

Abstract
传统监护仪故障诊断多依赖人工经验,诊断效率较低且故障维修文本数据未得到有效利用。针对以上问题,本文提出一种基于多特征文本表示以及改进的双向门控循环神经元网络(BiGRU)和注意力机制的监护仪故障智能诊断方法。首先,对文本进行预处理,采用基于转换器(Transformer)的语言激励双向编码器表示生成含有多种语言学特征的词向量;然后,通过改进的BiGRU和注意力机制对双向故障特征分别进行提取并加权;最后,使用加权损失函数降低类别不平衡对模型的影响。为证实所提方法的有效性,本文使用监护仪故障数据集进行验证,总体宏F1值达到91.11%。该结果表明,本文所建模型可实现故障文本的自动分类,或可为今后监护仪故障智能诊断提供辅助决策支持。
Keywords: 监护仪, 故障诊断, 文本挖掘, 预训练语言模型, 注意力机制
Abstract
The conventional fault diagnosis of patient monitors heavily relies on manual experience, resulting in low diagnostic efficiency and ineffective utilization of fault maintenance text data. To address these issues, this paper proposes an intelligent fault diagnosis method for patient monitors based on multi-feature text representation, improved bidirectional gate recurrent unit (BiGRU) and attention mechanism. Firstly, the fault text data was preprocessed, and the word vectors containing multiple linguistic features was generated by linguistically-motivated bidirectional encoder representation from Transformer. Then, the bidirectional fault features were extracted and weighted by the improved BiGRU and attention mechanism respectively. Finally, the weighted loss function is used to reduce the impact of class imbalance on the model. To validate the effectiveness of the proposed method, this paper uses the patient monitor fault dataset for verification, and the macro F1 value has achieved 91.11%. The results show that the model built in this study can realize the automatic classification of fault text, and may provide assistant decision support for the intelligent fault diagnosis of the patient monitor in the future.
Keywords: Patient monitor, Fault diagnosis, Text mining, Pre-trained language models, Attention mechanism
0. 引言
监护仪作为生命支持类医学装备之一,已成为临床诊断及治疗中必不可少的监测设备。监护仪由于应用范围广、零配件多,运行过程中不可避免地会发生各类故障。现阶段的监护仪故障诊断方法主要依靠维修人员及专家的经验进行排查,效率不高;且监护仪过往维修历史中所积累的大量文本记录尚未得到很好地利用,因此开展面向监护仪故障的智能诊断研究工作,是确保监护仪安全运行和持续使用的重要前提。
监护仪在长期使用过程中,产生大量故障维修文本,而计算机无法对文本进行直接运算,因此早期学者使用基于人工提取特征的专家系统和特征工程进行故障诊断[1-2]。随着自然语言处理(natural language processing,NLP)技术的发展,机器学习和深度学习越来越多地应用于基于文本挖掘的故障诊断之中,这类故障诊断方法的核心在于建立合适的故障维修文本表示和分类模型[3]。在文本表示方面,Wang等[4]通过词频—逆文档频率(term frequency-inverse document frequency,TF-IDF)方法将案例文本转化为向量,并在此基础上采用模糊语义推断得到故障原因的概率分布。侯通等[5]针对TF-IDF对短文本中高频词特征提取效果不佳的缺点,提出在TF-IDF中融合类别间特征词分布的算法,提高了故障诊断效果。但基于词频的方法无法表示文本的语义信息,造成文本特征丢失,并且容易导致维度爆炸。