

Abstract
In computed tomography (CT), the forward model consists of a linear Radon transform followed by an exponential nonlinearity based on the attenuation of light according to the Beer–Lambert Law. Conventional reconstruction often involves inverting this nonlinearity as a preprocessing step and then solving a convex inverse problem. However, this nonlinear measurement preprocessing required to use the Radon transform is poorly conditioned in the vicinity of high-density materials, such as metal. This preprocessing makes CT reconstruction methods numerically sensitive and susceptible to artifacts near high-density regions. In this paper, we study a technique where the signal is directly reconstructed from raw measurements through the nonlinear forward model. Though this optimization is nonconvex, we show that gradient descent provably converges to the global optimum at a geometric rate, perfectly reconstructing the underlying signal with a near minimal number of random measurements. We also prove similar results in the under-determined setting where the number of measurements is significantly smaller than the dimension of the signal. This is achieved by enforcing prior structural information about the signal through constraints on the optimization variables. We illustrate the benefits of direct nonlinear CT reconstruction with cone-beam CT experiments on synthetic and real 3D volumes. We show that this approach reduces metal artifacts compared to a commercial reconstruction of a human skull with metal dental crowns.
1. Introduction
Computed tomography (CT) is a core imaging modality in modern medicine (Food & Administration, 2023). X-ray CT is used to diagnose a wide array of conditions, plan treatments such as surgery or chemotherapy, and monitor their effectiveness over time. It can image any part of the body, and is widely performed as an outpatient imaging procedure.
CT systems work by rotating an X-ray source and detector around the patient, measuring how much of the emitted X-ray intensity reaches the detector at each angle. Because different tissues absorb X-rays at different rates, each of these measurements records a projection of the patient’s internal anatomy along the exposure angle. Algorithms then combine these projection measurements at different angles to recover a 2D or 3D image of the patient. This image is then interpreted by a medical professional (e.g. physician, radiologist, or medical physicist) to help diagnose, monitor, or plan treatment for a disease or injury.
CT scanners in use today typically consider the image reconstruction task as a linear inverse problem, in which the measurements are linear projections of the signal at known angles. Omitting measurement noise, we can write this standard linear measurement model as:
| (1.1) |
where is a vectorized version of the unknown signal (which commonly lies in 2D or 3D) and is a known, nonnegative measurement vector that denotes the weight each entry in the signal contributes to the integral along measurement ray . Computed over a set of regularly-spaced ray angles, this is exactly the Radon transform (Radon, 1917). This linear measurement model is quite convenient, as it enables efficient computations using the Fourier slice theorem—which equates linear projections in real-space to evaluation of slices through Fourier space—as well as strong recovery guarantees from compressive sensing (Kak & Slaney, 2001; Foucart & Rauhuti, 2013; Bracewell, 1990). This linear projection model is accurate for signals of low density, for which the incident X-rays pass through largely unperturbed.
However, consider the common setting in which the signal contains regions of density high enough to occlude X-rays, such as the metal implants used in dental crowns and artificial joints. Such high-density regions produce nonlinear measurements for which the Fourier slice theorem, and standard compressed sensing results, no longer hold. In practice, tomographic reconstruction algorithms that assume a linear projection as the measurement model produce streak-like artifacts around high-density regions, potentially obscuring otherwise measurable and meaningful signal.
To avoid such artifacts, in this paper we consider a nonlinear measurement model, which correctly models signals with arbitrary density. Equation (1.1) then becomes:
| (1.2) |
where the exponential nonlinearity accounts for occlusion and is due to the Beer-Lambert Law. In practice, the partial occlusions captured by eq. (1.2) are commonly incorporated into a linear model by inverting the nonlinearity, converting raw measurements from eq. (1.2) into processed measurements for which eq. (1.1) holds. Indeed, this logarithmic preprocessing step is built into commercial CT scanners (Fu et al., 2016), though some additional preprocessing for calibration and denoising is often performed before the logarithm. The logarithm is well-conditioned for but becomes numerically unstable as approaches unity, which corresponds to total X-ray absorption. This is particularly problematic for rays that pass through high-density materials, such as metal, as well as for very low-dose CT scans that use fewer X-ray photons.
Instead, we study reconstruction through direct inversion of eq. (1.2) via iterative gradient descent. We optimize a squared loss function over these nonlinear measurements , which is optimal for the case of Gaussian measurement noise—though extending this analysis to more realistic noise models is also of interest (Fu et al., 2016). By avoiding the ill-conditioned logarithm of a near-zero measurement, this approach is well-suited to CT reconstruction with low-dose X-rays as well as CT reconstruction with reduced metal artifacts. However, direct reconstruction through eq. (1.2) is more challenging than reconstruction through the linearized eq. (1.1), because the resulting loss function is nonconvex. While the linear inverse problem defined by eq. (1.1) can be solved in closed form by methods such as Filtered Back Projection (Radon, 1917; Kak & Slaney, 2001; Natterer, 2001), the nonlinear inverse problem defined by eq. (1.2) requires an iterative solution to a nonconvex optimization problem. We show that gradient descent with appropriate stepsize successfully recovers the global optimum of this nonconvex objective, suggesting that direct optimization through eq. (1.2) is a viable and desirable alternative to current methods that use eq. (1.1).
