

Abstract
Evaluating causal effects in the presence of interference is challenging in network-based studies of hard-to-reach populations. Like many such populations, people who inject drugs (PWID) are embedded in social networks and often exert influence on others in their network. In our setting, the study design is observational with a non-randomized network-based HIV prevention intervention. Information is available on each participant and their connections that confer possible HIV risk through injection and sexual behaviors. We considered two inverse probability weighted (IPW) estimators to quantify the population-level spillover effects of non-randomized interventions on subsequent health outcomes. We demonstrated that these two IPW estimators are consistent, asymptotically normal, and derived a closed-form estimator for the asymptotic variance, while allowing for overlapping interference sets (groups of individuals in which the interference is assumed possible). A simulation study was conducted to evaluate the finite-sample performance of the estimators. We analyzed data from the Transmission Reduction Intervention Project, which ascertained a network of PWID and their contacts in Athens, Greece, from 2013 to 2015. We evaluated the effects of community alerts on subsequent HIV risk behavior in this observed network, where the connections or links between participants were defined by using substances or having unprotected sex together. In the study, community alerts were distributed to inform people of recent HIV infections among individuals in close proximity in the observed network. The estimates of the risk differences for spillover using either IPW estimator demonstrated a protective effect. The results suggest that HIV risk behavior could be mitigated by exposure to a community alert when an increased risk of HIV is detected in the network.
Keywords: Causal Interference, Interference/dissemination, Network Studies, People who Use Drugs, HIV/AIDS, Inverse Probability Weights
1. Introduction.
The objective of this work is to evaluate causal effects in the presence of interference (also known as dissemination or spillover) where usual assumptions, such as partial or clustered interference Hudgens and Halloran (2008); Tchetgen Tchetgen and VanderWeele (2012), may no longer hold. This proves to be a challenging problem in network-based studies of hidden or hard-to-reach populations, such as people who inject drugs (PWID), where participants are frequently recruited through contact tracing. Worldwide in 2011, an estimated 10% of new HIV infections occur because of injection drug use, and this proportion was 30% outside Africa (Prejean et al., 2011; Lansky et al., 2014; Mathers et al., 2008). In Greece through 2010, there were only a few sporadic cases of HIV transmission among PWID and the HIV epidemic was traditionally concentrated among men having sex with men. From 2002 to 2010, less than 20 HIV cases were reported annually among PWID, representing 2% to 4% of newly diagnosed HIV infections per year. In 2011, the number of reported HIV cases among PWID increased 16-fold from the number reported in 2010 to a total of 260 cases. The emergence of the HIV outbreak among PWID in Athens coincided with an economic recession, highlighting its possible role in the outbreak due to the temporal ordering (Paraskevis et al., 2013). Investigation of the outbreak demonstrated that clustered HIV transmission among PWID was rare until 2009. Starting in 2010, a large proportion of HIV sequences from newly diagnosed PWID could be grouped into PWID-specific phylogenetic clusters, indicating that parenteral transmission with contaminated syringes or other injecting equipment was now occurring in this population. Prior to 2011, prevention and harm reduction services, including medication for opioid use disorder and syringe exchange distribution programs, were available; however, access to these services remained low among PWID. Most of the newly diagnosed PWID (about 70%) in 2011 were residents of Athens, suggesting that the outbreak was also geographically localized. (Sypsa et al., 2014; Nikolopoulos et al., 2015)
Effective interventions were urgently needed to prevent further transmission in Athens. The Transmission Reduction Intervention Project (TRIP) was a successful attempt to recruit and intervene in this population by contact tracing the injection and sexual networks of recently-infected PWID. The program then referred people found to be recently infected to engage in HIV treatment and care both to protect their own health and to reduce onward transmission of HIV to others, particularly during the early stage of HIV when there is a known increased risk of HIV transmission Nikolopoulos et al. (2015). Interestingly, this network study design can be used to investigate the connections or ties among people who are infected and uninfected, and thus can address questions about why certain groups of people who are uninfected remain that way despite having risk network ties to people who both have high viral loads and engage in risky behavior (Williams et al., 2018). The TRIP recruitment strategy successfully found more recently infected PWID than other strategies, such as a respondent driven sample or venue-based recruitment. These findings suggest that using strategically network-based approaches can accelerate seeking, testing, and treating recently-infected PWID. Moreover, reducing viral loads as early as possible is likely to decrease the expected number of transmissions in a community (Nikolopoulos et al., 2016).
Public health interventions often have disseminated effects, also known as indirect or spillover effects (Benjamin-Chung et al., 2017; Desrosiers et al., 2020). There can be disseminated effects of HIV behavioral interventions, suggesting that intervening among highly-connected individuals may maximize benefits to others (Rewley et al., 2020). Akin to other populations, PWID are embedded in social networks and communities (e.g., injection drug, non-injection drug, sexual risk network) in which they possibly exercise an influence upon other members (Hayes et al., 2000; Ghosh et al., 2017). This influence can be measured as a disseminated effect of specific interventions among individuals who were not exposed themselves but possibly receive intervention benefits from their connections to those exposed to the intervention. In PWID networks, interventions (e.g., educational training about HIV risk reduction, medical interventions such as pre-exposure prophylaxis, or treatment as prevention) may have disseminated effects, and intervention effects frequently depend on the network structure and intervention coverage levels. Disseminated effects may be larger in magnitude than direct effects (i.e., effect of receiving the intervention while holding the exposure of other individuals fixed), suggesting that an intervention has substantial effects in the network beyond those exposed themselves (Buchanan et al., 2018).
The current methodologies used to evaluate direct and disseminated effects among members of hidden or hard-to-reach populations in networks remain limited. In particular, relatively few methodological approaches for observational network-based studies have been developed, and methods that incorporate the observed connections (links, ties, or edges) in the underlying network structure are needed to understand the spillover mechanisms. In our setting, connections in the network refer to sexual and/or drug use partnerships. Recent methodological developments relaxed the no interference assumption and allowed for interference within clusters, known as partial interference (Sobel, 2006; Hong and Raudenbush, 2006; Hudgens and Halloran, 2008; Tchetgen Tchetgen and VanderWeele, 2012; Liu and Hudgens, 2014). In partial interference approaches, a clustering of observations is used to define the interference set (e.g., study clusters, provider practices, or geographic location) that allow for interference within but not across clusters; however, the information on connections within a particular cluster is typically not measured or utilized in the analytical approach (Aronow and Samii, 2017). Another approach defines interference by spatial proximity or network ties (Liu, Hudgens and Becker-Dreps, 2016; Forastiere, Airoldi and Mealli, 2021), allowing for overlapping interference sets (i.e., groups of individuals in which interference is assumed to be possible). In Liu, Hudgens and Becker-Dreps (2016), an IPW estimator was proposed for a generalized interference set that allowed for overlap between interference sets; however, the asymptotic variance was estimated under the assumption of partial interference defined by larger groupings or clusters of participants in the study. In a separate paper, the subclassification estimator and generalized propensity score were used to quantify effects, and a bootstrapping procedure with resampling at the individual-level or the cluster-level was used to quantify the variance (Forastiere, Airoldi and Mealli, 2021). However, these approaches either rely on partial interference defined by larger clusters or resort to bootstrapping to derive estimators of the variance. In practice, ignoring the overlapping interference sets while estimating the variance can lead to inaccurate inference and resampling approaches, particularly in a network setting, can also be computationally intensive.
While previous work allows for overlapping interference sets for point estimation, the asymptotic variances were estimated under the assumption of partial interference or used bootstrapping techniques (Liu, Hudgens and Becker-Dreps, 2016; Forastiere, Airoldi and Mealli, 2021). Our paper addresses an important gap by developing inverse probability weight estimators and deriving a closed-form variance estimator that allows for overlapping interference sets, possibly leading to a more statistically efficient estimator in network-based studies due to the use of additional information on connections between individuals. In our paper, we propose two inverse probability weighted (IPW) estimators where the interference set is defined as the set of the individual’s nearest neighbors within a sociometric network; that is, a network in which all or some of participants’ direct and indirect contacts are ascertained (Hadjikou et al., 2021). The first IPW estimator is a novel application of the estimator of the approach in Liu, Hudgens and Becker-Dreps (2016) to a sociometric network-based study setting. Originally, the asymptotic variance estimators were developed for clustered observational studies without explicit consideration of the connections in the study. We relax the partial interference assumption for variance estimation such that interference sets are uniquely defined by nearest neighbors for each individual. The second IPW estimator uses a generalized propensity score developed by Forastiere, Airoldi and Mealli (2021); however, we propose a weighted estimator instead of a stratified estimator for comparison to the first IPW estimator in this paper. For both estimators, we assume that the nearest neighbors comprise the interference sets and use this structure to calculate a novel closed-form variance estimator by applying M-estimation. We focus on comparing these two alternative IPW estimators in a network study with a non-randomized intervention and statistical inference approaches using M-estimation.
The rest of the paper is structured as follows. In Sections 2, we introduce the TRIP study design and setting. In Section 3 and 4, we define the notations and assumptions for nearest neighbors settings, then the estimands of interest for this setting. We provide definitions of the two IPW estimators with specific assumptions for each, and demonstrate that the estimator is consistent and asymptotically normal, and obtain a closed-form estimator of the corresponding variances in Section 5. In Section 6, a simulation study was conducted to demonstrate the finite-sample performance of both estimators and the results are summarized. The methods were then utilized to assess the direct and disseminated effects of community alerts on HIV risk behavior in the sociometric network study of PWID and their contacts, Transmission Reduction Intervention Project (TRIP) from 2013 to 2015 in Athens, Greece in Section 7. We discuss limitations of this approach and next steps for methodological work to quantify causal effects in network-based studies in Section 8.
2. TRIP Study Design.
The Transmission Reduction Intervention Project (TRIP) included PWID and their HIV risk networks and initially found individuals who were recently diagnosed with HIV (known as seeds) and their possible HIV risk partners through sexual and injection routes of transmission (Nikolopoulos et al., 2016; Psichogiou et al., 2019; Giallouros et al., 2021; Hadjikou et al., 2021; Pampaka et al., 2021). TRIP also recruited seeds with long-term HIV infection. TRIP used contact network tracing (i.e., nomination and coupon referrals) and venue recruitment methods to locate those who were at risk for HIV infection based on their proximity in the network to other recently-infected individuals. PWID who were participants in the ARISTOTLE study at HIV testing centers in Athens were initially recruited into the TRIP study if they were found to be recently infected or long-term infected with HIV. ARISTOTLE was a seek, test, treat, and retain intervention that used respondent-driven sampling to target PWID residing in Athens and aimed to contribute to the control of HIV transmission among PWID in Greece (Sypsa et al., 2014). Each recently-diagnosed and long-term infected individual was asked to identify their recent sexual and drug use partners and their partners’ partners in the six months prior to the interview. For the recently-diagnosed seeds, these direct contacts and their contacts’ contacts were then recruited and asked to identify their sexual and drug use partners, who were also recruited and linked back to other individuals recruited in the study. For seeds with long-term HIV infection, their contacts were recruited (i.e., one wave of contact tracing) and these individuals were recruited and their connections to other participants were ascertained. If any of these contacts were identified as recently infected with HIV, then their contacts and the contacts of their contacts (i.e., two waves of contact tracing) would be recruited as well and connections to other participants in the network were ascertained (Figure 1); otherwise, one wave of contact tracing was performed. The study also recruited HIV-negative individuals from allied projects who served as controls. The HIV-negative individuals were isolates (i.e., no connections to others in the network) unless reported as a contact by another participant. This resulted in a network consisting of individuals recently diagnosed with HIV and their possible HIV risk partners and the connections in the network were defined by sex or injection drug use partnerships. This information was used to create a final observed network in which each recruited individual is linked to all other individuals who named them as a contact or was named as a contact by them, regardless of recruitment order.
