

Abstract
Matrix factorization methods, which include Factor analysis (FA) and Principal Components Analysis (PCA), are widely used for inferring and summarizing structure in multivariate data. Many such methods use a penalty or prior distribution to achieve sparse representations (“Sparse FA/PCA”), and a key question is how much sparsity to induce. Here we introduce a general Empirical Bayes approach to matrix factorization (EBMF), whose key feature is that it estimates the appropriate amount of sparsity by estimating prior distributions from the observed data. The approach is very flexible: it allows for a wide range of different prior families and allows that each component of the matrix factorization may exhibit a different amount of sparsity. The key to this flexibility is the use of a variational approximation, which we show effectively reduces fitting the EBMF model to solving a simpler problem, the so-called “normal means” problem. We demonstrate the benefits of EBMF with sparse priors through both numerical comparisons with competing methods and through analysis of data from the GTEx (Genotype Tissue Expression) project on genetic associations across 44 human tissues. In numerical comparisons EBMF often provides more accurate inferences than other methods. In the GTEx data, EBMF identifies interpretable structure that agrees with known relationships among human tissues. Software implementing our approach is available at https://github.com/stephenslab/flashr.
Keywords: empirical Bayes, matrix factorization, normal means, sparse prior, unimodal prior, variational approximation
1. Introduction
Matrix factorization methods are widely used for inferring and summarizing structure in multivariate data. In brief, these methods represent an observed data matrix as:
| (1.1) |
where is an matrix, is a matrix, and is an matrix of residuals (whose entries we assume to be normally distributed, although the methods we develop can be generalized to other settings; see Section 6.4). Here we adopt the notation and terminology of factor analysis, and refer to as the “loadings” and as the “factors”.
The model (1.1) has many potential applications. One range of applications arise from “matrix completion” problems (e.g. Fithian et al., 2018): methods that estimate and in (1.1) from partially observed provide a natural and effective way to fill in the missing entries. Another wide range of applications come from the desire to summarize and understand the structure in a matrix Y : in (1.1) each row of is approximated by a linear combination of underlying “factors” (rows of), which—ideally—have some intuitive or scientific interpretation. For example, suppose represents the rating of a user for a movie . Each factor might represent a genre of movie (“comedy”, “drama”, “romance”, “horror” etc), and the ratings for a user could be written as a linear combination of these factors, with the weights (loadings) representing how much individual likes that genre. Or, suppose represents the expression of gene in sample . Each factor might represent a module of co-regulated genes, and the data for sample could be written as a linear combination of these factors, with the loadings representing how active each module is in each sample. Many other examples could be given across many fields, including psychology (Ford et al., 1986), econometrics (Bai and Ng, 2008), natural language processing (Bouchard et al., 2015), population genetics (Engelhardt and Stephens, 2010), and functional genomics (Stein-O’Brien et al., 2018).
The simplest approaches to estimating and/or in (1.1) are based on maximum likelihood or least squares. For example, Principal Components Analysis (PCA)—or, more precisely, truncated Singular Value Decomposition (SVD)—can be interpreted as fitting (1.1) by least squares, assuming that columns of are orthogonal and columns of are orthonormal (Eckart and Young, 1936). And classical factor analysis (FA) corresponds to maximum likelihood estimation of , assuming that the elements of are independent standard normal and allowing different residual variances for each column of (Rubin and Thayer, 1982). While these simple methods remain widely used, in the last two decades researchers have focused considerable attention on obtaining more accurate and/or more interpretable estimates, either by imposing additional constraints (e.g. non-negativity; Lee and Seung, 1999) or by regularization using a penalty term (e.g. Jolliffe et al., 2003; Witten et al., 2009; Mazumder et al., 2010; Hastie et al., 2015; Fithian et al., 2018), or a prior distribution (e.g. Bishop, 1999; Attias, 1999; Ghahramani and Beal, 2000; West, 2003). In particular, many authors have noted the benefits of sparsity assumptions on and/or — particularly in applications where interpretability of the estimates is desired—and there now exists a wide range of methods that attempt to induce sparsity in these models (e.g. Sabatti and James, 2005; Zou et al., 2006; Pournara and Wernisch, 2007; Carvalho et al., 2008; Witten et al., 2009; Engelhardt and Stephens, 2010; Knowles and Ghahramani, 2011; Bhattacharya and Dunson, 2011; Mayrink et al., 2013; Yang et al., 2014; Gao et al., 2016; Hore et al., 2016; Ročková and George, 2016; Srivastava et al., 2017; Kaufmann and Schumacher, 2017; Frühwirth-Schnatter and Lopes, 2018; Zhao et al., 2018). Many of these methods induce sparsity in the loadings only, although some induce sparsity in both loadings and factors.
In any statistical problem involving sparsity, a key question is how strong the sparsity should be. In penalty-based methods this is controlled by the strength and form of the penalty, whereas in Bayesian methods it is controlled by the prior distributions. In this paper we take an Empirical Bayes approach to this problem, exploiting variational approximation methods (Blei et al., 2017) to obtain simple algorithms that jointly estimate the prior distributions for both loadings and factors, as well as the loadings and factors themselves.
Both EB and variational methods have been previously used for this problem (Bishop, 1999; Lim and Teh, 2007; Raiko et al., 2007; Stegle et al., 2010). However, most of this previous work has used simple normal prior distributions that do not induce sparsity. Variational methods that use sparsity-inducing priors include Girolami (2001), which uses a Laplace prior on the factors (no prior on the loadings which are treated as free parameters), Hochreiter et al. (2010) which extends this to Laplace priors on both factors and loadings, with fixed values of the Laplace prior parameters; Titsias and Lázaro-Gredilla (2011), which uses a sparse “spike-and-slab” (point normal) prior on the loadings (with the same prior on all loadings) and a normal prior on the factors; and Hore et al. (2016) which uses a spike-and-slab prior on one mode in a tensor decomposition. (While this work was in review further examples appeared, including Argelaguet et al. 2018, which uses normal priors on the loadings and point-normal on the factors.)
Our primary contribution here is to develop and implement a more general EB approach to matrix factorization (EBMF). This general approach allows for a wide range of potential sparsity-inducing prior distributions on both the loadings and the factors within a single algorithmic framework. We accomplish this by showing that, when using variational methods, fitting EBMF with any prior family can be reduced to repeatedly solving a much simpler problem—the “empirical Bayes normal means” (EBNM) problem—with the same prior family. This feature makes it easy to implement methods for any desired prior family—one simply has to implement a method to solve the corresponding normal means problem, and then plug this into our algorithm. This approach can work for both parametric families (e.g. normal, point-normal, laplace, point-laplace) and non-parametric families, including the “adaptive shrinkage” priors (unimodal and scale mixtures of normals) from Stephens (2017). It is also possible to accommodate non-negative constraints on either and/or by using non-negative prior families. Even simple versions of our approach—e.g. using point-normal priors on both factors and loadings— provide more generality than most existing EBMF approaches and software.
A second contribution of our work is to highlight similarities and differences between EBMF and penalty-based methods for regularizing and/or . Indeed, our algorithm for fitting EBMF has the same structure as commonly-used algorithms for penalty-based methods, with the prior distribution playing a role analogous to the penalty (see Remark 3 later). While the general correspondence between estimates from penalized methods and Bayesian posterior modes (MAP estimates) is well known, the connection here is different, because the EBMF approach is estimating a posterior mean, not a mode (indeed, with sparse priors the MAP estimates of and are not useful because they are trivially 0). A key difference between the EBMF approach and penalty-based methods is that the EBMF prior is estimated by solving an optimization problem, whereas in penalty-based methods the strength of the penalty is usually chosen by cross-validation. This difference makes it much easier for EBMF to allow for different levels of sparsity in every factor and every loading: in EBMF one simply uses a different prior for every factor and loading, whereas tuning a separate parameter for every factor and loading by CV becomes very cumbersome.
The final contribution is that we provide an software package, flash (Factors and Loadings by Adaptive SHrinkage), implementing our flexible EBMF framework. We demonstrate the utility of these methods through both numerical comparisons with competing methods and through a scientific application: analysis of data from the GTEx (Genotype Tissue Expression) project on genetic associations across 44 human tissues. In numerical comparisons flash often provides more accurate inferences than other methods, while remaining computationally tractable for moderate-sized matrices (millions of entries). In the GTEx data, flash highlight both effects that are shared across many tissues (“dense” factors) and effects that are specific to a small number of tissues (“sparse” factors). These sparse factors often highlight similarities between tissues that are known to be biologically related, providing external support for the reliability of the results.
2. A General Empirical Bayes Matrix Factorization Model
We define the -factor Empirical Bayes Matrix Factorization (EBMF) model as follows:
| (2.1) |
| (2.2) |
| (2.3) |
| (2.4) |
Here is the observed data matrix, is an -vector (the th set of “loadings”), is a -vector (the th “factor”), and are pre-specified (possibly non-parametric) families of distributions, and are unknown “prior” distributions that are to be estimated, is an matrix of independent error terms, and is an unknown matrix of precisions which is assumed to lie in some space . (This allows structure to be imposed on , such as constant precision, , or column-specific precisions, , for example.) Our methods allow that some elements of may be “missing”, and can estimate the missing values (Section 4.1).
