

Version Changes
Revised. Amendments from Version 1
In this revised version, we have incorporated additional information and provided more comprehensive explanations regarding the individual scRNA-seq analysis, the integration analysis, and the downstream edgeR time-course analysis. We have also revised the design matrix used in the downstream pseudo-bulk time-course analysis. In particular, we have introduced a sample effect into the design, which enables the incorporation of differences between the five biological samples. This substantially increases the statistical power of the time-course analysis, resulting in the detection of more genes significantly associated with pseudotime. Figure 6 has been split into two separate Figures (Figure 6 and 7). This is because users need to first generate Figure 6 to decide the starting node before they proceed to the cell ordering and pseudotime calculation. The visualization of pseudotime (Figure 7) comes after that. Consequently, all the Figure numbers after Figure 7 will change accordingly.
Abstract
Background
Single-cell RNA sequencing (scRNA-seq) technologies have rapidly developed in recent years. The droplet-based single cell platforms enable the profiling of gene expression in tens of thousands of cells per sample. The goal of a typical scRNA-seq analysis is to identify different cell subpopulations and their respective marker genes. Additionally, trajectory analysis can be used to infer the developmental or differentiation trajectories of cells.
Methods
This article demonstrates a comprehensive workflow for performing trajectory inference and time course analysis on a multi-sample single-cell RNA-seq experiment of the mouse mammary gland. The workflow uses open-source R software packages and covers all steps of the analysis pipeline, including quality control, doublet prediction, normalization, integration, dimension reduction, cell clustering, trajectory inference, and pseudo-bulk time course analysis. Sample integration and cell clustering follows the Seurat pipeline while the trajectory inference is conducted using the monocle3 package. The pseudo-bulk time course analysis uses the quasi-likelihood framework of edgeR.
Results
Cells are ordered and positioned along a pseudotime trajectory that represented a biological process of cell differentiation and development. The study successfully identified genes that were significantly associated with pseudotime in the mouse mammary gland.
Conclusions
The demonstrated workflow provides a valuable resource for researchers conducting scRNA-seq analysis using open-source software packages. The study successfully demonstrated the usefulness of trajectory analysis for understanding the developmental or differentiation trajectories of cells. This analysis can be applied to various biological processes such as cell development or disease progression, and can help identify potential biomarkers or therapeutic targets.
Keywords: Single-cell RNA-seq, mammary gland, trajectory analysis, time course analysis, pseudo-bulk, differential expression analysis
Introduction
Single-cell RNA sequencing (scRNA-seq) has emerged as a popular technique for transcriptomic profiling of samples at the single-cell level. With droplet-based methods, thousands of cells can be sequenced in parallel using next-generation sequencing platforms. 1 , 2 One of the most widely used droplet-based scRNA-seq technologies is the 10x Genomics Chromium which enables profiling transcriptomes of tens of thousands of cells per sample. 3 A common goal of a scRNA-seq analysis is to investigate cell types and states in heterogeneous tissues. To achieve this, various pipelines have been developed, such as Seurat 4 and the Bioconductor’s OSCA pipeline, 5 and scanpy. 6 A typical scRNA-seq data analysis pipeline involves quality control, normalization, dimension reduction, cell clustering, and differential expression analysis.
With the advent of single-cell multiplexing technologies, the per sample cost of scRNA-seq experiments has significantly decreased. This makes it feasible and more affordable to conduct single-cell RNA-seq profiling across a variety of biological samples within a given experimental study. In a multiple sample single-cell experiment, an integration method is required to investigate all cells across all samples simultaneously. This ensures that sample and batch effects are appropriately considered in visualizing and clustering cells. Popular integration methods include the Seurat’s anchor-based integration method, 4 Harmony, 7 and the MNN. 8
After integration and cell clustering, differential expression analysis is often performed to identify marker genes for each cell cluster. Various methods have been developed at the single-cell level for finding marker genes. 9 , 10 Recently, the pseudo-bulk method has become increasingly popular due to its superior computational efficiency and its ability to consider biological variation between replicate samples. 11 Under this approach, pseudo-bulk expression profiles are formed by aggregating read counts for all cells within the same group (e.g., cluster, cell type) and from the same sample.
Trajectory inference is another popular downstream analysis that aims to study cell differentiation or cell type development. Popular software tools to perform trajectory analysis include monocle3 12 and slingshot. 13 These methods learn trajectories based on the change of gene expression and order cells along a trajectory to obtain pseudotime. 14 , 15 This allows for pseudotime-based time course analysis in single-cell experiments, which is extremely useful for investigating specific biological questions of interest.
Here we present a new single-cell workflow that integrates trajectory analysis and pseudo-bulking to execute a single-cell pseudo time course analysis. The inputs for this workflow are single-cell count matrices, such as those generated by 10x Genomic’s cellranger. The methods involved open source packages in R. The single-cell QC, clustering and integration analyses are performed in Seurat, whereas the trajectory analysis is conducted using monocle3. Once the pseudo-bulk samples are created and assigned pseudotime, a time course analysis is conducted in edgeR. 16 The analysis pipeline presented in this article can be used for examining dynamic cellular changes along a specific trajectory in any single-cell RNA-seq experiment with replicate samples.
Description of the biological experiment
The scRNA-seq data used to demonstrate this workflow consists of five mouse mammary epithelium samples at five different stages: embryonic, early postnatal, pre-puberty, puberty and adult. The puberty sample is from the study in Pal et al. 2017, 17 whereas the other samples are from Pal et al. 2021. 18 These studies examined the stage-specific single-cell profiles in order to gain insight into the early developmental stages of mammary gland epithelial lineage. The cellranger count matrix outputs of these five samples are available on the GEO repository as series GSE103275 and GSE164017.
Data preparation
Downloading the data
The cellranger output of each sample consists of three key files: a count matrix in mtx.gz format, barcode information in tsv.gz format and feature (or gene) information in tsv.gz format.
The outputs of the mouse mammary epithelium at embryonic stage (E18.5), post-natal 5 days (P5), 2.5 weeks (Pre-puberty), and 10 weeks (Adult) can be downloaded from GSE164017, 18 whereas the output of mouse mammary epithelium at 5 weeks (Puberty) can be downloaded from GSE103275. 17
We first create a data directory to store all the data files.
> data_dir <- "data" > if(!dir.exists(data_dir)){dir.create(data_dir, recursive=TRUE)}
We then download the barcode and count matrix files of the five samples.
> accessions <-c("GSM4994960","GSM4994962","GSM4994963","GSM2759554","GSM4994967") > stages <- c("E18-ME", "Pre-D5-BL6", "Pre-BL6", "5wk-1", "Adult-BL6") > file_suffixes <- c("barcodes.tsv.gz", "matrix.mtx.gz") > for ( i in 1:length(accessions) ) { + for (file_suffix in file_suffixes) { + filename <- paste0(accessions[i],"_",stages[i],"-",file_suffix) + url <- paste0("http://www.ncbi.nlm.nih.gov/geo/download/?acc=", + accessions[i],"&","format=file&","file=",filename) + download.file(url=url,destfile=paste0(data_dir,"/",filename)) + } + }
Since the five samples in this workflow are from two separate studies and were processed using different cellranger references but built from the same mouse genome (mm10), the feature information is slightly different between the two runs. In general, the same cellranger reference build is preferred for the sake of consistency, although the effect on the downstream analysis is negligible. Here, we download the feature information of both runs. The GSM2759554_5wk-1-genes.tsv.gz file contains the feature information for the 5wk-1 sample, whereas GSE164017_features.tsv.gz contains the feature information for the other four samples.
> GSE <- c("GSE164017", "GSM2759554") > feature_filenames <- c("GSE164017_features.tsv.gz", + "GSM2759554_5wk-1-genes.tsv.gz") > for (i in 1:length(GSE) ) { + url <- paste0("http://www.ncbi.nlm.nih.gov/geo/download/?acc=", + GSE[i],"&","format=file&","file=",feature_filenames[i]) + download.file(url=url,destfile=paste0(data_dir,"/",feature_filenames[i])) + }
A target information file is created to store all the sample and file information.
> samples <- c("E18.5-epi", "P5", "Pre-puberty", "Puberty", "Adult") > targets <- data.frame( + samples=samples, + stages=stages, + accessions=accessions, + matrix.file = paste0("data/",accessions[1:5],"_",stages[1:5],"-","matrix.mtx.gz"), + barcode.file = paste0("data/",accessions[1:5],"_",stages[1:5],"-","barcodes.tsv.gz"), + feature.file = paste0("data/",feature_filenames[c(1,1,1,2,1)])) > targets samples stages accessions matrix.file 1 E18.5-epi E18-ME GSM4994960 data/GSM4994960_E18-ME-matrix.mtx.gz 2 P5 Pre-D5-BL6 GSM4994962 data/GSM4994962_Pre-D5-BL6-matrix.mtx.gz 3 Pre-puberty Pre-BL6 GSM4994963 data/GSM4994963_Pre-BL6-matrix.mtx.gz 4 Puberty 5wk-1 GSM2759554 data/GSM2759554_5wk-1-matrix.mtx.gz 5 Adult Adult-BL6 GSM4994967 data/GSM4994967_Adult-BL6-matrix.mtx.gz barcode.file feature.file 1 data/GSM4994960_E18-ME-barcodes.tsv.gz data/GSE164017_features.tsv.gz 2 data/GSM4994962_Pre-D5-BL6-barcodes.tsv.gz data/GSE164017_features.tsv.gz 3 data/GSM4994963_Pre-BL6-barcodes.tsv.gz data/GSE164017_features.tsv.gz 4 data/GSM2759554_5wk-1-barcodes.tsv.gz data/GSM2759554_5wk-1-genes.tsv.gz 5 data/GSM4994967_Adult-BL6-barcodes.tsv.gz data/GSE164017_features.tsv.gz
Reading in the data
The downloaded cellranger outputs of all the samples can be read in one-by-one using the read10X function in the edgeR package. First, a DGElist object is created for each sample, which is then consolidated into a single DGElist object by merging them altogether.