Fig 1:
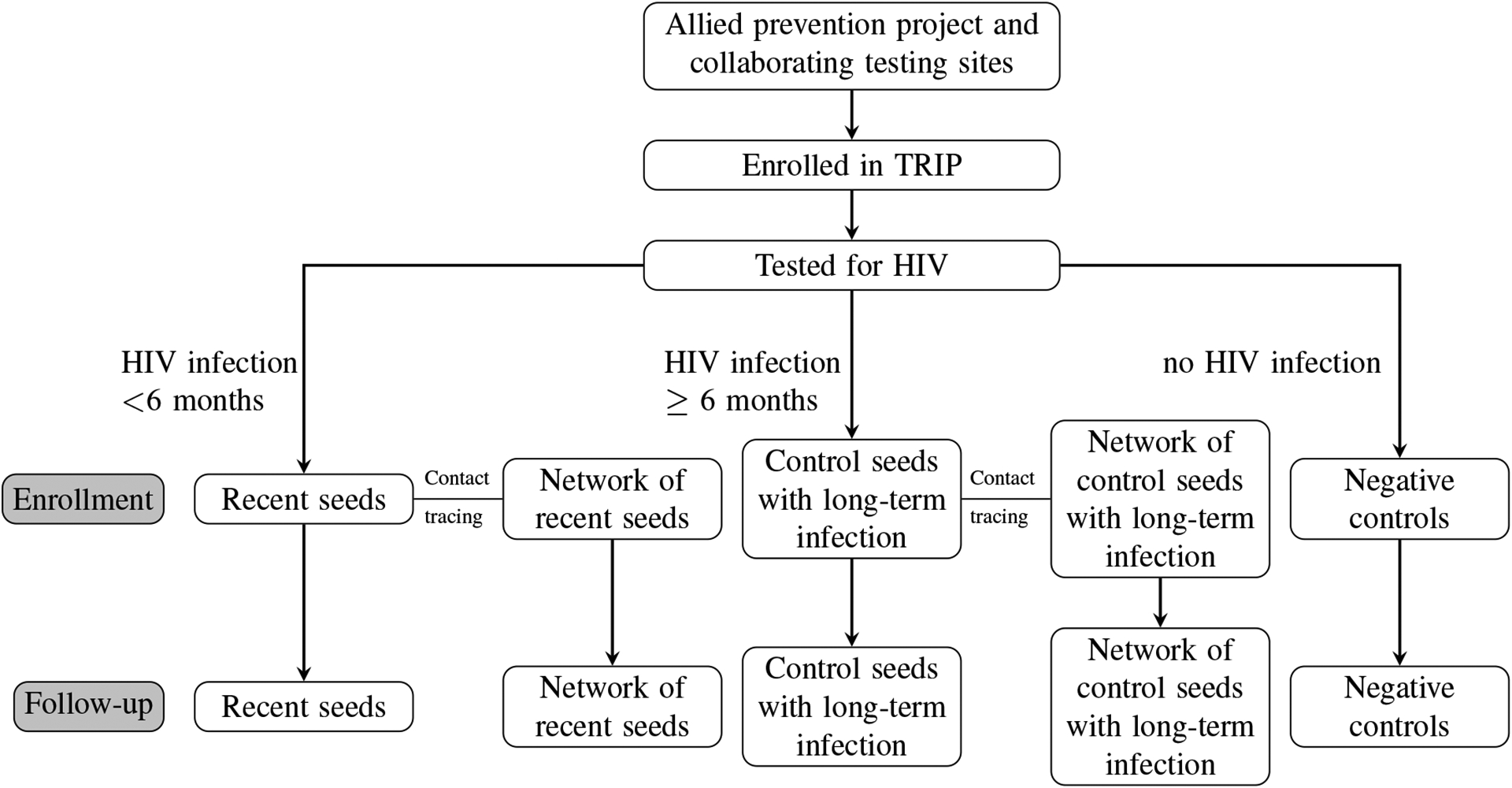
Flowchart of participant selection in TRIP (Pampaka et al., 2021)
Participants were interviewed at a baseline visit and 6-months after the baseline visit using a questionnaire to ascertain demographics, sexual and injection behaviors and partners in the prior 6 months, drug treatment, and antiretroviral treatment. In addition to HIV testing, the study provided access to treatment as prevention (TasP) for those with HIV, referrals for medical care, and distributed community alerts to inform members of the community about temporary increases in the risk for HIV acquisition. These alerts were paper flyers provided to participants and posted in locations frequented by members of the local PWID community. Participants were followed to ascertain demographics, risk behaviors, and substance use through interviews, HIV serostatus, timing of HIV infection, and HIV disease markers, including HIV viral load, through phylogenetic techniques approximately 6 months later. Complete details on the study design and recruitment can be found in Nikolopoulos et al. (2016); Psichogiou et al. (2019); Giallouros et al. (2021); Hadjikou et al. (2021); Pampaka et al. (2021).
For this study, we used data from the Athens, Greece site which was collected from 2013 to 2015 during the HIV outbreak that began following the economic recession in 2008 (Nikolopoulos et al., 2015; Williams et al., 2018). The network structure in TRIP included 356 participants and 542 shared connections. One of the participant was recruited twice as a network member of a recent seed and as a network member of a control seeds with long-term HIV infection. In our analysis, we only used the information for this participant corresponding to their records as a network member of a recent seed. In the network, 79 participants were isolates (i.e. not sharing connection with other network members) and removed for our analysis as spillover is not possible for isolates. In addition, 2 participants were removed due to missing values on HIV risk behavior in the past 6 months reported at baseline and 59 participants were removed from the network due to loss to follow-up that resulted in missing information at the 6-month visit, including HIV risk behavior, which was the the outcome of interest. Figure 2 represents the TRIP network with 216 participants after excluding isolates who were participants not connected with any other participants in the network and 25 participants (11.6%) of the 216 participants were exposed to the community alerts. The network characteristics and distribution of participant attributes are summarized in Table 1.
Fig 2:

The TRIP network consisted of 10 connected components. The size of each component was {185, 9, 6, 3, 3, 2, 2, 2, 2, 2}. The size of each component after using community detection to further divide the network into 20 components is {28, 26, 23, 19, 19, 18, 15, 12, 10, 9, 8, 7, 6, 3, 3, 2, 2, 2, 2, 2}. Dark shaded nodes represent the participants who were exposed to community alert and gray shaded nodes represent participants who were not exposed.
Table 1.
TRIP network characteristics and participant attribute variables after excluding isolates and 59 participants (21%) who were lost to follow up before their six-month visit1.
| Network Characteristics | Nodes | 216 |
| Edges | 362 | |
| Components | 10 | |
| Average Degree (SD) | 3.35 (2.75) | |
| Density | 0.016 | |
| Transitivity | 0.25 | |
| Assortativity | 0.25 | |
| Baseline Visit | ||
| Community alert | Exposed | 25 (11.6%) |
| Not Exposed | 191 (88.4%) | |
| HIV Status | Positive | 113 (52.3%) |
| Negative | 103 (47.7%) | |
| Date of first interview | Before ARISTOTLE ended | 110 (50.9%) |
| After ARISTOTLE ended | 106 (49.1%) | |
| Education | Primary School or less | 64 (29.6%) |
| High School (first 3 years) | 68 (31.5%) | |
| High School (last 3 years) | 52 (24.1%) | |
| Post High School | 32 (14.8%) | |
| Employment status | Employed | 33 (15.3%) |
| Unemployed; looking for work | 54 (25.0%) | |
| Can’ work; health reason | 101 (46.8%) | |
| Other | 28 (12.9%) | |
| Shared injection equipment in last 6 months | Yes | 159 (73.6%) |
| No | 57 (26.4%) | |
| Six-month Visit | ||
| Outcome: sharing injection equipment at the 6-month visit | Yes | 92 (42.6%) |
| No | 124 (57.4%) |
The transitivity measures the density of triads in a network. The assortativity quantifies the extent to which connected nodes share similar properties.
3. Notation.
We employ a potential outcomes framework for causal inference and assume the sufficient conditions for valid estimation of causal effects, which have been well-described (Ogburn et al., 2014; Liu, Hudgens and Becker-Dreps, 2016; Forastiere, Airoldi and Mealli, 2021). However, we relax the no dissemination or interference assumption (Rubin, 1980). In our setting, we evaluate the effect of a non-randomized intervention on a subsequent outcome in an observed network, where information is available on the nodes (i.e., each participant) and their links (i.e., HIV risk connections through sexual or injection behavior). We evaluate the effect of being exposed to community alerts on HIV risk behaviors (i.e., sharing injection equipment) reported at the 6-month follow up. According to the network-based study design of TRIP that recruited at least one wave of contact tracing for each participant of an HIV-infected seed, we anticipate that there could be dissemination or spillover between two individuals connected by an link (i.e., possible influence of their neighbors’ intervention exposure on an individual’s outcome). Based on reported connections, we assume that smaller groupings or neighbors for each individual can be identified in the data. Following Forastiere, Airoldi and Mealli (2021) and Liu, Hudgens and Becker-Dreps (2016), we make the nearest neighbors interference assumption (NIA). The NIA is a network analog to the partial interference assumption used for clusters (Sobel, 2006; Hudgens and Halloran, 2008); however, partial interference does not assume a unique interference set for each individual, but instead the set is the same for all individuals in a cluster. The NIA assumption applies to the nearest neighbors uniquely defined for each participant in the study, so the connections between individuals and their neighbors can now be explicitly considered in the estimands and estimation. This implies that the potential outcomes of a participant depend only on their own exposure and that of their nearest neighbors and not on the exposures of others in the network beyond the nearest neighbors, positing that an individual only has spillover from their first degree contacts. In other words, if the exposures of an individual and their neighbors are held fixed, then changing the exposures of others outside the nearest neighbors and the individual does not change the outcome for the individual.
Consider a finite population of individuals and each individual self-selects their exposure to a study intervention. Let denote each participant in the study and let be the binary exposure of participant with if exposed to an intervention and 0, otherwise. Let denote the vector of pre-exposure covariates for participant . These participants are connected through an observed network that can be represented by a binary adjacency matrix , with if participants and share an edge or connection, and , otherwise. We assume . Each participant is represented as a node in the network. The set of nodes in network is denoted by . Given an observed network, a component is a connected subnetwork that is not part of any larger connected subnetwork. A network that is itself connected has exactly one component. If has components, we denote the components . Denote the nearest neighbors of participant by and denote the nearest neighbors and participant . The degree of individual (or number of nearest neighbors) is denoted as . We denote the vector of intervention exposures for the nearest neighbors for participant as . In this setting, the outcome of participant depends not only on their own exposure, but also on the vector of their neighbors’ exposures (NIA). In other words, we let be the interference set of individual in which the neighbors’ exposures may affect the outcome of individual . We also denote the vector of pre-exposure covariates for the nearest neighbors for participant as . Denote realizations of exposures by and by . Similarly, denote realizations of covariates by and by .
Let denote the potential outcome of individual if they received intervention and their nearest neighbors received the vector of interventions denoted by . Let denote the observed outcome, which holds by causal consistency. Therefore, the potential outcomes are assumed to be deterministic functions and the observed outcomes are assumed to be random variables. In our study setting, represents an indicator for whether participant is exposed to community alerts and the pre-exposure covariates include HIV status ascertained in the TRIP study, date of first interview, education status, employment status, and report of shared drug use equipment (e.g. syringe) in last 6 months prior to baseline. The observed outcome is the status of sharing injection equipment in the last 6 months prior to the 6-month follow-up visit.
