

Abstract
For estimation of heterogeneity variance in meta‐analysis of log‐odds‐ratio, we derive new mean‐ and median‐unbiased point estimators and new interval estimators based on a generalized statistic, , in which the weights depend on only the studies' effective sample sizes. We compare them with familiar estimators based on the inverse‐variance‐weights version of , In an extensive simulation, we studied the bias (including median bias) of the point estimators and the coverage (including left and right coverage error) of the confidence intervals. Most estimators add to each cell of the table when one cell contains a zero count; we include a version that always adds . The results show that: two of the new point estimators and two of the familiar point estimators are almost unbiased when the total sample size and the probability in the Control arm () is 0.1, and when and is 0.2 or 0.5; for , all estimators have negative bias for small to medium sample sizes, but for larger sample sizes some of the new median‐unbiased estimators are almost median‐unbiased; choices of interval estimators depend on values of parameters, but one of the new estimators is reasonable when and another, when or ; and lack of balance between left and right coverage errors for small and/or implies that the available approximations for the distributions of and are accurate only for larger sample sizes.
Keywords: effective‐sample‐size weights, heterogeneity, inverse‐variance weights, random effects
Highlights.
What is already known
Use of inverse‐variance weights based on estimated variances in the conventional statistic makes it very difficult to approximate the null distribution of .
Related moment‐based estimators of the heterogeneity variance (), such as the DerSimonian‐Laird estimator, have considerable bias.
What is new
We study estimation of based on , a generalized statistic with fixed effective‐sample‐size weights.
For point estimation of we consider both mean‐unbiased and novel median‐unbiased estimators. The new estimators are based on the Farebrother approximation to the distribution of .
In an extensive simulation study, we compared four new point estimators of and two new interval estimators with traditional estimators.
We provide practical guidelines for choosing appropriate point and interval estimators for LOR.
For median bias, which was not studied previously, an important finding is that the majority of the standard estimators have negative bias for larger sample sizes. This means that their median values of are too low. Two new estimators consistently result in almost median‐unbiased estimation for moderate to large .
Potential impact for RSM readers outside the authors' field
We provide practical guidelines for choosing appropriate point and interval estimators of in meta‐analysis of log‐odds‐ratio.
Some popular estimators of heterogeneity variance such as the DL and REML point estimators and PL intervals have unacceptable bias or coverage. We recommend instead new point and interval estimators of that use constant effective‐sample‐size weights. Some of these estimators are already implemented in metafor.
1. INTRODUCTION
As the measure of effect, meta‐analyses of binary outcomes from randomized trials most often use the odds ratio (OR), preferably analyzed as log‐odds‐ratio (LOR). The customary random‐effects analyses assess heterogeneity by using Cochran's statistic 1 and estimate the between‐study variance, , for use in inverse‐variance weights. The resulting weights, based on estimated variances, underlie various shortcomings of that approach. Thus, for assessing heterogeneity and estimating , we have studied , a version of Cochran's statistic in which the weights involve only the studies' arm‐level sample sizes. belongs to a class of generalized statistics, introduced by DerSimonian and Kacker, 2 in which the are arbitrary positive constants.
Our initial motivation came from random‐effects meta‐analyses of mean difference (MD) and standardized mean difference (SMD) 3 and, later, LOR, 4 where a weighted mean whose weights involved only those effective sample sizes performed well in estimating the overall effect.
Further developments produced and accurate approximations to its distribution function, for testing heterogeneity of MD, 5 SMD, 5 and three binary effect measures (LOR, log‐relative‐risk, and risk difference). 6 Those studies also examined approximations for the customary statistic () and investigated estimates for in MD and SMD.
In the present paper, we derive from new point and interval estimators of for meta‐analysis of LOR. In particular, we study mean‐ and median‐unbiased estimators. Similar new estimators of are available in the procedure rma in metafor. 7 However, the performance of these point and interval estimators of had not been evaluated by simulations. Therefore, we carried out an extensive simulation study of the bias of the point estimators and the coverage of the confidence intervals. For comparison we included familiar point and interval estimators of .
Section 2 briefly reviews study‐level estimation of LOR. Section 3 reviews the generic random‐effects model and describes the statistic. Section 4 describes random‐effects models for LOR. Section 5 discusses approximations to the distributions of and . Section 6 introduces new point and interval estimators of for LOR. Section 7 describes the simulation design, and Section 8 summarizes the results. Section 9 examines an example of meta‐analysis using LOR. Section 10 offers a summary and discussion. The Supporting Information provides further details on the interval estimators, the simulation results, and the example.
2. STUDY‐LEVEL ESTIMATION OF LOG‐ODDS‐RATIO
Analyses of log‐odds‐ratio usually adopt binomial distributions to model the numbers of events. In Study (), and denote the numbers of events in the subjects in the Treatment arm and the subjects in the Control arm. Thus, we treat and as independent binomial variables:
| (1) |
The log‐odds‐ratio for Study is
| (2) |
where is an estimate of .
The customary estimators of and are (maximum likelihood). A reasonable alternative adds 0.5 to and adds 1 to : eliminates bias of order and provides the least biased estimator of log‐odds. 8
As inputs, a two‐stage meta‐analysis uses estimates of the () and estimates of their variances (). The (conditional, given and ) asymptotic variance of , derived by the delta method, is
| (3) |
estimated by substituting or for . The estimator of the variance using the and instead of in (3) is unbiased in large samples, but Gart et al. 8 note that it overestimates the variance for small sample sizes. As we explain in Section 4, the unconditional variance depends on the mechanism generating the and the .
3. RANDOM‐EFFECTS MODEL AND THE STATISTIC.
In the most widely used method for two‐stage meta‐analysis, 9 Cochran's statistic serves as the basis for testing heterogeneity and estimating , for use in the inverse‐variance weights, . is a weighted sum of the squared deviations of the estimated effects from their weighted mean :
| (4) |
In calculating , an estimate of is not yet available, so is simply , the reciprocal of the estimated variance of (as in Cochran 1 ). We denote the result by .
The process underlying the DerSimonian‐Laird 9 estimator of () derives the expected value of and rearranges the resulting expression to obtain in terms of and the . Substituting the observed value of for and the for the then yields . The convenient step of plugging in the , however, lacks justification; it inderlies the documented shortcomings of the DL method.
As an alternative, we base estimates of on , studied by Kulinskaya et al., 5 in which , the effective sample size in Study ().
In studying properties of estimators under the random‐effects model, we start by taking as given the observed study‐level effects ; that is, we condition on those values. The model includes a distribution for the true , conventionally . Taking expectations with respect to that model yields unconditional estimators, for comparison with the conditional ones.
The random‐effects model assumes that the are unbiased estimators of the and that the are the corresponding variances (i.e., the true conditional variances).
To develop estimators of based on , we define , , and . In this notation, and expanding , Equation (4) can be written as
| (5) |
We distinguish between the conditional distribution of (given the ) and the unconditional distribution, and the respective moments of . For instance, the conditional second moment of , denoted by , is ; and the unconditional second moment, denoted by , is .
Under the REM, it is straightforward to obtain the first moment of as
| (6) |
This expression is similar to Equation (4) in DerSimonian and Kacker 2 ; they use instead of the unconditional variance .
