

Abstract
Aims
In clinical practice, factors associated with cardiovascular disease (CVD) like albuminuria, education level, or coronary artery calcium (CAC) are often known, but not incorporated in cardiovascular risk prediction models. The aims of the current study were to evaluate a methodology for the flexible addition of risk modifying characteristics on top of SCORE2 and to quantify the added value of several clinically relevant risk modifying characteristics.
Methods and results
Individuals without previous CVD or DM were included from the UK Biobank; Atherosclerosis Risk in Communities (ARIC); Multi-Ethnic Study of Atherosclerosis (MESA); European Prospective Investigation into Cancer, The Netherlands (EPIC-NL); and Heinz Nixdorf Recall (HNR) studies (n = 409 757) in whom 16 166 CVD events and 19 149 non-cardiovascular deaths were observed over exactly 10.0 years of follow-up. The effect of each possible risk modifying characteristic was derived using competing risk-adjusted Fine and Gray models. The risk modifying characteristics were applied to individual predictions with a flexible method using the population prevalence and the subdistribution hazard ratio (SHR) of the relevant predictor. Risk modifying characteristics that increased discrimination most were CAC percentile with 0.0198 [95% confidence interval (CI) 0.0115; 0.0281] and hs-Troponin-T with 0.0100 (95% CI 0.0063; 0.0137). External validation was performed in the Clinical Practice Research Datalink (CPRD) cohort (UK, n = 518 015, 12 675 CVD events). Adjustment of SCORE2-predicted risks with both single and multiple risk modifiers did not negatively affect calibration and led to a modest increase in discrimination [0.740 (95% CI 0.736–0.745) vs. unimproved SCORE2 risk C-index 0.737 (95% CI 0.732–0.741)].
Conclusion
The current paper presents a method on how to integrate possible risk modifying characteristics that are not included in existing CVD risk models for the prediction of CVD event risk in apparently healthy people. This flexible methodology improves the accuracy of predicted risks and increases applicability of prediction models for individuals with additional risk known modifiers.
Keywords: Risk prediction, Cardiovascular, SCORE2, Coronary calcium score, Risk stratification, Biomarkers
See the editorial comment for this article ‘Flexible addition of risk modifiers on top of SCORE2 to improve long—term risk prediction in healthy individuals’, by J. Auer and G. Lamm, https://doi.org/10.1093/eurjpc/zwad222.
Introduction
Atherosclerotic cardiovascular disease (CVD) remains a major cause of both morbidity and mortality, despite declines in its incidence and mortality rates in several countries. Current guidelines advocate the use of risk prediction models to enhance healthcare and population-wide prevention.1,2 Risk models like the SCORE2 model3 and the atherosclerotic cardiovascular disease pooled cohort equations (PCE)1 integrate information on several conventional prognostic factors to estimate individual 10-year CVD event risks for apparently healthy people, those without prior CVD, diabetes mellitus, or severe comorbidity. The goal is to identify people at higher risk of CVD, as those benefit most from preventive action.4,5 These models are widely used and practical because they use easy to measure and generally available prognostic factors to calculate CVD risk. In clinical practice, however, there are often other prognostic factors known apart from those in the prediction model, for example, parental history of premature myocardial infarction, estimated glomerular filtration rate (eGFR), albuminuria, social–economic status, coronary artery calcium (CAC) score, or ankle–brachial index (ABI).
The 2021 European Society of Cardiology (ESC) CVD prevention guidelines state that some of these prognostic factors may modify predicted risk, but no clear quantitative solution is given as to how to deal with additional information for more accurate risk prediction in individual patients.2 In practice, healthcare providers and patients may decide to ignore a risk model’s prediction, because they feel the patient profile is not fully captured by the algorithm. These risk modifying characteristics are often not systematically collected, so the type and number of risk modifying characteristics differ among individual patients. As it is not feasible to develop a risk prediction model for every combination of available risk factors, a flexible methodology which can deal with any such possible risk modifying characteristics will help providers and patients to further personalize clinical practice. Therefore, the aims of the current study were to evaluate a methodology for the flexible addition of risk modifying characteristics on top of SCORE2 and to quantify the added value of several clinically relevant risk modifying characteristics.
Methods
Study design
The effect of pre-specified list of possible risk modifying characteristics was derived and internally validated in five contemporary European and North-American research cohorts: the UK Biobank (n = 363 513);6 the Atherosclerosis Risk in Communities Study (ARIC, fourth visit as a baseline, USA, n = 8796);7 the Multi-Ethnic Study of Atherosclerosis (MESA) study (USA, n = 5670);8 the European Prospective Investigation into Cancer, The Netherlands (EPIC-NL, n = 28 099); and Heinz Nixdorf Recall (HNR, Germany, n = 3679).9 Finally, all results were externally validated in real-world general practitioners data from the Clinical Practice Research Datalink (CPRD, UK, n = 518 015).10 In all data sources, participants below 40 years, above 80 years of age, and those with prior CVD or diabetes mellitus were excluded. Prior CVD was defined as history of any clinical diagnosis of atherosclerotic CVD, including angina pectoris, myocardial infarction, stroke, or peripheral artery disease. Detailed descriptions of all data sources can be found in Supplementary material online, Methods.
Predictors
Possible risk modifying characteristics were pre-specified based on existing literature and availability in the cohorts. The following characteristics were investigated in the current study: albuminuria, ABI, atrial fibrillation, chronic inflammatory disease, body mass index (BMI), carotid plaque, carotid intima-media thickness (cIMT), CAC percentile11 (absolute Agatston score was evaluated as a sensitivity analysis), parental history of premature myocardial infarction, lower education level, eGFR, C-reactive protein (CRP), high-sensitivity troponin-T, lipoprotein(a) [Lp(a)], N-terminal pro-B-type natriuretic peptide (NT-proBNP), number of medications, history of cancer (excluding non-melanoma skin cancer), and gestational hypertension including pre-eclampsia. The availability of each of the predictors in all the cohorts and all definitions are described in detail in Supplementary material online, Methods.
