

Abstract
Background:
Given the limited access to breast cancer (BC) screening, the authors developed and validated a mobile phone-artificial intelligence-based infrared thermography (AI-IRT) system for BC screening.
Materials and methods:
This large prospective clinical trial assessed the diagnostic performance of the AI-IRT system. The authors constructed two datasets and two models, performed internal and external validation, and compared the diagnostic accuracy of the AI models and clinicians. Dataset A included 2100 patients recruited from 19 medical centres in nine regions of China. Dataset B was used for independent external validation and included 102 patients recruited from Langfang People’s Hospital.
Results:
The area under the receiver operating characteristic curve of the binary model for identifying low-risk and intermediate/high-risk patients was 0.9487 (95% CI: 0.9231–0.9744) internally and 0.9120 (95% CI: 0.8460–0.9790) externally. The accuracy of the binary model was higher than that of human readers (0.8627 vs. 0.8088, respectively). In addition, the binary model was better than the multinomial model and used different diagnostic thresholds based on BC risk to achieve specific goals.
Conclusions:
The accuracy of AI-IRT was high across populations with different demographic characteristics and less reliant on manual interpretations, demonstrating that this model can improve pre-clinical screening and increase screening rates.
Keywords: accuracy, artificial intelligence, breast cancer, infrared thermography, screening
This novel artificial intelligence-based infrared thermography system for breast cancer pre-clinical screening based on a prospective multicenter cohort showed high sensitivity and specificity, with area under curve as high as 0.95.
Introduction
Highlights
Based on a prospective multicenter clinical trial (number: 04761211).
The system includes micro infrared camera, artificial intelligence, and big datasets.
Providing real-time automated breast screening, with high diagnostic accuracy.
The accuracy of novel breast screening was higher than that of manual reading.
Assisting ordinary people for breast screening and reduce breast cancer mortality.
Breast cancer (BC) is the most common malignancy among women worldwide (World Health Organization, 2020)1. Screening programs allow early diagnosis and treatment, significantly reducing mortality2. Screening strategies are adapted to local conditions according to NCCN guidelines3–5. Usually, pre-clinical screening involves breast self-examination (BSE), and clinical screening involves clinical breast examination, which is based on mammography and ultrasound combined with complementary techniques, including magnetic resonance imaging (MRI), digital breast tomosynthesis, or contrast-enhanced mammography. However, more than 50% of the global population does not have access to BC screening programs6–9. Furthermore, BSE is performed incorrectly by most women10. This situation has been exacerbated by the impact of COVID-19 in recent years11. Therefore, it is essential to develop new home-based BC pre-clinical screening methods.
Research on artificial intelligence (AI)-based medicine has advanced rapidly in recent years, especially diagnostic imaging of BC. AI systems can meet or exceed the diagnostic performance of human experts12. Although contemporary AI models are highly accurate for detecting BC, methodological problems, evidence gaps, and lack of portability limit the use of these systems in large-scale screening programs13. Clinical studies showed that diagnoses made by clinicians are more accurate than AI-based diagnoses; however, AI systems have high diagnostic potential. The diagnostic efficacy of different screening techniques varies greatly, and selecting the optimal technique is essential to improve the utility of AI systems in screening. Our previous study showed that infrared thermography (IRT) has high screening sensitivity. Niell et al. 14 showed that the sensitivity of ultrasound, mammography, BSE, and IRT for detecting BC was 52%, 50%, 18%, and 61%, respectively. Accumulated evidence supports that IRT is equivalent to standard breast imaging and clinical examination15–17.
The first IRT system used for BC diagnosis was proposed by Ray Lawson in 1956. Since then, infrared radiation has been used extensively in medical applications18. IRT is noninvasive, non-destructive, and radiation-free. The medical use of IRT has increased in recent years, despite its limited sensitivity and specificity (61% and 74%, respectively). In addition, technological advancements have increased the applicability of IRT19. For instance, Ekici and colleagues and Santiago Tello-Mijares used convolutional neural networks (CNNs) to classify breast tissue into normal and abnormal, and the screening accuracy reached 98.95%18,20. Nonetheless, the large size and high cost of IRT equipment limit its use in BC screening.
Given the high efficiency and automation of AI systems and the recent breakthrough successes of IRT, this study proposes using a portable home-based AI-assisted IRT system to assess the risk of BC. The proposed system included large datasets, an AI algorithm, and a portable IRT camera. The algorithm was trained on two models (binary and multinomial) and was validated using internal and external datasets. To the best of our knowledge, our training dataset is the largest prospective dataset used for this purpose21,22. Thus, this system can improve pre-clinical screening and increase screening rates.
Material and methods
Ethical approval
This prospective study was approved by the research ethics committee of Peking Union Medical College and Hospital (PUMCH) (Reference No. ZS-2446). All procedures involving human participants were approved by the institutional and national research committee and conformed to the ethical guidelines of the Declaration of Helsinki. All participants gave written informed consent. The results were reported according to TRIPOD and STROCSS criteria23. Supplemental Digital Content 1, http://links.lww.com/JS9/A898.
Portable AI-based IRT for BC screening
The system included hardware (a wearable device and an ultra-sensitive infrared camera [InfiRay, Supplementary Table 1, Supplemental Digital Content 2, http://links.lww.com/JS9/A899]), an AI algorithm, and a big data platform architecture. First, users attached the infrared camera to the mobile phone. Then, thermographic images were obtained using a standard protocol and were uploaded to an app. After that, images were automatically processed by the algorithm and scored according to the risk of BC as low (0), intermediate/high (1).
This system obtained images at room temperature with the patient at rest, as described previously24. Heat sources were eliminated from the room to minimize interferences. In addition, air currents from air-conditioning systems were directed away from the patient to avoid measurement errors. Thermograms were obtained in hospitals and community health centres. The patients recruited from outpatient and inpatient departments were evaluated in the examination room prepared by the research group. The general population was evaluated in examination rooms of community health centres. All examination rooms were prepared in accordance with the requirements of this research method and had closed doors and windows, no heating, and suitable temperature (18–25°C) and humidity (45–65%). Three repeated images were uploaded to improve image clarity. The patients with large breast volumes were asked to wear a chest brace to improve screening accuracy. The captured images were digitalized and stored on a computer.
Breast image analysis by human readers was based on heat dissipation in the vascular network of tumours25. Thus, the risk of BC was classified into three groups based on temperature gradients (TGs): TG-1 and TG-2 (low risk, score of 0), TG3 (intermediate risk, score of 1), and TG-4 and TG-5 (high risk, score of 2) (Supplementary Table 2, Supplemental Digital Content 2, http://links.lww.com/JS9/A899).
