

Abstract
Gradient-based meta-learning methods have primarily been applied to classical machine learning tasks such as image classification. Recently, PDE-solving deep learning methods, such as neural operators, are starting to make an important impact on learning and predicting the response of a complex physical system directly from observational data. Taking the material modeling problems for example, the neural operator approach learns a surrogate mapping from the loading field to the corresponding material response field, which can be seen as learning the solution operator of a hidden PDE. The microstructure and mechanical parameters of each material specimen correspond to the (possibly heterogeneous) parameter field in this hidden PDE. Due to the limitation on experimental measurement techniques, the data acquisition for each material specimen is commonly challenging and costly. This fact calls for the utilization and transfer of existing knowledge to new and unseen material specimens, which corresponds to sampling efficient learning of the solution operator of a hidden PDE with a different parameter field. Herein, we propose a novel meta-learning approach for neural operators, which can be seen as transferring the knowledge of solution operators between governing (unknown) PDEs with varying parameter fields. Our approach is a provably universal solution operator for multiple PDE solving tasks, with a key theoretical observation that underlying parameter fields can be captured in the first layer of neural operator models, in contrast to typical final-layer transfer in existing meta-learning methods. As applications, we demonstrate the efficacy of our proposed approach on PDE-based datasets and a real-world material modeling problem, illustrating that our method can handle complex and nonlinear physical response learning tasks while greatly improving the sampling efficiency in unseen tasks.
Keywords: Operator-Regression Neural Networks, Data-Driven Physics Modeling, Neural Operators, Transfer Learning, Meta-Learning, Scientific Machine Learning
1. Introduction
Few-shot learning is an important problem in machine learning, where new tasks are learned with a very limited number of labelled datapoints [1]. In recent years, significant progress has been made on few-shot learning using meta-learning approaches [2–12]. Broadly speaking, given a family of tasks, some of which are used for training and others for testing, meta-learning approaches aim to learn a shared multi-task representation that can generalize across the different training tasks, and result in fast adaptation to new and unseen testing tasks. Meta-learning learning algorithms have been successfully applied to conventional machine learning problems such as image classification, function regression, and reinforcement learning, but studies on few-shot learning approaches for complex physical system modeling problems have been limited. The call of developing a few-shot learning approach for complex physical system modeling problems, such as to learn the material response model from experimental measurements, is just as acute, while the typical understanding of how multi-task learning should be applied on this scenario is still nascent.
As a motivating example, we consider the scenario of new material discovery in the lab environment, where the material model is built based on experimental measurements of its responses subject to different loadings. Since the physical properties (such as the mechanical and structural parameters) in different material specimens vary, the model learnt from experimental measurements on one specimen would have large generalization errors on other specimens. As a result, the data-driven model has to be trained repeatedly with a large number of material specimens, which makes the learning process inefficient. Furthermore, experimental measurement acquisition of these specimens is often challenging and expensive. In some problems, a large amount of measurements are not even feasible. For example, in the design and testing of biosynthetic tissues, performing repeated loading would potentially induce the cross-linking and permanent set phenomenon, which notoriously alter the tissue durability [13]. As a result, it is critical to learn the physical response model of a new specimen with sample size as small as possible. Furthermore, since many characterization methods to obtain underlying material mechanistic and structural properties would require the use of destructive methods [14, 15], in practice many physical properties are not measured and can only be treated as hidden and unknown variables. Hence, we likely only have limited access to the measurements on the complex system responses caused by the change of these physical properties.
Supervised operator learning methods are typically used to address this class of problems. They take a number of observations on the loading field as input, and try to predict the corresponding physical system response field as output, corresponding to one underlying PDE (as one task). Herein, we consider the meta-learning of multiple complex physical systems (as tasks), such that all these tasks are governed by a common PDE with different (hidden) physical property or parameter fields. Formally, assume that we have a distribution over tasks, each task corresponds to a hidden physical property field that contains the task-specific mechanistic and structural information in our material modeling example. On task , we have a number of observations on the loading field and the corresponding physical system response field according to a hidden parameter field . Here, is the sample index, and are Banach spaces of function taking values in and , respectively. For task , our modeling goal is to learn the solution operator , such that the learnt model can predict the corresponding physical response field for any loading field 1. Without transfer learning, one needs to learn a surrogate solution operator for each task only based on the data pairs on this task, and repeat the training for every task. The learning procedure would require a relatively large amount of observation pairs and training time for each task. Therefore, this physical-based modeling scenario raises a key question: Given data from a number of parametric PDE solving (training) tasks with different unknown parameters, how can one efficiently learn an accurate surrogate solution operator for a test task with new and unknown parameters, with few data on this task2 ?
To address this question, we introduce MetaNO, a novel meta-learning approach for transferring knowledge between neural operators, which can be seen as transferring the knowledge of solution operators between governing (potentially unknown) PDEs with varying hidden parameter fields. Our main contributions are:
MetaNO is the first neural-operator-based meta-learning approach for multiple tasks, which not only preserves the generalizability to different resolutions and input functions from the integral neural operator architecture, but also improves sampling efficiency on new tasks – for comparable accuracy, MetaNO saves the number of measurements required by ~90%.
With rigorous operator approximation analysis, we made the key observation that the hidden parameter field can be captured by adapting the first layer of the neural operator model. Therefore, our MetaNO is substantially different from existed popular meta-learning approaches [5, 10], since the later typically rely on the adaptation of their last layers [12]. By construction, MetaNO serves as a provably universal solution operator for multiple PDE solving tasks.
On synthetic, benchmark, and real-world biological tissue datasets, the proposed method consistently outperforms existing non-meta transfer-learning baselines and other gradient-based meta-learning methods.
2. Background and Related Work
2.1. Hidden Physics Learning with Neural Networks
For many decades, physics-based PDEs have been commonly employed for predicting and monitoring complex system responses. Then traditional numerical methods were developed to solve these PDEs and provide predictions for desired system responses. However, three fundamental challenges usually present. First, the choice of governing PDE laws is often determined a priori and free parameters are often tuned to obtain agreement with experimental data, which makes the rigorous calibration and validation process challenging. Second, traditional numerical methods are solved for specific boundary and initial conditions, as well as loading or source terms. Therefore, they are not generalizable for other operating conditions and hence not effective for real-time prediction. Third, complex PDE systems such as turbulence flows and heterogeneous materials modeling problems usually require a very fine discretization, and are therefore very time-consuming for traditional solvers.
To provide an efficient surrogate model for physical responses, machine learning methods may hold the key. Recently, there has been significant progress in the development of deep neural networks (NNs) for learning the hidden physics of a complex system [17–25]. Among these methods, the neural operators show particular promises in resolving the above challenges, which aim to learn mappings between inputs of a dynamical system and its state, so that the network can serve as a surrogate for a solution operator [26–34].
Comparing with classical NNs, most notable advantages of neural operators are resolution independence and generalizability to different input instances. Moreover, comparing with the classical PDE modeling approaches, neural operators require only data with no knowledge of the underlying PDE. All these advantages make neural operators promising tools to PDE learning tasks. Examples include modeling the unknown physics law of real-world problems [35, 36] and providing efficient solution operator for PDEs [26–28, 37, 38]. On the other hand, data in scientific applications are often scarce and incomplete. Utilization of other relevant data sources could alleviate such a problem, yet no existing work have addressed the transferability of neural operators. Through the meta-learning techniques, our work fulfills the demand of such a transfer setting, with the same type of PDE system but different (hidden) physical properties.
2.2. Base Model: Integral Neural Operators
We briefly introduce the integral neural operator model, which will be utilized as the base model of this work. The integral neural operators, first proposed in [26] and further developed in [27–29, 39] comprises of three building blocks. First, the input function, , is lifted to a higher dimensional representation via and define an affine pointwise mapping, which are often taken as constant parameters, i.e., and . Then, the feature vector function goes through an iterative layer block where the layer update is defined via the action of the sum of a local linear operator, a nonlocal integral kernel operator, and a bias function: . Here, , is a sequence of functions representing values of the network at each hidden layer, taking values in are nonlinear operator layers. In this work, we employ the implicit Fourier neural operator (IFNO) as the base model3 and take the iterative layers as , where
| (2.1) |
and denote the Fourier transform and its inverse, respectively. defines a constant bias, is the weight matrix, and is a circulant matrix that depends on the convolution kernel is an activation function, which is often taken to be the popular rectified linear unit (ReLU) function. Finally, the output is obtained through a projection layer, by mapping the last hidden layer representation onto as: and are appropriately sized matrices and vectors that are part of the parameter set that we aim to learn, which are often taken as constant parameters and will be denoted as and , respectively. In the following, we denote the set of trainable parameters in the lifting layer as , the set from the iterative layer block as , and the set in the projection layer as .
The neural operator can be employed to learn an approximation for the solution operator, . Given , a labelled (context) set of observations, where the input is a set of independent and identically distributed (i.i.d.) random fields from a known probability distribution on , and is the observed but possibly noisy corresponding solution. Let be the domain of interest, we assume that all observations can be modeled with a parametric PDE form:
| (2.2) |
is the operator representing the possibly unknown governing law, e.g., balance laws. Then, the system response can be learnt by constructing a surrogate solution operator of (2.2): , where parameter set is obtained by solving the optimization problem:
| (2.3) |
Here denotes a properly defined cost functional which is often taken as the relative mean square error.
2.3. Gradient-Based Meta-Learning Methods
Traditionally, machine learning models are designed to address one single task by learning from the dataset corresponding to such a task. Hence, its efficacy relies on the quality and abundance of available data. To improve the learning efficacy in the small data regime, a significant body of work has tackled the challenge of few-shot learning using transfer-learning or meta-learning approaches, with the basic idea of utilizing prior knowledge gained from related (source) tasks to improve the learning performance on the target task. Among these two types of approaches, the basic idea of transfer-learning is to train a model from the source task and then refine the pre-trained model in the target task [40]. In comparison, meta-learning approaches aim to learn a generalizable representations that shared across the different training tasks, which can accelerate learning of test tasks [5, 41]. One of highly successful meta-learning algorithms is Model Agnostic Meta-Learning (MAML) [5], which led to the development of a series of related gradient-based meta-learning (GBML) methods [7, 9, 10, 42]. Almost-No-Inner-Loop algorithm (ANIL) [10] modifies MAML by freezing the final layer representation during local adaptation. Recently, theoretical analysis [12] found that the driving force causing MAML and ANIL to recover the general representation is the adaptation of the final layer of their models, which harnesses the underlying task diversity to improve the representation in all directions of interest.