> library(edgeR) > dge_all <- list() > for ( i in 1:5 ) { + y <- read10X(mtx = targets$matrix.file[i], + barcodes = targets$barcode.file[i], genes = targets$feature.file[i]) + y$samples$group <- targets$samples[i] + colnames(y) <- paste0(targets$accessions[i],"-",y$samples$Barcode) + y$genes$Ensembl_geneid <- rownames(y) + y$genes <- y$genes[,c("Ensembl_geneid","Symbol")] + y <- y[!duplicated(y$genes$Symbol),] + rownames(y) <- y$genes$Symbol + dge_all[[i]] <- y + } > rm(y) > common.genes <- Reduce(intersect, lapply(dge_all, rownames)) > for(i in 1:5) dge_all[[i]] <- dge_all[[i]][common.genes, ] > dge_merged <- do.call("cbind", dge_all)
The levels of group in the sample information data frame are reordered and renamed from the early embryonic stage to the late adult stage.
> dge_merged$samples$group <- factor(dge_merged$samples$group, levels=samples)
The number of genes, the total number of cells, and the number of cells in each sample are shown below.
> dim(dge_merged) [1] 26589 33735 > table(dge_merged$samples$group) E18.5-epi P5 Pre-puberty Puberty Adult 6969 3886 4183 5428 13269
Single-cell RNA-seq analysis
Quality control
Quality control (QC) is essential for single-cell RNA-seq data analysis. Common choices of QC metrics include number of expressed genes or features, total number of reads, and proportion of reads mapped to mitochondrial genes in each cell. The number of expressed genes and mitochondria read percentage in each cell can be calculated as follows.
> dge_merged$samples$num_exp_gene <- colSums(dge_merged$counts>0) > mito_genes <- rownames(dge_merged)[grep("^mt-",rownames(dge_merged))] > dge_merged$samples$mito_percentage <- + colSums(dge_merged$counts[mito_genes,])/ + colSums(dge_merged$counts)*100
These QC metrics can be visualized in the following scatter plots ( Figure 1).
> library(ggplot2) > my_theme_ggplot <- theme_classic() + + theme(axis.text=element_text(size=12), + axis.title=element_text(size=15,face="bold"), + plot.title=element_text(size=15,face="bold",hjust=0.5), + plot.margin=margin(0.5, 0.5, 0.5, 0.5, "cm")) > my_theme_facet <- + theme(strip.background=element_rect(colour="white",fill="white"), + strip.text=element_text(size=15, face="bold",color="black")) > my_colors_15 <- c("cornflowerblue", "darkorchid1", "firebrick1", "gold", + "greenyellow", "mediumspringgreen", "mediumturquoise", + "orange1", "pink", "deeppink3", "violet", "magenta", + "goldenrod4", "cyan", "gray90")
> p1 <- ggplot(data = dge_merged$samples, + aes(x=num_exp_gene, y=lib.size, color = group ) ) + + geom_point(size=0.5, show.legend=FALSE) + + facet_wrap(group~., ncol=1) + + scale_color_manual(values=my_colors_15 ) + + labs(x="Number of genes", y="Number of reads") + + my_theme_ggplot + my_theme_facet > p2 <- ggplot(data = dge_merged$samples, + aes(x = mito_percentage, y=lib.size, color = group ) ) + + geom_point(size = 0.5, show.legend = FALSE) + + facet_wrap(group~., ncol=1) + + scale_color_manual(values=my_colors_15) + + labs(x="Mito-percentage", y="Number of reads") + + my_theme_ggplot + my_theme_facet > patchwork::wrap_plots(p1, p2, ncol=2)
Figure 1. Scatter plots of quality control metrics across all the samples.

Each dot represents a cell. The plots on the left show number of reads vs number of genes detected, whereas those on the right show number of reads vs mitochondria read percentage.
Cells with a very low number of genes (<500) are considered of low quality and hence are removed from the analysis. Cells with high mitochondria read percentage (>10%) are also removed as high expression level of mitochondrial genes indicate damaged or dead cells. In general, these QC thresholds are dependent on the study data and hence should be considered carefully. For example, quiescent cells may normally have low RNA expression levels, and metabolically active cells may have a high mitochondrial content. Cells expressing a large number of genes are also removed as they are likely to be doublets. Even though a separate doublet detection analysis is performed later on, we notice from our own practice that the combination of both doublet detection and the removal of cells with large counts works the best. Different thresholds are selected for different samples based on the distribution of the number of genes expressed. Here, we choose 5000, 6000, 6000, 3000, 4000 for E18.5-epi, P5, pre-puberty, puberty and adult samples, respectively. In this workflow, most of the single-cell analysis is conducted using the Seurat package. We begin by reading in the scRNA-seq data from the five samples together with an initial QC process. Specifically, we filter out genes expressed in fewer than 3 cells and cells expressing fewer than 200 genes for each sample. Then the abovementioned QC thresholds are applied in order to further remove cells of low quality in each sample. The data after QC are stored as a list of five Seurat objects.
> library(Seurat) > n_genes_max <- c(5000, 6000, 6000, 3000, 4000) > data_seurat <- list() > for (i in 1:5) { + sel <- dge_merged$samples$group == samples[i] + y <- dge_merged[, sel] + data_seurat[[i]] <- CreateSeuratObject( counts=y$counts, + meta.data=y$samples, min.cells=3, min.features=200, + project=samples[i] ) + data_seurat[[i]] <- subset( data_seurat[[i]], + subset = (nFeature_RNA > 500) & (nFeature_RNA < n_genes_max[i]) & + (mito_percentage < 10) ) + } > names(data_seurat) <- samples
Standard Seurat analysis of individual sample
A standard Seurat analysis is performed for each individual sample. This would provide us some general information on how each individual sample looks like and what cell types present within them. More details on how to perform a scRNA-seq analysis can be found in Seurat online vignettes.
For each individual sample analysis, the default log normalization method in NormalizeData is applied to each sample. The top 2000 highly variable genes (HVGs) are identified by FindVariableFeatures. The normalized data of the 2000 highly variable genes are scaled by ScaleData to have a mean of 0 and a variance of 1. The principal component analysis (PCA) dimension reduction is performed on the highly variable genes by RunPCA. Uniform manifold approximation and projection (UMAP) dimension reduction is performed on the first 30 PCs by RunUMAP. Here we use the first 30 PCs to be consistent with the analysis in Pal et al. 2021. 18 Based on the Seurat vignette and our own practice, the number of PCs chosen would not change the results dramatically if it is large enough (> 10). Cell clustering is performed individually for each sample by FindNeighbors and FindClusters, which by default uses the Louvain algorithm. Cell clustering resolution is carefully chosen for each sample so that distinct cell types are grouped into separate clusters. For this dataset, the cell clustering resolution is set at 0.1, 0.1, 0.2, 0.2 and 0.2 for E18.5-epi, P5, pre-puberty, puberty and adult, respectively.
> data_seurat <- lapply(data_seurat, NormalizeData) > data_seurat <- lapply(data_seurat, FindVariableFeatures, nfeatures=2000) > data_seurat <- lapply(data_seurat, ScaleData) > data_seurat <- lapply(data_seurat, RunPCA, verbose = FALSE) > data_seurat <- lapply(data_seurat, RunUMAP, reduction = "pca", dims = 1:30) > data_seurat <- lapply(data_seurat, FindNeighbors, reduction="pca", dims=1:30) > resolutions <- c(0.1, 0.1, 0.2, 0.2, 0.2) > for(i in 1:5) + data_seurat[[i]] <- FindClusters(data_seurat[[i]], + resolution=resolutions[i], verbose=FALSE)
Removing potential doublets and non-epithelial cells
Although high-throughput droplet-based single-cell technologies can accurately capture individual cells, there are instances where a single droplet may contain two or more cells, which are known as doublets or multiplets. Here we use the scDblFinder package 19 to further remove potential doublets. To do that, each Seurat object in the list is first converted into a SingleCellExperiment object using the as.SingleCellExperiment function in Seurat. Then the scDblFinder function in the scDblFinder package is called to predict potential doublets on each SingleCellExperiment object. The scDblFinder output for each sample is stored in the corresponding Seurat object.
> library(scDblFinder) > for (i in 1:5) { + sce <- as.SingleCellExperiment(DietSeurat(data_seurat[[i]], + graphs=c("pca","umap")) ) + set.seed(42) + sce <- scDblFinder(sce) + data_seurat[[i]]$db_score <- sce$scDblFinder.score + data_seurat[[i]]$db_type <- factor( sce$scDblFinder.class, + levels=c("singlet", "doublet") ) + }
The main object of this single-cell experiment is to examine the early developmental stages of the mouse epithelial mammary gland. Hence, for the rest of the analysis we will mainly focus on the epithelial cell population which is typically marked by the Epcam gene. The cell clustering, the expression level of Epcam and doublet prediction results of each sample are shown below ( Figure 2).
> p1 <- lapply(data_seurat,function(x){DimPlot(x, pt.size=0.1, cols=my_colors_15) + + ggtitle(x$group[1]) + theme(plot.title=element_text(hjust=0.5))}) > p2 <- lapply(data_seurat, FeaturePlot, feature="Epcam", pt.size=0.1) > p3 <- lapply(data_seurat, DimPlot, group.by="db_type", pt.size=0.1, + cols=c("gray90", "firebrick1")) > patchwork::wrap_plots(c(p1,p2,p3), nrow=5, byrow=FALSE)
Figure 2. UMAP visualization of each individual samples.

The UMAP plots, in sequence from the top row to the bottom row, correspond to E18.5-epi, P5, Pre-puberty, Puberty, and Adult, respectively. In each row, cells are coloured by cluster on the left, by Epcam expression level in the middle, and by doublet prediction on the right.
By examining the expression level of the Epcam gene, together with some other known marker genes of basal, LP and ML, we select the following clusters in each sample as the epithelial cell population.
