

Abstract
Merging datafiles containing information on overlapping sets of entities is a challenging task in the absence of unique identifiers, and is further complicated when some entities are duplicated in the datafiles. Most approaches to this problem have focused on linking two files assumed to be free of duplicates, or on detecting which records in a single file are duplicates. However, it is common in practice to encounter scenarios that fit somewhere in between or beyond these two settings. We propose a Bayesian approach for the general setting of multifile record linkage and duplicate detection. We use a novel partition representation to propose a structured prior for partitions that can incorporate prior information about the data collection processes of the datafiles in a flexible manner, and extend previous models for comparison data to accommodate the multifile setting. We also introduce a family of loss functions to derive Bayes estimates of partitions that allow uncertain portions of the partitions to be left unresolved. The performance of our proposed methodology is explored through extensive simulations.
Keywords: data matching, data merging, entity resolution, microclustering
1. Introduction
When information on individuals is collected across multiple datafiles, it is natural to merge these datafiles to harness all available information. This merging requires identifying coreferent records, i.e., records that refer to the same entity, which is not trivial in the absence of unique identifiers. This problem arises in many fields, including public health (Hof et al. 2017), official statistics (Jaro 1989), political science (Enamorado et al. 2019), and human rights (Sadinle 2014, 2017, Ball and Price 2019).
Most approaches in this area have thus far focused on one of two settings. Record linkage has traditionally referred to the setting where the goal is to find coreferent records across two datafiles, where the files are assumed to be free of duplicates. Duplicate detection has traditionally referred to the setting where the goal is to find coreferent records within a single file. In practice, however, it is common to encounter problems that fit somewhere in between or beyond these two settings. For example, we could have multiple datafiles that are all assumed to be free of duplicates, or we might have duplicates in some files but not in others. In these general settings, the data collection processes for the different datafiles possibly introduce different patterns of duplication, measurement error, and missingness into the records. Further, dependencies among these data collection processes determine which specific subsets of files contain records of the same entity. We refer to this general setting as multifile record linkage and duplicate detection.
Traditional approaches to record linkage and duplicate detection have mainly followed the seminal work of Fellegi and Sunter (1969), by modeling comparisons of fields between pairs of records in a mixture model framework (Winkler 1994, Jaro 1989, Larsen and Rubin 2001). These approaches work under, and take advantage of, the intuitive assumption that coreferent records will look similar, and non-coreferent records will look dissimilar. However, these approaches output independent decisions for the coreference status of each pair of records, necessitating the use of ad hoc post-processing steps to reconcile incompatible decisions that ignore the logical constraints of the problem.
Our approach to multifile record linkage and duplicate detection builds on previous Bayesian approaches where the parameter of interest is defined as a partition of the records. These Bayesian approaches have been carried out in two frameworks. In the direct-modeling framework, one directly models the fields of information contained in the records (Matsakis 2010, Tancredi and Liseo 2011, Liseo and Tancredi 2011, Steorts 2015, Steorts et al. 2016, Tancredi et al. 2020, Marchant et al. 2021, Enamorado and Steorts 2020), which requires a custom model for each type of field. While this framework can provide a plausible generative model for the records, it can be difficult to develop custom models for complicated fields like strings, so most approaches are limited to modeling categorical data, with some exceptions (Liseo and Tancredi 2011, Steorts 2015). In the comparison-based framework, following the traditional approaches, one models comparisons of fields between pairs of records (Fortini et al. 2001, Larsen 2005, Sadinle 2014, 2017). By modeling comparisons of fields, instead of the fields directly, a generic modeling approach can be taken for any field type, as long as there is a meaningful measure of similarity for that field type.
Sadinle and Fienberg (2013) generalized Fellegi and Sunter (1969) by linking K > 2 files with no duplicates. However, in addition to inheriting the issues of traditional approaches, their approach does not scale well in the number of files or the file sizes encountered in practice. Steorts et al. (2016) presented a Bayesian approach in the direct-modeling framework for the general setting of multifile record linkage and duplicate detection, which has been extended by Steorts (2015) and Marchant et al. (2021). This approach uses a flat prior on arbitrary labels of partitions, which incorporates unintended prior information.
In light of the shortcomings of existing approaches, we propose an extension of Bayesian comparison-based models that explicitly handles the setting of multifile record linkage and duplicate detection. We first present in Section 2 a parameterization of partitions specific to the context of multifile record linkage and duplicate detection. Building on this parameterization, in Section 3 we construct a structured prior for partitions that can incorporate prior information about the data collection processes of the files in a flexible manner. As a by-product, a family of priors for K-partite matchings is constructed. In Section 4 we construct a likelihood function for comparisons of fields between pairs of records that accommodates possible differences in the datafile collection processes. In Section 5 we present a family of loss functions that we use to derive Bayes estimates of partitions. These loss functions have an abstain option which allow portions of the partition with large amounts of uncertainty to be left unresolved. Finally, we explore the performance of our proposed methodology through simulation studies in Section 6. In the Appendix we present an application of our proposed approach to link three Colombian homicide record systems.
2. Multifile Partitioning
Consider K files X1, ⋯, XK, each containing information on possibly overlapping subsets of a population of entities. The goal of multifile record linkage and duplicate detection is to identify the sets of records in X1, ⋯, XK that are coreferent, as illustrated in Figure 1. Identifying coreferent records across datafiles represents the goal of record linkage, and identifying coreferent records within each file represents the goal of duplicate detection.
Fig. 1.
