

Abstract
This paper introduces an innovative approach aimed at enhancing multi-attribute decision-making through the utilization of fuzzy pattern recognition, with a specific emphasis on engaging decision-makers more effectively. The methodology establishes a multi-attribute fuzzy pattern recognition model within a hybrid information system framework. It categorizes attributes into natural and abstract groups, standardizes them, and employs membership functions to transform them into degrees of membership. This adaptable approach permits the derivation of various decision criteria from the hybrid system. Subsequently, a testing set is generated from this system, and a suitable fuzzy operator is selected. The optimal solution is determined by assessing the similarity between the standard and testing sets. To underscore its effectiveness, a practical example is provided. Crucially, in the realm of multi-attribute decision-making, our method simplifies the process by reducing computational steps in contrast to the conventional TOPSIS model, while maintaining consistent outcomes. This streamlines the decision-making process and reduces complexity. We also demonstrate its applicability in multi-objective decision-making through a case study evaluating exemplary educators, thereby highlighting its adaptability and effectiveness. This method exhibits significant promise for enhancing multi-attribute decision-making and offers practical applications.
Subject terms: Applied mathematics, Information technology, Scientific data
Introduction
The emergence of multi-attribute fuzzy pattern decision-making is an eloquent response to the intricate quandaries presented by uncertainty, notably encompassing the pervasive haze of ambiguity woven into the tapestry of decision-making processes. In the realm of daily existence, the versatile tool of fuzzy language often finds its application to encapsulate the nebulous facets inherent in various phenomena. In such intricate settings, decision-making experts recurrently harness fuzzy language as a means to scrutinize divergent solutions, a strategic recourse driven by their inherent cognitive confines and subjective predilections.
However, the journey to effective multi-attribute fuzzy pattern decision-making has encountered methodological intricacies. Dong1 proffered a methodology pivoting on the fuzzy number vertex method to grapple with such complexities; however, its pragmatic feasibility has been marred by its inherent intricacy. The landscape of weight determination within the realm of multi-attribute fuzzy pattern decision-making has witnessed the inception of various strategies, encompassing the grayscale analysis method, the augmented fuzzy weighted average, and the upgraded fuzzy weighted average. The harmonious fusion of fuzzy numbers with the foundational bedrock of original multi-attribute decision-making paradigms has engendered enhanced congruence between theoretical constructs and practical exigencies. Noteworthy iterations of fuzzy numbers encompass intuitionistic triangular fuzzy numbers, intuitionistic trapezoidal fuzzy numbers, and Pythagorean fuzzy numbers.
Yue2 introduced a group decision model entrenched in the bastion of intuitionistic fuzzy numbers, adeptly amalgamating objective values while simultaneously streamlining the decision-making process. Concomitantly, Yi et al.3 ingeniously unveiled a three-branch decision model steeped in the edifice of Pythagorean fuzzy theory, a feat that encompassed the optimization of scoring functions and the novel instantiation of an action utility function for risk assessment. Subsequent contributions emanated from Zhang et al.4, who conceived a multi-attribute decision-making methodology scaffolded on the tenets of intuitionistic trapezoidal fuzzy numbers. This intricate stratagem encompassed the calculus of distances between trapezoidal fuzzy numbers, attribute weight determination via entropy and grayscale analysis, and the harmonious amalgamation of positive and negative ideal solutions in the framework of TOPSIS for the computation of grayscale relational projection values, culminating in the selection of the optimal alternative.
Concurrently, scholars such as Atanassov et al.5 embarked upon refining decision-making procedures through the strategic augmentation and extension of generalized net models. In a similar vein, Kacprzyk et al.5 furnished a robust framework encapsulating networks and fuzzy systems, alongside an auxiliary technique for inter-criteria analysis involving a three-dimensional exponential matrix. The visionary enterprise of Deng et al.6 manifested in the proposal of adversarial game decision-making within the realm of a fuzzy decision environment, this being facilitated through the utilization of fuzzy contradictory theory to model the intricate fabric of decision-making interactions. Meanwhile, the underpinning methodologies underwent evolution, an evolution epitomized by Zheng et al.7 who adroitly interwove trust relationships into a multi-attribute decision-making framework. The perennial conundrum of curtailing preference reversal within the precincts of the TOPSIS scheme became the focal point of intervention by Wang et al.8.
A retrospective glance into the 1970s unfurls the inception of the hierarchical analysis method9, a pivotal approach that methodically juxtaposes attribute merits and demerits across each tier to judiciously select a solution. Meanwhile, the entropy–TOPSIS method10,11 stands as a preeminent paradigm for multi-attribute decision assessment, enjoying wide-ranging applications across diverse industrial and agricultural spheres. Nonetheless, the actual domain of decision-making is characterized by a plethora of reference points and the enigma of pervasive fuzziness, compelling the expeditious assimilation of fuzzy sets12 and rough sets13 within the precincts of decision science. In the arena of fuzzy decision making, the harmonious symbiosis of fuzzy numbers14–22 with the scaffolding of original multi-attribute decision-making methodologies has engendered heightened compatibility between theoretical constructs and practical exigencies.
Within this intricate realm of information systems, Yao's three-branch decision method23–27 has ascended to prominence as a method of choice for the extraction of decision rules. This method, steering clear of conventional binary decision paradigms, introduces the novel dimension of delayed decision-making dynamics, aligning more astutely with the intricate nuances that typify human decision behavior. Notwithstanding, decision methods predicated on binary relations often bestow a solitary decision spectrum, circumscribed by the selection of binary relations. Notably, these information system-rooted decision methodologies, while seminal, at times grapple with the intricate task of effectively ranking solutions within the labyrinthine contours of multi-attribute decision-making. Regarding the latest multi-attribute decision-making methods, there are several studies concerning the application of multi-attribute decision-ranking methods28–30. In recent years, the application of fuzzy sets and information systems in multi-attribute decision making—although increasingly saturated—still has a certain degree of relevance31–37. The application of fuzzy pattern recognition in the field of medicine38 or in combination with fuzzy numbers39 for the study of intuitionistic fuzzy sets and fuzzy pattern recognition40 is also very popular. In addition, fuzzy pattern recognition is also applied in water quality identification41.
