

Summary
Though platform trials have been touted for their flexibility and streamlined use of trial resources, their statistical efficiency is not well understood. We fill this gap by establishing their greater efficiency for comparing the relative efficacy of multiple interventions over using several separate, 2-arm trials, where the relative efficacy of an arbitrary pair of interventions is evaluated by contrasting their relative risks as compared to control. In theoretical and numerical studies, we demonstrate that the inference of such a contrast using data from a platform trial enjoys identical or better precision than using data from separate trials, even when the former enrolls substantially fewer participants. This benefit is attributed to the sharing of controls among interventions under contemporaneous randomization. We further provide a novel procedure for establishing the noninferiority of a given intervention relative to the most efficacious of the other interventions under evaluation, where this procedure is adaptive in the sense that it need not be a priori known which of these other interventions is most efficacious. Our numerical studies show that this testing procedure can attain substantially better power when the data arise from a platform trial rather than multiple separate trials. Our results are illustrated using data from two monoclonal antibody trials for the prevention of HIV.
Keywords: COVID-19, Efficiency gain, Noninferiority test, Platform designs, Survival analysis, Vaccine efficacy
1. Introduction
This work is motivated by the World Health Organization (WHO) Solidarity Trials for coronavirus disease 2019 (COVID-19) vaccines (Krause and others, 2020) and treatments (WHO Solidarity Trial Consortium, 2021), which seek to concurrently evaluate multiple candidate vaccines and treatments to contain the burden and spread of COVID-19. To achieve this aim, the investigators are using a platform design (Sridhara and others, 2015; Saville and Berry, 2016; Woodcock and LaVange, 2017), sometimes also known as a multiarm multistage design (Royston and others, 2003; Parmar and others, 2017). Such designs enable a simultaneous evaluation of several public health interventions within a single trial. In contrast to more traditional multiarm designs, platform trials allow for the evaluation of candidate interventions that may be available at different times and various international sites. Having this flexibility increases the chances of generating reliable evidence to determine which interventions work effectively. Owing to these advantages, platform designs have recently been advocated to evaluate candidate interventions for the treatment or prevention of COVID-19 (Dean and others, 2020), HIV (Choko and others, 2017), and cancer (Meyer and others, 2020).
Platform trials make more efficient use of resources than separate, independently conducted trials by reducing the number of participants enrolled on the control arm (Woodcock and LaVange, 2017). Consequently, trial resources can be redistributed to enroll participants in the active intervention arms. For sponsors, this redistribution has the benefit of potentially decreasing the total required sample size, while, for participants, it has the appeal of increasing the chance that they will receive an experimental intervention that they could not receive outside of the trial. Moreover, by using centralized governance, platform trials amortize the cost of establishing study sites across multiple active interventions and can ensure common eligibility criteria and study procedures across all intervention-control comparisons. In addition, as each candidate’s active intervention is monitored for early evidence of benefit or harm, employing a platform design makes it possible to target trial resources to the study of active interventions that are more likely to be successful (Saville and Berry, 2016).
Methods for analyzing platform trial data should be able to accommodate key features of the design, including that candidate active interventions can be added to the trial once they become available, and those that show a lack of efficacy can be eliminated. To this end, several authors have advocated that, for each active intervention, controls that are under contemporaneous randomization should be used as comparators (Lee and Wason, 2020; Kopp-Schneider and others, 2020; Lee and others, 2021). Methods that restrict to contemporaneous comparisons can avoid estimation bias and anticonservative confidence interval coverage that may arise due to a potential temporal trend in the outcome or baseline characteristics of the control arm. Moreover, during periods when multiple active interventions are under randomization simultaneously, the contemporaneous control comparators may be shared between these various arms.
Analysis methods should also be able to accommodate the fact that, once an active intervention has been found to be efficacious, it may serve as an active control in the evaluation of the other candidate interventions (Woodcock and LaVange, 2017; Kaizer and others, 2018). One approach to make this evaluation would involve directly comparing the outcomes of a candidate’s active intervention to those on the active control. Unfortunately, this approach would be susceptible to the same temporal-trend-induced biases as described above. A less direct, but more robust, the method involves comparing the two interventions by contrasting their efficacies relative to their respective contemporaneous control arms. This method relies on a constancy assumption that, conditional on baseline covariates, the efficacy of an active intervention is the same across enrollment windows. Under this constancy condition that underlies the validity of many methodologies developed for noninferiority trials (Everson-Stewart and Emerson, 2010), this strategy will yield unbiased comparisons of the efficacies of the two interventions.
Though standard analyses can be used to evaluate the efficacy of each active intervention compared to its contemporaneous control, more care is needed to quantify uncertainty when contrasting the efficacies of various active interventions. The main challenge is that the overlap in the contemporaneous control groups for different interventions induces a positive correlation between their corresponding efficacy estimates. This positive correlation has been used as a means to justify not doing multiplicity adjustments in multiarm trials (Howard and others, 2018). In particular, the positive correlation induces a reduction in the family-wise error rate compared to independent separate trials, suggesting that multiplicity adjustment should not be required solely due to sharing control data. Since multiple testing corrections would not have been employed had separate trials been conducted, platform trials (WHO Solidarity Trial Consortium, 2021; Howard and others, 2021) have often followed multiarmed trials (Freidlin and others, 2008) in not including them. In this work, we follow this precedent and do not consider multiple testing in the platform trial setting. In another line of research, recent works have provided Bayesian strategies to describe and accommodate this positive correlation in platform trials when the outcomes are binary (Saville and Berry, 2016; Hobbs and others, 2018; Kaizer and others, 2018). To the best of our knowledge, there is no available frequentist method that properly addresses this issue, nor is there any approach that is applicable when the outcomes may be right censored. In this work, we introduce a theoretically grounded framework to account for this correlation when making cross-intervention comparisons with time-to-event outcomes based on platform trial data.
Our contributions are as follows:
1) In Section 3, we establish the joint asymptotic normality of intervention-specific conditional relative risk estimators. The limiting covariance matrix quantifies the positive correlation induced from sharing control participants between the active interventions.
2) In Section 4, we show that natural estimators of the relative efficacy of two interventions are statistically more efficient when applied to platform trial data rather than on data from separate, intervention-specific trials. This enables a substantial reduction in the sample size of the platform trials relative to that of the pooled separate trials, without sacrificing precision for evaluating efficacy.
3) In Section 5, we develop a noninferiority test that evaluates the efficacy of a given intervention relative to the most efficacious of the remaining interventions. This test is adaptive in the sense that there is no need to know, in advance, which of the remaining interventions should serve as the benchmark.
As is evident from the above, in this work, our focus is on the specification and efficiency of analysis methods for platform trials, rather than on design elements such as determining when to remove interventions from randomization due to an apparent lack of efficacy.
The randomization scheme, data structure, and assumptions that shape the framework of our proposed methods are introduced in Section 2. Numerical studies that support our theoretical findings are presented in Section 6, and an illustration of the proposed methods on data from the Antibody Mediated Prevention (AMP) trials (Corey and others, 2021) can be found in Section 7. Section 8 concludes.
2. Preliminaries
2.1. Randomization scheme
We consider platform designs in which the availability of active interventions may vary over discrete windows defined by time and location. Within each location, windows are contiguous and may be of unequal widths: a window starts when an active intervention is placed under or removed from randomization and ends when the next window begins. To simplify the presentation, we focus on a particular randomization scheme where, within each window, equal numbers of participants are expected to be enrolled in each available active intervention arm and to the control arm. More concretely, within an arbitrary window in which  active interventions are under simple randomization, each active intervention is assigned with probability
active interventions are under simple randomization, each active intervention is assigned with probability  , and control is also assigned with probability
, and control is also assigned with probability  . In settings where the different active interventions require different administration schedules or modalities, blinding may be maintained via the use of matched controls. To do this,
. In settings where the different active interventions require different administration schedules or modalities, blinding may be maintained via the use of matched controls. To do this,  -matched total control arms are used, where each matched control is designed to be as indistinguishable as possible from a particular active intervention. Each active intervention is assigned with probability
-matched total control arms are used, where each matched control is designed to be as indistinguishable as possible from a particular active intervention. Each active intervention is assigned with probability  and each matched control is assigned with probability
and each matched control is assigned with probability  , where all of these random assignments are made independently of participant covariates. The control arm is then taken to be the union of the
, where all of these random assignments are made independently of participant covariates. The control arm is then taken to be the union of the  -matched control arms. Matched controls were used in the WHO Solidarity Trial Vaccines (World Health Organization, 2020).
-matched control arms. Matched controls were used in the WHO Solidarity Trial Vaccines (World Health Organization, 2020).
An example of this randomization scheme is illustrated in Table 1, which represents a modification of a figure from the protocol for the WHO Solidarity Trial Vaccines. Three candidate active interventions are considered in this example, labeled as  ,
,  , and
, and 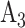 , and corresponding matched controls are under concurrent randomization. Intervention
, and corresponding matched controls are under concurrent randomization. Intervention 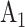 and its matched control
and its matched control 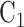 are under randomization in Windows 1–3 and 5; intervention
are under randomization in Windows 1–3 and 5; intervention 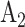 and its matched control
and its matched control 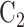 are under randomization in Windows 2–4; and intervention
are under randomization in Windows 2–4; and intervention 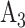 and its matched control
and its matched control 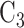 are under randomization in Windows 3–5. As the availability of active interventions may vary across enrollment windows, especially when windows represent geographic locations, it is possible for active interventions such as
are under randomization in Windows 3–5. As the availability of active interventions may vary across enrollment windows, especially when windows represent geographic locations, it is possible for active interventions such as 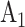 to go under randomization in nonconsecutive windows. For instance, some COVID-19 vaccines may not be administered in certain countries or at certain time points due to supply chain constraints. When assessing the efficacy of a given active intervention, the control group used for comparison consists of all participants who were enrolled in a matched or unmatched control arm during a period in which the active intervention was under randomization. This union of the matched and unmatched controls is referred to as the shared control arm. For example, for intervention
to go under randomization in nonconsecutive windows. For instance, some COVID-19 vaccines may not be administered in certain countries or at certain time points due to supply chain constraints. When assessing the efficacy of a given active intervention, the control group used for comparison consists of all participants who were enrolled in a matched or unmatched control arm during a period in which the active intervention was under randomization. This union of the matched and unmatched controls is referred to as the shared control arm. For example, for intervention 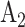 , the shared control arm consists of
, the shared control arm consists of 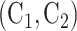 for Window 2,
for Window 2, 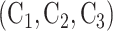 for Window 3, and
for Window 3, and 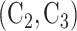 for Window 4.
for Window 4.
Table 1.