虽然潜在狄利克雷分布(latent Dirichlet allocation,LDA)可以避免这些问题[6-7],但由于监护仪故障维修文本长度短、噪声多,使用LDA提取文本特征效果并不佳。词向量(word to vector,Word2vec)模型是基于神经网络的概率语言模型[8],自发布以来一直被广泛使用和研究。Xu等[9]使用Word2vec模型将故障维修文本转化为向量,并通过卷积神经网络(convolutional neural network,CNN)构造分类器,实现对设备的故障诊断。林海香等[10]提出一种字词融合的故障维修文本表示方法,通过Word2vec模型获取文本的字向量和词向量,并将字向量、词向量和位置特征融合,进一步提高故障诊断的准确性。但Word2vec模型对于同一个词只有一个表示,无法解决语义歧义和上下文依赖性问题。在2018年预训练语言模型(pre-trained language models,PLM)提出后,许多研究人员基于PLM进行文本表示[11-13],提高了文本表示效果。但PLM在下游NLP任务中的表现常常受到预训练任务的影响;此外,研究人员普遍认为PLM尚需要进一步包含外部知识以优化性能[14-15]。在文本分类模型构建上,主流的方法包括:基于CNN的模型[16-17]、基于循环神经网络(recurrent neural network,RNN)的模型[18-19]、基于注意力机制的模型[20-21]及混合模型[22]。其中,CNN系列网络可以很好地提取局部特征,但池化层无法捕获单词位置信息;RNN系列网络用于捕捉文本全局特征,却很难用于大规模并行计算。注意力机制,受人脑信号处理机制的启发,最早应用于图像领域,后引入NLP任务[23];其可以学习重点语义信息,但却忽略了词的先后顺序。而监护仪故障维修文本由于是人工记录的信息,其文本具有较强的不规范性,对文本表示及特征提取都带来一定难度,因此基于监护仪故障维修文本的故障诊断尚需对文本进行深度挖掘才能实现诊断。
为此,本文提出基于转换器(Transformer)及语言驱动的双向编码器表示模型(linguistically-motivated bidirectional encoder representation from Transformer,LERT),将其用于故障维修文本的向量化表示,同时联合改进的双向门控循环神经元网络(imporved bidirectional gate recurrent unit,IBiGRU)和注意力机制(attention mechanism,Att)构建了IBiGRU-Att,在此基础上提出LERT和IBiGRU-Att结合的监护仪故障诊断模型(LERT-IBiGRU-Att)。该模型采用LERT获取包含多种特征的文本向量,解决故障维修文本特征少、噪音多等问题,并通过IBiGRU-Att分别获取前向与后向故障特征,并计算前向与后向故障维修文本中各词之间的权重关系,以增加对分类有重点作用的词的关注,同时通过使用加权损失函数降低类别不平衡对分类的影响,进一步提高监护仪故障维修文本的分类准确率。该模型可实现监护仪故障的准确定位,提高故障诊断可靠性和效率,为监护仪的故障诊断提供有效指导,并为实现高精度的故障维修文本分类提供新思路。
1. 故障维修文本分类模型构建
本文提出的LERT-IBiGRU-Att监护仪故障智能诊断模型如图1所示,图1中具体字符含义将在本章节1.1~1.4小节详细阐述。首先,将故障维修文本进行预处理,预处理后的文本通过LERT词嵌入层,得到每个词的嵌入向量;然后,将所有词向量输入IBiGRU-Att,分别提取前向和后向语义信息,并学习特征词间的权重;最后,再通过一个融合机制和归一化指数函数(softmax)层完成监护仪故障分类,并使用加权损失函数解决类别不平衡的问题。
图 1.

Intelligent fault diagnosis model of patient monitor
监护仪故障智能诊断模型
1.1. 监护仪故障维修文本预处理
由于监护仪故障维修文本是不同维修人员手工记录的信息,因此存在大量不规范文本及少量重复文本,因此需要对故障维修文本进行预处理。预处理内容包括:① 删除重复文本,故障现象描述相同的仅保留一条,避免模型的过拟合;② 去除长度过短的文本,长度过短的文本一般为“故障”、“损坏”等无意义文本;③ 对部分分类错误的故障维修文本进行重新归类。通过故障维修文本的预处理,可以使模型更好地提取语义特征。
1.2. 词嵌入层
由于模型无法直接对文本进行计算,因此需要将文本转化为向量,这个过程称为词嵌入。传统PLM在单一任务上进行预训练,仅获取文本的语义信息,因此本文提出基于LERT的词嵌入方法。LERT在掩码语言模型以及三种类型的语言任务上进行训练,包括词性标注、命名实体识别和依存句法分析。词性标注任务将词识别为动词、名词、形容词等词性;命名实体识别任务将词识别为实体与非实体,其中实体又包括实体开头、实体内部与实体结尾;依存句法分析任务将词识别为核心词或与核心词的依存关系。
LERT的预训练策略如图2所示,输入由起始字符([CLS])、文字序列(哈工大[M][M]冰城[M][M][M])和终止字符([SEP])组成。在输出结果中,LERT将第一个屏蔽词([M])预测为“位”,动词词性,属于非实体词及核心词。因此在下游任务中,监护仪故障维修文本通过LERT词嵌入后,文本向量中融合了语义特征、词性特征、实体特征、依存关系特征,相较于其他PLM获得了更多故障维修文本特征,为后续的特征提取和分类提供了更好的文本表示。
图 2.

