

Abstract
The relationship between perception and inference, as postulated by Helmholtz in the 19th century, is paralleled in modern machine learning by generative models like Variational Autoencoders (VAEs) and their hierarchical variants. Here, we evaluate the role of hierarchical inference and its alignment with brain function in the domain of motion perception. We first introduce a novel synthetic data framework, Retinal Optic Flow Learning (ROFL), which enables control over motion statistics and their causes. We then present a new hierarchical VAE and test it against alternative models on two downstream tasks: (i) predicting ground truth causes of retinal optic flow (e.g., self-motion); and (ii) predicting the responses of neurons in the motion processing pathway of primates. We manipulate the model architectures (hierarchical versus non-hierarchical), loss functions, and the causal structure of the motion stimuli. We find that hierarchical latent structure in the model leads to several improvements. First, it improves the linear decodability of ground truth factors and does so in a sparse and disentangled manner. Second, our hierarchical VAE outperforms previous state-of-the-art models in predicting neuronal responses and exhibits sparse latent-to-neuron relationships. These results depend on the causal structure of the world, indicating that alignment between brains and artificial neural networks depends not only on architecture but also on matching ecologically relevant stimulus statistics. Taken together, our results suggest that hierarchical Bayesian inference underlines the brain’s understanding of the world, and hierarchical VAEs can effectively model this understanding.
1. Introduction
Intelligent interactions with the world require representation of its underlying composition. This inferential process has long been postulated to underlie human perception [1–9], and is paralleled in modern machine learning by generative models [10–17], which learn latent representations of their sensory inputs. The question of what constitutes a “good” representation has no clear answer [18, 19], but several desirable features have been proposed. In the field of neuroscience, studies focused on object recognition have suggested that effective representations “untangle” the various factors of variation in the input, rendering them linearly decodable [20, 21]. This intuitive notion of linear decodability has emerged in the machine learning community under different names such as “informativeness” [22] or “explicitness” [23]. Additionally, it has been suggested that “disentangled” representations are desirable, wherein distinct, informative factors of variations in the data are separated [24–29]. Artificial neural networks (ANNs) are also increasingly evaluated based on their alignment with biological neural processing [30–38], because of the shared goals of ANNs and the brain’s sensory processing [25, 39, 40]. Such alignment also provides the possibility of gaining insights into the brain by understanding the operations within an ANN [41–47].
In this work, we investigate how the combination of (i) model architecture, (ii) loss function, and (iii) training dataset, affects learned representations, and whether this is related to the brain-alignment of the ANN [41, 44]. We focus specifically on understanding the representation of motion because large sections of the visual cortex are devoted to processing motion [34], and the causes of retinal motion (moving objects and self-motion [48]) can be manipulated systematically. Crucially, motion in an image can be described irrespective of the identity and specific visual features that are moving, just as the identity of objects is invariant to how they are moving. This separation of motion and object processing mirrors the division of primate visual processing into dorsal (motion) and ventral (object) streams [49–51].
We designed a naturalistic motion simulation based on distributions of ground truth factors corresponding to the location and depth of objects, motion of these objects, motion of the observer, and observer’s direction of gaze (i.e., the fixation point; Fig. 1a). Using our simulated retinal flow, we then trained and evaluated an ensemble of autoencoder-based models on our simulation. We based our evaluation on (1) whether the models untangle and disentangle the ground truth factors in our simulation; and (2) the degree to which their latent spaces could be directly related to neural data recorded in the dorsal stream of primates (area MT).
Figure 1:

Retinal Optic Flow Learning (ROFL): a simulation platform for synthesizing naturalistic optic flow patterns. (a) The general setup includes a moving or stationary observer and a solid background, with optional moving object(s) in the scene. More details are provided in the appendix (section 13). (b) Example frames showcasing different categories (see Table 1 for definitions). (c, d) Demonstrating the causal effects of varying a single ground truth factor while keeping all others fixed: (c) , the component of object position (measured in retinal coordinates, orange), and (d) , the component of the fixation point (measured in fixed coordinates, gray).
We introduce a new hierarchical variational autoencoder, the “compressed” Nouveau VAE (cNVAE) [52]. The cNVAE exhibited superior performance compared to other models across our multiple evaluation metrics. First, it discovered latent factors that accurately captured the ground truth factors in the simulation in a more disentangled manner than other models. Second, it achieved significant improvements in predicting neural responses compared to the previous state-of-the-art model [34], doubling the performance, with sparse mapping from its latent space to neural responses.
Taken together, these observations demonstrate the power of the synthetic data framework and show that a single inductive bias—hierarchical latent structure—leads to many desirable features of representations, including brain alignment.
2. Background & Related Work
Neuroscience and VAEs.
It has long been argued that perception reflects unconscious inference of the structure of the world constructed from sensory inputs. The concept of “perception as unconscious inference” has existed since at least the 19th century [1, 2], and more recently inspired Mumford [3] to conjecture that brains engage in hierarchical Bayesian inference to comprehend the world [3, 4]. These ideas led to the development of Predictive Coding [5, 9, 53–58], Bayesian Brain Hypothesis [6, 59–63], and Analysis-by-Synthesis [7], collectively suggesting that brains contain an internal generative model of the world [7, 8, 64]. A similar idea underlies modern generative models [15–17, 65–67], especially hierarchical variants of VAEs [52, 68–70].
The Nouveau VAE (NVAE) [52] and very deep VAE (vdvae) [68] demonstrated that deep hierarchical VAEs can generate realistic high-resolution images, overcoming the limitations of their non-hierarchical predecessors. However, neither work evaluated how the hierarchical latent structure changed the quality of learned representations. Additionally, both NVAE and vdvae have an undesirable property: their convolutional latents result in a latent space that is several orders of magnitude larger than the input space, defeating a main purpose of autoencoders: compression. Indeed, Hazami et al. [71] showed that a tiny subset (around 3%) of the vdvae latent space is sufficient for comparable input reconstruction. Here, we demonstrate that it is possible to compress hierarchical VAEs and focus on investigating their latent representations with applications to neuroscience data.
Evaluating ANNs on predicting biological neurons.
Several studies have focused on evaluating ANNs on their performance in predicting brain responses, but almost entirely on describing static (“ventral stream”) image processing [30, 33, 36]. In contrast, motion processing (corresponding to the dorsal stream) has only been considered thus far in Mineault et al. [34], who used a 3D ResNet (“DorsalNet”) to extract ground truth factors about self-motion from drone footage (“AirSim”, [72]) in a supervised manner. DorsalNet learned representations with receptive fields that matched known features of the primate dorsal stream and achieved state-of-the-art on predicting neural responses on the dataset that we consider here. In addition to our model architecture and training set, a fundamental difference between our approach and Mineault et al. [34] is that they trained their models using direct supervision. As such, their models have access to the ground truth factors at all times. Here, we demonstrate that it is possible to obtain ground truth factors “for free”, in a completely unsupervised manner, while achieving better performance in predicting responses of biological neurons.
Using synthetic data to train ANNs.
A core component of a reductionist approach to studying the brain is to characterize neurons based on their selectivity to a particular subset of pre-identified visual “features”, usually by presenting sets of “feature-isolating” stimuli [73]. In the extreme, stimuli are designed that remove all other features except the one under investigation [74]. While these approaches can inform how pre-selected feature sets are represented by neural networks, it is often difficult to generalize this understanding to more natural stimuli, which are not necessarily well-described by any one feature set. As a result, here we generate synthetic data representing a naturalistic distribution of natural motion stimuli. Such synthetic datasets allow us to manipulate the causal structure of the world, in order to make hypotheses about what aspects of the world matter for the representations learned by brains and ANNs [75]. Like previous work on synthesized textures [15], here we specifically manipulate the data generative structure to contain factors of variation due to known ground truth factors.
3. Approach: Data & Models
Retinal Optic Flow Learning (ROFL).
Our synthetic dataset framework, ROFL, generates the resulting optic flow from different world structures, self-motion trajectories, and object motion (Fig. 1a, see also [76]).
ROFL can be used to generate naturalistic flow fields that share key elements with those experienced in navigation through 3-D environments. Specifically, each frame contains global patterns that are due to self-motion, including rotation that can arise due to eye or head movement [77, 78]. In addition, local motion patterns can be present due to objects that move independently of the observer [48]. The overall flow pattern is also affected by the observer’s direction of gaze (fixation point [79], Fig. 1a).
ROFL generates flow vectors that are instantaneous in time, representing the velocity across the visual field resulting from the spatial configuration of the scene and motion vectors of self and object. Ignoring the time-evolution of a given scene (which can arguably be considered separably [80]) dramatically reduces the input space from [3 × H × W × T] to [2 × H × W], and allows a broader sampling of configurations without introducing changes in luminance and texture. As a result, we can explore the role of different causal structures in representation learning in ANNs.
The retinal flow patterns generated by a moving object depend on both the observer’s self-motion and the rotation of their eyes as they maintain fixation in the world, in addition to the motion of the object itself. For example, Fig. 1c demonstrates a situation where the observer is moving forward, and the object is moving to the right, with different object positions: an object on the left side will have its flow patterns distorted, while an object on the right will have its flow patterns largely unaffected because its flow vectors are parallel with that of the self-motion. In summary, ROFL allows us to simulate retinal optic flow with a known ground truth structure driven by object and self-motion.