Our simulations yield an exact calculation of conditional central moments of LOR, following the implementation of Kulinskaya and Dollinger. 10
4. RANDOM‐EFFECTS META‐ANALYSIS OF LOG‐ODDS‐RATIO
The standard REM for LOR assumes that for . The intercept may also be random. Further, and may be correlated. Equation (3) gives the conditional variance of . The full (unconditional) variance of depends on the generation mechanism for the and was derived in Kulinskaya et al. 11
Conventionally, the are assumed to be fixed. Then
| (7) |
where . For use in , this unconditional variance can be estimated by substituting for and for , where and is the estimated LOR. We refer to the estimate of as model‐based. Alternatively, a naïve estimate uses . Such a naïve estimate has the advantage that it maintains the variance inflation of in comparison with (using from Equation (3)). Whenever is used in Equation (7), replaces .
5. APPROXIMATIONS TO THE DISTRIBUTIONS OF AND
Our new interval estimators of (Section 6.2) involve the cumulative distribution function of . For LOR, is a quadratic form in asymptotically normal variables. The Farebrother algorithm, 12 applicable for quadratic forms in normal variables, provides a satisfactory approximation to the cdf for larger sample sizes (), though it may not behave well for small . 6 To apply it, we plug in estimated variances. As in Reference [13], we denote the Farebrother approximation for with effective‐sample‐size weights by F SSW. We further distinguish between a “model‐based” version and a “naïve” version of F SSW, according to whether we use or in Equation (7).
The null distribution of is usually approximated by the chi‐square distribution with degrees of freedom. For LOR, as also for both MD and SMD, this approximation is not accurate for small sample sizes. 14 For LOR, Kulinskaya and Dollinger 10 provided an improved approximation to the null distribution of based on fitting two moments of the gamma distribution; we denote this approximation by KD. For comparison, we study point and interval estimators of based on the chi‐square and KD approximations.
6. POINT AND INTERVAL ESTIMATORS OF FOR LOR
6.1. Point estimators
The unconditional variance of in the customary fixed‐intercept model, Equation (7), can be written as a sum of two terms,
| (8) |
where , , and . Rearranging the terms in Equation (6) with and replacing and with and (or ) give the naïve (or model‐based) moment estimator of .
| (9) |
where and . DerSimonian and Kacker 2 obtain a similar result; they use the conditional estimate, , instead of the unconditional estimate, , obtaining
| (10) |
We study both estimators with effective‐sample‐size weights. With the conditional estimated variances in Equation (10), we denote the estimator by SSC (for “Sample Sizes Conditional”); with the unconditional estimated variances, as in Equation (9), it is SSU (for “Sample Sizes Unconditional”). These estimators differ by a term of order and will be very similar for large sample sizes.
The estimators and arose from setting the observed value of equal to its expected value and solving for . Instead of the expected value, one could use the median of the distribution of given . 15 , 16 , 17 If the true (or approximate) cumulative distribution function is , a point estimator of can be found as
| (11) |
In the Farebrother approximation to the distribution of (Section 5), one can use either the conditional estimated variances or the unconditional estimated variances. We denote the resulting estimators by SMC and SMU (“Sample sizes Median (Un)Conditional”), respectively.
Choosing between the “model‐based” and the “naïve” estimate of in (8) yields “model‐based” and “naïve” versions of SSU and SMU: SSU model or SSU naïve and SMU model or SMU naïve.
The SSC and SMC estimators can be obtained from the procedure rma in metafor 7 by choosing as the method “GENQ” or “GENQM,” respectively, and specifying weights.
For comparison, our simulations (Section 7) include four estimators that use inverse‐variance weights: DerSimonian‐Laird 9 (DL), restricted maximum‐likelihood (REML), Mandel‐Paule 18 (MP), and an estimator (KD) based on the work of Kulinskaya and Dollinger 10 and discussed by Bakbergenuly et al. 4 KD uses an improved non‐null first moment of and has better performance than most other estimators of . In their review of methods for estimating the between‐study variance, Veroniki et al. 19 explain that DL is (by default) the most widely used, and they conclude that both REML and MP are better.
A perennial question involves whether analysts should add to each of only when one of them is zero, or in all studies. This is equivalent to using (whenever possible) or (always), respectively, when estimating and . To obtain evidence on this issue, we included the corresponding two versions, “only” and “always,” of DL, REML, MP, SSC, and SMC (we follow the prevalent practice of omitting “double‐zero” studies, in which two of those cell counts are zero).
Table 1 gives the full list of point estimators.
TABLE 1.
Point and interval estimators of in the simulations.
| Estimator | Description | Add | |
|---|---|---|---|
| “Only” | “Always” | ||
| Point estimators | |||
| DL | DerSimonian‐Laird, 9 a moment estimator based on approximation to distribution of | x | x |
| REML | Restricted Maximum Likelihood | x | x |
| MP | Mandel‐Paule, 18 a moment estimator based on approximation to distribution of | x | x |
| KD | Kulinskaya‐Dollinger, 10 Bakbergenuly et al. 4 a moment estimator based on improved Gamma approximation to | x | |
| SSC | Equation (10), effective‐sample‐size weights, conditional variance (3) of | x | x |
| SSU model | Equation (9), effective‐sample‐size weights, model‐based estimate of in unconditional variance (7) of | x | |
| SSU naïve | Equation (9), effective‐sample‐size weights, naïve estimate of in unconditional variance (7) of | x | |
| SMC | Median‐unbiased, Equation (11), effective‐sample‐size weights, conditional variance (3) of | x | x |
| SMU model | Median‐unbiased, Equation (11), effective‐sample‐size weights, model‐based estimate of in unconditional variance (7) of | x | |
| SMU naïve | Median‐unbiased, Equation (11), effective‐sample‐size weights, naïve estimate of in unconditional variance (7) of | x | |
| Confidence intervals | |||
| QP | Q‐profile, Viechtbauer, 20 Appendix S1.2 | x | x |
| PL | Profile Likelihood, Hardy & Thompson, 21 Appendix S1.1 | x | x |
| KD | Kulinskaya–Dollinger, 10 Bakbergenuly et al., 4 Appendix S1.3, profiled improved Gamma approximation to distribution of | x | |
| FPC | Farebrother Profile, that is, profiled Farebrother approximation to distribution of , effective‐sample‐size weights, conditional variance (3) of | x | x |
| FPU model | Farebrother Profile, effective‐sample‐size weights, model‐based estimate of in unconditional variance (7) of | x | |
| FPU naïve | Farebrother Profile, effective‐sample‐size weights, naïve estimate of in unconditional variance (7) of | x | |
6.2. Interval estimators
Straightforward use of the cumulative distribution function also yields a confidence interval for :
We use both the conditional estimated variances and the unconditional estimated variances in the Farebrother approximation to (Section 5); we refer to the resulting profile estimators as FPC and FPU (“Farebrother Profile (Un)Conditional”) intervals. Jackson 22 introduced a similar approach using conditional variances. The FPC interval can be obtained from the confint procedure in metafor 7 for “GENQ” or “GENQM” objects that used weights. For the FPU intervals, we further distinguish between a “model‐based” version and a “naïve” version, according to whether we use or in (8). Kulinskaya and Hoaglin 13 give the higher unconditional moments of required for the FPU intervals.