With the rapid advancement of information and computer technology, pattern recognition plays a pivotal role in the field of artificial intelligence. Fuzzy pattern recognition, in particular, finds extensive application in the domain of assessment. However, in the context of multi-attribute fuzzy pattern decision-making, the specific application of fuzzy pattern recognition remains underexplored. Concurrently, driven by the progress and development of modern technology, the trajectory of the multi-attribute decision-making process is shifting from a purely rational decision-making paradigm towards a more reference-based approach, grounded in the preferences of decision-makers. The increasingly intertwined relationship between behavioral decision-making and superiority underscores this evolution.
To transcend this landscape, this study adopts an innovative approach by integrating fuzzy pattern recognition into information systems. Through this approach, decision-makers' preferences and requirements are integrated into the process of establishing criterion sets and attributing weights, enhancing the fidelity to decision-makers’ actual needs. Additionally, due to the flexibility inherent in selecting the standard set, adjustments can be made in line with decision-makers' varying requirements, thereby rendering the overall decision-making process more adaptive and pliable. In contrast to traditional multi-attribute fuzzy pattern decision-making methods, the approach employed in this study, based on fuzzy pattern recognition, demonstrates enhanced efficiency and conciseness. It eliminates the need to determine positive and negative ideal solutions based on available information, requiring only the identification of a standard set and the selection of the same membership function to compute the set of interest. As a result, the computational process becomes more streamlined and efficient. Furthermore, the calculated results based on the fuzzy pattern recognition model are more reliable and accurate, thus furnishing decision-makers with increased confidence in their decision-making foundation.
In summation, this study introduces fuzzy pattern recognition into the realm of multi-attribute decision-making, effecting innovative enhancements to the decision-making process by aligning it more closely with actual requirements and bolstering its efficiency and reliability. This innovation not only expands the application scope of multi-attribute decision-making methods but also furnishes decision-makers with optimized and intelligent decision support.
This paper consists of four parts: Section “Introduction” presents the background of the investigation, Section “Preliminaries” provides preparatory knowledge, Section “Information system-based multi-attribute fuzzy pattern decision model” provides the algorithmic model, and Section “Example of an algorithm” provides a comparative calculation example with the traditional multi-attribute decision-making method TOPSIS to verify the model’s feasibility and superiority. An example of a company selecting talent is applied to verify the feasibility of multi-objective decision making.
Preliminaries
Fuzzy set operation rules
Definition 1 (Ref.2)
Let be a universe. A fuzzy set or a fuzzy subset of is defined by a function that assigns each element of to a value We use to denote the family of all fuzzy subsets of , i.e., the set of all functions from to , which is called the fuzzy power set of
Let there be two fuzzy sets and in a universe with affiliation functions of and , respectively. Then, the merge, intersection, and complement operations for fuzzy sets are defined as follows:
Merge: ;
Intersection: ;
Complement: .
Principles of fuzzy pattern recognition
Definition 2 (Ref.44)
Let be a fuzzy power set of the universe ; are all fuzzy subsets of . If the mapping satisfies
Normalization: ;
Symmetry: ;
Inequality: , then is called the closeness of to . is defined as the closeness function on .
Definition 3 (Ref.45)
Let be n fuzzy sets on a universe , and be an object to be identified on ; if
then we say that . is defined as the closeness function on .
Note: This definition is the principle of maximum affiliation in fuzzy pattern recognition.
Definition 4 (Ref.45)
Consider a universe and any mapping from to the closed interval .
Both determine , the fuzzy subset of of becomes the membership function of the fuzzy subset, is called the membership degree of u to , and a fuzzy subset is called a fuzzy set if there is no misunderstanding.
Fuzzy pattern recognition steps
The steps of fuzzy pattern recognition are given below41:
Step 1 Select the set of characteristic factors of the pattern ; each object has m sample attributes that make up the set of ; this forms the matrix of the measured attributes ;
Step 2 Classify attributes m by level c criteria model, then we have the attribute criteria matrix. ;
Step 3 Use the normalization formula to eliminate the influence of the physical dimension of different attribute characteristics and normalize characteristic values. We obtain the relative affiliation of the attributes of the sample to be identified to obtain the relative affiliation matrix of the attributes of the sample to be identified ;
Step 4 Similar to Step 3, we obtain the relative affiliation of each standard sample attribute and, similarly, obtain the relative affiliation matrix , ;
Step 5 Determine the attribute weights , which are generally determined by the entropy weighting method or expert weighting method;
Step 6 Construct a theoretical model for fuzzy pattern recognition, and construct a fuzzy pattern recognition matrix . =;
Step 7 Calculate the comprehensive evaluation index , (, which is the closeness of the solution. Then rank the best solution according to the principle of monological proximity.
Commonly used closeness formula
Hamming distance38
| 1 |
Euclidean distance38
| 2 |
Information system
Definition 5 (Ref.25)
Reference () Call an information system, where is a non-empty finite set of objects, ; denote the set of attributes as ; is an information function, and , we have .
On this basis, a multi-attribute fuzzy pattern decision-making method based on information systems is proposed.
Information system-based multi-attribute fuzzy pattern decision model
Information system establishment
The attributes are classified according to the characteristics of the values of different attributes in the information system. All affiliation functions and values are included.
Definition 1
A set of an information system is established based on the decision object, where is a non-empty finite set of objects, ; the set of attributes is , ; and are the value domains of natural and abstract attributes, respectively; is the information function. , , we have ; is the set of affiliation functions; is the set of affiliation values, and , , we have .
is a non-empty finite set of natural attributes, denoted as . is defined as a non-empty set of abstract attributes, which are expressed as . Their attribute values are in a non-numeric form such as language. The number of elements in is the same as the number of elements in , as shown in Table 1.
Table 1.
Improved information system GIS.
Compared with the traditional hybrid information system (Mixed Attribute Value Information System), the improved hybrid information system divides attributes by their value characteristics. This allows for separate data processing for different attribute value characteristics and improves data processing speed. In the process of selecting conditional and decision attributes, the improved hybrid information system can determine attributes according to the decision maker’s preferences, i.e., the selection of relatively rational natural attributes or abstract attributes that take into account the subjective opinions of decision makers. The decision maker’s preference is taken into account in the process of selecting decision-related and conditional attributes. The set of affiliation functions and the set of affiliation degrees are added to the hybrid information system. This facilitates the selection of the affiliation function after normalizing the attribute values and determining the associated values. Different affiliation functions exhibit different attribute characteristics, so the introduction of the affiliation function set helps the decision maker to express preference-related information.
