

Abstract.
Purpose
Transcranial focused ultrasound (tFUS) is a therapeutic ultrasound method that focuses sound through the skull to a small region noninvasively and often under magnetic resonance imaging (MRI) guidance. CT imaging is used to estimate the acoustic properties that vary between individual skulls to enable effective focusing during tFUS procedures, exposing patients to potentially harmful radiation. A method to estimate acoustic parameters in the skull without the need for CT is desirable.
Approach
We synthesized CT images from routinely acquired T1-weighted MRI using a 3D patch-based conditional generative adversarial network and evaluated the performance of synthesized CT (sCT) images for treatment planning with tFUS. We compared the performance of sCT with real CT (rCT) images for tFUS planning using Kranion and simulations using the acoustic toolbox, k-Wave. Simulations were performed for 3 tFUS scenarios: (1) no aberration correction, (2) correction with phases calculated from Kranion, and (3) phase shifts calculated from time reversal.
Results
From Kranion, the skull density ratio, skull thickness, and number of active elements between rCT and sCT had Pearson’s correlation coefficients of 0.94, 0.92, and 0.98, respectively. Among 20 targets, differences in simulated peak pressure between rCT and sCT were largest without phase correction () and smallest with Kranion phases (). The distance between peak focal locations between rCT and sCT was for all simulation cases.
Conclusions
Real and synthetically generated skulls had comparable image similarity, skull measurements, and acoustic simulation metrics. Our work demonstrated similar results for 10 testing cases comparing MR-sCTs and rCTs for tFUS planning. Source code and a docker image with the trained model are available at https://github.com/han-liu/SynCT_TcMRgFUS.
Keywords: transcranial focused ultrasound, acoustic simulation, image-guided, image translation, synthetic CT, conditional adversarial networks
1. Introduction
Transcranial focused ultrasound (tFUS) is a novel noninvasive method of focusing energy through the skull that often uses magnetic resonance imaging (MRI) for target identification, treatment planning, and closed-loop control of energy deposition.1 Focused ultrasound is clinically approved for thermally ablating the thalamus2 and, when used at lower energy levels, is being explored for other applications, such as drug delivery and neuromodulation.3 Precise focusing is critical for all tFUS procedures to minimize treatment of off-target tissues.4 Prior to tFUS, CT images are acquired to estimate regional skull density, speed of sound, and ultrasound attenuation during ultrasound wave propagation.5 Thermally ablative thalamotomy procedures use MR thermometry6 to intraoperatively monitor thermal dose and targeting accuracy. MR thermometry relies on the temperature dependence of the proton resonance frequency shift to linearly map phase differences between two time points to temperature change. Another tFUS application is neuromodulation, a nonthermal method that has been demonstrated in humans targeting the thalamus,7 somatosensory cortex,8 and primary visual cortex.9 During neuromodulation procedures, neuronavigation aids in real-time transducer placement by calculating the position and rotation of optically tracked tools and projecting the transducer’s focus onto pre-acquired images. The projected focus from optical tracking is usually a free-field estimate of the focus location,10 neglecting the inhomogenous layers of the skull known to shift and distort the focus.11 The inclusion of CT images in the neuromodulation planning process allows for incorporation of skull models to map the skull layers to acoustic properties and estimate spatial accuracy, spatial extent, and output pressure for patient-specific skull models. CT imaging burdens patients by requiring a longer screening time and increased risk due to radiation. For tFUS research in development and preclincal phases, it is unrealistic to obtain CT scans of a healthy participant. Therefore, it is desirable to replace the real CT (rCT) images with synthetic CT (sCT) images that are generated from other imaging modalities.
Values from CT images of the head are used in different ways during treatment planning for all tFUS procedures. One important metric is the skull density ratio (SDR), an estimate of the transparency of the skull to ultrasound. The SDR is not always predictive of the energy needed to generate a focal spot transcranially, but a lower SDR is generally interpreted to mean lower acoustic transmission through the skull.12,13 Although the precise method for computing SDR on a clinical system is proprietary, the metric is derived from the ratio of the Hounsfield units (HU) of trabecular to cortical bone along the line from a transducer element to the focus,13 and an open source software, Kranion, is available that is capable of generating SDR metrics highly correlated to those found in clinical systems.14 Along with SDR, Kranion can report a skull thickness (ST) measurement between bone layers and number of active elements (NAEs), or an element’s ray incident to the skull. Detailed spatial maps have been created from CT images to map acoustic properties and model the propagation of sound through the skull.5,15,16 Using modeling tools such as the acoustic toolbox, k-Wave,17 simulations are used to observe ultrasound waves interacting with subject-specific heterogeneous skulls, quantifying the focal shift, focus size, and energy loss caused by the aberrating skull.
The use of multi-element arrays during tFUS procedures is desirable because each individual element’s amplitude and phase can be precisely controlled. Electronically controlled elements are integral during tFUS procedures to move the transducer’s focus location without physically manipulating the transducer and to calculate phase shifts to correct for the skull.18,19 Several aberration correction methods that vary in run-time and focus restoration performance have been explored.14,20,21 For clinical thermoablation, the real-time estimation of amplitude and phase correction are essential as procedures require shifting the small focal volume throughout the brain to ablate the full target.19 The selection of correction method is usually dependent on a trade-off between time constraints and intensity required for a given application.
Deep-learning based methods have been previously used to generate sCTs from MR images.22 Dual-echo ultrashort TE (UTE) MR imaging23 was used to train a 2D U-Net24 that was efficient at generating realistic skulls, but UTE scans are not widely available and require development on an MR scanner as they are not standard protocols. An alternative to UTE images are T1-weighted images, but these can be more challenging to synthesize CT skulls from than UTE because UTE imaging can capture signals from tissues with a very short transverse relaxation time such as bone, providing more information for skull synthesis. For instance, Lei et al.25 proposed using patch-based features extracted from MRIs to train a sequence of alternating random forests based on an iterative refinement model. Maspero et al.26 trained three 2D conditional generative adversarial networks (cGANs),27 one for each plane, and combined the results to generate sCT from T1-weighted MRI. Gupta et al.28 proposed training a 2D U-Net on sagittal views of MRIs and synthesizing the HU of air, soft tissue, and bone in three output channels. However, 2D networks are limited by the lack of information of relationship between slices,29 and the synthetic images may have discontinuity between slices along the views that are not involved in training. The irregular skull geometry of sCT may lead to significant differences in tFUS planning. In very recent work done in parallel to ours,30 a 3D cGAN was proposed to synthesize the whole head CT from MR images. Here, we focus on the skull, which is the critical structure for tFUS.