Our simulations (Section 7) also include the profile‐likelihood interval, 21 the Q‐profile interval, 20 and the KD interval. 10 Table 1 gives the full list, and Section S1 in the Supporting Information gives further details.
7. SIMULATION DESIGN
Our simulation design followed that described in Bakbergenuly et al. 4 Briefly, we varied five parameters: the overall true effect (), the between‐studies variance (), the number of studies , the studies' total sample size ( or , the average sample size), and the probability in the control arm (). We kept the proportion of observations in the control arm () at .
The values of (0, 0.1, 0.5, 1, 1.5, and 2) aim to represent the range containing most values encountered in practice. LOR is a symmetric effect measure, so the sign of is not relevant.
The values of (0(0.1)1) systematically cover a reasonable range.
The numbers of studies (, 10, and 30) reflect the sizes of many meta‐analyses and have yielded valuable insights in previous work.
In practice, many studies' total sample sizes fall in the ranges covered by our choices , 40, 100, and 250 when all studies have the same , and , 60, 100, and 160 when sample sizes vary among studies). The choices of sample sizes corresponding to follow a suggestion of Sánchez‐Meca and Marín‐Martínez, 23 who constructed the studies' sample sizes to have skewness 1.464, which they regarded as typical in behavioral and health sciences. For Table 2 lists the sets of five sample sizes. The simulations for and used each set of unequal sample sizes twice and six times, respectively.
TABLE 2.
Values of parameters in the simulations.
| Parameter | Equal study sizes | Unequal study sizes |
|---|---|---|
| (number of studies) | 5, 10, 30 | |
|
or (average (individual) study size—total of the two arms) For and , the same set of unequal study sizes is used twice or six times, respectively. |
20, 40, 100, 250 |
30 (12,16,18,20,84), 60 (24,32,36,40,168), 100 (64,72,76,80,208), 160 (124,132,136,140,268) |
| (proportion of observations in the control arm) | 1/2 | |
| (probability in the control arm) | 0.1, 0.2, 0.5 | |
| (true value of LOR) | 0, 0.1, 0.5, 1, 1.5, 2 | |
| (variance of random effects) | 0 (0.1)1 | |
The values of , 0.1, 0.2, and 0.5, provide a typical range of small to medium risks.
The values of and the true effect defined the probabilities , and the counts and were generated from the respective binomial distributions. We used a total of repetitions for each combination of parameters (which we also call a situation). We discarded “double‐zero” and “double‐n” studies and reduced the observed value of accordingly. Next, we discarded repetitions with and used the observed number of repetitions for analysis.
The simulations used R statistical software. 24 We used metafor for all methods of interest that it implemented. Table 1 gives the full list of point and interval estimators of . The user‐friendly R programs implementing our methods are available on OSF. 25
8. SIMULATION RESULTS
Our eprint 26 reports the full simulation results. Here we describe the most important findings. We also refer to Figures S1 through S10 in the Supporting Information.
8.1. Bias in point estimation of for LOR
The relation of each estimator's bias to is roughly linear, with variation in intercept and, especially, in slope among the situations in the simulation. The slope varies most with and and to a lesser extent with , , and whether sample sizes are equal or unequal. In one of the more extreme examples, when , , and , the bias of SMC “only” when is at and at , whereas when , it is at and at . The estimators' traces combine to form various patterns (Figure 1).
FIGURE 1.
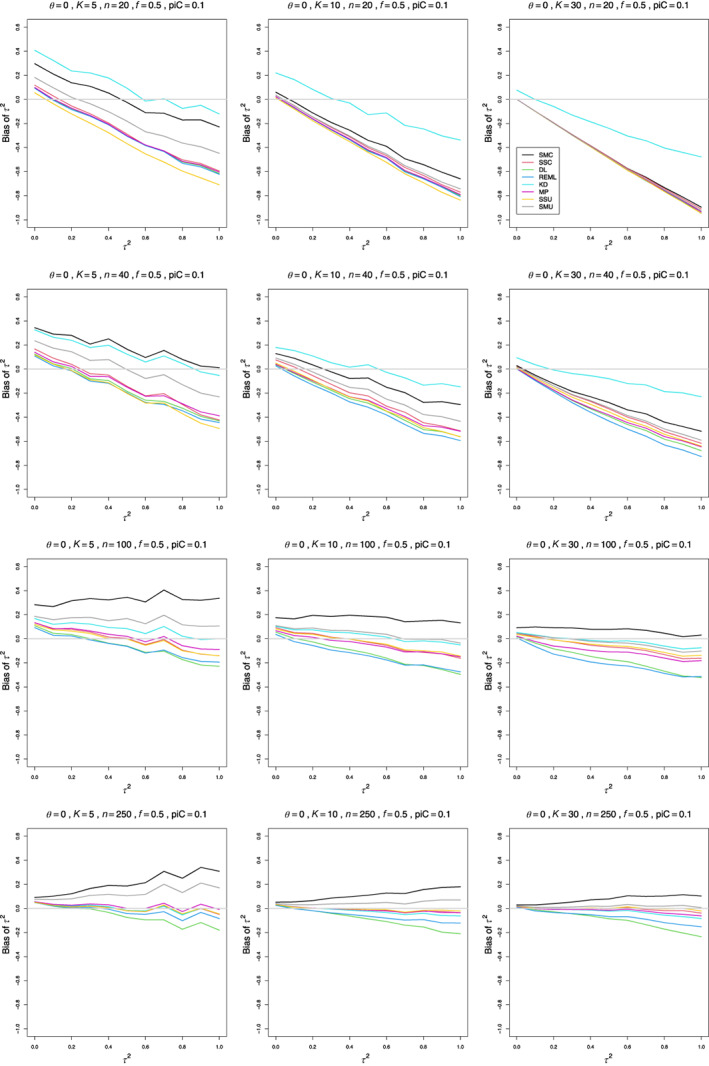
Bias of estimators of between‐study variance of LOR (the “only” versions of DL, REML, MP, and SMC; SSC “always”; KD; and the model versions of SMU and SSU) versus , for equal sample sizes , and , , , and . [Colour figure can be viewed at wileyonlinelibrary.com]
For small sample sizes, all estimators of have considerable bias, positive at and negative for larger . The traces are roughly parallel. The pattern becomes tighter as increases. When , a few estimators have bias that is almost constant in when When , the traces form a fan‐shaped pattern, in which the bias ranges from 0.02 to 0.07 when and from to when . The flattening and fan‐shaped pattern occur at somewhat smaller as increases. The fan‐shaped pattern appears by when and by when . For larger sample sizes, some estimators have negative trends (or no trend), and other have positive trends.
The best estimators, almost unbiased when and , are MP “only,” KD, SSU model, and SSC “always.” The same estimators are recommended for larger values of , where they generally become less biased earlier. When or , various transitions occur at smaller sample sizes (Figures S1 and S2).
For comparison, our simulations included the popular point estimators DL and REML. We focus on their “only” version. The trace for the bias of DL “only” is in the middle of the traces for the collection of estimators, or slightly lower. When or , its negative bias, increasing in size as increases, stands out (usually alone).
The trace for REML “only” lies very close to that for DL, except that when (or, less often, ), it is close to zero instead of trending negative.
To summarize, we recommend MP “only,” KD, SSU model, and SSC “always”; and we emphatically recommend against using DL and REML.
