

Abstract
Cardiac cine magnetic resonance imaging (MRI) has been used to characterize cardiovascular diseases (CVD), often providing a noninvasive phenotyping tool. While recently flourished deep learning based approaches using cine MRI yield accurate characterization results, the performance is often degraded by small training samples. In addition, many deep learning models are deemed a “black box,” for which models remain largely elusive in how models yield a prediction and how reliable they are. To alleviate this, this work proposes a lightweight successive subspace learning (SSL) framework for CVD classification, based on an interpretable feedforward design, in conjunction with a cardiac atlas. Specifically, our hierarchical SSL model is based on (i) neighborhood voxel expansion, (ii) unsupervised subspace approximation, (iii) supervised regression, and (iv) multi-level feature integration. In addition, using two-phase 3D deformation fields, including end-diastolic and end-systolic phases, derived between the atlas and individual subjects as input offers objective means of assessing CVD, even with small training samples. We evaluate our framework on the ACDC2017 database, comprising one healthy group and four disease groups. Compared with 3D CNN-based approaches, our framework achieves superior classification performance with 140× fewer parameters, which supports its potential value in clinical use.
1. INTRODUCTION
Assessment of cardiovascular disease (CVD) using cine magnetic resonance imaging (MRI) (e.g., multi-slice 2D cine MRI) has been used to visualize and quantify structure and function of the beating heart [1]. While manual evaluation of CVD using these complex spatiotemporal data is time-consuming and often non-reproducible, automatic CVD assessment can efficiently guide treatment, which is significant in reducing the risk of sudden death and the severity of symptoms.
Prior work on early diagnosis and prognosis of CVD using cardiac cine MRI [2, 1] depends on the accurate segmentation of the left ventricle in end-diastolic (ED) and end-systolic (ES) phases [3] to derive clinical parameters, such as ejection fraction (EF). However, EF or related volumetric measures often lack sensitivity and discrimination ability. For the past several years, deep learning (DL)-based approaches [4] have been actively developed in this area, demonstrating superior performance in phenotyping tasks. For example, convolutional neural networks (CNN)-based approaches have been the main workhorse behind this endeavor [5].
Although DL-based approaches have yielded outstanding performance for computer-aided diagnosis or prognosis, several difficulties arise, which hinders their wide adoption for clinical applications [5]. First, DL-based approaches usually rely on massive labeled training datasets [4]; collecting and accurately labeling a sufficiently large number of training datasets for clinical applications pose challenges due partly to costly labeling or privacy concerns over sensitive patient information [6]. Given a small number of training data, CNN-based models with a myriad of parameters are likely to overfit the training data, thus leading to performance degradation in deployment, when using datasets with a different distribution, compared with training data. More importantly, many DL models are considered a “black-box” [7, 8], for which DL models remain largely elusive in how the models yield a prediction and how reliable they are. The aforementioned issues motivate us to develop an interpretable framework that is compatible with a limited number of training datasets for clinical implementations.
In this work, we propose to develop a lightweight and interpretable model based on successive subspace learning (SSL) for accurate and efficient CVD classification [9]. We use two phases, including ED and ES, to represent the entire cardiac cycle. To encode objective and characteristic differences across individuals, we first construct a cardiac atlas from cine MRI using diffeomorphic groupwise registration. Second, we perform diffeomorphic registration between the atlas and individual subjects to yield 3D deformation fields in both phases. Since 3D deformation fields encode compression and expansion of each tissue point with respect to the mean representation, they can offer objective and detailed means of assessing CVD. Then, the interlaced concatenation of the deformation fields for both ED and ES phases is processed by our framework to explore the difference between the two phases. Our framework follows a multi-layer stacked design, in which each layer consists of the following modules: (i) direction-wise 3D neighborhood voxel construction for the sequential expansion of near-to-far neighborhood for local-to-global information extraction; (ii) unsupervised dimension reduction with direction-wise subspace approximation with adjusted bias (Saab) transform; (iii) supervised dimension reduction with novel class-wise entropy guided feature selection and label-assisted regression; and (iv) multi-layer feature concatenation for final classification with support vector machine (SVM). Notably, to address the sign confusion problem in DL, the Saab transform [10] has been proposed to replace nonlinear activation units [7]. More appallingly, its parameters are computed in a feedforward manner, which does not depend on the backpropagation and is thereby more mathematically interpretable [10, 11].