> epi_clusters <- list( + "E18.5-epi" = 0, + "P5" = c(1,3), + "Pre-puberty" = c(0:2, 5), + "Puberty" = 0:6, + "Adult" = 0:3 + )
Cells that are non-epithelial and those identified as potential doublets by scDblFinder are excluded from the subsequent analysis. The cellular barcodes of the remaining epithelial cells from each sample are stored in the list object called epi_cells. The respective number of epithelial cells that are retained for each sample is shown below.
> epi_cells <- list() > for (i in samples) { + epi_cells[[i]] <- rownames( + subset(data_seurat[[i]]@meta.data, + (db_type == "singlet") & (seurat_clusters %in% epi_clusters[[i]]))) + } > do.call(c, lapply(epi_cells, length)) E18.5-epi P5 Pre-puberty Puberty Adult 4343 1140 2546 4706 9341
Data integration
Integrating epithelial cells of five samples
Since we have five individual scRNA-seq samples, conducting an integration analysis is necessary to explore all cells across these samples simultaneously. In this workflow, we use the default anchor-based integration method of the Seurat package. Depending on the single-cell analysis workflow, users are free to use other integration methods they may prefer (e.g., Harmony and MNN). A Seurat object is first created from the merged DGEList object of epithelial cells using CreateSeuratObject function without filtering any cells ( min.features is set to 0). Lowly expressed genes are removed as they are not of any biological interest here. Here we keep genes expressed in at least 3 cells in each sample ( min.cells is set to 3) although different thresholds can be adopted in general depending on the data.
> epi_cells <- do.call(c, epi_cells) > dge_merged_epi <- dge_merged[, epi_cells] > seurat_merged <- CreateSeuratObject(counts = dge_merged_epi$counts, + meta.data = dge_merged_epi$samples, + min.cells = 3, min.features = 0, project = "mammary_epi")
Then the Seurat object is split into a list of five Seurat objects, where each object corresponds to one of the five samples. For each sample, the log normalization method is applied to normalize the raw count by NormalizeData, and highly variable genes are identified by FindVariableFeatures.
> seurat_epi <- SplitObject(seurat_merged, split.by = "group") > seurat_epi <- lapply(seurat_epi, NormalizeData) > seurat_epi <- lapply(seurat_epi, FindVariableFeatures, nfeatures = 2000)
The feature genes used for integration are chosen by SelectIntegrationFeatures, and these genes are used to identify anchors for integration by FindIntegrationAnchors. The integration process is performed by IntegrateData based on the identified anchors. Please note that the integration step is computationally intensive and might take a substantial amount of time to complete (20-40 minutes depending on the computational resource).
> anchor_features <- SelectIntegrationFeatures(seurat_epi, + nfeatures = 2000, verbose = FALSE) > anchors <- FindIntegrationAnchors(seurat_epi, verbose = FALSE, + anchor.features = anchor_features) > seurat_int <- IntegrateData(anchors, verbose = FALSE)
The integrated data are then scaled to have a mean of 0 and a variance of 1 by ScaleData. PCA is performed on the scaled data using RunPCA, followed by UMAP using RunUMAP. Same as before, we use 30 PCs for the sake of consistency and the results would not change dramatically provided a good amount of PCs (>10) are used. Cell clusters of the integrated data are identified by using FindNeighbors and FindClusters. We choose 0.2 as the cell clustering resolution after experimenting with different resolution parameters. This is because under this resolution the three major epithelial subpopulations, two intermediate cell clusters, and a small group of stroma cells can be clearly separated in distinct cell clusters.
> DefaultAssay(seurat_int) <- "integrated" > seurat_int <- ScaleData(seurat_int, verbose = FALSE) > seurat_int <- RunPCA(seurat_int, npcs = 30, verbose = FALSE) > seurat_int <- RunUMAP(seurat_int, reduction = "pca", + dims = 1:30, verbose = FALSE) > seurat_int <- FindNeighbors(seurat_int, dims = 1:30, verbose = FALSE) > seurat_int <- FindClusters(seurat_int, resolution = 0.2, verbose = FALSE)
UMAP plots are generated to visualize the integration and cell clustering results ( Figure 3). The UMAP plot indicates the presence of three major cell clusters (cluster 0, 1, and 2), which are bridged by intermediate clusters located in between them. Cells at the later stages largely dominate the three major cell clusters, while cells at the earlier stages are predominantly present in the intermediate clusters in the middle.
> seurat_int$group <- factor(seurat_int$group, levels = samples) > p1 <- DimPlot(seurat_int, pt.size = 0.1, cols = my_colors_15) > p2 <- DimPlot(seurat_int, pt.size = 0.1, group.by = "group", + shuffle = TRUE, cols = my_colors_15) + labs(title="") > p1 | p2
Figure 3. UMAP visualization of the integrated data.

Cells are coloured by cluster on the left and by original sample on the right.
Cell type identification
The mammary gland epithelium consists of three major cell types: basal myoepithelial cells, luminal progenitor (LP) cells and mature luminal (ML) cells. These three major epithelial cell populations have been well studied in the literature. By examining the classic marker genes of the three cell types, we are able to identify basal, LP and ML cell populations in the integrated data ( Figure 4). Here we use Krt14 and Acta2 for basal, Csn3 and Elf5 for LP, and Prlr and Areg for ML. We also examine the expression level of Hmgb2 and Mki67 as they are typical markers for cycling cells and the expression level of Igfbp7 and Fabp4 as they are marker genes for stromal cells.
> markers <- c("Krt14", "Acta2", "Csn3","Elf5", "Prlr","Areg", + "Hmgb2", "Mki67", "Igfbp7","Fabp4") > DefaultAssay(seurat_int) <- "RNA" > FeaturePlot(seurat_int, order = TRUE, pt.size = 0.1, features = markers, ncol = 2)
Figure 4. Feature plots of the integrated data.

Genes from the top row to the bottom rows are the markers of basal, LP, ML, cycling, and stromal cells, respectively.
Based on the feature plots, cluster 1, cluster 2 and cluster 0 represent the basal, LP and ML cell populations, respectively. Cluster 4 mainly consists of cycling cells, whereas cluster 3 seems to be a luminal intermediate cell cluster expressing both LP and ML markers. Cluster 5 consists of a few non-epithelial (stromal) cells that have not been filtered out previously.
The number of cells in each cluster for each sample is shown below.
> tab_number <- table(seurat_int$group, seurat_int$seurat_clusters)
> tab_number
0 1 2 3 4 5
E18.5-epi 171 878 29 2341 921 3
P5 272 347 47 351 120 3
Pre-puberty 381 1590 482 64 23 6
Puberty 1894 986 1535 20 265 6
Adult 4281 2495 2362 171 32 0
The proportion of cells in each cluster is calculated for each sample to compare the variation in cell composition across different stages.
> tab_ratio <- round(100*tab_number/rowSums(tab_number), 2) > tab_ratio <- as.data.frame.matrix(tab_ratio) > tab_ratio 0 1 2 3 4 5 E18.5-epi 3.94 20.2 0.67 53.90 21.21 0.07 P5 23.86 30.4 4.12 30.79 10.53 0.26 Pre-puberty 14.96 62.5 18.93 2.51 0.90 0.24 Puberty 40.25 20.9 32.62 0.42 5.63 0.13 Adult 45.83 26.7 25.29 1.83 0.34 0.00
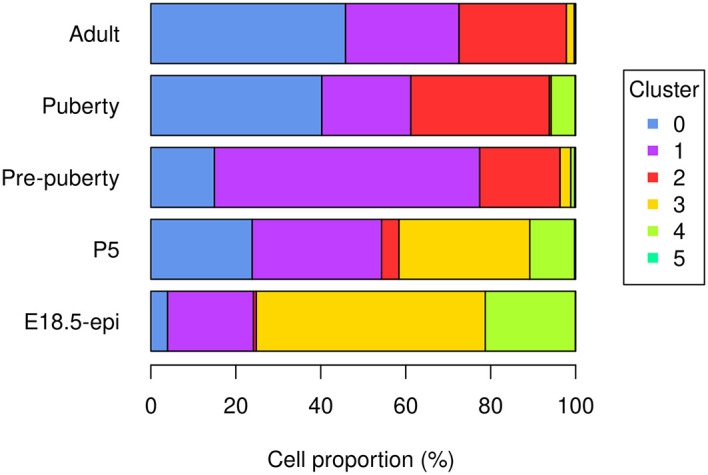
The bar plot ( Figure 5) shows the proportion of different cell types in samples at different developmental stages. Specifically, the proportion of basal cells (purple) demonstrates an ascending trend from E18.5 to pre-puberty stage, after which it declines towards adult stage. The LP cell proportion (red) rises from E18.5 to puberty stage, followed by a slight dip at adult stage. Although the proportion of ML cells (blue) is higher at P5 than pre-puberty stage, it shows an overall increasing trend. Cycling cells (green) constitute the highest proportion at E18.5 stage, but decrease to a smaller proportion at pre-puberty stage, with a slight increase at puberty stage, and subsequently, they reduce to a negligible proportion at adult stage. The augmented cycling cell proportion at puberty stage aligns with the ductal morphogenesis characteristics of the mammary gland. The luminal intermediate cell proportion (yellow) displays a decreasing trend from E18.5 stage to adult stage.
> par(mar=c(5, 7, 1, 7), xpd=TRUE) > barplot(t(tab_ratio), col=my_colors_15, xlab="Cell proportion (%)", + horiz = TRUE, las=1) > legend("right", inset = c(-0.3,0), legend = 0:5, pch = 15, + col=my_colors_15, title="Cluster")
Figure 5. Bar plot of cell proportion of each cluster in each sample.
Trajectory analysis with monocle3
Constructing trajectories and pseudotime
Many biological processes manifest as a dynamic sequence of alterations in the cellular state, which can be estimated through a “trajectory” analysis. Such analysis is instrumental in detecting the shifts between different cell identities and modeling gene expression dynamics. By treating single-cell data as a snapshot of an uninterrupted process, the analysis establishes the sequence of cellular states that forms the process trajectory. The arrangement of cells along these trajectories can be interpreted as pseudotime.