The term “Empirical Bayes” in EBMF means we fit (2.1)-(2.4) by obtaining point estimates for the priors and approximate the posterior distributions for the parameters given those point estimates. This contrasts with a “fully Bayes” approach that, instead of obtaining point estimates for , would integrate over uncertainty in the estimates. This would involve specifying prior distributions for as well as (perhaps substantial) additional computation. The EB approach has the advantage of simplicity - both conceptually and computationally—while enjoying many of the benefits of a fully Bayes approach. In particular it allows for sharing of information across elements of each loading/factor. For example, if the data suggest that a particular factor, , is sparse, then this will be reflected in a sparse estimate of , and subsequently strong shrinkage of the smaller elements of towards 0. Conversely, when the data suggest a non-sparse factor then the prior will be dense and the shrinkage less strong. By allowing different prior distributions for each factor and each loading, the model has the flexibility to adapt to any combination of sparse and dense loadings and factors. However, to fully capitalize on this flexibility one needs suitably flexible prior families and capable of capturing both sparse and dense factors. A key feature of our work is it allows for very flexible prior families, including non-parametric families.
Some specific choices of the distributional families and correspond to models used in previous work. In particular, many previous papers have studied the case with normal priors, where and are both the family of zero-mean normal distributions (e.g. Bishop, 1999; Lim and Teh, 2007; Raiko et al., 2007; Nakajima and Sugiyama, 2011). This family is particularly simple, having a single hyper-parameter, the prior variance, to estimate for each factor. However, it does not induce sparsity on either or ; indeed, when the matrix is fully observed, the estimates of and under a normal prior (when using a fully factored variational approximation) are simply scalings of the singular vectors from an SVD of (Nakajima and Sugiyama, 2011; Nakajima et al., 2013). Our work here extends these previous approaches to a much wider range of prior families that do induce sparsity on and/or .
We note that the EBMF model (2.1)-(2.4) differs in an important way from the sparse factor analysis (SFA) methods in Engelhardt and Stephens (2010), which use a type of Automatic Relevance Determination prior (e.g. Tipping, 2001; Wipf and Nagarajan, 2008) to induce sparsity on the loadings matrix. In particular, SFA estimates a separate hyperparameter for every element of the loadings matrix, with no sharing of information across elements of the same loading. In contrast, EBMF estimates a single shared prior distribution for elements of each loading, which, as noted above, allows for sharing of information across elements of each loading/factor.
3. Fitting the EBMF Model
To simplify exposition we begin with the case (“rank 1”); see Section 3.6 for the extension to general . To simplify notation we assume the families are the same, so we can write . To further lighten notation in the case we use instead of .
Fitting the EBMF model involves estimating all of . A standard EB approach would be to do this in two steps:
- Estimate and , by maximizing the likelihood:
over . (This optimum will typically not be unique because of identifiability issues; see Section 3.8.)(3.1) Estimate and using their posterior distribution: .
However, both these two steps are difficult, even for very simple choices of . Instead, following previous work (see Introduction for citations) we use variational approximations to approximate this approach. Although variational approximations are known to typically under-estimate uncertainty in posterior distributions, our focus here is on obtaining useful point estimates for ; results shown later demonstrate that the variational approximation can perform well in this task.
3.1. The Variational Approximation
The variational approach—see Blei et al. (2017) for review—begins by writing the log of the likelihood (3.1) as:
| (3.2) |
| (3.3) |
where
| (3.4) |
and
| (3.5) |
is the Kullback–Leibler divergence from to . This identity holds for any distribution . Because is non-negative, it follows that is a lower bound for the likelihood:
| (3.6) |
with equality when .
In other words,
| (3.7) |
where the maximization is over all possible distributions . Maximizing can thus be viewed as maximizing over . However, as noted above, this maximization is difficult. The variational approach simplifies the problem by maximizing but restricting the family of distributions for . Specifically, the most common variational approach — and the one we consider here—restricts to the family of distributions that “fully-factorize”:
| (3.8) |
The variational approach seeks to optimize over with the constraint . For we can write where and , and we can consider the problem as maximizing .
3.2. Alternating Optimization
We optimize by alternating between optimizing over variables related to l , over variables related to , and over . Each of these steps is guaranteed to increase (or, more precisely, not decrease) , and convergence can be assessed by (for example) stopping when these optimization steps yield a very small increase in . Note that may be multi-modal, and there is no guarantee that the algorithm will converge to a global optimum. The approach is summarized in Algorithm 1

The key steps in Algorithm 1 are the maximizations in Steps 4–6.
Step 4, the update of , involves computing the expected squared residuals:
| (3.9) |
| (3.10) |
This is straightforward provided the first and second moments of and are available (see Appendix A.1 for details).
Steps 5 and 6 are essentially identical except for switching the role of and . One of our key results is that each of these steps can be achieved by solving a simpler problem—the Empirical Bayes normal means (EBNM) problem. The next subsection (3.3) describes the EBNM problem, and the following subsection (3.4) details how this can be used to solve Steps 5 and 6.
3.3. The EBNM Problem
Suppose we have observations of underlying quantities , with independent Gaussian errors with known standard deviations . Suppose further that the elements of are assumed i.i.d. from some distribution, . That is,
| (3.11) |
| (3.12) |
where denotes the -dimensional normal distribution with mean and covariance matrix .
By solving the EBNM problem we mean fitting the model (3.11)-(3.12) by the following two-step procedure:
- Estimate by maximum (marginal) likelihood:
(3.13) - Compute the posterior distribution for given ,
(3.14)
Later in this paper we will have need for the posterior first and second moments, so we define them here for convenience:
| (3.15) |
| (3.16) |
Formally, this procedure defines a mapping (which depends on the family 𝒢) from the known quantities , to , where are given in (3.13) and (3.14). We use to denote this mapping:
| (3.17) |
Remark 1 Solving the EBNM problem is central to all our algorithms, so it is worth some study. A key point is that the EBNM problem provides an attractive and flexible way to induce shrinkage and/or sparsity in estimates of . For example, if is truly sparse, with many elements at or near 0, then the estimate will typically have considerable mass near 0, and the posterior means (3.15) will be “shrunk” strongly toward 0 compared with the original observations. In this sense solving the EBNM problem can be thought of as a model-based analogue of thresholding-based methods, with the advantage that by estimating from the data the EBNM approach automatically adapts to provide an appropriate level of shrinkage. These ideas have been used in wavelet denoising (Clyde and George, 2000; Johnstone et al., 2004; Johnstone and Silverman, 2005a; Xing et al., 2016), and false discovery rate estimation (Thomas et al., 1985; Stephens, 2017) for example. Here we apply them to matrix factorization problems.
3.4. Connecting the EBMF and EBNM Problems
The EBNM problem is well studied, and can be solved reasonably easily for many choices of (e.g. Johnstone and Silverman, 2005b; Koenker and Mizera, 2014a; Stephens, 2017). In Section 4 we give specific examples; for now our main point is that if one can solve the EBNM problem for a particular choice of then it can be used to implement Steps 5 and 6 in Algorithm 1 for the corresponding EBMF problem. The following Proposition formalizes this for Step 5 of Algorithm 1; a similar proposition holds for Step 6 (see also Appendix A).
Proposition 2 Step 5 in Algorithm 1 is solved by solving an EBNM problem. Specifically
| (3.18) |
where the functions and are given by
| (3.19) |
| (3.20) |
and denote the vectors whose elements are the first and second moments of under :
| (3.21) |
| (3.22) |
Proof See Appendix A. ■
For intuition into where the EBNM in Proposition 2 comes from, consider estimating in (2.1) with and known. The model then becomes independent regressions of the rows of on , and the maximum likelihood estimate for has elements:
| (3.23) |
with standard errors
| (3.24) |
Further, it is easy to show that
| (3.25) |
Combining (3.25) with the prior
| (3.26) |
yields an EBNM problem.
The EBNM in Proposition 2 is the same as the EBNM (3.25)-(3.26), but with the terms and replaced with their expectations under . Thus, the update for in Algorithm 1, with fixed, is closely connected to solving the EBMF problem for “known “.
3.5. Streamlined Implementation Using First and Second Moments
Although Algorithm 1, as written, optimizes over , in practice each step requires only the first and second moments of the distributions and . For example, the EBNM problem in Proposition 1 involves and and not . Consequently, we can simplify implementation by keeping track of only those moments. In particular, when solving the normal means problem, in (3.17), we need only return the posterior first and second moments (3.15) and (3.16). This results in a streamlined and intuitive implementation, summarized in Algorithm 2.

