

Abstract
The paper covers the design and analysis of experiments to discriminate between two Gaussian process models with different covariance kernels, such as those widely used in computer experiments, kriging, sensor location and machine learning. Two frameworks are considered. First, we study sequential constructions, where successive design (observation) points are selected, either as additional points to an existing design or from the beginning of observation. The selection relies on the maximisation of the difference between the symmetric Kullback Leibler divergences for the two models, which depends on the observations, or on the mean squared error of both models, which does not. Then, we consider static criteria, such as the familiar log-likelihood ratios and the Fréchet distance between the covariance functions of the two models. Other distance-based criteria, simpler to compute than previous ones, are also introduced, for which, considering the framework of approximate design, a necessary condition for the optimality of a design measure is provided. The paper includes a study of the mathematical links between different criteria and numerical illustrations are provided.
Keywords: Model discrimination, Gaussian random field, Kriging
Introduction
The term ‘active learning’ [cf. Hino (2020) for a recent review] has replaced the traditional (sequential or adaptive) ‘design of experiments’ in the computer science literature, typically when the response is approximated by Gaussian process regression [GPR, cf. Sauer et al. (2022)]. It refers to selecting the most suitable inputs to achieve the maximum of information from the outputs, usually with the aim of improving prediction accuracy. A good overview is given in Chapter 6 of Gramacy (2020).
Frequently the aim of an experiment—in the broad sense of any data acquisition exercise—may rather be the discrimination between two or more potential explanatory models. When data can be sequentially collected during the experimental process, the literature goes back to the classic procedure of Hunter and Reiner (1965) and has generated ongoing research [see e.g. Schwaab et al. (2008), Olofsson et al. (2018) and Heirung et al. (2019)]. When the design needs to be fixed before the experiment and thus no intermediate data will be available, the literature is less developed. While in the classical (non)linear regression case the criterion of T-optimality [cf. Atkinson and Fedorov (1975)] and the numerous papers extending it was a major step, a similar breakthrough for Gaussian process regression is lacking.
With this paper we would like to investigate various sequential/adaptive and non-sequential design schemes for discriminating between the covariance structure of GPRs and their relative properties. When the observations associated with the already collected points are available, one may base the criterion on the predictions and prediction errors (Sect. 3.1). On the one hand, one natural choice will be to put the next design point where the symmetric Kullback–Leibler divergence between those two predictive (normal) distributions differs most. On the other hand, when the associated observations are not available, the incremental construction of the designs could be based on the mean squared error (MSE) for both models, assuming in turn that either of the two models is the true one (Sect. 3.2). We theoretically investigate the asymptotic differences of the criteria with respect to their discriminatory power.
The static construction of a set of optimal designs of given size for nominal model parameters is the last mode we have considered (Sect. 4). Our first choice is to use the difference between the expected values of the log likelihood ratios, assuming in turn that either of the two models is the true one. This is actually a function of the symmetric Kullback–Leibler divergence, which also arises from Bayesian considerations. In a similar spirit, the Fréchet distance between two covariance matrices provides another natural criterion. Some further novel but simple approaches are considered in this paper as well. In particular we are interested whether complex likelihood-based criteria like the Kullback–Leibler-divergence can be effectively replaced by simpler ones based directly on the respective covariance kernels. The construction of optimal design measures for model discrimination (approximate design theory) is considered in Sect. 5, where we investigate the geometric properties for some of the newly introduced criteria.
Eventually, to compare the discriminatory power of the resulting designs from different criteria, one can compute the correct classification (hit) rates after selecting the model with the higher likelihood value. In Sect. 6, a numerical illustration is provided for two Matérn kernels with different smoothness. Furthermore, we confirm the theoretical considerations about optimal design measures from Sect. 5 on a numerical example.
Except for adaptive designs, where the parameter estimates are continuously updated as new data arrive, we assume that the parameters of the models between which we want to discriminate are known. Therefore, our results are relevant in situations where there is strong prior knowledge about the possible models, for example through previously collected data.
Notation
One of the most popular design criteria for discriminating between rival models is T-optimality (Atkinson and Fedorov 1975). This criterion is only applicable when the observations are independent and normally distributed with a constant variance. López-Fidalgo et al. (2007) generalised the normality assumption and developed an optimal discriminating design criterion to choose among non-normal models. The criterion is based on the log-likelihood ratio test under the assumption of independent observations. We denote by and the two rival probability density functions for one observation y at point x. The following system of hypotheses might be considered:
where is assumed to be the true model. A common test statistic is the log-likelihood ratio given as
where the null hypothesis is rejected when or equivalently when . The power of the test refers to the expected value of the log-likelihood ratio criterion under the alternative hypothesis . We have
| 1 |
where is the Kullback–Leibler distance between the true and the alternative model (Kullback and Leibler 1951).
Interchanging the two models in the null and the alternative hypothesis, the power of the test would be
| 2 |
If it is not clear in advance which of the two models is the true model, one might consider to search for a design optimising a convex combination of (1) and (2), most commonly using weights 1/2 for each model. This would be equivalent to maximising the symmetric Kullback–Leibler distance
In this paper we will consider random fields, i.e. we will allow for correlated observations. As we assume that the mean function is known and the same for all models, without loss of generality we can set the mean function equal 0 everywhere. We are solely concerned with discriminating with respect to the covariance structure of the random fields. When the random fields are Gaussian, we might still base the design strategy on the log-likelihood ratio criterion to choose among two rival models.