The primary outcome was CVD events, defined as a composite of cardiovascular mortality, non-fatal myocardial infarction, and non-fatal stroke (see Supplementary material online, Table S1), similar to the endpoint of the SCORE2 model.3 Follow-up was until the first non-fatal myocardial infarction, non-fatal stroke, or death or end of the event registration period. Follow-up was truncated at 10 years as the effect of predictors on the risk of CVD events within this period is of most interest. Deaths from non-cardiovascular causes were treated as competing events.
Statistical analysis
First, the effect of all risk modifying characteristics on top of the SCORE2 predictions was estimated using Fine and Gray competing risk models. This was performed separately for each characteristic. As not all individual patient data was in the same geographical location, derivation was performed separately for every cohort and subsequently pooled using inverse variance weighting with fixed effects. In the derivation models, single additional predictors were used together with the SCORE2 coefficients, which were added as ‘fixed predictors’ (offset term). The use of fixed predictors ensured that the adjustment was made to the exact coefficients as published. SCORE2 was previously derived sex-specifically and included the prognostic factors: age, systolic blood pressure, non-HDL cholesterol, and current smoking.3 For all continuous risk modifying characteristics, Akaike information criterion was used to check the linearity of the association with the outcome variable by comparing model fit of models with linear fit with squared or log-transformed variables.
The risk modifying characteristics can be applied to individual predictions of the SCORE2 model using the ‘naïve approach’,12–14 which modifies individual predicted risks based on the population prevalence and the subdistribution hazard ratio (SHR) of the relevant predictor. This method is described in more detail in Supplementary material online, Methods, including a worked out example (see Supplementary material online, Table S2). The naïve method is a flexible method as it can be used on top of the recalibrated SCORE2 risks for every region for which the prevalence or population mean of the risk modifying character is known and may be used to improve upon predictions using different combinations of risk modifying characteristics without the need to derive different prognostic models.
Internal validation was performed, to evaluate the benefit of adding of each risk modifying characteristic separately in all cohorts where this characteristic was available. Performance of the updated risks based on each characteristic was assessed in terms of discrimination, net categorical reclassification index (NRI), and goodness-of-fit. Discrimination was assessed using Harrell’s C-index, corrected for competing risks.15 All relevant discrimination measures were calculated in every cohort separately and subsequently pooled by weighting of the number of events in every cohort. The NRI was calculated based on the 2021 ESC prevention guideline cut-offs for individuals 50–69 years old: 5% and 10% 10-year CVD risk.2 The NRI was presented separately for events and non-events, and confidence intervals (CIs) were obtained using bootstrapping (r-package nricens).16,17 To assess whether model goodness-of-fit was negatively affected by the risk modification, visual assessment was conducted using predicted vs. observed risk plots—showing deciles of predicted risks plotted against CVD cumulative incidences. The intercept of the SCORE2 model was recalibrated to every cohort prior to these analyses.
In addition, sensitivity analyses evaluated the effect of adding multiple risk modifying characteristics at once with the naïve method. Analyses evaluating a varying number of risk modifying characteristics were performed in the MESA cohort, as this had the largest number of additional predictors available. In this analysis, first, the recalibrated risk was predicted for all participants. This risk was then modified with the required number of predictors for every individual. The risk modifying characteristics were randomly chosen for every MESA participant from all risk modifying characteristics available in MESA.
Handling of missing data is described in Supplementary material online, Methods. All analyses were performed with R-statistical programming (version 3.5.2, R Foundation for Statistical Computing, Vienna, Austria).
External validation in real-world clinical data
In clinical practice, most additional risk modifying characteristics as evaluated in the current study are not randomly measured. The fact that these predictors were measured itself may carry predictive information, and thus, the current approach was validated in care-as-usual primary care data from CPRD GOLD. For these analyses, only the individuals were used to which the SCORE2 model currently applies (only persons aged 40–69 years without diabetes mellitus or previous CVD). External validation was performed assessing the effect of modification with all available risk factors to modify SCORE2 risks on model calibration, discrimination, and NRI. This way, the real-world availability of these risk factors in the primary care setting was implemented in the validation. CAC score was not available in the CPRD GOLD data. In addition, a sensitivity analysis was performed in CPRD to evaluate the applicability of the methods and derived SHRs in combination with predicted risks from SCORE2-OP and PCE. The same SHRs were used as in the main analyses. For the analyses with SCORE2-OP, only individuals of 70 years or older were included. For the analyses with PCE risks, the respective target population was included (age 45–80 years, no prior DM or CVD).
Results
For the derivation of all predictor effects, 409 757 individuals were included from 5 cohorts. The mean age at baseline was 57 ± 8 years old, and 58% were female. Detailed participant characteristics are presented in Table 1. In a median of 10.0 years of follow-up [interquartile range (IQR) 10.0–10.0], 16 166 CVD events and 19 149 non-cardiovascular deaths were observed. The SHRs of all additional predictors are presented in Table 2 and Supplementary material online, Tables S3 and S4.
Table 1.
