

Abstract
This paper proposes a decorrelation-based approach to test hypotheses and construct confidence intervals for the low dimensional component of high dimensional proportional hazards models. Motivated by the geometric projection principle, we propose new decorrelated score, Wald and partial likelihood ratio statistics. Without assuming model selection consistency, we prove the asymptotic normality of these test statistics, establish their semiparametric optimality. We also develop new procedures for constructing pointwise confidence intervals for the baseline hazard function and baseline survival function. Thorough numerical results are provided to back up our theory.
Keywords: Proportional hazards model, censored data, high dimensional inference, survival analysis, decorrelation method
1 Introduction
The proportional hazards model (Cox, 1972) is one of the most important tools for analyzing time to event data, and finds wide applications in epidemiology, medicine, economics, and sociology (Kalbfleisch and Prentice, 2011). This model is semiparametric by treating the baseline hazard function as an infinite dimensional nuisance parameter. To infer the finite dimensional parameter of interest, Cox (1972, 1975) proposes the partial likelihood approach which is invariant to the baseline hazard function. In low dimensional settings, Tsiatis (1981); Andersen and Gill (1982) have established the consistency and asymptotic normality of the maximum partial likelihood estimator.
In high dimensional settings when the number of covariates d is larger than the sample size n, the partial maximum likelihood estimation is an ill-posed problem. To solve this problem, we resort to the penalized estimators (Tibshirani, 1997; Fan and Li, 2002; Gui and Li, 2005). Under the condition d = o(n1/4), Cai et al. (2005) establish the oracle properties for the maximum penalized partial likelihood estimator using the SCAD penalty. Other types of estimation procedures and their theoretical properties are studied by Zhang and Lu (2007); Wang et al. (2009); Antoniadis et al. (2010); Zhao and Li (2012). In particular, under the ultra-high dimensional regime that d = o(exp(n/s)), Bradic et al. (2011); Huang et al. (2013); Kong and Nan (2014) establish the oracle properties and statistical error bounds of maximum penalized partial likelihood estimator, where s denotes the number of nonzero elements in the parametric component of the Cox model.
Though significant progress has been made towards developing the estimation theory. Little work exists on the inferential aspects (e.g., testing hypothesis or constructing confidence intervals) of high dimensional proportional hazard models. A notable exception is Bradic et al. (2011), who establish the limiting distribution of the oracle estimator. However, such a result hinges on model selection consistency, which is not always possible in applications. To the best of our knowledge, uncertainty assessment for low dimensional parameters of high dimensional proportional hazards model remains an open problem. This paper aims to close this gap by developing valid inferential procedures and theory for high dimensional proportional hazards models. In particular, we test hypotheses and construct confidence intervals for a scalar component of a d dimensional parameter vector1. Compared with existing work, our method does not require any types of irrepresentable condition or the minimal signal strength condition, thus is more practical in applications.
More specifically, we develop a unified inferential framework by extending the classical score, Wald and partial likelihood ratio tests to high dimensional hazards models. The key ingredient of our construction of these tests is a novel high dimensional decorrelation device of the score function. Theoretically, we establish the asymptotic distributions of these test statistics under the null. Using the same idea, we construct optimal confidence intervals for the parameters of interest. In addition, we consider the problems on inferring the baseline hazard and survival functions and separately establish their asymptotic normalities.
The rest of this paper is organized as follows. In Section 2, we provide some background on the proportional hazards model. In Section 3, we propose the methods for conducting hypothesis testing and constructing confidence intervals for low dimensional components of regression parameters. In Section 4, we provide theoretical analysis of the proposed methods. The inference on the baseline hazard function is studied in Section 5. In Section 6, we investigate the empirical performance of these methods. Section 7 contains the summary and discussions. More technical details and an extension to the multivariate failure time data are presented in the Appendix.
2 Background
We start with an introduction of notation. Let a = (a1, …, ad)T ∈ ℝd be a d dimensional vector and A = [ajk] ∈ ℝd×d be a d by d matrix. Let supp(a) = {j : aj ≠ 0}. For 0 < q < ∞, we define ℓ0, ℓq and ℓ∞ vector norms as ‖a‖0 = card(supp(a)), and ‖a‖∞ = max1≤j≤d|aj|. We matrix define the matrix ℓ∞-norm as the elementwise sup-norm that ‖A‖∞ = max1≤j,k≤d|ajk|. Let Id be the identity in ℝd×d. For a sequence of random variables and a random variable Y, we denote Xn weakly converges to Y by . We denote [n] = {1, …, n}.
2.1 Cox’s Proportional Hazards Model
We briefly review the Cox’s proportional hazards model. Let Q be the time to event; R be the censoring time, and X(t) = (X1(t), …, Xd(t))T be the d dimensional time dependent covariates at time t. We consider the non-informative censoring setting that Q and R are conditionally independent given X(t). Let W = min{Q, R} and Δ = 1{Q ≤ R} denote the observed survival time and censoring indicator. Let τ be the end of study time. We observe n independent copies of {(X(t), W, Δ) : 0 ≤ t ≤ τ}
We denote λ{t|X(t)} as the conditional hazard rate function at time t given the covariates X(t). Under the proportional hazards model, we assume that
where λ0(t) is an unknown baseline hazard rate function, and β∗ ∈ ℝd is an unknown parameter.
2.2 Penalized Estimation
Following Andersen and Gill (1982), we introduce some counting process notation. For each i, let Ni(t) := 1{Wi ≤ t, Δi = 1} be the counting process, and Yi(t) := 1 {Wi ≥ t} be the at risk process for subject i. Assume that the process Yi(t) is left continuous with its right-hand limits satisfying ℙ(Yi(t) = 1, 0 ≤ t ≤ τ) > Cτ for some positive constant Cτ. The negative log-partial likelihood is
where .
When the dimension d is fixed and smaller than the sample size n, β∗ can be estimated by the maximum partial likelihood estimator (Andersen and Gill, 1982). However, in high dimensional settings where n < d, the maximum partial likelihood estimator is not well defined. To solve this problem, Fan and Li (2002) impose the sparsity assumption and propose the penalized estimator
| (2.1) |
where is a sparsity-inducing penalty function and λ is a tuning parameter. Bradic et al. (2011) and Huang et al. (2013) establish the rates of convergence and oracle properties of the maximum penalized partial likelihood estimators using SCAD and Lasso penalties. For notational simplicity, we focus on the Lasso penalized estimator in this paper and indicate that similar properties hold for the SCAD penalty. Existing works generally impose the following assumptions.
Assumption 2.1
The difference of the covariates is uniformly bounded:
for some constant CX > 0.
Assumption 2.2
For any set where and any vector v belonging to the cone, it holds that
Note that the bounded covariate condition in Assumption 2.1, which is imposed by both Bradic et al. (2011) and Huang et al. (2013), holds in most real applications. Assumption 2.2 is known as the compatibility factor condition which is also used by Huang et al. (2013). This assumption essentially bounds the minimal eigenvalue of the Hessian matrix ∇2ℒ(β∗) from below for those directions within the cone . In particular, the validity of this assumption has been verified in Theorem 4.1 of Huang et al. (2013). Under these assumptions, Huang et al. (2013) derive the rate of convergence of the Lasso estimator under the ℓ1-norm. More specifically, they prove that under Assumptions 2.1 and 2.2, if ‖β*‖0 = s and , it holds that
| (2.2) |
which establishes the estimation consistency in the high dimensional regime.
Additional Notations
For a vector u, we denote u⊗0 = 1, u⊗1 = u and u⊗2 = uuT. Denote
| (2.3) |
The gradient of ℒ(β) is
| (2.4) |
and the Hessian matrix of ℒ(β) is
| (2.5) |
We denote the population versions of above defined quantities by
| (2.6) |
and
| (2.7) |
where H∗ is the Fisher information matrix based on the partial likelihood.
3 Testing Hyptheses and Constructing Confidence Intervals
While estimation consistency has been established in high dimensions, it remains challenging to develop inferential procedures (e.g., confidence intervals and testing) for high dimensional proportional hazards model. In this section, we propose three novel hypothesis testing procedures. The proposed tests can be viewed as high dimensional counterparts of the conventional score, Wald, and partial likelihood ratio tests.
Hereafter, for notational simplicity, we partition the vector β as β = (α, θT)T, where α = β1 ∈ ℝ is the parameter of interest; θ = (β2, …, βd)T ∈ ℝd−1 is the vector of nuisance parameters, and we denote ℒ(β) by ℒ(α, θ). Let , and be the corresponding partitions of ∇2ℒ(β). Let , and be the corresponding partitions of H∗, where H∗ is defined in (2.7). For instances, and . Throughout this paper, without loss of generality, we test the hypothesis H0: α∗ = 0 versus H1: α∗ ≠ 0. Note that the extension to tests for a multi-dimensional vector , where d0 is fixed, is straightforward.
3.1 Decorrelated Score Test
In the classical low dimensional setting, we can exploit the profile partial score function
to conduct test, where is the maximum partial likelihood estimator for θ with a fixed α. Under the null hypothesis that α∗ = 0, when d is fixed while n goes to infinity, it holds that . If is larger than the (1 − η)th quantile of a chi-squared distribution with one degree of freedom, we reject the null hypothesis. Classical asymptotic theory shows that this procedure controls type I error with significance level η.
However, in high dimensions, the profile partial score function S(α) with replaced by a penalized estimator, say the corresponding components of in (2.1), does not yield a tractable limiting distribution due to the existence of a large number of nuisance parameters. To address this problem, we construct a new type of score function for α that is asymptotically normal even in high dimensions. The key component of our procedure is a high dimensional decorrelation device, aiming to handle the impact of the high dimensional nuisance vector.