Remark 3 Algorithm 2 has a very intuitive form: it has the flavor of an alternating least squares algorithm, which alternates between estimating given (Step 6) and given (Step 8), but with the addition of the ebnm step (Steps 7 and 9), which can be thought of as regularizing or shrinking the estimates: see Remark 1. This viewpoint highlights connections with related algorithms. For example, the (rank 1 version of the) SSVD algorithm from Yang et al. (2014) has a similar form, but uses a thresholding function in place of the ebnm function to induce shrinkage and/or sparsity.
3.6. The -factor EBMF Model
It is straightforward to extend the variational approach to fit the general factor model (2.1)-(2.4). In brief, we introduce variational distributions for , and then optimize the objective function . Similar to the rank-1 model, this optimization can be done by iteratively updating parameters relating to a single loading or factor, keeping other parameters fixed. And again we simplify implementation by keeping track of only the first and second moments of the distributions and , which we denote . The updates to ) are essentially identical to those for fitting the rank 1 model above, but with replaced with the residuals obtained by removing the estimated effects of the other factors:
| (3.27) |
Based on this approach we have implemented two algorithms for fitting the -factor model. First, a simple “greedy” algorithm, which starts by fitting the rank 1 model, and then adds factors , one at a time, optimizing over the new factor parameters before moving on to the next factor. Second, a “backfitting” algorithm (Breiman and Friedman, 1985), which iteratively refines the estimates for each factor given the estimates for the other factors. Both algorithms are detailed in Appendix A.
3.7. Selecting
An interesting feature of EB approaches to matrix factorization, noted by Bishop (1999), is that they automatically select the number of factors . This is because the maximum likelihood solution to is sometimes a point mass on 0 (provided includes this distribution). Furthermore, the same is true of the solution to the variational approximation (see also Bishop, 1999; Stegle et al., 2012). This means that if is set sufficiently large then some loading/factor combinations will be optimized to be exactly 0. (Or, in the greedy approach, which adds one factor at a time, the algorithm will eventually add a factor that is exactly 0, at which point it terminates.)
Here we note that the variational approximation may be expected to result in conservative estimation (i.e. underestimation) of compared with the (intractable) use of maximum likelihood to estimate . We base our argument on the simplest case: comparing vs . Let denote the degenerate distribution with all its mass at 0. Note that the rank-1 factor model (2.1), with (or ) is essentially a “rank-0” model. Now note that the variational lower bound, , is exactly equal to the log-likelihood when (or ). This is because if the prior is a point mass at 0 then the posterior is also a point mass, which trivially factorizes as a product of point masses, and so the variational family includes the true posterior in this case. Since is a lower bound to the log-likelihood we have the following simple lemma:
Lemma 4 If then .
Proof
| (3.28) |
■
Thus, if the variational approximation favors over the rank 0 model, then it is guaranteed that the likelihood would also favor over the rank 0 model. In other words, compared with the likelihood, the variational approximation is conservative in terms of preferring the rank 1 model to the rank 0 model. This conservatism is a double-edged sword. On the one hand it means that if the variational approximation finds structure it should be taken seriously. On the other hand it means that the variational approximation could miss subtle structure.
In practice Algorithm 2 can converge to a local optimum of that is not as high as the trivial (rank 0) solution, . We can add a check for this at the end of Algorithm 2, and set and when this occurs.
3.8. Identifiability
In EBMF each loading and factor is identifiable, at best, only up to a multiplicative constant (provided is a scale family). Specifically, scaling the prior distributions and by and respectively results in the same marginal likelihood, and also results in a corresponding scaling of the posterior distribution on the factors and loadings (e.g. it scales the posterior first moments by and the second moments by . However, this non-identifiability is not generally a problem, and if necessary it could be dealt with by re-scaling factor estimates to have norm 1.
4. Software Implementation: flash
We have implemented Algorithms 2, 4 and 5 in an R package, flash (“factors and loadings via adaptive shrinkage”). These algorithms can fit the EBMF model for any choice of distributional family : the user must simply provide a function to solve the EBNM problem for these prior families.
One source of functions for solving the EBNM problem is the “adaptive shrinkage” (ashr) package, which implements methods from Stephens (2017). These methods solve the EBNM problem for several flexible choices of , including:
, the set of all scale mixtures of zero-centered normals;
, the set of all symmetric unimodal distributions, with mode at 0;
, the set of all unimodal distributions, with mode at 0;
, the set of all non-negative unimodal distributions, with mode at 0.
These methods are computationally stable and efficient, being based on convex optimization methods (Koenker and Mizera, 2014b) and analytic Bayesian posterior computations.
We have also implemented functions to solve the EBNM problem for additional choices of in the package ebnm (https://github.com/stephenslab/ebnm). These include being the “point-normal” family:
, the set of all distributions that are a mixture of a point mass at zero and a normal with mean 0.
This choice is less flexible than those in ashr, and involves non-convex optimizations, but can be faster.
Although in this paper we focus our examples on sparsity-inducing priors with we note that our software makes it easy to experiment with different choices, some of which represent novel methodologies. For example, setting and yields an EB version of semi-non-negative matrix factorization (Ding et al., 2008), and we are aware of no existing EB implementations for this problem. Exploring the relative merits of these many possible options in different types of application will be an interesting direction for future work.
4.1. Missing Data
If some elements of are missing, then this is easily dealt with. For example, the sums over in (3.19) and (3.20) are simply computed using only the for which is not missing. This corresponds to an assumption that the missing elements of are “missing at random” (Rubin, 1976). In practice we implement this by setting whenever is missing (and filling in the missing entries of to an arbitrary number). This allows the implementation to exploit standard fast matrix multiplication routines, which cannot handle missing data. If many data points are missing then it may be helpful to exploit sparse matrix routines.
4.2. Initialization
Both Algorithms 2 and 4 require a rank 1 initialization procedure, init. Here, we use the softImpute function from the package softImpute (Mazumder et al., 2010), with penalty parameter , which essentially performs SVD when is completely observed, but can also deal with missing values in .
The backfitting algorithm (Algorithm 5) also requires initialization. One option is to use the greedy algorithm to initialize, which we call “greedy+backfitting”.
5. Numerical Comparisons
We now compare our methods with several competing approaches. To keep these comparisons manageable in scope we focus attention on methods that aim to capture possible sparsity in and/or . For EBMF we present results for two different shrinkage-oriented prior families, : the scale mixture of normals , and the point-normal family . We denote these flash and flash_pn respectively when we need to distinguish. In addition we consider Sparse Factor Analysis (SFA) (Engelhardt and Stephens, 2010), SFAmix (Gao et al., 2013), Nonparametric Bayesian Sparse Factor Analysis (NBSFA) (Knowles and Ghahramani, 2011), Penalized Matrix Decomposition (Witten et al., 2009) (PMD, implemented in the R package PMA), and Sparse SVD (Yang et al., 2014) (SSVD, implemented in package ssvd). Although the methods we compare against involve only a small fraction of the very large number of methods for this problem, the methods were chosen to represent a wide range of different approaches to inducing sparsity: SFA, SFAmix and NBSFA are three Bayesian approaches with quite different approaches to prior specification; PMD is based on a penalized likelihood with penalty on factors and/or loadings; and SSVD is based on iterative thresholding of singular vectors. We also compare with softImpute (Mazumder et al., 2010), which does not explicitly model sparsity in and , but fits a regularized low-rank matrix using a nuclear-norm penalty. Finally, for reference we also use standard (truncated) SVD.
All of the Bayesian methods (flash, SFA, SFAmix and NBSFA) are “self-tuning”, at least to some extent, and we applied them here with default values. According to Yang et al. (2014) SSVD is robust to choice of tuning parameters, so we also ran SSVD with its default values, using the robust option (method=“method”). The softImpute method has a single tuning parameter (, which controls the nuclear norm penalty), and we chose this penalty by orthogonal cross-validation (OCV; Appendix B). The PMD method can use two tuning parameters (one for and one for f) to allow different sparsity levels in vs . However, since tuning two parameters can be inconvenient it also has the option to use a single parameter for both and . We used OCV to tune parameters in both cases, referring to the methods as PMD.cv2 (2 tuning parameters) and PMD.cv1 (1 tuning parameter).
5.1. Simple Simulations
5.1.1. A Single Factor Example
We simulated data with under the single-factor model (2.1) with sparse loadings, and a non-sparse factor:
| (5.1) |
| (5.2) |
where denotes a point mass on 0, and . We simulated using three different levels of sparsity on the loadings, using . (We set the noise precision in these three cases to make each problem not too easy and not too hard.)
