is around 50%. The prevalence and secular trend only have mild effect on the information content of cells. For example, when the baseline prevalence is low (high) and the secular trend is decreasing (increasing), the information content of cells on the lower-right corner contains slightly less information than those on the upper-left corner, possibly due to implications of event rate close to zero or one. In general, the cells near treatment switch points still carry the most information in estimating the treatment odds ratio under both correlation models, similar to the benchmark results.
FIGURE 2.
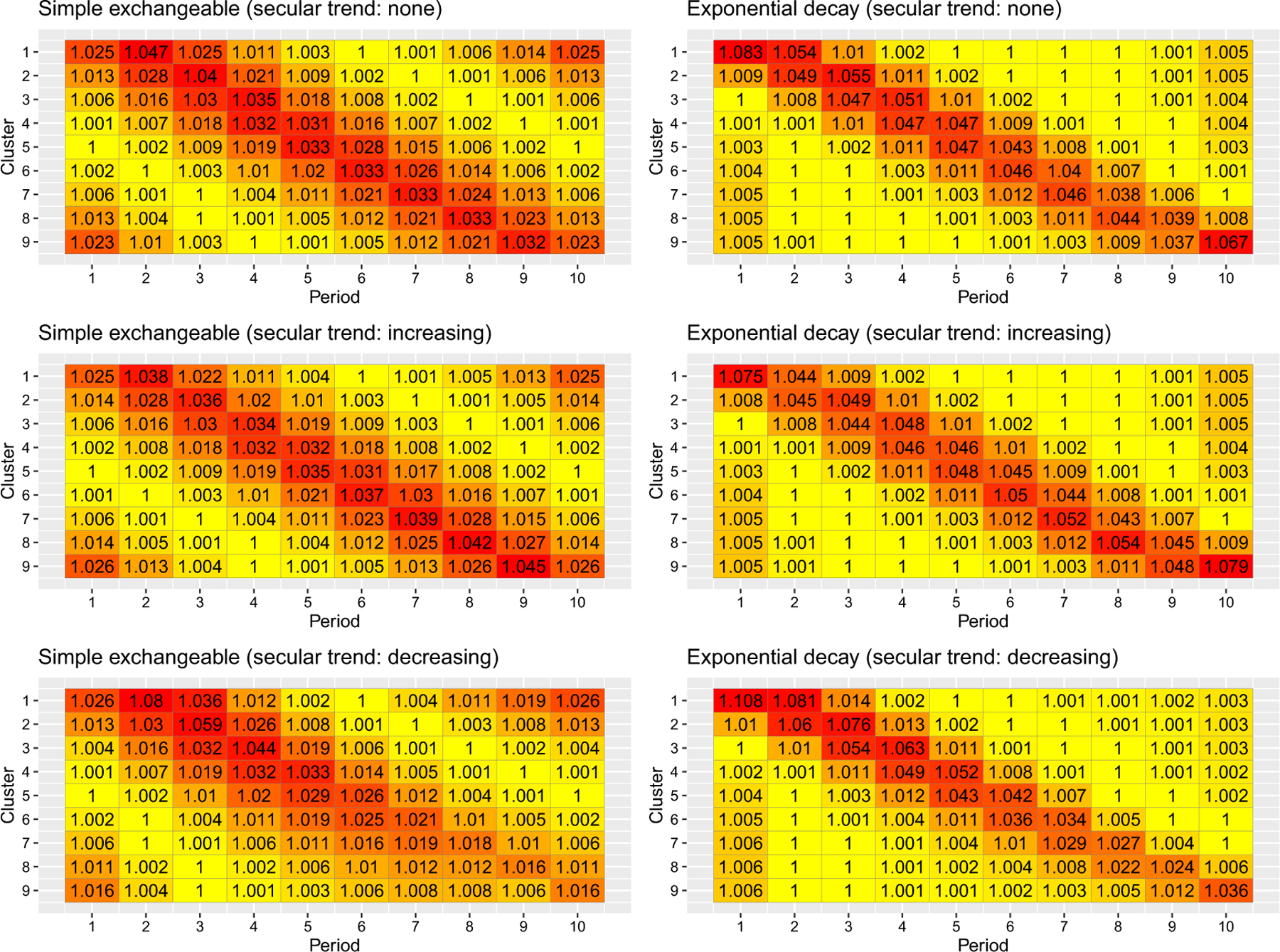
Information content of cells under two correlation models and three secular trends with a binary outcome and logistic link. The baseline prevalence is . [Colour figure can be viewed at wileyonlinelibrary.com]
However, when considering the information content of entire sequences and periods for binary outcomes with a logistic link function, the lack of centrosymmetry is more apparent. When the baseline prevalence is low (Figure 3), the earlier sequences (sequences where clusters start implementing the intervention earlier in time) are substantially more information-rich than the later sequences under both correlation models when the secular trend is decreasing, whereas the reverse holds when the secular trend is increasing. This information content pattern might be due to the low probability of event occurrence in certain sequences, which limit the information contribution to the estimation of the overall treatment odds ratio. Likewise, Figure 4 indicates that the earlier periods contribute substantially more information to estimate the treatment odds ratio than the later periods when the baseline prevalence is low and the secular trend is decreasing, as the cluster-period prevalence moves towards zero over time. The findings for high baseline prevalence is largely symmetric to those for low baseline prevalence (Figures S6 and S7). Overall, the information content patterns of sequences and periods are closest to centrosymmetric when the baseline prevalence is 50% and the secular trend is null (Figures S4 and S6). This is likely because the logistic link function is approximately linear in a small interval around 50% and the variance function is relatively stable in that region, and therefore the results are closer to the benchmark results obtained under the variance-stabilizing link function.
