

Abstract
A key challenge in quantum photonics today is the efficient and on-demand generation of high-quality single photons and entangled photon pairs. In this regard, one of the most promising types of emitters are semiconductor quantum dots, fluorescent nanostructures also described as artificial atoms. The main technological challenge in upscaling to an industrial level is the typically random spatial and spectral distribution in their growth. Furthermore, depending on the intended application, different requirements are imposed on a quantum dot, which are reflected in its spectral properties. Given that an in-depth suitability analysis is lengthy and costly, it is common practice to pre-select promising candidate quantum dots using their emission spectrum. Currently, this is done by hand. Therefore, to automate and expedite this process, in this paper, we propose a data-driven machine-learning-based method of evaluating the applicability of a semiconductor quantum dot as single photon source. For this, first, a minimally redundant, but maximally relevant feature representation for quantum dot emission spectra is derived by combining conventional spectral analysis with an autoencoding convolutional neural network. The obtained feature vector is subsequently used as input to a neural network regression model, which is specifically designed to not only return a rating score, gauging the technical suitability of a quantum dot, but also a measure of confidence for its evaluation. For training and testing, a large dataset of self-assembled InAs/GaAs semiconductor quantum dot emission spectra is used, partially labelled by a team of experts in the field. Overall, highly convincing results are achieved, as quantum dots are reliably evaluated correctly. Note, that the presented methodology can account for different spectral requirements and is applicable regardless of the underlying photonic structure, fabrication method and material composition. We therefore consider it the first step towards a fully integrated evaluation framework for quantum dots, proving the use of machine learning beneficial in the advancement of future quantum technologies.
Keywords: Quantum technology, Semiconductor quantum dot, Single photon source, Machine-learning-based evaluation, Convolutional autoencoder, Neural network regression
Subject terms: Computational science, Scientific data, Photonic devices, Quantum optics, Single photons and quantum effects, Applied physics
Subject terms: Computational science, Scientific data, Photonic devices, Quantum optics, Single photons and quantum effects, Applied physics
Introduction
Advances in fundamental research and engineering over the past years have enabled the active control of systems within the framework of quantum mechanics, leading to the emergence of next generation quantum technologies. Development in this field is motivated by two main aspects: On the one hand, the progressive miniaturisation of devices down to the nanoscale inevitably requires the explicit consideration of quantum effects1,2. On the other hand, in some areas, a superior performance is expected, for instance in metrology, where sensors based on quantum principles offer a significantly higher sensitivity3,4. At current, efforts focus on the transition from proof-of-concept laboratory applications to commercially available products5,6.
One promising branch of quantum technology is applied quantum optics, or photonics, which is built around the single photon, i.e. the elementary particle of light7,8. In general, photonic solutions are attractive since photons provide several degrees of freedom to encode information and combine high mobility with intrinsic robustness against decoherence and environmental noise. This makes them particularly advantageous, e.g. for long-distance communication through optical fibres9,10. Besides, photons are comparatively easy to manipulate, making photonic setups experimentally very accessible11,12. Obviously, the development of an efficient and on-demand single photon source is key, with brightness, purity and indistinguishability of the emitted photons taking priority13,14. Many setups today make use of spontaneous parametric down-conversion, where a pair of entangled photons is generated from laser light in a non-linear birefringent crystal. While photons produced this way are highly indistinguishable, there is an intrinsic trade-off between brightness and single photon purity due to the Poissonian statistics of down-conversion15,16. Improving on these limiting factors, quantum light sources embedding semiconductor quantum dots in photonic structures or cavity resonators have increasingly established themselves as promising candidates and valid alternative17,18.
Semiconductor quantum dots
Semiconductor quantum dots (QD) are nanoscale heterostructures with a lower band gap between the disjoint valence and the conduction band than their semiconductor environment. Their small size in terms of the de Broglie wavelength of electrons confines charge carriers (electrons, holes) in all three spatial dimensions, which results in a band structure allowing for discretised, i.e. quantised electronic states resembling the shells of atoms13,19. Their energetic landscape is graphically outlined in depth in Fig. 1a. Here, photons are represented as blue wavelets, while solid arrows trace optical transitions and dotted arrows indicate non-radiative relaxation. As shown, under above-band laser irradiation (dark blue), an electron is promoted from the low-energy valence band to the high-energy conduction band by absorbing a photon whose energy exceeds the band gap. Through non-radiative energy dissipation, the excited electron and the remaining hole relax to the respective lowest energy state of the QD (s-shell), forming a bound pair called exciton. This subsequently fluorescently recombines, i.e. the electron radiatively decays by emitting a single photon with the energy of the occupied QD state (light blue). The fluorescence wavelength is dependent on the quantisation of the QD states, which, in return, is directly determined by the size and geometry of the QD20,21.
Figure 1.
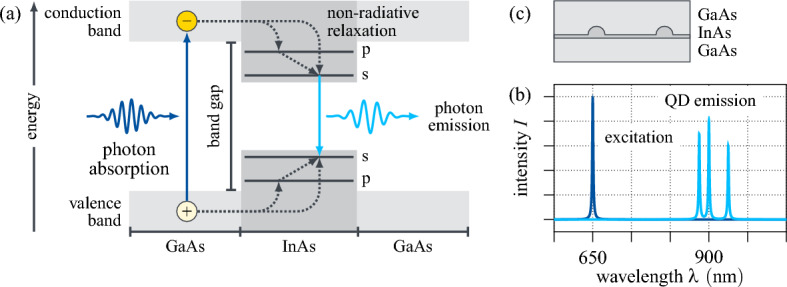
(a) Visual abstract of the fluorescent single photon emission of semiconductor QDs. Above-band excitation promotes an electron to the conduction band, from where it non-radiatively relaxes to the s-shell in the QD. The electron subsequently recombines with the electron hole left behind in the valence band and thereby emits a single photon with the energy of the QD state. (b) Schematic spectrum of the excitation laser (dark blue) and the QD emission (light blue). (c) Schematic side view of a QD sample formed through epitaxial self-assembly.
Interestingly, additional charge carriers can typically be found in a QD, causing real QD spectra to exhibit multiple emission lines. This is showcased in Fig. 1b, where the spectra of the excitation laser (dark blue) and the QD emission (light blue) are schematically plotted as functions of the photon wavelength .