LERT pre-training strategy
LERT预训练策略
对词向量提取的传统做法,是将词嵌入层输出的第一个词向量e1作为句向量用于分类,而舍弃其他词向量,但这种方法会导致部分特征丢失。因此本模型使用LERT词嵌入层输出的每个词向量用作于下游网络的输入。如图1所示,输入T经过LERT词嵌入层,输出为所有词向量(e1,e2,e3,···,en)组成的词向量矩阵E,过程如式(1)~(2)所示:
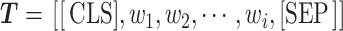 |
1 |
 |
2 |
其中,wi表示故障维修文本序列,i∈{1, 2, ···, n − 2},n表示最大输入字符长度,d表示词嵌入维度。
1.3. 特征提取层
门控循环单元(gate recurrent unit,GRU)只使用更新门和重置门两个门控开关,相较于长短时记忆(long short-term memory,LSTM)网络参数更少。单向GRU是根据t-1时刻的特征计算t时刻的特征,而t时刻的输出不包含t时刻之后的特征信息。因此本模型使用双向GRU(bidirectional GRU,BiGRU)提取故障维修文本上下文的长距离依赖关系,实现对故障特征的深度提取。在使用BiGRU提取双向特征时,传统做法是将BiGRU输出的双向特征拼接后直接输入注意力机制[24-25],但这种方法忽略了注意力机制对正、反向特征关注度不同的影响。因此本文提出的IBiGRU-Att特征提取层使用前向和后向两个独立的GRU网络,分别获得前向故障特征  和后向故障特征
和后向故障特征 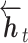 ,计算过程如式(3)~(4)所示:
,计算过程如式(3)~(4)所示:
 |
3 |
 |
4 |
其中,et为LERT词嵌入层输出的第t个位置的特征向量,t∈{0, 1, ···, n}, 为t − 1时刻输出的正向特征,
为t − 1时刻输出的正向特征,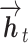 为t时刻的正向特征,
为t时刻的正向特征,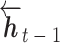 为t − 1时刻输出的反向特征,
为t − 1时刻输出的反向特征,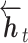 为t时刻的反向特征。
为t时刻的反向特征。
考虑到在故障维修文本中,每个词对不同故障类别的分类贡献是不同的,因此使用注意力机制可以学习特征向量中每个词之间的权重,体现每个词对全局特征的重要程度,最终得到加权后的故障特征向量。同时为了体现正、反向特征向量受注意力机制的影响不同,本模型将正、反向故障特征向量  与
与  分别输入注意力机制,并为其分配相互独立的参数进行学习,获得加权后的正、反向故障特征向量Ff与Fb,如图1所示。正向故障特征向量Ff计算过程如式(5)~(6)所示。同时在注意力计算时使用可训练的Q、K、V矩阵而不直接使用输入值,进一步增强模型的拟合能力。
分别输入注意力机制,并为其分配相互独立的参数进行学习,获得加权后的正、反向故障特征向量Ff与Fb,如图1所示。正向故障特征向量Ff计算过程如式(5)~(6)所示。同时在注意力计算时使用可训练的Q、K、V矩阵而不直接使用输入值,进一步增强模型的拟合能力。
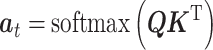 |
5 |
 |
6 |
其中,Q表示查询向量,K为对应的键值,V表示输入特征的向量;at为归一化处理后的相似度矩阵。
1.4. 融合输出层
通过IBiGRU-Att获得加权后的正向故障特征向量Ff与反向故障特征向量Fb,对其进行融合得到全局故障特征表示Fg后,将Fg作用于softmax分类器,从而得到故障类别的预测概率p,计算公式如式(7)~(8)所示:
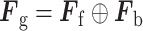 |
7 |
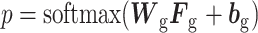 |
8 |
其中,符号“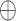 ”表示向量拼接,Wg与bg分别表示可训练的权重与偏置参数。
”表示向量拼接,Wg与bg分别表示可训练的权重与偏置参数。
由于监护仪各故障类型的样本数量分布不均,使用标准的多分类交叉熵损失函数会为各标签分配同等的权重值,模型会更多关注多数类标签,导致多数类标签容易出现过拟合。因此本模型采用带权重的交叉熵损失函数作为模型的损失函数(LOSS),提升对较少样本的故障类别的关注度,进而保证模型的鲁棒性。计算公式如式(9)~(10)所示:
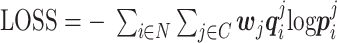 |
9 |
 |
10 |