FIGURE 3.
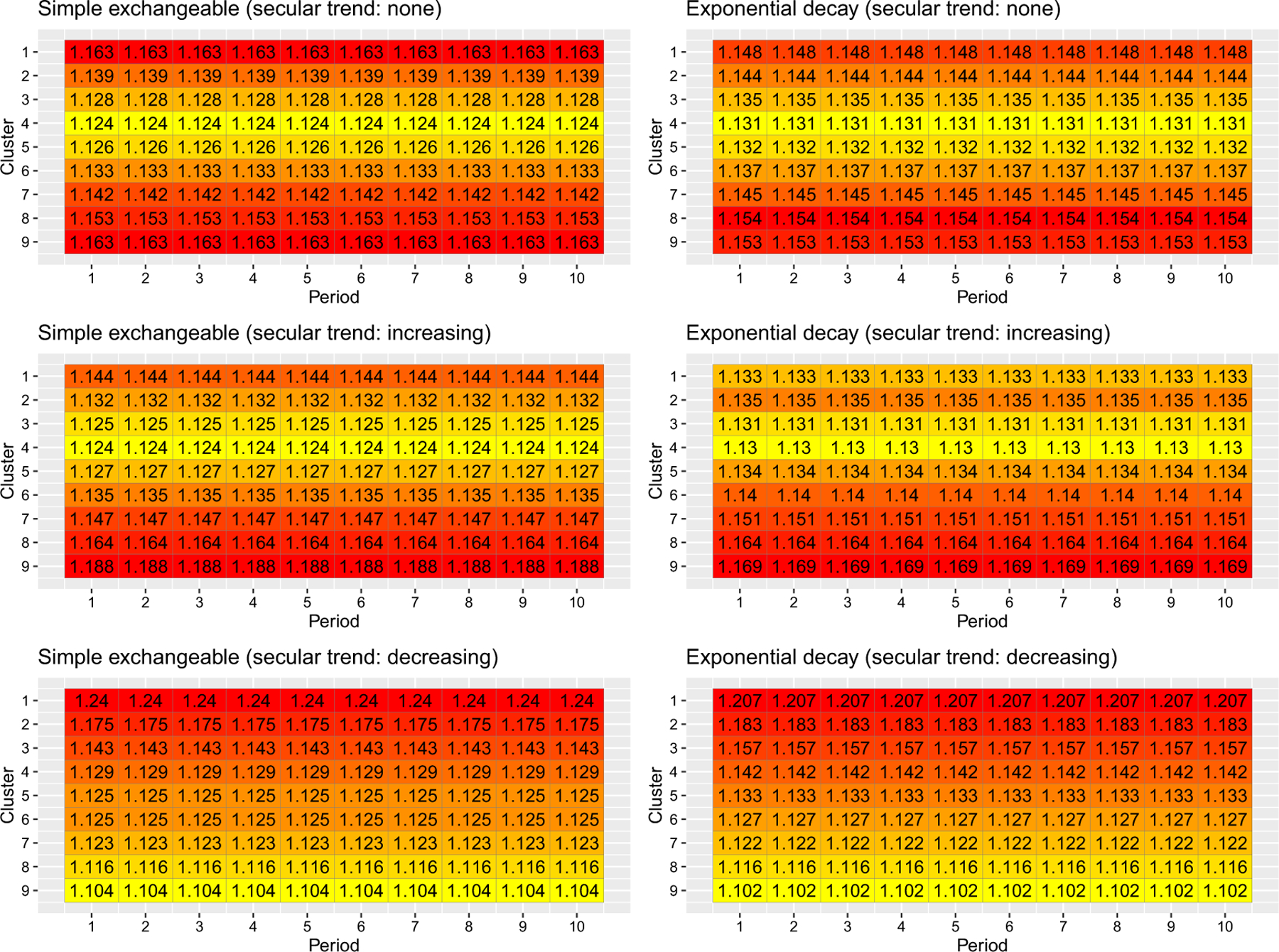
Information content of sequences under two correlation models and three secular trends with a binary outcome and logistic link. The baseline prevalence is . [Colour figure can be viewed at wileyonlinelibrary.com]
FIGURE 4.
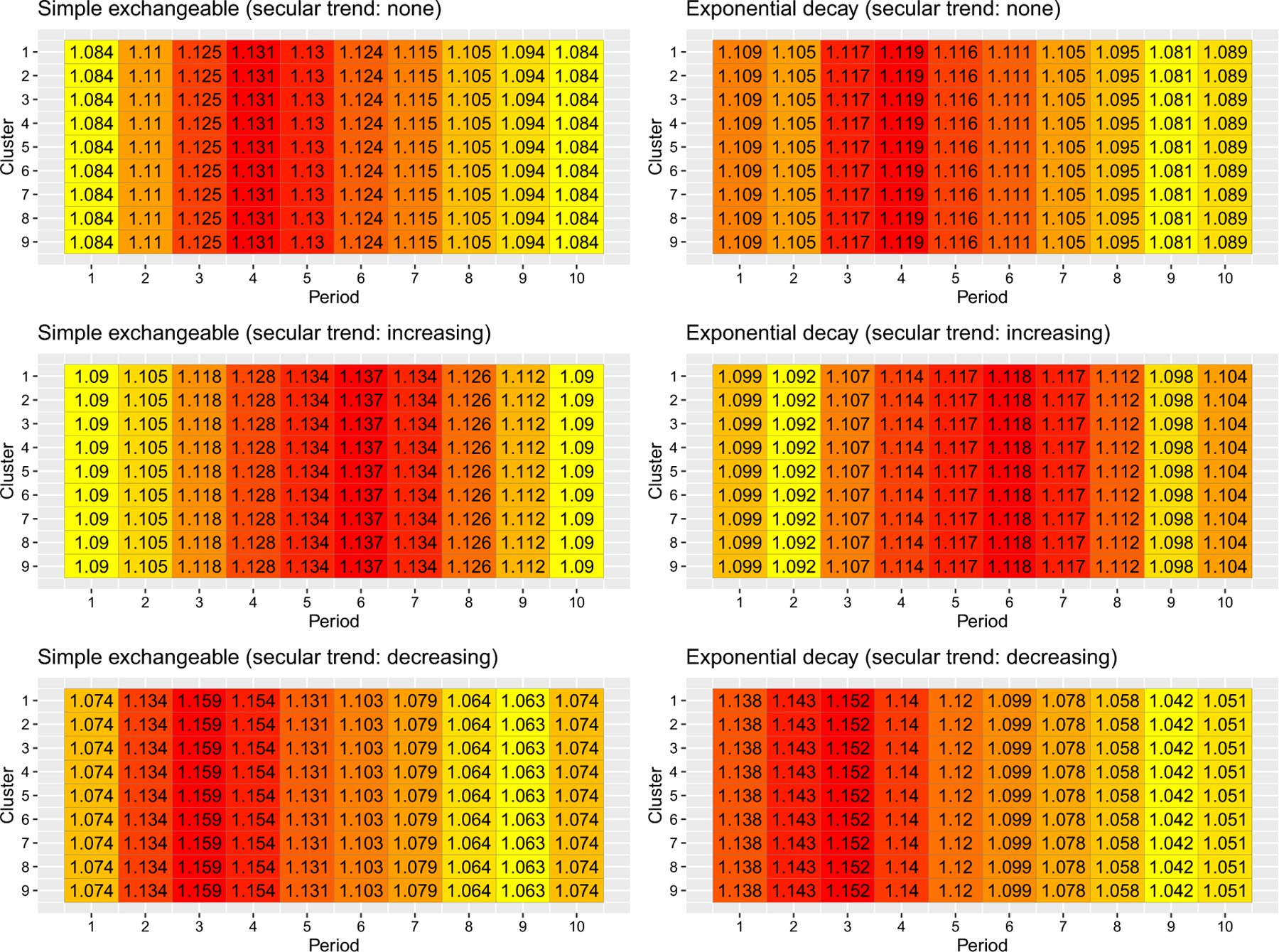
Information content of periods under two correlation models and three secular trends with a binary outcome and logistic link. The baseline prevalence is . [Colour figure can be viewed at wileyonlinelibrary.com]
4.2 |. Count outcome with a log link
With a count outcome and a log link, the information content of design cells exhibits an approximately centrosymmetric pattern, demonstrating that deviation from the variance-stabilizing link function has limited impact on the contribution from each cell (Figures S8 and S9). However, similar to the results with a binary outcome, the secular trend plays an important role in determining the information content of sequences and periods. For example, with a decreasing secular trend, earlier sequences and earlier periods have consistently larger information content than later sequences and later periods, regardless of the two correlation models and the direction of the treatment rate ratio (Figures S10–S13). With a null or increasing secular trend, the patterns of the information content of sequences and periods can depend on the direction of the treatment rate ratio and are generally not centrosymmetric in the designs we considered.
5 |. DATA EXAMPLE: THE WASHINGTON STATE EPT TRIAL
The Washington State Expedited Partner Therapy (EPT) trial is a stepped wedge trial rolling out a partner therapy intervention in I = 24 local health jurisdictions over T = 5 periods. Figure S14 presents a cluster-by-period diagram of the study. The primary outcome of the study is the binary chlamydia infection status, collected from women attending sentinel clinics in each 6-month time period (Golden et al., 2015). While this trial was originally a complete design, we use it as an illustrative