While there are several fabrication techniques and material compositions for the realisation of QDs, for this work, we consider self-assembled QD samples grown in the Stranski–Krastanow mode on a platform using molecular beam epitaxy22. A schematic cross-section of such an QD wafer is given in Fig. 1c. Despite having state-of-the-art performance in their photon emission properties, as a result of self-assembly, these QDs grow randomly distributed in space. On top of that, even when synthesised under the same growth conditions, their size can vary from dot to dot, resulting in different quantum confinement and therefore different emission wavelengths23. This implies, that in order to perform some intended experiment, a suitable QD has to be found on a given wafer. This is exemplarily illustrated in Fig. 2a, where a confocal -photoluminescence intensity map24 of a representative wafer is shown. The image is recorded using the measurement setup schematised in Fig. 2b: an above-band laser is scanned across the sample in a area, while the QD luminescence is collected and analysed in a spectrometer. Plotting the intensity over the spatial position yields the colour map on the left, where QDs appear as bright spots over a dark background. The normalised emission spectra of the yellow encircled QDs are given in Fig. 3. All three emit at a fluorescence wavelength of about . However, while in the first spectrum one optical transition is predominant, in the second one, in contrast, several transitions are excited simultaneously, resulting in the spectrum having multiple peaks. The third one, finally, besides having a significantly worse signal-to-noise ratio and an elevated baseline, exhibits a broadband feature in its emission spectrum at around . For use as single photon sources in photonic systems, QDs ideally emit at only one specific, spectrally isolated wavelength with high intensity. In this regard, only the first QD appears to be applicable. Nevertheless, this does not mean that the other two are to be discarded straight away. For instance, with more sophisticated excitation schemes a single desired optical transition can be addressed. Equally, spectrally matching a photonic resonator to the driven transition and exploiting cavity quantum electrodynamic effects can prove advantageous25,26. Then again, a seemingly perfect QD photon source can turn out to be unfit on closer inspection, e.g. in a polarisation measurement27 or a surface topography28. Overall, this implies the suitability of a semiconductor QD as single photon source cannot be definitively decided solely based on its emission spectrum, but that further analyses are necessary. However, given that these are usually either time-consuming and/or resource expensive promising candidates must be pre-selected. Currently, this is done by hand: specifically trained experts consider the emission spectra of all candidate QDs on a given sample and assess based on their subjective experience whether they meet the spectral requirements for additional in-depth investigations and an eventual application. This evaluation is neither trivial, nor are there any quantified conventions for it. Both in research and industrial applications, this manual selection process represents an actual bottleneck limiting the productivity and thus the scalability of photonic technologies.
Figure 2.

Confocal -photoluminescence intensity measurement. (a) Normalised emission intensity in a 50×50 μm2 area of a representative self-assembled InAs/GaAs QD sample. Three exemplary QDs are marked in yellow. (b) Schematic measurement setup: the QD sample is placed inside a Helium cryostat and excited by an above-band laser guided through a beamsplitter. The luminescence signal is collected and sent to a spectrometer.
Figure 3.
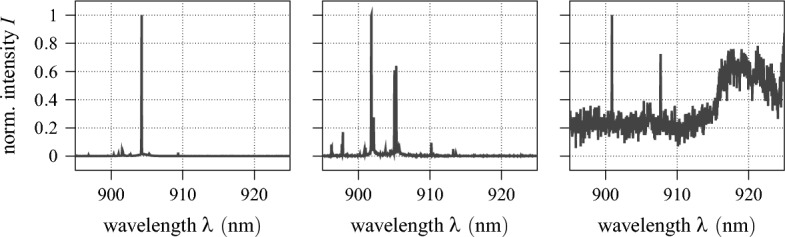
Emission spectra of the QDs encircled in Fig. 2a from left to right. The spectra are recorded between and wavelength in and normalised independently.
Contribution
This paper directly addresses this challenge. Here, we propose a data-driven machine-learning-based solution for the automated evaluation of the applicability of a semiconductor QD as single photon source based on its emission spectrum. Specifically, the goal is to build an expert system approximating the current experience-based suitability analysis. With this contribution, the (pre-)selection of viable QDs can be parallelised and processing times can be significantly reduced. Moreover, the technical relevance of this paper increases in the long-term, as methods like the one presented here are a necessary requirement for a large scale production of semiconductor QD single photon sources and thus for an industrial implementation of photonic technologies. To the authors’ best knowledge, at the time of writing, no such approach has yet been reported in the literature. In Ref.29, a machine-learning-based classifier of quantum sources is proposed, although it is limited to discriminating between the emission of single and non-single photons from nitrogen-vacancy centres in diamond. Otherwise, the focus lies on using machine learning to enhance the QD fabrication process itself30,31. In particular, a variety of methods is employed to either provide the design parameters of the synthesis32,33 or to make predictions about the resulting optical properties34,35.
This paper is structured as follows: after covering the physical background and relevance of the topic in the introduction, next, the evaluation algorithm is presented in depth and contextualized within the state of the art. It is subsequently implemented and its performance showcased, which, finally, allows for a discussion of the proposed solution.
Quantum dot evaluation method
The development of a method for evaluating the photonic usability of a semiconductor QD based on its emission spectrum is mathematically equivalent to the identification of a function that maps a given emission spectrum to a rating score , with encoding a potentially perfect single photon source recommended for further analyses, and a most likely unfit candidate. As discussed in section “Semiconductor quantum dots”, given the complexity of this gauging combined with the lack of established conventions and the subjectivity involved, an analytical derivation of such a function is highly impractical. Therefore, in this paper, a data-driven regressive approach is proposed instead.
Regression analysis is the statistical estimation of a functional relationship between an independent input and a dependent output by minimising a loss function
| 1 |
over the parameter vector of a pre-defined regression model using a set of available training data . As this involves detecting underlying patterns in the data, limiting redundancies and noise by reducing the dimension of the function space can significantly improve the overall performance of the regression. With high-dimensional data, it is therefore common practice to first compress the independent variable into a lower-dimensional feature vector from which to subsequently predict the dependent target variable 36,37.
Within the scope of this paper, this implies, a meaningful feature representation x is to be derived for the emission spectrum of a semiconductor QD. For this, we consider both explainable spectral parameters, extracted by conventional methods of signal processing, as well as an abstract latent representation learned by an autoencoder. A subset of minimally redundant, but maximally relevant features, that still sufficiently accurately describes the data38,39, is then selected by correlation analysis and used as input of a regression model . Here, we propose a multivariate neural network regressor, specifically designed to not only predict a technical suitability score , but to also return a measure of confidence for its estimate. A visual abstract of the overall scheme is given in Fig. 4. The top half outlines the pre-processing and training, whereas the bottom half visualises the workflow for predicting the output of some unknown test input , with its feature representation being passed to the now optimised regression model. The following sections elaborate on the neural network regression analysis, highlighted in yellow, and the feature engineering, marked in blue.
Figure 4.
