

Abstract
Clustered data are common in biomedical research. Observations in the same cluster are often more similar to each other than to observations from other clusters. The intraclass correlation coefficient (ICC), first introduced by R. A. Fisher, is frequently used to measure this degree of similarity. However, the ICC is sensitive to extreme values and skewed distributions, and depends on the scale of the data. It is also not applicable to ordered categorical data. We define the rank ICC as a natural extension of Fisher’s ICC to the rank scale, and describe its corresponding population parameter. The rank ICC is simply interpreted as the rank correlation between a random pair of observations from the same cluster. We also extend the definition when the underlying distribution has more than two hierarchies. We describe estimation and inference procedures, show the asymptotic properties of our estimator, conduct simulations to evaluate its performance, and illustrate our method in three real data examples with skewed data, count data, and three-level ordered categorical data.
Keywords: clustered data, intraclass correlation, rank association measures
1 |. INTRODUCTION
With clustered data, observations in the same cluster are often more similar to each other than to those from other clusters. The degree of similarity is frequently measured by the intraclass correlation coefficient (ICC). R. A. Fisher first introduced the ICC to assess familial resemblance of a trait between siblings.1 The ICC has since been used in various disciplines including epidemiology, genetics, and psychology. It also has been employed in clinical trial design.2,3 Fisher’s ICC measures the correlation between a random pair of observations from a random cluster. When the cluster size is infinite, Fisher’s ICC is equal to the variance of cluster means divided by the total variance.4 Because of this, the ICC has also been estimated with random effects models, in which it is estimated as the proportion of total variance attributable to the clusters.5,6
The ICC is fundamental to the analysis of clustered data. However, similar to Pearson’s correlation, it is sensitive to extreme values and skewed distributions, and it depends on the scale of the data. When a variable is transformed to a different scale, the ICC may change. For some non-Gaussian distributions, the ICC might be estimated using generalized linear random effects models. In this case, the ICC is defined on the link function transformed scale and it may be sensitive to the non-normality of random effects or the method used to derive the within-cluster variance.7 The ICC is also not applicable to ordered categorical data. For ordered categorical data, ordinal regression models with random effects may be used to estimate variance components, but the total variance is undefined unless numbers are assigned to levels of the ordinal response.8,9
Several studies have proposed nonparametric measures to evaluate intraclass similarity based on the notion of concordance. One measure is the probability that a random observation from a cluster does not fall between a random pair of observations from a different cluster 10 Another measure is the probability that a random pair of observations from a cluster does not fall between two random observations each from a different cluster.11 Shirahata performed comparisons between the two measures and a modification of Kendall’s measure of dependence.12 All three measures are rank-based; however, they are probabilities of concordance and do not share the same spirit as Fisher’s ICC, which is a correlation measure. Methods to estimate the ICC for categorical data have been developed, 13 but they ignore the order information when applied to ordered categorical data.
In this paper, we define the rank ICC as a natural extension of Fisher’s ICC to the rank scale. We provide its population parameter and extend it when the underlying distribution has more than two hierarchies. Our estimator of the rank ICC is insensitive to extreme values and skewed distributions, and does not depend on the scale of the data. It can be used for ordered categorical variables. We also show that our estimator is consistent and asymptotically normal.
This paper is organized as follows. Section 2 introduces population parameters for the rank ICC. Section 3 contains estimation and inference. Section 4 presents simulations evaluating the performance of our estimator. Section 5 illustrates our method in three applications. Section 6 provides a discussion. Proofs of consistency and asymptotic normality are in the Supporting Information. We have developed an R package, rankICC, available on CRAN, which implements our new method. The R script for the three application examples and simulations is on our Github page, https://github.com/shengxintu/rankICC.
2 |. POPULATION PARAMETERS
2.1 |. Two hierarchies
Consider a two-level hierarchical distribution. A random variable from the distribution is denoted as , where represents the cluster it belongs to and is the index within cluster . Fisher defined the ICC as the correlation between a random pair from the same cluster; that is, , where , indicating that two different observations are drawn from cluster . For a continuous hierarchical distribution, the ICC has also been expressed as the ratio of the between-cluster variance to the total variance;14 , where is the between-cluster variance (ie, the variance of cluster means), and is the within-cluster variance (ie, the mean of within-cluster variances). These two definitions are equivalent only when cluster sizes are infinite. In general, the relationship between these two definitions is
| (1) |
where is a random variable representing the mean of cluster . If cluster sizes are finite, because in (1) is negative. With equal cluster sizes of , the value of is constrained between and 1.1 Note that can be negative when cluster sizes are finite, whereas is always non-negative. While is a correlation measure, is a measure of the fraction of total variance attributable to cluster means. Hence, is a more general measure of the intraclass correlation.