其中,q为样本真实故障类别,p为样本预测故障类别,N为故障样本数,C为故障类别数,wj为第j类故障的损失权重,Nmax为最大故障样本数量的样本数,Nj为第j类样本数。
2. 实验
2.1. 实验数据集
监护仪故障数据来自陆军军医大学大坪医院2020年10月—2022年8月由人工记录的监护仪维修数据,包含飞利浦MP5、MP60、MP30型号(Koninklijke Philips N.V.,荷兰),金科威UT4000B、UT6000A型号(Philips Goldway Inc.,中国)及迈瑞PM-8000、IPM12、T8、N12/15/17、ePM12M及iMEC8型号(Mindray Inc.,中国)的监护仪故障数据。由于迈瑞监护仪故障数据包含重症监护、亚重症监护及转运监护等多型患者监护产品,因此本研究以迈瑞监护仪故障数据为研究对象,并对数据进行预处理形成监护仪故障诊断数据集。部分监护仪故障数据如表1所示,故障维修文本中存在一些不规范的表达,如口语化的描述:“仔细听有丝漏气声”、“血压有打气声音”,以及简化的表述:“导联线右胳膊(right arm,RA)”简化为“导联线RA”。监护仪故障诊断数据集共包含8 634条故障数据,将数据集按8∶2的比例划分为训练集和验证集,用于实验验证。
表 1. Patient monitor fault data.
监护仪故障数据
| 故障类别 | 故障现象描述 |
| 无创血压模块相关 | 点无创血压按钮时,气泵启动有声音,仔细听有丝漏气声。屏幕上压力数值保持在20~30之间,无法上去。 |
| 血氧饱和度模块相关 | 模块异响,且测量参数误差较大,怀疑模块气泵故障。 |
| 心电模块相关 | 导联线RA按扣无法连接电极片,会自动弹出,或用力按,扣上,无法取出。 |
| 屏幕模块相关 | 开机显示背光亮,按屏幕有声音,无法显示任何内容,血压有打气声音。 |
数据集中所有监护仪故障类别及对应的数据数量和分布情况如图3所示,无创血压模块相关、血氧饱和度模块相关、心电模块相关等故障为常发故障,数据量占比较大,而编码器相关、二氧化碳模块相关等故障数据量较少,数据集分布呈现不均衡现象。
图 3.

Patient monitor fault category and quantity distribution
监护仪故障类别及数量分布图
2.2. 实验设置
(1)实验环境:操作系统为Ubuntu18.04.6(Canonical Ltd., 英国),基于Pytorch1.7.1(Facebook Inc.,美国)深度学习框架,使用两块显卡(RTX3090,Nvidia Inc.,美国)进行并行训练。
(2)模型超参数:Word2vec模型使用经结巴(Jiebe)分词后的训练集数据进行训练,词向量维度为100维,预训练50个轮次。基于Transformer的轻量化双向编码表示(a lite bidirectional encoder representations from Transformers,ALBERT)使用Xu等[26]提出的PLM,词嵌入维度为384维。LERT使用Cui等[27]提出的小型PLM,词嵌入维度256维。CNN层分别使用卷积窗口为2、3、4的一维卷积核进行卷积操作,每种卷积核数量为100个。GRU层数为2层,词嵌入层、CNN层、GRU层和注意力层均使用随机失活机制,大小为随机失活率为15%。迭代次数为20轮次。
(3)评价指标:监护仪故障诊断为多分类问题,因此使用精确率P、召回率R、F1值作为模型的评价指标。同时由于数据集的类别之间存在不均衡现象,因此使用宏平均F1值(Macro-F1,M-F1)作为模型的总体评价指标,M-F1计算如式(11)所示。
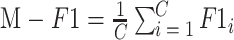 |
11 |
其中,C表示类别数,F1i表示第i类的F1值。
2.3. 实验结果及分析
2.3.1. 不同词嵌入方法的对比
通过使用不同的词嵌入方法对比,验证LERT词嵌入方法的有效性。本文分别采用TF-IDF、Word2vec模型、ALBERT与本文提出的LERT实现故障维修文本的词嵌入,并基于BiGRU实现监护仪的故障诊断。其中TF-IDF为基于词频的静态词向量表示,Word2vec模型为静态PLM,ALBERT与LERT均为动态PLM。不同词嵌入方法的实验结果如表2所示,其中,基于PLM的方法均获得了80%以上的M-F1值,相较于TF-IDF有较大提升。ALBERT基于Transformer编码器构建,使用大规模语料库进行训练,可以学习一词多义现象,其M-F1值相较于Word2vec模型有所提高。LERT通过多任务学习,可以更好地学习文本表示,获得了最高的故障诊断M-F1值,达到了88.73%。
表 2. Experimental results of different word embedding methods.
