

Abstract
Total chemical protein synthesis provides access to entire D‐protein enantiomers enabling unique applications in molecular biology, structural biology, and bioactive compound discovery. Key enzymes involved in the central dogma of molecular biology have been prepared in their D‐enantiomeric forms facilitating the development of mirror‐image life. Crystallization of a racemic mixture of L‐ and D‐protein enantiomers provides access to high‐resolution X‐ray structures of polypeptides. Additionally, D‐enantiomers of protein drug targets can be used in mirror‐image phage display allowing discovery of non‐proteolytic D‐peptide ligands as lead candidates. This review discusses the unique applications of D‐proteins including the synthetic challenges and opportunities.
Keywords: chemical protein synthesis, chemical ligation, D-proteins, mirror-image proteins, peptides, proteins, protein engineering
D‐protein enantiomers can be accessed through total chemical synthesis and their preparation enables establishment of mirror‐image life, structural analysis through racemic protein crystallography and discovery of proteolysis‐resistant ligands. Here, we highlight the recent advances in D‐protein and D‐peptide technology and discuss upcoming challenges and opportunities.
1. Introduction
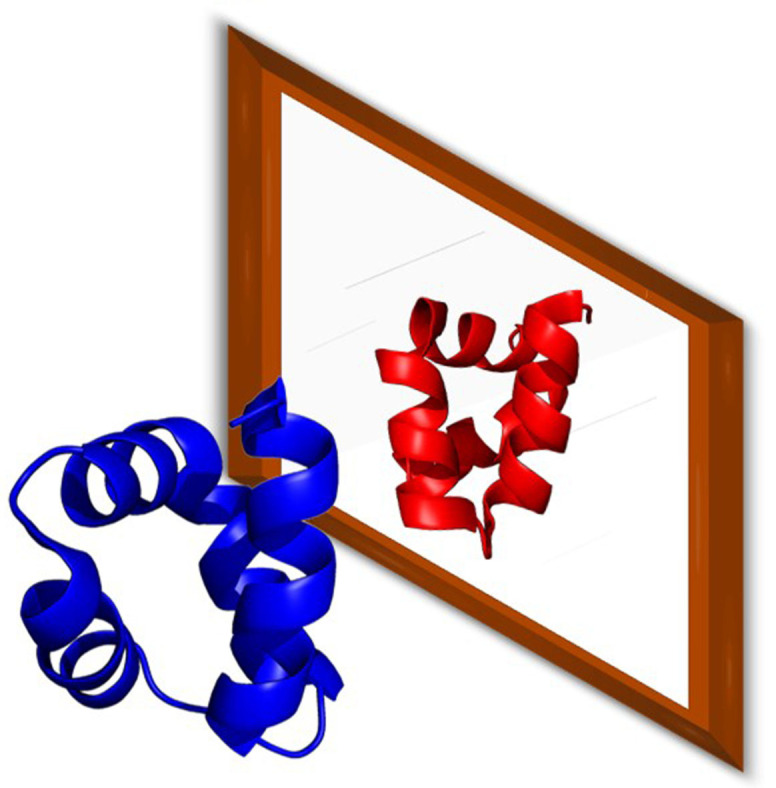
Proteins, like other biomolecules, are composed of chiral building blocks. [1] Ribosomes recruit L‐ (Levorotatory) amino‐acids for catalysis, and hence recombinant proteins are largely refrained in the L‐framework unless engineered ribosomes are used. [2] In contrast, incorporation of D‐ (Dextrorotatory) amino acids into L‐polypeptides requires the use of engineered ribosomes,[ 2a , 2b ] post‐translational modification systems (PLP‐dependent enzyme) [3] or non‐ribosomal peptide synthetases (NPRS). [4] At the time of writing, proteins entirely comprised of D‐amino acids have yet to be found in nature and must be synthesized via chemical routes. Though being more difficult to prepare, D‐amino acid proteins that fold into reciprocal chirality (Figure 1) possess extraordinary potentials in scientific research, spanning from the creation of mirror‐image life, mechanistic investigations of natural proteins to the isolation of ultra‐stable binders. [5] In this review, we will describe current research surrounding enantiomeric proteins including both the challenges and opportunities.
Figure 1.

Proteins comprised entirely of D‐amino acids fold into the mirror image of the corresponding L‐protein.
2. Research Surrounding D‐Protein Enantiomers
2.1. Towards ‘mirror‐image life’
Mirror‐image life which was first proposed by Louis Pasteur in 1860 [6] refers to the creation of an artificial biosystem with all macromolecules presented in their opposite enantiomeric forms. In these self‐replicating systems, L‐nucleic acids serve to store genetic information creating D‐protein workforce for biological function following the mirror‐image central dogma. [7] Indeed. the de novo design of living entities has gained significant attention because of our fundamental interest in understanding the origin of life. [8] While preparation of an entirely self‐replicating living entity in mirror image form is a major challenge, D‐enantiomers of key enzymes involved in the central dogma of molecular biology have been prepared (Figure 2). [5] These enantiomeric enzymes hold potentials in research. For example, mirror‐image polymerases can be used to generate L‐nucleotide aptamer libraries [9] or L‐genome for bioorthogonal information storage. [10] Also, an enantiomeric ribosome could facilitate access to D‐proteins through mirror‐image translation. Furthermore, creation of a self‐replicating mirror‐image entity can offer access to D‐proteins, L‐sugars and/or other enantiopure pharmaceutical compounds. Recent examples of preparing D‐enzymes towards mirror‐image life are summarized below:
Figure 2.

Recent advances in realizing mirror‐image synthetic biology using D‐protein enantiomers. Representative structures for illustrative purposes as D‐ASFV pol X (PDB: 1JQE), D‐Dpo4 (PDB: 3PR4), D‐Pfu (PDB: 2JGU), D‐LigA (PDB: 2Q2T), L5, L18 and L25 (PDB: 4YBB) constructed in PyMOL. [11]
2.1.1. Creation of artificial L‐polynucleotides by use of mirror‐image nucleic acid polymerases
Template‐directed polymerizations of the enantiomeric L–DNA and ‐RNA were first carried out using the D‐protein enantiomer of African swine fever virus polymerase X (D‐ASFV pol X). [12] Composed of only 174 residues, ASFV pol X is the smallest DNA polymerase known, hence an ideal candidate for total chemical synthesis. The longest polynucleotide successfully replicated by D‐ASFV pol x was 44 nucleotides in length but required fresh enzymes at each cycle due to its weak thermal stability. [12] A significant advancement was achieved by preparing the 358‐residue enantiomeric P2 DNA polymerase IV (Dpo4) from Saccharolobus solfataricus, which is sufficiently stable to temperature flux and could perform mirror‐image polymerase chain reaction (miPCR).[ 9 , 13 ] The D‐Dpo4 could successfully create a 120‐bp L–DNA sequence encoding the E. coli 5S ribosomal RNA gene rrfB. [9] Its thermostable variant D‐Dpo4‐3C could assemble a full L–DNA gene encoding protein Ssoo7d. [13] Interestingly, a further‐engineered variant D‐Dpo4‐5m‐Y12S was reported that was capable of both transcription and reverse transcription, laying a strong foundation for enabling mirror‐image life. [14]
In order to create a lengthy enantiomeric gene with high fidelity, access to polymerase enzymes with a low error rate is essential, thus an enantiomeric derivative of Pyrococcus furiosus (Pfu) DNA polymerase has been deduced. [15] Pfu is composed of 775 amino acids reaching 90 kDa in molecular weight, rendering its chemical synthesis challenging. To circumvent this issue, a split version of Pfu was prepared consisting of N‐ (467‐residue) and C‐ (308‐residue) fragments. Due to the significant cost of D‐isoleucine and its association with the aggregation of peptide fragments, most of them were replaced by other bulky residues including valine and leucine. [10] The split polymerase D‐Pfu could synthesize a 1.5‐kb mirror‐image gene from short, synthetic oligonucleotides. Interestingly, because of the inherent stability towards enzymatic cleavage, a trace amount of artificial L‐DNA preserved in water from a local pond remained amplifiable by D‐Pfu after one year, whereas D‐DNA could not be amplified by L‐Pfu after one day. This work is a clear leap forward in the pursuit of mirror‐image biology. In addition, the miPCR platform is potentially useful in molecular discovery programs generating nuclease‐resistant L‐nucleotide aptamers for critical drug targets. [9]
2.1.2. Other life‐essential, mirror‐image proteins
Enantiomeric ligase is another critical enzyme that can be used to create long stretches of L‐DNA. [16] Preparation of a mirror‐image ribosome is exceptionally challenging as it composes of multiple protein and nucleotide subunits. [17] Currently, three out of the ∼50 enantiomeric E. coli ribosomal proteins have been reported, including L5, L18 and L25. [18] The D‐ribosomal proteins were prepared with native post‐translational modifications and interacted specifically with L‐5S RNA to form a mirror‐image ribonucleoprotein complex. On the other hand, eukaryotic ribosomes consist of 79–80 proteins and four rRNAs, [17] requiring approximately 200 non‐ribosomal factors for assembly. [19] Both the ribosomal proteins and rRNA itself also bear post‐translational modifications, [20] adding further challenges to their preparation.
2.1.3. Remarks
The genome of the laboratory strain E. coli K12 encodes for approximately 4300 proteins, [21] but only a small fraction of their enantiomeric counterparts have been reported. [22] Many of these proteins bear intrinsic synthetic challenges, because of their size, post‐translational modifications and folding (see section 3). Construction of the necessary mirror‐image oligonucleotides is also a major challenge. Whilst the synthesis of relatively short oligonucleotides is possible from L‐xylose or L‐arabinose, [23] the resulting oligonucleotides suffer from lower purity.[ 9 , 12 , 13 ] With the advent of the high fidelity D‐Pfu capable of assembling complex genes, [10] one might argue that this challenge is within reach. Given the significant efforts, it is also expected that a mirror‐image ribosome from bacteria will soon be reported. In addition, mirror‐image tRNAs, tRNA synthetases, and translation factors will need to be prepared to enable the translation of L‐mRNA to D‐polypeptides. When made available, the mirror‐image translation system will be game‐changing in the landscape of enantiomeric protein synthesis. Finally, pursuit of a truly self‐replicating system will require an approach of devising a minimal cell and assembly of each essential component in mirror‐image form.
2.2. Racemic protein crystallography
Racemic protein crystallography utilizes synthetic protein enantiomers for crystallization and is a technology particularly useful at yielding atomistic structural insights. [24] Unlike native L‐proteins, racemic proteins can crystallize into achiral space groups possessing higher symmetry and order (Figure 3). [25] Solving structure based on racemic proteins can be advantageous. As illustrated in the first example, the phase issue in solving the structure of rubredoxin was vastly simplified, because the space group was found to be centrosymmetric with the crystal unit cell containing a center of inversion (Figure 3B). [26] The off‐diagonal phases of the X‐ray diffraction data obtained from a centrosymmetric crystal cancel out, restricting the phases to 0° or 180°, as opposed to the possible 0° to 360° arising from a homochiral crystal. [24] Additionally, the centrosymmetric crystal has high dimensionality. This generally results in rapid protein crystallization and structure solving with high‐resolution detail, in addition to unveiling solute and ligand interactions.[ 24 , 27 ]
Figure 3.

Illustrative comparison of (A) a homochiral crystal unit cell and (B) a racemic crystal unit cell containing an inversion center (e. g. P ).
Considering the higher order of crystal symmetry and favorable crystal growth, racemic protein crystallography has been used to resolve X‐ray structures of numerous proteins up to ultra‐high (sub‐angstrom) resolution (Table 1). Indeed, 13 (20 % so far) of the reported racemic crystal structures were resolved in the centrosymmetric space group P . Many quasi‐racemic crystal structures, in which the enantiomers differ slightly, are reported to adopt the space group P1 due to a lack of true symmetry. [28] However, it is more appropriate to classify these crystals as pseudo‐centrosymmetric or “pseudo‐P .”[ 25 , 29 ] While almost half of the racemic structures were resolved in centrosymmetric/pseudo‐centrosymmetric space groups, the other half were also resolved in chiral space groups (Table 1). Notably, there are no reported instances of a single enantiomer crystallizing into a chiral space group from a racemate. Thus, crystallization of proteins from racemates may have advantages beyond that explained by the achiral space group theory (for review – see ref. [24]).
Table 1.