example here and investigate the relative information contribution from each cluster-period, each entire cluster and each entire period with a binary outcome. Notice that we have six clusters receiving each of the four sequences, and therefore IC(i, j) = IC(k, j) and IC(i, •) = IC(k, •) for clusters i and k receiving the same sequence. Our focus in this data example is on the removal of each individual cell, each entire cluster or period, rather than the removal of arbitrary sets of cells, clusters, or periods. Therefore, the interpretation of findings pertain to each individual data element only rather than a set of data elements. We assume N = 305 women (estimated mean cluster-period size from the actual trial data) will contribute outcome observations during each period in each cluster. Furthermore, we assume the secular trend parameter as (β1, β2, β3, β4, β5)′ = (−2.443, −2.454, −2.535, −2.609, −2.537)′, corresponding to outcome prevalence of around 7.5% with minor period-to-period fluctuation, as well as the treatment effect δ = −0.141, corresponding to an odds ratio of 0.87; these parameters are based on previous GEE analysis of the EPT trial (Li et al., 2021). We consider both the simple exchangeable and exponential decay correlation structures, with α0 = 0.01 for both structures and a between-period decay rate ρ = 0.7 for the latter. Figures S15 and S17 present the information content patterns. As expected from our earlier numerical results, the information content of cluster-periods has an approximately centrosymmetric pattern, with the information-rich cluster-periods near treatment switch points, under both correlation models. In particular, each cluster-period within the set {(1, 4), (2, 4), (3, 4), (4, 4), (5, 4)} (all clusters receiving the first sequence) and the set {(16, 2), (17, 2), (18, 2), (19, 2), (20, 2)} (all clusters receiving the last sequence) has IC(i, j) ≈ 1 and contributes minimal information to the treatment effect estimate. Therefore, omitting the data collection from each one of these cluster-period cells individually would have resulted in negligible loss of study power compared to the original complete design. However, we have not investigated the successive removal of cells with low values of