Concretely, we make the following contributions:
We propose a Gaussian model of eq. (1.2) and show that gradient descent converges to the global optimum of this model at a geometric rate, despite the nonconvex formulation. These results hold with a near minimal number of random measurements. To prove this result we utilize and build upon intricate arguments for uniform concentration of empirical processes.
We also extend our result to a compressive sensing setting to show that a structured signal can be recovered from far fewer measurements than its dimension. In this case prior information about the signal structure is enforced via a convex regularizer; our result holds for any convex regularizer. We show that the required number of measurements is commensurate to an appropriate notion of statistical dimension that captures how well the regularizer enforces the structural assumptions about the signal. For example, for an -sparse signal and an regularizer our results require on the order of measurements, where is the dimension of the signal. This is the optimal sample complexity even for linear measurements.
We perform an empirical comparison of reconstruction quality in 3D cone-beam CT on both synthetic and real volumes, where our real dataset consists of a human skull with metal dental crowns. We show that direct reconstruction through eq. (1.2) yields reduction in metal artifacts compared to reconstruction by inverting the nonlinearity into eq. (1.1).
2. Problem Formulation
In practice, the measurement vectors are sparse, nonnegative, highly structured, and dependent on the rays , as only a small subset of signal values in will contribute to any particular ray. These vectors correspond to the weights in a discretized ray integral (projection) along the ‘th measurement ray in the Radon transform (Radon, 1917). We use these real, ray-structured measurement vectors in our synthetic and real-data experiments.
In our theoretical analysis, we make two simplifying alterations to eq. (1.2): (1) we model as a standard Gaussian vector, where the Gaussian randomness is an approximation of the randomness in the choice of ray direction, and (2) we wrap the inner product in a ReLU, to capture the physical reality that the raw integral of density along a ray, and the corresponding sensor measurement, must always be nonnegative. This nonnegativity is implicit in eq. (1.2) because represents a ray integral with only nonnegative weights as its entries, and the true density signal is also nonnegative; in our model eq. (2.1) we make nonnegativity explicit (subscript + denotes ReLU):
| (2.1) |
Here is a measurement corresponding to ray is the signal we want to recover, and are i.i.d. random Gaussian measurement vectors distributed as . In this paper we consider a least-squares loss of the form
| (2.2) |
which is optimal in the presence of Gaussian measurement noise. However, in our analysis we focus on the noiseless setting. We minimize this loss using subgradient descent starting from , with step size in step . More specifically, the iterates take the form
Here, we use the following subdifferential of :
We also consider a regularized (compressive sensing) setting where the number of measurements is significantly smaller than the dimension of the signal. In this case we optimize the augmented loss function
| (2.3) |
via subgradient descent. Here, is a regularizer enforcing a priori structure about the signal, with regularization weight . In our experiments, we use 3D total variation as , to encourage our reconstructed structure to have sparse gradients in 3D space.
We note that is a nonconvex objective, so it is not obvious whether or not subgradient descent will reach the global optimum. Do the iterates converge to the correct solution? How many iterations are required? How many measurements? How does the number of measurements depend on the signal structure and the choice of regularizer? In the following sections, we take steps to answer these questions.
3. Global Convergence in the Unregularized Setting
Our first result shows that in the unregularized setting, direct gradient-based updates converge globally at a geometric rate. We defer the proof of Theorem 1 to Appendix B.
Theorem 1 Consider the problem of reconstructing a signal from nonlinear CT measurements of the form , where the measurement vectors are generated i.i.d. . We consider a least-squares loss as in eq. (2.2) and run gradient updates of the form
starting from with and with for . Here, erfc is the complementary error function. As long as the number of measurements obeys
then
holds with probability at least . Here, , and are fixed positive numerical constants.
Theorem 1 answers some of the key questions from the previous section in the affirmative. Even though the nonlinear CT reconstruction problem is a nonconvex optimization, gradient descent converges to the global optimum, the true signal, at a geometric rate.
Further, the number of required measurements is on the order of , the dimension of the signal, which is near-minimal even for a linear forward model. In Theorem 2 we prove global convergence with even fewer measurements in the compressive sensing setting, when some prior knowledge of the signal structure is enforced through a convex regularizer.
We note that the initial step size used in Theorem 1 is a function of the signal norm , which is a priori unknown. However, we briefly describe how this quantity can be estimated from the available measurements. By averaging over the measurements, we have
where are i.i.d. standard Gaussian random variables. Since is a 1-Lipschitz function of , this quantity concentrates around its mean
We can invert this relationship to get a close estimate of from the average measurement value.
We also note that both the convergence rate and the number of measurements in Theorem 1 are exponentially dependent on . This is natural because as increases towards infinity the measurements approach the constant value 1 and the corresponding gradient of the loss approaches zero. Intuitively, this corresponds to trying to recover a CT scan of a metal box; if the walls of the box become infinitely absorbing of X-rays, we cannot hope to see inside it. Nonetheless, for real and realistic metal components in our experiments (Section 5) we do find good signal recovery following this approach.