Here, we use the monocle3 package to infer the development trajectory in the mouse mammary gland epithelial cell population. The Seurat object of the integrated data is first converted into a cell_data_set object to be used in monocle3.
> library(monocle3) > cds_obj <- SeuratWrappers::as.cell_data_set(seurat_int)
monocle3 re-clusters cells to assign them to specific clusters and partitions, which are subsequently leveraged to construct trajectories. If multiple partitions are used, each partition will represent a distinct trajectory. The calculation of pseudotime, which indicates the distance between a cell and the starting cell in a trajectory, is conducted during the trajectory learning process. These are done using the cluster_cells and learn_graph functions. To obtain a single trajectory and avoid a loop structure, both use_partition and close_loop are turned off in learn_graph.
> set.seed(42) > cds_obj <- cluster_cells(cds_obj) > cds_obj <- learn_graph(cds_obj, use_partition=FALSE, close_loop=FALSE)
Visualizing trajectories and pseudotime
The plot_cells function of monocle3 is used to generate a trajectory plot that superimposes the trajectory information onto the UMAP representation of the integrated data. By adjusting the label_principal_points parameter, the names of roots, leaves, and branch points can be displayed. Cells in the trajectory UMAP plot ( Figure 6) are coloured by cell cluster identified in the previous Seurat integration analysis.
Figure 6. UMAP visualization of trajectory inferred by monocle3.
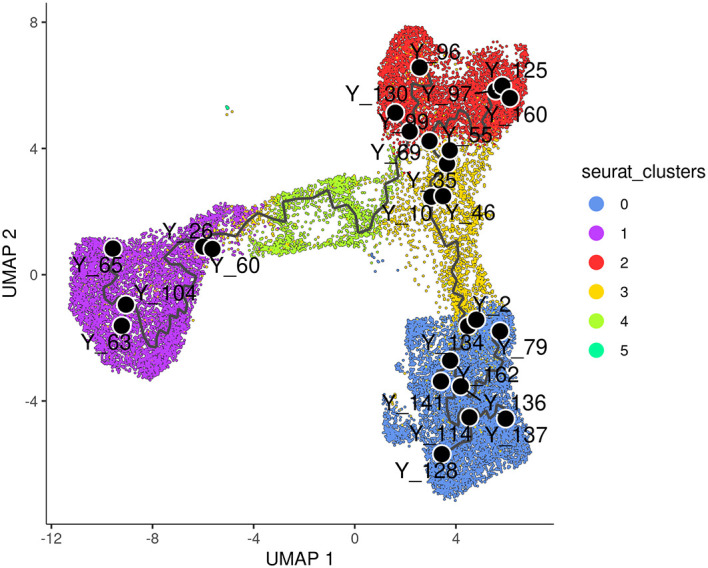
Cells are coloured by cluster.
> p1 <- plot_cells(cds_obj, color_cells_by="seurat_clusters", + group_label_size=4, graph_label_size=3, + label_cell_groups=FALSE, label_principal_points=TRUE, + label_groups_by_cluster=FALSE) + + scale_color_manual(values = my_colors_15) > p1
Along the monocle3 trajectory analysis, several nodes are identified and marked with black circular dots on the resulting plot, representing principal nodes along the trajectories. To establish the order of cells and calculate their corresponding pseudotime, it is necessary to select a starting node among the identified principal nodes. For this analysis, node “Y_65” in the basal population (cluster 1) was selected as the starting node, as mammary stem cells are known to be enriched in the basal population and give rise to LP and ML cells in the epithelial lineage. 20 It should be noted that node numbers may vary depending on the version of monocle3 used.
> cds_obj <- order_cells(cds_obj, root_pr_nodes="Y_65")
The cells are then ordered and assigned pseudotime values by the order_cells function in monocle3. The resulting pseudotime information can be visualized on the UMAP plot by using the plot_cells function, as demonstrated in the UMAP plot ( Figure 7).
> p2 <- plot_cells(cds_obj, color_cells_by="pseudotime", + label_groups_by_cluster=FALSE, label_leaves=FALSE, + label_branch_points=FALSE) > p2
Figure 7. UMAP visualization of pseudotime computed by monocle3.
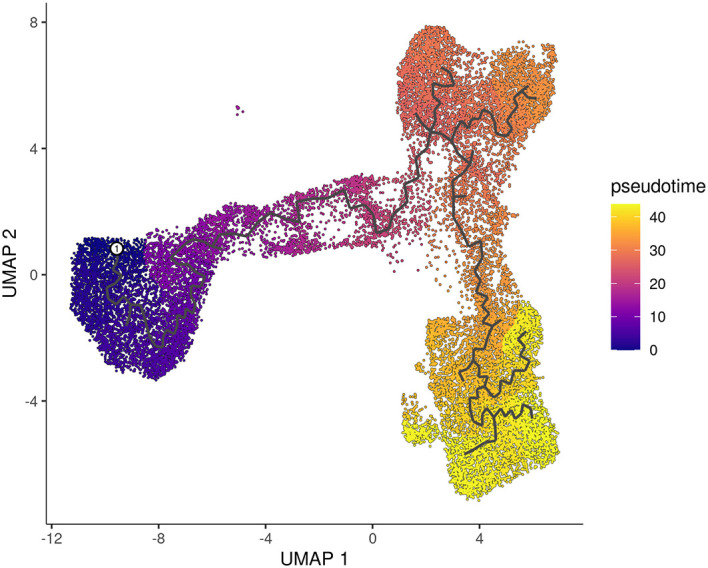
Cells are coloured by pseudotime.
The pseudotime function in monocle3 allows users to extract the pseudotime values of the cells from a cell_data_set object. This information can then be stored in the metadata of the Seurat object for further analysis.
> seurat_int$pseudotime <- pseudotime(cds_obj)Pseudo-bulk time course analysis with edgeR
Constructing pseudo-bulk profiles
After obtaining the pseudotime of each cell, we proceed to a time course analysis to identify genes that change significantly along the pseudotime. Our approach involves creating pseudo-bulk samples using a pseudo-bulking approach and performing an edgeR-style time course analysis.
To create the pseudo-bulk samples, read counts are aggregated for all cells with the same combination of sample and cluster. The number of cells used to construct each pseudo-bulk sample is added to the sample metadata. For simplicity, the average pseudotime of all cells in each pseudo-bulk sample is used as the pseudotime for that sample. One could also use the median of the cellwise pseudotime instead of the mean, but the results will not change dramatically.
> y <- dge_merged[, colnames(seurat_int)] > y$samples <- cbind(y$samples[, 1:3], + seurat_int@meta.data[, c("seurat_clusters", "pseudotime")]) > sample_cluster <- paste0(y$samples$group, "_C", y$samples$seurat_clusters) > avg_pseudotime <- tapply(y$samples$pseudotime, sample_cluster, mean) > cell_number <- table(sample_cluster) > y <- sumTechReps(y, ID = sample_cluster) > y$samples$pseudotime <- avg_pseudotime[colnames(y)] > y$samples$cell_number <- cell_number[colnames(y)]
The Entrez gene IDs are added to the gene information. Genes with no valid Entrez gene IDs are removed from the downstream analysis.
> library(org.Mm.eg.db) > entrez_id <- select(org.Mm.eg.db, keys = y$genes$Symbol, + columns = c("ENTREZID", "SYMBOL"), keytype = "SYMBOL") > y$genes$ENTREZID <- entrez_id$ENTREZID > y <- y[!is.na(y$genes$ENTREZID), ]
The samples are ordered by average pseudotime for the following analysis.
> y <- y[, order(y$samples$pseudotime)]
Filtering and normalization
We now proceed to the standard edgeR analysis pipeline, which starts with filtering and normalization. The sample information, such as library sizes, average pseudotime and cell numbers, are shown below.
> y$samples[, c("lib.size", "pseudotime", "cell_number")] lib.size pseudotime cell_number Pre-puberty_C1 11886898 4.65 1590 Adult_C1 9285265 4.77 2495 P5_C1 2680089 6.41 347 Puberty_C1 3112796 6.48 986 E18.5-epi_C1 8084434 10.16 878 E18.5-epi_C5 5179 15.61 3 P5_C5 24491 15.61 3 Pre-puberty_C5 57834 15.61 6 Puberty_C5 12278 15.61 6 Adult_C4 204212 19.25 32 E18.5-epi_C4 11725731 19.31 921 P5_C4 1917228 19.68 120 Puberty_C4 1860770 19.72 265 Pre-puberty_C4 289370 22.10 23 E18.5-epi_C3 15806768 28.03 2341 Puberty_C2 5841364 28.62 1535 P5_C3 3862152 28.94 351 E18.5-epi_C2 167242 29.14 29 Adult_C2 8320630 29.66 2362 P5_C2 347365 29.67 47 Pre-puberty_C2 4625160 30.51 482 Puberty_C3 63722 31.73 20 Pre-puberty_C3 1432336 32.64 64 Adult_C3 997670 33.99 171 Pre-puberty_C0 6024872 38.90 381 E18.5-epi_C0 990670 39.64 171 Adult_C0 27621462 40.44 4281 P5_C0 3113053 40.68 272 Puberty_C0 8806924 41.09 1894
To ensure the reliability of the analysis, it is recommended to remove pseudo-bulk samples that are constructed from a small number of cells. We suggest each pseudo-bulk sample should contain at least 30 cells. In this analysis, we identified seven pseudo-bulk samples that were constructed with less than 30 cells and removed them form the analysis.
> keep_samples <- y$samples$cell_number > 30 > y <- y[, keep_samples]
Genes with very low count number are also removed from the analysis. This is performed by the filterByExpr function in edgeR.
> keep_genes <- filterByExpr(y) > y <- y[keep_genes, , keep.lib.sizes=FALSE]
The number of genes and samples after filtering are shown below.