For a positive definite kernel and an n-point design , is the n-dimensional vector and is the (kernel) matrix with elements . Although x is not bold, it may correspond to a point in a (compact) set . Assume that Y(x) corresponds to the realisation of a random field , indexed by x in , with zero mean for all x and covariance for all . Our prediction of a future observation Y(x) based on observations corresponds to the best linear unbiased predictor (BLUP) . The associated prediction error is and we have
The index n will often be omitted when there is no ambiguity, and in that case , , , will refer instead to model i, with . We shall need to distinguish between the cases where the truth is model 0 or model 1, and following Stein (1999, p. 58) we denote by the expectation computed with model i assumed to be true. We reserve the notation to the case where the expectation is computed with the true model; i.e.,
Hence we have and calculation gives
| 3 |
with an obvious permutation of indices 0 and 1 when assuming the model 1 is true to compute .
If model 0 is correct, the prediction error is larger when we use model 1 for prediction than if we use the BLUP (i.e., model 0). Stein (1999, p. 58) shows that the relation
shown above is valid more generally for models with linear trends.
Also of interest is the assumed mean squared error (MSE) when we use model 1 for assessing the prediction error (because we think it is correct) while the truth is model 0, and in particular the ratio
which may be larger or smaller than one.
Another important issue concerns the choice of covariance parameters in and . Denote , , , where the define the variance, the may correspond to correlation lengths in a translation invariant model and are thus scalar in the isotropic case, and defines a correlation.
Prediction-based discrimination
For the incremental construction of a design for model discrimination, points are added conditionally on previous design points. We can distinguish the case where the observations associated with those previous points are available and can thus be used to construct a sequence of predictions (sequential, i.e., conditional, construction) from the unconditional case where observations are not used.
Sequential (conditional) design
Consider stage n, where n design points and n observations are available. Assuming that the random field is Gaussian, when model i is true we have . A rather natural choice is to choose the next design point where the symmetric Kullback–Leibler divergence between those two normal distributions differs most; that is,
| 4 |
Other variants could be considered as well, such as
They will not be considered in the rest of the paper.
If necessary one can use plug-in estimates and of and , for instance maximum likelihood (ML) or leave-one-out estimates based on and , when we choose . Note that the value of does not affect the BLUP . In the paper we do not address the issues related to the estimation of or of the correlation length or smoothness parameters of the kernel; one may refer to Karvonen et al. (2020) and the recent papers Karvonen (2022), Karvonen and Oates (2022) for a detailed investigation. The connection between the notion of microergodicity, related to the consistency of the maximum-likelihood estimator, and discrimination through a KL divergence criterion is nevertheless considered in Example 1 below.
Incremental (unconditional) design
Consider stage n, where n design points are available. We base the choice of the next point on the difference between the MSEs for both models, assuming that one or the other is true. For instance, assuming that model 0 is true, the difference between the MSEs is .
A first, un-normalised, version is thus
| 5 |
A normalisation seems in order here too, such as
| 6 |
A third criterion is based on the variation of the symmetric Kullback-Leibler divergence (10) of Sect. 4 when adding an -th point x to . Direct calculation, using
and the expression of the inverse of a block matrix, gives
We thus define
| 7 |
to be maximised with respect to .
Although the do not affect predictions, is proportional to . Unless specific information is available, it seems reasonable to assume that . Other parameters should be chosen to make the two kernels the most similar, which seems easier to consider in the approach presented in Sect. 4, see (11). In the rest of this section we suppose that the parameters of both kernels are fixed.
The un-normalised version given by (5) could be used to derive a one-step (non-incremental) criterion, in the same spirit as those of Sect. 4, through integration with respect to x for a given measure on . Indeed, we have
so that
where , , and . Similarly,
The matrices and can be calculated explicitly for some kernels and measures . This happens in particular when , the two kernels are separable, i.e., products of one-dimensional kernels on [0, 1], and is uniform on .
Example 1: exponential covariance, no microergodic parameters
We consider Example 6 in Stein (1999, p. 74) and take , . The example focuses on two difficulties: first, the two kernels only differ by their parameter values; second, the particular relation between the variance and correlation length makes the parameters not microergodic and they cannot be estimated consistently from observations on a bounded interval; see Stein (1999, Chap. 6). It is interesting to investigate the behaviour of the criteria (5), (6) and (7) in this particular situation.
We suppose that n observations are made at , . We denote the half-distance between two design points. The particular Markovian property of random processes with kernels simplifies the analysis. The prediction and MSE at a given only depend on the position of x relative to its two closest neighbouring design points; moreover, all other points have no influence. Therefore, due to the regular repartition of the , we only need to consider the behaviour in one (any) interval .
We always have as . Numerical calculation shows that for small enough, has a unique maximum in at the centre . The next design point that maximises is then taken at for one of the intervals, and we get
Similar results apply to the case where the design contains the endpoints 0 and 1 and its covering radius tends to zero, the points being not necessarily equally spaced: is then the centre of the largest interval and .
When is large compared to the correlation lengths and , there exist two maxima, symmetric with respect to , that get closer to the extremities of as increases, and corresponds to a local minimum of . This happens for instance when and .
A similar behaviour is observed for and : for small enough they both have a unique maximum in at , with now
Also, and as . For large values of compared to the correlation lengths and , there exist two maxima in , symmetric with respect to . When , this happens for instance when for and when for . However, in the second case the function is practically flat between the two maxima.
The left panel of Fig. presents , and for when () and , . The right panel is for , .
This behaviour of for small sheds light on the fact that is not estimable in this model. Indeed, consider a sequence of embedded -point designs , initialised with the design considered above and with , all these designs having the form , . Then, for . For k large enough, the increase in Kullback–Leibler divergence (10) from to is thus bounded by for some , so that the expected log-likelihood ratio remains bounded as .
