

Abstract
Anatomical consistency in biomarker segmentation is crucial for many medical image analysis tasks. A promising paradigm for achieving anatomically consistent segmentation via deep networks is incorporating pixel connectivity, a basic concept in digital topology, to model inter-pixel relationships. However, previous works on connectivity modeling have ignored the rich channel-wise directional information in the latent space. In this work, we demonstrate that effective disentanglement of directional sub-space from the shared latent space can significantly enhance the feature representation in the connectivity-based network. To this end, we propose a directional connectivity modeling scheme for segmentation that decouples, tracks, and utilizes the directional information across the network. Experiments on various public medical image segmentation benchmarks show the effectiveness of our model as compared to the state-of-the-art methods. Code is available at https://github.com/Zyun-Y/DconnNet.
1. Introduction
Maintaining anatomical consistency in the segmentation of medical images is important but challenging, as minor geometric errors may change the global topology [1, 2] and cause functional mistakes in downstream clinical decision-making [3]. Anatomical consistency in images can be expressed with topological properties, such as pixel connectivity and adjacency [4, 5]. As such, by directly modeling the mutual information between pixels or regions, graph-based methods have long been used to correct topological and geometrical errors [6–8]. However, such classic machine vision techniques usually depend on manually defined priors and thus are not easily generalizable for a wide variety of applications.
Alternative to the classic approaches, deep learning-based segmentation methods utilized an encoder-decoder architecture [9] to learn from a group of pixels in a particular receptive field at each layer. More recently, significant progress has been made in capturing the inter- pixel dependency inside a network’s latent space [10–12]; however, very few studies have been conducted on the problem modeling side of the networks. A typical segmentation network models the problem as a pure pixel-wise classification task and uses a segmentation mask as the only label. Yet, this pixel-wise modeling scheme is suboptimal as it does not directly exploit inter-pixel relationships and geometrical properties [14, 15]. Thus, these models may result in low spatial coherence (i.e., inconsistent predictions for neighboring pixels that share similar spatial features) in their prediction [16]. Especially, when applied to high noise/artifacts medical data, the lower spatial consistency may lead to topological issues [17].
The concept of pixel connectivity has long been used to ensure the basic topological duality of separation and connectedness in digital images [18]. More recently, in the context of deep learning, the connectivity masks, reviewed in Section 2.1, have been introduced as a topological extension of the segmentation mask [15]. Using connectivity masks as training labels has several advantages over segmentation masks. In terms of problem modeling, using a connectivity mask inherently changes the problem from pixel-wise classification to connectivity prediction, which models and enhances the topological representation between pixels of interest. In terms of label representation, a connectivity mask is more informative in three ways: first, a connectivity mask stores the categorical information among the connections of pixels and it is inter-pixel relation-aware; second, it sparsely represents edge pixels [16]; third, it contains rich directional information channel-wisely. Thus, a network trained with connectivity masks has both categorical (reflected by connectivity) and directional features in its latent space, each of which forms a specific sub-latent space, as shown in Fig. 1.
Figure 1.
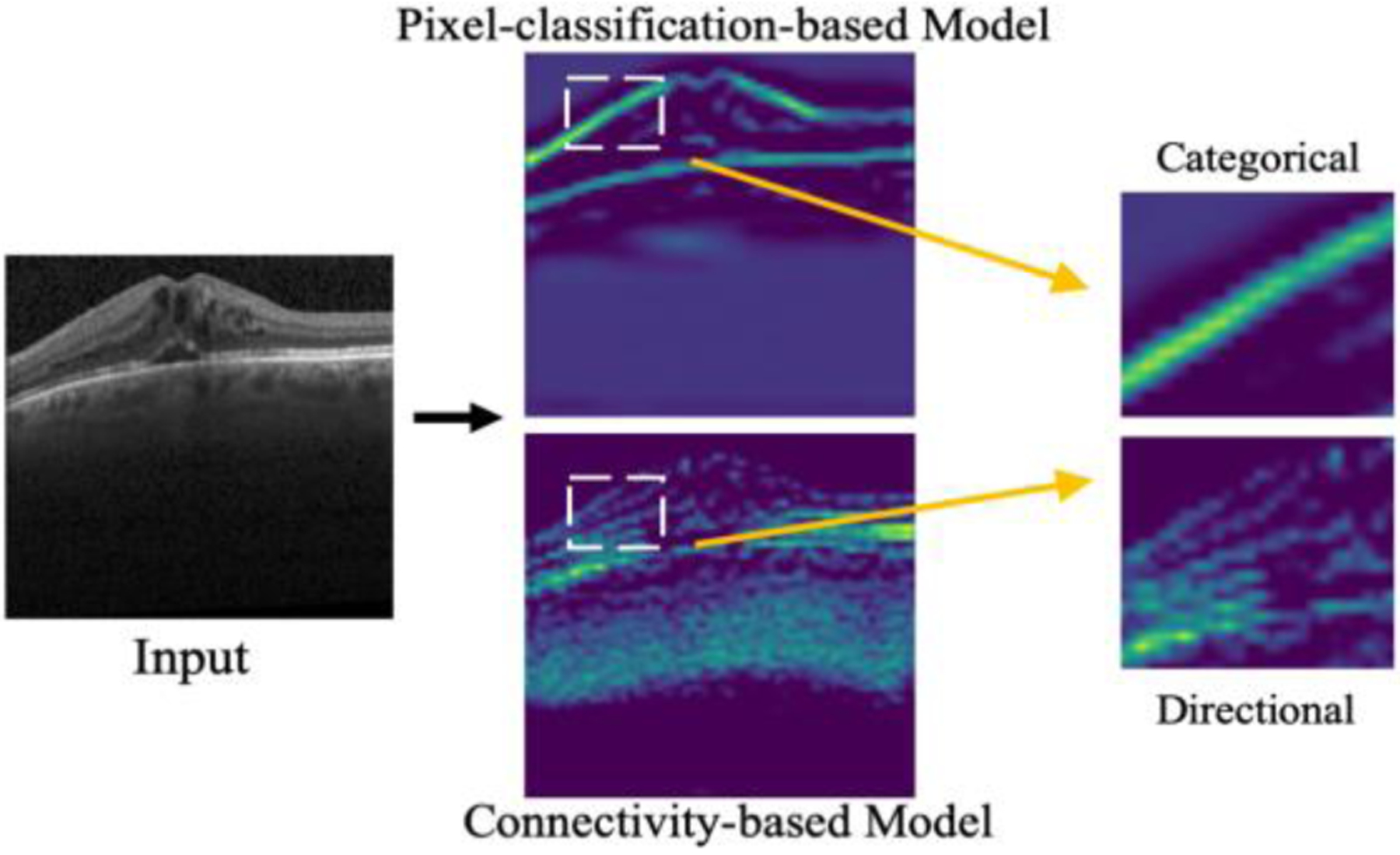
The latent space differences between traditional pixel-classification-based and connectivity-based models. In the former, only categorical features, e.g., boundaries, are highlighted; while in the latter, the feature map also contains directional information (e.g., the horizontal connections between boundary pixels).
In previous studies [15, 16, 19–22], these two groups of features were learned simultaneously through a shared network path which may result in highly coupled latent space and introduce redundancy [23]. Further, effectively disentangling meaningful subspaces from the shared latent space has been shown effective in accounting for the dependencies/independencies between features [24, 25].
Inspired by the idea of latent space disentanglement, in this paper, we propose a novel directional connectivity-based segmentation network (DconnNet) to disentangle the directional subspace from the shared latent space and utilize the extracted directional features to enhance the overall data representation, as in Fig. 2. The disentangling process is conducted by a sub-path slicing-based module called Sub-path Direction Excitation (SDE). The directional-based feature enhancement is applied in a coarse-to-fine manner using an Interactive Feature-space Decoder (IFD) with two top-down interactive decoding flows. Finally, we propose a novel Size Density loss (SDL) that alleviates the common data imbalance problem in medical datasets with a label size distribution-based weighting scheme. With experiments on different public medical image analysis benchmarks, we demonstrate the superiority of DconnNet against other state-of-art methods.
Figure 2.