8.2. Median bias of estimators of for LOR
We define median bias as . For a median, the median bias is zero.
For , all estimators have negative bias for small to medium sample sizes, (Figure 2). Interestingly, the median bias of most estimators is almost constant across the range of nonzero values. That level, however, varies with and . As increases, the bias becomes less negative (but not small), but increasing tends to make it more negative. DL “only,” REML “only,” and MP “only” depart from the almost constant pattern. As increases, the trace of DL “only” declines steeply (e.g., from at to at when , , , and , Figure S3), and the trace of REML “only” declines less steeply (and only when , Figure S4). The trace of MP “only” tends to have a positive slope when and and and and a negative slope when and and .
FIGURE 2.
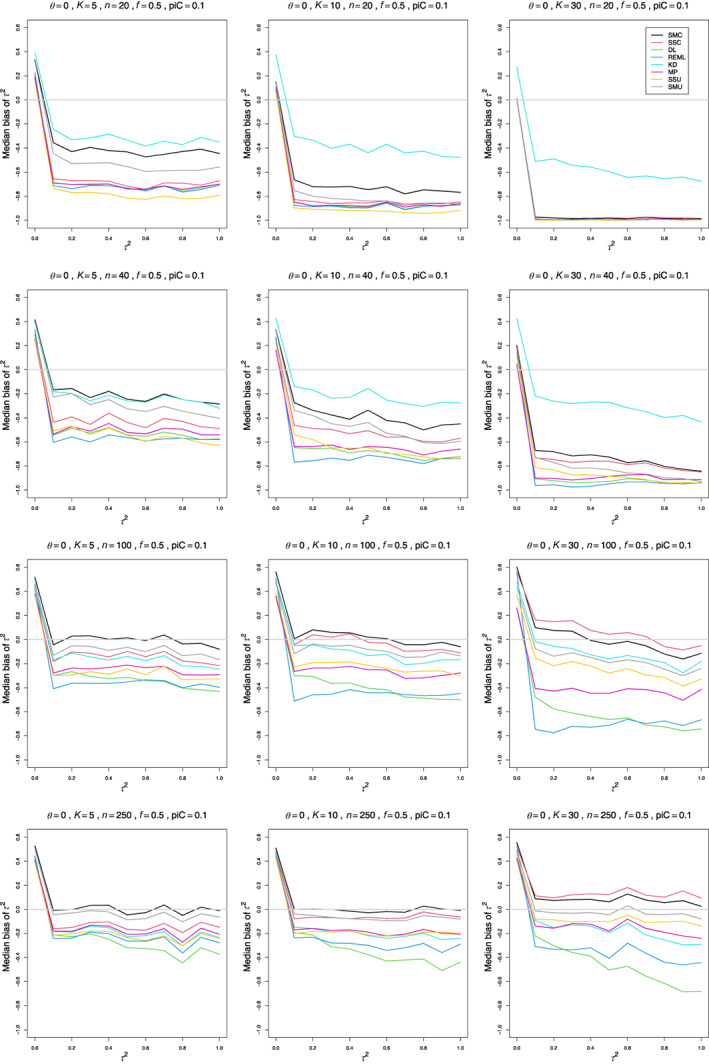
Median bias of estimators of between‐study variance of LOR (the “only” versions of DL, REML, MP, and SSC; SMC “always”; KD; and the model versions of SMU and SSU) versus for equal sample sizes and , , and . [Colour figure can be viewed at wileyonlinelibrary.com]
When or and , none of the estimators are satisfactory. KD comes closest, with median bias around at best. For and , SMC “always” and SMC “only” are better; in a few situations one or both have small positive or negative bias.
The majority of the standard estimators have negative bias for larger values of . This means that their median values of are too low. When for and for , the new median‐unbiased estimators perform well. We recommend SMC “always” and SMU model. Both consistently result in almost median‐unbiased estimation across the range of values.
8.3. Coverage of interval estimators of for LOR
The results of our simulations show a few general patterns, but specific choices of interval estimators depend on values of parameters or combinations of parameters. In particular, we often separate from and .
At coverage is always too high (essentially 1.00). For small , it is roughly flat when and or .
When and , coverage of most estimators remains too high when (Figure 3). KD and FPU model are close to 0.95 when . When and or , all estimators except KD break down: most have coverage at , and their coverage declines steeply as increases. Some form of breakdown persists for all . As increases, and or , coverage at moves toward 0.95. KD and FPC model (for ) seem the best choices.
FIGURE 3.
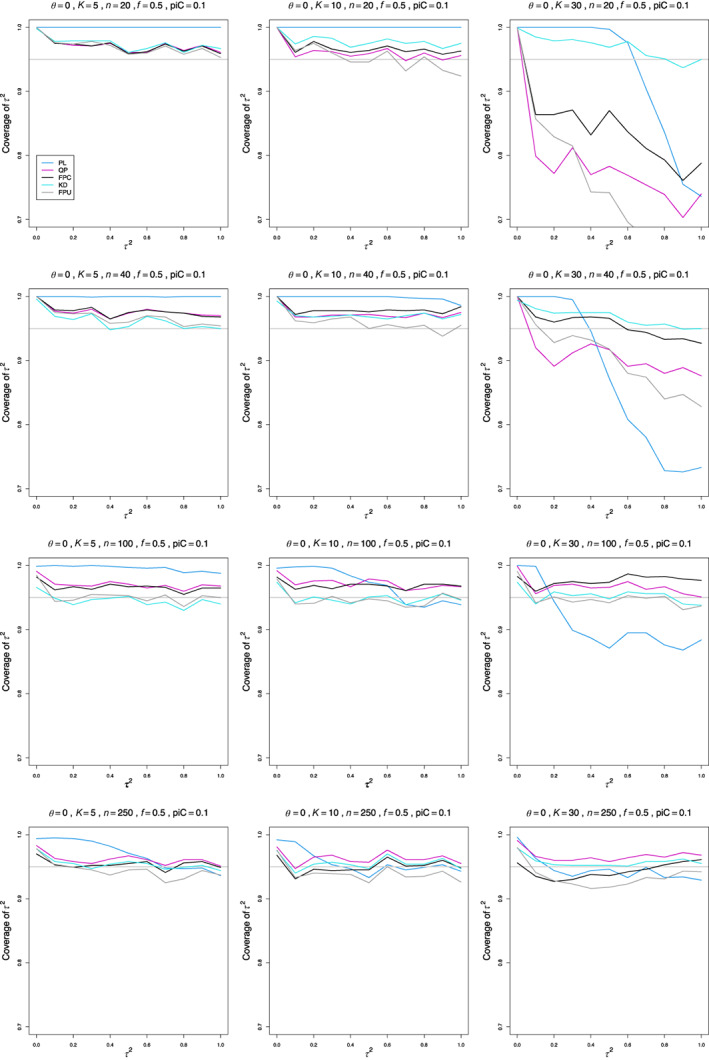
Coverage of 95% confidence intervals for between‐study variance of LOR (the “only” versions of PL, QP and FPC; KD; and the model version of FPU) versus , for equal sample sizes and , , , and . [Colour figure can be viewed at wileyonlinelibrary.com]
When or (Figures S5 and S6), the picture is simpler. Coverage when or becomes closer to (or equals) 0.95 as increases, except for the “always” versions of PL, QP, and FPC when . For , KD seems the best single choice.