4. Global Convergence in the Regularized Setting
We now turn our attention to the regularized setting. Our measurements again take the form for , where is the unknown but now a priori “structured” signal. In this case we wish to use many fewer measurements than the number of variables , to reduce the X-ray exposure to the patient without sacrificing the resolution of the reconstructed image or volume . Because the number of equations is significantly smaller than the number of variables , there are infinitely many reconstructions obeying the measurement constraints. However, it may still be possible to recover the original signal by exploiting knowledge of its structure. To this aim, let be a regularization function that reflects some notion of “complexity” of the “structured” solution. For the sake of our theoretical analysis we will use the following constrained optimization problem in lieu of eq. (2.3) to recover the signal:
| (4.1) |
We solve this optimization problem using projected gradient updates of the form
| (4.2) |
Here, denotes the projection of onto the constraint set
| (4.3) |
We wish to characterize the rate of convergence of the projected gradient updates eq. (4.2) as a function of the number of measurements, the available prior knowledge of the signal structure, and how well the choice of regularizer encodes this prior knowledge. For example, if we know our unknown signal is approximately sparse, using an norm for the regularizer is superior to using an regularizer. To make these connections precise and quantitative, we need a few definitions which we adapt verbatim from Oymak et al., (2017); Oymak & Soltanolkotabi (2017b); Soltanolkotabi (2019b).
Definition 1 (Descent set and cone) The set of descent of a function at a point is defined as
The cone of descent, or tangent cone, is the conic hull of the descent set, or the smallest closed cone that contains the descent set, i.e. .
The size of the descent cone determines how well the regularizer captures the structure of the unknown signal . The smaller the descent cone, the more precisely the regularizer describes the properties of the signal. We quantify the size of the descent cone using the notion of mean (Gaussian) width.
Definition 2 (Gaussian width) The Gaussian width of a set is defined as:
where the expectation is taken over . Throughout we use to denote the the unit ball/sphere of .
We now have all the definitions in place to quantify how well the function captures the properties of the unknown signal . This naturally leads us to the definition of the minimum required number of measurements.
Definition 3 (minimal number of measurements) Let be a cone of descent of at . We define the minimal sample function as
We shall often use the short hand with the dependence on implied. Here we define for an arbitrary point , but we will apply the definition at the signal .
We note that is exactly the minimum number of samples required for structured signal recovery from linear measurements when using convex regularizers. Specifically, the optimization problem
| (4.4) |
succeeds at recovering the unknown signal with high probability from measurements of the form if and only if .1 Given that in our Gaussian-approximated nonlinear CT reconstruction problem we have less information (we lose information when the input to the ReLU is negative), we cannot hope to recover structured signals from when using (4.1). Therefore, we can use as a lower-bound on the minimum number of measurements required for projected gradient descent iterations eq. (4.2) to succeed in recovering the signal of interest. With these definitions in place we are now ready to state our theorem in the regularized/compressive sensing setting. We defer the proof of Theorem 2 to Appendix C.
Theorem 2 Consider the problem of reconstructing a signal from nonlinear CT measurements of the form , where the measurement vectors are generated i.i.d. . We consider a constrained least-squares loss as in eq. (4.1) and run projected gradient updates of the form in eq. (4.2) starting from with and with for . Here, erfc is the complementary error function. As long as the number of measurements obeys
with denoting the minimal number of samples per Definition 3, then
holds with probability at least . Here, , and are fixed positive numerical constants.
Theorem 2 parallels Theorem 1, likewise showing fast geometric convergence to the global optimum despite nonconvexity. In this regularized setting, the sample complexity of our nonlinear reconstruction problem is on the order of , the number of measurements required for linear compressive sensing. In other words, the number of measurements required for regularized nonlinear CT reconstruction from raw measurements is within a constant factor of the number of measurements needed for the same reconstruction from linearized measurements. This is the optimal sample complexity for this nonlinear reconstruction task. For instance for an sparse signal for which , the above theorem states that on the order of nonlinear CT measurements suffices for our direct gradient-based approach to succeed. Finally, we would like emphasize that the above result is rather general as it applies to any type structure in the signal and can also deal with any convex regularizer.
5. Experiments
We support our theoretical analysis with experimental evidence that gradient-based optimization through the nonlinear CT forward model is effective for a wide range of signal densities, including signals that are dense enough that the same optimization procedure through the linearized forward model produces noticeable “metal artifacts.”
All of our experiments are based on the JAX implementation of Plenoxels (Sara Fridovich-Keil and Alex Yu et al., 2022), with a dense 3D grid of optimizable density values connected by trilinear interpolation. We use a cone-beam CT setup and optimize with mild total variation regularization. Our experiments do not focus on speed or measurement sparsity, though we fully expect our optimization objective to pair naturally with efficient ray sampling implementations and regularizers of choice.
5.1. Synthetic Data
Our synthetic experiments use a ground truth volume defined by the standard Shepp-Logan phantom (Shepp & Logan, 1974) in 3D, with the following modifications:
We scale down the voxel density values by a factor of 4, to more closely mimic the values in our real cone-beam CT skull dataset.
We adjust one of the ellipsoids to be slightly larger than standard (to make it more visible), and gradually increase its ground truth density to simulate a spectrum from soft tissue to bone to metal.
We simulate CT observations of this synthetic volume and then reconstruct using either the linearized forward model with the logarithm and eq. (1.1), or directly using eq. (1.2). We also use a small amount of total variation regularization, and constrain results to be nonnegative.
Results of this synthetic experiment are presented in Figure 1. As the density of the test ellipsoid increases, the linearized reconstruction experiences increasingly severe “metal artifacts,” while the nonlinear reconstruction continues to closely match the ground truth. PSNR values are reported over the entire reconstructed volume compared to the ground truth, where PSNR is defined as −10 log10 (MSE) and MSE is the mean squared voxel-wise error.