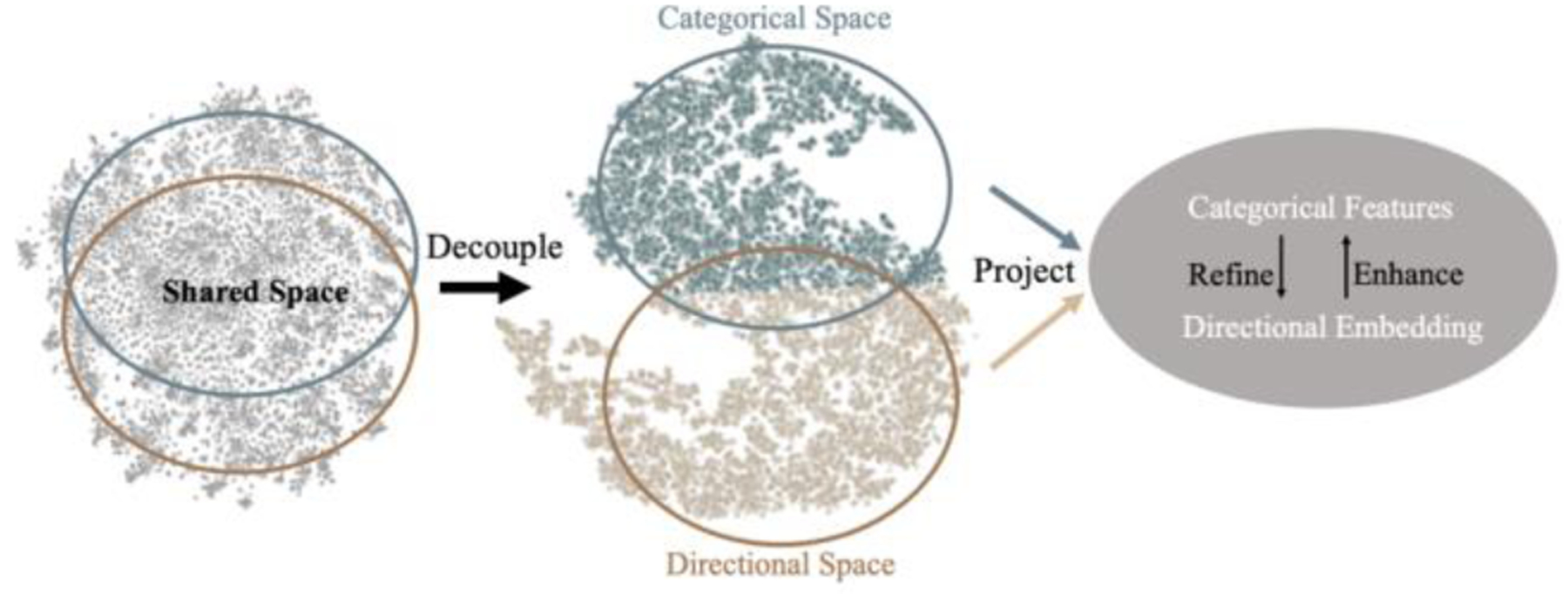
The flows of the two groups of latent features (categorical and directional) in the latent space of DconnNet, are visualized by T-SNE [13]. They were first disentangled (Sec 3.2) and then effectively fused in a projected shared manifold (Sec 3.3). The colors are rendered based on the results of clustering.
2. Related Work
2.1. Deep connectivity modeling
In topology, pixel connectivity describes how neighboring pixels are related to each other [4]. Following broad utilization in characterizing topological properties in classic image processing methods [26, 27], connectivity has found new applications in deep learning-based image segmentation [15, 16, 19–22]. The connectivity-based segmentation networks use the connectivity mask (Fig. 3) as the label, defined as an 8-channel mask with each channel representing if a pixel on the original image belongs to the same class of interest with one of its neighboring pixels at a specific direction. The connectivity mask was first introduced and applied to image segmentation in [15]. This idea was later extended by other works, including [16] which showed the bilateral property of pixel connectivity in saliency detection, and [28] which modeled the cross-modality connectivity for radar-video data fusion. Meanwhile, the effectiveness of connectivity modeling has been demonstrated in different applications such as remote sensing segmentation [19], path planning [20], and medical image segmentation [21, 22, 29]. Although significant progress has been made in this field, we demonstrate that the rich directional information in the connectivity masks has not yet been fully utilized.
Figure 3.
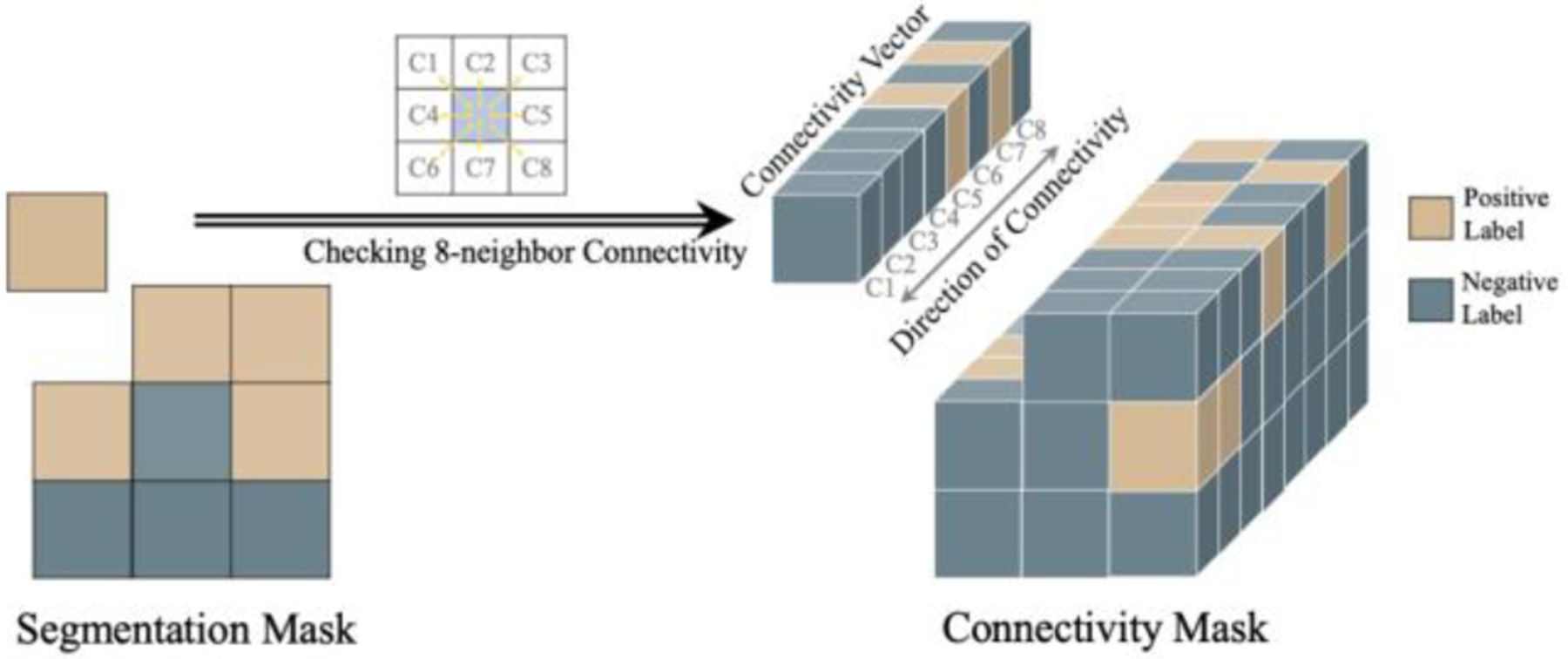
Illustration of generating the connectivity mask from the segmentation mask by traversing 8-neighbor pixel connectivity. For each pixel, channel ’s binary value in the converted connectivity vector carries the categorical information (connected or not connected) while encodes the directional information (direction of connection).
2.2. Interpretation of latent space
Latent space is an embedding of a set of features in a deep network. Interpretation, alignment, and disentanglement of latent spaces are important in different computer vision techniques such as unsupervised learning [30], multi-modal information fusion [24, 31], generative models [32, 33], knowledge distillation [34, 35], and transfer learning [36]. However, the interpretation of latent space is challenging because it usually requires implicit domain knowledge based on human judgment [37].
To interpret the latent space, researchers either apply dimension reduction tools such as PCA [38], T-SNE [13], or develop interactive analysis tools [39]. To manipulate latent space, a variation autoencoder (VAE) can be used to map the input to latent space and disentangle/match the different latent spaces [40, 41]. In this work, we utilize the intrinsic property of the connectivity mask and propose a simple yet effective sub-path slicing-based method to disentangle the directional subspace from the shared latent space, followed by a visual demonstration of the effectiveness of our disentanglement process with T-SNE.
2.3. Self-attention mechanism
Self-attention is widely used in computer vision as it can capture the dependencies between latent features. The self-attention mechanism is defined as:
| (1) |
where is the input feature map, is a unary function that computes the embedding of input, and is usually a matrix multiplication [10, 42] or a simple dot product [11, 43, 44], depending on the definition of is the attention/relation map which can be a mutual relation map by spatial- or channel-wisely computing the similarity between one pixel with other pixels in a feature map, or between two related feature maps from the same feature space [10, 42]; it can be a contextual-spatial relation map generated by similarity estimation between a feature map and a latent vector with abstract contextual meaning [44, 45]. Broadly speaking, can also be a single map [11] or a vector [43, 46] containing special contextual meaning.
3. Method
3.1. Directional space in connectivity modeling
Due to connectivity between different pixel classes and directions, there are two groups of features in the latent space of a connectivity-based network: categorical directional. Each group of features forms its specific subspace in the latent space. In a single-path connectivity network, these two subspaces are highly coupled (Fig. 2), resulting in low-discriminative features. We demonstrate that the efficient disentangling and effective utilization of the direction space can enhance the overall feature representation in the connectivity model.
In a connectivity mask, different channels represent different directions of the pixel connection. Thus, as the network goes deeper, it naturally stores directional information among channels. Based on this property, the directional features can be captured and manipulated through channel-wise operations. Specifically, we propose SDE to disentangle channel-wise directional features from the latent space, followed by IFD to extract the directional embeddings at different layers and use them to enhance the overall feature representation in a self-attention manner. The overall DconnNet structure is shown in Fig. 4.
Figure 4.