information content. Additional work is ongoing to investigate the impact of iterative removal of such cluster-period cells and the impacts of the removal of such cells on the information content of other cells within a design. Finally, the information content of entire clusters and entire periods exhibit slight lack of centrosymmetry, possibly as a result of low outcome prevalence. Under both correlation models, clusters randomized to receive treatment earlier in time tend to have larger information content than those to receive treatment later in time. Similarly, earlier periods tend to have slightly larger information content than the later periods.
6 |. CONCLUDING REMARKS
In this article, we provide several theoretical results on the information content of cluster-period cells, treatment sequences and periods when the outcome is discrete and the analysis proceeds by the GEEs with assumed correlation structures. These results provide means to formally quantify trade-offs involved when logistical, resource and patient-centered considerations are balanced against methodological implications in cluster randomized trials employing incomplete stepped wedge designs with an arbitrary link function and variance function. Additionally, we show that the application of the variance-stabilizing link function allows the insights of Kasza and Forbes (2019b) to apply to more general outcome types. While the centrosymmetric patterns of the information content do not hold exactly under the canonical link functions, our numerical explorations suggest that the information content of cells still remain approximately centrosymmetric, but the information content patterns of sequences and periods can be subject to other design parameters including the baseline event rate, the underlying secular trend and the underlying treatment effect. To facilitate the exploration of information content, we derive analytical results for obtaining the information content of design cells, sequences, and periods, and apply these results to the Washington State EPT trial. Because incomplete stepped wedge designs are becoming increasingly common and there is a rising interest in identifying which data elements may be omitted with a minimal loss of information about