Figure 1:

Synthetic experiments using the Shepp-Logan phantom, showing a slice through the reconstructed 3D volume. From top to bottom, we increase the density of the central test ellipsoid to simulate soft tissue, bone, and metal. Nonlinear reconstruction is robust even to dense “metal” elements of the target signal.
Note that this synthetic experiment does not include any measurement noise or miscalibration; the instability of the logarithm with respect to dense signals arises even when the only noise is due to numerical precision. We also note that even the densest synthetic “metal” ellipsoid we test is no denser than what we observe in our real CBCT skull dataset in Figure 2, with a real metal dental crown.
Figure 2:

Real experiments using a 3D human skull phantom with a metal dental crown; here we show a cross-section of the reconstructed volume. Note the streak artifact to the left of the metal crown (annotated in red) and the X artifact below it (annotated in purple) in the reference linearized reconstruction, which are not present in the nonlinear reconstruction.
5.2. Real Data
Our real data experiment uses a cone-beam CT phantom made from a human skull with metal dental crowns on some of the teeth. In Figure 2 we show slices of our nonlinear reconstruction compared to a reference commercial linearized reconstruction, as no ground truth is available for the real volume. The nonlinear reconstruction exhibits reduced metal-induced streak artifacts compared to the commercial reconstruction, highlighted in red and purple in the leftmost panel.
6. Related Work
Tomographic reconstruction.
The measurement model in eq. (1.2) is a discretized corollary of the Beer-Lambert Law that governs the attenuation of light as it passes through absorptive media. Inverting the exponential nonlinearity in this model recovers the Radon transform summarized by eq. (1.1), in which measurements are linear projections of the signal at chosen measurement angles. The Radon transform has a closed-form inverse transform, Filtered Back Projection (Radon, 1917; Kak & Slaney, 2001; Natterer, 2001), that leverages the Fourier slice theorem (Bracewell, 1990; Kak & Slaney, 2001). Filtered Back Projection is a well-understood algorithm that can be computed efficiently, and is a standard option in commercial CT scanners, but its reconstruction quality can suffer in the presence of either limited measurement angles or metal (highly absorptive) signal components (Fu et al., 2016).
Many methods exist to improve the quality of CT reconstruction in the limited-measurement regime, such as limited baseline tomography, which is of clinical interest because not all viewpoints may be accessible and every measurement angle requires exposing the patient to ionizing X-ray radiation. These methods typically involve augmenting the data-fidelity loss function with a regularization term that describes some prior knowledge of the signal to be reconstructed. Such priors include sparsity (implemented through an norm) in a chosen basis, such as wavelets (Foucart & Rauhuti, 2013; Chambolle et al., 1998), as well as gradient sparsity (implemented through total variation regularization) (Candes et al., 2006). Compressive sensing theory guarantees correct recovery with fewer measurements in these settings, as long as the true signal is well-described by the chosen prior (Foucart & Rauhuti, 2013). CT reconstruction with priors cannot be solved in closed form, but as long as the regularization is convex we are guaranteed that iterative optimization methods such as gradient descent, ISTA (Chambolle et al., 1998), and FISTA (Beck & Teboulle, 2009) will be successful.
Recently, reconstruction with even fewer measurements has been proposed by leveraging deep learning, through either neural scene representation (Rückert et al., 2022) or data-driven priors (Szczykutowicz et al., 2022). These methods may sacrifice convexity, and theoretical guarantees, in favor of more flexible and adaptive regularization that empirically reduces reconstruction artifacts in the limited-measurement regime. However, these methods are still based on the linear measurement model of eq. (1.1), making them susceptible to reconstruction artifacts near highly absorptive metal components. In some cases neural methods may reduce metal artifacts compared to traditional algorithms, but this reduction is achieved by leveraging strong and adaptive prior knowledge rather than the measurements of the present signal.
We propose to resolve these metal artifacts by reconstructing from raw nonlinear X-ray absorption measurements, rather than the preprocessed, linearized measurements produced by standard CT scanners. Our method may pair particularly well with new photon-counting CT scanners (Shikhaliev et al., 2005), which were approved by the FDA in 2021 (Food & Administration, 2021). These scanners measure raw X-ray photon counts, which should enable finer-grained noise modeling and correction as well as our method for principled reconstruction of signals with metal.
Signal reconstruction from nonlinear measurements.
There are a growing number of papers focused on reconstructing a signal from nonlinear measurements or single index models. Early papers on this topic focus on phase retrieval and ReLU nonlinearities (Oymak et al., 2018; Soltanolkotabi, 2017; Candes et al., 2015) and approximate reconstruction (Oymak & Soltanolkotabi, 2017a). These papers do not handle the compressive sensing/structured signal reconstruction setting. The paper (Soltanolkotabi, 2019a) deals with reconstruction from structured signals for intensity and absolute value nonlinearties but only achieves the optimal sample complexity locally. A more recent paper (Mei et al., 2018) deals with a variety of nonlinearities with bounded derivative activations. However, this paper does not handle non-differentiable activations and only deals with simple structured signals such as sparse ones. In contrast to the above paper, our activation is non-differentiable, we handle arbitrary structures in the signal, and our results apply for any convex regularizer.