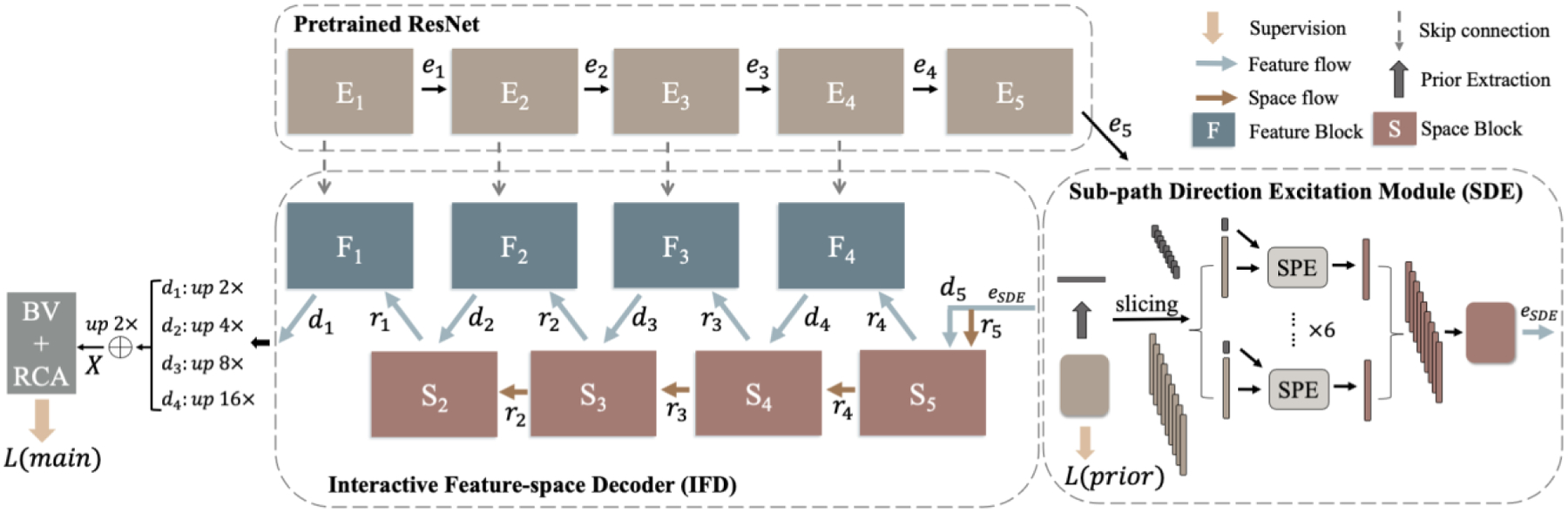
The overview of the proposed DconnNet. It contains three parts: a pretrained ResNet encoder, a Sub-path Direction Excitation Module, and an Interactive Feature-space Decoder. The term “up N×” means upsampling with a stride of N.
3.2. Sub-path Direction Excitation Module
Directional prior extraction.
Taking advantage of the channel-wise directional information in the connectivity mask, a direct way to get distinctive directional embedding is to coarsely supervise the intermediate features and squeeze the channels of the auxiliary connectivity output. We denote the encoder’s outputs as , where is the encoder layer. As shown in Fig. 5, we upsample , the last encoder output, to the input size and get a preliminary output called , which will be supervised to learn the connectivity mask in the loss calculation. Therefore, rich, distinctive directional information can be obtained from the channels of . Then, we squeeze [43] through a global average pooling (GAP) and map the vector to the same dimension as the latent feature map with a 1×1 convolutional kernel [44]:
| (2) |
| (3) |
where H and W are the height and the width of a feature map, is the channel of , and is the ReLu activation. The resulting has the directional information of a specific direction embedded in each entry. Next, we re-encode with a 1×1 convolution and apply a sigmoid gating function to normalize the projected vector:
| (4) |
Figure 5.
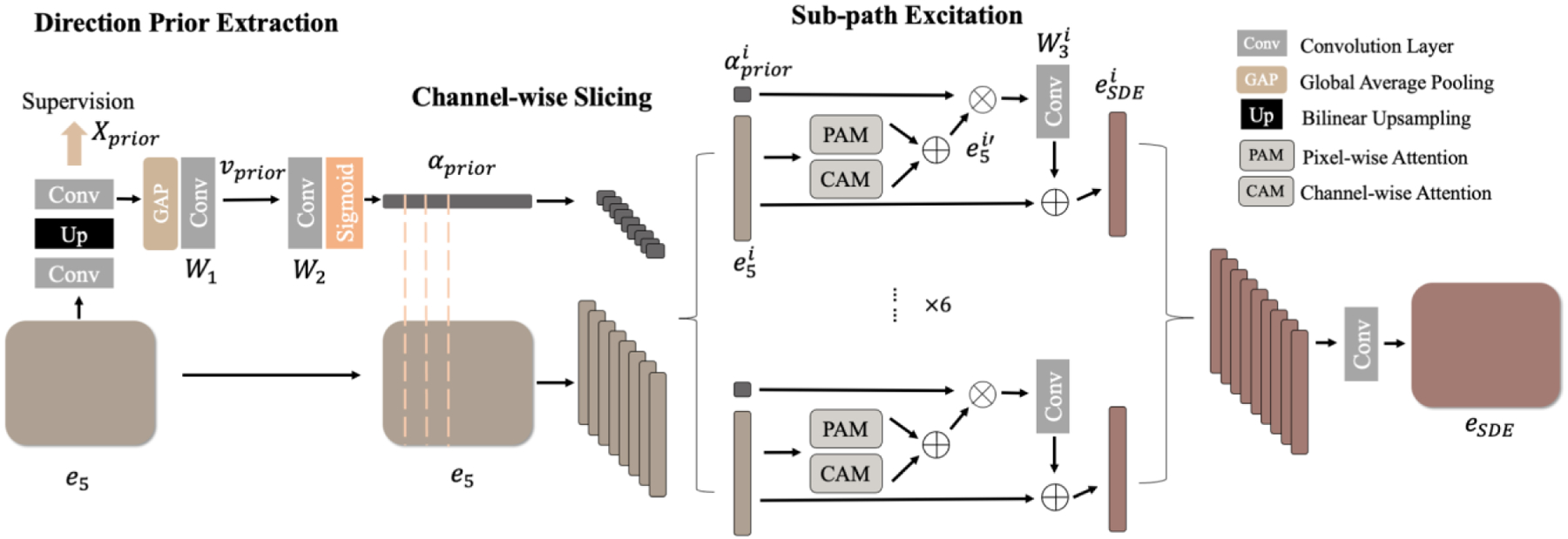
The SDE module, including three steps: direction prior extraction, channel-wise slicing, and sub-path excitation.
Since contains rich element-wise directional information, we call it the directional prior.
Channel-wise slicing.
To early disentangle the categorical and directional subspaces in the hidden layers, we split the latent features () and the directional prior () into eight parts by channel-wise slicing. We denote the slices as and .
Sub-path excitation (SPE).
We construct a sub-path for each pair of these feature-embedding slices. In each sub-path, we pass the feature slice through spatial and channel attention modules [10] to capture the long-range and inter-channel dependencies, resulting in . Next, we channel-wisely multiply the with to selectivity highlight or suppress features with specific directional information. Then, we recode the output with a 1×1 convolution kernel and residually output it as:
| (5) |
Finally, we stack all sub-paths outputs () into one and recode it, resulting in a new feature map, .
Due to the slicing operation, each group of slices will only contain part of the full features. However, the shrink of discriminative contextual information in directional and categorical features differs. Specifically, is a highly discriminative directional embedding as it is a low-level linear combination of unique directional features. Thus, channel-wise slicing will cause significant shrinkage of directional information in each slice. However, contains a group of high-level but less-discriminative categorical features which usually have low variations with others [47]. As a result, high channel-wise categorical correlation and redundancy [48] exist in . Therefore, a channel-wise slicing will result in less shrinkage [49] of high-discriminative categorical features in . By doing this, we contextual-unevenly divide the directional and categorical features in each sub-path and make each sub-path shift its focus to the dominant features. Specifically, inside each sub-path, the network learns how to focus on the dominant class-specific information with less distinctive directional information emphasized in the channels. Between sub-paths, the network learns different distinctive directional information. Then, once we stack the sub-paths back, the direction information will be naturally disentangled from the original latent space and embedded into the channels.
3.3. Interactive Feature-space Decoder
To ensure that the direction-dependent information can be effectively fused into feature maps in each layer, we propose an Interactive Feature-space Decoder with two top-down dynamically interactive flows, i.e., space flow and feature flow, as in Fig. 6.
Figure 6.
