

Abstract
The precision-recall curve (PRC) and the area under it (AUPRC) are useful for quantifying classification performance. They are commonly used in situations with imbalanced classes, such as cancer diagnosis and cell type annotation. We evaluated 10 popular tools for plotting PRC and computing AUPRC, which were collectively used in >3,000 published studies. We found the AUPRC values computed by the tools rank classifiers differently and some tools produce overly-optimistic results.
Introduction
Many problems in computational biology can be formulated as binary classification, in which the goal is to infer whether an entity (e.g., a cell) belongs to a target class (e.g., a cell type). Accuracy, precision, sensitivity (i.e., recall), specificity, and F1 score (Supplementary Figure 1) are some of the measures commonly used to quantify classification performance, but they all require a threshold of the classification score to assign every entity to either the target class or not. The receiver operating characteristic (ROC) and precision-recall curve (PRC) avoid this problem by considering multiple thresholds [1], which allows detailed examination of the trade-off between identifying entities of the target class and wrongly including entities not of this class. It is common to summarize these curves by the area under them (AUROC and AUPRC, respectively), which is a value between 0 and 1, with a larger value corresponding to better classification performance.
When the different classes have imbalanced sizes (e.g., the target cell type has few cells), AUPRC is a more sensitive measure than AUROC [1–4], especially when there are errors among the top predictions (Supplementary Figure 2). As a result, AUPRC has been used in a variety of applications, such as reconstructing biological networks [5], identifying cancer genes [6] and essential genes [7], determining protein binding sites [8], imputing sparse experimental data [9], and predicting patient treatment response [10]. AUPRC has also been extensively used as a performance measure in benchmarking studies, such as the ones for comparing methods for analyzing differential gene expression [11], identifying gene regulatory interactions [12], and inferring cell-cell communications [13] from single-cell RNA sequencing data.
Given the importance of PRC and AUPRC, we analyzed commonly used software tools and found that they produce contrasting results, some of which are overly-optimistic.
Results
Basics
For each entity, a classifier outputs a score to indicate how likely it belongs to the target (i.e., “positive”) class. Depending on the classifier, the score can be discrete (e.g., random forest) or continuous (e.g., artificial neural network). Using a threshold t, the classification scores can be turned into binary predictions by considering all entities with a score ≥ t as belonging to the positive class and all other entities as not. When these predictions are compared to the actual classes of the entities, precision is defined as the proportion of entities predicted to be positive that are actually positive, while recall is defined as the proportion of actually positive entities that are predicted to be positive (Supplementary Figure 1).
The PRC is a curve that shows how precision changes with recall. In the most common way to produce the PRC, each unique classification score observed is used as a threshold to compute a pair of precision and recall values, which forms an anchor point on the PRC. Adjacent anchor points are then connected to produce the PRC.
When no two entities have the same score (Figure 1a), it is common to connect adjacent anchor points directly by a straight line [14–19] (Figure 1b). Another method uses an expectation formula, which we will explain below, to connect discrete points by piece-wise linear lines [20] (Figure 1c). The third method is to use the same expectation formula to produce a continuous curve between adjacent anchor points [17, 21] (Figure 1d). A fourth method that has gained popularity, known as Average Precision (AP), connects adjacent anchor points by step curves [15, 19, 22, 23] (Figure 1e). In all four cases, PRC estimates a function of precision in terms of recall based on the observed classification scores of the entities, and AUPRC estimates the integral of this function using trapezoids (in the direct straight line case), interpolation lines/curves (in the expectation cases), or rectangles (in the AP case).
Figure 1:

Different methods for connecting adjacent anchor points on the PRC. a An illustrative data set with no two entities receiving the same classification score. b-e Different methods for connecting adjacent anchor points when there are no ties in classification scores, namely b direct straight line, c discrete expectation, d continuous expectation, and e AP. f An illustrative data set with different entities receiving the same classification score. Each group of entities with the same classification score defines a single anchor point (A, B, C, and D, from 3, 7, 2, and 1 entities, respectively). g-j Different methods for connecting anchor point B to its previous anchor point, A, namely g linear interpolation, h discrete expectation, i continuous expectation, and j AP. In c and h, tp is set to 0.5 and 1 in Formula 1, respectively (Supplementary text).