More generally, denote by the ordered points of an n-point design in [0, 1], . Let be such that . Then necessarily . Indeed, consider the following iterative modification of that cannot decrease : first, move to zero, then move to ; leave unchanged, but move to , etc. For n even, the design obtained is the duplication of an (n/2)-points design; for n odd, only the right-most point remains single. In the fist case, the minimum distance between points of is at most , in the second case it is at most . We then define . For n large enough, the increase in Kullback–Leibler divergence (10) from to is thus bounded by for some depending on and . Starting from some design , we thus have, for large enough,
which implies for some . Assuming, without any loss of generality, that model 0 is correct, we have (we get when we assume that model 1 is correct), implying in particular that does not tend to infinity a.s. and the ML estimator of is not strongly consistent.
Example 2: exponential covariance, microergodic parameters
Consider now two exponential covariance models with identical variances (which we take equal to one without any loss of generality): , .
Again, as and has a unique maximum at for small enough , with now
There are two maxima for in , symmetric with respect to for large : when , this happens for instance when . Nothing is changed for compared to Example 1 as the variances cancel in the ratios that define , see (3) and (6). The situation is quite different for , with
indicating that it is indeed possible to distinguish between the two models much more efficiently with this criterion than with the two others. Interestingly enough, the best choice for next design point is not at but always as close as possible to one of the endpoints or , with however a criterion value similar to that in the centre when is small enough, as . Here, the same sequence of embedded designs as in Example 1 ensures that as . Figure presents , and in the same configuration as in Fig. 1 but for the kernels , .
Fig. 2.

, and , , for () in Example 2. Left: , ; Right: ,
Fig. 1.

, and , , for () in Example 1. Left: , ; Right: ,
Example 3: Matérn kernels
Take and as the 3/2 and 5/2 Matérn kernels, respectively:
| 8 |
| 9 |
We take in and adjust in to minimise defined by Eq. (13) in Sect. 4 with the uniform measure on [0, 1], which gives . The left panel of Fig. shows and for and when . The right panel presents and for the same -point equally spaced design as in Example 1 and for and (the value of does not exceed and is not shown). The behaviours of and are now different in different intervals (they remain symmetric with respect to 1/2, however), the maximum of is obtained at the central point . The behaviour of could be related to the fact that discriminating between and amounts to estimating the smoothness of the realisation, which requires that some design points are close to each other.
Fig. 3.

Left: , and , . Right: and for and the same 11-point equally spaced design as in Example 1, with and
Distance-based discrimination
We will now consider criteria which are directly based on the discrepancies of the covariance kernels. Ideally those should be simpler to compute and still exhibit reasonable efficiencies and some similar properties. The starting point is again the use of the log-likelihood ratio criterion to choose among the two models. Assuming that the random field is Gaussian, the probability densities of observations for the two models are
The expected value of the log-likelihood ratio under model 0 is
and similarly
A good discriminating design should make the difference as large as possible; that is, we should choose that maximises
| 10 |
i.e. twice the symmetric Kullback–Leibler divergence between the normal distributions with densities and , see, e.g., Pronzato et al. (2019).
We may enforce the normalisation and choose the to make the two kernels most similar in the sense of the criterion considered; that is, maximise
| 11 |
The choice of and is important; in particular, unconstrained minimisation over the could make both kernels completely flat or on the opposite close to Dirac distributions. It may thus be preferable to fix and minimise over without constraints. Also, the Kullback–Leibler distance is sensitive to kernel matrices being near singularity, which might happen if design points are very close to each other. Pronzato et al. (2019) suggest a family of criteria based on matrix distances derived from Bregman divergences between functions of covariance matrices from Kiefer’s -class of functions (Kiefer 1974). If , these criteria are rather insensitive to eigenvalues close or equal to zero. Alternatively, they suggest criteria computed as Bregman divergences between squared volumes of random k-dimensional simplices for , which have similar properties.
The index n is omitted in the following and we consider fixed parameters for both kernels. The Fréchet-distance criterion
| 12 |
related to the Kantorovich (Wasserstein) distance, seems of particular interest due to the absence of matrix inversion. The expression is puzzling since the two matrices do not necessarily commute, but the paper Dowson and Landau (1982) is illuminating.
Other matrix “entry-wise" distances will be considered, in particular the one based on the (squared) Frobenius norm,
which corresponds to the substitution of for in (12) for . Denote more generally
where is the n-dimensional vector with all components equal to 1, the absolute value is applied entry-wise and denotes power p applied entry-wise.
Figure shows the values of the criteria , , and as functions of for the two kernels and given by (8) and (9) and the same regular design as in Example 1: , . The criteria are re-scaled so that their maximum equals one on the interval considered for . Note the similarity between and and the closeness between the distance-minimising for , and . Also note the good agreement with the value that minimises from Eq. (13), see Example 3. The optimal for is much different, however, showing that the criteria do not necessarily agree between them.
Fig. 4.