Allocation ratios of each active intervention versus its matched control and versus shared control in a platform trial. Within each window, each arm label 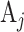 and
and 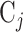 ,
, 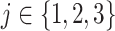 , denotes an equal number of participants who are expected to enroll in the trial during that window and be randomized to the corresponding arm. However, the arm labels may denote different numbers of participants across different windows. For example, in Window 1, each arm label might denote 500 participants so that a total of 500 participants would be expected to be enrolled and randomized to each of
, denotes an equal number of participants who are expected to enroll in the trial during that window and be randomized to the corresponding arm. However, the arm labels may denote different numbers of participants across different windows. For example, in Window 1, each arm label might denote 500 participants so that a total of 500 participants would be expected to be enrolled and randomized to each of 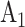 and
and 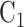 , whereas in Window 2 each arm label might denote 100 participants, so that a total of 200 participants would be expected enrolled and randomized to
, whereas in Window 2 each arm label might denote 100 participants, so that a total of 200 participants would be expected enrolled and randomized to 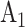 and 100 to
and 100 to 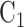

|
2.2. Data structure, assumptions, and estimands
We now describe the variables that are measured for each participant in the considered platform trial. The window in which a participant enrolls is denoted by 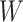 and their baseline covariates are denoted by
and their baseline covariates are denoted by 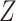 . We suppose that these covariates are discrete with finite support—it is possible that
. We suppose that these covariates are discrete with finite support—it is possible that 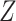 arises by combining multiple discrete covariates or by discretizing one or more continuous covariates into categorial subgroups. The randomization arm is indicated via a categorical variable
arises by combining multiple discrete covariates or by discretizing one or more continuous covariates into categorial subgroups. The randomization arm is indicated via a categorical variable 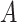 , which takes the value
, which takes the value 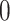 for control and the value
for control and the value 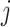 for intervention
for intervention 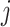 . To ease presentation, hereafter, we denote the
. To ease presentation, hereafter, we denote the 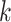 active interventions by
active interventions by 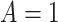 ,
, 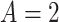 , etc., rather than by
, etc., rather than by 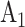 ,
, 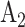 , etc., as was done in Table 1. The observed time
, etc., as was done in Table 1. The observed time 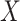 is defined as the minimum of a continuous event time
is defined as the minimum of a continuous event time 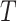 (e.g., time to virologically confirmed symptomatic COVID-19 infection) and a censoring time
(e.g., time to virologically confirmed symptomatic COVID-19 infection) and a censoring time 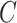 , and
, and 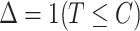 is a corresponding indicator of having observed the event. Enrollment is treated as time zero, so that
is a corresponding indicator of having observed the event. Enrollment is treated as time zero, so that 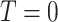 indicates that the participant experienced the event exactly at the time of enrollment. Uncensored binary outcomes emerge as a special case of this right-censoring setup by setting
indicates that the participant experienced the event exactly at the time of enrollment. Uncensored binary outcomes emerge as a special case of this right-censoring setup by setting 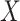 equal to the indicator that the binary outcome was observed to be equal to 1 and
equal to the indicator that the binary outcome was observed to be equal to 1 and 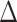 equal to 1 so that all outcomes are treated as uncensored. Interventions and windows are labeled sequentially so that the first active intervention (window) is labeled “intervention (window) 1,” the second is labeled “intervention (window) 2,” and so on. We use
equal to 1 so that all outcomes are treated as uncensored. Interventions and windows are labeled sequentially so that the first active intervention (window) is labeled “intervention (window) 1,” the second is labeled “intervention (window) 2,” and so on. We use 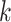 to denote the total number of active interventions,
to denote the total number of active interventions, 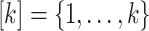 to denote the set of all active interventions, and
to denote the set of all active interventions, and 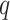 to denote the number of windows over the course of the trial. For an active intervention
to denote the number of windows over the course of the trial. For an active intervention 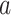 , we let
, we let 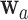 denote the set containing the windows in which intervention
denote the set containing the windows in which intervention 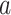 is under randomization. We observe
is under randomization. We observe 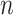 independent and identically distributed (iid) copies
independent and identically distributed (iid) copies 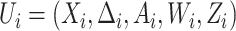 ,
, 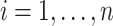 , drawn from a distribution
, drawn from a distribution 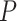 .
.
We will make use of the following condition, which often holds in randomized trial settings:
(C1) Randomized arm assignment: The baseline covariate
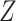 is independent of
is independent of 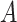 conditional on
conditional on 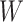 .
.
We will also make use of a constancy condition that the efficacy of an active intervention, defined in terms of a relative risk, should be stable across windows within specified strata. These strata are defined via the value of a coarsening 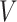 of
of 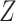 . More concretely,
. More concretely,  for a known, possibly many-to-one, function
for a known, possibly many-to-one, function 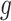 ; we similarly let
; we similarly let 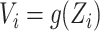 . By taking
. By taking 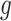 to be the identity or a constant function, we could make
to be the identity or a constant function, we could make 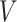 correspond to the original baseline covariate
correspond to the original baseline covariate 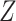 or a degenerate random variable, respectively. Alternatively, if
or a degenerate random variable, respectively. Alternatively, if 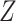 results from a combination of several discrete covariates (such as age group and sex), then
results from a combination of several discrete covariates (such as age group and sex), then 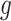 could be chosen as a coordinate projection that returns a particular one of those covariates (such as age group). Henceforth, we will take
could be chosen as a coordinate projection that returns a particular one of those covariates (such as age group). Henceforth, we will take 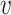 to be a generic realization of
to be a generic realization of 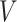 corresponding to a generic realization
corresponding to a generic realization 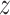 of
of 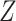 , that is,
, that is,  .
.
As the event rate may vary across windows, so does the survival function 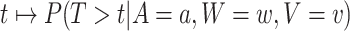 conditionally on being randomized to intervention
conditionally on being randomized to intervention 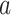 , enrolled in window
, enrolled in window 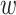 , and belonging to the stratum
, and belonging to the stratum 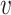 . The corresponding conditional relative risk is
. The corresponding conditional relative risk is
 |
(2.1) |
To avoid dividing by zero or considering degenerate cases where it is all but obvious that an intervention is efficacious or not, we suppose throughout that 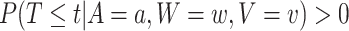 for all possible values of
for all possible values of 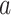 , namely when
, namely when  is control or any active intervention. In the context of vaccine trials, the vaccine efficacy is often defined as one minus the relative risk. The constancy condition at a specified time
is control or any active intervention. In the context of vaccine trials, the vaccine efficacy is often defined as one minus the relative risk. The constancy condition at a specified time 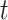 can be stated as follows.
can be stated as follows.
(C2) Constancy condition at time
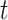 : For each active intervention
: For each active intervention 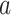 and stratum
and stratum  , there exists a
, there exists a 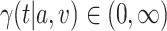 such that, for all windows
such that, for all windows 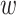 for which
for which 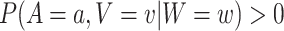 ,
, 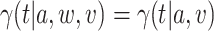 .
.
The above condition states that the conditional relative risks of the active interventions are invariant across windows and is plausible in many settings, for example, in vaccine trials (e.g., Fleming and others, 2021; Tsiatis and Davidian, 2021). When windows encode spatial information, this condition requires generalizability over space—the efficacy of an active intervention is the same across different locations where it is under randomization. In fact, the plausibility of this condition has been systematically evaluated across many disease areas, due to its importance to noninferiority analyses (D’Agostino and others, 2003; Fleming, 2008; Mauri and D’Agostino, 2017; Zhang and others, 2019; May and others, 2020). In Figure S1 of Appendix F of the Supplementary material available at Biostatistics online, we provide an illustration of the implications of C2 in a particular example. The above is distinct from proportional hazards assumptions that are often employed in analyses based on the Cox model. Indeed, unlike proportional hazards assumptions that require a constant hazard ratio between an intervention and the control, C2 allows for the efficacy of each active intervention, quantified in terms of relative risk, to vary over time since enrollment. This flexibility is important, for example, in vaccine studies, where vaccine efficacy is often low shortly after inoculation, ramps as the immune response builds and booster shots are administered, and subsequently wanes over time. The results in this work do not rely on a proportional hazards assumption.
Under C2 at time 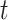 , the relative risk estimand further writes as
, the relative risk estimand further writes as
 |
(2.2) |
where the first equality simply multiplies the left-hand side by one, the second holds by C2, and the third holds by the law of total expectation. We require that 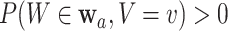 for all
for all 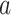 and
and 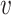 of interest, which guarantees that each considered relative risk estimand is well-defined. In this work, we will have three primary interests regarding the relative risk estimands defined above: (i) estimating the relative risk
of interest, which guarantees that each considered relative risk estimand is well-defined. In this work, we will have three primary interests regarding the relative risk estimands defined above: (i) estimating the relative risk 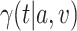 for one or more given interventions
for one or more given interventions 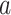 and strata
and strata 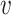 of
of 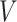 , (ii) contrasting
, (ii) contrasting  and
and 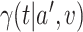 for two interventions
for two interventions 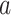 and
and 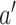 , and (iii) in a noninferiority analysis, contrasting
, and (iii) in a noninferiority analysis, contrasting 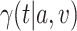 against
against 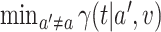 .
.
The constancy condition C2 only applies to active interventions 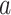 , covariate strata
, covariate strata 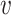 , and windows
, and windows 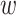 for which
for which 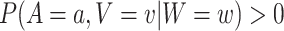 . This requirement is natural given that, when it fails, the conditional relative risk in (2.1) is not even well-defined. Indeed, if individuals from covariate stratum
. This requirement is natural given that, when it fails, the conditional relative risk in (2.1) is not even well-defined. Indeed, if individuals from covariate stratum 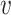 are never enrolled in window
are never enrolled in window 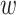 —say, because individuals from this stratum do not live near the location to which window
—say, because individuals from this stratum do not live near the location to which window 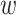 pertains—then it is not even clear how to define the relative risk of an intervention
pertains—then it is not even clear how to define the relative risk of an intervention 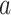 among those individuals in stratum
among those individuals in stratum 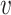 who enroll in window
who enroll in window 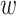 . Even if we restrict attention to windows
. Even if we restrict attention to windows 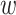 in which covariate stratum
in which covariate stratum  is enrolled with positive probability, a given intervention
is enrolled with positive probability, a given intervention 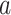 will likely not be under randomization in some of these windows, rendering the conditional relative risk in (2.1) ill-defined. To define the effect of intervention
will likely not be under randomization in some of these windows, rendering the conditional relative risk in (2.1) ill-defined. To define the effect of intervention 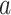 in such windows, counterfactual reasoning can be applied (e.g., Hernán and Robins, 2020). For each participant, this involves conceptualizing a counterfactual event time
in such windows, counterfactual reasoning can be applied (e.g., Hernán and Robins, 2020). For each participant, this involves conceptualizing a counterfactual event time 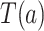 that would have occurred if, possibly contrary to fact, intervention
that would have occurred if, possibly contrary to fact, intervention 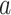 had been under randomization at their time of enrollment and they had been randomized to that intervention. Under standard causal assumptions (pp. 5–6 of Hernán and Robins, 2020), the counterfactual relative risk
had been under randomization at their time of enrollment and they had been randomized to that intervention. Under standard causal assumptions (pp. 5–6 of Hernán and Robins, 2020), the counterfactual relative risk 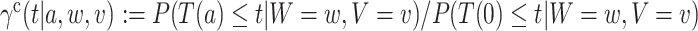 is equal to the relative risk in (2.1) whenever that quantity is well-defined, that is, whenever
is equal to the relative risk in (2.1) whenever that quantity is well-defined, that is, whenever 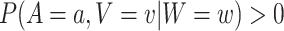 . Hence, under the natural counterfactual extension of the constancy condition that says that
. Hence, under the natural counterfactual extension of the constancy condition that says that 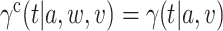 for all
for all 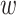 that are such that
that are such that 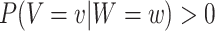 , the relative risk estimand of interest can be interpreted as defining the effect of intervention
, the relative risk estimand of interest can be interpreted as defining the effect of intervention 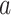 in all windows in which participants with
in all windows in which participants with  are under enrollment, rather than just in those windows in which participants with
are under enrollment, rather than just in those windows in which participants with  are under enrollment and
are under enrollment and 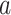 is under randomization. We leave further consideration of this counterfactual constancy condition to future work, and instead focus in the remainder on making inference about the quantity
is under randomization. We leave further consideration of this counterfactual constancy condition to future work, and instead focus in the remainder on making inference about the quantity 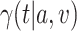 defined in C2, which is well-defined even in the absence of causal assumptions.
defined in C2, which is well-defined even in the absence of causal assumptions.
