

Abstract
In comparing two treatments via a randomized clinical trial, the analysis of covariance (ANCOVA) technique is often utilized to estimate an overall treatment effect. The ANCOVA is generally perceived as a more efficient procedure than its simple two sample estimation counterpart. Unfortunately, when the ANCOVA model is nonlinear, the resulting estimator is generally not consistent. Recently, various nonparametric alternatives to the ANCOVA, such as the augmentation methods, have been proposed to estimate the treatment effect by adjusting the covariates. However, the properties of these alternatives have not been studied in the presence of treatment allocation imbalance. In this article, we take a different approach to explore how to improve the precision of the naive two-sample estimate even when the observed distributions of baseline covariates between two groups are dissimilar. Specifically, we derive a bias-adjusted estimation procedure constructed from a conditional inference principle via relevant ancillary statistics from the observed covariates. This estimator is shown to be asymptotically equivalent to an augmentation estimator under the unconditional setting. We utilize the data from a clinical trial for evaluating a combination treatment of cardiovascular diseases to illustrate our findings.
Keywords: Ancillary statistic, Augmentation estimation procedure, Conditional inference, Stratified analysis
1. Introduction
In comparing two treatment groups, let be the parameter of interest for quantifying the between-group difference with respect to the study endpoint. For example, let be the outcome variable, be the binary treatment indicator, , and . Let be the corresponding two-sample estimator based on the data from a randomized clinical trial with the proportions of the patients assigned to Groups 1 and 0 being and , respectively. If is a binary outcome, may be the risk ratio or odds ratio (OR). In general, with a large sample size, the distribution of is approximately normal with mean . Inferences about can be made accordingly.
When the patient’s potentially predictive baseline covariate vector is available, we routinely utilize an analysis of covariance (ANCOVA) procedure to estimate . A typical ANCOVA model is a multicovariate regression model relating the outcome to the treatment assignment indicator and covariate vector . The estimated regression coefficient of or a transformation thereof is interpreted as an estimator of . Unfortunately, when the ANCOVA model is nonlinear (e.g., a logistic or proportional hazard model), the resulting estimator of the treatment effect is generally not consistent for of our interest (Gail, Wieand, and Piantadosi 1984; Struthers and Kalbfleisch 1986; Lin and Wei 1989). For example, the treatment effect for binary outcome is often measured by log OR
| (1) |
The multivariable logistic regression model assumes that the conditional log OR for given covariates ,
is a constant independent of . This quantity is the regression coefficient of in the model but, in general, is different from in (1). Therefore, it is inappropriate to use the regression coefficient of to estimate . However, ANCOVA may still be useful for two reasons: first, as a testing procedure for the presence of treatment effect, ANCOVA is generally valid without requiring the correct model specification and often more powerful than its simple two sample counterpart; second, when correctly specified, a version of ANCOVA can be used to estimate indirectly. Specifically, the potential outcomes of each individual is linked with his/her baseline covariates via appropriate regression model in both arms and the finite sample contrast of “predicted” outcomes measuring the treatment effect can be constructed accordingly. For example, noting that log OR equals to
one may estimate by
where
is the empirical cumulative distribution function of observed covariates and , and are the estimators of the intercept, coefficient of the treatment indicator, and coefficient of in the logistic regression model, respectively.
Since ANCOVA model is likely misspecified in practice, it is desirable to develop robust, nonparametric covariate-adjusted estimation procedures for , which are well summarized in a recent article by Rosenblum and van der Laan (2010). For instance, an augmentation estimation procedure with covariate adjustment provides a consistent estimator for (Robins, Rotnitzky, and Zhao 1994; Robins 1999; Leon, Tsiatis, and Davidian 2003; Bang and Robins 2005; Tsiatis 2006; Van Der Laan and Rubin 2006; Tsiatis et al. 2008; Lu and Tsiatis 2008; Zhang, Tsiatis, and Davidian 2008; Gilbert et al. 2009; Zhang and Gilbert 2010; Tian et al. 2012). Such an estimator, say, is asymptotically equivalent to a linear combination of and , where is the sample mean of the covariate vectors or a transformation thereof for treatment (see Appendix A for details). The distribution of is also approximately normal with mean . The standard error estimate for can be substantially smaller than that based on when the augmented covariates are highly correlated with the response endpoint. Unlike the ANCOVA, the augmentation method is a model-free technique. Note that the stochastic properties of the above estimators were studied only under an unconditional setting in the literature, that is, with the study size , their sample space is generated by all possible realizations of a random sample consisting of independent, identically distributed copies of . Under this unconditional setting, is asymptotically unbiased.
Another important goal of using the covariate-adjustment technique for estimating the treatment difference is to reduce bias of when, by chance, the observed distributions of the covariate vectors are dissimilar between two groups. Intuitively, can be severely biased for this case. As discussed above, however, is asymptotically unbiased unconditionally. Therefore, the bias of needs to be discussed in a conditional sense. Note that the study subjects’ covariates and their functions are ancillary statistics, that is, they are not directly related to the treatment difference . One may consider to make more “relevant” inference about by conditioning on summary ancillary statistics. Such a conditional approach helps us to study the stochastic behavior of with realizations of whose ancillary statistics would be similar to their observed counterparts (Cox 1958; Cox and Hinkley 1979; Fraser and McDunnough 1980; Berger et al. 1988; Casella 1992; Fraser 2004; Ghosh, Reid, and Fraser 2010). Unbiased estimator conditional on all observed individual covariates, which incorporate all aspects of covariate imbalance, can be constructed by regression modelling. The aforementioned estimator is one such example. Unfortunately, it is a parametric approach in nature and prone to model misspecification. For a nonparametric procedure, it is infeasible to make inference conditional on such a fine level. In this article, we consider a coarser procedures only conditional on certain ancillary statistics, which quantify the imbalance between two treatment groups with respect to covariates. The choice of the conditioning ancillary statistic is not unique (Basu 1959; Cox 1971; Ghosh, Reid, and Fraser 2010). For the present case, instead of conditioning on the entire set of observed covariates, a relevant ancillary statistic for studying the stochastic behavior of estimators for would be the aforementioned , which is a natural, and commonly used summary measure of covariate-imbalance in clinical studies (Pocock et al. 2002). This statistic is also routinely used for evaluating covariate imbalance after matching, for example, via the propensity score (PS) method (Resa and Zubizarreta 2016). With this ancillary statistic, the sample space considered consists of all realizations of a random sample consisting of independent copies of , whose imbalance measured by the two-sample covariate mean difference is identical to the observed counterpart. Figure 1 is a schematic plot of aforementioned sample spaces from the biggest to the smallest:
all realizations of copies of ;
all realizations of copies of with the same as observed;
all realizations of copies of with the same observed individual covariates in two groups.