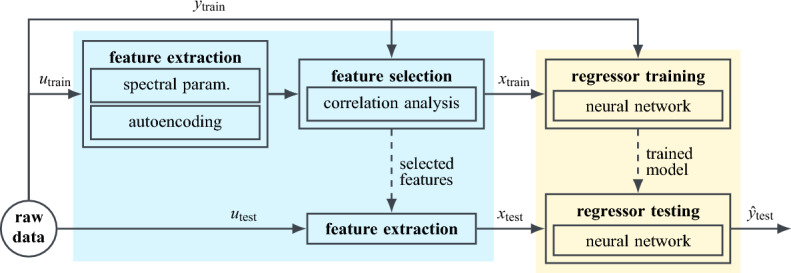
Visual abstract of a regression analysis scheme (yellow) including feature engineering (blue). In this paper, the independent input u corresponds to a measured QD emission spectrum , and the dependent output y to the evaluation score s ranking the QD’s technical usability as single photon source between 0 and 1 with confidence .
Neural network regression analysis
Overall, the performance of any regression analysis is determined by the ability of the trained model to generalise, i.e. to make accurate predictions for unknown inputs . Here, besides the quality of the training data and the numerical optimisation, the selection of the model function itself is key. In this regard, different regression techniques are distinguished. Most common is linear regression, which is easily implemented, but limited in its application40. For non-linear systems, kernel-based methods like support vector machines41 or Gaussian process models are widely established42. Lastly, artificial neural networks (NN) are a class of universal function approximators43 with a characteristic parameter structure of hierarchical layers intended to resemble interconnected biological neurons44. A fully connected feed-forward NN regression model is defined as
| 2 |
where denotes the number of layers. Besides the first layer , which is passed the feature vector , each layer is passed the output of the previous layer as input. The last layer, finally, returns the model predictions . A schematic depiction of the setup of an arbitrary layer is given in Fig. 5. Each layer comprises a non-linear activation function which is applied element-wise to the output of an affine mapping
| 3 |
where the weight matrix and the bias vector are the model parameters to be optimised during training. Note, that the general matrix multiplication in (3) can also be replaced by a discrete convolution with a set of learnable kernels45.
Figure 5.
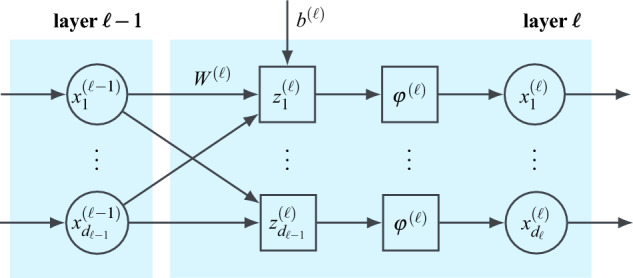
Schematic representation of a layer in a feed-forward NN.
Compared to conventional regression models, NN regressors stand out for their huge parameter space, which is further extended by the inclusion of additional connections, shortcuts or feedbacks between the layers in more sophisticated network architectures46,47. Because of this, NNs are particularly good at recognising patterns in unstructured data and making generalising predictions. Accordingly, they have been applied successfully to a wide range of problems, from the calibration of biosensing systems48, to the evaluation of chess positions49 and the identification of objects in images50.
Feature engineering
As discussed above, the use of properly optimised features is crucial for pattern detection in data analysis and thus for regressive function modelling, improving the overall performance and the prediction accuracy in particular. Like all spectral data, QD emission spectra are characterised by some rather self-evident features, first and foremost, the number of peaks , which infers how many optical transitions are excited at the same time. However, considering an ideal single photon source emits at only one specific wavelength, usually only the brightest peak with the maximum emission intensity is of interest. Its relative dominance can be quantified by the ratio of its amplitude to the height of the next larger peak, denoted by . Besides, its sharpness, best described by its full width at half maximum , and its minimum distance to neighbouring peaks determine the feasibility of isolating the corresponding level transition for single photon generation. Note, that at this stage, the exact emission wavelength is of secondary importance and will hence not be taken into account.
All of the mentioned features represent explainable parameters that can be extracted from the data using conventional methods of signal processing. Here, we employ the Ordered Statistics Constant False Alarm Rate (OS-CFAR) peak detection algorithm, which is commonly used in radar technology, as it is capable of adapting the detection threshold to the surrounding noise baseline51. As showcased in Fig. 6, this prevents spectral broadband features to be identified as a collection of subsequent individual peaks. Once the peaks have been localised within the spectrum, the algebraic computation of the corresponding feature values is straightforward.
Figure 6.
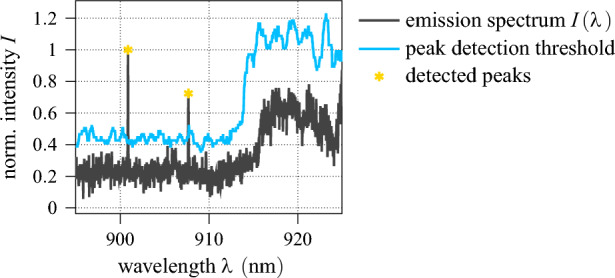
Working principle of the OS-CFAR peak detection algorithm51. Data points above the adaptive threshold are identified as spectral peaks.
These features, however, are not necessarily sufficient to describe every aspect of an emission spectrum and to fully evaluate QDs in regard to their suitability as single photon sources. Therefore, additional abstract features are extracted using a so-called autoencoder, an unsupervised machine learning technique for non-linear dimensionality reduction52 and representation learning53.
At its core, an autoencoder is a NN regression model estimating the identity function that projects an independent variable onto itself. However, the network is set up as such, that the output of one intermediate layer is of reduced dimension54,55. As can be seen in Fig. 7, this implies, the information contained in the data vector u is first encoded into a lower-dimensional latent feature vector and subsequently decoded again, in order to produce a reconstruction of the original input. Training the network by minimising the reconstruction error requires as little information as possible to be lost when propagating the data vector through the network. Hence, the latent representation is automatically optimised as well and can subsequently be extracted by evaluating only the encoder part of the network (blue). Note, that, while highly informative, the features derived this way are not necessarily explainable or unique. The residual reconstruction error , meanwhile, provides a measure for the loss of information and thus for deviations from learned patterns and regularities. It is therefore often considered in fault detection, for instance to catch sensor or actuator errors56,57. In the context of this paper, it is exploited to quantify noise and spectral oddities, like the broadband feature in Fig. 6.
Figure 7.
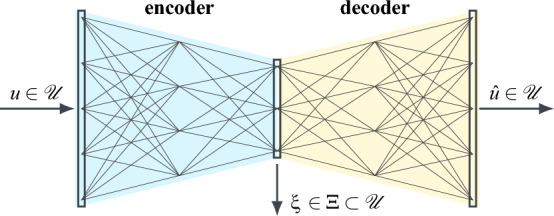
Schematic representation of an autoencoder NN. The input vector u is first encoded into a low-dimensional latent feature representation , which is subsequently decoded again to produce an estimate of the input.