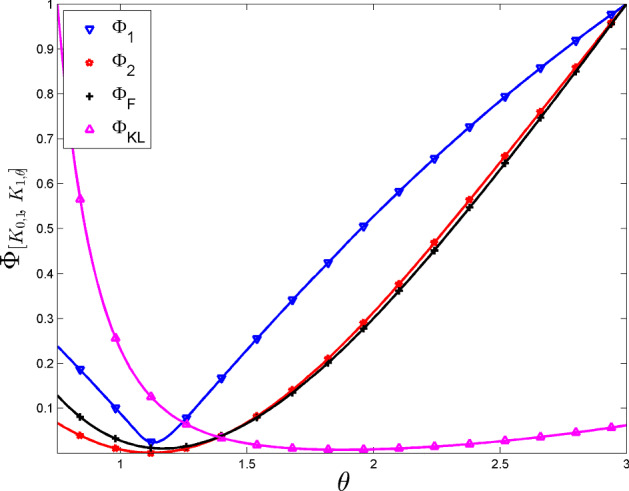
, , and as functions of for the same 11-point equally spaced design as in Example 1 and , given by (8) and (9), respectively
An interesting feature of the family of criteria , , is that they extend straightforwardly to a design measure version. Indeed, defining as the empirical measure on the points in , , we can write
where we define, for any design (probability) measure on ,
| 13 |
Denote by the directional derivative of at in the direction ,
Direct calculation gives
and thus in particular
One can easily check that the criterion is neither concave nor convex in general (as the matrix can have both positive and negative eigenvalues), but we nevertheless have a necessary condition for optimality.
Theorem 1
If the probability measure on maximises , then
| 14 |
Moreover, for -almost every .
The proof follows from the fact that for every when is optimal, which implies (14). As , the inequality necessarily becomes an equality on the support of .
This suggests the following simple incremental construction: at iteration n, with the current design and the associated empirical measure, choose . It will be used in the numerical example of Sect. 6.2.
Optimal design measures
In this section we explain why the determination of optimal design measures maximising is generally difficult, even when limiting ourselves to the satisfaction of the necessary condition in Theorem 1. At the same time, we can characterise measures that are approximately optimal for large p.
We assume that the two kernels are isotropic, i.e., such that , , and that the functions are differentiable except possibly at 0 where they only admit a right derivative. We define , , and assume that the kernels have been normalised so that ; that is, . Also, we only consider the case where the function has a unique global maximum on . This assumption is not very restrictive. Consider again the two Matérn kernels (8) and (9). Figure shows the evolution of for and with two different values of : and ; the latter minimises for being the uniform measure on [0, 1].
In the following, we shall consider normalised functions , such that . We denote by the (unique) value such that . On Fig. 5, when .
Fig. 5.
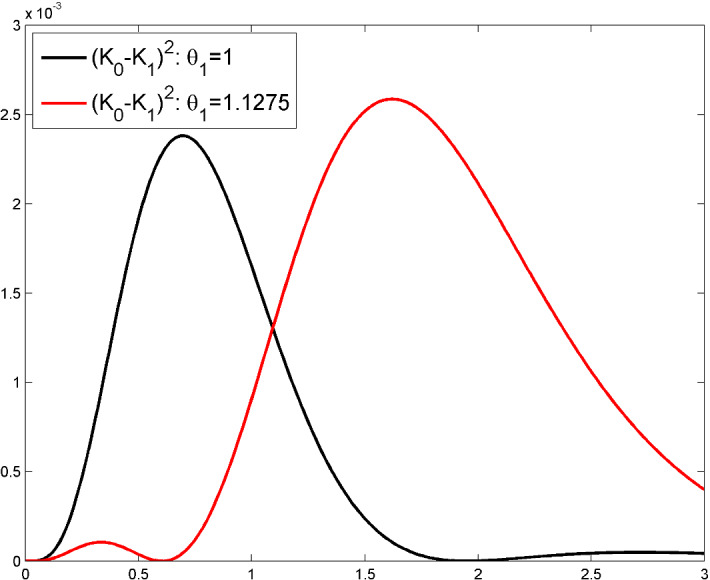
for and with two different values of
A simplified problem with an explicit optimal solution
Consider the extreme case where defined by
| 15 |
Note that for any ; we can thus restrict our attention to for the maximisation of defined by (13); that is, we consider
Theorem 2
When and is large enough to contain a regular d simplex with edge length , any measure allocating weight at each vertex of such a simplex maximises , and .
Proof
Since when is continuous with respect to the Lebesgue measure on , we can restrict our attention to measures without any continuous component. Assume that , with for all i and , . Consider the graph having the as vertices, with an edge (i, j) connecting and if and only if . We have
and Theorem 1 of Motzkin and Straus (1965) implies that is maximum when is uniform on the maximal complete subgraph of . The maximal achievable order is , obtained when the are the vertices of a regular simplex in with edge length . Motzkin and Straus (1965) also indicate in their Theorem 1 that . This is easily recovered knowing that is fully connected with order . Indeed, we then have
which is maximum when all equal .
Optimal designs for
The optimal designs of Theorem 2 are natural candidates for being optimal when we return to the case of interest . In the light of Theorem 1, for a given probability measure on , we consider the function
which must satisfy for all when is optimal. For an optimal measure as in Theorem 2, with support forming a regular d-simplex, we have
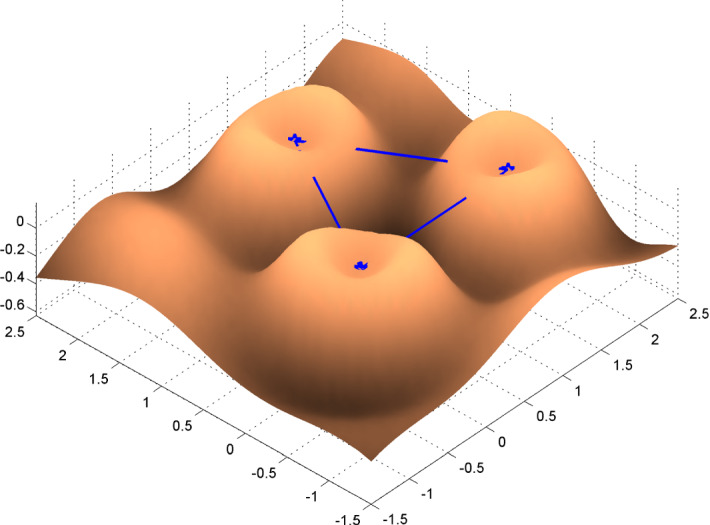
One can readily check that for all i (as for and ). Moreover, since is differentiable everywhere except possibly at zero, when the gradient of equals zero at each . However, these stationary points may sometimes correspond to local minima—a situation when of course is not optimal. The left panel of Fig. shows an illustration () for , and being the Matérn 5/2 kernel . The measure is supported at the vertices of the equilateral triangle (indicated in blue on the figure), with (the value where is maximum). Here the correspond to local minima of , is not differentiable at zero but so that is differentiable.