The main contribution of this work is summarized as:
To our knowledge, this is the first effort at exploring two-phase 3D deformation fields with an SSL framework for the CVD classification task.
Novel direction-wise Saab transform alongside class-wise entropy-guided feature selection is performed for efficient unsupervised/supervised dimension reduction for 4D deformation fields (3D spatial deformation+direction).
Thorough evaluations on the ACDC2017 database show superior CVD classification performance of our framework over 3D CNN-based approaches with 140× fewer parameters.
2. METHODOLOGY
2.1. Cardiac atlas and deformation field construction
Given ED and ES phases of cine MRI volumes from controls, we first construct a cardiac atlas for both ED and ES phases with group-wise diffeomorphic registration with cross-correlation as our similarity measure [12]. Second, using cine MRI volumes in both ED and ES phases, we compute multi-phase 3D deformation fields to encode relative deformations with respect to the mean ED and ES atlas volumes. This is achieved by diffeomorphic registration between the ED and ES volumes of each individual and the ED and ES atlas volumes, respectively. As a result, we have the deformation fields with three directions in each voxel. The region of interest (ROI) is cropped to , and the interlaced concatenation is used as input to our framework.
2.2. SSL based on two-phase deformation fields
Our framework follows a stacked design in a feedforward manner, which consists of cascade layers for local-to-global information extraction as shown in Fig.1. Each layer has (i) direction-wise 3D neighborhood voxel construction, (ii) unsupervised Saab transform, (iii) supervised class-wise entropy-guided feature selection, and (iv) SVM with multi-layer features concatenation.
Fig. 1.
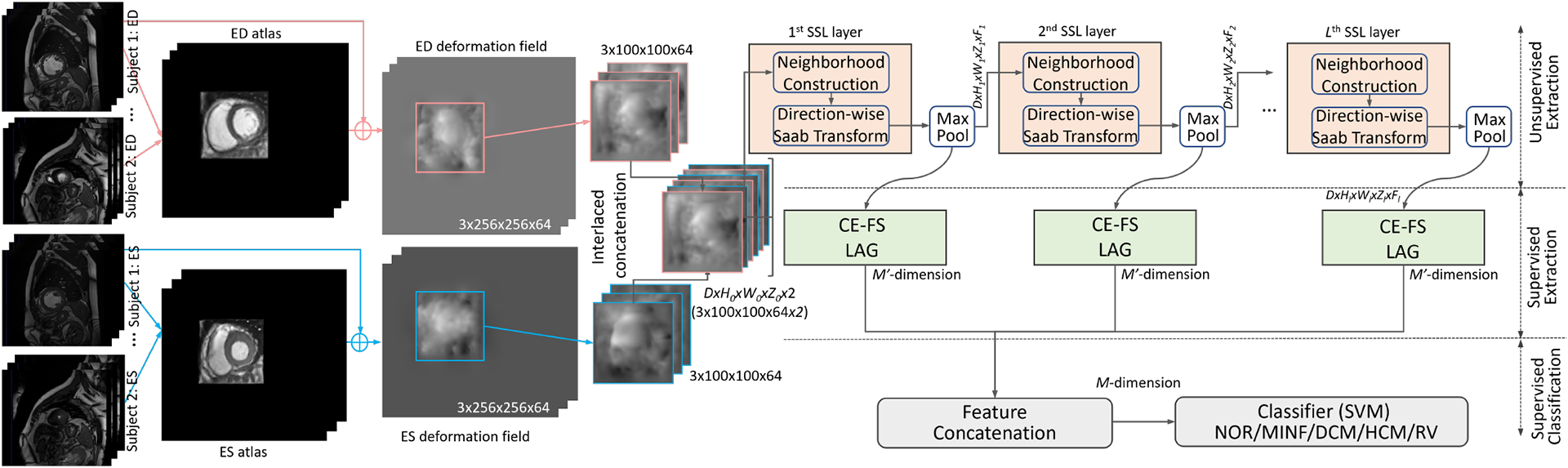
Illustration of our proposed SSL framework using stacked layers.