7. Discussion
In this paper, we consider the CT reconstruction problem from raw nonlinear measurements of the form for a signal and random measurement weights . Although this nonlinear measurement model can be easily transformed into a linear model via a logarithmic preprocessing step , and this transformation is common practice in clinical CT reconstruction, the logarithm is numerically unstable when the measurements approach unity. This occurs frequently in practice, notably when the signal contains metal and especially for low-dose CT scanners that reduce radiation exposure. In this setting, traditional linear reconstruction methods tend to produce “metal artifacts” such as streaks around metal implants. Reconstruction directly through the raw nonlinear measurements avoids this numerically unstable preprocessing, in exchange for solving a nonconvex nonlinear least squares objective instead of convex linear least squares.
We prove that gradient descent finds the global optimum in CT reconstruction from raw nonlinear measurements, recovering exactly the true signal despite the nonconvex optimization. Moreover, it converges at a geometric rate, which is considered fast even for convex optimization. This nonconvex optimization requires order measurements, where is the dimension of the unknown signal, the same order sample complexity as if we had reconstructed through a linear forward model.
We also extend our theoretical results to the compressive sensing setting, in which prior structural knowledge of the signal , enforced through a regularizer, allows for reconstruction with far fewer measurements than the dimension of the signal. Our results in this setting again parallel standard results from the linear reconstruction problem, even though we consider a nonlinear forward model and optimize a nonconvex formulation.
We also compare linearized and nonlinear CT reconstruction experimentally in the setting of 3D cone-beam CT, using both a synthetic 3D Shepp-Logan phantom for which we know the ground truth volume as well as a real human skull phantom with metal dental crowns. In both cases, we find that nonlinear reconstruction reduces metal artifacts compared to linearized reconstruction, whether that linearized reconstruction is done by gradient descent or a commercial algorithm.
Our work is a promising first step towards higher-quality CT reconstruction in the presence of metal components and low-dose X-rays, offering both practical and theoretical guidance for trustworthy reconstruction. Future work may extend our results both theoretically and experimentally to consider more realistic measurement noise settings such as Poisson noise, which is particularly timely given the emergence of new photon-counting CT scanners.
8. Acknowledgments
We would like to thank Claudio Landi and Giovanni Di Domenico, and their CT company SeeThrough for providing cone-beam CT measurements and their reference reconstruction of a human skull phantom. This material is based upon work supported by the National Science Foundation under award number 2303178 to SFK. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation. FV is partially supported by the SUPERB REU program. MS is supported by the NIH Director’s New Innovator award # DP2LM014564, the Packard Fellowship in Science and Engineering, a Sloan Fellowship in Mathematics, an NSF CAREER award #1846369 and DARPA FastNICS program, and NSF-CIF award #2008443.
A. APPENDIX
B. Proof of Theorem 1
In the following subsections we prove Theorem 1, beginning with a proof outline.
B.1. Proof Outline
The proof consists of the following four steps.
Step I: First iteration: Welcome to the neighborhood.
In the first step, we show that as long as the number of measurements is sufficiently large , the first iteration obeys
| (B.1) |
with probability at least , for a constant . We prove this in Appendix B.2.
Step II: Local pseudoconvexity.
In the second step, we show that our nonconvex objective function is locally strongly pseudoconvex inside this local neighborhood of eq. (B.1). Specifically, we show the correlation inequality
| (B.2) |
holds with , with probability at least as long as the number of measurements is at least for constants and .
We compute the in Equation (B.2) in two cases, where case 1 corresponds to and case 2 corresponds to . These cases are analyzed in Appendix B.3 and Appendix B.4, respectively. Combining cases 1 and 2, we have that the lower bound on from case 2 lower bounds the bound from case 1, as shown in Figure 3, so we use that bound in eq. (B.2). The sample complexity in eq. (B.2) is the maximum over the sample complexities of cases 1 and 2, which are and , respectively, for constants and .
Figure 3:
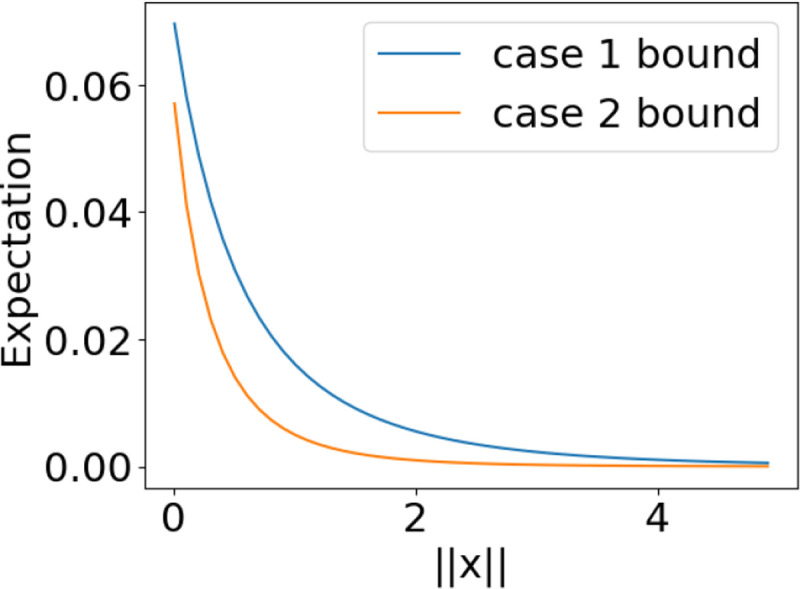
Case 2 provides a lower bound on the expected correlation for both cases.
Step III: Smoothness.
