

Summary
Adjusting for an unmeasured confounder is generally an intractable problem, but in the spatial setting it may be possible under certain conditions. We derive necessary conditions on the coherence between the exposure and the unmeasured confounder that ensure the effect of exposure is estimable. We specify our model and assumptions in the spectral domain to allow for different degrees of confounding at different spatial resolutions. One assumption that ensures identifiability is that confounding present at global scales dissipates at local scales. We show that this assumption in the spectral domain is equivalent to adjusting for global-scale confounding in the spatial domain by adding a spatially smoothed version of the exposure to the mean of the response variable. Within this general framework, we propose a sequence of confounder adjustment methods that range from parametric adjustments based on the Matérn coherence function to more robust semiparametric methods that use smoothing splines. These ideas are applied to areal and geostatistical data for both simulated and real datasets.
Keywords: Coherence, Conditional autoregressive prior, COVID-19, Matérn covariance, Spatial confounding
1. Introduction
A fundamental task in environmental and epidemiological applications is to use spatially correlated observational data to estimate the effect of exposures. A key assumption needed to identify the effect of the exposures is that all relevant confounding variables have been included in the statistical model. This no-missing-confounder assumption is generally impossible to verify, but in the spatial setting it may be possible to remove the effects of unmeasured confounding variables if they have strong spatial dependence. An unmeasured spatial confounder exists when spatially varying factors that influence both the exposures and response are not observed. When the unmeasured spatial confounder is not taken into account, the effect estimate of an exposure can be biased, and the bias depends on the spatial scales of the exposure and the unmeasured spatial confounder (Paciorek, 2010; Page et al., 2017).
A slightly different but related confounding issue in modelling spatial data was discussed in Clayton et al. (1993). They proposed to model the geographical patterns in the response using a spatial random effect term independent of exposure to account for unmeasured spatially structured covariates that influence the response. Then, confounding, i.e., confounding due to location, may arise if exposure also varies smoothly with location, and the location may act as a confounder. In this case, regressions with and without spatial random effects can give different inference results on regression coefficients (Reich et al., 2006; Hodges & Reich, 2010), a phenomena also known as spatial confounding. For confounding due to location, the unmeasured spatial covariates do not directly influence the exposure, but rather are multicollinear with the exposure, and the multicollinearity is more likely to occur when the spatial random effects and exposure are both spatially smooth. In this paper, we focus on spatial confounding due to an unmeasured spatial confounder, in which the confounding due to location can be considered as a special case when the association between exposure and missing spatial covariates is zero.
To account for spatial confounding due to location, Reich et al. (2006), Hughes & Haran (2013) and Prates et al. (2019) restricted the residual spatial process to be orthogonal to the exposure, an approach referred to as restricted spatial regression. However, the approach makes a strong orthogonality assumption and can perform poorly in coefficient inference when the model is misspecified (Hanks et al., 2015; Khan & Calder, 2022; Zimmerman & Hoef, 2022). Alternative approaches with a focus on decomposing spatial scales following Paciorek (2010) have appeared in the literature. The main idea is that the location confounding can be eliminated by first removing the smooth components from both the exposure and response (Thaden & Kneib, 2018) or just the exposure (Keller & Szpiro, 2020; Dupont et al., 2022), then the exposure effect can be estimated by assessing the local variations in the covariate and response. More recently, Marques et al. (2022) proposed a joint Gaussian Markov random field model for exposure and response. Their work was developed independently around the same time as ours and is related to a special case of our parametric model. The listed works attempt to alleviate spatial confounding, but, in general, adjusting for a missing confounding variable is impossible without further information or assumptions. It remains unclear how to specify assumptions and methods that lead to consistent estimation of the exposure effect in the presence of an unmeasured spatial confounding variable, which may posit a more complex confounding structure than location confounding.
Connections with causal inference have been made. For areal data, Thaden & Kneib (2018) and Schnell & Papadogeorgou (2020) proposed jointly modelling the spatial structure in exposure and the unmeasured confounder. The former uses a structural equation model while the latter uses a Gaussian Markov random field construction. Both these methods have connections with causal inference; see Reich et al. (2021) for a recent review of spatial causal inference. In the spatial causal effect setting, Osama et al. (2019) permitted the spatial causal effect to vary across space. Different assumptions on the confounding relationship may lead to a variety of approaches.
We propose new methods to couch spatial regression with missing spatial confounding variables using spectral methods. Similarly to Paciorek (2010), Page et al. (2017) and Keller & Szpiro (2020), the spatial scales of exposure and missing confounder are the focus, but we explicitly specify a joint model for these variables in the spectral domain and study their coherence, i.e., their correlation at different spatial scales. As an aside, from a temporal perspective, Stokes & Purdon (2017) and Faes et al. (2019) considered a frequency-domain measure of causality, although their estimators are quite different than those proposed here. The resulting effect estimate from our approach reveals that the optimal confounder adjustment is a function of the coherence function, providing fundamental insights on spatial confounding. We show that the optimal confounder adjustment is not estimable without further assumptions, and provide a set of conditions that allow us to identify the exposure effect. Parametric and nonparametric methods are developed to approximate the optimal confounding adjustment and identify the exposure effect, while accounting for uncertainty in this approximation. We consider both areal and point-referenced data for Gaussian and non-Gaussian responses. Proofs are given in the Supplementary Material.
2. Continuous-space modelling framework
2.1. Preliminaries
Let and be the observed exposure and confounder processes, respectively, at the spatial location , and let vectors and be the process evaluated at the set of locations , where and . For simplicity, we consider only a single exposure and confounding variable, but results extend to a multivariate setting; see the Supplementary Material. We do not assume that is on a complete grid nor that the observation locations are distinct, i.e., we allow for multiple observations at the same location with the inclusion of a nugget effect. Both and are assumed to be spatial processes, potentially with some nonspatial nugget variability.
Following the commonly used spatial regression model, we assume a linear additive relationship for the response . Here, we present the method for continuous response, but the extension to non-Gaussian cases is straightforward, and therefore the details for the generalized model are presented in the Supplementary Material.