When there are ties with multiple entities having the same score, which happens more easily with classifiers that produce discrete scores, these entities together define only one anchor point (Figure 1f). There are again four common methods for connecting such an anchor point to the previous anchor point, which correspond to the four methods for connecting anchor points when there are no ties (details in Supplementary text). The first method is to connect the two anchor points by a straight line [15, 18, 19] (Figure 1g). This method is known to easily produce overly-optimistic AUPRC values [2, 24], which we will explain below. The second method is to interpolate additional points between the two anchor points using a non-linear function and then connect the points by straight lines [14, 17, 20] (Figure 1h). The interpolated points appear at their expected coordinates under the assumption that all possible orders of the entities with the same score have equal probability. The third method uses the same interpolation formula as the second method but instead of creating a finite number of interpolated points, it connects the two anchor points by a continuous curve [17, 21] (Figure 1i). Finally, the fourth method comes naturally from the AP approach, which uses step curves to connect the anchor points [15, 19, 22, 23] (Figure 1j).
Using the four methods to connect anchor points when there are no ties and the four methods when there are ties can lead to very different AUPRC values (Figure 1, Supplementary Figure 3, and Supplementary text).
Conceptual and implementation issues of some popular software tools
We analyzed 10 tools commonly used to produce PRC and AUPRC (Supplementary Table 1). Based on citations and keywords, we estimated that these tools have been used in >3,000 published studies in total (Methods).
The 10 tools use different methods to connect anchor points on the PRC and therefore they can produce different AUPRC values (Table 1, Supplementary Figures 4–7, and Supplementary text). As a comparison, all 10 tools can also compute AUROC, and we found most of them to produce identical values (Supplementary text).
Table 1:
Methods used by the different software tools to connect anchor points and issues found in their calculation of AUPRC and construction of the PRC. For tools that can connect anchor points in multiple ways, we show each of them in a separate row. The AUPRC and PRC issues are defined in the text and detailed in Supplementary text. “—” means no issues found.
| Tool | Anchor points connection | AUPRC issues | PRC issues | |
|---|---|---|---|---|
| Without ties | With ties | |||
| ROCR | Direct straight line | Discrete expectation | ②⑤⚠ | || |
| Weka | AP | AP | — | || |
| scikit-learn | Direct straight line | Linear interpolation | ①② | (No visualization) |
| AP | AP | — | ||| | |
| PerfMeas | Direct straight line | Direct straight line* | ③④ | | |
| PRROC | Direct straight line | Discrete expectation | — | ⚠ |
| Continuous expectation | Continuous expectation | — | — | |
| TensorFlow | Continuous expectation | Continuous expectation | ⚠ | (No visualization) |
| precrec | Discrete expectation | Discrete expectation | — | — |
| TorchEval | AP** | AP | — | (No visualization) |
| MLeval | Direct straight line | Linear interpolation | ①③ | | |
| yardstick | Direct straight line | Linear interpolation | ①② | | |
| AP | AP | — | (No visualization) | |
PerfMeas orders entities with the same classification score by their order in the input and then defines anchor points as if there are no ties.
The source code of TorchEval states that it uses Riemann integral to compute AUPRC, which is equivalent to AP.
We found five conceptual issues with some of these tools when computing AUPRC values (Table 1):
-
①
Using the linear interpolation method to handle ties, which can produce overly-optimistic AUPRC values [2, 24]. When interpolating between two anchor points, linear interpolation produces higher AUPRC than the other three methods under conditions that can easily happen in real situations (Supplementary text)
-
②
Always using (0, 1) as the starting point of the PRC (procedurally produced or conceptually derived, same for ③ and ⑤ below), which is inconsistent with the concepts behind the AP and non-linear expectation methods when the first anchor point with a non-zero recall does not have a precision of one (Supplementary text)
-
③
Not producing a complete PRC that covers the full range of recall values from zero to one
-
④
Ordering entities with the same classification score by their order in the input and then handling them as if they have distinct classification scores
-
⑤
Not putting all anchor points on the PRC
These issues can lead to overly-optimistic AUPRC values or change the order of two AUPRC values (Supplementary text, Supplementary Figures 8–13).
Some of these tools also produce a visualization of the PRC. We found three types of issues with these visualizations (Table 1):
Producing a visualization of PRC that has the same issue(s) as in the calculation of AUPRC
Producing a PRC visualization that does not always start the curve at a point with zero recall
Producing a PRC visualization that always starts at (0, 1)
Finally, we also found some programming bugs and noticed that some tools require special attention for correct usage (both marked by ⚠ in Table 1).
Inconsistent AUPRC values and contrasting classifier ranks produced by the popular tools
To see how the use of different methods by the 10 tools and their other issues affect PRC analysis in practice, we applied them to evaluate classifiers in four realistic scenarios.