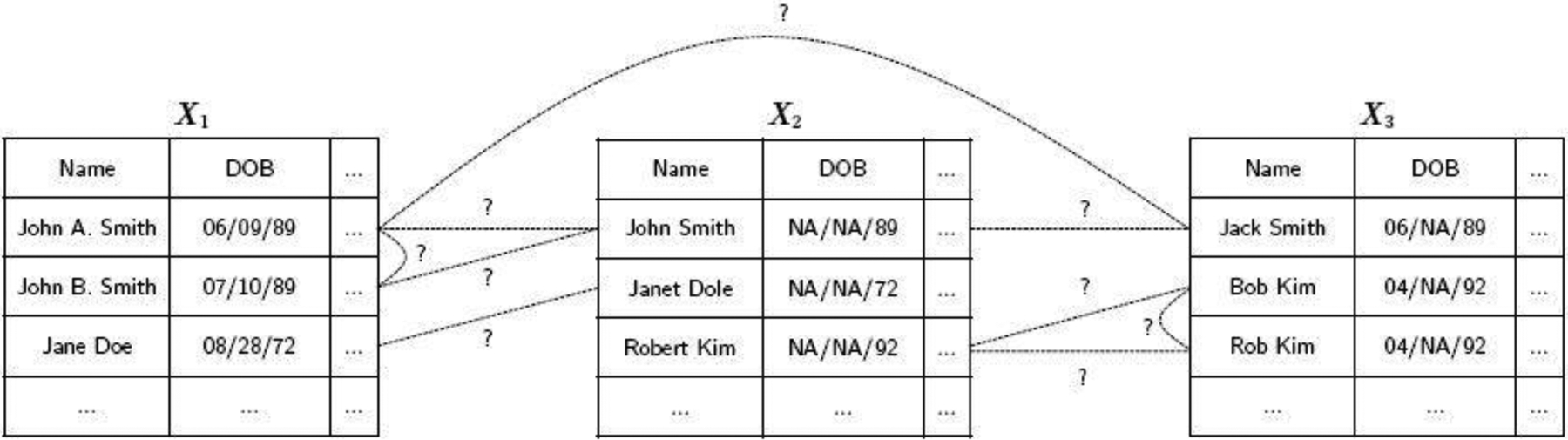
A toy example of the multifile record linkage and duplicate detection problem.
We denote the number of records contained in datafile Xk as rk, and the total number of records across all files as . We label the records in all datafiles in a consecutive order, that is, those in X1 as R1 = (1, ⋯, r1), those in X2 as R2 = (r1 + 1, ⋯, r1 + r2), and so on, finally labeling the records in XK as . We denote [r] = (1, ⋯, r), where it is clear that [r] = (R1, ⋯, RK), which represents all the records coming from all datafiles.
Formally, multifile record linkage and duplicate detection is a partitioning problem. A partition of a set is a collection of disjoint subsets, called clusters, whose union is the original set. In this context, the term coreference partition refers to a partition of all the records in X1, ⋯, XK, or equivalently a partition of [r], such that each cluster is exclusively composed of all the records generated by a single entity (Matsakis 2010, Sadinle 2014). This implies that there is a one-to-one correspondence between the clusters in and the entities represented in at least one of the datafiles. Estimating is the goal of multifile record linkage and duplicate detection.
2.1. Multifile Coreference Partitions
In the setting of multifile record linkage and duplicate detection, the datafiles are the product of K data collection processes, which possibly introduce different patterns of duplication, measurement error, and missingness. This indicates that records coming from different datafiles should be treated differently. To take this into account, we introduce the concept of a multifile coreference partition by endowing a coreference partition with additional structure to preserve the information on where records come from. Each cluster can be decomposed as c = c1 ∪⋯∪ ck ∪⋯∪ cK, where ck is the subset of records in cluster c that belong to datafile Xk, which leads us to the following definition.
Definition 1. The multifile coreference partition of datafiles X1, ⋯, XK is obtained from the coreference partition by expressing each cluster as a K-tuple (c1, ⋯, cK), where ck represents the records of c that come from datafile Xk.
For simplicity we will continue using the notation to denote a multifile coreference partition, although technically this new structure is richer and therefore different from a coreference partition that does not preserve the datafile membership of the records. The multifile representation of partitions is useful for decoupling the features that are important for within-file duplicate detection or for across-files record linkage.
For duplicate detection, the goal is to identify coreferent records within each datafile. This can be phrased as estimating the within-file coreference partition of each datafile Xk. Clearly, these can be obtained from the multifile partition by extracting the kth entry of each cluster . Two useful summaries of a given within-file partition are the number of within-file clusters , which is the number of unique entities represented in datafile Xk, and the within-file cluster sizes , which represent the number of records associated with each entity in datafile Xk.
On the other hand, in record linkage the goal is to identify coreferent records across datafiles. Given the within-file partitions, , the goal can be phrased as identifying which clusters across these partitions represent the same entities. This across-datafiles structure can be formally represented by a K-partite matching. Given K sets V1, ⋯, VK, a K-partite matching is a collection of subsets from such that each contains maximum one element from each Vk. If we think of each Vk as the set of clusters representing the entities in datafile Xk, then it is clear that the goal is to identify the K-partite matching that puts together the clusters that refer to the same entities across datafiles. This structure can be extracted from a multifile coreference partition , given that each element contains the coreferent clusters across all within-file partitions. Indeed, a multifile coreference partition can be thought of as a K-partite matching of within-file coreference partitions.
A useful summary of the across-datafile structure is the amount of entity-overlap between datafiles, represented by the number of clusters with records in specific subsets of the files. We can concisely summarize the entity-overlap of the datafiles through a contingency table. In particular, consider a 2K contingency table with cells indexed by h ∈ {0, 1}K and corresponding cell counts nh. Here, h represents a pattern of inclusion of an entity in the datafiles, where a 1 indicates inclusion and a 0 exclusion. For instance, if K = 3, n011 is the number of clusters representing entities with records in datafiles 2 and 3 but without records in datafile 1. We let and denote the (incomplete) contingency table of counts as , which we refer to as the overlap table. We ignore the cell {0}K which would represent entities that are not recorded in any of the K files. This cell is not of interest in this article, although it is the parameter of interest in population size estimation (see e.g. Bird and King 2018).
Example.