Characteristics of the included individuals at baseline
| ARIC | EPIC-NL | HNR | MESA | UK Biobank | CPRD | |
|---|---|---|---|---|---|---|
| n = 8796 | n = 28 099 | n = 3679 | n = 5670 | n = 363 513 | n = 518 015 | |
| Male sex | 3633 (41%) | 5569 (20%) | 1674 (46%) | 2646 (47%) | 158 190 (44%) | 260 424 (50%) |
| Age (years) | 63 ± 6 | 54 ± 7 | 59 ± 8 | 61 ± 10 | 58 ± 7 | 49 ± 9 |
| Former smoker | 3684 (42%) | 9709 (35%) | 1193 (32%) | 2066 (36%) | 178 466 (49%) | 126 207 (26%) |
| Current smoker | 1310 (15%) | 7908 (28%) | 850 (23%) | 764 (13%) | 36 177 (10%) | 119 246 (24%) |
| Body mass index (kg/m2) | 28.1 ± 5.0 | 26.0 ± 3.9 | 27.4 ± 4.3 | 28.0 ± 5.1 | 27.1 ± 4.6 | 25.9 ± 5.0 |
| Systolic blood pressure (mmHg) | 126 ± 18 | 129 ± 19 | 131 ± 20 | 125 ± 20 | 139 ± 19 | 130 ± 17 |
| Total cholesterol (mmol/L) | 5.2 (4.6–5.8) | 5.7 (5.1–6.4) | 6.0 (5.3–6.6) | 5.0 (4.4–5.6) | 5.8 (5.1–6.6) | 5.3 (4.7–6.1) |
| HDL cholesterol (mmol/L) | 1.3 (1.0–1.6) | 1.5 (1.2–1.8) | 1.5 (1.2–1.8) | 1.3 (1.1–1.6) | 1.4 (1.2–1.7) | 1.4 (1.1–1.7) |
| LDL cholesterol (mmol/L) | 3.2 (2.6–3.7) | 2.9 (2.4–3.5)a | 3.8 (3.2–4.4) | 3.0 (2.5–3.5) | 3.6 (3.1–4.2) | — |
| Triglycerides (mmol/L) | — | 1.2 (0.9–1.8)a | 1.4 (1.0–1.9) | 1.2 (0.9–1.8) | 1.5 (1.1–2.1) | — |
| Estimated GFR (mL/min/1.73 m2) | 87 ± 15 | 101 ± 12a | 80 ± 14 | 78 ± 15 | 98 ± 12 | 77 ± 13 |
| Ankle–brachial index <0.9 | 511 (6%) | — | — | 156 (3%) | — | 23 (12%) |
| CAC percentile | — | — | 55 (35–80) | 42 (31–72) | — | — |
| Carotid stenosis >25% | — | — | 53 (1%) | 646 (11%) | — | — |
| cIMT (mm) | — | — | 0.7 (0.6–0.8) | 0.8 (0.7–1.0) | — | — |
| CRP (mg/L) | 2.1 (1.0–4.6) | 1.2 (0.6–2.4)a | 1.3 (0.7–2.8) | 1.8 (0.8–3.9) | 1.3 (0.7–2.7) | 3.0 (1.2–5.0) |
| Gestational hypertension | — | 5252 (19%) | — | — | 563 (0%) | 1635 (0%) |
| Parental history of myocardial infarction | 903 (10%) | 4088 (15%) | 345 (9%) | 603 (11%) | — | — |
| History of cancer | — | 1448 (5%) | 257 (7%) | 316 (6%) | 30 800 (8%) | 26 465 (5%) |
| History of inflammatory disease | — | — | 290 (8%) | — | — | — |
| Lp(a) (mg/dL) | — | — | 5 (5–23) | — | 9 (4–34) | — |
| Lower education | 1454 (17%) | 12 443 (44%) | 38 (1%) | 899 (16%) | 482 (0%) | — |
| Albuminuria >30 mg/g | 435 (5%) | — | — | 356 (6%) | 26 247 (7%) | 1538 (24%) |
| Number of drugs (n) | 4.0 (2.0–7.0) | — | 1.0 (0.0–3.0) | 2.0 (1.0–4.0) | 1.0 (0.0–3.0) | 2.0 (1.0–3.0) |
| NT-ProBNP (pg/mL) | 66 (33–123) | — | 67 (38–120) | 51 (23–101) | — | — |
| hs-Troponin-T (pg/mL) | 4.0 (3.0–7.0) | — | — | 4.1 (3.0–6.7) | — | — |
n (%), mean ± SD, or median (interquartile range; IQR). Additional risk modifiers in CPRD were not imputed and shown here as percentage of available cases only.
GFR, glomerular filtration rate [calculated with Chronic Kidney Disease Epidemiology Collaboration (CKDEPI) 2009 formula]; CAC, coronary artery calcium score percentile; cIMT, carotid intima-media thickness; CRP, C-reactive protein; HDL, high-density lipoprotein; LDL, low-density lipoprotein; Lp(a), lipoprotein(a); NT-proBNP, N-terminal pro-B-type natriuretic peptide.
Only measured in 6% random sample.
Table 2.
Subdistribution hazard ratios of the additional predictors
| Predictor | Subdistribution hazard ratio (95% CI) |
|---|---|
| Ankle–brachial index (<0.9) | 1.46 (1.18–1.80) |
| Body mass index (kg/m2)† | 1.02 (0.81–1.32) |
| CAC percentile† | 1.78 (1.53–2.00) |
| History of cancer | 1.07 (1.00–1.13) |
| Carotid stenosis (>25%) | 1.54 (1.22–1.94) |
| Carotid intima-media thickness (mm)‡ | 1.02 (0.92–1.14) |
| Estimated GFR (mL/min/1.73m2)† | 0.91 (0.56–1.48) |
| CRP (mg/L)* | 1.31 (1.28–1.35) |
| History of chronic inflammatory disease | 0.95 (0.54–1.67) |
| Lower education level | 1.30 (1.18–1.43) |
| Parental history of myocardial infarction | 1.36 (1.20–1.53) |
| Former smoking (vs. never) | 1.05 (1.00–1.09) |
| Gestational hypertension | 1.15 (0.97–1.36) |
| Lp(a) (mg/dL)* | 1.14 (1.12–1.17) |
| Albuminuria (>30 mg/g) | 1.34 (1.26–1.43) |
| Number of drugs (n)† | 1.18 (1.05–1.32) |
| NT-ProBNP (pg/mL)* | 1.47 (1.37–1.57) |
| hs-Troponin-T (pg/mL)* | 1.55 (1.44–1.68) |
Predictors marked with (*) are log-transformed, predictors marked with (†) are squared, and predictors marked (‡) are linear. For all these continuous predictors, the subdistribution hazard ratios are presented as third vs. first quartile. To aid clinical interpretation, squared and log coefficients are additionally displayed in Supplementary material online, Table S3.
GFR, glomerular filtration rate [calculated with Chronic Kidney Disease Epidemiology Collaboration (CKDEPI) formula]; CAC, coronary artery calcium percentile; cIMT, carotid intima-media thickness; CRP, C-reactive protein; HDL, high-density lipoprotein; LDL, low-density lipoprotein; Lp(a), lipoprotein(a); NT-proBNP, N-terminal pro-B-type natriuretic peptide.