The following is an example of how to structure the required information system based on existing information.
Example 1
Two companies of different sizes in city A, and , have to choose a partner company for their city B strategy, and there are three companies in city B, , , and , for which they can choose. The relevant information is presented in Tables 2 and 3 below.
Table 2.
Companies’ information in City B.
Table 3.
Information sheet for real estate companies’ projects and renovation companies.
The information system is constructed according to Tables 2 and 3, where the domain ; the set of attributes , where the natural attribute , and the abstract attribute ; the attribute values are the values corresponding to each attribute in Table 3. Set the set of affiliation functions to .
Establishment of the standard set and the set to be tested
The following algorithm is based on fuzzy pattern recognition theory as a decision method, which was first proposed in 1991 by Chinese scholar Chen, and has since been widely used in the field of agriculture42; however, the decision method has certain drawbacks and tends to adopt empiricism in the process of determining evaluation indicators, while the determination of attribute weights is also limited to expert-given or other subjective attribute determination methods. In addition, fuzzy pattern recognition can also perform multi-objective matching, i.e., set-to-set matching in addition to point-to-set matching, which is more suitable for multi-objective decision making. Both methods are applied in this algorithm for fuzzy pattern recognition.
Step 1 Building the information system GIS.
If each attribute in is split into levels, and the values of the abstract attribute are converted into constants between 0 and 1, then each level is divided as shown in Table 4.
Table 4.
Division of abstract attribute levels.
| 1 | 1 | 1 |
The value obtained after the division is used as the normalized value of the attribute.
Step 2 Classify the objective function and find the weights.
The target attributes are selected from the attribute set and classified into attributes. The default target attribute is mixed, i.e., the natural attributes and For abstract attributes, the normalized values are determined according to the attribute abstraction hierarchy in Step 1. To eliminate the influence of different physical scales, decision-making-normalized values are compared with the maximum values of the same attribute.
In the domain of a standard information system, there are attributes, attributes are selected as target attributes—each target attribute is used as a reference sequence, and the remaining attributes are used to calculate the correlation to the target attribute using correlation analysis—and the sum of the correlations and the influence weight is obtained. Please refer to Table 5.
| 3 |
| 4 |
Table 5.
Relative values of natural attributes after removing physical dimensions.
The objective attributes are assigned weights using subjective or expert assignment methods so that the sum of the objective function’s attribute weights is 1.
Step 3 Determine the criterion set by choosing the affiliation function.
To construct a fuzzy set with each target attribute and non-target attribute, all fuzzy sets are merged to obtain the criterion set . This can be used to satisfy the decision makers’ preferences. The criteria matrix is constructed by determining the criteria scheme from the target attribute weights.
There are attributes in the subject of a standard information system’s domain, and attributes are selected as target attributes. The relative affiliation of the target attribute is denoted by , and the relative affiliation of the non-target attribute is denoted by.
The target attribute carries a weight , and satisfies,
| 5 |
and
| 6 |
Thus, the standard set is , and the standard matrix is . Example 2 is given below to verify the feasibility of Step 2.
Example 2
Using the direct economic losses of disasters as the target attribute, the influence weight of other attributes was calculated, as shown in Table 6.
Table 6.
2000–2003 disaster loss table.
| Year | 2000 | 2001 | 2002 | 2003 |
|---|---|---|---|---|
| Direct economic losses (RMB billion) | 2045.30 | 1942.20 | 1637.20 | 1884.20 |
| Crop damage area (thousand hectares) | 34,374.0 | 31,793.0 | 27,319.0 | 32,516.0 |
| Earthquake disaster losses (RMB billion) | 14.6792 | 14. 8449 | 1.47740 | 46.6040 |
The maximum value of the same attribute was selected and the physical dimension was eliminated to normalize the attribute value, shown in Table 7.
Table 7.
Disaster loss table after eliminating physical dimension.
| Year | 2000 | 2001 | 2002 | 2003 |
|---|---|---|---|---|
| Direct economic loss (RMB billion) | 1.00 | 0.95 | 0.80 | 0.92 |
| Crop damage area (thousand hectares) | 1.00 | 0.92 | 0.79 | 0.95 |
| Earthquake disaster losses (RMB billion) | 0.31 | 0.32 | 0.03 | 1.00 |
From this, the correlation between the area of crop damage (thousand hectares) () and earthquake damage (billion yuan) () and the direct economic damage (billion yuan) () was calculated using gray correlation analysis with correlation degrees of 0. 59 and 0. 48 to calculate the impact weight. Table 8 was obtained.
Table 8.
The weights of different attributes affecting the direct economic loss resulting from disasters.
| Attributes | Impact weights |
|---|---|
| Area of crop damage (thousand hectares) | 0.55 |
| Earthquake disaster damage (billion yuan) | 0.45 |
Set each attribute affiliation function to .
The resulting set of criteria is constructed as
and the standard matrix is
Step 4 Constructing the set to be tested.
The standard subject and the subject to be tested have the same or similar domains, and the target attributes in the set to be tested are selected according to the target attributes in the standard set and classified.
For the abstract attributes among the target attributes, the values are normalized according to the attribute abstraction hierarchy in Step 2. For the natural attributes of the subject to be measured, the natural attribute with the largest value in the subject to be measured is selected as the basis, and the remaining attributes are compared to the value . It can be worthwhile to denote
| 7 |
as a normalized value.
The influence weight of the non-target attributes on the target attributes in Step 3 is used as the influence weight of the non-target attributes on the target attributes in the subject of the information system domain to be tested. The normalized values are fuzzified by choosing the same affiliation function as in the standard set. The weights of the target attributes in the criterion set are assigned, and the sum of the attribute weights is 1. A fuzzy set is constructed for each target attribute and non-target attribute, and all fuzzy sets are merged to obtain the criterion set . This is the basis for satisfying the decision maker’s preferences. The target attribute weights are used to determine the solution to be tested, and the matrix is constructed.