To illustrate the concept of a multifile partition, consider two files with five and seven records respectively, so that X1 contains records 1 – 5 and X2 contains records 6 – 12. Suppose the coreference partition is {{1,9},{2},{3,8,10,11},{4,5,7},{6},{12}}. The corresponding multifile partition is . As illustrated in Figure 2, the within-file partitions can be extracted as and , and the within-file cluster sizes are d1 = (1,1,1,2) and d2 = (1,1,1,3,1). The overlap table in this case is {n11, n10, n01}, indicating that n11 = 3 entities are represented in both datafiles, n10 = 1 entity is represented only in the first datafile, and n01 = 2 entities are represented only in the second datafile. In total, there are unique entities represented in X1, unique entities represented in X2, and entities among both datafiles.
Fig. 2.
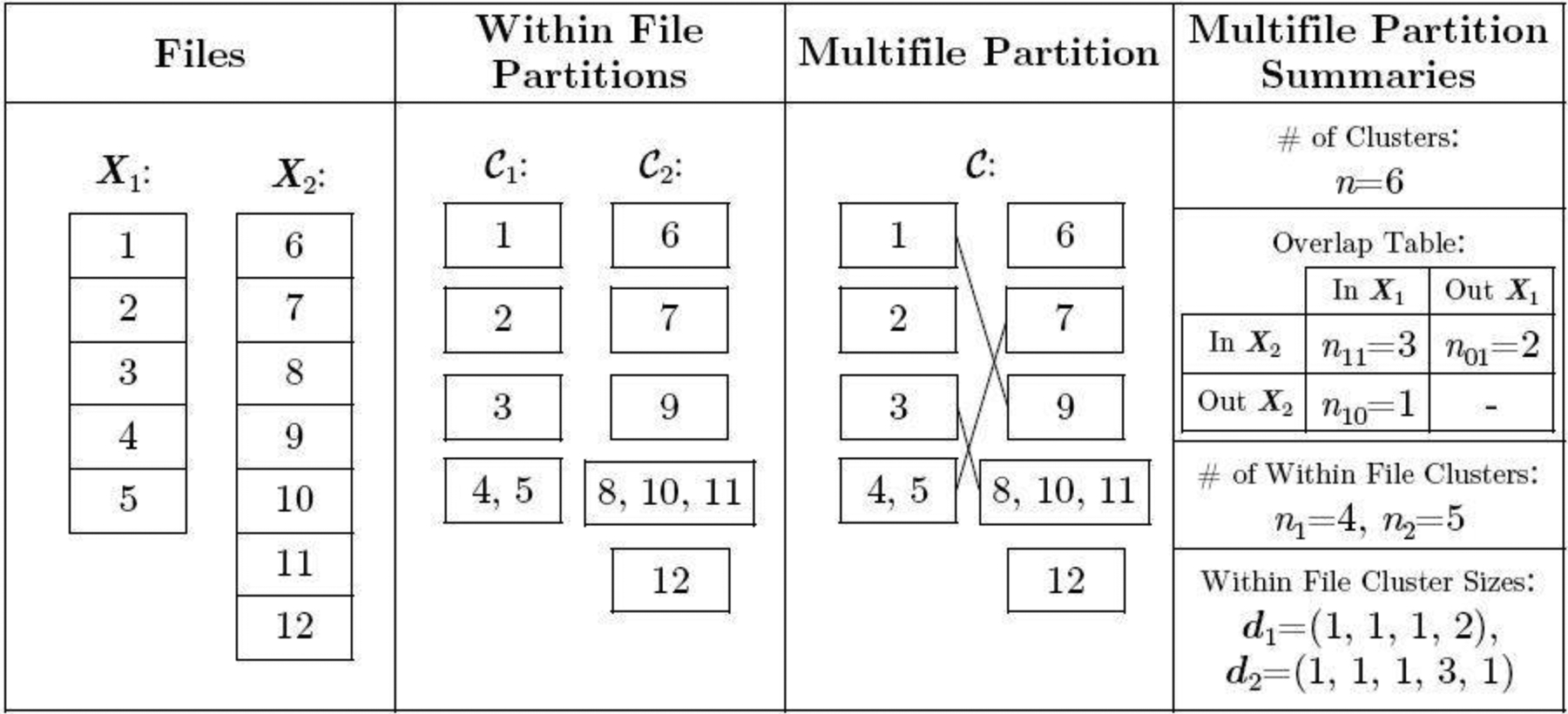
An illustration of a multifile partition of [12], where X1 contains records 1 – 5 and X2 contains records 6 – 12.
3. A Structured Prior for Multifile Partitions
Bayesian approaches to multifile record linkage and duplicate detection require prior distributions on multifile coreference partitions. We present a generative process for multifile partitions, building on our representation introduced in Section 2.1. The idea is to generate a multifile partition by first generating summaries that characterize it, as follows:
Generate the number of unique entities n represented in the datafiles, which also corresponds to the number of clusters of the multifile partition.
Given n, generate an overlap table so that , where . From n we can derive the number of entities in datafile Xk as , where hk is the kth entry of h.
For each k = 1, ⋯, K, given nk, independently generate a set of counts , representing the number of records associated with each entity in file Xk. From dk, we can derive the number of records in file Xk as . Index the r′k records as .
For each k = 1, ⋯, K, given dk, induce a within-file partition by randomly allocating R′k into nk clusters of sizes .
Given the overlap table n and within-file partitions , generate a K-partite matching of the within-file partitions by selecting uniformly at random from the set of all K-partite matchings with overlap table n. By definition, the result is a multifile coreference partition.
By parameterizing each step of this generative process, we can construct a prior distribution for multifile partitions, as we now show.
3.1. Parameterizing the Generative Process
Prior for the Number of Entities or Clusters.
In the absence of substantial prior information, we follow a simple choice for the prior on the number of clusters, by taking a uniform distribution over the integers less than some upper bound, U, i.e. . In practice, we set U to be the actual number of records across all datafiles r, which is observed. More informative specifications are discussed in Appendix A.
Prior for the Overlap Table.