The addition of most risk modifying characteristics led to a modest increase in discrimination. Risk modifying characteristics that increased discrimination most were CAC percentile with 0.0198 (95% CI 0.0115; 0.0281) and hs-Troponin-T with 0.0100 (95% CI 0.0063; 0.0137) (Figure 1). BMI, carotid stenosis, cIMT, CRP, and LPa modest but significant increases in discrimination were observed. Several common risk modifiers did not improve model discrimination (ABI, albuminuria, education level, eGFR, former smoking status, family history of CVD, gestational hypertension, history of cancer, and inflammatory disease). The number of drugs and NT-proBNP resulted in relatively high yet non-significant increases in C-statistic. CAC score led to a higher increase in discrimination and a similar NRI when added as CAC percentile, in comparison with when an absolute Agatston score was used (see Supplementary material online, Table S5). CAC percentile alone was even more predictive in comparison with a combined biomarker panel of hs-Troponin-T, NT-proBNP, and CRP. Still, the best discrimination was observed combining the CAC percentile and the biomarker panel, increasing the C-statistic by 0.0245 (95% CI 0.0157; 0.0333, Supplementary material online, Table S6).
Figure 1.

Effect of individual risk factors on the discrimination of the SCORE2 model. GFR, glomerular filtration rate [calculated with Chronic Kidney Disease Epidemiology Collaboration (CKDEPI) formula]; CAC, coronary artery calcium score percentile; cIMT, carotid intima-media thickness; CRP, C-reactive protein; HDL, high-density lipoprotein; LDL, low-density lipoprotein; Lp(a), lipoprotein(a); NT-proBNP, N-terminal pro-B-type natriuretic peptide. The effect of gestational hypertension was only evaluated in women.
The effect on calibration of using a single predictor to modify predicted risks was illustrated in Figure 2. For individuals with albuminuria, SCORE2 risks were slightly lower than observed, which was no longer apparent after modification of the risk using microalbuminuria. In individuals without albuminuria, predicted risks matched observed incidence both before and after modification of predicted risks.
Figure 2.

Illustration example showing the effect of additional stratification on microalbuminuria in real-world data. Calibration of SCORE2-predicted risks in all combined cohort data before and after modification of 10-year CVD risk in individuals known to have albuminuria (n = 1968) and known not to have albuminuria (n = 6010). Only individuals with available albuminuria data from routine clinical care data were included.
A clinical example was shown in Supplementary material online, Table S2, illustrating the application of the methodology for a 50-year-old smoking woman from Europe’s low-risk region. Her SCORE2-predicted risk was 5.3%. Her medical history shows a CAC percentile of p95. Implementing this in her risk prediction would almost double her risk to 10.2%. Another woman with exactly the same risk factor levels had no available CAC percentile, but a negative parental history of CVD before the age of 65. Implementing this information would slightly lower her 10-year risk (4.9%).
Addition of multiple predictors
In the lower risk deciles, no major over- or underestimation was observed regardless of the number of additional risk modifying characteristics added (Figure 3). For the highest risk decile, a minimal overestimation of predicted risks was observed even without adding risk factors. This overestimation increased gradually with adding more risk factors.
Figure 3.
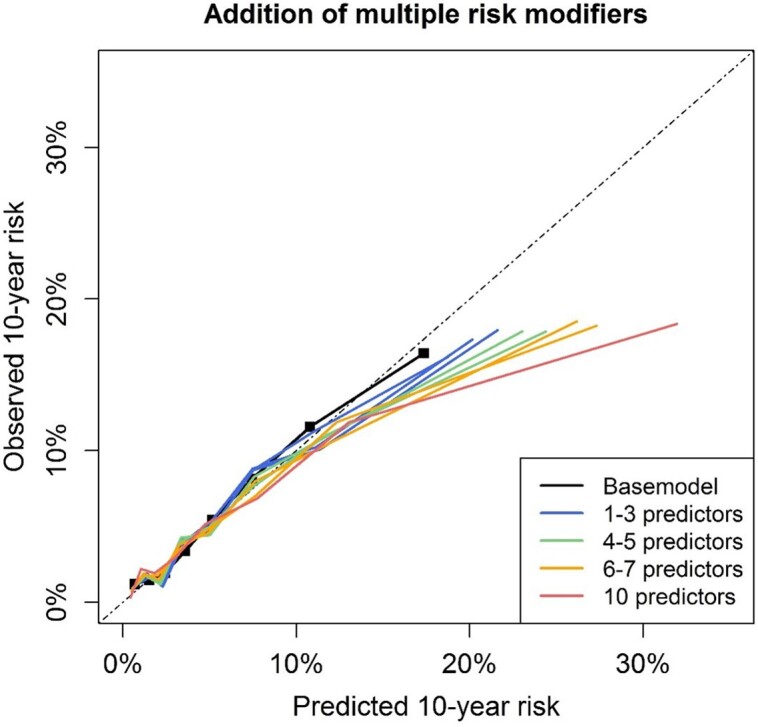
Effect of adding multiple random predictors on model calibration. Effect of adding multiple random risk modifiers at once for individuals of the MESA study, shown in deciles of predicted risk. Risk modifiers were randomly selected for every individual. Base model predictions were made with the SCORE2 model after recalibration of the model intercept to the MESA cohort.