We applied all methods to this rank-1 problem, specifying the true value . (The NBSFA software does not provide the option to fix , so is omitted here.) We compare methods in their accuracy in estimating the true low-rank structure using relative root mean squared error:
| (5.3) |
Despite the simplicity of this simulation, the methods vary greatly in performance (Figure 1). Both versions of flash consistently outperform all the other methods across all scenarios (although softImpute performs similarly in the non-sparse case). The next best performances come from softImpute (SI.cv), PMD.cv2 and SFA, whose relative performances depend on the scenario. All three consistently improve on, or do no worse than, SVD. PMD.cv1 performs similarly to SVD. The SFAmix method performs very variably, sometimes providing very poor estimates, possibly due to poor convergence of the MCMC algorithm (it is the only method here that uses MCMC). The SSVD method consistently performs worse than simple SVD, possibly because it is more adapted to both factors and loadings being sparse (and possibly because, following Yang et al. 2014, we did not use CV to tune its parameters). Inspection of individual results suggests that the poor performance of both SFAmix and SSVD is often due to over-shrinking of non-zero loadings to zero.
Figure 1:

Boxplots comparing accuracy of flash with several other methods in a simple rank-1 simulation. This simulation involves a single dense factor, and a loading that varies from strong sparsity (90% zeros, left) to no sparsity (right). Accuracy is measured by difference in each methods RRMSE from the flash RRMSE, with smaller values indicating highest accuracy. The axis is plotted on a nonlinear (square-root) scale to avoid the plots being dominated by poorer-performing methods.
5.1.2. A Sparse Bi-cluster Example (Rank 3)
An important feature of our EBMF methods is that they estimate separate distributions for each factor and each loading, allowing them to adapt to any combination of sparsity in the factors and loadings. This flexibility is not easy to achieve in other ways. For example, methods that use are generally limited to one or two tuning parameters because of the computational difficulties of searching over a larger space.
To illustrate this flexibility we simulated data under the factor model (2.1) with , and:
| (5.4) |
| (5.5) |
| (5.6) |
| (5.7) |
| (5.8) |
| (5.9) |
with all other elements of and set to zero for . This example has a sparse bi-cluster structure where distinct groups of samples are each loaded on only one factor (Figure 2a), and both the size of the groups and number of variables in each factor vary.
Figure 2:

Results from simulations with sparse bi-cluster structure .
We applied flash, softImpute, SSVD and PMD to this example. (We excluded SFA and SFAmix since these methods do not model sparsity in both factors and loadings.) The results (Figure 2) show that again flash consistently outperforms the other methods, and again the next best is softImpute. On this example both SSVD and PMD outperform SVD. Although SSVD and PMD perform similarly on average, their qualitative behavior is different: PMD insufficiently shrink the 0 values, whereas SSVD shrinks the 0 values well but overshrinks some of the signal, essentially removing the smallest of the three loading/factor combinations (Figure 2 b).
5.2. Missing Data Imputation for Real Data Sets
Here we compare methods in their ability to impute missing data using five real data sets. In each case we “hold out” (mask) some of the data points, and then apply the methods to obtain estimates of the missing values. The data sets are as follows:
MovieLens data, an (incomplete) matrix of user-movie ratings (integers from 1 to 5) (Harper and Konstan, 2016). Most users do not rate most movies, so the matrix is sparsely observed (94% missing), and contains about 100K observed ratings. We hold out a fraction of the observed entries and assess accuracy of methods in estimating these. We centered and scaled the ratings for each user before analysis.
GTEx eQTL summary data, a matrix of scores computed testing association of genetic variants (rows) with gene expression in different human tissues (columns). These data come from the Genotype Tissue Expression (GTEx) project (Consortium et al., 2015), which assessed the effects of thousands of “eQTLs” across 44 human tissues. (An eQTL is a genetic variant that is associated with expression of a gene.) To identify eQTLs, the project tested for association between expression and every near-by genetic variant, each test yielding a score. The data used here are the scores for the most significant genetic variant for each gene (the “top” eQTL). See Section 5.3 for more detailed analyses of these data.
Brain Tumor data, a matrix of gene expression measurements on 4 different types of brain tumor (included in the denoiseR package, Josse et al., 2018). We centered each column before analysis.
Presidential address data, a matrix of word counts from the inaugural addresses of 13 US presidents (1940–2009) (also included in the denoiseR package, Josse et al., 2018). Since both row and column means vary greatly we centered and scaled both rows and columns before analysis, using the biScale function from softImpute.
Breast cancer data, a matrix of gene expression measurements from Carvalho et al. (2008), which were used as an example in the paper introducing NBSFA (Knowles and Ghahramani, 2011). Following Knowles and Ghahramani (2011) we centered each column (gene) before analysis.
Among the methods considered above, only flash, PMD and softImpute can handle missing data. We add NBSFA (Knowles and Ghahramani, 2011) to these comparisons. To emphasize the importance of parameter tuning we include results for PMD and softImpute with default settings (denoted PMD, SI) as well as using cross-validation (PMD.cv1, SI.cv).
For these real data the appropriate value of is, of course, unknown. Both flash and NBSFA automatically estimate . For PMD and softImpute we specified based on the values inferred by flash and NBSFA. (Specifically, we used respectively for the five data sets.)
We applied each method to all 5 data sets, using 10-fold OCV (Appendix B) to mask data points for imputation, repeated 20 times (with different random number seeds) for each data set. We measure imputation accuracy using root mean squared error (RMSE):
| (5.10) |
where is the set of indices of the held-out data points.
The results are shown in Figure 3. Although the ranking of methods varies among data sets, flash, PMD.cv1 and SI.cv perform similarly on average, and consistently outperform NBSFA, which in turn typically outperforms (untuned) PMD and unpenalized softImpute. These results highlight the importance of appropriate tuning for the penalized methods, and also the effectiveness of the EB method in flash to provide automatic tuning.
Figure 3:
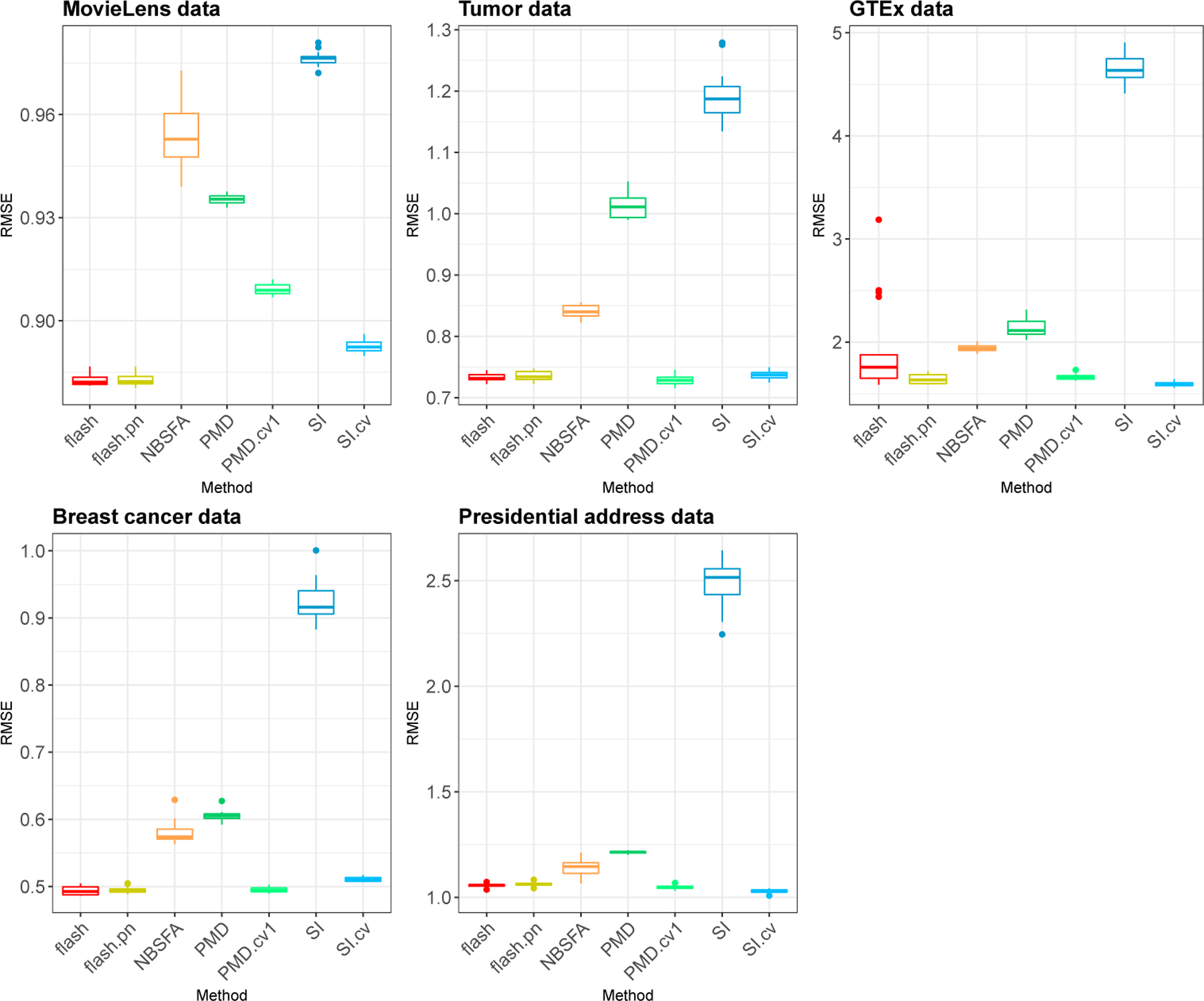
Comparison of the accuracy of different methods in imputing missing data. Each panel shows a boxplot of error rates (RMSE) for 20 simulations based on masking observed entries in a real data set.