We have
| (1) |
where and , a normal distribution with mean 0 and variance . The regression coefficient has a causal interpretation under the potential outcomes framework and the stable-unit-treatment-value, consistency and conditional-treatment-ignorability assumptions. If we observe the confounder , identification and estimation of is straightforward using multiple linear regression. However, we assume that is an unmeasured confounder, making not identifiable in general. We propose to exploit the spatial structure of to mitigate the effects of the unobserved confounder and specify assumptions in the spectral domain for identifying . Our inference procedure involves introducing a confounder adjustment variable to the linear model. The derivation of is based on the association between and in the spectral domain, while in the spatial domain, can be viewed as a smoothed version of under one of our assumptions for identification. Our work aims to identify and estimate , which has a causal interpretation under the potential outcomes framework and assumptions described in the Supplementary Material. Here instead of restating all elements of the causal framework, in the remaining sections, we assume that the confounder process contains all unmeasured confounders and mainly focus on mitigating the effects of . Therefore, we interpret as the effect of exposure under model (1) rather than the causal effect, as the latter requires additional assumptions that are not essential for inference in this work.
2.2. Spectral representation of confounding and identification
We model the dependence between and using their spectral representations. This allows for different dependencies at different spatial scales as each frequency corresponds to a spatial scale, with low frequency corresponding to large spatial scale. We assume that both and are mean-zero stationary Gaussian processes, and thus have spectral representations and , where is a frequency. The spectral processes and are Gaussian with and are independent across frequencies, so that, for any . At the same frequency, the covariance of the joint spectral process has the form
where and are variance parameters, and are spectral densities that determine the marginal spatial correlation of and , respectively, and the cross-spectral density determines the dependence between the spectral processes.
Normalizing the cross-spectral density by each marginal standard deviation, we can derive the coherence function that determines the correlations between the two spectral processes (Kleiber, 2017),
| (2) |
The scalar parameter controls the overall strength of cross-correlation.
Returning to the response model (1), we let be the spectral representation of the response. The conditional distribution of given , marginalizing over , is
| (3) |
The regression coefficient for is . The additional term is a result of attributing the effect of the unmeasured confounder on the response to the exposure, potentially inducing bias in estimating .
Therefore, is identified only if the projection operator can be assumed to be known or estimated for some prespecified . Of course, is generally not known and cannot be estimated without further assumptions because , and therefore , is not observed. We consider two approaches for identification: assume unconfoundedness at high frequencies, i.e., for large , so that high-frequency terms identify ; or specify a parsimonious coherence function with constraints on the parameters to ensure identification of through estimation of . We detail both approaches next.
For the case of unconfoundedness at high frequencies, if we assume that for large then and thus is identified. The assumption that for large implies that the cross-spectral density decreases to zero faster than the spectral density of , which means that confounding dissipates as the frequency increases, that is, as the scale of the spatial variation becomes smaller. High-frequency terms provide the most reliable information about because they correlate local changes in the exposure with local changes in the response. An extreme case of local information about the exposure effect is the difference in the response for two nearby sites with different levels of exposure. This local difference eliminates problems caused by omitted variables that vary smoothly over space. Of course, this cannot completely rule out missing confounding variables that covary with both the exposure and the response at high frequencies, but it does lessen the likelihood of spurious confounding effects.
For the case of parsimonious coherence, if we assume that for a constant , then the coherence in (2) simplifies to the constant function . Generalizing the use of a term from Gneiting et al. (2010), we refer to this as the parsimonious coherence model. This imposes the assumption that the correlation between the exposure and missing confounder is frequency invariant, and this greatly simplifies estimation because the model involves only two spectral densities that can be estimated using the marginal spatial covariances of the response and exposure, as described below. Moreover, if the marginal spectral densities differ for some frequencies then these frequencies can be used to identify . The expression in (3) simplifies under the parsimonious model to
| (4) |
It is important to establish the identifiability of parameters in (4). The and are not uniquely identified, nor are and , as they both appear in the model only through products. However, is identified, as is if . An alternative parameterization is to let and can be identified. The two expressions are equivalent, which does not affect the result of Theorem 1 below. The identifiability of under these conditions and that of the remaining parameters in (4) is established in the following theorem.
Theorem 1. Assume that for some , and set . Then parameters and , and functions and in model (4) are all identified.
2.3. Spatial representation of confounding and identification
Returning to the spatial domain, the response process can be written as
and is a mean-zero Gaussian process with spectral density independent of and . The function acts as a smoothing operator and, if it were known, then would be an appropriate adjustment to the mean to account for the unmeasured confounder. The form of the oracle confounder adjustment, i.e., if is known, is established in the following lemma.
Lemma 1. If is known then , where the kernel function is the inverse Fourier transform of .
The appealing consequence of Lemma 1 is that the oracle confounder adjustment is conveniently expressed as a kernel-smoothed function of the covariate of interest. It is also straightforward to show that, for any locations ,
| (5) |
and and . The product serves as a smoothing operator on . This representation is convenient for estimation and to determine the strength of confounding dependence between and .
Since is a smoothed version of , including it as a covariate in (5) effectively removes effects of the large-scale spatial trends in , so that the estimate of is largely determined by high-frequency terms. This expression also lays bare the importance of assuming that converges to zero for large frequencies or that and have different spectral densities. If restrictions are not placed on then it may be that and thus , giving the nonidentifiable model .
3. Continuous-space estimation strategies
3.1. The bivariate Matérn parametric model
The bivariate Matérn model (Gneiting et al., 2010; Apanasovich et al., 2012) is a flexible parametric model for the spectral densities and . The Matérn spectral density function for a process in two dimensions is , with smoothness and spatial range . The bivariate Matérn may have different parameters for each process, for , but constraints on the range and smoothness parameters are needed to ensure that the coherence is positive definite for all (Gneiting et al., 2010; Apanasovich et al., 2012). Another advantage of the Matérn parametric model is the closed-form expressions for both the spectral density and covariance functions. Under a common range assumption, as described in the next paragraph, the projection operator also has a closed-form Fourier transformation, allowing the estimation procedure to be performed completely in the spatial domain using (5).