A decade of racemic protein crystallography (at the time of writing).
|
Protein |
Function |
Length[a] |
Res. [Å] |
Space group |
PDB accession |
Structural insights |
Ref. |
|
|---|---|---|---|---|---|---|---|---|
|
Lacticin Q |
Bacteriocin |
53 |
0.96 |
P1 |
7P5R |
First reported crystal structure |
[31] |
|
|
CyO2 |
Bracelet cyclotide |
30 |
1.17 |
P1211 |
7RMQ |
First reported crystal structures of bracelet cyclotides |
[32] |
|
|
CyO2 (I11L) |
1.04 |
P1211 |
7RMR |
|||||
|
CyO2 (I11G) |
1.10 |
P1211 |
7RMS |
|||||
|
Hyen D |
1.35 |
P1211 |
7RIH |
|||||
|
Hyen D (I11L) |
1.22 |
P
|
7RII |
|||||
|
Hyen D (I11G) |
1.30 |
P1 |
7RIJ |
|||||
|
Calcicludine |
Kunitz‐type serine protease inhibitor homolog |
60 |
2.52 |
I41 |
6KZF |
Confirmation of novel disulfide surrogate bridge strategy (DADA) |
[33] |
|
|
rC5a‐desArg |
Rat anaphylatoxin |
76 |
1.80 |
P1 |
[g] |
New insights on C‐terminal conformation |
[34] |
|
|
Chimeric‐rC5a |
77 |
1.31 |
P212121 |
g |
Chimeric protein probes conjugated to small‐molecule antagonist |
[35] |
||
|
rC5a |
1.58 |
P
|
g |
|||||
|
M2‐TM[b] |
Ion channel TM helix |
24 |
2.00 |
P21 /c |
4RWB |
Investigations of a heterochiral coiled coil |
[27b] |
|
|
M2‐TM[c] |
1.05 |
P
|
4RWC |
|||||
|
M2‐TM (I39A)[c] |
1.55 |
P
|
6MPL |
[27a] |
||||
|
M2‐TM (I42A)[c] |
1.40 |
P
|
6MPM |
|||||
|
M2‐TM (I42E)[c] |
1.40 |
P
|
6MPN |
|||||
|
Melittin |
Honeybee venom |
27 |
1.27 |
C2 |
6O4M |
Retention of native quaternary structure |
[36] |
|
|
Ribifolin |
Orbitides from Jatropha |
8 |
0.99 |
P121/n1 |
6DKZ |
Unveil structures of Jatropha orbitides |
[37] |
|
|
Pohlianin C |
8 |
1.20 |
Pcab |
6LD0 |
||||
|
Jatrophidin |
8 |
1.03 |
P121/n1 |
6DL1 |
||||
|
GsMTx4 |
Spider venom |
34 |
1.75 |
P
|
g |
First reported crystal structure |
[38] |
|
|
BTD‐2 |
Baboon θ‐defensin |
18 |
1.45 |
P
|
5INZ |
Novel oligomeric state resembles mechanistically relevant assembly |
[39] |
|
|
Snakin‐1 |
Potato snakin |
63 |
1.50 |
P1 |
5E5Y |
Novel use of radiation damage induced phasing of quasi‐racemic crystals |
[40] |
|
|
1.60 |
P21/c |
5E5Q |
||||||
|
1.57 |
P21/c |
5E5T |
||||||
|
Ubiquitin |
Ubiquitin |
76 |
1.95 |
[d] |
[g] |
Confirm folding of synthetic protein |
[41] |
|
|
M1‐linked tri‐Ubs |
76[e] |
1.80 |
P1 |
5GO7 |
D‐monomeric Ub can facilitate Ub oligomer crystallization |
[28] |
||
|
M1‐linked tetra‐Ub |
2.18 |
P21 |
5GO8 |
|||||
|
K6‐linked di‐Ub |
1.15 |
P1 |
5GOB |
|||||
|
K11‐linked di‐Ub |
1.73 |
P1 |
5GOC |
|||||
|
K27‐linked di‐Ub |
1.15 |
P1 |
5GOD |
|||||
|
K29‐linked di‐Ub |
1.98 |
P2 |
5GOG |
|||||
|
K33‐linked di‐Ub |
1.95 |
P1 |
5GOH |
|||||
|
K48‐linked di‐Ub |
1.59 |
P1 |
5GOI |
|||||
|
K63‐linked di‐Ub |
1.55 |
P21212 |
5GOJ |
|||||
|
K11/K63‐linked tri‐Ub |
1.84 |
P22121 |
5GOK |
|||||
|
K27‐linked di‐Ub |
152 |
1.55 |
C2 |
5J8P |
Largest true synthetic racemic proteins to be crystallized |
[42] |
||
|
K27‐linked tri‐Ub |
228 |
2.10 |
H3 |
5JBV |
||||
|
VHP |
Vinillin headpiece domain |
35 |
2.10 |
P
|
3TRW |
Investigation of pentafluoro phenylalanine (F5Phe) amino acids on protein structure |
[43] |
|
|
VHP |
2.30 |
I‐4c2 |
3TRY |
|||||
|
VHP (F5Phe10) |
1.46 |
F222 |
3TJW |
|||||
|
VHP (F5Phe17) |
1.00 |
P1 |
3TRV |
|||||
|
VHP (β3‐hGln26) |
1.30 |
P1 |
5I1N |
Investigation of beta amino acids on protein structure |
[44] |
|||
|
VHP (ACPC26) |
1.35 |
P1 |
5I1O |
|||||
|
VHP (β3‐hLys30) |
1.40 |
P1 |
[g] |
|||||
|
VHP (APC30) |
1.12 |
P1 |
5I1S |
|||||
|
Ts3 |
Scorpion venom |
64 |
1.93 |
P
|
5CY0 |
First reported structure of Ts3 |
[45] |
|
|
Magainin 2 (L‐1) |
Amphibian HDP |
23 |
1.75 |
I‐42d |
4MGP |
Beta amino acid variants investigating phenylalanine zipper motif |
[46] |
|
|
Magainin 2 (L‐2) |
2.20 |
P21212 |
5CGN |
[47] |
||||
|
Magainin 2 (L‐3) |
1.50 |
P1 |
5CGO |
|||||
|
ShK |
Sea anemone venom |
35 |
0.97 |
P121/c |
4LFS |
Structure variation to NMR and enantiospecific activity |
[48] |
|
|
ShK analogue |
1.20 |
H‐3 |
4Z7P |
Structure activity relationships |
[49] |
|||
|
ShK (allo‐Thr13) |
0.90 |
P1 |
5I5B |
Investigation of side chain chirality on protein structure |
[50] |
|||
|
ShK (allo‐Thr31) |
1.30 |
P1211 |
5I5C |
|||||
|
ShK (allo‐Ile7) |
1.20 |
C2 |
5I5A |
|||||
|
Rv1738 |
M. tuberculosis protein |
94 |
1.50 |
C12/c1 |
4WPY |
First reported structure, unknown function |
[51] |
|
|
STFI‐1 |
Sunflower trypsin inhibitor |
14 |
1.25 |
P
|
4TTK |
Disulfide‐rich scaffolds for drug design |
[52] |
|
|
cVc1.1 |
Cone snail venom |
22 |
1.70 |
Pbca |
4TTL |
|||
|
kB1 |
Plant cyclotide |
29 |
1.90 |
P
|
4TTM |
|||
|
kB1 (G6A) |
1.25 |
P
|
4TTN |
|||||
|
kB1(V25A) |
2.30 |
P
|
4TTO |
|||||
|
Ser‐CCL1 |
Chemokine |
73 |
2.15 |
P1 |
4OIJ |
Crystal structure of a homogenous, glycosylated chemokine |
[53] |
|
|
Glycosylated Ser‐CCL1 |
73[f] |
2.10 |
P1 |
4OIK |
||||
|
DKP Ester Insulin |
Synthetic hormone+derivatives |
51 |
1.60 |
P
|
4IUZ |
Confirm folding of synthetic derivative |
[54] |
|
|
Ester insulin |
1.50 |
I213 |
5EN9 |
Confirmation of correctly folded synthetic protein for isotope experiments |
[55] |
|||
|
Human insulin |
1.35 |
I213 |
5ENA |
|||||
|
VEGF‐A/antagonist complex |
Vascular endothelial growth factor A+D‐protein binder |
102+56 |
1.60 |
P21/n |
4GLN |
First reported structure of a heterochiral protein complex by racemic crystallography |
[56] |
|
|
Crambin analogue |
Thionin protein |
46 |
1.08 |
P1211 |
3UE7 |
Novel linear‐loop peptide chain topology |
[29a] |
|
|
Kaliotoxin |
Scorpion venom |
38 |
0.95 |
P
|
3ODV |
Basis for structure activity relationships |
[57] |
|
|
Omwaprin |
Snake venom |
50 |
1.30 |
P21/c |
3NGG |
First reported structure |
[30] |
[a] Total amino acid length of synthetic protein enantiomer. [b] Crystallized from monoolein lipidic cubic phase. [c] Crystallized from racemic lipids. [d] Data unavailable. [e] Residues in D‐protein enantiomer. [f] 73 residues+oligosaccharide. [g] Not reported/deposited.
Racemic protein crystallography has been most frequently applied to study miniproteins containing fewer than 100 residues. These proteins are known to be difficult to crystallize because of their globular morphology which disfavors crystal packing. Meanwhile, their small sizes render the chemical synthesis of these proteins feasible (see section 3 below for synthetic approaches). [30] Some of the unique insights generated by racemic crystallography are listed in Table 1.
2.2.1. Quaternary states of protein
Oligomeric assemblies are thought to play a common role in the activity of a variety of antimicrobial peptides, particularly those acting on the bacterial membrane. [59] In an aim to elucidate its mechanism of action, the β‐sheet antimicrobial peptide originated from Baboons (BTD‐2) was chemically synthesized in both L‐ and D‐forms. Interestingly, racemic protein crystallography of BTD‐2 revealed a novel anti‐parallel trimeric form (Figure 4B). This supramolecular discovery is fibril‐like and is postulated to have critical roles in membrane disruption. [39] In another example, melittin is an α‐helical antimicrobial peptide isolated from honeybee venom which is known to exert its activity by disrupting the bacterial cell membrane. The tetrameric assembly observed in the solution state is also present in the racemic X‐ray crystal structure (Figure 4A). [36] Similarly, the tetrameric nature of magainin 2 was suggested to be critical for the activity of this amphibian host defense peptide (Figure 4C). [47]
Figure 4.

Quaternary structures by racemic protein crystallography; (A) Melittin tetramer (PDB: 6O4M); (B) BTD‐2 extended fibril‐like structure (PDB: 5INZ); (C) Magainin 2 phenylalanine zipper motif unaffected by β‐amino acid substitutions. D‐magainin 2 is shown in red and mutants L‐1 (Ala) shown in blue (PDB: 4MPG), L‐2 (APC) in green (PDB: 4CGN) and L‐3 (ACPC)(PDB: 5CGO) in magenta. β‐amino acids highlighted in orange; (D) M2‐TM helix forms heterochiral coiled coils, with a hendecad repeat identified in lipidic cubic phase (LCP, PDB: 4RWB) but absent in racemic β‐octylglucoside (DL‐OG, PDB: 4RWC). Mutation of sterically disruptive isoleucine residues to alanine (DL‐OG(I39A), PDB: 6MPL), (DL‐OG(I42A), PDB: 6MPM) or glutamate (DL‐OG(I42E), PDB: 6MPN) favored hendecad repeat motifs in chiral lipids; (E) Quaternary structure of VEGF‐A dimer bound to two D‐protein antagonist molecules (PDB: 4GLN). All structures were modelled in CCP4MG [58] with data obtained from the Protein Data Bank.
Heterochiral interactions between L‐ and D‐protein isomers observed during structure elucidation may also lead to fruitful development in binder creation. In the studies of the transmembrane helix of the influenza M2 ion channel protein (TM‐M2), [27b] a heterochiral coiled‐coil association was observed between the two peptide enantiomers in the presence of detergent octyl‐glucoside (DL‐OG) or within the monoolein lipid cubic phase (LCP) (Figure 4D). The LCP structure shows an 11‐residue helical repeat (hendecad, 3,4,4 spacing) in the coiled‐coil, which differs from homochiral coiled‐coils that adopts a 7‐residue helical repeat (heptad, 3,4 spacing). The crystals grown in DL‐OG do not form a hendecad repeat, as steric clashes involving Ile39 and Ile42 prevent proper 3,4,4 interaction. Substitution of these residues with alanine or glutamate produced the hendecad repeat coiled‐coil in the racemic DL‐OG structure, thus reinforcing the argument that hendecad repeats are a feature of heterochiral coiled coils. [27a] Such heterochiral interactions can be used to design D‐proteins drugs, which are generally non‐proteolytic and non‐immunogenic (see section 2.3). The resulting drug‐target complexes can also be resolved using racemic protein crystallography to aid in rational optimization (Figure 4E).
2.2.2. Post‐translationally modified proteins
While obtaining homogenous, post‐translationally modified (PTM'd) proteins through recombinant methods remains a major technical challenge, [60] chemical protein synthesis offers exquisite atomistic control and thus ensures homogeneity (see also section 3). Racemic protein crystallography of PTM'd proteins was first applied to the glycosylated chemokine Ser‐CCL1 protein, for which no structure was reported. [53] The protein was synthesized in the native L‐form, followed by site‐specific asparagine N‐glycosylation with the native biantennary D‐glycan. Synthesis of the corresponding D‐enantiomer without glycosylation enabled the co‐crystallization of the quasi‐racemic protein (Figure 5A).
Figure 5.

Quasi‐racemic protein crystallography of homogenous, post‐translationally modified proteins; (A) D‐Ser‐CCL facilitated crystallization of glycosylated L‐Ser‐CCL1 (PDB: 4OIK); (B) Monomeric D‐ubiquitin (D‐Ub) facilitated crystallization of L‐K6‐linked diUb (PDB: 5GOB); (C) Quasi‐racemic protein crystallography of L‐ and D‐K27‐linked diUb (PDB: 5J8P). All structures modelled in CCP4MG [58] with data obtained from the protein data bank.