2.2.1. Unsupervised subspace approximation
First, the neighborhood voxel union is constructed to define the region to be explored neighboring spatial content. Instead of the conventional image-based SSL [13], we propose a direction-wise 3D neighborhood voxel construction for our two-phase deformation fields. Each union has the size of and the step length of 1 in 3D space. Therefore, for an input sample with the size of , we have neighborhood unions after incorporating a boundary effect. Of note, we have in each direction of the first layer. Notably, the three directions are processed independently at the unsupervised feature extraction stage, which can be processed in parallel. Then, each union is flattened as a vector with the length of , which is to be compacted to a dimension vector in the -th layer with the Saab transform.
The Saab transform can be seen as a variant of principal component analysis (PCA), and the transform resorts to the direct current (DC) and alternating current (AC) anchor vectors, by expressing with a compacted approximation feature . Specifically, for the Saab transform in our -th layer, we configure 1DC vector and vectors. Of note, all of them have the length of as . Therefore, we can formulate the -th dimension of as an affine transform of . Specifically, we have:
| (1) |
where the bias term is a scalar [10]. Similar to PixelHop [10], we simply define , and split the anchor vectors into DC and AC vectors as:
| (2) |
We would expect the subspace of AC to be the orthogonal complement to the subspace of DC. Therefore, the AC component of can be formulated as . Then, we apply PCA to , and choose the top principal components as our AC anchor vectors. An anchor vector operates on a region of the input data, and generates a scalar, which is similar to the convolution operation in CNNs. The anchor vector can be seen as a filter [10]. In addition, using several anchor vectors is similar to using numerous filters in contemporary DL. Instead of iteratively learned filters in DL with supervised backpropagation, the anchor vectors in our framework are unsupervised as those are defined using PCA.
After the Saab transform of each union, we half the spacial size with the max-pooling operation and send it to the next SSL layer. With the multi-channel input, the neighborhood construction involves channels at each voxel position, which is processed in parallel simliar to PixelHop [10]. With the stacked SSL layers, the neighborhood unions are related to more original voxels to explore global features. Similarly, modern CNNs achieve a larger reception field, by using deeper layers. The detailed layer-wise unsupervised dimension reduction modules in our SSL model are provided in Table 1.
Table 1.
The details of unsupervised modules in our 5-layer model for two-phase deformation fields CVD diagnosis
| Input Size | Type | Filter Shape |
|---|---|---|
| 3 × [100 × 100 × 64 × 2] | D-Saab | 3 × F1 kernels of [3 × 3 × 6] |
| 3 × [98 × 98 × 123 × F1] | MaxPool | (2×2×2)-(1×1×1) |
| 3 × [49 × 49 × 62 × F1] | D-Saab | 3 × F2 kernels of [3 × 3 × 3] |
| 3 × [47 × 47 × 60 × F2] | MaxPool | (2×2×2)-(1×1×1) |
| 3 × [24 × 24 × 30 × F2] | D-Saab | 3 × F3 kernels of [3 × 3 × 3] |
| 3 × [22 × 22 × 28 × F3] | MaxPool | (2×2×2)-(1×1×1) |
| 3 × [11 × 11 × 14 × F3] | D-Saab | 3 × F4 kernels of [3 × 3 × 3] |
| 3 × [9 × 9 × 12 × F4] | MaxPool | (2×2×2)-(1×1×1) |
| 3 × [5 × 5 × 6 × F4] | D-Saab | 3 × F5 kernels of [3 × 3 × 3] |
| 3 × [3 × 3 × 3 × F5] | MaxPool | (2×2×2)-(1×1×1) |
2.2.2. Supervised dimension reduction
The supervised dimension reduction module is used to (i) select the discriminative feature channels using the label supervision, and (ii) unify the shape of features in each layer for the subsequent concatenation.
The channels in each voxel can have different importance for the CVD classification. Therefore, it can be helpful to apply a supervised feature selection. Following the processing of 2D images in PixelHop++ [14], we propose to use direction-wise voxel cross-entropy guided feature selection (CE-FS). Specifically, we only keep the channels with small entropy of each class, which explicitly enforces the feature of a voxel in each channel to be similar [14]. We use to denote the feature of the -th voxel of a class in the -th channel. Following [14], we can formulate the entropy of a sample as:
| (3) |
where we index the involved class category with , e.g., . Then, the calculated entropy of all classes for each channel is descending ordered. Only the top 50% channels with small entropy are kept for efficient classification.
Then, the label-assisted regression (LAG) [13] is applied to each layer to extract the final layer-wise feature with a length of 25 dimensions consistently.