the treatment effect with binary and count outcomes, our results serve to refine our understanding and theoretical underpinnings of incomplete designs when the endpoint is discrete. Of note, in our theoretical development and numerical studies, we have emphasized removal of a single data element (cluster-period cell, sequence or period) instead of multiple data elements. When the scientific interest lies in hunting for an optimal but highly incomplete design (Hooper et al., 2020), it may be useful to investigate the information content of k (k ≥ 2) cluster-periods (i.e., based on removal of k design cells) for which we currently only provide generic expressions in Appendix D in Data S1. The application of information content to inform incomplete designs through the iterative removal of cells with low information content is a current area of investigation.
Our numerical studies of the information content under the canonical link functions emphasize the importance of event rate and secular trend in planning stepped wedge trials with discrete outcomes. This is largely borne out from the information content patterns for each treatment sequence, as we vary the baseline prevalence and secular trend with a binary outcome. For example, when the baseline prevalence is one half and the secular trend is minimum, the first and last treatment sequence becomes equally information-rich about the treatment odds ratio, a result that has also been theoretically proved in Lawrie et al. (2015); Li et al. (2018a) and Matthews (2020) assuming linear mixed models with a Gaussian outcome. However, we observe that the information content of earlier sequences is consistently larger than that of the later sequences when the baseline prevalence deviates from one half and the secular trend continues to push the prevalence away from one half. In this case, it is possible that a more efficient stepped wedge design corresponds to the one that allocates more clusters to the first sequence while allocating fewer clusters to the last sequence, as opposed to uniform allocation. A more formal future investigation is needed to provide a definitive answer to the question of optimal allocation of treatment sequences in stepped wedge designs with binary outcomes.