Though the relative risk of interest does not depend on the full collection of baseline covariates 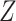 , the conditionally independent censoring condition C3 below generally makes it necessary to make use of
, the conditionally independent censoring condition C3 below generally makes it necessary to make use of 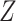 when estimating the relative risk, where
when estimating the relative risk, where 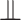 is used to denote (conditional) independence:
is used to denote (conditional) independence:
(C3) Conditionally independent censoring: For each active intervention
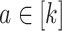 and covariate stratum
and covariate stratum  with
with 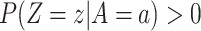 , it holds that
, it holds that 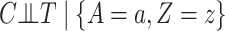 and
and  .
.
This condition will often be more plausible than the usual independent censoring assumption made in clinical trial analyses, which states that 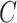 is independent of
is independent of 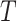 conditionally on
conditionally on 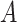 . Indeed, the random variable
. Indeed, the random variable 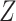 can contain baseline factors that are predictive of both the event and censoring times. For example, in an infectious disease outbreak setting, these factors may include behavioral risk information and the calendar time of enrollment. The key insight is that, under C3, the conditional survival function
can contain baseline factors that are predictive of both the event and censoring times. For example, in an infectious disease outbreak setting, these factors may include behavioral risk information and the calendar time of enrollment. The key insight is that, under C3, the conditional survival function 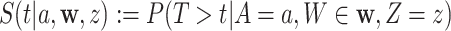 is identifiable as a functional of the distribution of the observed data. Consequently, to estimate
is identifiable as a functional of the distribution of the observed data. Consequently, to estimate 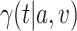 , it suffices to write this quantity as a function of this conditional survival function and the distribution of
, it suffices to write this quantity as a function of this conditional survival function and the distribution of 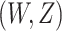 . Lemma B.1 of the Supplementary material available at Biostatistics online shows that this is indeed possible. In particular, under the randomization of arm assignment C1, the numerator and denominator on the right-hand side of (2.2) can be rewritten to show that
. Lemma B.1 of the Supplementary material available at Biostatistics online shows that this is indeed possible. In particular, under the randomization of arm assignment C1, the numerator and denominator on the right-hand side of (2.2) can be rewritten to show that
 |
(2.3) |
Even if C2 were to fail to hold, 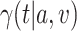 can be defined as above (see Appendix G of the Supplementary material available at Biostatistics online). In this case,
can be defined as above (see Appendix G of the Supplementary material available at Biostatistics online). In this case, 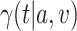 represents a particular summary of the efficacy of intervention
represents a particular summary of the efficacy of intervention 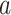 across windows. Nevertheless, C2 is advantageous since, when it holds, contrasts of the relative risks of different interventions can be interpreted as being independent of the particular windows under consideration. In Section 3.1, we will present so-called plug-in estimators that estimate each survival function and conditional probability above, and then insert them into the right-hand side of (2.3) to estimate the relative risk of interest.
across windows. Nevertheless, C2 is advantageous since, when it holds, contrasts of the relative risks of different interventions can be interpreted as being independent of the particular windows under consideration. In Section 3.1, we will present so-called plug-in estimators that estimate each survival function and conditional probability above, and then insert them into the right-hand side of (2.3) to estimate the relative risk of interest.
We conclude by introducing some other notation that will appear throughout in this article. We denote a 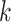 -variate column vector
-variate column vector 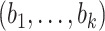 by
by 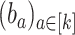 and a set
and a set 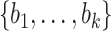 by
by 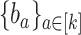 . Let
. Let 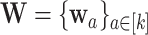 . We also let
. We also let 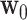 denote the collection of windows where the control is under randomization—by design,
denote the collection of windows where the control is under randomization—by design, 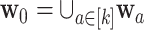 . Moreover, let
. Moreover, let 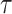 be the end of follow-up relative to enrollment,
be the end of follow-up relative to enrollment, 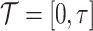 denote the range of possible observed times,
denote the range of possible observed times, 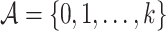 denote the set of all arms, and
denote the set of all arms, and 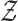 and
and 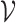 be the support of
be the support of 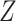 and
and 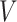 , respectively. We will write
, respectively. We will write 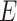 to denote the expectation operator under
to denote the expectation operator under 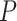 . We write
. We write 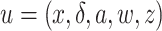 to denote a generic realization of
to denote a generic realization of 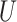 .
.
3. Inference and asymptotic properties
3.1. Estimated conditional relative risk
Our estimators of the conditional survival function in (2.3) will be based on the identity 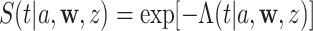 , where
, where 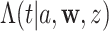 denotes the cumulative hazard function (CHF) at time
denotes the cumulative hazard function (CHF) at time 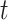 conditional on a randomization arm
conditional on a randomization arm  , enrollment windows belonging to a specified window set
, enrollment windows belonging to a specified window set 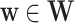 , and a baseline covariate stratum
, and a baseline covariate stratum  such that
such that 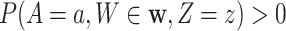 . Specifically, this function is defined as
. Specifically, this function is defined as 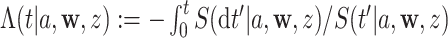 , which we refer to as the conditional CHF.
, which we refer to as the conditional CHF.
Though we will be most interested in estimating 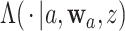 and
and 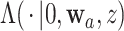 for one or more given interventions
for one or more given interventions 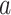 , it will simplify presentation to define an estimator of
, it will simplify presentation to define an estimator of 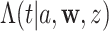 for a generic arm
for a generic arm  , set of windows
, set of windows 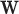 , and covariate stratum
, and covariate stratum 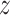 for which
for which 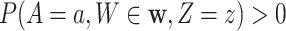 . We will estimate this conditional CHF using the conditional Nelson–Aalen estimator. To introduce this estimator, we define the stratified basic counting process in the stratum
. We will estimate this conditional CHF using the conditional Nelson–Aalen estimator. To introduce this estimator, we define the stratified basic counting process in the stratum 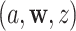 and the average size of the risk set at time
and the average size of the risk set at time 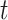 as
as 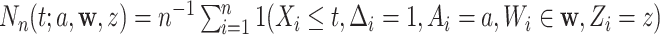 and
and 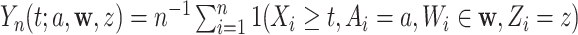 , respectively. The conditional Nelson–Aalen estimator at time
, respectively. The conditional Nelson–Aalen estimator at time 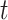 is given by
is given by 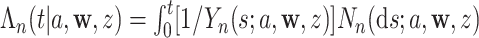 , and the conditional survival function can be estimated by
, and the conditional survival function can be estimated by 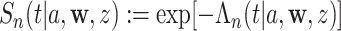 . For
. For 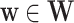 and
and 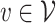 , let
, let 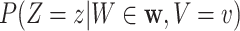 be estimated by
be estimated by 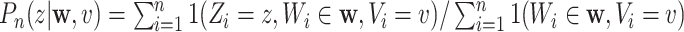 . Inserting these estimators into (2.3) naturally suggests a plug-in estimator of
. Inserting these estimators into (2.3) naturally suggests a plug-in estimator of 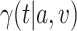 , namely
, namely 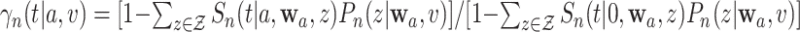 .
.
3.2. Asymptotic normality
To study the large-sample behavior of our proposed estimator of 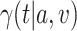 , it will be helpful to have characterized the joint asymptotic behavior of the estimators of the conditional survival functions
, it will be helpful to have characterized the joint asymptotic behavior of the estimators of the conditional survival functions 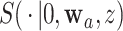 and
and 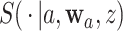 across different interventions
across different interventions 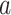 . This characterization is simplified by the fact that participants on different randomization arms are mutually exclusive—as a consequence of this fact,
. This characterization is simplified by the fact that participants on different randomization arms are mutually exclusive—as a consequence of this fact, 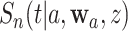 is independent of
is independent of 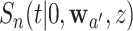 for every intervention
for every intervention 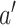 and of
and of 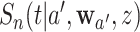 for every intervention arm
for every intervention arm 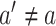 . The joint distribution of the conditional survival functions for the shared control arms within window sets in
. The joint distribution of the conditional survival functions for the shared control arms within window sets in 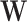 is more involved. Owing to the control-sharing between interventions
is more involved. Owing to the control-sharing between interventions 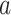 and
and 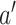 ,
, 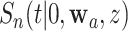 is not independent of
is not independent of 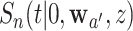 unless
unless 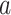 and
and 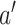 are never under contemporaneous randomization—that is, unless
are never under contemporaneous randomization—that is, unless 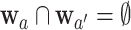 . Except in degenerate cases, the dependence is otherwise inevitable due to the mutual inclusion of participants who are under contemporaneous randomization in the estimation of
. Except in degenerate cases, the dependence is otherwise inevitable due to the mutual inclusion of participants who are under contemporaneous randomization in the estimation of 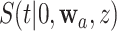 and
and 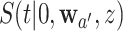 . To characterize this dependence, we derive the asymptotic behavior of the estimated stratified control-arm survival functions across all the intervention-specific window sets, namely
. To characterize this dependence, we derive the asymptotic behavior of the estimated stratified control-arm survival functions across all the intervention-specific window sets, namely  —see Lemma B.4 of the Supplementary material available at Biostatistics online for details. In the same lemma, we also establish the asymptotic normality of the estimated stratified intervention-arm survival functions across their designated window sets,
—see Lemma B.4 of the Supplementary material available at Biostatistics online for details. In the same lemma, we also establish the asymptotic normality of the estimated stratified intervention-arm survival functions across their designated window sets,  .