More specifically, we propose a decorrelated score test for H0: α∗ = 0. We first estimate θ∗ by using the ℓ1 penalized estimator in (2.1). Next, we calculate a linear combination of the partial score function to best approximate . The population version of the vector of coefficients in the best linear combination can be calculated as
| (3.1) |
where the last equality is by the second Bartlett identity (Tsiatis, 1981). In fact, w∗T∇θℒ(0, θ∗) can be interpreted as the projection of ∇αℒ(0, θ∗) onto the linear span of the partial score function ∇θℒ(0, θ∗). In high dimensions, one cannot directly estimate w∗ by the corresponding sample version since the problem is ill-posed. Motivated by the definition of w∗ in (3.1), we estimate it by the Dantzig selector,
| (3.2) |
where λ′ is a tuning parameter. Since w∗ is of high dimension d − 1, we impose the sparsity condition on w∗. Given and , we propose a decorrelated score function for α as
| (3.3) |
Geometrically, the decorrelated score function is approximately orthogonal to any component of the nuisance score function ∇θℒ(0, θ∗). This orthogonality property, which does not hold for the original score function , reduces the variability caused by the nuisance parameters. A geometric illustration of the decorrelation-based methods is provided in Figure 1, which also incorporates the illustration of the decorrelated Wald and partial likelihood ratio tests to be introduced in the following subsections. Technically, the uncertainty of estimating θ in the partial score function can be reduced by subtracting the decorrelation term . As will be shown in the next section, this is a key step to establish the result that the decorrelated score function weakly converges to N(0, Hα|θ) under the null, where . This further explains why the decorrelated score function rather than the original score function should be used as the inferential function in high dimensions. On the other hand, in the low dimensional setting, it can be shown that the decorrelated score function is asymptotically equivalent to the profile partial score function S(α).
Figure 1.
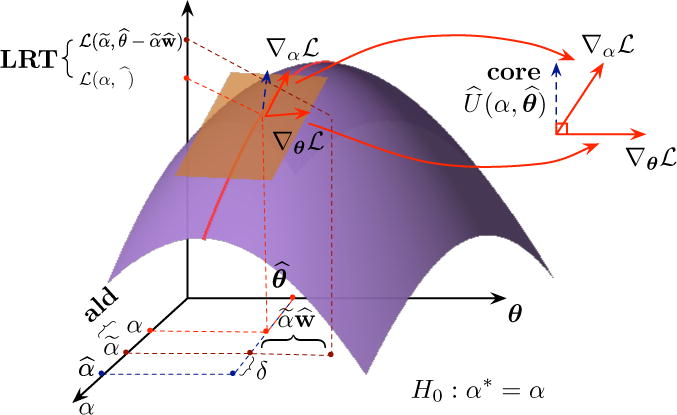
Geometric illustration of the decorrelated score, Wald and partial likelihood ratio tests. The purple surface corresponds to the log-partial likelihood function. The orange plane is the tangent plane of the surface at point . The two red arrows in the orange plane represent ∇αℒ and ∇θℒ. The correlated score function in blue is the projection of ∇αℒ onto the space orthogonal to ∇θℒ. Given Lasso estimator , the decorrelated Wald estimator is , where . The decorrelated partial likelihood ratio test compares the log-partial likelihood function values at and .
To test if α* = 0, we need to standardize in order to construct the test statistic. We estimate Hα|θ by
| (3.4) |
Hence, we define the decorrelated score test statistic as
| (3.5) |
In the next section, we show that under the null, converges weakly to a chi-squared distribution with one degree of freedom. Given a significance level η ∈ (0,1), the score test ψS(η) is
| (3.6) |
where denotes the (1 − η)th quantile of a chi-squared random variable with one degree of freedom, and the null hypothesis α∗ = 0 is rejected if and only if ψS(η) = 1.
3.2 Confidence Intervals and Decorrelated Wald Test
The decorrelated score test does not provide a confidence interval for α∗ with a desired coverage probability. In low dimensions, by examing the limiting distribution of the maximum partial likelihood estimator, we can get a confidence interval for α∗ (Andersen and Gill, 1982), which is equivalent to the classical Wald test. This subsection extends the classical Wald test for the proportional hazards model to high dimensional settings to construct confidence intervals for the parameters of interest.
The key idea of performing Wald test is to derive a regular estimator for α∗. Our procedure is based on the deccorelated score function in (3.3). Since serves as an approximately unbiased estimating equation for α, the root of the equation with respect to α defines an estimator for α*. However, searching for the root may be computationally intensive, especially when α is multi-dimensional. To reduce the computational cost, we exploit a closed-form estimator obtained by linearizing at the initial estimator . More specifically, let be the ℓ1 penalized estimator in (2.1), we adopt the following one-step estimator,
| (3.7) |
In the next section, we prove that converges weakly to . Hence, let Z1−η/2 be the (1 − η/2)-th quantile of N(0, 1). We show that
is a 100(1 − η)% confidence interval for α∗.
From the perspective of hypothesis testing, the decorrelated Wald test statistic for H0: α∗ = 0 versus H1: α∗ ≠ 0 is
| (3.8) |
Consequently, the decorrelated Wald test at significance level η is
| (3.9) |
and the null hypothesis α∗ = 0 is rejected if and only if ψW(η) = 1.
3.3 Decorrelated Partial Likelihood Ratio Test
In low dimsional settings, the partial likelihood ratio test statistic is where and are the maximum partial likelihood estimators under the null and alternative, respectively. Hence, PLRT evaluates the validity of the null hypothesis by comparing the partial likelihood under H0 with that under H1. Similar to the partial score test, the partial likelihood ratio test also fails in the high dimensional setting due to the presence of a large number of nuisance parameters. In this section, we propose a new version of the partial likelihood ratio test which is valid in high dimensions.
To handle the impact of high dimensional nuisance parameters, we define the (negative) decorrelated partial likelihood for α as . The reason for this name is that the derivative of ℒdecor(α) with respect to α evaluated at α = 0 is identical to the decorrelated score function in (3.3). The decorrelated partial likelihood ℒdecor(α) plays the same role as the profile partial likelihood in the low dimensional setting. Hence, the decorrelated partial likelihood ratio test statistic is defined as
| (3.10) |
and is given in (3.7). As discussed in the previous subsection, is a one-step approximation of the global minimizer of ℒdecor(α). Hence, the log-likelihood ratio evaluates the validity of the null hypothesis by comparing the decorrelated partial likelihood under H0 with that under H1. This is a natural extension of the classical partial likelihood ratio test to the high dimensional setting.
In the next section, we show that converges weakly to a chi-squared distribution with one degree of freedom. Therefore, a decorrelated partial likelihood ratio test with significance level η is
| (3.11) |
and ψL(η) = 1 indicates a rejection of the null hypothesis.
4 Asymptotic Properties
In this section, we derive the limiting distributions of the decorrelated test statistics under the null hypothesis. More detailed proofs are provided in Appendix A. In our analysis, we make the following regularity assumptions.
Assumption 4.1
The true hazard is uniformly bounded, i.e., .
Assumption 4.2
It holds that ‖w∗‖0 = s′ ≍ s, and .
Assumption 4.3
The Fisher information matrix is bounded, , and its minimum eigenvalue is also bounded from below, Λmin(H∗) ≥ Ch > 0, which implies that .
To connect these assumptions with existing literature, Assumptions 4.1 and 4.2 extend Assumption (iv) of Theorem 3.3 in van de Geer et al. (2014a) to the proportional hazards model. In particular, the sparsity assumption of w∗ ensures that the Dantzig selector converges to w∗ at a fast rate. Assumption 4.3 is related to the Fisher information matrix, which is essential even in low dimensional settings.
Our main result characterizes the asymptotic normality of the decorrelated score function in (3.3) under the null.
Theorem 4.4
Under Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3, let , and n−1/2s3 log d = o(1). Under the null hypothesis that α∗ = 0, the decorrelated score function defined in (3.3) satisfies
| (4.1) |
and
As we have discussed before, the limiting variance of the decorrelated score function can be estimated by . The next lemma shows the consistency of .
Lemma 4.5
Suppose Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold. If and , we have
where is defined in (3.4).
By Theorem 4.4 and Lemma 4.5, the next corollary shows that under the null hypothesis, type I error of the decorrelated score test ψS(η) in (3.6) converges asymptotically to the significance level η. Let the associated p-value of the decorrelated score test be , where Φ(·) is the cumulative distribution function of the standard normal random variable and is the score test statistic defined in (3.5). The distribution of PS converges to a uniform distribution asymptotically.
Corollary 4.6
Suppose Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold, , and n−1/2s3 log d = o(1). The decorrelated score test and the its corresponding p-value satisfy
where Unif[0, 1] denotes a random variable uniformly distributed in [0, 1].
We then analyze the decorrelated Wald test under the null. We derive the limiting distribution of the one-step estimator defined in (3.7) in the next theorem.
Theorem 4.7
Suppose Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold, and , , n−1/2s3 log d = o(1). When the null hypothesis α∗ = 0 holds, the decorrelated estimator satisfies
| (4.2) |
Utilizing the asymptotic normality of , we can establish the limiting type I error of ψW (η) in (3.9), in the next corollary. Note that, it is straightforward to generalize the result to be , where for any α∗. This gives us a confidence interval of α∗.