In the first scenario, we analyzed data from a COVID-19 study [25] in which patient blood samples were subjected to Cellular Indexing of Transcriptomes and Epitopes by Sequencing (CITE-seq) assays [26]. We constructed a classifier for predicting CD4+ T cells, which groups the cells based on their transcriptome data alone and assigns a single cell type label to each group. Using cell type labels defined by the original authors as reference, which were obtained using both antibody-derived tags (ADTs) and transcriptome data, we computed the AUPRC of the classifier. Figure 2a shows that the 10 tools produced 6 different AUPRC values, ranging from 0.416 to 0.684. In line with the conceptual discussions above, the AP method generally produced the smallest AUPRC values while the linear interpolation method generally produced the largest, although individual issues of the tools created additional variations of the AUPRC values computed.
Figure 2:
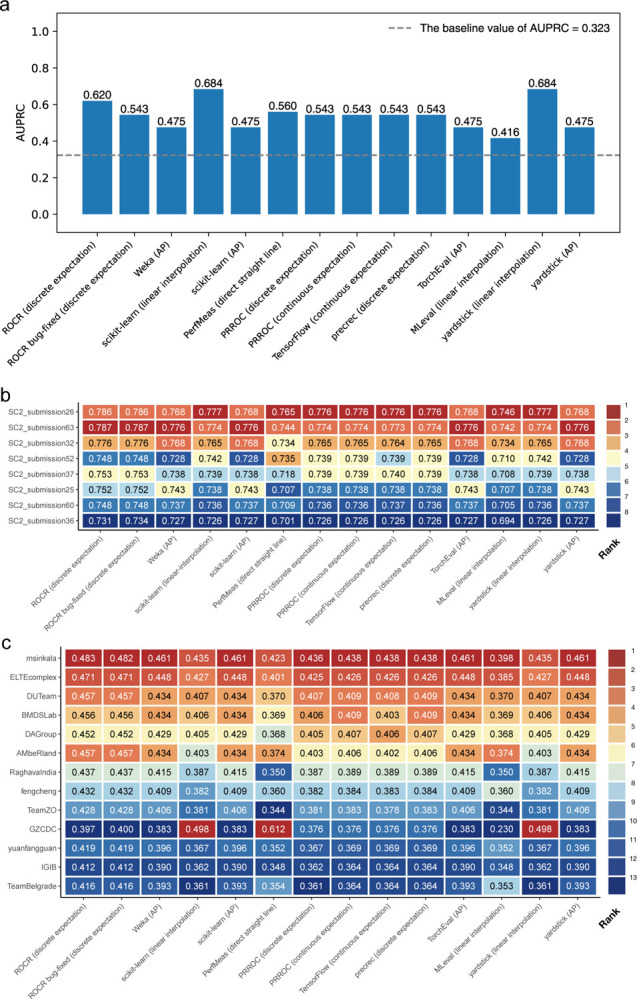
The AUPRC values computed by the 10 tools in several realistic scenarios. a Predicting CD4+ T cells from single-cell transcriptomic data. b Predicting inflammatory bowel disease cases that belong to the Ulcerative Colitis subtype in the sbv IMPROVER Metagenomics Diagnosis for Inflammatory Bowel Disease Challenge. Only the top 8 submissions according to PRROC (discrete expectation) AUPRC values are included. c Predicting cases with preterm prelabor rupture of membranes in the DREAM Preterm Birth Prediction Challenge. In b and c, each entry shows the AUPRC value and the background color indicates its rank among the competitors.
In the second scenario, we compared the performance of different classifiers that predict whether a patient has the Ulcerative Colitis (UC) subtype of inflammatory bowel disease (IBD) or does not have IBD, based on metagenomic data (processed taxonomy-based profile) [27]. The predictions made by these classifiers were submitted to the sbv IMPROVER Metagenomics Diagnosis for IBD Challenge. Their performance was determined by comparing against diagnosis of these patients based on clinical, endoscopic, and histological criteria. Figure 2b shows that based on the AUPRC values computed, the 10 tools ranked the classifiers differently. For example, among the top 8 submissions with the highest performance, the classifier in submission 26 was ranked first in 8 cases, sole second place in 2 cases, and tied second place with another classifier in 4 cases (Figure 2b and Supplementary Figure 14). We observed similar rank flips when considering the top 30 submissions (Supplementary Figures 15 and 16).
In the third scenario, we compared the performance of different classifiers in identifying preterm prelabor rupture of the membranes (PPROM) cases from normal pregnancy in the DREAM Preterm Birth Prediction Challenge [28]. Based on the AUPRC values produced by the 10 tools, the 13 participating teams were ranked very differently (Figure 2c and Supplementary Figure 17). For example, Team “GZCDC” was ranked first (i.e, highest) in 3 cases, tenth in 4 cases, and thirteenth (i.e., lowest) in 7 cases. In addition to differences in the ranks, some of the AUPRC values themselves are also very different. For example, the AUPRC values computed by PerfMeas and MLeval have a Pearson correlation of −0.759, which shows that their evaluations of the 13 teams were almost completely opposite.