In this paper, we define average potential outcomes using a Bernoulli allocation strategy (Tchetgen Tchetgen and VanderWeele, 2012), where represents the counterfactual scenario in which individuals in receive the exposure with probability and we refer to this parameter as the intervention coverage for the nearest neighbors. This is essentially like standardizing the observed exposure vectors to study population in which the exposure assignment mechanism follows a Bernoulli distribution with probability . This allows stochasticity in the intervention assignment for individuals who are possibly members of more than one nearest neighbors. In the observational study, we are not assuming that are independent Bernoulli random variables; however, this distribution of exposure is used to define the counterfactuals. We use information collected in a sociometric network with a non-randomized intervention for estimation. Let denote the probability of the nearest neighbors of individual receiving intervention exposure under allocation strategy . The allocation strategy can also be considered as the intervention coverage level for the nearest neighbors. Let denote the probability of individual receiving exposure and denote the probability of individual together with their nearest neighbors receiving the set of exposures .
4. Estimands.
We follow notations from Liu, Hudgens and Becker-Dreps (2016) to define the estimands. Define to be the average potential outcome for individual under allocation strategy and exposure where the summation is over all possible values of . Averaging over all individuals, we define the population average potential outcome as . We also define the marginal average potential outcome for individual under allocation strategy by and define the marginal population average potential outcome as .
We consider different contrasts of these average causal effects often of interest in network-based studies. We define these on the risk difference scale and analogous effects can be defined on the ratio scale. The direct effect is defined as , which compares the average potential outcomes when a participant is exposed to the intervention compared to when a participant is not exposed under allocation strategy . For example, in TRIP study, the direct effect is a difference in the risk of reporting HIV risk behaviors when a participant is exposed to community alerts versus when a participant is not exposed with of their nearest neighbors exposed to alerts. The disseminated (i.e., indirect or spillover) effect is , which compares the average potential outcomes of unexposed individuals under two different allocation strategies and . The composite or total effect is defined as , which is a function of both the direct and disseminated effects and is a measure of the maximal intervention effect (assuming that ), comparing average potential outcomes for exposed participants under allocation strategy to unexposed participants under allocation strategy . Lastly, the overall effect is , which is the difference in average potential outcomes under two different allocation strategies.
5. IPW Identification Assumptions and Estimators.
In an observational study of a network, interventions are typically not randomized at either the network or individual-level, but rather individuals and their nearest neighbors typically self-select their own exposures. Therefore, identification of causal effects does not benefit from exchangeability achieved by randomization and adjustment for a sufficient set of pre-exposure covariates at both the individual- and network-level is needed to quantify causal effects. In this section, we apply two different IPW estimators (Liu, Hudgens and Becker-Dreps, 2016; Forastiere, Airoldi and Mealli, 2021) to a setting with the interference set defined by nearest neighbors in observed networks with components. We assume that the observed network can be expressed as the union of components denoted by for (Figure 3). We quantify the variance accounting for correlation within components of the full observed network. Importantly, we now incorporate the nearest neighbor structure in the estimating equations used to calculate the closed-form variances because this better reflects the underlying structure through which dissemination operates in the observed network. Individuals who share a connection or link are more likely to influence each other, as opposed to individuals who are clustered together, possibly in a large grouping like a component. In Liu, Hudgens and Becker-Dreps (2016), information on their connections or distance in the network between individuals is either not available or not used for statistical inference and the assumption is nonetheless made that these individuals could all possibly influence each other within the set (i.e., a generalized interference set).
Fig 3:
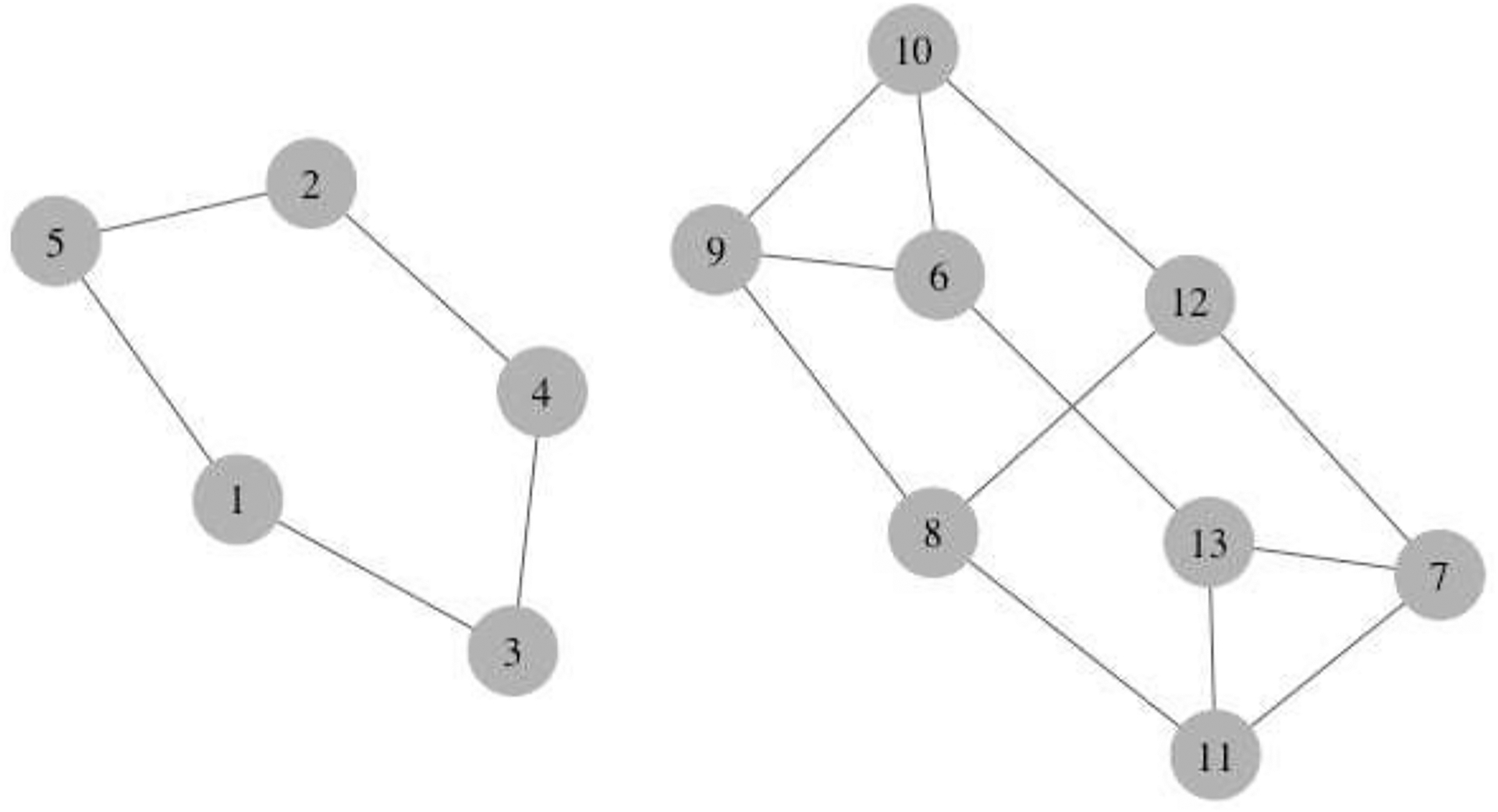
A sample network with two components. and . The nearest neighbors of node 2 are , of node 3 are , and of node 6 are .
5.1. Assumptions.
Assumption 1. (Exchangeability) Assume that conditional on pre-exposure covariate vector and the covariates of their nearest neighbors , the intervention allocation for individual and their nearest neighbors is independent of all potential outcomes
Assumption 2. (Positivity) Assume that and for all , and .
Assumption 3. (Treatment variation irrelavance) We assume that the treatment or intervention assignment mechanism does not affect the outcome. More precisely, if there are different versions of the intervention, we assume that those are irrelevant for the causal contrasts of interest and that we have one version of intervention and one version of no intervention. (Forastiere, Airoldi and Mealli, 2021).
Assumption 4. (Conditional exposure independence) Conditional on the exposure and covariates for individual and their neighbors and the neighbor-level random effect , the exposure for individual and the exposure for the neighbors are independent. That is, given the nearest neighbor-level random effect and ,
The nearest neighbor-level random effect accounts for possible correlation of exposures among individual and their neighbors . This assumption is used to estimate the propensity score of IPW1 (defined in Section 5.2).
Assumption 5. (Nearest neighbors interference) The outcome for an individual depends their own exposure and the exposures of only other individuals who are their nearest neighbors (Forastiere, Airoldi and Mealli, 2021). By consistency, the following holds:
For example, in Figure 3, , which is that the outcome for individual 1 is affected by their own exposure and the exposure of individual 3 and 5 only and no other individuals’ exposures in either the component or network.
Assumption 6. (Stratified interference) The outcome for an individual depends on their own exposure and on the total number of exposed nearest neighbors (Hudgens and Halloran, 2008; Sobel, 2006).
Assumption 7. (Reducible propensity score assumption) The individual exposure does not depend on neighbors’ covariates and neighbors’ exposures do not depend on individual covariates (Forastiere, Airoldi and Mealli, 2021).
Exchangeability (Assumption 1), positivity (Assumption 2), and treatment variation irrelevance (Assumption 3) are necessary assumptions for causal inference under the potential outcomes framework (Rubin, 1980). Due to the lack of randomization of the intervention, we require a conditional exchangeability assumption for both the individual and their neighbors, which allows for identification of causal contrasts related to both the individual’s exposure and the allocation strategy for their neighbors. The positivity assumption ensures we have individuals and their neighbors exposed (and not exposed) at each level of the covariates. We also assume treatment variation irrelevance for the intervention, which ensures we have only one version of being exposed to the intervention and one version of not being exposed, which clarifies how we define the potential outcomes related to each intervention exposure. In this work, we assume that only the first degree neighbors’ exposures can influence an individual’s outcome, which allows us to focus locally in the network to evaluate spillover. Assumption 6 and 7 apply to IPW2 only and are discussed in Section 5.2; however, assumption 6 may also be applied to IPW1 (defined in Section 5.2) when there are concerns about positivity violations.
5.2. Estimators.
Under the Assumptions 1, 2, 3, 4 and 5, the first IPW estimator is an adaptation of the one proposed by Liu, Hudgens and Becker-Dreps (2016), and we define the interference sets by the nearest neighbors for each individual in the observed network, and then use this nearest neighbor structure within each component when deriving the closed-form variance estimator in Section 5.3. Define the IPW estimator for exposure with allocation strategy as
| (1) |
where is the nearest neighbors-level exposure propensity score. We assume that conditional on the nearest neighbor-level random effect and the exposure and covariates for individual and the neighbors , the exposures of nearest neighbors and the exposure of individual are independent. In other words, the dependency between the exposures for individual and their neighbors is captured by both the fixed exposures and covariates and nearest neighbor-level random effect. To model the propensity score, the probability of exposure following a Bernoulli distribution and conditional on observed baseline covariates is given by
where ,
and . Here, is the nearest neighbors-level random effect accounting for possible correlation of exposures among individual and their neighbors .
The marginal population-level average potential outcome estimator is
| (2) |
Under the Assumptions 1, 2, 3, 5, 6 and 7, the second IPW estimator uses an individual and nearest neighbors propensity score as defined in Forastiere, Airoldi and Mealli (2021). The potential outcomes of individual depend on the total number of exposed neighbors, (and let ). In particular,
The IPW estimator for exposure with coverage is defined as
| (3) |
and the IPW marginal estimator as
| (4) |
Let
be the probability of individual has exposed neighbors and
denote the probability of exposure for individual together with exposed neighbors.
