

Abstract
Kidney transplantation is the preferred treatment for people suffering from end-stage renal disease. Successful kidney transplants still fail over time, known as graft failure; however, the time to grant failure, or graft survival time, can vary significantly between different recipients. A significant biological factor affecting graft survival times is the compatibility between the human leukocyte antigens (HLAs) of the donor and recipient. We propose to model HLA compatibility using a network, where the nodes denote different HLAs of the donor and recipient, and edge weights denote compatibilities of the HLAs, which can be positive or negative. The network is indirectly observed, as the edge weights are estimated from transplant outcomes rather than directly observed. We propose a latent space model for such indirectly-observed weighted and signed networks. We demonstrate that our latent space model can not only result in more accurate estimates of HLA compatibilities, but can also be incorporated into survival analysis models to improve accuracy for the downstream task of predicting graft survival times.
Index Terms—: human leukocyte antigens, indirectly-observed network, biological network, weighted network, signed network, survival analysis, Cox proportional hazards, graft survival
I. Introduction
Kidney transplantation is by far the preferred treatment for people suffering from end-stage renal disease (ESRD), an advanced state of chronic kidney disease. Despite the advantages of kidney transplants, most patients with ESRD are treated with dialysis, primarily because there exist an insufficient number of compatible donors for patients. Kidney transplants (and other organ transplants in general) inevitably fail over time, referred to as graft failure. These patients then require a replacement with another kidney transplant, or they must return to the waiting list while being treated with dialysis.
The time to graft failure, or graft survival time, is determined by a variety of factors. A significant biological factor affecting clinical survival times of transplanted organs is the compatibility between the human leukocyte antigens (HLAs) of the organ donor and recipient. Mismatches between donor and recipient HLAs may cause the recipient’s immune response to launch an attack against the transplanted organ, resulting in worse outcomes, namely shorter graft survival time to transplant failure. However, it is extremely rare to identify donors that have a perfect HLA match with recipients (less than 10%), so most transplants (more than 90%) involve different degrees of mismatched HLAs. Interestingly, HLA mismatches appear not to be equally harmful. Prior work indicates that some mismatches may still lead to good post-transplant outcomes [1, 2], suggesting differing levels of compatibility between donor and recipient HLAs.
Nemati et al. [3] proposed an approach to encode donor and recipient HLAs into feature representations that accounts for biological mechanisms behind HLA compatibility. By adding these features to a Cox proportional hazards (CoxPH) model, they were able to improve the prediction accuracy for the graft survival time for kidney transplants. Their CoxPH model also provides estimates of the compatibilities between donor and recipient HLAs through the coefficients of the model. However, most donor-recipient HLA pairs are infrequently observed, with many HLA pairs occurring in less than 1% of all transplants. These estimated compatibilities are thus extremely noisy, and in some cases, have standard errors as large or larger than the estimates themselves!
In this paper, we propose to represent HLA compatibility as a network, where the edge weight between a donor HLA and a recipient HLA denotes the compatibility. We propose a latent space model for the HLA compatibility network, which is a weighted, signed, and bipartite network with extremely noisy edge weights. The latent space model allows us to use compatibilities of other HLA pairs in the network to improve the estimated compatibility of a given HLA pair.
Our main contributions are as follows:
We introduce the notion of an HLA compatibility network between donor and recipient HLAs, a noisy signed and weighted network estimated from outcomes of kidney transplants involving those HLAs.
We propose a latent space model for the HLA compatibility network to capture the underlying structure between HLAs and better predict their compatibilities.
We demonstrate that applying our latent space model to the HLA compatibility network results in more accurate predictions of the compatibilities.
We find that the predicted compatibilities from our latent space model can further improve accuracy for the downstream task (see Figure 1) of predicting outcomes of kidney transplants, namely the graft survival times.
Fig. 1.

End-to-end evaluation of HLA compatibility estimates using downstream task of survival prediction. The HLA compatibility estimates from the Cox PH model (red line) are compared against the updated HLA compatibility estimates from the latent space model (blue line) for survival prediction accuracy.
II. Background
A. Human Leukocyte Antigens (HLAs)
The Human Leukocyte Antigens system is a system of proteins expressed on a transplant’s cell that recognizes the immunogenicity of a kidney transplant from a donor [2, 4]. The HLA system includes three primary HLA loci, denote as HLA-A, HLA-B, and HLA-DR. For each HLA locus, there are many diverse HLA proteins. The general way to express HLA antigens is using two-digit, or low-resolution typing, where each HLA is identified by “HLA” followed by a hyphen: a letter indicating the locus, and a 1-digit or 2-digit number which indicates the HLA protein, e.g. HLA-A1 [5]. In this paper, we drop the “HLA” prefix and refer to HLA-A1 as simply A1.