In the fourth scenario, we compared 29 classifiers that predicted target genes of transcription factors in the DREAM5 challenge [29]. Again, some classifiers received very different ranking based on the AUPRC values computed by the different tools (Supplementary Figures 18 and 19). For example, the classifier named “Other4” was ranked second based on the AUPRC values computed by PerfMeas but it was ranked twenty-fifth based on the AUPRC values computed by MLeval. In general, tools that use the discrete expectation, continuous expectation, and AP methods are in good agreements in this scenario, but they differ substantially from tools that use the linear interpolation method.
Conclusions
Due to their highly technical nature, it is easy to overlook the inconsistencies and issues of the software tools used for producing PRC and AUPRC. Some possible consequences include reporting overly-optimistic AUPRC, ranking classifiers differently by different tools, and introducing biases to the evaluation process, such as inflating the AUPRC of classifiers that produce discrete scores.
Methods
Information about the tools
In this study, we included 12 tools commonly used for PRC and ROC analyses (Supplementary Table 1). For each tool, we analyzed the latest stable version of it as of August 15, 2023. Because TorchEval had not released a stable version, we analyzed the latest version of it, version 0.0.6. Among the 12 tools, ten can compute both AUROC and AUPRC, while the remaining two can only compute AUROC. We focused on these 10 tools in the study of PRC and AUPRC. Some tools provide multiple methods for computing AUROC/AUPRC.
For tools with an associated publication, we obtained its citation count from Google Scholar. If a tool has multiple associated publications, we selected the one with the largest number of citations. As a result, the citation counts we report in Supplementary Table 1 are underestimates if different publications associated with the same tool are not always cited together.
The Comprehensive R Archive Network (CRAN) packages PerfMeas and MLeval did not have an associated formal publication but only release notes. In each of these cases, we used the package name as keyword to search on Google Scholar and then manually checked the publications returned to determine the number of publications that cited these packages.
The CRAN package yardstick also did not have an associated formal publication. However, we were not able to use the same strategy as PerMeas and MLeval to determine the number of publications that cited the yardstick package since “yardstick” is an English word and the search returned too many publications to be verified manually. Therefore, we only counted the number of publications that cited yardstick’s release note, which is likely an underestimate of the number of publications that cited yardstick.
All citation counts were collected on October 9, 2023.
For tools with an associated formal publication, based on our collected lists of publications citing the tools, we further estimated the number of times the tools were actually used in the studies by performing keyword-based filtering. Specifically, if the main text or figure captions of a publication contains either one of the keywords “AUC” and “AUROC”, we assumed that the tool was used in that published study to perform ROC analysis. In the case of PRC, we performed filtering in two different ways and reported both sets of results in Supplementary Table 1. In the first way, we assumed a tool was used in a published study if the main text or figure captions of the publication contains any one of the following keywords: “AUPR”, “AU-PR”, “AUPRC”, “AU-PRC”, “AUCPR”, “AUC-PR”, “PRAUC”, “PR-AUC”, “area under the precision recall”, and “area under precision recall”. In the second way, we assumed a tool was used in a published study if the main text or figure captions of the publication contains both “area under” and “precision recall”.
For the CRAN packages PerfMeas and MLeval, we estimated the number of published studies that actually used them by searching Google Scholar using the above three keyword sets each with the package name appended. We found that for all the publications we considered as using the packages in this way, they were also on our lists of publications that cite these packages. We used the same strategy to identify published studies that used the CRAN package yardstick. We found that some of these publications were not on our original list of publications that cite yardstick, and therefore we added them to the list and updated the citation count accordingly.
TorchEval was officially embedded into PyTorch in 2022. Due to its short history, among the publications that cite the PyTorch publication, we could not find any of them that used the TorchEval library.
Data collection and processing
We used four realistic scenarios to illustrate the issues of the AUPRC calculations.