The rank ICC, to be defined below, is the rank-based version of Fisher’s ICC, similar to Spearman’s rank correlation which is the rank-based version of Pearson’s correlation.15 The relationship between the population parameters of Fisher’s ICC and the rank ICC is identical to the relationship between those of Pearson’s correlation and Spearman’s rank correlation. The population parameters of Fisher’s ICC and Pearson’s correlation are correlations on the original scale of the variables, while the population parameter of Spearman’s rank correlation is the grade correlation (ie, the correlation between CDFs) for continuous variables,15 or more generally, the correlation of the population versions of midranks or ridits.16,17
Let be the CDF of the two-level hierarchical distribution. Let and . The population version of the rank ICC is defined as
| (2) |
where is a random pair drawn from a random cluster and . If is continuous, , because and its variance is 1/12. If has a discrete or mixture distribution, corresponds to the population version of ridits.16 The rank ICC given in (2) is therefore Fisher’s ICC on the cumulative probability scale. The rank ICC has the same boundaries as Fisher’s ICC and can be negative with finite cluster sizes.
2.2 |. Multiple hierarchies
We extend the definition of the rank ICC to multiple hierarchies. For ease of understanding, we begin with three hierarchies. Starting from the innermost level, the three levels are named level 1, level 2, and level 3. One example is a population of schools, in which there are different classrooms and different students within each classroom. Here level 1 is the student, level 2 is the classroom, and level 3 is the school. Correlation may exist within both level-2 and level-3 units. A random variable drawn from a three-level hierarchical distribution is denoted as , where , and are indices for levels 3, 2, and 1, respectively. Let be the CDF of the three-level hierarchical distribution and . The rank ICC at level 2, denoted as , measures the correlation between a random pair of level −1 observations from the same level-2 unit. It is defined as
| (3) |
where . The rank ICC at level 3, denoted as , measures the correlation between a random pair of level-1 observations from the same level-3 unit but different level-2 units. It is defined as
| (4) |
where but and can be equal or different. At level 3, there are two potential sources of within-cluster correlation: one due to different level-2 units within the same level-3 unit and the other due to different level-1 units within the same level-2 unit. Our definition of captures the former; the latter has already been captured by . If we were to ignore the second level and consider the rank correlation between two random level-1 units from the same level-3 unit irrespective of their level-2 information, the resulting definition would reflect both sources of correlation, which is not ideal; it could be quite different from with a small number of level-2 units within each level-3 unit. Our rank ICC definitions given by (3) and (4) have comparable interpretations to previously proposed definitions of ICC for 3 hierarchies on the original scale.18
The general definition of the rank ICC for a multiple-level hierarchical distribution can be similarly defined. Let be the number of hierarchies and denote a random variable from a -level hierarchical distribution, where are indices for levels , respectively. The CDF of the -level hierarchical distribution is denoted as , and . The rank ICC at level measures the correlation between level-1 observations from the same level- unit and different level- unit:
| (5) |
where , and for , and can be the same or different.
3 |. ESTIMATION AND INFERENCE
3.1 |. Estimation
Since the rank ICC can be viewed as a function of the underlying distribution , then our estimator of is . Given two-level data with a total number of observations of , a nonparametric estimator of the CDF is , where is the weight of observation and . The weight depends on how we believe the data reflect the composition of the underlying hierarchical distribution; for example, corresponds to equal weights for clusters and corresponds to equal weights for observations. Other weighting options will be described later in this section. The weight of cluster is denoted as . Similarly, we estimate , and define . Then our estimator of is , where is a random pair drawn from a random cluster and .
Because the rank ICC measures the correlation of a random pair from the same cluster, we could consider Monte Carlo estimation. That is, we first randomly select clusters with replacement and then randomly draw pairs of observations from the selected clusters. Then could be estimated as the sample correlation of between the sampled pairs of observations. As the number of sampled pairs increases, the estimate of this approach will converge to a limit, which is our estimator:
| (6) |
where , and is the number of possible unordered pairs in cluster .
The estimator given by (6) is consistent for and is asymptotically normal. The proof of consistency and asymptotic normality and the variance estimation of are in the Supporting Information. The results allow us to compute standard errors (SEs) of and to construct confidence intervals (CIs) for .
The selection of weights, , warrants additional discussion. For populations with finite and unequal cluster sizes, if there is ambiguity in the relative contributions of clusters in a hierarchical distribution, then the rank ICC can have some ambiguity. One could assume all clusters have an equal contribution regardless of their cluster sizes, in which case it would be sensible to set . Or one could assume the relative contributions are proportional to cluster sizes, in which case it would be sensible to set . The choice of should be driven by subject matter knowledge. For example, if one is measuring the repeatability of an assay by collecting specimens (one per person) and measuring them multiple, unequal numbers of times, then it seems sensible to assume the clusters (people) contribute equally in the population. In contrast, if one is interested in the correlation of a trait between individuals within the same family, then it may (or may not) be sensible to assume each family contributes proportionally to the family size. These two weighting approaches have been applied to estimating the ICC on the original scale under variable cluster sizes.19 For perfectly balanced data, is the same regardless of the weighting approach used.