Each person has two sets of HLAs, one inherited from the father and one from the mother. Therefore, each donor and recipient has 6 HLAs, and anywhere from 0 to 6 of the HLAs can be mismatched. The compatibility between the mismatched HLAs of the kidney donor and recipient has shown to be a significant factor affecting transplanted kidneys’ survival times [2, 4, 6]. A pair of kidney donors and recipients with higher HLA compatibility receive a higher possibility of getting a good transplant outcome.
B. Survival Analysis
Survival analysis focuses on analyzing time-to-event data, where the objective is typically to model the expected duration until an event of interest occurs for a given subject [7]. For many subjects, however, the exact time of the event is unknown due to censoring, which may occur for many reasons, including the event not yet occurring, or the subject dropping out from the study. We briefly introduce some survival analysis terminology and models relevant to this paper.
Let denote the time that the event of interest (graft failure) occurs. The hazard function is defined as
and denotes the rate of the event of interest occurring at time given that it did not occur prior to time . A common assumption in survival analysis is the proportional hazards assumption, which assumes that covariates are multiplicatively related to the hazard function. In the Cox proportional hazards model, the hazard function takes the form
where is a baseline hazard function, denotes the jth covariate for subject , and denotes the coefficient for the th covariate. Note that the hazard ratio for any two subjects is independent of the baseline hazard function . Assume that the th covariate is binary. If we consider two groups of subjects who differ only in the th covariate, then the hazard ratio is given by , and the log of the hazard ratio is thus .
C. Latent Space Models
Network models are favored to represent relations among interacting units. Hoff et al. [8] first proposed a network model called latent space model for network analysis. They developed a class of models where the probability of a edge existence between two entities depends on their positions in an unobserved Euclidean space or latent space. Let denotes the adjacency matrix of a network, with for node pairs with an edge and otherwise. They assume independence between node pairs, and the log odds of an edge being formed between nodes is given by , where denotes observed covariates between nodes , denotes the latent positions in a -dimensional latent space for nodes and , and and are the linear parameters. Within the context of this parameterization, two nodes have higher probability to form an edge if they have closer latent positions.
D. Related Work
1). Extensions of Latent Space Models:
The latent space model provides a visual and interpretable spatial representation for relational data. Hoff et al.’s model [8] was extended by researchers for more complex network based on data structures, including bipartite networks [9], discrete-time dynamic networks [10], and multimodal networks [11]. The node-specific random effects were added to the latent space model by [12] to capture the degree heterogeneity. In this work, we propose a HLA latent space model for a signed, weighted bipartite network to capture the relation within HLA compatibility networks.
2). Predicting Kidney Transplant Outcomes:
A variety of approaches have been proposed for predicting outcomes for kidney transplants, as well as other organ transplants. Due to the high rate of censored subjects in this type of data, most approaches use some form of survival prediction, including an ensemble model that combines CoxPH models with random survival forests [13] and a deep learning-based approach [14].
The most relevant prior work is that of Nemati et al. [3], who propose a variety of feature representations for HLA for predicting graft survival time. They experimented with these different feature representations using CoxPH models, gradient boosted trees, and random survival forests and found that including HLA information could result in small improvements of up to 0.007 in the prediction accuracy as measured by Harrell’s concordance index (C-index) [15].
III. HLA Compatibility Networks
A. Data Description
This study used data from the Scientific Registry of Transplant Recipients (SRTR). The SRTR data system includes data on all donor, wait-listed candidates, and transplant recipients in the U.S., submitted by the members of the Organ Procurement and Transplantation Network (OPTN). The Health Resources and Services Administration (HRSA), U.S. Department of Health and Human Services provides oversight to the activities of the OPTN and SRTR contractors.
We use the same inclusion criteria and data preprocessing as in Nemati et al. [3], which we briefly summarize in the following. We consider only transplants performed between the years 2000 and 2016 with deceased donors, recipients aged 18 years or older, and only candidates who are receiving their first transplant. We use death-censored graft failure as the clinical endpoint (prediction target), so that patients who died with a functioning graft are treated as censored since they did not exhibit the event of interest (graft failure). For censored instances, the censoring date is defined to be the last follow-up date. We consider a total of 106, 372 kidney transplants, for which 74.6% are censored.
1). HLA Representation:
We encode HLA information using the HLA types and pairs of the donor and recipient for each transplant. These HLA type and pair features are constructed according to the approach of Nemati et al. [3]. HLA types for the donor and recipient are represented by a one-hot-like encoding, resulting in binary variables such as DON_A1, DON_A2, …, REC_A1, REC_A2, …, where the value for a donor (resp. recipient) HLA type variable is one if the donor (resp. recipient) for the transplant possesses that HLA type. An HLA type that is a split of a broad type has ones in the columns for both the split and broad. For example, DON_A23 = 1 for a transplant if the donor possesses the HLA type A23. Since A23 is a split of the broad A9, DON_A9 = 1 for this transplant also.