.
To derive the aforementioned distributional results, we establish that the estimators of the conditional survival functions are asymptotically linear. We recall that an estimator 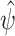 of an estimand
of an estimand 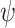 is called asymptotically linear if there exists a mean-zero, finite-variance function
is called asymptotically linear if there exists a mean-zero, finite-variance function 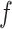 such that
such that 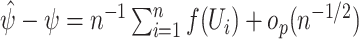 , where we write
, where we write 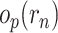 to denote a term that converges to zero in probability as
to denote a term that converges to zero in probability as 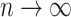 even once divided by
even once divided by 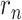 . The function
. The function 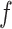 is known as the influence function of
is known as the influence function of 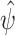 . The joint limiting distribution of several asymptotically linear estimators
. The joint limiting distribution of several asymptotically linear estimators 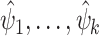 can be derived using Slutsky’s lemma and the central limit theorem: indeed, letting
can be derived using Slutsky’s lemma and the central limit theorem: indeed, letting 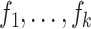 denote the influence functions of
denote the influence functions of 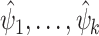 , we have that
, we have that 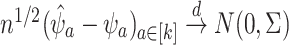 , where
, where 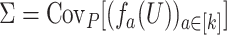 . A delta method is also available for asymptotically linear estimators, which makes it possible to compute the influence function of a real-valued function of one or more asymptotically linear estimators
. A delta method is also available for asymptotically linear estimators, which makes it possible to compute the influence function of a real-valued function of one or more asymptotically linear estimators 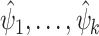 via the dot product of the gradient of the function and the influence functions of
via the dot product of the gradient of the function and the influence functions of 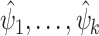 .
.
We use such a delta-method argument to translate the asymptotic linearity of 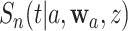 ,
, 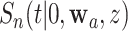 , and
, and 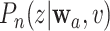 over
over 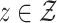 into an asymptotic linearity result for the estimator
into an asymptotic linearity result for the estimator 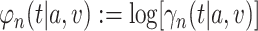 of the log-relative risk
of the log-relative risk 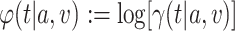 . In particular, the following theorem shows that
. In particular, the following theorem shows that 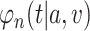 is an asymptotically linear with influence function
is an asymptotically linear with influence function 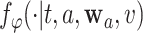 , where the form of
, where the form of 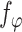 is given in Appendix B.1 of the Supplementary material available at Biostatistics online. As the proof is an immediate consequence of Lemmas B.2–B.5 of the Supplementary material available at Biostatistics online, it is omitted.
is given in Appendix B.1 of the Supplementary material available at Biostatistics online. As the proof is an immediate consequence of Lemmas B.2–B.5 of the Supplementary material available at Biostatistics online, it is omitted.
Theorem 3.1
Given C1–C3, the stratum
and with
defined in (B.4),
(3.4)

4. Efficiency gains from sharing controls
4.1. Motivation
In this section, we will demonstrate the statistical efficiency that can be gained from running a platform trial with a shared control arm as opposed to using separate control arms, as is done in more traditional clinical trial designs. Two forms of gains can be realized by using a platform design.
The first follows immediately from the design’s use of a shared control arm. In particular, a platform trial conducted contemporaneously with and in the same population as separate, intervention-specific trials will generally attain the same statistical power for marginal evaluation of each active intervention as can the separate trials, while enrolling fewer participants on control. Indeed, due to the use of a shared control arm, fewer total participants can be enrolled in a platform trial than in separate, intervention-specific trials, while still maintaining the same sample sizes for the comparison of each active intervention versus control. This point is illustrated in Table 2, which compares a 3-arm platform trial to two separate 2-arm trials. The 3-arm platform trial in that table corresponds to the same setting as was illustrated in Table 1, except for being limited to only two interventions and using  to label the shared control arm. The corresponding separate trials enroll the same number of individuals to each active intervention in the same windows but enroll twice as many controls in windows where both active interventions are under randomization.
to label the shared control arm. The corresponding separate trials enroll the same number of individuals to each active intervention in the same windows but enroll twice as many controls in windows where both active interventions are under randomization.
Table 2.
Randomization schemes and the expected enrollment size per active intervention arm in each window under an illustrative 3-arm platform trial versus two 2-arm separate trials, where the expected enrollment size per arm in Window  is denoted by
is denoted by  ,
, 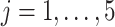 , for both trials
, for both trials
|
|
The second advantage enjoyed by platform designs, which is a key finding of this work, involves a gain in efficiency for comparisons of the efficacy of different active interventions. Such comparisons are useful, for example, when aiming to evaluate the noninferiority of one intervention relative to another. Before providing theoretical insights as to the reasons for and generality of this gain, we present a simple numerical example illustrating how significant it can be in practice. To do this, we provide simulation results in a simple, binary outcome setting in which no covariates are measured. This setting can be seen to be a special case of the more general right-censored setup studied in this article by letting 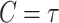 ,
, 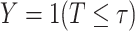 with
with 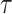 denoting the end of follow-up, taking the covariate
denoting the end of follow-up, taking the covariate 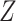 to be a degenerate random variable that only takes the value 0, and taking the function
to be a degenerate random variable that only takes the value 0, and taking the function 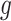 used to define
used to define 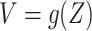 to be the identity function. Since
to be the identity function. Since 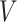 is trivial and there is only one-time point
is trivial and there is only one-time point 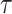 of interest, we write
of interest, we write  , rather than
, rather than  , to denote the relative risk of
, to denote the relative risk of  in this example. We compare the statistical power for various hypothesis tests based on data from 3-arm platform trials versus two separate 2-arm trials.
in this example. We compare the statistical power for various hypothesis tests based on data from 3-arm platform trials versus two separate 2-arm trials.
(a) a standard 3-arm platform trial with a single window in which both active interventions are under randomization and the sample size is selected to achieve 90
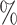 power for marginal tests of
power for marginal tests of 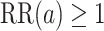 via 0.025-level Wald tests at the design alternative of
via 0.025-level Wald tests at the design alternative of 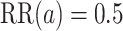 ,
, 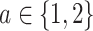 ,
,(b) two separate 2-arm trials with sample sizes similarly selected for 90
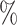 power, and
power, and(c) an expanded 3-arm platform trial that contains a single randomization window as (a) does, but whose total sample size (controls and active interventions combined) is equal to the sum of the total sample sizes of the two separate trials in (b).
For settings (a) and (b), we select the sample sizes of each arm to ensure 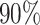 power to marginally detect
power to marginally detect 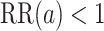 via 0.025-level Wald tests at the design alternative of
via 0.025-level Wald tests at the design alternative of 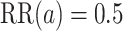 ,
, 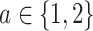 . The power calculations used to determine sample sizes for (a) and (b) result in 1750 participants enrolled to each active intervention and 1750 participants enrolled to each control arm, namely the shared control in (a) and each separate control arm in (b). With marginal significance levels of 0.025, the null hypotheses to be tested are
. The power calculations used to determine sample sizes for (a) and (b) result in 1750 participants enrolled to each active intervention and 1750 participants enrolled to each control arm, namely the shared control in (a) and each separate control arm in (b). With marginal significance levels of 0.025, the null hypotheses to be tested are 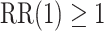 ,
,  , and
, and 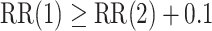 , where Wald tests are used in all settings. In Table 3, we present the power of rejecting these null hypotheses, along with the enrollment sizes of intervention and control arms in each data set. Consistent with the earlier discussion regarding the equal power for marginal tests obtained by platform designs and separate trial designs that enroll the same number of participants to each active intervention, the platform trial (a) and the separate trial (b) achieve the same power for the tests of
, where Wald tests are used in all settings. In Table 3, we present the power of rejecting these null hypotheses, along with the enrollment sizes of intervention and control arms in each data set. Consistent with the earlier discussion regarding the equal power for marginal tests obtained by platform designs and separate trial designs that enroll the same number of participants to each active intervention, the platform trial (a) and the separate trial (b) achieve the same power for the tests of 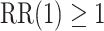 and
and 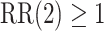 . As the increasing sample size increases power, it also follows naturally that the expanded platform trial (c) attains higher power than (a), and therefore (b) as well, for these marginal tests. It is perhaps more surprising that both platform trials considered attain considerably higher power (19–28
. As the increasing sample size increases power, it also follows naturally that the expanded platform trial (c) attains higher power than (a), and therefore (b) as well, for these marginal tests. It is perhaps more surprising that both platform trials considered attain considerably higher power (19–28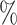 on an absolute scale) for testing
on an absolute scale) for testing  than do the separate trials in (b). This is true for (a) in spite of the fact that fewer total participants are enrolled in that trial than in the combined separate trials. In the remainder of this section, we provide analytical arguments establishing the generality of this improvement in power that platform designs enjoy for comparisons of the efficacies of different active interventions. When giving these arguments, we consider the general case where the outcome may be right-censored, covariates may be conditioned upon or adjusted for, and several interventions may be under randomization in any given window.
than do the separate trials in (b). This is true for (a) in spite of the fact that fewer total participants are enrolled in that trial than in the combined separate trials. In the remainder of this section, we provide analytical arguments establishing the generality of this improvement in power that platform designs enjoy for comparisons of the efficacies of different active interventions. When giving these arguments, we consider the general case where the outcome may be right-censored, covariates may be conditioned upon or adjusted for, and several interventions may be under randomization in any given window.
Table 3.