We hypothesize that sCT generated from MRI can yield comparable clinical metrics for transcranial ultrasound that are derived from CT. If sCT are highly similar to rCTs, the proposed workflow for tFUS planning can be reduced to a single subject scan, rather than the multiple scans that are traditionally obtained, as shown in Fig. 1. Our study used two open-source software tools to compare skull metrics derived from sCT and rCT images using 10 testing cases with two targets. We evaluated the performance of the rCT and sCT skulls using Kranion to report the SDR, ST, and NAEs. Acoustic simulations were performed using k-Wave to calculate the pressure field formed from interactions with each CT, and the aberration correction performance capabilities were compared through a fast ray-tracing method and a computationally expensive time reversal technique. From each simulation, we quantified the maximum intracranial pressure, focal shift between the peak pressure and intended target locations, and focal volumes. Demonstration of the similarity between sCT and rCT would show feasibility of synthesizing realistic CT skulls from T1-weighted MRI.
Fig. 1.

Comparison between the traditional tFUS planning routine and our proposed method. In traditional planning, a patient needs to be scanned twice for CT and MRI separately, in which the CT is used to extract important parameters, such as skull density and thickness, for tFUS planning. By contrast, we propose generating an sCT from MRI for parameter extraction, reducing the screening time and the risk due to radiation.
Built upon our previous work,31 we perform more extensive experiments in this study to validate our developed technique from aspects of image similarity and acoustic simulations. For image similarity, we compare our cGAN-based method against another mainstream synthesis approach to demonstrate the superiority of our method for our application. For acoustic simulations, we include aberration correction in our acoustic analysis as it is an essential step for clinical procedures to restore the maximum pressure at the intended target and thus is important to compare the performance of phases calculated from sCTs against rCTs.
2. Methods
2.1. Dataset and Pre-processing
In this study, our dataset included 86 paired CT and T1-weighted MRI scans of Parkinson patients who underwent Deep Brain Stimulation from Vanderbilt University Medical Center. Informed consent was obtained from all subjects included in this study. The in-plane resolution of CT images ranged from 0.4297 to 0.5449 mm with a slice thickness of 0.67 mm, whereas the MR images had an isotropic voxel size of 1 mm. To prepare the paired CT-MRI dataset for network training, we applied a series of image pre-processing procedures as follows. First, for each subject, we spatially aligned the MRI and CT images by rigid registration. Specifically, we registered the low-resolution MRI scans to the high-resolution CT images to preserve the HU values in high-resolution CT images. Rigid registration was used based on the assumption that the shape and size of brain anatomical structures do not vary for the same subject in different imaging modalities. Here, we employed an open-source medical imaging library ANTsPy for rigid registration, in which mutual information was used as the cost function. Second, to discard the irrelevant brain regions to our skull synthesis task, we filtered out the non-skull regions from the CT images. Specifically, we extracted a binary mask of the skull region using an empirically selected threshold, i.e., 400 HU. We then took the largest connected component of the mask to remove other isolated regions. To preserve some contextual information around the skull, we further performed morphological dilation to the skull mask with a ball-shaped structuring element with a radius of four voxels. This dilated mask was used to filter the raw CT image to obtain the skull-only CT image. In addition, for CT images, we clipped the intensity values to the range of HU and linearly scaled them to . For MRI scans, we applied -score normalization to each scan, which was further clipped to the percentile of the intensity values, followed by a linearly scaling to .
2.2. Network Architecture and Training
As an extension of our previous work,31 we adopted a 3D patch-based cGAN to generate a sCT skull image given a T1-weighted MRI. Our 3D cGAN consisted of a generator and a discriminator , where was trained to generate realistic CT skulls to fool the discriminator and was trained to classify the rCT and sCT skulls. For the generator , we followed the network architecture in pix2pix,27 i.e., 2D ResNet32 with nine residual blocks, and extended the network to 3D. The residual blocks were useful for shuttling the low-level features extracted from MR images, e.g., the location of prominent edges, directly to the deeper layers. At the output layer of , we used Tanh as the activation function to map the logits to a bounded range of . As shown in DCGAN,33 this bounded output range allowed the model to learn more quickly to saturate during the training process. For the discriminator , we adopted a 3D PatchGAN classifier,27 which could be run convolutionally to provide the ultimate output by averaging all responses across the whole volume.
Due to the limit of GPU memory, the network input was a 3D patch randomly cropped from the whole MRI volume . Similarly, the corresponding CT patch was cropped from the same spatial position from the whole CT volume . The loss function of cGAN is expressed as
| (1) |
Note that the input of the 3D PatchGAN classifier was also conditioned on , as it was found to be critical for GAN to produce realistic outputs.27 A L1 reconstruction loss , which encouraged less blurring27 was used and is expressed as
| (2) |
In addition, we included an additional edge-aware loss 34,35 to further align the edges between and . Specifically, we computed the edge maps with a 3D Sobel filter and minimized the L1 distance between the edge maps. The edge-aware loss function is expressed as
| (3) |
The final objective function was the weighted sum of the three loss terms, which is expressed as
| (4) |
We followed the standard training strategy to train our cGAN:36 we updated the parameters of and alternatively per gradient descent step. We used the Adam optimizer37 with an initial learning rate as and momentum parameters and . A mini-batch size of 1 was used. During training, we applied online intensity augmentations38 including random intensity shifts with an offset ranging from and random contrast adjustment with gamma ranging from (0.5, 1.5). Both intensity augmentations were applied with a probability of 0.2. This augmentation strategy aimed to simulate the varying intensity distributions of MRI scans, especially when they were acquired from different sites or with different protocols. We did not augment the intensity values of CT images to preserve the physical meaning of the skull HU values. During the inference phase, we used a sliding window to generate sCT patches across the whole volume and fused the results by averaging multiple predictions over each pixel. We set the overlapping ratio between the sliding windows as 0.75 of the patch dimension, i.e., . For post-processing, we obtained a skull mask from the sCT image following the same steps as in pre-processing, i.e., global threshold, connected component analysis, and morphological dilation. This mask was used to remove the false positive predictions outside the skull regions.