In the first scenario, we downloaded CITE-seq data produced from COVID-19 patient blood samples by the COVID-19 Multi-Omic Blood ATlat (COMBAT) consortium [25]. We downloaded the data from https://doi.org/10.5281/zenodo.6120249 and used the data in the “COMBAT-CITESeq-DATA” archive in this study. We then used a standard procedure to cluster the cells based on the transcriptome data and identified CD4+ T cells. Specifically, we extracted the raw count matrix of the transcriptome data and ADT features (“X” object) and the annotation data frame (“obs” object) from the H5AD file. We dropped all ADT features (features with names starting with “AB-”) and put the transcriptome data along with the annotation data frame into Seurat (version 4.1.1). We then log-normalized the transcriptome data (method “NormalizeData()”, default parameters), identified highly-variable genes (method “FindVariableFeatures()”, number of variable genes set to 10,000), scaled the data (method “ScaleData()”, default parameters), performed principal component analysis (method “RunPCA()”, number of principal components set to 50), constructed the shared/knearest neighbor (SNN/kNN) graph (method “FindNeighbours()”, default parameters), and performed Louvain clustering of the cells (method “FindClusters()”, default parameters). We then extracted the clustering labels generated and concatenated them with cell type, major subtype, and minor subtype annotations provided by the original authors, which were manually curated using both ADT and transcriptome information.
Our procedure produced 29 clusters, which contained 836,148 cells in total. To mimic a classifier that predicts CD4+ T cells using the transcriptome data alone, we selected one cluster and “predicted” all cells in it as CD4+ T cells and all cells in the other 28 clusters as not, based on which we computed an AUPRC value by comparing these “predictions” with the original authors’ annotations. We repeated this process for each of the 29 clusters in turn, and chose the one that gave the highest AUPRC as the final cluster of predicted CD4+ T cells.
For the second scenario, we obtained the data set used in the sbv IMPROVER (Systems Biology Verification combined with Industrial Methodology for PROcess VErification in Research) challenge on inflammatory bowel disease diagnosis based on metagenomics data [27]. The challenge involved 12 different tasks, and we focused on the task of identifying UC samples from non-IBD samples using the processed taxonomy-based profile as features. The data set contained 32 UC samples and 42 non-IBD samples, and therefore the baseline AUPRC was . There were 60 submissions in total, which used a variety of classifiers. We obtained the classification scores in the submissions from Supplementary Information 4 of the original publication [27]. When we extracted the classification scores of each submission, we put the actual positive entities before the actual negative entities. This ordering did not affect the AUPRC calculations of most tools except those of PerfMeas, which depend on the input order of the entities with the same classification score.
To see how the different tools rank the top submissions, we first computed the AUPRC of each submission using PRROC (option that uses the discrete expectation method to handle ties) since we did not find any issues with its AUPRC calculations (Table 1). We then analyzed the AUPRC values produced by the 10 tools based on either the top 8 (Figure 2b and Supplementary Figure 14) or top 30 (Supplementary Figures 15 and 16) submissions.
For the third scenario, we downloaded the data set used in the Dialogue on Reverse Engineering Assessment and Methods (DREAM) Preterm Birth Prediction Challenge [28] from https://www.synapse.org/#!Synapse:syn22127152. We collected the classification scores, from the object “prpile” in each team’s RData file, and the actual classes produced based on clinical evidence, from “anoSC2_v21_withkey.RData” (https://www.synapse.org/#!Synapse:syn22127343). The challenge contained 7 scenarios, each of which had 2 binary classification tasks. For each scenario, 10 different partitioning of the data into training and testing sets were provided. We focused on the task of identifying PPROM cases from the controls under the D2 scenario defined by the challenge. For this task, the baseline AUPRC value averaged across the 10 testing sets was 0.386. There were 13 participating teams in total. For each team, we extracted its classification scores and placed the actual positive entities before the actual negative entities. For submissions that contained negative classification scores, we re-scaled all the scores to the range between 0 and 1 without changing their order since TensorFlow expects all classification scores to be between zero and one (Supplementary text). Finally, for each team, we computed its AUPRC using each of the 10 testing sets and reported their average. We note that the results we obtained by using PRROC (option that uses the continuous expectation method to handle ties) were identical to those reported by the challenge organizer.
For the fourth scenario, we obtained the data set used in the DREAM5 challenge on reconstructing transcription factor-target networks based on gene expression data [29]. The challenge included multiple networks and we focused on the E. coli in silico Network 1, which has a structure that corresponds to the real E. coli transcriptional regulatory network [29]. We obtained the data from Supplementary Data of the original publication [29]. There were 29 submissions in total. For each submission, we extracted the classification scores of the predicted node pairs (each pair involves one potential transcription factor and one gene it potentially regulates) from Supplementary Data 4 and compared them with the actual classes (positive if the transcription factor actually regulates the gene; negative if not) in the gold-standard network from Supplementary Data 3. Both the submissions and the gold-standard were not required to include all node pairs. To handle this, we excluded all node pairs in a submission that were not included in the gold-standard (because we could not judge whether they are actual positives or actual negatives), and assigned a classification score of 0 to all node pairs in the gold-standard that were not included in a submission (because the submission did not give a classification score to them). The gold-standard contained 4,012 interacting node pairs and 274,380 non-interacting node pairs, and therefore the baseline AUPRC value was .
