

Abstract
We present multiPrime, a novel tool that automatically designs minimal primer sets for targeted next‐generation sequencing, tailored to specific microbiomes or genes. MultiPrime enhances primer coverage by designing primers with mismatch tolerance and ensures both high compatibility and specificity. We evaluated the performance of multiPrime using a data set of 43,016 sequences from eight viruses. Our results demonstrated that multiPrime outperformed conventional tools, and the primer set designed by multiPrime successfully amplified the target amplicons. Furthermore, we expanded the application of multiPrime to 30 types of viruses and validated the work efficacy of multiPrime‐designed primers in 80 clinical specimens. The subsequent sequencing outcomes from these primers indicated a sensitivity of 94% and a specificity of 89%.
Keywords: degenerate primer design, minimal primer set, multiplex PCR, targeted next‐generation sequencing
This study introduces multiPrime, a novel tool tailored for the wide‐ranging detection of target sequences through targeted next‐generation sequencing (tNGS). By integrating degenerate primer design principles with effective mismatch handling, multiPrime demonstrates enhanced precision and specificity in the identification of diverse sequence types. This breakthrough presents a prospective pathway for optimizing the development of tNGS. In performance comparison, multiPrime excelled over conventional tools in terms of execution time, primer coverage, and the number of candidate primers. It offers a streamlined and versatile solution for the rapid and cost‐effective detection of diverse microbiomes.
Highlights
MultiPrime is a user‐friendly and one‐step tool for designing targeted next‐generation sequencing primer sets.
It integrates degenerate primer design theory with mismatch handling, resulting in improved accuracy and specificity in detecting broad‐spectrum sequences.
It outperformed conventional programs in terms of run time, primer number, and primer coverage.
The versatility and potential of multiPrime are highlighted by its potential application in detecting single or multiple genes, exons, antisense strands, RNA, or other specific DNA segments.
INTRODUCTION
Targeted next‐generation sequencing (tNGS) has become an increasingly important strategy for exploring the crucial roles of the microbiome due to its high speed, cost efficiency, and broad range. Metagenomic next‐generation sequencing (mNGS) [1, 2, 3] and metatranscriptomic next‐generation sequencing [4, 5] allow a comprehensive analysis of the microbiomes. However, these methods encounter challenges, such as human and environmental microbial genome contamination, necessitating substantial read counts and sample sizes. As a result, these techniques are time‐consuming, expensive, and always challenging to interpret. Though host DNA depletion during DNA extraction has been employed to mitigate human genome contamination [6, 7], their feasibility in resource‐limited and urgent scenarios remains limited, echoing the situation with hybridization‐based next‐generation sequencing. In contrast, polymerase chain reaction (PCR)‐based tNGS [8, 9] is a simple and cost‐effective method to enrich multiple target sequences simultaneously [10]. This method enables rapid amplification of known microbial genomes, as well as virulence or drug resistance genes, from small sample size, yielding results within hours. For example, PCR amplification of rRNA gene sequences using broad‐taxonomic‐range primers has been instrumental in microbial community composition analysis [11, 12, 13, 14]. Yet, the complexity of some microbiomes, such as the virome, presents unique challenges due to the absence of conserved regions and the vast genetic diversity [15, 16]. Consequently, the application of tNGS to such cases requires innovative approaches.
Critical to the success of tNGS is primer design, while factors like melting temperature, GC content, and secondary structure play pivotal roles in the efficient annealing of primers and target [17, 18, 19, 20, 21, 22]. Many software programs have been developed to assist in primer design [23] but few are tailored to the specific needs of tNGS. Existing methods can be categorized into three groups. Conventional PCR primer design tools prove laborious for large‐scale target sets [24, 25, 26], while degenerate primers from sequence alignments [27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39] or K‐mer generation [40, 41, 42, 43] require a delicate balance between coverage and degeneracy [31, 36, 44]. Machine learning algorithms [45, 46, 47, 48] and other approaches [49, 50, 51] have been explored but often encounter limitations when confronted with the challenge of handling degenerate bases and intricate target sequences. Despite these efforts, the challenge of designing primers for large and diverse targets persists.