Beyond applications such as image classification and reinforcement learning, a few approaches have studied hidden-physics learning under meta [43–46] or even transfer setting [47, 48]. Among these meta-learning works, [43, 44] are designed for specific physical applications, while [45, 46] focus on on dynamics forecasting by learning the temporal evolution information directly [45] or learning time-invariant features [46]. Hence, none of these works have provided a generic approach nor theoretical understanding on how to transfer the multi-task knowledge between a series of complex physical systems, such that all these tasks are governed by a common parametric PDE with different physical parameters.
3. Meta-Learnt Neural Operator
To transfer the multi-task knowledge between a series of complex systems governed by different hidden physical parameters, we proposed to leverage the integral neural operator with a meta-learning setting. Before elaborating our novel meta-learnt neural operator architecture, MetaNO, we formally state the transfer-learning problem setting for PDE with different parameters.
Assume that we have a set of training tasks such that , and for each training task we have a set of observations of loading field/respond field data pairs . Each task can be modeled with a parametric PDE form
| (3.1) |
where is the hidden task-specific physical parameter field for the common governing law. Given a new and unseen test task, , and a (usually small) context set of labelled samples on it, our goal is to obtain the approximated solution operator model on the test task as . To provide a quantitative metric of the performance for each method, we reserve a separate set of labelled samples on the test task as the target set, and measure averaged relative errors of on this set. In the few-shot learning context, we are particularly interested in the small-sample scenario where .
3.1. A Novel Meta-Learnt Neural Operator Architecture
We now propose MetaNO, which applies task-wise adaptation only to the first layer, i.e., the lifting layer, with the full algorithm outlined in Algorithm 1. We point out that MetaNO is substantially different from existed popular meta-learning approaches such as MAML and ANIL, since the later rely on the adaptation of their last layer, as shown in [12]. This property makes MetaNO more suitable for PDE solving tasks as will be discussed in theoretical analysis below and confirmed in empirical evaluations of Section 4.
Algorithm 1.
MetaNO
| Meta-Train Phase: |
| Input: a batch of training tasks and labelled data pairs on each task. |
| Output: common parameters and across all tasks. |
| 1. Initialize , and . |
| 2. Solve for from the optimization problem in (3.2). |
| Meta-Test Phase: |
| Input: a test task and few labelled data pairs on it. |
| Output: the task-wise parameter and the corresponding surrogate PDE solution operator for the test task. |
| 3. Solve for the lift layer parameter from the optimization problem in (3.3). |
| 4. (For cases with large and/or small ), fine tune all parameters on the test task. |
Similar as in other meta-learning approaches [49–52], the MetaNO algorithm consists of two phases: 1) a meta-train phase which learns shared iterative layers parameters and projection layer parameters from training tasks; 2) a meta-test phase which transfers the learned knowledge and rapidly learning surrogate solution operators for unseen test tasks with unknown physical parameter field, where only a few labelled samples are provided. In the meta-train phase, a batch of tasks is drawn from the training tasks set, with a context set of numbers of labelled loading field/response field data pairs, , provided on each task. Then, we seek the common iterative and projection parameters, and the task-wise lifting parameters by solving the optimization problem:
| (3.2) |
Then, in the meta-test phase, we adapt the knowledge to a new and unseen test task , with limited data on the context set on this task. In particular, we fix the common parameters and , then solve for the task-wise parameter via:
| (3.3) |
One can then fine tune all test task parameters for further improvements. Finally, the surrogate PDE solution operator on the test task is obtained as:
and will be evaluated on a reserved target data set on the test task.
3.2. Universal Solution Operator
To see the inspiration of the proposed architecture, without loss of generality, we assume that the underlying task parameter field , modeling the physical property field, is normalized and satisfying for all , where . Denoting as a function from physical parameter fields to loading fields , we take the Fréchet derivative of with respect to and obtain:
Substituting the above formulation into (3.1) yields:
Denoting and , we can reformulate (3.1) into a more generic form:
Note that this parametric PDE form is very general and applicable to many science and engineering applications – besides our motivating example on material modeling, other examples include the monitoring of tissue degeneration problems [13], the detection of subsurface flows [53], the nondestructive inspection in aviation [54], and the prediction of concrete structures deterioration [55], etc.
In the following, we show that MetaNOs are universal solution operators for the multi-task PDE solving problem in (3.4), in the sense that they can approximate a fixed point method to a desired accuracy. For simplicity, we consider a domain , and scalar-valued functions . These functions are assumed to be sufficiently smooth and measured at uniformly distributed nodes , with for all and . Then, (3.4) can be formulated as an implicit system of equations:
| (3.5) |
where is the solution we seek, is the reparameterized loading vector, and is the original loading vector. Here, we notice that all task-specific information is encoded in and can be captured in the lifting layer parameter. Therefore, when seeing (3.5) as an implicit problem of and , it is actually independent of the task parameter field , i.e., this problem is task-independent. In the following, we refer to (3.5) without the task index, as , for notation simplicity.
To solve for from the nonlinear system , a popular approach would be to use fixed-point iteration methods such as the Newton-Raphson method. With an initial guess of the solution (denoted as ), the process is repeated to produce successively better approximations to the roots of (3.5), from the solution of iteration (denoted as to that of (denoted as as:
| (3.6) |
until a sufficiently precise value is reached. In the following, we show that as long as Assumptions 1 and 2 hold, i.e., there exists a converging fixed point method, then MetaNO can be seen as an resemblance of the fixed point method in (3.6) and hence acts as an universal approximator of the solution operator for (3.4).
Assumption 1. There exists a fixed point equation, for the implicit of problem (3.5), such that is a continuous function satisfying and for any two vectors . Here, is a constant independent of .
Assumption 2. With the initial guess , the fixed-point iteration converges, i.e., for any given , there exists an integer such that
for all possible input instances and their corresponding solutions .
Intuitively, Assumptions 1 and 2 ensure the hidden PDEs to be numerically solvable with a converging iterative solver, which is a typical required condition of numerical PDE solving problems. Then, we have our universal approximation theorem as below. The main result of this theorem is to show that for any desired accuracy , one can find a sufficiently large and sets of parameters , such that the resultant MetaNO model acts as a fixed point method with the desired prediction for all tasks and samples.
Theorem 1 (Universal approximation). Given Assumptions 1–2, let the activation function for all iterative kernel integration layers be the ReLU function, and the activation function in the projection layer be the identity function. Then for any , there exist sufficiently large layer number and feature dimension number , such that one can find a parameter set for the multi-task problem, , such that the corresponding MetaNO model satisfies
for all loading instance and tasks.
We now provide the detailed proof for Theorem 1, based on Assumptions 1 and 2. Intuitively, these assumptions mean the underlying implicit problem is solvable with a converging fixed point method. This condition is a basic requirement by numerical PDEs, and it generally holds true in many applications governed by nonlinear and complex PDEs, such as in our three experiments.
Here, we prove that the MetaNO is universal, i.e., given a fixed point method satisfying Assumptions 1 and 2, one can find parameter sets whose output approximates to a desired accuracy, , for all tasks. For the task-wise parameters, with a slight abuse of notation, we denote as the collection of the pointwise weight matrices at each discretization point in for the -th task, and for the bias in the lifting layer. Then, for the parameters shared among all tasks, in the iterative layer we denote as the collection of pointwise bias vectors for the local linear transformation, and for the Fourier coefficients of the kernel . For simplicity, here we have assumed that the Fourier coefficient is not truncated, and all available frequencies are used. Then, for the projection layer we seek , and . For the simplicity of notation, in this section we organize the feature vector in a way such that the components corresponding to each discretization point are adjacent, i.e., and .
We point out that under this circumstance, the (discretized) iterative layer can be written as
with
Here, with being the component associated with each discretization point is a block diagonal matrix formed by and denote the discrete Fourier transform and its inverse, respectively. By further taking , a matrix with all its elements being zero, it suffices to show the universal approximation property for an iterative layer as follows:
where with and being an by all-ones matrix.
For the proof of this main theorem, we need the following approximation property of a shallow neural network, with its detailed proof provided in [39]:
Lemma 1. Given a continuous function , and a non-polynomial and continuous activation function , for any constant there exists a shallow neural network model such that
for sufficiently large feature dimension . Here, , and are matrices/vectors which are independent of .
We now proceed to the proof of Theorem 1:
Proof. Since all satisfies Assumptions 1–2, for any , we first pick a sufficiently large integer such that the -th layer iteration result of this fixed point formulation satisfies for all tasks. By taking in Lemma 1, there exists a sufficiently large feature dimension and one can find , and , such that satisfies
where is the contraction parameter of , as defined in Assumption 1. By this construction, we know that has independent rows. Denoting , there exists the right inverse of , which we denote as , such that
where is the by identity matrix, is a by block matrix with each of its element being either 1 or 0. Hence, for any vector , we have . Moreover, we note that has a very special structure: from the -th to the -th column of , all nonzero elements are on its -th row. Correspondingly, we can also choose to have a special structure: from the -th to the -th row of , all nonzero elements are on its -th column. Hence, when multiplying with , there will be no entanglement between different components of . That means, can be seen as a pointwise weight function.
We now construct the parameters of MetaNO as follows. In this construction, we choose the feature dimension as . With the input , for the lift layer we set
and . Here, . As such, the initial layer of feature is then given by
Here, we point out that and can be seen as pointwise weight and bias functions, respectively.
Next we construct the shared iterative layer , by setting
Note that is independent of , and falls into the formulation of , by letting and . For the -th layer of feature vector, we then arrive at
where denotes the (spatially discretized) hidden layer feature at the th iterative layer of the IFNO. Subsequently, we note that the second part of the feature vector, , satisfies
Hence, the first part of the feature vector, , satisfies the following iterative rule:
and
Finally, for the projection layer , we set the activation function in the projection layer as the identity function, (the identity matrix of size ), , and . Denoting the output , we now show that can approximate with a desired accuracy :
4. Empirical Evaluation
In this section, we demonstrate the empirical effectiveness of the proposed MetaNO approach. Specifically, we conduct experiments on a synthetic dataset from a nonlinear PDE solving problem, a benchmark dataset of heterogeneous materials subject to large deformation, and a real-world dataset from biological tissue mechanical testing. We compare the proposed method against competitive GBML methods as well as two non-meta transfer-learning baselines. All of the experiments are implemented using PyTorch with Adam optimizer, and performed on a workstation with two 2.2 24-core CPUs and eight NVIDIA Tesla T4 GPUs. For a fair comparison, for each algorithm, we tune the hyperparameters, including the learning rate from {0.1, 0.01, 0.001, 0.0001, 0.00001, 0.000001}, the decay rate from {0.5, 0.7, 0.9}, the weight decay parameter from {0.01, 0.001, 0.0001, 0.00001, 0.000001}, and the inner loop learning rate for the baseline GBML methods (MAML and ANIL) from {0.01, 0.001, 0.0001, 0.00001, 0.000001}, to minimize the error on a separate validation dataset. In all experiments we decrease the learning rate with a ratio of learning rate decay rate every 100 epochs. A detailed description of each baseline method is provided in Appendix A.