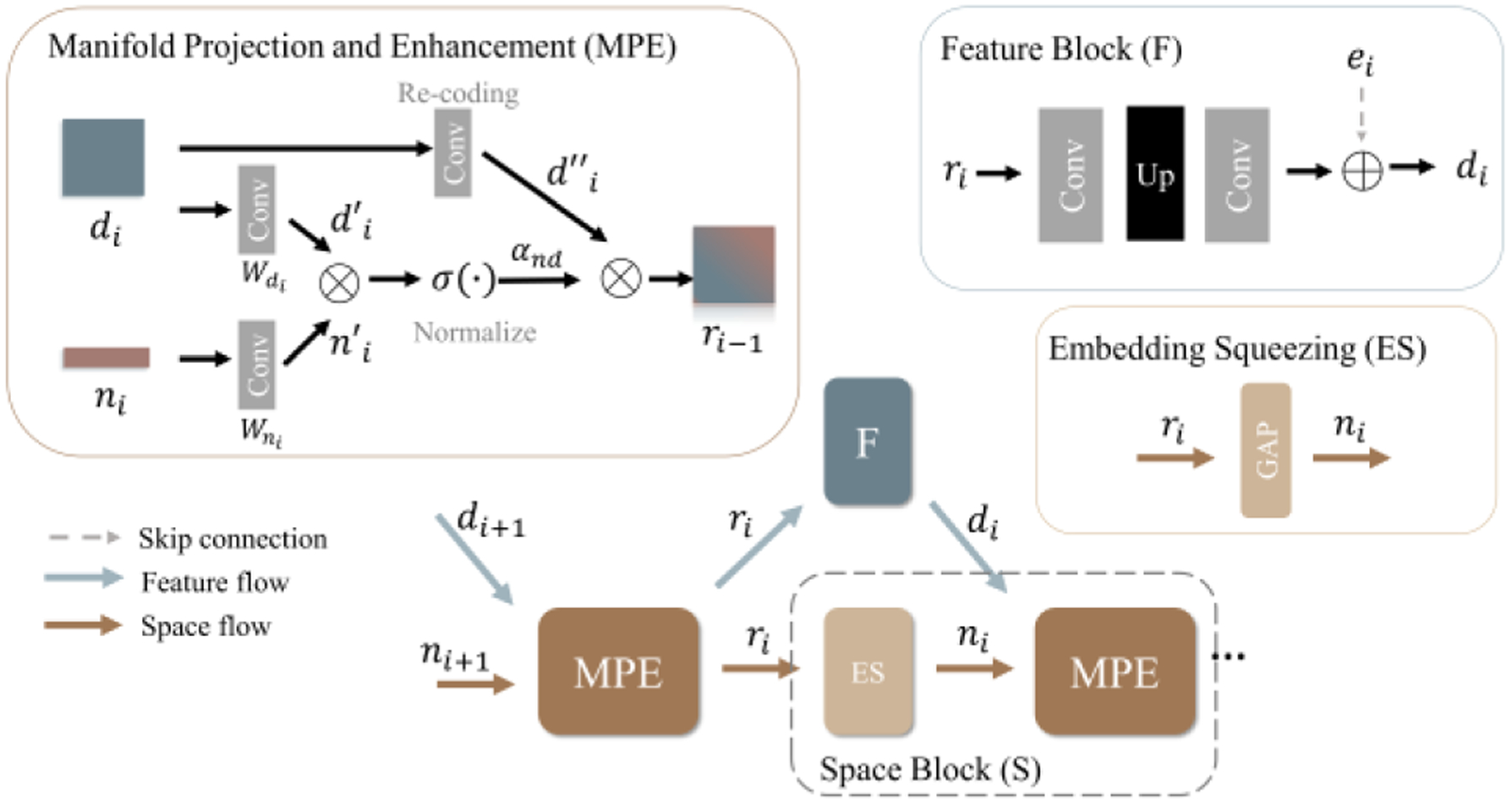
The Interactive Feature-space Decoder (IFD).
Feature maps.
There are two types of feature maps in each layer of IFD: the main feature map and the direction-enhanced map . At the first decoder layer (), they are both initialized as the outputs of SDE:
| (6) |
and are updated separately in the space and feature flows.
Space flow.
In each space flow, a Space Block (S), which contains the embedding squeezing (ES) module and the manifold projection and enhancement (MPE) module, is used to enhance the directional representation. The ES module takes as the input and outputs a directional embedding , a high-level directional representation as:
| (7) |
Then, we use as the input of MPE to enhance the directional representation in the main feature map . In MPE, we first project both the main feature map and directional embedding onto a shared manifold at the current resolution with two convolutional projectors:
| (8) |
where and . Next, we model the category-direction relation by calculating the similarity between the projected directional embedding and feature map with a channel-wise dot product and a sigmoid activation:
| (9) |
where is the normalized category-direction attention map in which the direction-relevant features are enhanced and the irrelevant features are suppressed across channels. Next, we enhance the directional information in the re-encoded original feature map with the attention map using a point-wise inner multiplication:
| (10) |
By doing this, we effectively fuse the directional information into the feature map, resulting in a new direction-enhanced map , which will be further used as the input of feature flow and to generate the directional embedding for the next layer.
Feature flow.
Each feature flow contains a Feature Block (F), including two convolutional layers and an upsampling layer with a skip connection. It takes as the input and outputs the upsampled main feature map .
This top-down design and dynamic interactions between the two flows are mutually beneficial. Specifically, the embedding extracted by space flow effectively fuses the directional information into the feature map from the feature flow. On the other hand, the generated by feature flow refines the directional representation by adding supplementary directional information at a higher resolution to the space flow via MPE and ES.
3.4. Connectivity output
We integrate the main feature maps to to get the final connectivity output . Every eight channels of represent the connectivity of one class. In line with [16], we use the Bilateral Voting (BV) module in (11) and the Region-guided Channel Aggregation (RCA) module in (12) to get the final segmentation map.
| (11) |
| (12) |
where j is the channel, } represent the location of neighboring pixel, is the Bicon map, is the final segmentation prediction [16].
3.5. Loss function
The total loss function of our work is:
| (13) |
where represents the main output and represents the auxiliary output from SDE. Each loss contains two parts, the Size Density Loss and the original Bicon loss [16] :
| (14) |
Size Density Loss.
Considering the imbalanced nature of the medical data, we propose a novel imbalanced loss function based on the label size distribution of the classes of interests in the dataset, called Size Density Loss.
Before training, we sample all the training images and calculate the size of the label (total positive pixel number) on each image. Based on the extracted size distribution, for each class , we calculate the probability density function of label size , i.e., . Then, in the training phase, for each training image, we calculate its label size for each class and get its size density weight as:
| (15) |
We define the as a variant of Dice loss [50]:
| (16) |
where is the final segmentation prediction, is the stabilization term [51] and is usually set as 1.
Bicon Loss term.
We use the Bicon Loss for connectivity modeling, as originally defined in [16]:
| (17) |
4. Experiments
4.1. Datasets and evaluation metrics
We used three popular and diverse medical benchmark datasets in this paper. Specifically, we used Retouch [52] and ISIC2018 [53] datasets to evaluate the DconnNet performance for large-scale medical segmentation. We used CHASEDB1 [54] dataset to assess the topological performance of the DconnNet.
Retouch
Retouch is an OCT retinal fluids segmentation benchmark that has been widely used [55, 56] for assessing computer vision methods. It contains three classes of disease biomarkers: intraretinal fluid (IRF), subretinal fluid (SRF), and pigment epithelial detachment (PED). Retouch contains a training set of 70 OCT volumes from three OCT scanners, with frame sizes spanning from 512 ×496 to 512 × 1024 pixels. Retouch is a two-level balanced dataset: at the image level, biomarkers do not span the whole volume; at the pixel level, each biomarker has a relatively small size compared to the background. Since the testing labels are unavailable, we implemented the volume-level 3-fold cross-validation (CV) for each scanner on the training data set. Following the official guidelines [52], we used volume-level Dice [65] (), image-level Dice (), absolute volume difference (), and volume-wise balanced accuracy [66] () to evaluate the results.
ISIC 2018
ISIC 2018 is a popular medical segmentation benchmark [67–70] containing 2594 images of various types of skin lesions at different resolutions. Following [71], we used 5-fold CV and evaluated the results with Dice, IOU, accuracy (ACC), and precision (PREC) metrics.
CHASEDB1
CHASEDB1 is a vessel segmentation dataset containing 28 fundus images with a resolution of 999× 960 pixels and two sets of manual annotations. The first manual annotation is adopted in this work as in [72]. We conducted 5-fold CV and evaluated the results with two volumetric metrics and ; and three topology-similarity-based metric , 0- and 1-Betti numbers ( and ) [73] to measure the topological similarity.
4.2. Experimental details
We generated the connectivity mask for each image via simple matrix operations [16]. We used the ImageNet [74] pretrained ResNet [75] as our encoder. The hyperparameter setting differed across datasets. For the Retouch dataset, we resized each image to 256×256 with no data augmentation and trained DconnNet with a ‘poly’ learning rate strategy. For ISIC2018, we resized images to 224×320 and used the same data augmentation and the parameter settings in [71]. For CHASEDB1, to fully use the limited data, we resized to 960×960 pixels and applied the same augmentations as in [60]. Since the CHASEDB1 dataset has a limited sample size, we did not apply SDL loss to this dataset. We did not use any pre-processing for training and no post-processing for evaluation. The framework is built on PyTorch 1.7.0 [76]. All experiments are performed with a GPU NVIDIA GeForce GTX 3090 Ti.
5. Results
5.1. Retinal fluid segmentation
Comparison of state-of-the-art methods.
We compared the proposed DconnNet with eight state-of-the-art models for relevant applications, including DeepLab V3+ [57], U-Net [58], Attention UNet [59], CE-Net [60], nnU-Net [61], CPFNet [62], CPFNet-backboned Curvature Loss [63], and MsTGANet [64] in Table 1, which shows the superior performance of the proposed model. Specifically, the improvements on and demonstrate that our model has a consistent prediction on the small fluid regions, while the improvements on AVD and BACC demonstrate that our model has an overall more accurate prediction on the fluid regions, regardless of the target size.
Table 1.