When , approaches the (discontinuous) function , suggesting that may become close to being optimal for when p is large enough. However, when is large, is never truly optimal, no matter how large p is. Indeed, suppose that contains a point corresponding to the symmetric of a vertex of the simplex defining the support of with respect to the opposite face of that simplex. Direct calculation gives
The right panel of Fig. 6 shows an illustration for and being the Matérn 3/2 and Matérn 5/2 kernels and , respectively. The measure is supported at the vertices of the equilateral triangle with vertices with now . At the point , symmetric to , indicated in red on the figure, we have
| 16 |
where the second equality follows from for all , implying that is not optimal. Another, more direct, proof of the non-optimality of is to consider the measure that sets weights at all and weights at and its symmetric . Direct calculation gives
The first term on the right-hand side comes from the d vertices , , each one having weight and being at distance of all other vertices, those having total weight . The second term comes from the two symmetric points and , each one with weight . Each of these two points is at distance from d vertices with weights and at distance L of the other opposite point with weight . We get after simplification
showing that is not optimal. Note that, for symmetry reasons, the design is not optimal for large enough . The determination of a truly optimal design seems very difficult. In the simplified problem of Sect. 5.1, where the criterion is based on the function defined by (15), the measures and supported on and points, respectively, have the same criterion value for all .
Fig. 6.

Surface plot of (), the support of corresponds to the vertices of the equilateral triangle in blue. Left: and (), ; Right: , (), ; the red point is the symmetric of the origin (0, 0) with respect to the opposite side of the triangle. (Color figure online)
Although is not optimal, since (as takes its maximum value 1 for ), (16) suggests that may be only marginally suboptimal when p is large enough. Moreover, as the right panel of Fig. 6 illustrates, a design supported on a regular simplex is optimal provided that is small enough and p is large enough to make concave at each (for symmetry reasons, we only need to check concavity at one vertex). In fact, is sufficient. Indeed, assuming that and that is twice differentiable everywhere, with second-order derivative , except possibly at zero, direct calculation gives
which is negative-definite (since , being maximal at ). The right panel of Fig. 6 gives an illustration. Note that on the left panel, and the correspond to local minimas of . Figure shows a plot of for and and being the Matérn 3/2 and Matérn 5/2 kernels and , respectively, suggesting that the form of optimal designs may be in general quite complicated.
Fig. 7.
Surface plot of (), the support of corresponds to the vertices of the equilateral triangle in blue: , (), . (Color figure online)
A numerical example
Exact designs
In this section, we consider numerical evaluations of designs resulting from the prediction-based and distance-based criteria. Here, the rival models are the isotropic versions of the covariance kernels used in Example 3 (Sect. 3.2) for the design space , discretised at equally spaced points in each dimension. For an agreement on the setting of correlation lengths in both kernels, we have applied a minimisation procedure. Specifically, we have taken in and adjusted the parameter in the second kernel minimising each of the distance-based criteria for the design corresponding to the full grid. This resulted in , 1.0285, 1.0955 and 1.3403, respectively, for and . We have finally chosen , which seems to be compatible with the above values.
The left panel in Fig. shows the plot of the two Matérn covariance functions at the assumed parameter values. This plot illustrates the similarity of the kernels which we aim to discriminate. The right panel in the figure refers to the plot of the absolute difference between the covariance kernels. The red line corresponds to the distance where the absolute difference between them is maximal. This is denoted by , which is equal to in this case.
The sequential approach is the only case where the observations corresponding to the previous design points are used in the design construction. In our example, we simulate the data according to the assumed model. We use this information to estimate the parameter setting at each step. The (box)plots of the maximum likelihood (ML) estimates and of the inverse correlation lengths and of and , respectively, are presented in Fig. . This refers to the case where the first kernel, Matérn 3/2, is the data generator. The estimates converge to their null value, , drawn as a red dashed line in the left panel of Fig. 9, as expected due to the consistency of the ML estimator in this case. For the second kernel to be similar to the first one (i.e., less smooth), the estimates have increased (see the right panel). The decrease of the correlation length causes the covariance kernel to drop faster as a function of distance. We defer from presenting the opposite case (where the Matérn 5/2 is the data generator), which is similar.
Fig. 9.

Maximum likelihood estimates of the correlation lengths in Matérn kernels. (Color figure online)
Apart from the methods applied in Sect. 4, we have considered some other static approaches for discrimination. -optimal design is a natural candidate that can be applied in the distance-based fashion. For -optimality, we require the general form of the Matérn covariance kernel, which is based on the modified Bessel function of the second kind (denoted by ). It is given by
| 17 |
Smoothness, , is considered as the parameter of interest, while the correlation length is assumed as nuisance. The first off-diagonal element in the information matrix, associated with the estimation of parameters , is
| 18 |
see, e.g., Eq. (6.19) in Müller (2007). The other elements in the information matrix are calculated similarly. We have used the supplementary material of Lee et al. (2018) to compute the partial derivatives of the Matérn covariance kernel. Finally, the -criterion is
| 19 |
where is the element of the information matrix corresponding to the nuisance parameter (i.e., in both partial derivatives are calculated with respect to ). In the examples to follow we consider local -optimal design; that is, the parameters and are set at given values.