Datasets
The datasets were obtained from a prospective clinical trial (PUMCH-ESSB, NCT: 04761211). The effectiveness and safety of AI-IRT were evaluated from 1 August 2020, to 1 July 2021. This prospective study used real-world data and followed clinical practice and NCCN guidelines26. With the help of recruitment notices issued by multiple centres nationwide, the participants came from two sources: (1) patients seeking medical treatment in hospitals, including outpatients and inpatients, and (2) community populations recruited in community health service centres. The general population was recruited in community health service centres (Supplementary Fig. 1, Supplemental Digital Content 3, http://links.lww.com/JS9/A900). Dataset A included 2100 patients recruited from 19 medical centres in nine regions of China (Supplementary Table 3, Supplemental Digital Content 2, http://links.lww.com/JS9/A899). The patients were randomly assigned to a training set (70%, for model training), a validation set (15%, for hyperparameter tuning), or an internal test set (15%, for model evaluation). Each patient was included in only one of these datasets. Dataset B included 102 patients recruited from Langfang People’s Hospital and was used for reader study. In reader study, the diagnostic accuracy (independent external validation) was compared between our model and six clinicians with expertise in IRT image analysis. The readers were blinded to dataset enrichment levels and clinical and AI system information.
All the patients underwent routine screening and treatment for breast disease. Outpatients underwent ultrasound and mammography within 3 months before recruitment, while inpatients underwent ultrasound, mammography, or MRI examinations within 3 months before recruitment. The general population underwent ultrasound examination. Imaging data (ultrasound, mammography, MRI, and IRT) and clinicopathological characteristics were collected at screening and follow-up. The clinicians classified lesions in mammography, ultrasound, and MRI images according to the Breast Imaging Reporting and Data System (BI-RADS). Mammography and ultrasonography images were reviewed in consensus by two researchers, and disagreements were resolved by a third researcher.
The inclusion criteria were patients who underwent ultrasound or mammography examinations within the past 3 months and those aged 18–80. The exclusion criteria were pregnant or lactating women and patients with nipple discharge, latex-associated allergies, skin diseases, and inflammatory breast diseases, including mastitis and idiopathic granulomatous mastitis. In addition, given that inflammatory reactions caused by biopsy and surgery may influence the results, patients who underwent breast surgery or fine-needle aspiration biopsy within 6 months before recruitment were also excluded from the analysis. Examinations with invalid patient identifiers, duplicate images, nonstandard images, images with missing metadata, and images of patients lost to follow-up were excluded.
Labels
Each evaluated breast was assigned a score based on the risk of BC, as follows: 0 (low risk, BI-RADS 1), 1 (intermediate risk, BI-RADS 2 and 3 or benign in pathology), and 2 (high risk, BI-RADS 4, 5 and 6 or malignant in pathology). In addition, each image was scored according to the number of malignant lesions, as follows: 0 (R0L0), 1 (R0L1, R1L0, or R1L1), and 2 (R0L2, R2L0, R1L2, R2L1, or R2L2). Images with scores 1 and 2 were grouped in the binary model. All cancer-positive results were accompanied by at least one pathology report, whereas cases scored as 0 or 1 had at least one follow-up examination 1 month after diagnosis.
Histological classification
AI-IRT was performed preoperatively in all patients who underwent surgery or biopsy. IRT images in the metadata were classified as benign or malignant following NHSBSP guidelines. In addition, pathology reports were reviewed by board-certified pathologists and categorized according to histological findings.
AI system
The risk of BC was scored as follows: 0 (low), 1 (intermediate), and 2 (high). The AI system consisted of three stages: image preprocessing, feature extraction, and lesion classification. The deep learning model was trained to produce three continuous scores , where i ∈ {0, 1, 2}, , and 0<P i <1. is the probability that a patient belongs to type i. Depending on the clinical application, network parameters were optimized to enhance the performance of the models. In binary classification, a score of 0 was considered negative, and scores 1 and 2 were considered positive. The score describing positivity was and was thresholded to make binary decisions. The classification is shown in Fig. 1A-B.
Figure 1.

Overview of the artificial intelligence-based infrared thermography system for detecting breast cancer. (A) Each breast was assigned a score based on ultrasound, mammography, and pathology images. (B) Images were preprocessed to extract data on breast laterality and then processed by an artificial intelligence algorithm and scored as 0 (low), 1 (intermediate), and 2 (high) according to the risk of breast cancer. (C) The system was evaluated using an internal test set (area under the curve: 0.9487, 95% CI: 0.9231–0.9744; accuracy: 0.8698, 95% CI: 0.8276–0.905, n=315) and two models (binary and multinomial). 3D, 3 dimensional; PRC, precision-recall curve; ROC, receiver operating characteristic curve.
Image processing
RGB images were captured, cropped according to the contour of the breasts, and resized to 240 × 480 × 3. The images were split into two halves (left and right breast, designated as “R” and “L”). Right breast images were flipped horizontally. The following augmentations (P=0.5) were applied during the training phase: random rotation between −10° and +10°, random rescaling between 0.9 and 1.1, and random translation up to 3% of image size. The two halves of each image were combined into a six-channel square image (240 × 240 × 6). All infrared images were captured before the patient visit, and researchers responsible for image processing were blinded to patient information to reduce the selection bias caused by anthropic factors.
Training
MobileNetV3-Small (pre-trained on ImageNet) was used for feature extraction26. The choice of MobileNetV3-Small was based on the need for flexibility and adaptability (Supplementary Fig. 2, Supplemental Digital Content 3, http://links.lww.com/JS9/A900). MobileNetV3-Small, a variant of the MobileNetV3 architecture, is an efficient and compact deep learning model designed for mobile and edge devices. Moreover, MobileNetV3-Small is designed as a smaller counterpart to MobileNetV3-Large and is more suitable for resource-constrained environments focused on smaller models and lower computational costs rather than maximal accuracy. The architecture is characterized by the following main components:
Initial convolution layer for initial preprocessing of input data.
Bottleneck layers—the core of the MobileNetV3-Small architecture—composed of depthwise separable convolutions, which are more efficient than standard convolutions. Further, these layers use squeeze-and-excitation (SE) modules for recalibrating feature maps.
Final convolution layers for producing the final output of the model.