不同词嵌入方法的实验结果
| 词嵌入方法 | TF-IDF | Word2vec模型 | ALBERT | LERT |
| M-F1 | 77.28% | 85.41% | 87.26% | 88.73% |
2.3.2. 故障特征提取层对比实验
通过LERT实现故障维修文本的词嵌入,分别使用CNN、GRU、双向LSTM(bidirectional LSTM,BiLSTM)、BiGRU共4种不同的特征提取层,完成监护仪的故障诊断,对比特征提取层对模型性能的影响。
基于不同故障特征提取层的实验结果如表3所示。对于文本序列,基于RNN的模型可以更好地捕捉序列间的关系,提取上下文的语义特征,因此M-F1值高于基于窗口滑动的CNN模型。由于人工记录的不规范性,对监护仪故障维修文本的分析往往需要结合上下文语义进行理解,而GRU模型仅考虑单向文本序列间的特征,无法捕捉逆向序列特征,因此其M-F1值低于从两个时序方向提取故障特征的BiGRU模型。且GRU相较于LSTM参数降低,训练速度更快,因此本研究选择BiGRU作为监护仪故障诊断模型的特征提取层,并在BiGRU的基础上对模型进行改进。
表 3. Experimental results of different fault feature extraction layers.
基于不同故障特征提取层的实验结果
| 模型 | CNN | GRU | BiLSTM | BiGRU |
| M-F1 | 87.68% | 88.07% | 88.26% | 88.73% |
2.3.3. 消融实验
为了验证IBiGRU与加权损失函数的有效性,构建4组实验进行对比。其中,第1组为原始的LERT加BiGRU模型,第2组增加注意力机制模块,第3组在第2组基础上增加使用带权重的交叉熵损失函数,第4组在第3组基础上使用IBiGRU网络,即本文的LERT-IBiGRU-Att方法。
4组实验的实验结果如表4所示,注意力机制可以识别出对分类有意义的重点词汇,提高故障诊断性能,同时带权重的交叉熵损失函数可以增加对小类别故障的关注度,缓解数据不平衡问题,进一步增加诊断效果。第4组的IBiGRU-Att将前、后向语义分离,分别学习前、后向语义权重,避免了第3组中的BiGRU将前、后向语义融合输出对注意力机制造成干扰的问题,进一步提高故障特征提取效果,其评价指标相较于第3组均有所提高。
表 4. The effect of improving methods on model performance.
改进方法对模型性能的影响
| 组别 | 注意力 机制 |
加权损失 函数 |
IBiGRU | 评价指标 | ||
| P | R | M-F1 | ||||
| 第1组 | × | × | × | 89.79% | 88.55% | 88.73% |
| 第2组 | √ | × | × | 90.36% | 89.72% | 89.74% |
| 第3组 | √ | √ | × | 90.61% | 90.37% | 90.33% |
| 第4组 | √ | √ | √ | 92.11% | 91.33% | 91.11% |
4组模型在训练集和验证集上的迭代曲线如图4所示。相较于第2组,第3组在训练集和验证集上的损失值更大,这是因为使用带权重的交叉熵损失函数后,增加了小样本故障类别的损失权重,因此整体损失值增大。同时由于增加了对小样本的关注度,因此在迭代到第7轮次后,第3组在验证集的M-F1值大于第2组。相较于第3组,第4组在训练过程中可获得最低的损失值及最高的M-F1值,这是因为对正、反向故障特征分别学习可以提高注意力机制学习效果,进而提升模型性能。
图 4.