2.3. Study Design
2.3.1. Evaluation of image similarity
In our experiment, we randomly split the entire dataset into subgroups containing 66 images for training, 10 for validation, and the remaining 10 for testing. We trained the networks for a total of 1500 epochs and determined the best weighting factors and by a grid search based on the validation set. To better evaluate the performance of skull synthesis, we only computed the mean absolute error (MAE) within the skull region of the ground truth. We also evaluated the synthesis performance of our 3D patch-based cGAN against the other mainstream MR-CT translation approach, i.e., autoencoder.23,28 For fair comparison, we used the same backbone architecture for autoencoder as the generator of our cGAN model. The objective function for training autoencoder is the same as cGAN but without the adversarial loss.
2.3.2. Target selection
The left or right ventral intermediate nucleus (Vim) of the thalamus was used as the target of interest for acoustic evaluation. The right and left Vim segmentation regions were identified by the “Ventral_Lateral_Nucleus” label from the International Consortium Brain Mapping (ICBM)39 template atlas. The ICBM atlas was registered to each test case MR image with a transformation calculated from an affine registration using 3D Slicer’s (version 4.11.2)40 General Registration (BRAINS)’ module. The output transformation from the registration was applied to the segmented labels and exported as a binary volume as a guide to position the transducer in Kranion.
2.3.3. Evaluation of skull metrics using Kranion
In Kranion, we placed a virtual 990-element hemispherical array transducer so that the focus was positioned at the right or left Vim, so there were 2 targets for each skull in our test dataset of 10 skulls. The transducer geometry is comparable to the the 1024-element ExAblate transducer (Insightec, Tirat Carmel, Israel). The transducer was tilted along the x and y axes and rotated so that the most NAEs with the sCT skull was displayed on Kranion’s graphical interface, without exceeding 10 deg in each direction to simulate a realistic scenario. The average and cortical bone speeds were maintained as 2705 and , respectively. The skull measurements, transducer element coordinates, and focus coordinates were exported after positioning the transducer at the target with the sCT. The corresponding rCT replaced the sCT skull, and the output files were exported. For each virtual targeting procedure (), we calculated the SDR, the ST (the distance between skull boundaries along a ray path), and the NAE between the rCT and sCT. The SDR and ST were averaged across all active elements returned from Kranion. Similarity and statistical significance was determined with Pearson’s correlation coefficient and Wilcoxon signed-rank test () for metrics derived from rCT and sCT.
2.3.4. Acoustic simulation using k-Wave
Once the transducer was positioned about the respective Vim target, the CT image, MR image, transducer element positions, and focus position from the Kranion scene were imported into MATLAB to run full-wave acoustic simulations with the open-source toolbox k-Wave.17 k-Wave solves the first order acoustic wave equation using the k-space pseudospectral method. The CT and MR images were resampled using the imresize3 function in MATLAB (Mathworks, Natick, Massachusetts, United States) to an isotropic grid spacing of 0.52 mm and was further zero padded to a grid size of to ensure that all transducer elements were inside the simulation space. A threshold of 400 HU was used to extract a skull mask from the CT image, and an upper limit of 2000 HU was applied to account for the high radio density contribution from any implants in the skull. The intracranial space was set to a constant value of brain tissue, and the remainder of the simulation grid that contained the transducer was set as water. Table 1 shows the respective acoustic parameters used for all simulations.5,41,42 The heterogeneous skull layers were incorporated in simulations using a linear approximation to map HU to bone porosity and related porosity to the speed of sound, density, and absorption with the following equations:5
| (5) |
| (6) |
| (7) |
| (8) |
Table 1.
Acoustic properties used for all simulations.
| Speed of sound () | Density () | Absorption () |
|---|---|---|
| — | — |
The transducer was modeled using the makeMultiBowl function in k-Wave with an element diameter of 8 mm and radius of curvature of 150 mm, and all elements were directed toward the focus position. Simulations were performed at a frequency of 650 kHz, which maintained a spatial discretization greater than 4.3 points per wavelength (PPW) in water. Three simulations were performed for each target: a simulation without aberration compensation, a simulation with an applied time delay derived from skull thickness calculations from Kranion, and a simulation with corrections from time reversal. Simulations without correction were performed with the same input amplitude and phase for all elements. Directly applying phases calculated from Kranion to each element was unsuccessful in restoring the focus compared with the no correction case, which was similarly observed by Lu et al.21 Instead, Lu et al. calculated time delays using the skull thickness calculated from Kranion as
| (9) |
| (10) |
where was the radius of the transducer array, was the skull thickness from Kranion for each element , was 1500 , and was the mean calculated from each skull after conversion by Eqs. (5) and (6). Phase correction from time reversal was performed by placement of a virtual point source at the target location that recorded the time-varying pressure for each element. The respective amplitude and phases were extracted with the extractAmpPhase function (taking an FFT of the signal close to the source signal) in k-Wave, and the average phase was calculated for all points of a bowl and subtracted from the initial phase. Only the newly acquired phases were applied without changing the input amplitude. To minimize the simulation time, a 100 cycle waveform was used; this was the minimum number of cycles to propagate to the target and return to the transducer. All simulations were run on a Quadro P6000 GPU (NVIDIA Corporation, Santa Clara, California, United States). The root-mean-squared (RMS) pressure was recorded for each voxel location of the grid. To assess the simulation similarity between rCT and sCT, we compared the peak pressure (maximum intracranial pressure) and the pressure at the target. We also characterized the beam properties by evaluating focal shift between the peak and target locations, the distance vector between rCT and sCT, and the focal size and volume. Statistical analysis of simulated pressure fields between rCT and sCT were performed with the Wilcoxon signed-rank test ().