Coverage of PL is usually too high, and in some situations it seems trapped at 1.00.
8.4. Left and right coverage error
It is often informative to approach estimation of coverage by separating its complement, the coverage error or “miscoverage,” into two parts, corresponding to whether the value of the parameter is to the left of the lower confidence limit or to the right of the upper confidence limit. Efron and Tibshirani in Reference [27], section 13.5 denote these by “miss left” and “miss right.” A CI that had a small miss‐left percentage would overcover on the left; if it had a large percentage, it would undercover. The confidence intervals that we studied aim to have miscoverage equal to 2.5% on each side (Section 6.2), but an approximation for the distribution of may not provide the desired balance, even if the overall coverage is close to 95%. Thus, our simulations included the miss‐left and miss‐right percentages.
In general, the miss‐left percentages are typically lower than 2.5% for small sample sizes and/or control‐arm probabilities, but they improve for and for larger (Figures 4, S7, S8). A low miss‐left percentage means that the confidence interval includes an excess of low values.
FIGURE 4.
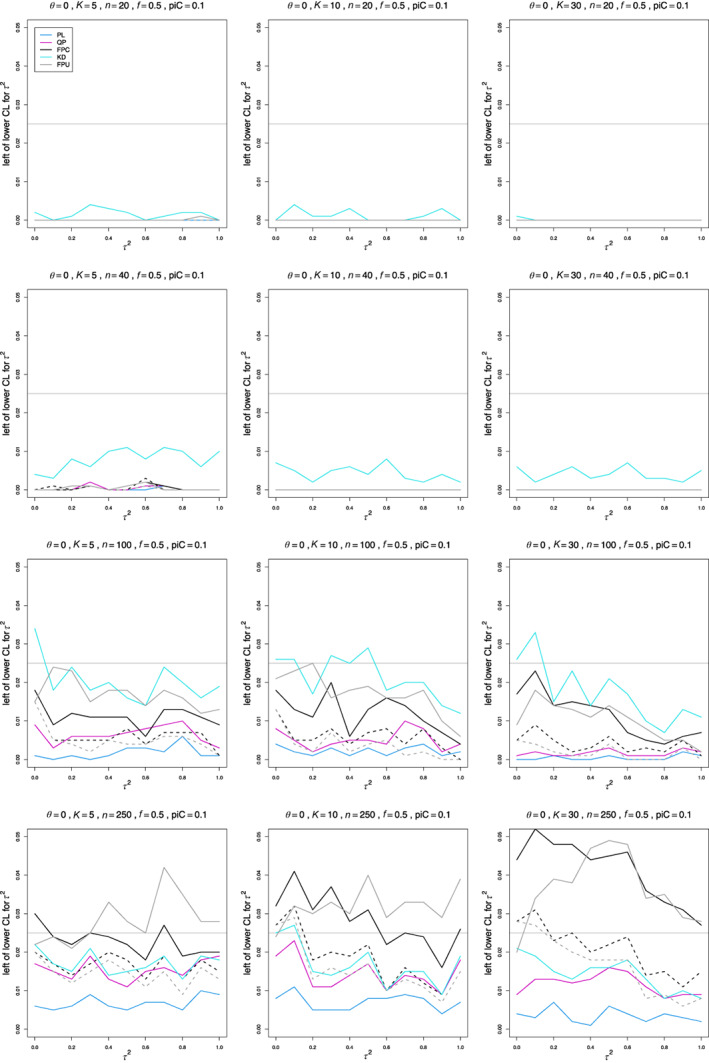
Miss‐left probability of PL, QP, KD, FPC, and FPU 95% confidence intervals for between‐study variance of LOR versus , for equal sample sizes and , , , and . Solid lines: the “only” versions of PL, QP and FPC; KD; and the model version of FPU. Dashed lines: the “always” version of FPC and the naïve version of FPU. [Colour figure can be viewed at wileyonlinelibrary.com]
The miss‐left percentages of KD, FPU naïve, and FPC “always” are closer to 2.5% from , and miss‐left percentages of QP are typically lower than nominal when but improve for larger .
The only exceptions to typically lower than nominal miss‐left percentages are the FPC “only” and FPU model intervals, whose percentages for are often higher than nominal for and sometimes when . KD occasionally has high percentages for high values of when . PL miss‐left percentages are especially low for all sample sizes.
The miss‐right percentages are often higher than nominal, but they improve for larger and (Figures 5, S9, S10). is especially challenging.
FIGURE 5.
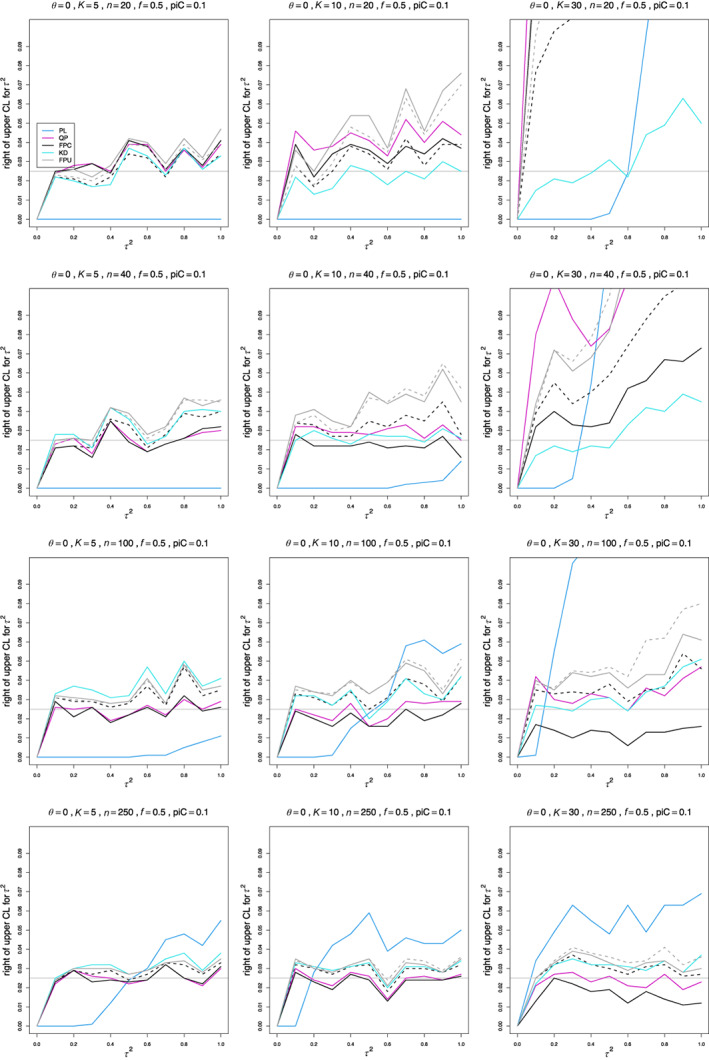
Miss‐right probability of PL, QP, KD, FPC, and FPU 95% confidence intervals for between‐study variance of LOR versus , for equal sample sizes and , , , and . Solid lines: the “only” versions of PL, QP and FPC; KD; and the model version of FPU. Dashed lines: the “always” version of FPC and the naïve version of FPU. [Colour figure can be viewed at wileyonlinelibrary.com]
For , the miss‐right percentages of KD, QP “always,” and FPC “always” are closest to 2.5% when and , but increase for larger . When or , the percentages of FPC “only” and QP “only” are reasonably close to 2.5% when . The percentages of KD are consistently close to 2.5% for . For , the range of results is larger. The percentages of KD, QP “only,” and FPC “always” are close to 2.5% when . The percentages for all other estimators are typically higher, with the exception of FPU model, which has lower than nominal percentages. PL produces erratic percentages, from 0 to above 10%. For larger values of , the miss‐right percentages of all estimators, with the exception of PL, improve earlier, so that those of KD, QP “only,” and FPC “always” are all close to 2.5% when and , even when .