The propensity score is the joint probability distribution of individual exposure and nearest neighbors exposure given the covariates and . Here, we express this as a product of the individual propensity score, , and nearest neighbors propensity score, .
We assume that the individual exposure follows a Bernoulli distribution
with probability defined as the individual propensity score, modeled as a function of a covariate vector using a logit link
Furthermore, we assume that the total number of exposed neighbors follows a binomial distribution
with probability modeled as a function of the nearest neighbors covariate vector using a logit link
where is an aggregate function of the vector . For instance, the proportion of females or males in the nearest neighbors or average age of an individual’s nearest neighbors.
We assume that conditional on the nearest neighbors covariates and the exposure for individual , the exposures of nearest neighbors are independent and identically distributed. In other words, the dependency between neighbors’ exposure is captured by the correlation with the exposure for individual and the covariates of the nearest neighbors.1 Therefore, the propensity score can be factor into two marginal distributions and as follows:
Under allocation strategy , and , we consider the following risk difference estimators of the direct, disseminated (indirect), composite (total), and overall effects:
where corresponds to the two IPW estimators that we defined above.
Proposition 1. If the propensity scores and are known, then and .
Proof of Proposition 1 is shown in Appendix A of the Supplementary Material (Lee et al., 2022). Using these unbiased estimators when the propensity score is known, the estimation of the causal effects will also be unbiased because the causal effects are contrasts of these marginal quantities.
5.3. Large sample properties of the inverse probability of sampling weighted estimator.
The large sample variance estimators can be derived using M-estimation theory (Boos and Stefanski, 2013). We assume that the observed network can be expressed as the union of components; that is, non-overlapping groups of individuals (Liu, Hudgens and Becker-Dreps, 2016). Consider a social network with individuals and components denoted by with . Let denote the outcome, exposure, and covariates for individual in component , respectively. Let be the set of nodes in , and . The observable random variables for are assumed to be independent but not necessarily identically distributed with distribution . We assume that the components are a random sample from the infinite super-population of groups and the size of each component is bounded (Boos and Stefanski, 2013).
Recall, for IPW1, the parameters of the exposure propensity score model include coefficients for the fixed effects and the random effect, while for IPW2, the parameters include coefficients for the fixed effects from two logistic models (see Section 5.2). Let the set of coefficients of fixed effects and the random effects in the propensity score when using IPW1, and be the set of coefficients in the propensity score when using IPW2. To generalize notation, we set the dimension of to be and refer to these parameters as in the estimating equations below. Let be the component-level average potential outcomes defined as
To conduct inference, we use independent components, while preserving the underlying connections of an individual’s nearest neighbors comprising the network structure of each component. That is, by extending Liu, Hudgens and Becker-Dreps (2016), every individual is now assigned their own propensity score based on the observed network structure defined by their nearest neighbors (see Section 5.2). Whereas in Liu, Hudgens and Becker-Dreps (2016), statistical inference was conducted by assuming partial interference in which the study population was partitioned into non-overlapping groups and all individuals in a group were assigned one group-level propensity score. To simplify the notation in this section, we write the propensity score as and let the observed outcome for individual in component be denoted by . Note that the potential outcomes are random due to the random sampling of the components. With this partition of the network, the inverse probability weighted estimator for exposure and strategy presented in Section 5.2 equals
| (5) |
Let , where , and . Let . Similar to the approach in Liu, Hudgens and Becker-Dreps (2016), let the average component size in the study population be defined as , which is the mean component size in the population. We use this to redefine the inverse probability weighted estimators in equation 5 because equally weighting individuals ignoring components may result in biased estimators (Basse and Feller (2018)). With the average component size, the inverse probability weighted estimator for exposure and strategy presented in Section 5.2 equals
| (6) |
The estimating equations corresponding to the estimator in equation (5) are defined as follows
and
Let
such that . Note that is the solution for for this vector of estimating equations. In addition, (Boos and Stefanski, 2013). Let and with the expectation take across all components in the population.
Proposition 2. Under suitable regularity conditions and due to the unbiased estimating equations, as converges in probability to and converges in distribution to , where the covariance matrix is given by
Additional details for Proposition 2 are shown in Appendix B of the Supplementary Material (Lee et al., 2022). A consistent sandwich estimator of Σ is given in Appendix B. We demonstrate how to obtain the variance for the estimator of the disseminated effect . An analogous procedure can be performed to obtain the variance for the estimators of the direct, overall and total effects. Let
Followed with Slutsky’s Theorem and an application of the Delta method as , is a consistent estimator of and converges in distribution to , where and . A consistent sandwich estimator of the variance of is given in Appendix B. This variance estimator can be used to construct Wald-type confidence intervals (CIs) for the disseminated effects.
6. Simulation.
A simulation study was conducted to evaluate the performance of the two IPW estimators and their corresponding closed-form variance estimators. We focused on the evaluation of the finite sample bias and coverage of the corresponding 95% Wald-type confidence intervals. The network characteristics (e.g., number of components, number of nodes in each component) and parameters of potential outcome models were motivated using empirical estimates from the TRIP data. In this simulation study, we considered regular network where each node has the same number of neighbors. We first generate network components as regular networks of degree four for each node. The number of nodes in each component is sampled from a Poisson distribution with average 10. We conducted several simulations where the numbers of components is from the set {10, 50, 100, 150, 200}. Given a generated network, a total of 1,000 data sets were simulated in the following steps.
- Step 1. A baseline covariate was randomly generated as . We then generated all possible potential outcomes
- Step 2. Assign the random effect to each component in the network to allow for correlation between the outcomes within components. The exposure was generated as
Step 3. We then obtain the corresponding observed outcomes from the potential outcomes that we generated in Step 1. The true parameters were calculated by averaging the potential outcomes as described in Section 4 that we generated in Step 1.
For each simulated data set, the , and were computed for and . The estimated standard errors were derived using the appropriate entries from the variance matrix in Appendix B, then averaged across simulations to obtain the average standard error (ASE). Empirical standard error (ESE) was the standard deviation of estimated means across all simulated data sets. Empirical coverage probability (ECP) is the proportion of the instances that the true parameters were contained in the Wald-type 95% confidence intervals based on the estimated standard errors among the 1000 simulations with a margin of error equal to 0.014. In our main scenario, we simulated networks with component size in average 10 and increased the number of components to evaluate the performance of IPW1 and IPW2 for estimation of the average potential outcomes (Tables A1 to A5). The complete simulation results are summarized in Appendix C of the Supplementary Material (Lee et al., 2022).
Figure 4 shows that the finite sample bias approaches zero and ECPs approach the nominal 0.95 level when the number of components increases from 10 to 200. In Table A5, the ECPs of the estimator IPW1 under all allocation strategies were close to the nominal level and ECPs of IPW2 approach the nominal level when the allocation strategies had a coverage level around 50% in the observed data. To compare the performance of our variance estimator to an estimator for the asymptotic variance that assumes partial interference (Liu, Hudgens and Becker-Dreps, 2016), we used observed components in the network as groups to define partial interference sets. The partial interference assumption for variance estimation resulted in higher ASE and ECP, as compared to the asymptotic variance defined in Appendix B, which was closer to the ESE (Figure 5).
Fig 4:
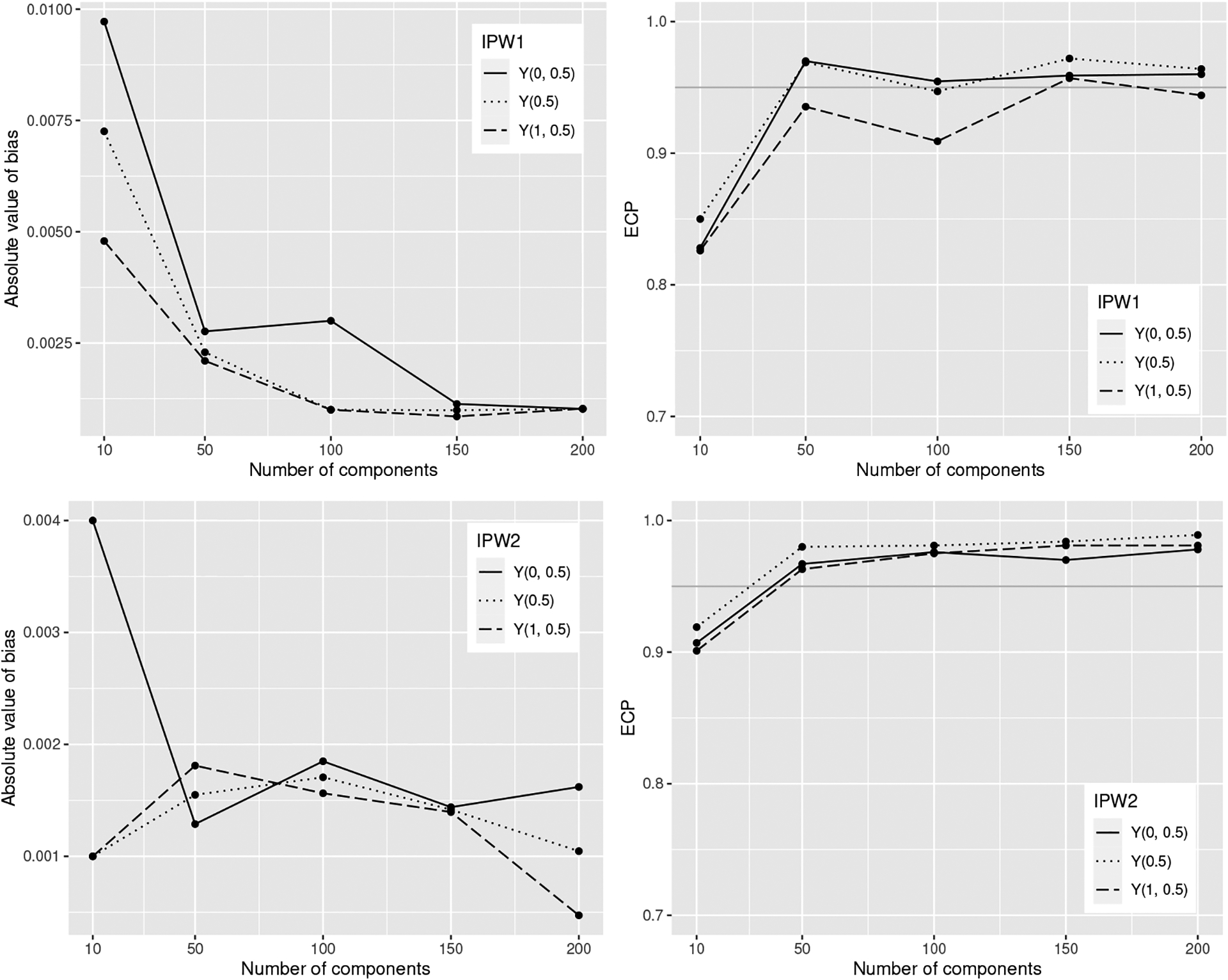
Absolute bias (left) estimator and corresponding Wald 95% confidence intervals empirical coverage probability (ECP) (right) of IPW1 (top) and IPW2 (bottom) for different number of components in the network
Fig 5:
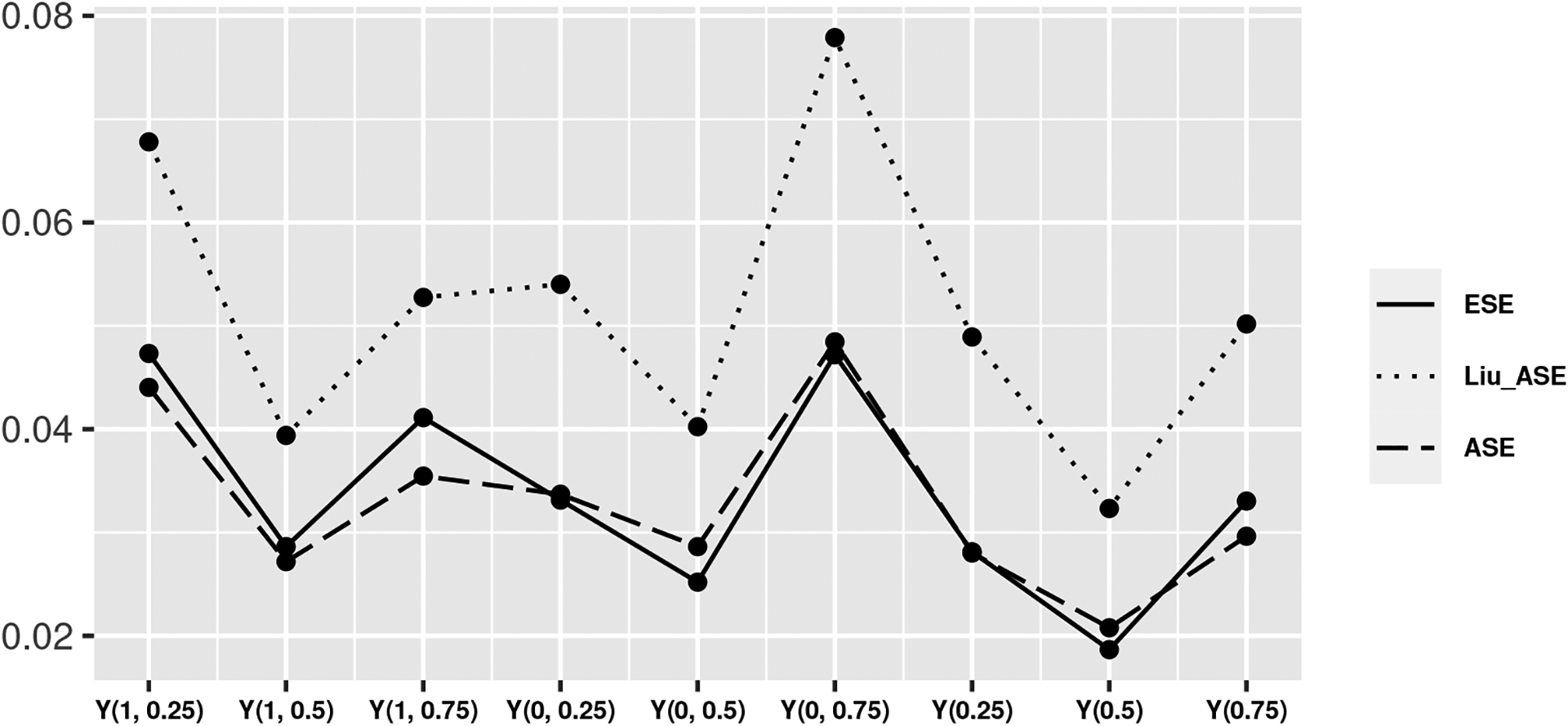
Given a network with 100 components, comparison of the average empirical standard error (ESE), the average standard error (ASE) based on variance estimator in Appendix B, and average standard error (Liu ASE) based on variance estimator in Liu, Hudgens and Becker-Dreps (2016) of the average potential outcomes under allocation strategies 25%, 50%, and 75%.