> dim(y)
[1] 11550 22
Normalization is performed by the trimmed mean of M values (TMM) method 21 implemented in the calcNormFactors function in edgeR.
> y <- calcNormFactors(y)
A Multi-dimensional scaling (MDS) plot serves as a valuable diagnostic tool for investigating the relationship among samples. MDS plots are produced using the plotMDS function in edgeR ( Figure 8).
> par(mar = c(5.1, 5.1, 2.1, 2.1), mfrow=c(1,2)) > cluster <- y$samples$seurat_clusters > group <- y$samples$group > plotMDS(y, labels = round(y$samples$pseudotime, 2), + xlim=c(-6,4), ylim=c(-3,3), col=my_colors_15[cluster]) > legend("topleft", legend=levels(cluster), col=my_colors_15, pch=16) > plotMDS(y, labels = round(y$samples$pseudotime, 2), + xlim=c(-6,4), ylim=c(-3,3), col=my_colors_15[group]) > legend("topleft", legend=levels(group), col=my_colors_15, pch=16)
Figure 8. Multi-dimensional scaling (MDS) plot of the pseudo-bulk samples labelled by pseudotime.

Samples are coloured by original cell cluster on the left and by developmental stage on the right.
On the MDS plot, pseudo-bulk samples derived from the same cell cluster are close to each other. The samples are positioned in ascending order of pseudotime from left to right, suggesting a continuous shift in the gene expression profile throughout the pseudotime.
Design matrix
The aim of a time course experiment is to examine the relationship between gene abundances and time points. Assuming gene expression changes smoothly over time, we use a natural cubic spline with degrees of freedom of 3 to model gene expression along the pseudotime. In general, any degrees of freedom in range of 3 to 5 is reasonable provided there are sufficient time points for the degrees of freedom of the residuals.
The spline design matrix is generated by ns function in splines. The three spline coefficients of the design matrix (i.e., Z1, Z2 and Z3) do not have any particular meaning in general. However, we can re-parametrize the design matrix using QR decomposition so that the first coefficient Z1 represents the linear trend in pseudotime.
> t1 <- y$samples$pseudotime > X <- splines::ns(as.numeric(t1),df = 3) > A <- cbind(1,t1,X) > QR <- qr(A) > r <- QR$rank > R_rank <- QR$qr[1:r,1:r] > Z <- t(backsolve(R_rank,t(A),transpose=TRUE)) > Z <- Z[,-1] > design <- model.matrix(~ Z)
Since the five samples are from different timepoints, the pseudo-bulk samples derived from these five samples are not independent replicates. The sample effect at the pseudo-bulk level can also be seen from the MDS plot ( Figure 8 right). Hence, we add the sample effect to the design in addition to the re-parametrized spline coefficients. The full design matrix is shown below.
> group <- y$samples$group > design <- model.matrix(~ Z + group) > colnames(design) <- gsub("group", "", colnames(design)) > design (Intercept) Z1 Z2 Z3 P5 Pre-puberty Puberty Adult 1 1 -0.3593 -0.0550 -0.3206 0 1 0 0 2 1 -0.3572 -0.0572 -0.3116 0 0 0 1 3 1 -0.3285 -0.0887 -0.1837 1 0 0 0 4 1 -0.3271 -0.0901 -0.1780 0 0 1 0 5 1 -0.2626 -0.1489 0.0887 0 0 0 0 6 1 -0.1034 -0.0918 0.4047 0 0 0 1 7 1 -0.1024 -0.0900 0.4042 0 0 0 0 8 1 -0.0958 -0.0775 0.4002 1 0 0 0 9 1 -0.0951 -0.0761 0.3997 0 0 1 0 10 1 0.0505 0.2625 0.0541 0 0 0 0 11 1 0.0609 0.2746 0.0262 0 0 1 0 12 1 0.0666 0.2796 0.0118 1 0 0 0 13 1 0.0790 0.2862 -0.0180 0 0 0 1 14 1 0.0792 0.2863 -0.0185 1 0 0 0 15 1 0.0940 0.2854 -0.0491 0 1 0 0 16 1 0.1313 0.2389 -0.1021 0 1 0 0 17 1 0.1551 0.1804 -0.1195 0 0 0 1 18 1 0.2410 -0.1584 -0.1106 0 1 0 0 19 1 0.2540 -0.2199 -0.1034 0 0 0 0 20 1 0.2682 -0.2885 -0.0947 0 0 0 1 21 1 0.2722 -0.3084 -0.0922 1 0 0 0 22 1 0.2794 -0.3435 -0.0876 0 0 1 0 attr(,"assign") [1] 0 1 1 1 2 2 2 2 attr(,"contrasts") attr(,"contrasts")$group [1] "contr.treatment"
Dispersion estimation
The edgeR package uses negative binomial (NB) distribution to model read counts of each gene across all the sample. The NB dispersions are estimated by the estimateDisp function. The estimated common, trended and gene-specific dispersions can be visualized by plotBCV ( Figure 9).
> y <- estimateDisp(y, design) > sqrt(y$common.dispersion) [1] 0.588 > plotBCV(y)
Figure 9. A scatter plot of the biological coefficient of variation (BCV) against the average abundance of each gene in log2 count-per-million (CPM).
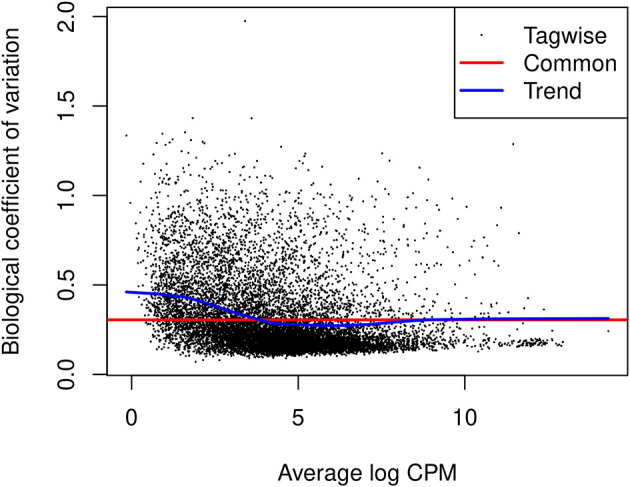
The square-root estimates of the common, trended and gene-wise NB dispersions are shown.
The NB model can be extended with quasi-likelihood (QL) methods to account for gene-specific variability from both biological and technical sources. 22 , 23 Note that only the trended NB dispersion is used in the QL method. The gene-specific variability is captured by the QL dispersion, which is the dispersion parameter of the negative binomial QL generalized linear model.
The glmQLFit function is used to fit a QL model and estimate QL dispersions. The QL dispersion estimates can be visualized by plotQLDisp ( Figure 10).
> fit <- glmQLFit(y, design, robust=TRUE) > plotQLDisp(fit)
Figure 10. A scatter plot of the quarter-root QL dispersion against the average abundance of each gene in log2 count-per-million (CPM).
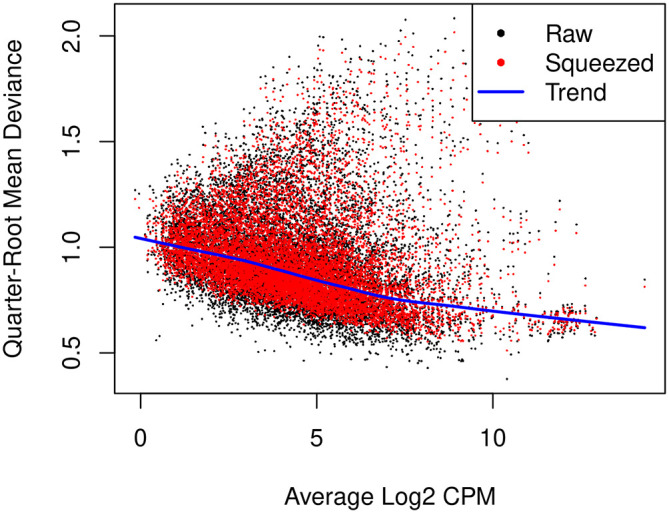
Estimates are shown for the raw, trended and squeezed dispersions.
Time course trend analysis
The QL F-tests are performed by glmQLFTest in edgeR to identify genes that change significantly along the pseudotime. The tests are conducted on all three covariates of the spline model matrix. This is because the significance of any of the three coefficients would indicate a strong correlation between gene expression and pseudotime.
> res <- glmQLFTest(fit, coef=2:4)
The number of genes significantly associated with pseudotime (FDR < 0.05) are shown below.
> summary(decideTests(res)) Z3-Z2-Z1 NotSig 4843 Sig 6707
Top significant genes can be viewed by topTags.
> topTags(res, n=10L) Coefficient: Z1 Z2 Z3 Ensembl_geneid Symbol ENTREZID logFC.Z1 logFC.Z2 logFC.Z3 logCPM Fhod3 ENSMUSG00000034295 Fhod3 225288 -13.88 1.1400 1.201 4.73 Mlph ENSMUSG00000026303 Mlph 171531 10.83 1.5074 2.449 5.98 Luzp2 ENSMUSG00000063297 Luzp2 233271 -13.93 0.0755 2.317 2.16 Ptpre ENSMUSG00000041836 Ptpre 19267 -8.28 1.9119 0.113 5.45 Aoc1 ENSMUSG00000029811 Aoc1 76507 16.04 -3.3051 -18.932 5.02 Col27a1 ENSMUSG00000045672 Col27a1 373864 -8.71 1.0071 -2.231 4.02 Jph2 ENSMUSG00000017817 Jph2 59091 -15.64 -5.8376 3.242 2.20 Popdc2 ENSMUSG00000022803 Popdc2 64082 -17.44 -7.3846 3.814 2.32 Myh11 ENSMUSG00000018830 Myh11 17880 -16.38 -3.4680 2.343 7.94 Tns1 ENSMUSG00000055322 Tns1 21961 -9.56 1.1794 -3.453 3.87 F PValue FDR Fhod3 331.3 4.26e-16 4.92e-12 Mlph 136.9 1.07e-12 6.17e-09 Luzp2 121.9 2.92e-12 9.08e-09 Ptpre 118.6 3.72e-12 9.08e-09 Aoc1 469.7 4.27e-12 9.08e-09 Col27a1 115.4 4.72e-12 9.08e-09 Jph2 104.5 1.11e-11 1.83e-08 Popdc2 101.0 1.49e-11 2.15e-08 Myh11 121.6 2.03e-11 2.60e-08 Tns1 90.7 3.72e-11 4.25e-08
The logFC.Z1, logFC.Z2, and logFC.Z3 values in the table above denote the estimated coefficients of Z1, Z2, and Z3 for each gene. It should be noted that these values do not carry the same interpretation as log-fold changes in traditional RNA-seq differential expression analysis. For each gene, the sign of the coefficient logFC.Z1 indicates whether the expression level of that gene increases or decreases along pseudotime in general. The top increasing and the top decreasing genes are listed below.