There are attributes in the subject of an information system domain to be tested, and attributes are selected as target attributes, The relative affiliation of the target attribute is denoted by and the relative affiliation of the non-target attribute is denoted by , and the weight of the target attribute is , which satisfies
| 8 |
and
| 9 |
Thus, the set to be measured is , and the matrix to be measured is .
Step 5 Selecting the fuzzy pattern recognition criterion and choosing the optimal solution.
The combined attribute value of two fuzzy vectors calculated by the closeness formula is called the closeness of these two fuzzy vectors.
Step 6 Information system-based multi-attribute fuzzy pattern decision-making process.
A table of steps and a flowchart of the information system-based multi-attribute fuzzy pattern decision-making process is given below (Table 9 and Fig. 1).
Table 9.
Multi-attribute decision-making process based on information system and fuzzy pattern recognition.

Figure 1.
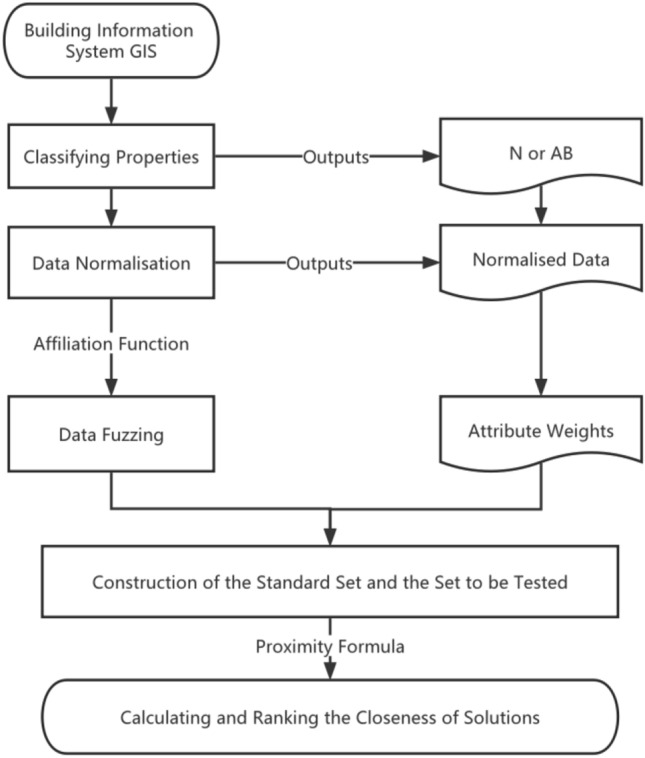
Multi-attribute decision-making process based on information system and fuzzy pattern recognition.
Example of an algorithm
The correlation method used in this example is gray correlation analysis. The first step is to introduce the gray correlation analysis, which is the degree of influence of different factors on a particular factor in a gray system. The essence of the idea is to determine whether a series of curves is closely related to each other based on their similarity in geometry, as shown in Table 10.
Table 10.
Gray correlation analysis process.

To demonstrate the advantage of the multi-attribute decision method, a comparative example with the TOPSIS method is given below. The TOPSIS algorithm cannot handle mixed-attribute problems, so a conventional TOPSIS example is chosen.
Example 3
Comparative example between the proposed method and the TOPSIS method.
Among Table 11, and have an inverse effect on the selection result and has a positive effect on the selection result, that is, and are negatively related to the decision result and is positively related to the decision result.
Table 11.
Decision information.
| 50.8 | 4.3 | 8.7 | |
| 200.0 | 4.9 | 7.2 | |
| 71.4 | 2.5 | 5.0 | |
| 10.2 | 2.4 | 0.3 |
The TOPSIS method was used to select the best solution among five subjects. The data are normalized to obtain the following Table 12.
Table 12.
Standardized attribute values.
| 0.1937 | 0.3281 | 0.0342 | |
| 0.0492 | 0.2879 | 0.0413 | |
| 0.1378 | 0.5643 | 0.0594 | |
| 0.9648 | 0.5879 | 0.9907 |
In assigning weights to each attribute, the same weights are given in this case; thus, the matrix after the assignment is the same as the data in Table 12 used to select the optimal solution.
Then, we select the positive and negative ideal solutions based on the available data:
Calculating the distance between different solutions and positive and negative ideal solutions by the Formula (10), we obtain the following Table 13.
| 10 |
Table 13.
Distances between different schemes and positive and negative ideal solutions.
| 1.2558 | 0.1465 | |
| 1.3527 | 0.0071 | |
| 1.2457 | 0.2913 | |
| 0.0000 | 1.3577 |
In Table 14, the combined evaluation values of the different options are given and ranked with the Formula (11). A higher reference value corresponds to a better evaluation result.
| 11 |
Table 14.
Combined evaluation value and ranking of different solutions.
| Programs | Combined evaluation value | Rankings |
|---|---|---|
| 0.1045 | 3 | |
| 0.0052 | 4 | |
| 0.1895 | 2 | |
| 1.0000 | 1 |
The following calculation is performed using the method mentioned in this paper.
Construct a GIS information system where and ; given , , where is defined as in Formula (12).
| 12 |
After careful consideration, it was determined that the resulting information table does not have decision attributes, i.e., it is a decision problem aimed at choosing the most solutions. Therefore, all attributes are conditional attributes.
To ensure the comparability effect, the standardized attribute values are selected to be calculated directly as the affiliation degree, while the same weight is assigned to all attributes. The positive ideal solution found with TOPSIS is selected as the standard set, and the Hemming proximity is used to calculate the proximity between different solutions for the standard set, shown in Table 15 below.
Table 15.
Program proximity and sequencing.
| Programs | Program proximity | Rankings |
|---|---|---|
| 0.3375 | 3 | |
| 0.2733 | 4 | |
| 0.4060 | 2 | |
| 1.0000 | 1 |
Comparing the two methods, the same conclusions were reached and the validity of the scheme was verified.
We can find that the method provided in this paper is more concise in terms of the calculation process when the standardization conditions and weights are the same. Further, the selection of the control criteria provided in this paper is more flexible. The criteria set can be determined directly based on the needs of decision makers, which improves the participation of decision makers.