Supplementary Material
Acknowledgments
QC is supported by National Natural Science Foundation of China under Award Number 32100515. KYY is supported by National Cancer Institute of the National Institutes of Health under Award Number P30CA030199, National Institute on Aging of the National Institutes of Health under Award Numbers U54AG079758 and R01AG085498, and internal grants of Sanford Burnham Prebys Medical Discovery Institute. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Footnotes
Code availability
We have submitted all the code used in our study for the review process. We will create a GitHub repository to allow public free access to our code.
Competing interests
The authors declare that they have no competing interests.
Data availability
All data used in this study can be accessed following the procedure described in the “Data collection and processing” part of the Methods section.
References
- [1].Saito Takaya and Rehmsmeier Marc. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE, 10(3):e0118432, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].Davis Jesse and Goadrich Mark. The relationship between precision-recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, pages 233–240, 2006. [Google Scholar]
- [3].He Haibo and Garcia Edwardo A. Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering, 21(9):1263–1284, 2009. [Google Scholar]
- [4].Lichtnwalter Ryan and Chawla Nitesh V. Link prediction: fair and effective evaluation. In 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, pages 376–383. IEEE, 2012. [Google Scholar]
- [5].Cao Qin, Anyansi Christine, Hu Xihao, Xu Liangliang, Xiong Lei, Tang Wenshu, Mok Myth TS, Cheng Chao, Fan Xiaodan, Gerstein Mark, et al. Reconstruction of enhancer–target networks in 935 samples of human primary cells, tissues and cell lines. Nature Genetics, 49(10):1428–1436, 2017. [DOI] [PubMed] [Google Scholar]
- [6].Schulte-Sasse Roman, Budach Stefan, Hnisz Denes, and Marsico Annalisa. Integration of multiomics data with graph convolutional networks to identify new cancer genes and their associated molecular mechanisms. Nature Machine Intelligence, 3(6):513–526, 2021. [Google Scholar]
- [7].Hong Chenyang, Cao Qin, Zhang Zhenghao, Kwok-Wing Tsui Stephen, and Yip Kevin Y. Reusability report: Capturing properties of biological objects and their relationships using graph neural networks. Nature Machine Intelligence, 4(3):222–226, 2022. [Google Scholar]
- [8].Sielemann Janik, Wulf Donat, Schmidt Romy, and Bräutigam Andrea. Local DNA shape is a general principle of transcription factor binding specificity in Arabidopsis thaliana. Nature Communications, 12(1):6549, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Li Zhijian, Kuppe Christoph, Ziegler Susanne, Cheng Mingbo, Kabgani Nazanin, Menzel Sylvia, Zenke Martin, Kramann Rafael, and Costa Ivan G. Chromatin-accessibility estimation from single-cell ATAC-Seq data with scOpen. Nature Communications, 12(1):6386, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Chowell Diego, Yoo Seong-Keun, Valero Cristina, Pastore Alessandro, Krishna Chirag, Lee Mark, Hoen Douglas, Shi Hongyu, Kelly Daniel W, Patel Neal et al. Improved prediction of immune checkpoint blockade efficacy across multiple cancer types. Nature Biotechnology, 40(4):499–506, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Dal Molin Alessandra, Baruzzo Giacomo, and Di Camillo Barbara. Single-cell RNA-sequencing: assessment of differential expression analysis methods. Frontiers in Genetics, 8:62, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Pratapa Aditya, Jalihal Amogh P, Law Jeffrey N, Bharadwaj Aditya, and Murali TM. Benchmarking algorithms for gene regulatory network inference from single-cell transcriptomic data. Nature Methods, 17(2):147–154, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Dimitrov Daniel, Türei Dénes, Garrido-Rodriguez Martin, Burmedi Paul L, Nagai James S, Boys Charlotte, Ramirez Flores Ricardo O, Kim Hyojin, Szalai Bence, Costa Ivan G, et al. Comparison of methods and resources for cell-cell communication inference from single-cell RNA-Seq data. Nature Communications, 13(1):3224, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Sing Tobias, Sander Oliver, Beerenwinkel Niko, and Lengauer Thomas. ROCR: visualizing classifier performance in R. Bioinformatics, 21(20):3940–3941, 2005. [DOI] [PubMed] [Google Scholar]