The naive estimator is asymptotically unbiased only in the largest sample space. When correctly specified, is asymptotically unbiased in all three, including the smallest sample space. Our bias-correction proposal operates in the intermediate sample space.
Figure 1.
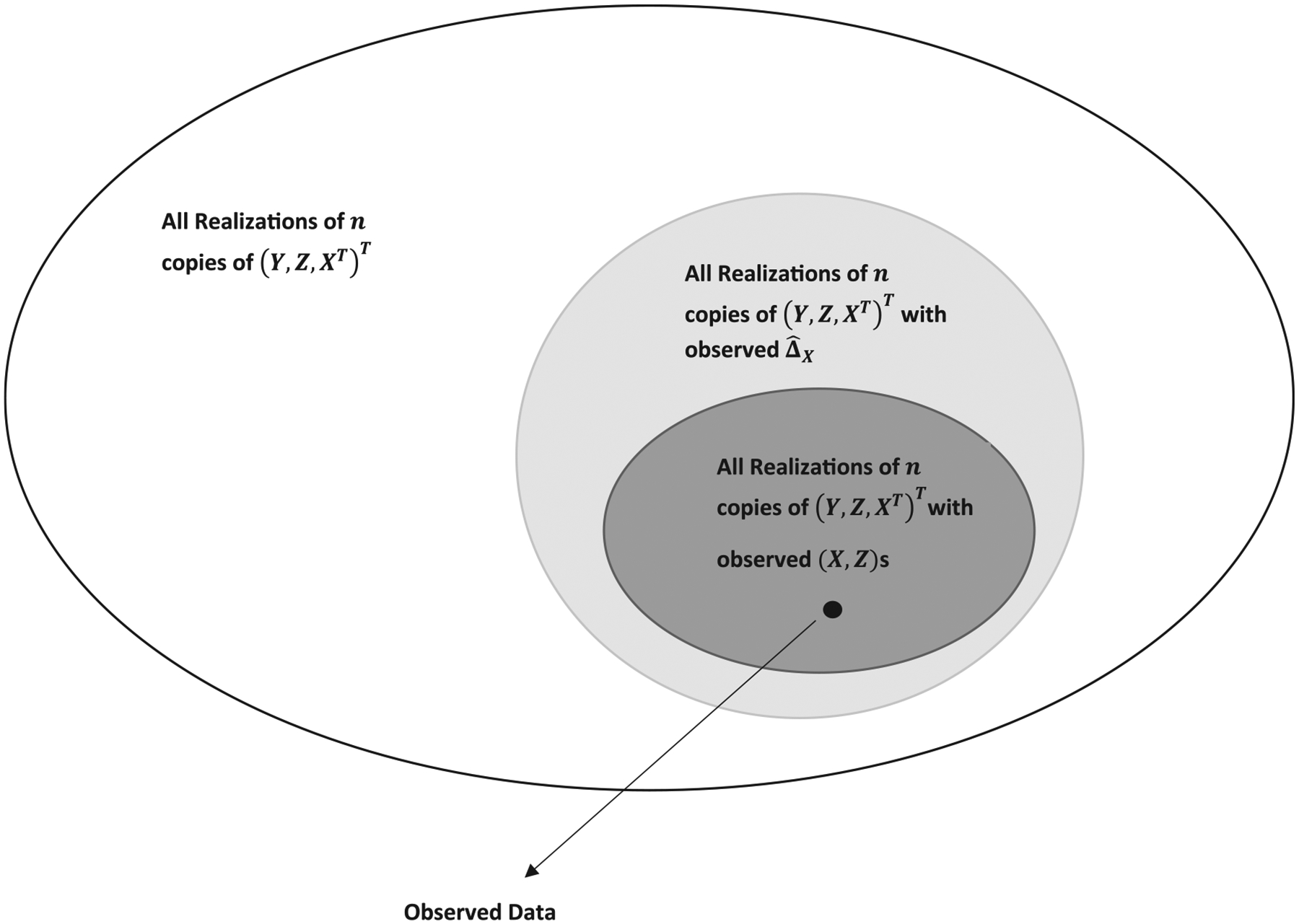
The sample spaces within which the statistical inference is made.
In this article, we show that based on this conditional inference principle, a bias-adjusted estimator reduces the bias of . We also show that unconditionally, is asymptotically equivalent to and can be viewed as an efficiency augmented estimator itself. We used the data from a comparative clinical trial to evaluate treatments for cardiovascular diseases to illustrate our findings. Furthermore, a numerical study is conducted to examine the performance of . We find via this study that if the covariates of the ancillary statistics are highly correlated with the outcome variable and/or the treatment allocation proportions, can be substantially better than two sample estimator .
2. The Distributions of Conditioning on and a Bias-Adjusted Estimator
Let , where is a smooth function characterizing the contrast between and . Then is the two sample naive estimator for , where and are the simple naive estimators for and , respectively. Under the random treatment assignments for designing the study, and are approximately normal with mean 0 and covariance matrix
where
are the estimated variance of , the estimated covariance matrix between and , and the estimated covariance matrix of , respectively. Here and are the partial derivatives of with respect to the first and second argument, respectively. Now, let be the observed value of . Then for large , the distribution of given is approximately normal with mean and variance .
The following theorem summarizes this large sample approximation under mild assumptions.
Theorem. Let , be the iid copies of and . Assume that is a finite, nondegenerate matrix; the characteristic function of is integrable; and is a regular estimator for , that is, is asymptotically equivalent to a sum of iid random quantities. Then
converges weakly to a Gaussian distribution with mean and variance , where , and , and are the population counterparts of , and , respectively.
Note that the assumptions under which the theorem holds are rather mild. For instance, the second assumption holds if the component of covariates is either discrete or continuous with a squared integrable density function. The proof of the theorem is given in Appendix B. It follows from the theorem that, when is not zero, is not consistent under this conditional argument. A bias-adjusted estimator for is
To illustrate how the inference procedure based on behaves asymptotically under various scenarios, let us consider a simple case of with a single covariate . Here, the bias is
If the correlation between the covariate and response is weak, the bias can be negligible. On the other hand, if a covariate is strongly associated with the response in at least one arm, then the bias would not be trivial. Furthermore, if is small, then is almost identical to . On the other hand, if the distributions of and do not overlap much, can be quite large, and may be fairly different from . In general, if the observed distributions of and are similar and is small, and would have similar variances. The term represents the reduction from to .
As a general example to illustrate how to construct , suppose that is the log-transformed OR, that is, , then
where , and are the sample size, empirical covariance between and , and the variance-covariance matrix of in the th group, , respectively.