Results on Retouch dataset. Model size (M) and testing speed (FPS) are also reported. The best results are bold.
| Method | Size / Speed | ||||
|---|---|---|---|---|---|
| DeepLabv3+ [57] | 60.2 | 82.7 | 0.023 | 86.5 | 59.3 / 38 |
| U-Net [58] | 66.1 | 84.2 | 0.021 | 87.4 | 13.4 / 38 |
| Att-UNet [59] | 65.3 | 83.4 | 0.022 | 86.6 | 34.9 / 36 |
| CE-Net [60] | 67.3 | 84.2 | 0.026 | 84.6 | 29.0 / 37 |
| nnU-Net [61] | 67.2 | 84.3 | 0.023 | 86.4 | 30.0 / 20 |
| CPFNet [62] | 69.0 | 85.7 | 0.022 | 88.0 | 43.3 / 37 |
| Curvature [63] | 68.2 | 84.7 | 0.024 | 87.1 | 43.3 / 37 |
| MsTGANet [64] | 68.9 | 85.0 | 0.023 | 87.1 | 11.6 / 37 |
| DconnNet | 78.2 | 87.7 | 0.020 | 90.5 | 36.4 / 40 |
Qualitative study.
In Fig. 7, we compared DconnNet with the top-six baselines. In image (a), all competing methods missed the tiny SRF region, while our DconnNet made an accurate prediction. In (b), all methods, except DconnNet, either made false positive (FP) segmentations of IRF or an incomplete segmentation on PED. In (c), only our DconnNet made the topologically connected prediction for PED and accurately segmented the IRF and SRF regions.
Figure 7.
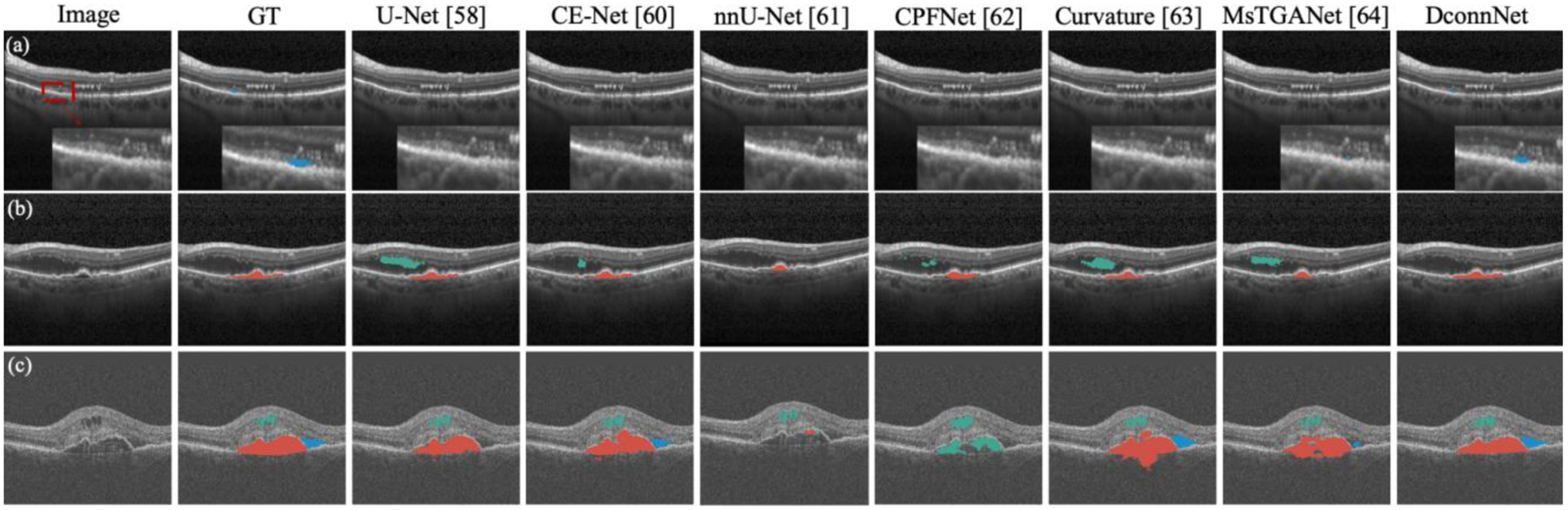
Visual comparison between the proposed DconnNet and other state-of-the-art methods on Retouch dataset. Different colors of masks represent different biomarker classes. Green: IRF; blue: SRF; red: PED.
5.2. Skin lesion segmentation
Comparison of state-of-the-art methods.
In Table 2, we compared our method with U-Net [58], BCDU-Net [77], CE-Net [60], nnU-Net [61], HiFormer [78], CPFNet [62], FATNet [79], and Ms RED [71]. The proposed DconnNet outperformed all competitive models.
Table 2.
Results on ISIC2018 dataset. The best results are bold.
| Method | ||||
|---|---|---|---|---|
| U-Net [58] | 88.41 | 81.23 | 95.53 | 90.7 |
| BCDU-Net [77] | 88.33 | 80.84 | 95.48 | 89.68 |
| CE-Net [60] | 89.23 | 82.34 | 95.76 | 91.51 |
| nnU-Net [61] | 89.24 | 82.35 | 95.79 | 91.45 |
| HiFormer [78] | 88.54 | 81.45 | 95.59 | 91.09 |
| CPFNet [62] | 89.34 | 82.64 | 95.89 | 91.38 |
| FATNet [79] | 88.84 | 81.79 | 95.62 | 91.18 |
| Ms RED [71] | 89.48 | 82.71 | 95.89 | 91.83 |
| DconnNet | 90.43 | 83.91 | 96.39 | 91.54 |
Qualitative study.
Due to limited space, in Figs. 8 and 9, we only compare the best-performing methods. In Fig. 8, DconnNet can accurately segment the lesion even under strong clinical confounders (e.g., the hairs in the first image). Also, DconnNet could learn the topology of skin lesions and make connected predictions in all cases, while others showed topological errors.
Figure 8.
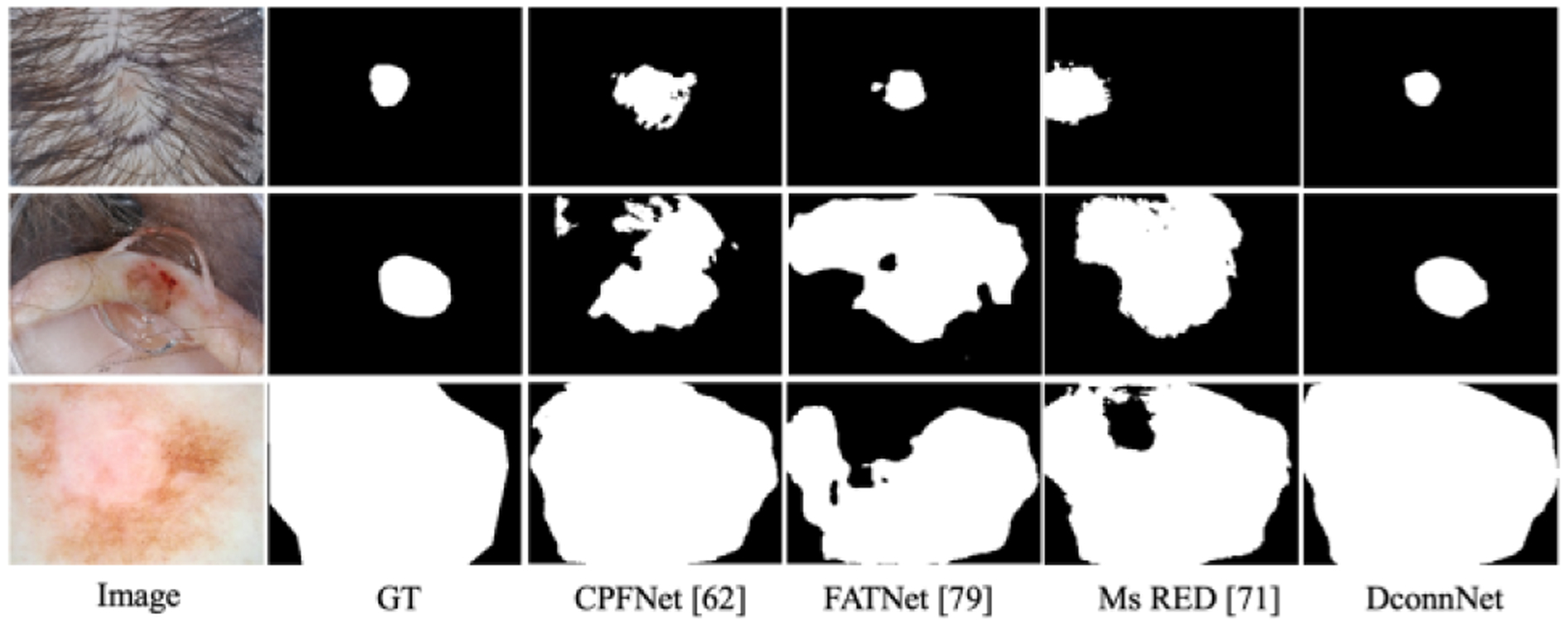
Visualization on ISIC2018 dataset.
Figure 9.