In all experiments, we considered the averaged relative error, , as the error metric. We repeat each experiment for 5 times, and report the averaged relative errors and their standard errors.
4.1. Example 1: Synthetic Data Sets and Ablation Study
We first consider the PDE-solution-finding problem of the Holzapfel-Gasser-Odgen (HGO) model [56], which describes the deformation of hyperelastic, anisotropic, and fiber-reinforced materials. In this example, the goal is to find its displacement field under different boundary loadings. The specimen is assumed to be subject to a uniaxial tension on the top edge (see Figure 2(a)). Therefore, we take the input function as the padded traction loading field, and the output function as the corresponding displacement field.
Figure 2:
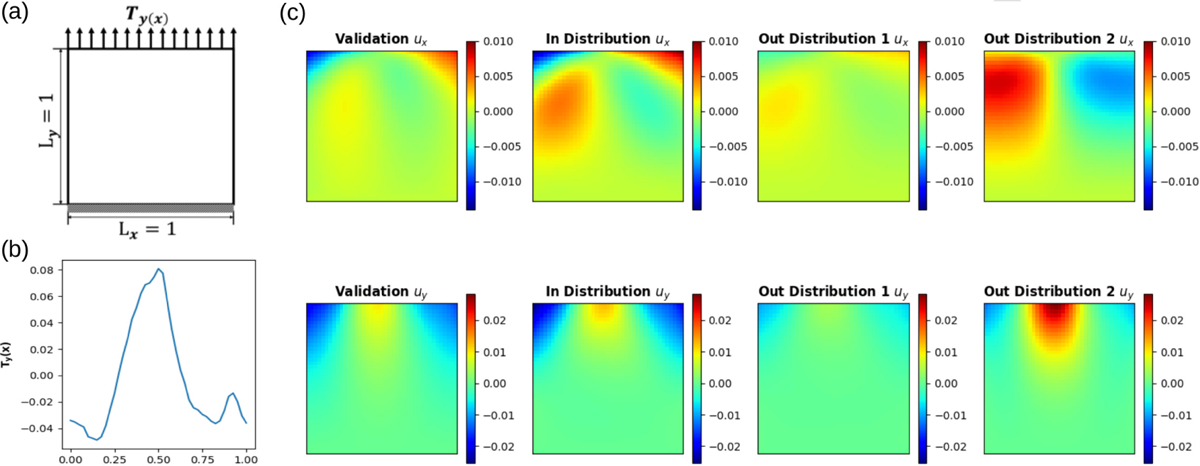
Problem setup of example 1: the synthetic data sets. (a) A unit square specimen subject to uniaxial tension with Neumann-type boundary condition. (b) & (c) Visualization of an instances of the loading field , and the corresponding ground-truth solutions from the in-distribution and out-of-distribution tasks, showing the solution diversity across different tasks, due to the change of underlying hidden material parameter set. □
Data Generation.
To generate training and test samples, the Holzapfel-Gasser-Odgen (HGO) model [56] was employed to describe the constitutive behavior of the material in this example, with its strain energy density function given as:
Here, 〈⋅〉 denotes the Macaulay bracket, and the fiber strain of the two fiber groups is defined as:
where and are fiber modulus and the exponential coefficient, respectively, is the Young's modulus for the non-fibrous ground matrix, and is the Poisson ratio. Moreover, is the is the first invariant of the right Cauchy-Green tensor is the deformation gradient, and is related with such that . For the fiber group with angle direction from the reference direction, is the fourth invariant of the right Cauchy-Green tensor , where . To generate samples for different specimens, different specimens (tasks) correspond to different material parameter sets, .
To investigate the performance of MetaNO in few-shot learning, we generate 59 training, 1 validation tasks, and 5 in-distribution (ID) test tasks by sampling different physical parameters from the same uniform distribution. To further evaluate the generalizability when the physical parameters of test tasks are outside the training regime, we also generate 2 out-of-distribution (OOD) test tasks with physical parameters from different distributions. For the training tasks, the validation task, and the in-distribution (ID) test task, their physical parameters are sampled from: , , and . For the two out-of-distribution (OOD) test tasks, we sample their parameters following 4, and . To generate the high-fidelity (ground-truth) dataset, we sampled 500 different vertical traction conditions on the top edge from a random field, following the algorithm in [36, 58]. is taken as the restriction of a random field, , on the top edge. Here, is a Gaussian white noise random field on represents a correlation function, and are the wave numbers on and directions, respectively. Then, for each sampled traction loading, we solved the displacement field on the entire domain by minimizing potential energy using the finite element method implemented in FEniCS [59]. In particular, the displacement filed was approximated by continuous piecewise linear finite elements with triangular mesh, and the grid size was taken as 0.025. The finite element solution was interpolated onto , a structured 41 × 41 grid which will be employed as the discretization in our neural operators. The distribution of training and ID/OOD tasks are demonstrated in Figure 3, where one can see that the first OOD task (denoted as “OOD Task1”) corresponds to a stiffer material sample and smaller deformation for each given loading, while the second OOD task (denoted as “OOD Task2”) generates a softer material sample and larger deformation. For each training task, we generate 500 data pairs , by sampling the vertical traction loading from a Gaussian random field. Then, the corresponding ground-truth displacement field is obtained using the finite element method implemented in FEniCS [59]. For test tasks, we train with numbers of labelled data pairs (the context set), and evaluate the model on a reserved dataset with 200 data pairs (the target set) on each test task. An 8-layer IFNO is employed as the base model.
Figure 3:
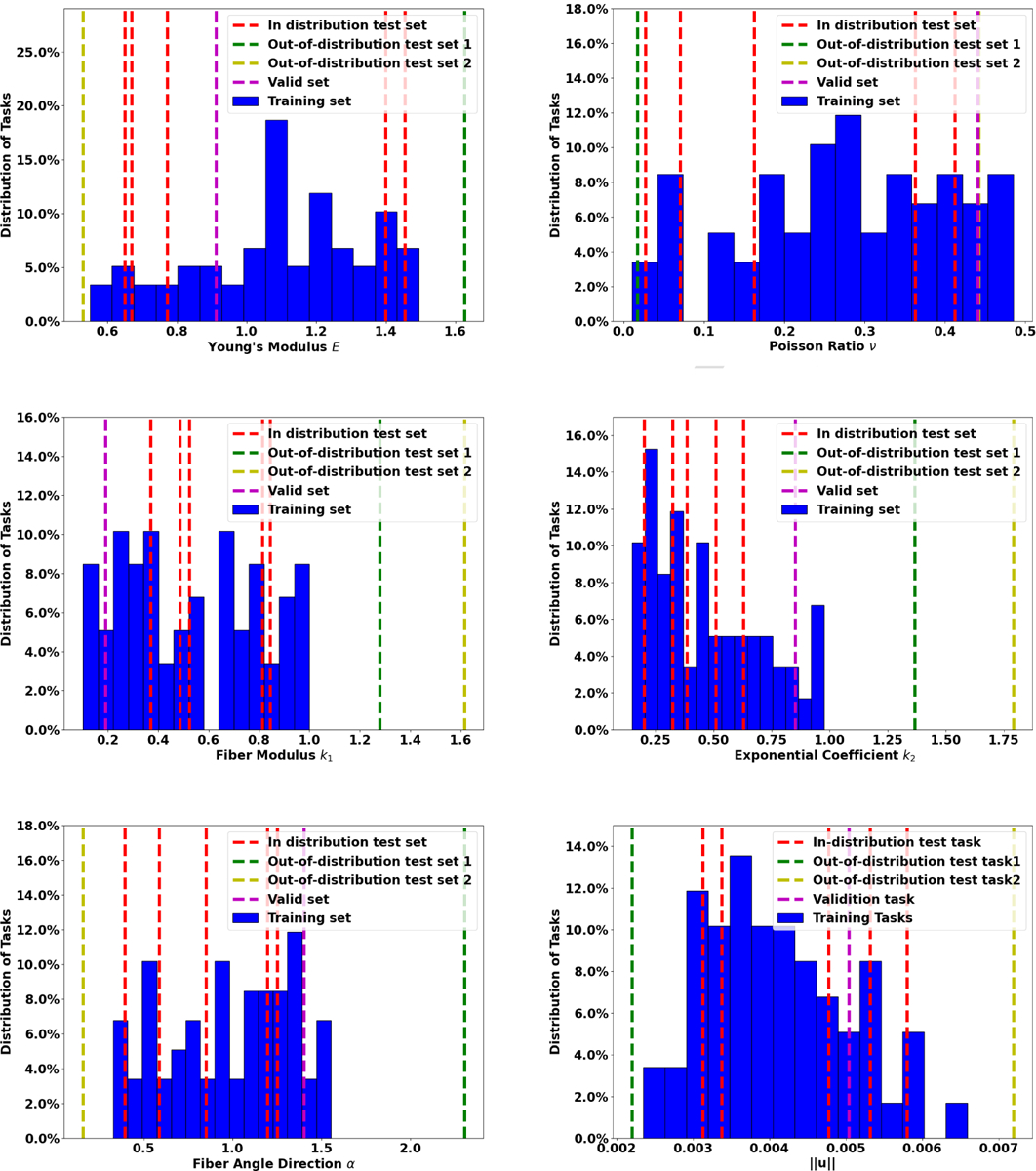
Distribution of physical parameters of different tasks in example 1, and the resultant magnitude of material response, , on an exemplar loading instance shown in Figure 2(b).
Ablation Study.
We first conduct an ablation study on 4 variants of the proposed algorithm: 1) to use the full meta-train and meta-test phases as in Algorithm 1 (denotes as “MetaNO”); 2) to perform steps 1–3 of Algorithm 1, such that only the lifting layer is adapted in the meta-test phase (denotes as “MetaNO-”); 3) to apply task-wise adaptation only to the iterative layers instead of the lift layer in both meta-train and meta-test phases (denoted as “MetaMid”); 4) to apply task-wise adaptation only to the projection layer instead of the lift layer in both meta-train and meta-test phases (denoted as “MetaLast”). We study if the successful “adapting last layers” strategy of MAML and ANIL in image classification problems would apply for our PDE solving problem. Besides these four settings, we also report the few-shot learning results with five baseline methods: 1) Learn a neural operator model only based on the context data set of the test task (denoted as “Single”); 2) Pretrain a neural operator model based on all training task data sets, then fine-tune it based on the context test task data set (denoted as “Pretrain1”); 3) Pretrain a single neural operator model based on the context data set of one training task, then fine-tune it based on the context test task data set (denoted as “Pretrain2”); To remove the possible dependency on the pre-training task, in this baseline we randomly select five training tasks for the purpose of pretraining and report the averaged results. 4) MAML, and 5) ANIL. For all experiments we use the full context data set on each training task .