Note that is equivalent or asymptotically equivalent to augmentation estimators (Tsiatis et al. 2008; Tian et al. 2012). The justification of this unconditional equivalence is given in Appendix A. Note that in this article, the dimension of the covariate vector is small relative to the sample size. It is interesting to explore how to deal with the case with a high-dimensional covariate vector for future research.
Remark 1. For the continuous outcome, the treatment effect can be assessed by the mean difference between two groups. For the survival outcome, the treatment effect can be measured by the difference in restricted mean survival time (RMST, Zhao et al. 2016). In both cases, the naive estimator for the treatment effect can be easily constructed. The construction of the bias adjusted estimator follows the same procedure as that used for the log OR with minor modifications on the relevant variance and covariance estimations. We illustrate the bias adjustment as well as relevant statistical inference procedure in Appendix C.
3. Example
In this section, we used the data from a cardiovascular trial: “Valsartan in acute myocardial infarction” (VALIANT) study (Pfeffer et al. 2003) to illustrate our findings. The study patients were equally randomized to three groups: ARB valsartan, captopril, and a combination of these two drugs. Here, we consider a binary outcome as the endpoint, which indicates whether the patient had hospitalization/death by month 18. Since the 18-month incidence rates of hospitalization/death from two mono-therapies are almost identical, we combined the data from these two mono-therapy groups to evaluate the effect of combo-therapy. Note that pooling two groups is not a common practice and for illustrative purpose only. The study enrolled a total of 14,703 patients. The observed event rates for mono- and combo are 0.58 and 0.57, indicating that there was no benefit from the combo with respect to this outcome. On the other hand, with the data from 302 patients in Australia, the mono-therapy somehow appears to be statistically significantly better than its combo counterpart based on the simple two sample estimate (the observed event rates for combo and mono are 0.80 and 0.67, respectively). Now, let be the log OR, and be its naive estimate. The point estimate of OR (combo vs. mono), that is, and 0.95 confidence interval are 1.99 and (1.12, 3.51), respectively. Among 24 countries participated in the VALIANT study, Australia was the only one whose patients appear to have better outcomes for the mono-therapy. It is not clear whether Australian patients were quite different from those from the rest of world to have such a discrepancy on the treatment effect. On the other hand, since the sizable treatment by country interaction is rare in practice, the statistically significant OR for Australian patients may be a false discovery. To explore this further for Australia patients, we found that there was treatment allocation imbalance between these two treatment groups with respect to, for example, the patient’s binary preexisting diabetes status (DIAS) and baseline heart rate (HR), which is a potential source of the bias of the naive estimator. In Figure 2, we show the fitted curves stratified by DIAS via two logistic regression models with the treatment assignment being the outcome and standardized and as the independent variables. If the randomization treatment allocation scheme were working for Australia patients, these two curves would be flat around 2/3. Figure 2 indicates that there was indeed nontrivial treatment allocation imbalance between the mono and combo groups. Now, let be the biased-adjusted estimate for the log OR. The corresponding bias-adjusted estimator of OR, that is, and the 0.95 confidence interval conditional on the observed imbalance in DIAS, and are 1.68 and (0.95, 2.94), respectively. Here, the point estimator is closer to 1 and the confidence interval contains the null value. In view of the data from other countries, the adjustment toward the null is likely in the right direction. Note that one of the reasons we considered the HR variable to the third order for the conditioning inference is that most distributions can be characterized with their first three moments. This conditioning setting would be approximately the same as that with the entire distribution of HR.
Figure 2.
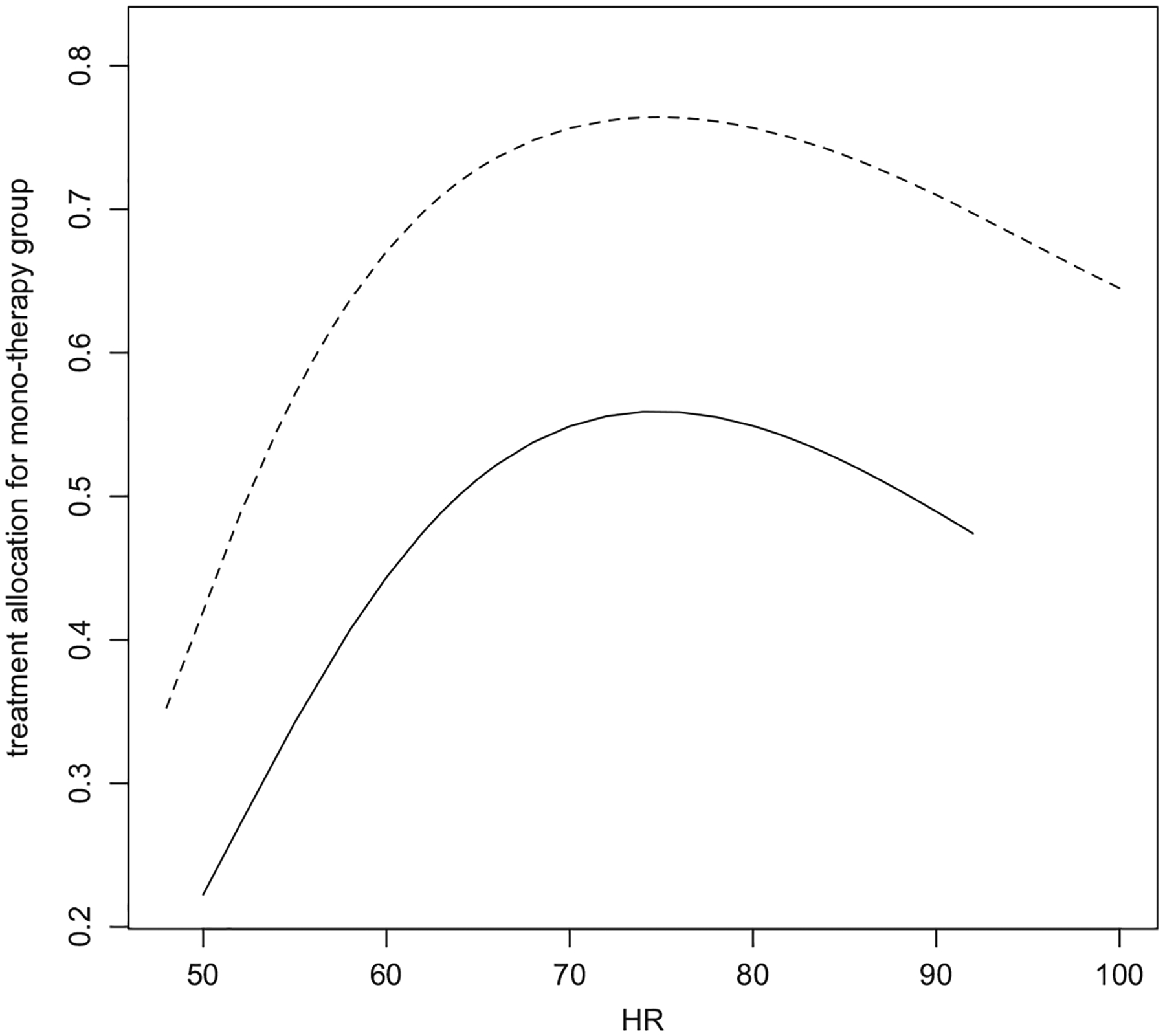
The treatment allocation proportions to mono-therapy group: solid line is for DIAS = 1; dashed line is for DIAS = 0. HR stands for heart rate.