2.2.3. Multi-level feature integration
With the extracted features in each layer with both unsupervised and supervised dimension reductions, we sequentially concatenate them in all three directions as our final sample-wise CVD feature. We empirically choose SVM as our CVD classification model, which has been well established and has been widely used for classification purposes. Of note, as a supervised machine learning model, SVM is trained with the training datasets.
3. EXPERIMENTS
We evaluate our framework on the ACDC2017 database, which consists of a total of 99 subjects, including 20 normal subjects (NOR), 20 myocardial infarction (MINF) subjects, 19 dilated cardiomyopathy (DCM) subjects, 20 hypertrophic cardiomyopathy (HCM) subjects, and 20 abnormal right ventricle (RV) subjects. For each subject, cine MRI short-axis slices, including ED and ES phases, were acquired. Notably, we consistently resampled the training samples with the size of 256 × 256 × 64. We followed the 5-fold cross-validation to split the subjects with uniform categorical sampling.
We empirically used five SSL layers and configured , and . Notably, the maintained energy ratio in the unsupervised dimension reduction module was controlled by the quantity of the Saab filters, i.e., . In addition, we implemented the compared DL models using the Pytorch toolkit.
As comparison methods, we used the ResNet-based 3D CNN [15] and 3D self-attention [16] based classification model for the 3D CVD classification task. Specifically, the ResNet [17] and self-attention network [16] have been widely used for 3D medical classification tasks [15, 18, 16]. To adapt these methods for our multi-direction 3D deformation fields, we configured independent convolutional layers for each direction as [19]. Then, the extracted direction-wise features in the first fully connected (FC) layer were concatenated. We used the threshold of 0.5 for the final prediction of the DL approaches. Notably, we fixed 3 FC layers and validated the convolutional layers of 3D CNN and self-attention layers from three to ten layers. We chose the best-performed layer for ResNet-based 3D CNN and 3D self-attention, i.e., five or six layers, respectively.
In Fig.2, we plot the receiver operating characteristic (ROC) curves of each CVD class. We can see that our framework outperformed the compared 3D CNN models. As well, the area under the ROC curves of each class are also reported in Fig. 2. To facilitate the following LAG modules, CE-SF is applied as a preliminary supervised dimension reduction method. We provided the ablation study of CE-SF (i.e., SSL w/o CE-FS) with doubled feature vectors for the subsequent LAG model, which yielded inferior performance with an increase of 18% overall processing time.
Fig. 2.
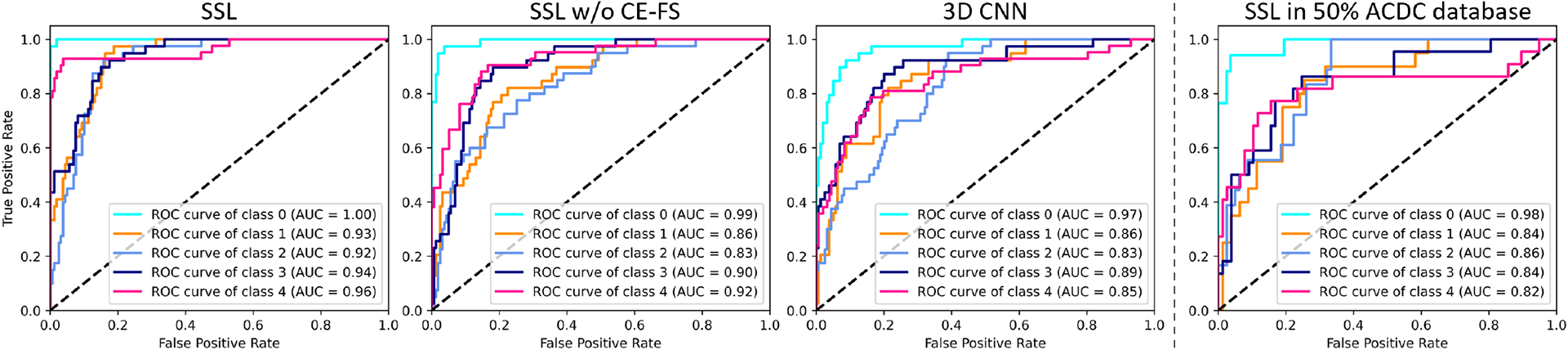
Comparison of the ROC curves of (a) SSL, (b) SSL w/o CE-FS, (c) 3D CNN, and (d) SSL with half ACDC2017 data. Classes 0 to 4 represent the NOR, MINF, DCM, HCM, and RV, respectively.