To fill this critical gap, we introduce multiPrime, a novel tool developed for multiplex PCR of diverse nucleotide sequences. The main point of its innovation is an integrated mismatch‐tolerant methodology. At its core, multiPrime leverages the fundamental Watson‐Crick hybridization between complementary bases, a process that inherently accommodates minor mismatches. Despite these variations, the prevailing thermodynamic stability of accurately paired bases typically takes precedence over unpaired ones [52]. This mechanism gives rise to primer‐template mismatch annealing—a dynamic that, although it may affect PCR efficiency, does not hinder the amplification process outright. Empirical support from a plethora of studies underscores the robustness of this approach, placing it on par with the outcomes attained through perfect primer‐template annealing [50, 53, 54, 55, 56, 57, 58], such as established amplification refractory mutation system PCR (ARMS‐PCR) [59]. In the dynamic landscape of nucleotide sequence analysis, multiPrime aims to strike a delicate balance between the specificity and efficiency of primers [60]. It further advances the field by seamlessly integrating permissive mismatches into primer design strategies [61, 62], thereby enhancing the dimensions of the primer set—its size, coverage, and efficiency. This synergistic approach opens up promising avenues, offering a nuanced solution that adeptly navigates the complexities posed by expansive and varied target sequences. Within the framework of our study, we have harnessed the power of viruses as a rich and immensely diverse genetic source to establish this innovative methodology. This methodology paves the way for uncomplicated ultra‐multiplex PCR, presenting a potent tool that holds potential not only within the realm of virome but also for the broader application of tNGS across diverse nucleotide sequences. Through this innovative approach, we embark on a journey toward advancing tNGS methodologies, offering a streamlined and versatile solution for the rapid and cost‐effective detection of diverse microbiomes, as well as for the comprehensive unraveling of the intricacies inherent in such diverse microbiotic ecosystems.
RESULTS
Target amplification through primer‐template mismatch annealing
To assess the effect of primer‐template mismatches annealing on target amplification, we partitioned primer into three equal nonoverlapping regions: the 5′ end (5′), middle (Mid), and 3′ end (3′). We then designed primers with 0–1 mismatches in these regions to evaluate their ability of target amplification on the Oxford Nanopore Technology (ONT) platform. Our results showed that primers with one mismatch worked effectively (Supporting Information: Figure S5A,B). However, the efficiency of PCR was reduced, with the greatest impact observed when the mismatch was located in the 3′ end (70% and 53%, Supporting Information: Figure S5B). Next, we designed primers with up to two mismatches in the middle and 5′ positions and examined the efficiency of the primers. We found that these primers worked well, with a relative efficiency of at least 68% (Supporting Information: Figure S5B). To further investigate the effects of mismatch number on target amplification, we modified a universal influenza primer, M30F2 [63], by introducing a single nucleotide substitution (A–G) at the 3′ end. This modified primer was named M30F2‐mis. Two primer sets were utilized, each containing only one of the two primers, to evaluate the efficiency of both primers independently. The primers were tested with single‐end 75 sequencing and we observed that primers with 0, 1, and 2 mismatches (F0, F1, and F2 of both primers and F3 of M30F2, Supporting Information: Figure S5D) displayed relatively high efficiency (≥61%), indicating that the primers could function well despite imperfect annealing (F0, F1, and F2 of M30F2‐mis, Supporting Information: Figure S5D). The average relative efficiency of F3 (three mismatches) in M30F2‐mis was 56%, whereas it was only 2% in one of the three replicates (Supporting Information: Table S1). These findings suggest that three mismatches could significantly reduce PCR efficiency. Additionally, our observations demonstrate a comparable performance between primers containing mismatches and those devoid of mismatches. Notably, we also identified a reduction in dimer formation within the primer set (Supporting Information: Figure S6). Overall, our results indicated that one or two mismatches located at the 5′ end or middle regions of primers have a marginal impact on primer‐template annealing.
MultiPrime significantly reduces the size of primer sets while enhancing the coverage and compatibility of these sets
MultiPrime designs primers that can tolerate up to X (0, 1, or 2) mismatches, thereby reducing degeneracy and improving coverage. For example, to cover all 10 input sequences (Supporting Information: Figure S7A), a primer with a high dependency value of 512 would be required (Supporting Information: Figure S7B). Alternatively, by allowing for a single mismatch in primer design, four potential primers were identified that could cover all 10 targets with a significantly lower degeneracy of 4. To investigate the extent of achievable improvement through mismatch tolerance, we designed primers for 1000 sequences of human rotavirus A by allowing for 0, 1, and 2 mismatches (Figure 1A). In silico results showed that primers with 1 or 2 mismatches significantly improved primer coverage, demonstrating that using fewer primers with mismatch tolerance can lead to a broader spectrum of coverage. In terms of the ability to design degenerate primers, we compared the performance of multiPrime's primer design module with that of DegePrime—a widely used program for designing degenerate primers for bacterial species that has been shown to outperform other programs such as HYDEN. We discovered that the primers designed by multiPrime with one mismatch tolerance had significantly higher coverage than those produced by DegePrime (Figure 1B), particularly when the entropy of the primer region was less than 3 (Figure 1C). This advantage was even more pronounced when comparing combinations of primer pairs (Figure 1D). The results showed that the multiPrime primer design module yielded higher‐coverage primers with either one primer pair (98.7%) or two primer pairs (100%), while DegePrime required at least four primers to attain comparable coverage (97.8%). Additionally, we embarked on an iterative primer design using DegePrime for the uncovered sequences. Regrettably, this approach was impeded by primer compatibility concerns, thwarting the integration of supplementary primers to augment coverage (Figure 1E).