The following uses the choice of the bias affiliation function to compare the effects on the decision results. The calculated affiliation matrix is obtained as .
After calculating the program posting schedule, we obtain Table 16.
Table 16.
Program proximity and sequencing.
| Programs | Program proximity | Rankings |
|---|---|---|
| 0.0973 | 3 | |
| 0.0025 | 4 | |
| 0.3481 | 2 | |
| 1.0000 | 1 |
By comparing Table 15 with Table 16, it is clear that by choosing different affiliation functions to classify the data characteristics, belongs to the biased large affiliation function, making the differences between the different schemes more obvious.
If the decision maker places extra importance on an attribute, the attribute can be considered a “secondary decision attribute” and the weight is calculated by associating the remaining attributes with it, as demonstrated in the following example.
Select as the “secondary decision attribute” and calculate the association degree between , , and , obtaining Table 17.
Table 17.
Degree of correlation between attributes.
| 0.4620 | 0.8205 |
Calculating the weight division of different attributes yields Table 18.
Table 18.
The weight of each attribute with as the “secondary decision attribute”.
| 0.4381 | 0.3595 | 0.2024 |
In this way, the affiliation function matrix is obtained by combining the affiliation matrix with the weights.
Option is chosen as the standard set, and the calculation is performed using the Hemming proximity to obtain the ranking results as shown in Table 19.
Table 19.
Proximity and sorting after selecting “Sub-Decision Properties”.
| Programs | Program proximity | Rankings |
|---|---|---|
| 0.7057 | 3 | |
| 0.6677 | 4 | |
| 0.7930 | 2 | |
| 1.0000 | 1 |
By comparing Tables 16 and 19, we find that after the decision maker selects the preferred attribute, it can be set as a “sub-decision attribute” and the weights can be calculated by grayscale correlation analysis to emphasize the decision maker’s preference while considering the interaction between different attributes. Although the decision result does not change, the change in the proximity can be seen; after choosing as “this decision attribute”, the difference between options , , and is reduced, and the decision maker’s preference is well-expressed.
An example is given to verify a simple application of the method in multi-objective decision-making. The example in question pertains a decision-making problem of a hybrid information system.
Example 4
Two departments of a school, A and B, are recruiting in the job market. There are five applicants, and department A plans to recruit one member, and department B also plans to recruit one member. Relevant information is listed in Tables 20 and 21.
Table 20.
Recruitment of departments A and B in the past 3 years.
| Recruiters | Interview results | Written test results | Work experience | Communication skills | |
|---|---|---|---|---|---|
| Department A | 90 | 85 | 2 years | Excellent | |
| 92 | 83 | 3 years | Excellent | ||
| 95 | 83 | 5 years | Excellent | ||
| Department B | 80 | 100 | 1 year | Qualified | |
| 83 | 96 | 4 years | Medium | ||
| 90 | 92 | 2 years | Good |
Table 21.
Information of five candidates to be hired.
| Interview results | Written test results | Work experience | Communication skills | |
|---|---|---|---|---|
| Number 1 | 90 | 90 | 1 year | Good |
| Number 2 | 84 | 99 | 1 year | Medium |
| Number 3 | 85 | 96 | 2 years | Medium |
| Number 4 | 98 | 83 | 4 years | Excellent |
| Number 5 | 78 | 98 | 3 years | Qualified |
To construct an information system based on Tables 20 and 21, we consider the following: domain = {accepted person}, = {interview score ,written test score , work experience , communication skills }. Now, we distinguish between the set of natural attributes = {interview scores written scores } and the set of abstract attributes = {work experience , communication skills } based on the characteristics of the attributes in the argument domain .
The target attributes for department are interview performance and communication skills ; for department , the target attributes are written test performance and work experience . Given an affiliation function for each attribute, the affiliation values are the same as those obtained after normalization in Table 14; the abstract attributes are ranked as shown in Table 22 below. The results of de-quantizing all attributes are given in Table 23.
Table 22.
Abstract Attribute Hierarchy.
| Work experience | Grades | Communication skills | Grades |
|---|---|---|---|
| 1 year | 0.20 | Excellent | 1.00 |
| 2 years | 0.40 | Good | 0.75 |
| 3 years | 0.60 | Medium | 0.50 |
| 4 years | 0.80 | Qualified | 0.25 |
| 5 years | 1.00 |
Table 23.
Hiring information obtained after de-quantizing.
| Recruiters | Interview results | Written test results | Work experience | Communication skills | |
|---|---|---|---|---|---|
| Department A | 0.95 | 1.00 | 0.40 | 1.00 | |
| 0.97 | 0.98 | 0.60 | 1.00 | ||
| 1.00 | 0.98 | 1.00 | 1.00 | ||
| Department B | 0.89 | 1.00 | 0.20 | 0.25 | |
| 0.92 | 0.96 | 0.80 | 0.50 | ||
| 1.00 | 0.92 | 0.40 | 0.75 |
The results of using gray correlation analysis to obtain the weight of non-target attributes on target attributes in sector are shown in Table 24.
Table 24.
Remaining attributes in department affect the weight of target attributes.
| Written test results | Work experience | |
|---|---|---|
| Interview results | 0.61 | 0.39 |
| Communication skills | 0.62 | 0.38 |
The interview results and communication skills are given equal weight in the target attributes, both 0.5. We combined these weights with the fuzzy concentration algorithm to construct a set of criteria for hiring personnel in department as follows:
The non-target attributes in department B are weighted against the target attributes as shown in Table 25.
Table 25.
Influence weight of remaining attributes in department B on target attributes.
| Interview results | Communication skills | |
|---|---|---|
| Written test results | 0.59 | 0.41 |
| Work experience | 0.43 | 0.57 |
Written test score and communication ability are given the same weight in the target attribute, both being 0.5. We combined these with the fuzzy set algorithm to construct the criteria set of hiring personnel in department as
From this, write the standard matrix
In the following, we construct the set to be tested and de-quantized the information regarding the prospective employees, as shown in Table 26.
Table 26.