With the bivariate Matérn modelling assumption, the projection operator has the form . Therefore, if the cross-spectral density decays faster than the covariate spectral density, the confounding adjustment will be smaller for higher frequencies, i.e., . Comparison of the ratio of spectral densities such that is complicated in general, and so we explore the special cases of common range, common smoothness and parsimonious models below. For each special case, we discuss the parameter settings that ensure unconfoundedness at high frequencies.
The common range model takes for ,
| (6) |
In this case, we have unconfoundedness at high frequencies, , if and only if , i.e., the cross-covariance is smoother than the covariate covariance. On the other hand, if we assume a common smoothness for then and confounding persists at high frequencies, regardless of the range parameters. Therefore, a common range parameterization allows us to identify the exposure effect by reducing high-resolution confounding while a common smoothness parameterization will not. For simplicity, we assume a common range in the remainder of this section.
Figure 1 illustrates the confounder adjustment in (5) for the bivariate Matérn model with a common range and different smoothness for increasing values of . Increasing implies increasing decay rates of . The original simulated is plotted in the left panel of Fig. 1 with , in which case we have and thus a completely confounded model. In the cases with the confounder adjustment is a smoothed version of . Therefore, including as a covariate in the model removes large-scale trends in to adjust for confounding at low frequencies.
Fig. 1.

Example confounder adjustment for the bivariate Matérn: is generated from Matérn with and on a 50 × 50 grid with grid spacing one. The panels show the confounder adjustment for and for . For .
The unmeasured confounder cannot be observed, making it difficult to estimate all the parameters in the bivariate Matérn model. Therefore, additional constraints are required for identifiability of the remaining parameters in addition to . These are provided in the next theorem
Theorem 2. Assuming that and a common range parameter, sufficient conditions for identifiability of the remaining parameters are a large cross-smoothness parameter and .
The common range model simplifies further under the parsimonious model in (4) with and . This is the parsimonious Matérn model of Gneiting et al. (2010), i.e., the cross-smoothness equals the average of the marginal smoothness parameters, . Under this model, the confounder adjustment becomes
| (7) |
and thus if and only if , i.e., the missing confounder is smoother than the exposure. On the other hand, if then . However, is not needed here as the identification strategy for the parsimonious coherence is established in Theorem 1.
3.2. Semiparametric model
Rather than indirectly modelling the projection operator via a model for the cross-covariance function, in this section we directly model using a flexible mixture model. We use a linear combination of cubic B-splines of order 4,
where the are B-spline basis functions, the are the associated coefficients and for grid spacing . A uniform sequence of knots is placed to cover the interval , such that and . The interval upper bound is the largest spectrum that can be observed from uniformly spaced data due to aliasing (Fuentes & Reich, 2010). We have restricted the projection operator to be isotropic by taking the Euclidean norm of the two-dimensional frequency , but this can be relaxed by using bivariate spline functions. Other mixture priors (Reich & Fuentes, 2012; Jang et al., 2017; Chen et al., 2021) can also be used for modelling the projection operator.
The B-spline mixture model for does not have a closed-form inverse Fourier transformation. We approximate the kernel-smoothed function with a finite sum at a set of equally spaced frequencies with spacing and following Qadir & Sun (2020):
Here and is a Bessel function of the first kind of order (Watson, 1995). This approximation allows us to directly compute confounder adjustment in the spatial domain, which would otherwise require the Fourier transform of data to perform analysis in the spectral domain. The confounder adjustment is then given by , where
| (8) |
When is observed on a grid, the integral can be approximated as with . For nongridded data, the covariate can be interpolated to a grid and this discrete approximation to the grid can be applied. Other numerical approximations to integrals can be applied to nongridded data such as the finite element method (Johnson, 2012, Ch. 12). The confounder adjustment covariates are precomputed to reduce computation during model fitting. We then fit the spatial model
| (9) |
where for identification and is modelled as a Gaussian process with nugget. The coefficients are given intrinsic autoregressive priors with full conditional distributions , where is the mean of the coefficients with , so and .
4. Discrete-space methodology
4.1. A spectral model for confounding
We extend our methodology to the discrete case for a spatial domain comprised of regions. For region , let and be the response, exposure and confounding variables, respectively. Let and define similarly. We model using the conditional autoregressive model (Gelfand et al., 2010) with the Leroux parameterization (Leroux et al., 2000),
where is the mean vector, determines the overall variance, controls the strength of spatial dependence and is an matrix specifying the spatial dependence. For the discrete case, the spatial dependence between the regions is often described by an adjacency structure. Let if regions and are adjacent and 0 otherwise, and let be the number of regions adjacent to region . Then has off-diagonal element and ith diagonal element . We denote this model as .
An advantage of the Leroux parameterization is that the spatial covariance can be written as
where the spectral decomposition of is for orthonormal eigenvector matrix and diagonal eigenvalue matrix with kth diagonal element , ordered so that . Assuming that all variables have the same adjacency structure , this allows us to project the model into the spectral domain using the graph Fourier transform (Sandryhaila & Moura, 2013), and . This transformation decorrelates the model and gives
where is the sum of the kth column of and are independent across . To exploit this decorrelation property of the graph Fourier transform, we conduct all analyses of Gaussian data for the discrete spatial domain in the spectral scale.
Comparing the discrete to continuous cases, the eigenvalue is analogous to frequency . Terms with small have large variance and measure large-scale trends in the data. For example, it can be shown that if the locations form a connected graph then and is proportional to the mean of . In contrast, terms with large have small variance and represent small-scale features. Using this analogy, in the remainder of this section we extend two of the continuous-domain methods of § 3 to the discrete case.
4.2. Bivariate conditional autoregressive model
As in § 2, we assume a joint model for and . We assume that the pairs are independent across , and Gaussian with mean zero and covariance
| (10) |
where and are variance parameters, and are variance functions that determine the covariance of and , respectively, and scalar and function determine the dependence between and . For the Leroux conditional autoregressive model, we have for so that the marginal distributions are and .
One possible parametric cross-covariance model is . As with the bivariate Matérn, has the same functional form as and . Constraints are required to ensure that the covariance in (10) is positive definite, i.e., that
| (11) |
for all . Necessary conditions for (11) to hold for all are and , but these conditions are not sufficient and not even necessary when considering only .
Assuming that the covariance parameters give a valid covariance, then marginalizing over and setting , as in § 2, for identification gives
| (12) |
where and . Therefore, as , and thus the high-resolution confounding effect is smallest when is smaller than .