However, in practice, there is often uncertainty in how we should assume clusters contribute to the underlying distribution and we may want to consider different weighting schemes. In fact, there may be bias-variance considerations that might suggest using weights that do not exactly match the true cluster contributions. For example, consider a population with equal cluster contribution. When is close to zero, observations in the same cluster are almost independent, so treating all observations equally regardless of the cluster size can be more efficient than weighting observations inversely proportional to the size of their cluster. In contrast, when is close to one, observations in the same clusters are almost redundant, favoring equal weight per cluster. But whether is close to zero or one is often unknown before analysis. Therefore, one might use an iterative procedure to identify a more efficient weighting scheme. One approach is to use a linear combination of the two weights above, where the combination depends on the value of ; that is, . We call this the combination approach. Another approach is to compute the effective sample size (ESS)20 for the clusters (ie, and weight clusters and their observations in clusters accordingly; that is, and . We call this second approach the ESS approach. These approaches require a working value of . We implement iterative procedures in which we (a) start with an initial value of , (b) update the weights, and (c) compute a new estimate of . We repeat steps (b) and (c) multiple times until the estimate of converges. Our simulations suggest that the choice of the initial value has no effect on the final estimate.
With three or more hierarchies, the estimation of the rank ICC is similar to that described above for two hierarchies. Given three-level nested data , the nonparametric estimator for the CDF is , where . Similarly, . Let . The general form of the estimator of is
| (7) |
where and . The general form of the estimator of is
| (8) |
where , and is the total number of possible unordered pairs in a level-3 unit; . We show the asymptotic normality and consistency of and in the Supporting Information. There are several options for with three-level data, such as assigning equal weights to all level-1 units (ie, , assigning equal weights to all level-2 units (ie, , or assigning equal weights to all level-3 units (ie, .
3.2.|. Inference
The distribution of can be approximated using asymptotics. The asymptotic standard error (SE) of , presented in the Supporting Information, can be used to construct confidence intervals for under normality. Because is bounded, one might also consider estimating the large sample distribution of the Fisher transformed value (ie, by the delta method to obtain confidence intervals.21
An alternative approach for estimating the distribution of is bootstrapping. There are two general ways to implement bootstrapping in clustered data; the cluster bootstrap and the two-stage bootstrap.22,23 In the cluster bootstrap, clusters are randomly selected with replacement. The two-stage bootstrap has an extra step, where in the selected clusters the observations are randomly drawn with replacement. In our setting, this intracluster sampling in the two-stage bootstrap can cause positive bias in estimating , because the same observation may be sampled twice in a two-stage bootstrap sample, thus inflating the estimated ICC, particularly in settings with smaller cluster sizes. Hence, we recommend using the cluster bootstrap for bootstrapping.
The standard errors of and with three hierarchies can be similarly computed. We have derived analytic formulas for asymptotic SEs of and given by (7) and (8) in the Supporting Information. In addition, one could bootstrap. Considering computational efficiency and the bias caused by intracluster sampling with replacement, we suggest a one-stage bootstrap for bootstrapping with three hierarchies; that is, only sampling level-3 units with replacement.
4 |. SIMULATIONS
A simple additive model was used to generate two-level data: , where and with varying in [0, 1]. Let be the observation of the jth individual in the ith cluster, where ; and is the cluster size of the ith cluster. We considered three scenarios: (I) ; (II) ; (III) , where ’s are i.i.d. following a log-normal distribution such that and ). In Scenarios I and II, since is normally distributed, the rank ICC is .24 The rank ICC is identical in Scenarios I and II while Fisher’s ICC, , is sensitive to skewness and depends on the scale of interest (Figure 1). When the variable of interest is normal (Scenario I), is close to . In Scenario III, is not normally distributed so we empirically computed by generating a million clusters each with 2 observations, and then computing Spearman’s rank correlation.
FIGURE 1.

Parameters of rank ICC and Fisher’s ICC as a function of the within-cluster correlation of under normality (Scenario I) and after exponentiating the data (Scenario II).
We first evaluated the performance of our estimator of for two-level data. The simulations were conducted at different sample sizes , and 1000 with an equal cluster size . Furthermore, we also performed simulations with various configurations of cluster size at uniformly ranging from 2 to 50; and for half of the clusters and for the other half. Unless stated otherwise, for estimation, we assigned equal weights to clusters (ie, ), which corresponds with the underlying equal cluster contribution in the simulated hierarchical distribution. We computed 95% confidence intervals for using the asymptotic SE and bootstrapping.
The bias of our estimator and the coverage of 95% CIs based on the asymptotic SE under the different scenarios described above are shown in Figures 2 and 3. In summary, our estimator of had very low bias and good coverage with modest numbers of clusters across all scenarios we considered. It was also robust to the skewed data in Scenarios II and III. Although our estimator had slightly negative bias with a small number of clusters, this bias decreased as the number of clusters increased. Confidence intervals for based on the asymptotic SE approximately covered at their nominal 0.95 level with ≥200 clusters for all true values of . For smaller values of , coverage could be low for ≤100 clusters. Fisher transformation did not appear to improve coverage (Web Figure 1). The performance of estimators was fairly similar regardless of the size of clusters (Figure 3). Additional simulations reported in Web Tables 1–5 show that confidence intervals based on both the cluster bootstrap SE and percentiles had good coverage.