Power of various tests under (a) a standard 3-arm platform trial with a single window in which powered at 90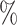 for tests of the marginal nulls, (b) two 2-arm separate trials with sample sizes similarly selected for 90
for tests of the marginal nulls, (b) two 2-arm separate trials with sample sizes similarly selected for 90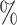 power, and (c) an expanded 3-arm platform trial with a single randomization window as in trial (a), but whose total sample size (controls and interventions combined) is equal to the sum of the total sample sizes of the two separate trials in (b). The total sample size reflects the total number of participants enrolled in the platform trial or across the two separate trials. The arm-specific sample sizes listed reflect the expected number of participants to be on control (shared control for the platform trial, sum of the two control arms for the two separate trials) or active interventions (total participants on interventions 1 and 2)
power, and (c) an expanded 3-arm platform trial with a single randomization window as in trial (a), but whose total sample size (controls and interventions combined) is equal to the sum of the total sample sizes of the two separate trials in (b). The total sample size reflects the total number of participants enrolled in the platform trial or across the two separate trials. The arm-specific sample sizes listed reflect the expected number of participants to be on control (shared control for the platform trial, sum of the two control arms for the two separate trials) or active interventions (total participants on interventions 1 and 2)
| Sample size | Null | ||||||
|---|---|---|---|---|---|---|---|
| Total | Controls | Interventions |
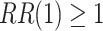
|
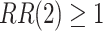
|
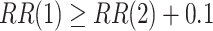
|
||
| (a) Platform | 5250 | 1750 | 3500 | 0.99 | 0.90 | 0.69 | |
| (b) Separate | 7000 | 3500 | 3500 | 0.99 | 0.90 | 0.50 | |
| (c) Expanded platform | 7000 | 2333 | 4667 | 1.00 | 0.95 | 0.78 | |
4.2. Theoretical guarantees
We consider the case where the goal is to compare the relative risks of two candidate interventions 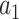 and
and 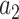 within a stratum
within a stratum 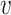 and at a given time point
and at a given time point 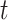 . We allow this comparison to be made based on a differentiable contrast function
. We allow this comparison to be made based on a differentiable contrast function 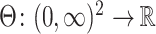 , and we refer to
, and we refer to 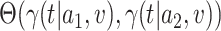 as the relative efficacy of interventions
as the relative efficacy of interventions 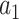 and
and 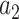 . For brevity, we let
. For brevity, we let 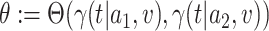 , where the values of
, where the values of 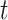 ,
, 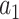 ,
, 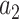 , and
, and 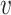 are treated as fixed for the remainder of this subsection. Our analysis will apply to any contrast function
are treated as fixed for the remainder of this subsection. Our analysis will apply to any contrast function  that satisfies the following condition.
that satisfies the following condition.
(C4)
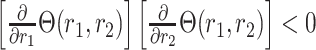 for all
for all 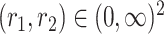 .
.
The above is satisfied by additive and multiplicative contrasts of the relative risks, namely 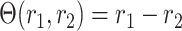 and
and 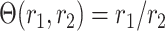 . In Appendix C of the Supplementary material available at Biostatistics online, we argue that the above condition is in fact natural whenever
. In Appendix C of the Supplementary material available at Biostatistics online, we argue that the above condition is in fact natural whenever 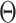 is to be used to determine the superiority or noninferiority of
is to be used to determine the superiority or noninferiority of 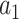 relative to
relative to 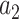 .
.
To quantify the efficiency gains that can be realized by running a platform trial, we compare the widths of confidence intervals for 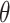 based on data from two settings. In the first, the data
based on data from two settings. In the first, the data 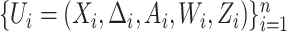 arise as
arise as 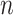 iid observations in a platform trial (see Section 2.2). In the second, the pooled data from
iid observations in a platform trial (see Section 2.2). In the second, the pooled data from 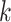 separate independent trials are used. Specifically, these pooled data take the form
separate independent trials are used. Specifically, these pooled data take the form 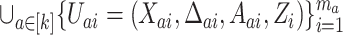 , where
, where 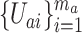 contains the data from the individual separate trial evaluating active intervention
contains the data from the individual separate trial evaluating active intervention 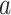 . We suppose that each
. We suppose that each 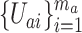 is an iid sample from some distribution
is an iid sample from some distribution  . The data structure observed in each separate trial is similar to that observed in the platform trial, except that no window variables are observed and
. The data structure observed in each separate trial is similar to that observed in the platform trial, except that no window variables are observed and 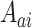 has support in
has support in 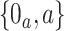 , where
, where 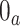 denotes the control arm in the separate trial for intervention
denotes the control arm in the separate trial for intervention 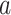 . As in the platform trial, the observed time
. As in the platform trial, the observed time 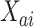 is the minimum of an event time
is the minimum of an event time 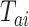 and a censoring time
and a censoring time  , and
, and 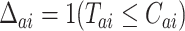 . We similarly suppose conditionally independent censoring and randomization, in this case that
. We similarly suppose conditionally independent censoring and randomization, in this case that 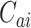 is independent of
is independent of 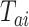 given
given 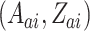 and
and 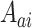 is independent of
is independent of 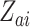 . The overall size of this pooled data set is
. The overall size of this pooled data set is 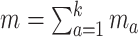 .
.
In our theoretical analysis, we focus on the case where the platform trial and the separate trials are identical in all regards except for the fact that a shared control arm is used in the platform trial, whereas a different control arm is used in each of the separate trials. We, therefore, wish to ensure that the population enrolled, the efficacy of each intervention, and the distribution of the censoring and event times is similar across the two settings. To formalize this, we impose a condition relating the distribution 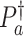 that gave rise to data in the separate trial for intervention
that gave rise to data in the separate trial for intervention 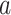 to the conditional distribution of
to the conditional distribution of 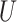 under
under 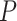 conditionally on
conditionally on 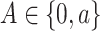 and
and 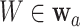 . Below, we denote this conditional distribution by
. Below, we denote this conditional distribution by 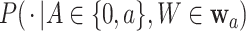 and use
and use 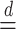 to mean equality in distribution.
to mean equality in distribution.
(C5) Platform and separate trials enroll from the same population: For all
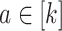 ,
, 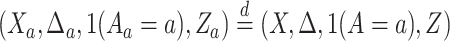 , where
, where 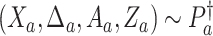 , and
, and 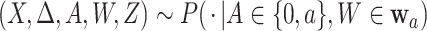 .
.
Under this condition, the relative risk of intervention 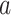 as compared to control through time
as compared to control through time 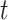 , conditionally on covariate level
, conditionally on covariate level 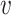 , is the same in the platform trial and in the separate trials. This condition also implies that the active intervention is assigned with probability
, is the same in the platform trial and in the separate trials. This condition also implies that the active intervention is assigned with probability 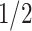 in each separate trial.
in each separate trial.
We also require that the platform trial and separate trials provide similar relative precision for estimating  and
and 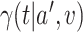 for any active interventions
for any active interventions 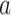 and
and 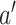 . We formalize this notion in terms of the standard errors for nonparametric estimators of these two quantities. In the separate trials, the standard error of the estimator of
. We formalize this notion in terms of the standard errors for nonparametric estimators of these two quantities. In the separate trials, the standard error of the estimator of 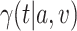 will be on the order of
will be on the order of 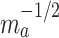 . In the platform trial, it will be on the order of
. In the platform trial, it will be on the order of 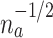 , where
, where  denotes the number of observations that are expected to be used in the evaluation of the relative risk of active intervention
denotes the number of observations that are expected to be used in the evaluation of the relative risk of active intervention 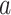 . The following condition imposes that, asymptotically, the ratio of the standard errors between interventions
. The following condition imposes that, asymptotically, the ratio of the standard errors between interventions  and
and 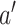 should be the same across the two trials.
should be the same across the two trials.
(C6) Platform and separate trials have the same relative precision across interventions: For all
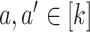 , it holds that
, it holds that 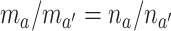 .
.
In addition to the interpretation given above, C6 can be interpreted in terms of the relative sizes of the different active intervention arms in the platform trial and the separate trials. To see this, note that a total of 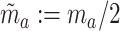 and
and 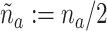 participants are expected to be randomized to intervention
participants are expected to be randomized to intervention 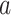 in the separate and platform trials, respectively. Moreover, by straightforward calculations, the above condition implies that
in the separate and platform trials, respectively. Moreover, by straightforward calculations, the above condition implies that 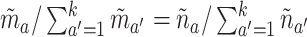 (see the proof of Lemma B.9 in Appendix B.4 of the Supplementary material available at Biostatistics online for these calculations). Hence, C6 requires allocating the same fraction of the total active intervention to participants across the separate trials to the trial for intervention
(see the proof of Lemma B.9 in Appendix B.4 of the Supplementary material available at Biostatistics online for these calculations). Hence, C6 requires allocating the same fraction of the total active intervention to participants across the separate trials to the trial for intervention 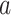 as was allocated in the platform trial.
as was allocated in the platform trial.
We now exhibit an estimator for the relative risk 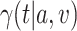 based on the data from the separate trial for a given active intervention
based on the data from the separate trial for a given active intervention 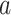 . For a covariate level
. For a covariate level  , let
, let  . We estimate the relative risk through time
. We estimate the relative risk through time 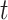 via
via
 |
where, for 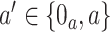 ,
, 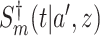 is the stratified Kaplan–Meier estimator of the probability that
is the stratified Kaplan–Meier estimator of the probability that 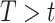 within the stratum where
within the stratum where 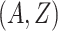 equals
equals 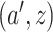 based on data from the separate trial for intervention
based on data from the separate trial for intervention 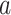 .
.
We now provide the forms of the confidence intervals for  that we consider based on data from the platform trial and separate trials. Each of these intervals is built based on asymptotic normality results that appear in the Supplementary material available at Biostatistics online. Lemma B.6 of the Supplementary material available at Biostatistics online shows that the estimator
that we consider based on data from the platform trial and separate trials. Each of these intervals is built based on asymptotic normality results that appear in the Supplementary material available at Biostatistics online. Lemma B.6 of the Supplementary material available at Biostatistics online shows that the estimator  based on platform data satisfies
based on platform data satisfies 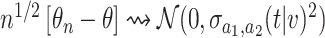 , where
, where  denotes convergence in distribution and the form of
denotes convergence in distribution and the form of 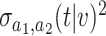 is given in (B.11). Similarly, Lemma B.7 of the Supplementary material available at Biostatistics online establishes that the estimator
is given in (B.11). Similarly, Lemma B.7 of the Supplementary material available at Biostatistics online establishes that the estimator 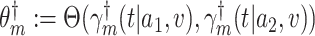 based on separate trial data satisfies
based on separate trial data satisfies 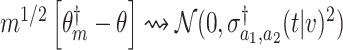 , where
, where 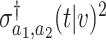 is defined in (B.13). Let
is defined in (B.13). Let 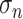 and
and 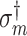 denote consistent estimators of
denote consistent estimators of 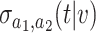 and
and 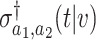 , respectively. Fix a significance level
, respectively. Fix a significance level 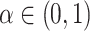 and let
and let 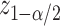 denote the
denote the  quantile of a standard normal distribution. Asymptotically valid two-sided
quantile of a standard normal distribution. Asymptotically valid two-sided 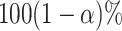 confidence intervals for the relative efficacy
confidence intervals for the relative efficacy 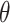 are given by
are given by
 |
These intervals are based on the platform trial and separate trial data, respectively. The interval 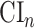 is a Wald-type interval based on an estimator of
is a Wald-type interval based on an estimator of 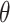 that is asymptotically efficient within the nonparametric model where the only assumption made on the platform trial data-generating distribution is that intervention assignment is randomized (see C1), and
that is asymptotically efficient within the nonparametric model where the only assumption made on the platform trial data-generating distribution is that intervention assignment is randomized (see C1), and 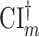 is similarly based on an efficient estimator in the model where the only assumption made on the separate trial data-generating distributions is that intervention assignment is randomized. As a consequence, if the platform trial interval
is similarly based on an efficient estimator in the model where the only assumption made on the separate trial data-generating distributions is that intervention assignment is randomized. As a consequence, if the platform trial interval 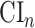 were to be asymptotically shorter than the separate trial interval
were to be asymptotically shorter than the separate trial interval 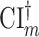 , then the platform trial would enable a more efficient estimation of the contrast
, then the platform trial would enable a more efficient estimation of the contrast 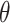 . The following theorem shows that this is indeed the case. Below
. The following theorem shows that this is indeed the case. Below 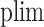 denotes a probability limit.
denotes a probability limit.