The compressed NVAE (cNVAE).
The latent space of the NVAE is partitioned into groups, , where is the number of groups. The latent groups are serially dependent, meaning that the distribution of a given latent group depends on the value of the preceding latents, such that the prior is given by , and approximate posterior is given by (more details in section 9.1. Additionally, different latent groups in the NVAE operate at different spatial scales (Fig. 2, left), with multiple groups per scale. Crucially, such scale-dependent grouping is absent from non-hierarchical VAEs (Fig. 2, right).
Figure 2:
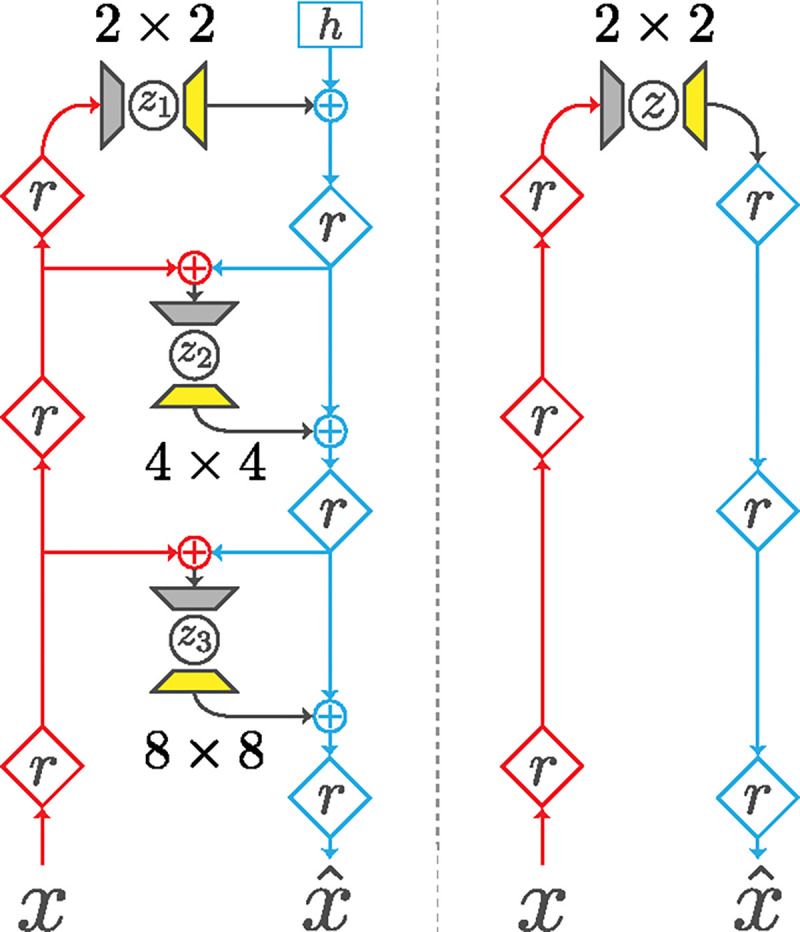
Architecture comparison. Left, compressed NVAE (cNVAE); right, non-hierarchical VAE. We modified the NVAE sampler layer (grey trapezoids) and introduced a deconvolution expand layer (yellow trapezoids). The encoder (inference) and decoder (generation) pathways are depicted in red and blue, respectively. , residual block; , trainable parameter; +, feature combination.
The cNVAE closely follows the NVAE [52], with one important difference: the original NVAE latent space is convolutional, and ours is not. We modified the sampler layers (grey trapezoids, Fig. 2) such that their receptive field sizes match the spatial scale they operate on. Thus, sampler layers integrate over spatial information before sampling from the approximate posterior. The spatial patterns of each latent dimension are then determined by expand modules (yellow trapezoids, Fig. 2), based on a deconvolution step. Further details about the processing of the sampler and expand layers are provided in Supplementary section 9.2.
Our modification of the NVAE serves two purposes. First, it decouples spatial information from the functionality of latent variables, allowing them to capture abstract features that are invariant to particular spatial locations. Second, it has the effect of compressing the input space into a lower-dimensional latent code. We explain this in more detail in Supplementary section 9.3.
Our model has the following structure: 3 latent groups operating at the scale of 2 × 2; 6 groups at the scale of 4 × 4; and 12 groups at the scale of 8 × 8 (Table 4, Fig. 2). Therefore, the model has 3 + 6 + 12 = 21 hierarchical latent groups in total. Each latent group has 20 latent variables, which results in an overall latent dimensionality of 21 × 20 = 420. See Table 4 and Supplementary section 9.3 for more details.
Alternative models.
We evaluated a range of unsupervised models alongside cNVAE, including standard (non-hierarchical) VAEs [11, 12], a hierarchical autoencoder with identical architecture as the cNVAE but trained only with reconstruction loss (cNAE), and an autoencoder (AE) counterpart for the VAE (Table 2). All models had the same latent dimensionality (Table 4), and approximately the same number of parameters and convolutional layers. We used endpoint error as our measure of reconstruction loss, which is the Euclidean norm of the difference between actual and reconstructed flow vectors. This metric works well with optical flow data [81].
Table 2:
Model details. Here, hierarchical means that there are parallel pathways for information to flow from the encoder to the decoder (Fig. 2), which is slightly different from the conventional notion. For variational models, this implies hierarchical dependencies between latents in a statistical sense [68]. This hierarchical dependence is reflected in the KL term for the cNVAE, where L is the number of hierarchical latent groups. See Supplementary section 9.3 for more details and section 9.1 for a derivation. All models have an equal # of latent dimensions (420, see Table 4), approximately the same # of convolutional layers, and # of parameters (~ 24 M). EPE, endpoint error.
| Model | Architecture | Loss | Kullback–Leibler term (KL) |
|---|---|---|---|
| cNVAE | Hierarchical | EPE +β * KL | , where |
| VAE | Non-hierarchical | EPE +β * KL | |
| cNAE | Hierarchical | EPE | - |
| AE | Non-hierarchical | EPE | - |
Model representations.
We define a model’s internal representation to be either the mean of each Gaussian for variational models (i.e., samples drawn from at zero temperature), or the bottleneck activations for autoencoders. For hierarchical models (cNVAE, cNAE), we concatenate representations across all levels (Table 4).
Training details.
Models were trained for 160,000 steps at an input scale of 17 × 17, requiring slightly over a day on Quadro RTX 5000 GPUs. Please refer to Supplementary section 9.4 for additional details.
Disentanglement and -VAEs.
A critical decision when optimizing VAEs involves determining the weight assigned to the KL term in the loss function compared to the reconstruction loss. Prior research has demonstrated that modifying a single parameter, denoted as , which scales the KL term, can lead to the emergence of disentangled representations [82, 83]. Most studies employing VAEs for image reconstruction typically optimize the standard evidence lower bound (ELBO) loss, where is fixed at a value of 1 [11, 52, 68]. However, it should be noted that due to the dependence of the reconstruction loss on the input size, any changes in the dimensionality of the input will inevitably alter the relative contribution of the KL term, and thus the “effective” [82].
Furthermore, Higgins et al. [16] recently established a strong correspondence between the generative factors discovered by -VAEs and the factors encoded by inferotemporal (IT) neurons in the primate ventral stream. The alignment between these factors and IT neurons exhibited a linear relationship with the value of . In light of these findings, we explicitly manipulate the parameter within a range spanning from 0.01 to 10 to investigate the extent to which our results depend on its value.
4. Results
Our approach is based on the premise that the visual world contains a hierarchical structure. We use a simulation containing a hierarchical structure (ROFL, described above) and a hierarchical VAE (the cNVAE, above) to investigate how these choices affect the learned latent representations. While we are using a relatively simple simulation generated from a small number of ground truth factors, , we do not specify how should be represented in our model or include in the loss. Rather, we allow the model to develop its own latent representation in a purely unsupervised manner. See Supplementary section 9.6 for more details on our approach.
We first consider hierarchical and non-hierarchical VAEs trained on the fixate-1 condition (see Table 1, throughout this work, fixate-1 is used unless stated otherwise). We extracted latent representations from each model and estimated the mutual information (MI) between the representations and ground truth factors such as self-motion, etc. For fixate-1, each data sample is uniquely determined using 11 ground truth factors (Table 1), and the models have latent dimensionality of 420 (Table 4). Thus, the resulting MI matrix has shape 11 × 420, where each entry shows how much information is contained in that latent variable about a given ground truth factor.
Table 1:
ROFL categories used in this paper. ground truth factors include fixation point (+2); velocity of the observer when self-motion is present (+3); and, object position & velocity (+6). Figure 1b showcases a few example frames for each category. The stimuli can be rendered at any given spatial scale N, yielding an input shape of 2 × N × N. Here we work with N = 17.
| Category | Description | Dimensionality |
|---|---|---|
| fixate-1 | A moving observer maintains fixation on a background point. In addition, the scene contains one independently moving object. | 11 = 2 + 3 + 6 |
| fixate-0 | Same as fixate-1 but without the object. | 5 = 2 + 3 |
| obj-1 | A single moving object, stationary observer. | 8 = 2 + 6 |
Functional specialization emerges in the cNVAE.