4. Simulation Study
We further explore the finite sample properties of the proposed estimator via simulation studies. Mimicking the VALIANT study, we first generate the binary diabetes status and standardized heart rate, (DIAS, HR), for 300 patients via the following distributions
which are estimated using the observed Australia data. We then randomly assign 300 simulated patients into two groups with 200 patients in the mono-therapy group and 100 patients in the combo-therapy group. The four-dimensional covariate vector of interest is . To examine the finite sample performance of the proposed method, we need to perform the conditional inference only among samples with a given imbalance in covariates. To this end, we examine , the mean difference in covariates between two groups, in each of the simulated datasets and only keep those with approximately the “same” covariates imbalance as that observed in Australian patients. Specifically, we require that the observed . The center and width of these intervals are the corresponding component of observed in Australian patients and 20% of the (unconditional) standard deviation thereof, respectively. After obtaining 5000 such datasets, we generate the binary outcome via the logistic regression model
where
is the maximum likelihood estimator (MLE) of the regression coefficient based on Australia data, and are expectation of DIAS and , respectively, and , or 4 is the tuning parameter to control the size of the covariate effect. For each simulated dataset, we obtain the naive and bias adjusted estimators for . In the first setting, we let , that is, the distribution of does not dependent and there is no treatment effect. In the second setting, we let , representing a higher incidence rate in group . In this case, the true value of can be obtained by computing
where the expectation is with respect to . Based on 5000 such simulated datasets with approximately the same covariates imbalance, we obtain the empirical biases of estimators with and without adjusting covariates imbalance and the empirical coverage level of the corresponding 95% confidence intervals. The results are summarized in Table 1. When the covariates effect is strong , the naive estimator has a nontrivial bias, especially relative to its standard error. The estimated variance of the naive estimator overestimates the conditional variability and yields wide confidence intervals. Even with this upward bias in variance estimation, the 95% confidence interval based on the naive estimator fails to cover the truth at the nominal level, since the interval is centered at a biased location. On the other hand, the estimated variance of the adjusted estimator approximates the underlying conditional variance and the empirical coverage level of the 95% confidence interval is fairly close 0.95. When there is no covariates effect , two estimators have a comparable performance as anticipated. If we consider unconditional distribution of these two estimators, we don’t need to restrict to the generated data with the given covariate imbalance and the bias-adjusted estimator becomes a version of efficiency augmented estimator in the literature. In such a case, one may expect that both estimators are asymptotically unbiased but the variance of the bias-adjusted estimator is smaller than that of the naive estimator. The results based on 5000 simulations are summarized in Table 2, which confirms the efficiency improvement reported in the literature. We have also compared the “bias-adjusted” estimator with the efficiency augmented counterpart proposed by Tsiatis et al. (2008) and Zhang, Tsiatis, and Davidian (2008) unconditionally and obtained almost identical results as shown in Figure 3, which is consistent with their asymptotic equivalence. In Figure 4, we have plotted the density functions of the naive estimator (both unconditional and conditional on the covariates imbalance, ) to highlight the fact that the distribution of an estimator can be substantially altered by conditioning on an ancillary statistics. In the same figure, we have also plotted the density functions of the bias adjusted estimator for comparison purpose. It is clear that the biased-adjusted estimator is unbiased both conditionally and unconditionally.
Table 1.
The simulation results for the log-transformed OR with binary endpoints based on 5000 simulations conditional on the observed imbalance in baseline covariates.
| |Bias| | ESE | SEE | ECP | |Bias| | ESE | SEE | ECP | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.012 | 0.313 | 0.295 | 0.941 | 1.00 | 0.005 | 0.363 | 0.343 | 0.939 | |
| 0 | 0 | 0.012 | 0.302 | 0.297 | 0.951 | 1.00 | 0.004 | 0.353 | 0.346 | 0.950 | |
| 2 | 0 | 0.017 | 0.261 | 0.252 | 0.946 | 0.90 | 0.003 | 0.296 | 0.288 | 0.949 | |
| 2 | 0 | 0.259 | 0.259 | 0.270 | 0.841 | 0.90 | 0.261 | 0.294 | 0.302 | 0.872 | |
| 4 | 0 | 0.016 | 0.208 | 0.210 | 0.952 | 0.69 | 0.005 | 0.229 | 0.230 | 0.953 | |
| 4 | 0 | 0.404 | 0.210 | 0.250 | 0.657 | 0.69 | 0.391 | 0.231 | 0.264 | 0.705 | |
ESE: empirical standard error; SEE: average standard error estimator; ECP: empirical coverage level of the 95% confidence intervals.
Table 2.
Unconditional distribution: the simulation results for the log-transformed OR with binary endpoints based on 5000 simulations.
| |Bias| | ESE | SEE | ECP | |Bias| | ESE | SEE | ECP | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.011 | 0.296 | 0.294 | 0.949 | 1.00 | 0.009 | 0.348 | 0.343 | 0.949 | |
| 0 | 0 | 0.011 | 0.295 | 0.297 | 0.954 | 1.00 | 0.009 | 0.347 | 0.346 | 0.952 | |
| 2 | 0 | 0.010 | 0.258 | 0.254 | 0.950 | 0.90 | 0.005 | 0.290 | 0.287 | 0.949 | |
| 2 | 0 | 0.003 | 0.276 | 0.272 | 0.948 | 0.90 | 0.014 | 0.305 | 0.302 | 0.949 | |
| 4 | 0 | 0.009 | 0.214 | 0.209 | 0.945 | 0.69 | 0.004 | 0.228 | 0.227 | 0.951 | |
| 4 | 0 | 0.000 | 0.254 | 0.251 | 0.950 | 0.69 | 0.003 | 0.263 | 0.263 | 0.953 | |
ESE: empirical standard error; SEE: average standard error estimator; ECP: empirical coverage level of the 95% confidence intervals.
Figure 3.