FIGURE 2.

Bias and coverage of 95% confidence intervals for our estimator of at different true values of and different numbers of clusters under Scenarios I (normality), II (exponentiated outcomes), and III (exponentiated cluster means). The number of observations per cluster was set at 30.
FIGURE 3.
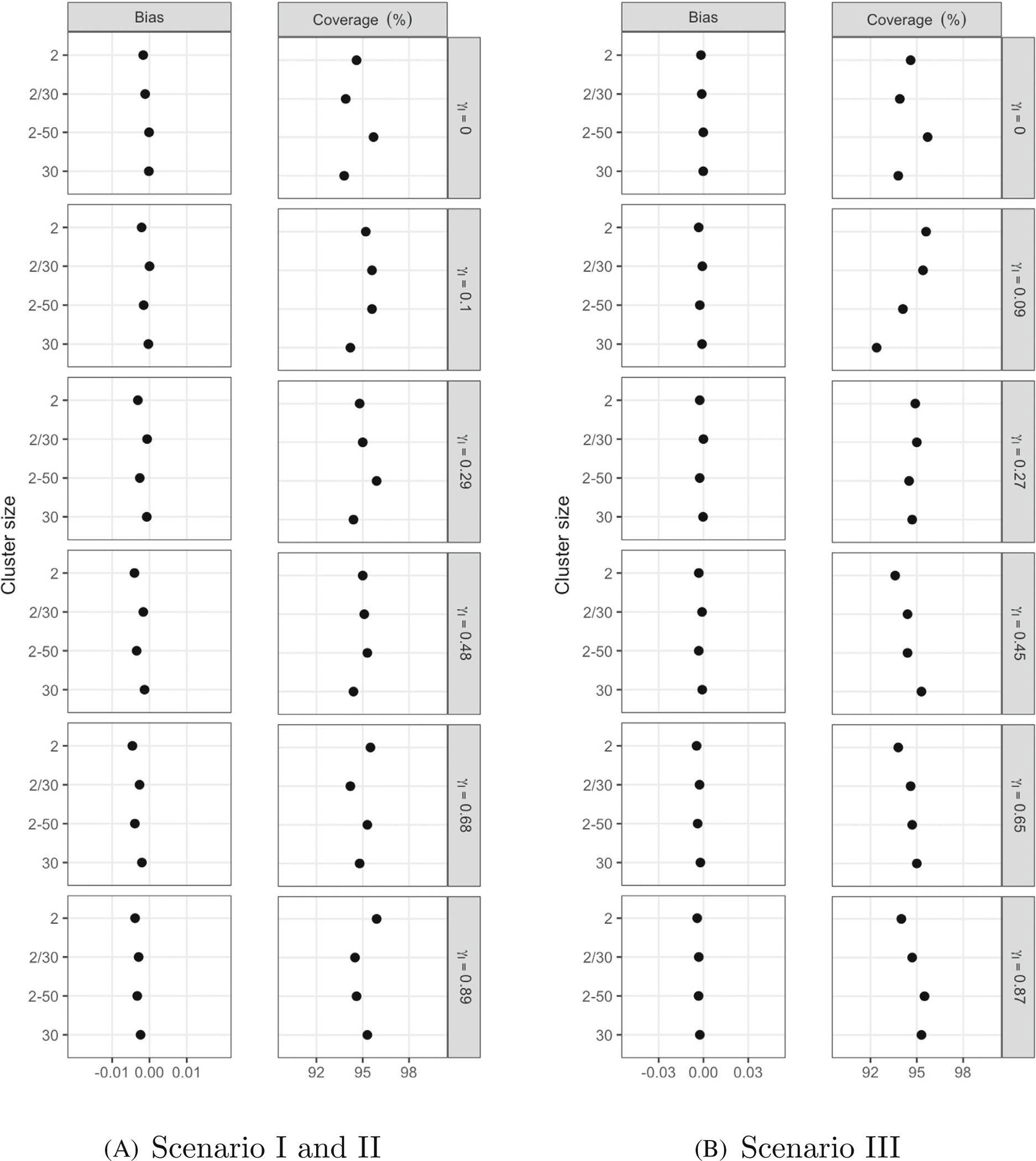
Bias and coverage of 95% confidence intervals for our estimator of at different true values of and different cluster sizes under Scenarios I (normality), II (exponentiated outcomes), and III (exponentiated cluster means). The number of clusters was set at 200. “2–50” means the cluster size follows a uniform distribution from 2 to 50, “2/30” means half of the clusters have size 2 and half have 30.
We then evaluated the performance of our estimator of when the cluster size is 2 in the population and the rank ICC varies between −1 and 1. Let and be the two observations in cluster . We generated the two observations in cluster as follows: and , where , ), and varies over [−1, 1] (we set and when ). We conducted 1000 simulations at . Our estimator of had low bias and good coverage (Figure 4).
FIGURE 4.