Figure 3 shows the MI matrix for the latent space of cNVAE (top) and VAE (bottom). While both models achieved a good reconstruction of validation data (Fig. 14), the MI matrix for cNVAE exhibits clusters corresponding to distinct ground truth factors at different levels of the hierarchy. Specifically, object-related factors of variation are largely captured at the top 2 × 2 scale, while information about fixation point can be found across the hierarchy, and self-motion is largely captured by 8 × 8 latent groups. In contrast, non-hierarchical VAE has no such structure, suggesting that the inductive bias of hierarchy enhances the quality of latent spaces, which we quantify next.
Figure 3:
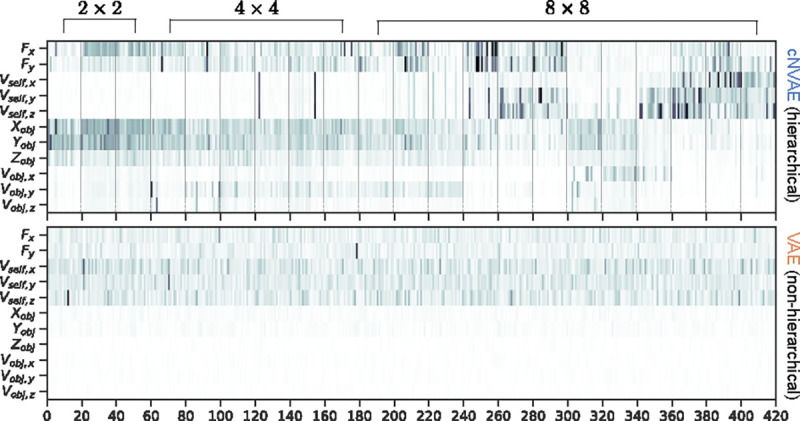
Mutual information between latent variables (x-axis) and ground truth factors (y-axis) is shown for cNVAE (top) and VAE (bottom). Dashed lines indicate 21 hierarchical latent groups of 20 latents each, comprising a 420-dimensional latent space. These groups operate at three different spatial scales, as indicated. In contrast, the VAE latent space lacks such grouping and operates solely at the spatial scale of 2 × 2 (see Fig. 2 and Table 4 for details on model latent configurations).
Evaluating the latent code.
To demonstrate the relationship between ground truth factors and latent representations discovered by the cNVAE visible in Fig. 3. we apply metrics referred to as “untangling” and “disentengling”. Additionally, in a separate set of experiments, we also evaluate model representations by relating them to MT neuron responses, which we call “brain-alignment”. We discuss each of these in detail in the following sections.
Untangling: the cNVAE untangles factors of variation.
One desirable feature of a latent representation is whether it makes information about ground truth factors easily (linearly) decodable [20, 21, 84]. This concept has been introduced in the context of core object recognition as “untangling”. Information about object identity that is “tangled” in the retinal input is untangled through successive nonlinear transforms, thus making it linearly available for higher brain regions to extract [20]. This concept is closely related to the “informativeness” metric of Eastwood and Williams [22] and “explicitness” metric of Ridgeway and Mozer [23].
To assess the performance of our models, we evaluated the linear decodability of the ground truth factors, , from model latent codes, . Based on the scores obtained by predicting from using linear regression (Fig. 4), the cNVAE greatly outperforms competing models, faithfully capturing all ground truth factors. In contrast, the non-hierarchical VAE fails to capture object-related variables. Notably, the cNVAE can recover the fixation point location in physical space almost perfectly. The fixation location has a highly nontrivial effect on the flow patterns, and varying it causes both global and local changes in the flow patterns (Fig. 1d).
Figure 4:

Hierarchical VAE untangles underlying factors of variation in data. The linear decodability of ground truth factors (x-axis) from different latent codes is shown. Untangling scores averaged across all ground truth factors are cNVAE = 0.898, NVAE = 0.639, VAE = 0.548, cNAE = 0.456, AE = 0.477, PCA = 0.236, and Raw = 0.235. For variational models, the best performing values were selected: cNVAE, ; VAE, (see Supplementary section 9.5 for more details).
Furthermore, cNVAE is the only model that reliably captures object position and velocity: especially note (last column in Fig. 4). Inferring object motion from complex optic flow patterns involves two key components. First, the model must extract self-motion from flow patterns. Second, the model must understand how self-motion influences flow patterns globally. Only then can the model subtract self-motion from global flow vectors to obtain object motion. In vision science, this is known as the “flow-parsing hypothesis” [85–88]. Such flow-parsing is achieved by the cNVAE but none of the other models. See Supplementary section 11 for further discussion of this result and its implications.
Disentanglement: the cNVAE produces more disentangled representations.
The pursuit of disentanglement in neural representations has garnered considerable attention [23, 82, 89–97]. In particular, Locatello et al. [19] established that learning fully disentangled representations is fundamentally impossible without inductive biases. Prior efforts such as -VAE [82] demonstrated that increasing the weight of the KL loss (indicated by ) promotes disentanglement in VAEs. More recently, Whittington et al. [89] demonstrated that simple biologically inspired constraints such as non-negativity and energy efficiency encourage disentanglement. Here, we demonstrate that another biological inductive bias, hierarchy in the latent space, will promote disentanglement of the latent representations learned by VAEs.
To evaluate the role of hierarchy, we adopted the DCI framework [22] which offers a well-rounded evaluation of latent representations. The approach involves training a simple decoder (e.g., lasso regression) that predicts data generative factors from a latent code ; followed by computing a matrix of relative importances (e.g., based on lasso weights) which is then used to evaluate different aspects of the code quality: Informativeness — measures whether contains easily accessible information about (similar to untangling from above). Disentanglement—measures whether individual latents correspond to individual generative factors. Completeness—measures how many are required to capture any single . If a single latent contributes to ’s prediction, the score will be 1 (complete). If all latent variables equally contribute to ’s prediction, the score will be 0 (maximally overcomplete). Note that “completeness” is also referred to as “compactness” [23]. See Fig. 9 and Supplementary section 9.7.1 for more details, ref. [98] for a review, and ref. [99] for a recent extension of the DCI framework.
We follow the methods outlined by Eastwood and Williams [22] with two modifications: (1) we replaced lasso with linear regression to avoid the strong dependence on the lasso coefficient that we observed, and (2) we estimate the matrix of relative importances using a feature permutation-based algorithm (sklearn.inspection.permutation_importance), which measures the relative performance drop that results from shuffling a given latent.
We found that cNVAE outperforms competing models across all metrics for a broad range of values (Fig. 5). The observed pattern of an inverted U shape is consistent with previous work [82], which suggests that there is an optimal that can be empirically determined. In this case, cNVAE with achieved the best average DCI score. Further, we found that VAEs lacking hierarchical structure learn highly overcomplete codes, such that many latents contribute to predicting a single ground truth factor. In conclusion, the simple inductive bias of hierarchy in the latent space led to a substantial improvement in VAE performance across all components of the DCI metric.
Figure 5:
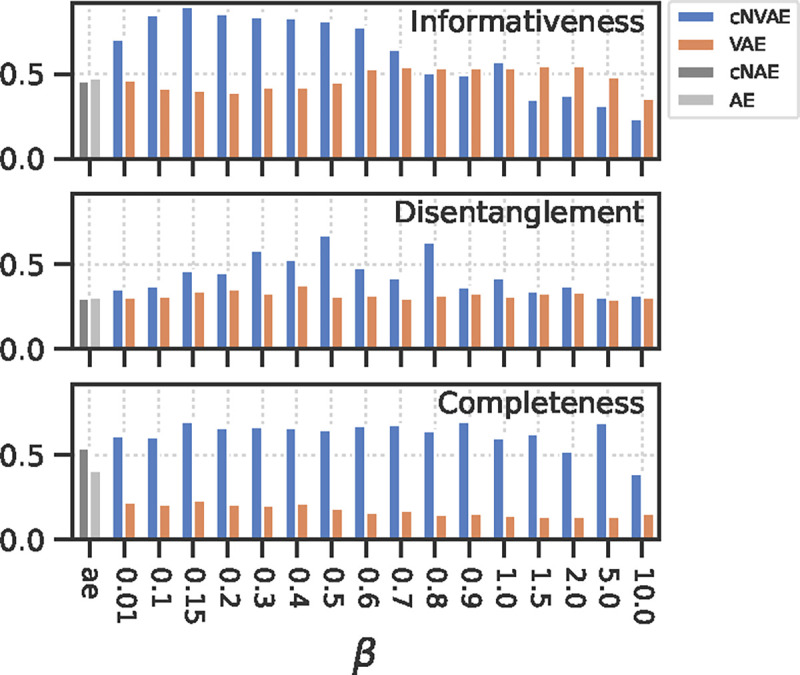
Evaluating the learned latent codes using the DCI framework [22]. Larger values are better for all metrics. Note that informativeness is closely related to untangling [20, 21]. See also Fig. 9.
Brain-alignment: the cNVAE aligns more closely with MT neurons.