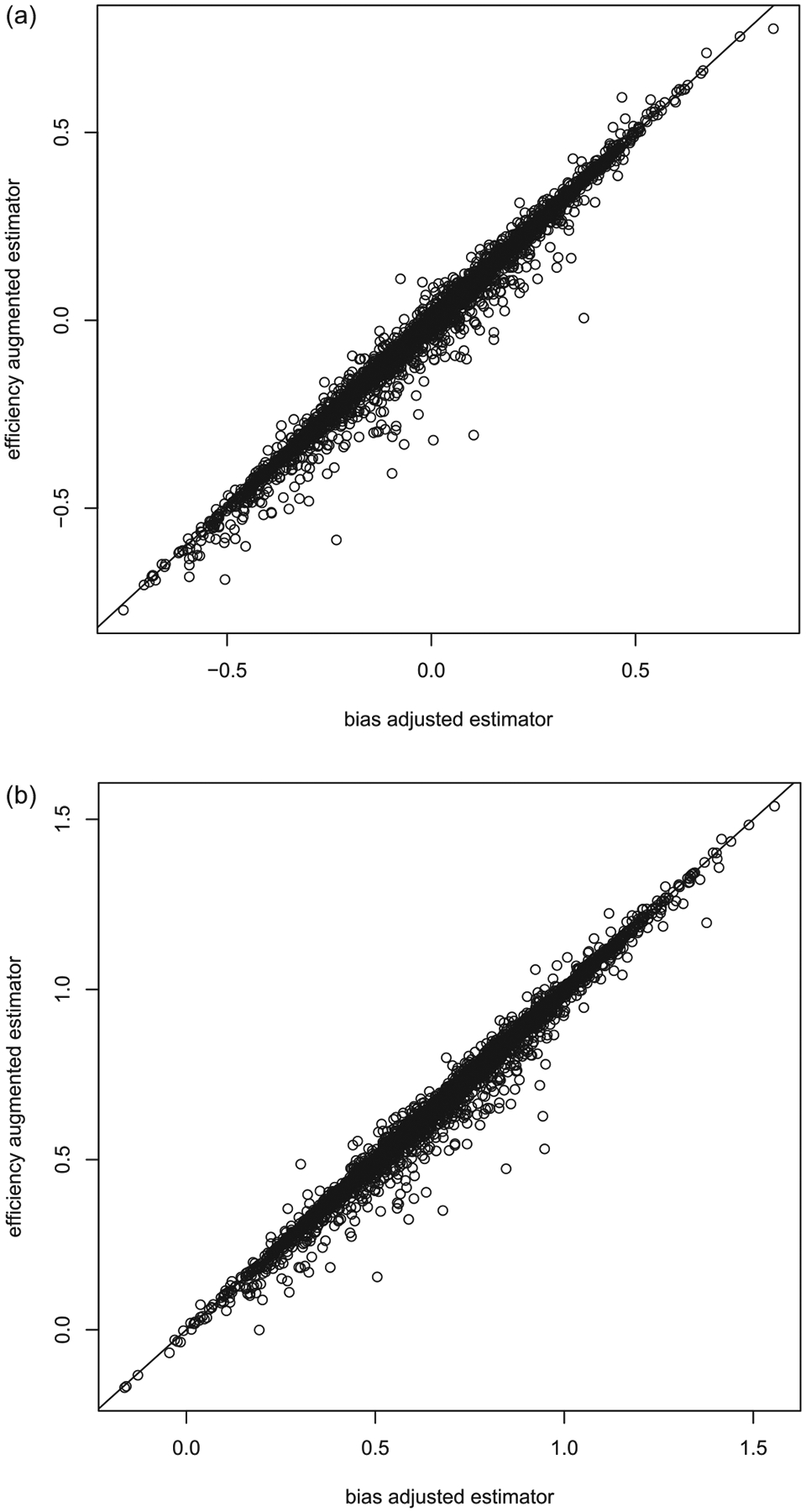
(a) The comparison between the efficiency augmented and bias adjusted estimators for binary outcomes when . Here the median of over 5000 simulations is 0.02 with being the empirical standard deviation of over 5000 simulations. (b) The comparison between the efficiency augmented and bias adjusted estimators for binary outcomes when . Here the median of over 5000 simulations is 0.02 with being the empirical standard deviation of over 5000 simulations.
Figure 4.
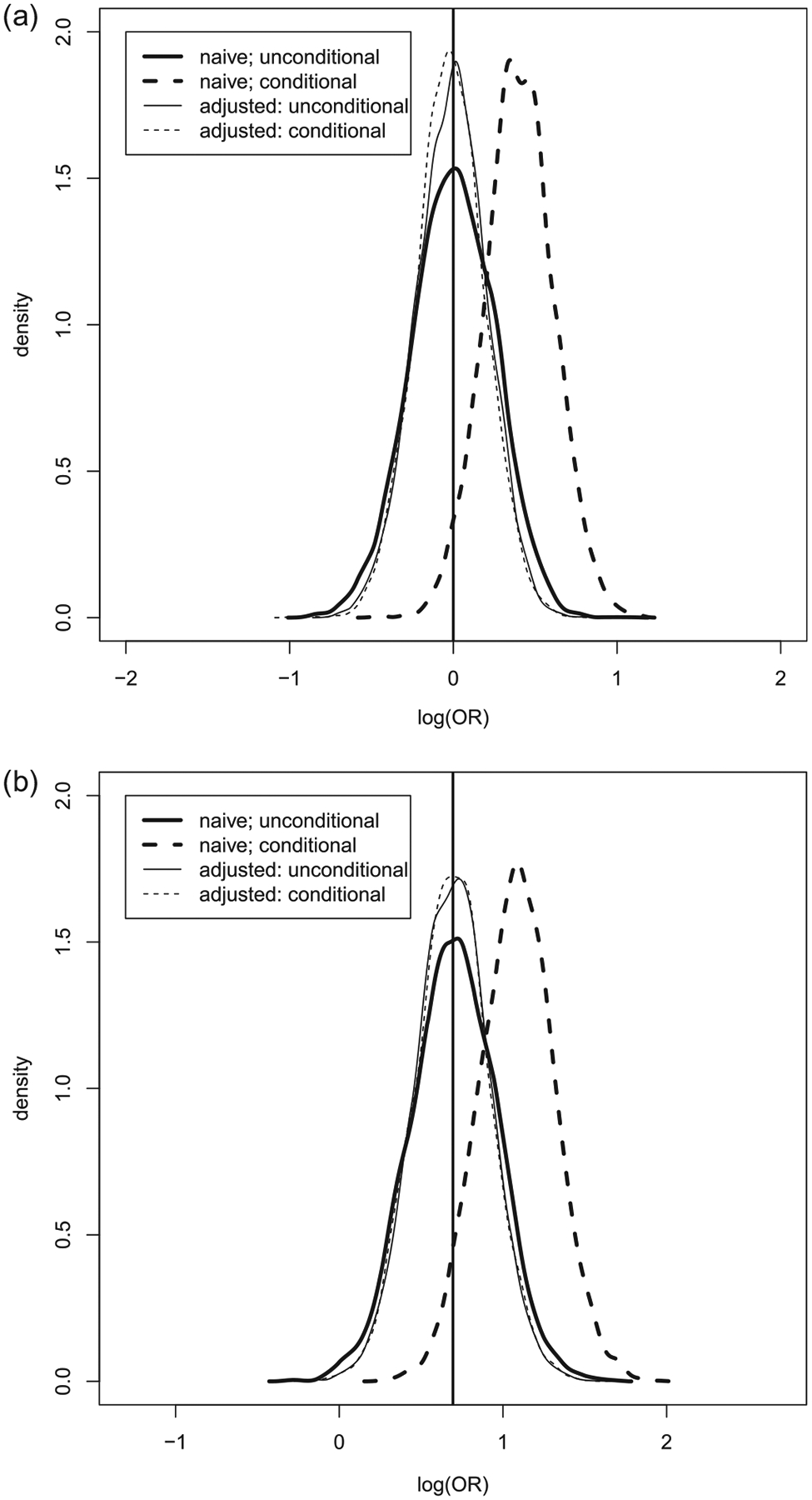
(a) The empirical density functions for and when . (b) The empirical density functions for and when .