Bias and coverage of 95% confidence intervals for our estimator of at different true positive and negative values of when the cluster size in the population was 2. The number of clusters was set at 200.
We next compared the performance of the four weighting approaches with (1) equal within-cluster variances and equal or unequal cluster sizes, and (2) within-cluster variances varying by cluster size. For (1), we used the same simulations described in the first paragraph of this section. For (2), we supposed the numbers of small clusters of size 2 and large clusters of size 30 are equal in the population, and simulated the data as , with , where for small clusters and for large clusters and varying over [0, 1]. We conducted 1000 simulations at . Results of the two sets of simulations are shown in Figure 5 and Web Figure 2. When cluster sizes were equal and within-cluster variances were equal, the estimates of the four weighting approaches were identical. When cluster sizes were unequal and within-cluster variances were equal, the four methods all had low bias and their mean squared errors were dominated by their variances. As hypothesized, assigning equal weights to clusters had the lowest efficiency when the rank ICC was close to zero, because treating large and small clusters equally resulted in lost information, even though the data were simulated in a manner such that equal cluster weighting matched the cluster contribution in the population. In contrast, when within-cluster variances varied by cluster sizes, assigning equal weights to observations contrary to the underlying distribution led to bias. The two iterative approaches had lower mean squared errors than assigning equal weights to clusters or to observations when the rank ICC was close to zero.
FIGURE 5.

Root mean squared error (RMSE), bias, and empirical SE of estimates obtained by the four weighting approaches for our estimator of . “Equal clusters” refers to assigning equal weights to clusters, “Equal obs” refers to assigning equal weights to observations, “ESS” refers to the iterative weighting approach based on the effective sample size, and “Combination” refers to the iterative weighting approach based on the linear combination of equal weights for clusters and equal weights for observations. We set the tolerance of the two iterative approaches to 0.00001.
We also evaluated the performance of our estimator of for ordered categorical variables. We simulated data of 3-level, 5-level, and 10-level ordered categorical variables by discretizing in Scenario I with cut-offs at quantiles (ie, using the 1/3 and 2/3 quantiles for 3 levels; the 0.2, 0.4, 0.6, 0.8 quantiles for 5 levels; and the 0.1, 0.2, …, 0.8, 0.9 quantiles for 10 levels). Similar to Scenario III, we empirically computed for the ordered categorical variables (Figure 6). The rank ICCs of the 5-level and 10-level variables are close to the rank ICC of the continuous variable, while the rank ICC of the 3-level variable is slightly smaller. We conducted simulations for 3-level and 10-level ordered categorical variables at different sample sizes , and 1000 with an equal cluster size . Our estimator of of the ordered categorical variables generally had low bias and good coverage (Web Figure 3).
FIGURE 6.

Parameters of rank ICC as a function of the within-cluster correlation of when data are continuous or discretized into ordered categorical variables with 3,5, or 10 levels.
We also investigated the performance of our estimators of and for data with three hierarchies. Let be the observation of the kth level-1 unit in the jth level-2 unit and the ith level-3 unit, where , . We generated three-level data as follows: , where , , , and , . Because of normality, the true rank ICCs are arcsin and . We conducted 1000 simulations for different sample sizes , and 1000 under equal cluster sizes (ie, and ). Moreover, we also performed simulations under various patterns of cluster sizes: , where “ 2–15 “ means the cluster size follows a uniform distribution from 2 to 15, “2/15” means half of the clusters have size 2 and a half have 15. The results for and are shown in Figure 7, and the other results are in Web Figures 3 and 4 and Web Tables 6 and 7. Our estimators of and had very low bias and good coverage in all cases we considered. The asymptotic SE and the one-stage bootstrap had good performance in constructing confidence intervals, and the former was computationally efficient.
FIGURE 7.

Bias and coverage of 95% confidence intervals for our estimators of and at different true values of and and different numbers of level-3 units. The number of level-2 units in a level-3 unit was set at 15. The number of level-1 units in a level-2 unit was set at 2.
5 |. APPLICATIONS
5.1 |. Albumin-creatinine ratio
In a cross-sectional study, 598 people living with HIV in Nigeria on stable dolutegravir-based antiretroviral therapy provided first-morning void urine specimens at two visits 4 to 8 weeks apart.25 The collected urine specimens were used to calculate the urine albumin-creatinine ratio (uACR). There is interest in estimating the intraclass correlation of uACR. Each patient is considered a cluster, and each cluster has two observations. The uACR measurements are right-skewed, and the empirical distributions of the first and second UACR measurements were comparable (Figure 8). The rank ICC estimate was 0.217 (95% CI: 0.140–0.295, Table 1). The traditional ICC estimate on the original scale obtained from a random effects model was 0.493, which was driven by a single pair of measurements with extreme values. After removing that pair, the rank ICC estimate was almost unchanged (0.213, 95% CI: 0.136–0.291) while the traditional ICC on the original scale dropped dramatically to 0.160, illustrating the robustness of the rank ICC compared to the traditional ICC. Instead of removing extreme observations, one could consider transforming the data. The traditional ICC estimate was 0.254 after log transformation and 0.345 after square root transformation, illustrating the sensitivity of the traditional ICC to the choice of scale.