Corollary 4.8
Under Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3, suppose , and n−1/2s3 log d = o(1). The type I error of the decorrelated Wald test ψW(η) and its corresponding p-value satisfy
In addition, an asymptotic (1 − η) × 100% confidence interval of α∗ is
Finally, we characterize the limiting distribution of the decorrelated partial likelihood ratio test statistic introduced in (3.10).
Theorem 4.9
Suppose Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold, , and n−1/2s3 log d = o(1). If the null hypothesis α∗ = 0 holds, the decorrelated likelihood ratio test statistic in (3.10) satisfies
| (4.3) |
This theorem justifies the decorrelated partial likelihood ratio test ψL(η) in (3.11). Also, let the p-value associated with the decorrelated partial likelihood ratio test be , where F(·) is the cumulative distribution function of . Similar to Corollaries 4.6 and 4.8, we characterize the type I error of the test ψL(η) in (3.11) and its corresponding p-value below.
Corollary 4.10
Suppose Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold, , and n−1/2s3 log d = o(1). The type I error of the decorrelated partial likelihood ratio test ψL(η) with significance level η and its associated p-value PL satisfy
By Corollaries 4.6, 4.8 and 4.10, we see that the decorrelated score, Wald and partial likelihood ratio tests are asymptotically equivalent as summarized in the next corollary.
Corollary 4.11
Suppose Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold, , and n−1/2s3 log d = o(1). If the null hypothesis α* = 0 holds, the test statistics in (3.5), in (3.8), and in (3.10) are asymptotically equivalent, i.e.,
To summarize this subsection, Corollaries 4.6, 4.8 and 4.10 characterize the asymptotic distributions of the proposed decorrelated test statistics under the scaling when n−1/2s3 log d = o(1) under the null hypothesis. It is known that is the semiparametric information lower bound for inferring α. Theorem 4.7 shows that achieves the semiparametric information bound, which indicates the semiparametric efficiency of . Using the asymptotic equivalence in Corollary 4.11, all of our test statistics are semiparametrically efficient (van der Vaart, 2000).
Remark 4.12
All the theoretical results in this section are still valid if we replace the Lasso penalty with nonconvex SCAD or MCP penalties as long as the consistency result (2.2) holds.
Remark 4.13
When the model is misspecified, we denote the oracle parameter as
where is the expectation under the true model. Our proposed methods are still applicable to test if and construct confidence intervals for .
Remark 4.14
Existing works mainly consider high dimensional inferences for linear and generalized models; see Lockhart et al. (2014); Chernozhukov et al. (2013); van de Geer et al. (2014b); Javanmard and Montanari (2013) and Zhang and Zhang (2014). More specifically, Lockhart et al. (2014) consider conditional inference, while we consider unconditional inference. The others propose estimators that are asymptotically normal. Compared with existing approaches, we provide a unified framework which are more general in two aspects: (i) Our framework can deal with nonconvex penalties, while it is unclear if existing works are still valid under nonconvex penalities. (ii) Our framework based on the decorrelated score function provides a natural approach to deal with the misspecified model. In contrast, most existing methods assume the model must be correct.
5 Inference on the Baseline Hazard Function
The baseline hazard function
is treated as a nuisance function in the log-partial likelihood method. In practice, inferences on the baseline hazard function is also of interest. To the best of our knowledge, estimating the baseline hazard function or the survival function and construct confidence intervals in high dimensions remains unexplored. In this section, we extend the decorrelation approach to construct confidence intervals for the baseline hazard function and the survival function. All the proof details are provided in Appendix B.
We consider the following Breslow-type estimator for the baseline hazard function. Given an ℓ1-penalized estimator derived from (2.1), the direct plug-in estimator for the baseline hazard function at time t is
| (5.1) |
Since the plug-in estimator does not posses a tractable distribution, inference based on the estimator is difficult. To handle this problem, we adopt the decorrelation approach as in the previous sections and estimate Λ0(t) by the sample version of , where
and the gradient ∇Λ0(t, β*) is taken with respect to the corresponding β component, and H* is the Fisher information matrix defined in (2.7). Similar to Section 3.1, we directly estimate by the following Dantzig selector
| (5.2) |
where δ is a tuning parameter. It can be shown that the estimator converges to u*(t) = H*−1∇Λ0(t, β*) under the following regularity assumption.
Assumption 5.1
It holds that .
Note that Assumption 5.1 plays the same role as Assumption 4.2 in the previous section. Corollary B.2 in Appendix B characterizes the rate of convergence of . Hence, the decorrelated baseline hazard function estimator at time t is
| (5.3) |
Based on the estimator (5.3), the survival function S0(t) = exp{−Λ0(t)} is estimated by . The main theorem of this section characterizes the asymptotic normality of and as follows.
Theorem 5.2
Suppose Assumptions 2.1, 2.2, 4.1, 4.3 and 5.1 hold, , and n−1/2s3 log d = o(1). We have, for any t ∈ [0,τ], the decorrelated baseline hazard function estimator in (5.3) satisfies
and
| (5.4) |
The estimated survival function satisfies
Given Theorem 5.2, we further need to estimate the limiting variances and . To this end, we use
where is defined in (5.1).
We conclude this section by the following corollary which provides confidence intervals for Λ0(t) and S0(t).
Corollary 5.3
Suppose Assumptions 2.1, 2.2, 4.2, 4.3 and 5.1 hold, , and n−1/2s3 log d = o(1). For any t > 0 and 0 < η < 1,
and
6 Numerical Results
This section reports numerical results of our proposed methods using both simulated and real data. We test the methods proposed in Section 3 and Section 5 by considering empirical behaviors for inferences on the individual regression coefficients βj’s and the baseline hazard function Λ0(t).
6.1 Inference on the Parametric Component
We first investigate empirical performances of the decorrelated score, Wald and partial likelihood ratio tests on the parametric component β as proposed in Section 3. To estimate β∗ and w∗, we choose the tuning parameters λ by 10-fold cross-validation and set . We find that our simulation results are insensitive to the choice of λ′. We conduct decorrelated score, Wald and partial likelihood ratio tests for β1 which is set to be 0 under null hypothesis H0: β1 = 0 versus alternative Ha: β1 ≠= 0, where we set the significance level to be η = 0.05. In each setting, we simulate n = 150 independent samples from a multivariate Gaussian distribution Nd(0, Σ) for d = 100, 200, or 500, where Σ is a Toeplitz matrix with Σjk = ρ|j−k| and ρ = 0.25, 0.4, 0.6 or 0.75. The cardinality of the active set s is either 2 or 3, and the regression coefficients in the active set are either all 1’s (Dirac) or drawn randomly from the uniform distribution Unif[0, 2]. We set the baseline hazard rate function to be identity. Thus, the i-th survival time follows an exponential distribution with mean . The i-th censoring time is independently generated from an exponential distribution with mean , where U ~ Unif[1, 3]. As discussed in Fan and Li (2002), this censoring scheme results in about 30% censored samples.
The above simulation is repeated 1,000 times. The empirical type I errors of the decorrelated score, Wald and partial likelihood ratio tests are summarized in Tables 1 and 2. We see that the empirical type I errors of all three tests are close to the desired 5% significance level, which supports our theoretical results. This observation holds for the whole range of ρ, s and d specified in the data generating procedures. In addition, as expected, the empirical type I errors further deviate from the significance level as d increases for all three tests, illustrating the effects of dimensionality d on finite sample performance.
Table 1.
Average Type I error of the decorrelated tests with η = 5% where (n, s) = (150, 2).
| Method | d | ρ = 0.25 | ρ = 0.4 | ρ = 0.6 | ρ = 0.75 | ||||
|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||
| Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | ||
| Score | 100 | 5.1% | 5.2% | 5.1% | 4.9% | 5.2% | 5.1% | 4.9% | 5.0% |
| 200 | 5.2% | 4.8% | 5.3% | 4.8% | 5.3% | 5.6% | 4.7% | 4.6% | |
| 500 | 6.1% | 6.4% | 5.5% | 4.6% | 4.2% | 4.4% | 3.9% | 3.7% | |
|
| |||||||||
| Wald | 100 | 5.2% | 5.3% | 5.1% | 5.0% | 5.2% | 4.9% | 5.0% | 5.1% |
| 200 | 5.4% | 4.7% | 5.3% | 4.8% | 4.6% | 4.7% | 4.3% | 4.6% | |
| 500 | 6.3% | 6.1% | 5.9% | 5.5% | 5.8% | 4.2% | 4.5% | 3.9% | |
|
| |||||||||
| PLRT | 100 | 4.9% | 4.8% | 5.1% | 5.2% | 5.0% | 5.2% | 4.8% | 4.7% |
| 200 | 5.7% | 5.5% | 5.3% | 5.5% | 4.8% | 5.6% | 4.6% | 4.5% | |
| 500 | 6.2% | 6.2% | 5.9% | 5.3% | 4.5% | 4.2% | 3.8% | 3.6% | |
Table 2.