Conditional on n, we use a Dirichlet-multinomial distribution as our prior on the overlap table . Given a collection of positive hyperparameters for each cell of the overlap table, , and letting , the prior for the overlap table under this choice is . Due to conjugacy, α can be interpreted as prior cell counts, which can be used to incorporate prior information about the overlap between datafiles. In the absence of substantial prior information, when the number of files is not too large and the overlap table is not expected to be sparse, we recommend setting α = (1, ⋯, 1). In Appendix A we discuss alternative specifications when the overlap table is expected to be sparse.
Prior for the Within-File Cluster Sizes.
Given the number of entities in datafile Xk, , we generate the within-file cluster sizes assuming that . Here pk (·) represents the probability mass function of a distribution on the positive integers, so that . We do not expect a priori many duplicates per entity, and therefore we expect the counts in dk to be mostly ones or to be very small (Miller et al. 2015, Zanella et al. 2016). We therefore use a similar approach to Klami and Jitta (2016), and use distributions truncated to the range {1, ⋯, Uk}, where Uk is a file-specific upper bound on cluster sizes. We further use distributions where prior mass is concentrated at small values. A default specification is to use a Poisson distribution with mean 1 truncated to {1, ⋯, Uk}, i.e. pk (dki) ∝ (dki!)–1 I (dki ∈{1, ⋯, Uk}). More informative options could be used for pk(·) by using any distribution on {1, ⋯, Uk}, where this could vary from file to file if some files were known to have more or less duplication. See Appendix A for more discussion.
Prior for the Within-File Partitions.
Given the within-file cluster sizes dk, the number of ways of assigning records to clusters 1, ⋯, nk, respectively, is given by the multinomial coefficient , with . However, the ordering of the clusters is irrelevant for constructing the within-file partition of R′k. There are nk ! ways of ordering the nk clusters of , which leads to partitions of R′k into clusters of sizes . We then have .
Prior for the K-Partite Matching.
Given the overlap table n and the within-file partitions , our prior over K-partite matchings of the within-file partitions is uniform. Thus we just need to count the number of K-partite matchings with overlap table n. This is taken care of by Proposition 1, proven in Appendix A.
Proposition 1. The number of K-partite matchings that have the same overlap table, , is . Thus .
The Structured Prior for Multifile Partitions.
Letting quantities followed by mean they are computable from , the density of our structured prior for multifile partitions is
| (1) |
3.2. Comments and Related Literature
The structured prior for multifile partitions allows us to incorporate prior information about the total number of clusters, the overlap between files, and the amount of duplication in each file. If we restrict the prior for the within-file cluster sizes to be pk (dki) = I (dki = 1) for a given datafile Xk, then we enforce the assumption that there are no duplicates in that file. Imposing this restriction for all datafiles leads to the special case of a prior for K-partite matchings, which is of independent interest, as we are not aware of any such constructions outside of the bipartite case (Fortini et al. 2001, Larsen 2005, Sadinle 2017).
Our prior construction, where priors are first placed on interpretable summaries of a partition and then a uniform prior is placed on partitions which have those summaries, mimics the construction of the priors on bipartite matchings of Fortini et al. (2001), Larsen (2005) and Sadinle (2017), and the Kolchin and allelic partition priors of Zanella et al. (2016) and Betancourt, Sosa and Rodríguez (2020). While the Kolchin and allelic partition priors could both be used as priors for multifile partitions, these do not incorporate the datafile membership of records. Using these priors in the multifile setting would imply that the sizes of clusters containing records from only one file have the same prior distribution as the sizes of clusters containing records from two files, which should not be true in general.
Miller et al. (2015) and Zanella et al. (2016) proposed the microclustering property as a desirable requirement for partition priors in the context of duplicate detection: denoting the size of the largest cluster in a partition of [r] by Mr, a prior satisfies the microclustering property if Mr / r → 0 in probability as r →∞. A downside of priors with this property is that they can still allow the size of the largest cluster to go to ∞ as r increases. For this reason Betancourt, Sosa and Rodríguez (2020) introduced the stronger bounded microclustering property, which we believe is more practically important: for any r, Mr is finite with probability 1. Our prior satisfies the bounded microclustering property as .
While our parameter of interest is a partition of r records, the prior developed in this section is a prior for a partition of a random number of records. In practice we condition on the file sizes, , and use the prior , which alters the interpretation of the prior. A similar problem occurs for the Kolchin partition priors of Zanella et al. (2016). This motivated the exchangeable sequences of clusters priors of Betancourt, Zanella and Steorts (2020), which are similar to Kolchin partition priors, but lead to a directly interpretable prior specification. It would be interesting in future work to see if an analogous prior could be developed for our structured prior for multifile partitions. Despite this limitation, we demonstrate in simulations in Section 6 that incorporating strong prior information into our structured prior for multifile partitions can lead to improved frequentist performance over a default specification.
4. A Model for Comparison Data
We now introduce a comparison-based modeling approach to multifile record linkage and duplicate detection, building on the work of Fellegi and Sunter (1969), Jaro (1989), Winkler (1994), Larsen and Rubin (2001), Fortini et al. (2001), Larsen (2005) and Sadinle (2014, 2017). Working under the intuitive assumption that coreferent records will look similar, and non-coreferent records will look dissimilar, these approaches construct statistical models for comparisons computed between each pair of records.
There are two implications of the multifile setting described in Section 2 that are important to consider when constructing a model for the comparison data. First, models for the comparison data should account for the fact that the distribution of the comparisons between record pairs might potentially change across different pairs of files. For example, if files Xk and Xk′ are not accurate, whereas files Xq and Xq′ are, then the distribution of comparisons between Xk and Xk′ will look very different compared with the distribution of comparisons between Xq and Xq′. Second, the fields available for comparison will vary across pairs of files. For example, files Xk and Xk′ may have collected information on a field that file Xq did not. In this scenario, we would like a model that is able to utilize this extra field when linking Xk and Xk′, even though it is not available in Xq. In this section we introduce a Bayesian comparison-based model that explicitly handles the multifile setting by constructing a likelihood function that models comparisons of fields between different pairs of files separately. The separate models are able to adapt to the level of noise of each file pair, and the maximal number of fields are able to be compared for each file pair.