The iterative curves of 4 sets of models on training and test datasets
四组模型在训练集和验证集上的迭代曲线
2.3.4. 模型对比实验
为进一步验证本文所提出的LERT-IBiGRU-Att监护仪故障诊断模型方法的有效性,选择了3个其他已广泛使用的方法进行对比,具体方法如下:
(1)TF-IDF 结合反向传播(back propagation,BP)网络(TF-IDF+BP):通过TF-IDF提取出故障维修文本的词频特征后使用BP网络进行文本分类,是较为简单的文本分类方法[28]。
(2)Word2vec模型结合多池化CNN(multi-pooling CNN,MCNN)(Word2vec模型 + MCNN):周庆华等[29]提出使用Word2vec模型进行词嵌入,并通过MCNN进行文本的特征提取的故障文本挖掘分类方法。MCNN可以保留更多故障维修文本的有效特征,避免单一池化受多干扰词语的影响。
(3)多神经网络模型融合的文本分类模型(text classification model fused with multiple neural network,FMNN):邓维斌等[30]提出一种PLM、CNN、RNN以及注意力机制的FMNN。FMNN将多粒度语义特征进行提取,并通过融合机制实现文本的分类。
模型对比实验结果如表5所示,本文提出的LERT-IBiGRU-Att模型在故障诊断性能方面表现最佳,其故障诊断M-F1值为91.11%。具体而言,基于TF-IDF的方法仅以词频构成文档的序列值特征,词与词之间相互无关联,容易造成语义信息的丢失,因此TF-IDF + BP方法的故障诊断M-F1值仅为76.74%。Word2vec模型能够学习文本的上下文关系,提高文本表示的效果,且MCNN提升了模型对有效特征的提取效果,因此,各类别故障诊断结果均得到提升。但对于“主控板相关”类别故障,其故障特征包含其他类别的故障特征,导致分类较为困难,Word2vec模型 + MCNN方法在该类的故障诊断P值仅为69.39%。FMNN使用多模型融合的方法,故障诊断M-F1值相较于Word2vec模型 + MCNN方法有所提高,但在“二氧化碳模块相关”和“主控板相关”的故障类别中,其F1值低于Word2vec模型 + MCNN方法,这是由于监护仪的故障维修文本具有特征稀疏的特点,较深的网络可能会导致模型性能过剩,反而效果不佳。因此,本文所建模型针对监护仪故障维修文本的特点,分别从词嵌入、故障特征提取及分类三方面进行优化,进一步提高故障诊断F1值,特别是在“主控板相关”类别中,故障诊断P值达到83.17%,相较于其他方法有明显提升,证明了本文提出的故障诊断模型的有效性。
表 5. Patient monitor fault diagnosis results based on different models.
基于不同模型的监护仪故障诊断结果
| 模型 | 评价 指标 |
监护仪故障诊断数据集 | M-F1 | ||||||||
| 电源模块 相关 |
屏幕模块 相关 |
编码器 相关 |
无创血压 模块相关 |
有创血压 模块相关 |
血氧饱和度 模块相关 |
心电模块 相关 |
二氧化碳 模块相关 |
主控板 相关 |
|||
| TF-IDF + BP | P | 83.64% | 88.14% | 95.65% | 85.41% | 89.16% | 87.95% | 88.08% | 74.60% | 50.93% | 76.74% |
| R | 91.29% | 95.71% | 33.85% | 97.84% | 78.72% | 95.42% | 96.22% | 55.95% | 31.98% | ||
| F1 | 87.30% | 91.76% | 50.00% | 91.21% | 83.62% | 91.54% | 91.97% | 63.95% | 39.29% | ||
| Word2vec模型 + MCNN | P | 83.46% | 89.08% | 96.67% | 90.46% | 93.42% | 88.96% | 91.60% | 98.72% | 69.39% | 87.32% |
| R | 93.42% | 94.51% | 87.88% | 96.61% | 88.75% | 94.63% | 96.62% | 90.59% | 38.20% | ||
| F1 | 88.16% | 91.72% | 92.06% | 93.43% | 91.03% | 91.71% | 94.05% | 94.48% | 49.28% | ||
| FMNN | P | 89.82% | 93.96% | 93.44% | 90.97% | 97.67% | 93.06% | 90.53% | 96.15% | 58.33% | 88.77% |
| R | 91.44% | 96.07% | 93.44% | 97.21% | 97.67% | 95.47% | 96.49% | 89.29% | 40.70% | ||
| F1 | 90.62% | 95.00% | 93.44% | 93.99% | 97.67% | 94.25% | 93.42% | 92.59% | 47.95% | ||