Normalization of the information of the people to be hired.
| Interview results | Written test results | Work experience | Communication skills | |
|---|---|---|---|---|
| Number 1 | 0.92 | 0.91 | 0.20 | 0.75 |
| Number 2 | 0.86 | 1.00 | 0.20 | 0.50 |
| Number 3 | 0.87 | 0.97 | 0.40 | 0.50 |
| Number 4 | 1.00 | 0.84 | 0.80 | 1.00 |
| Number 5 | 0.80 | 0.99 | 0.60 | 0.25 |
This was used to construct a matrix for each candidate.
The Euclidean approximation is chosen for the standard set and the set to be tested, and the ranking depicted in Fig. 2 is obtained.
Figure 2.

Histogram of approximate degree of applicability of candidates.
From Fig. 2 and Table 27, we can see that for department A: No. 4 > No. 1 > No. 2 > No. 3 > No. 5; for department B: No. 1 > No. 5 > No. 2 > No. 3 > No. 4.
Table 27.
Ranking of candidates for departments A and B.
| Number 1 | Number 2 | Number 3 | Number 4 | Number 5 | |
|---|---|---|---|---|---|
| Department A | 0. 73 | 0. 68 | 0. 59 | 0. 91 | 0. 44 |
| Department B | 0. 81 | 0. 79 | 0. 75 | 0. 68 | 0. 80 |
Therefore, it is recommended that department A hires candidate number 4 and department B hires candidate number 1.
From the above two examples, we can observe the following advantages of the model presented in this paper:
Compared to the traditional fuzzy pattern recognition methods mentioned in references 38–41, the approach presented in this paper integrates information systems with pattern recognition, reducing the number of attributes that may be overlooked in the decision-making process. It can also be adapted to rapidly evolving decision-making requirements. Furthermore, it combines information systems with attribute requirements and attribute value characteristics, enhancing the model's decision-making capability when dealing with mixed semantics in information systems.
The method employed in this paper calculates attribute weights using replaceable correlation analysis. In contrast to the weight calculation methods based on information entropy mentioned in references 13 and 23, this paper allows for the modification of weight measurement and determination methods based on different decision-making conditions, offering greater flexibility in determining conditional attribute weights. Additionally, it takes into account the subjective opinions of decision-makers. Decision attributes and conditional attributes are identified within the original attributes. The model constructs a fuzzy pattern recognition scheme for decision attributes. The calculated proximity value represents a comprehensive evaluation, considering both decision attributes and conditional attributes. Compared to TOPSIS, the calculation process in this paper is significantly simplified.
In comparison to the traditional three-branch decision-making processes discussed in references 24–27, this paper utilizes information systems as decision information carriers. However, it does not employ rough set theory to construct decision rules. Instead, it adopts an approach similar to machine learning, transforming information from the information system into fuzzy sets that can be used to calculate proximity. Additionally, this method draws inspiration from AHP and TOPSIS decision-making techniques to rank the calculated solutions, thereby arriving at a decision.
The decision-making method presented in this paper offers greater functionality compared to the multi-attribute decision-making methods mentioned in references 4, 9, and 12. When there is only one decision attribute, the method proposed in this chapter can be used as a multi-attribute decision-making approach for handling mixed information. Furthermore, when the problem is transformed into a multi-objective decision, the methods outlined in this chapter also demonstrate problem-solving capabilities.
Conclusion
This paper presents a pioneering approach that unites the domains of fuzzy pattern recognition and information systems, culminating in the innovative proposal of a fuzzy pattern decision method. This novel method represents an endeavor to chart a new course in multi-attribute decision-making. It intricately amalgamates the strengths of fuzzy pattern recognition and information systems, addressing the challenges associated with attribute selection in fuzzy pattern recognition while concurrently enabling the representation of decision-making-related quaternions as fuzzy subsets within information systems.
In contrast to conventional multi-attribute fuzzy pattern decision-making methods, this paradigm eliminates the need for constructing positive and negative fuzzy ideal solutions rooted in information system data. Instead, it establishes a standard set tailored to align with the decision maker's preferences. Notably, the method integrates decision makers into three pivotal aspects: criteria selection, attribute weight determination, and the affiliation function, accentuating the unique characteristics of attributes. The flexibility in selecting the affiliation function aligns with decision makers' subjective inclinations. Furthermore, the method accommodates decision maker preferences and needs without invoking behavioral decisions.
It is essential to acknowledge the limitations of this model. Notably, the selection of the affiliation function may, at times, rely on experiential judgments, suggesting room for improvement in this aspect. Additionally, the method's applicability is confined to specific decision environments.
Moreover, through a comparative analysis of examples, it becomes apparent that the model proposed in this paper has certain limitations and benefits from prior decision-making experience to enhance decision accuracy. In the absence of prior decision-making experience, the results may be more influenced by the decision-maker's subjective preferences, potentially leading to decisions that overlook objective facts. Therefore, the scope of application for the multi-attribute decision-making model presented in this paper should be decision scenarios that fully consider the subjective needs of the decision maker, assuming a certain level of decision-making experience.
For future refinement, the model could be extended to encompass incomplete information systems, resulting in a nuanced approach that combines fuzzy pattern recognition with incomplete information systems. The flexibility in criteria set selection could be leveraged to determine attribute weights through a fusion of tolerance relations and gray correlation analysis. Furthermore, attributes' significance and information completeness could collaborate to determine attribute weights in the test set, optimizing the utilization of available information and aligning with decision maker preferences within the context of incomplete information systems. This approach could be harmonized with the interplay between behavioral decisions and dominance, further reinforcing decision preferences. This innovative avenue suggests a trajectory for solving multi-attribute decision-making challenges within the realm of incomplete information systems.
Furthermore, the algorithm outlined in this paper could be enriched by introducing intuitionistic fuzzy numbers, enabling the construction of intuitionistic fuzzy sets. The proximity between intuitionistic fuzzy sets could serve as the foundation for decision-making, culminating in a comprehensive comparison with existing algorithms to assess the merits and drawbacks of each approach.
Author contributions
Z.S. offered the original draft, conceptualization, simulation, and validation. X.K. supervised and reviewed the manuscript.