Another application involves the study of branched ubiquitin chains, where the folding of the branched protein molecules could be solved through racemic protein crystallography. Similarly, D‐ubiquitin was prepared in unmodified form [41] and used to facilitate crystallization of the resulting branched L‐ubiquitin proteins (Figure 5B). [28] A further example involved the preparation of branched ubiquitin proteins in both enantiomeric forms for racemic protein crystallography (Figure 5C), but the iso‐peptide linkages of the D‐proteins contained a non‐native cysteine residue scar to facilitate ligation. [42]
A key challenge, as presented in the former examples, is the preparation of PTM'd proteins in all D‐form. Glycosylated proteins possess glycans in native D‐chirality which would require complex synthesis from the corresponding L‐carbohydrates for a true racemic crystal. In addition, preparation of branched ubiquitin chains requires the use of non‐natural amino acids as auxiliaries for attachment of the ubiquitin, but they often suffer from poor ligation efficiency (see section 3.3.2.). [42]
2.2.3. Remarks
Challenges associated with D‐protein synthesis, folding and PTMs hamper the application of racemic protein crystallography. The average size of a protein ranges from 283–438 residues in length [61] with many bearing PTMs. Obtaining enough D‐protein for crystallization screening (generally in milligram range) remains labor‐intensive and uneconomical, typically requiring multiple chemical steps and protein refolding. Nevertheless, racemic protein crystallography of miniproteins remains an excellent method for deciphering molecular interactions, particularly serendipitous intermolecular interactions that deem difficult to obtain using homochiral protein crystallography, solution state NMR and/or computational structure prediction.[ 27 , 39 , 44 , 50 ] Perhaps, a more promising avenue is to conduct quasi‐racemic crystallography where a minimal D‐protein is used to facilitate crystallization of a larger L‐protein with (pseudo‐)repeated domains. [28]
2.3. Identification of drug candidates through mirror‐image phage display and related screening technologies
Polypeptide binders can offer significant selectivity and potency, and hence are excellent candidates for the treatment of various diseases and human disorders. One major bottleneck is that many peptide candidates suffer from proteolytic degradation, both limiting the option of the delivery methods and eliciting unwanted immune responses caused by major histocompatibility complex (MHC) presentation by immune cells. [62] Peptides comprised of D‐amino acids are a viable approach as they are non‐recognizable by endogenous proteases. [63] It has been suggested that D‐peptide binders can be made by retro‐inversion (RI) which relies on flipping the entire peptide chain from the N‐ to C‐ termini to offset the flip in the side chain chirality. [64] Though some success has been seen in short binders, it was quickly discovered that this double‐flip approach did not reinstate the true peptide structure and, in some cases, could drastically weaken the peptide binding. [65] Another approach was to use D‐peptides to mimic the shape of the L‐peptide agonist when presented in an MHC, without reference to the L‐peptide sequence, acting as a stable vaccine candidate. [66] Recently, binders composed of both D‐ and L‐residues have been developed through ribosomal engineering [67] or in silico protein design. [68] In order to create binders entirely composed of D‐amino acids, the most routine approach is mirror‐image phage display (MIPD). [69] In MIPD, D‐enantiomers of protein targets are synthesized and subjected to L‐peptide screening (Figure 6). Due to the nature of mirror‐image symmetry, the same‐sequence D‐peptide will bind to the native L‐protein target with equal affinity, thus yielding an inherently non‐proteolytic peptide binder. MIPD has discovered D‐peptide binders for a range of targets (Table 2). Key examples are summarized in Table 2.
Figure 6.

Process of mirror‐image phage display. Natural chirality L‐proteins are represented in blue, and mirror‐image synthetic D‐proteins are represented in red. Purple beads represent protein immobilization.
Table 2.
D‐peptide binders identified through mirror‐image phage display of D‐protein targets in the last decade (at the time of writing).
|
Protein |
Function |
Length[b] |
Name |
Type |
Length[c] |
Kd [μM][d] |
Ref. |
|---|---|---|---|---|---|---|---|
|
ARQ23 |
Androgen receptor |
46 |
QF2D‐2 |
Linear |
16 |
11 |
|
|
Annexin A1 NTD |
Surface marker in malignant tumor vasculature |
16 |
D‐TIT7 |
Linear |
7 |
8.5 x10−3 |
|
|
Tau PHF6* |
Microtubule‐associated protein |
6 |
MMD3 |
Linear |
12 |
[e] |
|
|
MMD3rev |
Linear |
12 |
[e] |
||||
|
Tau PHF6 |
p‐NH |
Linear |
12 |
[e] |
|||
|
TD28 |
Linear |
12 |
[e] |
||||
|
Immunoglobulin variable domain of TIGIT |
Immune checkpoint |
119 |
D‐TBP‐3 |
Linear |
12 |
5.6 |
|
|
Epidermal growth factor |
Mitogenic factor |
53 |
D‐PI_4 |
Linear |
12 |
54 |
|
|
Fibroblast growth factor‐inducible 14 CRD |
TWEAK (tumor necrosis factor‐like weak inducer of apoptosis) receptor |
43 |
D‐FNB |
Linear |
12 |
0.28 |
|
|
Aβ‐1‐42 |
Monomeric precursor of AB oligomers and fibrils |
42 |
Mosd1 |
Linear |
12 |
[e] |
|
|
Immunoglobulin variable domain of PD‐L1 |
Programmed cell death protein 1 |
124 |
D‐PPA‐1 |
Linear |
12 |
0.51 |
|
|
VEGF‐A |
Vascular endothelial growth factor |
102 |
RFX‐V1a2a |
Bivalent scaffold |
53+58 |
8 x10−4 |
|
|
RFX001 |
GB1 scaffold |
56 |
8.5 x10−2 |
||||
|
gp41N‐trimer pocket mimic |
HIV envelope protein ectodomain |
42 |
PIE12‐trimer |
Flanking disulfide cyclic |
8 [f] |
[e] |
|
|
MDM2 |
Oncogenic E3 ubiquitin ligase |
85 |
D‐PMIα |
Linear |
12 |
5.3 x 10−2 |
[a] Most potent binder from phage panning experiments presented. [b] Total amino acid length of synthetic protein enantiomer target. [c] Amino acid length of peptide binder identified through phage display. [d] Reported dissociation constant of D‐peptide binder to native L‐target used in phage display. [e] Kd not reported. [f] Length of original, un‐crosslinked peptide identified through phage display.
2.3.1. D‐Peptides as potential anticancer lead candidates
Growth factor proteins and/or their receptors are overexpressed in many types of cancer, [70] and hence development of their antagonists can hinder malignant tumor growth as a form of treatment in cancer therapy. [71] Consequently, enantiomeric segments of both the epidermal growth factor (EGF) and vascular endothelial growth factor (VEGF‐A) were synthesized for MIPD.[ 56 , 72 ] A 12‐residue linear D‐peptide ligand for EGF, D‐PI_4, was identified with both binding affinity and half‐maximal inhibitory concentration (IC50) in micromolar range. [72] In the case of VEGF‐A, the mini‐protein GB1 was used as a template scaffold to create a 56 residue D‐mini‐protein RFX001.D that has a binding affinity as low as 85 nM.[ 56 , 73 ] A heterochiral protein complex between a vascular endothelial growth factor (L‐VEGF‐A) and a D‐protein antagonist was also solved using racemic protein crystallography (Figure 4E), providing a foundation for structure‐based optimization of the D‐protein antagonist. [56] Upon optimization, the binder RFX037.D was created, increasing both binding affinity (K D=6 nM vs 85 nM) and thermal stability (T m >95 °C vs 33 °C). [74] Of note, RFX037.D was non‐immunogenic in mice, whereas the L‐enantiomer generated a strong immune response. In an extension of the MIPD against VEGF‐A, bivalent D‐protein ligands were also developed using orthogonal MIPD assays with two different scaffold mini‐proteins (53 and 58 residues). [75] The two best scaffolds were connected via a covalent linkage to yield the bivalent D‐protein RFX‐V1a2a, with sub‐nanomolar (K D=0.8 nM) affinity for VEGF‐A.
Other key targets for cancer treatment are immune checkpoints, [76] which are often suppressed by cancer cells to avoid recognition by the innate immune system. The immunoglobulin‐like variable (IgV) domains are known to govern immune checkpoints, and thus enantiomeric counterparts of the IgV domains of the programmed‐cell death protein ligand 1 (PD‐L1, 124 residues) and the T‐cell immunoglobulin and ITIM domain (TGIT, 119 residues) were synthesized for MIPD. [77] After five rounds of biopanning, binders with micromolar affinity and IC50 were achieved, presenting themselves as promising drug candidates. [77a] One specific binder D‐TBP‐3 demonstrated proteolytic stability and, importantly, the ability to penetrate through tumor tissue in mice which resulted in tumor suppression. [77b]
2.3.2. D‐peptides as lead preventive therapeutic candidates
The development of potent D‐peptide antagonists of the HIV‐1 envelope protein gp41 was shown to prevent viral fusion and entry into cells. [78] A trimeric version of one of the isolated candidates could block pocket‐specific viral entry with an IC50 as low as 250 pM. [78a] Further pharmacokinetic optimization and synthetic scale‐up yielded the cholesterol‐conjugated trimeric D‐peptide CPT31, [79] which is currently in Phase Ia clinical trials for the treatment of HIV.
In another study, MIPD was used to create D‐peptides with high affinity for the microtubule‐binding protein Tau, preventing self‐aggregation in the treatment of tauopathies. [80] The hexapeptides PHF6 (VQIINK) and PHF6* (VQIVYK) were found to promote Tau aggregation in tauopathies such as Alzheimer's disease, and their enantiomers have been used as a target for MIPD.[ 80 , 83 ] Notably, two peptide candidates, MMD3 and MMD3rev, demonstrated cell‐penetrating properties, with the ability to cross the cell membrane of neurons. [83]
2.3.3. Remarks
Despite all the research efforts, there is no D‐peptide therapeutic that has yet reached the market. To our knowledge, CPT31 is the only D‐peptide candidate that has entered early‐stage clinical trials, and the estimated success rate of bringing a binder from phase I to approval is 14 %. [87] Discovery of D‐peptide binders remains challenging hampering downstream clinical research and product development. The ultimate challenge of MIPD lies within the preparation of the enantiomeric protein target. Not only can size be a concern, but both the PTM and protein folding status can also pose major synthetic challenges (see section 3 for synthetic approaches). Except for the Tau targeting peptides, many targets are restricted to extracellular protein domains, as cell‐penetrating properties of peptide binders are often weak. In addition, the use of MIPD to identify competitive antagonists is limited by the arbitrary selection of off‐target binders. Efforts have been directed to computation‐based approaches with the goal to replace the tedious synthesis with in silico studies, including the docking of mirror‐image helices derived from the PDB; [88] screening of D‐tri/tetra peptides against the target active site; [89] virtual affinity maturation based on existing heterochiral structures. [90] However, existing in silico methods suffer from a lack of library diversity and polypeptide binder size, limiting the best example to a binding affinity of 20 μM. [89]
3. The Current State of the Art in D‐Polypeptide Preparation
The most common issue encountered in enantiomeric protein research surrounds their preparation. Since polypeptides entirely composed of D‐amino acids cannot be made recombinantly at the time of writing, they must be prepared by chemical synthesis and the current state‐of‐the‐art is summarized as below:
3.1. Solid phase peptide synthesis (SPPS)
Allowing stepwise addition of protected amino acids on an insoluble polymer support, solid phase peptide synthesis (SPPS) facilitates access to D‐polypeptide chains. [91] Fmoc‐protected amino acids have gained popularity over the past two decades as they facilitate the use of milder cleavage conditions. [92] Efficient reagents that allow high conversion of amino acid coupling have been reported. [93] The systematic nature of SPPS has also led to automated systems. [94] When paired with microwave irradiation, each amino acid coupling cycle can be performed in four minutes. [95] Recently, a fully automated system for SPPS, where the assembly is complete in a flow system has been developed, yielding complete coupling cycles in less than two minutes, and a full protein up to 164 residues has been assembled. [96] However, a major drawback is its requirement for a large excess of amino acids (6–60 equivalents), a major financial burden when it comes to D‐polypeptide synthesis. This is especially the case when the target proteins contain diastereomeric D‐isoleucine, which is significantly higher in cost than other building blocks.
3.2. Chemical ligation
To bring down the cost, convergent synthesis of proteins through the assembly of smaller polypeptides by chemical ligation has been achieved. [97] In general, two peptide fragments are chemically bought together by reacting two latent reaction motifs located at the termini. Various methods for chemical protein ligation have been developed, although some suffer drawbacks when preparing polypeptides in opposite chirality due to requiring modified amino acids (Table 3, Entries 1–4). On the other hand, native chemical ligation (NCL) and serine‐threonine ligation (STL) employ canonical cysteine or serine/threonine residues, though the latter is yet to be reported in D‐protein synthesis. NCL is commonly used whereby the thiol group of an N‐terminal cysteine peptide and a C‐terminal thioester of a reacting pair undergo trans‐thioesterification, followed by an S‐to‐N acyl shift to yield a traceless native peptide bond (Figure 7).
Table 3.