3. Results
3.1. Image Similarity Results
We performed both quantitative and qualitative evaluations of image similarity on our testing set. Quantitatively, we show the box and whisker plot in Fig. 2. Specifically, the MAEs between rCTs and sCTs in skull regions were HU and for cGAN and autoencoder, respectively. We performed paired t-test and found that the difference in mean MAE was statistically significant (-value ). Qualitatively, as shown in Fig. 3, we found that, at the inferior part of the skull, the synthesized skull exhibited a larger difference than at the superior part. The synthetic skull generated by cGAN also included more details and had a sharper appearance compared with the one generated by autoencoder. Finally, we note that our synthesized skulls do not have discontinuity between slices and are highly comparable to real skulls, as shown in Fig. 4.
Fig. 2.
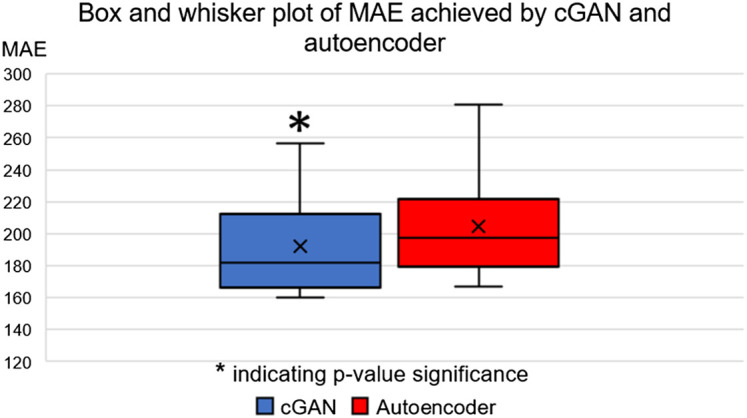
Box and whisker plot of MAE values achieved by cGAN and autoencoder on the testing set.
Fig. 3.

Qualitative results of an example case from the testing set. We compare the two mainstream MR-CT translation methods: autoencoder (middle column) and our cGAN (right column). The major differences between two approaches are highlighted by orange arrows.
Fig. 4.

Visual comparison between real (upper row) and synthetic (lower row) skull. Isosurfaces emphasize that sCTs are visually comparable to rCTs and contiguous.
3.2. Skull Metric Results
Metrics from Kranion exhibit a strong similarity between rCT and sCT across all 20 evaluated targets [Figs. 5(a)–5(c)]. The Pearson’s Correlation Coefficients for the skull density ratio, skull thickness, and NAEs are 0.94 (), 0.92 (), and 0.98 (), respectively, demonstrating a strong positive linear correlation of these metrics and a significant correlation between rCT and sCT. -values calculated from the Wilcoxon signed rank test found differences between rCT and sCT derived SDR () and ST (), but found no difference in NAE between the populations (). Trend lines from paired comparisons between rCT and sCT revealed generally higher SDR and lower ST for sCT compared with rCT. Table 2 summarizes the mean and standard deviation for SDR, ST, and NAE for the full group comparison. The mean differences between rCT and sCT were , , and for SDR, ST, and NAE, respectively. Of the 990 elements that comprised the transducer array, overlapping and non-overlapping elements were compared for each target between rCT and sCT (Fig. 6). On average, elements overlapped between rCT and sCT, with 98.9% in the most overlapping case and 92.8% in the least overlapping case [Figs. 7(a) and 7(b), respectively].
Fig. 5.

Kranion-derived skull metrics. (a)–(c) There was a strong linear relationship between the skull density ratio, skull thickness, and NAEs between the rCT and sCT for both targets. High Pearson’s correlation coefficients shown in the bottom right corner of each plot were observed between all three skull metrics. (d)–(f) A comparison between rCT and sCT for individual test points, observing that the sCT generally had a higher SDR and a lower skull thickness compared with the corresponding rCT.
Table 2.
Mean ± standard deviation calculated for each skull metric from Kranion.
| CT | SDR | ST | NAE |
|---|---|---|---|
| rCT | |||
| sCT |
Fig. 6.

NAEs. For all 20 evaluted targets, the active elements calculated from Kranion are compared with the rCT and sCT skulls. Of the 990 elements, the distribution of overlapping active, overlapping inactive, and non-overlapping rCT and sCT active elements are distinguished.
Fig. 7.

Active elements were similar between rCT and sCT. Visual comparisons are shown for two representative cases to evaluate overlapping active and inactive elements between rCT and sCT. Plots are color coded, showing the distribution of active and inactive elements of the 990 element hemispherical array for the (a) most overlapping case with 98.9% of the active and inactive elements overlapping between rCT and sCT, and the (b) least overlapping case with 92.8% overlapping. From left to right, elements for the rCT skull, sCT skull, and then compared between rCT and sCT for the overlapping and non-overlapping elements. The case numbers noted in the titles of each subplot correspond with the bar plot in Fig 6.
3.3. Acoustic Simulation Results
Acoustic simulation results from k-Wave are summarized in Table 3. The RMS pressure at the intracranial peak and target locations were compared without phase correction and with applied phases calculated from Kranion and time reversal [Fig. 8(a)]. The mean difference in peak pressure between rCT and sCT was , , and for no phase correction, Kranion phases, and TR corrected phases, respectively [Fig 8(b)]. From statistical testing, we observed no difference of peak pressure between rCT and sCT simulations for the case without correction () but observed a difference with Kranion phases () and TR corrected phases (). Similar relationship were noted for target pressure comparisons between rCT and sCT (no correction: , Kranion: , and TR: ). The largest distance vector between rCT and sCT peak pressure locations was noted in the case of no correction () and the largest focal volume difference (), but both metrics were improved when phase correction was applied [Figs. 8(c) and 8(d)]. Kranion calculated phases reduced the distance vector of the peak location between rCT and sCT to and the focal volume to . For the TR simulations, there was no focal shift observed between rCT or sCT skulls except for one case in which a 0.5 mm offset was observed (evaluated target No. 10). TR simulations had the smallest difference in focal volume of . An example comparing rCT and sCT’s pressure fields with TR-corrected phases is shown in Fig. 9.