As outlined in section “Quantum dot evaluation method”, subsequently, a set of minimally redundant, but maximally relevant features is to be selected to be used as input x for the NN regression model estimating a QD’s viability as single photon source. The results hereof are presented in the next section.
Results
In this section, the proposed evaluation algorithm is implemented and validated. For this, we consider single layer semiconductor QDs within a n–i–n diode structure. The QDs are located in the vertical antinode of a planar cavity formed by a bottom distributed Bragg reflector (DBR) and a lower reflectivity top DBR. More information on the samples can be found in22, alongside comprehensive optical and quantum optical characterisations. Using an above-band excitation laser close to saturation, a dataset of emission spectra is recorded in a spectral range of in , thus giving an input dimension of . Moreover, a total of 300 spectra is labelled redundantly by a team of seven experienced experts in the field, i.e. personal biases are reduced to a minimum by the assignment of a score average s between 0 and 1 that rates the viability of the emitting QD as source of single, indistinguishable photons with isolated, bright emission lines and low background. An approximate representation of the score distribution is given by the histogram in Fig. 8.
Figure 8.
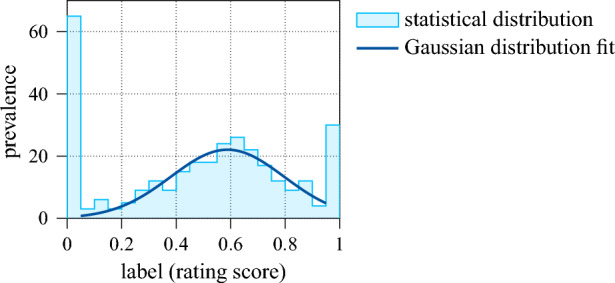
Rating score distribution in the labelled dataset as histogram.
Excluding the marginal extrema, the distribution is roughly Gaussian (dark blue curve). Lastly, to augment the data, each sample is spectrally shifted twice by a random number of pixels. As this does not affect any spectral properties qualitatively, the size of both the labelled and unlabelled dataset is increased by a factor of three, which benefits the training of the various machine learning models. For this, as is common practice, 80% of the data is used, with the remaining 20% being retained for testing and to track possible overfitting. Note, that this split is applied to both the labelled and the unlabelled dataset.
In the following, first, the results of the autoencoder feature extraction are presented, then, a suitable subset of features is selected by correlation analysis, and eventually, the performance of the rating score prediction by NN regression is showcased.
Autoencoder representation learning
For the derivation of an abstract feature representation for QD emission spectra, in this paper, an autoencoder with latent space dimension is proposed. This is the result of a hyper-parameter optimisation and represents a trade-off between the loss of too much information in case the latent space dimension is too small, and a reduced correlation of the autoencoder states with the rating score in case the latent space dimension is too large. Taking normalised input data with , the encoder part handles the feature learning and the dimensionality reduction. For the former, typically, deep convolutional NNs are employed, which excel at pattern detection, but potentially suffer from vanishing or exploding gradients during optimisation58. In this regard, residual blocks, i.e. sequences of two convolutional layers with a skip connection, offer some numeric benefits, as any derivation yields at least an identity matrix. Moreover, the mapping of linear relations is facilitated59,60.
For the dimensionality reduction, in return, max pooling is state of the art. This is a downsampling technique, where the output of a convolutional layer is divided into blocks of equal size, with only the maximum value of each block being propagated further. Since this way the most dominant entries are retained, the overall performance of the network is not significantly impaired. On the contrary, max pooling introduces a certain degree of translational invariance and improves the computational efficiency of the network61,62.
Here, the encoder is set up as a series of four residual units, each consisting of two residual blocks followed by max pooling (ref. Fig. 9). As denoted, the results of the convolutional mappings are batch normalised before being passed to the rectified linear unit (ReLU) activation function63
| 4 |
In each residual unit, the four convolutional layers have the same structure and hyper-parameters (output shape, kernel size, stride, padding), whereas a max pooling dimensionality reduction by factor three is adopted throughout. Lastly, the compact latent representation is produced by a fully connected feed-forward layer. For the subsequent recovery of the input vector and the associated increase in dimensionality, the decoder comprises six sequential transposed convolutional layers64. Since the input data is normalised, the sigmoid activation function
| 5 |
is used here to constrain the output value range such that . A summary of the autoencoder’s complete architecture is given in Table 1. Overall, the autoencoder has 233313 training parameters, which are optimised with respect to the squared -norm using the computationally efficient ADAM algorithm with learning rate scheduling65 and a batch size of 512. As the autoencoder training is unsupervised, the unlabelled dataset is used for it. Fig. 10 displays the training and test learning curve of the autoencoder over 200 epochs of optimisation. Clearly, both decay approximately exponentially towards 0, indicating that the autoencoder’s learnt latent representation is optimised without significant overfitting. The performance of the fully trained autoencoder is further showcased in Fig. 11, where the reconstructions of the three model spectra from Fig. 3 are shown. Note, that these are part of the test data and therefore not previously known. As can be seen, the first two spectra are recovered reasonably well, with all major peaks captured and the reconstruction errors correspondingly low. In contrast, the autoencoder struggles to reconstruct the third spectrum, as both the worse signal-to-noise ratio and the spectral broadband feature constitute sever deviations from learnt patterns and regularities. As discussed in section “Feature engineering”, the reconstruction error is considered as feature precisely to take such cases into account. On the other hand, no physical meaning could be inferred for the autoencoder’s latent states.
Figure 9.
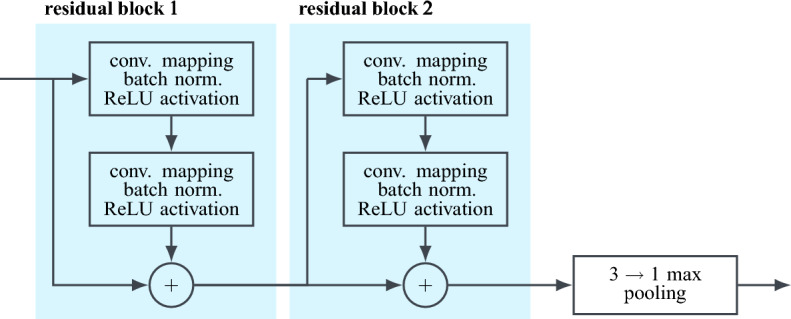
Schematic visualisation of a residual unit, consisting of two residual blocks followed by max pooling.
Table 1.