Synthetic methods used in chemical protein synthesis, indicating use in reported D‐protein synthesis and potential issues encountered with use.
|
Entry |
|
|
|
Used in D‐protein synthesis |
|
|---|---|---|---|---|---|
|
# |
Synthetic method |
Reagents |
Y / N |
Potential issues |
Ref. |
|
|
Ligation method |
|
|
|
|
|
|
|
|
|
|
|
|
1 |
Native chemical ligation |
+ thiol catalyst |
Y |
Dependence on suitable cysteine or alanine residues. |
[97a] |
|
|
|
|
|
|
|
|
2 |
Serine/threonine ligation |
+ acidolysis |
N |
Requires suitable Ser/Thr. Slower reaction kinetics than NCL. |
[145] |
|
3 |
KAHA ligation |
|
N |
Accessibility of enantiomeric reagent. |
[146] |
|
|
|
|
|
|
|
|
4 |
Selenocysteine NCL |
+ thiol catalyst |
N |
Accessibility of enantiomeric reagent. |
[123a] |
|
|
NCL reactive end |
|
|
|
|
|
|
Thioester surrogate |
|
|
|
|
|
|
|
|
|
|
|
|
5 |
Hydrazides |
Activation+NaNO2 + Thiol |
Y |
Oxidation incompatible with Thz. Low temperature activation needed (<−15 °C). |
[100] |
|
|
|
|
|
|
|
|
6 |
Dbz |
Activation 4‐nitrophenyl chloroformate or NaNO2 or isoamyl nitrite +thiol |
Y |
Di‐acylation side product with excess Gly. |
[16, 147] |
|
|
|
|
|
|
|
|
7 |
MeDbz |
Activation 4‐nitrophenyl chloroformate +thiol |
N |
Difficult to activate off‐resin. |
[98] |
|
|
|
|
|
|
|
|
8 |
SEA |
Activation of SEA OFF TCEP+thiol |
N |
Latent SEAOFF thioester incompatible with TCEP during ligations. |
[148] |
|
|
N‐cysteine protection |
|
|
|
|
|
|
|
|
|
|
|
|
9 |
Thz |
Deprotection MeONH2 |
Y |
Incompatible with hydrazide oxidation. |
[103] |
|
|
|
|
|
|
|
|
10 |
Cys(Tfacm) |
Deprotection pH 11.5 |
N |
Accessibility of enantiomeric reagent. |
[149] |
|
|
|
|
|
|
|
|
11 |
TFA‐Thz |
Deprotection Base then MeONH2 |
Y |
Accessibility of enantiomeric reagent. |
[41] |
|
|
|
|
|
|
|
|
12 |
N3‐Cys |
Deprotection TCEP |
N |
Accessibility of enantiomeric reagent. |
[150] |
|
|
|
|
|
|
|
|
13 |
Cys(Dobz) |
Deprotection H2O2 |
N |
Accessibility of enantiomeric reagent. Harsh deprotection conditions. |
[151] |
|
|
Desulfurization |
|
|
|
|
|
14 |
Metal‐based |
Pd/Al2O3 Or Raney Nickel+ H2 (g) |
Y |
Removal of metal impurities can be problematic. Use of hydrogen gas. Potential side reactions with Trp and Met Quenched by thiol catalyst. Native Cys must be protected. |
[108] |
|
15 |
Metal‐free radical based |
VA‐044 TCEP tert‐butylthiol |
Y |
Quenched by thiol catalyst. Native Cys must be protected. |
[106] |
|
16 |
Beta/gamma thiol amino acids |
β‐thiol‐Phe β‐thiol‐Val β‐thiol‐Leu β‐thiol‐Asp β‐thiol‐Asn β‐thiol‐Arg γ‐thiol‐Val γ‐thiol‐Thr γ‐thiol‐Ile γ‐thiol‐Pro γ‐thiol‐Glu γ‐thiol‐Gln γ‐thiol‐Lys 2‐thiol‐Trp |
N |
Accessibility of enantiomeric reagent. Commercially available D‐Penicillamine (β‐thiol‐Val) could be used for D‐peptide ligation at Val, if directly following a glycine residue. |
[152] |
|
|
Thiol catalysts for one‐pot ligation‐desulfurization |
|
|
|
|
|
|
|
|
|
|
|
|
17 |
MPAA‐hydrazide |
pKa=6.6 Removal Aldehyde‐resin capture |
N |
Preparation of MPAA‐hydrazide reagent coupled with use in large excess is uneconomical. |
[153] |
|
|
|
|
|
|
|
|
18 |
Trifluoroethanthiol |
pKa=7.3 Removal Evaporation (bp=37 °C) |
N |
Malodorous and volatile, though could be used for D‐protein synthesis. |
[154] |
|
|
|
|
|
|
|
|
19 |
Methyl thioglycolate |
pKa=7.9 Removal none |
Y |
Slower kinetics with C‐terminal beta‐branched residue. |
[41] |
|
|
Solubility enhancers |
|
|
|
|
|
|
|
|
|
|
|
|
20 |
Helping hand v1 |
Installation Amine labelling with lysine side chain Removal Hydrazine (aq) |
N |
Additional steps to incorporate and remove tag. Potential issues with stability. |
[119a] |
|
|
|
|
|
|
|
|
21 |
Helping hand v2 |
Installation Amine labelling with lysine side chain Removal Hydrazine (aq) Or Hydroxylamine (aq) |
N |
Additional steps to incorporate and remove tag. |
[119b] |
|
|
|
|
|
|
|
|
22 |
Removable backbone modification v1 |
Installation Standard Fmoc‐SPPS Removal pH 7 then TFA |
Y |
Limited to Gly only. Lengthy synthesis of building block. Additional steps to incorporate and remove tag. |
[117, 155] |
|
|
|
|
|
|
|
|
23 |
Removable backbone modification v2 |
Installation Reductive amination Acetylation Removal Deacetylation (Cys (aq)) then TFA |
Y |
Additional steps to incorporate and remove tag. |
[77b, 118] |
|
|
Protein folding |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Disulfide #1 Removal TFA |
|
|
|
|
|
|
|
|
|
|
|
|
|
Disulfide #2 Removal Iodine or PdCl2 |
|
|
|
|
|
|
|
|
|
|
|
24 |
Cysteine orthogonal protection |
Disulfide #3 Removal UV light (350 nm) |
Y |
Practically limited to two disulfide bonds. Accessibility of a third, orthogonally protected D‐Cys building block. |
[52, 128] |
|
25 |
“Ambidextrous” chaperone |
GroEL/ES protein chaperone |
Y |
Mostly unnecessary for in‐vitro protein folding. Limited scope reported. |
[121b] |
|
|
Post‐translational modifications |
|
|
|
|
|
26 |
Lys ubiquitination |
δ‐mercapto lysine for NCL followed by desulfurization |
N |
Accessibility of enantiomeric reagent. |
[136a] |
|
27 |
Solid‐phase isopeptide bond formation |
N |
Requires assembly of large fragments by SPPS – not cost‐effective with D‐amino acids |
[156] |
|
|
|
|
|
|
|
|
|
28 |
Installation Coupling to lysine side chain PTM NCL to Ub‐thioester Auxiliary removal TFA |
N |
Low efficiency of ligation. Glycyl auxiliary replaced with Cys in preparation of enantiomeric di‐ and tri‐ubiquitin proteins. |
[28, 42] |
|
|
29 |
Lys trimethylation |
Fmoc‐Lys(Me3)‐OH |
N |
Accessibility of enantiomeric reagent. |
[133a, 151] |
|
30 |
Lys acetylation |
Fmoc‐Lys(Ac)‐OH |
N |
Accessibility of enantiomeric reagent. |
[133b] |
|
31 |
Asn N‐Glycosylation |
Fmoc‐Asn(Glycan)−OH or Boc‐Asn(Xan)−OH (and) further glycosylation on‐resin or in solution. |
N |
Accessibility of enantiomeric reagent (would also require L‐sugars). |
[53, 157] |
|
32 |
Oligosaccharide coupled directly to free Asn side chain during Boc‐SPPS. |
N |
Accessibility of enantiomeric reagent (would also require L‐sugars). |
[158] |
|
|
33 |
Thr O‐Glycosylation |
Fmoc‐Thr(Glycan)−OH |
N |
Accessibility of enantiomeric reagent (would also require L‐sugars). |
[131b] |
|
34 |
Cys S‐palmitoylation |
Fmoc‐Cys(Mmt)−OH Mmt removal on‐resin with 2 % TFA Reaction with palmitic anhydride |
N |
Incompatible with NCL. Potentially viable for D‐protein synthesis via STL or Sec NCL. |
[137a] |
|
35 |
Fmoc‐Cys(palmityl)‐OH |
N |
Incompatible with NCL. Fmoc‐D‐Cys(palmityl) must be synthesized. |
[137b] |
|
|
36 |
Tyr sulfation |
Fmoc‐Tyr(OTBS)−OH Deprotection and sulfation on‐resin with: |
N |
Accessibility of enantiomeric reagent. |
[131b] |
|
|
|
|
|
|
|
|
|
|
+DIEPA |
|
|
|
|
37 |
Ser phosphorylation |
|
Y |
Accessibility of enantiomeric reagent. |
[18, 130b, 159] |
|
38 |
Tyrosine phosphorylation |
|
N |
Accessibility of enantiomeric reagent. |
[131a] |
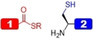
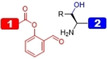
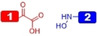
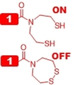
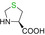
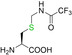
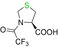
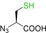
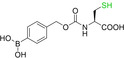
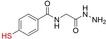
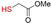
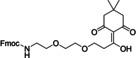
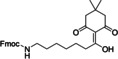
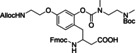
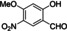
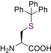
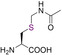
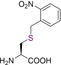
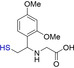
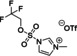
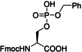
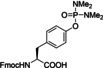
Figure 7.

Reaction scheme of native chemical ligation.
3.2.1. Thioester preparation
Activated thioesters cannot be anchored at the C‐terminus during Fmoc‐SPPS due to their sensitivity to base treatment which is routinely used during deprotection. Consequently, inert precursors including the refined Dawson linker have been developed (Table 3, Entry 6). Following SPPS, the base‐stable 3,4‐diaminobenzoic acid (Dbz) derivative is activated and subjected to thiolysis to yield the thioester for native chemical ligation. More recently, a second generation Dawson linker recruits an N‐methylated amino group minimizing unwanted acylation when an excess of glycine reagent is used (Table 3, Entry 7). [98] Assembly of peptides directly onto the linker amine is a simple and useful feature of the Dawson linker. Alternatively, the C‐terminal peptide hydrazide can be used to create a C‐terminal thioester (Table 3, Entry 5). [99] Activated by the addition of sodium nitrite, the hydrazide can be oxidized into an acyl azide which can be subjected to thiolysis in situ. [100] Hydrazine resins are prepared fresh before use, but it has recently been shown that resins can be prepared with Fmoc‐hydrazine facilitating long term storage and facile loading quantification. [101]
In the convergence of multiple peptide fragments to prepare larger synthetic proteins, some central fragments will be ligated at both N‐ and C‐termini. To prevent intramolecular side‐reactions (cyclization), the peptide can be prepared as a thioester surrogate, whereby a C‐terminal functional group remains inert in NCL and can be subsequently activated for the next ligation step. The peptide hydrazide is the most common choice in this instance due to the facile in situ activation and has been used to prepare numerous D‐proteins, including the mirror‐image TIGIT domain discussed earlier. [77b] Other methods for generating thioester surrogates, such as SEA chemistry (Table 3, Entry 8), [102] could also be used but have yet to be applied to D‐protein synthesis.
3.2.2. N‐terminal cysteine protection
In the pursuit of more complex protein targets, sequential NCL steps will require orthogonal N‐terminal cysteine protecting groups for middle segments (Table 3, Entries 9–13). A common and reliable choice is the protection of cysteine in a thiazolidine ring (Thz), due to the facile conversion into cysteine, compatibility with ligation conditions and its commercial availability in both enantiomeric forms. [103] However, Thz was found to be unstable under the oxidation conditions required for peptide hydrazide oxidation. [99] Numerous efforts have been directed to the development of other orthogonal, N‐terminal cysteine protecting groups to facilitate sequential peptide hydrazide ligations (Table 3, Entries 9–12). Preparation of their enantiomeric counterpart is theoretically simple. Indeed, TFA‐Thz, which is stable to hydrazide oxidation, was used in the preparation of enantiomeric polymerase D‐Dpo4 [9] and ubiquitin. [41]
3.2.3. NCL beyond cysteine
Due to the low abundance of cysteine residues in proteins (<2 %), [104] significant efforts have been directed to link peptides with alternative amino acids. [105] Desulfurization converts the reactive cysteine thiol CH2SH to the CH3 group of alanine, [106] which is significantly higher in abundance (>8 %). [107] Techniques include hydrogenation over Pd/Al2O3 or Raney nickel (Table 3, Entry 14). [106] Given the issues associated with purity, a metal‐free desulfurization alternative has been developed through a free‐radical mechanism (Table 3, Entry 15; Figure 8A). However, native cysteines must be protected during desulfurization reactions. Acetamidomethyl cysteine (Cys(Acm)) is commonly employed in D‐protein synthesis, and is commercially available in both L‐ and D‐ enantiomers for Fmoc‐SPPS (Figure 8B). [108] Following desulfurization, the Acm group can be removed using mercury acetate, [137] iodine, [138] or more recently, PdCl2. [109]
Figure 8.

(A) Mechanism of metal‐free radical desulfurization, (B) acetamidomethyl cysteine (Cys(Acm)) and (C) penicillamine buildings blocks for Fmoc‐SPPS.
Thiols may also be inserted into other canonical amino acids and can be removed by desulfurization (for review, see ref. [110]). However, this approach has not been applied in D‐protein synthesis because of challenges associated with synthesizing the enantiomeric building blocks (Table 3, Entry 16). Commercially available D‐penicillamine (D‐Pen) may be a viable option for ligation at valine (Figure 8C), [111] but this residue is associated with slow ligation kinetics with all C‐terminal thioester sites other than glycine. [112] NCL can also proceed by employing a temporarily inserted thiol auxiliary which can be removed by acid cleavage. [113] Such auxiliaries enable the generation of the lysine isopeptide bonds in the synthesis of branched ubiquitin chains (Table 3, Entry 28).[ 28 , 42 ] Nevertheless, this approach has not yet been applied in the synthesis of the mirror‐image D‐counterparts (see section 3.3.2.3). [42]
3.2.4. One‐pot approach
During the synthesis of large protein targets, it becomes advantageous to conduct steps in a ‘one‐pot’ fashion minimizing lengthy and yield‐reducing purification maneuvers. For example, directly after a NCL reaction, the desulfurization step can be performed in one pot, followed by Cys(Acm) deblocking without intermediate purification. [109] A primary limitation of performing desulfurization immediately after NCL is that: a large excess of thiol catalyst such as 4‐mercaptophenylacetic acid (MPAA) is needed to improve ligation rates but they also quench the desulfurization reaction. [114] Efforts have been directed toward finding new thiol catalysts that are compatible with desulfurization (Table 3, Entries 17–19). Methyl thioglycolate was found to not interfere with desulfurization whilst providing good catalytic properties, and it has been used in the synthesis of mirror‐image ubiquitin for racemic protein crystallography studies. [41] Other efforts to reduce the number of HPLC purification steps include one‐pot ligations of numerous fragments and performing chemical ligations on a solid support.[ 57 , 115 ]
3.2.5. Enhancing solubility of hydrophobic peptide fragments
The nature of protein has implications on the experimental design. Hydrophobic proteins such as membrane proteins can suffer from aggregation and poor solubility. [116] A solution that can address these issues is to recruit the first‐generation removable backbone modification (RBM), which minimizes aggregation whilst allowing conjugation to a poly‐arginine solubility tag (Table 3, Entry 22). [117] However, the RBM is installed via a removable glycine auxiliary and thus has limited scope. A second‐generation RBM was designed to be installed into all other amino acids, including the challenging Val‐Ile junction, making this highly attractive for the synthesis of membrane proteins (Table 3, Entry 23; Figure 9). [118] The RBM tags have been employed in the synthesis of the mirror‐image TIGIT membrane protein domain. [77b] In addition to RBMs, removable solubilizing tags could also be incorporated onto lysine side chains (Fmoc‐Ddae‐OH) or (Fmoc‐Ddap‐OH) using the ‘helping‐hand’ strategies (Table 3, Entries 20, 21). [119] Whilst no D‐proteins are currently reported using this method, these tags could possibly be installed onto commercially available D‐amino acid building blocks. The lysine tags can also be employed to install click handles for templated chemical protein ligations. [120]
Figure 9.

