

Abstract
Artificial intelligence (AI) and data sharing go hand in hand. In order to develop powerful AI models for medical and health applications, data need to be collected and brought together over multiple centers. However, due to various reasons, including data privacy, not all data can be made publicly available or shared with other parties. Federated and swarm learning can help in these scenarios. However, in the private sector, such as between companies, the incentive is limited, as the resulting AI models would be available for all partners irrespective of their individual contribution, including the amount of data provided by each party. Here, we explore a potential solution to this challenge as a viewpoint, aiming to establish a fairer approach that encourages companies to engage in collaborative data analysis and AI modeling. Within the proposed approach, each individual participant could gain a model commensurate with their respective data contribution, ultimately leading to better diagnostic tools for all participants in a fair manner.
Keywords: federated learning, machine learning, medical data, fairness, data sharing, artificial intelligence, development, artificial intelligence model, applications, data analysis, diagnostic tool, tool
Introduction
Due to its impressive ability to process large amounts of data quickly and identify patterns and trends that may not be immediately apparent to humans, artificial intelligence (AI) has the potential to greatly assist society in a wide range of sectors, including health care [1,2]. In medicine, for example, AI has proven to be extremely helpful in the identification of potential risk factors and diagnostic targets for diseases, the discovery of new drugs and vaccines, and the development of tailored treatment plans [3,4]. However, the reliability and generalizability of an AI model depend heavily on large amounts of training data that are diverse and representative of the population [5]. An effective strategy for achieving this is to collect data from multiple centers [6]. Thus, data sharing between parties is a crucial prerequisite of any AI development.
Deciding what to do with your data is always context specific. Your goals determine the most appropriate way to use your data and whether data can be shared with third parties. This involves balancing the benefits and potential harm in light of your context. If you, for example, operate within a public administration, your organization might aim at creating value primarily for all current member inhabitants, with or without a wider perspective on other parts of the world and on future challenges. Now, if you operate in a for-profit company, the primary goal might be centered around achieving economic success, whereas in nongovernmental organizations, the organization may prioritize a political, societal, or environmental agenda. Every setting has its own goals, some explicitly stated and some silently present, including ethical and other generic considerations, all with the power to guide decisions. As long as the data are retained within the organization's boundaries, the organization is in control of what its data are actually used for. Conflicts about opposing goals can be resolved internally, maximizing the potential to do good in a context-specific meaning.
As we aim to maximize the potential of using and reusing data by sharing it with others, we find ourselves traversing complex terrain. Sharing data can be approached in various ways along a continuum, ranging from the most constricted, such as running analyses on the data and only sharing condensed bits of information (eg, aggregate or summary measures or model parameters), to the least constricted, such as providing full access as open data, for anyone to use at any time and for any application. Every organization may judge, based on their goals and permissions, which part of their own data to share with whom and in what way. For example, achieving public administration’s goals usually includes sharing data as openly as possible for most data entities in their primary ownership, by that, maximizing the potential for use or reuse of that data for the benefit of all [7]. On the other hand, for-profit companies usually refrain from sharing their own business-related data, as the reuse of such information by competing companies might negatively impact their own economic success.
Sharing data can help us gather a significant amount of data to train robust and highly predictive AI models, which could have a profound impact on society, such as improving medical diagnoses for patients. In health care applications, the implementation of health information exchange solutions has facilitated the efficient sharing of health data across different organizations [8]. Health information exchange aims to enhance clinical decision-making processes and reduce mortality by aggregating health information from multiple entities [9]. This exchange of information can occur either internally, that is, within a single organization, or externally among multiple organizations [10]. Numerous factors come into play when organizations consider sharing their data with external parties, which include net revenues and patient care quality [11]. Nevertheless, sharing data, especially clinical data, entails considerable challenges from a privacy standpoint and necessitates compliance with regulatory frameworks such as the General Data Protection Regulation. To address these challenges, new approaches like federated learning (FL) [12] and swarm learning (SL) [13] have emerged in recent years. These methods allow the training of machine learning models collaboratively on distributed devices without compromising sensitive data. This optimizes the use of clinical data in AI without sharing any patient data.
In FL, a central system governs the learning process, while in SL, the parties communicate directly with each other without a central coordinator [14] (Figure 1). By using these techniques, each collaborating partner can train a separate AI model locally on their available data, and then these models can be combined into a privacy-preserving global AI model. To enhance privacy further, FL and SL can be combined with other privacy techniques, such as homomorphic encryption or secure multiparty computation. FL and SL have already been used in several studies [15-17].