Average type I error of the decorrelated tests with η = 5% where (n, s) = (150, 3).
| d | ρ = 0.25 | ρ = 0.4 | ρ = 0.6 | ρ = 0.75 | |||||
|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||
| Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | ||
| Score | 100 | 5.2% | 5.2% | 4.8% | 5.3% | 5.3% | 4.9% | 5.3% | 4.8% |
| 200 | 5.2% | 4.6% | 4.7% | 5.3% | 5.4% | 5.8% | 4.5% | 4.8% | |
| 500 | 6.3% | 6.5% | 5.8% | 4.4% | 5.2% | 4.6% | 3.6% | 3.4% | |
|
| |||||||||
| Wald | 100 | 5.1% | 4.9% | 5.3% | 4.7% | 5.2% | 4.9% | 5.0% | 5.1% |
| 200 | 4.8% | 4.6% | 4.9% | 5.1% | 5.2% | 5.7% | 4.2% | 4.4% | |
| 500 | 6.5% | 6.8% | 6.2% | 5.9% | 5.1% | 4.5% | 3.9% | 4.2% | |
|
| |||||||||
| PLRT | 100 | 5.3% | 5.2% | 5.0% | 5.3% | 5.4% | 5.2% | 4.9% | 4.8% |
| 200 | 5.5% | 5.3% | 5.4% | 4.6% | 5.2% | 5.7% | 5.4% | 4.3% | |
| 500 | 6.5% | 6.3% | 5.7% | 5.5% | 4.8% | 4.1% | 3.7% | 3.2% | |
We also investigate the empirical power of the proposed tests. Instead of setting β1 = 0, we generate the data with β1 = 0.05, 0.1, 0.15, …, 0.55, following the same simulation scheme introduced above. We plot the rejection rates of the three decorrelated tests for testing H0 : β1 = 0 with significance level 0.05 and ρ = 0.25 in Figure 2. We see that when d = 100, the three tests share similar power. However, for larger d (e.g., d = 500), the decorrelated partial likelihood ratio test is the most powerful test. In addition, the Wald test is less effective for problems with higher dimensionality. Based on our simulation results, we recommend the decorrelated partial likelihood ratio test for inference in high dimensional problems.
Figure 2.
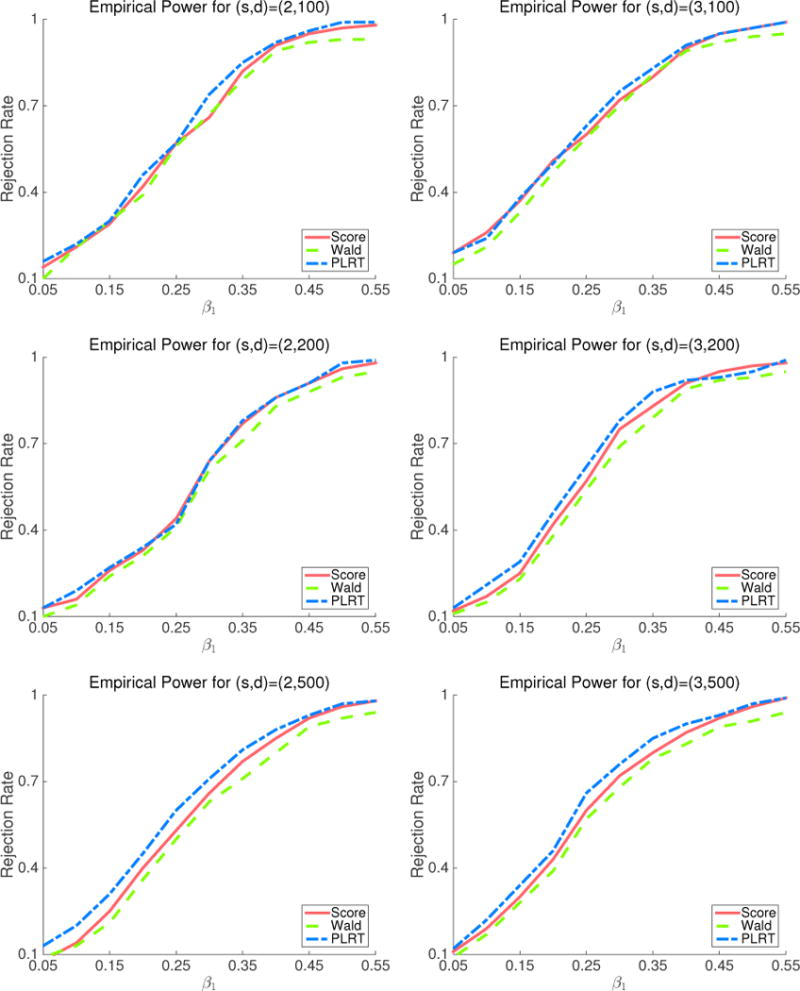
Empirical rejection rates of the decorrelated score, Wald and partial likelihood ratio tests on simulated data with different active set sizes and dimensionality.
6.2 Inference on the Baseline Hazard Function on Simulated Data
In this section, we demonstrate the empirical performance of the decorrelated inference procedure on the baseline hazard function Λ0(t) proposed as in Section 5. We consider three scenarios with Λ0(t) = t, t2/2 and t3/3. Note that when Λ0(t) = p−1tp, the survival time follows a Weibull distribution with shape parameter p and scale parameter , i.e., . We use the same data generating procedures for the covariate Xi’s, parameter β∗ and censoring time R as in the previous subsection.
In each simulation, we construct 95% confidence intervals for Λ0(t) at t = 0.2 using the procedures proposed in Section 5. The simulation is repeated 1,000 times. The results for the empirical coverage probabilities of Λ0(t) are summarized in Tables 3 and 4. It is seen that the coverage probabilities are all between 93% and 97%, which matches our theoretical results.
Table 3.
Empirical coverage probability of 95% confidence intervals for Λ0(t) at t = 0.2 with (n, s) = (150, 2)
| Λ0(t) | d | ρ = 0.25 | ρ = 0.4 | ρ = 0.6 | ρ = 0.75 | ||||
|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||
| Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | ||
| t | 100 | 95.3% | 95.1% | 94.7% | 95.1% | 95.2% | 94.6% | 95.4% | 94.9% |
| 200 | 95.5% | 95.8% | 95.7% | 95.3% | 94.6% | 94.5% | 94.4% | 94.2% | |
| 500 | 95.9% | 96.2% | 95.5% | 94.8% | 94.3% | 94.1% | 93.7% | 93.5% | |
|
| |||||||||
| t 2 | 100 | 95.1% | 95.3% | 95.2% | 95.0% | 95.4% | 94.7% | 95.2% | 95.3% |
| 200 | 95.5% | 94.8% | 95.4% | 94.7% | 94.6% | 94.0% | 94.4% | 94.5% | |
| 500 | 96.6% | 96.7% | 96.1% | 95.4% | 94.9% | 94.3% | 93.8% | 93.6% | |
|
| |||||||||
| t 3 | 100 | 95.2% | 95.0% | 95.1% | 95.3% | 94.8% | 95.1% | 95.2% | 94.7% |
| 200 | 95.4% | 94.7% | 94.6% | 95.5% | 95.2% | 95.8% | 94.6% | 94.3% | |
| 500 | 96.6% | 95.9% | 96.3% | 95.9% | 94.5% | 94.7% | 93.6% | 93.4% | |
Table 4.
Empirical coverage probability of 95% confidence intervals for Λ0(t) at t = 0.2 with (n, s) = (150, 3)
| Λ0(t) | d | ρ = 0.25 | ρ = 0.4 | ρ = 0.6 | ρ = 0.75 | ||||
|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||
| Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | Dirac | Unif[0, 2] | ||
| t | 100 | 95.1% | 94.8% | 94.8% | 95.2% | 95.3% | 95.1% | 94.8% | 95.4% |
| 200 | 95.6% | 95.3% | 95.4% | 95.2% | 94.7% | 94.8% | 94.2% | 94.3% | |
| 500 | 96.2% | 95.9% | 95.8% | 96.1% | 95.2% | 94.3% | 93.3% | 93.6% | |
|
| |||||||||
| t 2 | 100 | 95.3% | 94.7% | 95.3% | 94.9% | 94.5% | 95.3% | 95.4% | 95.2% |
| 200 | 94.7% | 94.5% | 95.4% | 95.2% | 94.1% | 94.9% | 94.3% | 93.8% | |
| 500 | 96.5% | 96.2% | 95.8% | 96.0% | 95.5% | 95.1% | 93.2% | 93.7% | |
|
| |||||||||
| t 3 | 100 | 95.0% | 95.2% | 94.6% | 94.8% | 95.1% | 95.4% | 94.9% | 95.5% |
| 200 | 95.3% | 95.5% | 95.2% | 94.5% | 94.3% | 94.6% | 93.8% | 93.5% | |
| 500 | 95.9% | 96.3% | 95.7% | 96.0% | 95.4% | 94.7% | 93.6% | 93.1% | |
To further examine the performance of our method, we conduct additional simulation studies by plotting the 95% confidence intervals of Λ0(t) at t = 0.05, 0.1, 0.15, …, 0.5, with Λ0(t) = t and t2/2. The results are presented in Figures 3 and 4.
Figure 3.