The number of trainable parameters was ~1.5 million. The loss of a single prediction was defined as , where is the input, is the target, is the weight, and is the predicted score for each type . The weights were set to 1, 2, and 1. Training loss was minimized using mini-batch stochastic gradient descent (batch size=8) and AdamW optimizer. The initial learning rate was 0.0001 and decreased by a factor of 0.9 for every three epochs. The neural network was trained for 30 epochs.
Model weight selection
The model weights that achieved maximum performance on the validation dataset were saved for test set inference. Performance was quantified using Youden’s J statistic and accuracy for the binary and multinomial classification, respectively. In the binary classification, the operating point was chosen to maximize Youden’s J statistic on the validation set. The operating point was derived only from the validation dataset to avoid analytical bias. We trained the model 1000 times with different random seeds and reported the results that achieved the best performance.
Software
Neural network models were built using Python version 3.7 and the packages NumPy version 1.19.5, PIL version 8.1.0 (for image processing), PyTorch version 1.8.1, and torchvision version 0.9.1 (for deep learning). Metric evaluation and statistical analysis were performed using Sklearn version 0.24.2. The sample size was calculated using PASS version 11.0. Statistical analyses and figure creation were performed using R software version 3.5.3 and SPSS software version 25.0 (IBM Corp.).
Statistical analysis
We evaluated the performance of the AI system and human readers using the following metrics in the binary model: area under the receiver operating characteristic curve (AUROC), area under the precision-recall curve, sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV). Confusion matrices were used to compare the diagnostic performance between the multinomial model and readers. In the reader study, the accuracy, error rate, false negative rate, false positive rate, sensitivity, and specificity of the AI system and readers were compared. Risk scores were calculated for each patient. Categorical variables were expressed as percentages, and differences in these variables were analyzed using the χ2 test or Fisher’s exact test. Continuous variables were analyzed using Student’s t‐test. All tests were two-sided, and P values of less than 0.05 were considered statistically significant. The sample size was calculated based on the hypothesis that AI-IRT is more sensitive than traditional IRT. Assuming a sensitivity of 86% and specificity of 75%, a sample of 2167 subjects was necessary to reach a statistical significance of P less than 0.05 (two-sided) with 80% power.
Results
Screening system
The system was composed of an infrared camera, an AI algorithm, and large datasets (Fig. 2). Users attached the infrared camera to their mobile phones, and thermal images were acquired in standing posture using standard protocols. The images can be automatically read by artificial intelligence by uploading to the appropriative application. Results shows in low-risk, intermediate/high-risk. The patient screening pathway of being flagged as low and intermediate/high risk by AI-IRT is recommended in Supplementary Fig. 3, Supplemental Digital Content 3, http://links.lww.com/JS9/A900.
Figure 2.

Artificial intelligence-based infrared thermography system. AI, artificial intelligence; AI-IRT, artificial intelligence infrared thermography system.
Datasets
The datasets were obtained from a prospective clinical trial (PUMCH-ESSB, NCT: 04761211), and the effectiveness and safety of the system were evaluated in 20 health centres from ten regions of China (Fig. 3). A total of 2202 patients were included in the analysis (2100 in dataset A, and 102 in dataset B). In dataset A, patients were randomized into a training set (n=1470), a validation set (n=315), and an internal test set (n=315). Dataset B was used to assess diagnostic accuracy (independent external validation), as well as the reader study.
Figure 3.

A prospective clinical trial of the artificial intelligence infrared thermography system (AI-IRT). We built two datasets representative of the Chinese population that underwent BC screening in 20 health centres from 10 geographical regions of China. Two artificial intelligence models were trained to identify BC risk using the training and validation sets in dataset A. The models were compared with actual results using the test set from dataset A for 1000 iterations. The model with the best accuracy was used to evaluate data reproducibility across populations in both datasets. The diagnostic performance between AI-IRT and clinicians (surgeons and radiologists) was evaluated using dataset B.
The median patient age was 56 (interquartile range, 41–69) years, and 82% of the participants were female. In the total cohort, 1120 (51%), 567 (26%), and 515 (23%) patients were scored as 0, 1, and 2, respectively. In dataset A, 1089 (52%), 541 (26%), and 470 (22%) patients were scored as 0, 1, and 2, respectively. The population was screened using ultrasound (100%), mammography (51.1%), and MRI (26.2%). All patients were followed up for 6 months. The clinical characteristics of our cohort are summarized in Table 1. In total, 577 (26%) patients underwent surgery, and 339 (59%) of these cases were malignant. The median tumour size was 1.7 (0.4–13.5) cm, and the most common mammographic density (MD) was BI-RADS C(59.1%). The baseline clinicopathological characteristics of the operated patients are summarized in Table 2.
Table 1.
Characteristics of the study population.
| Dataset A | ||||
|---|---|---|---|---|
| Total | Training and validation set | Testing set | Dataset B | |
| Patients, N | 2202 | 1785 | 315 | 102 |
| Male | 405 (18) | 341 (19) | 55 (17) | 9 (9) |
| Female | 1797 (82) | 1444 (81) | 260 (83) | 93 (91) |
| Age (year), N | ||||
| <40 | 507 (23) | 408 (23) | 81 (26) | 18 (18) |
| 40–69 | 1175 (53) | 933 (52) | 174 (55) | 68 (67) |
| ≥70 | 520 (24) | 444 (25) | 60 (19) | 16 (16) |
| Score, N | ||||
| 0 | 1120 (51) | 926 (52) | 163 (52) | 31 (30) |
| 1 | 567 (26) | 460 (26) | 81 (26) | 26 (26) |
| 2 | 515 (23) | 399 (22) | 71 (22) | 45 (44) |
| No surgery, N | 1625 (74) | 1336 (75) | 239 (76) | 50 (49) |
| Surgerya, N | 577 (26) | 449 (25) | 76 (24) | 52 (51) |
| Benign | 238 (41) | 194 (43) | 27 (36) | 17 (33) |
| Malignant | 339 (59) | 255 (57) | 49 (64) | 35 (67) |
Data are presented as n (%) unless otherwise specified.
Including patients who received surgery or biopsy.
Table 2.