The parsimonious cross-covariance model is , giving for all . With this simplification, any and give a valid covariance, and the terms in (12) reduce to and . Here, the missing confounder need not be smoother than the exposure, i.e., , for identifying as the assumption for identification is parsimonious coherence. As long as , the remaining parameters can also be identified, as established in the next theorem.
Theorem 3. Assuming that and , then the parameters in the parsimonious model (13) below are all identifiable.
We have fixed in Theorem 3 so we can estimate , but this is unnecessary. The alternative parameterization can be used, which does not affect the results, as discussed in § 2.2.
In the spatial domain, the parsimonious model is
| (13) |
where and is diagonal with th diagonal element . The term adjusts for missing spatial confounders and the term captures spatial variation that is independent of . In this case with , the confounder adjustment smooths by first projecting into the spectral domain by multiplying by , then dampening the high-frequency terms with large and thus small by multiplying by , and finally projecting back in the spatial domain by multiplying by . Marques et al. (2022) developed a Bayesian method to mitigate spatial confounding. Their model is related to our parsimonious Leroux conditional autoregressive model, except they used a Gaussian Markov random field model using the stochastic partial differential equation approach (Lindgren et al., 2011) for X and Z, and a penalized complexity prior for .
4.3. Semiparametric conditional autoregressive model
Mirroring § 3.2, rather than specifying a parametric joint model for , we directly specify a flexible model for the confounder adjustment, . The joint model is specified first with the conditional model
In the spatial domain, this implies that , where is diagonal with diagonal elements . Therefore, with any valid marginal distribution of , the joint model of and is well defined. Since is observed, we do not need a model for its marginal distribution.
Marginalizing over the unknown gives
| (14) |
where . Following § 3.2, we assume that so that and are uncorrelated for the highest-frequency term. This implies that and , and thus the final term supplies unbiased information about the true exposure effect . Of course, a single unbiased term is insufficient for estimation, and so we further assume that varies smoothly over to permit semiparametric estimation of .
We fit model (14) with a covariate effect that is allowed to vary with to separate associations at different spatial resolutions. Although other smoothing techniques are possible, the frequency-specific coefficients are smoothed using the basis expansion , where the are cubic B-spline basis functions and the are the associated coefficients. Analogously to the semiparametric continuous-space model in § 3.2, we employ equally spaced B-splines (Eilers & Marx, 1996) with an intrinsic autoregressive prior on . Under the assumption that , we use the posterior distribution of to summarize the effect .
In the spatial domain, the semiparametric conditional autoregressive model can be written as (9), i.e.,
where is the diagonal matrix with spline basis functions, , on the diagonal and the regression coefficients are modelled as described below (8). The constructed covariates can be precomputed prior to estimation, and thus computation resembles a standard spatial analysis with known covariates. As above, under the assumption of no confounding for large , we use the posterior of to summarize the exposure effect. As our estimation of relies on a B-spline estimate at an endpoint, it may be associated with relatively large uncertainty. Therefore, other smoothing techniques may also be considered to test the sensitivity of the estimate to the chosen method of estimation.
5. Simulation study
5.1. Discrete space
Data are generated at locations on a 40 × 40 square grid with grid spacing one. The conditional autoregressive model uses rook neighbourhood structure so that if and only if . Data are generated from and , where is the kernel smoothing matrix with bandwidth , i.e., and . Including the kernel smoothed in the mean of induces low-resolution dependence between and . In all cases we take and , and we vary the strength of dependence via , and the kernel bandwidth . The value of can be chosen without loss of generality, as only the product of and can be uniquely identified. For each parameter combination, we generate 500 datasets; see the data examples in the Supplementary Material.
Figure 2 plots the induced correlations in the spectral domain for each scenario with . The correlation is nonzero for only low-frequency terms when , but correlation spills over to high-frequency terms when , especially when . Therefore, the assumption of no confounding at high frequencies is questionable when , and these scenarios are used to examine sensitivity to this key assumption. Also, these scenarios violate the parsimonious assumption of constant correlation across frequency, and so they illustrate the effects of misspecifying the parametric model.
Fig. 2.

Correlations in the spectral domain for the simulation study: by for different kernel bandwidths and strengths of exposure/confounder dependence ; the correlations in the spatial domain (over locations) are 0.62 when and when and when and , and 0.62 when and .
For each simulated dataset, we fit the standard Leroux conditional autoregressive model that has for all , the parametric parsimonious bivariate conditional autoregressive model and the semiparametric model with varying across using a cubic B-spline basis expansion. We compare two priors for , the variance of the coefficient process , for the semiparametric model. The penalized complexity prior shrinks the process towards the constant function to avoid overfitting (Franco-Villoria et al., 2019); the second prior for the variance induces a Un (0, 1) prior on the proportion of overall model variance explained by variation in to balance all levels of spatial confounding. The prior distributions for all models are given in the Supplementary Material. We fit the semiparametric models for all and select the number of basis functions using the deviance information criterion (Spiegelhalter et al., 2002). All methods are fit using Markov chain Monte Carlo with 25000 iterations and the first 5000 discarded as burn-in.
Table 1 compares methods in terms of the root mean squared error, bias, posterior standard deviation averaged over datasets and empirical coverage of 95% intervals for , and Fig. 3 summarizes the sampling distribution of against . The standard method performs well in the first scenario with no unmeasured confounder, , but in all other scenarios the standard method is biased and has coverage at or near zero. The standard method allows for spatially dependent residuals, but this does not eliminate spatial confounding bias. Since the standard model assumes that and are independent, when and are highly correlated, all spatial variability is attributed to the exposure effect, leading to bias and small posterior standard deviation.
Table 1.