In the third step, we show
| (B.3) |
holds with probability at least . , for a constant . This smoothness condition is proved in Appendix (B.5).
Step IV: Completing the proof via combining Steps I-III.
Finally, we combine the first three steps into a complete proof. At the core of the proof is the following lower bound on the correlation between the loss gradient and the error vector
| (B.4) |
for positive constants and . This starting point is similar to the proof of Lemma 7.10 in Candes et al. (2015), with some modifications necessary for the nonlinear CT reconstruction problem. To prove eq. (B.4) we first combine eq. (B.2) and eq. (B.3) to conclude that
Thus eq. (B.4) holds with and for a new constant , with probability at least , for a constant (by a union bound over the first three steps of the proof). Using eq. (B.4) with adequate choice of stepsize suffices to prove geometric convergence.
In (a) we expand the square. In (b) we apply eq. (B.4). In (c) we choose , making the second term negative. Applying this relation inductively over steps of gradient descent yields geometric convergence with rate , provided that the step size is less than for .
The number of measurements required in theorem 1 is the maximum over the number of samples required for each of the first two steps of the proof. For the first step, measurements are sufficient to reach our neighborhood of radius . For case 1 in the second step, measurements are sufficient for correlation concentration. For case 2 in the second step, measurements are sufficient for concentration. Maximizing over these bounds yields the result in theorem 1 (note that the constants change during the maximization).
B.2. First Step: Welcome to the Neighborhood
We first consider what happens in expectation when we take our first gradient step starting from an initialization at . The expectation is over the randomness in the Gaussian measurement vector . We have
In (a) we evaluate and , where for the latter we use as the sub-differential even though is nondifferentiable at 0 due to the non-differentiability of ReLU (this choice is also justified as it is the expected gradient of around a small random initialization around 0). In (b) we plug in the value of the measurement . In (c) we use linearity of expectation and evaluate the first term, . In (d) we separate the leading into components parallel and orthogonal to , and evaluate the expectation of the orthogonal term to zero. In (e) we replace with for a scalar Gaussian , as these have the same distribution. In (f) we evaluate the remaining expectation. In (g) we choose so that in expectation, our first step exactly recovers the signal .
Because in practice we do not have access to an expectation over infinite measurements, we also care about the concentration of this first gradient step. This first-step concentration determines the local neighborhood around the signal that our gradient descent will operate within for the remaining iterations.
In (a) we separate into components parallel and orthogonal to . In (b) we replace with for a standard scalar Gaussian , as these have the same distribution. In (c) we simplify the second term by rewriting it with a standard Gaussian vector with free dimensions (constrained to be orthogonal to ), and independent of for all . In (d) we write and .
Note that the first term has expectation computed above, and the second term has expectation zero because and are independent, and is mean zero. The first term is aligned with the signal but with a scaling factor ; we can bound the deviation of this scaling from its mean using Hoeffding’s concentration bound for sums of sub-Gaussian random variables. We use the definition of sub-Gaussianity provided by Definition 2.2 in Wainwright (2019), for which has sub-Gaussian parameter 1. We omit the leading constant , and apply the Hoeffding bound as presented in Proposition 2.5 in Wainwright (2019) to conclude that
with probability at least .
The second term is a nonnegative scaling times a standard -dimensional Gaussian vector with degrees of freedom (because it is orthogonal to ). Since is bounded in [0, 1], we can upper bound this scaling by . Then the norm of the random vector can also be bounded using Exercise 5.2.4 in Vershynin (2018), to conclude that
with probability at least for a constant , where in (a) we evaluate the expectation of a Gaussian norm with degrees of freedom and in (b) we upper bound by and do a change of variables to replace with . Putting these together with a union bound, we have that
with probability at least , where in (a) we change variables and replace with , and is a constant. If we choose , this simplifies to
with probability at least , for a constant . For our first step to lie within a distance of , we need the number of measurements to satisfy
The denominator in this expression is lower bounded by 0.2 for all , so we can also guarantee the first step concentration to this neighborhood using measurements.
B.3. Correlation Concentration: Case 1
Consider the correlation
where . Now note that if we have and it implies . Thus we have
Using the above we can conclude that
In (a) we plug in the indicator inequality, and accordingly remove the now-superfluous ReLU. In (b) we use the notation, and regroup terms. To continue, we divide both sides by and use the notation .
To continue note that the function
has non-positive derivative as
for all values of and . This implies that is a non-increasing function of . Thus, we can conclude that
Thus we can focus on lower bounding
over the set
where we reintroduce superfluous ReLUs around as it will be convenient in the next steps. To continue, note that the function has derivative
It is easy to verify numerically that for this gradient is maximized around , with maximum value . Thus, for all
As a result the function is a -Lipschitz function of . Thus for any and we have
We now define the random variable and note that the Lipschitzness of implies that for any we have
Since is a sub-Gaussian random variable with sub-Gaussian norm on the order of , we have that
for some constant . We use to denote any universal constant; note that this constant may vary between different lines. Thus using the centering rule for sub-Gaussian random variables, the centered processes obey
Using the rotational invariance property of sub-Gaussian random variables, this implies that the stochastic process
has sub-Gaussian increments. That is,
Thus using Exercise 8.6.5 of Vershynin (2018) we can conclude that
holds with probability at least . Thus, we conclude that for all obeying we have
with probability at least , for a constant .