Theorem 4.1
Suppose that C1–C6 hold and
in such a way that
for some
. Let
. Denote the widths of
and
by
and
, respectively.
(i) If
, then the platform trial interval is shorter asymptotically, that is,
.
(ii) If
, then the platform trial interval is no longer asymptotically, that is,
.
The above theorem shows that, under conditions, running a platform trial will never harm the precision of a confidence interval contrasting two different interventions and will improve it in some cases. To see the lack of harm, note that 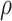 is never greater than one, and therefore Theorem 4.1 implies that the confidence interval based on the platform trial data is never wider than that based on the separate trial data if
is never greater than one, and therefore Theorem 4.1 implies that the confidence interval based on the platform trial data is never wider than that based on the separate trial data if 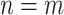 . In fact, a stronger conclusion holds: the platform trial confidence interval is asymptotically no wider than that separate trial confidence interval provided the expected number of participants that are enrolled to each active intervention
. In fact, a stronger conclusion holds: the platform trial confidence interval is asymptotically no wider than that separate trial confidence interval provided the expected number of participants that are enrolled to each active intervention 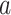 is equal in these two settings—that is,
is equal in these two settings—that is, 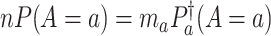 for all
for all 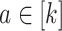 ; the conclusion can be shown to hold since
; the conclusion can be shown to hold since 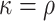 in these cases (see Lemma B.9 in Appendix B.4 of the Supplementary material available at Biostatistics online). Because the platform trial utilizes a shared control arm, enforcing the same number of expected participants enrolled on the active interventions allows for the platform trial to be smaller (
in these cases (see Lemma B.9 in Appendix B.4 of the Supplementary material available at Biostatistics online). Because the platform trial utilizes a shared control arm, enforcing the same number of expected participants enrolled on the active interventions allows for the platform trial to be smaller (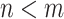 ) whenever there is at least one window in the platform trial in which two or more interventions are under randomization. More generally, when there is at least one such window, the platform trial can yield shorter confidence intervals even in cases where it enrolled fewer participants—this is true, in particular, when
) whenever there is at least one window in the platform trial in which two or more interventions are under randomization. More generally, when there is at least one such window, the platform trial can yield shorter confidence intervals even in cases where it enrolled fewer participants—this is true, in particular, when 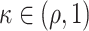 . In fact, as we show in our simulations, there are realistic cases where this gain in precision is considerable.
. In fact, as we show in our simulations, there are realistic cases where this gain in precision is considerable.
5. Adaptive noninferiority test
We now provide a testing procedure to investigate the noninferiority of a specified intervention—assumed to be intervention 1 here without loss of generality—as compared to the most efficacious of the other interventions. We call intervention 1 noninferior to intervention 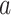 if
if 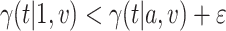 , where
, where 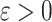 is a specified noninferiority margin, and noninferior to the most efficacious of the other interventions if
is a specified noninferiority margin, and noninferior to the most efficacious of the other interventions if 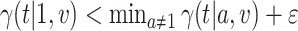 . Note that the event considered in this work is harmful (e.g., COVID-19 infection), so smaller relative risks are preferable and the minimum is taken. If the event is desirable (e.g., recovery), the maximum should be used instead. If it is not a priori known whether any of the other interventions are in fact efficacious, noninferiority alone is insufficient to determine that an intervention has clinically meaningful efficacy. To handle such cases, it is natural to further require that the relative risk of intervention 1 falls below some specified threshold
. Note that the event considered in this work is harmful (e.g., COVID-19 infection), so smaller relative risks are preferable and the minimum is taken. If the event is desirable (e.g., recovery), the maximum should be used instead. If it is not a priori known whether any of the other interventions are in fact efficacious, noninferiority alone is insufficient to determine that an intervention has clinically meaningful efficacy. To handle such cases, it is natural to further require that the relative risk of intervention 1 falls below some specified threshold  . This leads to a null hypothesis test of
. This leads to a null hypothesis test of
 |
The null 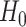 rewrites as a union of
rewrites as a union of 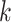 marginal null hypotheses. In particular,
marginal null hypotheses. In particular, 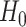 holds if and only if at least one of the following marginal nulls holds:
holds if and only if at least one of the following marginal nulls holds: 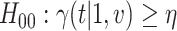 or
or 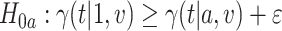 for some
for some 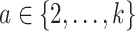 . Consequently, the alternative hypothesis
. Consequently, the alternative hypothesis 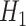 corresponds to the intersection of the complementary marginal alternatives, namely
corresponds to the intersection of the complementary marginal alternatives, namely 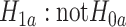 , with
, with 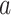 varying over
varying over 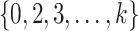 . These observations suggest testing the null
. These observations suggest testing the null  at significance level
at significance level 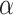 by running (unadjusted)
by running (unadjusted) 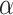 -level tests of the marginal nulls
-level tests of the marginal nulls 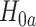 versus
versus 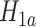 , with
, with 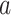 varying over
varying over 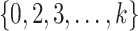 and rejecting
and rejecting 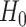 if and only if all of these
if and only if all of these 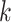 marginal tests reject. This test of
marginal tests reject. This test of 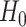 versus
versus 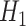 , which we refer to as an intersection test, necessarily controls the type-1 error asymptotically provided the marginal tests do so, since
, which we refer to as an intersection test, necessarily controls the type-1 error asymptotically provided the marginal tests do so, since
 |
(5.5) |
where 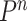 denotes the distribution of
denotes the distribution of 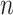 independent draws from
independent draws from 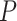 and the final inequality holds because, under
and the final inequality holds because, under 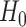 , there is at least one
, there is at least one 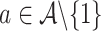 for which
for which 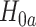 holds. The intersection test asymptotically has type-1 error of exactly
holds. The intersection test asymptotically has type-1 error of exactly 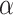 when there is only one
when there is only one 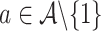 such that
such that 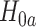 holds and all of the
holds and all of the 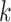 marginal tests are both consistent against all fixed alternatives and have type-1 error
marginal tests are both consistent against all fixed alternatives and have type-1 error 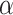 against all null configurations (see Appendix E of the Supplementary material available at Biostatistics online for a proof). A natural implementation of the intersection test, which is the one we employ in our simulations, bases the marginal tests on Wald-type confidence intervals constructed using Lemma B.5 of the Supplementary material available at Biostatistics online. The marginal test of
against all null configurations (see Appendix E of the Supplementary material available at Biostatistics online for a proof). A natural implementation of the intersection test, which is the one we employ in our simulations, bases the marginal tests on Wald-type confidence intervals constructed using Lemma B.5 of the Supplementary material available at Biostatistics online. The marginal test of 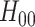 rejects if the upper bound of a two-sided
rejects if the upper bound of a two-sided 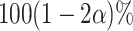 confidence interval for
confidence interval for 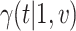 is smaller than
is smaller than 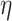 and the marginal test of
and the marginal test of 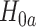 ,
, 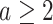 , rejects if the upper bound of a two-sided
, rejects if the upper bound of a two-sided 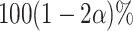 confidence interval for
confidence interval for 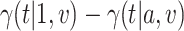 is smaller than
is smaller than  .
.
6. Numerical studies
We now present numerical studies to imitate the evaluation of  vaccines in a placebo-controlled platform trial versus in multiple separate trials. Within each window, enrollment is uniform over calendar time. Table S1 of Appendix F of the Supplementary material available at Biostatistics online summarizes the enrollment timelines of active interventions by windows (until 3 months post-trial initiation), along with the window widths and the enrollment size per arm in each window. A four-category baseline variable
vaccines in a placebo-controlled platform trial versus in multiple separate trials. Within each window, enrollment is uniform over calendar time. Table S1 of Appendix F of the Supplementary material available at Biostatistics online summarizes the enrollment timelines of active interventions by windows (until 3 months post-trial initiation), along with the window widths and the enrollment size per arm in each window. A four-category baseline variable 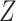 is measured for each participant, where the distribution of this variable depends on the enrollment window. In particular,
is measured for each participant, where the distribution of this variable depends on the enrollment window. In particular, 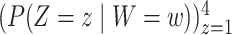 is equal to (0.1, 0.2, 0.3, 0.4) when
is equal to (0.1, 0.2, 0.3, 0.4) when 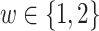 and (0.4, 0.3, 0.2, 0.1) otherwise. Within each stratum of
and (0.4, 0.3, 0.2, 0.1) otherwise. Within each stratum of 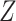 , placebo participants have piecewise-constant hazard functions that change values only at the calendar times indicating a transition between windows (Months 1, 1.5, 2, and 2.5). The strata where
, placebo participants have piecewise-constant hazard functions that change values only at the calendar times indicating a transition between windows (Months 1, 1.5, 2, and 2.5). The strata where 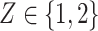 are the lower-risk strata, and their hazard functions across windows (1, 2, 3, 4, 5) are such that the corresponding 6-month attack rates in the placebo arm are equal to (12
are the lower-risk strata, and their hazard functions across windows (1, 2, 3, 4, 5) are such that the corresponding 6-month attack rates in the placebo arm are equal to (12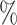 , 12
, 12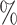 , 6
, 6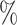 , 4
, 4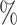 , and 4
, and 4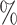 ). The strata where
). The strata where 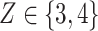 are the higher-risk strata, and the hazard functions are chosen so that the 6-month attack rates are twice those as in the lower-risk strata. Though the event is somewhat rare, all vaccine-versus-shared-placebo comparisons include 150 events shortly after enrollment opens—the median across Monte Carlo repetitions ranges from a median 2.5 months for intervention 4–4.5 months for intervention 5. The hazard ratio vaccine efficacy—defined as one minus the hazard ratio of vaccine versus placebo recipients—is presented in Table S1 of the Supplementary material available at Biostatistics online. For simplicity, this vaccine efficacy is made to be constant over time. The time for loss to follow-up is taken to follow a
are the higher-risk strata, and the hazard functions are chosen so that the 6-month attack rates are twice those as in the lower-risk strata. Though the event is somewhat rare, all vaccine-versus-shared-placebo comparisons include 150 events shortly after enrollment opens—the median across Monte Carlo repetitions ranges from a median 2.5 months for intervention 4–4.5 months for intervention 5. The hazard ratio vaccine efficacy—defined as one minus the hazard ratio of vaccine versus placebo recipients—is presented in Table S1 of the Supplementary material available at Biostatistics online. For simplicity, this vaccine efficacy is made to be constant over time. The time for loss to follow-up is taken to follow a 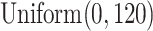 distribution that is independent of all other variables under consideration, so that there is 10
distribution that is independent of all other variables under consideration, so that there is 10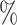 annual loss to follow-up during the study, which runs for a total of 18 calendar months.
annual loss to follow-up during the study, which runs for a total of 18 calendar months.