To evaluate the performance of models in predicting neuronal activity in response to motion stimuli, we used an existing dataset of N = 141 MT neurons recorded while presented with random dot kinematograms representing smoothly changing combinations of optic flow velocity fields [100, 101]. A subset of these neurons (N = 84) are publicly available on crcns.org and were recently used in Mineault et al. [34] that we compare to.
To measure neuronal alignment, we first determined the mapping from each model’s latent representation to MT neuron responses (binned spike counts, Fig. 6a). Here, the latent representation is defined as the mean of predicted Gaussian distributions for VAEs, and the bottleneck activations for AEs. We learn this linear latent-to-neuron mapping using ridge regression. Figure 6b shows the average firing rate of an example neuron along with model predictions. Because sensory neurons have a nonzero response latency, we determined each neuron’s optimal response latency, which maximized cross-validated performance. The resulting distribution of best-selected latencies (Fig. 6c) peaked around 100 ms: consistent with known MT latencies [100]. We also empirically optimized ridge coefficients to ensure each neuron has its best fit. Figure 6d shows that the models capture the receptive field properties of MT neurons as measured by the spike-triggered average stimulus. To evaluate performance, we follow methods established by Mineault et al. [34]: whenever repeated trials were available, we report Pearson’s on that held-out data, normalized by maximum explainable variance [102]. When repeats were not available, we performed 5-fold cross-validation and reported the held-out performance using Pearson’s between model prediction and spike trains.
Figure 6:

(a) Experimental setup form [100, 101]. (b) Both models explain MT neural variability well. (c) Distribution of best estimated latencies. (d) Spike-triggered averages (STA) are shown.
Evaluating brain alignment.
We use two measures of brain alignment: the success at predicting the neural response (Pearson’s , Fig. 7. Table 3); and, the “alignment” between neurons and individual model latents (Fig. 8, [16]). These mirror the untangling and completeness metrics described above (more details are provided below).
Figure 7:

All models (pretrained on fixate-1) perform comparably in predicting MT neuron responses. Dashed line corresponds to the previous state-of-the-art on this data [103].
Table 3:
Both cNVAE and VAE perform well in predicting MT neuron responses, surpassing previous state-of-the-art models by more than a twofold improvement. Moreover, the clear gap between fixate-1 and other categories highlights the importance of pretraining data [104].
| Model | Pretraining dataset | Performance, R (μ ± se; N = 141) | |||
|---|---|---|---|---|---|
|
| |||||
| β = 0.5 | β = 0.8 | β = 1 | β = 5 | ||
|
| |||||
| cNVAE | fixate-1 | .506 ± .018 | .517 ± .017 | .494 ± .018 | .486 ± .016 |
| fixate-0 | .428 ± .018 | .450 ± .019 | .442 ± .019 | .469 ± .018 | |
| obj-1 | .471 ± .018 | .465 ± .018 | .477 ± .017 | .468 ± .018 | |
|
| |||||
| VAE | fixate-1 | .508 ± .019 | .481 ± .018 | .494 ± .018 | .509 ± .018 |
|
| |||||
| cNAE | fixate-1 | .476 ± .018 | |||
|
| |||||
| AE | fixate-1 | .495 ± .019 | |||
|
| |||||
| CPC [105] | AirSim [72] | .250 ± .020 (Mineault et al. [34]) | |||
|
| |||||
| DorsalNet | AirSim [72] | .251 ± .019 (Mineault et al. [34]) | |||
Figure 8:

Hierarchical models (cNVAE, cNAE) are more aligned with MT neurons since they enable sparse latent-to-neuron relationships. (a) Alignment score measures the sparsity of permutation feature importances. when all latents are equally important in predicting neuron ; and, when a single latent predicts the neuron. (b) Feature importances are plotted for an example neuron (same as in Fig. 6b). cNVAE predicts this neuron’s response in a much sparser manner compared to non-hierarchical VAE . Supplementary section 9.5 contains a discussion of our rationale in choosing these values. (c) Alignment across values, and autoencoders (ae).
All models predict MT neuron responses well.
After training a large ensemble of unsupervised models on fixate-1 and learning the neural mapping, we found that both hierarchical (cNVAE & cNAE) and non-hierarchical (VAE & AE) variants had similar ability to predict neural responses (Fig. 7). The performance did depend on the loss function itself, with the variational loss outperforming simple autoencoder reconstruction loss (Table 3).
Hierarchical VAEs are more aligned with MT neurons.
We next tested how these factors affect neural alignment, i.e., how closely neurons are related to individual latents in the model. Figure 8a demonstrates what we mean by “alignment”: a sparse latent-to-neuron relationship means larger alignment, indicative of a similar representational “form” [16]. See Fig. 10 for an illustration of this idea. To formalize this notion, we use feature permutation importance (described above), applied to the ridge regression models. This yields a 420-dimensional vector per neuron. Each dimension of this vector captures the importance of a given latent variable in predicting the responses of the neuron. We normalize these vectors and interpret them as the probability of importance. We then define alignment score of neuron as , where is interpreted as the importance of –th latent variable in predicting neuron (Fig. 8a). This concept is closely related to the “completeness” score from the DCI framework as discussed above.
For almost all values, the cNVAE exhibited a greater brain alignment than non-hierarchical VAE (Fig. 8c; cNVAE > VAE, paired t–test; see Fig. 16 and Table 5). Similarly, for the autoencoders, we found that the hierarchical variant outperformed the non-hierarchical one (cNAE > AE). Based on these observations, we conclude that higher brain alignment is primarily due to hierarchical latent structure. However, note that hierarchy in the traditional sense did not matter: all these models had approximately the same number of convolutional layers and parameters.
Factors leading to brain-alignment.
To test the effect of the training dataset (i.e., category of ROFL) on model performance, we trained cNVAE models using fixate-0, fixate-1, and obj-1 categories (Table 1), while also exploring a variety of values. We found that fixate-1 clearly outperformed the other two ROFL categories (Table 3), suggesting that both global (e.g., self-motion) and local (e.g., object motion) sources of variation are necessary for learning MT-like representations. The effect of loss function was also visible: some values led to more alignment. But this effect was small compared to the effect of hierarchical architecture (Fig. 8c).
5. Discussion
We introduced a new framework for understanding and evaluating the representation of visual motion learned by artificial and biological neural networks. This framework provides a way to manipulate causes in the world and evaluate whether learned representations untangle and disentangle those causes. In particular, our framework makes it possible to test the influence of architecture (Fig. 2), loss function (Table 2), and training set (Table 1) on the learned representations, encompassing 3 out of the 4 core components of a recently proposed neuroconnectionist research programme [41]. Our framework brings hypothesis-testing to understand [biological] neural processing of vision and provides an interpretive framework to understand neurophysiological data.
The goal of the present work was to establish our framework and demonstrate its potential. To this end, we made several simplifying choices, such as training on individual flow frames rather than time-evolving videos. We provide a detailed discussion of study limitations in Supplementary section 8. Future work will address these by rendering images in simulations and using image-computable models, incorporating real eye-tracking and scene data in ROFL [80, 106], testing our approach on more data from other brain areas such as MST [107, 108], and using more sophisticated methods to measure representational alignment between ANNs and brains [109–112].
Conclusion.
We used synthetic data to test how causal structure in the world affects the representations learned by autoencoder-based models and evaluated the learned representations based on how they represent ground truth factors and how well they align with biological brains. We found that a single inductive bias, hierarchical latent structure, leads to desirable representations and increased brain alignment.
Supplementary Material
7. Acknowledgments
This work was supported by NSF IIS-2113197 (HV and DAB), NSF DGE-1632976 (HV), and NIH R00EY032179 (JLY). We thank our anonymous reviewers for their helpful comments, and the developers of the software packages used in this project, including PyTorch [113], NumPy [114], SciPy [115], scikit-learn [116], pandas [117], matplotlib [118], and seaborn [119].
6. Code & Data
Our code and model checkpoints are available here: https://github.com/hadivafaii/ROFL-cNVAE.
References
- [1].Von Helmholtz Hermann. Handbuch der physiologischen Optik. Vol. 9. Voss, 1867. [Google Scholar]
- [2].al-Haytham Ibn. Book of optics (Kitab Al-Manazir). 1011–1021 AD.