There are several potential limitations of the study. First, we have investigated the information content in stepped wedge trials when the assumed correlation model is correctly specified. This is consistent with the prior investigations based on linear mixed models and represents a typical practice for study design calculations (Kasza & Forbes, 2019b). When the correlation model is expected to deviate from the underlying true correlation model, the information content should be derived based on the robust sandwich variance and is a function of both the assumed correlation structure and the underlying true correlation structure. For example, the GEEs assuming working independence correspond to a computationally efficient estimator for analyzing stepped wedge designs with marginal models, albeit with a potential loss in statistical efficiency due to not capitalising on within-cluster correlations. It would be interesting to explore the patterns of information content based on such an estimator with continuous and discrete outcomes. The results will be reported in a separate study. More generally, when the assumed working correlation structure is not the identity matrix but deviates from the underlying true correlation structure, evaluation of information content requires identification of the probability limits of the misspecified working correlation estimators, which are challenging to quantify analytically. Of note, the results for misspecified linear mixed models derived in Kasza and Forbes (2019a) may shed light on this evaluation for continuous outcomes. For binary outcomes, simulation-based evaluation may be a useful and practical approach to address this more complex question. Second, our analytical results are based on the equal cluster-period size assumption. A recent study indicates that the efficiency loss due to unequal cluster-period sizes is not dramatic when the correlation model is correctly specified in stepped wedge trials (Tian et al., 2022). Nevertheless, it remains of interest to extend our derivation to allow for unequal cluster-period sizes, such as along the lines of Kasza et al. (2021) with a linear mixed model. Finally, our information content results are based on marginal models with a population-averaged interpretation, and may or may not be directly applicable to generalized linear mixed models with a cluster-specific interpretation. Future work is needed to develop the theory for incomplete stepped wedge designs under the class of generalized linear mixed models.
Supplementary Material
ACKNOWLEDGEMENTS
Research in this article was funded through a Patient-Centered Outcomes Research Institute® (PCORI® Award ME-2019C1-16196), and an Australian Research Council Discovery Project (DP210101398). The statements presented in this article are solely the responsibility of the authors and do not necessarily represent the views of PCORI®, its Board of Governors or Methodology Committee. Dr. Preisser has received a stipend for service as a merit reviewer from PCORI®. Dr. Preisser did not serve on the Merit Review panel that reviewed his project. The authors thank Zibo Tian for helpful discussions and computational assistance with the R Shiny App. We also thank the editor, associate editor and two anonymous referees for their valuable suggestions, which greatly improved the exposition of this work.
Funding information
Australian Research Council Discovery Project, Grant/Award Number: DP210101398; Patient-Centered Outcomes Research Institute, Grant/Award Number: ME-2019C1-16196
Footnotes
SUPPORTING INFORMATION
Additional supporting information can be found online in the Supporting Information section at the end of this article.