In these comparisons, as in the simulations, the two flash methods typically performed similarly. The exception is the GTEx data, where the scale mixture of normals performed worse. Detailed investigation revealed this to be due to a very small number of very large “outlier” imputed values, well outside the range of the observed data, which grossly inflated RMSE. These outliers were so extreme that it should be possible to implement a filter to avoid them. However, we did not do this here as it seems useful to highlight this unexpected behavior. (Note that this occurs only when data are missing, and even then only in one of the five data sets considered here.)
5.3. Sharing of Genetic Effects on Gene Expression Among Tissues
To illustrate flash in a scientific application, we applied it to the GTEx data described above, a matrix of scores, with reflecting the strength (and direction) of effect of eQTL in tissue . We applied flash with using the greedy+backfitting algorithm (i.e. the backfitting algorithm, initialized using the greedy algorithm).
The flash results yielded 26 factors (Figure 4–5) which summarize the main patterns of eQTL sharing among tissues (and, conversely, the main patterns of tissue-specificity). For example, the first factor has approximately equal weight for every tissue, and reflects the fact that many eQTLs show similar effects across all 44 tissues. The second factor has strong effects only in the 10 brain tissues, from which we infer that some eQTLs show much stronger effects in brain tissues than other tissues.
Figure 4:
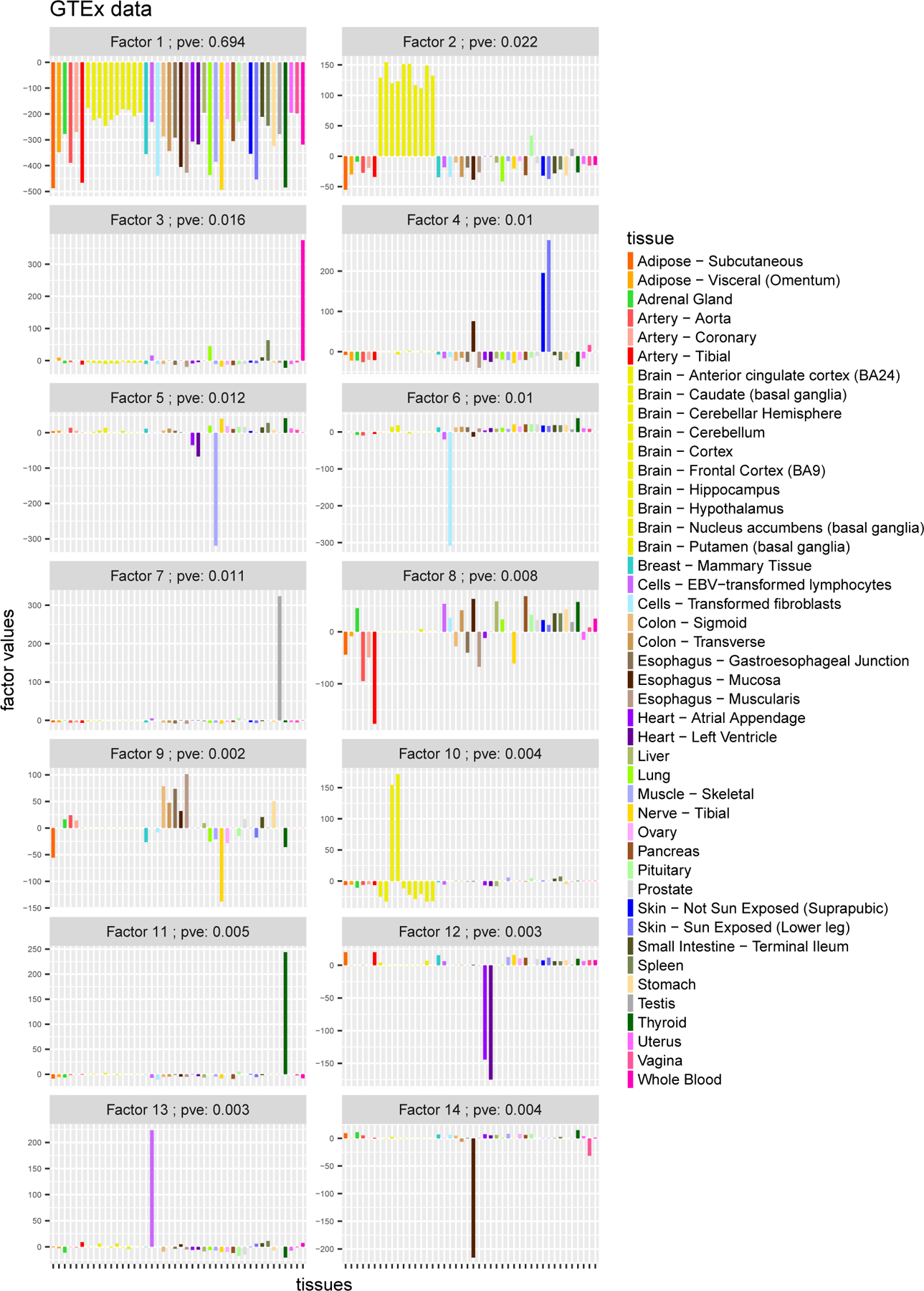
Results from running flash on GTEx data (factors 1 – 8). The pve (“Percentage Variance Explained”) for loading/factor is defined as where . It is a measure of the amount of signal in the data captured by loading/factor (but its naming as “percentage variance explained” should be considered loose since the factors are not orthogonal).
Figure 5:

Results from running flash on GTEx data (factors 15 – 26)
Subsequent factors tend to be sparser, and many have a strong effect in only one tissue, capturing “tissue-specific” effects. For example, the 3rd factor shows a strong effect only in whole blood, and captures eQTLs that have much stronger effects in whole blood than other tissues. (Two tissues, “Lung” and “Spleen”, show very small effects in this factor but with the same sign as blood. This is intriguing since the lung has recently been found to make blood cells—see Lefrançais et al. 2017—and a key role of the spleen is storing of blood cells.) Similarly Factors 7, 11 and 14 capture effects specific to “Testis”, “Thyroid” and “Esophagus Mucosa” respectively.
A few other factors show strong effects in a small number of tissues that are known to be biologically related, providing support that the factors identified are scientifically meaningful. For example, factor 10 captures the two tissues related to the cerebellum, “Brain Cerebellar Hemisphere” and “Brain Cerebellum”. Factor 19 captures tissues related to female reproduction, “Ovary”, “Uterus” and “Vagina”. Factor 5 captures “Muscle Skeletal”, with small but concordant effects in the heart tissues (“Heart Atrial Appendage” and “Heart Left Ventricle”). Factor 4, captures the two skin tissues (“Skin Not Sun Exposed Suprapubic”, “Skin Sun Exposed Lower leg”) and also “Esophagus Mucosa”, possibly reflecting the sharing of squamous cells that are found in both the surface of the skin, and the lining of the digestive tract. In factor 24, “Colon Transverse” and “Small Intestine Terminal Ileum” show the strongest effects (and with same sign), reflecting some sharing of effects in these intestinal tissues. Among the 26 factors, only a few are difficult to interpret biologically (e.g. factor 8).
To highlight the benefits of sparsity, we contrast the flash results with those for softImpute, which was the best-performing method in the missing data assessments on these data, but which uses a nuclear norm penalty that does not explicitly reward sparse factors or loadings. The first eight softImpute factors are shown in Figure 6. The softImpute results—except for the first two factors—show little resemblance to the flash results, and in our view are harder to interpret.
Figure 6:

Results from running softImpute on GTEx data (factors 1–8). The factors are both less sparse and less interpretable than the flash results.
5.4. Computational Demands
It is difficult to make general statements about computational demands of our methods, because both the number of factors and number of iterations per factor can vary considerably depending on the data. However, to give a specific example, running our current implementation of the greedy algorithm on the GTEx data (a 16,000 by 44 matrix) takes about 140s (wall time) for and 650s for (on a 2015 MacBook Air with a 2.2 GHz Intel Core i7 processor and 8Gb RAM). By comparison, a single run of softImpute without CV takes 2–3s, so a naive implementation of 5-fold CV with 10 different tuning parameters and 10 different values of would take over 1000s (although one could improve on this by use of warm starts for example).
6. Discussion
Here we discuss some potential extensions or modifications of our work.