Figure 1.
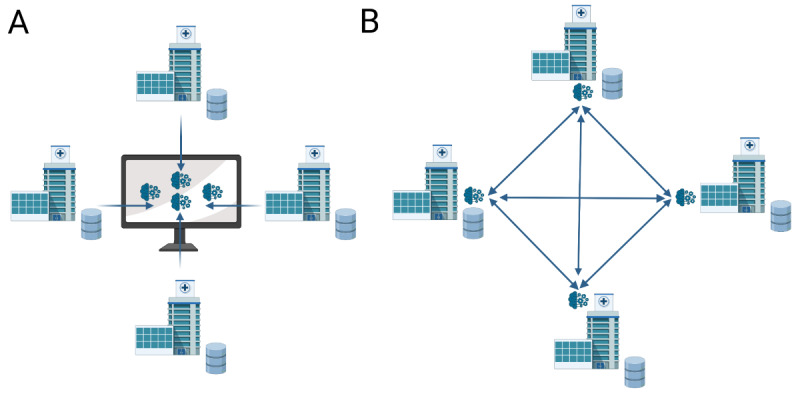
Federated and swarm learning. (A) Federated approach. (B) Swarm learning approach. Created by Biorender.com
Sharing Data With Shared Benefits
In specific circumstances, collaborative efforts and sharing data can be advantageous for all parties, even when they are competing companies. This practice of collaborating with competitors, known as co-opetition, is especially helpful for firms seeking to innovate as they allow for pooling resources to reach a goal that an individual firm may not be able to reach on its own. Additionally, co-opetition can lead to greater efficiency and economies of scale [18]. However, it is important to acknowledge that the benefits of collaboration may be imbalanced among all parties involved. Therefore, it is desirable to produce a mechanism to encourage companies to participate in collaborative data analyses, while ensuring a fair balance of input and benefits among all participants. Collecting data and training AI models require investments in terms of data infrastructure as well as IT infrastructure [19]. From an economic perspective, data sharing directly impacts the efficiency and effectiveness of technology. In general, access to a significant amount of high-quality data helps to ensure that AI algorithms are unbiased and capable of making accurate predictions. This, in turn, leads to better decision-making and ultimately to an overall improvement in the economic performance of the company. However, collecting diverse and representative data can be costly, especially if it involves acquiring additional resources and dedicating more time to the process. Therefore, it is important to weigh the benefits of using a particular data set against the costs of collecting and using it. The weighing can help to ensure that data are used in a cost-effective and efficient manner. From an economic perspective, fairness could be defined as receiving a return commensurate with the investments made. Therefore, when it comes to AI, it would be desirable for organizations to obtain AI models that perform proportionally to the amount of cost they incur. Generally, the process of data collection, preparation, and analysis is not a trivial one [20,21]. Many organizations invest a considerable amount of time and financial resources into acquiring, managing, and analyzing data which then could be used for further tasks such as training AI models. If several organizations cooperate with each other to develop better AI models, then it is reasonable that those that provide more resources toward the collaboration receive relatively better models than their counterparts. This point can be best illustrated in the area of FL and SL. Although technological advances have accelerated the creation of huge amount of data in many fields, some organizations still lack sufficient data to develop accurate AI models. FL and SL can address such data limitation problems by enabling multiple organizations to collaboratively train AI models that typically outperform models trained individually within each organization.
Example
Overview
In this section, we discuss a case scenario to examine our offered approach.
Problem Description
Imagine 3 companies offering the same products or services, with different data collection and management processes, and they aim to develop AI systems, for example, recommender systems, to enhance their revenue. Suppose, for instance, the first company has a basic process for data management with low investments and therefore a lower revenue from their AI system. The second company has optimized its data management with more investments, thus gaining a higher revenue. Finally, suppose the third company has invested the most in data management, obtaining the highest revenue among the 3. If the 3 companies decide to use FL or SL to maximize their revenue, the first company would benefit the most with the highest gain-to-invest ratio, and the third company would benefit the least with the lowest gain-to-invest ratio. This would not be fair from an economic point of view. Based on the economic notion of fairness, we identify an FL or SL system as fair if nodes receive models commensurate with their contributions to the learning process. This cannot be accomplished with a typical FL or SL system in which all nodes ultimately receive the same model. Instead, an alternative framework is necessary to allow nodes to obtain personalized models based on their contributions.