- [15].Pedregosa Fabian, Varoquaux Gaël, Gramfort Alexandre, Michel Vincent, Thirion Bertrand, Grisel Olivier, Blondel Mathieu, Prettenhofer Peter, Weiss Ron, Dubourg Vincent, et al. Scikit-learn: machine learning in Python. the Journal of Machine Learning Research, 12:2825–2830, 2011. [Google Scholar]
- [16].Valentini G and Re M. PerfMeas: performance measures for ranking and classification tasks. R package version, 1(1), 2014. [Google Scholar]
- [17].Grau Jan, Grosse Ivo, and Keilwagen Jens. PRROC: computing and visualizing precision-recall and receiver operating characteristic curves in R. Bioinformatics, 31(15):2595–2597, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].John CR. MLeval: machine learning model evaluation. R package version, 3, 2020. [Google Scholar]
- [19].Kuhn Max and Vaughan Davis. yardstick: tidy characterizations of model performance. R package version 0.0, 8, 2021. [Google Scholar]
- [20].Saito Takaya and Rehmsmeier Marc. Precrec: fast and accurate precision–recall and ROC curve calculations in R. Bioinformatics, 33(1):145–147, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Abadi Martín, Agarwal Ashish, Barham Paul, Brevdo Eugene, Chen Zhifeng, Citro Craig, Corrado Greg S, Davis Andy, Dean Jeffrey, Devin Matthieu, et al. Tensor-Flow: large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467, 2016. [Google Scholar]
- [22].Hall Mark, Frank Eibe, Holmes Geoffrey, Pfahringer Bernhard, Reutemann Peter, and Witten Ian H. The WEKA data mining software: an update. ACM SIGKDD Explorations Newsletter, 11(1):10–18, 2009. [Google Scholar]
- [23].Paszke Adam, Gross Sam, Massa Francisco, Lerer Adam, Bradbury James, Chanan Gregory, Killeen Trevor, Lin Zeming, Gimelshein Natalia, Antiga Luca, et al. PyTorch: an imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems, 32, 2019. [Google Scholar]
- [24].Flach Peter and Kull Meelis. Precision-recall-gain curves: PR analysis done right. Advances in Neural Information Processing Systems, 28, 2015. [Google Scholar]
- [25].COvid-19 Multi-omics Blood ATlas (COMBAT) Consortium. A blood atlas of COVID-19 defines hallmarks of disease severity and specificity. Cell, 185(5):916–938.e58, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Stoeckius Marlon, Hafemeister Christoph, Stephenson William, Houck-Loomis Brian, Chattopadhyay Pratip K, Swerdlow Harold, Satija Rahul, and Smibert Peter. Simultaneous epitope and transcriptome measurement in single cells. Nature Methods, 14(9):865–868, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Khachatryan Lusine, Xiang Yang, Ivanov Artem, Glaab Enrico, Graham Garrett, Granata Ilaria, Giordano Maurizio, Maddalena Lucia, Piccirillo Marina, Manipur Ichcha, Baruzzo Giacomo, Cappellato Marco, Avot Batiste, Stan Adrian, Battey James, Lo Sasso Giuseppe, Boue Stephanie, Ivanov Nikolai V., Peitsch Manuel C., Hoeng Julia, Falquet Laurent, Di Camillo Barbara, Guarracino Mario R., Ulyantsev Vladimir, Sierro Nicolas, and Poussin Carine. Results and lessons learned from the sbv IMPROVER metagenomics diagnostics for inflammatory bowel disease challenge. Scientific Reports, 13:6303, 2023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Tarca Adi L, Pataki Bálint Ármin, Romero Roberto, Sirota Marina, Guan Yuanfang, Kutum Rintu, Gomez-Lopez Nardhy, Done Bogdan, Bhatti Gaurav, Yu Thomas, et al. Crowdsourcing assessment of maternal blood multi-omics for predicting gestational age and preterm birth. Cell Reports Medicine, 2(6), 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Marbach Daniel, Costello James C, Küffner Robert, Vega Nicole M, Prill Robert J, Camacho Diogo M, Allison Kyle R, Kellis Manolis, Collins James J, et al. Wisdom of crowds for robust gene network inference. Nature Methods, 9(8):796–804, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Keilwagen Jens, Grosse Ivo, and Grau Jan. Area under precision-recall curves for weighted and unweighted data. PLoS ONE, 9(3):e92209, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Boyd Kendrick, Eng Kevin H, and Page C David. Area under the precision-recall curve: point estimates and confidence intervals. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2013, Prague, Czech Republic, September 23–27, 2013, Proceedings, Part III 13, pages 451–466. Springer, 2013. [Google Scholar]
- [32].Su Wanhua, Yuan Yan, and Zhu Mu. A relationship between the average precision and the area under the ROC curve. In Proceedings of the 2015 International Conference on the Theory of Information Retrieval, pages 349–352, 2015. [Google Scholar]