Discrete-space simulation study comparing four methods: the standard Leroux model, the parametric parsimonious model, the semiparametric model with a penalized complexity prior and the semiparametric model with a uniform prior on the proportion of variance (semi-). Data are generated with dependence between exposure and confounder controlled by and kernel bandwidth . Standard errors are given in parentheses and all results are multiplied by 100
| Scenario | Method | RMSE | Bias | SD | Cov | ||
|---|---|---|---|---|---|---|---|
| 1 | Standard | — | 0 | 1.2 (0.0) | 0.0 (0.1) | 1.3 (0.0) | 95.2 (1.0) |
| Parametric | 1.3 (0.0) | 0.0 (0.1) | 1.4 (0.0) | 95.4 (0.9) | |||
| Semiparametric | 4.4 (0.3) | 0.0 (0.2) | 2.5 (0.1) | 95.0 (1.0) | |||
| Semi- | 4.5 (0.4) | 0.0 (0.2) | 2.5 (0.1) | 94.8 (1.0) | |||
| 2 | Standard | 1 | 1 | 19.0 (0.1) | 18.9 (0.1) | 1.4 (0.0) | 0.0 (0.0) |
| Parametric | 14.0 (0.l) | 13.8 (0.1) | 1.7 (0.0) | 0.0 (0.0) | |||
| Semiparametric | 7.7 (0.3) | −0.9 (0.3) | 8.3 (0.1) | 96.6 (0.8) | |||
| Semi- | 8.0 (0.3) | −0.7 (0.4) | 8.9 (0.1) | 97.2 (0.7) | |||
| 3 | Standard | 1 | 2 | 34.3 (0.1) | 34.3 (0.1) | 1.7 (0.0) | 0.0 (0.0) |
| Parametric | 20.6 (0.2) | 20.4 (0.1) | 2.0 (0.0) | 0.0 (0.0) | |||
| Semiparametric | 9.5 (0.3) | 0.6 (0.4) | 9.3 (0.1) | 94.4 (1.0) | |||
| Semi- | 9.5 (0.3) | 0.8 (0.4) | 9.4 (0.1) | 96.0 (0.9) | |||
| 4 | Standard | 2 | 1 | 5.6 (0.1) | 5.4 (0.1) | 1.4 (0.0) | 3.8 (0.9) |
| Parametric | 2.1 (0.1) | 1.2 (0.1) | 1.6 (0.0) | 85.4 (1.6) | |||
| Semiparametric | 8.2 (0.2) | −0.9 (0.4) | 9.3 (0.1) | 96.6 (0.8) | |||
| Semi- | 8.2 (0.3) | −0.7 (0.4) | 9.2 (0.1) | 95.8 (0.9) | |||
| 5 | Standard | 2 | 2 | 8.8 (0.1) | 8.7 (0.1) | 1.5 (0.0) | 0.0 (0.0) |
| Parametric | 2.5 (0.1) | −1.1 (0.1) | 1.8 (0.0) | 84.0 (1.6) | |||
| Semiparametric | 10.2 (0.3) | −0.6 (0.5) | 10.3 (0.1) | 94.8 (1.0) | |||
| Semi- | 10.4 (0.3) | −0.6 (0.5) | 10.3 (0.1) | 94.0 (1.1) |
RMSE, root-mean-squared error; SD, average posterior standard deviation; Cov, coverage of 95% posterior intervals.
Fig. 3.

Performance for the discrete simulation study: median (solid) and 95% confidence interval (dashed) for for the standard model (red), semiparametric model with the penalized complexity prior (green), and parametric model (blue) for data generated with dependence between exposure, and confounder controlled by and kernel bandwidth . The black lines are the true .
The parametric model performs well in scenario 1, and respectably in scenarios 4 and 5 where there is no confounding at high frequencies and parametric model assumptions do not hold. In fact, the parametric model is nearly identical to the standard model in the first case with no spatial confounding, suggesting that little is lost by allowing for a parametric confounding adjustment when it is not needed. However, the parametric model gives bias and low coverage in the cases with , and thus the form of spatial confounding does not match the parametric model. The estimated curves in Fig. 3 show that the parametric form of the model cannot match the slow decline in the true correlation of Fig. 2 when . However, the parametric model is still able to recover reasonably well the truth for ; it appears that there is some robustness to the parsimonious coherence assumption for the parametric model if the unconfoundedness at high frequencies assumption holds.
The semiparametric methods have low bias and coverage near the nominal level for all five scenarios. However, the posterior standard deviation is always larger for the semiparametric models than the standard or parametric models. Therefore, in these cases, the semiparametric methods are robust, but conservative for estimating a casual effect in the presence of spatial confounding. Surprisingly, the semiparametric methods are insensitive to the choice of prior. Despite the two prior specifications having very different motivations, the results are similar, likely because the deviance information criterion often selects a small number of basis functions that negates the influence of the prior for .
5.2. Continuous space
Data in the continuous space are generated similarly to the discrete case. The data are simulated on a 23 × 23 unit square grid. We simulated and , where is the Matérn correlation matrix defined by parameters and , and is the kernel smoothing matrix with bandwidth . In all cases we take , spatial range parameters and , and we vary , and the kernel bandwidth . For each combination of these parameters, we generate 100 datasets. For each simulated dataset, we fit four models: the standard Matérn model in § 3.1 with , and thus no confounding adjustment, the bivariate Matérn model with common range in (6), the parsimonious Matérn model in (7) and the semiparametric model in § 3.2. Prior distributions and computing details are given in the Supplementary Material.
The results mirror those in the discrete case and therefore the result table is deferred to the Supplementary Material. The semiparametric method maintains nearly the nominal coverage and low bias across all scenarios. The parametric Matérn models have bias and low coverage for the simulation settings where the data are not simulated with a Matérn covariance. The common range Matérn model dramatically reduces root-mean-square error and improves coverage compared to the parsimonious Matérn model, but neither is sufficiently flexible for these cases.
6. Real data examples
6.1. Analysis of the Scottish lip cancer dataset
All model fits in this section were carried out using the eCAR package found in R (R Development Core Team, 2023) that was created to fit the discrete space methods. We first consider the well-known lip cancer dataset, see Fig. 4, available in the R package CAR-Bayesdata. The data cover districts in Scotland. Three variables are recorded for each district: the recorded number of lip cancer cases, , the expected number of lip cancer cases computed using indirect standardization based on Scotland-wide disease rates, , and the percentage of the district’s workforce employed in agriculture, fishing and forestry, . Since we have non-Gaussian responses, the generalized models presented in the Supplementary Material are used.
Fig. 4.