6.1. Orthogonality Constraint
Our formulation here does not require the factors or loadings to be orthogonal. In scientific applications we do not see any particular reason to expect underlying factors to be orthogonal. However, imposing such a constraint could have computational or mathematical advantages. Formally adding such a constraint to our objective function seems tricky, but it would be straightforward to modify our algorithms to include an orthogonalization step each update. This would effectively result in an EB version of the SSVD algorithms in Yang et al. (2014), and it seems likely to be computationally faster than our current approach. One disadvantage of this approach is that it is unclear what optimization problem such an algorithm would solve (but the same is true of SSVD, and our algorithms have the advantage that they deal with missing data.)
6.2. Non-negative Matrix Factorization
We focused here on the potential for EBMF to induce sparsity on loadings and factors. However, EBMF can also encode other assumptions. For example, to assume the loadings and factors are non-negative, simply restrict to be a family of non-negative-valued distributions, yielding “Empirical Bayes non-negative Matrix Factorization” (EBNMF). Indeed, the ashr software can already solve the EBNM problem for some such families , and so flash already implements EBNMF. In preliminary assessments we found that the greedy approach is problematic here: the non-negative constraint makes it harder for later factors to compensate for errors in earlier factors. However, it is straightforward to apply the backfitting algorithm to fit EBNMF, with initialization by any existing NMF method. The performance of this approach is an area for future investigation.
6.3. Tensor Factorization
It is also straightforward to extend EBMF to tensor factorization, specifically a CANDE-COMP/PARAFAC decomposition (Kolda and Bader, 2009):
| (6.1) |
| (6.2) |
| (6.3) |
| (6.4) |
| (6.5) |
The variational approach is easily extended to this case (a generalization of methods in Hore et al., 2016), and updates that increase the objective function can be constructed by solving an EBNM problem, similar to EBMF. It seems likely that issues of convergence to local optima, and the need for good initializations, will need some attention to obtain good practical performance. However, results in Hore et al. (2016) are promising, and the automatic-tuning feature of EB methods seems particularly attractive here. For example, extending PMD to this case—allowing for different sparsity levels in and would require 3 penalty parameters even in the rank 1 case, making it difficult to tune by CV.
6.4. Non-Gaussian Errors
It is also possible to extend the variational approximations used here to fit non-Gaussian models, such as binomial data; see for example Jaakkola and Jordan (2000); Seeger and Bouchard (2012); Klami (2015). The extension of our EB methods using these ideas is detailed in Wang (2017).
Acknowledgments
We thank P. Carbonetto for computational assistance, and P. Carbonetto, D. Gerard, and A. Sarkar for helpful conversations and comments on a draft manuscript. Computing resources were provided by the University of Chicago Research Computing Center. This work was supported by NIH grant HG002585 and by a grant from the Gordon and Betty Moore Foundation (Grant GBMF #4559).
Appendix A. Variational EBMF with Factors
Here we describe in detail the variational approach to the factor model, including deriving updates that we use to optimize the variational objective. (These derivations naturally include the model as a special case, and our proof of Proposition 5 below includes Proposition 2 as a special case.)
Let denote the variational distributions on the loadings/factors:
| (A.1) |
| (A.2) |
The objective function is thus a function of , and , as well as the precision :
| (A.3) |
| (A.4) |
We optimize by iteratively updating parameters relating to , a single loading or factor , keeping other parameters fixed. We simplify implementation by keeping track of only the first and second moments of the distributions and , which we denote . We now describe each kind of update in turn.
A.1. Updates for Precision Parameters
Here we derive updates to optimize over the precision parameters . Focusing on the parts of that depend on gives:
| (A.5) |
| (A.6) |
where is defined by:
| (A.7) |
| (A.8) |
If we constrain then we have
| (A.9) |
For example, assuming constant precision yields:
| (A.10) |
Assuming column-specific precisions , which is the default in our software, yields:
| (A.11) |
Other variance structures are considered in Appendix A.5 of Wang (2017).
A.2. Updating Loadings and Factors
The following Proposition, which generalizes Proposition 2 in the main text, shows how updates for loadings (and factors) for the -factor EBMF model can be achieve by solving an EBNM problem.
Proposition 5 For the -factor model, arg is solved by solving an EBNM problem. Specifically
| (A.12) |
where the functions and are given by (3.19) and (3.20), denote the vectors whose elements are the first and second moments of under , and denotes the residual matrix (3.27).
Similarly, is solved by solving an EBNM problem. Specifically,
| (A.13) |
where the functions and are given by
| (A.15) |
A.2.1. A Lemma on the Normal Means Problem
To prove Proposition 5 we introduce a lemma that characterizes the solution of the normal means problem in terms of an objective that is closely related to the variational objective.
Recall that the EBNM model is:
| (A.16) |
| (A.17) |
where .
Solving the EBNM problem involves estimating by maximum likelihood:
| (A.18) |
where
| (A.19) |
It also involves finding the posterior distributions:
| (A.20) |
Lemma 6 Solving the EBNM problem also solves:
| (A.21) |
where
| (A.22) |
with and , and .
Equivalently, (A.21)-(A.22) is solved by in (A.18) and in (A.20), with and .
Proof The log likelihood can be written as
| (A.23) |
| (A.24) |
| (A.25) |
| (A.26) |
| (A.27) |
where
| (A.28) |
and
| (A.29) |
Here denotes the posterior distribution . This identity holds for any distribution .
Rearranging (A.27) gives:
| (A.30) |
Since , with equality when is maximized over by setting . Further
| (A.31) |
so
| (A.32) |
It remains only to show that has the form (A.22).
| (A.33) |
Thus
| (A.34) |
■
A.2.2. Proof of Proposition 5
We are now ready to prove Proposition 5.
Proof We prove the first part of the proposition since the proof for the second part is essentially the same.
The objective function (A.3) is:
| (A.35) |
| (A.36) |
where is a constant with respect to and
| (A.37) |
| (A.38) |
Based on Lemma 6, we can solve this optimization problem (A.36) by solving the EBNM problem with:
| (A.39) |
| (A.40) |
■
A.3. Algorithms
Just as with the rank 1 EBMF model, the updates for the rank model require only the first and second moments of the variational distributions . Thus we implement the updates in algorithms that keep track of the first moments and and second moments ( and ), and the precision .
Algorithm 3 implements a basic update for , and for the parameters relating to a single factor . Note that the latter updates are identical to the updates for fitting the single factor EBMF model, but with replaced with the residuals obtained by removing the estimated effects of the other factors.

Based on these basic updates we implemented two algorithms for fitting the -factor EBMF model: the greedy algorithm, and the backfitting algorithm, as follows.
A.3.1. Greedy Algorithm
The greedy algorithm is a forward procedure that, at the th step, adds new factors and loadings by optimizing over while keeping the distributions related to previous factors fixed. Essentially this involves fitting the single-factor model to the residuals obtained by removing previous factors. The procedure stops adding factors when the estimated new factors (or loadings) are identically zero. The algorithm as follows:

A.3.2. Backfitting Algorithm
The backfitting algorithm iteratively refines a fit of factors and loadings, by updating them one at a time, at each update keeping the other loadings and factors fixed. The name comes from its connection with the backfitting algorithm in Breiman and Friedman (1985), specifically the fact that it involves iteratively re-fitting to residuals.

A.4. Objective Function Computation
The algorithms above all involve updates that will increase (or, at least, not decrease) the objective function . However, these updates do not require computing the objective function itself. In iterative algorithms it can be helpful to compute the objective function to monitor convergence (and as a check on implementation). In this subsection we describe how this can be done. In essence, this involves extending the solver of the EBNM problem to also return the value of the log-likelihood achieved in that problem (which is usually not difficult).
The objective function of the EBMF model is:
| (A.41) |
The calculation of is straightforward and and can be calculated using the log-likelihood of the EBNM model using the following Lemma 7.
Lemma 7 Suppose solves the EBNM problem with data :
| (A.42) |
where are the estimated posterior distributions of the normal means parameters . Then
| (A.43) |
where is the log of the likelihood for the normal means problem (A.27).
Proof We have from (A.28)
| (A.44) |
| (A.45) |
| (A.46) |
And the result follows from noting that . ■
A.5. Inference with Penalty Term
Conceivably, in some settings one might like to encourage solutions to the EBMF problem be sparser than the maximum-likelihood estimates for would produce. This could be done by extending the EBMF model to introduce a penalty term on the distributions so that the maximum likelihood estimates are replaced by maximizing a penalized likelihood. We are not advocating for this approach, but it is straightforward given existing machinery, and so we document it here for completeness.
Let and denote penalty terms on and , so the penalized log-likelihood would be:
| (A.47) |
where and are defined in (3.4) and (3.5). And the corresponding penalized variational objective is:
| (A.48) |
It is straightforward to modify the algorithms above to maximize this penalized objective: simply modify the EBNM solvers to solve a corresponding penalized normal means problem. That is, instead of estimating the prior by maximum likelihood, the EBNM solver must now maximize the penalized log-likelihood:
| (A.49) |
where denote the log-likelihood for the EBNM problem. (The computation of the posterior distributions given is unchanged).