Second generation removable backbone modification. 4‐Methoxy‐5‐nitrosalicylaldehyde is installed onto backbone nitrogen during Fmoc‐SPPS, followed by assembly of peptide main chain and desired tag sequence. Reversible acetylation of phenol group controls TFA lability for tag removal.
3.2.6. Remarks
Since the advent of chemical ligation methods, protein synthesis has transformed into a rapidly evolving field of research. Particularly, native chemical ligation has facilitated the synthesis of numerous D‐proteins: enantiomeric venom toxins,[ 30 , 34 , 35 , 36 , 38 , 45 , 48 , 50 , 52 , 57 ] growth factors,[ 56 , 72 , 74 , 75 ] and enzymes,[ 5 , 7 , 9 , 12 , 13 , 14 , 121 ] including the 90 kDa split‐enzyme D‐Pfu. [10] The pursuit of more complex D‐proteins is perplexed by their size and post‐translational modification status. Multi‐segment, one‐pot approaches can improve efficiency, but many recruit unique amino‐acid reagents that need to be prepared in the laboratories. [122] Another issue involves the rates of ligation reactions, which can potentially be increased by adopting selenocysteine NCL, [123] and template‐directed chemical ligations. [124] Easier access to protected building blocks, and their commercial availability, will greatly improve the possibilities for D‐protein chemical synthesis. Design of synthetic routes to D‐proteins can also be assisted by computational approaches such as the open‐source ‘Alligator’ tool. [125] Perhaps, the ultimate goal for D‐polypeptide production is to completely circumvent chemical synthesis, with the entire mirror‐image translational machinery (ribosome, rRNA, tRNA, tRNA synthetase, etc.) served as a replacement.
3.3. Transformation from D‐polypeptide to mirror‐image protein
A somewhat overlooked challenge is the complexity of protein folding that researchers may need to address during synthetic protein preparation. [126] Typically, a solution of the protein in chaotropic conditions such as guanidine or urea is prepared and then diluted into a refolding buffer. [127] Many larger proteins require chaperones for efficient folding, particularly in vivo where direct control of refolding conditions is limited. Recently, it was shown that the GroEL/ES chaperone protein can efficiently fold both enantiomers (L‐ and D‐) of synthetic DapA protein. [121b] This observation suggested that the protein chaperone activity can be achiral and may find broad utility in the pursuit of mirror‐image life systems. Two specific challenges associated with protein folding that will be discussed here include correct oxidation of disulfide bonds and installation of post‐translational modifications.
3.3.1. Disulfide bond formation
Correct folding of the disulfide bonds is case‐dependent, often requiring extensive screening and optimization for each protein. Nevertheless, preparation of enantiomeric disulfide‐rich proteins for racemic crystallography has broad utility in generating new structural insights (Table 1 and Figure 10).[ 30 , 34 , 45 , 50 , 52 ] One common method for disulfide bond formation involves diluting the reduced D‐polypeptide chain from chaotropic agents in the presence of reduced and oxidized thiols as redox reagents, as reported in the synthesis of D‐rC5a. [35] However, misfolded D‐protein often arises as thermodynamically trapped by‐products containing mismatched disulfide bonds and adducts with thiol reagents.[ 30 , 45 ] Oxidation by air or DMSO has been used, following careful optimization of buffer additives, reagent concentrations, and pH. However, this method often results in low yields (typically <50 %), requires large solvent volumes, and proceeds over several days.[ 30 , 45 , 49 ] To gain additional control, orthogonal cysteine protection followed by pairwise cysteine oxidation may be used. Recently, an orthogonal cysteine protection scheme was developed, encoding a rapid system for disulfide oxidation (Table 3, Entry 24). Using palladium and UV light mediated deprotections, it was shown that up to three correctly paired disulfide bonds could be formed in less than 13 minutes. [128] The use of trityl (Trt) and acetamidomethyl (Acm) protecting groups has been reported for formation two disulfide bonds in a D‐protein (Table 3, Entry 24). [52] Another protecting group that can be used is the 2‐nitrobenzyl group but must be chemically synthesized (Table 3, Entry 24). [128] Disulfide bond formation can also be directed without the use of chaotropic agents or orthogonal protection schemes, such as cysteine‐penicillamine pairings or repeat‐proline (CPPC) motifs. [129]
Figure 10.

Examples of disulfide‐rich D‐proteins prepared by chemical synthesis, with structures resolved by racemic protein crystallography.
3.3.2. Post‐translational modifications
To achieve a true, mirror‐image protein with reciprocal stereospecific protein activity, PTMs must be incorporated into the D‐polypeptide product. Serine and tyrosine phosphorylation are common PTMs. [130] Whilst the L‐serine equivalent (Table 3, Entry 37) is commercially available, the corresponding protected D‐Ser building block must be accessed through chemical synthesis. [18] This has been demonstrated in the synthesis of mirror‐image ribosomal proteins which are essential in the binding of L‐RNA molecules. [18] Phosphorylation and sulfation of tyrosine residues have been incorporated into chemical synthesis of L‐proteins [131] using similar protected building blocks (Table 3, Entry 36 & 38). It is reasonable that equivalent building blocks can be prepared in D‐enantiomeric form. Indeed, tyrosine phosphorylation is a PTM observed in many transcriptional regulators and has been shown to impact DNA binding. [130c]
Glycosylation is another widespread PTM found in proteins. [132] However, the sugars attached to the protein are chiral existing almost exclusively in D‐form. [1a] Mirror‐image glycoprotein would require installation of L‐sugar polymers onto the D‐polypeptide and has not yet been reported. However, quasi‐racemic protein crystallography of synthetic glycoprotein Ser‐CCL1 could be facilitated using the un‐glycosylated D‐enantiomer. [53] In many cases, glycans can play important roles in protein or nucleotide binding, [132] and therefore achieving mirror‐image protein glycosylation is a key milestone in research surrounding D‐proteins, particularly in the area of MIPD.
Other promising PTMs include lysine trimethylation or acetylation, both of which have been incorporated into the chemical synthesis of L‐histones (Table 3, Entries 29, 30). [133] Preparation of the corresponding D‐histones would require the synthesis of the lysine building blocks in D‐form. A more challenging lysine PTM is site‐specific ubiquitination. [134] Chemical synthesis of branched ubiquitin chains in native L‐form has been reported, [135] typically employing a δ‐mercapto lysine to facilitate ligation, followed by desulfurization (Table 3, Entry 26).[ 134 , 136 ] However, preparation of the branched ubiquitin chains for racemic protein crystallography utilized an auxiliary for NCL, following subsequent removal with TFA to generate a native glycine at the branched ligation site (Figure 11A).[ 28 , 42 ] During preparation of the D‐enantiomers of ubiquitinated proteins, the auxiliary was replaced with a cysteine residue to circumvent the low efficiency of the ligations, leaving a non‐native cysteine as a scar at the ligation site (Figure 11B). [42]
Figure 11.

Methods for branched protein ligation used in preparation of poly‐ubiquitins; (A) glycyl auxiliary mediated NCL for preparation of branched L‐proteins and (B) cysteine mediated NCL for preparation of branched D‐proteins.
Palmitoylation also serves as a promising PTM for incorporation into D‐proteins and has been applied to the synthesis of cysteine palmitoylated L‐proteins (Table 3, Entries 34, 35). [137] Palmitic acid is achiral and could be conjugated to D‐cysteine or other D‐amino acid residues. Synthesis of palmitoylated D‐proteins may find use in racemic protein crystallography [26] which has been applied to reveal the structure of transmembrane protein domains in racemic detergents. [27] In addition, palmitoylation is a useful modification for pharmacokinetic optimization of peptide drugs, [138] including the FDA‐approved Liraglutide. [139] This modification may find use in prolonging the half‐life of D‐peptide drug candidates, as encountered with the conjugation of cholesterol to the promising D‐peptide drug candidate, CPT31. [79]
3.3.3. Remarks
Folding of D‐polypeptide chains into the desired protein conformation is a challenging task, and often requires optimization in a case dependent manner. Protein refolding protocols can be pre‐established using the native recombinant L‐counterparts, [140] and they are often sufficient to fold the corresponding D‐enantiomer. In the case where disulfide bond formation is involved, oxidants such as cystine or glutathione disulfide can be used. [52] Alternatively, orthogonal protection schemes can be implemented.[ 52 , 128 ] Most PTM installations can be achieved, particularly the achiral components such as phosphorylation. [18] However, chiral PTMs such as glycosylation largely remains an unresolved synthetic challenge. [53] A plausible solution would be to obtain a mirror‐image enzyme (such as endo‐glycoside hydrolase), [141] capable of assembling the necessary polysaccharide building block from L‐sugars, much like the enantiomeric polymerase enzymes discussed earlier.[ 9 , 10 , 13 , 14 ]
4. Perspectives
Applications of synthetic D‐protein enantiomers are vast but remains to be challenged by the difficulty in their preparation, particularly when their complexity increases with their size, folding and post‐translational modifications. The ability to translate L‐mRNA into D‐proteins will be truly revolutionary. The first milestone will be the complete assembly of an enantiomeric ribosome, comprised of D‐proteins and L‐rRNAs. Since three out of ∼50 mirror‐image E. coli ribosomal proteins [18] and efficient L‐nucleotide polymerases[ 7 , 9 , 10 , 12 , 13 , 14 , 16 ] have been reported, it is anticipated that this ambition will be achieved in the future. Mirror‐image translation could then be achieved in vitro, [142] using D‐aminoacyl‐tRNA synthetases to load the L‐tRNAs along with the mirror‐imaged translational factors. Subsequently, all D‐proteins needed in mirror‐image life, racemic protein crystallography and D‐targets for mirror‐image phage display may be obtained by suppling the exogenous L‐nucleic acids encoding the desired protein. Perhaps, preparation of entire D‐polypeptides can also be achieved using “Flexizyme” technology, [143] which has been reported to incorporate D‐amino acids into peptide chains without using enantiomeric translation components.[ 2b , 67a , 67b ] Chemical synthesis remains superior at atomistic control allowing researchers to incorporate building blocks without constraints associated with ribosome‐based systems. Complex D‐protein targets can be achieved via: engineering of split enzymes, [10] mutational installation of suitable ligation sites [10] and in silico design of accessible D‐enzymes. [16] For protein crystallography, smaller D‐proteins can be used to facilitate crystallization of complex L‐proteins by quasi‐racemic protein crystallography. [28] In addition, discovery of D‐peptide binders could be achieved via computational‐based approaches.[ 88 , 89 , 144 ] Together, while there are unsolved challenges, D‐polypeptide research remains to have strong potentials that can generate explosive impacts on numerous research topics.
Conflict of interest
The authors declare no conflict of interest.
5.
Biographical Information
Alexander Lander (left) is a PhD student at Cardiff University working under the supervision of Louis Luk. He obtained his BSc in Chemistry and MSc in Medicinal Chemistry from Cardiff University, with a research placement at Instituto Químico de Sarrià. His research focuses on utilizing D‐proteins for structural studies of antimicrobial proteins and development of D‐peptide inhibitors of new drug targets. Yi Jin (center) is a Wellcome Trust Sir Henry Dale Fellow at Manchester Institute of Biotechnology. She obtained her BSc and MSc in organic chemistry at Xiamen University, China, and her PhD in enzymology in the University of Sheffield under Jon P. Waltho and G. Mike Blackburn. After three years in protein crystallography and chemical biology with Gideon J. Davies, FRS, FMedSci, at the University of York, she moved to Cardiff University in 2017 as a tenured University Research Fellow and then in 2021 progressed to the University of Manchester. Her research focuses on investigating proteins that can provide solutions to antibiotic resistance via chemical biology that integrates chemical synthesis, protein crystallography and NMR spectroscopy, and molecular biology. Louis Y. P. Luk (right) is a senior lecturer at the School of Chemistry of Cardiff University. He obtained his BSc in Chemistry and Microbiology & Immunology at the University of British Columbia. He obtained his PhD at the same university under the supervisor of Martin E. Tanner, followed by post‐doctoral studies in the laboratories of Stephen B. H. Kent at the University of Chicago and Rudolf K. Allemann at Cardiff University. He became a University Research Fellow in 2015 and recently became Senior Lecturer at Cardiff University (2020). His current research combines his training, focusing on enzyme engineering, bioconjugation chemistry and protein synthesis.