Data availability
All data generated or analyzed during this study are included within the published article.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Dong M, Li S, Zhang H. Approaches to group decision making with incomplete information based on power geometric operators and triangular fuzzy AHP. Expert Syst. Appl. 2015;42:7846–7857. doi: 10.1016/j.eswa.2015.06.007. [DOI] [Google Scholar]
- 2.Yue Z. Aggregating crisp values into intuitionistic fuzzy number for group decision making. Appl. Math. Model. 2014;38:2969–2982. doi: 10.1016/j.apm.2013.11.020. [DOI] [Google Scholar]
- 3.Yi J-H, Liu Y, Forrest JY-L, Guo X-G, Xu X-J. A three-way decision approach with S-shaped utility function under Pythagorean fuzzy information. Expert Syst. Appl. 2022;210:118370. doi: 10.1016/j.eswa.2022.118370. [DOI] [Google Scholar]
- 4.Zhang X, Jin F, Liu P. A grey relational projection method for multi-attribute decision making based on intuitionistic trapezoidal fuzzy number. Appl. Math. Model. 2013;37:3467–3477. doi: 10.1016/j.apm.2012.08.012. [DOI] [Google Scholar]
- 5.Atanassov K, Sotirova E, Andonov V. Generalized net model of multicriteria decision making procedure using intercriteria analysis. Advances in Fuzzy Logic and Technology 2017: Proceedings of: EUSFLAT-2017–The 10th Conference of the European Society for Fuzzy Logic and Technology, September 11–15, 2017, Warsaw, Poland IWIFSGN’2017–The Sixteenth International Workshop on Intuitionistic Fuzzy Sets and Generalized Nets, September 13–15, 2017, Warsaw, Poland, Volume 1 10. Springer International Publishing, 2018: 99-111.
- 6.Deng X, Jiang W. D number theory based game-theoretic framework in adversarial decision making under a fuzzy environment. Int. J. Approx. Reason. 2019;106:194–213. doi: 10.1016/j.ijar.2019.01.007. [DOI] [Google Scholar]
- 7.Zheng J, Wang Y-M, Zhang K, Gao J-Q, Yang L-H. A heterogeneous multi-attribute case retrieval method for emergency decision making based on bidirectional projection and TODIM. Expert Syst. Appl. 2022;203:117382. doi: 10.1016/j.eswa.2022.117382. [DOI] [Google Scholar]
- 8.Wang Z, Hao H, Gao F, Zhang Q, Zhang J, Zhou Y. Multi-attribute decision making on reverse logistics based on DEA-TOPSIS: A study of the Shanghai End-of-life vehicles industry. J. Clean. Prod. 2019;214:730–737. doi: 10.1016/j.jclepro.2018.12.329. [DOI] [Google Scholar]
- 9.Çoker D. Fuzzy rough sets are intuitionistic L-fuzzy sets. Fuzzy Sets Syst. 1998;96:381–383. doi: 10.1016/S0165-0114(97)00249-2. [DOI] [Google Scholar]
- 10.Dhanasekar S, Rani JJ, Annamalai M. Transportation problem for interval-valued trapezoidal intuitionistic fuzzy numbers. Int. J. Fuzzy Log. Intell. Syst. 2022;22:155–168. doi: 10.5391/IJFIS.2022.22.2.155. [DOI] [Google Scholar]
- 11.Wan S, Dong J, Yang D. Trapezoidal intuitionistic fuzzy prioritized aggregation operators and application to multi-attribute decision making. Iran. J. Fuzzy Syst. 2015;12:1–32. [Google Scholar]
- 12.dos Santos BM, Godoy LP, Campos LMS. Performance evaluation of green suppliers using entropy-TOPSIS-F. J. Clean. Prod. 2019;207:498–509. doi: 10.1016/j.jclepro.2018.09.235. [DOI] [Google Scholar]
- 13.Du Y, Liu P. Extended fuzzy VIKOR method with intuitionistic trapezoidal fuzzy numbers. Inform.-Int. Interdiscip. J. 2011;14:2575–2583. [Google Scholar]
- 14.Gireesha O, Kamalesh A, Krithivasan K, Sriram VS. A fuzzy-multi attribute decision making approach for efficient service selection in cloud environments. Expert Syst. Appl. 2022;206:117526. doi: 10.1016/j.eswa.2022.117526. [DOI] [Google Scholar]
- 15.Li S, Yuan X, Li H. Approximation of intuitionistic fuzzy numbers by trapezoidal intuitionistic fuzzy numbers. J. Intell. Fuzzy Syst. 2017;33:389–402. doi: 10.3233/JIFS-161720. [DOI] [Google Scholar]
- 16.Pan Y. Revised hierarchical analysis method based on crisp and fuzzy entries. Int. J. Gen. Syst. 1997;26:115–131. doi: 10.1080/03081079708945173. [DOI] [Google Scholar]
- 17.Polkowski L. A rough set paradigm for unifying rough set theory and fuzzy set theory. In: Polkowski L, editor. Rough Sets, Fuzzy Sets, Data Mining, and Granular Computing, Proceedings of the 9th International Conference, RSFDGrC 2003, Chongqing, China, 26–29 May 2003. Springer; 2003. pp. 70–77. [Google Scholar]
- 18.Shakeel M, Abdullah S, Shahzad M, Siddiqui N. Geometric aggregation operators with interval-valued Pythagorean trapezoidal fuzzy numbers based on Einstein operations and their application in group decision making. Int. J. Mach. Learn. Cybern. 2019;10:2867–2886. doi: 10.1007/s13042-018-00909-y. [DOI] [Google Scholar]
- 19.Shakeel M, Abduulah S, Shahzad M, Mahmood T, Siddiqui N. Averaging aggregation operators with pythagorean trapezoidal fuzzy numbers and their application to group decision making. J. Intell. Fuzzy Syst. 2019;36:1899–1915. doi: 10.3233/JIFS-17238. [DOI] [Google Scholar]
- 20.Wang G, Li J. Approximations of fuzzy numbers by step type fuzzy numbers. Fuzzy Sets Syst. 2017;310:47–59. doi: 10.1016/j.fss.2016.08.003. [DOI] [Google Scholar]
- 21.Guang-Quan Z. On fuzzy number-valued fuzzy measures defined by fuzzy number-valued fuzzy integrals I. Fuzzy Sets Syst. 1992;45:227–237. doi: 10.1016/0165-0114(92)90123-L. [DOI] [Google Scholar]
- 22.Xu X, Arshad M, Mahmood A. Talent competitiveness evaluation of the chongqing intelligent industry based on using the entropy TOPSIS method. Information. 2021;12:288. doi: 10.3390/info12080288. [DOI] [Google Scholar]
- 23.Yao Y. Three-way decisions with probabilistic rough sets. Inf. Sci. 2010;180:341–353. doi: 10.1016/j.ins.2009.09.021. [DOI] [Google Scholar]
- 24.Yao Y. The superiority of three-way decisions in probabilistic rough set models. Inf. Sci. 2011;181:1080–1096. doi: 10.1016/j.ins.2010.11.019. [DOI] [Google Scholar]
- 25.Yao Y. An Outline of a Theory of Three-Way Decisions. RSCTC; 2012. pp. 1–17. [Google Scholar]
- 26.Yao, Y. Rough sets and three-way decisions. In Rough Sets and Knowledge Technology, Proceedings of the10th International Conference, RSKT 2015, Held as Part of the International Joint Conference on Rough Sets, IJCRS 2015, Tianjin, China, 20–23 November 2015; Proceedings 10; Springer International Publishing: Cham, Switzerland, 2015; pp. 62–73.