For example, the ashr software (Stephens, 2017) provides the option to include a penalty on to encourage overestimation of the size of the point mass on zero. This penalty was introduced to ensure conservative behavior in False Discovery Rate applications of the normal means problem. It is unclear that such a penalty is desirable in the matrix factorization application. However, the above discussion shows that using this penalty (e.g. within the ebnm function used by the greedy or backfitting algorithms) can be thought of as solving a penalized version of the EBMF problem.
Appendix B. Orthogonal Cross Validation
Cross-validation assessments involving “holding out” (hiding) data from methods. Here we introduce a novel approach to selecting the data to be held out, which we call Orthogonal Cross Validation (OCV). Although not the main focus of our paper, we believe that OCV is a novel and appealing approach to selecting hold-out data for factor models, e.g. when using CV to select an appropriate dimension for dimension reduction methods, as in Owen and Wang (2016).
Generic -fold CV involves randomly dividing the data matrix into parts and then, for each part, training methods on the other parts before assessing error on that part, as in Algorithm 6.

The novel part of OCV is in how to choose the “hold-out” pattern. We randomly divide the columns and rows into sets. and put these sets into orthogonal parts, and then take all with the chosen column and row indices as “hold-out” .
To illustrate this scheme, we take 3-fold CV as an example. We randomly divide the columns into 3 sets and the rows into 3 sets as well. The data matrix is divided into 9 partition (by row and column permutation):
Then and are orthogonal to each other. Then the data matrix is marked as:
In OCV, each fold contains equally balanced part of data matrix and includes all the row and column indices. This ensures that all i’s and ’s are included into each . In 3-fold OCV, we have:
| (B.1) |
| (B.2) |
where and . We can see for each “hold-out” part, and show up once and only once. In this sense the hold-out pattern is “balanced”.
Contributor Information
Wei Wang, Department of Statistics, University of Chicago, Chicago, IL, USA.
Matthew Stephens, Department of Statistics and Department of Human Genetics, University of Chicago, Chicago, IL, USA.
References
- Argelaguet Ricard, Velten Britta, Arnol Damien, Dietrich Sascha, Zenz Thorsten, John C Marioni Florian Buettner, Huber Wolfgang, and Stegle Oliver. Multi-omics factor analysis—a framework for unsupervised integration of multi-omics data sets. Molecular systems biology, 14(6):e8124, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Attias Hagai. Independent factor analysis. Neural Computation, 11(4):803–851, 1999. [DOI] [PubMed] [Google Scholar]
- Bai Jushan and Ng Serena. Large Dimensional Factor Analysis. Now Publishers Inc, 2008. [Google Scholar]
- Bhattacharya Anirban and Dunson David B. Sparse Bayesian infinite factor models. Biometrika, pages 291–306, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bishop Christopher M.. Variational principal components. In Ninth International Conference on Artificial Neural Networks (Conf. Publ. No. 470), volume 1, pages 509–514. IET, 1999. [Google Scholar]
- Blei David M, Kucukelbir Alp, and McAuliffe Jon D. Variational inference: A review for statisticians. Journal of the American Statistical Association, 112(518):859–877, 2017. [Google Scholar]
- Bouchard Guillaume, Naradowsky Jason, Riedel Sebastian, Rocktäschel Tim, and Vlachos Andreas. Matrix and tensor factorization methods for natural language processing. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing: Tutorial Abstracts, pages 16–18, Beijing, China, July 2015. Association for Computational Linguistics. doi: 10.3115/v1/P15-5005. URL https://www.aclweb.org/anthology/P15-5005. [DOI] [Google Scholar]
- Breiman Leo and Friedman Jerome H.. Estimating optimal transformations for multiple regression and correlation. Journal of the American Statistical Association, 80(391):580–598, 1985. doi: 10.1080/01621459.1985.10478157. URL http://www.tandfonline.com/doi/abs/10.1080/01621459.1985.10478157. [DOI] [Google Scholar]
- Carvalho Carlos M., Chang Jeffrey, Lucas Joseph E., Nevins Joseph R., Wang Quanli, and West Mike. High-dimensional sparse factor modeling: Applications in gene expression genomics. Journal of the American Statistical Association, 103(484):1438–1456, 2008. ISSN; 0162–1459. doi: 10.1198/016214508000000869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clyde Merlise and George Edward I. Flexible empirical Bayes estimation for wavelets. Journal of the Royal Statistical Society Series B, 62(4):681–698, 2000. doi: 10.1111/1467-9868.00257. [DOI] [Google Scholar]
- Consortium GTEx et al. The genotype-tissue expression (GTEx) pilot analysis: Multitissue gene regulation in humans. Science, 348(6235):648–660, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ding Chris HQ, Li Tao, and Jordan Michael I. Convex and semi-nonnegative matrix factorizations. IEEE transactions on pattern analysis and machine intelligence, 32(1):45–55, 2008. [DOI] [PubMed] [Google Scholar]
- Eckart C and Young G. The approximation of one matrix by another of lower rank. Psychometrika, 1:211–218, 1936. [Google Scholar]
- Engelhardt Barbara E and Stephens Matthew. Analysis of population structure: a unifying framework and novel methods based on sparse factor analysis. PLoS Genetics, 6(9): e1001117, sep 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fithian William, Mazumder Rahul, et al. Flexible low-rank statistical modeling with missing data and side information. Statistical Science, 33(2):238–260, 2018. [Google Scholar]
- Ford J Kevin, MacCallum Robert C, and Tait Marianne. The application of exploratory factor analysis in applied psychology: A critical review and analysis. Personnel Psychology, 39(2):291–314, 1986. [Google Scholar]
- Frühwirth-Schnatter Sylvia and Lopes Hedibert Freitas. Sparse Bayesian factor analysis when the number of factors is unknown. arXiv preprint arXiv:1804.04231, 2018. [Google Scholar]
- Gao Chuan, Brown Christopher D, and Engelhardt Barbara E. A latent factor model with a mixture of sparse and dense factors to model gene gene expression data with confounding effects. arXiv:1310.4792v1, 2013. [Google Scholar]
- Gao Chuan, McDowell Ian C., Zhao Shiwen, Brown Christopher D., and Engelhardt Barbara E.. Context specific and differential gene co-expression networks via Bayesian biclustering. PLoS Computational Biology, 12(7):1–39, 07 2016. doi: 10.1371/journal.pcbi.1004791. URL 10.1371/journal.pcbi.1004791. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ghahramani Zoubin and Beal Matthew J. Variational inference for Bayesian mixtures of factor analysers. In Advances in neural information processing systems, pages 449–455, 2000. [Google Scholar]
- Girolami Mark. A variational method for learning sparse and overcomplete representations. Neural Computation, 13(11):2517–2532, 2001. [DOI] [PubMed] [Google Scholar]
- Harper F Maxwell and Konstan Joseph A. The Movielens datasets: History and context. ACM Transactions on Interactive Intelligent Systems, 5(4):19, 2016. [Google Scholar]
- Hastie Trevor, Mazumder Rahul, Lee Jason D, and Zadeh Reza. Matrix completion and low-rank SVD via fast alternating least squares. Journal of Machine Learning Research, 16(1):3367–3402, 2015. [PMC free article] [PubMed] [Google Scholar]
- Hochreiter Sepp, Bodenhofer Ulrich, Heusel Martin, Mayr Andreas, Mitterecker Andreas, Kasim Adetayo, Khamiakova Tatsiana, Suzy Van Sanden Dan Lin, Talloen Willem, Bijnens Luc, Göhlmann Hinrich W. H., Shkedy Ziv, and Clevert Djork-Arné. FABIA: factor analysis for bicluster acquisition. Bioinformatics, 26(12):1520–1527, 04 2010. ISSN; 1367–4803. doi: 10.1093/bioinformatics/btq227. URL 10.1093/bioinformatics/btq227. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hore Victoria, Ana Viñuela Alfonso Buil, Knight Julian, Mark I McCarthy Kerrin Small, and Marchini Jonathan. Tensor decomposition for multiple-tissue gene expression experiments. Nature Genetics, 48(9):1094–1100, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jaakkola Tommi S. and Jordan Michael I.. Bayesian parameter estimation via variational methods. Statistics and Computing, 10:25–37, 2000. [Google Scholar]
- Johnstone Iain M. and Silverman Bernard W.. Empirical Bayes selection of wavelet thresholds. The Annals of Statistics, 33(4):1700–1752, 2005a. [Google Scholar]
- Johnstone Iain M and Silverman Bernard W. EBayesthresh: R and s-plus programs for empirical Bayes thresholding. J. Statist. Soft, 12:1–38, 2005b. [Google Scholar]
- Johnstone Iain M, Silverman Bernard W, et al. Needles and straw in haystacks: Empirical Bayes estimates of possibly sparse sequences. The Annals of Statistics, 32(4):1594–1649, 2004. [Google Scholar]
- Jolliffe Ian T, Trendafilov Nickolay T, and Uddin Mudassir. A modified principal component technique based on the lasso. Journal of Computational and Graphical Statistics, 12(3): 531–547, 2003. [Google Scholar]
- Josse Julie, Sardy Sylvain, and Wager Stefan. denoiseR: A package for low rank matrix estimation, 2018.