Acknowledgments
The authors apologize to the researchers in the field whose work the authors were unable to discuss, given the limited scope of this review. Review of the current literature surrounding D‐proteins was aided by use of the protein chemical synthesis database (http://pcs‐db.fr). [160] The authors thank Dr. Pierre Rizkallah for the discussion of racemic protein crystallography and comments on the manuscript. A.J.L. is funded by an EPSRC scholarship (2107414). Y.J. thanks the Wellcome Trust (218568/Z/19/Z) for the financial support. L.Y.P.L. thanks BBSRC (BB/T015799/1) for the financial support.
Lander A. J., Jin Y., Luk L. Y. P., ChemBioChem 2023, 24, e202200537.
A previous version of this manuscript has been deposited on a preprint server (https://chemrxiv.org/engage/chemrxiv/article‐details/631479015351a3da7fee908b).
Contributor Information
Dr. Yi Jin, Email: yi.jin@manchester.ac.uk.
Dr. Louis Y. P. Luk, Email: lukly@cardiff.ac.uk.
Data Availability Statement
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
References
- 1.
- 1a. Davankov V. A., Symmetry-Basel 2018, 10 749; [Google Scholar]
- 1b. Carenzi G., Sacchi S., Abbondi M., Pollegioni L., Amino Acids 2020, 52, 849–862. [DOI] [PubMed] [Google Scholar]
- 2.
- 2a. Dedkova L. M., Fahmi N. E., Golovine S. Y., Hecht S. M., Biochemistry 2006, 45, 15541–15551; [DOI] [PubMed] [Google Scholar]
- 2b. Goto Y., Murakami H., Suga H., RNA 2008, 14, 1390–1398; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2c. Kuncha S. K., Kruparani S. P., Sankaranarayanan R., J. Biol. Chem. 2019, 294, 16535–16548. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Kobayashi J., Shimizu Y., Mutaguchi Y., Doi K., Ohshima T., J. Mol. Catal. B 2013, 94, 15–22. [Google Scholar]
- 4. Ogasawara Y., Dairi T., Front. Microbiol. 2018, 9, 156. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Milton R., Milton S., Kent S., Science 1992, 256, 1445–1448. [DOI] [PubMed] [Google Scholar]
- 6.L. Pasteur, Société Chimique de Paris 1860, Reprint No. 14 (Alembic Club, 1905).
- 7. Peplow M., Nat. News 2016, 533, 303. [DOI] [PubMed] [Google Scholar]
- 8.
- 8a. Szostak J. W., Bartel D. P., Luisi P. L., Nature 2001, 409, 387–390; [DOI] [PubMed] [Google Scholar]
- 8b. Forster A. C., Church G. M., Mol. Syst. Biol. 2006, 2, 45; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8c. Gibson D. G., Glass J. I., Lartigue C., Noskov V. N., Chuang R.-Y., Algire M. A., Benders G. A., Montague M. G., Ma L., Moodie M. M., Science 2010, 329, 52–56. [DOI] [PubMed] [Google Scholar]
- 9. Jiang W., Zhang B., Fan C., Wang M., Wang J., Deng Q., Liu X., Chen J., Zheng J., Liu L., Zhu T. F., Cell Discov. 2017, 3, 17037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Fan C., Deng Q., Zhu T. F., Nat. Biotechnol. 2021, 1548–1555. [DOI] [PubMed] [Google Scholar]
- 11.L. Schrödinger, W. DeLano, The PyMOL Molecular Graphics System, Version 2.0, 2015.
- 12. Wang Z., Xu W., Liu L., Zhu T. F., Nat. Chem. 2016, 8, 698–704. [DOI] [PubMed] [Google Scholar]
- 13. Pech A., Achenbach J., Jahnz M., Schülzchen S., Jarosch F., Bordusa F., Klussmann S., Nucleic Acids Res. 2017, 45, 3997–4005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Wang M., Jiang W., Liu X., Wang J., Zhang B., Fan C., Liu L., Pena-Alcantara G., Ling J.-J., Chen J., Zhu T. F., Chem 2019, 5, 848–857. [Google Scholar]
- 15. Cline J., Braman J. C., Hogrefe H. H., Nucleic Acids Res. 1996, 24, 3546–3551. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Weidmann J., Schnölzer M., Dawson P. E., Hoheisel J. D., Cell Chem. Biol. 2019, 26, 645–651.e643. [DOI] [PubMed] [Google Scholar]
- 17. de la Cruz J., Karbstein K., Woolford J. L. Jr, Annu. Rev. Biochem. 2015, 84, 93–129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Ling J.-J., Fan C., Qin H., Wang M., Chen J., Wittung-Stafshede P., Zhu T. F., Angew. Chem. Int. Ed. 2020, 59, 3724–3731; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2020, 132, 3753–3760. [Google Scholar]
- 19. Klinge S., Woolford J. L., Nat. Rev. Mol. Cell Biol. 2019, 20, 116–131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Liu Y., Holmstrom E., Zhang J., Yu P., Wang J., Dyba M. A., Chen D., Ying J., Lockett S., Nesbitt D. J., Nature 2015, 522, 368–372. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Ishihama Y., Schmidt T., Rappsilber J., Mann M., Hartl F. U., Kerner M. J., Frishman D., BMC Genomics 2008, 9, 102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Rohden F., Hoheisel J. D., Wieden H.-J., Trends Biochem. Sci. 2021, 46, 931–943. [DOI] [PubMed] [Google Scholar]
- 23. Song W.-S., Liu S.-X., Chang C.-C., J. Org. Chem. 2018, 83, 14923–14932. [DOI] [PubMed] [Google Scholar]
- 24. Yeates T. O., Kent S. B. H., Annu. Rev. Biophys. 2012, 41, 41–61. [DOI] [PubMed] [Google Scholar]
- 25. Wukovitz S. W., Yeates T. O., Nat. Struct. Biol. 1995, 2, 1062–1067. [DOI] [PubMed] [Google Scholar]
- 26. Zawadzke L. E., Berg J. M., Proteins Struct. Funct. Genet. 1993, 16, 301–305. [DOI] [PubMed] [Google Scholar]
- 27.
- 27a. Kreitler D. F., Yao Z., Steinkruger J. D., Mortenson D. E., Huang L., Mittal R., Travis B. R., Forest K. T., Gellman S. H., J. Am. Chem. Soc. 2019, 141, 1583–1592; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27b. Mortenson D. E., Steinkruger J. D., Kreitler D. F., Perroni D. V., Sorenson G. P., Huang L., Mittal R., Yun H. G., Travis B. R., Mahanthappa M. K., Forest K. T., Gellman S. H., Proc. Natl. Acad. Sci. USA 2015, 112, 13144–13149. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Gao S., Pan M., Zheng Y., Huang Y. C., Zheng Q. Y., Sun D. M., Lu L. N., Tan X. D., Tan X. L., Lan H., Wang J. X., Wang T., Wang J. W., Liu L., J. Am. Chem. Soc. 2016, 138, 14497–14502. [DOI] [PubMed] [Google Scholar]
- 29.
- 29a. Mandal K., Pentelute B. L., Bang D., Gates Z. P., Torbeev V. Y., Kent S. B. H., Angew. Chem. Int. Ed. 2012, 51, 1481–1486; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2012, 124, 1510–1515; [Google Scholar]
- 29b. Pentelute B. L., Gates Z. P., Tereshko V., Dashnau J. L., Vanderkooi J. M., Kossiakoff A. A., Kent S. B. H., J. Am. Chem. Soc. 2008, 130, 9695–9701. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Banigan J. R., Mandal K., Sawaya M. R., Thammavongsa V., Hendrickx A. P. A., Schneewind O., Yeates T. O., Kent S. B. H., Protein Sci. 2010, 19, 1840–1849. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Lander A. J., Li X., Jin Y., Luk L. Y. P., ChemRxiv preprint 2020, 10.26434/chemrxiv.12444554.v1. [DOI] [Google Scholar]
- 32. Huang Y.-H., Du Q., Jiang Z., King G. J., Collins B. M., Wang C. K., Craik D. J., Molecules 2021, 26, 5554. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Qu Q., Gao S., Wu F., Zhang M.-G., Li Y., Zhang L.-H., Bierer D., Tian C.-L., Zheng J.-S., Liu L., Angew. Chem. Int. Ed. 2020, 59, 6037–6045; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2020, 132, 6093–6101. [Google Scholar]
- 34. Zuo C., Zhang B., Wu M., Bierer D., Shi J., Fang G.-M., Chin. Chem. Lett. 2019, 31, 693–696. [Google Scholar]
- 35. Zuo C., Shi W.-W., Chen X.-X., Glatz M., Riedl B., Flamme I., Pook E., Wang J., Fang G.-M., Bierer D., Liu L., Sci. China Chem. 2019, 62, 1371–1378. [Google Scholar]
- 36. Kurgan K. W., Kleman A. F., Bingman C. A., Kreitler D. F., Weisblum B., Forest K. T., Gellman S. H., J. Am. Chem. Soc. 2019, 141, 7704–7708. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Ramalho S. D., Wang C. K., King G. J., Byriel K. A., Huang Y.-H., Bolzani V. S., Craik D. J., J. Nat. Prod. 2018, 81, 2436–2445. [DOI] [PubMed] [Google Scholar]
- 38. Qu Q., Gao S., Li Y.-M., J. Pept. Sci. 2018, 24, e3112. [DOI] [PubMed] [Google Scholar]
- 39. Wang C. K., King G. J., Conibear A. C., Ramos M. C., Chaousis S., Henriques S. T., Craik D. J., J. Am. Chem. Soc. 2016, 138, 5706–5713. [DOI] [PubMed] [Google Scholar]
- 40. Yeung H., Squire C. J., Yosaatmadja Y., Panjikar S., López G., Molina A., Baker E. N., Harris P. W. R., Brimble M. A., Angew. Chem. Int. Ed. 2016, 55, 7930–7933; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2016, 128, 8062–8065. [Google Scholar]
- 41. Huang Y.-C., Chen C.-C., Gao S., Wang Y.-H., Xiao H., Wang F., Tian C.-L., Li Y.-M., Chem. Eur. J. 2016, 22, 7623–7628. [DOI] [PubMed] [Google Scholar]
- 42. Pan M., Gao S., Zheng Y., Tan X., Lan H., Tan X., Sun D., Lu L., Wang T., Zheng Q., Huang Y., Wang J., Liu L., J. Am. Chem. Soc. 2016, 138, 7429–7435. [DOI] [PubMed] [Google Scholar]
- 43. Mortenson D. E., Satyshur K. A., Guzei I. A., Forest K. T., Gellman S. H., J. Am. Chem. Soc. 2012, 134, 2473–2476. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Kreitler D. F., Mortenson D. E., Forest K. T., Gellman S. H., J. Am. Chem. Soc. 2016, 138, 6498–6505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Dang B., Kubota T., Mandal K., Correa A. M., Bezanilla F., Kent S. B., Angew. Chem. Int. Ed. 2016, 55, 8639–8642; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2016, 128, 8781–8784. [Google Scholar]
- 46. Hayouka Z., Mortenson D. E., Kreitler D. F., Weisblum B., Forest K. T., Gellman S. H., J. Am. Chem. Soc. 2013, 135, 15738–15741. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Hayouka Z., Thomas N. C., Mortenson D. E., Satyshur K. A., Weisblum B., Forest K. T., Gellman S. H., J. Am. Chem. Soc. 2015, 137, 11884–11887. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Dang B., Kubota T., Mandal K., Bezanilla F., Kent S. B., J. Am. Chem. Soc. 2013, 135, 11911–11919. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49. Murray J. K., Qian Y.-X., Liu B., Elliott R., Aral J., Park C., Zhang X., Stenkilsson M., Salyers K., Rose M., Li H., Yu S., Andrews K. L., Colombero A., Werner J., Gaida K., Sickmier E. A., Miu P., Itano A., McGivern J., Gegg C. V., Sullivan J. K., Miranda L. P., J. Med. Chem. 2015, 58, 6784–6802. [DOI] [PubMed] [Google Scholar]
- 50. Dang B., Shen R., Kubota T., Mandal K., Bezanilla F., Roux B., Kent S. B., Angew. Chem. Int. Ed. 2017, 56, 3324–3328; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2017, 129, 3372–3376. [Google Scholar]
- 51. Bunker R. D., Mandal K., Bashiri G., Chaston J. J., Pentelute B. L., Lott J. S., Kent S. B. H., Baker E. N., Proc. Natl. Acad. Sci. USA 2015, 112, 4310–4315. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Wang C. K., King G. J., Northfield S. E., Ojeda P. G., Craik D. J., Angew. Chem. Int. Ed. 2014, 53, 11236–11241; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2014, 126, 11418–11423. [Google Scholar]
- 53. Okamoto R., Mandal K., Sawaya M. R., Kajihara Y., Yeates T. O., Kent S. B. H., Angew. Chem. Int. Ed. 2014, 53, 5194–5198; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2014, 126, 5294–5298. [Google Scholar]
- 54. Avital-Shmilovici M., Mandal K., Gates Z. P., Phillips N. B., Weiss M. A., Kent S. B. H., J. Am. Chem. Soc. 2013, 135, 3173–3185. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Mandal K., Dhayalan B., Avital-Shmilovici M., Tokmakoff A., Kent S. B. H., ChemBioChem 2016, 17, 421–425. [DOI] [PubMed] [Google Scholar]
- 56. Mandal K., Uppalapati M., Ault-Riché D., Kenney J., Lowitz J., Sidhu S. S., Kent S. B. H., Proc. Natl. Acad. Sci. USA 2012, 109, 14779–14784. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57. Pentelute B. L., Mandal K., Gates Z. P., Sawaya M. R., Yeates T. O., Kent S. B. H., Chem. Commun. 2010, 46, 8174–8176. [DOI] [PubMed] [Google Scholar]
- 58. McNicholas S., Potterton E., Wilson K. S., Noble M. E. M., Acta Crystallogr. Sect. D 2011, 67, 386–394. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Marín-Medina N., Ramírez D. A., Trier S., Leidy C., Appl. Microbiol. Biotechnol. 2016, 100, 10251–10263. [DOI] [PubMed] [Google Scholar]
- 60. Rosano G. L., Ceccarelli E. A., Front. Microbiol. 2014, 5, 172–172. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61. Kozlowski L. P., Nucleic Acids Res. 2017, 45, D1112-D1116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62. Lien S., Lowman H. B., Trends Biotechnol. 2003, 21, 556–562. [DOI] [PubMed] [Google Scholar]
- 63. Lau J. L., Dunn M. K., Bioorg. Med. Chem. 2018, 26, 2700–2707. [DOI] [PubMed] [Google Scholar]
- 64. Goodman M., Chorev M., Acc. Chem. Res. 1979, 12, 1–7. [Google Scholar]
- 65.