- [3].Mumford David. “On the computational architecture of the neocortex: II The role of cortico-cortical loops”. In: Biological cybernetics 66.3 (1992), pp. 241–251. DOI: 10.1007/BF00198477. [DOI] [PubMed] [Google Scholar]
- [4].Lee Tai Sing and Mumford David. “Hierarchical Bayesian inference in the visual cortex”. In: JOSA A 20.7 (2003), pp. 1434–1448. DOI: 10.1364/JOSAA.20.001434. [DOI] [PubMed] [Google Scholar]
- [5].Rao Rajesh PN and Ballard Dana H. “Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects”. In: Nature neuroscience 2.1 (1999), pp. 79–87. DOI: 10.1038/4580. [DOI] [PubMed] [Google Scholar]
- [6].Knill David C and Pouget Alexandre. “The Bayesian brain: the role of uncertainty in neural coding and computation”. In: TRENDS in Neurosciences 27.12 (2004), pp. 712–719. DOI: 10.1016/j.tins.2004.10.007. [DOI] [PubMed] [Google Scholar]
- [7].Yuille Alan and Kersten Daniel. “Vision as Bayesian inference: analysis by synthesis?” In: Trends in cognitive sciences 10.7 (2006), pp. 301–308. DOI: 10.1016/j.tics.2006.05.002. [DOI] [PubMed] [Google Scholar]
- [8].Friston Karl. “A theory of cortical responses”. In: Philosophical transactions of the Royal Society B: Biological sciences 360.1456 (2005), pp. 815–836. DOI: 10.1098/rstb.2005.1622. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Clark Andy. “Whatever next? Predictive brains, situated agents, and the future of cognitive science”. In: Behavioral and brain sciences 36.3 (2013), pp. 181–204. DOI: 10.1017/S0140525X12000477. [DOI] [PubMed] [Google Scholar]
- [10].Dayan Peter et al. “The helmholtz machine”. In: Neural computation 7.5 (1995), pp. 889–904. DOI: 10.1162/neco.1995.7.5.889. [DOI] [PubMed] [Google Scholar]
- [11].Kingma Diederik P and Welling Max. “Auto-encoding variational bayes”. In: (2014). arXiv: 1312.6114v11[stat.ML]. [Google Scholar]
- [12].Rezende Danilo Jimenez et al. “Stochastic backpropagation and approximate inference in deep generative models”. In: International conference on machine learning. PMLR. 2014, pp. 1278–1286. URL: https://proceedings.mlr.press/v32/rezende14.html. [Google Scholar]
- [13].Schott Lukas et al. “Towards the first adversarially robust neural network model on MNIST”. In: International Conference on Learning Representations. 2019. URL: https://openreview.net/forum?id=S1EHOsC9tX. [Google Scholar]
- [14].Yildirim Ilker et al. “Efficient inverse graphics in biological face processing”. In: Science advances 6.10 (2020), eaax5979. DOI: 10.1126/sciadv.aax5979. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Storrs Katherine R et al. “Unsupervised learning predicts human perception and misperception of gloss”. In: Nature Human Behaviour 5.10 (2021), pp. 1402–1417. DOI: 10.1038/s41562-021-01097-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Higgins Irina et al. “Unsupervised deep learning identifies semantic disentanglement in single inferotemporal face patch neurons”. In: Nature communications 12.1 (2021), p. 6456. DOI: 10.1038/s41467-021-26751-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Marino Joseph. “Predictive coding, variational autoencoders, and biological connections”. In: Neural Computation 34.1 (2022), pp. 1–44. DOI: 10.1162/neco_a_01458. [DOI] [PubMed] [Google Scholar]
- [18].Higgins Irina et al. “Towards a definition of disentangled representations”. In: (2018). arXiv: 1812.02230[cs.LG]. [Google Scholar]
- [19].Locatello Francesco et al. “Challenging common assumptions in the unsupervised learning of disentangled representations”. In: international conference on machine learning. PMLR. 2019, pp. 4114–4124. URL: https://proceedings.mlr.press/v97/locatello19a.html. [Google Scholar]
- [20].DiCarlo James J and Cox David D. “Untangling invariant object recognition”. In: Trends in cognitive sciences 11.8 (2007), pp. 333–341. DOI: 10.1016/j.tics.2007.06.010. [DOI] [PubMed] [Google Scholar]
- [21].DiCarlo James J et al. “How does the brain solve visual object recognition?” In: Neuron 73.3 (2012), pp. 415–434. DOI: 10.1016/j.neuron.2012.01.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Eastwood Cian and Williams Christopher K. I.. “A framework for the quantitative evaluation of disentangled representations”. In: International Conference on Learning Representations. 2018. URL: https://openreview.net/forum?id=By-7dz-AZ. [Google Scholar]
- [23].Ridgeway Karl and Mozer Michael C. “Learning Deep Disentangled Embeddings With the F-Statistic Loss”. In: Advances in Neural Information Processing Systems. Vol. 31. Curran Associates, Inc., 2018. URL: https://papers.nips.cc/paper_files/paper/2018/hash/2b24d495052a8ce66358eb576b8912c8-Abstract.html. [Google Scholar]
- [24].Bengio Yoshua et al. “Representation learning: A review and new perspectives”. In: IEEE transactions on pattern analysis and machine intelligence 35.8 (2013), pp. 1798–1828. DOI: 10.1109/TPAMI.2013.50. [DOI] [PubMed] [Google Scholar]
- [25].Lake Brenden M et al. “Building machines that learn and think like people”. In: Behavioral and brain sciences 40 (2017), e253. DOI: 10.1017/S0140525X16001837. [DOI] [PubMed] [Google Scholar]
- [26].Peters Jonas et al. Elements of causal inference: foundations and learning algorithms. The MIT Press, 2017. URL: https://mitpress.mit.edu/9780262037310/elements-of-causal-inference. [Google Scholar]
- [27].LeCun Yann et al. “Deep learning”. In: Nature 521.7553 (2015), pp. 436–444. DOI: 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- [28].Schmidhuber Jürgen. “Learning factorial codes by predictability minimization”. In: Neural computation 4.6 (1992), pp. 863–879. DOI: 10.1162/neco.1992.4.6.863. [DOI] [Google Scholar]
- [29].Tschannen Michael et al. “Recent advances in autoencoder-based representation learning”. In: (2018). arXiv: 1812.05069[cs.LG]. [Google Scholar]
- [30].Schrimpf Martin et al. “Brain-score: Which artificial neural network for object recognition is most brain-like?” In: BioRxiv (2018), p. 407007. DOI: 10.1101/407007. [DOI] [Google Scholar]
- [31].Yamins Daniel LK et al. “Performance-optimized hierarchical models predict neural responses in higher visual cortex”. In: Proceedings of the national academy of sciences 111.23 (2014), pp. 8619–8624. DOI: 10.1073/pnas.1403112111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Khaligh-Razavi Seyed-Mahdi and Kriegeskorte Nikolaus. “Deep supervised, but not unsupervised, models may explain IT cortical representation”. In: PLoS Computational Biology 10.11 (2014), e1003915. DOI: 10.1371/journal.pcbi.1003915. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].Yamins Daniel LK and DiCarlo James J. “Using goal-driven deep learning models to understand sensory cortex”. In: Nature Neuroscience 19.3 (2016), pp. 356–365. DOI: 10.1038/nn.4244. [DOI] [PubMed] [Google Scholar]
- [34].Mineault Patrick et al. “Your head is there to move you around: Goal-driven models of the primate dorsal pathway”. In: Advances in Neural Information Processing Systems. Ed. by Ranzato M. et al. Vol. 34. Curran Associates, Inc., 2021, pp. 28757–28771. URL: https://papers.nips.cc/paper/2021/hash/f1676935f9304b97d59b0738289d2e22Abstract.html. [Google Scholar]
- [35].Elmoznino Eric and Bonner Michael F. “High-performing neural network models of visual cortex benefit from high latent dimensionality”. In: bioRxiv (2022), pp. 2022–07. DOI: 10.1101/2022.07.13.499969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Conwell Colin et al. “What can 1.8 billion regressions tell us about the pressures shaping high-level visual representation in brains and machines?” In: bioRxiv (2023). DOI: 10.1101/2022.03.28.485868. [DOI] [Google Scholar]
- [37].Sexton Nicholas J and Love Bradley C. “Reassessing hierarchical correspondences between brain and deep networks through direct interface”. In: Science Advances 8.28 (2022), eabm2219. DOI: 10.1126/sciadv.abm2219. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Tuckute Greta et al. “Many but not all deep neural network audio models capture brain responses and exhibit correspondence between model stages and brain regions”. In: bioRxiv (2023). DOI: 10.1101/2022.09.06.506680. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Richards Blake et al. “The application of artificial intelligence to biology and neuroscience”. In: Cell 185.15 (2022), pp. 2640–2643. DOI: 10.1016/j.cell.2022.06.047. [DOI] [PubMed] [Google Scholar]
- [40].Zador Anthony et al. “Catalyzing next-generation Artificial Intelligence through NeuroAI”. In: Nature Communications 14.1 (2023), p. 1597. DOI: 10.1038/s41467-023-37180-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Doerig Adrien et al. “The neuroconnectionist research programme”. In: Nature Reviews Neuroscience (2023), pp. 1–20. DOI: 10.1038/s41583-023-00705-w. [DOI] [PubMed] [Google Scholar]
- [42].Kanwisher Nancy et al. “Using artificial neural networks to ask ‘why’ questions of minds and brains”. In: Trends in Neurosciences (2023). DOI: 10.1016/j.tins.2022.12.008. [DOI] [PubMed] [Google Scholar]
- [43].Cao Rosa and Yamins Daniel. “Explanatory models in neuroscience: Part 1–taking mechanistic abstraction seriously”. In: (2021). arXiv: 2104.01490v2[q-bio.NC]. [Google Scholar]
- [44].Richards Blake A et al. “A deep learning framework for neuroscience”. In: Nature neuroscience 22.11 (2019), pp. 1761–1770. DOI: 10.1038/s41593-019-0520-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [45].Barrett David GT et al. “Analyzing biological and artificial neural networks: challenges with opportunities for synergy?” In: Current opinion in neurobiology 55 (2019), pp. 55–64. DOI: 10.1016/j.conb.2019.01.007. [DOI] [PubMed] [Google Scholar]
- [46].Serre Thomas. “Deep learning: the good, the bad, and the ugly”. In: Annual review of vision science 5 (2019), pp. 399–426. DOI: 10.1146/annurev-vision-091718-014951. [DOI] [PubMed] [Google Scholar]
- [47].Kriegeskorte Nikolaus. “Deep neural networks: a new framework for modeling biological vision and brain information processing”. In: Annual review of vision science 1 (2015), pp. 417–446. DOI: 10.1101/029876. [DOI] [PubMed] [Google Scholar]
- [48].Gibson James J. “The visual perception of objective motion and subjective movement”. In: Psychological review 61.5 (1954), p. 304. DOI: 10.1037/h0061885. [DOI] [PubMed] [Google Scholar]
- [49].Ungerleider Leslie and Mishkin Mortimer. “Two cortical visual systems”. In: Analysis of visual behavior (1982), pp. 549–586. URL: https://www.cns.nyu.edu/~tony/vns/readings/ungerleider-mishkin-1982.pdf.