Baseline characteristics of operated patients.
| Total n=577 | Dataset A n=525 | Dataset B n=52 | P value | |
|---|---|---|---|---|
| Sex | 0.237 | |||
| Male | 54 (9.4) | 52 (9.9) | 2 (3.8) | |
| Female | 523 (90.6) | 473 (90.1) | 50 (96.2) | |
| Age (year) | 0.071 | |||
| <40 | 153 (26.5) | 139 (26.5) | 14 (26.9) | |
| 40–69 | 358 (62.0) | 321 (61.1) | 37(71.2) | |
| ≥70 | 66 (11.4) | 65 (12.4) | 1 (1.9) | |
| Tumour size (cm)a | 2.06±1.41 | 2.06±1.43 | 2.10±1.21 | 0.863b |
| BI-RADS | 0.564c | |||
| 1 | 9 (1.6) | 8 (1.5) | 1 (1.9) | |
| 2 | 104 (18.0) | 92 (17.5) | 12 (23.1) | |
| 3 | 341 (59.1) | 315 (60.0) | 26 (50.0) | |
| 4 | 86 (14.9) | 77 (14.7) | 9 (17.3) | |
| Unknown | 37 (6.4) | 33 (6.3) | 4 (7.7) | |
| Pathological results | 0.434 | |||
| Benign | 173 (30.0) | 157 (29.9) | 16 (30.8) | |
| Premalignant | 64 (11.1) | 61 (11.6) | 3 (5.8) | |
| Malignant | 340 (58.9) | 307 (58.5) | 33 (63.5) | |
| T stage | 0.894c | |||
| T0 (DCIS) | 28 (8.2) | 26 (8.5) | 2 (6.1) | |
| T1 | 213 (62.6) | 191 (62.2) | 22 (66.7) | |
| T2 | 88 (25.9) | 79 (25.7) | 9 (27.3) | |
| T3 | 11 (3.2) | 11 (3.6) | 0 | |
| N stage | 0.972c | |||
| N0 | 236 (69.4) | 211 (68.7) | 25 (75.8) | |
| N1 | 52 (15.3) | 48 (15.6) | 4 (12.1) | |
| N2 | 27 (7.9) | 25 (8.1) | 2 (6.1) | |
| N3 | 25 (7.4) | 23 (7.5) | 2 (6.1) | |
| ER | 0.305 | |||
| Positive | 253 (74.4) | 226 (73.6) | 27 (81.8) | |
| Negative | 87 (25.6) | 81 (26.4) | 6 (18.2) | |
| PR | 0.263 | |||
| Positive | 228 (67.1) | 203 (66.1) | 25 (75.8) | |
| Negative | 112 (32.9) | 104 (33.9) | 8 (24.2) | |
| HER-2 | 0.135 | |||
| Positive | 48 (14.1) | 40 (13.0) | 8 (24.2) | |
| Negative | 292 (85.9) | 267 (87.0) | 25 (75.8) | |
| Ki67 (%)a | 35.80±24.86 | 35.85±24.45 | 35.30±28.83 | 0.905 |
Data are presented as n (%). Data were analyzed using the χ2 test unless otherwise specified. P values of less than 0.05 were considered statistically significant.
BI-RADS, breast imaging reporting and data system; DCIS, ductal carcinoma in situ; ER, oestrogen receptor; PR, progesterone receptor; HER-2, human epidermal growth factor receptor 2.
Data are means ± SD.
Student’s t‐test
Fisher’s exact test.
Performance of AI-IRT
AI systems based on a binary model and a multinomial model were developed. In dataset A, the binary model achieved an AUROC of 0.9487 (95% CI: 0.9231–0.9744) in identifying low-risk and intermediate/high-risk patients. In addition, the accuracy, sensitivity, specificity, PPV, and NPV of this model were 0.8698 (95% CI: 0.8276–0.905), 0.9325, 0.8026, 0.8352, and 0.9173, respectively. The multinomial model achieved an accuracy of 0.8254 (95% CI: 0.7789–0.8657) for classifying images based on risk (low, intermediate, and high). The validation of the two models is shown in Figure 1C. To evaluate the reproducibility of the results across populations and screening settings, we used dataset A for training, internal validation, and testing and dataset B for external validation and diagnostic accuracy assessment. In dataset B, the AUROC of the binary model was 0.9120 (95% CI: 0.8460–0.9790), and the accuracy of the multinomial model was 0.7353 (95% CI: 0.6387–0.8178) (Fig. 1C).
Comparison with a reader study
We compared the performance of the AI system and human readers (three board-certified radiologists and three surgeons with 12.5 (6–28) years of clinical experience in BC screening using IRT (Supplementary Table 4, Supplemental Digital Content 2, http://links.lww.com/JS9/A899). The readers were given 2100 images, the results of dataset A, and the diagnostic standards established by thermologists18. Then, the readers were given dataset B.
The percentage of patients with normal, benign, and malignant tissue in dataset B was 30%, 26%, and 44%, respectively (Table 1). The AI algorithm and readers were blinded to clinical information. AUROC, area under the precision-recall curve, and accuracy were used to compare the diagnostic ability of the binary model and clinicians. The diagnostic performance of the multinomial model and clinicians was compared using confusion matrices (Fig. 4). The average accuracy of readers using the binary and multinomial classification was 0.8088 and 0.5817, respectively. The accuracy of AI-IRT using these two models was 0.8627 (95% CI: 0.7804–0.9229) and 0.7353 (95% CI: 0.6387–0.8178), respectively (Fig. 4). Data on diagnostic performance are shown in Table 3. The error rate, false negative rate, and false positive rate of the AI-IRT were 13.73%, 15.49%, and 16.13%, respectively (Supplementary Table 5, Supplemental Digital Content 2 http://links.lww.com/JS9/A899).
Figure 4.
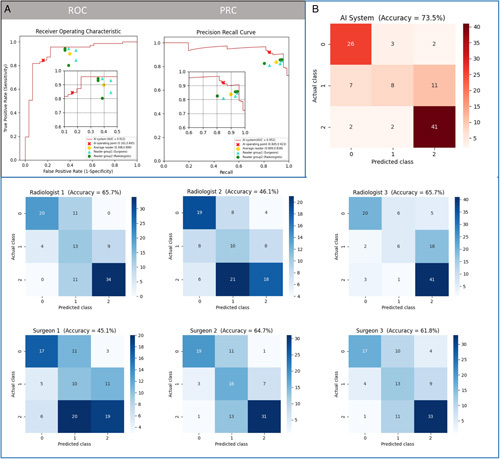
Performance of artificial intelligence-based infrared thermography (AI-IRT) and clinicians in predicting the risk of breast cancer. Diagnostic accuracy of AI-IRT using an external dataset (area under the curve for binary model: 0.9120, 95% CI: 0.8460–0.9790; accuracy for multinomial model: 0.7353, 95% CI: 0.6387–0.8178, n= 102). The accuracy of AI-IRT in detecting BC in 102 patients was higher than that of clinicians. (A) The performance of the binary model and clinicians (102 images) was evaluated by the area under the receiver operating characteristic curve (AUROC) and the area under the precision-recall curve (AUPRC). Each data point represents the analysis of one clinician. (B) Diagnostic performance of a multinomial AI system and clinicians using confusion matrices.