Figure 1.
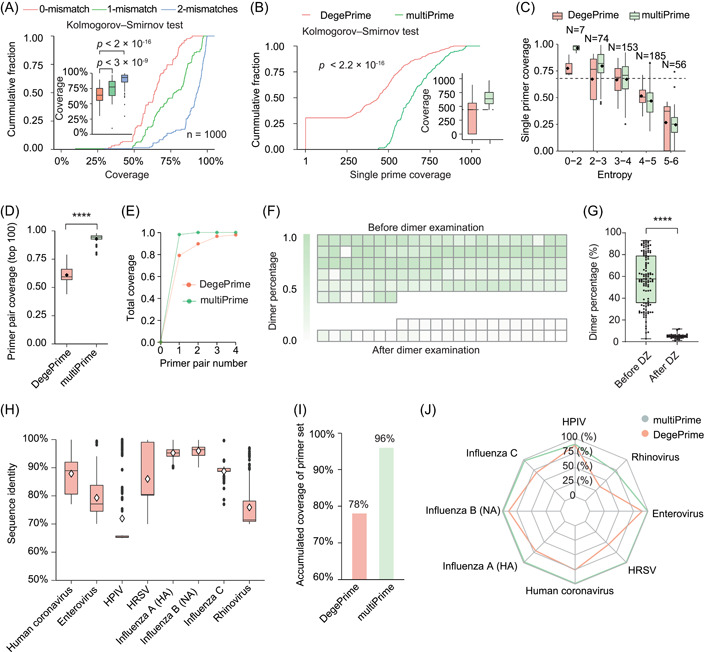
MultiPrime efficiently broadens the spectrum and enhances compatibility. (A) The coverage of primers designed by multiPrime using 1000 sequences, allowing for 0, 1, and 2 mismatches. (B) The cumulative fraction of single primer coverage for primers designed by multiPrime and DegePrime. (C) The coverage of single primers designed by multiPrime and DegePrime in different entropy regions. (D) The top 100 primer pair coverage values for DegePrime and multiPrime. (E) The number of primer pairs required to achieve satisfactory coverage. A heatmap (F) and boxplot (G) were used to show that the percentage of dimers was significantly reduced by dimer examination. Before dimer examination (Before DZ) was defined as the primer set combination without dimer examination. After dimer examination (after DZ) was defined as the primer set combination with dimer examination. (H) The sequence identity of the eight viruses was used for validation. (I) The accumulated coverage of the core primer set was evaluated across all eight viruses. The primer set was designed by multiPrime (v2.0.2) with the following parameters: identity: 0.8; seq_number_ANI: 60; drop: “T”; coordinate: 0; Others: Default. For detailed definitions of the parameters, see YAML files on GitHub. (J) Accumulated coverage of each individual virus by the primer set. HPIV, human parainfluenza virus; HRSV, human respiratory syncytial virus. ****p < 0.0001 by t‐test (two‐sided).
While reducing the number of primers in primer sets using multiPrime can significantly decrease the likelihood of primer incompatibility, dimer formation remains a significant challenge. To address this challenge, we employed an empirical loss function to assess potential dimers in the primer set. We optimized the threshold of the loss function using 154 next‐generation libraries from five batches with an average 213‐plex PCR system designed by multiPrime (Supporting Information: Figure S8). Our results indicated that the proportion of dimers was significantly reduced from 57.23 ± 23.5% (n = 117) to 4.97 ± 2.07% (n = 37) (Figure 1F,G, Supporting Information: Table S2).