As shown in Figure 4, MetaNO- and MetaNO are both able to quickly adapt with few data pairs – to achieve a test error below 5%, “Single” and the two transfer-learning baselines (“Pretrain1”, “Pretrain2”) require 100+ data pairs, while MetaNO- and MetaNO requires only 4 data pairs. On the other hand, MetaMid, MetaLast, MAML and ANIL have similar performance. They all require 100 data pairs to achieve a < 5% test error. In particular, when using only 4 data pairs on the target task, “MetaNO-” has relative test error, while “MetaMid” and “MetaLast” have and relative test errors, respectively. This observation verifies our finding on the multi-task parametric PDE solution operator learning problem, where one should adapt the first layer, not the middle layers or the last ones. A detailed comparison on the computational time and test errors of these “MetaNO-” and “MetaNO” is provided in Table 1. Herein, the total time of MetaNO- includes the Meta-Train Phase (Steps 1 and 2) and the step of solving for in the Meta-Test Phase (Step 3) of Algorithm 1, and the total time of MetaNO includes all steps of both the Meta-Train and Meta-Test Phases (Steps 1–4). Since the Meta-Train Phase took the majority of training time (45612 seconds), although “MetaNO” requires an additional fine-tuning step, its computational cost is of a similar scale as “MetaNO-”. When comparing the test errors, we can see that the additional fine-tune step only improves the performance in the larger-sample regime (when ). This fact shows that when given sufficient training context sets, adapting the first layer can capture the underlying task diversity so further fine-tuning may not be needed, especially in the small data regime.
Figure 4:
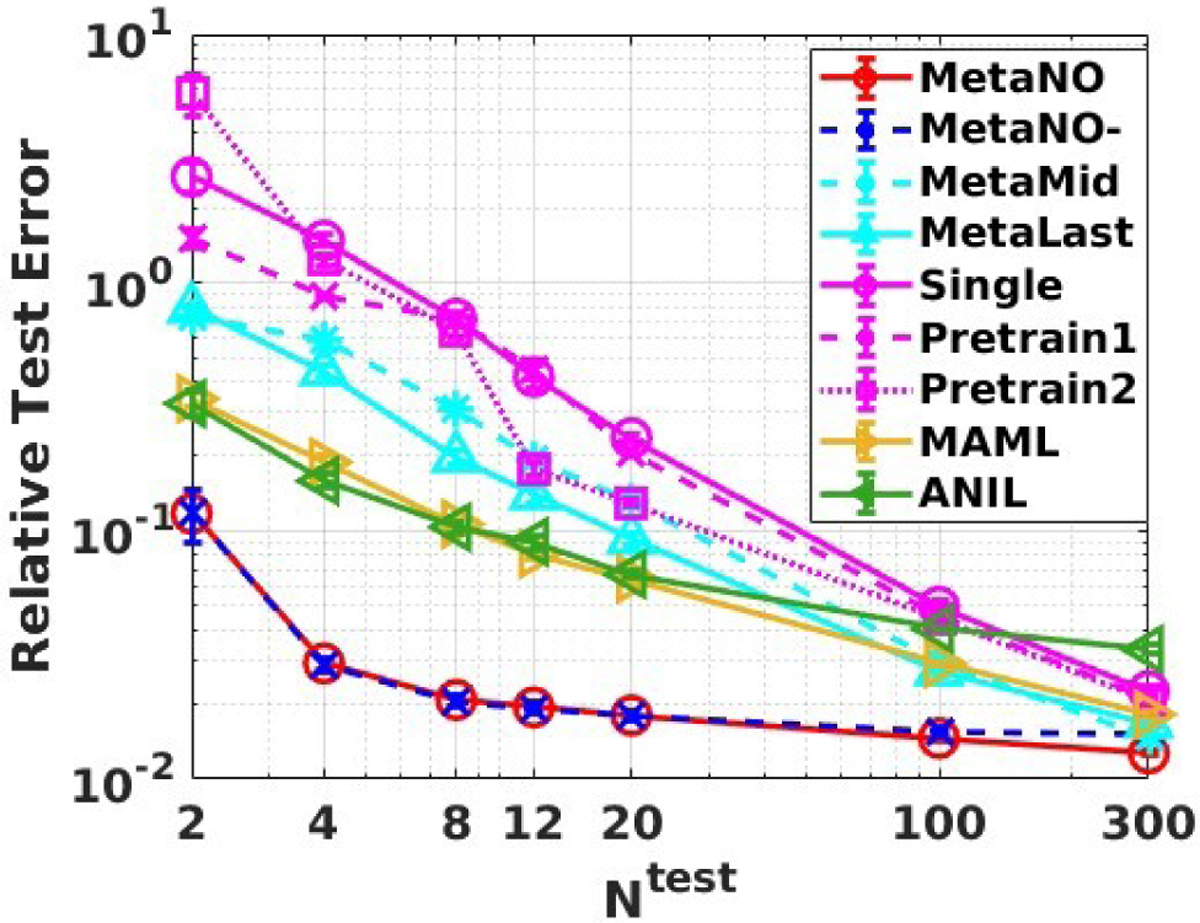
Results of the ablation study on example 1: the synthetic data set. Comparison on test errors in the in-distribution test, when using the full context set on training tasks and different sizes of context set on test tasks.
Table 1:
A comparison of the computational costs (in seconds) and test errors (in relative norm) of MetaNO and MetaNO-, in the ablation study on example 1. Here, the total time of MetaNO- includes the Meta-Train Phase (Steps 1 and 2) and the step of solving for in the Meta-Test Phase (Step 3), and the total time of MetaNO includes all steps of both the Meta-Train and Meta-Test Phases (Steps 1–4).
| MetaNO- | MetaNO | ||||
|---|---|---|---|---|---|
| N test | Step 4 | Test Error | Test Error | ||
| 2 | 25 | 11.70%±14.01% | 11.72%±14.02% | ||
| 4 | 49 | 2.91%±0.90% | 2.93%±0.90% | ||
| 8 | 98 | 2.07%±0.53% | 2.08%±0.53% | ||
| 12 | 147 | 1.94%±0.56% | 1.92%±0.55% | ||
| 20 | 247 | 1.82%±0.41% | 1.80%±0.39% | ||
| 100 | 1025 | 1.56%±0.35% | 1.46%±0.26% | ||
| 300 | 2282 | 1.53%±0.34% | 1.27%±0.15% | ||
Effect of Varying Training Context Set Sizes.
In this study, we investigate the effect of different training task context sizes on four meta-learnt models: MetaNO, MetaNO-, MAML, and ANIL. The comparison on test errors are demonstrated in the top plot of Figure 5. Here, MetaNO- and MetaNO did not have any inner loop updates. All parameters from all training tasks are optimized together. In MAML and ANIL we use half of the context set for inner loop updates (support set) and the other half for outer loop updates (target set). One can see that when , MetaNO- and MetaNO have similar performance and consistently beat MAML and ANIL for both context set sizes. With the increase of , the fine-tuning strategy on the test context set becomes more helpful where we see MetaNO becomes more accurate than MetaNO- and MAML beats ANIL. Such effect is more evident on small training context set cases. Perhaps unsurprisingly, with the training task context size varying from 50 to 500, all methods have improved performance with decreasing relative test errors (with the same colors for the same methods across different context dataset). In addition, as the context set size in the test task grows, fine-tuning will gradually have better performance as MetaNO and MAML beats MetaNO- and ANIL, respectively. Overall, in all combinations of and , MetaNO achieves the best performance among all models.
Figure 5:
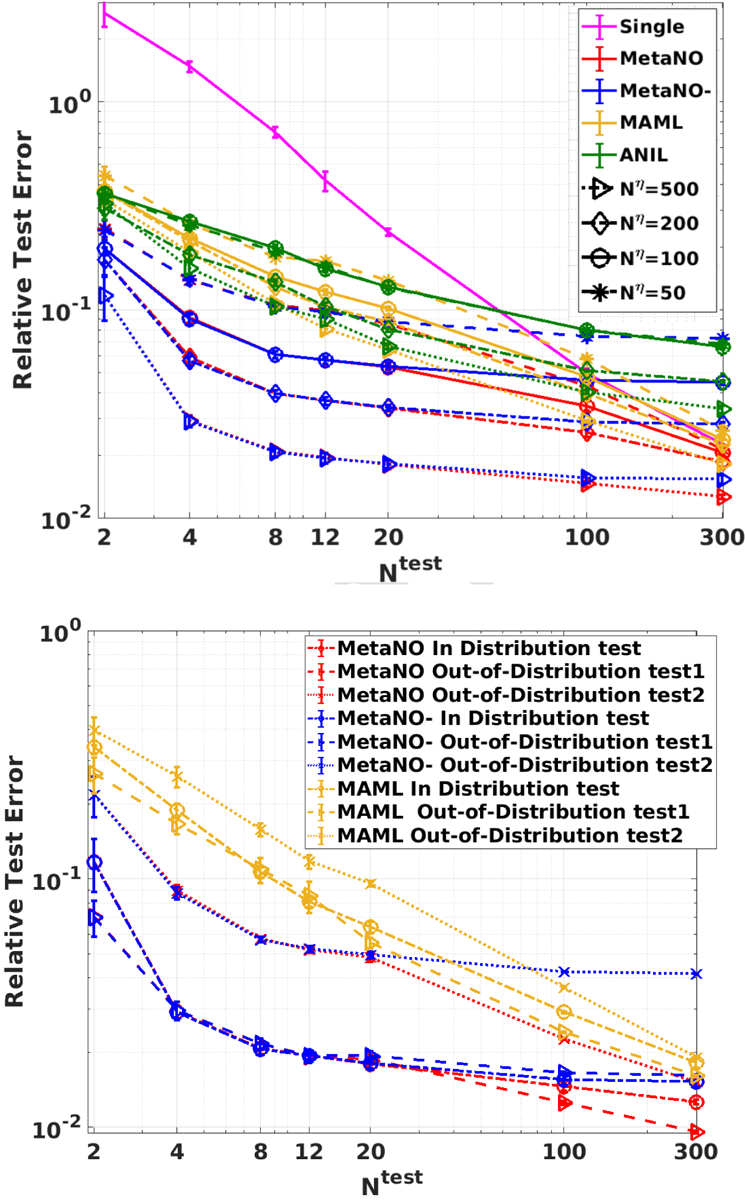
Results on on example 1: the synthetic data set. Top: The relative test error results showing the effect of varying training task context set sizes . Bottom: The relative error of MetaNO and MAML in in-distribution and out-of distribution tests.