4.1. Comparison Data
We construct comparison vectors for pairs of records to provide evidence for whether they correspond to the same entity. For k ≤ k′, let denote the set of all record pairs between files Xk and Xk′, and let F be the total number of different fields available from the K files. For each file pair (k, k′), k ≤ k′, and record pair , we compare each field f = 1, …, F using a similarity measure , which will depend on the data type of field f. For unstructured categorical fields such as race, can be a binary comparison which checks for agreement. For more structured fields containing strings or numbers, should be able to capture partial agreements. For example, string fields can be compared using a string metric like the Levenshtein edit distance (see e.g. Bilenko et al. 2003), and numeric fields can be compared using absolute differences. Comparison will be missing if field f is not recorded in record i or record j, which includes the case where field f is not recorded in datafiles Xk or Xk′.
While we could directly model the similarity measures , this would require a custom model for each type of comparison, which inherits similar problems to the direct modeling of the fields themselves. Instead, we follow Winkler (1990) and Sadinle (2014, 2017) in dividing the range of into Lf + 1 intervals that represent varying levels of agreement, with If0 representing the highest level of agreement, and representing the lowest level of agreement. We then let if , where larger values of represent larger disagreements between records i and j in field f. Finally, we form the comparison vector . Constructing the comparison data this way allows us to build a generic modeling approach. In particular, extending Fortini et al. (2001), Larsen (2005) and Sadinle (2014, 2017), our model for the comparison data is
where is a multifile partition, denotes record i’s cluster in , indicates that records i and j are coreferent, Mkk′ (mkk′) is a model for the comparison data among coreferent record pairs from the file pair Xk and Xk′, Ukk′ (ukk′) is a model for the comparison data among non-coreferent record pairs from datafile pair Xk and Xk′, and mkk′ and ukk′ are vectors of parameters.
In the next section we make two further assumptions that simplify the model parameterization. Before doing so, we note a few limitations of our comparison-based model. First, computing comparison vectors scales quadratically in the number of records. Second, comparison vectors for different record pairs are not actually independent conditional on the partition (see Section 2 of Tancredi and Liseo 2011). Third, modeling discretized comparisons of record fields represents a loss of information. While the first limitation is computational and unavoidable in the absence of blocking (see Appendix B), the other two limitations are inferential. Despite these limitations, we find in Section 6 that the combination of our structured prior for multifile partitions and our comparison-based model can produce linkage estimates with satisfactory frequentist performance.
4.2. Conditional Independence and Missing Data
Under the assumptions that the fields in the comparison vectors are conditionally independent given the multifile partition of the records and that missing comparisons are ignorable (Sadinle 2014, 2017), the likelihood of the observed comparison data, γobs, becomes
| (2) |
Here , , , , Iobs(·) is an indicator of whether its argument was observed, and Φ = (m, u) where m collects all of the and u collects all of the . For a given multifile partition , represents the number of record pairs in that belong to the same cluster with observed agreement at level l in field f, and represents the number of record pairs in that do not belong to the same cluster with observed agreement at level l in field f.
5. Bayesian Estimation of Multifile Partitions
Bayesian estimation of the multifile coreference partition is based on the posterior distribution , where is our structured prior for multifile partitions (1), is the likelihood from our model for comparison data (2), and p(Φ) represents a prior distribution for the Φ = (m, u) model parameters. We now specify this prior p(Φ), outline a Gibbs sampler to sample from , and present a strategy to obtain point estimates of the multifile partition .
5.1. Priors for m and u
We will use independent, conditionally conjugate priors for and , namely and . In this article we will use a default specification of . We believe this prior specification is sensible for the u parameters, following the discussion in Section 3.2 of Sadinle (2014), as comparisons amongst non-coreferent records are likely to be highly variable and it is more likely than not that eliciting meaningful priors for them is too difficult. For the m parameters, it might be desirable in certain applications to introduce more information into the prior. For example, one could set to incorporate the prior belief that higher levels of agreement should have larger prior probability than lower levels of agreement. Another route would be to use the sequential parameterization of the m parameters, and the associated prior recommendations, described in Sadinle (2014).
5.2. Posterior Sampling
In Appendix B we outline a Gibbs sampler that produces a sequence of samples from the posterior distribution , which we will use to obtain Monte Carlo approximations of posterior expectations involved in the derivation of point estimates , as presented in the next section. In Appendix B, we discuss the computational complexity of the Gibbs sampler, how computational performance can be improved through the usage of indexing techniques, and the initialization of the Gibbs sampler.
5.3. Point Estimation
In a Bayesian setting, one can obtain a point estimate of the multifile partition using the posterior and a loss function . The Bayes estimate is the multifile partition that minimizes the expected posterior loss , although in practice such expectations are approximated using posterior samples. Previous examples of loss functions for partitions included Binder’s loss (Binder 1978) and the variation of information (Meilă 2007), both recently surveyed in Wade and Ghahramani (2018). The quadratic and absolute losses presented in Tancredi and Liseo (2011) are special cases of Binder’s loss, and Steorts et al. (2016) drew connections between their proposed maximal matching sets and the losses of Tancredi and Liseo (2011).
In many applications there may be much uncertainty on the linkage decision for some records in the datafiles. For example, in Figure 1 it is unclear which of the records with last name “Smith” are coreferent. It is thus desirable to leave decisions for some records unresolved, so that the records can be hand-checked during a clerical review, which is common in practice (see e.g. Ball and Price 2019). In the classification literature, leaving some decisions unresolved is done through a reject option (see e.g. Herbei and Wegkamp 2006), which here we will refer to as an abstain option. We will refer to point estimates with and without an abstain option as partial estimates and full estimates, respectively. We now present a family of loss functions for multifile partitions which incorporate an abstain option, building upon the family of loss functions for bipartite matchings presented in Sadinle (2017).