External validation in real-world data
For external validation in real-world clinical data, 518 015 individuals were included; detailed participant characteristics are presented in Table 1. During 5.9 years of follow-up (IQR 2.5–9.4), 12 675 CVD events and 28 998 fatal non-CVD events were observed. Disease history (cancer and gestational hypertension) and number of medications were available in all individuals (see Supplementary material online, Table S7). Other risk modifying characteristics commonly available were former smoking status (77%), BMI (85%), and eGFR (29%). Information on a median of four (IQR 3–5) risk modifying characteristics was available per person. Unadjusted, the C-index of the SCORE2 model in the CPRD data was 0.737 (95% CI 0.732–0.741) (Figure 4). Risk modification with all available risk modifying characteristics did not lead to miscalibration of SCORE2 risks. After reclassification using all available information on risk modifying characteristics in this real-world data set, the C-index increased to 0.740 (95% CI 0.736–0.745) (Figure 4). The NRI for adding all these predictors was +0.041 (95% CI 0.036; 0.046) for events and −0.017 (95% CI −0.018; −0.016) for non-events. A gain in discrimination and positive NRI was observed in both men and women (Table 3). Risk factors most effectively increasing discrimination, among those with available data for the risk factor, were albuminuria, CRP, and the number of drugs (see Supplementary material online, Figure S1). Within those with predicted 10-year CVD risks between 7.5% and 12.5%, the C-index was 0.006 (95% CI 0.003–0.010) higher when using all available risk modifying characteristics, and the NRI was 0.078 (95% CI 0.067; 0.086) for events and −0.073 (95% CI −0.076; −0.070) for non-events.
Figure 4.

External validation in the real-world data of CPRD using all available risk modifiers (n = 517 595). Calibration in the CPRD data of the original low-risk region SCORE2 model (left) and after reclassification using all available information on risk modifying characteristics in this real-world data set (right).
Table 3.
External validation results stratified on sex
| Original C-index (95% CI) | C-index using all risk modifiers (95% CI) | NRI event (95% CI) | NRI non-event (95% CI) | NRI combined (95% CI) | |
|---|---|---|---|---|---|
| Men | 0.687 (0.681–0.693) | 0.691 (0.685–0.697) | 0.033 (0.026; 0.039) | −0.015 (0.016; −0.014) | 0.018 (0.012; 0.025) |
| Women | 0.746 (0.737–0.754) | 0.753 (0.744–0.751) | 0.062 (0.052; 0.072) | −0.019 (−0.020; −0.018) | 0.043 (0.033; 0.053) |
Sensitivity analyses
After applying the methodology to the PCE-predicted risks, discrimination increased slightly as well: the C-index increased from 0.751 (95% CI 0.747–0.754) when using the original PCE to 0.754 (95% CI 0.750–0.757) after reclassification using all available information on risk modifying characteristics in CPRD. The NRI was 0.023 (95% CI 0.019; 0.027) for events and −0.012 (−0.013; −0.012) for non-events. Using SCORE2-OP risks in the persons aged 70 years or older showed a similar increase in discrimination. The C-index increased from 0.628 (95% CI 0.621–0.634) when using the original SCORE2-OP risk score to 0.636 (95% CI 0.630–0.643) after reclassification using all available information on risk modifying characteristics in CPRD. The NRI was +0.015 (95% CI 0.010; 0.021) for events and −0.011 (95% CI −0.014; −0.009) for non-events.
Discussion
The current report describes flexible methods for handling additional risk modifying characteristics on top of basic prediction models for the prediction of CVD risk in apparently healthy people. The effect of several common additional risk modifying characteristics was quantified for use in clinical practice, increasing clinical utility in terms of improved applicability as well as increased discrimination and NRI while not negatively affecting calibration. External validation in real-world routine care data showed similar improvements in model performance as were observed in cohort data.
The methodology presented in the current study improves the clinical utility of CVD prediction models for apparently healthy individuals in several ways. First, the applicability of prediction models is improved upon in the presence of potential risk modifying characteristics. Current and previous guidelines acknowledged some of these factors may alter predicted 10-year CVD risks, but offer no clear solutions on how to mathematically deal with the presence of certain factors.2 If such factors are available but not incorporated in the prediction, both physicians and patients may intuitively feel the predicted risks are over- or underestimated and be reluctant to rely upon predicted risks. As the degree of this potential inaccuracy is unknown, risk communication and treatment decisions based on predicted risk become more difficult. Using the methodology presented in the current study, these risk modifying characteristics can be incorporated in the risk prediction algorithm, thereby improving confidence in predicted risks. For individuals with certain risk modifiers present, this will also result in more relevant predicted risks. Second, results from the current study show that these risk modifications improve upon discrimination on top of the SCORE2 model, in cohort data as well as in real-world data. Reclassification was especially improved in future events with most risk modifiers, thereby slightly reducing accuracy of the classification for future non-events. Most importantly, calibration was not affected by adding the risk factors available in clinical practice. Even though the discrimination on population level was only modestly improved, the risk for a single high risk individual might be importantly impacted.
The methodology as described in the current paper can be applied to add a single modifying characteristic, but also with a few risk modifying characteristics at once. Using too many risk modifying characteristics at once may lead to overestimation of CVD risk in the higher risk deciles, which gradually increases with a higher number of risk modifying characteristics. As this group is generally well above treatment thresholds, the effect of this overestimation is likely limited in clinical practice. The reason for this overestimation is the fact that the different risk modifiers as used in the current study are not corrected for each other, but may carry overlapping predictive information. The maximum of risk modifying characteristics that can be added while ensuring accurate risks is hard to define. This is because it likely depends on an individual’s predicted risk, as well as the effect size and collinearity of the risk modifiers. In the CPRD cohort, a median of four risk modifiers could be added without visible effect on the calibration, suggesting at least up until this number of risk modifiers could be added.
There are several other strategies available to handle additional available risk modifiers. One possibility is to use prediction models developed with more prognostic factors, including the one of interest, like the MESA CHD risk score.18 A disadvantage of using more extensive risk models is the decreased clinical applicability because it requires more variables to be known in clinical practice or a separate algorithm to be derived for individuals with and without the predictor present. In addition, it would require well-validated models for each relevant combination of predictor availability. More extensive models have not yet been well calibrated to European clinical practice using representative registry data. An alternative approach has been proposed by the Chronic Kidney Disease (CKD) Prognosis Consortium, consisting of a ‘patch’ to enhance predicted risks according to kidney disease measures eGFR and albuminuria.19 This method uses the difference between the individual expected eGFR and actual eGFR to modify predicted risks, rather than the absolute value as used in the current study. An advantage of this method could be that the effects of eGFR and albuminuria are adjusted for each other—potentially benefitting those with moderate to severe chronic kidney disease. The method described in the current study may best benefit apparently healthy individuals due to the flexibility of the method and broad range of potential risk modifiers.