Donor-recipient HLA pairs are also represented by a one-hot-like encoding, resulting in binary variables such as DON_A1_REC_A1, DON_A1_REC_A2, …, where the value for such an HLA pair variable is one if the donor and recipient possess the specified HLA types, and the HLA pair is active. Some HLA pairs are inactive due to asymmetry in the roles of donor and recipient HLA types; we refer interested readers to Nemati et al. [3] for additional details. Broads and splits are handled in the same manner as for HLA types. For example, DON_A23_REC_A1 = 1 for a transplant if the donor possesses A23, and the recipient possess A1, and the HLA pair (A23, A1) is active. If this is the case, then DON_A9_REC_A1 = 1 also because A23 is a split of the broad A9.
B. HLA Compatibility Network Construction
While it is possible to construct a network of donors and recipients directly from transplants (i.e. with donors and recipients as nodes and an edge denoting a transplant from a donor to a recipient), this directly-observed network is of very little interest scientifically. Each donor node has maximum degree of 2 because that is the maximum number of kidneys they can donate. Each recipient node also has very small degree denoting the number of transplants they have received. The network consists of many small components that are not connected.
We instead consider the indirectly-observed HLA compatibility network, where nodes denote HLA types. We consider a separate set of donor nodes and recipient nodes since the effects of an HLA type may differ when it appears on the donor compared to recipient side. To avoid confusion between a donor and recipient node, we use uppercase letters for the HLA type of a donor node (e.g. A1) and lowercase letters for the HLA types of a recipient node (e.g. a1).
We propose the following definition of HLA compatibility using hazard ratios, which are commonly used in survival analysis as described in Section III-B
Definition III.1. We define the compatibility between a donor HLA and a recipient HLA as sum of the negative log of the hazard ratios for donor , for recipient , and for the donor-recipient pair .
Let and denote the negative logs of the hazard ratios for donor HLA type and recipient HLA type , respectively. Let denote the negative log of the hazard ratio for the donor-recipient HLA pair . Then, the compatibility of donor HLA and recipient HLA from Definition III.1 can be written as
| (1) |
1). Estimating HLA Compatibilities:
The compatibilities of the donor and recipient HLA types are unknown, so we must estimate them from the transplant data. To estimate the compatibilities, we first remove all HLA types and pairs that were not observed in at least 100 transplants1. We fit an -penalized CoxPH model to the data. We use 2-fold cross-validation to tune the penalty parameter to maximize the partial log-likelihood on the validation folds. The result is a set of coefficients for each of the covariates, including basic covariates such as age and race, as well as the HLA types and the HLA pairs. The negated coefficients for the donor HLA type , the recipient HLA type , and the donor-recipient HLA pair can be substituted into (1) to obtain the estimated compatibility of . Since positive coefficients in the CoxPH model are associated with higher probability of graft failure, we negate the estimated coefficients so that positive compatibilities are associated with lower probability of graft failure.
2). HLA Compatibility Network:
The HLA compatibilities can be represented as a network with both node and edge weights. There are two types of nodes in the network: donor nodes and recipient nodes. Each donor node has an unknown true weight , and each recipient node has an unknown true weight . Each edge connects a donor node to a recipient node and has true weight .
In the HLA compatibility network, the true node and edge weights are terms from (1) and are unobserved. We observe only a noisy version of the weights in the form of the estimated CoxPH coefficients. We model the observed node and edge weights as independent realizations of Gaussian random variables in the following manner:
Observed donor node weight: .
Observed recipient node weight: .
Observed edge weight by .
We can thus view the observed node and edge weights as estimates of the true node and edge weights, respectively. The estimated CoxPH coefficients also have estimated standard errors, which we can use as estimates for .
There are 3 separate HLA compatibility networks, one for each of the 3 loci: HLA-A, HLA-B, and HLA-DR. The HLA-A compatibility network estimated using the observed node and edge weights is shown in Figure 2. Notice that node and edge weights can be both positive and negative. All donor-recipient pairs that have been observed in at least 100 transplants contain an edge in the network. The variation in edge weights can be quite large, ranging from roughly −0.3 to 0.3 in A and DR and about −0.4 to 0.4 in B.
Fig. 2.

Heat maps illustrating node and edge weights in the HLA compatibility networks for HLA-A. Rows and columns are ordered by their positions from fitting a 1-D latent space model to the network. Entries along the diagonal should be more positive (red), as these nodes are closer in the latent space, and entries should turn more negative (blue) further away from the diagonal.