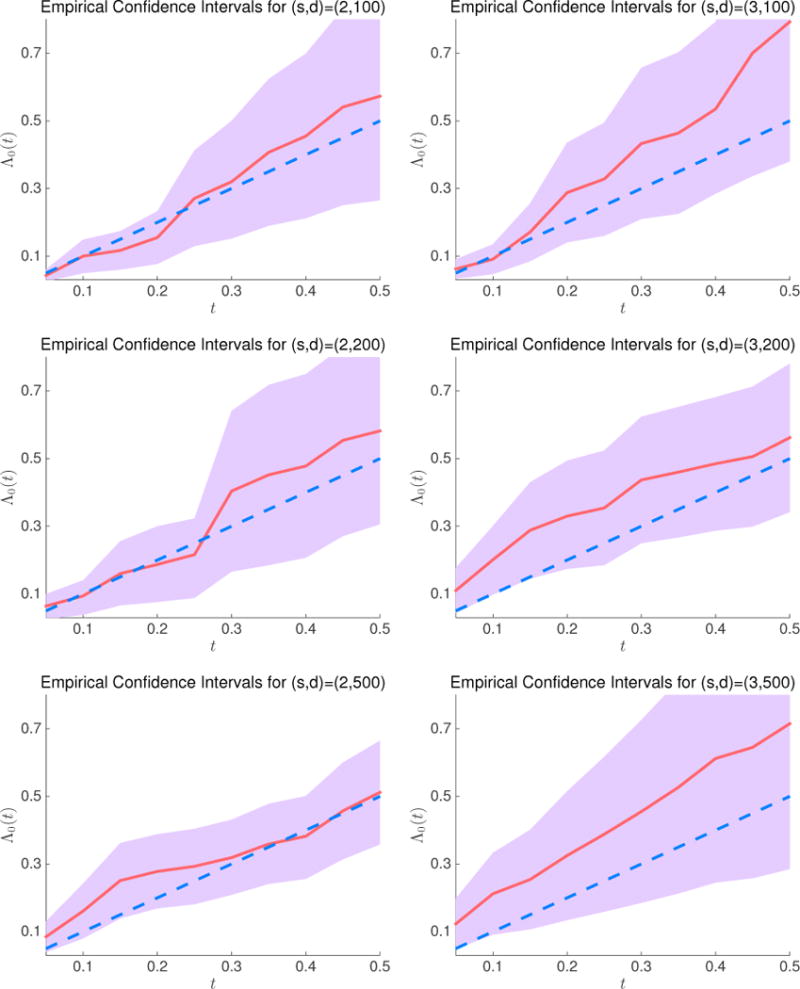
95% confidence intervals for the baseline hazard function at t = 0.05, 0.1, …, 0.5. The red solid line denotes the estimated baseline hazard function , and blue dashed line denotes Λ0(t) = t.
Figure 4.
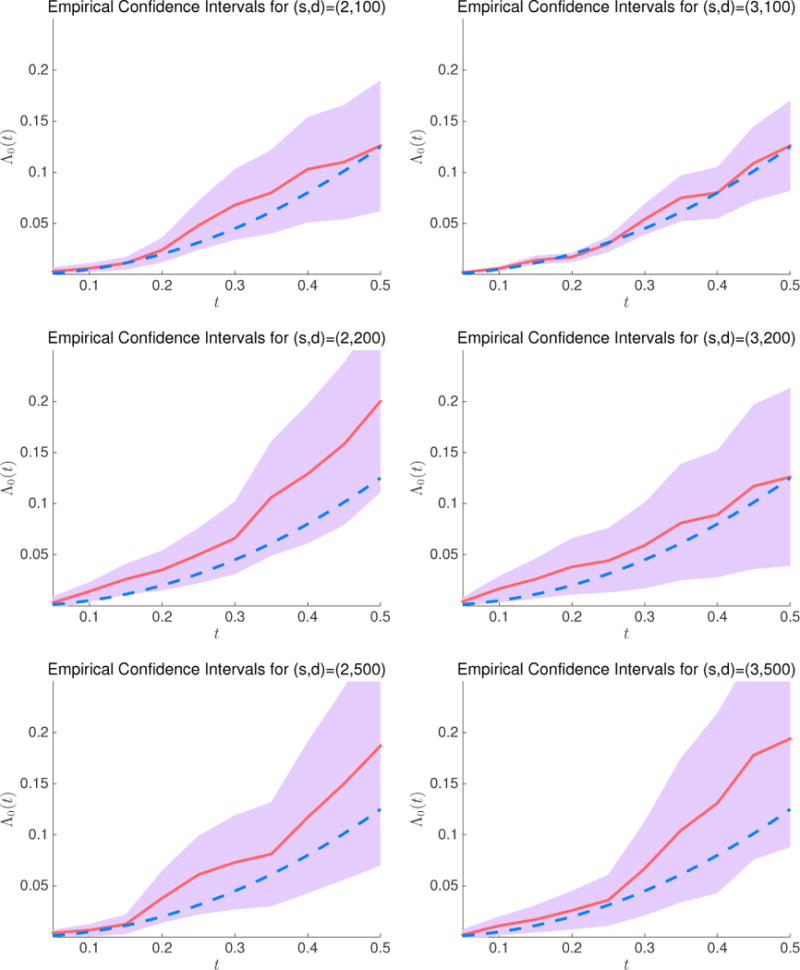
95% confidence intervals for the baseline hazard function at t = 0.05, 0.1, …, 0.5. The red solid line denotes the estimated baseline hazard function , and the blue dashed line denotes Λ0(t) = t2/2.
6.3 Analyzing a Gene Expression Dataset
We apply the proposed testing procedures to analyze a genomic data set, which is collected from a diffuse large B-cell lymphoma study analyzed by Alizadeh et al. (2000). One of the goals in this study is to investigate how the gene expression levels in B-cell malignancies are associated with the survival time. The expression values for over 13,412 genes in B-cell malignancies are measured by microarray experiments. The data setcontains 40 patients with diffuse large B-cell lymphoma who are recruited and followed until death or the end of the study. A small proportion (≈5%) of the gene expression values are not well measured and are treated as missing values by Alizadeh et al. (2000). For simplicity, we impute the missing values of each gene by the median of the observed values of the same gene. The average survival time is 43.9 months and the censored rate is 55%. Since the sample size n = 40 is small, we conduct pre-screening by fitting univariate proportional hazards models and only keep d = 200 genes with the smallest p-values.
We apply the proposed score, Wald and partial likelihood ratio tests to the pre-screened data. The same strategy for choosing the tuning parameters as that in the simulation studies is adopted. We repeatedly apply the hypothesis tests for all parameters. To control the family-wise error rate due to the multiple testing, the p-values are adjusted by the Bonferroni’s method. To be more conservative, we only report the genes with adjusted p-values less than 0.05 by all of the three methods in Table 5. Many of the genes which are significant in the hypothesis tests are biologically related to lymphoma. For instance, the relation between lymphoma and genes FLT3 (Meierhoff et al., 1995), CDC10 (Di Gaetano et al., 2003), CHN2 (Nishiu et al., 2002) and Emv11 (Hiai et al., 2003) have been experimentally confirmed. This provides evidence that our methods can be used to discover scientific findings in applications involving high dimensional datasets.
Table 5.
Genes with the adjuste p-values less than 0.05 using score, Wald and partial likelihood ratio tests for the large B-cell lymphoma gene expression dataset.
| Gene | Score | Wald | PLRT |
|---|---|---|---|
| FLT3 | 1.01 × 10−2 | 2.86 × 10−2 | 1.72 × 10−2 |
| GPD2 | 3.91 × 10−2 | 4.67 × 10−3 | 7.44 × 10−3 |
| PTMAP1 | 7.86 × 10−3 | 4.84 × 10−3 | 3.75 × 10−3 |
| CDC10 | 3.52 × 10−3 | 2.63 × 10−3 | 1.10 × 10−3 |
| Emv11 | 4.96 × 10−3 | 2.77 × 10−4 | 3.49 × 10−4 |
| CHN2 | 1.79 × 10−2 | 2.73 × 10−2 | 3.58 ×10−3 |
| Ptger2 | 1.78 ×10−2 | 1.32 × 10−2 | 2.47 × 10−3 |
| Swq1 | 4.04 × 10−3 | 4.21 × 10−2 | 3.67 × 10−2 |
| Cntn2 | 4.05 × 10−3 | 4.84 × 10−2 | 4.03 × 10−2 |
7 Discussion
We proposed a novel decorrelation-based approach to conduct inference for both the parametric and nonparametric components of high dimensional Cox’s proportional hazards models. Unlike existing works, our methods do not require conditions on model selection consistency or minimal signal strength. Theoretical properties of the proposed methods are established. Extensive numerical investigations are conducted on the simulated and real datasets to examine the finite sample performances of our methods. To the best of our knowledge, this paper for the first time provides a unified framework on uncertainty assessment of high dimensional Cox’s proportional hazards models. Our methods can be extended to conduct inference for other high-dimensional survival models such as censored linear model (Müller and van de Geer, 2014) and additive hazards model (Lin and Lv, 2013).
In this paper, we focus on the Cox’s proportional hazards model for the univariate survival data. In practice, many biomedical studies involve multiple survival outcomes. For instance, in the Framingham Heart Study by Dawber (1980), both time to coronary heart disease and time to cerebrovascular accident are observed. How the inference can be drawn by jointly analyzing the multivariate survival data in the high dimensional setting remains largely unexplored. To address this problem, we extend the proposed hypothesis testing procedures to deal with the multivariate survival data. More details are presented in Appendix D.
The proposed methods involve two tuning parameters λ and λ′. The presence of multiple tuning parameters in the inferential procedures is encountered in many recent works even under high dimensional linear models (Chernozhukov et al., 2013; van de Geer et al., 2014b; Javanmard and Montanari, 2013; Zhang and Zhang, 2014). Theoretically, we establish the asymptotic normality of the test statistics when and . Empirically, our numerical results suggest that cross-validation seems to be a practical procedure for the choice of λ. As an important future investigation, it is of interest to provide rigorous theoretical justification of practical procedures such as cross-validation for the choice of tuning parameters.
Supplementary Material
Acknowledgments
We thank Professor Bradic for providing very helpful comments. This research is partially supported by the grants NSF CAREER DMS 1454377, NSF IIS1408910, NSF IIS1332109, NIH R01MH102339, NIH R01GM083084, and NIH R01HG06841.