- Kaufmann Sylvia and Schumacher Christian. Identifying relevant and irrelevant variables in sparse factor models. Journal of Applied Econometrics, 32(6):1123–1144, 2017. [Google Scholar]
- Klami Arto. Polya-gamma augmentations for factor models. In Asian Conference on Machine Learning, pages 112–128, 2015. [Google Scholar]
- Knowles David and Ghahramani Zoubin. Nonparametric Bayesian sparse factor. Annals of Applied Statistics, 5(2B):1534–1552, 2011. doi: 10.1214/10-AOAS435. [DOI] [Google Scholar]
- Koenker Roger and Mizera Ivan. Convex optimization, shape constraints, compound decisions, and empirical Bayes rules. Journal of the American Statistical Association, 109 (506):674–685, 2014a. [Google Scholar]
- Koenker Roger and Mizera Ivan. Convex optimization in R. Journal of Statistical Software, 60(5):1–23, 2014b. doi: 10.18637/jss.v060.i05. [DOI] [Google Scholar]
- Kolda Tamara G and Bader Brett W. Tensor decompositions and applications. SIAM review, 51(3):455–500, 2009. [Google Scholar]
- Lee DD and Seung HS. Learning the parts of objects by non-negative matrix factorization. Nature, 401(6755):788–791, 1999. doi: 10.1038/44565. [DOI] [PubMed] [Google Scholar]
- Lefrançais Emma, Ortiz-muñoz Guadalupe, Caudrillier Axelle, Mallavia Beñat, Liu Fengchun, Sayah David M, Thornton Emily E, Headley Mark B, David Tovo, Coughlin Shaun R, Krummel Matthew F, Leavitt Andrew D, Passegué Emmanuelle, and Looney Mark R. The lung is a site of platelet biogenesis and a reservoir for haematopoietic progenitors. Nature, 544(7648):105–109, 2017. doi: 10.1038/nature21706. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lim Yew Jin and Teh Yee Whye. Variational Bayesian approach to movie rating prediction. In Proceedings of KDD cup and workshop, volume 7, pages 15–21. Citeseer, 2007. [Google Scholar]
- Mayrink Vinicius Diniz, Lucas Joseph Edward, et al. Sparse latent factor models with interactions: Analysis of gene expression data. The Annals of Applied Statistics, 7(2): 799–822, 2013. [Google Scholar]
- Mazumder Rahul, Hastie Trevor, and Tibshirani Robert. Spectral regularization algorithms for learning large incomplete matrices. Journal of Machine Learning Research, 11(Aug): 2287–2322, 2010. [PMC free article] [PubMed] [Google Scholar]
- Nakajima Shinichi and Sugiyama Masashi. Theoretical analysis of Bayesian matrix factorization. Journal of Machine Learning Research, 12:2583–2648, 2011. [Google Scholar]
- Nakajima Shinichi, Sugiyama Masashi, Babacan S Derin, and Tomioka Ryota. Global analytic solution of fully-observed variational bayesian matrix factorization. Journal of Machine Learning Research, 14(Jan):1–37, 2013. [Google Scholar]
- Owen Art B and Wang Jingshu. Bi-cross-validation for factor analysis. Statistical Science, 31(1):119–139, 2016. [Google Scholar]
- Pournara Iosifina and Wernisch Lorenz. Factor analysis for gene regulatory networks and transcription factor activity profiles. BMC bioinformatics, 8:61, 2007. ISSN; 1471–2105. doi: 10.1186/1471-2105-8-61. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Raiko Tapani, Ilin Alexander, and Karhunen Juha. Principal component analysis for large scale problems with lots of missing values. In European Conference on Machine Learning, pages 691–698. Springer, 2007. [Google Scholar]
- Ročková Veronika and George Edward I. Fast Bayesian factor analysis via automatic rotations to sparsity. Journal of the American Statistical Association, 111(516):1608–1622, 2016. [Google Scholar]
- Rubin Donald B. Inference and missing data. Biometrika, 63(3):581–592, 1976. [Google Scholar]
- Rubin Donald B and Thayer Dorothy T. EM algorithms for ML factor analysis. Psychometrika, 47(1):69–76, 1982. [Google Scholar]
- Sabatti Chiara and James Gareth M. Bayesian sparse hidden components analysis for transcription regulation networks. Bioinformatics, 22(6):739–746, 2005. [DOI] [PubMed] [Google Scholar]
- Seeger Matthias and Bouchard Guillaume. Fast variational Bayesian inference for non-conjugate matrix factorization models. In Artificial Intelligence and Statistics, pages 1012–1018, 2012. [Google Scholar]
- Srivastava Sanvesh, Engelhardt Barbara E, and Dunson David B. Expandable factor analysis. Biometrika, 104(3):649–663, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stegle Oliver, Parts Leopold, Durbin Richard, and Winn John. A Bayesian framework to account for complex non-genetic factors in gene expression levels greatly increases power in eqtl studies. PLoS Computational Biology, 6(5):e1000770, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stegle Oliver, Parts Leopold, Piipari Matias, Winn John, and Durbin Richard. Using probabilistic estimation of expression residuals (PEER) to obtain increased power and interpretability of gene expression analyses. Nature Protocols, 7(3):500–507, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stein-O’Brien Genevieve L, Arora Raman, Culhane Aedin C, Favorov Alexander V, Garmire Lana X, Greene Casey S, Goff Loyal A, Li Yifeng, Ngom Aloune, Ochs Michael F, et al. Enter the matrix: factorization uncovers knowledge from omics. Trends in Genetics, 34 (10):790–805, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stephens Matthew. False discovery rates: a new deal. Biostatistics, 18(2):275–294, Apr 2017. doi: 10.1093/biostatistics/kxw041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thomas DC, Siemiatycki J, Dewar R, Robins J, Goldberg M, and Armstrong BG. The problem of multiple inference in studies designed to generate hypotheses. American Journal of Epidemiology, 122(6):1080–95, Dec 1985. [DOI] [PubMed] [Google Scholar]
- Tipping Michael E. Sparse Bayesian learning and the relevance vector machine. Journal of Machine Learning Research, 1(Jun):211–244, 2001. [Google Scholar]
- Titsias Michalis K. and Lázaro-Gredilla Miguel. Spike and slab variational inference for multi-task and multiple kernel learning. In Shawe-Taylor J, Zemel RS, Bartlett PL, Pereira F, and Weinberger KQ, editors, Advances in Neural Information Processing Systems 24, pages 2339–2347. Curran Associates, Inc., 2011. URL http://papers.nips.cc/paper/4305-spike-and-slab-variational-inference-for-multi-task-and-multiple-kernel-learning.pdf. [Google Scholar]
- Wang Wei. Applications of Adaptive Shrinkage in Multiple Statistical Problems. PhD thesis, The University of Chicago, 2017. [Google Scholar]
- West Mike. Bayesian factor regression models in the “large p, small n” paradigm. Bayesian Statistics 7 - Proceedings of the Seventh Valencia International Meeting, pages 723–732, 2003. ISSN; 08966273. doi: 10.1.1.18.3036. [Google Scholar]
- Wipf David P. and Nagarajan Srikantan S.. A new view of automatic relevance determination. In Platt JC, Koller D, Singer Y, and Roweis ST, editors, Advances in Neural Information Processing Systems 20, pages 1625–1632. Curran Associates, Inc., 2008. URL http://papers.nips.cc/paper/3372-a-new-view-of-automatic-relevance-determination.pdf. [Google Scholar]
- Witten Daniela M., Tibshirani Robert, and Hastie Trevor. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics, 10(3):515–534, 2009. doi: 10.1093/biostatistics/kxp008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xing Zhengrong, Carbonetto Peter, and Stephens Matthew. Smoothing via adaptive shrinkage (smash): denoising Poisson and heteroskedastic Gaussian signals. arXiv preprint arXiv:1605.07787, 2016. [Google Scholar]
- Yang Dan, Ma Zongming, and Buja Andreas. A sparse singular value decomposition method for high-dimensional data. Journal of Computational and Graphical Statistics, 23(4):923–942, 2014. [Google Scholar]
- Zhao Shiwen, Barbara E Engelhardt Sayan Mukherjee, and Dunson David B. Fast moment estimation for generalized latent Dirichlet models. Journal of the American Statistical Association, pages 1–13, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zou Hui, Hastie Trevor, and Tibshirani Robert. Sparse principal component analysis. Journal of Computational and Graphical Statistics, 15(2):265–286, 2006. ISSN; 1061–8600. doi: 10.1198/106186006X113430. [DOI] [Google Scholar]