- [33].Schütze Hinrich, Manning Christopher D, and Raghavan Prabhakar. Introduction to information retrieval, volume 39. Cambridge University Press; Cambridge, 2008. [Google Scholar]
- [34].Everingham Mark, Van Gool Luc, Williams Christopher KI, Winn John, and Zisserman Andrew. The pascal visual object classes (VOC) challenge. International Journal of Computer Vision, 88:303–338, 2010. [Google Scholar]
- [35].Lupu Mihai, Mayer Katja, Kando Noriko, and Trippe Anthony J. Current challenges in patent information retrieval, volume 37. Springer, 2017. [Google Scholar]
- [36].Hirling Dominik, Tasnadi Ervin, Caicedo Juan, Caroprese Maria V, Sjögren Rickard, Aubreville Marc, Koos Krisztian, and Horvath Peter. Segmentation metric misinterpretations in bioimage analysis. Nature Methods, pages 1–4, 2023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Azzone Michele, Barucci Emilio, Moncayo Giancarlo Giuffra, and Marazzina Daniele. A machine learning model for lapse prediction in life insurance contracts. Expert Systems with Applications, 191:116261, 2022. [Google Scholar]
- [38].He Haibo and Ma Yunqian. Imbalanced Learning: foundations, algorithms, and applications. John Wiley & Sons, 2013. [Google Scholar]
- [39].Chu Yanyi, Zhang Yan, Wang Qiankun, Zhang Lingfeng, Wang Xuhong, Wang Yanjing, Salahub Dennis Russell, Xu Qin, Wang Jianmin, Jiang Xue, et al. A transformer-based model to predict peptide–HLA class I binding and optimize mutated peptides for vaccine design. Nature Machine Intelligence, 4(3):300–311, 2022. [Google Scholar]
- [40].Miller Danielle, Stern Adi, and Burstein David. Deciphering microbial gene function using natural language processing. Nature Communications, 13(1):5731, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Schwab Patrick, Mehrjou Arash, Parbhoo Sonali, Celi Leo Anthony, Hetzel Jürgen, Hofer Markus, Schölkopf Bernhard, and Bauer Stefan. Real-time prediction of COVID-19 related mortality using electronic health records. Nature Communications, 12(1):1058, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [42].Ye Qing, Hsieh Chang-Yu, Yang Ziyi, Kang Yu, Chen Jiming, Cao Dongsheng, He Shibo, and Hou Tingjun. A unified drug–target interaction prediction framework based on knowledge graph and recommendation system. Nature Communications, 12(1):6775, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [43].Majdandzic Antonio, Rajesh Chandana, and Koo Peter K. Correcting gradient-based interpretations of deep neural networks for genomics. Genome Biology, 24(1):1–13, 2023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [44].Wang Weibing, Gao Lin, Ye Yusen, and Gao Yong. CCIP: predicting CTCF-mediated chromatin loops with transitivity. Bioinformatics, 37(24):4635–4642, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [45].Fawcett Tom. An introduction to ROC analysis. Pattern Recognition Letters, 27(8):861–874, 2006. [Google Scholar]
- [46].Muschelli John III. ROC and AUC with a binary predictor: a potentially misleading metric. Journal of Classification, 37(3):696–708, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [47].Hanley James A and McNeil Barbara J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology, 143(1):29–36, 1982. [DOI] [PubMed] [Google Scholar]
- [48].Cortes Corinna and Mohri Mehryar. AUC optimization vs. error rate minimization. Advances in Neural Information Processing Systems, 16, 2003. [Google Scholar]
- [49].Robin Xavier, Turck Natacha, Hainard Alexandre, Tiberti Natalia, Lisacek Frédérique, Sanchez Jean-Charles, and Müller Markus. pROC: an open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinformatics, 12(1):1–8, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [50].Sachs Michael C. plotROC: a tool for plotting ROC curves. Journal of Statistical Software, 79, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [51].Harrell Frank E Jr, Lee Kerry L, and Mark Daniel B. Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Statistics in Medicine, 15(4):361–387, 1996. [DOI] [PubMed] [Google Scholar]
- [52].Mason Simon J and Graham Nicholas E. Areas beneath the relative operating characteristics (ROC) and relative operating levels (ROL) curves: statistical significance and interpretation. Quarterly Journal of the Royal Meteorological Society: A journal of the atmospheric sciences, applied meteorology and physical oceanography, 128(584):2145–2166, 2002. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
All data used in this study can be accessed following the procedure described in the “Data collection and processing” part of the Methods section.