A Proofs in Section 4
In this section, we provide the detailed proofs in Section 4. We first provide a key lemma which characterizes the asymptotic normality of ∇ℒ(β∗). This lemma is essential in our later proofs to derive the asymptotic distributions of the test statistics.
Lemma A.1
Under Assumptions 2.1, 4.2 and 4.3, for any vector v ∈ ℝd, if and , it holds that
Proof
Let . By the definition of ∇ℒ(β*) in (2.4), we have
Thus, by the identity , we have
For the first term S, denote by
We have , and Var(n−1/2S) = 1. Thus S is a sum of n independent random variables with mean 0. To get the asymptotic distribution of n−1/2S, we verify the Lyapunov condition. Indeed, we have
where the inequality follows by Assumption 4.3 for some constant C, and the equality holds by Lemma C.1 and Assumption 2.1. Thus, the Lyapunov condition holds by our scaling assumption that s′3/2n−1/2 = o(1). Apply Lindeberg Feller Central Limit Theorem, we have .
Next, we prove that the second term E = oℙ(1). Since
By Lemma C.1, it holds that . It holds that, for some constant C > 0,
It remains to bound the term . By Theorem 2.11.9 and Example of 2.11.16 of van der Vaart and Wellner (1996), converges weakly to a tight Gaussian process G(t). Furthermore, by Strong Embedding Theorem of Shorack and Wellner (2009), there exists another probability space such that converges almost surely to , where * indicates the existences in a new probability space. This implies that . We have, by our assumption , the term E satisfies that
Combining this with the result that concludes the proof. □
Next, we characterize the rate of convergence of the Dantzig selector in (3.2) in the following lemma.
Lemma A.2
Under Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3, If , we have
| (A.1) |
where and w* are defined in (3.2) and (3.1), respectively.
Proof
As shown in Lemma C.6, under Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3, the condition (C.7) in Lemma C.8 is satisfied for . Consequently, we have
which concludes the proof. □
Proof of Theorem 4.4
To derive the asymptotic distribution of , we start with decomposing into several terms.
| (A.2) |
where the second equality holds by the mean value theorem for some , and .
We consider the terms S, E1 and E2 separately. For the first term S, by Lemma A.1, taking . We have,
| (A.3) |
For the term E1, we have,
| (A.4) |
where by Lemma C.8, and by Lemma C.3.
For the term E2, we have,
| (A.5) |
Considering the terms E21 and E22 separately, first, we have,
| (A.6) |
where the inequality holds by Hölder’s inequality. For the first term in the above inequality, we have
| (A.7) |
since by (2.2) and by Lemma C.5.
For the second term in (A.6), by Hölder’s inequality, we have
| (A.8) |
where the last equality holds since by Assumption 4.2, by Lemma C.5, and by (2.2). Plugging (A.7) and (A.8) into (A.6), we have
| (A.9) |
For the second term E22 in (A.5), we have,
| (A.10) |
where we use the results that by Lemma C.8, by (2.2), and by Lemma C.5.
Plugging (A.6) and (A.10) into (A.5), we have . Combining it with (A.4), we have
| (A.11) |
where the last equality holds by the assumption that n−1/2s3 log d = o(1) and s ≍ s′. Combining (A.11), (A.3) and (A.2), our claim (4.1) holds as desired. □
Proof of Lemma 4.5
By the definition of Hα|θ and , we have
| (A.12) |
We consider the two terms separately. For the first term E1, we have by Lemma C.5, . For the second term E2, we have,
For the term E21, we have, by Hölder’s inequality,
| (A.13) |
where the last inequality holds by the fact that , and by Assumption 4.3.
For the second term E22, we have, by Hölder’s inequality,
| (A.14) |
where the last equality holds by the assumption that , the result by (A.1) and by Lemma C.5 that .
Combining (A.13) and (A.14), we have, . Together with the result that , the claim holds as desired. □
Proof of Theorem 4.7
Based on our construction of in (3.7), we have
| (A.15) |
where (A.15) holds by the mean value theorem for some and u ∈ [0, 1]. For the term R1, note that
where the equality holds by mean-value theorem with for some u ∈ [0, 1]. Under the null hypothesis α* = 0, by Theorem 3.2 of Huang et al. (2013), . By regularity condition and Lemma 4.5, it also holds that . Thus, we have
| (A.16) |
where the second equality holds by Theorem 4.4. Thus, by triangle inequality, we have
where the last equality holds by (A.16) and Lemma 4.5.
For the term R2, we have,
where the last inequality holds by the fact that , and Lemma 4.5.
Consequently, it holds that,
and the last equality follows by Theorem 4.4 and our the assumption that n−1/2s3 log d = o(1). The claim follows as desired. □
Proof of Theorem 4.9
We have
| (A.17) |
where the first equality follows by the mean-value theorem with , , , and for some .
We first look at the term T1. Under the null hypothesis α* = 0, and by Theorems 4.4 and 4.7, respectively, where Z ~ N(0,Hα|θ). We have,
| (A.18) |
Next, we look at the term T2,
| (A.19) |
It holds by Theorem 4.7 that . Together with the regularity condition , we have,
| (A.20) |
Considering the term T22, we have
| (A.21) |
For the first term |R1|, we have, by Lemma C.5, . For the second term,
| (A.22) |
where the last equality follows by (2.2), Lemma C.4, Lemma C.8 and the sparsity Assumption 4.1 of w*.
For the third term |R3|, we have
Note that by Lemma C.8 and Lemma C.4, by Lemma C.4 and Assumption 4.2, and by Assumption 4.3 and Lemma C.8. We have .
Combining the results above, we have,
| (A.23) |
where the second equality follows by Theorem 4.7 that under the null hypothesis, and the last equality follows by the assumption that n−1/2s′s2 log d = o(1).
Combining (A.20) and (A.23) with (A.19), we have
| (A.24) |
Plugging (A.18) and (A.24) into (A.17), by Theorem 4.4,
which concludes the proof. □
B Proofs in Section 5
In this section, we provide detailed proofs in Section 5.
Lemma B.1
Under Assumptions 2.1, 2.2, 4.2, 4.3 and 5.1, .
Proof
By the definition of in (5.1), we have,
where the last inequality follows by the same argument in Lemma C.5. □
A corollary of Lemma B.1 and Lemma C.8 follows immediately which characterizes the rate of convergence of .
Corollary B.2
Under Assumptions 2.1, 2.2, 4.2, 4.3 and 5.1, if we have,
Proof of Theorem 5.2
We first decompose into two terms that
Let . For the first term , we have
Since Mi(t) is a martingale, becomes a sum of martingale residuals. By Andersen and Gill (1982), we have, as n → ∞, , where
For the second term I2(t), we have, by mean value theorem, for some , and 0 ≤ t, t′ ≤ 1,
Next, we consider the two terms R1 and R2. For the term R1, we have
It holds that by (2.2) and Lemma B.1, and . Summing them up, by triangle inequality, we have .
For the term R2, we have
where the last inequality holds by Lemma C.3 and C.5.
Meanwhile, by Lemma A.1, taking v = u∗(t), we have the term , where . Thus, we have,
and .
Following the standard martingale theory, the covariance between I1(t) and I2(t) is 0. Our claim holds as desired. □
C Technical Lemmas
In this section, we prove some concentration results of the sample gradient ∇ℒ(β∗) and sample Hessian matrix ∇2ℒ(β∗). The mathematical tools we use are mainly from empirical process theory.
We start from introducing the following notations. Let ‖·‖ℙ,r denote the Lr(ℙ)-norm. For any given ε > 0 and the function class ℱ, let N[](ε, ℱ, Lr(ℙ)) and N(ε, ℱ, L2(ℚ)) denote the bracketing number and the covering number, respectively. The quantifies log N[](ε, ℱ, Lr(ℙ)) and log N(ε, ℱ, L2(ℚ)) are called entropy with bracketing and entropy, respectively. In addition, let F be an envelope of ℱ where |f| ≤ F for all f ∈ ℱ. The bracketing integral and uniform entropy integral are defined as
and
respectively, where the supremum is taken over all probability measures ℚ with ‖F‖ℚ,2 > 0. Denote the empirical process by , where and . The following three Lemmas characterize the bounds for the expected maximal empirical processes and the concentration of the maximal empirical processes.
Lemma C.1
Under Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3, there exist some constant C > 0, such that, for r = 0, 1, 2, with probability at least ,
where s(r)(t, β*) and S(r)(t, β*) are defined in (2.6) and (2.3).
Proof
We will only prove the case for r = 1, and the cases for r = 0 and 2 follow by the similar argument. For j = 1,…, d, let
where and denote the j-th component of S(1)(t, β*) and s(1)(t, β*), respectively. We will prove a concentration result of Ej.
First, we show the class of functions {Xj(t)Y (t) exp (XT(t)β*) : t ∈ [0, τ]} has bounded uniform entropy integral. By Lemma 9.10 of Kosorok (2007), the class ℱ = {Xj(t) : t ∈ [0, τ]} is a VC-hull class associated with a VC class of index 2. By Corollary 2.6.12 of van der Vaart and Wellner (1996), the entropy of the class ℱ satisfies log N(∈‖F‖Q,2, ℱ, L2(ℚ)) ≤ C′(1/∈) for some constant C′ > 0, and hence ℱ has the uniform entropy integral . By the same argument, we have that {exp{X(t)T β*} : t ∈ [0, τ]} also has a uniform entropy integral. Meanwhile, by example 19.16 of van der Vaart and Wellner (1996), {Y (t) : t ∈ [0, τ]} is a VC class and hence has bounded uniform entropy integral. Thus, by Theorem 9.15 of Kosorok (2007), we have {Xj(t)Y(t)exp{X(t)Tβ*} : t ∈ [0, τ]} has bounded uniform entropy integral.