5.3.1. A Family of Loss Functions with an Abstain Option
For the purpose of this section we will represent a multifile partition as a vector Z = (Z1, ⋯, Zr) of labels, where Zi ∈{1, …, r}, such that Zi = Zj if . We represent a Bayes estimate here as a vector Z = (Z1, …, Zr), where Zi ∈{1, …, r, A}, with A representing an abstain option intended for records whose linkage decisions are not clear and need further review. We assign different losses to using the abstain option and to different types of matching errors. We propose to compute the overall loss additively, as . To introduce the expression for the ith-record-specific loss Li (Z, Z), we use the notation Δij = I (Zi = Zj), and likewise .
The proposed individual loss for record i is
| (3) |
That is, λA represents the loss from abstaining from making a decision; λFNM is the loss from a false non-match (FNM) decision, that is, deciding that record i does not match any other record when in fact it does ; λFM1 is the loss from a type 1 false match (FM1) decision, that is, deciding that record i matches other records when it does not actually match any other record ; and λFM2 is the loss from a type 2 false match (FM2), that is, a false match decision when record i is matched to other records but it does not match all of the records it should be matching .
The posterior expected loss is , where
| (4) |
and quantities computed with respect to the posterior distribution, , can all be approximated using posterior samples. While this presentation is for general positive losses λFNM, λFM1, λFM2 and λA, these only have to be specified up to a proportionality constant (Sadinle 2017). If we do not want to allow the abstain option, then we can set λA = ∞ and the derived full estimate Z will have a linkage decision for all records. Although we have been using partition labelings Z, the expressions in (3) and (4) are invariant to different labelings of the same partition. In the two-file case, Sadinle (2017) provided guidance on how to specify the individual losses λFNM, λFM1, λFM2 and λA in cases where there is a notion of false matches being worse than false non-matches or vise versa. Sadinle (2017) also gave recommendations for default values of these losses that lead to good frequentist performance in terms not over- or under-matching across repeated samples. In Appendix C, we discuss how our proposed loss function differs from the loss function of Sadinle (2017) and propose a strategy for approximating the Bayes estimate.
6. Simulation Studies
To explore the performance of our proposed approach for linking three duplicate-free files, as in the application to the Colombian homicide record systems of Appendix E, we present two simulation studies under varying scenarios of measurement error and datafile overlap. The two studies correspond to scenarios with equal and unequal measurement error across files, respectively. Both studies present results based on full estimates. In Appendix D we further explore the performance of our proposed approach for linking three files with duplicates, with results based on full and partial estimates.
6.1. General Setup
We start by describing the general characteristics of the simulations. For each of the simulation scenarios we conduct 100 replications, for each of which we generate three files as follows. For each of n = 500 entities, is drawn from a categorical distribution with probabilities , where h represents the subset of files the entity appears in, and so we change the values of across simulation scenarios to represent varying amounts of file overlap. Files are then created by generating the implied number of records for each entity. In the additional simulations considered in Appendix D, the generated number of records for each entity depends not only on h, but also on the duplication mechanism.
All records are generated using a synthetic data generator developed in Tran et al. (2013), which allows for the incorporation of different forms of measurement error in individual fields, along with dependencies between fields we would expect in applications. The data generator first generates clean records before distorting them to create the observed records. In particular, each observed record will have a fixed number of erroneous fields, where errors selected uniformly at random from a set of field dependent errors displayed in Table 3 of Sadinle (2014) (reproduced in Appendix D), with a maximum of two errors per field. We generate records with seven fields of information: sex, given name, family name, age, occupation, postal code, and phone number.
For each simulation replicate, we construct comparison vectors as given in Table 4 of Sadinle (2014) (reproduced in Appendix D). We use the model for comparison data proposed in Section 4 with flat priors on m and u as discussed in Section 5.1, and the structured prior proposed in Section 3 with a uniform prior on the number of clusters and α = (1, ⋯, 1) as described in Section 3.1. Using the Gibbs sampler presented in Appendix B we obtain 1, 000 samples from the posterior distribution of multifile partitions, and discard the first 100 as burn-in. In Appendix D we discuss convergence of the Gibbs sampler, present running times of the proposed approach, and present an extra simulation exploring the running time of the approach with a larger number of records. We then approximate the Bayes estimate Z for multifile partitions using the loss function described in Section 5.3.1 as described in Appendix C. For full estimates, we use the default values of λFNM = λFM1 = 1 and λFM2 = 2 recommended by Sadinle (2017). In Appendix D we explore alternative specifications of the loss function.
We will assess the performance of the Bayes estimate using precision and recall with respect to the true coreference partition Z. Let be the set of all record pairs. Using notation from Section 5.3.1, let be the number of true matches (record pairs correctly declared coreferent), be the number of false matches (record pairs incorrectly declared coreferent), and the number of false non-matches (record pairs incorrectly declared non-coreferent). Then precision is TM (Z, Z) / [TM (Z, Z) + FM (Z, Z)], the proportion of record pairs declared as coreferent that were truly coreferent, and recall is TM (Z, Z) / [TM (Z, Z) + FNM (Z, Z)], the proportion of record pairs that were truly coreferent that were correctly declared as coreferent. Perfect performance corresponds to precision and recall both being 1. In the simulations, we computed the median, 2nd, and 98th percentiles of these measures over the 100 replicate data sets. Additionally, in Appendix D, we assess the performance of the Bayes estimate when estimating the number of entities, n.
6.2. Duplicate-Free Files, Equal Errors Across Files
In this simulation study we explore the performance of our methodology by varying the number of erroneous fields per record over {1,2,3,5}, and also varying , which determines the amount of overlap, over four scenarios:
High Overlap: p001 = p010 = p100 = 0.4 / 3, p011 = p101 = p110 = 0.15, p111 = 0.15,
Medium Overlap: p001 = p010 = p100 = 0.7 / 3, p011 = p101 = p110 = 0.05, p111 = 0.15,
Low Overlap: p001 = p010 = p100 = 0.8 / 3, p011 = p101 = p110 = 0.05 / 3, p111 = 0.15,
No-Three-File Overlap: p001 = p010 = p100 = 0.55 / 3, p011 = p101 = p110 = 0.15, p111 = 0.