Maps for the Scotland lip cancer dataset: (a) standard mortality ratio and (b) mortality rate in the agriculture, fishing and forestry workforce.
We fit the spatial Poisson regression model , where is the log relative risk in district . We model as . For the parametric approach, we use the same priors as in § 5.1 and, for the semiparametric model, we employ INLA (Rue et al., 2009) and use the penalized complexity prior with basis functions, chosen via the deviance information criterion; results are stable for . We also fit two standard nonspectral methods where is constant over : a Poisson regression with the percentage of the workforce employed in agriculture, fishing and forestry as the covariate and a Poisson regression that includes Leroux conditional autoregressive random effects.
Figure 5 plots the posterior of by the eigenvalue for each model. The standard methods have positive posterior mean and their 95% intervals exclude 1, indicating a significant increase in risk for lip cancer for a unit difference in the percentage of the workforce employed in agriculture, fishing and forestry. The spectral methods, which attempt to account for spatial confounding, do not agree with the standard methods: the estimated trends toward 1 for large , meaning that the results of the standard models should be interpreted with caution because the strength of the relationship between these variables is weak at the local spatial scale. These results are consistent with a missing confounding variable with the same large-scale spatial pattern as lip cancer disease and the percentage of the workforce employed in agriculture, fishing and forestry.
Fig. 5.

Effect of the percentage of the workforce employed in agriculture, fishing and forestry on lip cancer in Scotland: posterior mean (solid lines) and 95% credible interval (dashed lines) of for the spectral parametric model (black), the spectral semiparametric model with (green), a Poisson regression on the percentage of the workforce employed in agriculture, fishing and forestry (red) and a Poisson regression with residuals modelled as Leroux (blue).
6.2. Analysis of COVID-19 mortality and PM2.5 exposure
Wu et al. (2020) noted that many of the pre-existing conditions that increase the mortality risk of COVID-19 are connected with long-term exposure to air pollution. They conducted a study and found that a difference of in ambient fine particulate matter, PM2.5, is positively associated with a 15% difference in the COVID-19 mortality rate. To further illustrate our proposed methods, we analyse the data collected by Wu et al. (2020) in an attempt to estimate the effect of PM2.5 on COVID-19 mortality using spatial methods.
The response is the cumulative COVID-19 mortality counts through May 12, 2020 for US counties. County-level exposure to PM2.5 was calculated by averaging results from an established exposure prediction model for the years 2000–16; see Wu et al. (2020) for more details. Eight counties and 12 Virginia cities were missing from the database, so we imputed their values using neighbourhood means with neighbours defined by counties that share a boundary. This resulted in mortality counts and PM2.5 measures for counties; see Fig. 6. In addition to PM2.5 exposure, 20 potential confounding variables, e.g., the percentage of the population at least 65 years old, are included in our modelling; see Wu et al. (2020) for the complete set of potential confounding covariates. For county , denote as the number of deaths attributed to COVID-19, as the population, as the average PM2.5 and as the vector of 20 known confounding variables. Similar to Wu et al. (2020), we fit a negative-binomial regression model , where is the size parameter and the probability of success. Under this model, the mean is . We parameterize the model in terms of and . The prior is and the mean is linked to the linear predictor as , where , the offset term is the county population and is a vector of regression coefficients associated with the confounding variables. Following the non-Gaussian models in the Supplementary Material, the linear predictor becomes , where is a design matrix that includes an intercept term. We fit this model using the parametric and semiparametric approaches detailed in § 4.2 and § 4.3. The negative-binomial model is chosen to mimic the analysis in Wu et al. (2020). We also considered a binomial and Poisson model and inferences were relatively unchanged.
Fig. 6.

(a) Average PM2.5 () over 2000–16 and (b) the log COVID-19 mortality rate through May 12, 2020. Counties with no deaths are shaded grey.
We compare our method to a variant of the model employed in Wu et al. (2020), which we refer to as the standard spatial model, i.e., a negative-binomial regression with all control variables and county random effects modelled using the Leroux model. Following Wu et al. (2020), two separate analyses using all counties and counties that reported at least 10 confirmed COVID-19 deaths were conducted; this was done to account for the fact that the size of an outbreak in a given county may be positively associated with both the COVID-19 mortality rate and PM2.5, thus introducing confounding bias.
Figure 7 displays model fits using the full and reduced data. The estimated difference in the COVID-19 mortality rate, associated with a difference of of PM2.5, under the standard spatial model is 16% (95% confidence interval: 1.08, 1.25), and 12% (95% confidence interval: 1.04, 1.21) in the full and reduced analyses, respectively. The posterior mean estimates from the parametric and semiparametric spectral models generally agree with the standard spatial approach, but the posterior standard deviation is higher for the spectral methods. In this analysis, the spectral methods support the standard spatial model and serve as a check of sensitivity to adjustments for missing confounders.
Fig. 7.