Next, taking the envelop F as supt ∈ [0, τ] |Xj(t)Y (t) exp {XT (t)β*}|, by Lemma 19.38 of van der Vaart (2000),
for some positive constants C1 and C. By McDiarmid’s inequality, we have, for any Δ > 0,
for some positive constant C2 and L, and the desired result follows by taking a union bound over j = 1, …, d. □
Lemma C.2
Suppose the Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold, and . We have, for r = 0, 1, 2 and t ∈ [0, τ],
Proof
Similar to the previous Lemma, we only prove the case for r = 1, and the other two cases follow by the similar argument. For the case r = 1, we have
| (C.1) |
| (C.2) |
where (C.1) holds by the Assumption 2.1 for some constant CX > 0; (C.2) holds by Assumption 4.1 that and exp(|x|) ≤ 1+2|x| for any |x| sufficiently small, and the last equality holds by (2.2). Our claim holds as desired. □
Lemma C.3
Under Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3, there exists a positive constant C, such that with probability at least ,
Proof
By definition, we have, for all j = 1, …, d,
| (C.3) |
For the first term, we have for all t ∈ [0, τ],
| (C.4) |
By Assumption 2.1 and the fact that ℙ(y(τ) > 0) > 0, we have that for some constant C1 > 0. In addition,
where ℱj denotes the class of functions f: [0, τ] → ℝ which have uniformly bounded variation and satisfy supt∈[0,τ] |f(t) − ej(t)| ≤ δ1 for some δ1. By constructing ℓ∞ balls centered at piecewise constant functions on a regular grid, one can show that the covering number of the class ℱj satisfies for some positive constants C2, C3. Let . Note that for any two f1, f2, ∈ ℱj,
By Theorem 2.7.11 of van der Vaart and Wellner (1996), the bracketing number of the class satisfies , where . Hence, has bounded bracketing integral. An application of Corollary 19.35 of van der Vaart (2000) yields that
for some constant C4 > 0. Then, by McDiarmid’s inequality,
for some constant C5. Following by the union bound, we have with probability at least ,
Note that the second term of (C.3) is a sum of i.i.d. mean-zero bounded random variables. Following by the Hoeffding inequality and the union bound, we have with probability at least ,
for some constant C. The claim follows as desired. □
Lemma C.4
Under Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3, for any 1 ≤ j, k ≤ d, there exists a positive constant C, such that with probability at least ,
| (C.5) |
Proof
By the definitions of ∇2ℒ(β*) and H* in (2.5) and (2.7), we have
For the term T1, we have, with probability at least ,
where the last inequality follows by Lemma C.1. Next, by Assumption 2.1, we have
Consequently, T2 becomes an i.i.d. sum of mean 0 bounded random variables. Hoeffding’s inequality gives that with probability at least , . Meanwhile, the terms T3 and T4 can be bounded similarly. Our claim holds as desired. □
Lemma C.5
Under Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3, let be the estimator for β* estimated by (2.1) satisfying the result in (2.2) that with . Then, we have, for any with u ∈ [0, 1],
Proof
Let ξ = maxu≥0 maxi,i′ |∆T{Xi(u) − Xi′ (u)}|, where . By Lemma 3.2 of Huang et al. (2013), it holds that,
| (C.6) |
where A ⪯ B means that the matrix B − A is a positive semidefinite matrix.
Note that the diagonal elements of a positive semidefinite matrix can only be nonnegative. In addition, for a positive semidefinite matrix A ∈ ℝd×d, it is easy to see that . We have,
By (2.2) that , which implies that as is on the line segment connecting β* and . Hence, . By triangle inequality,
We consider the two terms separately, for the first term E1, we have, by (C.6) and taking the Taylor’s expansion of exp(2ξ),
Since , and by Assumption 4.3, we have,
and as . In addition, by Lemma C.4. It further implies that . □
Lemma C.6
Under Assumptions 2.1, 2.2 4.1, 4.2 and 4.3, it holds that
Proof
By triangle inequality, we have
It is seen that E1 = 0 by the definition of in (3.1). In addition, by Lemma C.5. For the term E3, we have
For the term E31, by the definition of ∇2ℒ(·) in (2.5), we have
For the term T1, we have
For ease of notation, in the rest of the proof, let and S*(r)(t): = S(r)(t, β*) for r = 0, 1, 2. We have, for the k-th component of T1,
Consequently, it holds that
where the last equality holds by Assumptions 2.1 and 4.1 that is bounded, S*(0)(t) is bounded away from 0, and by Lemma C.2 that .
The term T2 can be bounded by the similar argument, and our claim holds as desired. □
Lemma C.7
Under Assumptions 2.1 and 2.2, and if n−1/2s3 log d = o(1), the RE condition holds for the sample Hessian matrix . Specifically, for the vectors in the cone , we have
Proof
By Lemma 3.2 of Huang et al. (2013), we have exp(−2ξb)∇2ℒ(β) ⪯ ∇2ℒ(β+b), where ξb = maxu≥0 maxi,i′,k,k′ |bT{Xik(u) − Xi′k′(u)}|. Let . By Assumption 2.1 that ‖{Xik(u) − Xi′k′(u)}‖∞ ≤ CX, we have by (2.2), we have . By the scaling assumption that n−1/2s3 log d = o(1), we have . Consequently, exp(−2ξb) ≥ 1/2. We have . Since the cone is a subset of ℝd, our claim follows as desired. □
Lemma C.8
Under Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3, if
| (C.7) |
we have, the Dantzig selector defined in (3.2) satisfies
Proof
We first derive the result that the vector belongs to the cone . By our assumption (C.7), and since by the optimality condition of Dantzig selector in (D.2), we have
where we use the fact that .
By triangle inequality, we have
Summing up the above two inequalities, we have
| (C.8) |
Meanwhile, by the feasibility conditions of the Dantzig selector and w*, we have
| (C.9) |
By Lemma C.8, it holds that
which implies that
Consequently, we have
By (C.8), it holds that
as desired. □
D Extensions to Multivariate Failure Time Data
In real applications, it is also of interest to study multivariate failure time outcomes. For example, Cai et al. (2005) consider the time to coronary heart disease and time to cerebrovascular accident. In their study, the primary sampling unit is the family. Using multivariate model, it takes the advantage to incorporate the assumption that the failure times for subjects within a family are likely to be correlated. In this section, we extend our method to conduct inference in the high dimensional multivariate failure time setting.
To be more specific about the model, assume there are n independent clusters (families). Each cluster i contains Mi subjects, and for each subject, there are K types of failure may occur. Thus, it is reasonable to assume that the number K is fixed that does not increase with dimensionality d and sample size n. For example, Cai et al. (2005) study the time to coronary heart disease and the time to cerebrovascular accident where K = 2. Denote the covariates of the kth failure type of subject m in cluster i at time t by Xikm(t). The marginal hazards model is taken as
where the baseline hazard functions Λ0k(t)’s are treated as nuisance parameters, and the model is known as mixed baseline hazards model. Using this model, our inference procedures are conducted based on the pseudo-partial likelihood approach, since the working model does not assume any correlation for the different failure times within each cluster. The log pseudo-partial likelihood loss function is
where Yikm(t) and Nikm(t) denote the at risk indicator and the number of observed failure event at time t of the kth type on subject m in cluster i, and for each k. The penalized maximum pseudo likelihood estimator is
| (D.1) |
To connect the multivariate failure time model with Cox’s proportional hazards model, first, we observe that we can drop the index m. This is by the fact that, for each (i, m) where i ∈ {1, …n} and m ∈ {1, …, Mi}, we can map (i, m) to , and we define . It is not difficult to see the mapping is a bijection. After the mapping, the penalized estimator remains the same. Thus, without loss of generality, we assume Mi = 1 for all i, and we drop the index m. Next, we observe that the loss function is decomposable that
where
Thus, the loss function of multivariate failure time model can be decomposed into a sum of K loss functions of Cox’s proportional hazards models. However, the extension of the inference of the Cox model to multivariate failure time model is not trivial since the loss function is derived from a pseudo-likelihood function.
First, we extend the estimation procedure to the multivariate failure time model in the high dimensional setting, where we take . It is not difficult to obtain that (2.2) holds for the multivariate failure time model. An alternative approach is that we estimate β∗ using each type k of failure time independently. Specifically, we construct the estimator by
Since for each , by (2.2), it is readily seen that .
We extend the decorrelated score, Wald and partial likelihood ratio tests to the multivariate failure time model. We first introduce some notation. For k = 1, …, K,
where their corresponding population versions are
Next, we derive the gradient and Hessian matrix at the point β of the loss function,
and
The population version of the gradient and Hessian matrix are
and
For notational simplicity, let H∗ = H(β∗).
Note that, utilizing the decomposable structure, by the similar argument, the concentration results in Appendix C hold for the empirical gradient and Hessian matrix. We estimate the decorrelation vector by the following Dantzig selector
| (D.2) |
where δ is a tuning parameter. The rate of convergence of follows by the similar argument as in Lemma C.8.
We first introduce the decorrelated score test in multivariate failure time model. Suppose the null hypothesis is H0: α∗ = 0, and the alternative hypothesis is Hα: α∗ ≠ 0. The decorrelated score function is constructed similar to (3.3) that
| (D.3) |
The main technical difference between the multivariate failure time model and the univariate Cox’s model is that, the loss function of Cox’s model is a log profile likelihood function, and Bartlett’s identity holds. In multivariate case, this identity does not hold. We need the following lemma which is analogous to Lemma A.1. We omit the proof details to avoid repetition.