These are intended to represent a range of scenarios that could occur in practice. In the high overlap scenario 60% of the entities are expected to be in more than one datafile, in the low overlap scenario 80% of the entities are expected to be represented in a single datafile, and in the no-three-file overlap scenario no entities are represented in all datafiles.
To implement our methodology, in addition to the general set-up described in Section 6.1, we restrict the prior for the within-file cluster sizes so that they have size one with probability one, incorporating the assumption of no-duplication within files (see Section 3.2). Imposing this restriction for all datafiles leads to a prior for tripartite matchings. To illustrate the impact of using our structured prior, we compare with the results obtained using our model for comparison data with a flat prior on tripartite matchings.
The results of the simulation are seen in Figure 3. We see that our proposed approach performs consistently well across different settings, with the exception of the no-three-file overlap setting under high measurement error, where the precision decreases dramatically. The approach using a flat prior on tripartite matchings has poor precision in comparison, and it is particularly low when the amount of overlap is low. This suggests that our structured prior improves upon the flat prior by protecting against over-matching (declaring noncoreferent record pairs as coreferent). In Appendix D we demonstrate how the performance in the no-three-file overlap setting can be improved through the incorporation of an informative prior for the overlap table through α.
Fig. 3.

Performance comparison for simulation with equal measurement error across files. Black lines refer to results under our structured prior, grey lines to results under the flat prior, solid lines show medians, and dashed lines show 2nd and 98th percentiles.
6.3. Duplicate-Free Files, Unequal Errors Across Files
In this simulation study we have different patterns of measurement error across the three files. Rather than each field in each record having a chance of being erroneous according to Table 3 of Sadinle (2014), we will use the following measurement error mechanism to generate the data. For each record in the first file, age is missing, given name has up to seven errors, and all other fields are error free. For each record in the second file, sex and occupation are missing, last name has up to seven errors, and all other fields are error free. For each record in the third file, phone number and postal code have up to seven errors and all other fields are error free. Under this measurement error mechanism, there is enough information in the error free fields to inform pairwise linkage of the files. We further vary over the no-three-file and high overlap settings from Section 6.2.
Our goal in this study is to demonstrate that having both the structured prior for partitions and the separate models for comparison data from each file-pair can lead to better performance than not having these components. We will compare our model as described in Section 6.2 to both our model for comparison data with a flat prior on tripartite matchings (as in Section 6.2) and a simplification of our model for comparison data using a single model for all file-pairs but with our structured prior for partitions.
The results of the simulation are given in Figure 4. We see that our proposed approach outperforms both alternative approaches in both precision and recall in both overlap settings. This suggests that both the structured prior for tripartite matchings and the separate models for comparison data from each file-pair can help improve performance over alternative approaches. We note that in the no-three-file (high) overlap setting the precision of the proposed approach is greater than or equal to the precision of the approach using a single model for all file-pairs in 98 (100) of the 100 replications.
Fig. 4.

Performance comparison for simulation with unequal measurement error across files. “Proposed” refers to our proposed approach, “Single Model” refers to the approach using a single model for all file-pairs and our structured prior for partitions, and “Flat Prior” refers to the approach using our model for comparison data with a flat prior on tripartite matchings. Dots show medians, and bars show 2nd and 98th percentiles.
7. Discussion and Future Work
The methodology proposed in this article makes three contributions. First, the multifile partition parameterization, specific to the context of multifile record linkage and duplicate detection, allows for the construction of our structured prior for partitions, which provides a flexible mechanism for incorporating prior information about the data collection processes of the files. This prior is applicable to any Bayesian approach which requires a prior on partitions, including direct-modeling approaches such as Steorts et al. (2016). We are not aware of any priors for K-partite matchings when K > 2, so we hope our construction will lead to more development in this area. The second contribution is an extension of previous comparison-based models that explicitly handles the multifile setting. Allowing separate models for comparison data from each file pair leads to higher quality linkage. The third is a novel loss function for multifile partitions which can be used to derive Bayes estimates with good frequentist properties. Importantly, the loss function allows for linkage decisions to be left unresolved for records with large matching uncertainty. As with our structured prior on partitions, the loss function is applicable to any Bayesian approach which requires point estimates of partitions, including direct-modeling approaches.
There are a number of directions for future work. One direction is the modeling of dependencies between the comparison fields (see e.g. Larsen and Rubin 2001), which should further improve the quality of the linkage. Another direction is the development of approaches to jointly link records and perform a downstream analysis, thereby propagating the uncertainty from the linkage. See Section 7.2 of Binette and Steorts (2020) for a recent review of such joint models. In this direction, a natural task to consider next is population size estimation, where the linkage of the datafiles plays a central role (Tancredi and Liseo 2011, Tancredi et al. 2020).
Supplementary Material
Acknowledgments
This research was supported by the NSF under grant SES-1852841 and by the NIH-NIDA under award R21DA051756. The authors thank Jorge A. Restrepo for providing the Colombian homicide data.