Table 3.
Mean differences between rCT and sCT for metrics calculated from acoustic simulations presented as mean ± standard deviation. TR: time reversal.
| Simulation | Peak pressure (%) | Focal position (mm) | Focal volume (%) |
|---|---|---|---|
| No correction | |||
| Kranion | |||
| TR |
Fig. 8.

(a) Acoustic simulation results from k-Wave. For each evaluated target, the peak intracranial RMS pressure (transparent bars) and the pressure at the target (solid bars) are shown for rCT and sCT, grouped by phase correction type. (b)–(d) A group summary of all 20 test cases are shown for RMS pressure, focal shift, and focal volume.
Fig. 9.

Simulated pressure field after applying phases calculated from time reversal. An example of the resultant pressure field with TR-corrected phases targeting the left Vim is shown (evaluated target No. 4). (a) The first row contains the pressure field simulated with the rCT skull volume, overlaid on the CT and MR images and enlarged in the final column to better see the focal shape and size. (b) Similarly, the sCT skull and simulated acoustic field is presented with similar overlays. (c) The percent difference of the pressure fields between rCT and sCT was calculated using the rCT peak pressure as the ground truth and is presented in the final row, denoting the intended location with the red dot. The evaluated target was selected as the representative case as it had the largest percent different at the spatial peak location. Qualitatively and quantitatively the spatial extent of the foci are very similar between the rCT and sCT results, with the main difference identified as the maximum pressure.
4. Discussion and Conclusions
tFUS is being explored for a number of applications.43 Patient-specific information is required to model effects of the skull during tFUS, and the current gold standard uses a CT to generate a subject-specific map of acoustic properties of the skull. We explored the feasibility of replacing rCT images with sCT images for tFUS procedures. We hypothesized that results from acoustic simulations with sCT skulls would yield equivalent focal size, location, and pressure compared with simulations with ground truth skulls and evaluated this by comparing the pressure field from three simulation scenarios varying the skull compensation methods. We compared skull-derived metrics used clinically to determine patient eligibility using rCT and sCT. Successful replacement of rCT images with an image generated from routine MR scans could improve tFUS procedure planning by incorporating a subject’s skull without causing additional burden on the patient. Through our work here, we showed that the sCT skulls generated by our proposed 3D patch-based cGAN (1) do not have discontinuity between slices and (2) are highly comparable to rCTs when used to predict skull properties for transcranial ultrasound procedures.
Image similarity between synthesized and real skulls were first evaluated by qualitative inspection and quantitative assessment. We explored the effectiveness of two mainstream MR-CT synthesis approaches and demonstrated the superiority of cGAN. Through open-source software, Kranion, we compared clinically relevant skull metrics and active elements derived from rCT and sCT and found that they were highly correlated. Statistical testing revealed a difference in skull density ratio and skull thickness, in which SDR was slightly overestimated for sCT and conversely ST was underestimated when compared with rCT. Koh et al. reported correlation coefficients of 0.95 and 0.90 for SDR and ST, respectively, comparable to our reported results in this study of 0.94 and 0.92, respectively. Acoustic simulations using k-Wave provided a more detailed assessment of ultrasound interaction with the synthetic skulls. Without any skull compensation techniques applied, the peak intracranial pressure difference was higher than that reported of Koh et al. ( versus ). We speculate that this is due to key differences in the simulation setups: (1) our simulations were performed at a higher frequency (650 kHz versus 200 kHz) and (2) we modeled the large hemispherical ExAblate array transducer whereas Koh et al. modeled a single-element transducer. A higher fundamental frequency was used for all transducer modeling in this study to match the clinical system that it was modeled after. Because attenuation is frequency dependent, at higher frequencies we expect a greater decrease in intensity at the focus.15 The hemispherical array has a much larger surface area than the smaller, single-element transducer (radius of curvature of 150 mm versus 55 mm); thus a greater amount of skull area influences the simulation outcome, which increases sensitivity to skull differences.
Our study simulated three different tFUS scenarios: no correction for phases offset by the skull, corrections calculated from ray-tracing, and modeling of a virtual source followed by time-reversed phases to restore pressure at the target. TR corrected simulations had the smallest mean difference focal position and volume between rCT and sCT, but application of Kranion-calculated phases had the smallest peak pressure difference. Because the Kranion phases were dependent on the skull thicknesses from Kranion, which we found to be highly correlated between rCT and sCT, we expected the simulation results from applying the phases to be similar. The mean phase difference was smaller for phases calculated from Kranion than TR-corrected simulations, but the TR-corrected simulations more fully encapsulated the internal structure of the skull.5 Similar work has evaluated the skull correction performance capabilities of artificial skulls and applied the phases in an experimental context beyond modeling and simulations.4,44,45 One study reconstructed a virtual CT from a T1-weighted MR image and compared calculated phases from Insightec’s ExAblate system, resulting in an average phase difference between the real and MR-generated CT of radians, and application of the phases was successfully demonstrated in thermal experiments using head phantoms.4 A study using the same transducer as Wintermark et al. compared UTE-derived MR images with rCT images of head phantoms and found no statistical difference between peak temperatures achieved for thermal experiments.44 Most recently, Leung et al. generated skulls from UTE images and calculated phases from the Insightec system but applied phases in a water bath setup, measuring the pressure field behind a skull using a hydrophone; they reported comparable beam profile results when compared with rCTs.45
Regarding peak intracranial pressure differences observed between rCT and sCT, the mean difference computed in our study falls within an expected range of variability of 10% that was observed through an intercomparison study across 11 simulation tools.46 Because the modeled array was large, the grid size necessary to fit all elements would be to maintain in water at 650 kHz and satisfy 3D convergence testing requirements to avoid simulation instabilities.47 For a single time-reversed simulation, the total run-time on a CPU is . We instead opted to use GPU-accelerated simulations to reduce the computation time, but the GPU’s memory constraints required us to decrease the spatial resolution to 4.3 PPW. Although the coarser spatial resolution was used for all results reported in this work, we ran a single test case at 0.33 isotropic voxel size ( in water) to quantify simulation differences without phase correction and with TR-corrected phases for rCT and sCT (). All low-resolution simulations underestimated pressure when compared with high-resolution simulations, shown in Fig. S1 in the Supplementary Material, with the average difference between high and low resolution peak intracranial pressure being . We acknowledge that this pressure discrepancy is high, but we note that a relative peak pressure difference between rCT and sCT was similar [high resolution = and low resolution = (raw values shown in Table S1 in the Supplementary Material)]. Similar focal volume differences between rCT and sCT were observed for high and low resolution simulations, shown in Table S2 in the Supplementary Material. Although the distance vector between rCT and sCT was larger when calculated with high resolution simulation results for the no correction case, we think that this transducer’s focus is highly aberrated without phase corrections applied. With TR-correction applied, we found that the vector was offset by a single spatial step size for high and low resolution simulations. Overall, GPU simulations resulted in an underestimation of pressure, but most measurements in the present study do not incorporate these pressure estimates.