Lemma D.1
For any vector v ∈ ℝd if ‖v‖0 ≤ s′ and it holds that
By the similar argument as in Theorem 4.4, we derive the asymptotic normality of in the next theorem.
Theorem D.2
Suppose that Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold. Let be defined in (D.3). Under the null hypothesis that α∗ = 0 and if , , n−1/2s3 log d = o(1), we have
Proof
By the definition of and mean value theorem, we have, for some z, z′ ∈ [0, 1], and ,
Using Lemma D.1, taking b = (1, −w∗T)T and by the assumption that ‖w∗‖0 ≤ s0, it holds that
Following a similar proof as that in Theorem 4.4 and utilizing the separable in multivariate failure time model, we have and . This concludes our proof. □
Remark D.3
Under the assumptions of D.2, using plug-in estimator converges to σ2 at the rate of .
Next, we extend the decorrelated Wald test to the multivariate failure time model, which constructs confidence intervals for α*. We first estimate β* by ℓ1-penalized estimator . Let
We derive the asymptotic normality of in the next theorem.
Theorem D.4
Suppose Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold. For and n−1/2s3 log d = o(1) under the null hypothesis that α* = 0, we have
and σ2 = Ωαα−2w*T Ωθα + w*TΩθθw*, .
Proof
By the definition of , we have,
where the second equality holds by mean value theorem for some and υ ∈ [0, 1]. For the first term above, we have where Z ~ N(0, σ2/γ4) by Theorem D.2. In addition, and by the similar argument in Theorem 4.7. This concludes the proof. □
Finally, we extend the decorrelated partial likelihood ratio test to the multivariate failure time model. The test statistic is
Under the null hypothesis, the test statistic follows a weighted chi-squared distribution as shown in the following theorem.
Theorem D.5
Suppose Assumptions 2.1, 2.2, 4.1, 4.2 and 4.3 hold. If , and n−1/2s3 log d, under the null hypothesis α* = 0, we have
and σ2 = Ωαα−2w*T Ωθα + w*TΩθθw*, .
Proof
We have, by mean value theorem, for some , , and and 0 ≤ v1, v2, v3, v4 ≤ 1,
We first look at the term L. By Theorem D.2, we have , and by Theorem D.4 , we have
Next, we look at the term E,
By Theorem D.4, it holds that . In addition, by the similar argument as in Theorem 4.9, we have E2 = oℙ(n−1). Thus, we have
which concludes our proof. □
Footnotes
It is straightforward to extend the setting from univariate scalar to multivariate parameter vector.
Contributor Information
Ethan X. Fang, Email: xingyuan@princeton.edu.
Yang Ning, Email: yangning@princeton.edu.
Han Liu, Email: hanliu@princeton.edu.
References
- Alizadeh AA, Eisen MB, Davis RE, Ma C, Lossos IS, Rosenwald A, Boldrick JC, Sabet H, Tran T, Yu X, et al. Distinct types of diffuse large B-cell lymphoma identified by gene expression profiling. Nature. 2000;403:503–511. doi: 10.1038/35000501. [DOI] [PubMed] [Google Scholar]
- Andersen PK, Gill RD. Cox’s regression model for counting processes: a large sample study. Ann Statist. 1982:1100–1120. [Google Scholar]
- Antoniadis A, Fryzlewicz P, Letué F. The Dantzig selector in Cox’s proportional hazards model. Scand J Stat. 2010;37:531–552. [Google Scholar]
- Bradic J, Fan J, Jiang J. Regularization for Cox’s proportional hazards model with NP-dimensionality. Ann Statist. 2011;39:3092–3120. doi: 10.1214/11-AOS911. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cai J, Fan J, Li R, Zhou H. Variable selection for multivariate failure time data. Biometrika. 2005;92:303–316. doi: 10.1093/biomet/92.2.303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chernozhukov V, Chetverikov D, Kato K. Gaussian approximations and multiplier bootstrap for maxima of sums of high-dimensional random vectors. Ann Statist. 2013;41:2786–2819. [Google Scholar]
- Cox DR. Regression models and life-tables. J R Stat Soc Ser B Stat Methodol. 1972;34:187–220. [Google Scholar]
- Cox DR. Partial likelihood. Biometrika. 1975;62:269–276. [Google Scholar]
- Dawber TR. The Framingham Study: the epidemiology of atherosclerotic disease. Vol. 84. Harvard University Press; Cambridge: 1980. [Google Scholar]
- Di Gaetano N, Cittera E, Nota R, Vecchi A, Grieco V, Scanziani E, Botto M, Introna M, Golay J. Complement activation determines the therapeutic activity of rituximab in vivo. J Immunol. 2003;171:1581–1587. doi: 10.4049/jimmunol.171.3.1581. [DOI] [PubMed] [Google Scholar]
- Fan J, Li R. Variable selection for Cox’s proportional hazards model and frailty model. Ann Statist. 2002;30:74–99. [Google Scholar]
- Gui J, Li H. Penalized Cox regression analysis in the high-dimensional and low-sample size settings, with applications to microarray gene expression data. Bioinformatics. 2005;21:3001–3008. doi: 10.1093/bioinformatics/bti422. [DOI] [PubMed] [Google Scholar]
- Hiai H, Tsuruyama T, Yamada Y. Pre-B lymphomas in SL/Kh mice: A multi-factorial disease model. Cancer Science. 2003;94:847–850. doi: 10.1111/j.1349-7006.2003.tb01365.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang J, Sun T, Ying Z, Yu Y, Zhang C-H. Oracle inequalities for the Lasso in the Cox model. Ann Statist. 2013;41:1142–1165. doi: 10.1214/13-AOS1098. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Javanmard A, Montanari A. Confidence intervals and hypothesis testing for high-dimensional statistical models. NIPS. 2013:1187–1195. [Google Scholar]
- Kalbfleisch JD, Prentice RL. The statistical analysis of failure time data. Vol. 360. John Wiley & Sons; 2011. [Google Scholar]
- Kong S, Nan B. Non-asymptotic oracle inequalities for the high-dimensional Cox regression via Lasso. Stat Sinica. 2014;24:25–42. doi: 10.5705/ss.2012.240. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kosorok MR. Introduction to Empirical Processes and Semiparametric Inference. Springer: 2007. [Google Scholar]
- Lin W, Lv J. High-dimensional sparse additive hazards regression. J Amer Statist Asooc. 2013;108:247–264. [Google Scholar]
- Lockhart R, Taylor J, Tibshirani RJ, Tibshirani R, et al. A significance test for the Lasso. Ann Statist. 2014;42:413–468. doi: 10.1214/13-AOS1175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meierhoff G, Dehmel U, Gruss H, Rosnet O, Birnbaum D, Quentmeier H, Dirks W, Drexler H. Expression of FLT3 receptor and FLT3-ligand in human leukemia-lymphoma cell lines. Leukemia. 1995;9:1368–1372. [PubMed] [Google Scholar]
- Müller P, van de Geer S. Censored linear model in high dimensions. 2014 arXiv:1405.0579. [Google Scholar]
- Nishiu M, Yanagawa R, Nakatsuka S-i, Yao M, Tsunoda T, Nakamura Y, Aozasa K. Microarray analysis of gene-expression profiles in diffuse large b-cell lymphoma: Identification of genes related to disease progression. Cancer Science. 2002;93:894–901. doi: 10.1111/j.1349-7006.2002.tb01335.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shorack GR, Wellner JA. Empirical Processes with Applications to Statistics. Vol. 59. SIAM; 2009. [Google Scholar]
- Tibshirani R. The Lasso method for variable selection in the Cox model. Stat Med. 1997;16:385–395. doi: 10.1002/(sici)1097-0258(19970228)16:4<385::aid-sim380>3.0.co;2-3. [DOI] [PubMed] [Google Scholar]
- Tsiatis AA. A large sample study of Cox’s regression model. Ann Statist. 1981;9:93–108. [Google Scholar]
- van de Geer S, Bühlmann P, Ritov Y, Dezeure R. On asymptotically optimal confidence regions and tests for high-dimensional models. Ann Statist. 2014a;42:1166–1202. [Google Scholar]
- van de Geer S, Bühlmann P, Ritov Y, Dezeure R. On asymptotically optimal confidence regions and tests for high-dimensional models. Ann Statist. 2014b;42:1166–1202. [Google Scholar]
- van der Vaart AW. Asymptotic Statistics. Cambridge University Press; 2000. [Google Scholar]
- van der Vaart AW, Wellner JA. Weak Convergence and Empirical Processes. Springer: 1996. [Google Scholar]
- Wang S, Nan B, Zhu N, Zhu J. Hierarchically penalized Cox regression with grouped variables. Biometrika. 2009;96:307–322. [Google Scholar]
- Zhang C-H, Zhang SS. Confidence intervals for low dimensional parameters in high dimensional linear models. J R Stat Soc Ser B Stat Methodol. 2014;76:217–242. [Google Scholar]
- Zhang HH, Lu W. Adaptive Lasso for Cox’s proportional hazards model. Biometrika. 2007;94:691–703. [Google Scholar]
- Zhao SD, Li Y. Principled sure independence screening for Cox models with ultra-high-dimensional covariates. J Multivariate Anal. 2012;105:397–411. doi: 10.1016/j.jmva.2011.08.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.