From a Bayesian perspective, models can be discriminated optimally when the difference between the expected entropies of the prior and the posterior model probabilities is maximised. This criterion underlies a famous sequential procedure put forward by Box and Hill (1967) and Hill and Hunter (1969). Since such criteria typically cannot be computed analytically, several bounds were derived. The upper bound proposed by Box and Hill (1967) is equivalent to the symmetric Kullback-Leibler divergence . Hoffmann (2017) derives a lower bound based on a lower bound for the Kullback–Leibler divergence between a mixture of two normals, which is given by Eq. (A3) and is denoted by . Here, we assume equal prior probabilities. A more detailed account of Bayesian design criteria and their bounds is given in Appendix A.
Table collects simulation results for the given example. We have included the sequential procedure (4) as a benchmark for orientation. For all other approaches the true parameter values are used in the covariance kernels. Concerning static (distance-based) designs based on maximisation of , for each design size considered we first built a an incremental design and then used a classical exchange-type algorithm to improve it. These designs are thus not necessarily nested, i.e., for .
Each design of size n was then evaluated by generating independent sets of n observations generated with the assumed true model, evaluating the likelihood functions for these sets of observations for both models, and then deciding for each set of observations which model has the higher likelihood value. The hit rate is the fraction of sets of observations where the assumed true model has the higher likelihood value. The procedure was repeated by assuming the other model to be the true one. The two hit rates are then averaged and stated in Table 1, which contains the results for all the criteria and design sizes we considered. For the special case of the sequential construction (4), the design path depends on the observations generated at the previously selected design points; that is, unlike for the other criteria, for a given design size n each random run produces a different design. To compute the hit rates for a particular n we used independent runs of the experiment.
Table 1.
Comparison of average hit rates in different methods for the first numerical example
| Average hit rate | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Design size | 5 | 6 | 7 | 8 | 9 | 10 | 20 | 30 | 40 | 50 |
| Sequential (4) | 0.500 | 0.535 | 0.540 | 0.595 | 0.570 | 0.640 | 0.695 | 0.715 | 0.740 | 0.770 |
| 0.505 | 0.500 | 0.530 | 0.525 | 0.505 | 0.510 | 0.520 | 0.535 | 0.585 | 0.635 | |
| 0.520 | 0.545 | 0.575 | 0.585 | 0.615 | 0.650 | 0.785 | 0.875 | 0.900 | 0.910 | |
| 0.520 | 0.545 | 0.575 | 0.585 | 0.615 | 0.650 | 0.785 | 0.870 | 0.915 | 0.925 | |
| 0.580 | 0.625 | 0.670 | 0.795 | 0.925 | 0.950 | |||||
| 0.525 | 0.520 | 0.555 | 0.540 | 0.550 | 0.610 | 0.725 | 0.890 | 0.910 | 0.920 | |
| 0.525 | 0.520 | 0.555 | 0.540 | 0.550 | 0.610 | 0.715 | 0.860 | 0.890 | 0.910 | |
| 0.580 | 0.625 | 0.670 | 0.795 | 0.895 | 0.925 | |||||
| 0.610 | 0.700 | 0.795 | 0.895 | 0.940 | ||||||
| 0.540 | 0.575 | 0.590 | 0.620 | 0.650 | 0.675 | 0.850 | 0.855 | 0.925 | ||
Bold numbers indicate the highest average hit rate achieved for each design size
The hit rates reported in Table 1 reflect the discriminatory power of the corresponding designs. One can observe that and as expected are outperforming in terms of hit rates. The Bayesian lower bound criterion is similar to the symmetric . The sequential design strategy (4) does not behave as well as the outperforming ones. It is, however, the realistic scenario that one might consider in applications as it does not assume knowledge of the kernel parameters. The effect of this knowledge can thus be partially calibrated for by comparing the first line against the other criteria.
Optimal design measure for
Theorem 1 also allows the use of approximate designs as it presents a necessary condition for optimality of the family of criteria . This is more extensively discussed in the previous section. Here we present the numerical results for two specific cases of and . To reach a design which might be numerically optimal (or at least nearly optimal), we have applied the Fedorov–Wynn algorithm (Fedorov 1971; Wynn 1970) on a dense regular grid of candidate points.
Numerical results show that for very small p (e.g., ) explicit optimal measures are hard to derive. The left panel in Fig. presents the measure obtained for . To construct , we have first calculated an optimal design on a dense grid by applying 1000 iterations of the Fedorov–Wynn algorithm (see the comment following Theorem 1); the design measure obtained is supported on 9 grid points. We then applied a continuous optimisation algorithm (library NLopt (Johnson 2021) through its R-interface nloptr) initialised at this 9-point design. The 9 support points of the resulting design measure are independent of the grid size; they receive unequal weights, proportional to the disk areas on Fig. 10-left. Any translation or rotation of yields the same value of .
Fig. 10.