We consider estimators in two cases: (i) reducing 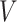 to a constant variable and estimating the marginal relative risk and (ii) taking
to a constant variable and estimating the marginal relative risk and (ii) taking  and estimating the conditional relative risk. All results in the main text pertain to the estimation of the marginal relative risk, and results for estimators of the covariate-stratified relative risk are reported in Appendix H of the Supplementary material available at Biostatistics online. We compare the statistical efficiency of using data from a platform trial (total sample size of 40 400) rather than separate trials (total sample size of 69 800) in the estimation for relative risk ratios of intervention 7 versus other interventions at
and estimating the conditional relative risk. All results in the main text pertain to the estimation of the marginal relative risk, and results for estimators of the covariate-stratified relative risk are reported in Appendix H of the Supplementary material available at Biostatistics online. We compare the statistical efficiency of using data from a platform trial (total sample size of 40 400) rather than separate trials (total sample size of 69 800) in the estimation for relative risk ratios of intervention 7 versus other interventions at 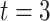 or 6 (months) postenrollment, under moderate loss to follow-up and administrative censoring at 6, 9, 12, or 18 calendar months post-trial initiation. The efficiency gain is measured by confidence-interval-width ratios—the lower the values of these ratios are, the more efficient the platform trial will be as compared to the separate trials.
or 6 (months) postenrollment, under moderate loss to follow-up and administrative censoring at 6, 9, 12, or 18 calendar months post-trial initiation. The efficiency gain is measured by confidence-interval-width ratios—the lower the values of these ratios are, the more efficient the platform trial will be as compared to the separate trials.
Similar coverage was observed for the confidence intervals based on platform trial data and separate trial data. In particular, the empirical percentiles (0 , 25
, 25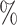 , 50
, 50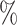 , 75
, 75 , and 100
, and 100 ) of the confidence interval coverage across the total of 72 scenarios considered were (91.8
) of the confidence interval coverage across the total of 72 scenarios considered were (91.8 , 93.7
, 93.7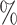 , 94.5
, 94.5 , 95
, 95 , and 95.7
, and 95.7 ) for the platform trial and (91.4
) for the platform trial and (91.4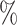 , 93.4
, 93.4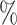 , 94
, 94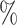 , 94.5
, 94.5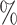 , and 95.6
, and 95.6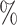 ) for the separate trials. Figure S2 of Appendix H of the Supplementary material available at Biostatistics online displays the efficiency gain of running a platform trial over running separate trials for the marginal and conditional estimands. Across all settings considered, analyses based on the platform trial were at least as efficient, and often more efficient, than those based on the separate trial data. This is true in spite of the fact that the platform trial enrolled over 40
) for the separate trials. Figure S2 of Appendix H of the Supplementary material available at Biostatistics online displays the efficiency gain of running a platform trial over running separate trials for the marginal and conditional estimands. Across all settings considered, analyses based on the platform trial were at least as efficient, and often more efficient, than those based on the separate trial data. This is true in spite of the fact that the platform trial enrolled over 40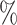 fewer participants than the separate trials. This result is consistent with our theoretical guarantees in Section 4.2. Further details on these efficiency gains, broken down by evaluation time
fewer participants than the separate trials. This result is consistent with our theoretical guarantees in Section 4.2. Further details on these efficiency gains, broken down by evaluation time 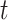 and administrative censoring time can be found in Figures S3 and S4 in Appendix H of the Supplementary material available at Biostatistics online. There we also present results under scenarios in which the sample size is smaller (Figures S5–S7 in Appendix H.1 of the Supplementary material available at Biostatistics online) and the constancy condition C2 fails (Figures S8 and S9 in Appendix H.2 of the Supplementary material available at Biostatistics online).
and administrative censoring time can be found in Figures S3 and S4 in Appendix H of the Supplementary material available at Biostatistics online. There we also present results under scenarios in which the sample size is smaller (Figures S5–S7 in Appendix H.1 of the Supplementary material available at Biostatistics online) and the constancy condition C2 fails (Figures S8 and S9 in Appendix H.2 of the Supplementary material available at Biostatistics online).
We evaluated the performance of the adaptive noninferiority test described in Section 5. The evaluation of this test contains two scenarios: one with intervention 7 serving as the prespecified candidate whose noninferiority will be evaluated, and the other with intervention 9 serving as this candidate. Relative efficacy was quantified using the differences of the marginal relative risk of the prespecified candidate and that of the other active interventions. We also evaluate the performance of a likelihood ratio type test, which is described in Appendix D of the Supplementary material available at Biostatistics online. We set the significance level at 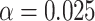 and the efficacy threshold at
and the efficacy threshold at 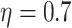 . In Figure 1, we report the empirical rejection rates (over 1000 Monte Carlo simulation runs) to evaluate the power and type-1 error control based on the data from the platform trial and the data from separate independent trials, with all the observations censored at
. In Figure 1, we report the empirical rejection rates (over 1000 Monte Carlo simulation runs) to evaluate the power and type-1 error control based on the data from the platform trial and the data from separate independent trials, with all the observations censored at 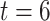 and under moderate loss to follow-up. From the figure, we see that type-1 errors of both the intersection test and the likelihood ratio type test are conservatively controlled by the test data from either trial. The tests based on the data from the platform trial yields higher power than the one based on separate independent trials, and the intersection tests attain considerably higher power than the likelihood ratio type tests.
and under moderate loss to follow-up. From the figure, we see that type-1 errors of both the intersection test and the likelihood ratio type test are conservatively controlled by the test data from either trial. The tests based on the data from the platform trial yields higher power than the one based on separate independent trials, and the intersection tests attain considerably higher power than the likelihood ratio type tests.
Fig. 1.

The empirical rejection rates of the intersection test and the likelihood ratio type test for different preselected active interventions based on data from the platform trial and separate trials, evaluated at 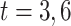 (in months postenrollment) with varying margin values, the significance level of
(in months postenrollment) with varying margin values, the significance level of 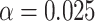 and the efficacy threshold
and the efficacy threshold 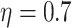 , when all the observations are censored at 6 calendar months post-trial initiation and subject to moderate loss to follow-up.
, when all the observations are censored at 6 calendar months post-trial initiation and subject to moderate loss to follow-up.
We also evaluated an oracle noninferiority test that tested a simpler null hypothesis than the intersection test, namely the hardest-to-be-rejected null among the 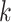 total marginal null hypothesis tests (of
total marginal null hypothesis tests (of  and
and  ,
, 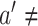 the prespecified intervention
the prespecified intervention  ) described in Section 5. The hardness of a marginal null hypothesis was quantified via the statistical power of testing this marginal null. The oracle test imitates an idealized setting where it is possible to set a priori a single benchmark intervention for the noninferiority test. This setting is certainly unrealizable in practice since evaluating it relies on knowing the true operating characteristics of tests of the
) described in Section 5. The hardness of a marginal null hypothesis was quantified via the statistical power of testing this marginal null. The oracle test imitates an idealized setting where it is possible to set a priori a single benchmark intervention for the noninferiority test. This setting is certainly unrealizable in practice since evaluating it relies on knowing the true operating characteristics of tests of the  total marginal null hypotheses. As the intersection test must reject all
total marginal null hypotheses. As the intersection test must reject all  of these null hypotheses, it will necessarily have lower power than the oracle. Nevertheless, the intersection test achieved only slightly lower power than did the oracle test in all considered scenarios. In particular, the power of the intersection test relative to that of the oracle test ranged from 0.4
of these null hypotheses, it will necessarily have lower power than the oracle. Nevertheless, the intersection test achieved only slightly lower power than did the oracle test in all considered scenarios. In particular, the power of the intersection test relative to that of the oracle test ranged from 0.4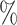 to 11.6
to 11.6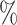 lower on an absolute scale when intervention 7 was preselected and from 0
lower on an absolute scale when intervention 7 was preselected and from 0 to 4.3
to 4.3 when intervention 9 was preselected.
when intervention 9 was preselected.
7. Data illustration
In two parallel AMP trials, referred to as HVTN 703 and HVTN 704, participants were randomly assigned in a 1:1:1 ratio to control group, low-dose intervention group, and high-dose intervention group (Corey and others, 2021). The primary endpoint was the post-trial days to type-1 human immunodeficiency virus (HIV-1) infection through the week 80 study visit. The annual loss to follow-up rates were 6.3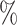 in HVTN 703 and 9.4
in HVTN 703 and 9.4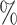 in HVTN 704. The two trials were conducted in different populations, with HVTN 703 enrolling at-risk women in sub-Saharan Africa and HVTN 704 enrolling at-risk cisgender men and transgender persons in the Americas and Europe. Following Corey and others (2021), we stratified our analyses by trial, thereby reporting separate prevention efficacy estimates for the two trials.
in HVTN 704. The two trials were conducted in different populations, with HVTN 703 enrolling at-risk women in sub-Saharan Africa and HVTN 704 enrolling at-risk cisgender men and transgender persons in the Americas and Europe. Following Corey and others (2021), we stratified our analyses by trial, thereby reporting separate prevention efficacy estimates for the two trials.
To illustrate our developed testing procedure, we created open platform trial data sets by subsampling data from the parallel, multiarm AMP trials as described below. A subset of the participants in the original trial were enrolled in the platform trials we considered. In these platform trials, we fixed the total number of participants enrolled to each active intervention to be approximately 320 in HVTN 703 and 450 in HVTN 704, which is approximately half the total number of participants enrolled to the active arms in the original trials. To enroll participants, the data for each trial were divided into four chronological windows, each containing a quarter of the sample; the resulting sample sizes for intervention groups over windows are presented in Figure S10 of the Supplementary material available at Biostatistics online. Participants were resampled, without replacement, from HVTN 703 or HVTN 704 to generate platform trial data sets that have a desired level of overlap in the control arm. More concretely, we sought to fix the proportion of controls shared at a value ranging from 0.25 to 0.50, where this proportion is defined as the number of controls that are shared by the two arms divided by the total number of controls enrolled in the platform trial. Details can be found in Appendix I of the Supplementary material available at Biostatistics online.