| LERT-IBiGRU-Att | P | 89.26% | 92.02% | 95.31% | 93.79% | 98.84% | 94.98% | 90.40% | 90.80% | 83.17% | 91.11% |
| R | 96.43% | 98.30% | 96.83% | 97.76% | 97.70% | 97.12% | 98.26% | 91.86% | 47.73% | ||
| F1 | 92.70% | 95.05% | 96.06% | 95.74% | 98.27% | 96.04% | 94.17% | 91.33% | 60.65% | ||
3. 结论
本文提出一种基于监护仪故障维修文本挖掘的故障诊断模型。首先,该模型利用LERT进行故障维修文本的词嵌入,以获得多种语言学特征的文本表示;然后,通过IBiGRU-Att提取和加权文本的前、后向特征,从而改善了注意力机制的效果;最后,采用加权损失函数来提升对小类别关注度,减小数据不均衡对模型的影响。为验证所提模型的有效性,本文进行了多方面的对比,包括词嵌入方法对比、特征提取层对比及消融实验,并与其他相关研究方法进行了对比。实验结果表明,该模型可实现监护仪故障文本的有效分类,可为监护仪的故障诊断提供辅助指导,并为医疗设备故障诊断领域提供一种新的参考。然而,由于故障维修文本数据的局限性,导致监护仪故障定位的范围相对较广。因此,未来工作将探索利用多模态数据对监护仪进行故障诊断,例如信号数据、分析模型等,通过混合故障诊断方法,进一步提高故障诊断的准确性与细粒度。
重要声明
利益冲突声明:本文全体作者均声明不存在利益冲突。
作者贡献声明:贺祥飞主要负责算法程序设计、数据记录与分析及论文编写;张和华、黄靖主要负责项目主持、平台搭建、论文审阅修订、协调沟通以及计划安排;赵德春主要负责提供实验指导、数据分析指导以及论文审阅修订;李洋、聂瑞、刘相花负责数据的记录与分析以及论文的修订。
Funding Statement
省部级装备维修科学研究与改革项目(145BZB170025000X)
References
- 1.范莉萍, 郎朗, 肖晶晶, 等 基于故障树的多参数监护仪故障智能诊断专家系统研究. 生物医学工程学杂志. 2022;39(3):586–595. doi: 10.7507/1001-5515.202110009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Chen Mengqi, Qu Rong, Fang Weiguo Case-based reasoning system for fault diagnosis of aero-engines. Expert Systems with Applications. 2022;202:117350. doi: 10.1016/j.eswa.2022.117350. [DOI] [Google Scholar]
- 3.赵京胜, 宋梦雪, 高祥, 等 自然语言处理中的文本表示研究. 软件学报. 2022;33(1):102–128. [Google Scholar]
- 4.Wang Z, Wang J, Chen S Fault location of strip steel surface quality defects on hot-rolling production line based on information fusion of historical cases and process data. IEEE Access. 2020;8:171240–171251. doi: 10.1109/ACCESS.2020.3024582. [DOI] [Google Scholar]
- 5.侯通, 郑启明, 姚新文, 等 基于文本挖掘的轨道电路细粒度故障致因分析方法. 铁道学报. 2022;44(10):73–81. doi: 10.3969/j.issn.1001-8360.2022.10.010. [DOI] [Google Scholar]
- 6.Yu D, Xiang B Discovering topics and trends in the field of artificial intelligence: using LDA topic modeling. Expert Systems with Applications. 2023;225:120114. doi: 10.1016/j.eswa.2023.120114. [DOI] [Google Scholar]
- 7.Gupta R K, Agarwalla R, Naik B H, et al Prediction of research trends using LDA based topic modeling. Global Transitions Proceedings. 2022;3(1):298–304. doi: 10.1016/j.gltp.2022.03.015. [DOI] [Google Scholar]
- 8.Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space.(2013-09-07)[2023-5-23]. https: //arxiv.org/abs/1301.3781.