Autoencoder architecture summary.
| Layer | Output shape | Parameter | |
|---|---|---|---|
| Residual unit | Kernel 3, stride 3, padding 1 | 248 | |
| Residual unit | Kernel 3, stride 3, padding 1 | 3344 | |
| Residual unit | Kernel 3, stride 3, padding 1 | 13,216 | |
| Residual unit | Kernel 3, stride 3, padding 1 | 52,032 | |
| Flatten | – | ||
| Linear feed-forward | 12,304 | ||
| Linear feed-forward | 78,336 | ||
| Reshape | – | ||
| Transposed conv. layer | Kernel 7, stride 3 | 57,664 | |
| Transposed conv. layer | Kernel 6, stride 3 | 12,448 | |
| Transposed conv. layer | Kernel 6, stride 3 | 3152 | |
| Transposed conv. layer | Kernel 3, stride 1, padding 1 | 424 | |
| Transposed conv. layer | Kernel 3, stride 1, padding 1 | 116 | |
| Transposed conv. layer | Kernel 5, stride 1 | 29 |
Figure 10.
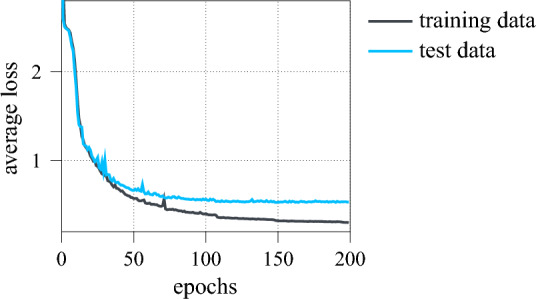
Average training and test loss of the autoencoder during training.
Figure 11.

Autoencoder reconstruction of three model QD emission spectra.
Feature selection
Combining the autoencoder’s latent representation and reconstruction error with the aforementioned characteristic spectral parameters, overall, a set of 22 features
| 6 |
can be extracted from each QD emission spectrum . These are, however, neither inherently independent, nor necessarily impacting the suitability evaluation subject to this paper. Therefore, two correlation studies are performed to select a subset of minimally redundant, but maximally relevant features to be used as input vector x for the NN regression model. For both, the absolute of Spearman’s rank correlation coefficient is used, as it is not limited to linear relationships, but rather measures monotonicity66. First, using the available labelled training data, the correlation between each feature and the rating score is computed. The results hereof are listed in Table 2. In particular, the reconstruction error and the maximum emission intensity stand out for their strong correlation of with the target value. Subsequently, only features with a correlation coefficient are retained, which reduces the set of features under consideration to
| 7 |
where the significant amount of latent features justifies the use of the autoencoder. The remaining features are subject to a cross-correlation analysis. The results are visualised in Fig. 12. Clearly, the reconstruction error and the maximum emission intensity are also correlated comparatively strongly with each other. Furthermore, both show a moderate cross-correlation with the remaining latent features . Since for the reconstruction error this can be attributed to the shared origin, i.e. the autoencoder, the maximum emission intensity is omitted in order to limit redundancies. This leaves five features, that combined form the input vector
| 8 |
of the NN regression model estimating a QD’s viability as single photon source. The comparatively high relevance and impact of the reconstruction error is revisited in section “Evaluation score prediction”.
Table 2.
Absolute Spearman correlation between each feature and the rating score.
| 0.438 | 0.198 | 0.106 | 0.509 | 0.391 | 0.094 | 0.244 | 0.376 | 0.276 |
| 0.208 | 0.588 | 0.064 | 0.559 | 0.488 | 0.398 | 0.379 |
Significant values with |ρ| > 0.6 are in bold.
Figure 12.
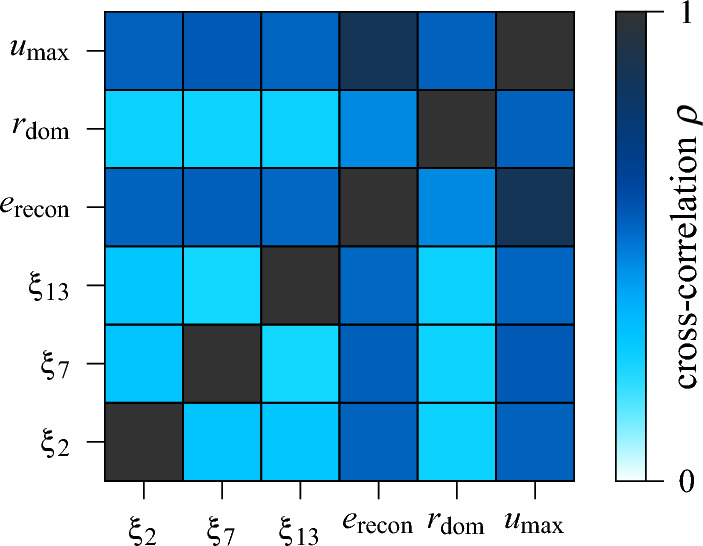
Absolute of Spearman’s rank cross-correlation coefficient between features in (7).
Evaluation score prediction
The last building block of the proposed QD evaluation scheme is the NN regression model. Considering the goal is to replicate an expert’s experienced based decision process with its inherent subjectivity, the network is set up as such, that not only a rating score prediction is returned, but also a measure of confidence for it. To do so, using the training data, the Gaussian negative log-likelihood loss function
| 9 |
is minimised over for the multivariate NN regression model with vector-valued output. For accurate predictions, this causes the optimiser to drive , whereas for inaccurate predictions, must inevitably increase for the second summand to be minimised. Note, that this is accomplished without supervision. Given that (9) is the negative natural logarithm of a normal distribution, can be interpreted as standard deviation of the prediction and is hence referred to as such67.
The regression model itself is designed as a fully connected feed-forward NN with four layers, using the sigmoid activation function (4) throughout to constrain the predictions to . Table 3 provides further details regarding the architecture of the network. As before, the ADAM optimisation algorithm is employed with a batch size of 64 and the resulting training and test learning curves over 2000 epochs are given in Fig. 13. Despite several outliers, both curves clearly decay and the network is accordingly optimised with negligible overfitting. In fact, considering the widespread score as accuracy metric for regression analysis68, a training score of 96%, and a test score of 95% is achieved. For reference, taking the reconstruction error, i.e. the strongest feature, as single input for the regression model such that , yields a test score of 84%. Considering the reconstruction error primarily quantifies noise, this implies, that differentiating candidate QD spectra solely with respect to the signal-to-noise ratio would lead to significantly worse results.
Table 3.
NN regression model architecture summary.
| Layer | Output shape | Parameter |
|---|---|---|
| linear feed-forward | 120 | |
| linear feed-forward | 420 | |
| linear feed-forward | 420 | |
| linear feed-forward | 42 |
Figure 13.