In addition to the main simulation scenarios that vary the number of components, we also used a regular network of degree 4 with 100 components to compare scenarios with a different exposure generating mechanism without random effects, and a scenario in which the stratified interference assumption is violated. In addition to this simulated regular network, we used the TRIP network structure to investigate the performance when community detection was used to further divide the network to larger number of component in the network. We also considered a scenario where we regenerated the network in each simulated dataset. Specifically, we considered the following additional five scenarios:
- We used the exposure generating mechanism without random effects as one way to misspecify the propensity score
In Table 2, the ECPs of IPW2 were below the nominal level when the exposure mechanism was misspecified, while finite sample performance of IPW1 remained largely similar to settings with a correctly specified exposure mechanism. - We used a different exposure generating model given by
Unlike the previous exposure generating model, this model results in more individuals who have none or 25% of their neighbors exposed in the simulated data (Figure 6). In Table A6, both IPW estimators have higher ECPs for allocation strategy 25% (IPW1: 94%, IPW2: 97%) and lower at allocation strategy 75% (IPW1: 68%, IPW2: 71%) in this scenario, suggesting that the finite sample performance of both estimators for the point estimates and ASEs were better under allocation strategies for which there were more individuals with of their neighbors exposed in the simulated data. - We considered an outcome model where the stratified interference assumption was violated while the exposure generating model was defined as in Step 2
We used the potential outcome model given by
The simulation results in Table 3 showed that both estimators did not perform well with respect to the point estimates, as the magnitude of absolute bias was larger. The ECPs of IPW1 were all greater than 95% which suggested over-coverage. The ECPs of IPW2 had coverage above the nominal level or slightly below the nominal level of 95%. - We considered the network structure similar to our motivating study TRIP. Based on previous simulation results, a small number of components may result in poor finite-sample performance of variance estimators. To increase the number of components for estimation of the asymptotic variance of the estimated causal effects, we employed an efficient modularity-based, fast greedy approach to detect communities to further divide large connected components of the TRIP network into a total of 20 smaller components. Modularity takes large values when there are more substantial connections among some individuals than expected if the connections were randomly assigned (Clauset, Newman and Moore, 2004). More precisely, each node initially belongs to a separate component, and components are merged iteratively such that each merge yields the largest increase in the current value of modularity. The algorithm stops when it is not possible to increase the modularity any further. As a result, components each comprise a unique set of participants and there are more links between the participants within components than across components in the TRIP network. By ignoring links across components, we treat the obtained communities as independent units to possibly improve the estimation of the variance. Importantly, we still define the interference sets using the nearest neighbors for point estimation of the causal effects. In this scenario, we use potential outcome model in Step 1 and exposure generating model in Step 2. The simulation results on the TRIP network with and without community detection (Table 4) demonstrated that the ECPs of both IPW1 and IPW2 had coverage above the nominal level (97%-100%) when using the TRIP network with only 10 components. After further divide the network using community detection, the ECPs have coverage slightly below the nominal level in some cases. To simulate more realistic covariates, we considered a scenario with additional baseline covariates in a TRIP network with 20 components. Two binary variables, and , and two continuous variables, and , were added into the exposure generating model
The results are summarized in Table 5. The estimators had coverage below the nominal level using IPW1; however, IPW2 performed slightly better in terms of ECP. In the previous scenarios, we considered a network that is generated once (or fixed) and simulated 1000 datasets based on the one network. To evaluate the impact of uncertainty in the network structure, we also considered a scenario where we regenerated the network in each simulated dataset. We first generate a degree four regular network with 100 components, then Step 1–3, repeated 1000 times for each dataset (Table 6). The results are mostly comparable to the results that generated one simulated network and simulated 1000 datasets on a fixed network (Table A3).
Table 2.
Results from 1000 simulated datasets on a network with 100 components for IPW1 (left) and IPW2 (right) for exposed , not exposed , and marginal estimators under allocation strategies 25%, 50%, and 75% using exposure generating model .
| IPW1 | IPW2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Bias | ESE | ASE | ECP | Bias | ESE | ASE | ECP | |
| 0.0013 | 0.048 | 0.046 | 0.91 | 0.0149 | 0.039 | 0.036 | 0.86 | |
| −0.0003 | 0.027 | 0.028 | 0.96 | 0.0016 | 0.022 | 0.024 | 0.96 | |
| −0.0032 | 0.041 | 0.041 | 0.93 | 0.0093 | 0.035 | 0.033 | 0.88 | |
| −0.0051 | 0.039 | 0.040 | 0.94 | 0.0093 | 0.033 | 0.031 | 0.90 | |
| −0.0018 | 0.028 | 0.029 | 0.95 | 0.0018 | 0.023 | 0.025 | 0.97 | |
| 0.0004 | 0.053 | 0.051 | 0.92 | 0.0195 | 0.045 | 0.042 | 0.83 | |
| −0.0035 | 0.032 | 0.032 | 0.94 | 0.0107 | 0.027 | 0.026 | 0.88 | |
| −0.0010 | 0.021 | 0.021 | 0.97 | 0.0017 | 0.016 | 0.018 | 0.97 | |
| −0.0023 | 0.033 | 0.030 | 0.93 | 0.0118 | 0.029 | 0.028 | 0.86 | |
Fig 6:
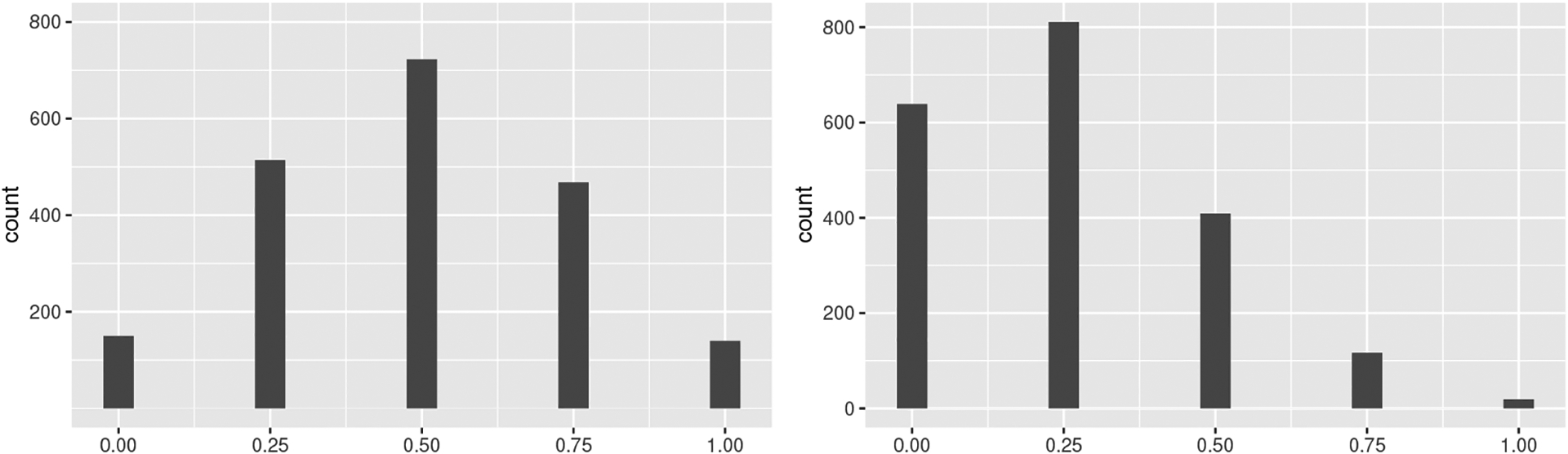
The frequency of the proportion of exposed neighbors in one simulated data when using the exposure generating models (left) and (right)
Table 3.