The performance of cGAN-generated skulls may be improved by incorporating additional MRI contrast such as zero-echo time (ZTE) into the training process. A recent work evaluated CTs generated from learned T1-weighted MR images, ZTE MR images, and direct conversion from ZTE to HU.48 Tested through acoustic analysis, ZTE outperformed learned T1-weighted and direct ZTE conversion images for four regions in the brain with low variation. This work suggests that ZTE or other imaging sequences can be integrated with convolutional neural networks and tested to observe improvements in similarity between skulls.
To assess any biases in our model, we performed a 5-fold cross validation (full description and results can be found in the Supplementary Material) in which our network underwent five configurations of training, validation, and testing from our full dataset of 86 paired CT and MR images. Although the k-fold cross validation showed strong correlation between metrics calculated from Kranion targeting the left ventral intermediate nucleus of the thalamus for all five folds ( rCT and sCT skull pairs) the lower correlation coefficients between some folds identified limitations in our study. The first limitation is that 10 test cases cannot fully account for the heterogeneity of the skulls and additional testing cases are required to deem our synthetically generated skulls as suitable replacements of rCT images for tFUS procedures. Alternatively, a larger number of training MR-CT pairs for the network could include a wider range of skulls and minimize differences seen between folds.
Our work evaluated CT images synthetically generated from 3D cGAN with rCT scans for potential use in tFUS thermal and nonthermal applications for a multi-element array. Our initial study found that sCTs generated from the 3D cGAN were comparable to rCTs and could replace the need for CT scans with a routine T1-weighted MR image, but this requires larger test or training datasets to fully capture the variability of human skulls. Patient selection for tFUS is assessed by metrics characterizing the skull; we showed that sCTs are comparable to rCTs for all skulls. Good similarity was demonstrated for three acoustic simulation scenarios that may arise for tFUS applications. Replacement of rCTs with sCTs would decrease patient burden of additional scan time, minimize exposure to radiation, and eliminate the need to register a pre-acquired CT to the MRI—a known source of error.
Supplementary Material
Acknowledgments
This work was supported by National Institutes of Health (NIH, Grant No. U18EB029351) and the Advanced Computing Center for Research and Education (ACCRE) of Vanderbilt University. All acoustic simulations were run on a Quadro P6000 GPU donated by NVIDIA Corporation. The content is solely the responsibility of the authors and does not necessarily represent the official views of these institutes.
Biographies
Han Liu received his BS degree in biomedical engineering and electrical engineering at Rensselaer Polytechnic Institute and his MS degree in biomedical engineering at Yale University. He is currently pursuing a PhD in computer science at Vanderbilt University. His research interests are in the broad areas of computer vision, deep learning, and medical image analysis.
Michelle K. Sigona received her BS degree in biomedical engineering from Arizona State University in 2017. She is currently pursuing a PhD in biomedical engineering at Vanderbilt University. Her research interests include transcranial focused ultrasound therapies and acoustic simulations of propagation through the skull.
Thomas J. Manuel is a PhD student developing therapeutic ultrasound for neuromodulation and drug delivery to the brain. His interests extend to cavitation monitoring systems, MRI guidance of transcranial ultrasound procedures, and simulations of transcranial ultrasound scenarios.
Li Min Chen, MD, PhD, is professor of radiology and radiological science. Her research interests focus on using neuroimaging, neuromodulation, transcranial electrophysiology, and tracer histology to dissect touch and pain circuits in the brain and spinal cord in animal models. She has served as the PI on NIH and DoD grants and on NIH and NSF grant application review panels.
Benoit M. Dawant, PhD, is the Cornelius Vanderbilt Chair in Engineering and a professor of electrical and computer engineering at Vanderbilt University. He is an IEEE fellow and the director of the Vanderbilt Institute for Surgery and Engineering. He has more than 20 year of experience in the areas of medical image processing and analysis, and image-guided surgical procedures.
Charles F. Caskey, PhD, has worked in the field of ultrasound since 2004. He received his doctoral degree for studies on the bioeffects of ultrasound during microbubble-enhanced drug delivery under Dr. Katherine Ferrara at the University of California – Davis in 2008. He currently leads an ultrasound laboratory at Vanderbilt University Institute of Imaging Science where his group focuses on developing new uses for ultrasound, including neuromodulation, drug delivery, and functional imaging.
Disclosures
No conflicts of interest, financial or otherwise, are declared by the authors.
Contributor Information
Han Liu, Email: han.liu@vanderbilt.edu.
Michelle K. Sigona, Email: michelle.k.sigona@vanderbilt.edu.
Thomas J. Manuel, Email: thomas.j.manuel@vanderbilt.edu.