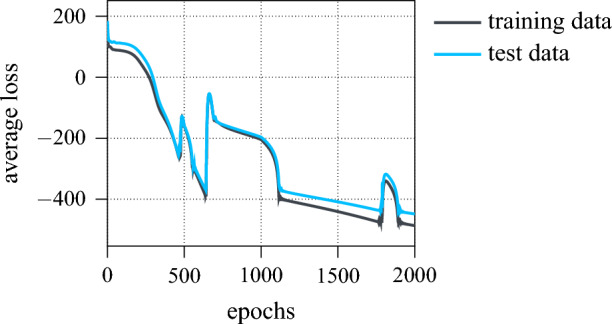
Average training and test loss of the NN regression model during training.
The general performance of the fully trained network is plotted in Fig. 14. Here, the predicted rating scores are plotted over the ground truth, on the left for one entire test batch, on the right for randomly selected test samples of equal label increment with the estimated 95% confidence interval (). The identity represents perfect estimation. As can be seen, the predictions are overall quite accurate with a mean absolute deviation of 0.05 corresponding to a relative error of 5%. In particular, the assignment of rating score zero is both very precise and with high confidence, whereas low, but non-zero ratings are slightly overestimated. Nonetheless, the ground truth always lies within the estimated 95% confidence interval and the predictions are therefore throughout reasonably good.
Figure 14.
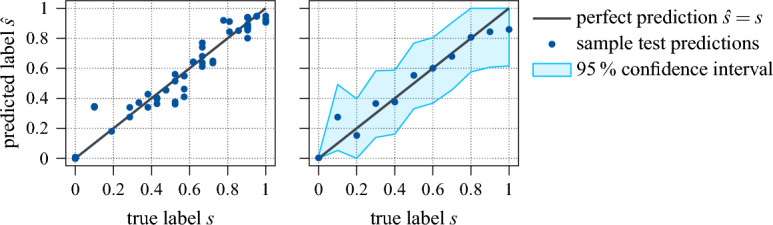
Prediction of the NN regression model, plotted as function of the actual label. Left: Predictions for one test batch. Right: Predictions for test samples with equidistant true labels (increment 0.1).
To illustratively showcase the practical use of the proposed method, two example spectra are given in Fig. 15, alongside their respective label predictions. Both QDs are, solely based on their emission spectrum, to be considered as candidates of mediocre quality. For the model spectra given in Fig. 3, meanwhile, rating scores of are predicted from left to right, whereas they had been labelled , respectively. As can be seen, both the expert as well as the proposed expert system agree on their evaluation, highlighting the potential for automatisation in this field.
Figure 15.

Additional QD emission spectra examples, drawn from the labelled test dataset.
Discussion and outlook
The main objective of this paper was the development of a method to automatically evaluate the viability of a semiconductor QD as single photon source based on its emission spectrum. For this, combining spectral analysis and an autoencoder, a suitable feature representation for QD emission spectra is derived and a NN regression model is trained on a given set of expert labelled data. Overall, the proposed solution achieves highly convincing results by reliably predicting accurate ratings for unknown test inputs. Embedding the evaluation algorithm in a user application and establishing a required minimum rating enables the automation of the manual pre-selection of candidate QDs for further analyses. This does not only significantly reduce processing times, but also introduces a certain degree of objectivity and comparability. Overall, this work showcases how machine learning can support and benefit the ongoing development of quantum technologies by solving practical challenges.
However, several aspects are to be pointed out in this context. First, in this paper, a regressive rather than a classification based approach is employed. This has the advantage, that the cut-off score can be chosen freely to render the selection more conservative or more radical. In fact, it can even be defined as a function of the estimated measure of confidence of the rating prediction. Secondly, note, that the data used here to train the regression model was labelled by a team of experts to eliminate any personal bias. In practice, however, different experts work on different topics and therefore have different spectral requirements. In particular, the distinction between exciton, biexciton and trion excitation is technically highly relevant. This can be accounted for by optimising the network only with regard to the labels assigned by one expert. In this case, the trained model will replicate their personal assessment and will be tuned to their application scenario. Since only a comparatively small dataset is required to be re-labelled and the cross-training of the prediction model is of low computational effort, adapting the proposed evaluation method is considerably more efficient than adjusting a rating system not based on machine learning, for which a plethora of decision variables and threshold values would have to be fine-tuned. Note, that the demand for QDs of one specific emission wavelength can be met by simply filtering the evaluated and selected spectra accordingly, which is why this parameter was not included as feature in the analysis. Finally, it should be mentioned, that while this work focusses on self-assembled QDs grown in the Stranski–Krastanow mode by molecular beam epitaxy, comparable challenges arise with other fabrication methods as well. However, since the solution proposed here is transferable, the same approach can be adopted for each fabrication method, material composition and photonic structure.
In the long-term, the framework presented in this paper is to be expanded to a fully automated evaluation tool for semiconductor QDs, capable of taking into account not only emission spectra, but also further measurements and custom requirements, in order to streamline and support the synthesis of high quality single photon sources.
Author contributions
Conceptualization: E.C., S.L.P., P.M., C.T.; Methodology: E.C., F.J., C.T.; Software: E.C., F.J.; Sample generation: M.S., A.D.W., A.L., M.J., S.L.P., P.M.; Data acquisition: E.C., L.W., R.J., A.B., M.S., A.D.W., A.L., M.J.; Data curation: E.C., F.J.; Data analysis: E.C., F.J., C.T.; Validation: E.C., L.W., R.J., A.B., S.L.P.; Visualization and figures: E.C., F.J., L.W., R.J., A.B.; Writing, coordination/editing: E.C.; Writing, physics background: E.C., L.W., R.J., A.B., M.S., A.D.W., A.L., M.J., S.L.P., P.M.; Writing, machine learning methods: E.C., F.J., C.T.; Writing, discussion/outlook: E.C., L.W., R.J., S.L.P.; Project administration: E.C., P.M., C.T.; Funding acquisition: P.M., C.T. All authors have reviewed and agreed to the published version of the manuscript.
Funding
Open Access funding enabled and organized by Projekt DEAL. This work was conducted in the framework of the Graduate School 2642/1 “Towards Graduate Experts in Photonic Quantum Technologies” (project ID 431314977) funded by the German Research Foundation (DFG—Deutsche Forschungsgemeinschaft).