Results from 1000 simulated datasets on a network with 100 components for (left) and (right) for exposed , not exposed , and marginal estimators under allocation strategies 25%, 50%, and 75% using an outcome model where the stratified interference assumption is violated.
| True | IPW1 | IPW2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | ESE | ASE | ECP | Bias | ESE | ASE | ECP | ||
| 0.9965 | 0.0039 | 0.068 | 0.074 | 0.96 | 0.0345 | 0.090 | 0.074 | 0.84 | |
| 0.9885 | 0.0041 | 0.033 | 0.047 | 0.99 | 0.0051 | 0.006 | 0.048 | 1.00 | |
| 0.9724 | −0.0134 | 0.067 | 0.077 | 0.96 | −0.1540 | 0.115 | 0.148 | 0.93 | |
| 0.9943 | −0.0179 | 0.066 | 0.078 | 0.97 | −0.1682 | 0.121 | 0.154 | 0.92 | |
| 0.9821 | 0.0015 | 0.034 | 0.048 | 0.99 | 0.0032 | 0.008 | 0.049 | 1.00 | |
| 0.9583 | 0.0060 | 0.069 | 0.074 | 0.95 | 0.0398 | 0.085 | 0.070 | 0.81 | |
| 0.9949 | −0.0125 | 0.050 | 0.063 | 0.98 | −0.1175 | 0.100 | 0.122 | 0.92 | |
| 0.9853 | 0.0028 | 0.022 | 0.040 | 1.00 | 0.0042 | 0.005 | 0.035 | 1.00 | |
| 0.9689 | −0.0086 | 0.050 | 0.062 | 0.97 | −0.1056 | 0.094 | 0.117 | 0.94 | |
Table 4.
Results from 1000 simulated datasets on TRIP network for 10 components (left) and using community detection to further divide the network to 20 components (right) for exposed , not exposed , and marginal estimators under allocation strategies 25%, 50%, and 75%.
| True | 10 components | 20 components | |||||||
|---|---|---|---|---|---|---|---|---|---|
| IPW1 | IPW2 | IPW1 | IPW2 | ||||||
| Bias | ECP | Bias | ECP | Bias | ECP | Bias | ECP | ||
| 0.2473 | 0.0098 | 0.986 | 0.0167 | 0.988 | 0.0098 | 0.849 | 0.0036 | 0.890 | |
| 0.2265 | 0.0021 | 0.998 | 0.0112 | 0.986 | 0.0021 | 0.946 | 0.0064 | 0.920 | |
| 0.2058 | −0.0020 | 0.987 | 0.0126 | 0.997 | −0.0020 | 0.894 | 0.0057 | 0.943 | |
| 0.2304 | <0.0001 | 0.996 | 0.0046 | 0.999 | <0.0001 | 0.920 | 0.0021 | 0.968 | |
| 0.2778 | 0.0010 | 1.000 | 0.0029 | 1.000 | 0.0010 | 0.954 | 0.0017 | 0.974 | |
| 0.3275 | 0.0073 | 0.996 | 0.0038 | 1.000 | 0.0073 | 0.896 | 0.0019 | 0.992 | |
| 0.2346 | 0.0025 | 0.999 | 0.0133 | 0.971 | 0.0025 | 0.943 | 0.0061 | 0.915 | |
| 0.2521 | 0.0015 | 1.000 | 0.0121 | 0.993 | 0.0015 | 0.982 | <0.0001 | 0.917 | |
| 0.2362 | 0.0004 | 1.000 | 0.0130 | 0.998 | 0.0004 | 0.937 | 0.0046 | 0.940 | |
Table 5.
Results from 1000 simulated datasets on TRIP network further dividing the network into 20 components using (left) and (right) for exposed , not exposed , and marginal estimators under allocation strategies 25%, 50%, and 75% with exposure generating model .
| True | IPW1 | IPW2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | ESE | ASE | ECP | Bias | ESE | ASE | ECP | ||
| 0.2493 | 0.0445 | 0.161 | 0.095 | 0.61 | 0.0409 | 0.100 | 0.075 | 0.71 | |
| 0.2274 | 0.0295 | 0.179 | 0.094 | 0.64 | 0.0197 | 0.089 | 0.073 | 0.80 | |
| 0.2057 | 0.0194 | 0.290 | 0.111 | 0.57 | 0.0422 | 0.093 | 0.065 | 0.64 | |
| 0.2295 | 0.0160 | 0.141 | 0.087 | 0.72 | 0.0214 | 0.064 | 0.060 | 0.86 | |
| 0.2765 | 0.0306 | 0.149 | 0.092 | 0.69 | 0.0318 | 0.063 | 0.067 | 0.86 | |
| 0.3264 | 0.0589 | 0.189 | 0.113 | 0.59 | 0.0923 | 0.094 | 0.076 | 0.56 | |
| 0.2345 | 0.0231 | 0.115 | 0.077 | 0.71 | 0.0263 | 0.054 | 0.055 | 0.84 | |
| 0.2520 | 0.0300 | 0.118 | 0.079 | 0.70 | 0.0258 | 0.053 | 0.059 | 0.87 | |
| 0.2358 | 0.0293 | 0.227 | 0.099 | 0.60 | 0.0547 | 0.072 | 0.058 | 0.62 | |
Table 6.
Results from 1000 simulated datasets with the network regenerated for each dataset with 100 components for (left) and (right) for exposed , not exposed , and marginal estimators under allocation strategies 25%, 50%, and 75%.
| True | IPW1 | IPW2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | ESE | ASE | ECP | Bias | ESE | ASE | ECP | ||
| 0.2489 | 0.0023 | 0.0487 | 0.0467 | 0.89 | −0.0099 | 0.0518 | 0.0457 | 0.93 | |
| 0.2270 | 0.0018 | 0.0271 | 0.0274 | 0.94 | −0.0037 | 0.0324 | 0.0317 | 0.96 | |
| 0.2058 | −0.0008 | 0.0425 | 0.0500 | 0.90 | −0.0052 | 0.0275 | 0.0274 | 0.96 | |
| 0.2281 | <0.0001 | 0.0366 | 0.0491 | 0.93 | −0.0013 | 0.0223 | 0.0237 | 0.97 | |
| 0.2745 | 0.0015 | 0.0257 | 0.0298 | 0.97 | −0.0023 | 0.0230 | 0.0246 | 0.96 | |
| 0.3249 | 0.0050 | 0.0479 | 0.0541 | 0.92 | −0.0018 | 0.0161 | 0.0177 | 0.98 | |
| 0.2333 | 0.0006 | 0.0296 | 0.0388 | 0.94 | −0.0051 | 0.0340 | 0.0329 | 0.94 | |
| 0.2508 | 0.0017 | 0.0187 | 0.0213 | 0.97 | −0.0168 | 0.0542 | 0.0510 | 0.94 | |
| 0.2356 | 0.0007 | 0.0336 | 0.0387 | 0.91 | −0.0081 | 0.0295 | 0.0289 | 0.95 | |
7. Evaluation of disseminated effects of community alerts in the Transmission Reduction Intervention Project.
We applied the estimators proposed in Section 5.2 to estimate the causal effects of community alerts at baseline on report of risk behavior at the six-month visit. We assumed that TRIP was an undirected network because the links were defined by if two individuals engaged had sex or injected drugs together in the six months before the baseline interview as reported by at least one participant in the dyad. This was an attempt to reduce the impact of possible missing links in the analysis due to stigma of sexual and drug use behaviors. The community alerts intervention status of the index participant and their neighbors was defined with respect to the baseline visit date of the index participant. The network structure in TRIP had 10 connected components with 216 participants and 362 shared connections (average degree is 3.35) after excluding isolates and 59 participants who were lost to follow-up before their six-month visit. Among the 216 participants in TRIP, 25 participants (11.6%) received a community alert about the increased risk for HIV acquisition in close proximity in their network from the study team. We evaluated if information in the community alerts was disseminated to their the nearest neighbors and ultimately, if this resulted in a reduction in risk behavior among others in the network beyond those who were exposed to the alert themselves (Figure 2). Among participants with complete information on the questions related to sharing injection equipment, we considered the report of sharing injection equipment (or not) at the 6-month visit as the binary outcome, including sharing a syringe, cooker, filter or rinse water, or backloading to share injection drugs. The following baseline covariates were included in the adjusted models: HIV status, shared drug equipment (e.g., syringe) in last six months, the calendar date at first interview, education (primary school, high school, and post high school), and employment status (employed, unemployed/looking for a work, canť work because of health reason, and other). HIV status was ascertained in this study from a blood sample from each participant collected by a health program physician (Nikolopoulos et al., 2016). Given the study population included PWID in one geographic location, we assume that social desirability leading to possible reporting bias is comparable between the two exposure groups. Under this assumption, the reporting bias could be effectively eliminated when estimating contrasts between exposure groups.
We consider each of the assumptions in Section 5.1 in this setting. TRIP is an observational study with a nonrandomized intervention. Conditional exchangeability is required to identify causal effects. We also assume that if there are multiple versions of the community alerts that these different versions are irrelevant for causal contrasts of interest and this results in one version of exposure to the community alerts intervention and one version of no exposure to this intervention. TRIP recruited at least one wave of contact tracing for each participant of an HIV-infected seed; therefore, we expect that there could be dissemination or spillover between two individuals connected by a first-degree link (i.e., possible influence of their neighbors’ intervention exposure on an individual’s outcome). Based on the complex structure of the TRIP network resulting in possibly many different vectors of , a stratified interference may be more appropriate to ensure that the positivity assumption holds. For the reducible propensity score assumption, the neighbors’s covariates were not significantly associated with their index individual’s exposure and the neighbors’s exposure was not significant associated with the index individual’s covariates, so Assumption 7 used for IPW2 may be plausible in this analysis (data not shown).
For the analysis, we reported the point estimates and corresponding Wald-type 95% confidence intervals of each causal effect using both IPW1 and IPW2 estimators under allocation strategies 20%, 30%, 40%, and 50% because the most of individuals in the TRIP study had 20% to 50% of their nearest neighbors exposed to community alerts. The normality of random effects in IPW1 was tested using a diagnostic test for mixed effects model in Tchetgen Tchetgen and Coull (2006) and this resulted in a -value under the null hypothesis that the mixing distribution is normal. Due to this result and better finite-sample performance for IPW2 with a smaller number of components (see Section 6), we recommend IPW2 as a more appropriate estimator in this setting given the small number of components in the TRIP network. Based on the simulation scenario 4 results that showed better finite sample performance for 20 components, we used community detection to further divide the TRIP network into 20 components to possibly improve the finite-sample performance of the variance estimators. We report the variance estimates with and without dividing TRIP network 10 observed components to 20 components in Table 7. In addition to including the full set of covariates to adjust for measured confounding in the weight models, we conducted sensitivity analyses to evaluate the impact of different sets of covariates on the model results. We first considered univariate models; that is, adjustment for only one covariate at a time. Second, we estimated the effects using the full set of covariates, excluding one covariate at a time. Lastly, we estimated the effects without adjustment for any covariates. The results were largely robust to the set of measured covariates used to adjust for confounding. In addition, the results that used community detection to further divide TRIP into 20 components to estimate the asymptotic variances were comparable to an analysis that used the 10 observed components. All models results are summarized in Appendix D of the Supplementary Material (Lee et al., 2022). The study protocol was reviewed and approved by the University of Rhode Island Institutional Review Board. All analyses were conducted using R (version 3.6.2), and R packages: igraph: Network Analysis and Visualization (version 1.3.4), lme4: Linear Mixed-Effects Models using ‘Eigen’ and S4 (version 1.1–30), and numDeriv: Accurate Numerical Derivatives (version 2016.8–1.1).
Table 7.