Left: The optimal measure for . Right: The optimal measure for . (Color figure online)
As the order p increases, we eventually reach an optimal measure with only three support points and equal weights. The right panel in Fig. 10 corresponds to the optimal design measure computed for . This has, similarly as before, resulted from application of a continuous optimisation initialised at an optimal 3-point design calculated with the Fedorov–Wynn algorithm on a grid. This optimal design measure has three support points, drawn as blue dots, with equal weights 1/3 represented by the areas of the red disks. The blue line segments between every two locations have length , reflecting the ideal interpoint distance (see the right panel of Fig. 8), in agreement with corresponding discussions in Sect. 5. Also here the optimal designs are rotationally and translationally invariant, and thus any design of such type is optimal as long as the design region is large enough to fit it.
Fig. 8.

Left: Plot of the Matérn covariance functions at the assumed parameter setting. Right: . (Color figure online)
Conclusions
In this paper we have considered the design problem for the discrimination of Gaussian process regression models. This problem differs considerably from the well-treated one in standard regression models and thus offers a multitude of challenges. While the KL-divergence is a straightforward criterion, it comes with the price of being computationally demanding and lacking convenient simplifications such as design measures. We have therefore introduced a family of criteria that allow such a simplification at least in special cases and have investigated its properties. We have also compared the performance of these and other potential criteria on several examples and see that KL-divergence can be effectively replaced by simpler criteria without much loss in efficiency. In particular designs based on the Fréchet-distance between covariance kernels seem to be competitive. Results from the approximate design computations indicate that for classical isotropic kernels, designs with support points placed at the vertices of a simplex of suitable size are optimal for distance-based criteria for a large enough p when the design region is small enough and are marginally suboptimal otherwise.
As a next step, it would be interesting to investigate the properties of the discrimination designs under parameter uncertainty, for example by considering minimax or Bayesian designs.
A referee has indicated that our techniques could be used for discriminating the intricately convoluted covariances stemming from deep Gaussian processes (as defined in Damianou and Lawrence (2013)) from more conventional ones. This is an interesting issue of high relevance for computer simulation experiments that certainly needs to be explored in the future.
Acknowledgements
This work was partly supported by project INDEX (INcremental Design of EXperiments) ANR-18-CE91-0007 of the French National Research Agency (ANR) and I3903-N32 of the Austrian Science Fund (FWF). Note that refereeing for this article was organized outside of the editorial manager system by the S.I. editor such that the chief editor (one of the coauthors) was not able to identify the referees. We are grateful to the two referees for their careful reading and their suggestions, which led to an improvement of the paper.
Appendix A: Notes on Box–Hill–Hunter Bayesian criteria for model discrimination between Gaussian random fields
Chapter 5 of Hoffmann (2017) contains an overview of Bayesian design criteria for model discrimination and some useful bounds on them. We assume there are M models . The most common Bayesian design criterion for model discrimination has the following form:
| A1 |
where the data are observed at the design , denotes the prior and the posterior model probability of model and is the marginal distribution of with respect to the models. Hence, this criterion is the (expected) difference of the model entropy and the conditional model entropy (conditional on the observations). The posterior model probability is defined by
where is the likelihood of model (marginalised over the parameters), and is given by
The first term in (A1) does not depend on the design and can therefore be ignored.
A common alternative formulation of criterion (A1) is the one adopted by Box and Hill (1967) and Hill and Hunter (1969), which will henceforth be called Box-Hill-Hunter (BHH) criterion:
| A2 |
In our case, if we assume point priors for the kernel parameters, we have
where is the mean vector of model i at design , is the kernel matrix of model i with elements given by , and is the normal pdf with mean vector and variance-covariance matrix .
For example, for a static design involving n design points, we set and assume that for each design . The model probabilities would just be the prior model probabilities before having collected any observations.
In a sequential design setting, where n observations have already been observed at locations and we want to find the optimal design point x where to collect our next observation, we have and set to the conditional mean and to the conditional variance , where , see Sect. 3.1. The prior model probabilities would have to be set to the posterior model probabilities given the already observed data:
It follows that is a mixture of normal distributions. The criterion representations (A1) and (A2) cannot be computed directly. However, several bounds have been developed for the criterion, the most famous being the classic upper bound derived by Box and Hill (1967).
Appendix A.1: Upper bound
The upper bound has the following form (see also Hoffmann (2017, Thm. 5.2, p. 168)):
For , the formula simplifies to
This is equivalent to the symmetric Kullback–Leibler divergence that we use as the criterion (with and ).
Appendix A.2: Lower bound
Hershey and Olsen (2007, Sect. 7) derive a lower bound for the Kullback–Leibler divergence between a mixture of two normals, see also Hoffmann (2017, Thm. 5.4 and Cor. 5.5, pp. 173–174). This result is then used by Hoffmann (2017) to find a lower bound for the BHH criterion (Hoffmann 2017, Thm. 5.9, p. 178). This lower bound is given by
where
For , which is the relevant case for our setup, we get
| A3 |
where , which we are also using to compute designs in Sect. 6.1 (again with and ).
Funding Information
Open access funding provided by Austrian Science Fund (FWF).
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Elham Yousefi, Email: elham.yousefi@jku.at.
Luc Pronzato, Email: pronzato@i3s.unice.fr.
Markus Hainy, Email: markus.hainy@jku.at.