IV. HLA Latent Space Model
We utilize a latent space model to learn the hidden features underlying the HLA compatibility network. Within the context of the latent space model, donors and recipients’ node positions are embedded in the latent space where a pair of donor-recipient in the observed HLA network with higher edge weight is put closer. Thus, the HLA compatibilities could be induced through distances between nodes in the latent space.
A. Model Description
In the HLA latent space model, we let and denote the th donor node and the th recipient node in the latent space. Let and denote the number of donor nodes and recipient nodes, respectively. Unlike Hoff’s latent distance model [8] which models the binary relations between nodes using a logistic regression, we model the affinities between distances in the latent space and edge weights in the observed network using the linear relation .
Moreover, we employ the donor and recipient node effect terms to the model as in [11, 12] to capture the true node weights. Then, the compatibility between donor node and recipient node is given by
| (2) |
where and are scalar parameters. The observed data consists of the set of node and edge weights , modeled as described in Section III-B2.
B. Estimation Procedure
The proposed model has the set of unknown parameters . represent the latent positions of donor and recipient nodes in a -dimensional Euclidean space. Therefore, and are and matrices, respectively. Each pair of nodes is associated with a donor node effect and a recipient node effect . and are the slope and intercept terms of the linear relationship. We constrain the slope to be positive to keep the node pairs with higher edge weights closer together in the latent space.
Beginning with the likelihood of latent distance model derived by Hoff et al. [8], we can write the likelihood of our proposed HLA latent space model as
where denotes the set of all unknown parameters. The probability distributions for the observations are given by
where denotes the modeled HLA pair compatibilities that depend on the latent positions calculated in (2), and is the variance of edge weights. and are the HLA node weights, and and are the variances of the node weights.
We optimize the log-likelihood of the model using the L-BFGS-B [16] optimizer implemented in SciPy.
Parameter Initialization:
We employ a multidimensional scaling (MDS) algorithm [17] as an initialization for the latent space positions. MDS attempts to find a set of positions where each point represents one of the entities, and the distances between points depend on their dissimilarity for each pair of entities. As the HLA compatibility network is a weighted bipartite network, we do not have edge weights between node pairs within the same group: donor-donor edge weights and recipient-recipient edge weights. Instead, we use the correlation coefficients between nodes based on their edge weights with the other type of node. For example, we compute the correlation coefficient between the edge weights of two donors nodes with all recipient nodes. We then define the dissimilarity matrix with entries given by , where represents the weights or correlation coefficients between node pair , and . All other parameters are initialized randomly.
V. Simulation Experiments
To make a pilot evaluation of our proposed model, we fit our model to simulated networks. We simulate the HLA bipartite networks with number of nodes , parameters , latent dimension . The latent positions and donor and recipient effects are sampled independently from a standard Normal distribution: . We compute the true weights using (2). The noise of the simulated weights is controlled by the variance .
Similar to the latent space model of Huang et al. [18], is not identifiable because it enters multiplicatively into (2). The latent positions are also not identifiable in a latent space model, as noted by Hoff et al. [8], and can only be identified up to a rotation. Thus, we set in all simulations and use a Procrustes transform to rescale and rotate the latent positions to best match the true latent positions.
Low noise simulated network:
We first fit the HLA latent space model to the low noise simulated network by setting . After fitting the model, we compute the root mean square error (RMSE) and R-squared values between the actual parameters and estimated parameters which is shown in Table I. Both RMSE and R-squared indicate an accurate prediction for all the parameters and the weight prediction.
Table I.
Error between estimated and actual parameters by fitting the HLA latent space model to 15 simulated networks. Mean ± standard error is shown for each parameter.
| Parameters | Low noise | High noise | |
|---|---|---|---|
| RMSE | 0.124 ± 0.001 | 1.264 ± 0.014 | |
| 0.014 ± 0.002 | 0.111 ± 0.007 | ||
| 0.024 ± 0.010 | 0.101 ± 0.006 | ||
| 0.105 ± 0.018 | 0.173 ± 0.015 | ||
| 0.097 ± 0.015 | 0.170 ± 0.012 | ||
| 0.047 ± 0.068 | 0.779 ± 0.107 | ||
| R squared | 0.990 ± 0.001 | 0.555 ± 0.018 | |
| 0.989 ± 0.004 | 0.482 ± 0.064 | ||
| 0.989 ± 0.004 | 0.571 ± 0.056 | ||
| 0.937 ± 0.026 | 0.860 ± 0.024 | ||
| 0.924 ± 0.034 | 0.854 ± 0.025 |
High noise simulated network:
Since the real data has extremely noisy edge weights, we conduct another experiment by setting a high variance to the simulation where . As we increase the noise, the RMSE increases as expected. The R-squared for nodal effect and still indicate reasonable estimates. The R-squared for , and is about 0.5, indicating moderately accurate estimates, which we consider acceptable for high noisy estimation.