We can estimate and lower bound the expectation above using a numerical average over many (50000) two-dimensional Gaussian samples, with the two dimensions corresponding to and , minimizing over all correlations between and at least (i.e. all correlations in this case). We arrive at the following lower bound, for and .
This bound is illustrated in a “proof by picture” in Figure 4.
Figure 4:

Lower bound on the expected correlation in case 1.
B.4. Correlation Concentration: Case 2
In this case we will focus on controlling the correlation inequality in the region where
Consider the correlation
In (a) we provide a lower bound by introducing an additional indicator function on , which allows us to remove the ReLU. In (b) we use the notation , and combine terms. In (c) we again provide a lower bound by adding an indicator to restrict . By flipping the sign of we can alternatively lower bound
over the set
To this aim note that for we have and . Thus,
To continue, we introduce the notation , and divide both sides by . Thus we have
Thus it suffices to lower bound
over
To continue using Jensen’s inequality we have
where we have defined the function
which is a 1-Lipschitz function of . We now define the random variable and note that the Lipschitzness of implies that for any we have
Since is a sub-Gaussian random variable with sub-Gaussian norm on the order of , we have that
for some constant . We use to denote any universal constant; note that this constant may vary between different lines. Using the centering rule for sub-Gaussian random variables, the centered processes obey
Using the rotational invariance property of sub-Gaussian random variables, this implies that the stochastic process
has sub-Gaussian increments. That is,
Thus using Exercise 8.6.5 of Vershynin (2018) we can conclude that
holds with probability at least . In the last line we used the fact that the surface area of a spherical cap with distance at least away from the center is bounded by . By using , this implies that
holds with probability at least , for a constant .
We can estimate and lower bound the expectation above using a numerical average over many (50000) two-dimensional Gaussian samples, with the two dimensions corresponding to and , minimizing over all correlations between and at most (i.e. all correlations in this case). We arrive at the following lower bound, for and .
This bound is illustrated in a “proof by picture” in Figure 5
Figure 5:

Lower bound on the expected correlation in case 2.
B.5. Bounding the Gradient Norm
Consider the gradient and note that
where denotes the set of all real -dimensional unit-norm vectors. To continue, we use the Cauchy-Schwarz inequality:
where is the operator norm of a matrix comprised by stacking the vectors , and in (a) we used the fact that the function is 1-Lipschitz. Finally, using the fact that with probability at least , we conclude that
with probability at least , where is a constant since we have the number of measurements at least a constant times the number of unknowns. This completes the proof of smoothness of the gradient towards the global optimum.
C. Proof of Theorem 2
The general strategy of the proof is similar to Theorem 1 but requires delicate modifications in each step. Concretely, we have the following four steps.
Step I: First iteration: Welcome to the neighborhood.
In the first step we show that the first iteration obeys
with high probability as long as . We prove this in subsection C.1.
Step II: Local pseudoconvexity.
In this step we prove that the loss function is locally strongly pseudoconvex. Specifically we show that for all that also belong to the local neighborhoood we have
with high probability as long as
Here, the value of is the same as in Theorem 1 (see Appendix B.1). We prove this in subsection C.2 by again considering two cases.
Step III: Local smoothness.
We also use the fact that the loss function is locally smooth, that is,
holds with probability at least .per Section B.5.
Step IV: Completing the proof via combining steps I-III.
In this step we show how to combine the previous steps to complete the proof of the theorem. First, note that by the first step the first iteration will belong to the local neighborhood and thus belongs to the set . Next, note that
Squaring both sides and using the local psudoconvexity inequality from Step II we conclude that
Next we use the local smoothness from Step III to conclude that
where in the last line we used the fact that , completing the proof.
C.1. Proof of Step I
The beginning of this proof is the same as the unregularized version where we note that
Now similar to the unregularized case we have
with probability at least , where in (a) we change variables and replace with , and is a constant. If we choose , this simplifies to
with probability at least , for a constant . For our first step to lie within a distance of , we need the number of measurements to satisfy
The denominator in this expression is lower bounded by 0.2 for all , so we can also guarantee the first step concentration to this neighborhood using measurements.
C.2. Proof of Step II
The proof of this step is virtually identical to that of the unregularized case. The only difference is that when we apply Exercise 8.6.5 of Vershynin (2018) is replaced with (indeed this exercise is stated with ). As a result in the two cases we conclude
Case I: In this case using the above yields
holds with probability at least , for a constant . Case II: In this case using the above yields
holds with probability at least , for a constant .
Thus the remainder of the proof is identical and the only needed change in this entire step is to replace with .
Footnotes
We would like to note that only approximately characterizes the minimum number of samples required. A more precise characterization is where . However, since our results have unspecified constants we avoid this more accurate characterization.