> tab <- topTags(res, n=Inf)$table > tab$trend <- ifelse(tab$logFC.Z1 > 0, "Up", "Down") > tab.up <- tab[tab$trend == "Up", ] > tab.down <- tab[tab$trend == "Down", ] > head(tab.up) Ensembl_geneid Symbol ENTREZID logFC.Z1 logFC.Z2 logFC.Z3 logCPM F Mlph ENSMUSG00000026303 Mlph 171531 10.83 1.51 2.449 5.98 136.9 Aoc1 ENSMUSG00000029811 Aoc1 76507 16.04 -3.31 -18.932 5.02 469.7 Mpzl3 ENSMUSG00000070305 Mpzl3 319742 5.37 0.92 0.723 4.90 89.8 Prr15l ENSMUSG00000047040 Prr15l 217138 13.35 2.39 3.568 4.63 87.7 Elf5 ENSMUSG00000027186 Elf5 13711 5.90 8.90 7.192 6.26 97.5 Lrrc26 ENSMUSG00000026961 Lrrc26 227618 13.99 3.05 3.276 4.68 82.9 PValue FDR trend Mlph 1.07e-12 6.17e-09 Up Aoc1 4.27e-12 9.08e-09 Up Mpzl3 4.04e-11 4.25e-08 Up Prr15l 4.97e-11 4.78e-08 Up Elf5 5.80e-11 5.06e-08 Up Lrrc26 8.00e-11 5.44e-08 Up > head(tab.down) Ensembl_geneid Symbol ENTREZID logFC.Z1 logFC.Z2 logFC.Z3 logCPM F Fhod3 ENSMUSG00000034295 Fhod3 225288 -13.88 1.1400 1.201 4.73 331 Luzp2 ENSMUSG00000063297 Luzp2 233271 -13.93 0.0755 2.317 2.16 122 Ptpre ENSMUSG00000041836 Ptpre 19267 -8.28 1.9119 0.113 5.45 119 Col27a1 ENSMUSG00000045672 Col27a1 373864 -8.71 1.0071 -2.231 4.02 115 Jph2 ENSMUSG00000017817 Jph2 59091 -15.64 -5.8376 3.242 2.20 104 Popdc2 ENSMUSG00000022803 Popdc2 64082 -17.44 -7.3846 3.814 2.32 101 PValue FDR trend Fhod3 4.26e-16 4.92e-12 Down Luzp2 2.92e-12 9.08e-09 Down Ptpre 3.72e-12 9.08e-09 Down Col27a1 4.72e-12 9.08e-09 Down Jph2 1.11e-11 1.83e-08 Down Popdc2 1.49e-11 2.15e-08 Down
Line graphs are produced to visualize the relationship between gene expression level and pseudotime for the top 6 increasing and the top 6 decreasing genes ( Figure 11).
Figure 11. Line graphs of expression level of top genes along pseudotime.

The red line represents the predicted expression level in log2-CPM along pseudotime.
For each gene, the expression levels (in log2-CPM) are averaged across five samples, and the line is smoothed using its predicted expression level at 100 evenly spaced pseudotime points within the pseudotime range. The smooth curves for the first 6 genes exhibit a generally increasing trend in gene expression over pseudotime, while the curves for the last 6 genes show a general decreasing trend.
> design2 <- model.matrix(~ X + group) > fit2 <- glmQLFit(y, design2, robust=TRUE) > pt <- y$samples$pseudotime > pt_new <- round(seq(min(pt), max(pt), length.out=100), 2) > X_new <- predict(X, newx=pt_new) > topGenes <- c(rownames(tab.up)[1:6], rownames(tab.down)[1:6]) > par(mfrow=c(4,3)) > for(i in 1:12) { + Symbol <- topGenes [i] + beta <- coef(fit2)[Symbol,] + AverageIntercept <- beta[1] + mean(c(0,beta[5:8])) + Trend <- AverageIntercept + X_new %*% beta[2:4] + Trend <- (Trend + log(1e6))/log(2) + plot(pt_new, Trend,type="l", frame=FALSE, col="red", lwd=2, xlab="Pseudotime", ylab="Log2CPM", main=Symbol) +}
A heatmap is generated to examine the top 20 up and top 20 down genes collectively ( Figure 12). In the heatmap, pseudo-bulk samples are arranged in increasing pseudotime from left to right. The up genes are on the top half of the heatmap whereas the down genes are on the bottom half. The heatmap shows a gradual increase in expression levels of the up genes from left to right, while the down genes display the opposite trend.
> logCPM.obs <- edgeR::cpm(y, log=TRUE, prior.count=fit$prior.count) > topGenes <- c(rownames(tab.up)[1:20], rownames(tab.down)[1:20]) > z <- logCPM.obs[topGenes, ] > z <- t(scale(t(z))) > ComplexHeatmap::Heatmap(z, name = "Z score", + cluster_rows = FALSE,cluster_columns = FALSE)
Figure 12. Heatmap of top 20 up and top 20 down genes.

Rows are genes and columns are pseudo-bulk samples.
Time course functional enrichment analysis
Gene ontology analysis
To interpret the results of the time course analysis at the functional level, we perform gene set enrichment analysis. Gene ontology (GO) is one of the commonly used databases for this purpose. The GO terms in the GO databases are categorized into three classes: biological process (BP), cellular component (CC) and molecular function (MF). In a GO analysis, we are interested in finding GO terms that are over-represented or enriched with significant genes.
GO analysis is usually directional. For simplicity, we re-perform the QL F-test on the Z1 coefficient to identify genes that exhibit a general linear increase or decrease along pseudotime. The numbers of genes with a significant increasing or decreasing linear trend are shown below.
> res_2 <- glmQLFTest(fit, coef=2) > summary(decideTests(res_2)) Z1 Down 2742 NotSig 6273 Up 2535
To perform a GO analysis, we apply the goana function to the above test results. Note that Entrez gene IDs are required for goana, which has been added to the ENTREZID column in the gene annotation. The top enriched GO terms can be viewed using topGO function.
> go <- goana(res_2, geneid="ENTREZID", species="Mm") > topGO(go, truncate.term = 30, n=15) Term Ont N Up Down P. Up P.Down GO:0071944 cell periphery CC 2928 695 1029 0.003837 4.73e-60 GO:0009653 anatomical structure morpho... BP 1828 345 669 0.999801 6.61e-42 GO:0005576 extracellular region CC 995 212 415 0.707860 1.19e-39 GO:0030312 external encapsulating stru... CC 297 43 174 0.999620 9.63e-39 GO:0031012 extracellular matrix CC 297 43 174 0.999620 9.63e-39 GO:0005886 plasma membrane CC 2650 646 877 0.000352 2.21e-36 GO:0062023 collagen-containing extrace... CC 240 34 145 0.999223 1.69e-34 GO:0007155 cell adhesion BP 833 169 350 0.894200 5.69e-34 GO:0040011 locomotion BP 1186 245 458 0.879526 6.97e-34 GO:0006928 movement of cell or subcell... BP 1361 282 508 0.885421 2.59e-33 GO:0032501 multicellular organismal pr... BP 4101 838 1238 0.998415 4.06e-33 GO:0048731 system development BP 2741 536 886 0.999787 2.18e-32 GO:0032502 developmental process BP 3917 776 1188 0.999971 3.33e-32 GO:0048856 anatomical structure develo... BP 3657 724 1118 0.999941 3.45e-31 GO:0007275 multicellular organism deve... BP 3188 615 995 0.999992 1.74e-30
It can be seen that most of the top GO terms are down-regulated. Here, we choose the top 10 down-regulated terms for each GO category and show the results in a bar plot ( Figure 13).
> top_go <- rbind.data.frame(topGO(go, ont =c("BP"), sort="Down",n=10), + topGO(go, ont =c("CC"), sort="Down",n=10), + topGO(go, ont =c("MF"), sort="Down",n=10)) > d <- transform(top_go, P_DE = P.Down, neg_log10_P = -log10(P.Down)) > d$Term <- factor(d$Term,levels = d$Term) > ggplot(data = d, aes(x = neg_log10_P, y = Term, fill = Ont) ) + + geom_bar(stat = "identity", show.legend = TRUE) + + labs(x="-log10 (P value)", y="", title = "Down") + + facet_grid(Ont~.,scales = "free",space = "free") + + my_theme_ggplot + my_theme_facet + + scale_fill_manual(values = my_colors_15[-2]) + + theme(strip.text = ggplot2::element_blank())
Figure 13. Bar plot of −log 10 p-values of the top 10 down-regulated GO terms under each GO category.

KEGG pathway analysis
The Kyoto Encyclopedia of Genes and Genomes 24 (KEGG) is another commonly used database for exploring signaling pathways to understand the molecular mechanism of diseases and biological processes. A KEGG analysis can be done by using kegga function.
The top enriched KEGG pathways can be viewed by using topKEGG function.