VI. Real Data Experiments
A. Model-based Exploratory Analysis
In the HLA latent space model, we expect negative relationships between HLA pair coefficients (edge weights) and pair distances in Euclidean space. We fix the latent dimension to be in three HLA networks (A, B, DR) to visualize the latent positions of the nodes. After fitting the HLA latent space model, the 2-D latent space plots for all three HLA loci are shown in Figure 3.
Fig. 3.
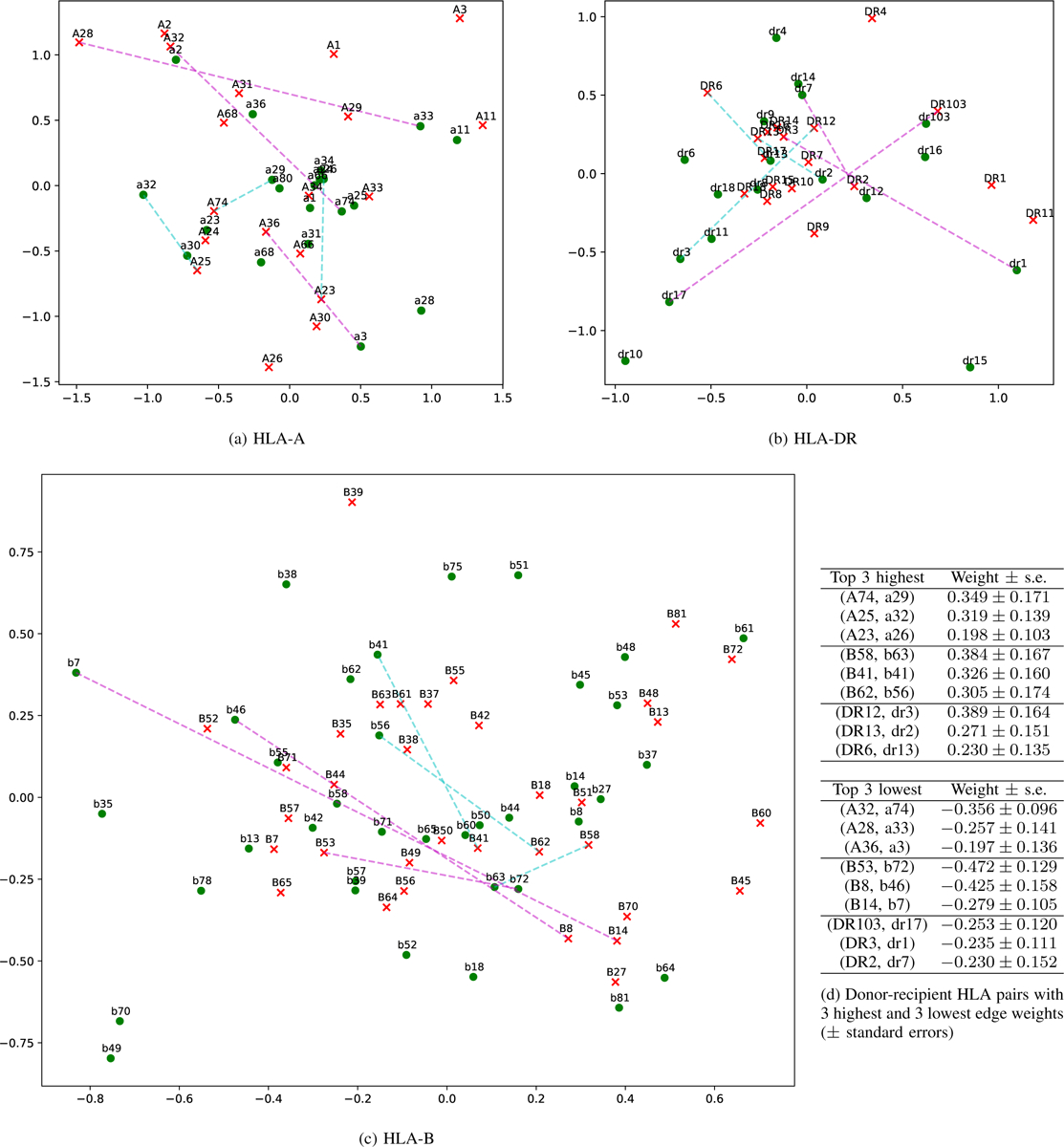
The 2-D latent space plot for HLA networks for all 3 loci. Red x: donor node; green circle: recipient node. The 3 highest and lowest edge weights are shown with dashed cyan and magenta lines, respectively. Donor-recipient pairs with the highest edge weights tend to be placed closer together in the latent space compared to those with the lowest edge weights.