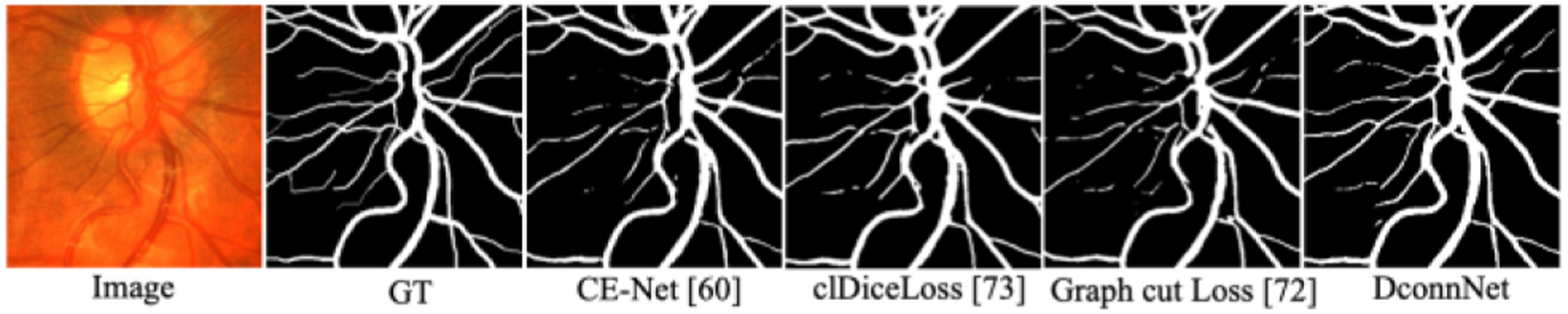
Visualization on CHASEDB1 dataset.
5.3. Topological vessel segmentation
We used this experiment to demonstrate the topology-preserving ability of DconnNet in vessel segmentation, in which anatomical consistency is crucial. Due to the limited sampling size, we did not use SDL in this experiment.
Comparison of state-of-the-art methods.
We compared the results of DconnNet versus up-to-date leading methods, including U-Net [58], Att-UNet [59], GT-DLA [80], CE-Net [60], clDiceLoss [73], and Graph Cut Loss [72] in Table 3. Our method surpassed other methods on all metrics. The superior performances of DconnNet on clDice, , and , reflect the topological similarity between predictions and labels.
Table 3.
Results on CHASEDB1. The best results are bold.
Qualitative study on the vessel topology.
In Fig. 9, we visually compared different methods. While in part due to limited training data DconnNet could not make perfect predictions across the whole images, it visually outperformed other methods. Our model’s predicted vessels are mostly connected and with no significant topological errors. Other models showed more topological issues, e.g., in the form of non-simply connected regions.
5.4. Ablation study
We conducted ablation studies to compare directional connectivity modeling with the traditional segmentation-based modeling and the naïve connectivity modeling [16]. All experiments in this section are on the Retouch Dataset.
Overall ablation study.
The overall ablation study is reported in Table 4. The backbone (Exp. 1), a pretrained ResNet [75] encoder with a regular decoder, is from [62]. Exp. 2 is identical to [16] with a different backbone. Both connectivity modeling (Exp. 2) and directional modeling (Exp. 3 and 4) result in significant performance improvements. Especially, the considerable increases in the terms demonstrate that the model is becoming stable when dealing with the small fluid regions. Finally, by adding SDL (Exp. 5), all metrics got improved showing the impact of the distribution-based weighting scheme.
Table 4.
Ablation study of the Retouch Dataset. Conn stands for connectivity modeling with . DS stands for dice loss.
| Conn | Module | Loss | |||||||
|---|---|---|---|---|---|---|---|---|---|
| SDE | IFD | DS | SDL | ||||||
| 1 | √ | 83.2 | 65.0 | 0.025 | 87.0 | ||||
| 2 | √ | √ | 85.8 | 70.3 | 0.024 | 87.7 | |||
| 3 | √ | √ | √ | 86.2 | 73.7 | 0.023 | 87.9 | ||
| 4 | √ | √ | √ | √ | 86.7 | 75.2 | 0.023 | 88.3 | |
| 5 | √ | √ | √ | √ | 87.7 | 78.2 | 0.020 | 90.5 | |
Directional prior in SDE.
The directional prior in the SDE module was designed to provide an initial prior to disentangle the directional features which will later be utilized across the entire network. Thus, Table 5 compares two experiments: the complete DconnNet and the one without directional prior, i.e., only PAM and CAM in each sub-path of SDE. Even when most of the network structure was kept unchanged, the network performed worse without the guidance of an initial directional embedding prior.
Table 5.
Ablation study on directional prior.
| DconnNet | ||||
|---|---|---|---|---|
| w/o. prior | 86.3 | 72.3 | 0.023 | 89.1 |
| w/. prior | 87.7 | 76.6 | 0.020 | 90.5 |
Sub-path attention vs. single-path attention.
In SDE, we applied a sub-path attention unit in each slice to capture the dependency between the contextual-unevenly sliced directional and categorical features. To demonstrate the effectiveness of the sub-path attention, we compared our proposed SDE with the alternative single-path attention units. We first compared it with a regular dual attention unit [10] which is the direct alternative to our SDE since we used the same module in each sub-path. We also conducted an experiment with the non-local unit [42]. The results are shown in Table 6, which shows all metrics increase after introducing the sub-path mechanism.
Table 6.
Ablation study on Sub-path attention. Backbone_Conn is the connectivity-based modeling on backbone [16], DA is the dual attention, and NL is the non-local module.
Disentanglement of directional subspace.
To show that the directional subspace is disentangled from the shared latent space with the proposed sub-path slicing method, we conducted two experiments on the DconnNet’s latent space. First, we used T-SNE to visualize the learned patch-wise feature maps in the latent spaces before and after the SDE module of a trained DconnNet, as shown in Fig. 2. Applying SDE decoupled the latent space and changed the latent features’ centered distribution to a polarized distribution. We interpret this as the decoupling process between the directional subspace and categorical subspace.
Then, to show the well-structured directional subspace between channels, we visualize the learned channel embeddings in the latent spaces before and after the SDE module of a trained DconnNet, as in Fig. 10. After SDE, the channel embeddings naturally grouped into several distinctive parts, demonstrating the effectiveness of the sub-path excitation.
Figure 10.

Visualization of latent channel embeddings of DconnNet before and after SDE module using T-SNE. The colors in (b) indicate the unsupervised clustering result. When applied to SDE, the channel embeddings naturally grouped into several distinctive parts.
Comparison of size density loss.
Exp. 4 and 5 in Table 4 demonstrated the superiority of the proposed SDL in connectivity modeling. This subsection further analyzes SDL in a pixel-classification-based segmentation setting.
In Table 7, we compared SDL with alternative loss functions with a similar idea of weighting the region-based Dice loss, including Exponential Logarithmical Loss [81], Focal Dice Loss [82], Dice loss [50], and Generalised Dice [83] based on two networks: U-Net and CPFNet. Our SDL achieves the highest both image- and volume-wise. Moreover, it shows more stability when dealing with a two-level imbalanced medical dataset compared to feedback-based losses (e.g., Focal-like losses) since it is less sensitive to FP prediction on the negative training images.
Table 7.
Ablation study on loss function on Retouch Dataset.
Model size.
Table 1 compares different model sizes. DconnNet (36.42M parameters) performed far better than the backbone (33.16M) with only ~3M extra parameters. In SDE, due to the channel slicing, we quadratically reduced the size of each sub-path attention (0.196M) from the full-size dual attention [10] (23.35M), resulting in the small size of the proposed SDE in Table 8. Also, changing the network to connectivity modeling only takes extra 0.03M parameters. Given the relatively small parameter increase, 3D connectivity modeling is a potential future direction for 3D image segmentation.
Table 8.
The components’ size of DconnNet.
| Module | ResNetEncoder | SDE | IFD | Final Decoder | Connect. Modeling | Total | |
|---|---|---|---|---|---|---|---|
| FeatureBlock | SpaceBlock | ||||||
| Para. (M) | 21.80 | 1.57 | 11.35 | 1.49 | 0.18 | 0.03 | 36.42 |
6. Conclusion
This paper proposed a novel directional connectivity modeling network (DconnNet) for medical image segmentation. The core idea is to disentangle the directional subspace from the shared latent space and use the extracted directional features to enhance the overall data representation. We demonstrated the effectiveness of DconnNet in three ways. First, by statistical comparisons to other state-of-the-art methods, we showed the overall better performance of DconnNet. Then, we demonstrated its topology-preserving ability by qualitatively and quantitively comparing DconnNet to other methods on a topologically sensitive dataset to other methods. Third, by visualizing the latent space of DconnNet, we revealed the disentanglement process of the directional subspace.
Acknowledgment
This research was supported in part by NIH R01 EY030124, U01 EY034687, R01 EY031033, UG1 EY033287, P30 EY005722, and R01 AG072732.
Contributor Information
Ziyun Yang, Duke University, Durham, NC, United States.
Sina Farsiu, Duke University, Durham, NC, United States.