Lack of balance in the miss‐left and miss‐right percentages for small sample sizes and/or control‐arm probabilities agrees with our findings 13 that the chi‐square approximation for and the Farebrother approximation for are accurate only for larger sample sizes.
9. EXAMPLE: SMOKING CESSATION
Stead et al. 28 conducted a systematic review of clinical trials on the use of physician advice for smoking cessation. We use the data from the subgroup of interventions in which the treatment involved only one visit (Comparison 3.1.4, p. 54). The first version of the report was published in 2001. In an update, published in 2004, 17 studies included this comparison. The 2013 update included one more study, by Unrod (2007). For each study, Table S1 gives the number of subjects in the treatment and control arms and the number who were nonsmokers at the longest follow‐up time reported (either 6 months or 12 months). The definition of “nonsmoker” varied among the studies. Some studies required sustained abstinence, and others only asked about smoking status at that time. Stead et al. 28 analyzed relative risk. Kulinskaya and Hoaglin 6 showed that both OR and RR are reasonable effect measures for these data. Here we consider estimation of in two meta‐analyses of LOR.
The studies were mostly balanced, though two studies had substantially more subjects in the treatment arm. Sample sizes varied from 182 to 3128, with an average of 836 patients per study. The mean probabilities of smoking cessation in both arms were rather low, at in the treatment arm and in the control arm.
The standard IV‐based meta‐analysis of LOR for the original 17 studies gives with standard error and for the intervention effect (). The fixed‐weights estimate of is higher, at . In testing for heterogeneity, , and the chi‐square approximation on 16 df provides a p‐value of (). The p‐values for the KD and F SSW naïve methods (which Kulinskaya and Hoaglin 6 recommend) are very close, at 0.035 and 0.038, respectively.
Table 3 shows striking differences: the SSC and SSU estimates of are more than twice as large as the standard IV estimates. This agrees with our simulations, which showed large positive biases of SSC and SSU for low values of . All confidence intervals have zero as the lower limit (Table 4). This result contradicts the significant p‐values from the KD and F SSW naïve tests, but it can be explained by the inflated confidence level of all six confidence intervals near zero. Adding to the numbers of events somewhat reduces the estimated values and the upper confidence limits. This would somewhat reduce the positive biases and the inflation in coverage. Because of the large sample sizes, there are only minor differences between conditional and unconditional model‐based or naïve estimators of and confidence intervals.
TABLE 3.
Estimated values of in the meta‐analysis of LOR for the data of Stead et al. on the use of physician advice for smoking cessation.
| Example | Add 1/2 | DL | REML | MP | KD | SSC | SSU model | SSU naïve | SMC | SMU model | SMU naïve |
|---|---|---|---|---|---|---|---|---|---|---|---|
|
Stead et al. (17 studies) |
Always | 0.0627 | 0.0696 | 0.0701 | 0.0887 | 0.1715 | 0.1725 | 0.1680 | 0.2014 | 0.2043 | 0.1972 |
| Only | 0.0675 | 0.0769 | 0.0754 | 0.1776 | 0.2098 | ||||||
|
Stead et al. (18 studies) |
Always | 0.0514 | 0.0537 | 0.0576 | 0.0740 | 0.1634 | 0.1642 | 0.1601 | 0.1913 | 0.1939 | 0.1873 |
| Only | 0.0555 | 0.0597 | 0.0623 | 0.1697 | 0.1997 |
TABLE 4.
95% confidence intervals for the between‐study variance in the meta‐analysis of LOR for the data of Stead et al. on the use of physician advice for smoking cessation.
| Example | Add 1/2 | QP | PL | KD | FPC | FPU model | FPU naïve |
|---|---|---|---|---|---|---|---|
|
Stead et al. (17 studies) |
Always | [0, 0.3745] | [0, 0.3445] | [0, 0.3910] | [0, 0.7583] | [0, 0.7554] | [0, 0.7389] |
| Only | [0, 0.3957] | [0, 0.3713] | [0, 0.8075] | ||||
|
Stead et al. (18 studies) |
Always | [0, 0.3267] | [0, 0.2915] | [0, 0.3419] | [0, 0.6992] | [0, 0.6969] | [0, 0.6820] |
| Only | [0, 0.3455] | [0, 0.3139] | [0, 0.7458] |
Addition of the 18th study somewhat increased the p‐value for the standard test, to , and the KD p‐value to , but hardly affected the p‐values of the SSW‐based methods. The recommended F SSW naïve test rejects homogeneity at the 5% significance level, with . The estimated values are somewhat smaller, and all confidence intervals still start at zero.
To better understand the properties of the estimation methods for very small values of in this example, we performed additional simulations with 1000 repetitions in the relevant intervals of values, and , keeping the sample sizes as in the example and using the probabilities . Figure 6 shows the results. In agreement with our main series of simulations, KD, MP “only”, SSC “always,” and SSU model are the least biased estimators of , whereas SMC “only” is the least median‐biased. Table S2 gives summary statistics for these five estimators when and , and and . Additionally, Table S2 provides summary statistics when and , but the control arm probabilities are less extreme, at .
FIGURE 6.
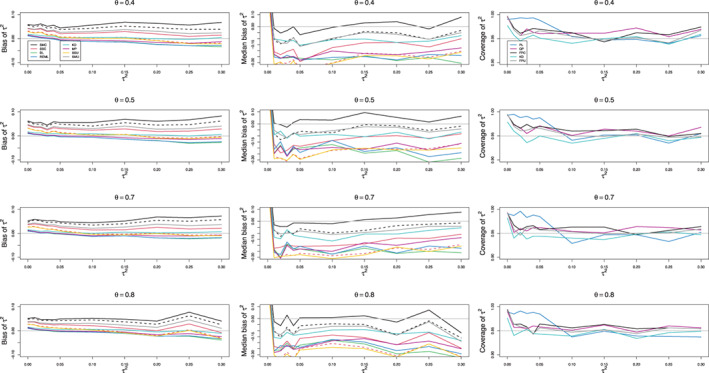
Bias, median bias, and coverage at 95% nominal confidence level of point and interval estimators of for the example of meta‐analysis by Stead et al. Solid lines: the “only” versions of DL, REML, MP, SSC, and SMC; KD; the model versions of SSU and SMU point estimators; the “only” versions of PL, QP, and FPC; FPU model, and KD intervals. Dashed lines: the “always” versions of SSC and SMC point estimators. [Colour figure can be viewed at wileyonlinelibrary.com]
Both lower and upper quartiles for the first four estimators of are comparable, though the upper quartile of SMC “only” is somewhat higher. However, the three effective‐sample‐size estimators have a much longer right tail than KD and MP “only.” This shape explains their much higher mean values. Comparing the medians, SMC “only” is almost median‐unbiased in all five scenarios, whereas SSC “always” and SSU model have the lowest medians, followed by MP “only” and then KD. This pattern is especially noticeable when the control arm probabilities are low. The lower the median, the more often these estimators would underestimate true heterogeneity. The differences between distributions decrease quite considerably for larger control arm probabilities, so the KD and MP “only” densities practically coincide, as do the densities of SSC “always” and SSU model (Figure 7). Overall, KD is the best mean‐unbiased estimator, and SMC “only” is the best median‐unbiased estimator. Which one to prefer depends very much on the context of the research. All confidence intervals provide reasonable coverage, though KD is sometimes too liberal, and PL too conservative (Figure 6).