In-Distribution and Out-Of-Distribution Tests.
On bottom Figure 5, we demonstrate the relative test error of MetaNO against MAML in both ID and OOD tasks. We can see that test errors of these 3 tasks are in a similar scale as the error on training tasks. The error from OOD task1 is comparable to the averaged ID test task error, while the error from OOD task2 is much larger, as expected by the data property: due to the fact that the solutions in OOD task1 generally have smaller magnitude and hence its solution operator lies more in a linear regime, which makes the solution operator learning task easier. probably due to the fact that the solutions in OOD task1 generally have smaller magnitude and hence its solution operator lies more in a linear regime, which makes the solution operator learning task easier. In all three cases, MetaNO outperforms MAML, hence validating the good generalization performance of MetaNO.
4.2. Example 2: Benchmark Mechanical MNIST Datasets
We further test MetaNO and five baseline methods on benchmark Mechanical MNIST [60]. Mechanical MNIST is a benchmark dataset of heterogeneous material undergoing large deformation, modeled by the Neo-Hookean material with a varying modulus converted from the MNIST bitmap images [60]. It contains 70,000 heterogeneous material specimens, and each specimen is governed by the Neo-Hookean material with a varying modulus converted from the MNIST bitmap images. On each specimen, we have 32 loading/response data pairs on a structured 27 by 27 grid, under the uniaxial extension, shear, equibiaxial extension, and confined compression load scenarios, respectively5.
Data Generation and Settings.
Here in, we randomly select one specimen corresponding to hand-written number 0 and 2 – 9 respectively as training tasks. Then, among the specimens corresponding to 1, we randomly select six specimens: one for validation and the rest five as the test tasks. Visualization of the ground-truth solutions corresponding to one common loading from different tasks is provided in Figure 6(a), together with the underlying (hidden) microstructure pattern which determines the parameter set . On the meta-train phase, we use the full context data set of all 32 samples for each training task. On the meta-test phase, we reserve 20 data pairs on the test task as the target set for evaluation, then train each model under the few-shot learning setting with labelled data pairs as the context set. All approaches are developed based on an 32-layer IFNO model.
Figure 6:
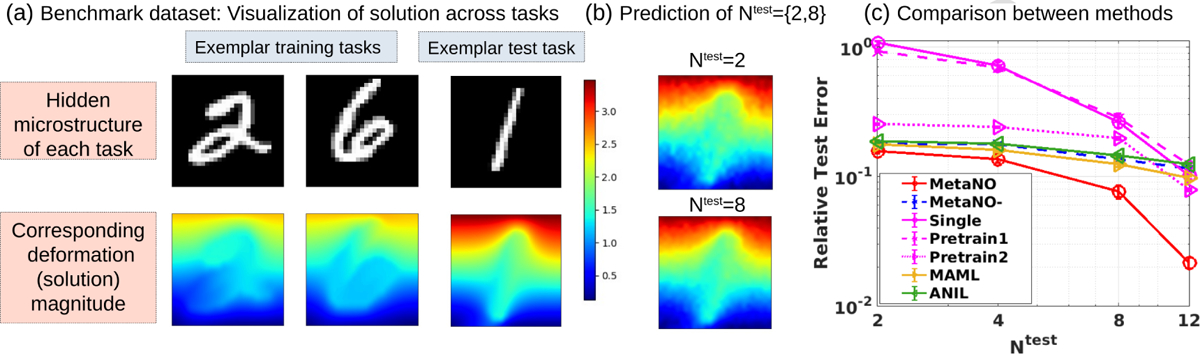
Results on example 2: the benchmark (Mechanical MNIST [60]) dataset. (a) The visualization of different tasks, their underlying microstructure field , and the corresponding ground-truth solution. (b) Prediction results based on few samples and on a test task. (c) Comparison of MetaNO and five baseline methods.
Results.
Besides the diversity of tasks as seen in Figure 6(a), notice that we also have a small number of training tasks , and a relatively small training context set size . All these facts make the transfer learning on this benchmark dataset challenging. We present the results in Figure 6(b) and (c). The neural operator model learned by MetaNO again outperforms the baseline single/transfer learning models and the state-of-the-art GBML models. Our MetaNO model achieves 15% error when using only 2 labelled data pair on the test task, while the Single model has high errors due to overfitting. This fact highlights the importance of learning across multi-tasks: when the total number of measurements on each specimen is limited, it is necessary to transfer the knowledge across specimens. Moreover, while MetaNO-, MAML, and ANIL all have a similar performance in this example, the fine-tuning step in MetaNO seems to substantially improve the accuracy, especially when gets larger. This observation is consistent with previous finding on varying training task context sizes.
4.3. Example 3: Application on Real-World Data Sets
We now take a step further to demonstrate the performance of our method on a real-world physical response dataset, which is not generated by solving PDEs. We consider the problem of learning the mechanical response of multiple biological tissue specimens from DIC displacement tracking measurements. We measure the biaxial loading of tricuspid valve anterior leaflet (TVAL) specimens from a porcine heart, such that each specimen (as a task) corresponds to a different region of the leaflet. Due to material heterogeneity of biological tissues, these specimens contain different mechanical and structural properties. However, these properties are generally not observable without damaging the tissue. Therefore, this example provides a proof-of-principle demonstration that how MetaNO applies to learning tasks where the governing equations and physical properties are both unknown, and the dataset has unavoidable measurement noise.
Data Generation.
We now briefly provide the data generation procedure for the tricuspid valve anterior leaflet (TVAL) response modeling example. To generate the data, we firstly followed the established biaxial testing procedure, including acquisition of a healthy porcine heart and retrieval of the TVAL [61, 62]. Then, we sectioned the leaflet tissue and applied a speckling pattern to the tissue surface using an airbrush and black paint [63–65]. The painted specimen was then mounted to a biaxial testing device (BioTester, CellScale, Waterloo, ON, Canada). To generate samples for each specimen, we performed 7 protocols of displacement-controlled testing to target various biaxial stresses: . Here, and denote the first Piola-Kirchhoff stresses in the - and -directions, respectively. Each stress ratio was performed for three loading/unloading cycles. Throughout the test, images of the specimen were captured by a CCD camera, and the load cell readings and actuator displacements were recorded at 5 Hz. After testing, the acquired images were analyzed using the digital image correlation (DIC) module of the BioTester’s software. The pixel coordinate locations of the DIC-tracked grid were then exported and extrapolated to a 21 by 21 uniform grid. In this example, we have the DIC measurements on 16 specimens, with 500 data pairs of loadings and material responses from the 7 protocols on each specimen. These specimens are divided into three groups: 12 for the purpose of meta-train, 1 for validation, and 3 for test. This reflects a common challenge in scientific applications, we not only have limited samples per task, the number of available training tasks is also limited. To demonstrate the diversity of these specimens due to the material heterogeneity in biological tissues, in Figure 7 we plot the processed displacement field of two exemplar training specimens and the validation and test specimens. For each model, the results are reported as the average of all 3 test tasks.
Figure 7:
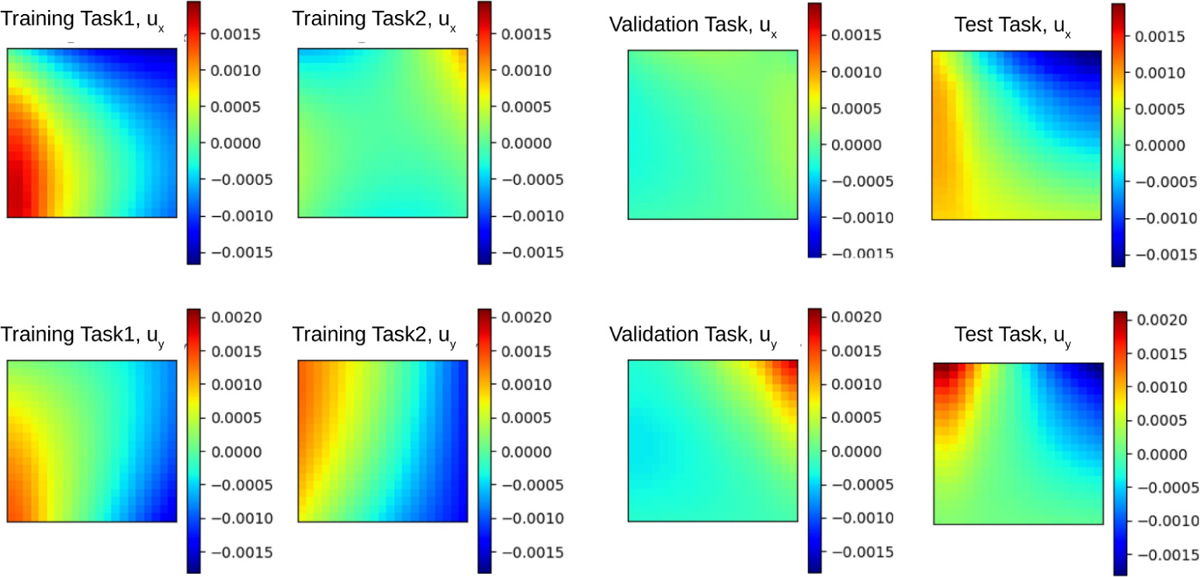
Visualization of the processed dataset in example 3: learning the biological tissue responses. Subject to the same loading instance, different columns show the corresponding ground-truth solutions from different tasks, showing the solution diversity across different tasks due to the change of underlying hidden material parameter field.
Results.
Herein, we aim to model the tissue response by learning a neural operator mapping the boundary displacement loading to the interior displacement field on each tissue specimen. We use 13 specimens for training and validation with context size , and provide the test results as the average on the rest 3 specimens. With a 4-layer IFNO as the base model, we train each model based on samples, and then evaluate the performance on another 200 samples. The results are provided in Figure 8. MetaNO performs the best among all the methods across all , beating MAML and ANIL by a significant margin. Interestingly, MAML and ANIL did not even beat the “Pretrain1” method, possibly due to the low efficacy of the adapting last layers strategy and the small number of training tasks.