Potential Solution
In order to investigate this problem, we simulated an SL network in which nodes collaboratively train personalized machine learning models with performance levels proportional to their contributions. In this simulation, we define a node’s contribution as the number of data points they provide for the learning process. Since having more data typically lead to better models, it is reasonable to assume that nodes contributing a larger amount of data play a more significant role in the training process. In this example, we assume that only informative data are used and do not take into account any fraudulent approaches where useless data are provided by a client. The detection of fraudulent behavior in collaborative work through computational methods is a subject for further investigation and is outside the scope of this study.
For this simulation, we considered 3 nodes, each with a distinct number of data samples. The nodes use an SL system based on random forest [22], which is a supervised machine learning technique for classification and regression problems. We used an example data set on maternal health for which the goal is to develop models capable of predicting the degree of risk during pregnancy based on associated risk factors [23]. To investigate the difference in contributions, we divided the data set comprising 1014 samples among 3 nodes using a distribution ratios of 0.1, 0.3, and 0.6, respectively. We performed a 10-fold cross-validation and repeated the experiment 100 times with different sample distributions among the nodes but maintaining the same contribution ratio, thereby eliminating the chance of any variations in data quality at each node. We also repeated the same experiment for the case of individual training, that is, with nodes training their models locally without any collaboration. Figure 2 shows the results of the simulation. When using a typical SL approach, the resulting model will be the same for each node, thus, the performance gain is inverse to the data contribution. In the fair SL approach, the party contributing the majority of the data (the third node) gets the best final model, while all others get models that outperform those trained only on their local data. It is evident that through collaboration, nodes acquire models with a better performance compared to those trained locally. Furthermore, the results show that, in the fair scenario, nodes with greater contributions obtain models with better performance on average, whereas in the original SL approach, all nodes get the same final model, and the gains in performance are inversely proportional to their data contribution.
Figure 2.
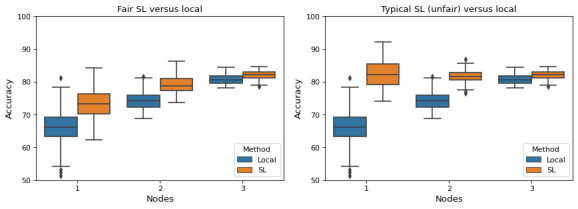
Accuracies distribution for local and SL models across nodes. Node 1 contributes the least proportion of data, whereas node 3 contributes the largest proportion. Left: fair scenario, in which models are commensurate with contributions. Right: unfair scenario, in which all nodes receive the same model. SL: swarm learning.
Discussion
Based on the results, we argue that within such a fair SL framework, first, organizations with more resources are more likely to cooperate with other parties for a collaborative learning task since the payoff will be fair. Second, organizations providing fewer resources still benefit from cooperation with other parties and are still likely to take part in the task. In conclusion, using fair and diverse data sets for training AI is essential for achieving efficient and effective decision-making from an economic perspective. Ensuring that the training data are representative of the population for which it will be used, balancing the costs and benefits of data, and complying with regulations and guidelines can help to promote the responsible and ethical use of AI in the economic sphere.
Abbreviations
- AI
artificial intelligence
- FL
federated learning
- SL
swarm learning
Footnotes
Authors' Contributions: MT contributed to literature search, figures, study design, data collection, data analysis, data interpretation, writing—original draft, methodology, and software. LG contributed to literature search, and writing—review and editing. AR contributed to literature search, writing, methodology, and writing—original draft. ML contributed to writing—review and editing. DH contributed to literature search, figures, study design, conceptualization, funding acquisition, project administration, supervision, and writing—review and editing.
Conflicts of Interest: None declared.