In the current study, a wide range of potential risk modifiers were analysed. These risk modifiers were chosen based on prior evidence, recommendation as potential risk modifiers in the ESC CVD prevention guidelines, and on availability of the risk modifier in the data sets available in the current study. CAC score was clearly the most effective risk modifier in terms of improved discrimination and reclassification. Other risk modifiers showed some benefit (hs-Troponin-T, BMI, carotid stenosis, cIMT, CRP, and LPa). However, some risk modifiers showed no discriminative improvement in the current study. This could be caused by the heterogeneity in definitions as used in the current study for gestational hypertension (for example, reflected by the large differences in prevalence between EPIC-NL and UKB) or by the low availability (for example, inflammatory disease only available in HNR).
Our study did not consider the potential cost, convenience, and acceptability of routinely measuring the risk modifiers that were studied. In addition to improvement in terms of accuracy and clinical applicability, these additional aspects should be considered before their routine measurement with the aim of risk prediction can be recommended for clinical practice, especially with regard to the limited discriminative improvement with several risk modifiers. For individuals in whom these risk modifying characteristics have already been measured, these can be incorporated in CVD risk predictions with the results of the current study.
In the current study, CAC score was used to update individual risk predictions after transformation to CAC percentiles, which was also shown to most effectively increase model discrimination. Previous studies have found that the predictive value of the direct Agatston value may be higher in comparison with that of the CAC percentiles.20 An important difference with the current study is the fact that in the current analyses, the predictive value on top of an existing model was evaluated, rather than the predictive value of solely Agatston or MESA percentile. In addition, the current methodology did not allow for changes in the original SCORE2 baseline hazard or coefficients. The MESA percentiles, which are already adjusted for age, sex, and race, may be most suitable in this situation. For future studies aiming to directly incorporate CAC measures into risk scores, results of the current study may not directly apply and the log-transformed Agatston score could be the superior measure.
An important strength of the proposed methodology is the flexibility of the method. The method can be easily implemented in online calculators such as on www.U-prevent.com to accommodate additional risk stratification based on whichever predictors are available. In those cases, in which one of the many evaluated predictors is available, this can be incorporated in the risk prediction, improving model applicability and prediction accuracy. In those cases where no additional risk modifiers are available, no additional information is required and risks can be predicted with the regular SCORE2 model. Another strength is use of large and contemporary data sets with long follow-up duration for both derivation and validation in the current study. The validation in the real-world data in CPRD GOLD showed that the methodology can be used with routinely measured medical data. Moreover, the methodology as described in the current study accounts for the impact of competing risks by non-CVD outcomes, similar to the SCORE2 model itself. This statistical adjustment prevents overestimation of CVD risk, which is especially of importance for individuals with higher risks of non-CVD mortality, such as older persons.
There are also some limitations which have to be considered. First, an assumption of the methodology is knowledge of the population prevalence of the risk modifier of interest. These prevalence estimates for North America and Western Europe were obtained from powerful, contemporary cohorts. In cohort data, there is often a certain degree of healthy participant bias, possibly affecting the derived risk factor prevalence estimates and, with that, systematic over- or underestimation of predicted risks. In the current study, however, no evidence was observed of systematic miscalibration in the external validation in the relatively unselected population of CPRD.10 For regions outside of Western Europe and North America, reliable local risk factor prevalence would be preferred to ensure reliable implementation of this methodology in clinical practice.
Second, the effect of some relevant risk modifying characteristics was not evaluated in the current study. Potentially relevant predictors which might further improve risk prediction, but were not available in the data sets used for the current study, include frailty, social deprivation, and environmental factors.2,21–23 Future studies could apply the methodology presented in the current study to those risk modifiers as well, and results could be combined with those of the current study. Race/ethnicity may also improve risk prediction but was not included in the current study because of the close correlation between race/ethnicity and social economic determinants.24 Future research is needed to study the prognostic relevance of race in relation to cardiovascular risk, using data sets that include social economic information. Future studies could apply the methodology presented in the current study to those risk modifiers as well, and results could be combined with those of the current study. In addition, some of the variables, including CAC percentiles, were not available in the real-world data, which may have underestimated the total gain in discriminative power from adding all risk modifiers in the external validation.
Also, the current approach is relatively complicated for calculating by hand and use in combination with paper risk charts. For such instances, a step-wise, categorized approach could be preferable with some risk factors like CAC, advising, for example, to initiate preventive therapy in those with intermediate risk and CAC score of 100 and higher. However, the approach as described in the current paper is a very easy solution for those using online calculators, in which the actual calculation is programmed. This way, the method can be used quantitatively by only adding the extra risk modifier to the calculator to obtain individual predictions taking into account this additional risk modifier. The updated individual predictions can then be compared with the relevant treatment thresholds in local guidelines.
Conclusions
In conclusion, a solution was presented on how to implement additional risk modifying characteristics on top of existing models for the prediction of CVD event risk in apparently healthy people. The methods were shown to be accurate using a broad range of potential risk modifying characteristics and were accurate even when using multiple risk modifying characteristics. The methodology presented in the current paper modestly increases discrimination for the whole population, but the risk for a single high risk individual can be importantly impacted, leading to different treatment decisions. Allowing for incorporation of these factors in clinical practice will increase confidence in predicted risks in those cases where a risk modifier is present, thereby improving upon clinical applicability of existing prediction models.
Supplementary material
Supplementary material is available at European Journal of Preventive Cardiology.
Supplementary Material
Acknowledgements
The use of CPRD data was approved by the Independent Scientific Advisory Committee for MHRA database research (protocol number 20_155R).
Contributor Information
Steven H J Hageman, Department of Vascular Medicine, University Medical Center Utrecht, PO Box 85500, 3508 GA, Utrecht, The Netherlands.
Carmen Petitjean, British Heart Foundation Cardiovascular Epidemiology Unit, Department of Public Health and Primary Care, University of Cambridge, Cambridge, UK; Victor Phillip Dahdaleh Heart and Lung Research Institute, University of Cambridge, Cambridge, UK.