Table 3.
Performance of the AI model and clinicians in predicting the risk of breast cancer
| Sensitivity* | Specificity* | Accuracy (binary model) | Accuracy (multinomial model) | PPV* | NPV* | |
|---|---|---|---|---|---|---|
| AI model | 0.8451 | 0.8387 | 0.8627 | 0.7353 | 0.9231 | 0.7027 |
| Surgeons | ||||||
| Reader 1 | 0.8451 | 0.5484 | 0.7549 | 0.4510 | 0.8108 | 0.6071 |
| Reader 2 | 0.9437 | 0.6129 | 0.8431 | 0.6471 | 0.8481 | 0.8261 |
| Reader 3 | 0.9296 | 0.5484 | 0.8137 | 0.6176 | 0.8250 | 0.7727 |
| Average | 0.9061 | 0.5699 | 0.8039 | 0.5719 | 0.8280 | 0.7353 |
| Radiologists | ||||||
| Reader 4 | 0.8028 | 0.6129 | 0.7451 | 0.4608 | 0.8261 | 0.5758 |
| Reader 5 | 0.9437 | 0.6452 | 0.8529 | 0.6569 | 0.8590 | 0.8333 |
| Reader 6 | 0.9296 | 0.6452 | 0.8431 | 0.6569 | 0.8571 | 0.8000 |
| Average | 0.8920 | 0.6344 | 0.8137 | 0.5915 | 0.8474 | 0.7364 |
Abbreviations: AI, artificial intelligence; PPV, positive predictive value; NPV, negative predictive value.
for binary model.
Subgroup analysis
Since the binary model showed better applicability, patients were stratified by tumour type (benign or malignant), age, and sex in binary model (Table 4). The diagnostic accuracy of AI-IRT was high across groups using the binary model. In the test cohort, the accuracy of AI-IRT was 100% in the male subgroup and 84.2% in the female subgroup, while the accuracy was highest in patients older than 70 years, with AUROC of 0.910 (95% CI: 0.822–0.998). In the external validation cohort, the accuracy of AI-IRT was 100% in the male subgroup and 84.9% in the female subgroup. Similarly, the accuracy was highest in patients aged older than or equal to 70 years, with AUROC of 0.964 (95% CI: 0.868–1.000).
Table 4.
Subgroup analysis of the binary model in a test cohort and an external validation cohort.
| AUROC (95% CI) | Accuracy (%) | Specificity (%) | Sensitivity (%) | PPV (%) | NPV (%) | |
|---|---|---|---|---|---|---|
| Internal test cohort (n=315) | ||||||
| Sex | ||||||
| Male | — | 100 | 100 | — | — | 100 |
| Female | 0.929 (0.899–0.958) | 84.2 | 89.8 | 80.3 | 91.7 | 76.4 |
| Age (year) | ||||||
| <40 | 0.931 (0.879–0.982) | 84.0 | 83.0 | 85.3 | 88.6 | 78.4 |
| 40–69 | 0.960 (0.936–0.984) | 87.4 | 94.0 | 81.3 | 93.7 | 82.1 |
| ≥70 | 0.910 (0.822–0.998) | 90.0 | 97.8 | 64.3 | 90.0 | 90.0 |
| Diagnosis | ||||||
| Clinical | 0.899 (0.860–0.938) | 82.8 | 93.3 | 60.5 | 80.7 | 83.5 |
| P-benign | — | 100 | — | 100 | 100 | — |
| P-malignant | — | 100 | — | 100 | 100 | — |
| External validation cohort (n=102) | ||||||
| Sex | ||||||
| Male | — | 100 | 100 | — | — | 100 |
| Female | 0.880 (0.792–0.968) | 84.9 | 77.3 | 87.3 | 92.5 | 65.4 |
| Age (year) | ||||||
| <40 | 0.941 (0.829–1.000) | 88.9 | 94.1 | — | — | 94.1 |
| 40–69 | 0.854 (0.737–0.971) | 83.8 | 75.0 | 86.5 | 91.8 | 63.2 |
| ≥70 | 0.964 (0.868–1.000) | 93.8 | 100 | 50.0 | 100 | 93.3 |
| Diagnosis | ||||||
| Clinical | 0.801 (0.672–0.930) | 74.0 | 86.7 | 55.0 | 73.3 | 74.3 |
| P-benign | — | 100 | — | 100 | 100 | — |
| P-malignant | — | 97.1 | — | 100 | 97.1 | — |
AUROC, area under the receiver operating characteristic curve; NPV, negative predictive value; P-benign, benign lesion in pathology; P-malignant, malignant lesion in pathology; PPV, positive predictive value.
Potential clinical application
In view of the above results, the binary model was used in the large-scale pre-clinical screening of BC. The detection threshold was defined based on risk. Low-risk patients in a high-risk population were identified accurately using a low detection threshold, whereas high-risk patients in a low-risk population were identified using a high threshold. In dataset A (testing set), NPV was 100% at a specificity of 34.4%, and PPV was 100% at a sensitivity of 32.2%. In dataset B, NPV was 92.3% at a specificity of 38.7%, and PPV was 96.7% at a sensitivity of 40.8%. The diagnostic sensitivity of AI-IRT in high-risk patients was 100%.
Discussion
This study is the first to propose using a portable AI-IRT system for the pre-clinical screening of BC. Two prospective datasets were created, and two models were trained and validated. The binary model was chosen for screening. The accuracy of AI-IRT was high across populations with different demographic characteristics. Moreover, the accuracy of the AI-IRT system was higher than that of clinicians, indicating the potential to use this system independently.
The diagnostic efficacy of this technology relies on the performance of AI algorithms. Most studies on AI-based detection of BC used a validation dataset when training AI models. Nonetheless, few studies validated these models using independent external datasets13. The diagnostic performance of AI-IRT was higher than that of radiologists and surgeons. The sensitivity of AI-IRT to detect intermediate-risk and high-risk patients was similar to that of readers, whereas the specificity, PPV, and accuracy of AI-IRT were higher [83.87%, 92.31% and 0.8627 (95% CI: 0.7804–0.9229), respectively]. The binary model accurately and independently classified images into two groups (low and intermediate-high risk) using a diagnostic threshold. Moreover, this study is the first to compare the diagnostic performance of AI-IRT and clinicians. The results showed that our model was significantly more sensitive than traditional IRT and less reliant on clinicians’ interpretation.