Werner G. Müller, Email: werner.mueller@jku.at
Henry P. Wynn, Email: h.wynn@lse.ac.uk
References
- Atkinson AC, Fedorov VV. The design of experiments for discriminating between two rival models. Biometrika. 1975;62(1):57–70. doi: 10.1093/biomet/62.1.57. [DOI] [Google Scholar]
- Box GEP, Hill WJ. Discrimination among mechanistic models. Technometrics. 1967;9(1):57–71. doi: 10.2307/1266318. [DOI] [Google Scholar]
- Damianou A, Lawrence ND (2013) Deep Gaussian Processes. In: Proceedings of the sixteenth international conference on artificial intelligence and statistics. PMLR, pp 207–215. https://proceedings.mlr.press/v31/damianou13a.html
- Dowson DC, Landau BV. The Fréchet distance between multivariate normal distributions. J Multivar Anal. 1982;12(3):450–455. doi: 10.1016/0047-259X(82)90077-X. [DOI] [Google Scholar]
- Fedorov VV. The design of experiments in the multiresponse case. Theory Probab Appl. 1971;16(2):323–332. doi: 10.1137/1116029. [DOI] [Google Scholar]
- Gramacy RB. Surrogates: Gaussian process modeling, design, and optimization for the applied sciences. Boca Raton: Chapman and Hall/CRC; 2020. [Google Scholar]
- Heirung TAN, Santos TLM, Mesbah A. Model predictive control with active learning for stochastic systems with structural model uncertainty: online model discrimination. Comput Chem Eng. 2019;128:128–140. doi: 10.1016/j.compchemeng.2019.05.012. [DOI] [Google Scholar]
- Hershey JR, Olsen PA (2007) Approximating the Kullback Leibler divergence between Gaussian mixture models. In: 2007 IEEE international conference on acoustics, speech and signal processing—ICASSP ’07, pp IV–317–IV–320, 10.1109/ICASSP.2007.366913
- Hill WJ, Hunter WG. A note on designs for model discrimination: variance unknown case. Technometrics. 1969;11(2):396–400. doi: 10.1080/00401706.1969.10490695. [DOI] [Google Scholar]
- Hino H (2020) Active learning: problem settings and recent developments. arxiv:2012.04225
- Hoffmann C (2017) Numerical aspects of uncertainty in the design of optimal experiments for model discrimination. PhD thesis, Ruprecht-Karls-Universität Heidelberg. 10.11588/heidok.00022612
- Hunter W, Reiner A. Designs for discriminating between two rival models. Technometrics. 1965;7(3):307–323. doi: 10.1080/00401706.1965.10490265. [DOI] [Google Scholar]
- Johnson SG (2021) The NLopt nonlinear-optimization package. http://github.com/stevengj/nlopt
- Karvonen T (2022) Asymptotic bounds for smoothness parameter estimates in Gaussian process interpolation. arxiv:2203.05400
- Karvonen T, Oates C (2022) Maximum likelihood estimation in Gaussian process regression is ill-posed. arxiv:2203.09179
- Karvonen T, Wynne G, Tronarp F, et al. Maximum likelihood estimation and uncertainty quantification for Gaussian process approximation of deterministic functions. SIAM/ASA J Uncertain Quantif. 2020;8(3):926–958. doi: 10.1137/20M1315968. [DOI] [Google Scholar]
- Kiefer J. General equivalence theory for optimum designs (approximate theory) Ann Stat. 1974;2(5):849–879. doi: 10.1214/aos/1176342810. [DOI] [Google Scholar]
- Kullback S, Leibler RA. On information and sufficiency. Ann Math Stat. 1951;22(1):79–86. doi: 10.1214/aoms/1177729694. [DOI] [Google Scholar]
- Lee XJ, Hainy M, McKeone JP, et al. ABC model selection for spatial extremes models applied to South Australian maximum temperature data. Comput Stat Data Anal. 2018;128:128–144. doi: 10.1016/j.csda.2018.06.019. [DOI] [Google Scholar]
- López-Fidalgo J, Tommasi C, Trandafir PC. An optimal experimental design criterion for discriminating between non-normal models. J R Stat Soc. 2007;69(2):231–242. doi: 10.1111/j.1467-9868.2007.00586.x. [DOI] [Google Scholar]
- Motzkin TS, Straus EG. Maxima for graphs and a new proof of a theorem of Turán. Can J Math. 1965;17:533–540. doi: 10.4153/CJM-1965-053-6. [DOI] [Google Scholar]
- Müller WG. Collecting spatial data: optimum design of experiments for random fields. 3. Berlin: Springer; 2007. [Google Scholar]
- Olofsson S, Deisenroth MP, Misener R (2018) Design of experiments for model discrimination using Gaussian process surrogate models. In: Eden MR, Ierapetritou MG, Towler GP (eds) 13th International symposium on process systems engineering (PSE 2018), computer aided chemical engineering, vol 44. Elsevier, pp 847–852, 10.1016/B978-0-444-64241-7.50136-1
- Pronzato L, Wynn HP, Zhigljavsky A. Bregman divergences based on optimal design criteria and simplicial measures of dispersion. Stat Pap. 2019;60(2):545–564. doi: 10.1007/s00362-018-01082-8. [DOI] [Google Scholar]
- Sauer A, Gramacy RB, Higdon D. Active learning for deep Gaussian process surrogates. Technometrics. 2022 doi: 10.1080/00401706.2021.2008505. [DOI] [Google Scholar]
- Schwaab M, Luiz Monteiro J, Carlos Pinto J. Sequential experimental design for model discrimination: taking into account the posterior covariance matrix of differences between model predictions. Chem Eng Sci. 2008;63(9):2408–2419. doi: 10.1016/j.ces.2008.01.032. [DOI] [Google Scholar]
- Stein M. Interpolation of spatial data: some theory for kriging. Heidelberg: Springer; 1999. [Google Scholar]
- Wynn HP. The sequential generation of -optimum experimental designs. Ann Math Stat. 1970;41(5):1655–1664. doi: 10.1214/aoms/1177696809. [DOI] [Google Scholar]