FIGURE 8.

Scatter plot of the first and second uACR measurements of each person in the example of albumin-creatinine ratio.
TABLE 1.
Estimates of rank ICC and traditional ICC of uACR in the example of albumin-creatinine ratio.
| Original data | Extreme values removed | Log transformation | Square root transformation | |
|---|---|---|---|---|
| Rank ICC [95% CI] | 0.217 [0.140, 0.295] | 0.213 [0.136, 0.291] | 0.217 [0.140, 0.295] | 0.217 [0.140, 0.295] |
| ICC | 0.493 | 0.160 | 0.254 | 0.345 |
5.2 |. Status epilepticus
The Bridging the Childhood Epilepsy Treatment Gap in Africa (BRIDGE) study is a noninferiority randomized clinical trial of childhood epilepsy care at 60 randomly selected primary healthcare centers (PHCs) in northern Nigeria.26 The trial is designed to understand if task-shifting childhood epilepsy treatment by trained community health workers can be as effective at reducing seizures as treatment by trained physicians. The study recruited 1507 children with untreated epilepsy from the participating PHCs. Each child’s number of seizures in the six months prior to randomization was collected (Figure 9), with a median of 10 (range 1–50). There is interest in estimating the ICC for the number of seizures across PHCs. Cluster size ranged from 19 to 31 children per PHC. Since the PHCs were the units of randomization in this study, it seems reasonable to treat them equally. The rank ICC based on assigning equal weights to clusters was estimated as 0.0482 (95% CI: 0.023–0.073), which suggested low association between the number of seizures in children within a PHC (Table 2). Other methods of weight assignment yielded similar estimates: assigning equal weights to children resulted in an estimate of 0.0514 (95% CI: 0.025–0.078), the ESS weighting approach yielded 0.0496 (95% CI: 0.024–0.075), and the combination weighting approach resulted in 0.0512 (95% CI: 0.025–0.078). For comparison, the ICC estimated using a linear random effects model was 0.0426, and the ICCs estimated using generalized linear random effects models were 0.0268 (quasi-Poisson) and 0.0168 (negative binomial).7
FIGURE 9.

Histogram of numbers of seizures of children with untreated epilepsy from the 60 primary healthcare centers in the example of status epilepticus.
TABLE 2.
Estimates of rank ICC and traditional ICC for the number of seizures across the primary healthcare centers in the sample of status epilepticus.
| Equal weights for clusters | 0.0482 [0.023, 0.073] | |
| Rank ICC [95% CI] | Equal weights for observations | 0.0514 [0.025, 0.078] |
| Iterative weighting based on the effective sample size | 0.0496 [0.024, 0.075] | |
| Iterative weighting based on the combination | 0.0512 [0.025, 0.078] | |
| Linear | 0.0426 | |
| ICC | Quasi-Poisson link | 0.0268 |
| Negative binomial link | 0.0168 |
5.3 |. Patient health Questionaire-9 score
In a third example, we used baseline data from the Homens para Saúde Mais (HoPS+) study, a clustered randomized controlled trial in Zambézia Province, Mozambique.27 The trial aimed to measure the impact of incorporating male partners with HIV into prenatal care for pregnant women living with HIV on retention in care, adherence to treatment, and mother-to-child HIV transmission. The trial enrolled 813 couples living with HIV (with a pregnant female) at 24 clinical sites. Depressive symptoms at the time of study enrollment were evaluated with the Patient Health Questionaire-9 (PHQ-9), a nine-item scale that measures depressive symptoms over the previous two weeks. The ordinal PHQ-9 score had a median of 2 (interquartile range 0–5), ranging from 0 to 27 (Figure 10). The data have three levels: the innermost level is the person, the middle level is the couple, and the outer level is the clinical site. The number of couples at a clinical site ranged from 2 to 68. Our estimates assigned equal weights to couples. The estimated rank ICC at the couple level, , was 0.678 (95% CI: 0.518–0.838), suggesting substantial clustering of PHQ-9 scores within couples (Table 3). The estimated rank ICC at the clinical site level, , was 0.397 (95% CI: 0.242–0.552), which was higher than expected, suggesting a fairly high correlation within clinics. This was confirmed by the estimated rank ICC among females at the clinical level (0.418, 95% CI: 0.260–0.576) and among males (0.395, 95% CI: 0.243–0.548). For comparison, the ICC estimates obtained from a linear random effects model were 0.792 at the couple level and 0.474 at the clinical site level, both larger than their rank ICC counterparts.
FIGURE 10.

Scatter plot of PHQ-9 scores of male and female partners enrolled in the clustered randomized clinical trial in the example of Patient Health Questionaire-9 score.
TABLE 3.