The estimated risk differences and 95% confidence intervals (CIS) estimated using the TRIP network with the original 10 network components, and 95% CIs estimated by dividing TRIP network into 20 components, of the effects of community alerts at baseline on HIV risk behavior at 6 months adjusted for full set of measured confounding variables under allocation strategies 20%, 30%, 40%, and 50%
| Effects | IPW1 | IPW2 | |||||
|---|---|---|---|---|---|---|---|
| RD | 95% CI | RD | 95% CI | ||||
| 10 components | 20 components | 10 components | 20 components | ||||
| Direct | (20%, 20%) | −0.06 | (−0.14, 0.01) | (−0.39, 0.26) | 0.01 | (−0.08, 0.10) | (−0.19, 0.21) |
| Direct | (30%, 30%) | −0.10 | (−0.24, 0.04) | (−0.48, 0.29) | −0.09 | (−0.19, 0.02) | (−0.27, 0.10) |
| Direct | (40%, 40%) | −0.14 | (−0.36, 0.09) | (−0.52, 0.24) | −0.16 | (−0.40, 0.09) | (−0.38, 0.07) |
| Direct | (50%, 50%) | −0.18 | (−0.49, 0.14) | (−0.52, 0.17) | −0.21 | (−0.56, 0.15) | (−0.47, 0.06) |
| Indirect | (30%, 20%) | 0.01 | (−0.02, 0.03) | (−0.03, 0.04) | 0.00 | (−0.01, 0.02) | (−0.04, 0.05) |
| Indirect | (40%, 20%) | −0.01 | (−0.03, 0.01) | (−0.06, 0.04) | −0.01 | (−0.02, 0.01) | (−0.09, 0.07) |
| Indirect | (50%, 20%) | −0.03 | (−0.07, 0.00) | (−0.10, 0.03) | −0.02 | (−0.04, −0.01) | (−0.14, 0.10) |
| Indirect | (40%, 30%) | −0.01 | (−0.03, −0.00) | (−0.04, 0.01) | −0.01 | (−0.02, −0.00) | (−0.05, 0.03) |
| Indirect | (50%, 40%) | −0.03 | (−0.05, 0.00) | (−0.06, 0.01) | −0.01 | (−0.03, −0.00) | (−0.06, 0.03) |
| Indirect | (50%, 30%) | −0.04 | (−0.08, 0.00) | (−0.09, 0.01) | −0.02 | (−0.04, −0.01) | (−0.11, 0.06) |
| Total | (30%, 20%) | −0.09 | (−0.22, 0.04) | (−0.49, 0.31) | −0.08 | (−0.17, 0.01) | (−0.28, 0.12) |
| Total | (40%, 20%) | −0.15 | (−0.36, 0.07) | (−0.53, 0.24) | −0.16 | (−0.40, 0.07) | (−0.37, 0.05) |
| Total | (50%, 20%) | −0.21 | (−0.53, 0.11) | (−0.54, 0.11) | −0.23 | (−0.58, 0.12) | (−0.43, −0.02) |
| Total | (40%, 30%) | −0.15 | (−0.38, 0.08) | (−0.52, 0.22) | −0.17 | (−0.41, 0.08) | (−0.37, 0.04) |
| Total | (50%, 40%) | −0.20 | (−0.53, 0.13) | (−0.52, 0.12) | −0.22 | (−0.58, 0.14) | (−0.45, 0.01) |
| Total | (50%, 30%) | −0.22 | (−0.56, 0.12) | (−0.53, 0.09) | −0.23 | (−0.59, 0.13) | (−0.44, −0.02) |
| Overall | (30%, 20%) | −0.01 | (−0.03, 0.01) | (−0.08, 0.06) | −0.03 | (−0.06, 0.01) | (−0.07, 0.02) |
| Overall | (40%, 20%) | −0.05 | (−0.12, 0.02) | (−0.15, 0.05) | −0.07 | (−0.18, 0.03) | (−0.15, 0.00) |
| Overall | (50%, 20%) | −0.11 | (−0.27, 0.05) | (−0.21, −0.01) | −0.13 | (−0.32, 0.06) | (−0.21, −0.04) |
| Overall | (40%, 30%) | −0.04 | (−0.10, 0.02) | (−0.07, −0.01) | −0.05 | (−0.12, 0.02) | (−0.08, −0.01) |
| Overall | (50%, 40%) | −0.06 | (−0.15, 0.03) | (−0.09, −0.03) | −0.05 | (−0.14, 0.03) | (−0.08, −0.03) |
| Overall | (50%, 30%) | −0.10 | (−0.25, 0.05) | (−0.14, −0.06) | −0.10 | (−0.26, 0.05) | (−0.16, −0.05) |
Direct, indirect, total, and overall effect estimates and their corresponding Wald-type 95% confidence intervals of both estimators for different allocation strategies and 0.5 adjusting for all measured confounding variables are reported in Table 7. All estimates of the risk differences for both estimators IPW1 and IPW2 were protective, excluding the indirect effect under allocation strategy 30% and 20%, using IPW1 and using IPW2; however, these did not achieve statistical significance. These results suggest that the likelihood of reporting HIV risk behavior was reduced not only by an participan’s exposure to community alerts, but also by the proportion of an participan’s nearest neighbors exposed to community alerts from the study team. We report the confidence interval obtained using 10 components. Specifically, the estimated direct effect was (95% CI: −0.49, 0.14), estimated using IPW1 and (95% CI: −0.56, 0.15) when estimated with IPW2; that is, we expect 18 fewer reports of risk behavior per 100 participants if a participant receives the alert compared to if a participant does not receive an alert with 50% intervention coverage (i.e., 50% of their neighbors receiving alerts) when estimated using IPW1 (21 per 100 fewer using IPW2). The indirect effect is (95% CI:−0.07, 0.00), estimated using IPW1 Under allocation strategies 20% versus 50% and (95% CI:−0.04, −0.01) when estimated with IPW2; in other words, we expect 4 fewer reports of risk behavior per 100 participants if a participant does not receive an alert with 50% intervention coverage compared to only 20% intervention coverage when estimated using IPW1 (2 per 100 fewer using IPW2). The total effects (95% CI:−0.53, 0.11) estimated using IPW1 and (95% CI:−0.58, 0.12) estimated using IPW2. We expect 21 fewer reports of risk behavior per 100 participants when estimated using IPW1 if a participant receives an alert with 50% of their nearest neighbors alerted versus if a participant does not receive an alert and only 20% of their nearest neighbors receive an alert (23 per 100 fewer using IPW2). The overall effects, (95% CI:−0.27, 0.05) using IPW1 and (95%CI:−0.32, 0.06) using IPW2. When estimated using IPW1, we expect 11 fewer reports of risk behavior per 100 participants if 50% of the nearest neighbors and participant receive alerts compared to if only 20% of the nearest neighbors and participant receive alerts (13 per 100 fewer using IPW2).
8. Discussion.
In this paper, methods for evaluating disseminated effects were developed for the setting of network-based studies by leveraging a nearest neighbor interference set. The proposed approach uses connections (i.e. links) between individuals in a network and allows for overlapping interference sets within each component of the network. The two proposed estimators were shown to be consistent and asymptotically normal. Importantly, a consistent, closed-form estimator of the asymptotic variance was derived. The simulation study demonstrated that the two IPW estimators had reasonable finite-sample performance in terms of consistency and empirical coverage for a large number (> 100) of components in the observed network. The proposed variance estimators incorporate the observed network structure by assigning each individual a unique propensity score defined by their own nearest neighbors in which the nearest neighbors for individuals can overlap. We compared the performance of our variance estimators to the estimators for the asymptotic variances that assume partial interference with component-level propensity scores (Liu, Hudgens and Becker-Dreps, 2016) by using the observed network components as partial interference sets. In Figure 5, our variance estimators were more efficient and closer to the empirical standard error by utilizing the network structure in a nearest neighbors level propensity score as compared to Liu’s estimator. In the additional simulation scenario 4, the empirical coverage probabilities were above the nominal level (97%-100%) when using the TRIP network with only 10 components. This may be a result of the uncertainty due to the imbalanced component size observed in TRIP, where the total number of nodes was 216 and the largest component had size 186. After using community detection to further divide the network into a larger number of components , the coverage level then decreased to average of 93%.
Based on the simulation results, both estimators performed well in terms of finite sample bias. IPW2 demonstrated better performance for variance estimation (i.e., ASE was closer to ESE) when the number of network components was small (< 50), while IPW1 had lower coverage for the confidence intervals. When the number of network components was large (≥ 100), the estimated average standard error for IPW1 resulted in confidence intervals with coverage around the nominal level, while IPW2 tended to have coverage above the nominal level. Based on these findings, the estimation of these effects in TRIP network using IPW2 may be preferred over IPW1 due to the small number of network components with the caveat that these recommendations may be sensitive to specification in the simulation scenarios, including features of the study design. In addition, we explored adding additional covariates with larger parameter values in the exposure generating model (Table 5). In this case, the estimators had slightly larger bias compared to Table 4 and ECP somewhat below the nominal, while IPW2 had slightly higher coverage than IPW1. As reported in Table 3, a violation of the stratified interference assumption when the exposure mechanism is misspecified resulted in deviations from the nominal coverage level for both estimators.
With these methods, we now have an approach to quantify the social and biological influence on the determinants of risk and HIV transmission in HIV risk networks of PWIDs (Friedman and Aral, 2001) when evaluating the impact of interventions, such as TasP, or how interventions permeate a risk network (Nikolopoulos et al., 2016; Friedman et al., 2014). These new methodologies will improve the identification of best preventive practices for PWID and provide evidence to expedite policy changes to improve access to HIV treatment and risk reduction interventions in subpopulations of high-risk drug users. In the TRIP study, these methods allowed for quantification of the extent to which the community alerts intervention reduced onward transmission to others in the community by tracking incident infections in the risk networks as measured through the proxy of self-reported HIV risk behaviors. Correctly conducted and analyzed studies among PWID will improve existing interventions, inform new interventions, and has the potential to reduce incident HIV infections in this subpopulation.
Studies of network effects among PWID are rich with future methodological problems. The simulation study indicated that the asymptotic variance estimators of the IPW estimators had coverage below the nominal level when the number of components in the network is limited (<50), while both IPW estimators were unbiased in finite samples (<5%; bias/true value). Finite sample correction for estimating asymptotic variances is needed when the network has small number of components. As the approach in this paper used components as independent units for the variance estimation, developing methodologies with heterogeneous correlation structures within a large size component should be included in future work. Furthermore, the outcome of interest may be missing due to participant loss to follow-up in some intervention-based studies when outcomes are ascertained post-intervention. For example, 21% of TRIP participants were lost to follow-up by the six-month visit. Future work should include development of censoring methods to evaluate the IPW outcomes in the presence of missing outcomes or alternative methods to also address missing links in the network. With regard to real data application, the impact of unmeasured confounding is important because this would violate the conditional exchangeability assumption; however, sensitivity analyses in the presence of interference currently only exist for two-stage randomized trials with clustering features (VanderWeele, Tchetgen Tchetgen and Halloran, 2014). Designing sensitivity analyses to assess the bias of unmeasured confounding in network-based studies should be included in future research. In addition, if the spillover set actually included two-degree neighbors or other sets of individuals in the network, the nearest neighbors interference assumption would not be valid. We recommend the development of future methods that consider alternative definitions of the spillover set in the network. For example, we could also have a violation of the stratified interference assumption if in fact one of the neighbors was a closer contact or more important to the index participant. We recommend for future work the incorporation of edge weights into this method to reflect variations in the strength of connections relevant for spillover. With these improved inferential methods, investigators will be able to answer questions they were previously unable to address in network-based studies, leading to more effective intervention implementation and far-reaching policy change to prevent HIV infection, reduce risk behavior, ultimately, improve HIV treatment and care among PWID. In addition to study HIV transmission among PWID, this method can also be applied in a wider context to study sexually transmitted infection diseases such as genital herpes and trichomoniasis among adolescents and young adults, men who have sex with men, or pregnant women.