MultiPrime outperforms conventional methods in primer set optimization for large and diverse sequences
Multiple sequence alignment (MSA) can be inefficient when dealing with large‐scale sequences due to the required computational power and time. Therefore, we investigated the feasibility of randomly selecting a certain number of sequences from each class for primer design. To determine the number of sequences needed to achieve satisfactory coverage, 20,723 CDSs of influenza A were used. We randomly selected 10–2500 input sequences for evaluation using multiPrime to assess the resulting coverage. Our analysis demonstrated that a minimum of 200 input sequences are required to ensure precise primer coverage. Additionally, the number of candidate primers decreased rapidly when the number of input sequences exceeded 1000 (Supporting Information: Figure S9A). Furthermore, the run time for the MSA increased significantly as the number of input sequences increased (Supporting Information: Figure S9B). These findings suggest that the optimal range for efficient and effective primer design is from 200 to 1000 input sequences.
There is no MSA‐dependent software available that can automatically and efficiently design a minimal primer set for the 43,016 sequences derived from eight different viruses currently. To address this limitation, we modified multiPrime by replacing its primer design module with DegePrime. We then conducted a comparative analysis of the performance of the modified multiPrime and the original version. The high diversity of the input sequences was demonstrated by the identity of each virus (Figure 1H). Our analysis revealed that multiPrime's primer design module outperformed DegePrime in terms of primer design efficiency. In particular, multiPrime's primer design module required only 17 min to design primers, while DegePrime required 48 min. The primer set designed by multiPrime achieved a coverage of over 96% and 95%, with different parameters, significantly higher than that achieved by the DegePrime modified version (78% and 69%, respectively) (Figure 1I, Supporting Information: Table S3). The coverage achieved by multiPrime's primer set for each virus was also significantly higher than that of the DegePrime primer set (Figure 1J). We also compared our tool with Primux, which is a K‐mer creation‐dependent tool. However, Primux encountered a segmentation fault and crashed after running for approximately 70 h. These results indicate that multiPrime is effective in dealing with large and diverse sequences, while conventional primer design software such as DegePrime or Primux is inadequate, even when combined with our strategy.
Experimentally validating primer‐target amplicons using a long‐read sequencing platform
To verify whether the target sequences were being amplified as designed, we utilized the primer set to amplify PCR products from 30 clinical specimens and three negative control samples and subsequently sequenced the product using a long‐read sequencing platform (Oxford Nanopore Technology [ONT]). All viruses were accurately identified with the target amplicon, and no virus reads were detected in the negative controls, indicating the high specificity of the primer set (Figure 2A, Supporting Information: Table S4). Furthermore, the detection of two target viruses in one clinical specimen and 2–4 clinical specimens in one tube demonstrated the capability of the primer set to detect complex infections, which is crucial for accurate diagnosis and treatment.
Figure 2.
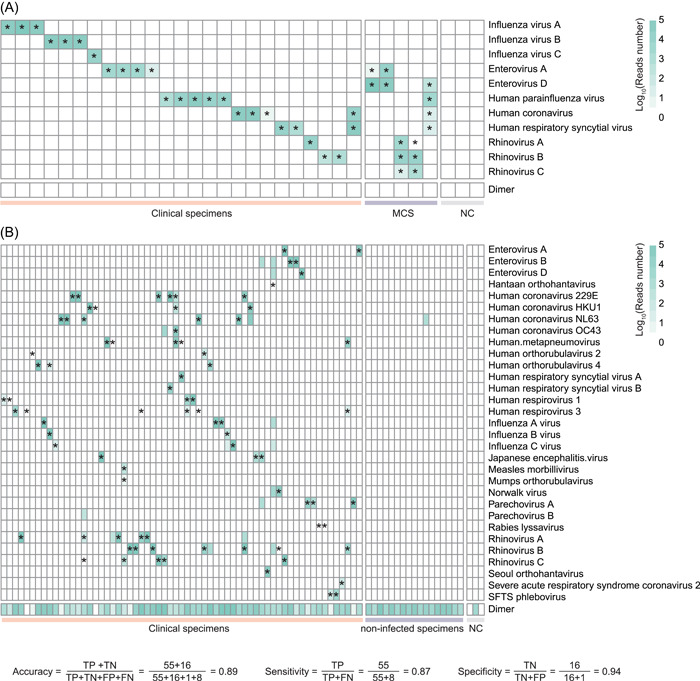
Validation of two primer sets designed by multiPrime using two sequencing platforms. (A) Validation of the primer set on the ONT platform. MCS, mixed clinical specimens (2–4 clinical specimens in one tube); NC, negative control; stars indicate the target virus. (B) Validation of the primer set on the NextSeq. 500 platform. The primer set was designed by multiPrime (v2.0.3) with the following parameters: coordinate: 4; seq_number_ANI: 10; Others: Default. Clinical NC, normal clinical specimen, which refers to samples obtained from healthy individuals devoid of any viral sequences; NC, negative control refers to intentionally empty samples without any template; stars indicate the target virus.