Lisa Pennells, British Heart Foundation Cardiovascular Epidemiology Unit, Department of Public Health and Primary Care, University of Cambridge, Cambridge, UK; Victor Phillip Dahdaleh Heart and Lung Research Institute, University of Cambridge, Cambridge, UK.
Stephen Kaptoge, British Heart Foundation Cardiovascular Epidemiology Unit, Department of Public Health and Primary Care, University of Cambridge, Cambridge, UK; Victor Phillip Dahdaleh Heart and Lung Research Institute, University of Cambridge, Cambridge, UK.
Romin Pajouheshnia, Division of Pharmacoepidemiology and Clinical Pharmacology, Utrecht Institute for Pharmaceutical Sciences (UIPS), Utrecht University, Utrecht, The Netherlands.
Taavi Tillmann, Institute of Family Medicine and Public Health, University of Tartu, Tartu, Estonia.
Michael J Blaha, Johns Hopkins Ciccarone Center for the Prevention of Heart Disease, Johns Hopkins Hospital, Baltimore, USA.
Robyn L McClelland, Department of Biostatistics, University of Washington, Seattle, WA, USA.
Kunihiro Matsushita, Department of Epidemiology, Johns Hopkins Bloomberg School of Public Health, Baltimore, USA.
Vijay Nambi, Center for Cardiovascular Disease Prevention, Michael E DeBakey Veterans Affairs Hospital, Houston, USA; Department of Medicine, Baylor College of Medicine, Houston, USA.
Olaf H Klungel, Division of Pharmacoepidemiology and Clinical Pharmacology, Utrecht Institute for Pharmaceutical Sciences (UIPS), Utrecht University, Utrecht, The Netherlands.
Patrick C Souverein, Division of Pharmacoepidemiology and Clinical Pharmacology, Utrecht Institute for Pharmaceutical Sciences (UIPS), Utrecht University, Utrecht, The Netherlands.
Yvonne T van der Schouw, Julius Center for Health Sciences and Primary Care, University Medical Center Utrecht, Utrecht University, Utrecht, The Netherlands.
W M Monique Verschuren, Centre for Nutrition, Prevention and Health Services, National Institute for Public Health and the Environment, Bilthoven, The Netherlands.
Nils Lehmann, Institute for Medical Informatics, Biometry and Epidemiology, University Hospital Essen, University Duisburg-Essen, Essen, Germany.
Raimund Erbel, Institute for Medical Informatics, Biometry and Epidemiology, University Hospital Essen, University Duisburg-Essen, Essen, Germany.
Karl-Heinz Jöckel, Institute for Medical Informatics, Biometry and Epidemiology, University Hospital Essen, University Duisburg-Essen, Essen, Germany.
Emanuele Di Angelantonio, British Heart Foundation Cardiovascular Epidemiology Unit, Department of Public Health and Primary Care, University of Cambridge, Cambridge, UK; Victor Phillip Dahdaleh Heart and Lung Research Institute, University of Cambridge, Cambridge, UK; British Heart Foundation Centre of Research Excellence, University of Cambridge, Cambridge, UK; National Institute for Health and Care Research Blood and Transplant Research Unit in Donor Health and Behaviour, University of Cambridge, Cambridge, UK; Health Data Research UK Cambridge, Wellcome Genome Campus and University of Cambridge, Cambridge, UK; Health Data Science Research Centre, Human Technopole, Milan, Italy.
Frank L J Visseren, Department of Vascular Medicine, University Medical Center Utrecht, PO Box 85500, 3508 GA, Utrecht, The Netherlands.
Jannick A N Dorresteijn, Department of Vascular Medicine, University Medical Center Utrecht, PO Box 85500, 3508 GA, Utrecht, The Netherlands.
Author contributions
J.A.N.D., E.DA., F.L.J.V., T.T., and S.H.J.H. contributed to the conception or design of the work. M.J.B., R.L.M., K.M., V.N., O.H.K., R.P., P.C.S., Y.T.v.d.S., W.M.M.V., N.L., R.E., and K.-H.J. contributed to data acquisition of all included cohort data. S.H.J.H., C.P., L.P., and S.K. contributed to the analyses. S.H.J.H. drafted the manuscript, which was critically revised by all co-authors. All gave final approval and agree to be accountable for all aspects of work ensuring integrity and accuracy.
Funding
The MESA study was supported by contracts 75N92020D00001, HHSN268201500003I, N01-HC-95159, 75N92020D00005, N01-HC-95160, 75N92020D00002, N01-HC-95161, 75N92020D00003, N01-HC-95162, 75N92020D00006, N01-HC-95163, 75N92020D00004, N01-HC-95164, 75N92020D00007, N01-HC-95165, N01-HC-95166, N01-HC-95167, N01-HC-95168, and N01-HC-95169 from the National Heart, Lung, and Blood Institute and by grants UL1-TR-000040, UL1-TR-001079, and UL1-TR-001420 from the National Center for Advancing Translational Sciences (NCATS). The Atherosclerosis Risk in Communities study has been funded in whole or in part with Federal funds from the National Heart, Lung, and Blood Institute, National Institutes of Health, Department of Health and Human Services, under Contract nos. 75N92022D00001, 75N92022D00002, 75N92022D00003, 75N92022D00004, and 75N92022D00005. This work was supported by core funding from the: British Heart Foundation (RG/18/13/33946), the BHF Chair Award (CH/12/2/29428), the Cambridge British Health Foundation Centre of Research Excellence (RE/18/1/34212), and the National Institute for Health and Care Research Cambridge Biomedical Research Centre (BRC-1215-20014; NIHR203312) [*].
Data availability
The data underlying this article were provided by representatives of all included cohorts. Data from each cohort may be shared on request to the respective representatives, depending on cohort-specific policies. R-scripts used for the current analyses will be shared on reasonable request.