References
- 1.Luján-García JE, Yáñez-Márquez C, Villuendas-Rey Y, Camacho-Nieto O. A transfer learning method for pneumonia classification and visualization. Appl Sci. 2020;10(8):2908. doi: 10.3390/app10082908. https://www.mdpi.com/2076-3417/10/8/2908 . [DOI] [Google Scholar]
- 2.Schwarz J, Heider D. GUESS: projecting machine learning scores to well-calibrated probability estimates for clinical decision-making. Bioinformatics. 2019;35(14):2458–2465. doi: 10.1093/bioinformatics/bty984. https://academic.oup.com/bioinformatics/article/35/14/2458/5216311?login=false .5216311 [DOI] [PubMed] [Google Scholar]
- 3.Fatima M, Pasha M. Survey of machine learning algorithms for disease diagnostic. J Intell Learn Syst Appl. 2017;9(1):1–16. doi: 10.4236/jilsa.2017.91001. https://www.scirp.org/journal/paperinformation.aspx?paperid=73781 . [DOI] [Google Scholar]
- 4.Thomas S, Abraham A, Baldwin J, Piplani S, Petrovsky N. Artificial intelligence in vaccine and drug design. Methods Mol Biol. 2022;2410:131–146. doi: 10.1007/978-1-0716-1884-4_6. [DOI] [PubMed] [Google Scholar]
- 5.Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. Commun ACM. 2017;60(6):84–90. doi: 10.1145/3065386. [DOI] [Google Scholar]
- 6.Chalkidou A, Shokraneh F, Kijauskaite G, Taylor-Phillips S, Halligan S, Wilkinson L, Glocker B, Garrett P, Denniston AK, Mackie A, Seedat F. Recommendations for the development and use of imaging test sets to investigate the test performance of artificial intelligence in health screening. Lancet Digit Health. 2022;4(12):e899–e905. doi: 10.1016/S2589-7500(22)00186-8. https://linkinghub.elsevier.com/retrieve/pii/S2589-7500(22)00186-8 .S2589-7500(22)00186-8 [DOI] [PubMed] [Google Scholar]
- 7.Mons B, Neylon C, Velterop J, Dumontier M, da Silva Santos LOB, Wilkinson MD. Cloudy, increasingly FAIR; revisiting the FAIR data guiding principles for the European Open Science Cloud. Inf Serv Use. 2017;37(1):49–56. doi: 10.3233/isu-170824. https://content.iospress.com/articles/information-services-and-use/isu824 . [DOI] [Google Scholar]
- 8.Rudin RS, Motala A, Goldzweig CL, Shekelle PG. Usage and effect of health information exchange: a systematic review. Ann Intern Med. 2014;161(11):803–811. doi: 10.7326/M14-0877.1983413 [DOI] [PubMed] [Google Scholar]
- 9.Kierkegaard P, Kaushal R, Vest JR. Applications of health information exchange information to public health practice. AMIA Annu Symp Proc. 2014;2014:795–804. https://europepmc.org/abstract/MED/25954386 . [PMC free article] [PubMed] [Google Scholar]
- 10.Esmaeilzadeh P, Sambasivan M. Health Information Exchange (HIE): a literature review, assimilation pattern and a proposed classification for a new policy approach. J Biomed Inform. 2016;64:74–86. doi: 10.1016/j.jbi.2016.09.011. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(16)30124-1 .S1532-0464(16)30124-1 [DOI] [PubMed] [Google Scholar]
- 11.Miller AR, Tucker C. Health information exchange, system size and information silos. J Health Econ. 2014;33:28–42. doi: 10.1016/j.jhealeco.2013.10.004.S0167-6296(13)00136-7 [DOI] [PubMed] [Google Scholar]
- 12.McMahan B, Moore E, Ramage D, Hampson S, y Arcas BA. Communication-efficient learning of deep networks from decentralized data. Artif Intell Stat. 2017;54:1273–1282. PMLR https://proceedings.mlr.press/v54/mcmahan17a?ref=https://githubhelp.com. [Google Scholar]