FIGURE 7.
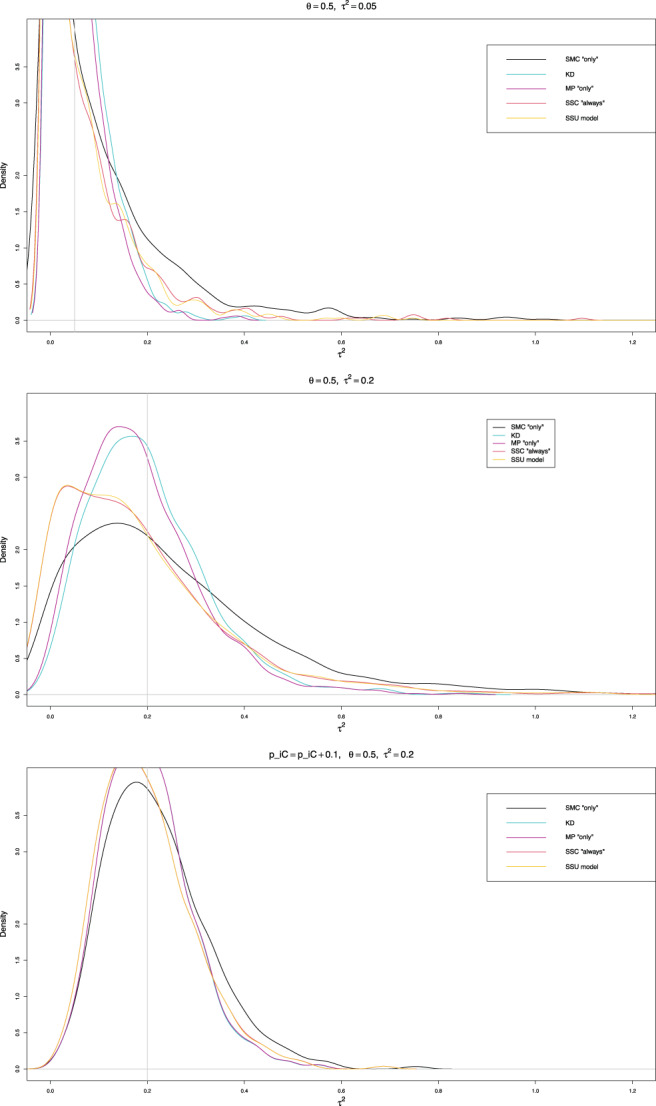
Density plots of the point estimators of for the example of meta‐analysis by Stead et al.: the “only” versions of MP and SMC; the “always” version of SSC; the model version of SMU; and KD. [Colour figure can be viewed at wileyonlinelibrary.com]
10. DISCUSSION
Estimation of heterogeneity variance is an important part of any meta‐analysis. Apart from its importance per se, it also affects the value of an estimated pooled effect and its estimated variability. In this paper, we studied estimation of based on , a generalized statistic with fixed effective‐sample‐size weights, and compared four proposed new point estimators of (SSC, SMC, SSU, and SMU) and two new interval estimators (FPC and FPU) with traditional estimators based on the statistic with inverse‐variance weights, .
The new point estimators based on the expected value of involve estimates () of the variances of the . We obtained SSC from the conditional variances and SSU from the unconditional variances of the . Similarly, our novel point estimators based on the median of the Farebrother approximation to the distribution of are SMC and SMU, and our profile interval estimators are FPC and FPU.
For each unconditional estimator, we investigated two approaches to estimation of (which is used in the calculation of the second and fourth central moments of ), “naïve” estimation of from and and “model‐based” estimation using the fixed‐effects meta‐analysis estimate of the overall effect to obtain from . Additionally, we considered two versions of the traditional and the unconditional estimators of : adding to the four cell counts always, or only when one of those counts is zero. Thus, our simulation study examined a total of 15 point estimators of and 9 interval estimators (Table 1).
For mean bias, the best estimators are MP “only,” KD, SSU model, and SSC “always.” The DL and REML estimators have the worst bias. For median bias, which was not studied previously, an important finding is that the majority of the standard estimators have negative bias for larger values of . This means that their median values of are too low. We recommend SMC “always” and SMU model. Both consistently result in almost median‐unbiased estimation across the range of values for moderate to large .
Coverage of the confidence intervals depends on , , and . There is also some dependence on and . However, KD, FPC “always,” and FPU model are the best choices overall. PL is the worst choice. We also considered left and right coverage errors separately. Typically, the miss‐left rates are below, and the miss‐right rates are above, the nominal 2.5% level, especially so for small sample sizes and/or control arm probabilities. Arguably, this is not bad, as it would reduce the width of the confidence intervals. 29 Lack of balance in the miss‐left and miss‐right rates agrees with our findings 13 that the chi‐square approximation for and the Farebrother approximation for are accurate only for larger sample sizes.
Alongside the novel two‐stage estimators using sample‐size‐based weights, our simulation study involved a variety of established inverse‐variance‐based two‐stage estimators of heterogeneity. With a very few exceptions, such as MP and, especially, KD, their performance is not impressive. One‐stage meta‐analysis is often suggested as a better choice. However, we previously considered quality of one‐stage estimation in GLMM‐based binomial‐normal models. 11 , 30 and found it lacking. Also, it is useful to remember that GLMMs are still asymptotic methods that use normal likelihood.
Ideally, for meta‐analyses of log‐odds‐ratio, a single point estimator of would have acceptably low bias (and, perhaps, median bias) for a substantial region of , , , , and . Similarly, a single confidence interval would have close to nominal coverage of . Our results show some progress toward those goals, by demonstrating advantages of new estimators in some situations and, importantly, by demonstrating that some popular estimators have unacceptable bias or coverage. The goals, however, require further research. In the interim, effective education can help users avoid methods that perform poorly.
AUTHOR CONTRIBUTIONS
Elena Kulinskaya: Conceptualization; funding acquisition; methodology; software; visualization; writing – original draft; writing – review and editing. David C. Hoaglin: Conceptualization; investigation; methodology; writing – original draft; writing – review and editing.
CONFLICT OF INTEREST STATEMENT
The authors declare no conflicts of interest.
Supporting information
Data S1: Supporting Information.
ACKNOWLEDGMENTS
The work by E. Kulinskaya was supported by the Economic and Social Research Council [grant number ES/L011859/1].