In Table 2, we show the accuracy of different methods. To further investigate the performance with a smaller number of datasets, we uniformly selected 75% and 50% of 100 subjects for 5-fold validation. Our SSL outperformed the compared DL-based models consistently by a larger margin especially in the case of a smaller number of datasets. Furthermore, we provided the ROC curves using 50% of the ACDC2017 database. We can see that our SSL model can be robust even with very limited training data. Of note, the number of parameters of our SSL framework was about 140× fewer than the compared 3D CNN architectures. The much fewer parameters can alleviate the difficulty of using a limited number of training datasets. Experimental results from our ablation study of SSL w/o CE-FS also showed its efficacy. Moreover, we provided the ablation study of the interlaced concatenation, which is denoted as SSL w/o IC. The performance drop compared with the SSL demonstrates that exploring the difference between ED and ES phases in an early voxel union was necessary.
Table 2.
Comparison of the 5-fold cross-validation accuracy on different proportion of ACDC2017 database
| Methods | Parameters | ACDC | 75%ACDC | 50%ACDC |
|---|---|---|---|---|
| ResNet 3D CNN | ~5.6M | 0.88 | 0.83 | 0.68 |
| 3D Self Attention | ~8.5 M | 0.85 | 0.78 | 0.72 |
| SSL w/o CE-FS | ~0.04 M | 0.92 | 0.90 | 0.84 |
| SSL w/o IC | ~0.04 M | 0.91 | 0.87 | 0.84 |
| SSL | ~0.04 M | 0.95 | 0.91 | 0.86 |
The number of SSL layers is important for our CVD classification task to balance performance and efficiency. In Table 3, we show the detailed sensitivity study using a different number of SSL layers. The performance was relatively stable after four layers. Notably, there was a performance drop for deeper DL methods with more to-be-trained parameters.
Table 3.
Sensitivity study of the stacked layers. The 5-fold cross-validation accuracy on full ACDC2017 is reported
| Layers | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|
| ResNet 3D CNN | 0.76 | 0.86 | 0.88 | 0.87 | 0.85 | 0.83 |
| 3D Self Attention | 0.79 | 0.82 | 0.85 | 0.85 | 0.83 | 0.80 |
| SSL | 0.85 | 0.92 | 0.95 | 0.95 | 0.95 | 0.96 |
4. CONCLUSION
In this work, we proposed a novel lightweight and interpretable framework with two-phase deformation fields for the CVD classification task. In particular, the class-wise entropy-guided feature selection was proposed to achieve accurate classification. We evaluated our framework on the ACDC2017 database using a different number of training datasets, demonstrating superior performance over 3D CNN and self-attention DL models, with about 140× fewer parameters. It is important to note that our framwork is based on the feedforward Saab transform for which our framework is deemed more interpretable than CNNs, which rely on backpropagation. Taken together, our framework offers the potential to be used for clinical practice with a limited number of imaging data.
ACKNOWLEDGMENT
The authors would like to thank Dr. Reza Nezafat for his valuable insights and helpful discussions.
Footnotes
COMPLIANCE WITH ETHICAL STANDARDS
This research study was conducted retrospectively using human subject data made available in open access by Automated Cardiac Diagnosis Challenge (ACDC)’ 17.