- [50].Goodale Melvyn A and Milner A David. “Separate visual pathways for perception and action”. In: Trends in neurosciences 15.1 (1992), pp. 20–25. DOI: 10.1016/0166-2236(92)90344-8. [DOI] [PubMed] [Google Scholar]
- [51].Ungerleider L. G. and Pessoa L.. “What and where pathways”. In: Scholarpedia 3.11 (2008). revision #91940, p. 5342. DOI: 10.4249/scholarpedia.5342. [DOI] [Google Scholar]
- [52].Vahdat Arash and Kautz Jan. “NVAE: A Deep Hierarchical Variational Autoencoder”. In: Advances in Neural Information Processing Systems. Vol. 33. Curran Associates, Inc., 2020, pp. 19667–19679. URL: https://papers.nips.cc/paper_files/paper/2020/hash/e3b21256183cf7c2c7a66be163579d37-Abstract.html. [Google Scholar]
- [53].Srinivasan Mandyam Veerambudi et al. “Predictive coding: a fresh view of inhibition in the retina”. In: Proceedings of the Royal Society of London. Series B. Biological Sciences 216.1205 (1982), pp. 427–459. DOI: 10.1098/rspb.1982.0085. [DOI] [PubMed] [Google Scholar]
- [54].Bastos Andre M et al. “Canonical microcircuits for predictive coding”. In: Neuron 76.4 (2012), pp. 695–711. DOI: 10.1016/j.neuron.2012.10.038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [55].Dong Dawei W and Atick Joseph J. “Temporal decorrelation: a theory of lagged and non-lagged responses in the lateral geniculate nucleus”. In: Network: Computation in neural systems 6.2 (1995), p. 159. DOI: 10.1088/0954-898X_6_2_003. [DOI] [Google Scholar]
- [56].Singer Wolf. “Recurrent dynamics in the cerebral cortex: Integration of sensory evidence with stored knowledge”. In: Proceedings of the National Academy of Sciences of the United States of America 118 (2021). DOI: 10.1073/pnas.210104311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [57].Mikulasch Fabian A et al. “Where is the error? Hierarchical predictive coding through dendritic error computation”. In: Trends in Neurosciences 46.1 (2023), pp. 45–59. DOI: 10.1016/j.tins.2022.09.007. [DOI] [PubMed] [Google Scholar]
- [58].Millidge Beren et al. “Predictive Coding: Towards a Future of Deep Learning beyond Backpropagation?” In: International Joint Conference on Artificial Intelligence. 2022. DOI: 10.24963/ijcai.2022/774. [DOI] [Google Scholar]
- [59].Knill David C and Richards Whitman. Perception as Bayesian inference. Cambridge University Press, 1996. DOI: 10.1017/CBO9780511984037. [DOI] [Google Scholar]
- [60].Vilares Iris and Kording Konrad. “Bayesian models: the structure of the world, uncertainty, behavior, and the brain”. In: Annals of the New York Academy of Sciences 1224.1 (2011), pp. 22–39. DOI: 10.1111/j.1749-6632.2011.05965.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [61].Gregory Richard Langton. “Perceptions as hypotheses”. In: Philosophical Transactions of the Royal Society of London. B, Biological Sciences 290.1038 (1980), pp. 181–197. DOI: 10.1098/RSTB.1980.0090. [DOI] [PubMed] [Google Scholar]
- [62].Lochmann Timm and Deneve Sophie. “Neural processing as causal inference”. In: Current opinion in neurobiology 21.5 (2011), pp. 774–781. DOI: 10.1016/j.conb.2011.05.018. [DOI] [PubMed] [Google Scholar]
- [63].Shivkumar Sabyasachi et al. “A probabilistic population code based on neural samples”. In: Advances in Neural Information Processing Systems. Ed. by Bengio S. et al. Vol. 31. Curran Associates, Inc., 2018. URL: https://papers.nips.cc/paper_files/paper/2018/hash/5401acfe633e6817b508b84d23686743-Abstract.html. [Google Scholar]
- [64].Olshausen Bruno A.. “Perception as an Inference Problem”. In: The cognitive neurosciences (5th edition) (2014). Ed. by Gazzaniga Michael and Mangun George R.. DOI: 10.7551/mitpress/9504.003.0037. URL: http://rctn.org/bruno/papers/perception-as-inference.pdf. [DOI] [Google Scholar]
- [65].Csikor Ferenc et al. “Top-down effects in an early visual cortex inspired hierarchical Variational Autoencoder”. In: SVRHM 2022 Workshop @ NeurIPS. 2022. URL: https://openreview.net/forum?id=8dfboOQfYt3. [Google Scholar]
- [66].Miliotou Eleni et al. “Generative Decoding of Visual Stimuli”. In: Proceedings of the 40th International Conference on Machine Learning. Ed. by Krause Andreas et al. Vol. 202. Proceedings of Machine Learning Research. PMLR, July 2023, pp. 24775–24784. URL: https://proceedings.mlr.press/v202/miliotou23a.html. [Google Scholar]
- [67].Huang Yujia et al. “Neural Networks with Recurrent Generative Feedback”. In: Advances in Neural Information Processing Systems. Vol. 33. Curran Associates, Inc.,2020. URL: https://papers.nips.cc/paper_files/paper/2020/hash/0660895c22f8a14eb039bfb9beb0778f-Abstract.html. [Google Scholar]
- [68].Child Rewon. “Very Deep {VAE}s Generalize Autoregressive Models and Can Outperform Them on Images”. In: International Conference on Learning Representations. 2021. URL: https://openreview.net/forum?id=RLRXCV6DbEJ. [Google Scholar]
- [69].Sønderby Casper Kaae et al. “Ladder Variational Autoencoders”. In: Advances in Neural Information Processing Systems. Vol. 29. Curran Associates, Inc., 2016. URL: https://papers.nips.cc/paper_files/paper/2016/hash/6ae07dcb33ec3b7c814df797cbda0f87Abstract.html. [Google Scholar]
- [70].Maaløe Lars et al. “BIVA: A Very Deep Hierarchy of Latent Variables for Generative Modeling”. In: Advances in Neural Information Processing Systems. Vol. 32. Curran Associates, Inc., 2019. URL: https://papers.nips.cc/paper_files/paper/2019/hash/9bdb8b1faffa4b3d41779bb495d79fb9-Abstract.html. [Google Scholar]
- [71].Hazami Louay et al. “Efficientvdvae: Less is more”. In: (2022). arXiv: 2203.13751v2 [cs.LG]. [Google Scholar]
- [72].Shah Shital et al. “Airsim: High-fidelity visual and physical simulation for autonomous vehicles”. In: Field and Service Robotics: Results of the 11th International Conference. Springer. 2018, pp. 621–635. DOI: 10.1007/978-3-319-67361-5_40. [DOI] [Google Scholar]
- [73].Rust Nicole C and Movshon J Anthony. “In praise of artifice”. In: Nature neuroscience 8.12 (2005), pp. 1647–1650. DOI: 10.1038/nn1606. [DOI] [PubMed] [Google Scholar]
- [74].Julesz Bela. “Foundations of cyclopean perception”. In: (1971). URL: https://books.google.com/books/about/Foundations_of_Cyclopean_Perception.html?id=K_NfQgAACAAJ.
- [75].Golan Tal et al. “Controversial stimuli: Pitting neural networks against each other as models of human cognition”. In: Proceedings of the National Academy of Sciences 117.47 (2020), pp. 29330–29337. DOI: 10.1073/pnas.1912334117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [76].Beyeler Michael et al. “3D visual response properties of MSTd emerge from an efficient, sparse population code”. In: Journal of Neuroscience 36.32 (2016), pp. 8399–8415. DOI: 10.1523/JNEUROSCI.0396-16.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [77].Gibson James J. “The perception of the visual world”. In: (1950). URL: https://psycnet.apa.org/record/1951-04286-000.