Kulinskaya E, Hoaglin DC. Estimation of heterogeneity variance based on a generalized Q statistic in meta‐analysis of log‐odds‐ratio. Res Syn Meth. 2023;14(5):671‐688. doi: 10.1002/jrsm.1647
DATA AVAILABILITY STATEMENT
Our full simulation results are available as an arXiv e‐print (arXiv:2208.00707v1). The user‐friendly R program implementing all studied estimators of heterogeneity variance \$\tau^2\$ in meta‐analysis of log‐odds‐ratio with related confidence intervals is available at https://osf.io/5n3vd
REFERENCES
- 1. Cochran WG. The combination of estimates from different experiments. Biometrics. 1954;10(1):101‐129. [Google Scholar]
- 2. DerSimonian R, Kacker R. Random‐effects model for meta‐analysis of clinical trials: an update. Contemp Clin Trials. 2007;28(2):105‐114. [DOI] [PubMed] [Google Scholar]
- 3. Bakbergenuly I, Hoaglin DC, Kulinskaya E. Estimation in meta‐analyses of mean difference and standardized mean difference. Stat Med. 2020;39(2):171‐191. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Bakbergenuly I, Hoaglin DC, Kulinskaya E. Methods for estimating between‐study variance and overall effect in meta‐analysis of odds ratios. Res Synth Methods. 2020;11(3):426‐442. doi: 10.1002/jrsm.1404 [DOI] [PubMed] [Google Scholar]
- 5. Kulinskaya E, Hoaglin DC, Bakbergenuly I, Newman J. A Q statistic with constant weights for assessing heterogeneity in meta‐analysis. Res Synth Methods. 2021;12:711‐730. doi: 10.1002/jrsm.1491 [DOI] [PubMed] [Google Scholar]
- 6. Kulinskaya E, Hoaglin DC. Simulations for the Q statistic with constant and inverse variance weights for binary effect measures. 2022. arXiv:2206.08907v1 [statME].
- 7. Viechtbauer W. Conducting meta‐analyses in R with the metafor package. J Stat Softw. 2010;36:3 https://www.metafor-project.org. [Google Scholar]
- 8. Gart JJ, Pettigrew HM, Thomas DG. The effect of bias, variance estimation, skewness and kurtosis of the empirical logit on weighted least squares analyses. Biometrika. 1985;72(1):179‐190. [Google Scholar]
- 9. DerSimonian R, Laird N. Meta‐analysis in clinical trials. Control Clin Trials. 1986;7(3):177‐188. [DOI] [PubMed] [Google Scholar]
- 10. Kulinskaya E, Dollinger MB. An accurate test for homogeneity of odds ratios based on Cochran's Q‐statistic. BMC Med Res Methodol. 2015;15(1):49. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Kulinskaya E, Hoaglin DC, Bakbergenuly I. Exploring consequences of simulation design for apparent performance of methods of meta‐analysis. Stat Methods Med Res. 2021;30(7):1667‐1690. PMID: 34110941. doi: 10.1177/09622802211013065 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Farebrother RW, Algorithm AS 204: the distribution of a positive linear combination of χ 2 random variables. J R Stat Soc Ser C. 1984;33(3):332‐339. [Google Scholar]
- 13. Kulinskaya E, Hoaglin DC. On the Q statistic with constant weights in meta‐analysis of binary outcomes. 2022. Available at Research Square. doi: 10.21203/rs.3.rs-2121915/v1 [DOI] [PMC free article] [PubMed]
- 14. Viechtbauer W. Hypothesis tests for population heterogeneity in meta‐analysis. Br J Math Stat Psychol. 2007;60:29‐60. [DOI] [PubMed] [Google Scholar]
- 15. Bakbergenuly I, Hoaglin DC, Kulinskaya E. On the Q statistic with constant weights for standardized mean difference. Br J Math Stat Psychol. 2021;75:444‐465. doi: 10.1111/bmsp.12263 [DOI] [PubMed] [Google Scholar]
- 16. Brown GW. On small‐sample estimation. Ann Math Stat. 1947;18:582‐585. [Google Scholar]
- 17. Viechtbauer W. Median‐unbiased estimators for the amount of heterogeneity in meta‐analysis. Paper presented at: 9th European Congress of Methodology. European Association of Methodology. 2021.
- 18. Mandel J, Paule RC. Interlaboratory evaluation of a material with unequal numbers of replicates. Anal Chem. 1970;42(11):1194‐1197. [Google Scholar]
- 19. Veroniki AA, Jackson D, Viechtbauer W, et al. Methods to estimate the between‐study variance and its uncertainty in meta‐analysis. Res Synth Methods. 2016;7:55‐79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Viechtbauer W. Confidence intervals for the amount of heterogeneity in meta‐analysis. Stat Med. 2007;26(1):37‐52. [DOI] [PubMed] [Google Scholar]
- 21. Hardy RJ, Thompson SG. A likelihood approach to meta‐analysis with random effects. Stat Med. 1996;15:619‐629. [DOI] [PubMed] [Google Scholar]
- 22. Jackson D. Confidence intervals for the between‐study variance in random effects meta‐analysis using generalised Cochran heterogeneity statistics. Res Synth Methods. 2013;4(3):220‐229. doi: 10.1002/jrsm.1081 [DOI] [PubMed] [Google Scholar]
- 23. Sánchez‐Meca J, Marín‐Martínez F. Testing the significance of a common risk difference in meta‐analysis. Comput Stat Data Anal. 2000;33(3):299‐313. [Google Scholar]
- 24. R Core Team . R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing; 2016. [Google Scholar]
- 25. Kulinskaya E, Hoaglin DC. R programs for estimation of heterogeneity variance for log‐odds‐ratio using the generalised Q statistic with constant and inverse variance weights. OSF. 2022. https://osf.io/5n3vd
- 26. Kulinskaya E, Hoaglin DC. Simulations for estimation of heterogeneity variance in constant and inverse variance weights meta‐analysis of log‐odds‐ratios. 2022. arXiv:2208.00707v1 [stat.ME]. doi: 10.48550/arxiv.2208.00707 [DOI]
- 27. Efron B, Tibshirani RJ. An Introduction to the Bootstrap. Boca Raton, Florida: Chapman & Hall/CRC. 1993. [Google Scholar]
- 28. Stead L, Buitrago D, Preciado N, Sanchez G, Hartmann‐Boyce J, Lancaster T. Physician advice for smoking cessation. Cochrane Database Syst Rev. 2013. Art. No. CD000165. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Jackson D, Bowden J. Confidence intervals for the between‐study variance in random‐effects meta‐analysis using generalised heterogeneity statistics: should we use unequal tails? BMC Med Res Methodol. 2016;16:116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Bakbergenuly I, Kulinskaya E. Meta‐analysis of binary outcomes via generalized linear mixed models: a simulation study. BMC Med Res Methodol. 2018;18:70. doi: 10.1186/s12874-018-0531-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data S1: Supporting Information.
Data Availability Statement
Our full simulation results are available as an arXiv e‐print (arXiv:2208.00707v1). The user‐friendly R program implementing all studied estimators of heterogeneity variance \$\tau^2\$ in meta‐analysis of log‐odds‐ratio with related confidence intervals is available at https://osf.io/5n3vd