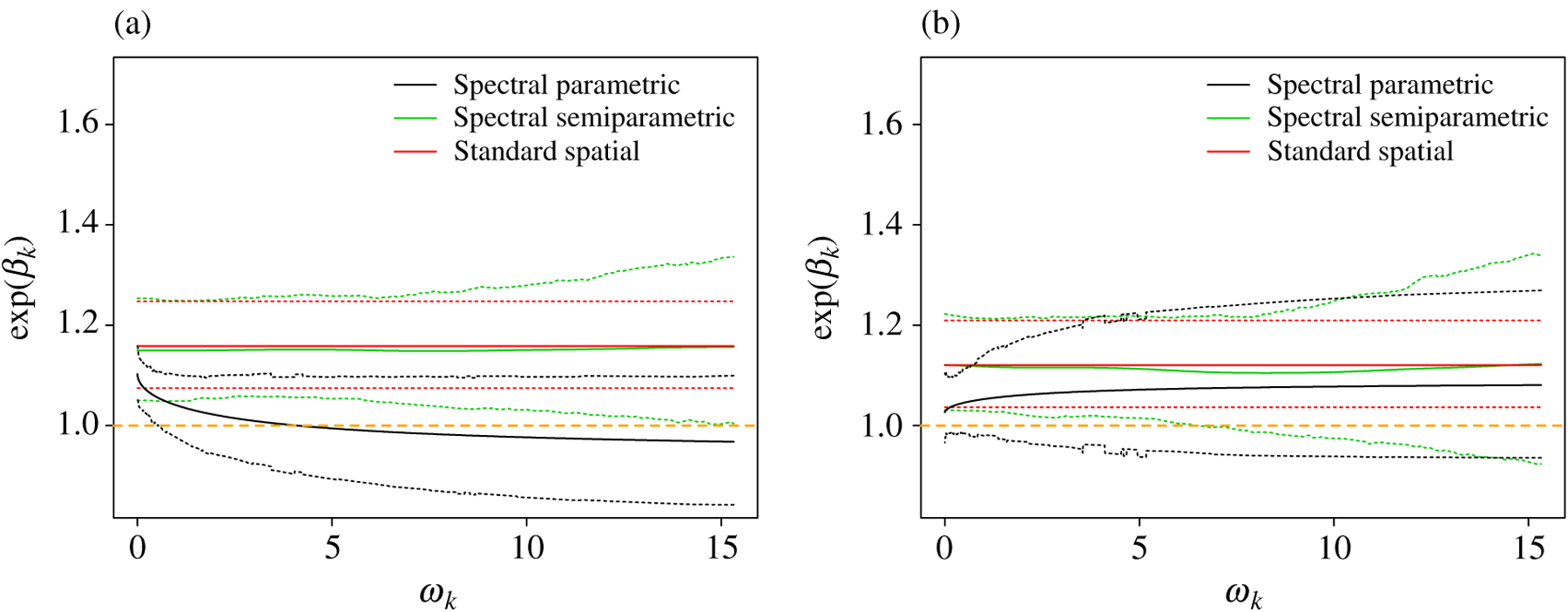
Results for the COVID-19 example: the posterior mean (solid) and 95% credible interval (dashed) of the mortality rate ratio associated with a difference of of PM2.5, . Results are for (a) all counties and (b) counties that reported at least 10 confirmed COVID-19 deaths. The standard spatial approach refers to a regression model including all confounders and a spatial Leroux model for county random effects.
7. Discussion
Our work is the first to study the problem of spatial confounding in the spectral domain and model the coherence between the exposure and the unmeasured spatial confounder. We provide theoretical results that help understand the study in Paciorek (2010), where extensive simulations illustrate the bias obtained under different combinations of spatial scales for and . New spectral methods are also proposed to adjust for unmeasured spatial confounding variables, and sufficient conditions are provided to ensure that the exposure effect is identifiable, including the important case without a nugget effect in the treatment and/or response variable. These ideas are developed for continuous and discrete spatial domains, and Gaussian and non-Gaussian data.
We have assumed that and are stationary Gaussian processes in developing our methodology. Such modelling assumptions often work well with weak nonstationarity. With strong nonstationarity under model misspecification, we believe that the semiparametric model is more robust, and that estimation will be primarily driven by observations from the regions that have variations at smaller spatial scales. We recommend gravitating towards the semiparametric approach. The parametric parsimonious model depends on scale-invariant coherence between the exposure and the unmeasured confounder; it also relies on parsimonious parameterization for estimation of . The semiparametric model depends on the assumption that their coherence tends to zero for large frequencies. While neither of these assumptions are empirically verifiable, we believe that the latter assumption is more reasonable in practice. The semiparametric methods are also easier to implement computationally as the confounding adjustment takes the form of smoothed covariates; it is straightforward to pass these constructed variables into standard spatial computing packages. However, the continuous-space semiparametric model requires numerical approximations to integrals. When the exposure observations are highly spatially irregular, our implementation in § 3.2 can be problematic. In this case, we recommend seeking other numerical approximations to integrals.
Supplementary Material
Acknowledgement
This work was partially supported by the National Institutes of Health and the King Abdullah University of Science and Technology.
Footnotes
Supplementary material
The Supplementary Material includes an extension of the proposed methods to multiple predictors and non-Gaussian observations, details of the causal assumptions for the spatial framework, proofs of the lemmas and theorems, prior distributions and computing details for both discrete and continuous cases, and a results table for the continuous-space simulation study. The R code is available at https://github.com/yawenguan/spatial_confounding.
Contributor Information
YAWEN GUAN, Department of Statistics, University of Nebraska, 343C Hardin Hall, Lincoln, Nebraska 68583, U.S.A..
GARRITT L. PAGE, Department of Statistics, Brigham Young University, 238 TMCB, Provo, Utah 84602, U.S.A.
BRIAN J. REICH, Department of Statistics, North Carolina State University, 2311 Stinson Drive, Raleigh, North Carolina 27695, U.S.A.
MASSIMO VENTRUCCI, Department of Statistical Sciences, University of Bologna, Via Zamboni 33, Bologna 40126, Italy.
SHU YANG, Department of Statistics, North Carolina State University, 2311 Stinson Drive, Raleigh, North Carolina 27695, U.S.A..