References
- 1. Goff DC, Lloyd-Jones DM, Bennett G, Coady S, D’Agostino RB, Gibbons R, et al. 2013 ACC/AHA guideline on the assessment of cardiovascular risk: A report of the American College of Cardiology/American Heart Association task force on practice guidelines. Circulation 2014;129:49–73. [Google Scholar]
- 2. Visseren FLJ, Mach F, Smulders YM, Carballo D, Koskinas KC, Bäck M, et al. 2021 ESC guidelines on cardiovascular disease prevention in clinical practice. Eur J Prev Cardiol 2022;29:5–115. [DOI] [PubMed] [Google Scholar]
- 3. Hageman S, Pennells L, Ojeda F, Kaptoge S, Kuulasmaa K, de Vries T, et al. SCORE2 risk prediction algorithms: new models to estimate 10-year risk of cardiovascular disease in Europe. Eur Heart J 2021;42:2439–2454. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. van der Leeuw J, Ridker PM, van der Graaf Y, Visseren FLJ. Personalized cardiovascular disease prevention by applying individualized prediction of treatment effects. Eur Heart J 2014;35:837–843. [DOI] [PubMed] [Google Scholar]
- 5. Dorresteijn JAN, Visseren FLJ, Ridker PM, Wassink AMJ, Paynter NP, Steyerberg EW, et al. Estimating treatment effects for individual patients based on the results of randomised clinical trials. BMJ 2011;343:d5888. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Hewitt J, Walters M, Padmanabhan S, Dawson J. Cohort profile of the UK Biobank: diagnosis and characteristics of cerebrovascular disease. BMJ Open 2016;6:e009161. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Fretz A, Schneider ALC, McEvoy JW, Hoogeveen R, Ballantyne CM, Coresh J, et al. The association of socioeconomic status with subclinical myocardial damage, incident cardiovascular events, and mortality in the ARIC study. Am J Epidemiol 2016;183:452–461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Bild DE, Bluemke DA, Burke GL, Detrano R, Diez Roux AV, Folsom AR, et al. Multi-ethnic study of atherosclerosis: objectives and design. Am J Epidemiol 2002;156:871–881. [DOI] [PubMed] [Google Scholar]
- 9. Schmermund A, Möhlenkamp S, Stang A, Grönemeyer D, Seibel R, Hirche H, et al. Assessment of clinically silent atherosclerotic disease and established and novel risk factors for predicting myocardial infarction and cardiac death in healthy middle-aged subjects: rationale and design of the Heinz Nixdorf Recall study. Am Heart J 2002;144:212–218. [DOI] [PubMed] [Google Scholar]
- 10. Herrett E, Gallagher AM, Bhaskaran K, Forbes H, Mathur R, van Staa T, et al. Data resource profile: Clinical Practice Research Datalink (CPRD). Int J Epidemiol 2015;44:827–836. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. McClelland RL, Chung H, Detrano R, Post W, Kronmal RA. Distribution of coronary artery calcium by race, gender, and age: results from the Multi-Ethnic Study of Atherosclerosis (MESA). Circulation 2006;113:30–37. [DOI] [PubMed] [Google Scholar]
- 12. Berkelmans GFN, Read SH, Gudbjörnsaottir S, Wild SH, Franzen S, van der Graaf Y, et al. Dealing with missing patient characteristics when using cardiovascular prediction models in clinical practice; 2018.
- 13. Tyrer J, Duffy SW, Cuzick J. A breast cancer prediction model incorporating familial and personal risk factors. Statist Med 2004;23:1111–1130. [DOI] [PubMed] [Google Scholar]
- 14. Kooter AJ, Kostense PJ, Groenewold J, Thijs A, Sattar N, Smulders YM. Integrating information from novel risk factors with calculated risks. Circulation 2011;124:741–745. [DOI] [PubMed] [Google Scholar]
- 15. Wolbers M, Koller MT, Witteman JCM, Steyerberg EW. Prognostic models with competing risks. Epidemiology 2009;20:555–561. [DOI] [PubMed] [Google Scholar]
- 16. Kerr KF, Wang Z, Janes H, McClelland RL, Psaty BM, Pepe MS. Net reclassification indices for evaluating risk prediction instruments. Epidemiology 2014;25:114–121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Pencina MJ, D’Agostino RB, Steyerberg EW. Extensions of net reclassification improvement calculations to measure usefulness of new biomarkers. Stat Med 2011;30:11–21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. McClelland RL, Jorgensen NW, Budoff M, Blaha MJ, Post WS, Kronmal RA, et al. 10-year coronary heart disease risk prediction using coronary artery calcium and traditional risk factors. J Am Coll Cardiol 2015;66:1643–1653. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Matsushita K, Jassal SK, Sang Y, Ballew SH, Grams ME, Surapaneni A, et al. Incorporating kidney disease measures into cardiovascular risk prediction: development and validation in 9 million adults from 72 datasets. EClinicalMedicine 2020;27:100552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Budoff MJ, Nasir K, McClelland RL, Detrano R, Wong N, Blumenthal RS, et al. Coronary calcium predicts events better with absolute calcium scores than age-sex-race/ethnicity percentiles. J Am Coll Cardiol 2009;53:345–352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Kivimäki M, Steptoe A. Effects of stress on the development and progression of cardiovascular disease. Nat Rev Cardiol 2018;15:215–229. [DOI] [PubMed] [Google Scholar]
- 22. Afilalo J, Alexander KP, Mack MJ, Maurer MS, Green P, Allen LA, et al. Frailty assessment in the cardiovascular care of older adults. J Am Coll Cardiol 2014;63:747–762. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Münzel T, Hahad O, Sørensen M, Lelieveld J, Duerr GD, Nieuwenhuijsen M, et al. Environmental risk factors and cardiovascular diseases: a comprehensive expert review. Cardiovasc Res 2022;118:2880–2902. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Jones DW, Chambless LE, Folsom AR, Heiss Gerardo, Hutchinson RG, Sharrett AR, et al. Risk factors for coronary heart disease in African Americans: the Atherosclerosis Risk in Communities study, 1987–1997. Arch Intern Med 2002;162:2565. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The data underlying this article were provided by representatives of all included cohorts. Data from each cohort may be shared on request to the respective representatives, depending on cohort-specific policies. R-scripts used for the current analyses will be shared on reasonable request.