- 13.Warnat-Herresthal S, Schultze H, Shastry KL, Manamohan S, Mukherjee S, Garg V, Sarveswara R, Händler K, Pickkers P, Aziz NA, Ktena S, Tran F, Bitzer M, Ossowski S, Casadei N, Herr C, Petersheim D, Behrends U, Kern F, Fehlmann T, Schommers P, Lehmann C, Augustin M, Rybniker J, Altmüller J, Mishra N, Bernardes JP, Krämer B, Bonaguro L, Schulte-Schrepping J, De Domenico E, Siever C, Kraut M, Desai M, Monnet B, Saridaki M, Siegel CM, Drews A, Nuesch-Germano M, Theis H, Heyckendorf J, Schreiber S, Kim-Hellmuth S, COVID-19 Aachen Study (COVAS) Nattermann J, Skowasch D, Kurth I, Keller A, Bals R, Nürnberg P, Rieß O, Rosenstiel P, Netea MG, Theis F, Mukherjee S, Backes M, Aschenbrenner AC, Ulas T, Deutsche COVID-19 Omics Initiative (DeCOI) Breteler MMB, Giamarellos-Bourboulis EJ, Kox M, Becker M, Cheran S, Woodacre MS, Goh EL, Schultze JL. Swarm learning for decentralized and confidential clinical machine learning. Nature. 2021;594(7862):265–270. doi: 10.1038/s41586-021-03583-3. https://www.nature.com/articles/s41586-021-03583-3 .10.1038/s41586-021-03583-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Näher AF, Vorisek CN, Klopfenstein SAI, Lehne M, Thun S, Alsalamah S, Pujari S, Heider D, Ahrens W, Pigeot I, Marckmann G, Jenny MA, Renard BY, von Kleist M, Wieler LH, Balzer F, Grabenhenrich L. Secondary data for global health digitalisation. Lancet Digit Health. 2023;5(2):e93–e101. doi: 10.1016/S2589-7500(22)00195-9. https://linkinghub.elsevier.com/retrieve/pii/S2589-7500(22)00195-9 .S2589-7500(22)00195-9 [DOI] [PubMed] [Google Scholar]
- 15.Saldanha OL, Quirke P, West NP, James JA, Loughrey MB, Grabsch HI, Salto-Tellez M, Alwers E, Cifci D, Ghaffari Laleh N, Seibel T, Gray R, Hutchins GGA, Brenner H, van Treeck M, Yuan T, Brinker TJ, Chang-Claude J, Khader F, Schuppert A, Luedde T, Trautwein C, Muti HS, Foersch S, Hoffmeister M, Truhn D, Kather JN. Swarm learning for decentralized artificial intelligence in cancer histopathology. Nat Med. 2022;28(6):1232–1239. doi: 10.1038/s41591-022-01768-5. https://europepmc.org/abstract/MED/35469069 .10.1038/s41591-022-01768-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Nasirigerdeh R, Torkzadehmahani R, Matschinske J, Frisch T, List M, Späth J, Weiss S, Völker U, Pitkänen E, Heider D, Wenke NK, Kaissis G, Rueckert D, Kacprowski T, Baumbach J. sPLINK: a hybrid federated tool as a robust alternative to meta-analysis in genome-wide association studies. Genome Biol. 2022;23(1):32. doi: 10.1186/s13059-021-02562-1. https://genomebiology.biomedcentral.com/articles/10.1186/s13059-021-02562-1 .10.1186/s13059-021-02562-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Hauschild AC, Lemanczyk M, Matschinske J, Frisch T, Zolotareva O, Holzinger A, Baumbach J, Heider D. Federated random forests can improve local performance of predictive models for various healthcare applications. Bioinformatics. 2022;38(8):2278–2286. doi: 10.1093/bioinformatics/btac065. https://academic.oup.com/bioinformatics/article/38/8/2278/6525214?login=false .6525214 [DOI] [PubMed] [Google Scholar]
- 18.Gnyawali DR, Park BJ(R) Co-opetition between giants: collaboration with competitors for technological innovation. Res Policy. 2011;40(5):650–663. doi: 10.1016/j.respol.2011.01.009. [DOI] [Google Scholar]
- 19.Schwartz R, Dodge J, Smith NA, Etzioni O. Green AI. Commun ACM. 2020;63(12):54–63. doi: 10.1145/3381831. [DOI] [Google Scholar]
- 20.Roh Y, Heo G, Whang SE. A survey on data collection for machine learning: a big data—AI integration perspective. IEEE Trans Knowl Data Eng. 2021;33(4):1328–1347. doi: 10.1109/tkde.2019.2946162. [DOI] [Google Scholar]
- 21.Polyzotis N, Roy S, Whang SE, Zinkevich M. Data lifecycle challenges in production machine learning. SIGMOD Rec. 2018;47(2):17–28. doi: 10.1145/3299887.3299891. [DOI] [Google Scholar]
- 22.Breiman B. Random forests. Mach Learn. 2001:45–32. https://link.springer.com/article/10.1023/a:1010933404324 . [Google Scholar]
- 23.Ahmed M, Kashem MA. IoT based risk level prediction model for maternal health care in the context of Bangladesh. 2020 2nd International Conference on Sustainable Technologies for Industry 4.0 (STI); 19-20 December 2020; Dhaka, Bangladesh. 2020. pp. 1–6. [DOI] [Google Scholar]