We report inference for the relative efficacy of the low-dose intervention relative to that of the high-dose intervention (on an additive scale), where lower relative efficacy values indicate more favorable performance of the low-dose intervention. Because the trial results were already public when we received the data, we were not able to prespecify a noninferiority margin 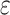 or efficacy threshold
or efficacy threshold 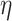 . Therefore, here we focus on reporting the widths of 95
. Therefore, here we focus on reporting the widths of 95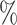 confidence intervals for the relative efficacy through week 80, averaged across the data sets considered. Figure 2 displays these widths. In both trials, there is a trend towards more shared control data between two dose groups yielding tighter confidence intervals.
confidence intervals for the relative efficacy through week 80, averaged across the data sets considered. Figure 2 displays these widths. In both trials, there is a trend towards more shared control data between two dose groups yielding tighter confidence intervals.
Fig. 2.

The confidence interval widths of the relative efficacy (on an additive scale) of the low-dose intervention relative to the high-dose intervention in HVTN 703 and HVTN 704, evaluated at week 80.
8. Conclusion
This article established that platform trials can lead to more precise estimation of the relative efficacy of two different interventions. To this end, the joint distributions of estimators of the efficacy of multiple active interventions versus contemporaneous control were established. Such joint distributions were also shown to enable adaptive tests of noninferiority wherein the identity of the most efficacious comparator intervention need not be known in advance. Simulations were provided to support this asymptotic theory. In this study, a platform trial enrolled approximately 67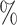 as many participants as would have separate, independent trials and yet yielded up to 25
as many participants as would have separate, independent trials and yet yielded up to 25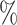 narrower confidence intervals for contrasts of the efficacies of two interventions.
narrower confidence intervals for contrasts of the efficacies of two interventions.
Though the positive correlation that we established for the joint distribution of the efficacy estimates across the different arms is advantageous for contrasting the efficacy of different interventions, it also has a disadvantage. To see why, note that, due to the use of a single-shared placebo arm, there is a possibility that, by random chance, an unusually high or low number of events will be observed on the placebo arm. As a consequence, many of the arm-specific efficacy estimators may provide unusually high or low estimates of efficacy. This can, in turn, lead to scenarios where many interventions are falsely suggested to be efficacious or inefficacious (Howard and others, 2018). Though such challenges may be avoided by employing an appropriate multiple testing correction, such procedures have previously been viewed as undesirable for platform trials that involve many stakeholders since they can disincentivize participation in these economical designs in favor of conducting more costly, intervention-specific trials. Therefore, as mentioned in Section 1, recent platform trials have followed multiarmed trials in not using a multiplicity adjustment (WHO Solidarity Trial Consortium, 2021; Howard and others, 2021). An alternative means to avoid elevated false (non)discovery rates in platform designs is to simply increase the size of the placebo arm. Rather than reducing the correlation between arm-specific estimates, this instead directly reduces the variance of these estimates. Since the efficiency gains that we showed in this article allowed the platform trials to be substantially smaller than the corresponding separate trials, the placebo arm could be substantially increased in size while still resulting in a smaller-sized trial than would have been two separate trials and improved precision for comparing the efficacy of multiple interventions. In any given setting, pretrial simulation studies can be conducted to determine whether modifying the platform trial allocation ratio in this manner yields a design with the investigators’ desired operating characteristics.
Supplementary Material
Acknowledgments
Conflict of Interest: Alex Luedtke received WHO funds to develop the analysis plan for the Solidarity Trial Vaccines.
Contributor Information
Tzu-Jung Huang, Vaccine and Infectious Disease Division, Fred Hutchinson Cancer Research Center, Seattle, WA 98109, USA.
Alex Luedtke, Department of Statistics, University of Washington, Seattle, WA 98195, USA and Vaccine and Infectious Disease Division, Fred Hutchinson Cancer Research Center, Seattle, WA 98109, USA.
Software
Code can be found at https://github.com/tzujunghuang/ImprovedEfficiency_via_PlatformDesigns.
Supplementary Material
Supplementary material is available online at http://biostatistics.oxfordjournals.org.
Funding
The National Institutes of Health (NIH) (DP2-LM013340 and 5UM1AI068635-09).
References
- Choko, A., Fielding, K., Stallard, N., Maheswaran, H., Lepine, A., Desmond, N., Kumwenda, M. and Corbett, E. (2017). Investigating interventions to increase uptake of HIV testing and linkage into care or prevention for male partners of pregnant women in antenatal clinics in Blantyre, Malawi: study protocol for a cluster randomised trial. Trials 18, 349. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Corey, L., Gilbert, P., Juraska, M., Montefiori, D., Morris, L., Karuna, S., Edupuganti, S., Mgodi, N., de Camp, A., Rudnicki, E.. and others. (2021). Two randomized trials of neutralizing antibodies to prevent HIV-1 acquisition. New England Journal of Medicine 384, 1003–1014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- D’Agostino, R., Massaro, J. and Sullivan, L. (2003). Non-inferiority trials: design concepts and issues — the encounters of academic consultants in statistics. Statistics in Medicine 22, 169–186. [DOI] [PubMed] [Google Scholar]
- Dean, N., Gsell, P., Brookmeyer, R., Crawford, F., Donnelly, C., Ellenberg, S., Fleming, T., Halloran, M., Horby, P., Jaki, T.. and others. (2020). Creating a framework for conducting randomized clinical trials during disease outbreaks. New England Journal of Medicine 382, 1366–1369. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Everson-Stewart, S. and Emerson, S. (2010). Bio-creep in non-inferiority clinical trials. Statistics in Medicine 29, 2769–2780. [DOI] [PubMed] [Google Scholar]
- Fleming, T. (2008). Current issues in non-inferiority trials. Statistics in Medicine 27, 317–332. [DOI] [PubMed] [Google Scholar]
- Fleming, T., Krause, P., Nason, M., Longini, I. and Henao-Restrepo, A. (2021). COVID-19 vaccine trials: The use of active controls and non-inferiority studies. Clinical Trials 18, 335–342. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Freidlin, B., Korn, E., Gray, R. and Martin, A. (2008). Multi-arm clinical trials of new agents: Some design considerations. Clinical Cancer Research 14, 4368–4371. [DOI] [PubMed] [Google Scholar]
- Hernán, M. and Robins, J. (2020). Causal Inference: What If. Boca Raton, USA:Chapman & Hall/CRC. [Google Scholar]
- Hobbs, B., Chen, N. and Lee, J. (2018). Controlled multi-arm platform design using predictive probability. Statistical Methods in Medical Research 27, 65–78. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Howard, D., Brown, J., Todd, S. and Gregory, W. (2018). Recommendations on multiple testing adjustment in multi-arm trials with a shared control group. Statistical Methods in Medical Research 27, 1513–1530. [DOI] [PubMed] [Google Scholar]
- Howard, D., Hockaday, A., Brown, J., Gregory, W., Todd, S., Munir, T., Oughton, J., Dimbleby, C. and Hillmen, P. (2021). A platform trial in practice: adding a new experimental research arm to the ongoing confirmatory FLAIR trial in chronic lymphocytic leukaemia. Trials 22, 1–13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kaizer, A., Hobbs, B. and Koopmeiners, J. (2018). A multi-source adaptive platform design for testing sequential combinatorial therapeutic strategies. Biometrics 74, 1082–1094. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kopp-Schneider, A., Calderazzo, S. and Wiesenfarth, M. (2020). Power gains by using external information in clinical trials are typically not possible when requiring strict type I error control. Biometrical Journal 62, 361–374. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krause, P., Fleming, T., Longini, I., Henao-Restrepo, A., Peto, R., Dean, N., Halloran, B., Huang, Y., Gilbert, P., DeGruttola, V.. and others. (2020). COVID-19 vaccine trials should seek worthwhile efficacy. Lancet 396, 741–743. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee, K., Brown, L., Jaki, T., Stallard, N. and Wason, J. (2021). Statistical consideration when adding new arms to ongoing clinical trials: the potentials and the caveats. Trials 22, 203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee, K. and Wason, J. (2020). Including non-concurrent control patients in the analysis of platform trials: is it worth it? BMC Medical Research Methodology 20, 165. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mauri, L. and D’Agostino, R. (2017). Challenges in the design and interpretation of noninferiority trials. New England Journal of Medicine 3771357–1367. [DOI] [PubMed] [Google Scholar]
- May, S., Brown, S., Schmicker, R., Emerson, S., Nkwopara, E. and Ginsburg, A. (2020). Non-inferiority designs comparing placebo to a proven therapy for childhood pneumonia in low-resource settings. Clinical Trials 17, 129–137. [DOI] [PubMed] [Google Scholar]
- Meyer, E., Mesenbrink, P., Dunger-Baldauf, C., Fülle, H., Glimm, E., Li, Y., Posch, M. and König, F. (2020). The evolution of master protocol clinical trial designs: a systematic literature review. Clinical Therapeutics 42, 1330–1360. [DOI] [PubMed] [Google Scholar]
- Parmar, M., Sydes, M., Cafferty, F., Choodari-Oskooei, B., Langley, R., Brown, L., Phillips, P., Spears, M., Rowley, S., Kaplan, R.. and others. (2017). Testing many treatments within a single protocol over 10 years at MRC Clinical Trials Unit at UCL: multi-arm, multi-stage platform, umbrella and basket protocols. Clinical trials 14, 451–461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Royston, P., Parmar, M. and Qian, W. (2003). Novel designs for multi-arm clinical trials with survival outcomes with an application in ovarian cancer. Statistics in Medicine 22, 2239–2256. [DOI] [PubMed] [Google Scholar]
- Saville, B. and Berry, S. (2016). Efficiencies of platform clinical trials: a vision of the future. Clinical Trials 13, 358–366. [DOI] [PubMed] [Google Scholar]
- Sridhara, R., He, K., Nie, L., Shen, Y. and Tang, S. (2015). Current statistical challenges in oncology clinical trials in the era of targeted therapy. Statistics in Biopharmaceutical Research 7, 348–356. [Google Scholar]
- Tsiatis, A. and Davidian, M. (2021). Estimating vaccine efficacy over time after a randomized study is unblinded. Biometrics. [DOI] [PMC free article] [PubMed] [Google Scholar]
- WHO Solidarity Trial Consortium. (2021). Repurposed antiviral drugs for COVID-19 – Interim WHO Solidarity Trial results. New England Journal of Medicine 384, 497–511. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Woodcock, J. and LaVange, L. (2017). Master protocols to study multiple therapies, multiple diseases, or both. New England Journal of Medicine 377, 62–70. [DOI] [PubMed] [Google Scholar]
- World Health Organization. (2020). An international randomised trial of candidate vaccines against COVID-19. Technical Report 0419, World Health Organization. [Google Scholar]
- Zhang, L., Chen, D., Jin, H., Li, G. and Quan, H. (2019). Contemporary Biostatistics with Biopharmaceutical Applications. Cham, Switzerland:Springer. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.