Figure 8:
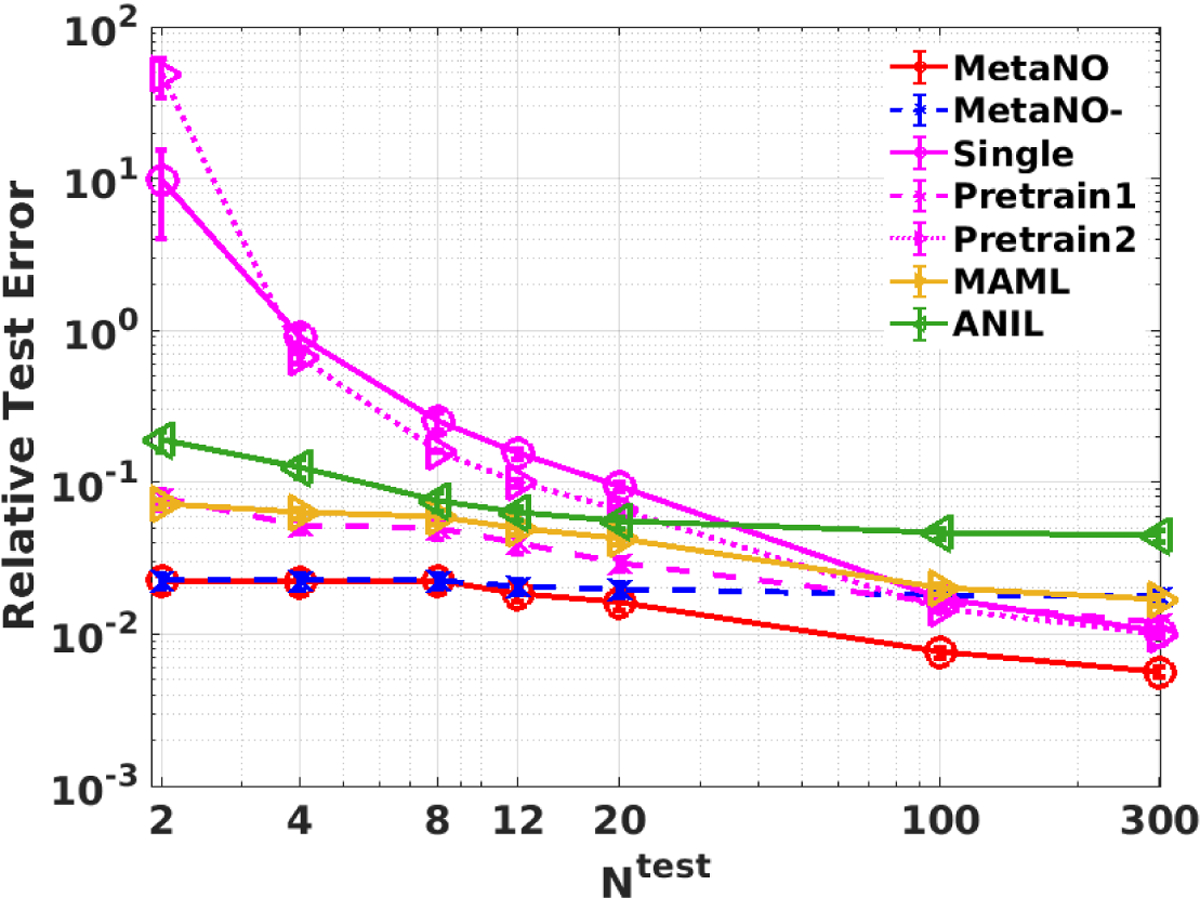
Comparison of MetaNO and five baseline methods in example 3: learning the biological tissue responses. This example features measurement noise and a small number of available tasks.
5. Summary and Future Directions
In this paper we propose MetaNO, the first neural-operator-based meta-learning approach that is designed to achieve good transferability in learning complex physical system responses. In particular, we focus on the scenario that the physical responses of different systems can be modeled by a common parametric PDE, and the behavior of each system (specimen) is governed by a different underlying parameter field. Then, based on the observed data from several known systems, the goal is to efficiently learn a surrogate model, which acts as the surrogate solution operator for the hidden PDE, for a new and unseen system. Comparing with existed transfer-learning techniques, our MetaNO features a novel first layer adaption architecture, which is theoretically motivated and shown to be a universal solution operator for multiple parametric PDE solving tasks. We demonstrate the effectiveness of our proposed MetaNO algorithm on various synthetic, benchmark, and real-world datasets, showing promises with significant improvement in sample efficiency over baseline methods.
Although in this paper we focus on material modeling problems in experiments, the proposed approach is a machine learning model that can handle different PDEs with heterogeneous coefficients, which is common in physics problems and not limited in material modeling. For example, another suitable example is climate modeling, where cities responses, temperature exposures, and impacts are all heterogeneous, resulting in different parameters in the PDE model. Here we choose material as the application mainly due to the availability of data. For future work, we will investigate the applicability of the proposed approach to other scientific domains. Moreover, we point out that the universal approximator property of MetaNO relies on the assumption that all systems are governed by a common parametric PDE. As such, a set of common characteristic solution operator features can be obtained from the training tasks in the form of the common layer parameters, and then can be utilized to accelerate the learning efficacy in the test task. Therefore, we anticipate the method to suffer from performance deterioration when handling the transferability between different types of PDEs, e.g., when all training tasks are solving diffusion problems but the test task is on an advection problem. It would be an interesting future direction of extending MetaNO to handle such a challenging scenario. In this paper, we employed the implicit Fourier neural operator [39] as the base model. As another natural extension, one might consider the proposed meta-learning approach based on other types of neural operators and neural networks, such as the graph neural operators [26, 29] and the general graph neural networks [66, 67]. As such, the model will be capable to handle measurements from unstructured grid points and domains, which be valuable for applications with complex and possibly evolving domain geometries.
Figure 1:
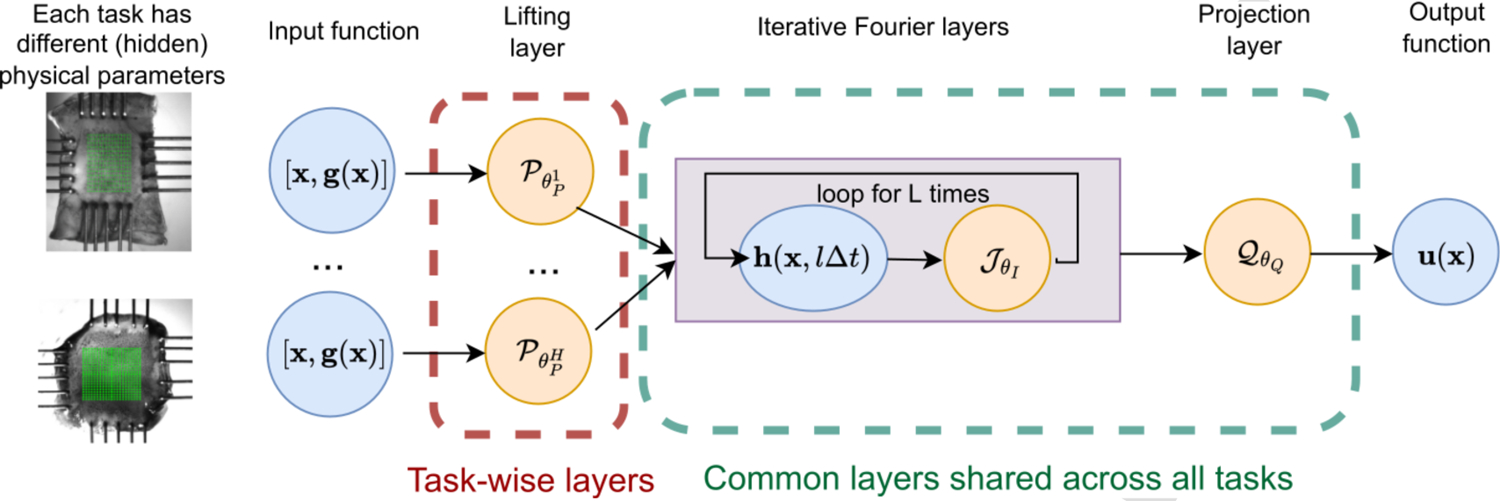
The architecture of MetaNO based on an integral neural operator model.
Acknowledgements
L. Zhang, H. You and Y. Yu would like to acknowledge support by the National Science Foundation under award DMS-1753031 and the AFOSR grant FA9550-22-1-0197. C.-H. Lee would like to thank the support from the National Institutes of Health (NIH) Grant R01 HL159475 and the Presbyterian Health Foundation Team Science Grants. Portions of this research were conducted on Lehigh University’s Research Computing infrastructure partially supported by NSF Award 2019035.
Appendix A. Formulation of Baseline Methods
In this section, we discuss each baseline methods in details and how they are used in our experiments. A meta-learning baseline in our problem setting would be to apply MAML and ANIL to a neural operator architecture. Here we formally state the implementation of ANIL and MAML for the problem described above, and they will serve as the baselinebaseline meta-based methods in our empirical experiments.
MAML.
The MAML algorithm proposed in [5] aims to find an initialization, , across all tasks, so that new tasks can be learnt with very few gradient updates and examples. First, a batch of tasks are drawn from the training task set. For each task , the context set of loading field/response field data pairs is split to a support set of samples, , which will be used for inner loop updates, and a target set of samples, , for outer loop updates. Then, for the inner loop, let and be the task-wise parameter after -th gradient update. During each inner loop update, the task-wise parameter is updated via
| (A.1) |
where is the loss on the support set of the -th task, and is the step size. After inner loop updates, the initial parameter is updated with a fixed step size :
| (A.2) |
Then, on the test task, , an inner loop adaptation is performed based on few labelled samples until convergence, and the approximated solution operator model is obtained on the test task as .
ANIL.
In [10], ANIL was proposed as a modified version of MAML with inner loop updates only for the final layer. The inner loop update formulation of (A.1) is modified as
| (A.3) |
where is the task-wise parameter on the final (projection) layer after th gradient update. Then, the same outer loop updates are performed following (A.2).
Single/Pretrain1/Pretrain2.
We also implemented 3 non-meta-learning baseline approaches.
Single: Learn a neural operator model only based on the context data set of the test task.
Pretrain1: Pretrain a neural operator model based on all training task data sets, then fine-tune it based on the context test task data set.
Pretrain2: Pretrain a single neural operator model based on the context data set of one training task, then fine-tune it based on the context test task data set. To remove the possible dependency on the pre-training task, in this baseline we randomly select five training tasks for the purpose of pretraining and report the averaged results.
Appendix B. Training Details
In the following we briefly describe the hyperparameter settings employed in running of each algorithm. The code and the processed datasets will be publicly released at Github for readers to reproduce the experimental results.