Li Min Chen, Email: limin.chen@vumc.org.
Benoit M. Dawant, Email: benoit.dawant@vanderbilt.edu.
Charles F. Caskey, Email: charles.f.caskey@vanderbilt.edu.
References
- 1.Jolesz F. A., “MRI-guided focused ultrasound surgery,” Annu. Rev. Med. 60, 417 (2009). 10.1146/annurev.med.60.041707.170303 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Elias W. J., et al. , “A pilot study of focused ultrasound thalamotomy for essential tremor,” N. Engl. J. Med. 369(7), 640–648 (2013). 10.1056/NEJMoa1300962 [DOI] [PubMed] [Google Scholar]
- 3.Meng Y., Hynynen K., Lipsman N., “Applications of focused ultrasound in the brain: from thermoablation to drug delivery,” Nat. Rev. Neurol. 17(1), 7–22 (2021). 10.1038/s41582-020-00418-z [DOI] [PubMed] [Google Scholar]
- 4.Wintermark M., et al. , “T1-weighted MRI as a substitute to CT for refocusing planning in mr-guided focused ultrasound,” Phys. Med. Biol. 59(13), 3599 (2014). 10.1088/0031-9155/59/13/3599 [DOI] [PubMed] [Google Scholar]
- 5.Aubry J.-F., et al. , “Experimental demonstration of noninvasive transskull adaptive focusing based on prior computed tomography scans,” J. Acoust. Soc. Am. 113(1), 84–93 (2003). 10.1121/1.1529663 [DOI] [PubMed] [Google Scholar]
- 6.Rieke V., Butts Pauly K., “MR thermometry,” J. Magn. Reson. Imaging 27(2), 376–390 (2008). 10.1002/jmri.21265 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Legon W., et al. , “Neuromodulation with single-element transcranial focused ultrasound in human thalamus,” Hum. Brain Mapp. 39(5), 1995–2006 (2018). 10.1002/hbm.23981 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Lee W., et al. , “Image-guided transcranial focused ultrasound stimulates human primary somatosensory cortex,” Sci. Rep. 5(1), 1–10 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Lee W., et al. , “Transcranial focused ultrasound stimulation of human primary visual cortex,” Sci. Rep. 6(1), 1–12 (2016). 10.1038/srep34026 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Kim H., et al. , “Image-guided navigation of single-element focused ultrasound transducer,” Int. J. Imaging Syst. Technol. 22(3), 177–184 (2012). 10.1002/ima.22020 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Sun J., Hynynen K., “Focusing of therapeutic ultrasound through a human skull: a numerical study,” J. Acoust. Soc. Am. 104(3), 1705–1715 (1998). 10.1121/1.424383 [DOI] [PubMed] [Google Scholar]
- 12.Boutet A., et al. , “The relevance of skull density ratio in selecting candidates for transcranial mr-guided focused ultrasound,” J. Neurosurg. 132(6), 1785–1791 (2019). 10.3171/2019.2.JNS182571 [DOI] [PubMed] [Google Scholar]
- 13.Chang W. S., et al. , “Factors associated with successful magnetic resonance-guided focused ultrasound treatment: efficiency of acoustic energy delivery through the skull,” J. Neurosurg. 124(2), 411–416 (2016). 10.3171/2015.3.JNS142592 [DOI] [PubMed] [Google Scholar]
- 14.Sammartino F., et al. , “Kranion, an open-source environment for planning transcranial focused ultrasound surgery,” J. Neurosurg. 132(4), 1249–1255 (2019). 10.3171/2018.11.JNS181995 [DOI] [PubMed] [Google Scholar]
- 15.Pichardo S., Sin V. W., Hynynen K., “Multi-frequency characterization of the speed of sound and attenuation coefficient for longitudinal transmission of freshly excised human skulls,” Phys. Med. Biol. 56(1), 219 (2010). 10.1088/0031-9155/56/1/014 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Marquet F., et al. , “Non-invasive transcranial ultrasound therapy based on a 3D CT scan: protocol validation and in vitro results,” Phys. Med. Biol. 54(9), 2597 (2009). 10.1088/0031-9155/54/9/001 [DOI] [PubMed] [Google Scholar]
- 17.Treeby B. E., Cox B. T., “k-Wave: Matlab toolbox for the simulation and reconstruction of photoacoustic wave fields,” J. Biomed. Opt. 15(2), 021314 (2010). 10.1117/1.3360308 [DOI] [PubMed] [Google Scholar]
- 18.Kyriakou A., et al. , “A review of numerical and experimental compensation techniques for skull-induced phase aberrations in transcranial focused ultrasound,” Int. J. Hyperth. 30(1), 36–46 (2014). 10.3109/02656736.2013.861519 [DOI] [PubMed] [Google Scholar]
- 19.Meng Y., et al. , “Technical principles and clinical workflow of transcranial MR-guided focused ultrasound,” Stereotact. Funct. Neurosurg. 99(4), 329–342 (2021). 10.1159/000512111 [DOI] [PubMed] [Google Scholar]
- 20.Bancel T., et al. , “Comparison between ray-tracing and full-wave simulation for transcranial ultrasound focusing on a clinical system using the transfer matrix formalism,” IEEE Trans. Ultrasonics Ferroelectr. Freq. Control 68(7), 2554–2565 (2021). 10.1109/TUFFC.2021.3063055 [DOI] [PubMed] [Google Scholar]
- 21.Lu N., et al. , “Two-step aberration correction: application to transcranial histotripsy,” Phys. Med. Biol. 67(12), 125009 (2022). 10.1088/1361-6560/ac72ed [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Guo S., et al. , “Feasibility of ultrashort echo time images using full-wave acoustic and thermal modeling for transcranial MRI-guided focused ultrasound (tcMRgFUS) planning,” Phys. Med. Biol. 64(9), 095008 (2019). 10.1088/1361-6560/ab12f7 [DOI] [PubMed] [Google Scholar]
- 23.Su P., et al. , “Transcranial MR imaging–guided focused ultrasound interventions using deep learning synthesized CT,” Am. J. Neuroradiol. 41(10), 1841–1848 (2020). 10.3174/ajnr.A6758 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Ronneberger O., Fischer P., Brox T., “U-net: convolutional networks for biomedical image segmentation,” Lect. Notes Comput. Sci. 9351, 234–241 (2015). 10.1007/978-3-319-24574-4_28 [DOI] [Google Scholar]
- 25.Lei Y., et al. , “MRI-based pseudo CT synthesis using anatomical signature and alternating random forest with iterative refinement model,” J. Med. Imaging 5(4), 043504 (2018). 10.1117/1.JMI.5.4.043504 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Maspero M., et al. , “Deep learning-based synthetic CT generation for paediatric brain MR-only photon and proton radiotherapy,” Radiother. Oncol. 153, 197–204 (2020). 10.1016/j.radonc.2020.09.029 [DOI] [PubMed] [Google Scholar]
- 27.Isola P., et al. , “Image-to-image translation with conditional adversarial networks,” in Proc. IEEE Conf. Comput. Vision and Pattern Recognit., pp. 1125–1134 (2017). 10.1109/CVPR.2017.632 [DOI] [Google Scholar]
- 28.Gupta D., et al. , “Generation of synthetic CT images from MRI for treatment planning and patient positioning using a 3-channel U-net trained on sagittal images,” Front. Oncol. 9, 964 (2019). 10.3389/fonc.2019.00964 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Yu Q., et al. , “Thickened 2D networks for efficient 3D medical image segmentation,” arXiv:1904.01150 (2019).