Data and code availability
Both code and data will be made available by the corresponding author upon reasonable request.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Acín A, et al. The quantum technologies roadmap: A European community view. New J. Phys. 2018;20:080201. doi: 10.1088/1367-2630/aad1ea. [DOI] [Google Scholar]
- 2.Thew R, Jennewein T, Sasaki M. Focus on quantum science and technology initiatives around the world. Quantum Sci. Technol. 2020;5:010201. doi: 10.1088/2058-9565/ab5992. [DOI] [Google Scholar]
- 3.Pirandola S, Bardhan BR, Gehring T, Weedbrook C, Lloyd S. Advances in photonic quantum sensing. Nat. Photonics. 2018;12:724–733. doi: 10.1038/s41566-018-0301-6. [DOI] [Google Scholar]
- 4.Polino E, Valeri M, Spagnolo N, Sciarrino F. Photonic quantum metrology. AVS Quantum Sci. 2020;2:024703. doi: 10.1116/5.0007577. [DOI] [Google Scholar]
- 5.Dowling JP, Milburn GJ. Quantum technology: The second quantum revolution. Philos. Trans. Ser. A Math. Phys. Eng. Sci. 2003;361:1655–1674. doi: 10.1098/rsta.2003.1227. [DOI] [PubMed] [Google Scholar]
- 6.Schleich WP, et al. Quantum technology: from research to application. Appl. Phys. B. 2016;122:94. doi: 10.1007/s00340-016-6353-8. [DOI] [Google Scholar]
- 7.O’Brien JL, Furusawa A, Vučković J. Photonic quantum technologies. Nat. Photonics. 2009;3:687–695. doi: 10.1038/nphoton.2009.229. [DOI] [Google Scholar]
- 8.Politi A, Matthews J, Thompson MG, O’Brien JL. Integrated quantum photonics. IEEE J. Sel. Top. Quantum Electron. 2009;15:1673–1684. doi: 10.1109/JSTQE.2009.2026060. [DOI] [Google Scholar]
- 9.Gisin N, Thew R. Quantum communication. Nat. Photonics. 2007;1:165–171. doi: 10.1038/nphoton.2007.22. [DOI] [Google Scholar]
- 10.Muralidharan S, et al. Optimal architectures for long distance quantum communication. Sci. Rep. 2016;6:20463. doi: 10.1038/srep20463. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Slussarenko S, Pryde GJ. Photonic quantum information processing: A concise review. Appl. Phys. Rev. 2019;6:041303. doi: 10.1063/1.5115814. [DOI] [Google Scholar]
- 12.Benyoucef M, Bennett A, Götzinger S, Lu C-Y. Photonic quantum technologies. Adv. Quantum Technol. 2020;3:2000007. doi: 10.1002/qute.202000007. [DOI] [Google Scholar]
- 13.Michler P. Quantum Dots for Quantum Information Technologies. Springer International Publishing; 2017. [Google Scholar]
- 14.Michler P, Portalupi SL. Semiconductor Quantum Light Sources: Fundamentals, Technologies and Devices. De Gruyter; 2024. [Google Scholar]
- 15.Eisaman MD, Fan J, Migdall A, Polyakov SV. Invited review article: Single-photon sources and detectors. Rev. Sci. Instrum. 2011;82:071101. doi: 10.1063/1.3610677. [DOI] [PubMed] [Google Scholar]
- 16.Somaschi N, et al. Near-optimal single-photon sources in the solid state. Nat. Photonics. 2016;10:340–345. doi: 10.1038/NPHOTON.2016.23. [DOI] [Google Scholar]
- 17.Aharonovich I, Englund D, Toth M. Solid-state single-photon emitters. Nat. Photonics. 2016;10:631–641. doi: 10.1038/NPHOTON.2016.186. [DOI] [Google Scholar]
- 18.Senellart P, Solomon G, White A. High-performance semiconductor quantum-dot single-photon sources. Nat. Nanotechnol. 2017;12:1026–1039. doi: 10.1038/NNANO.2017.218. [DOI] [PubMed] [Google Scholar]
- 19.Michler P. Single Semiconductor Quantum Dots. Nanoscience and Technology. 1. Springer; 2009. [Google Scholar]
- 20.Schmidt KH, Medeiros-Ribeiro G, Garcia J, Petroff PM. Size quantization effects in InAs self-assembled quantum dots. Appl. Phys. Lett. 1997;70:1727–1729. doi: 10.1063/1.118682. [DOI] [Google Scholar]
- 21.Mutavdžić D, et al. Determination of the size of quantum dots by fluorescence spectroscopy. Analyst. 2011;136:2391–2396. doi: 10.1039/C0AN00802H. [DOI] [PubMed] [Google Scholar]
- 22.Strobel T, et al. A unipolar quantum dot diode structure for advanced quantum light sources. Nano Lett. 2023;23:6574–6580. doi: 10.1021/acs.nanolett.3c01658. [DOI] [PubMed] [Google Scholar]
- 23.Michler P, editor. Single quantum dots: Fundamentals, applications and new concepts. Topics in Applied Physics. 1. Springer; 2003. [Google Scholar]
- 24.Liu J, et al. Cryogenic photoluminescence imaging system for nanoscale positioning of single quantum emitters. Rev. Sci. Instrum. 2017;88:023116. doi: 10.1063/1.4976578. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Michler P, et al. A quantum dot single-photon turnstile device. Science (New York, N.Y.) 2000;290:2282–2285. doi: 10.1126/science.290.5500.2282. [DOI] [PubMed] [Google Scholar]
- 26.Arakawa Y, Holmes MJ. Progress in quantum-dot single photon sources for quantum information technologies: A broad spectrum overview. Appl. Phys. Rev. 2020;7:1. doi: 10.1063/5.0010193. [DOI] [Google Scholar]
- 27.Huber D, Reindl M, Aberl J, Rastelli A, Trotta R. Semiconductor quantum dots as an ideal source of polarization-entangled photon pairs on-demand: A review. J. Opt. 2018;20:073002. doi: 10.1088/2040-8986/aac4c4. [DOI] [Google Scholar]
- 28.Sapienza L, et al. Combined atomic force microscopy and photoluminescence imaging to select single InAs/GaAs quantum dots for quantum photonic devices. Sci. Rep. 2017;7:6205. doi: 10.1038/s41598-017-06566-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Kudyshev ZA, et al. Rapid classification of quantum sources enabled by machine learning. Adv. Quantum Technol. 2020;3:2000067. doi: 10.1002/qute.202000067. [DOI] [Google Scholar]
- 30.Peng J, Muhammad R, Wang S-L, Zhong H-Z. How machine learning accelerates the development of quantum dots? . Chin. J. Chem. 2021;39:181–188. doi: 10.1002/cjoc.202000393. [DOI] [Google Scholar]
- 31.Mei AB, et al. Optimization of quantum-dot qubit fabrication via machine learning. Appl. Phys. Lett. 2021;118:204001. doi: 10.1063/5.0040967. [DOI] [Google Scholar]
- 32.Voznyy O, et al. Machine learning accelerates discovery of optimal colloidal quantum dot synthesis. ACS Nano. 2019;13:11122–11128. doi: 10.1021/acsnano.9b03864. [DOI] [PubMed] [Google Scholar]
- 33.Luo JB, Chen J, Liu H, Huang CZ, Zhou J. High-efficiency synthesis of red carbon dots using machine learning. Chem. Commun. (Cambridge, England) 2022;58:9014–9017. doi: 10.1039/d2cc03473e. [DOI] [PubMed] [Google Scholar]