REFERENCES
- [1].Liu Xiaofeng, Xing Fangxu, Gaggin Hanna K, Wang Weichung, Kuo C-C Jay, El Fakhri Georges, and Woo Jonghye, “Segmentation of cardiac structures via successive subspace learning with saab transform from cine mri,” in 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC). IEEE, 2021, pp. 3535–3538. [DOI] [PubMed] [Google Scholar]
- [2].Ammar Abderazzak, Bouattane Omar, and Youssfi Mohamed, “Automatic cardiac cine mri segmentation and heart disease classification,” Computerized Medical Imaging and Graphics, vol. 88, pp. 101864, 2021. [DOI] [PubMed] [Google Scholar]
- [3].Gaggin Hanna K and Januzzi James L Jr, “Biomarkers and diagnostics in heart failure,” Biochimica et Biophysica Acta (BBA)-Molecular Basis of Disease, vol. 1832, no. 12, pp. 2442–2450, 2013. [DOI] [PubMed] [Google Scholar]
- [4].Goodfellow Ian, Bengio Yoshua, Courville Aaron, and Bengio Yoshua, Deep learning, vol. 1, MIT press Cambridge, 2016. [Google Scholar]
- [5].Shen Dinggang, Wu Guorong, and Suk Heung-Il, “Deep learning in medical image analysis,” Annual review of biomedical engineering, vol. 19, pp. 221–248, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Liu Xiaofeng, Xing Fangxu, El Fakhri Georges, and Woo Jonghye, “Memory consistent unsupervised off-the-shelf model adaptation for source-relaxed medical image segmentation,” Medical Image Analysis, p. 102641, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Kuo C-C Jay, “Understanding convolutional neural networks with a mathematical model,” Journal of Visual Communication and Image Representation, vol. 41, pp. 406–413, 2016. [Google Scholar]
- [8].Wang Jing, Xie Wanqing, Cheng Mingmei, Wu Qun, Wang Fangyun, Li Pei, Fan Bo, Zhang Xin, Wang Binbin, and Liu Xiaofeng, “Assessment of transcatheter or surgical closure of atrial septal defect using interpretable deep keypoint stadiometry,” Research, vol. 2022, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Rouhsedaghat Mozhdeh, Monajatipoor Masoud, Azizi Zohreh, and Kuo C-C Jay, “Successive subspace learning: An overview,” arXiv, 2021. [Google Scholar]
- [10].Kuo C-C Jay, Zhang Min, Li Siyang, Duan Jiali, and Chen Yueru, “Interpretable convolutional neural networks via feedforward design,” Journal of Visual Communication and Image Representation, vol. 60, pp. 346–459, 2019. [Google Scholar]
- [11].Fan Fenglei, Xiong Jinjun, and Wang Ge, “On interpretability of artificial neural networks,” arXiv preprint arXiv:2001.02522, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Avants BB, Epstein CL, Grossman M, and Gee JC, “Symmetric diffeomorphic image registration with cross-correlation: Evaluating automated labeling of elderly and neurodegenerative brain,” Medical image analysis, vol. 12, no. 1, pp. 26–41, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Chen Yueru and Kuo C-C Jay, “Pixelhop: A successive subspace learning (SSL) method for object recognition,” Journal of Visual Communication and Image Representation, p. 102749, 2020. [Google Scholar]
- [14].Chen Yueru, Rouhsedaghat Mozhdeh, You Suya, Rao Raghuveer, and Kuo C-C Jay, “Pixelhop++: A small successive-subspace-learning-based (ssl-based) model for image classification,” in 2020 IEEE International Conference on Image Processing (ICIP). IEEE, 2020, pp. 3294–3298. [Google Scholar]
- [15].Korolev Sergey, Safiullin Amir, Belyaev Mikhail, and Dodonova Yulia, “Residual and plain convolutional neural networks for 3d brain mri classification,” in 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017). IEEE, 2017, pp. 835–838. [Google Scholar]
- [16].Wang Jing, Liu Xiaofeng, Wang Fangyun, Zheng Lin, Gao Fengqiao, Zhang Hanwen, Zhang Xin, Xie Wanqing, and Wang Binbin, “Automated interpretation of congenital heart disease from multi-view echocardiograms,” Medical image analysis, vol. 69, pp. 101942, 2021. [DOI] [PubMed] [Google Scholar]
- [17].He Kaiming, Zhang Xiangyu, Ren Shaoqing, and Sun Jian, “Identity mappings in deep residual networks,” in ECCV. Springer, 2016, pp. 630–645. [Google Scholar]
- [18].Singh Satya P, Wang Lipo, Gupta Sukrit, Goli Haveesh, Padmanabhan Parasuraman, and Gulyás Balázs, “3d deep learning on medical images: A review,” arXiv preprint arXiv:2004.00218, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Nie Dong, Lu Junfeng, Zhang Han, Adeli Ehsan, Wang Jun, Yu Zhengda, Liu LuYan, Wang Qian, Wu Jinsong, and Shen Dinggang, “Multi-channel 3D deep feature learning for survival time prediction of brain tumor patients using multi-modal neuroimages,” Scientific reports, vol. 9, no. 1, pp. 1–14, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]