Previous studies demonstrated the high accuracy of IRT assisted by AI for BC detection. Nicandro et al. 27 showed that the accuracy of thermography using Bayesian network classifiers was 71.88%. Tello-Mijares and colleagues found that the accuracy of CNN, random forest, multilayer perceptron, and Bayes network was 100%, 85.71%, 100%, and 78.57%, respectively18. Ekici observed that a CNN with Bayes optimization was more accurate for BC detection than a non-optimized CNN (98.95% vs. 97.91%)20. Nonetheless, few studies assessed the utility of AI-IRT for BC screening in China. Our group is the first to research the applicability of IRT for BC screening in China. In recent years, we developed this portable, automated, AI-assisted diagnostic tool and conducted clinical trials as IRT and artificial intelligence technologies advance. Our two models had good accuracy and AUROC using internal and external datasets, consistent with the literature. However, previous models used a binary classification (presence or absence of cancer) of patient data, whereas ours used pre-clinical screening labels (normal or not) and multinomial classification with data come from all the population, which is more practical and precise13,18,20,22,27.
Former studies did not assess whether the image datasets used to train and test the models were representative, whether AI models could recognize normal images and whether patients with different risk should use the same threshold. Our study addressed these problems using pre-clinical screening labels (normal or not) and an AI algorithm with threshold setting based on risk. Our models were practical and based on BI-RADS. The overall accuracy of the multinomial model was lower than that of the binary model using an internal dataset (0.8254 vs. 0.8698) and an external dataset (0.7353 vs. 0.8627). The diagnostic accuracy of the multinomial model was moderate, and the sensitivity and specificity for normal, benign, and malignant tissue were 0.9202, 0.6296, 0.8310 and 0.8158, 0.9060, 0.9795, respectively, using an internal dataset, and 0.8387, 0.30769, 0.9111 and 0.8732, 0.93421, 0.7719, respectively, using an external dataset. However, this system is useful for automated screening. The AUROC of the binary model using the internal and external datasets was 94% and 91%, respectively. Most studies only assessed the performance of stand-alone AI models and a computer-aided diagnostic system for BC detection28–30. Our study focused on detecting suspected cases, not confirming the diagnosis of BC, thus improving pre-clinical screening. Although we intended to identify healthy individuals to reduce the waste of medical resources and enable suspected and confirmed patients to receive timely treatment, we did not allow missed diagnoses. Thus, missed diagnoses were reduced by increasing sensitivity at the cost of decreasing specificity.
To the best of our knowledge, no large randomized prospective studies have assessed the utility of AI systems for BC screening. Retrospective studies used public and institutional datasets13,31. The percentage of patients with BC in these datasets was 26.5% (0.80–55.0%)28,32,33. However, the ratio of patients with normal, benign, and malignant tissue in our cohort was 2:1:1. Men were included in our cohort to increase representativeness, given that one out of every 100 BC patients is male34. In all the datasets, the male-to-female ratio was 9:41, and the percentage of patients with normal, benign, and malignant tissue was 51%, 26%, and 23%, respectively. These results demonstrate the usefulness of our model for real-life screening.
Several studies explored the potential applicability of AI-based screening of BC. Previously, the most commonly used modalities for BC screening are ultrasound, digital mammography, and MRI. AI-based digital mammography is well established, and some of the algorithms have achieved an AUC of approximately 0.930 However, the radiation risk, pain, and inapplicability of dense breasts limit the promotion of this technology for screening. AI-based ultrasound imaging is radiation-free and can differentiate between benign and malignant breast lesions based on B-mode features according to the BI-RADS. Shen and colleagues evaluated eight BI-RADS computerized sonographic features to differentiate breast lesions. The model achieved an AUC of 0.976 with an accuracy of 91.7%35. Nonetheless, most current evidences for AI in breast screening were small, retrospective studies and that most of AI algorithms were developed for assisting radiologists in decision-making, rather than screening36,37. In addition, MRI is used in complementary screening because of inherent limitations, including low accuracy, high cost, complex testing, time-consumption and potential safety risks. In contrast, AI-IRT is a noninvasive, radiation-free, and convenient tool with unique advantages for screening Asian women, who tend to have dense breasts. AI-IRT can be a screening method independently without clinicians.
Moreover, we further evaluated the health economics of IRT, ultrasound, and mammography. The cost per BC detected was calculated by dividing the total cost of a screening program by the number of BCs detected38,39. We found that one detected BC would require screening 1397 women by mammography at the cost of 419600 RMB (US$ 61077), 663 women by ultrasound at the cost of 152990 RMB (US$ 22269), and 1120 women by infrared thermography at the cost of 146100 RMB (US$ 21266). Thus, AI-IRT is more cost-effective than digital mammography and ultrasound imaging systems based on AI.
This study has limitations. First, we evaluated diagnostic performance using thermographic images only. In clinical practice, IRT complements diagnosis. Thus, the lack of image quality control and cancer screening guidelines for IRT limited the power of the study. For instance, considering the restrictions of the future transformation population of the system on the product price, we chose the IRT system with the best cost-effectiveness without compromising image quality. Second, clinicians have limited experience in analyzing IRT images and use the recommendations of experienced thermologists18, increasing the risk of not accurately delineating tumour. Third, diagnostic efficacy was analyzed using a limited number of images, precluding the use of multinomial models. Thus, larger studies using AI algorithms and clinicopathological parameters are needed to improve the efficiency of AI-IRT. Fourth, the exclusion criteria limit the pre-clinical screening for those concerned that the study may adversely affect on patients. Since IRT is useful to pregnant women and patients with latex allergies and other skin disorders, we intend to include these patient groups in a future study. Fifth, for centres with other equipment, including mammography and ultrasound, obtaining IRT equipment may require additional expenses. In addition, the proposed system requires mobile phones and thus may have limited use in under-resourced communities. With the popularity of mobile devices such as smartphones, however, this limitation is gradually improving.
Notwithstanding these limitations, this prospective study demonstrated the high diagnostic accuracy of AI-IRT, improving pre-clinical screening. AI-IRT combined with the binary model accurately and automatically classified IRT images into two groups (low and intermediate/high risk) using a specific detection threshold. Moreover, the diagnostic accuracy of this model was high across groups after stratification by age and sex and could potentially complement other screening strategies.