We have repeated the simulation for continuous as well as survival outcomes. In the former case, the outcome is generated via
where and are MLEs of the log-normal regression model based on Australia data. For the latter case, the survival time is the exponential of the generated continuous outcome. The censoring time is generated uniformly between 18 and 39 months, corresponding to the minimal and maximal censoring time in the VALIANT data, respectively. For the survival outcome, the parameter of interest is the difference in RMST
where months is the maximum observed survival time in the Australia data. The results for the continuous endpoints are presented in Tables 3 and 4 for the conditional and unconditional distributions, respectively. Likewise, the results for the survival endpoints are presented in Tables 5 and 6. The results are similar to those for binary outcomes.
Table 3.
The simulation results for the mean difference with continuous endpoints based on 5000 simulations conditional on the observed imbalance in baseline covariates.
| |Bias| | ESE | SEE | ECP | |Bias| | ESE | SEE | ECP | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.002 | 0.254 | 0.247 | 0.945 | −1 | 0.002 | 0.254 | 0.247 | 0.945 | |
| 0 | 0 | 0.003 | 0.246 | 0.249 | 0.956 | −1 | 0.003 | 0.246 | 0.249 | 0.956 | |
| 1 | 0 | 0.002 | 0.254 | 0.247 | 0.945 | −1 | 0.000 | 0.254 | 0.247 | 0.945 | |
| 1 | 0 | 0.384 | 0.246 | 0.294 | 0.775 | −1 | 0.384 | 0.246 | 0.294 | 0.775 | |
| 4 | 0 | 0.002 | 0.254 | 0.247 | 0.945 | −1 | 0.002 | 0.254 | 0.247 | 0.945 | |
| 4 | 0 | 0.766 | 0.247 | 0.400 | 0.529 | −1 | 0.766 | 0.247 | 0.400 | 0.529 | |
ESE: empirical standard error; SEE: average standard error estimator; ECP: empirical coverage level of the 95% confidence intervals.
Table 4.
Unconditional distribution: the simulation results for the mean difference with continuous endpoints based on 5000 simulations.
| |Bias| | ESE | SEE | ECP | |Bias| | ESE | SEE | ECP | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.002 | 0.253 | 0.247 | 0.942 | −1 | 0.002 | 0.253 | 0.247 | 0.942 | |
| 0 | 0 | 0.003 | 0.250 | 0.249 | 0.947 | −1 | 0.003 | 0.250 | 0.249 | 0.947 | |
| 2 | 0 | 0.002 | 0.253 | 0.247 | 0.942 | −1 | 0.002 | 0.253 | 0.247 | 0.942 | |
| 2 | 0 | 0.009 | 0.308 | 0.304 | 0.944 | −1 | 0.009 | 0.308 | 0.304 | 0.944 | |
| 4 | 0 | 0.002 | 0.253 | 0.247 | 0.942 | −1 | 0.002 | 0.253 | 0.247 | 0.942 | |
| 4 | 0 | 0.015 | 0.435 | 0.427 | 0.943 | −1 | 0.015 | 0.435 | 0.427 | 0.943 | |
ESE: empirical standard error; SEE: average standard error estimator; ECP: empirical coverage level of the 95% confidence intervals.
Table 5.
The simulation results for the difference in RMST with survival endpoints based on 5000 simulations conditional on the observed imbalance in baseline covariates.
| |Bias| | ESE | SEE | ECP | |Bias| | ESE | SEE | ECP | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.019 | 1.553 | 1.511 | 0.941 | −4.77 | 0.002 | 1.470 | 1.420 | 0.938 | |
| 0 | 0 | 0.022 | 1.501 | 1.524 | 0.951 | −4.77 | 0.000 | 1.418 | 1.433 | 0.948 | |
| 2 | 0 | 0.045 | 1.514 | 1.512 | 0.949 | −4.66 | 0.029 | 1.456 | 1.451 | 0.950 | |
| 2 | 0 | 1.144 | 1.494 | 1.612 | 0.878 | −4.66 | 1.324 | 1.441 | 1.531 | 0.880 | |
| 4 | 0 | 0.115 | 1.483 | 1.479 | 0.951 | −4.45 | 0.058 | 1.470 | 1.457 | 0.949 | |
| 4 | 0 | 2.360 | 1.467 | 1.711 | 0.749 | −4.45 | 2.180 | 1.453 | 1.651 | 0.763 | |
ESE: empirical standard error; SEE: average standard error estimator; ECP: empirical coverage level of the 95% confidence intervals.
Table 6.
Unconditional distribution: The simulation results for the difference in RMST with survival endpoints based on 5000 simulations.
| |Bias| | ESE | SEE | ECP | |Bias| | ESE | SEE | ECP | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.034 | 1.551 | 1.511 | 0.941 | −4.77 | 0.014 | 1.472 | 1.419 | 0.935 | |
| 0 | 0 | 0.036 | 1.537 | 1.525 | 0.945 | −4.77 | 0.016 | 1.456 | 1.434 | 0.943 | |
| 2 | 0 | 0.020 | 1.522 | 1.494 | 0.945 | −4.66 | 0.018 | 1.466 | 1.431 | 0.939 | |
| 2 | 0 | 0.035 | 1.615 | 1.603 | 0.948 | −4.66 | 0.041 | 1.545 | 1.525 | 0.947 | |
| 4 | 0 | 0.062 | 1.482 | 1.465 | 0.950 | −4.45 | 0.037 | 1.471 | 1.442 | 0.945 | |
| 4 | 0 | 0.033 | 1.708 | 1.711 | 0.947 | −4.45 | 0.020 | 1.665 | 1.656 | 0.946 | |
ESE: empirical standard error; SEE: average standard error estimator; ECP: empirical coverage level of the 95% confidence intervals.