- 65a. Li C., Zhan C. Y., Zhao L., Chen X. S., Lu W. Y., Lu W. Y., Bioorg. Med. Chem. 2013, 21, 4045–4050; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65b. Li C., Pazgier M., Li J., Li C. Q., Liu M., Zou G. Z., Li Z. Y., Chen J. D., Tarasov S. G., Lu W. Y., Lu W. Y., J. Biol. Chem. 2010, 285, 19572–19581. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66. Miles J. J., Tan M. P., Dolton G., Edwards E. S. J., Galloway S. A. E., Laugel B., Clement M., Makinde J., Ladell K., Matthews K. K., Watkins T. S., Tungatt K., Wong Y., Lee H. S., Clark R. J., Pentier J. M., Attaf M., Lissina A., Ager A., Gallimore A., Rizkallah P. J., Gras S., Rossjohn J., Burrows S. R., Cole D. K., Price D. A., Sewell A. K., J. Clin. Invest. 2018, 128, 1569–1580. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.
- 67a. Imanishi S., Katoh T., Yin Y., Yamada M., Kawai M., Suga H., J. Am. Chem. Soc. 2021, 143, 5680–5684; [DOI] [PubMed] [Google Scholar]
- 67b. Liu W., de Veer S. J., Huang Y.-H., Sengoku T., Okada C., Ogata K., Zdenek C. N., Fry B. G., Swedberg J. E., Passioura T., Craik D. J., Suga H., J. Am. Chem. Soc. 2021, 143, 18481–18489; [DOI] [PubMed] [Google Scholar]
- 67c. Katoh T., Suga H., J. Am. Chem. Soc. 2022, 144, 2069–2072; [DOI] [PubMed] [Google Scholar]
- 67d. Katoh T., Suga H., Annu. Rev. Biochem. 2022, 91, 221–243. [DOI] [PubMed] [Google Scholar]
- 68. Bhardwaj G., Mulligan V. K., Bahl C. D., Gilmore J. M., Harvey P. J., Cheneval O., Buchko G. W., Pulavarti S. V. S. R. K., Kaas Q., Eletsky A., Huang P.-S., Johnsen W. A., P. Greisen, Jr. , Rocklin G. J., Song Y., Linsky T. W., Watkins A., Rettie S. A., Xu X., Carter L. P., Bonneau R., Olson J. M., Coutsias E., Correnti C. E., Szyperski T., Craik D. J., Baker D., Nature 2016, 538, 329–335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69. Schumacher T. N. M., Mayr L. M., Minor D. L., Milhollen M. A., Burgess M. W., Kim P. S., Science 1996, 271, 1854–1857. [DOI] [PubMed] [Google Scholar]
- 70. Witsch E., Sela M., Yarden Y., Physiology 2010, 25, 85–101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71. Verhaar E. R., Woodham A. W., Ploegh H. L., Semin. Immunol. 2020, 101425. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72. Díaz-Perlas C., Varese M., Guardiola S., Sánchez-Navarro M., García J., Teixidó M., Giralt E., ChemBioChem 2019, 20, 2079–2084. [DOI] [PubMed] [Google Scholar]
- 73. Uppalapati M., Lee D. J., Mandal K., Li H., Miranda L. P., Lowitz J., Kenney J., Adams J. J., Ault-Riché D., Kent S. B., Sidhu S. S., ACS Chem. Biol. 2016, 11, 1058–1065. [DOI] [PubMed] [Google Scholar]
- 74. Uppalapati M., Lee D. J., Mandal K., Li H., Miranda L. P., Lowitz J., Kenney J., Adams J. J., Ault-Riché D., Kent S. B. H., Sidhu S. S., ACS Chem. Biol. 2016, 11, 1058–1065. [DOI] [PubMed] [Google Scholar]
- 75. Marinec P. S., Landgraf K. E., Uppalapati M., Chen G., Xie D., Jiang Q., Zhao Y., Petriello A., Deshayes K., Kent S. B. H., Ault-Riche D., Sidhu S. S., ACS Chem. Biol. 2021, 16, 548–556. [DOI] [PubMed] [Google Scholar]
- 76. Sharma P., Allison J. P., Science 2015, 348, 56–61. [DOI] [PubMed] [Google Scholar]
- 77.
- 77a. Chang H.-N., Liu B.-Y., Qi Y.-K., Zhou Y., Chen Y.-P., Pan K.-M., Li W.-W., Zhou X.-M., Ma W.-W., Fu C.-Y., Qi Y.-M., Liu L., Gao Y.-F., Angew. Chem. Int. Ed. 2015, 54, 11760–11764; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2015, 127, 11926–11930; [Google Scholar]
- 77b. Zhou X., Zuo C., Li W., Shi W., Zhou X., Wang H., Chen S., Du J., Chen G., Zhai W., Zhao W., Wu Y., Qi Y., Liu L., Gao Y., Angew. Chem. Int. Ed. 2020, 59, 15114–15118; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2020, 132, 15226–15230. [Google Scholar]
- 78.
- 78a. Welch B. D., VanDemark A. P., Heroux A., Hill C. P., Kay M. S., Proc. Natl. Acad. Sci. USA 2007, 104, 16828–16833; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78b. Welch B. D., Francis J. N., Redman J. S., Paul S., Weinstock M. T., Reeves J. D., Lie Y. S., Whitby F. G., Eckert D. M., Hill C. P., Root M. J., Kay M. S., J. Virol. 2010, 84, 11235–11244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79. Redman J. S., Francis J. N., Marquardt R., Papac D., Mueller A. L., Eckert D. M., Welch B. D., Kay M. S., Mol. Pharm. 2018, 15, 1169–1179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.
- 80a. Dammers C., Yolcu D., Kukuk L., Willbold D., Pickhardt M., Mandelkow E., Horn A. H. C., Sticht H., Malhis M. N., Will N., Schuster J., Funke S. A., PLoS One 2016, 11, 18; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80b. Zhang X. C., Zhang X. Y., Zhong M. L., Zhao P., Guo C., Li Y., Wang T., Gao H. L., ACS Chem. Neurosci. 2020, 11, 4240–4253. [DOI] [PubMed] [Google Scholar]
- 81. Kolkwitz P. E., Mohrlüder J., Willbold D., Biomol. Eng. 2022, 12, 157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82. Nonaka M., Mabashi-Asazuma H., Jarvis D. L., Yamasaki K., Akama T. O., Nagaoka M., Sasai T., Kimura-Takagi I., Suwa Y., Yaegashi T., Huang C.-T., Nishizawa-Harada C., Fukuda M. N., PLoS One 2021, 16, e0241157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83. Malhis M., Kaniyappan S., Aillaud I., Chandupatla R. R., Ramirez L. M., Zweckstetter M., Horn A. H. C., Mandelkow E., Sticht H., Funke S. A., ChemBioChem 2021, 22, 3049–3059. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84. Li Z., Xie J., Peng S., Liu S., Wang Y., Lu W., Shen J., Li C., Bioconjugate Chem. 2017, 28, 2167–2179. [DOI] [PubMed] [Google Scholar]
- 85. Rudolph S., Klein A. N., Tusche M., Schlosser C., Elfgen A., Brener O., Teunissen C., Gremer L., Funke S. A., Kutzsche J., Willbold D., PLoS One 2016, 11, e0147470. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86. Liu M., Li C., Pazgier M., Li C., Mao Y., Lv Y., Gu B., Wei G., Yuan W., Zhan C., Lu W. Y., Lu W., Proc. Natl. Acad. Sci. USA 2010, 107, 14321–14326. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87. Wong C. H., Siah K. W., Lo A. W., Biostatistics 2018, 20, 273–286. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.
- 88a. Engel H., Guischard F., Krause F., Nandy J., Kaas P., Höfflin N., Köhn M., Kilb N., Voigt K., Wolf S., Aslan T., Baezner F., Hahne S., Ruckes C., Weygant J., Zinina A., Akmeriç E. B., Antwi E. B., Dombrovskij D., Franke P., Lesch K. L., Vesper N., Weis D., Gensch N., Di Ventura B., Öztürk M. A., Synth. Syst. Biotechnol. 2021, 6, 402–413; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88b. Garton M., Nim S., Stone T. A., Wang K. E., Deber C. M., Kim P. M., Proc. Natl. Acad. Sci. USA 2018, 115, 1505–1510. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89. Hernández González J. E., Eberle R. J., Willbold D., Coronado M. A., Front. Mol. Biosci. 2022, 8, 816166. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90. Garton M., Sayadi M., Kim P. M., PLoS One 2017, 12, e0187524. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91. Merrifield R. B., J. Am. Chem. Soc. 1963, 85, 2149–2154. [Google Scholar]
- 92. Behrendt R., White P., Offer J., J. Pept. Sci. 2016, 22, 4–27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 93. Valeur E., Bradley M., Chem. Soc. Rev. 2009, 38, 606–631. [DOI] [PubMed] [Google Scholar]
- 94. Tofteng A. P., Malik L., Pedersen S. L., Sorensen K. K., Jensen K. J., Chim. Oggi 2011, 29, 28–31. [Google Scholar]
- 95. Collins J. M., Porter K. A., Singh S. K., Vanier G. S., Org. Lett. 2014, 16, 940–943. [DOI] [PubMed] [Google Scholar]
- 96. Simon M. D., Heider P. L., Adamo A., Vinogradov A. A., Mong S. K., Li X., Berger T., Policarpo R. L., Zhang C., Zou Y., Liao X., Spokoyny A. M., Jensen K. F., Pentelute B. L., ChemBioChem 2014, 15, 713–720. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 97.
- 97a. Dawson P., Muir T., Clark-Lewis I., Kent S., Science 1994, 266, 776–779; [DOI] [PubMed] [Google Scholar]
- 97b. Kent S. B., Chem. Soc. Rev. 2009, 38, 338–351. [DOI] [PubMed] [Google Scholar]
- 98. Blanco-Canosa J. B., Nardone B., Albericio F., Dawson P. E., J. Am. Chem. Soc. 2015, 137, 7197–7209. [DOI] [PubMed] [Google Scholar]
- 99. Fang G.-M., Li Y.-M., Shen F., Huang Y.-C., Li J.-B., Lin Y., Cui H.-K., Liu L., Angew. Chem. Int. Ed. 2011, 50, 7645–7649; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2011, 123, 7787–7791. [Google Scholar]
- 100. Zheng J.-S., Tang S., Qi Y.-K., Wang Z.-P., Liu L., Nat. Protoc. 2013, 8, 2483–2495. [DOI] [PubMed] [Google Scholar]
- 101. Huang Y.-C., Chen C.-C., Li S.-J., Gao S., Shi J., Li Y.-M., Tetrahedron 2014, 70, 2951–2955. [Google Scholar]
- 102. Melnyk O., Simonneau C., Vicogne J., in Chemical Ligation, Wiley-VCH, Weinheim, 2017, pp. 89–123. [Google Scholar]
- 103. Bang D., Kent S. B., Angew. Chem. Int. Ed. 2004, 43, 2534–2538; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2004, 116, 2588–2592. [Google Scholar]
- 104. Chalker J. M., Bernardes G. J. L., Lin Y. A., Davis B. G., Chem. Asian J. 2009, 4, 630–640. [DOI] [PubMed] [Google Scholar]
- 105. Agouridas V., El Mahdi O., Diemer V., Cargoët M., Monbaliu J.-C. M., Melnyk O., Chem. Rev. 2019, 119, 7328–7443. [DOI] [PubMed] [Google Scholar]
- 106. Yan L. Z., Dawson P. E., J. Am. Chem. Soc. 2001, 123, 526–533. [DOI] [PubMed] [Google Scholar]
- 107. Doolittle R. F., in Prediction of Protein Structure and the Principles of Protein Conformation (Ed.: Fasman G. D.), Springer US, 1989, pp. 599–623. [Google Scholar]
- 108. Pentelute B. L., Kent S. B. H., Org. Lett. 2007, 9, 687–690. [DOI] [PubMed] [Google Scholar]
- 109. Maity S. K., Jbara M., Laps S., Brik A., Angew. Chem. Int. Ed. 2016, 55, 8108–8112; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2016, 128, 8240–8244. [Google Scholar]
- 110. Jin K., Li X., Chem. Eur. J. 2018, 24, 17397–17404. [DOI] [PubMed] [Google Scholar]
- 111. Haase C., Rohde H., Seitz O., Angew. Chem. Int. Ed. 2008, 47, 6807–6810; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2008, 120, 6912–6915. [Google Scholar]
- 112. Chen J., Wan Q., Yuan Y., Zhu J., Danishefsky S. J., Angew. Chem. Int. Ed. 2008, 47, 8521–8524; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2008, 120, 8649–8652. [Google Scholar]
- 113. Kulkarni S. S., Sayers J., Premdjee B., Payne R. J., Nat. Chem. Rev. 2018, 2, 0122. [Google Scholar]
- 114. Johnson E. C. B., Kent S. B. H., J. Am. Chem. Soc. 2006, 128, 6640–6646. [DOI] [PubMed] [Google Scholar]
- 115. Jbara M., Seenaiah M., Brik A., Chem. Commun. 2014, 50, 12534–12537. [DOI] [PubMed] [Google Scholar]
- 116. Olschewski D., Becker C. F., Mol. BioSyst. 2008, 4, 733–740. [DOI] [PubMed] [Google Scholar]
- 117. Zheng J.-S., Yu M., Qi Y.-K., Tang S., Shen F., Wang Z.-P., Xiao L., Zhang L., Tian C.-L., Liu L., J. Am. Chem. Soc. 2014, 136, 3695–3704. [DOI] [PubMed] [Google Scholar]
- 118. Zheng J.-S., He Y., Zuo C., Cai X.-Y., Tang S., Wang Z. A., Zhang L.-H., Tian C.-L., Liu L., J. Am. Chem. Soc. 2016, 138, 3553–3561. [DOI] [PubMed] [Google Scholar]
- 119.