Supplementary Material
Appendices: Estimating Causal Effects of HIV Prevention Interventions with Interference in Network-based Studies among People Who Inject Drugs
The appendices include the following: 1) additional details for Proposition 1 and Proposition 2; 2) the simulation results from 1000 simulation data set on networks with 10, 50, 100, 150, 200 components; 3) and the point estimates for direct, indirect, total, and overall effects under allocation strategies 20%, 30%, 40% and 50% and their corresponding 95% confidence intervals for the effect of community alerts at baseline on HIV risk behavior at 6-month follow up in TRIP using different set of measured confounding variables.
Acknowledgements.
These findings are presented on behalf of the Transmission Reduction Intervention Project (TRIP). We would like to thank all of the TRIP investigators, data management teams, and participants who contributed to this project. We thank Ke Zhang for her editorial comments. The project described was supported by the Avenir Award Program for Research on Substance Abuse and HIV/AIDS (DP2) from National Institute on Drug Abuse of the National Institutes of Health Award Number DP2DA046856. Dr. Samuel Friedman was partially supported by the National Institute on Drug Abuse of the National Institutes of Health Award Number DP1DA034989, which funded Preventing HIV Transmission by Recently-Infected Drug Users (TRIP), and the National Institute on Drug Abuse of the National Institutes of Health Award Number P30DA011041, which supported the Center for Drug Use and HIV Research at New York University. Dr. M. Elizabeth Halloran was partially supported by the National Institute of Allergy and Infectious Diseases of the National Institutes of Health Award Number R01AI085073 titled Causal Inference in Infectious Disease Prevention Studies. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Footnotes
In principle, we could compute the nearest neighbors propensity score as a product of the individual propensity scores for all neighbors for all exposure combinations such that under the assumption of independence of given a nearest neighbor-level random effects and individual exposure and covariates. This would be one correct way of computing the nearest neighbors propensity score. Instead in this estimator, we use an alternative solution where the nearest neighbors propensity score is estimated assuming a binomial model conditional on a summary statistics of the nearest neighbors covariates. This approach, while approximate, is more straightforward and works when the dependency among neighbors’ exposures cannot be attributed to a latent factor shared by all units belonging to the same nearest neighbor set in the network.
Dataset and codes
The TRIP datasets are available upon reasonable request to the corresponding author subject to approval by the TRIP investigators. The simulation code and datasets are available from the corresponding author on reasonable request. Codes and a sample dataset can be found on github: https://github.com/uri-ncipher/Nearest-Neighbor-estimators.
REFERENCES
- Aronow P and Samii C (2017). Estimating average causal effects under general interference, with application to a social network experiment. The Annals of Applied Statistics 11 1912–1947. [Google Scholar]
- Basse G and Feller A (2018). Analyzing two-stage experiments in the presence of interference. Journal of the American Statistical Association 113 41–55. [Google Scholar]
- Benjamin-Chung J, Arnold B, Berger D, Luby S, Miguel E, Colford J and Hubbard A (2017). Spillover effects in epidemiology: Parameters, study designs and methodological considerations. International Journal of Epidemiology 47 332–347. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boos D and Stefanski L (2013). M-Estimation (Estimating Equations) 297–337.
- Buchanan A, Vermund S, Friedman S and Spiegelman D (2018). Assessing Individual and Disseminated Effects in Network-Randomized Studies. American Journal of Epidemiology 187 2449–2459. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clauset A, Newman MEJ and Moore C (2004). Finding community structure in very large networks. Phys. Rev. E 70 066111. [DOI] [PubMed] [Google Scholar]
- Desrosiers A, Kumar P, Dayal A, Alex L, Akram A and Betancourt T (2020). Diffusion and spillover effects of an evidence-based mental health intervention among peers and caregivers of high risk youth in Sierra Leone: study protocol. BMC Psychiatry 20. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Forastiere L, Airoldi EM and Mealli F (2021). Identification and Estimation of Treatment and Interference Effects in Observational Studies on Networks. Journal of the American Statistical Association 116 901–918. [Google Scholar]
- Friedman S and Aral S (2001). Social networks, risk-potential networks, health, and disease. Journal of Urban Health 73 411–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friedman SR, Downing MJ, Smyrnov P, Nikolopoulos G, Schneider JA, Livak B, Magiorkinis G, Slobodianyk L, Vasylyeva TI, ParasKevis D et al. (2014). Socially-integrated transdisciplinary HIV prevention. AIDS and Behavior 18 1821–1834. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ghosh D, Krishnan A, Gibson B, Brown S-E, Latkin CA and Altice FL (2017). Social Network Strategies to Address HIV Prevention and Treatment Continuum of Care Among At-risk and HIVinfected Substance Users: A Systematic Scoping Review. AIDS and Behavior 21 1183–1207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Giallouros G, Pantavou K, Pampaka D, Pavlitina E, Piovani D, Bonovas S and NiKolopoulos GK (2021). Drug Injection-Related and Sexual Behavior Changes in Drug Injecting Networks after the Transmission Reduction Intervention Project (TRIP): A Social Network-Based Study in Athens, Greece. International Journal of Environmental Research and Public Health 18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hadjikou A, Pavlopollou ID, Pantavou K, Georgiou A, Williams LD, Christaki E, Voskarides K, Lavranos G, Lamnisos D, Pouget ER et al. (2021). Drug injection-related norms and high-risk behaviors of people who inject drugs in Athens, Greece. AIDS Research and Human Retroviruses 37 130–138. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hayes R, Alexander ND, Bennett S and Cousens S (2000). Design and analysis issues in cluster-randomized trials of interventions against infectious diseases. Statistical Methods in Medical Research 9 95–116. [DOI] [PubMed] [Google Scholar]
- Hong G and Raudenbush SW (2006). Evaluating kindergarten retention policy: A case study of causal inference for multilevel observational data. Journal of the American Statistical Association 101 901–910. [Google Scholar]
- Hudgens MG and Halloran ME (2008). Toward causal inference with interference. Journal of the American Statistical Association 103 832–842. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lansky A, Finlayson T, Johnson C, Holtzman D, Wejnert C, Mitsch A, Gust D, Chen R, Mizuno Y and Crepaz N (2014). Estimating the number of persons who inject drugs in the United States by meta-analysis to calculate national rates of HIV and hepatitis C virus infections. PLoS One 9 e 97596. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee T, Buchanan A, Katenka N, Forastiere L, Halloran M, Friedman S and Nikolopou-los G (2022). Appendices: Estimating Causal Effects of Non-Randomized HIV Prevention Interventions with Interference in Network-based Studies among People who Inject Drugs. [DOI] [PMC free article] [PubMed]
- LIU L and Hudgens MG (2014). Large sample randomization inference of causal effects in the presence of interference. Journal of the American Statistical Association 109 288–301. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu L, Hudgens MG and Becker-Dreps S (2016). On inverse probability-weighted estimators in the presence of interference. Biometrika 103 829–842. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mathers BM, Degenhardt L, Phillips B, Wiessing L, Hickman M, Strathdee SA, Wodak A, Panda S, Tyndall M, Toufik A et al. (2008). Global epidemiology of injecting drug use and HIV among people who inject drugs: a systematic review. The Lancet 372 1733–1745. [DOI] [PubMed] [Google Scholar]
- Nikolopoulos G, Sypsa V, Bonovas S, Paraskevis D, Malliori M, Hatzakis A and Friedman S (2015). Big Events in Greece and HIV Infection Among People Who Inject Drugs. Substance use & misuse 50 1–14 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nikolopoulos GK, Pavlitina E, Muth SQ, Schneider J, Psichogiou M, Williams LD, Paraskevis D, Sypsa V, Magiorkinis G, Smyrnov P et al. (2016). A network intervention that locates and intervenes with recently HIV-infected persons: The Transmission Reduction Intervention Project (TRIP). Scientific Reports 6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ogburn EL, VanderWeele TJ et al. (2014). Causal diagrams for interference. Statistical Science 29 559–578. [Google Scholar]
- Pampaka D, Pantavou K, Giallouros G, Pavlitina E, Williams LD, Piovani D, Bonovas S and Nikolopoulos GK (2021). Mental Health and Perceived Access to Care among People Who Inject Drugs in Athens, Greece. Journal of Clinical Medicine 10 1181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Paraskevis D, Nikolopoulos G, Fotiou A, Tsiara C, Paraskeva D, Sypsa V, Lazanas MK, Gargalianos-Kakolyris P, Psichogiou M, Skoutelis A, Wiessing L, Friedman S, Des Jarlais D, Terzidou M, Kremastinou J, Malliori M and Hatzakis A (2013). Economic Recession and Emergence of an HIV-1 Outbreak among Drug Injectors in Athens Metropolitan Area: A Longitudinal Study. PLoS One 8 e78941. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Prejean J, Song R, Hernandez A, Ziebell R, Green T, Walker F, Lin LS, An Q, Mermin J, Lansky A et al. (2011). Estimated HIV incidence in the United States, 2006–2009. PLoS One 6 e17502. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Psichogiou M, Giallouros G, Pantavou K, Pavlitina E, Papadopoulou M, Williams LD, Hadjikou A, Kakalou E, Skoutelis A, Protopapas K et al. (2019). Identifying, linking, and treating people who inject drugs and were recently infected with HIV in the context of a network-based intervention. AIDS care. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rewley J, Fawzi MCS, McAdam K, Kaaya S, Liu Y, Todd J, Andrew I and Onnela JP (2020). Evaluating spillover of HIV knowledge from study participants to their network members in a stepped-wedge behavioural intervention in Tanzania. BMJ Open 10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rubin DB (1980). Discussion of Randomization analysis of experimental data in the Fisher randomization test” by D. Basu. Journal of the American Statistical Association 75 591–593. [Google Scholar]
- Sobel ME (2006). What do randomized studies of housing mobility demonstrate? Causal inference in the face of interference. Journal of the American Statistical Association 101 1398–1407. [Google Scholar]
- Sypsa V, Paraskevis D, Malliori M, Nikolopoulos G, Panopoulos A, Kantzanou M, Katsoulidou A, Psichogiou M, Fotiou A, Pharris A, Van de Laar M, Wiessing L, Des Jarlais D, Friedman S and HatzaKis A (2014). Homelessness and Other Risk Factors for HIV Infection in the Current Outbreak Among Injection Drug Users in Athens, Greece. American Journal of Public Health 105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tchetgen Tchetgen E and Coull B (2006). A diagnostic test for the mixing distribution in a generalised linear mixed model. Biometrika 93 1003–1010. [Google Scholar]
- Tchetgen Tchetgen EJ and VanderWeele TJ (2012). On causal inference in the presence of interference. Statistical Methods in Medical Research 21 55–75. [DOI] [PMC free article] [PubMed] [Google Scholar]
- VanderWeele T, Tchetgen Tchetgen E and Halloran M (2014). Interference and Sensitivity Analysis. Statistical science : a review journal of the Institute of Mathematical Statistics 29 687–706. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Williams L, Kostaki E, Pavlitina E, Paraskevis D, Hatzakis A, Schneider J, Smyrnov P, Hadjikou A, Nikolopoulos G, Psichogiou M and Friedman S (2018). Pockets of HIV Non-infection Within Highly-Infected Risk Networks in Athens, Greece. Frontiers in Microbiology 9. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Appendices: Estimating Causal Effects of HIV Prevention Interventions with Interference in Network-based Studies among People Who Inject Drugs
The appendices include the following: 1) additional details for Proposition 1 and Proposition 2; 2) the simulation results from 1000 simulation data set on networks with 10, 50, 100, 150, 200 components; 3) and the point estimates for direct, indirect, total, and overall effects under allocation strategies 20%, 30%, 40% and 50% and their corresponding 95% confidence intervals for the effect of community alerts at baseline on HIV risk behavior at 6-month follow up in TRIP using different set of measured confounding variables.