5. Discussion
For the conventional causal inference procedures, for example, the PS method, we assume that the underlying population distributions of the covariate vectors between two groups are expected to be different. Then unconditionally, the naive two sample estimator is not consistent. The PS method tries to reduce this systematic bias. Under our setting, the underlying distributions of the covariate vectors between two groups are the same due to treatment allocation randomization, but the corresponding observed distributions may be different by chance. For this situation, the parametric ANCOVA is a standard practice for obtaining an estimator for the treatment effect to reduce bias. Note that the ANCOVA is a conditional inference procedure (i.e., conditional on all the individual patients’ covariates). However, if a nonlinear ANCOVA model is not correctly specified, it is not clear how to interpret the resulting treatment effect estimate. Our nonparametric approach cannot consider this fine level of conditioning. We derived the new procedure by taking advantage of study randomization and using a conditional inference argument based on an ancillary summary statistic reflecting the observed covariate imbalance. As far as we know, there are no such methods similar to our proposal in the literature. On the other hand, it is a pleasant surprise that this conditional procedure turns out to be asymptotically equivalent to a class of augmentation methods unconditionally. This connection may enhance the usage of the augmentation procedures in practice. Now, we may claim that the new estimator improves the asymptotic efficiency unconditionally and is “unbiased” conditional on observed covariates imbalance at the same time.
Like ANCOVA or efficiency augmentation methods, the choice of covariates in our conditional procedure can be crucial. The bias adjusted estimators conditional on different covariates imbalances are all valid but have different interpretations. Thus, we suggest identifying those covariates before implementing the conditional analysis. Empirically, one may first include variables, which show imbalances via the standard two-sample test. Since the bias reduction can be substantial if the covariates of concern are highly correlated with the outcome, we suggest to additionally include covariates empirically associated with the outcome based on univariate analysis. The number of covariates in the bias adjustment procedure may be determined a priori based on the sample size to avoid over adjustment. In practice, one may examine the conditional number of the matrix , which would be near-singular if over adjusted. Note that theoretically, the procedures proposed by Zhu et al. (2011) and Tian et al. (2012), which have built-in variable selection algorithms, are only valid under the unconditional setting. For the unconditional case, the two sample naive and any augmented estimators are consistent, therefore, the choice of augmentation terms is solely driven by their variance. On the other hand, when we deal with the current (conditional) case, the naive estimator may not be consistent. It is not clear how to generalize these variable selection methods to the conditional setting. Further research along this line is needed.
The generalization to more general observational studies is possible by considering the new ancillary statistics
where is the correct PS. However, such an extension requires the knowledge of the PS, which is a difficult task by itself. Furthermore, the bias associated with the ancillary statistics is merely the “residual bias” after the PS adjustment, which removes the systematic bias between two groups. Thus, it is less important than, for example, developing a good PS model at the first place. If we can correctly specify the conditional distribution of outcome given covariates in both groups, the model-based ANCOVA method can be used to construct an unbiased estimator even for data from an observational study. However, such a model-based method may be rather sensitive to model misspecification. Covariate matching, such as the one based on PS, is also a common approach to recover the balance in baseline covariates, and is often used to quantify imbalance after matching (Stuart 2010). This further justifies the usage of this type of ancillary statistic in our conditional inference.
Stratified analysis can be regarded as a special case of the covariate-adjusted procedure. On the other hand, due to its discrete nature of possible values of the covariates, using the present conditioning approach, one may consider the ancillary statistics consisting of the entire observed covariate vectors for stratified analysis. For the general case when some of the covariates are continuous, however, such a fine level of conditioning would be difficult, if not impossible to implement.
Acknowledgments
The authors thank the editor, associate editor, and two referees for their constructive comments. Further, the authors thank Prof. Marc Alan Pfeffer for providing data to support this research.
Funding
This research is partially supported by NIH funding: R01 HL089778 (NIH/NHLBI), ROO HSO22193 (NIH/AHRQ), and R21 AGO49385 (NIH/NIA) and ECS 27304117 (GRF/ECS).
Appendix A: Equivalence Between and
Let , be the iid copies of . The efficiency-augmented estimator for studied by Tsiatis et al. (2008) and Zhang, Tsiatis, and Davidian (2008) is given by
where
Here, is the sample size for the th group, and and are the least squares estimators of and in regression model , respectively. Using the fact that , we have
Since and ,
Now, . It follows that
where is the empirical estimate for and is the empirical estimate for . Note that in constructing the bias-adjusted estimator,
This, coupled with the fact that , implies that
and
Therefore
as for any positive .
Appendix B: Proof of Theorem
In Appendix B, we will drive the limiting distribution of
given under the following three conditions that
(A1) is a finite, nondegenerate matrix;
(A2) the characteristic function of is integrable;
(A3) is a regular estimator for , that is,
where
are iid random variables, , and .
Under Condition (A3),
| (B.1) |
where and . Let and . Then converges weakly to , a Gaussian vector with mean and a finite covariate matrix , where
Here
Now, let be a sequence of vectors such that , a constant vector, as , where is the support of . It follows from Steck (1957) that under Conditions (A1) and (A2),
| (B.2) |
where is the cumulative distribution function of the conditional distribution of given , and is the cumulative distribution function of the conditional Gaussian distribution of given .
Let be the support of . For any sequence of vectors , such that also converges to , as , where . Therefore,
| (B.3) |
Note that the first equality is a direct consequence of (B.1), and the last equality is implied by (B.2) and the fact that is uniform continuous in .
Now, let . Since is a conditional Gaussian distribution function with mean , (B.3) implies given converges to a conditional Gaussian distribution with mean almost surely. Since and , the bias-adjusted estimator is an asymptotically unbiased estimator for under the conditional setting with asymptotic variance .
Appendix C: The Adjusted Estimators for the Continuous and Survival Endpoints
For the continuous endpoint, the parameter of interest is the mean difference
where . A commonly used estimator for can be constructed as . The components used in the bias adjustment can be estimated as
For the survival endpoint subject to right censoring, we observe , where and is the censoring time. The treatment effect is measured by the difference in RMST
for fixed , and . The naive estimator of can be constructed as
where is the Kaplan–Meier (KM) estimator for the survival function of based on observations from group . Note that is a nonparametric estimator for in that its validity does not depend on any specific parametric or semiparametric assumption in contrast to the hazard ratio. It follows from the classical results about the KM estimator in survival analysis,
where is the cumulative hazard function of , and Therefore, the variance components used in the bias adjustment can be estimated as
and
where is the Nelson–Aalen estimator for the cumulative hazard function of , , and .