- [78].Warren William H Jr and Hannon Daniel J. “Direction of self-motion is perceived from optical flow”. In: Nature 336.6195 (1988), pp. 162–163. DOI: 10.1038/336162A0. [DOI] [Google Scholar]
- [79].Inigo Thomas J. et al. Spherical retinal flow for a fixating observer. Tech. rep. 1994. URL: https://repository.upenn.edu/entities/publication/f9b44866-54cd-483d-8a17-a51fb732958a. [Google Scholar]
- [80].Matthis Jonathan Samir et al. “Retinal optic flow during natural locomotion”. In: PLOS Computational Biology 18.2 (2022), e1009575. DOI: 10.1371/journal.pcbi.1009575. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [81].Ilg Eddy et al. “Flownet 2.0: Evolution of optical flow estimation with deep networks”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017, pp. 2462–2470. DOI: 10.1109/CVPR.2017.179. [DOI] [Google Scholar]
- [82].Higgins Irina et al. “beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework”. In: International Conference on Learning Representations. 2017. URL: https://openreview.net/forum?id=Sy2fzU9gl. [Google Scholar]
- [83].Burgess Christopher P et al. “Understanding disentangling in -VAE”. In: (2018). arXiv: 1804.03599[stat.ML]. [Google Scholar]
- [84].Kriegeskorte Nikolaus and Diedrichsen Jörn. “Peeling the onion of brain representations”. In: Annual review of neuroscience 42 (2019), pp. 407–432. DOI: 10.1146/annurev-neuro-080317-061906. [DOI] [PubMed] [Google Scholar]
- [85].Rushton Simon K and Warren Paul A. “Moving observers, relative retinal motion and the detection of object movement”. In: Current Biology 15.14 (2005), R542–R543. DOI: 10.1016/j.cub.2005.07.020. [DOI] [PubMed] [Google Scholar]
- [86].Warren Paul A and Rushton Simon K. “Optic flow processing for the assessment of object movement during ego movement”. In: Current Biology 19.18 (2009), pp. 1555–1560. DOI: 10.1016/j.cub.2009.07.057. [DOI] [PubMed] [Google Scholar]
- [87].Warren Paul A and Rushton Simon K. “Perception of object trajectory: Parsing retinal motion into self and object movement components”. In: Journal of vision 7.11 (2007), pp. 2–2. DOI: 10.1167/7.11.2. [DOI] [PubMed] [Google Scholar]
- [88].Peltier Nicole E et al. “Optic flow parsing in the macaque monkey”. In: Journal of vision 20.10 (2020), pp. 8–8. DOI: 10.1167/jov.20.10.8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [89].Whittington James C. R. et al. “Disentanglement with Biological Constraints: A Theory of Functional Cell Types”. In: The Eleventh International Conference on Learning Representations. 2023. URL: https://openreview.net/forum?id=9Z_GfhZnGH. [Google Scholar]
- [90].Lachapelle Sebastien et al. “Synergies between Disentanglement and Sparsity: Generalization and Identifiability in Multi-Task Learning”. In: Proceedings of the 40th International Conference on Machine Learning. Ed. by Krause Andreas et al. Vol. 202. Proceedings of Machine Learning Research. PMLR, July 2023, pp. 18171–18206. URL: https://proceedings.mlr.press/v202/lachapelle23a.html. [Google Scholar]
- [91].Kumar Abhishek et al. “Variational Inference of Disentangled Latent Concepts from Unlabeled Observations”. In: International Conference on Learning Representations. 2018. URL: https://openreview.net/forum?id=H1kG7GZAW. [Google Scholar]
- [92].Kim Hyunjik and Mnih Andriy. “Disentangling by factorising”. In: International Conference on Machine Learning. PMLR. 2018, pp. 2649–2658. URL: http://proceedings.mlr.press/v80/kim18b.html. [Google Scholar]
- [93].Chen Ricky T. Q. et al. “Isolating Sources of Disentanglement in Variational Autoencoders”. In: Advances in Neural Information Processing Systems. Ed. by Bengio S. et al. Vol. 31. Curran Associates, Inc., 2018. URL: https://papers.nips.cc/paper_files/paper/2018/hash/1ee3dfcd8a0645a25a35977997223d22-Abstract.html. [Google Scholar]
- [94].Rolinek Michal et al. “Variational autoencoders pursue pca directions (by accident)”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019, pp. 12406–12415. URL: https://openaccess.thecvf.com/content_CVPR_2019/html/Rolinek_Variational_Autoencoders_Pursue_PCA_Directions_by_Accident_CVPR_2019_paper.html. [Google Scholar]
- [95].van Steenkiste Sjoerd et al. “Are Disentangled Representations Helpful for Abstract Visual Reasoning?” In: Advances in Neural Information Processing Systems. Vol. 32. Curran Associates, Inc., 2019. URL: https://papers.nips.cc/paper_files/paper/2019/hash/bc3c4a6331a8a9950945a1aa8c95ab8a-Abstract.html. [Google Scholar]
- [96].Dittadi Andrea et al. “On the Transfer of Disentangled Representations in Realistic Settings”. In: International Conference on Learning Representations. 2021. URL: https://openreview.net/forum?id=8VXvj1QNRl1. [Google Scholar]
- [97].Johnston W Jeffrey and Fusi Stefano. “Abstract representations emerge naturally in neural networks trained to perform multiple tasks”. In: Nature Communications 14.1 (2023), p. 1040. DOI: 10.1038/s41467-023-36583-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [98].Carbonneau Marc-André et al. “Measuring disentanglement: A review of metrics”. In: IEEE transactions on neural networks and learning systems (2022). DOI: 10.1109/TNNLS.2022.3218982. [DOI] [PubMed] [Google Scholar]
- [99].Eastwood Cian et al. “DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability”. In: The Eleventh International Conference on Learning Representations. 2023. URL: https://openreview.net/forum?id=462z-gLgSht. [Google Scholar]
- [100].Cui Yuwei et al. “Diverse suppressive influences in area MT and selectivity to complex motion features”. In: Journal of Neuroscience 33.42 (2013), pp. 16715–16728. DOI: 10.1523/JNEUROSCI.0203-13.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [101].Cui Yuwei et al. “Inferring cortical variability from local field potentials”. In: Journal of Neuroscience 36.14 (2016), pp. 4121–4135. DOI: 10.1523/JNEUROSCI.2502-15.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [102].Sahani Maneesh and Linden Jennifer. “How Linear are Auditory Cortical Responses?” In: Advances in Neural Information Processing Systems. Vol. 15. MIT Press, 2002. URL: https://papers.nips.cc/paper_files/paper/2002/hash/7b4773c039d539af17c883eb9283dd14-Abstract.html. [Google Scholar]
- [103].Mineault Patrick J et al. “Hierarchical processing of complex motion along the primate dorsal visual pathway”. In: Proceedings of the National Academy of Sciences 109.16 (2012), E972–E980. DOI: 10.1073/pnas.1115685109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [104].Simoncelli Eero P. and Olshausen Bruno A.. “Natural image statistics and neural representation.” In: Annual review of neuroscience 24 (2001), pp. 1193–216. DOI: 10.1146/annurev.neuro.24.1.1193. [DOI] [PubMed] [Google Scholar]
- [105].van den Oord Aaron et al. “Representation Learning with Contrastive Predictive Coding”. In: (2019). arXiv: 1807.03748[cs.LG]. [Google Scholar]
- [106].Muller Karl S et al. “Retinal motion statistics during natural locomotion”. In: Elife 12 (2023), e82410. DOI: 10.7554/eLife.82410. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [107].Wild Benedict and Treue Stefan. “Primate extrastriate cortical area MST: a gateway between sensation and cognition”. In: Journal of neurophysiology 125.5 (2021), pp. 1851–1882. DOI: 10.1152/jn.00384.2020. [DOI] [PubMed] [Google Scholar]
- [108].Wild Benedict et al. “Electrophysiological dataset from macaque visual cortical area MST in response to a novel motion stimulus”. In: Scientific Data 9 (2022). DOI: 10.1038/s41597-022-01239-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [109].Williams Alex H et al. “Generalized Shape Metrics on Neural Representations”. In: Advances in Neural Information Processing Systems. Vol. 34. Curran Associates, Inc., 2021. URL: https://papers.nips.cc/paper_files/paper/2021/hash/252a3dbaeb32e7690242ad3b556e626b-Abstract.html. [PMC free article] [PubMed] [Google Scholar]
- [110].Duong Lyndon et al. “Representational Dissimilarity Metric Spaces for Stochastic Neural Networks”. In: The Eleventh International Conference on Learning Representations. 2023. URL: https://openreview.net/forum?id=xjb563TH-GH. [Google Scholar]
- [111].Klabunde Max et al. “Similarity of Neural Network Models: A Survey of Functional and Representational Measures”. In: (2023). arXiv: 2305.06329[cs.LG]. [Google Scholar]
- [112].Canatar Abdulkadir et al. A Spectral Theory of Neural Prediction and Alignment. 2023. arXiv: 2309.12821[q-bio.NC]. [Google Scholar]