> kegg <- kegga(res_2, geneid="ENTREZID", species="Mm") > topKEGG(kegg, truncate.path=40, n=15) Pathway N Up Down P.Up P.Down mmu03010 Ribosome 127 79 3 1.07e-22 1.00e+00 mmu05171 Coronavirus disease - COVID-19 161 92 15 1.91e-22 1.00e+00 mmu04510 Focal adhesion 157 19 81 1.00e+00 2.79e-14 mmu04512 ECM-receptor interaction 56 5 40 9.97e-01 5.48e-14 mmu04974 Protein digestion and absorption 49 7 35 9.36e-01 2.11e-12 mmu04015 Rap1 signaling pathway 150 15 71 1.00e+00 1.92e-10 mmu04921 Oxytocin signaling pathway 93 9 48 9.99e-01 4.92e-09 mmu04151 PI3K-Akt signaling pathway 243 32 98 1.00e+00 4.99e-09 mmu04020 Calcium signaling pathway 115 18 54 9.64e-01 3.98e-08 mmu05200 Pathways in cancer 373 55 134 1.00e+00 5.16e-08 mmu05414 Dilated cardiomyopathy 53 4 31 9.99e-01 6.08e-08 mmu01100 Metabolic pathways 1062 302 219 1.10e-07 9.95e-01 mmu04360 Axon guidance 143 22 62 9.81e-01 1.60e-07 mmu04024 cAMP signaling pathway 119 19 54 9.59e-01 1.65e-07 mmu05412 Arrhythmogenic right ventricular card... 44 3 26 9.98e-01 5.38e-07
The results show that most of the top enriched KEGG pathways are down-regulated. Here, we select the top 15 down-regulated KEGG pathways and visualize their significance in a bar plot ( Figure 14).
> top_path <- topKEGG(kegg,sort="Down",n=15) > data_for_barplot <- transform(top_path, P_DE=P.Down, neg_log10_P=-log10(P.Down)) > data_for_barplot$Pathway <- factor(data_for_barplot$Pathway, + levels=data_for_barplot$Pathway) > ggplot(data=data_for_barplot,aes(x=neg_log10_P, y=Pathway) ) + + geom_bar(stat="identity", show.legend=FALSE, fill=my_colors_15[1]) + + labs(x="-log10 (P value)", y="", title="Down" ) + + my_theme_ggplot
Figure 14. Bar plot of −log 10 p-values of the top 15 down-regulated KEGG pathways.

Among the top down-regulated pathways, the PI3K-Akt signaling pathway is noteworthy as it is typically involved in cell proliferation and plays a crucial role in mammary gland development.
To assess the overall expression level of the PI3K-Akt signaling pathway across pseudotime, a plot is generated by plotting the average expression level of all the genes in the pathway against pseudotime. The information of all the genes in the pathway can be obtained by getGeneKEGGLinks and getKEGGPathwayNames.
> kegg_links <- getGeneKEGGLinks("mmu") > p_names <- getKEGGPathwayNames("mmu") > p1 <- p_names[grep("PI3K", p_names$Description), ] > p1_GeneIDs <- subset(kegg_links, PathwayID == p1$PathwayID)$GeneID > tab_p1 <- tab[tab$ENTREZID %in% p1_GeneIDs, ] > d <- logCPM.obs[tab_p1$Symbol,] > d <- apply(d, 2, mean) > d <- data.frame(avg_logCPM = d, avg_pseudotime = y$samples$pseudotime) > head(d) avg_logCPM avg_pseudotime Pre-puberty_C1 4.43 4.65 Adult_C1 4.69 4.77 P5_C1 4.70 6.41 Puberty_C1 4.18 6.48 E18.5-epi_C1 4.46 10.16 Adult_C4 3.53 19.25
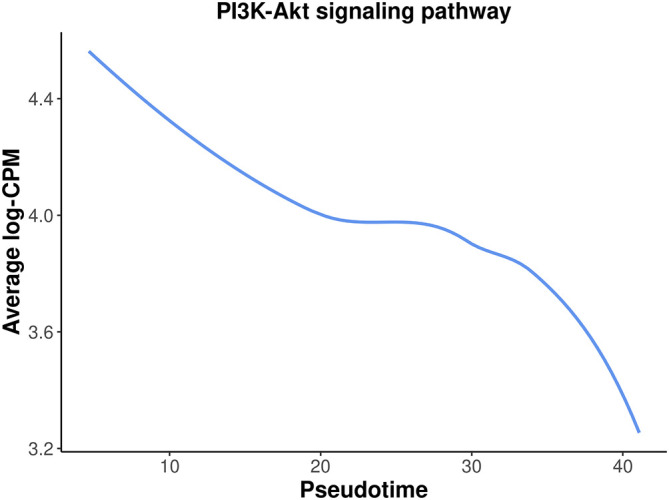
The plot below clearly illustrates a significant down-regulation of the PI3K-Akt pathway along pseudotime ( Figure 15).
> ggplot(data = d,aes(x = avg_pseudotime, y = avg_logCPM) ) + + geom_smooth(color=my_colors_15[1],se = FALSE) + + labs(x="Pseudotime", y="Average log-CPM", + title = "PI3K-Akt signaling pathway" ) + + my_theme_ggplot
Figure 15. A smooth curve of PI3K-Akt signaling pathway expression level against pseudotime.
Discussion
In this article, we demonstrated a complete workflow of a pseudo-temporal trajectory analysis of scRNA-seq data. This workflow takes single-cell count matrices as input and leverages the Seurat pipeline for standard scRNA-seq analysis, including quality control, normalization, and integration. The scDblFinder package is utilized for doublet prediction. Trajectory inference is conducted with monocle3, while the edgeR QL framework with a pseudo-bulking strategy is applied for pseudo-time course analysis. Alternative methods and packages can be used interchangeably with the ones implemented in this study, as long as they perform equivalent functions. For instance, the Bioconductor workflow may be substituted for the Seurat pipeline in scRNA-seq analysis, whereas the slingshot package may replace monocle3 for performing trajectory analysis.
This workflow article utilized 10x scRNA-seq data from five distinct stages of mouse mammary gland development, with a focus on the lineage progression of epithelial cells. By performing a time course analysis based on pseudotime along the developmental trajectory, we successfully identified genes and pathways that exhibit differential expression patterns over the course of pseudotime. The results of this extensive analysis not only confirm previous findings in the literature regarding the mouse mammary gland epithelium, but also reveal genes and pathways that exhibit continuous changes along the epithelial lineage. The analytical framework presented here can be utilized for any single-cell experiments aimed at studying dynamic changes along a specific path, whether it involves cell differentiation or the development of cell types.
Packages used
This workflow depends on various packages from the Bioconductor project version 3.15 and the Comprehensive R Archive Network (CRAN), running on R version 4.2.1 or higher. The complete list of the packages used for this workflow are shown below:
> sessionInfo()
R version 4.2.1 (2022-06-23)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: CentOS Linux 7 (Core)
Matrix products: default
BLAS: /stornext/System/data/apps/R/R-4.2.1/lib64/R/lib/libRblas.so
LAPACK: /stornext/System/data/apps/R/R-4.2.1/lib64/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_AU.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_AU.UTF-8 LC_COLLATE=en_AU.UTF-8
[5] LC_MONETARY=en_AU.UTF-8 LC_MESSAGES=en_AU.UTF-8
[7] LC_PAPER=en_AU.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_AU.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods base
other attached packages:
[1] org.Mm.eg.db_3.15.0 AnnotationDbi_1.58.0
[3] monocle3_1.2.9 SingleCellExperiment_1.18.0
[5] SummarizedExperiment_1.26.1 GenomicRanges_1.48.0
[7] GenomeInfoDb_1.32.2 IRanges_2.30.0
[9] S4Vectors_0.34.0 MatrixGenerics_1.8.0
[11] matrixStats_0.62.0 Biobase_2.56.0
[13] BiocGenerics_0.42.0 scDblFinder_1.10.0
[15] sp_1.5-0 SeuratObject_4.1.0
[17] Seurat_4.1.1 ggplot2_3.3.6
[19] edgeR_3.38.1 limma_3.55.5
loaded via a namespace (and not attached):
[1] utf8_1.2.2 R.utils_2.11.0 reticulate_1.25
[4] lme4_1.1-29 tidyselect_1.1.2 RSQLite_2.2.14
[7] htmlwidgets_1.5.4 grid_4.2.1 BiocParallel_1.30.3
[10] Rtsne_0.16 munsell_0.5.0 ScaledMatrix_1.4.0
[13] codetools_0.2-18 ica_1.0-2 statmod_1.4.36
[16] scran_1.24.0 xgboost_1.6.0.1 future_1.26.1
[19] miniUI_0.1.1.1 withr_2.5.0 spatstat.random_2.2-0
[22] colorspace_2.0-3 progressr_0.10.1 highr_0.9
[25] knitr_1.39 ROCR_1.0-11 tensor_1.5
[28] listenv_0.8.0 labeling_0.4.2 GenomeInfoDbData_1.2.8
[31] polyclip_1.10-0 bit64_4.0.5 farver_2.1.0
[34] parallelly_1.32.0 vctrs_0.4.1 generics_0.1.2
[37] xfun_0.31 doParallel_1.0.17 R6_2.5.1
[40] clue_0.3-61 ggbeeswarm_0.6.0 rsvd_1.0.5
[43] locfit_1.5-9.5 cachem_1.0.6 bitops_1.0-7
[46] spatstat.utils_2.3-1 DelayedArray_0.22.0 assertthat_0.2.1
[49] promises_1.2.0.1 BiocIO_1.6.0 scales_1.2.0
[52] rgeos_0.5-9 beeswarm_0.4.0 gtable_0.3.0
[55] beachmat_2.12.0 Cairo_1.5-15 globals_0.15.0
[58] goftest_1.2-3 rlang_1.0.2 GlobalOptions_0.1.2
[61] splines_4.2.1 rtracklayer_1.56.0 lazyeval_0.2.2
[64] spatstat.geom_2.4-0 BiocManager_1.30.18 yaml_2.3.5
[67] reshape2_1.4.4 abind_1.4-5 httpuv_1.6.5
[70] tools_4.2.1 ellipsis_0.3.2 spatstat.core_2.4-4
[73] RColorBrewer_1.1-3 proxy_0.4-27 ggridges_0.5.3
[76] Rcpp_1.0.8.3 plyr_1.8.7 sparseMatrixStats_1.8.0
[79] zlibbioc_1.42.0 purrr_0.3.4 RCurl_1.98-1.7
[82] rpart_4.1.16 deldir_1.0-6 GetoptLong_1.0.5
[85] pbapply_1.5-0 viridis_0.6.2 cowplot_1.1.1
[88] zoo_1.8-10 ggrepel_0.9.1 cluster_2.1.3
[91] magrittr_2.0.3 data.table_1.14.2 RSpectra_0.16-1
[94] scattermore_0.8 circlize_0.4.15 lmtest_0.9-40
[97] RANN_2.6.1 fitdistrplus_1.1-8 patchwork_1.1.1
[100] mime_0.12 evaluate_0.15 xtable_1.8-4
[103] XML_3.99-0.10 shape_1.4.6 gridExtra_2.3
[106] compiler_4.2.1 scater_1.24.0 tibble_3.1.7