References
- [1].Bazin PL, and Pham DL, “Topology correction of segmented medical images using a fast-marching algorithm,” Comput. Methods Programs Biomed, vol. 88, no. 2, pp. 182–90, 2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].Clough JR, Byrne N, Oksuz I, Zimmer VA, Schnabel JA, and King AP, “A topological loss function for deep-learning based image segmentation using persistent homology,” IEEE TPAMI, vol. 44, no. 12, pp. 8766–8778, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Hu X, Li F, Samaras D, and Chen C, “Topology-preserving deep image segmentation,” in NIPS, vol. 32, 2019. [Google Scholar]
- [4].Kong TY, and Rosenfeld A, “Digital topology: Introduction and survey,” Comput. Gr. Image Process, vol. 48, no. 3, pp. 357–393, 1989. [Google Scholar]
- [5].Saha PK, Strand R, and Borgefors G, “Digital topology and geometry in medical imaging: a survey,” IEEE Trans. Med. Imag, vol. 34, no. 9, pp. 1940–1964, 2015. [DOI] [PubMed] [Google Scholar]
- [6].Nath SK, Palaniappan K, and Bunyak F, “Cell segmentation using coupled level sets and graph-vertex coloring,” in MICCAI, pp. 101–108, 2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Kriegeskorte N, and Goebel R, “An efficient algorithm for topologically correct segmentation of the cortical sheet in anatomical MR volumes,” Neuroimage, vol. 14, no. 2, pp. 329–346, 2001. [DOI] [PubMed] [Google Scholar]
- [8].Liu M, Colas F, and Siegwart R, “Regional topological segmentation based on mutual information graphs,” in ICRA, pp. 3269–3274, 2011. [Google Scholar]
- [9].Long J, Shelhamer E, and Darrell T, “Fully convolutional networks for semantic segmentation,” in CVPR, pp. 3431–3440, 2015. [DOI] [PubMed] [Google Scholar]
- [10].Fu J, Liu J, Tian H, Li Y, Bao Y, Fang Z, and Lu H, “Dual Attention Network for Scene Segmentation,” in CVPR, pp. 3141–3149, 2019. [Google Scholar]
- [11].Zhao H, Zhang Y, Liu S, Shi J, Loy CC, Lin D, and Jia J, “PSANet: Point-wise Spatial Attention Network for Scene Parsing,” in ECCV, pp. 270–286, 2018. [Google Scholar]
- [12].Chen LC, Papandreou G, Kokkinos I, Murphy K, and Yuille AL, “DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs,” IEEE TPAMI, vol. 40, no. 4, pp. 834–848, 2018. [DOI] [PubMed] [Google Scholar]
- [13].Van der Maaten L, and Hinton G, “Visualizing data using t-SNE,” JMLR, vol. 9, no. 11, 2008. [Google Scholar]
- [14].Liu H, Liu F, Fan X, and Huang D, “Polarized self-attention: Towards high-quality pixel-wise mapping,” Neurocomputing, vol. 506, pp. 158–167, 2022. [Google Scholar]
- [15].Kampffmeyer M, Dong N, Liang X, Zhang Y, and Xing EP, “ConnNet: A long-range relation-aware pixel-connectivity network for salient segmentation,” IEEE Trans. Image Process, vol. 28, no. 5, pp. 2518–2529, 2018. [DOI] [PubMed] [Google Scholar]
- [16].Yang Z, Soltanian-Zadeh S, and Farsiu S, “BiconNet: An Edge-preserved Connectivity-based Approach for Salient Object Detection,” Pattern Recognit, vol. 121, pp. 108231, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Borne L, Rivière D, Mancip M, and Mangin J-F, “Automatic labeling of cortical sulci using patch- or CNN-based segmentation techniques combined with bottom-up geometric constraints,” Med. Image Anal, vol. 62, pp. 101651, 2020. [DOI] [PubMed] [Google Scholar]
- [18].Rosenfeld A, and Klette R, “Digital geometry,” Information Sciences, vol. 148, no. 1, pp. 123–127, 2002. [Google Scholar]
- [19].Li X, Wang Y, Zhang L, Liu S, Mei J, and Li Y, “Topology-Enhanced Urban Road Extraction via a Geographic Feature-Enhanced Network,” IEEE Trans. Geosci. Remote Sens, vol. 58, no. 12, pp. 8819–8830, 2020. [Google Scholar]
- [20].Ma H, Li C, Liu J, Wang J, and Meng MQH, “Enhance Connectivity of Promising Regions for Sampling-Based Path Planning,” IEEE Trans. on Autom. Sci. Eng, early access. doi: 10.1109/TASE.2022.3191519, 2022. [DOI] [Google Scholar]
- [21].Qin Y, Chen M, Zheng H, Gu Y, Shen M, Yang J, Huang X, Zhu Y-M, and Yang G-Z, “Airwaynet: a voxel-connectivity aware approach for accurate airway segmentation using convolutional neural networks,” in MICCAI, pp. 212–220, 2019. [Google Scholar]
- [22].Yang Z, Soltanian-Zadeh S, Chu KK, Zhang H, Moussa L, Watts AE, Shaheen NJ, Wax A, and Farsiu S, “Connectivity-based Deep Learning Approach for Segmentation of the Epithelium in In Vivo Human Esophageal OCT Images,” Biomed. Opt. Express, vol. 12, no. 10, pp. 6326–6340, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Jia Y, Salzmann M, and Darrell T, “Factorized latent spaces with structured sparsity,” in NIPS, vol. 23, 2010. [Google Scholar]
- [24].Gu J, Wang Z, Ouyang W, Li J, and Zhuo L, “3d hand pose estimation with disentangled cross-modal latent space,” in WACV, pp. 391–400, 2020. [Google Scholar]
- [25].Salzmann M, Ek CH, Urtasun R, and Darrell T, “Factorized orthogonal latent spaces,” in AISTATS, pp. 701–708, 2010. [Google Scholar]
- [26].Rudra AK, Chowdhury AS, Elnakib A, Khalifa F, Soliman A, Beache G, and El-Baz A, “Kidney segmentation using graph cuts and pixel connectivity,” Pattern Recognit. Lett, vol. 34, no. 13, pp. 1470–1475, 2013. [Google Scholar]
- [27].Fontaine M, Macaire L, and Postaire J-G, “Image segmentation based on an original multiscale analysis of the pixel connectivity properties,” in ICIP, pp. 804–807, 2000. [Google Scholar]
- [28].Long Y, Morris D, Liu X, Castro M, Chakravarty P, and Narayanan P, “Radar-camera pixel depth association for depth completion,” in CVPR, pp. 12507–12516, 2021. [Google Scholar]
- [29].Rasti R, Biglari A, Rezapourian M, Yang Z, and Farsiu S, “RetiFluidNet: A Self-Adaptive and Multi-Attention Deep Convolutional Network for Retinal OCT Fluid Segmentation,” IEEE Trans. Med. Imag, (In Press), 2023. [DOI] [PubMed] [Google Scholar]
- [30].Cai Y, Lin K-Y, Zhang C, Wang Q, Wang X, and Li H, “Learning a Structured Latent Space for Unsupervised Point Cloud Completion,” in CVPR, pp. 5543–5553, 2022. [Google Scholar]
- [31].Yang L, and Yao A, “Disentangling latent hands for image synthesis and pose estimation,” in CVPR, pp. 9877–9886, 2019. [Google Scholar]
- [32].Arvanitidis G, Hansen LK, and Hauberg S, “Latent space oddity: on the curvature of deep generative models,” in ICLR, 2018. [Google Scholar]
- [33].Li Z, Tao R, Wang J, Li F, Niu H, Yue M, and Li B, “Interpreting the latent space of GANs via measuring decoupling,” IEEE Trans. Artif. Intell, vol. 2, no. 1, pp. 58–70, 2021. [Google Scholar]
- [34].Yang C, Zhou H, An Z, Jiang X, Xu Y, and Zhang Q, “Cross-image relational knowledge distillation for semantic segmentation,” in CVPR, pp. 12319–12328, 2022. [Google Scholar]
- [35].Hu M, Maillard M, Zhang Y, Ciceri T, La Barbera G, Bloch I, and Gori P, “Knowledge distillation from multi-modal to mono-modal segmentation networks,” in MICCAI, pp. 772–781, 2020. [Google Scholar]
- [36].Delhaisse B, Esteban D, Rozo L, and Caldwell D, “Transfer learning of shared latent spaces between robots with similar kinematic structure,” in IJCNN, pp. 4142–4149, 2017. [Google Scholar]
- [37].Liu Y, Jun E, Li Q, and Heer J, “Latent space cartography: Visual analysis of vector space embeddings,” Comp. Graphics Forum, pp. 67–78, 2019. [Google Scholar]
- [38].Abdi H, and Williams LJ, “Principal component analysis,” Wiley Interdiscip. Rev. Comput. Stat, vol. 2, no. 4, pp. 433–459, 2010. [Google Scholar]
- [39].Heimerl F, and Gleicher M, “Interactive analysis of word vector embeddings,” Comp. Graphics Forum, vol. 37, no. 3, pp. 253–265, 2018. [Google Scholar]
- [40].Zheng Z, and Sun L, “Disentangling latent space for vae by label relevant/irrelevant dimensions,” in CVPR, pp. 12192–12201, 2019. [Google Scholar]
- [41].Notin P, Hernández-Lobato JM, and Gal Y, “Improving black-box optimization in VAE latent space using decoder uncertainty,” in NIPS, vol. 34, pp. 802–814, 2021. [Google Scholar]
- [42].Luo Z, Mishra A, Achkar A, Eichel J, Li S, and Jodoin P, “Non-local Deep Features for Salient Object Detection,” in CVPR, pp. 6593–6601, 2017. [Google Scholar]