Appendix B.1. Example 1: Synthetic Data Sets
Base model:
As the base model for all algorithms, we construct an architecture for IFNO [39] as follows. First, the input loading field instance is lifted to a higher dimensional representation via lift layer , which is parameterized as a 1-layer feed forward linear layer with width . Then for the iterative layer in (2.1), we implement with fast Fourier transform (FFT) with input channel and output channel widths both set as 32 and the truncated Fourier modes set as 8. The local linear transformation parameter, , is parameterized as a 1-layer feed forward network with width (32,32). In the projection layer, a 2-layer feed forward network with width (32,128,2) is employed. To accelerate the training procedure, we apply the shallow-to-deep training technique to initialize the optimization problem. In particular, we start from the NN model with depth , train until the loss function reaches a plateau, then use the resultant parameters to initialize the parameters for the next depth, with , and . In the synthetic experiments, we set the layer depth as .
MetaNO:
During the meta-train phase, we train for the task-wise parameters and the common parameters and on all 59 training tasks, with the context set of 500 samples on each task. After meta-train phase, we load and and the averaged among all 59 tasks as initialization, then tune the hyperparameters based on the validation task. In particular, the 500 samples on the validation task is split into two parts: 300 samples are reserved for the purpose of training (as the context set) and the rest 200 samples are used for evaluation (as the target set). Then we train for the lift layer on the validation task, and tune the learning rate, the decay rate, and the weight decay parameter for different context set sizes , to minimize the loss on the target set. Based on the chosen hyperparameters, we perform the test on the test task by training for the lift layer on different numbers of samples on its context set, then evaluate and report the performance based on its target set. We repeat the procedure on the test task with selected hyperparameters with different 5 random seeds, and calculate means and standard errors for the resultant test errors on target set.
MAML&ANIL:
For MAML and ANIL, we use the same architecture as the base model, and also split the training tasks for the purpose of training (59 tasks) and validation (1 task) as in MetaNO. During the meta-train phase, for each task we randomly split the available 500 samples to two sets: 250 samples in the support set used for inner loop updates, and the rest in the target set for outer loop updates. During the inner loop update, we train for the task-wise parameter with one epoch, following the standard settings of MAML and ANIL [5, 10]. Then, the model hyperparameters, including the learning rate, weight decay, decay rate, and inner loop learning rate, are tuned. In the meta-test phase, we load the initial parameter and train for all parameters (in MAML) or the last-layer parameters (in ANIL) until the optimization algorithm converges. Similar as in MetaNO, we first tune the hyperparameters on the validation task, then evaluate the performance on the test task.
Appendix B.2. Example 2: Mechanical MNIST
Base model:
As the base model for all algorithms, we construct two IFNO architectures, for the prediction of and , the displacement fields in the - and -directions, respectively. On each architecture, the input loading field instance is mapped to a higher dimensional representation via a lifting layer parameterized as a 1-layer feed forward linear layer with width (4,64). Then for the iterative layer in (2.1), we set the number of truncated Fourier mode as 13, and parameterize the local linear transformation parameter, , as a 1-layer feed forward network with width (64,64). In the projection layer, a 2-layer feed forward network with width (64,128,1) is employed. In this example we also apply the shallow-to-deep technique to accelerate the training, and set the layer depth as .
MetaNO:
During the meta-train phase, we train for the task-wise parameters and the common parameters and on all 9 training tasks, with the context set of 32 samples on each task. After the meta-train phase, we load and and the averaged among all 9 tasks as initialization, then train on the validation task. In particular, the 32 samples on the validation task is split into two parts: 12 samples are reserved for the purpose of training (as the context set) and the rest 20 samples are used for the purpose of evaluation (as the target set). Then we train the lift layer on the validation task, and tune the learning rate, the decay rate, and the weight decay parameter for different context set sizes , to minimize the loss on the target set. Based on the chosen hyperparameters, we perform the meta-test phase on the test task by training for the lift layer on different numbers of samples on its context set, then evaluate and report the performance based on its target set. We repeat the procedure with different 5 random seeds on each of the 5 test tasks, and calculate means and standard errors for the resultant test errors on the target set.
MAML&ANIL:
For MAML and ANIL, we use the same architecture as the base model. During the meta-train phase, for each task we randomly split the available 32 samples to two sets: 16 samples in the support set used for inner loop updates, and the rest in the target set for outer loop updates. During the inner loop update, we also follow the standard settings of MAML and ANIL [5, 10], and tune the hyperparameters following the same procedure as elaborated above for Example 1.
Appendix B.3. Example 3: Experimental Measurements on Biological Tissues
Base model:
As the base model, we first construct the lifting layer as a 1-layer feed forward linear layer with width (4,16). Then for the iterative layer in we keep 8 truncated Fourier modes and parameterize the local linear transformation parameter, , a 1-layer feed forward network with width (16,16). In the projection layer, a 2-layer feed forward network with width (16,64,1) is employed. We construct two 4-layer IFNO architectures, for the prediction of and , the displacement fields in the - and -directions, respectively.
MetaNO:
During the meta-train phase, we train for the task-wise parameters and the common parameters and on all 12 tasks, with the context set of 500 samples on each task. After meta-train phase, we load and and the averaged among all 12 tasks as initialization, then tune the hyperparameters based on the validation task. In particular, the 500 samples on the validation task is divided into two parts: 300 samples are reserved for the purpose of training (as the context set) and the rest 200 samples are used for evaluation (as the target set). Based on the chosen hyperparameters, we perform the test on the test tasks by training for the lift layer on different numbers of samples on its context set, then evaluate the performance based on its target set.
MAML&ANIL:
For MAML and ANIL, we use the same architecture as the base model, and also split the training tasks for the purpose of training and validation as in MetaNO. During the meta-train phase, for each task we randomly split the available 500 samples to two sets: 250 samples in the support set used for inner loop updates, and the rest in the target set for outer loop updates. During the inner loop update, we train for the task-wise parameter with one epoch, following the standard settings of MAML and ANIL [5,10].
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
We dedicate this paper to Prof. Thomas J.R. Hughes for his lifetime achievements, pioneering contributions to computational mechanics and applied mathematics, and distinguished editorship of Computer Methods in Applied Mechanics and Engineering for more than four decades.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Without ambiguity, in the following context we will neglect the subscript and denote as for notation simplicity.
In some meta-learning literature, e.g., [16], these small sets of labelled data pairs on a new task (or any task) is called the context, and the learnt model will be evaluated on an additional set of unlabelled data pairs, i.e., the target.
We also point out that the proposed multi-task strategy is generic and hence also applicable to other neural operators [26–29, 32].
Here we sample both ID and OOD tasks from the same range of , due to the fact that [0.01, 0.49] is the range of Poisson ratio for common materials [57].
We have excluded small deformation samples with the maximum displacement magnitude ≤ 0.1.
References
- [1].Wang Y, Yao Q, Kwok JT, Ni LM, Generalizing from a few examples: A survey on few-shot learning, ACM computing surveys (csur) 53 (3) (2020) 1–34. [Google Scholar]
- [2].Koch G, Zemel R, Salakhutdinov R, et al. , Siamese neural networks for one-shot image recognition, in: ICML deep learning workshop, Vol. 2, Lille, 2015, p. 0. [Google Scholar]
- [3].Vinyals O, Blundell C, Lillicrap T, Wierstra D, et al. , Matching networks for one shot learning, Advances in neural information processing systems 29. [Google Scholar]
- [4].Snell J, Swersky K, Zemel R, Prototypical networks for few-shot learning, Advances in neural information processing systems 30. [Google Scholar]
- [5].Finn C, Abbeel P, Levine S, Model-agnostic meta-learning for fast adaptation of deep networks, in: International Conference on Machine Learning, Vol. 70, PMLR, 2017, pp. 1126–1135. [Google Scholar]
- [6].Santoro A, Bartunov S, Botvinick M, Wierstra D, Lillicrap T, Meta-learning with memory-augmented neural networks, in: International conference on machine learning, PMLR, 2016, pp. 1842–1850. [Google Scholar]
- [7].Antoniou A, Edwards H, Storkey A, How to train your maml, arXiv preprint arXiv:1810.09502. [Google Scholar]
- [8].Ravi S, Larochelle H, Optimization as a model for few-shot learning.