- 30.Koh H., et al. , “Acoustic simulation for transcranial focused ultrasound using GAN-based synthetic CT,” IEEE J. Biomed. Health. Inf. 26(1), 161–171 (2021). 10.1109/JBHI.2021.3103387 [DOI] [PubMed] [Google Scholar]
- 31.Liu H., et al. , “Synthetic CT skull generation for transcranial mr imaging–guided focused ultrasound interventions with conditional adversarial networks,” Proc. SPIE 12034, 120340O (2022). 10.1117/12.2612946 [DOI] [Google Scholar]
- 32.He K., et al. , “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vision and Pattern Recognit., pp. 770–778 (2016). 10.1109/CVPR.2016.90 [DOI] [Google Scholar]
- 33.Radford A., Metz L., Chintala S., “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv:1511.06434 (2015).
- 34.Luo Y., et al. , “Edge-preserving MRI image synthesis via adversarial network with iterative multi-scale fusion,” Neurocomputing 452, 63–77 (2021). 10.1016/j.neucom.2021.04.060 [DOI] [Google Scholar]
- 35.Fan Y., et al. , “Temporal bone CT synthesis for MR-only cochlear implant preoperative planning,” Proc. SPIE 12466, 124661I (2023). 10.1117/12.2647443 [DOI] [Google Scholar]
- 36.Goodfellow I., et al. , “Generative adversarial nets,” in Adv. Neural Inf. Process. Syst. 27 (2014). [Google Scholar]
- 37.Kingma D. P., Ba J., “Adam: a method for stochastic optimization,” arXiv:1412.6980 (2014).
- 38.Cardoso M. J., et al. , “Monai: an open-source framework for deep learning in healthcare,” arXiv:2211.02701 (2022).
- 39.Mazziotta J. C., et al. , “A probabilistic atlas of the human brain: theory and rationale for its development,” Neuroimage 2(2), 89–101 (1995). [DOI] [PubMed] [Google Scholar]
- 40.Pieper S., Halle M., Kikinis R., “3D Slicer,” in 2004 2nd IEEE Int. Symp. Biomedical Imaging: Nano to Macro (IEEE Cat No. 04EX821), IEEE; (2004). [Google Scholar]
- 41.Duck F. A., Physical Properties of Tissues: A Comprehensive Reference Book, Academic Press; (2013). [Google Scholar]
- 42.Constans C., et al. , “A 200–1380-khz quadrifrequency focused ultrasound transducer for neurostimulation in rodents and primates: transcranial in vitro calibration and numerical study of the influence of skull cavity,” IEEE Trans. Ultrasonics Ferroelectr. Freq. Control 64(4), 717–724 (2017). 10.1109/TUFFC.2017.2651648 [DOI] [PubMed] [Google Scholar]
- 43.Krishna V., Sammartino F., Rezai A., “A review of the current therapies, challenges, and future directions of transcranial focused ultrasound technology: advances in diagnosis and treatment,” JAMA Neurol. 75(2), 246–254 (2018). 10.1001/jamaneurol.2017.3129 [DOI] [PubMed] [Google Scholar]
- 44.Miller G. W., et al. , “Ultrashort echo-time MRI versus ct for skull aberration correction in MR-guided transcranial focused ultrasound: in vitro comparison on human calvaria,” Med. Phys. 42(5), 2223–2233 (2015). 10.1118/1.4916656 [DOI] [PubMed] [Google Scholar]
- 45.Leung S. A., et al. , “Comparison between MR and CT imaging used to correct for skull-induced phase aberrations during transcranial focused ultrasound,” Sci. Rep. 12, 13407 (2022). 10.1038/s41598-022-17319-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Aubry J.-F., et al. , “Benchmark problems for transcranial ultrasound simulation: Intercomparison of compressional wave models,” J. Acoust. Soc. Am. 152(2), 1003–1019 (2022). 10.1121/10.0013426 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Robertson J. L., et al. , “Accurate simulation of transcranial ultrasound propagation for ultrasonic neuromodulation and stimulation,” J. Acoust. Soc. Am. 141(3), 1726–1738 (2017). 10.1121/1.4976339 [DOI] [PubMed] [Google Scholar]
- 48.Miscouridou M., et al. , “Classical and learned MR to pseudo-CT mappings for accurate transcranial ultrasound simulation,” IEEE Trans. Ultrasonics Ferroelectr. Freq. Control 69(10), 2896–2905 (2022). 10.1109/TUFFC.2022.3198522 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.