- [43].Hu J, Shen L, and Sun G, “Squeeze-and-Excitation Networks,” in CVPR, pp. 7132–7141, 2018. [Google Scholar]
- [44].Zheng Z, Zhong Y, Wang J, and Ma A, “Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery,” in CVPR, pp. 4095–4104, 2020. [DOI] [PubMed] [Google Scholar]
- [45].Ding X, Shen C, Che Z, Zeng T, and Peng Y, “SCARF: A Semantic Constrained Attention Refinement Network for Semantic Segmentation,” in ICCVW, pp. 3002–3011, 2021. [Google Scholar]
- [46].Zhang H, Dana K, Shi J, Zhang Z, Wang X, Tyagi A, and Agrawal A, “Context encoding for semantic segmentation,” in CVPR, pp. 7151–7160, 2018. [Google Scholar]
- [47].Ayinde BO, Inanc T, and Zurada JM, “Redundant feature pruning for accelerated inference in deep neural networks,” Neural Networks, vol. 118, pp. 148–158, 2019. [DOI] [PubMed] [Google Scholar]
- [48].Kahatapitiya K, and Rodrigo R, “Exploiting the redundancy in convolutional filters for parameter reduction,” in WACV, pp. 1410–1420, 2021. [Google Scholar]
- [49].Denil M, Shakibi B, Dinh L, Ranzato MA, and De Freitas N. J. A. i. n. i. p. s., “Predicting parameters in deep learning,” in NIPS, vol. 26, 2013. [Google Scholar]
- [50].Milletari F, Navab N, and Ahmadi S, “V-Net: Fully convolutional neural networks for volumetric medical image segmentation,” in 3DV, pp. 565–571, 2016. [Google Scholar]
- [51].Jadon S, “A survey of loss functions for semantic segmentation,” in CIBCB, pp. 1–7, 2020. [Google Scholar]
- [52].Bogunović H et al. , “RETOUCH: The Retinal OCT Fluid Detection and Segmentation Benchmark and Challenge,” IEEE Trans. Med. Imag, vol. 38, no. 8, pp. 1858–1874, 2019. [DOI] [PubMed] [Google Scholar]
- [53].Codella N et al. , “Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic),” arXiv preprint arXiv:1902.03368, 2019. [Google Scholar]
- [54].Fraz MM, Remagnino P, Hoppe A, Uyyanonvara B, Rudnicka AR, Owen CG, and Barman SA, “An ensemble classification-based approach applied to retinal blood vessel segmentation,” IEEE Trans. Biomed. Eng, vol. 59, no. 9, pp. 2538–2548, 2012. [DOI] [PubMed] [Google Scholar]
- [55].Mahapatra D, Bozorgtabar B, and Shao L, “Pathological retinal region segmentation from oct images using geometric relation-based augmentation,” in CVPR, pp. 9611–9620, 2020. [Google Scholar]
- [56].Reiß S, Seibold C, Freytag A, Rodner E, and Stiefelhagen R, “Every annotation counts: Multi-label deep supervision for medical image segmentation,” in CVPR, pp. 9532–9542, 2021. [Google Scholar]
- [57].Chen L-C, Zhu Y, Papandreou G, Schroff F, and Adam H, “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation,” in ECCV, pp. 833–851, 2018 [Google Scholar]
- [58].Ronneberger O, Fischer P, and Brox T, “U-Net: Convolutional networks for biomedical image segmentation,” in MICCAI, pp. 234–241, 2015. [Google Scholar]
- [59].Oktay O et al. , “Attention U-Net: Learning Where to Look for the Pancreas,” in MIDL, 2018. [Google Scholar]
- [60].Gu Z, Cheng J, Fu H, Zhou K, Hao H, Zhao Y, Zhang T, Gao S, and Liu J, “CE-Net: Context encoder network for 2D medical image segmentation,” IEEE Trans. Med. Imag, vol. 38, no. 10, pp. 2281–2292, 2019. [DOI] [PubMed] [Google Scholar]
- [61].Isensee F, Jaeger PF, Kohl SAA, Petersen J, and Maier-Hein KH, “nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation,” Nature Methods, vol. 18, no. 2, pp. 203–211, 2021. [DOI] [PubMed] [Google Scholar]
- [62].Feng S, Zhao H, Shi F, Cheng X, Wang M, Ma Y, Xiang D, Zhu W, and Chen X, “CPFNet: Context Pyramid Fusion Network for Medical Image Segmentation,” IEEE Trans. Med. Imag, vol. 39, no. 10, pp. 3008–3018, 2020. [DOI] [PubMed] [Google Scholar]
- [63].Xing G, Chen L, Wang H, Zhang J, Sun D, Xu F, Lei J, and Xu X, “Multi-Scale Pathological Fluid Segmentation in OCT With a Novel Curvature Loss in Convolutional Neural Network,” IEEE Trans. Med. Imag, vol. 41, no. 6, pp. 1547–1559, 2022. [DOI] [PubMed] [Google Scholar]
- [64].Wang M, Zhu W, Shi F, Su J, Chen H, Yu K, Zhou Y, Peng Y, Chen Z, and Chen X, “MsTGANet: Automatic Drusen Segmentation from Retinal OCT Images,” IEEE Trans. Med. Imag, vol. 41, no. 2, pp. 394–406, 2022. [DOI] [PubMed] [Google Scholar]
- [65].Dice LR, “Measures of the amount of ecologic association between species,” Ecology, vol. 26, no. 3, pp. 297–302, 1945. [Google Scholar]
- [66].Brodersen KH, Ong CS, Stephan KE, and Buhmann JM, “The Balanced Accuracy and Its Posterior Distribution,” in ICPR, pp. 3121–3124, 2010. [Google Scholar]
- [67].Seibold CM, Reiß S, Kleesiek J, and Stiefelhagen R, “Reference-guided pseudo-label generation for medical semantic segmentation,” in AAAI, pp. 2171–2179, 2022. [Google Scholar]
- [68].Abhishek K, Hamarneh G, and Drew MS, “Illumination-based transformations improve skin lesion segmentation in dermoscopic images,” in CVPRW, pp. 728–729, 2020. [Google Scholar]
- [69].Li D, Yang J, Kreis K, Torralba A, and Fidler S, “Semantic segmentation with generative models: Semi-supervised learning and strong out-of-domain generalization,” in CVPR, pp. 8300–8311, 2021. [Google Scholar]
- [70].Azad R, Bozorgpour A, Asadi-Aghbolaghi M, Merhof D, and Escalera S, “Deep frequency re-calibration u-net for medical image segmentation,” in ICCV, pp. 3274–3283, 2021. [Google Scholar]
- [71].Dai D, Dong C, Xu S, Yan Q, Li Z, Zhang C, and Luo N, “Ms RED: A novel multi-scale residual encoding and decoding network for skin lesion segmentation,” Med. Image Anal, vol. 75, pp. 102293, 2022. [DOI] [PubMed] [Google Scholar]
- [72].Zheng Z, Oda M, and Mori K, “Graph Cuts Loss to Boost Model Accuracy and Generalizability for Medical Image Segmentation,” in ICCV, pp. 3304–3313, 2021. [Google Scholar]
- [73].Shit S et al. , “clDice-a novel topology-preserving loss function for tubular structure segmentation,” in CVPR, pp. 16560–16569, 2021. [Google Scholar]
- [74].Deng J, Dong W, Socher R, Li LJ, Kai L, and Li F-F, “ImageNet: A large-scale hierarchical image database,” in CVPR, pp. 248–255, 2009. [Google Scholar]
- [75].He K, Zhang X, Ren S, and Sun J, “Deep Residual Learning for Image Recognition,” in CVPR, pp. 770–778, 2016. [Google Scholar]
- [76].Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, and Antiga L, “Pytorch: An imperative style, high-performance deep learning library,” in NIPS, pp. 8026–8037, 2019. [Google Scholar]
- [77].Azad R, Asadi-Aghbolaghi M, Fathy M, and Escalera S, “Bi-directional ConvLSTM U-Net with densley connected convolutions,” in ICCVW, pp. 0–0, 2019. [Google Scholar]
- [78].Heidari M, Kazerouni A, Soltany M, Azad R, Aghdam EK, Cohen-Adad J, and Merhof D, “Hiformer: Hierarchical multi-scale representations using transformers for medical image segmentation,” arXiv preprint arXiv:2207.08518, 2022. [Google Scholar]
- [79].Wu H, Chen S, Chen G, Wang W, Lei B, and Wen Z, “FAT-Net: Feature adaptive transformers for automated skin lesion segmentation,” Med. Image Anal, vol. 76, pp. 102327, 2022. [DOI] [PubMed] [Google Scholar]
- [80].Li Y, Zhang Y, Liu J-Y, Wang K, Zhang K, Zhang G-S, Liao X-F, and Yang G, “Global Transformer and Dual Local Attention Network via Deep-Shallow Hierarchical Feature Fusion for Retinal Vessel Segmentation,” IEEE Trans. Cybern, early access. doi: 10.1109/TCYB.2022. 3194099, 2022. [DOI] [PubMed] [Google Scholar]
- [81].Wong KCL, Moradi M, Tang H, and Syeda-Mahmood T, “3D Segmentation with Exponential Logarithmic Loss for Highly Unbalanced Object Sizes,” in MICCAI, pp. 612–619, 2018. [Google Scholar]
- [82].Zhao R, Qian B, Zhang X, Li Y, Wei R, Liu Y, and Pan Y, “Rethinking Dice Loss for Medical Image Segmentationin” in ICDM, pp. 851–860, 2020. [Google Scholar]
- [83].Sudre CH, Li W, Vercauteren T, Ourselin S, and Jorge Cardoso M, “Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations,” in Deep Learn. Med. Image Anal. Int. Workshop Multimodal Learn. Clin. Decis. Support, pp. 240–248, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]