- 34.Nguyen HA, et al. Predicting indium phosphide quantum dot properties from synthetic procedures using machine learning. Chem. Mater. 2022;34:6296–6311. doi: 10.1021/acs.chemmater.2c00640. [DOI] [Google Scholar]
- 35.Yoshida H, et al. Ultrafast inverse design of quantum dot optical spectra via a joint TD-DFT learning scheme and deep reinforcement learning. AIP Adv. 2022;12:115316. doi: 10.1063/5.0127546. [DOI] [Google Scholar]
- 36.Fahrmeir L, Kneib T, Lang S, Marx BD. Regression: Models, Methods and Applications. 2. Springer; 2021. [Google Scholar]
- 37.Zheng A, Casari A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists. Beijing: O’Reilly; 2018. [Google Scholar]
- 38.Peng H, Long F, Ding C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005;27:1226–1238. doi: 10.1109/TPAMI.2005.159. [DOI] [PubMed] [Google Scholar]
- 39.Zhao Z, Anand R, Wang M. Maximum relevance and minimum redundancy feature selection methods for a marketing machine learning platform. In: Singh L, editor. 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA) IEEE; 2019. pp. 442–452. [Google Scholar]
- 40.Maulud D, Abdulazeez AM. A review on linear regression comprehensive in machine learning. J. Appl. Sci. Technol. Trends. 2020;1:140–147. doi: 10.38094/jastt1457. [DOI] [Google Scholar]
- 41.Kavitha, S., Varuna, S. & Ramya, R. A comparative analysis on linear regression and support vector regression. In 2016 Online International Conference on Green Engineering and Technologies (IC-GET), 1–5 (IEEE, 2016). 10.1109/GET.2016.7916627/BibUnstructured>
- 42.Rasmussen CE, Williams CKI. Gaussian Processes for Machine Learning. Adaptive Computation and Machine Learning. 3. Cambridge: MIT Press; 2008. [Google Scholar]
- 43.Hornik K, Stinchcombe M, White H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989;2:359–366. doi: 10.1016/0893-6080(89)90020-8. [DOI] [Google Scholar]
- 44.Da Silva IN, Spatti DH, Andrade Flauzino R, Liboni LHB, Reis Alves SFD. Artificial Neural Networks: A Practical Course. Springer eBook Collection. 1. Springer International Publishing; 2017. [Google Scholar]
- 45.Habibi Aghdam H. Guide to Convolutional Neural Networks: A Practical Application to Traffic-Sign Detection and Classification. Springer eBook Collection. Cham: Springer International Publishing; 2017. [Google Scholar]
- 46.Sadeeq MA, Abdulazeez AM. 2020 International Conference on Advanced Science and Engineering (ICOASE) IEEE; 2020. Neural networks architectures design, and applications: A review; pp. 199–204. [Google Scholar]
- 47.Ajit A, Acharya K, Samanta A. 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE) IEEE; 2020. A review of convolutional neural networks; pp. 1–5. [Google Scholar]
- 48.Corcione E, Pfezer D, Hentschel M, Giessen H, Tarín C. Machine learning methods of regression for plasmonic nanoantenna glucose sensing. Sensors (Basel, Switzerland) 2021 doi: 10.3390/s22010007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Silver D, et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science (New York, N.Y.) 2018;362:1140–1144. doi: 10.1126/science.aar6404. [DOI] [PubMed] [Google Scholar]
- 50.Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. Commun. ACM. 2017;60:84–90. doi: 10.1145/3065386. [DOI] [Google Scholar]
- 51.Rohling, H. Radar CFAR thresholding in clutter and multiple target situations. In IEEE Transactions on Aerospace and Electronic SystemsAES-19, 608–621. 10.1109/TAES.1983.309350 (1983).
- 52.Hinton GE, Salakhutdinov RR. Reducing the dimensionality of data with neural networks. Science (New York, N.Y.) 2006;313:504–507. doi: 10.1126/science.1127647. [DOI] [PubMed] [Google Scholar]
- 53.Tschannen, M., Bachem, O. & Lucic, M. Recent advances in autoencoder-based representation learning. arXiv:1812.05069
- 54.Kramer MA. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991;37:233–243. doi: 10.1002/aic.690370209. [DOI] [Google Scholar]
- 55.Rokach L, Maimon O, Shmueli E. Machine Learning for Data Science Handbook. Springer International Publishing; 2023. [Google Scholar]
- 56.Fan J, Wang W, Zhang H. 2017 IEEE 15th International Conference on Industrial Informatics (INDIN) IEEE; 2017. AutoEncoder based high-dimensional data fault detection system; pp. 1001–1006. [Google Scholar]
- 57.Qian J, Song Z, Yao Y, Zhu Z, Zhang X. A review on autoencoder based representation learning for fault detection and diagnosis in industrial processes. Chemom. Intell. Lab. Syst. 2022;231:104711. doi: 10.1016/j.chemolab.2022.104711. [DOI] [Google Scholar]
- 58.Aggarwal CC. Neural Networks and Deep Learning: A Textbook. Springer; 2018. [Google Scholar]
- 59.He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. arXiv:1512.03385
- 60.Alzubaidi L, et al. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data. 2021;8:53. doi: 10.1186/s40537-021-00444-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Yamaguchi K, Sakamoto K, Akabane T, Fujimoto Y. First International Conference on Spoken Language Processing (ICSLP 1990) ISCA; 1990. A neural network for speaker-independent isolated word recognition; pp. 1077–1080. [Google Scholar]
- 62.Zafar A, et al. A comparison of pooling methods for convolutional neural networks. Appl. Sci. 2022;12:8643. doi: 10.3390/app12178643. [DOI] [Google Scholar]
- 63.Fukushima K. Visual feature extraction by a multilayered network of analog threshold elements. IEEE Trans. Syst. Sci. Cybern. 1969;5:322–333. doi: 10.1109/TSSC.1969.300225. [DOI] [Google Scholar]
- 64.Zeiler MD, Krishnan D, Taylor GW, Fergus R. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE; 2010. Deconvolutional networks; pp. 2528–2535. [Google Scholar]
- 65.Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv:1412.6980
- 66.Spearman C. The proof and measurement of association between two things. Am. J. Psychol. 1904;15:72. doi: 10.2307/1412159. [DOI] [PubMed] [Google Scholar]
- 67.Nix DA, Weigend AS. Proceedings of 1994 IEEE International Conference on Neural Networks (ICNN’94) IEEE Neural Networks Council; 1994. Estimating the mean and variance of the target probability distribution; pp. 55–60. [Google Scholar]
- 68.Draper NR, Smith H. Applied Regression Analysis. Wiley Series in Probability and Statistics. 3. Wiley; 1998. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Both code and data will be made available by the corresponding author upon reasonable request.