REFERENCES
- Anscombe FJ (1948). The transformation of poisson, binomial and negative-binomial data. Biometrika, 35, 246–254. [Google Scholar]
- Barker D, McElduff P, D’Este C, & Campbell MJ (2016). Stepped wedge cluster randomised trials: A review of the statistical methodology used and available. BMC Medical Research Methodology, 16, 1–19. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bartlett MS (1947). The use of transformations. Biometrics, 3, 39–52. [PubMed] [Google Scholar]
- Bowden R, Forbes AB, & Kasza J (2021). On the centrosymmetry of treatment effect estimators for stepped wedge and related cluster randomized trial designs. Statistics & Probability Letters, 172, 109022. [Google Scholar]
- Copas AJ, Lewis JJ, Thompson JA, Davey C, Baio G, & Hargreaves JR (2015). Designing a stepped wedge trial: Three main designs, carry-over effects and randomisation approaches. Trials, 16, 1–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davis-Plourde K, Taljaard M, & Li F (2021). Sample size considerations for stepped wedge designs with subclusters. Biometrics [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deng CY (2011). A generalization of the Sherman–Morrison–Woodbury formula. Applied Mathematics Letters, 24, 1561–1564. [Google Scholar]
- Girling AJ, & Hemming K (2016). Statistical efficiency and optimal design for stepped cluster studies under linear mixed effects models. Statistics in Medicine, 35, 2149–2166. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Golden MR, Kerani RP, Stenger M, Hughes JP, Aubin M, Malinski C, & Holmes KK (2015). Uptake and population-level impact of expedited partner therapy (EPT) on chlamydia trachomatis and Neisseria gonorrhoeae: The Washington State community-level randomized trial of EPT. PLoS Medicine, 12, 1–22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grantham KL, Kasza J, Heritier S, Hemming K, & Forbes AB (2019). Accounting for a decaying correlation structure in cluster randomized trials with continuous recruitment. Statistics in Medicine, 38, 1918–1934. [DOI] [PubMed] [Google Scholar]
- Heazell AE, Weir CJ, Stock SJ, Calderwood CJ, Burley SC, Froen JF, Geary M, Hunter A, McAuliffe FM, Murdoch E, & Rodriguez A (2017). Can promoting awareness of fetal movements and focusing interventions reduce fetal mortality? A stepped-wedge cluster randomised trial (affirm). BMJ Open, 7, e014813. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hemming K, Lilford R, & Girling AJ (2015). Stepped-wedge cluster randomised controlled trials: A generic framework including parallel and multiple-level designs. Statistics in Medicine, 34, 181–196. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hemming K, & Taljaard M (2020). Reflection on modern methods: When is a stepped-wedge cluster randomized trial a good study design choice? International Journal of Epidemiology, 49, 1043–1052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hooper R, Kasza J, & Forbes A (2020). The hunt for efficient, incomplete designs for stepped wedge trials with continuous recruitment and continuous outcome measures. BMC Medical Research Methodology, 20, 1–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hooper R, Teerenstra S, de Hoop E, & Eldridge S (2016). Sample size calculation for stepped wedge and other longitudinal cluster randomised trials. Statistics in Medicine, 35, 4718–4728. [DOI] [PubMed] [Google Scholar]
- Hughes JP, Granston TS, & Heagerty PJ (2015). Current issues in the design and analysis of stepped wedge trials. Contemporary Clinical Trials, 45, 55–60. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hussey MA, & Hughes JP (2007). Design and analysis of stepped wedge cluster randomized trials. Contemporary Clinical Trials, 28, 182–191. [DOI] [PubMed] [Google Scholar]
- Kasza J, Bowden R, & Forbes AB (2021). Information content of stepped wedge designs with unequal cluster-period sizes in linear mixed models: Informing incomplete designs. Statistics in Medicine, 40, 1736–1751. [DOI] [PubMed] [Google Scholar]
- Kasza J, & Forbes AB (2019a). Inference for the treatment effect in multiple-period cluster randomised trials when random effect correlation structure is misspecified. Statistical Methods in Medical Research, 28, 3112–3122. [DOI] [PubMed] [Google Scholar]
- Kasza J, & Forbes AB (2019b). Information content of cluster–period cells in stepped wedge trials. Biometrics, 75, 144–152. [DOI] [PubMed] [Google Scholar]