Footnotes
SUPPLEMENTARY MATERIAL
Appendices: Supplementary appendices A–E. (.pdf file)
R-package multilink: Code implementing the proposed methodology. (.tar.gz file)
Simulation code and data: Code and data used to run simulations. (.zip file)
References
- Ball P and Price M (2019), ‘Using statistics to assess lethal violence in civil and inter-state war’, Annual Review of Statistics and its Application 6, 63–84. [Google Scholar]
- Betancourt B, Sosa J and Rodríguez A (2020), ‘A Prior for Record Linkage Based on Allelic Partitions’, arXiv preprint arXiv:2008.10118. [Google Scholar]
- Betancourt B, Zanella G and Steorts RC (2020), ‘Random Partition Models for Microclustering Tasks’, Journal of the American Statistical Association pp. 1–13. [Google Scholar]
- Bilenko M, Mooney RJ, Cohen WW, Ravikumar P and Fienberg SE (2003), ‘Adaptive Name Matching in Information Integration’, IEEE Intelligent Systems 18(5), 16–23. [Google Scholar]
- Binder DA (1978), ‘Bayesian cluster analysis’, Biometrika 65(1), 31–38. [Google Scholar]
- Binette O and Steorts RC (2020), ‘(Almost) All of Entity Resolution’, arXiv preprint arXiv:2008.04443. [DOI] [PubMed] [Google Scholar]
- Bird SM and King R (2018), ‘Multiple systems estimation (or capture-recapture estimation) to inform public policy’, Annual Review of Statistics and its Application 5, 95–118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Enamorado T, Fifield B and Imai K (2019), ‘Using a probabilistic model to assist merging of large-scale administrative records’, American Political Science Review 113(2), 353–371. [Google Scholar]
- Enamorado T and Steorts RC (2020), Probabilistic Blocking and Distributed Bayesian Entity Resolution, in ‘International Conference on Privacy in Statistical Databases’, Springer, pp. 224–239. [Google Scholar]
- Fellegi IP and Sunter AB (1969), ‘A theory for record linkage’, Journal of the American Statistical Association 64(328), 1183–1210. [Google Scholar]
- Fortini M, Liseo B, Nuccitelli A and Scanu M (2001), ‘On Bayesian record linkage’, Research in Official Statistics 4(1), 185–198. [Google Scholar]
- Herbei R and Wegkamp MH (2006), ‘Classification with reject option’, Canadian Journal of Statistics 34(4), 709–721. [Google Scholar]
- Hof MH, Ravelli AC and Zwinderman AH (2017), ‘A probabilistic record linkage model for survival data’, Journal of the American Statistical Association 112(520), 1504–1515. [Google Scholar]
- Jaro MA (1989), ‘Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida’, Journal of the American Statistical Association 84(406), 414–420. [Google Scholar]
- Klami A and Jitta A (2016), Probabilistic size-constrained microclustering, in ‘ Proceedings of the Thirty-Second Conference on Uncertainty in Artificial Intelligence’, AUAI Press, pp. 329–338. [Google Scholar]
- Larsen MD (2005), Advances in Record Linkage Theory: Hierarchical Bayesian Record Linkage Theory, in ‘Proceedings of the Section on Survey Research Methods’, American Statistical Association, pp. 3277–3284. [Google Scholar]
- Larsen MD and Rubin DB (2001), ‘Iterative Automated Record Linkage Using Mixture Models’, Journal of the American Statistical Association 96(453), 32–41. [Google Scholar]
- Liseo B and Tancredi A (2011), ‘Bayesian Estimation of Population Size via Linkage of Multivariate Normal Data Sets’, Journal of Official Statistics 27(3), 491–505. [Google Scholar]
- Marchant NG, Kaplan A, Elazar DN, Rubinstein BI and Steorts RC (2021), ‘d-blink: Distributed end-to-end Bayesian entity resolution’, Journal of Computational and Graphical Statistics pp. 1–16. [Google Scholar]
- Matsakis NE (2010), Active Duplicate Detection with Bayesian Nonparametric Models, PhD thesis, Massachusetts Institute of Technology. [Google Scholar]
- Meilă M (2007), ‘Comparing clusteringsan information based distance’, Journal of Multivariate Analysis 98(5), 873–895. [Google Scholar]
- Miller J, Betancourt B, Zaidi A, Wallach H and Steorts RC (2015), ‘Microclustering: When the cluster sizes grow sublinearly with the size of the data set’, arXiv preprint arXiv:1512.00792. [Google Scholar]
- Sadinle M (2014), ‘Detecting duplicates in a homicide registry using a Bayesian partitioning approach’, The Annals of Applied Statistics 8(4), 2404–2434. [Google Scholar]
- Sadinle M (2017), ‘Bayesian estimation of bipartite matchings for record linkage ‘, Journal of the American Statistical Association 112(518), 600–612. [Google Scholar]
- Sadinle M and Fienberg SE (2013), ‘A Generalized Fellegi–Sunter Framework for Multiple Record Linkage With Application to Homicide Record Systems’, Journal of the American Statistical Association 108(502), 385–397. [Google Scholar]
- Steorts RC (2015), ‘Entity Resolution with Empirically Motivated Priors’, Bayesian Analysis 10(4), 849–875. [Google Scholar]
- Steorts RC, Hall R and Fienberg SE (2016), ‘A Bayesian approach to graphical record linkage and deduplication’, Journal of the American Statistical Association 111(516), 1660–1672. [Google Scholar]
- Tancredi A and Liseo B (2011), ‘A Hierarchical Bayesian Approach to Record Linkage and Size Population Problems’, Annals of Applied Statistics 5(2B), 1553–1585. [Google Scholar]
- Tancredi A, Steorts R and Liseo B (2020), ‘A Unified Framework for De-Duplication and Population Size Estimation (with Discussion)’, Bayesian Analysis 15(2), 633–682. [Google Scholar]
- Tran K-N, Vatsalan D and Christen P (2013), GeCo: an online personal data generator and corruptor, in ‘Proceedings of the 22nd ACM International Conference on Information & Knowledge Management’, pp. 2473–2476. [Google Scholar]
- Wade S and Ghahramani Z (2018), ‘Bayesian cluster analysis: Point estimation and credible balls (with discussion)’, Bayesian Analysis 13(2), 559–626. [Google Scholar]
- Winkler WE (1990), String Comparator Metrics and Enhanced Decision Rules in the Fellegi–Sunter Model of Record Linkage, in ‘Proceedings of the Section on Survey Research Methods’, American Statistical Association, pp. 354–359. [Google Scholar]
- Winkler WE (1994), Advanced Methods for Record Linkage, in ‘Proceedings of the Section on Survey Research Methods’, American Statistical Association, pp. 467–472. [Google Scholar]
- Zanella G, Betancourt B, Miller JW, Wallach H, Zaidi A and Steorts RC (2016), Flexible models for microclustering with application to entity resolution, in ‘Advances in Neural Information Processing Systems’, pp. 1417–1425. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.