References
- Apanasovich TV, Genton MG & Sun Y (2012). A valid Matérn class of cross-covariance functions for multivariate random fields with any number of components. J. Am. Statist. Assoc 107, 180–93. [Google Scholar]
- Chen K, Dai F, Marchiori E & Theodoridis S (2021). Novel compressible adaptive spectral mixture kernels for Gaussian processes with sparse time and phase delay structures. ar Xiv: 1808.00560v8. [Google Scholar]
- Clayton DG, Bernardinellli L & Montomoli C (1993). Spatial correlation in ecological analysis. Int. J. Epidemiol 22, 1193–202. [DOI] [PubMed] [Google Scholar]
- Dupont E, Wood SN & Augustin N (2022). Spatial+: a novel approach to spatial confounding. Biometrics 78, 1279–90. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eilers PHC & Marx BD (1996). Flexible smoothing with b-splines and penalties. Statist. Sci 11, 89–102. [Google Scholar]
- Faes L, Krohova J, Pernice R, Busacca A & Javorka M (2019). A new frequency domain measure of causality based on partial spectral decomposition of autoregressive processes and its application to cardiovascular interactions. In 2019 41st Ann. Int. Conf. IEEE Eng. Med. Biol. Soc. (EMBC), pp. 4258–61. Piscataway, NJ: IEEE Press. [DOI] [PubMed] [Google Scholar]
- Franco-Villoria M, Ventrucci M & Rue H (2019). A unified view on Bayesian varying coefficient models. Electron. J. Statist 13, 5334–59. [Google Scholar]
- Fuentes M & Reich B (2010). Spectral domain. In Handbook of Spatial Statistics, Gelfand AE, Diggle P, Fuentes M & Guttorp P, eds. Boca Raton, FL: CRC Press, pp. 57–77. [Google Scholar]
- Gelfand AE, Diggle P, Fuentes M & Guttorp P, Ed. (2010). Handbook of Spatial Statistics. Boca Raton, FL: CRC Press. [Google Scholar]
- Gneiting T, Kleiber W & Schlather M (2010). Matérn cross-covariance functions for multivariate random fields. J. Am. Statist. Assoc 105, 1167–77. [Google Scholar]
- Hanks EM, Schliep EM, Hooten MB & Hoeting JA (2015). Restricted spatial regression in practice: geostatistical models, confounding, and robustness under model misspecification. Environmetrics 26, 243–54. [Google Scholar]
- Hodges JS & Reich BJ (2010). Adding spatially-correlated errors can mess up the fixed effect you love. Am. Statistician 64, 325–34. [Google Scholar]
- Hughes J & Haran M (2013). Dimension reduction and alleviation of confounding for spatial generalized linear mixed models. J. R. Statist. Soc. B 75, 139–59. [Google Scholar]
- Jang PA, Loeb A, Davidow M & Wilson AG (2017). Scalable Levy process priors for spectral kernel learning. In Advances in Neural Information Processing Systems, pp. 3943–52. New York: Curran Associates. [Google Scholar]
- Johnson C (2012). Numerical Solution of Partial Differential Equations by the Finite Element Method. New York: Dover Publications. [Google Scholar]
- Keller JP & Szpiro AA (2020). Selecting a scale for spatial confounding adjustment. J. R. Statist. Soc. A 183, 1121–43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Khan K & Calder CA (2022). Restricted spatial regression methods: implications for inference. J. Am. Statist. Assoc 117, 482–94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kleiber W (2017). Coherence for multivariate random fields. Statist. Sinica 27, 1675–97. [Google Scholar]
- Leroux BG, Lei X & Breslow N (2000). Estimation of disease rates in small areas: a new mixed model for spatial dependence. In Statistical Models in Epidemiology, the Environment, and Clinical Trials, Halloran ME & Berry D, eds. New York: Springer, pp. 179–91. [Google Scholar]
- Lindgren F, Rue H & Lindström J (2011). An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach. J. R. Statist. Soc. B 73, 423–98. [Google Scholar]
- Marques I, Kneib T & Klein N (2022). Mitigating spatial confounding by explicitly correlating Gaussian random fields. Environmetrics 33, e2727. [Google Scholar]
- Osama M, Zachariah D & Schön TB (2019). Inferring heterogeneous causal effects in presence of spatial confounding. In Proc. 36th Int. Conf. Mach. Learn., Long Beach, California, vol. 97, Chaudhuri K & Salakhutdinov R, eds. PMLR, pp. 4942–50. [Google Scholar]
- Paciorek CJ (2010). The importance of scale for spatial-confounding bias and precision of spatial regression estimators. Statist. Sci 25, 107–25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Page GL, Liu Y, He Z & Sun D (2017). Estimation and prediction in the presence of spatial confounding for spatial linear models. Scand. J. Statist 44, 780–97. [Google Scholar]
- Prates MO, Assunção RM & Rodrigues EC (2019). Alleviating spatial confounding for areal data problems by displacing the geographical centroids. Bayesian Anal. 14, 623–47. [Google Scholar]
- Qadir GA & Sun Y (2020). Semiparametric estimation of cross-covariance functions for multivariate random fields. Biometrics 77, 547–60. [DOI] [PubMed] [Google Scholar]
- R Development Core Team (2023). R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. ISBN 3-900051-07-0, http://www.R-project.org. [Google Scholar]
- Reich BJ & Fuentes M (2012). Nonparametric Bayesian models for a spatial covariance. Statist. Methodol 9, 265–74. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reich BJ, Hodges JS & Zadnik V (2006). Effects of residual smoothing on the posterior of the fixed effects in disease-mapping models. Biometrics 62, 1197–206. [DOI] [PubMed] [Google Scholar]
- Reich BJ, Yang S, Guan Y, Giffin AB, Miller MJ & Rappold A (2021). A review of spatial causal inference methods for environmental and epidemiological applications. Int. Statist. Rev 89, 605–34. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rue H, Martino S & Chopin N (2009). Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J. R. Statist. Soc. B 71, 319–92. [Google Scholar]
- Sandryhaila A & Moura JMF (2013). Discrete signal processing on graphs: graph Fourier transform. In 2013 IEEE Int. Conf. Acoust. Speech Sig. Proces., pp. 6167–70. Piscataway, NJ: IEEE Press. [Google Scholar]
- Schnell P & Papadogeorgou G (2020). Mitigating unobserved spatial confounding when estimating the effect of supermarket access on cardiovascular disease deaths. Ann. Appl. Statist 14, 2069–95. [Google Scholar]
- Spiegelhalter DJ, Best NG, Carlin BP & Van Der Linde A (2002). Bayesian measures of model complexity and fit. J. R. Statist. Soc. B 64, 583–639. [Google Scholar]
- Stokes PA & Purdon PL (2017). A study of problems encountered in Granger causality analysis from a neuroscience perspective. Proc. Nat. Acad. Sci 114, E7063–72. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thaden H & Kneib T (2018). Structural equation models for dealing with spatial confounding. Am. Statistician 72, 239–52. [Google Scholar]
- Watson GN (1995). A Treatise on the Theory of Bessel Functions. Cambridge: Cambridge University Press. [Google Scholar]
- Wu X, Nethery RC, Sabath BM, Braun D & Dominici F (2020). Air pollution and COVID-19 mortality in the United States: strengths and limitations of an ecological regression analysis. Sci. Adv 6, 1–6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zimmerman DL & Hoef JMV (2022). On deconfounding spatial confounding in linear models. Am. Statistician 76, 159–67. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.