The AI-IRT system can be deployed outside the clinical setting and is a promising screening device that precludes the need for clinical examinations, thus reducing medical costs. The whole family can use AI-IRT, and family members can screen each other using established protocols. In addition, elderly patients can undergo AI-IRT screening with the assistance of general practitioners from community health service centres. Although IRT complements conventional diagnostic methods at its current stage of development, the potential impact of the proposed system is large, given that IRT is noninvasive, radiation-free, and convenient, and more than 3 billion women undergo BC screening each year worldwide. Therefore, we intend to conduct a larger prospective validation study and submit it to China’s National Medical Products Administration.
Ethics approval
This prospective study was approved by the research ethics committee of Peking Union Medical College and Hospital (PUMCH). All procedures involving human participants were approved by the institutional and national research committee and conformed to the ethical guidelines of the Declaration of Helsinki. The results were reported according to TRIPOD guidelines.
Sources of funding
This work was supported by the CAMS Innovation Fund for Medical Sciences (CIFMS) (No. 2021-I2M-C&T-B-018), National High-Level Hospital Clinical Research Funding (2022-PUMCH-A-018, 2022-PUMCH-C-043), Fundamental Research Funds for the Central Universities (No. 3332021012), Tsinghua University-Peking Union Medical College Hospital Initiative Scientific Research Program (No. 2019Z), and Beijing Hope Run Special Fund of the Cancer Foundation of China (LC2021B12).
Author contribution
X.W.: writing—original draft; writing—review and editing, funding acquisition, project administration. K.C.: software. G.Z.: investigation and methodology. Z.Z.: formal analysis. T.Z., Y.Z., F.M., Y.L., S.S., X.Z., X.W., Y.Z., X.Q., H.G., X.W., Y.X., Q.Y., C.Y., J.L., D.L., W.L., M.L., X.M., J.T.: resources. Q.S.: supervision. J.Z.: software. L.H.: data curation and supervision.
Conflicts of interest disclosure
The authors declare that they have no conflicts of interest.
Research registration unique identifying number (UIN)
Name of the registry: Effect and safty of smart bra(PUMCH).
Unique Identifying number or registration ID: NCT04761211.
Hyperlink to your specific registration (must be publicly accessible and will be checked): https://clinicaltrials.gov/show/NCT04761211.
Guarantor
Qiang Sun, Xuefei Wang.
Data availability
The datasets generated and analyzed during the present study are available from the corresponding author on reasonable request.
Provenance and peer review
Not commissioned, externally peer-reviewed.
consent
All participants gave written informed consent.
Supplementary Material
Footnotes
X.W., K.C. and G.Z. are contributed equally.
Sponsorships or competing interests that may be relevant to content are disclosed at the end of this article.
Supplemental Digital Content is available for this article. Direct URL citations are provided in the HTML and PDF versions of this article on the journal’s website, www.lww.com/international-journal-of-surgery.
Published online 2 September 2023
Contributor Information
Xuefei Wang, Email: 1210548954@qq.com.
Kuanyu Chou, Email: Kuanyuchou19931026@gmail.com.
Guochao Zhang, Email: 18801038718@163.com.
Zhichao Zuo, Email: zuozhichao1991@sina.com.
Ting Zhang, Email: 657833193@qq.com.
Yidong Zhou, Email: zhouyd@pumch.cn.
Feng Mao, Email: mmc8941@me.com.
Yan Lin, Email: birds90@163.com.
Songjie Shen, Email: pumcssj@163.com.
Xiaohui Zhang, Email: zhangxiaohui@pumch.cn.
Xuejing Wang, Email: steffaustin@163.com.
Ying Zhong, Email: zhongying@pumch.cn.
Xue Qin, Email: 45189997@qq.com.
Hailin Guo, Email: Hai0826@126.com.
Xiaojie Wang, Email: jie926000@163.com.
Yao Xiao, Email: 632103740@qq.com.
Qianchuan Yi, Email: 285837664@qq.com.
Cunli Yan, Email: 617322368@qq.com.
Jian Liu, Email: 372783011@qq.com.
Dongdong Li, Email: dongdongpaopao@sina.com.
Wei Liu, Email: 147649106@qq.com.
Mengwen Liu, Email: liumengwen_0815@126.com.
Xiaoying Ma, Email: 18997230851@163.com.
Jiangtao Tao, Email: 664890724@qq.com.
Qiang Sun, Email: sunqiangpumc2020@sina.com.
Jidong Zhai, Email: zhaijidong@tsinghua.edu.cn.
Likun Huang, Email: sxsrmyysqb@163.com.
References
- 1.Sung H, Ferlay J, Siegel RL, et al. Global cancer statistics 2020: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin 2021;71:209–249. [DOI] [PubMed] [Google Scholar]
- 2.Tabar L, Yen AM, Wu WY, et al. Insights from the breast cancer screening trials: how screening affects the natural history of breast cancer and Screening mammography is underused, resulting in unnecessary breast cancer deaths. Screening for Breast Cancer 1157 implications for evaluating service screening programs. Breast J. 2015;21:13–220. [DOI] [PubMed] [Google Scholar]
- 3.Gradishar WJ, Moran MS, Abraham J, et al. Breast cancer, version 3.2022, nccn clinical practice guidelines in oncology. J Natl Compr Canc Netw 2022;20:691–722. [DOI] [PubMed] [Google Scholar]
- 4.Buranello MC, Meirelles M, Walsh IAP, et al. Breast cancer screening practice and associated factors: Women's Health Survey in Uberaba MG Brazil, 2014. Cien Saude Colet 2018;23:2661–2670. [DOI] [PubMed] [Google Scholar]
- 5.Babu GR, Samari G, Cohen SP, et al. Breast cancer screening among females in Iran and recommendations for improved practice: a review. Asian Pac J Cancer Prev 2011;12:1647–1655. [PubMed] [Google Scholar]
- 6.Sreedevi A, Quereshi MA, Kurian B, et al. Screening for breast cancer in a low middle income country: predictors in a rural area of Kerala, India. Asian Pac J Cancer Prev 2014;15:1919–1924. [DOI] [PubMed] [Google Scholar]