From examining the latent positions, we find that pairs of nodes with higher edge weights tend to appear closer together in the latent space and vice versa. For example, in the HLA-A plot, donor A74 and recipient A29 have a high weight of 0.349 and tend to be placed close together in the 2-D plot. Conversely, donor A28 and recipient a33 have a low weight of −0.257 and are placed on opposite sides of the latent space. We draw cyan dashed lines indicating the top 3 highest weight pairs and magenta dashed lines indicating the top 3 lowest weight pairs in all three 2-D HLA latent space plots. By comparing the latent space plot and the edge weights, we discover that A and B have a relatively good fit, while DR is slightly worse, with some cyan lines longer than magenta.
B. HLA Compatibility Prediction
Next, we evaluate the ability of our latent space model to predict HLA compatibilities. We split the transplant data 50/50 into training/test, and we fit the -penalized CoxPH model two times, once each on the training and test folds. We obtained two sets of HLA compatibility data: denotes the first (training) fold, and denotes the second (test) fold. We then fit the proposed HLA latent space model on the data and evaluate prediction accuracy on the data.
1). Evaluation Metrics:
We consider 3 measures of prediction accuracy:
Root mean squared error (RMSE) between the predicted and observed weights on .
Mean log-probability on : We use a Gaussian distribution with mean given by the observed weight on and standard deviation given by its standard error to compute the log probability. This is equivalent to a negated weighted RMSE where higher weight is given to HLA pair coefficients with smaller standard errors.
Sign prediction accuracy: We threshold the predicted and observed weights at 0 and compute the binary classification accuracy.
We consider also the prediction accuracy for the downstream task of graft survival time prediction, which we describe in Section VI-C.
2). Comparison Baselines:
We compare our proposed latent space model against 3 other methods:
Cox proportional hazards (CoxPH): Directly uses the estimated CoxPH coefficients without any further processing.
Non-negative matrix tri-factorization (NMTF): A technique for learning low-dimensional feature representation of relational data that decomposes the given matrix into three smaller matrices [19] rather than two matrices as in standard non-negative matrix factorization. As we have negative values in our HLA network, we first apply a logistic function to transform all compatibilities to (0, 1). We then apply NMTF. Finally, we use a logit function to transform the values back to the original domain with both positive and negative values.
Principal component analysis (PCA): A classical linear dimensionality reduction technique that project the given matrix into a lower dimensional space. We reconstruct the compatibilities from the first principal components.
For all of the methods, we choose the number of dimensions that returns the best mean log-probability on .
3). Results:
From Table II, note that the predicted weights using other models to refine the estimated compatibilities are more accurate for each of the 4 metrics and 3 loci compared to directly using the CoxPH coefficients. Among the refinement methods, the LSM and NMTF have similar prediction accuracy, and both significantly outperform PCA. We note that, while the NMTF is competitive to our LSM in prediction accuracy, the LSM can provide useful interpretations through the latent space, as shown in Section VI-A. Finally, notice the difficulty of the HLA compatibility prediction problem—the sign prediction accuracy on all 3 loci are quite low, from 51% to 58%, despite the improvement from using the refinement.
Table II.
Evaluation metrics for HLA compatibility and graft survival time prediction. our proposed lsm performs competitively on HLA compatibility prediction on all 3 loci and achieves the best c-index for graft survival time prediction.
| Metric | Model | HLA-A | HLA-B | HLA-DR |
|---|---|---|---|---|
| RMSE | CoxPH | 0.159 | 0.191 | 0.168 |
| CoxPH + LSM | 0.110 | 0.139 | 0.129 | |
| CoxPH + NMTF | 0.112 | 0.140 | 0.122 | |
| CoxPH + PCA | 0.124 | 0.149 | 0.138 | |
| Mean log-prob. | CoxPH | 0.609 | 0.374 | 0.541 |
| CoxPH + LSM | 0.911 | 0.657 | 0.800 | |
| CoxPH + NMTF | 0.936 | 0.659 | 0.885 | |
| CoxPH + PCA | 0.887 | 0.606 | 0.776 | |
| Sign prediction | CoxPH | 0.535 | 0.515 | 0.510 |
| CoxPH + LSM | 0.542 | 0.576 | 0.552 | |
| CoxPH + NMTF | 0.542 | 0.522 | 0.573 | |
| CoxPH + PCA | 0.535 | 0.528 | 0.564 | |
| C-index | CoxPH | 0.614 | ||
| CoxPH + LSM | 0.625 | |||
| CoxPH + NMTF | 0.623 | |||
| CoxPH + PCA | 0.621 |
C. Graft Survival Time Prediction
One difficulty of evaluating the HLA compatibility predictions from Section VI-B is that the CoxPH coefficients from both data splits have very high standard errors. As a result, the prediction target (the HLA compatibility on the test set) is extremely noisy. Recall that the initial HLA compatibility estimates are obtained from fitting a CoxPH model tuned to maximize prediction accuracy for the graft survival times. It is unclear whether improved prediction accuracy of the HLA compatibilities on the test set also lead to improved prediction accuracy of graft survival.