References
- Bang H, and Robins JM (2005), “Doubly Robust Estimation in Missing Data and Causal Inference Models,” Biometrics, 61, 962–973. [DOI] [PubMed] [Google Scholar]
- Basu D (1959), “The Family of Ancillary Statistics,” Sankhyā, 21, 247–256. [Google Scholar]
- Berger JO, Wolpert RL, Bayarri M, DeGroot M, Hill BM, Lane DA, and LeCam L (1988), “The Likelihood Principle,” Lecture Notes-Monograph Series, 6, 1–199. [Google Scholar]
- Casella G (1992), “Conditional Inference From Confidence Sets,” Lecture Notes-Monograph Series, 17, 1–12. [Google Scholar]
- Cox DR (1958), “Some Problems Connected With Statistical Inference,” The Annals of Mathematical Statistics, 29, 357–372. [Google Scholar]
- ——— (1971), “The Choice Between Alternative Ancillary Statistics,” Journal of the Royal Statistical Society, Series B, 33, 251–255. [Google Scholar]
- Cox DR, and Hinkley DV (1979), Theoretical Statistics, Boca Raton, FL: CRC Press. [Google Scholar]
- Fraser D (2004), “Ancillaries and Conditional Inference,” Statistical Science, 19, 333–369. [Google Scholar]
- Fraser D, and McDunnough P (1980), “Some Remarks on Conditional and Unconditional Inference for Location-Scale Models,” Statistische Hefte, 21, 224–231. [Google Scholar]
- Gail MH, Wieand S, and Piantadosi S (1984), “Biased Estimates of Treatment Effect in Randomized Experiments With Nonlinear Regressions and Omitted Covariates,” Biometrika, 71, 431–444. [Google Scholar]
- Ghosh M, Reid N, and Fraser D (2010), “Ancillary Statistics: A Review,” Statistica Sinica, 20, 1309–1332. [Google Scholar]
- Gilbert PB, Sato A, Sun X, and Mehrotra DV (2009), “Efficient and Robust Method for Comparing the Immunogenicity of Candidate Vaccines in Randomized Clinical Trials,” Vaccine, 27, 396–401. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Leon S, Tsiatis AA, and Davidian M (2003), “Semiparametric Estimation of Treatment Effect in a Pretest-Posttest Study,” Biometrics, 59, 1046–1055. [DOI] [PubMed] [Google Scholar]
- Lin DY, and Wei L-J (1989), “The Robust Inference for the Cox Proportional Hazards Model,” Journal of the American Statistical Association, 84, 1074–1078. [Google Scholar]
- Lu X, and Tsiatis AA (2008), “Improving the Efficiency of the Log-Rank Test Using Auxiliary Covariates,” Biometrika, 95, 679–694. [Google Scholar]
- Pfeffer MA, Swedberg K, Granger CB, Held P, McMurray JJ, Michelson EL, Olofsson B, Östergren J, Yusuf S, and CHARM Investigators and Committees (2003), “Effects of Candesartan on Mortality and Morbidity in Patients With Chronic Heart Failure: The CHARM-Overall Programme,” The Lancet, 362, 759–766. [DOI] [PubMed] [Google Scholar]
- Pocock SJ, Assmann SE, Enos LE, and Kasten LE (2002), “Subgroup Analysis, Covariate Adjustment and Baseline Comparisons in Clinical Trial Reporting: Current Practice and Problems,” Statistics in Medicine, 21, 2917–2930. [DOI] [PubMed] [Google Scholar]
- Resa M, and Zubizarreta JR (2016), “Evaluation of Subset Matching Methods and Forms of Covariate Balance,” Statistics in Medicine, 35, 4961–4979. [DOI] [PubMed] [Google Scholar]
- Robins JM (1999), “Marginal Structural Models Versus Structural Nested Models as Tools for Causal Inference,” Statistical Models in Epidemiology: The Environment and Clinical Trials, 116, 95–134. [Google Scholar]
- Robins JM, Rotnitzky A, and Zhao LP (1994), “Estimation of Regression Coefficients When Some Regressors Are Not Always Observed,” Journal of the American Statistical Association, 89(427), 846–866. [Google Scholar]
- Rosenblum M, and van der Laan MJ (2010), “Simple, Efficient Estimators of Treatment Effects in Randomized Trials Using Generalized Linear Models to Leverage Baseline Variables,” The International Journal of Biostatistics, 6, 13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steck G (1957), Limit Theorems for Conditional Distributions, ed. Steck GP, California: University of California Press. [Google Scholar]
- Struthers CA, and Kalbfleisch JD (1986), “Misspecified Proportional Hazard Models,” Biometrika, 73, 363–369. [Google Scholar]
- Stuart EA (2010), “Matching Methods for Causal Inference: A Review and a Look Forward,” Statistical Science, 25, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tian L, Cai T, Zhao L, and Wei L-J (2012), “On the CovariateAdjusted Estimation for an Overall Treatment Difference With Data From a Randomized Comparative Clinical Trial,” Biostatistics, 13, 256–273. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tsiatis AA (2006), “Information-Based Monitoring of Clinical Trials,” Statistics in Medicine, 25, 3236–3244. [DOI] [PubMed] [Google Scholar]
- Tsiatis AA, Davidian M, Zhang M, and Lu X (2008), “Covariate Adjustment for Two-Sample Treatment Comparisons in Randomized Clinical Trials: A Principled Yet Flexible Approach,” Statistics in Medicine, 27, 4658–4677. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Der Laan MJ, and Rubin D (2006), “Targeted Maximum Likelihood Learning,” U.C. Berkeley Division of Biostatistics Working Paper Series 213 [Google Scholar]
- Zhang M, and Gilbert PB (2010), “Increasing the Efficiency of Prevention Trials by Incorporating Baseline Covariates,” Statistical Communications in Infectious Diseases, 2, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang M, Tsiatis AA, and Davidian M (2008), “Improving Efficiency of Inferences in Randomized Clinical Trials Using Auxiliary Covariates,” Biometrics, 64, 707–715. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao L, Claggett B, Tian L, Uno H, Pfeffer MA, Solomon SD, Trippa L, and Wei L (2016), “On the Restricted Mean Survival Time Curve in Survival Analysis,” Biometrics, 72, 215–221. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu L, Li L, Li R, and Zhu L-X (2011), “Model-Free Feature Screening for Ultrahigh Dimensional Data,” Journal of American Statistical Association, 106, 1464–1475. [DOI] [PMC free article] [PubMed] [Google Scholar]