References
- Beck Amir and Teboulle Marc. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM journal on imaging sciences, 2(1):183–202, 2009. [Google Scholar]
- Bracewell R. N.. Numerical Transforms. Science, 248(4956):697–704, May 1990. doi: 10.1126/science.248.4956.697. [DOI] [PubMed] [Google Scholar]
- Candes E.J., Romberg J., and Tao T.. Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE Transactions on Information Theory, 52(2):489–509, 2006. doi: 10.1109/TIT.2005.862083. [DOI] [Google Scholar]
- Candes Emmanuel J, Li Xiaodong, and Soltanolkotabi Mahdi. Phase retrieval via wirtinger flow: Theory and algorithms. IEEE Transactions on Information Theory, 61(4):1985–2007, 2015. [Google Scholar]
- Chambolle Antonin, De Vore Ronald A, Lee Nam-Yong, and Lucier Bradley J. Nonlinear wavelet image processing: variational problems, compression, and noise removal through wavelet shrinkage. IEEE Transactions on image processing, 7(3):319–335, 1998. [DOI] [PubMed] [Google Scholar]
- U.S. Food and Drug Administration. FDA Clears First Major Imaging Device Advancement for Computed Tomography in Nearly a Decade, 2021. URL https://www.fda.gov/news-events/press-announcements/fda-clears-first-major-imaging-device-advancement-computed-tomography-nearly-decade.
- U.S. Food and Drug Administration. Computed Tomography (CT), 2023. URL https://www.fda.gov/radiation-emitting-products/medical-x-ray-imaging/computed-tomography-ct.
- Foucart Simon and Rauhuti Holger. A Mathematical Introduction to Compressive Sensing. Birkhauser, 2013. [Google Scholar]
- Fu Lin, Lee Tzu-Cheng, Kim Soo Mee, Alessio Adam M, Kinahan Paul E, Chang Zhiqian, Sauer Ken, Kalra Mannudeep K, and De Man Bruno. Comparison between pre-log and post-log statistical models in ultra-low-dose ct reconstruction. IEEE transactions on medical imaging, 36(3):707–720, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kak Avinash C and Slaney Malcolm. Principles of computerized tomographic imaging. SIAM, 2001. [Google Scholar]
- Mei Song, Bai Yu, and Montanari Andrea. The landscape of empirical risk for nonconvex losses. The Annals of Statistics, 46(6A):2747–2774, 2018. [Google Scholar]
- Natterer Frank. The Mathematics of Computerized Tomography. Society for Industrial and Applied Mathematics, 2001. [Google Scholar]
- Oymak Samet and Soltanolkotabi Mahdi. Fast and reliable parameter estimation from nonlinear observations. SIAM Journal on Optimization, 27(4):2276–2300, 2017a. doi: 10.1137/17M1113874. URL 10.1137/17M1113874. [DOI] [Google Scholar]
- Oymak Samet and Soltanolkotabi Mahdi. Fast and reliable parameter estimation from nonlinear observations. SIAM Journal on Optimization, 27(4):2276–2300, 2017b. [Google Scholar]
- Oymak Samet, Recht Benjamin, and Soltanolkotabi Mahdi. Sharp time-data tradeoffs for linear inverse problems. IEEE Transactions on Information Theory, 64(6):4129–4158, 2017. [Google Scholar]
- Oymak Samet, Recht Benjamin, and Soltanolkotabi Mahdi. Isometric sketching of any set via the Restricted Isometry Property. Information and Inference: A Journal of the IMA, 7(4):707–726, 03 2018. ISSN 2049–8764. doi: 10.1093/imaiai/iax019. URL 10.1093/imaiai/iax019. [DOI] [Google Scholar]
- Radon Johann. Uber die bestimmung von funktionen durch ihre integralwerte langs gewissez mannigfaltigheiten, ber. Verh. Sachs. Akad. Wiss. Leipzig, Math Phys Klass, 69, 1917. [Google Scholar]
- Rückert Darius, Wang Yuanhao, Li Rui, Idoughi Ramzi, and Heidrich Wolfgang. Neat: Neural adaptive tomography. ACM Trans. Graph., 41(4), jul 2022. ISSN 0730–0301. doi: 10.1145/3528223.3530121. URL 10.1145/3528223.3530121 [DOI] [Google Scholar]
- Fridovich-Keil Sara and Yu Alex, Tancik Matthew, Chen Qinhong, Recht Benjamin, and Kanazawa Angjoo. Plenoxels: Radiance fields without neural networks. In CVPR, 2022. [Google Scholar]
- Shepp Lawrence A and Logan Benjamin F. The fourier reconstruction of a head section. IEEE Transactions on nuclear science, 21(3):21–43, 1974. [Google Scholar]
- Polad M Shikhaliev Tong Xu, and Molloi Sabee. Photon counting computed tomography: concept and initial results. Medical physics, 32(2):427–436, 2005. [DOI] [PubMed] [Google Scholar]
- Soltanolkotabi Mahdi. Learning relus via gradient descent. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pp. 2004?2014, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964. [Google Scholar]
- Soltanolkotabi Mahdi. Structured signal recovery from quadratic measurements: Breaking sample complexity barriers via nonconvex optimization. IEEE Transactions on Information Theory, 65(4):2374–2400, 2019a. doi: 10.1109/TIT.2019.2891653. [DOI] [Google Scholar]
- Soltanolkotabi Mahdi. Structured signal recovery from quadratic measurements: Breaking sample complexity barriers via nonconvex optimization. IEEE Transactions on Information Theory, 65(4):2374–2400, 2019b. [Google Scholar]
- Szczykutowicz Timothy P, Toia Giuseppe V, Dhanantwari Amar, and Nett Brian. A review of deep learning ct reconstruction: concepts, limitations, and promise in clinical practice. Current Radiology Reports, 10(9):101–115, 2022. [Google Scholar]
- Vershynin Roman. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018. [Google Scholar]
- Wainwright Martin J. High-dimensional statistics: A non-asymptotic viewpoint, volume 48. Cambridge university press, 2019. [Google Scholar]