- Kasza J, Hemming K, Hooper R, Matthews JN, & Forbes AB (2019). Impact of non-uniform correlation structure on sample size and power in multiple-period cluster randomised trials. Statistical Methods in Medical Research, 28, 703–716. [DOI] [PubMed] [Google Scholar]
- Kasza J, Taljaard M, & Forbes AB (2019). Information content of stepped-wedge designs when treatment effect heterogeneity and/or implementation periods are present. Statistics in Medicine, 38, 4686–4701. [DOI] [PubMed] [Google Scholar]
- Kenyon S, Dann S, Hope L, Clarke P, Hogan A, Jenkinson D, & Hemming K (2017). Evaluation of a bespoke training to increase uptake by midwifery teams of nice guidance for membrane sweeping to reduce induction of labour: A stepped wedge cluster randomised design. Trials, 18, 1–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lawrie J, Carlin JB, & Forbes AB (2015). Optimal stepped wedge designs. Statistics and Probability Letters, 99, 210–214. [Google Scholar]
- Li F (2020). Design and analysis considerations for cohort stepped wedge cluster randomized trials with a decay correlation structure. Statistics in Medicine, 39, 438–455. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li F, Forbes AB, Turner EL, & Preisser JS (2019). Power and sample size requirements for GEE analyses of cluster randomized crossover trials. Statistics in Medicine, 38, 636–649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li F, Hughes JP, Hemming K, Taljaard M, Melnick ER, & Heagerty PJ (2020). Mixed-effects models for the design and analysis of stepped wedge cluster randomized trials: An overview. Statistical Methods in Medical Research, 30, 612–639. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li F, Turner EL, & Preisser JS (2018a). Optimal allocation of clusters in cohort stepped wedge designs. Statistics and Probability Letters, 137, 257–263. [Google Scholar]
- Li F, Turner EL, & Preisser JS (2018b). Sample size determination for GEE analyses of stepped wedge cluster randomized trials. Biometrics, 74, 1450–1458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li F, & Wang R (2022). Stepped wedge cluster randomized trials: A methodological overview. World Neurosurgery, 161, 323–330. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li F, Yu H, Rathouz PJ, Turner EL, & Preisser JS (2021). Marginal modeling of cluster-period means and intraclass correlations in stepped wedge designs with a binary outcome. Biostatistics, 2. 10.1093/biostatistics/kxaa056 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Matthews J, & Forbes AB (2017). Stepped wedge designs: Insights from a design of experiments perspective. Statistics in Medicine, 36, 3772–3790. [DOI] [PubMed] [Google Scholar]
- Matthews JN (2020). Highly efficient stepped wedge designs for clusters of unequal size. Biometrics, 76, 1167–1176. [DOI] [PubMed] [Google Scholar]
- Ouyang Y, Li F, Preisser JS, & Taljaard M (2022). Sample size calculators for planning stepped-wedge cluster randomized trials: A review and comparison. International Journal of Epidemiology, 9, 2022. 10.1093/ije/dyac123 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Preisser JS, Lu B, & Qaqish BF (2008). Finite sample adjustments in estimating equations and covariance estimators for intracluster correlations. Statistics in Medicine, 27, 5764–5785. [DOI] [PubMed] [Google Scholar]
- Preisser JS, & Qaqish BF (1996). Deletion diagnostics for generalised estimating equations. Biometrika, 83, 551–562. [Google Scholar]
- Preisser JS, Young ML, Zaccaro DJ, & Wolfson M (2003). An integrated population-averaged approach to the design, analysis and sample size determination of cluster-unit trials. Statistics in Medicine, 22, 1235–1254. [DOI] [PubMed] [Google Scholar]
- Qaqish BF (2003). A family of multivariate binary distributions for simulating correlated binary variables. Biometrika, 90, 455–463. [Google Scholar]
- Scott JM, DeCamp A, Juraska M, Fay MP, & Gilbert PB (2017). Finite-sample corrected generalized estimating equation of population average treatment effects in stepped wedge cluster randomized trials. Statistical Methods in Medical Research, 26, 583–597. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tian Z, Preisser JS, Esserman D, Turner EL, Rathouz PJ, & Li F (2022). Impact of unequal cluster sizes for gee analyses of stepped wedge cluster randomized trials with binary outcomes. Biometrical Journal, 64, 419–439. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.