Estimates of rank ICC and traditional ICC of PHQ-9 score at the couple level and the clinical site level in the example of Patient Health Questionaire-9 score.
| The couple level | The clinical site level | Females at the clinical level | Males at the clinical level | |
|---|---|---|---|---|
| Rank ICC [95% CI] | 0.678 [0.518, 0.838] | 0.397 [0.242, 0.552] | 0.418 [0.260, 0.576] | 0.395 [0.243, 0.548] |
| ICC | 0.792 | 0.474 | 0.452 | 0.497 |
6 |. DISCUSSION
In this paper, we defined the rank ICC as a natural extension of Fisher’s ICC to the rank scale, and described its population parameter. Our approach maintains the spirit of Fisher’s ICC while creating a nonparametric rank ICC measure analogous to Spearman’s rank correlation. The rank ICC is simply interpreted as the rank correlation between a pair of observations from the same cluster. We also extended the rank ICC for distributions with more than two hierarchies (ie, Equation (5)). Our estimator of the rank ICC is insensitive to extreme values and skewed distributions, and does not depend on the scale of the data. It is also consistent and asymptotically normal, with low bias and good coverage in our simulations. Our framework is general, and applicable to any orderable variables with estimable distributions.
We also discussed assigning weights to clusters and observations under different cases when estimating the rank ICC for two-level data with heterogeneous cluster sizes. In general, the selection of weights should be driven by subject matter knowledge. However, in practice, there may be uncertainty in how clusters contribute to the underlying distribution, and efficiency considerations might guide the choice of weights.
There is a relationship between the rank ICC and Spearman’s rank correlation when the cluster size is two. With two ordered observations per cluster following the same marginal distribution, the population parameter of the rank ICC is mathematically equal to that of Spearman’s rank correlation between the first and second observations. However, their estimation procedures differ; in estimating Spearman’s rank correlation, we separately estimate the variances and means of the first and second observations, but in estimating , we pool the data to estimate their overall variance and mean. For example, in the albumin-creatinine ratio study, the estimate of Spearman’s rank correlation between the first and second uACR measurements was 0.236, close but not equal to the rank ICC estimate, 0.217.
Our rank ICC fills an important gap in the analysis of clustered data. Given Fisher’s introduction of the ICC nearly 100 years ago, we are surprised that a rank-based ICC has not been developed until now. We suspect that some researchers may have simply ranked their data and then used the ratio of the between-cluster and total variances on the rank scale as a rank-based ICC measure, as suggested by others for ordered categorical data.8,9 Although not completely unreasonable, such an approach is ad hoc and does not correspond with a sensible population parameter. Alternatively, some researchers may prefer estimating the similarity within clusters via constructing models for continuous and ordered categorical clustered data, in particular random effects models.28–30 With linear mixed models, the ICC is calculated using estimates of the variance of the random effects and the residuals. These model-derived ICC estimates may be sensitive to the choice of the model: for example, the form of the linear predictor, potential response variable transformation, non-normality of residuals, and/or non-normality of random effects. With generalized random effects models (eg, for count or ordinal response variables), the ICC is evaluated on the continuous latent variable scale after a link transformation, which complicates interpretation and remains sensitive to model choice.29 These models may also be sensitive to the method used to derive the within-cluster variance.7 In contrast, our rank ICC does not require fitting a model and provides a simple and interpretable one-number summary of within-cluster similarity across many types of variables.
Our rank ICC has some limitations. It does not adjust for the effect of other variables on within-cluster similarity. For example, in the status epilepticus study (Section 5.2), there may be interest in measuring the intraclass correlation after adjusting for child age. Our rank ICC cannot do this, whereas a model-derived ICC estimate can. Future work could consider extensions to develop covariate-adjusted conditional and partial rank ICCs. An additional limitation is that our rank ICC appears to have slightly negative bias with small numbers of clusters when is large; this problem goes away as the number of clusters increases. Furthermore, our rank ICC can be time-consuming to calculate with very large sample sizes. In such settings, analysts may consider empirically estimating the rank ICC by randomly sampling clusters with replacement, then sampling pairs of observations from the selected clusters, and finally estimating Spearman’s correlation across many sampled pairs.
Future work could consider the use of the rank ICC in designing clustered randomized controlled trials for skewed or ordered categorical outcomes.
Supplementary Material
ACKNOWLEDGEMENTS
We would like to thank the study investigators for providing data used in our example applications. This study was supported in part by funding from the National Institutes of Health (R01AI093234; U01DK112271 for Nigerian uACR study; R01NS113171 for BRIDGE; and R01MH113478 for HoPS+).
Funding information
National Institutes of Health, Grant/Award Numbers: R01AI093234, R01MH113478, R01NS113171, U01DK112271
Footnotes
CONFLICT OF INTEREST STATEMENT
The authors declare no potential conflict of interest.
SUPPORTING INFORMATION
Additional supporting information can be found online in the Supporting Information section at the end of this article.
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are available from the corresponding author upon reasonable request.