- [113].Paszke Adam et al. “PyTorch: An Imperative Style, High-Performance Deep Learning Library”. In: Advances in Neural Information Processing Systems. Vol. 32. Curran Associates, Inc., 2019. URL: https://papers.nips.cc/paper_files/paper/2019/hash/bdbca288fee7f92f2bfa9f7012727740-Abstract.html. [Google Scholar]
- [114].Harris Charles R. et al. “Array programming with NumPy”. In: Nature 585.7825 (Sept. 2020), pp. 357–362. DOI: 10.1038/s41586-020-2649-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [115].Virtanen Pauli et al. “SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python”. In: Nature Methods 17 (2020), pp. 261–272. DOI: 10.1038/s41592-019-0686-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [116].Pedregosa Fabian et al. “Scikit-learn: Machine learning in Python”. In: the Journal of machine Learning research 12 (2011), pp. 2825–2830. DOI: 10.5555/1953048.2078195. [DOI] [Google Scholar]
- [117].The pandas development team. pandas-dev/pandas: Pandas. Version latest. Feb. 2020. DOI: 10.5281/zenodo.3509134. [DOI] [Google Scholar]
- [118].Hunter John D. “Matplotlib: A 2D graphics environment”. In: Computing in science & engineering 9.03 (2007), pp. 90–95. DOI: 10.1109/MCSE.2007.55. [DOI] [Google Scholar]
- [119].Waskom Michael L. “Seaborn: statistical data visualization”. In: Journal of Open Source Software 6.60 (2021), p. 3021. DOI: 10.21105/joss.03021. [DOI] [Google Scholar]
- [120].Adelson Edward H and Bergen James R. “Spatiotemporal energy models for the perception of motion”. In: Josa a 2.2 (1985), pp. 284–299. DOI: 10.1364/JOSAA.2.000284. [DOI] [PubMed] [Google Scholar]
- [121].Nishimoto Shinji and Gallant Jack L. “A three-dimensional spatiotemporal receptive field model explains responses of area MT neurons to naturalistic movies”. In: Journal of Neuroscience 31.41 (2011), pp. 14551–14564. DOI: 10.1523/JNEUROSCI.6801-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [122].Han Yena et al. “System identification of neural systems: If we got it right, would we know?” In: International Conference on Machine Learning. PMLR. 2023, pp. 12430–12444. URL: https://proceedings.mlr.press/v202/han23d.html. [Google Scholar]
- [123].Hu Jie et al. “Squeeze-and-excitation networks”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018, pp. 7132–7141. DOI: 10.1109/CVPR.2018. 00745. [DOI] [Google Scholar]
- [124].Ioffe Sergey and Szegedy Christian. “Batch normalization: Accelerating deep network training by reducing internal covariate shift”. In: International conference on machine learning. pmlr. 2015, pp. 448–456. URL: https://proceedings.mlr.press/v37/ioffe15.html. [Google Scholar]
- [125].Salimans Tim and Kingma Durk P. “Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks”. In: Advances in Neural Information Processing Systems. Ed. by Lee D. et al. Vol. 29. Curran Associates, Inc., 2016. URL: https://papers.nips.cc/paper_files/paper/2016/hash/ed265bc903a5a097f61d3ec064d96d2e-Abstract.html. [Google Scholar]
- [126].Ramachandran Prajit et al. “Searching for Activation Functions”. In: International Conference on Learning Representations. 2018. URL: https://openreview.net/forum?id=SkBYYyZRZ. [Google Scholar]
- [127].Elfwing Stefan et al. “Sigmoid-weighted linear units for neural network function approximation in reinforcement learning”. In: Neural Networks 107 (2018), pp. 3–11. DOI: 10.1016/j.neunet.2017.12.012. [DOI] [PubMed] [Google Scholar]
- [128].Bowman Samuel R. et al. “Generating Sentences from a Continuous Space”. In: Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning. Berlin, Germany: Association for Computational Linguistics, Aug. 2016, pp. 10–21. DOI: 10.18653/v1/K16-1002. [DOI] [Google Scholar]
- [129].Fu Hao et al. “Cyclical Annealing Schedule: A Simple Approach to Mitigating KL Vanishing”. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, June 2019, pp. 240–250. DOI: 10.18653/v1/N19-1021. [DOI] [Google Scholar]
- [130].Vahdat Arash et al. “DVAE++: Discrete Variational Autoencoders with Overlapping Transformations”. In: Proceedings of the 35th International Conference on Machine Learning. Ed. by Dy Jennifer and Krause Andreas. Vol. 80. Proceedings of Machine Learning Research. PMLR, July 2018, pp. 5035–5044. URL: https://proceedings.mlr.press/v80/vahdat18a.html. [Google Scholar]
- [131].Chen Xi et al. “Variational Lossy Autoencoder”. In: International Conference on Learning Representations. 2017. URL: https://openreview.net/forum?id=BysvGP5ee. [Google Scholar]
- [132].Kingma Diederik P and Ba Jimmy. “Adam: A method for stochastic optimization”. In: (2014). arXiv: 1412.6980[cs.LG]. [Google Scholar]
- [133].Loshchilov Ilya and Hutter Frank. “SGDR: Stochastic Gradient Descent with Warm Restarts”. In: International Conference on Learning Representations. 2017. URL: https://openreview.net/forum?id=Skq89Scxx. [Google Scholar]
- [134].Benjamini Yoav and Hochberg Yosef. “Controlling the false discovery rate: a practical and powerful approach to multiple testing”. In: Journal of the Royal statistical society: series B (Methodological) 57.1 (1995), pp. 289–300. DOI: 10.1111/J.2517-6161.1995.TB02031.X. [DOI] [Google Scholar]
- [135].Cohen Jacob. Statistical power analysis for the behavioral sciences. Academic press, 1988. DOI: 10.2307/2529115. [DOI] [Google Scholar]
- [136].DeAngelis Gregory C. and Angelaki Dora E.. “Visual–Vestibular Integration for Self-Motion Perception”. In: The Neural Bases of Multisensory Processes (2012), pp. 629–644. DOI: 10.1201/9781439812174. [DOI] [Google Scholar]
- [137].Von Holst Eduard. “Relations between the central nervous system and the peripheral organs”. In: British Journal of Animal Behaviour (1954). DOI: 10.1016/S0950-5601(54)80044-X. [DOI] [Google Scholar]
- [138].MacNeilage Paul R et al. “Vestibular facilitation of optic flow parsing”. In: PLoS One 7.7 (2012), e40264. DOI: 10.1371/journal.pone.0040264. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [139].Cullen Kathleen E and Zobeiri Omid A. “Proprioception and the predictive sensing of active self-motion”. In: Current opinion in physiology 20 (2021), pp. 29–38. DOI: 10.1016/j.cophys.2020.12.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [140].Royden Constance S and Hildreth Ellen C. “Human heading judgments in the presence of moving objects”. In: Perception & psychophysics 58 (1996), pp. 836–856. DOI: 10.3758/BF03205487. [DOI] [PubMed] [Google Scholar]
- [141].Warren William H Jr and Saunders Jeffrey A. “Perceiving heading in the presence of moving objects”. In: Perception 24.3 (1995), pp. 315–331. DOI: 10.1068/p240315. [DOI] [PubMed] [Google Scholar]
- [142].Horrocks Edward AB et al. “Walking humans and running mice: perception and neural encoding of optic flow during self-motion”. In: Philosophical Transactions of the Royal Society B 378.1869 (2023), p. 20210450. DOI: 10.1098/rstb.2021.0450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [143].Noel Jean-Paul et al. “Causal inference during closed-loop navigation: parsing of self-and object-motion”. In: Philosophical Transactions of the Royal Society B 378.1886 (2023), p. 20220344. DOI: 10.1098/rstb.2022.0344. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [144].Lee Denis N. “The optic flow field: The foundation of vision”. In: Philosophical Transactions of the Royal Society of London. B, Biological Sciences 290.1038 (1980), pp. 169–179. DOI: 10.1098/rstb.1980.0089. [DOI] [PubMed] [Google Scholar]
- [145].Lappe Markus et al. “Perception of self-motion from visual flow”. In: Trends in cognitive sciences 3.9 (1999), pp. 329–336. DOI: 10.1016/S1364-6613(99)01364-9. [DOI] [PubMed] [Google Scholar]
- [146].Higgins Irina et al. “Symmetry-based representations for artificial and biological general intelligence”. In: Frontiers in Computational Neuroscience 16 (2022), p. 836498. DOI: 10.3389/fncom.2022.836498. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [147].Anselmi Fabio et al. “On invariance and selectivity in representation learning”. In: Information and Inference: A Journal of the IMA 5.2 (2016), pp. 134–158. DOI: 10.1093/imaiai/iaw009. [DOI] [Google Scholar]
- [148].Bronstein Michael M et al. “Geometric deep learning: Grids, groups, graphs, geodesics, and gauges”. In: (2021). arXiv: 2104.13478[cs.LG]. [Google Scholar]
- [149].Gulrajani Ishaan et al. “PixelVAE: A Latent Variable Model for Natural Images”. In: International Conference on Learning Representations. 2017. URL: https://openreview.net/forum?id=BJKYvt5lg. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Our code and model checkpoints are available here: https://github.com/hadivafaii/ROFL-cNVAE.