We thus propose an end-to-end evaluation of our HLA compatibility estimates by incorporating them into the graft survival prediction, as shown in Figure 1. After fitting the latent space model, we replace the CoxPH coefficients for the HLA types with the negated estimates of donor and recipient effects given by and , respectively. We also replace the CoxPH coefficients for the HLA pairs with the negated estimates of the donor-recipient pair weights .
The question we are seeking to answer here is as follows: Does replacing the estimated CoxPH coefficients with the estimated HLA compatibilities from our latent space model improve accuracy on the downstream task-graft survival prediction? To evaluate this, we use the same 50/50 training/test splits from Section VI-B and compare the C-indices on the test splits between the trained CoxPH model and the updated CoxPH coefficients using our latent space model.
The answer to this question is yes, as shown by the C-indices in Table II. Notice that our proposed latent space model improves the C-index by about 0.011 compared to directly using the CoxPH coefficients. The NMTF and PCA provide smaller improvements of 0.009 and 0.007, respectively. We note that an improvement of 0.011 in the C-index for graft survival prediction in kidney transplantation is a large improvement! For comparison, using the same dataset and inclusion criteria, Nemati et al. [3] evaluated C-indices using 6 different HLA representations across 3 different survival prediction algorithms and found achieved a maximum improvement of 0.007. Similarly, using the same dataset but slightly different inclusion criteria, Luck et al. [14] achieved a maximum improvement of 0.005. The appreciable improvement in C-index demonstrates the utility of our latent space modeling approach not only for interpreting HLA compatibilities, but also for graft survival prediction.
VII. Conclusion
We proposed a model for HLA compatibility in kidney transplantation using an indirectly-observed weighted and signed network. The weights were estimated from a CoxPH model fit to data on over 100k transplants, yet they are very noisy, with standard errors sometimes on the same order of magnitude as the mean weight estimates themselves.
Our main contribution was to develop a latent space model for the HLA compatibility network. The latent space model provided both an interpretable visualization of the HLA compatibilities and used the network structure to improve the estimated weights. We found that the latent space model not only resulted in more accurate estimated weights, but also improved graft survival prediction accuracy when the estimated weights were substituted back into the CoxPH model.
Limitations and Future Work:
We chose to use a linear model for the HLA compatibilities for simplicity. Both weight estimation and survival prediction accuracy could also potentially be improved by incorporating non-linearities into the model. Furthermore, if we consider improving survival prediction accuracy as our objective, then our proposed approach can be viewed as a two-stage process: first estimate weights by maximizing the CoxPH partial log-likelihood, and then refine the weight estimates by maximizing the latent space model log-likelihood. The improvement in survival prediction accuracy from this two-stage process suggests that accuracy could potentially be further improved by jointly maximizing both objective functions. Indeed, this is an interesting avenue for future work that we are currently exploring.
Acknowledgment
The authors thank Robert Warton, Dulat Bekbolsynov, and Stanislaw Stepkowski for their assistance with the HLA data.
The research reported in this publication was supported by the National Library of Medicine of the National Institutes of Health under Award Number R01LM013311 as part of the NSF/NLM Generalizable Data Science Methods for Biomedical Research Program. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
The data reported here have been supplied by the Hennepin Healthcare Research Institute (HHRI) as the contractor for the Scientific Registry of Transplant Recipients (SRTR). The interpretation and reporting of these data are the responsibility of the author(s) and in no way should be seen as an official policy of or interpretation by the SRTR or the U.S. Government. Notably, the principles of the Helsinki Declaration were followed.
Footnotes
This research was partially conducted while the authors were at the University of Toledo.
The estimated hazard ratios for these rarely occurring HLA types and pairs have extremely high standard errors, and in some cases, including them creates instabilities in estimating the CoxPH coefficients.
Contributor Information
Zhipeng Huang, Department of Computer and Data Sciences, Case Western Reserve University, Cleveland, OH 44106 USA.