- 119a. Disotuar M. M., Petersen M. E., Nogueira J. M., Kay M. S., Chou D. H., Org. Biomol. Chem. 2019, 17, 1703–1708; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 119b. Fulcher J. M., Petersen M. E., Giesler R. J., Cruz Z. S., Eckert D. M., Francis J. N., Kawamoto E. M., Jacobsen M. T., Kay M. S., Org. Biomol. Chem. 2019, 17, 10237–10244. [DOI] [PubMed] [Google Scholar]
- 120. Erickson P. W., Fulcher J. M., Spaltenstein P., Kay M. S., Bioconjugate Chem. 2021, 32, 2233–2244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 121.
- 121a. Weidmann J., Schnölzer M., Dawson P. E., Hoheisel J. D., Cell Chem. Biol. 2019, 26, 645–651.e643; [DOI] [PubMed] [Google Scholar]
- 121b. Weinstock M. T., Jacobsen M. T., Kay M. S., Proc. Natl. Acad. Sci. USA 2014, 111, 11679–11684. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 122. Raibaut L., Ollivier N., Melnyk O., Chem. Soc. Rev. 2012, 41, 7001–7015. [DOI] [PubMed] [Google Scholar]
- 123.
- 123a. Metanis N., Keinan E., Dawson P. E., Angew. Chem. Int. Ed. 2010, 49, 7049–7053; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2010, 122, 7203–7207; [Google Scholar]
- 123b. Firstova O., Agouridas V., Diemer V., Melnyk O., in Chemical Protein Synthesis (Ed.: Li X.), Springer US, 2022, pp. 213–239; [DOI] [PubMed] [Google Scholar]
- 123c. Cargoët M., Diemer V., Raibaut L., Lissy E., Snella B., Agouridas V., Melnyk O., in Peptide and Protein Engineering: From Concepts to Biotechnological Applications (Eds.: Iranzo O., Roque A. C.), Springer US, 2020, pp. 1–12; [Google Scholar]
- 123d. Diemer V., Ollivier N., Leclercq B., Drobecq H., Vicogne J., Agouridas V., Melnyk O., Nat. Commun. 2020, 11, 2558. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 124. Vázquez O., Seitz O., J. Pept. Sci. 2014, 20, 78–86. [DOI] [PubMed] [Google Scholar]
- 125. Jacobsen M. T., Erickson P. W., Kay M. S., Bioorg. Med. Chem. 2017, 25, 4946–4952. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 126. Lee C. L., Liu H., Wong C. T. T., Chow H. Y., Li X., J. Am. Chem. Soc. 2016, 138, 10477–10484. [DOI] [PubMed] [Google Scholar]
- 127.
- 127a. Bacchi M., Jullian M., Sirigu S., Fould B., Huet T., Bruyand L., Antoine M., Vuillard L., Ronga L., Chavas L. M. G., Nosjean O., Ferry G., Puget K., Boutin J. A., Protein Sci. 2016, 25, 2225–2242; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 127b. Sørensen H. P., Sperling-Petersen H. U., Mortensen K. K., Protein Expression Purif. 2003, 31, 149–154. [DOI] [PubMed] [Google Scholar]
- 128. Laps S., Atamleh F., Kamnesky G., Sun H., Brik A., Nat. Commun. 2021, 12, 870. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 129.
- 129a. Yao S., Moyer A., Zheng Y., Shen Y., Meng X., Yuan C., Zhao Y., Yao H., Baker D., Wu C., Nat. Commun. 2022, 13, 1539; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 129b. Wu Y., Fan S., Dong M., Li J., Kong C., Zhuang J., Meng X., Lu S., Zhao Y., Wu C., Chem. Sci. 2022, 13, 7780–7789. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 130.
- 130a. Pagano G. J., Arsenault R. J., Expert Rev. Proteomics 2019, 16, 431–441; [DOI] [PubMed] [Google Scholar]
- 130b. Bondalapati S., Mansour W., Nakasone M. A., Maity S. K., Glickman M. H., Brik A., Chem. Eur. J. 2015, 21, 7360–7364; [DOI] [PubMed] [Google Scholar]
- 130c. Getz L. J., Runte C. S., Rainey J. K., Thomas N. A., J. Bacteriol. 2019, 201, e00205–00219. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 131.
- 131a. Jensen T. M. T., Bartling C. R. O., Karlsson O. A., Åberg E., Haugaard-Kedström L. M., Strømgaard K., Jemth P., ACS Chem. Biol. 2021, 16, 1191–1200; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 131b. Hsieh Y. S. Y., Wijeyewickrema L. C., Wilkinson B. L., Pike R. N., Payne R. J., Angew. Chem. Int. Ed. 2014, 53, 3947–3951; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2014, 126, 4028–4032. [Google Scholar]
- 132. Kim E. J., Bond M. R., Love D. C., Hanover J. A., Crit. Rev. Biochem. Mol. Biol. 2014, 49, 327–342. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 133.
- 133a. Guidotti N., Lechner C. C., Bachmann A. L., Fierz B., ChemBioChem 2019, 20, 1124–1128; [DOI] [PubMed] [Google Scholar]
- 133b. Shimko J. C., North J. A., Bruns A. N., Poirier M. G., Ottesen J. J., J. Mol. Biol. 2011, 408, 187–204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 134. Gui W. J., Davidson G. A., Zhuang Z. H., RSC Chem. Biol. 2021, 2, 450–467. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 135. Zhou Y., Xie Q., Wang H., Sun H., J. Pept. Sci. 2022, 28, e3367. [DOI] [PubMed] [Google Scholar]
- 136.
- 136a. Ajish Kumar K., Haj-Yahya M., Olschewski D., Lashuel H. A., Brik A., Angew. Chem. 2009, 121, 8234–8238; [DOI] [PubMed] [Google Scholar]; Angew. Chem. Int. Ed. 2009, 48, 8090–8094; [DOI] [PubMed] [Google Scholar]
- 136b. El Oualid F., Merkx R., Ekkebus R., Hameed D. S., Smit J. J., de Jong A., Hilkmann H., Sixma T. K., Ovaa H., Angew. Chem. 2010, 122, 10347–10351; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. Int. Ed. 2010, 49, 10149–10153; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 136c. Kumar K. A., Bavikar S. N., Spasser L., Moyal T., Ohayon S., Brik A., Angew. Chem. 2011, 123, 6261–6265; [DOI] [PubMed] [Google Scholar]; Angew. Chem. Int. Ed. 2011, 50, 6137–6141; [DOI] [PubMed] [Google Scholar]
- 136d. Kumar K. S. A., Spasser L., Erlich L. A., Bavikar S. N., Brik A., Angew. Chem. Int. Ed. 2010, 49, 9126–9131; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2010, 122, 9312–9317; [Google Scholar]
- 136e. Mulder M. P. C., El Oualid F., ter Beek J., Ovaa H., ChemBioChem 2014, 15, 946–949; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 136f. Sun H., Brik A., Acc. Chem. Res. 2019, 52, 3361–3371. [DOI] [PubMed] [Google Scholar]
- 137.
- 137a. Huang D.-L., Montigny C., Zheng Y., Beswick V., Li Y., Cao X.-X., Barbot T., Jaxel C., Liang J., Xue M., Tian C.-L., Jamin N., Zheng J.-S., Angew. Chem. Int. Ed. 2020, 59, 5178–5184; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2020, 132, 5216–5222; [Google Scholar]
- 137b. Chisholm T. S., Kulkarni S. S., Hossain K. R., Cornelius F., Clarke R. J., Payne R. J., J. Am. Chem. Soc. 2020, 142, 1090–1100. [DOI] [PubMed] [Google Scholar]
- 138. Mulvihill E. E., Curr. Opin. Lipidol. 2018, 29, 95–103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 139. Knudsen L. B., Lau J., Front. Endocrinol. 2019, 10, 155. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 140. Hashemzadeh M. S., Mohammadi M., Ghaleh H. E. G., Sharti M., Choopani A., Panda A. K., Protein Pept. Lett. 2021, 28, 122–130. [DOI] [PubMed] [Google Scholar]
- 141. Kobayashi S., Proc. Jpn. Acad. Ser. B 2007, 83, 215–247. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 142. Garenne D., Haines M. C., Romantseva E. F., Freemont P., Strychalski E. A., Noireaux V., Nat. Rev. Methods Primers 2021, 1, 49. [Google Scholar]
- 143. Goto Y., Katoh T., Suga H., Nat. Protoc. 2011, 6, 779–790. [DOI] [PubMed] [Google Scholar]
- 144. Woolfson D. N., J. Mol. Biol. 2021, 433, 167160. [DOI] [PubMed] [Google Scholar]
- 145. Liu H., Li X., Acc. Chem. Res. 2018, 51, 1643–1655. [DOI] [PubMed] [Google Scholar]
- 146. Rohrbacher F., Wucherpfennig T. G., Bode J. W., Top. Curr. Chem. 2015, 363, 1–31. [DOI] [PubMed] [Google Scholar]
- 147.
- 147a. Blanco-Canosa J. B., Dawson P. E., Angew. Chem. Int. Ed. 2008, 47, 6851–6855; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2008, 120, 6957–6961; [Google Scholar]
- 147b. Noguchi T., Ishiba H., Honda K., Kondoh Y., Osada H., Ohno H., Fujii N., Oishi S., Bioconjugate Chem. 2017, 28, 609–619. [DOI] [PubMed] [Google Scholar]
- 148. Raibaut L., Adihou H., Desmet R., Delmas A. F., Aucagne V., Melnyk O., Chem. Sci. 2013, 4, 4061–4066. [Google Scholar]
- 149. Tang S., Si Y.-Y., Wang Z.-P., Mei K.-R., Chen X., Cheng J.-Y., Zheng J.-S., Liu L., Angew. Chem. Int. Ed. 2015, 54, 5713–5717; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2015, 127, 5805–5809. [Google Scholar]
- 150. Pan M., He Y., Wen M., Wu F., Sun D., Li S., Zhang L., Li Y., Tian C., Chem. Commun. 2014, 50, 5837–5839. [DOI] [PubMed] [Google Scholar]
- 151. Li J., Li Y., He Q., Li Y., Li H., Liu L., Org. Biomol. Chem. 2014, 12, 5435–5441. [DOI] [PubMed] [Google Scholar]
- 152. Wan Q., Danishefsky S. J., Angew. Chem. Int. Ed. 2007, 46, 9248–9252; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2007, 119, 9408–9412. [Google Scholar]
- 153. Moyal T., Hemantha H. P., Siman P., Refua M., Brik A., Chem. Sci. 2013, 4, 2496–2501. [Google Scholar]
- 154. Thompson R. E., Liu X., Alonso-García N., Pereira P. J. B., Jolliffe K. A., Payne R. J., J. Am. Chem. Soc. 2014, 136, 8161–8164. [DOI] [PubMed] [Google Scholar]
- 155. Guo Q.-Y., Zhang L.-H., Zuo C., Huang D.-L., Wang Z. A., Zheng J.-S., Tian C.-L., Protein Cell 2019, 10, 211–216. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 156. Kumar K. A., Spasser L., Ohayon S., Erlich L. A., Brik A., Bioconjugate Chem. 2011, 22, 137–143. [DOI] [PubMed] [Google Scholar]
- 157.
- 157a. Murakami M., Kiuchi T., Nishihara M., Tezuka K., Okamoto R., Izumi M., Kajihara Y., Sci. Adv. 2016, 2, e1500678; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 157b. Graf C. G. F., Schulz C., Schmälzlein M., Heinlein C., Mönnich M., Perkams L., Püttner M., Boos I., Hessefort M., Lombana Sanchez J. N., Weyand M., Steegborn C., Breiden B., Ross K., Schwarzmann G., Sandhoff K., Unverzagt C., Angew. Chem. Int. Ed. 2017, 56, 5252–5257; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2017, 129, 5336–5341. [Google Scholar]
- 158. Murakami M., Okamoto R., Izumi M., Kajihara Y., Angew. Chem. Int. Ed. 2012, 51, 3567–3572; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2012, 124, 3627–3632. [Google Scholar]
- 159.
- 159a. Msallam M., Sun H., Meledin R., Franz P., Brik A., Chem. Sci. 2020, 11, 5526–5531; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 159b. Haj-Yahya M., Gopinath P., Rajasekhar K., Mirbaha H., Diamond M. I., Lashuel H. A., Angew. Chem. Int. Ed. 2020, 59, 4059–4067; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2020, 132, 4088–4096. [Google Scholar]
- 160. Agouridas V., El Mahdi O., Cargoët M., Melnyk O., Bioorg. Med. Chem. 2017, 25, 4938–4945. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data sharing is not applicable to this article as no new data were created or analyzed in this study.