- 9.Xu Z, Chen B, Zhou S, et al A text-driven aircraft fault diagnosis model based on a Word2vec and priori-knowledge convolutional neural network. Aerospace. 2021;8(4):1–15. [Google Scholar]
- 10.林海香, 赵正祥, 陆人杰, 等 基于字词融合的高铁道岔多级故障诊断组合模型. 电子测量与仪器学报. 2022;36(10):217–226. [Google Scholar]
- 11.Huan H, Yan J, Xie Y, et al Feature-enhanced nonequilibrium bidirectional long short-term memory model for Chinese text classification. IEEE Access. 2020;8:199629–199637. doi: 10.1109/ACCESS.2020.3035669. [DOI] [Google Scholar]
- 12.贾宝惠, 姜番, 王玉鑫, 等 基于民机维修文本数据的故障诊断方法. 航空学报. 2023;44(5):258–272. [Google Scholar]
- 13.郭崇慧, 徐良辰, 魏伟, 等 基于文本挖掘的新型冠状病毒肺炎诊疗方案演化分析. 生物医学工程学杂志. 2021;38(2):197–209. doi: 10.7507/1001-5515.202011079. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Qiu X, Sun T, Xu Y, et al Pre-trained models for natural language processing: a survey. Science China Technological Sciences. 2020;63:1872–1897. doi: 10.1007/s11431-020-1647-3. [DOI] [Google Scholar]
- 15.Jawahar G, Sagot B, Seddah D. What does BERT learn about the structure of language? // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence: Association for Computational Linguistics, 2020: 3651–3657.
- 16.Akhter M P, Zheng Jiangbin, Naqvi I R, et al Document-level text classification using single-layer multisize filters convolutional neural network. IEEE Access. 2020;8:42689–42707. doi: 10.1109/ACCESS.2020.2976744. [DOI] [Google Scholar]
- 17.蒲晓蓉, 陈柯成, 刘军池, 等 COVID-19 中国诊疗方案的机器学习智能分析方法. 生物医学工程学杂志. 2020;37(3):365–372. doi: 10.7507/1001-5515.202003045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.沙尔旦尔·帕尔哈提, 米吉提·阿不里米提, 艾斯卡尔·艾木都拉 基于稳健词素序列和LSTM的维吾尔语短文本分类. 中文信息学报. 2020;34(1):63–70. doi: 10.3969/j.issn.1003-0077.2020.01.009. [DOI] [Google Scholar]
- 19.赵宏, 傅兆阳, 王乐 基于特征融合的中文文本情感分析方法. 兰州理工大学学报. 2022;48(3):94–102. doi: 10.3969/j.issn.1673-5196.2022.03.014. [DOI] [Google Scholar]
- 20.方正云, 杨政, 李丽敏, 等 基于交叉注意力机制的多视图项目文本分类方法. 中文信息学报. 2022;36(7):123–131. doi: 10.3969/j.issn.1003-0077.2022.07.014. [DOI] [Google Scholar]
- 21.刘鹏程, 孙林夫, 张常有, 等 基于交互注意力机制网络模型的故障文本分类. 计算机集成制造系统. 2021;27(1):72–89. [Google Scholar]
- 22.Li Y, Zhang S, Lai C Agricultural text classification method based on dynamic fusion of multiple features. IEEE Access. 2023;11:27034–27042. doi: 10.1109/ACCESS.2023.3253386. [DOI] [Google Scholar]
- 23.Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate.(2016-05-19)[2023-5-23]. arXiv:1409.0473.
- 24.陈可嘉, 刘惠 基于改进BiGRU-CNN的中文文本分类方法. 计算机工程. 2022;48(5):59–66,73. [Google Scholar]
- 25.吴庭伟, 王梦灵, 易树平, 等 多尺度核电质量文本故障信息语义抽取方法. 中国机械工程. 2023;34(8):976–981,992. doi: 10.3969/j.issn.1004-132X.2023.08.012. [DOI] [Google Scholar]
- 26.Xu L, Hu H, Zhang X W, et al. CLUE: a Chinese language understanding evaluation benchmark//Proceedings of the 28th International Conference on Computational Linguistics. Barcelona: International Committee on Computational Linguistics, 2020: 4762–4772.
- 27.Cui Yiming, Che Wanxiang, Wang Shijin, et al. LERT: a linguistically-motivated pre-trained language model.(2022-11-10)[2023-5-23]. arXiv:2211.05344.
- 28.Shi L, Li A, Zhang L Sustainable fault diagnosis of imbalanced text mining for CTCS-3 data preprocessing. Sustainability. 2021;13(4):1–14. [Google Scholar]
- 29.周庆华, 李晓丽 基于MCNN的铁路信号设备故障短文本分类方法研究. 铁道科学与工程学报. 2019;16(11):2859–2865. [Google Scholar]
- 30.邓维斌, 朱坤, 李云波, 等 FMNN: 融合多神经网络的文本分类模型. 计算机科学. 2022;49(3):281–287. doi: 10.11896/jsjkx.210200090. [DOI] [Google Scholar]