- 27.Yao Y. Three-way decision and granular computing. Int. J. Approx. Reason. 2018;103:107–123. doi: 10.1016/j.ijar.2018.09.005. [DOI] [Google Scholar]
- 28.Vinogradova I. Multi-attribute decision-making methods as a part of mathematical optimization. Mathematics. 2019;7:915. doi: 10.3390/math7100915. [DOI] [Google Scholar]
- 29.Qin Y, Qi Q, Shi P, Lou S, Scott PJ, Jiang X. Multi-attribute decision-making methods in additive manufacturing: The state of the art. Processes. 2023;11:497. doi: 10.3390/pr11020497. [DOI] [Google Scholar]
- 30.Rao RV, Lakshmi J. R-method: A simple ranking method for multi-attribute decision-making in the industrial environment. J. Proj. Manag. 2021;6:223–230. [Google Scholar]
- 31.Riaz M, Hashmi MR. Linear Diophantine fuzzy set and its applications towards multi-attribute decision-making problems. J. Intell. Fuzzy Syst. 2019;37:5417–5439. doi: 10.3233/JIFS-190550. [DOI] [Google Scholar]
- 32.Biswas P, Pramanik S, Giri BC. A new methodology for neutrosophic multi-attribute decision making with unknown weight information. Neutrosophic Sets Syst. 2014;3:42–52. [Google Scholar]
- 33.Ullah K, Garg H, Mahmood T, Jan N, Ali Z. Correlation coefficients for T-spherical fuzzy sets and their applications in clustering and multi-attribute decision making. Soft Comput. 2020;24:1647–1659. doi: 10.1007/s00500-019-03993-6. [DOI] [Google Scholar]
- 34.Trinkūnienė E, Podvezko V, Zavadskas EK, Jokšienė I, Vinogradova I, Trinkūnas V. Evaluation of quality assurance in contractor contracts by multi-attribute decision-making methods. Econ. Res.-Ekon. Istraživanja. 2017;30:1152–1180. doi: 10.1080/1331677x.2017.1325616. [DOI] [Google Scholar]
- 35.Ming T, Teng W, Jodaki S. A model to investigate the effect of information technology and information systems on the ease of managers’ decision-making. Kybernetes. 2021;50:100–117. doi: 10.1108/K-10-2019-0712. [DOI] [Google Scholar]
- 36.Aydiner AS, Tatoglu E, Bayraktar E, Zaim S. Information system capabilities and firm performance: Opening the black box through decision-making performance and business-process performance. Int. J. Inf. Manag. 2019;47:168–182. doi: 10.1016/j.ijinfomgt.2018.12.015. [DOI] [Google Scholar]
- 37.Taha MMR, Lucero J. Damage identification for structural health monitoring using fuzzy pattern recognition. Eng. Struct. 2005;27:1774–1783. doi: 10.1016/j.engstruct.2005.04.018. [DOI] [Google Scholar]
- 38.Yong D, Wenkang S, Feng D, Qi L. A new similarity measure of generalized fuzzy numbers and its application to pattern recognition. Pattern Recognit. Lett. 2004;25:875–883. doi: 10.1016/j.patrec.2004.01.019. [DOI] [Google Scholar]
- 39.Boran FE, Akay D. A biparametric similarity measure on intuitionistic fuzzy sets with applications to pattern recognition. Inf. Sci. 2013;255:45–57. doi: 10.1016/j.ins.2013.08.013. [DOI] [Google Scholar]
- 40.Chu C-H, Hung K-C, Julian P. A complete pattern recognition approach under Atanassov’s intuitionistic fuzzy sets. Knowl. -Based Syst. 2014;66:36–45. doi: 10.1016/j.knosys.2014.04.014. [DOI] [Google Scholar]
- 41.Shouyu C, Guangtao F. A DRASTIC-based fuzzy pattern recognition methodology for groundwater vulnerability evaluation. Hydrol. Sci. J. 2003;48:211–220. doi: 10.1623/hysj.48.2.211.44700. [DOI] [Google Scholar]
- 42.Zhou R, Jin J, Cui Y, Ning S, Bai X, Zhang L, Zhou Y, Wu C, Tong F. Agricultural drought vulnerability assessment and diagnosis based on entropy fuzzy pattern recognition and subtraction set pair potential. Alex. Eng. J. 2022;61:51–63. doi: 10.1016/j.aej.2021.04.090. [DOI] [Google Scholar]
- 43.Pal S K, Mitra S. Neuro-fuzzy pattern recognition. 1999.
- 44.Pedrycz W. Fuzzy sets in pattern recognition: Methodology and methods. Pattern Recogn. 1990;23(1–2):121–146. doi: 10.1016/0031-3203(90)90054-O. [DOI] [Google Scholar]
- 45.Zadeh LA. Fuzzy sets. Inform. Control. 1965;8(3):338–353. doi: 10.1016/S0019-9958(65)90241-X. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All data generated or analyzed during this study are included within the published article.