Kevin S. Xu, Department of Computer and Data Sciences, Case Western Reserve University, Cleveland, OH 44106 USA
References
- [1].Doxiadis II, Smits JM, Geziena M, Persijn GG, van Houwelingen HC, van Rood JJ, and Claas FH, “Association between specific hla combinations and probability of kidney allograft loss: the taboo concept,” The Lancet, vol. 348, no. 9031, pp. 850–853, 1996. [DOI] [PubMed] [Google Scholar]
- [2].Claas FH, Witvliet MD, Duquesnoy RJ, Persijn GG, and Doxiadis II, “The acceptable mismatch program as a fast tool for highly sensitized patients awaiting a cadaveric kidney transplantation: short waiting time and excellent graft outcome,” Transplant, vol. 78, no. 2, pp. 190–193, 2004. [DOI] [PubMed] [Google Scholar]
- [3].Nemati M, Zhang H, Sloma M, Bekbolsynov D, Wang H, Stepkowski S, and Xu KS, “Predicting kidney transplant survival using multiple feature representations for hlas,” in Int. Conf. Artif. Med. Springer, 2021, pp. 51–60. [PMC free article] [PubMed] [Google Scholar]
- [4].Konvalinka A and Tinckam K, “Utility of hla antibody testing in kidney transplantation,” J. Am. Soc. of Nephrology, vol. 26, no. 7, pp. 1489–1502, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Shankarkumar U, “The human leukocyte antigen (hla) system,” J. Hum. Genetic, vol. 4, no. 2, pp. 91–103, 2004. [Google Scholar]
- [6].Kosmoliaptsis V, Mallon D, Chen Y, Bolton EM, Bradley JA, and Taylor CJ, “Alloantibody responses after renal transplant failure can be better predicted by donor–recipient hla amino acid sequence and physicochemical disparities than conventional hla matching,” Am. J. Transplant, vol. 16, no. 7, pp. 2139–2147, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Wang P, Li Y, and Reddy CK, “Machine learning for survival analysis: A survey,” ACM Comput. Surv, vol. 51, no. 6, pp. 1–36, 2019. [Google Scholar]
- [8].Hoff PD, Raftery AE, and Handcock MS, “Latent space approaches to social network analysis,”J. Am. Stats. Assoc, vol. 97, no. 460, pp. 1090–1098, 2002. [Google Scholar]
- [9].Friel N, Rastelli R, Wyse J, and Raftery AE, “Interlocking directorates in irish companies using a latent space model for bipartite networks,” Nat’l. Acad. Sci, vol. 113, no. 24, pp. 6629–6634, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Sewell DK and Chen Y, “Latent space models for dynamic networks,” Am. Stats. Assoc, vol. 110, no. 512, pp. 1646–1657, 2015. [Google Scholar]
- [11].Wang SS, Paul S, and De Boeck P, “Joint latent space model for social networks with multivariate attributes,” arXiv prepr. arXiv:1910.12128, 2019. [DOI] [PubMed] [Google Scholar]
- [12].Hoff PD, “Bilinear mixed-effects models for dyadic data,” Am. Stats. Assoc, vol. 100, no. 469, pp. 286–295, 2005. [Google Scholar]
- [13].Mark E, Goldsman D, Gurbaxani B, Keskinocak P, and Sokol J, “Using machine learning and an ensemble of methods to predict kidney transplant survival,” PLoS ONE, vol. 14, no. 1, p. e0209068, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Luck M, Sylvain T, Cardinal H, Lodi A, and Bengio Y, “Deep learning for patient-specific kidney graft survival analysis,” arXiv prepr. arXiv:1705.10245, 2017. [Google Scholar]
- [15].Harrell FE, Califf RM, Pryor DB, Lee KL, and Rosati RA, “Evaluating the yield of medical tests,” JAMA, vol. 247, no. 18, pp. 2543–2546, 1982. [PubMed] [Google Scholar]
- [16].Byrd RH, Lu P, Nocedal J, and Zhu C, “A limited memory algorithm for bound constrained optimization,” SIAM sci. comput, vol. 16, no. 5, pp. 1190–1208, 1995. [Google Scholar]
- [17].Cox MA and Cox TF, “Multidimensional scaling,” in Handbook of data visualization. Springer, 2008, pp. 315–347. [Google Scholar]
- [18].Huang Z, Soliman H, Paul S, and Xu KS, “A mutually exciting latent space hawkes process model for continuous-time networks,” arXiv prepr. arXiv:2205.09263, 2022. [Google Scholar]
- [19].Li T, Zhang Y, and Sindhwani V, “A non-negative matrix tri-factorization approach to sentiment classification with lexical prior knowledge,” in Jt. Conf. ACL and Int. Jt. Conf. NLP AFNLP, 2009, pp. 244–252. [Google Scholar]