[109] KernSmooth_2.23-20 crayon_1.5.1 R.oo_1.25.0
[112] minqa_1.2.4 htmltools_0.5.2 mgcv_1.8-40
[115] later_1.3.0 tidyr_1.2.0 DBI_1.1.3
[118] ComplexHeatmap_2.12.0 MASS_7.3-57 boot_1.3-28
[121] leidenbase_0.1.11 Matrix_1.5-3 cli_3.3.0
[124] R.methodsS3_1.8.2 parallel_4.2.1 metapod_1.4.0
[127] igraph_1.3.2 pkgconfig_2.0.3 GenomicAlignments_1.32.0
[130] terra_1.5-34 plotly_4.10.0 scuttle_1.6.2
[133] spatstat.sparse_2.1-1 foreach_1.5.2 vipor_0.4.5
[136] dqrng_0.3.0 XVector_0.36.0 stringr_1.4.0
[139] digest_0.6.29 sctransform_0.3.3 RcppAnnoy_0.0.19
[142] spatstat.data_2.2-0 Biostrings_2.64.0 leiden_0.4.2
[145] uwot_0.1.11 DelayedMatrixStats_1.18.0 restfulr_0.0.15
[148] shiny_1.7.1 Rsamtools_2.12.0 nloptr_2.0.3
[151] rjson_0.2.21 lifecycle_1.0.1 nlme_3.1-158
[154] jsonlite_1.8.0 SeuratWrappers_0.3.0 BiocNeighbors_1.14.0
[157] viridisLite_0.4.0 fansi_1.0.3 pillar_1.7.0
[160] lattice_0.20-45 GO.db_3.15.0 KEGGREST_1.36.2
[163] fastmap_1.1.0 httr_1.4.3 survival_3.3-1
[166] remotes_2.4.2 glue_1.6.2 iterators_1.0.14
[169] png_0.1-7 bit_4.0.4 bluster_1.6.0
[172] stringi_1.7.6 blob_1.2.3 BiocSingular_1.12.0
[175] memoise_2.0.1 dplyr_1.0.9 irlba_2.3.5
[178] future.apply_1.9.0Funding Statement
This work was supported by the Medical Research Future Fund (MRF1176199 to YC), a University of Melbourne Research Scholarship to JC, the National Health and Medical Research Council (Fellowship 1154970 to GKS) and the Chan Zuckerberg Initiative (2021-237445 to GKS and YC). The WEHI is supported by the Australian Government Independent Research Institutes Infrastructure Support Scheme and a Victorian State Government Operational Infrastructure Support Grant.
The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
[version 2; peer review: 2 approved
Data availability
Underlying data
The single-cell RNA-seq datasets used in this study were obtained from the Gene Expression Omnibus (GEO) with accession numbers of GSE103275 17 and GSE164017. 18
Software availability
Source code available from: https://github.com/jinming-cheng/TimeCoursePaperWorkflow
Archived source code at time of publication: https://doi.org/10.5281/zenodo.7879833 25
License: GNU General Public License version 3 (GPL-3.0-only)
All the packages used in this workflow are publicly available from the Bioconductor project (version 3.15) and the Comprehensive R Archive Network ( CRAN).
References
- 1. Macosko EZ, Basu A, Satija R, et al. : Highly parallel genome-wide expression profiling of individual cells using nanoliter droplets. Cell. 2015;161(5):1202–1214. 10.1016/j.cell.2015.05.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Klein AM, Mazutis L, Akartuna I, et al. : Droplet barcoding for single-cell transcriptomics applied to embryonic stem cells. Cell. 2015;161(5):1187–1201. 10.1016/j.cell.2015.04.044 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Zheng GX, Terry JM, Belgrader P, et al. : Massively parallel digital transcriptional profiling of single cells. Nat. Commun. 2017;8:14049. 10.1038/ncomms14049 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Hao Y, Hao S, Andersen-Nissen E, 3rd, et al. : Integrated analysis of multimodal single-cell data. Cell. 2021;184(13):3573–3587.e29. 10.1016/j.cell.2021.04.048 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Amezquita RA, Lun ATL, Becht E, et al. : Orchestrating single-cell analysis with Bioconductor. Nat. Methods. 2020;17(2):137–145. 10.1038/s41592-019-0654-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Wolf FA, Angerer P, Theis FJ, et al. : SCANPY: large-scale single-cell gene expression data analysis. Genome Biol. 2018 Feb 6;19(1):15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Korsunsky I, Millard N, Fan J, et al. : Fast, sensitive and accurate integration of single-cell data with Harmony. Nat. Methods. 2019;16(12):1289–1296. 10.1038/s41592-019-0619-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Haghverdi L, Lun ATL, Morgan MD, et al. : Batch effects in single-cell RNA-sequencing data are corrected by matching mutual nearest neighbors. Nat. Biotechnol. 2018;36(5):421–427. 10.1038/nbt.4091 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Risso D, Perraudeau F, Gribkova S, et al. : A general and flexible method for signal extraction from single-cell RNA-seq data. Nat. Commun. 2018;9(1):284. 10.1038/s41467-017-02554-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Lun AT, McCarthy DJ, Marioni JC: A step-by-step workflow for low-level analysis of single-cell RNA-seq data with Bioconductor. F1000Res. 2016;5:2122. 10.12688/f1000research.9501.2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Crowell HL, Soneson C, Germain PL, et al. : muscat detects subpopulation-specific state transitions from multi-sample multi-condition single-cell transcriptomics data. Nat. Commun. 2020;11(1):6077. 10.1038/s41467-020-19894-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Cao J, Spielmann M, Qiu X, et al. : The single-cell transcriptional landscape of mammalian organogenesis. Nature. 2019;566(7745):496–502. 10.1038/s41586-019-0969-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Street K, Risso D, Fletcher RB, et al. : Slingshot: cell lineage and pseudotime inference for single-cell transcriptomics. BMC Genomics. 2018;19(1):477. 10.1186/s12864-018-4772-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Trapnell C, Cacchiarelli D, Grimsby J, et al. : The dynamics and regulators of cell fate decisions are revealed by pseudotemporal ordering of single cells. Nat. Biotechnol. 2014;32(4):381–386. 10.1038/nbt.2859 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Saelens W, Cannoodt R, Todorov H, et al. : A comparison of single-cell trajectory inference methods. Nat. Biotechnol. 2019;37(5):547–554. 10.1038/s41587-019-0071-9 [DOI] [PubMed] [Google Scholar]
- 16. McCarthy DJ, Chen Y, Smyth GK: Differential expression analysis of multifactor RNA-Seq experiments with respect to biological variation. Nucleic Acids Res. 2012;40(10):4288–4297. 10.1093/nar/gks042 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Pal B, Chen Y, Vaillant F, et al. : Construction of developmental lineage relationships in the mouse mammary gland by single-cell RNA profiling. Nat. Commun. 2017;8(1):1627. 10.1038/s41467-017-01560-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Pal B, Chen Y, Milevskiy MJG, et al. : Single cell transcriptome atlas of mouse mammary epithelial cells across development. Breast Cancer Res. 2021;23(1):69. 10.1186/s13058-021-01445-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Germain PL, Lun AT, Meixide CG, et al. : Doublet identification in single-cell sequencing data using scDblFinder. F1000Res. 2021;10:979. 10.12688/f1000research.73600.2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Shackleton M, Vaillant F, Simpson KJ, et al. : Generation of a functional mammary gland from a single stem cell. Nature. 2006;439(7072):84–88. 10.1038/nature04372 [DOI] [PubMed] [Google Scholar]
- 21. Robinson MD, Oshlack A: A scaling normalization method for differential expression analysis of RNA-seq data. Genome Biol. 2010;11(3):R25. 10.1186/gb-2010-11-3-r25 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Lund SP, Nettleton D, McCarthy DJ, et al. : Detecting differential expression in RNA-sequence data using quasi-likelihood with shrunken dispersion estimates. Stat. Appl. Genet. Mol. Biol. 2012;11(5): Article 8. 10.1515/1544-6115.1826 [DOI] [PubMed] [Google Scholar]
- 23. Chen Y, Lun AT, Smyth GK: From reads to genes to pathways: differential expression analysis of RNA-Seq experiments using Rsubread and the edgeR quasi-likelihood pipeline. F1000Res. 2016;5:1438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Kanehisa M, Goto S: KEGG: Kyoto Encyclopedia of Genes and Genomes. Nucleic Acids Res. 2000;28(1):27–30. 10.1093/nar/28.1.27 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Cheng J, Smyth GK, Chen Y: Source code of a single-cell RNA-seq pseudo-temporal trajectory analysis. Zenodo. May 2023. 10.5281/zenodo.7879833 [DOI]