- 7.Dibisa TM, Gelano TF, Negesa L, et al. Breast cancer screening practice and its associated factors among women in Kersa District, Eastern Ethiopia. Pan Afr Med J 2019;33:144. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Hajian Tilaki K, Auladi S. Awareness, attitude, and practice of breast cancer screening women, and the associated socio-demographic characteristics, in northern iran. Iran J Cancer Prev 2015;8:e3429. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Boulos DN, Ghali RR. Awareness of breast cancer among female students at Ain Shams University, Egypt. Glob J Health Sci 2013;6:154–161. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Simi A, Yadollahie M, Habibzadeh F. Knowledge and attitudes of breast self examination in a group of women in Shiraz, southern Iran. Postgrad Med J 2009;85:283–287. [DOI] [PubMed] [Google Scholar]
- 11.Vanni G, Pellicciaro M, Materazzo M, et al. Lockdown of breast cancer screening for covid-19: Possible scenario. In Vivo 2020;34:3047–3053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nat Med 2019;25:44–56. [DOI] [PubMed] [Google Scholar]
- 13.Houssami N, Kirkpatrick-Jones G, Noguchi N, et al. Artificial Intelligence (AI) for the early detection of breast cancer: a scoping review to assess AI's potential in breast screening practice. Expert Rev Med Devices 2019;16:351–362. [DOI] [PubMed] [Google Scholar]
- 14.Niell BL, Freer PE, Weinfurtner RJ, et al. Screening for breast cancer. Radiol Clin North Am 2017;55:1145–1162. [DOI] [PubMed] [Google Scholar]
- 15.Rassiwala M, Mathur P, Mathur R, et al. Evaluation of digital infra-red thermal imaging as an adjunctive screening method for breast carcinoma: a pilot study. Int J Surg 2014;12:1439–1443. [DOI] [PubMed] [Google Scholar]
- 16.Venkataramani K, Mestha LK, Ramachandra L, et al. Semi-automated breast cancer tumor detection with thermographic video imaging. Annu Int Conf IEEE Eng Med Biol Soc 2015;2015:2022–2025. [DOI] [PubMed] [Google Scholar]
- 17.Prasad SS, Ramachandra L, Kumar V, et al. Evaluation of efficacy of thermographic breast imaging in breast cancer: a pilot study. Breast Dis 2016;36:143–147. [DOI] [PubMed] [Google Scholar]
- 18.Ekici S, Jawzal H. Breast cancer diagnosis using thermography and convolutional neural networks. Med Hypotheses 2020;137:109542. [DOI] [PubMed] [Google Scholar]
- 19.Hakim A, Awale RN. Thermal Imaging - An Emerging Modality for Breast Cancer Detection: a Comprehensive Review. J Med Syst 2010;44:136. [DOI] [PubMed] [Google Scholar]
- 20.Tello-Mijares S, Woo F, Flores F. Breast cancer identification via thermography image segmentation with a gradient vector flow and a convolutional neural network. J Healthc Eng 2019;2019:9807619. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.McKinney SM, Sieniek M, Godbole V, et al. International evaluation of an AI system for breast cancer screening. Nature 2020;577:89–94. [DOI] [PubMed] [Google Scholar]
- 22.Shen Y, Shamout FE, Oliver JR, et al. Artificial intelligence system reduces false-positive findings in the interpretation of breast ultrasound exams. Nat Commun 2021;12:5645. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Agha R, Abdall-Razak A, Crossley E, et al. STROCSS 2019 Guideline: Strengthening the reporting of cohort studies in surgery. Int J Surg 2019;72:156–165. [DOI] [PubMed] [Google Scholar]
- 24.Pacifific chiropractic and research center, what is the procedure like, breast thermogr. Accessed 26 September 2019. https://breastthermography.com
- 25.Euhus D, Di Carlo PA, Khouri NF. Breast cancer screening. Surg Clin North Am 2015;95:991–1011. [DOI] [PubMed] [Google Scholar]
- 26.Andrew H, Mark S, Grace C. Searching for mobilenetv3. [submitted on 6 may 2019 (v1), last revised 20 nov 2019 (this version, v5). https://arxiv.org/abs/1905.02244.pdf
- 27.Nicandro CR, Efrén MM, María Yaneli AA, et al. Evaluation of the diagnostic power of thermography in breast cancer using Bayesian network classifiers. Comput Math Methods Med 2013;2013:264246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Rodriguez-Ruiz A, Lång K, Gubern-Merida A, et al. Stand-alone artificial intelligence for breast cancer detection in mammography: comparison with 101 radiologists. J Natl Cancer Inst 2019;111:916–922. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Parmeggiani D, Avenia N, Sanguinetti A, et al. Artificial intelligence against breast cancer (A.N.N.E.S-B.C.-Project). Ann Ital Chir 2012. 83:1–5. [PubMed] [Google Scholar]
- 30.Chougrad H, Zouaki H, Alheyane O. Deep convolutional neural networks for breast cancer screening. Comput Methods Programs Biomed 2018;157:19–30. [DOI] [PubMed] [Google Scholar]
- 31.Maíra AS, Jessiane MSP, Fabrício LS. Breast cancer diagnosis based on mammary thermography and extreme learning machines. Res Biomed Eng 2018;34:45–53. [Google Scholar]
- 32.Al-Masni MA, Al-Antari MA, Park JM, et al. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput Methods Programs Biomed 2018;157:85–94. [DOI] [PubMed] [Google Scholar]
- 33.Ayer T, Alagoz O, Chhatwal J, et al. Breast cancer risk estimation with artificial neural networks revisited: discrimination and calibration. Cancer 2010;116:3310–3321. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Zehr KR. Diagnosis and treatment of breast cancer in men. Radiol Technol 2019;91:51m–61m. [PubMed] [Google Scholar]
- 35.Shen WC, Chang RF, Moon WK, et al. Breast ultrasound computeraided diagnosis using BI-RADS features. Acad Radiol 2007;14:928–939. [DOI] [PubMed] [Google Scholar]
- 36.Freeman K, Geppert J, Stinton C, et al. Use of artifcial intelligence for image analysis in breast cancer screening programmes: systematic review of test accuracy. BMJ 2021;374:n1872. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Hickman SE, Woitek R, Le EPV, et al. Machine learning for workflow applications in screening mammography: systematic review and meta-analysis. Radiology 2022;302:88–104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Feig S. Comparison of costs and benefits of breast cancer screening with mammography, ultrasonography, and MRI. Obstet Gynecol Clin North Am 2011;38:179–196. [DOI] [PubMed] [Google Scholar]
- 39.Shen S, Zhou Y, Xu Y, et al. A multi-centre randomised trial comparing ultrasound vs mammography for screening breast cancer in high-risk Chinese women. Br J Cancer 2015;112:998–1004. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The datasets generated and analyzed during the present study are available from the corresponding author on reasonable request.