- [9].Nichol A, Schulman J, Reptile: a scalable metalearning algorithm, arXiv preprint arXiv:1803.02999 2 (3) (2018) 4 [Google Scholar]
- [10].Raghu A, Raghu M, Bengio S, Vinyals O, Rapid learning or feature reuse? towards understanding the effectiveness of maml, arXiv preprint arXiv:1909.09157. [Google Scholar]
- [11].Tripuraneni N, Jin C, Jordan M, Provable meta-learning of linear representations, in: International Conference on Machine Learning, PMLR, 2021, pp. 10434–10443. [Google Scholar]
- [12].Collins L, Mokhtari A, Oh S, Shakkottai S, Maml and anil provably learn representations, arXiv preprint arXiv:2202.03483. [Google Scholar]
- [13].Zhang W, Sacks MS, Modeling the response of exogenously crosslinked tissue to cyclic loading: The effects of permanent set, Journal of the Mechanical Behavior of Biomedical Materials 75 (2017) 336–350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Misfeld M, Sievers H-H, Heart valve macro-and microstructure, Philosophical Transactions of the Royal Society B: Biological Sciences 362 (1484) (2007) 1421–1436. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Rieppo J, Hallikainen J, Jurvelin JS, Kiviranta I, Helminen HJ, Hyttinen MM, Practical considerations in the use of polarized light microscopy in the analysis of the collagen network in articular cartilage, Microscopy research and technique 71 (4) (2008) 279–287. [DOI] [PubMed] [Google Scholar]
- [16].Xu J, Ton J-F, Kim H, Kosiorek A, Teh YW, Metafun: Meta-learning with iterative functional updates, in: International Conference on Machine Learning, PMLR, 2020, pp. 10617–10627. [Google Scholar]
- [17].Ghaboussi J, Pecknold DA, Zhang M, Haj-Ali RM, Autoprogressive training of neural network constitutive models, International Journal for Numerical Methods in Engineering 42 (1) (1998) 105–126. [Google Scholar]
- [18].Ghaboussi J, Garrett J Jr, Wu X, Knowledge-based modeling of material behavior with neural networks, Journal of engineering mechanics 117 (1) (1991) 132–153. [Google Scholar]
- [19].Carleo G, Cirac I, Cranmer K, Daudet L, Schuld M, Tishby N, Vogt-Maranto L, Zdeborová L, Machine learning and the physical sciences, Reviews of Modern Physics 91 (4) (2019) 045002. [Google Scholar]
- [20].Karniadakis GE, Kevrekidis IG, Lu L, Perdikaris P, Wang S, Yang L, Physics-informed machine learning, Nature Reviews Physics 3 (6) (2021) 422–440. [Google Scholar]
- [21].Zhang L, Han J, Wang H, Car R, Weinan E, Deep potential molecular dynamics: a scalable model with the accuracy of quantum mechanics, Physical Review Letters 120 (14) (2018) 143001. [DOI] [PubMed] [Google Scholar]
- [22].Cai S, Mao Z, Wang Z, Yin M, Karniadakis GE, Physics-informed neural networks (PINNs) for fluid mechanics: A review, Acta Mechanica Sinica (2022) 1–12. [Google Scholar]
- [23].Pfau D, Spencer JS, Matthews AG, Foulkes WMC, Ab initio solution of the many-electron schrödinger equation with deep neural networks, Physical Review Research 2 (3) (2020) 033429. [Google Scholar]
- [24].He Q, Laurence DW, Lee C-H, Chen J-S, Manifold learning based data-driven modeling for soft biological tissues, Journal of Biomechanics 117 (2021) 110124. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Besnard G, Hild F, Roux S, “finite-element” displacement fields analysis from digital images: application to portevin-le châtelier bands, Experimental mechanics 46 (6) (2006) 789–803. [Google Scholar]
- [26].Li Z, Kovachki N, Azizzadenesheli K, Liu B, Bhattacharya K, Stuart A, Anandkumar A, Neural operator: Graph kernel network for partial differential equations, arXiv preprint arXiv:2003.03485. [Google Scholar]
- [27].Li Z, Kovachki N, Azizzadenesheli K, Liu B, Stuart A, Bhattacharya K, Anandkumar A, Multipole graph neural operator for parametric partial differential equations, Advances in Neural Information Processing Systems 33 (2020) NeurIPS; 2020. [Google Scholar]
- [28].Li Z, Kovachki NB, Azizzadenesheli K, Bhattacharya K, Stuart A, Anandkumar A, Fourier NeuralOperator for Parametric Partial Differential Equations, in: International Conference on Learning Representations, 2020. [Google Scholar]
- [29].You H, Yu Y, D'Elia M, Gao T, Silling S, Nonlocal kernel network (NKN): A stable and resolution-independent deep neural network, Journal of Computational Physics (2022) arXiv preprint arXiv:2201.02217. [Google Scholar]
- [30].Ong YZ, Shen Z, Yang H, IAE-NET: Integral autoencoders for discretization-invariant learning-doi: 10.13140/RG.2.2.25120.87047/2. [DOI] [Google Scholar]
- [31].Gupta G, Xiao X, Bogdan P, Multiwavelet-based operator learning for differential equations, in: Beygelzimer A, Dauphin Y, Liang P, Vaughan JW (Eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=LZDiWaC9CGL [Google Scholar]
- [32].Lu L, Jin P, Karniadakis GE, Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators, arXiv preprint arXiv:1910.03193. [Google Scholar]
- [33].Lu L, Jin P, Pang G, Zhang Z, Karniadakis GE, Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators, Nature Machine Intelligence 3 (3) (2021) 218–229. [Google Scholar]
- [34].Goswami S, Bora A, Yu Y, Karniadakis GE, Physics-informed neural operators, 2022. arXiv preprint arXiv:2207.05748 [Google Scholar]
- [35].Yin M, Ban E, Rego BV, Zhang E, Cavinato C, Humphrey JD, Em Karniadakis G, Simulating progressive intramural damage leading to aortic dissection using DeepONet: an operator-regression neural network, Journal of the Royal Society Interface 19 (187) (2022) 20210670. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Yin M, Zhang E, Yu Y, Karniadakis GE, Interfacing finite elements with deep neural operators for fast multiscale modeling of mechanics problems, Computer Methods in Applied Mechanics and Engineering, in press (2022) 115027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Lu L, He H, Kasimbeg P, Ranade R, Pathak J, One-shot learning for solution operators of partial differential equations, arXiv preprint arXiv:2104.05512. [Google Scholar]
- [38].Lu L, Meng X, Cai S, Mao Z, Goswami S, Zhang Z, Karniadakis GE, A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data, arXiv preprint arXiv:2111.05512. [Google Scholar]
- [39].You H, Zhang Q, Ross CJ, Lee C-H, Yu Y, Learning deep implicit fourier neural operators (IFNOs) with applications to heterogeneous material modeling, Computer Methods in Applied Mechanics and Engineering 398 (2022) 115296. doi: 10.1016/j.cma.2022.115296. [DOI] [Google Scholar]
- [40].Pan SJ, Yang Q, A survey on transfer learning, IEEE Transactions on knowledge and data engineering 22 (10) (2009) 1345–1359. [Google Scholar]
- [41].Thrun S, Pratt L, Learning to learn: Introduction and overview, in: Learning to learn, Springer, 1998, pp. 3–17. [Google Scholar]
- [42].Hospedales T, Antoniou A, Micaelli P, Storkey A, Meta-learning in neural networks: A survey, 2020. arXiv preprint arXiv:2004.05439. [DOI] [PubMed] [Google Scholar]
- [43].Mai H, Le TC, Hisatomi T, Chen D, Domen K, Winkler DA, Caruso RA, Use of meta models for rapid discovery of narrow bandgap oxide photocatalysts, iScience (2021) 103068. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [44].Zhang L, You H, Yu Y, Metanor: A meta-learnt nonlocal operator regression approach for metamaterial modeling, arXiv preprint arXiv:2206.02040. [Google Scholar]
- [45].Yin Y, Ayed I, de Bézenac E, Baskiotis N, Gallinari P, Leads: Learning dynamical systems that generalize across environments, Advances in Neural Information Processing Systems 34 (2021) 7561–7573. [Google Scholar]
- [46].Wang R, Walters R, Yu R, Meta-learning dynamics forecasting using task inference, arXiv preprint arXiv:2102.10271 [Google Scholar]
- [47].Kailkhura B, Gallagher B, Kim S, Hiszpanski A, Han TY-J, Reliable and explainable machine-learning methods for accelerated material discovery, npj Computational Materials 5 (1) (2019) 1–9. [Google Scholar]
- [48].Goswami S, Kontolati K, Shields MD, Karniadakis GE, Deep transfer learning for partial differential equations under conditional shift with deeponet, arXiv preprint arXiv:2204.09810. [Google Scholar]
- [49].Yoon J, Kim T, Dia O, Kim S, Bengio Y, Ahn S, Bayesian model-agnostic meta-learning, in: Proceedings of the 32nd International Conference on Neural Information Processing Systems (NeurIPS 2018), 2018, pp. 7343–7353. [Google Scholar]
- [50].Vanschoren J, Meta-learning: A survey, 2018. arXiv preprint arXiv:1810.03548. [Google Scholar]
- [51].Yang H, Kwok J, Efficient variance reduction for meta-learning, in: International Conference on Machine Learning, PMLR, 2022, pp. 25070–25095. [Google Scholar]
- [52].Kalais K, Chatzis S, Stochastic deep networks with linear competing units for model-agnostic meta-learning, in: International Conference on Machine Learning, PMLR, 2022, pp. 10586–10597. [Google Scholar]
- [53].Dejam M, Hassanzadeh H, Chen Z, Pre-darcy flow in porous media, Water Resources Research 53 (10) (2017) 8187–8210. [Google Scholar]
- [54].Fallah F, Ghajari M, Safa Y, Computational modelling of dynamic delamination in morphing composite blades and wings, The International Journal of Multiphysics 13 (4) (2019) 393–430. [Google Scholar]
- [55].Wei C, Wojnar CS, Wu C, Hydro-chemo-mechanical phase field formulation for corrosion induced cracking in reinforced concrete, Cement and Concrete Research 144 (2021) 106404. [Google Scholar]
- [56].Holzapfel GA, Gasser TC, Ogden RW, A new constitutive framework for arterial wall mechanics and a comparative study of material models, Journal of Elasticity and the Physical Science of Solids 61 (1) (2000) 1–48. [Google Scholar]
- [57].Bischofs IB, Schwarz US, Effect of poisson ratio on cellular structure formation, Physical review letters 95 (6) (2005) 068102. [DOI] [PubMed] [Google Scholar]
- [58].Lang A, Potthoff J, Fast simulation of gaussian random fields, Monte Carlo Methods and Applications 17 (3) (2011) 195–214. doi:doi: 10.1515/mcma.2011.009. URL 10.1515/mcma.2011.009 [DOI] [Google Scholar]
- [59].Alnæs M, Blechta J, Hake J, Johansson A, Kehlet B, Logg A, Richardson C, Ring J, Rognes ME, Wells GN, The fenics project version 1.5, Archive of Numerical Software 3 (100). [Google Scholar]
- [60].Lejeune E, Mechanical mnist: A benchmark dataset for mechanical metamodels, Extreme Mechanics Letters 36 (2020) 100659. [Google Scholar]
- [61].Ross CJ, Laurence DW, Richardson J, Babu AR, Evans LE, Beyer EG, Childers RC, Wu Y, Towner RA, Fung K-M, Mir A, Burkhart HM, Holzapfel GA, Lee C-H, An investigation of the glycosaminoglycan contribution to biaxial mechanical behaviours of porcine atrioventricular heart valve leaflets, Journal of The Royal Society Interface 16 (156) (2019) 20190069. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [62].Laurence D, Ross C, Jett S, Johns C, Echols A, Baumwart R, Towner R, Liao J, Bajona P, Wu Y, et al. , An investigation of regional variations in the biaxial mechanical properties and stress relaxation behaviors of porcine atrioventricular heart valve leaflets, Journal of Biomechanics 83 (2019) 16–27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [63].Zhang DS, Arola DD, Applications of digital image correlation to biological tissues, Journal of Biomedical Optics 9 (4) (2004) 691–699. [DOI] [PubMed] [Google Scholar]
- [64].Lionello G, Cristofolini L, A practical approach to optimizing the preparation of speckle patterns for digital-image correlation, Measurement Science and Technology 25 (10) (2014) 107001. [Google Scholar]
- [65].Palanca M, Tozzi G, Cristofolini L, The use of digital image correlation in the biomechanical area: a review, International Biomechanics 3 (1) (2016) 1–21. [Google Scholar]
- [66].Li A, Zhang YJ, Isogeometric analysis-based physics-informed graph neural network for studying traffic jam in neurons, Computer Methods in Applied Mechanics and Engineering 403 (2023) 115757. [Google Scholar]
- [67].Li A, Barati Farimani A, Zhang YJ, Deep learning of material transport in complex neurite networks, Scientific reports 11 (1) (2021) 11280. [DOI] [PMC free article] [PubMed] [Google Scholar]