REFERENCES
- 1.Fisher R. Statistical Methods for Research Workers. Edinburgh: Oliver & Boyd; 1925. [Google Scholar]
- 2.Murray DM, Varnell SP, Blitstein JL. Design and analysis of group-randomized trials: a review of recent methodological developments. Am J Public Health. 2004;94(3):423–432. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Hedges LV, Hedberg EC. Intraclass correlation values for planning group-randomized trials in education. Educ Eval Policy Anal. 2007;29(1):60–87. [Google Scholar]
- 4.Harris JA. On the calculation of intra-class and inter-class coefficients of correlation from class moments when the number of possible combinations is large. Biometrika. 1913;9(3/4):446–472. [Google Scholar]
- 5.Shrout P, Fleiss J. Intraclass correlations: uses in assessing rater reliability. Psychol Bull. 1979;86(2):420–428. [DOI] [PubMed] [Google Scholar]
- 6.Donner A. A review of inference procedures for the intraclass correlation coefficient in the one-way random effects model. Int Stat Rev. 1986;54(1):67–82. [Google Scholar]
- 7.Nakagawa S, Johnson PCD, Schielzeth H. The coefficient of determination R2 and intra-class correlation coefficient from generalized linear mixed-effects models revisited and expanded. J R Soc Interface. 2017;14:20170213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Hallgren K. Computing inter-rater reliability for observational data: an overview and tutorial. Tutor Quant Methods Psychol. 2012;8:23–34. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Denham B. Categorical Statistics for Communication Research. Ltd: John Wiley and Sons; 2016. [Google Scholar]
- 10.Rothery P. A nonparametric measure of intraclass correlation. Biometrika. 1979;66(3):629–639. [Google Scholar]
- 11.Shirahata S. Intraclass rank tests for independence. Biometrika. 1981;68(2):451–456. [Google Scholar]
- 12.Shirahata S. Nonparametric measures of intraclass correlation. Commun Stat Theory Methods. 1982;11:1707–1721. [Google Scholar]
- 13.Chakraborty H, Solomon N, Anstrom KJ. A method to estimate intra-cluster correlation for clustered categorical data. Commun Stat Theory Methods. 2021;52(2):429–444. [Google Scholar]
- 14.Fieller E, Smith C. Note on the analysis of variance and intraclass correlation. Ann Eugenics. 1951;16:97–104. [DOI] [PubMed] [Google Scholar]
- 15.Kruskal WH. Ordinal measures of association. J Am Stat Assoc. 1958;53(284):814–861. [Google Scholar]
- 16.Bross IDJ. How to use ridit analysis. Biometrics. 1958;14:18–38. [Google Scholar]
- 17.Kendall M. Rank Correlation Methods. London: Charles Griffin; 1970. [Google Scholar]
- 18.Siddiqui O, Hedeker D, Flay BR, Hu FB. Intraclass correlation estimates in a school-based smoking prevention study. Outcome and mediating variables, by sex and ethnicity. Am J Epidemiol. 1996;144(4):425–433. [DOI] [PubMed] [Google Scholar]
- 19.Karlin S, Cameron EC, Williams PT. Sibling and parent-offspring correlation estimation with variable family size. Proc Natl Acad Sci U S A. 1981;78(5):2664–2668. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Kish L. Survey Sampling. London: Wiley; 1965. [Google Scholar]
- 21.Fisher RA. Frequency distribution of the values of the correlation coefficient in samples from an indefinitely large population. Biometrika. 1915;10(4):507–521. [Google Scholar]
- 22.Davison AC, Hinkley DV. Bootstrap Methods and Their Application. Cambridge Series in Statistical and Probabilistic. Cambridge: Mathematics Cambridge University Press; 1997. [Google Scholar]
- 23.Field CA, Welsh AH. Bootstrapping clustered data. J R Stat Soc Ser B Stat Methodol. 2007;69(3):369–390. [Google Scholar]
- 24.Pearson KG. On Further Methods of Determining Correlation. Cambridge: Cambridge University Press; 1907. [Google Scholar]
- 25.Wudil U, Aliyu M, Prigmore H, et al. Apolipoprotein-1 risk variants and associated kidney phenotypes in an adult HIV cohort in Nigeria. Kidney Int. 2021;100:146–154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Aliyu MH, Abdullahi AT, Iliyasu Z, et al. Bridging the childhood epilepsy treatment gap in northern Nigeria (BRIDGE): Rationale and design of pre-clinical trial studies. Contemp Clin Trials Commun. 2019;15:100362. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Audet CM, Graves E, Barreto E, et al. Partners-based HIV treatment for seroconcordant couples attending antenatal and postnatal care in rural Mozambique: A cluster randomized trial protocol. Contemp Clin Trials Commun. 2018;71:63–69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Agresti A, Natarajan R. Modeling clustered ordered categorical data: A survey. Int Stat Rev. 2001;69(3):345–371. [Google Scholar]
- 29.Skrondal A, Rabe-Hesketh S. Generalized Latent Variable Modeling: Multilevel, Longitudinal and Structural Equation Models. Boca Raton, FL: Chapman & Hall/CRC; 2004. [Google Scholar]
- 30.Koo TK, Li MY. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J Chiropr Med. 2016;15(2):155–163. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.