We then assigned all target reads to their primers and estimated the effectiveness of the primers by comparing them to primers that were perfectly annealed. Our analysis revealed that the number of mismatches between the primer and template DNA plays a vital role in primer‐template annealing efficiency. Moreover, mismatches located at the 3′ end of the primer and 5′‐adjacent positions may lead to a relatively high decrease in primer efficiency (Supporting Information: Figure S10A). To verify the impact of mismatch number and position on primer design, we synthesized a DNA fragment (NC_001488.1:4925‐5423) and constructed a template vector. We designed a degenerate primer and estimated its relative efficiency (Supporting Information: Table S5). Our analysis showed that mismatches located at the 3′ end (–1) had the most significant impact on primer efficiency, while those adjacent to the 5′ end (–17) had a smaller impact than those at the 3′ end. Mismatches in the middle (−12) had the smallest effect (Supporting Information: Figure S10B).
Experimental validation of the primer set's efficacy in capturing diverse sequences
To assess the efficacy of the primer set in capturing diversity and abundance, we devised primers targeting 16 epidemic pathogens and contrasted the outcomes with those of mNGS using three samples. The results demonstrated that our primer set facilitated target detection at a level comparable to mNGS. Notably, all designated targets were successfully identified, with their corresponding read counts significantly surpassing those obtained through mNGS (Figure 3A–C, Supporting Information: Table S6). These findings underscore the effectiveness of the multiPrime‐designed primer set in capturing both the diversity and abundance of targeted sequences.
Figure 3.
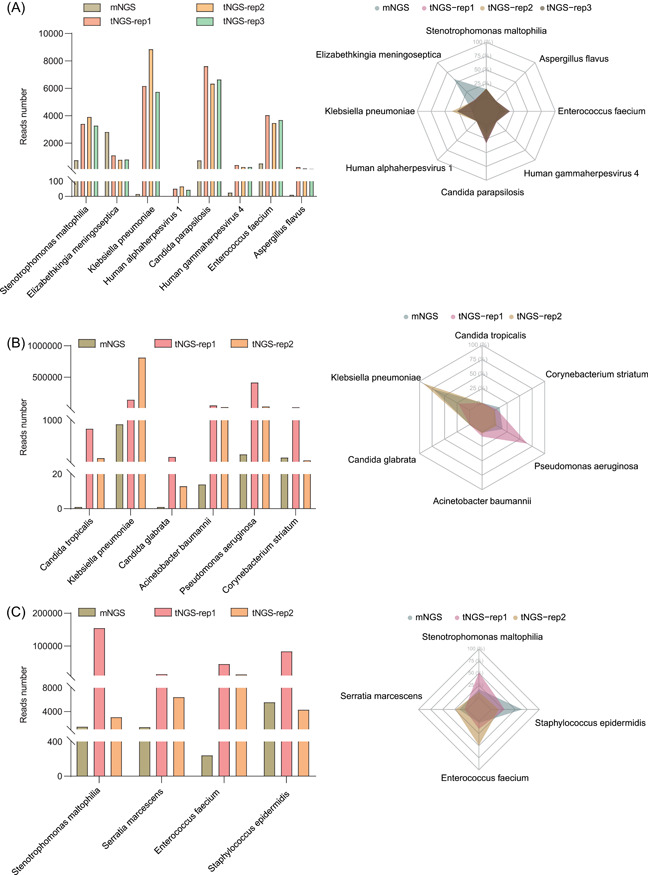
The efficacy of the primer set in capturing diversity sequences. Target read number (barplot, left) and percentages (radarplot, right) were obtained from both metagenomic next‐generation sequencing and targeted next‐generation sequencing analyses for three clinical specimens: clinical specimen 1 (A), clinical specimen 2 (B), and clinical specimen 3 (C). These specimens collectively contained a total of 16 pathogens, including fungi and bacteria.
Application of multiprime in the development of a primer set for tNGS for 30 viruses
To further confirm the accuracy and effectiveness of the primer set designed by multiPrime, we designed a larger set of primers targeting 30 viruses, ensuring that 3′ end mismatches were avoided. Subsequently, we evaluated this larger primer set using a cohort of 80 clinical specimens. Our results showed that the primer set was able to detect viruses using next‐generation sequencing with a single‐end 75 sequencing model (Figure 2B, Supporting Information: Table S7). The primer set yielded a sensitivity of 87%, a specificity of 94%, and an accuracy of 89% (Supporting Information: Table S8). Among the 63 infected specimens, only Hantaan orthohantavirus and rabies lyssavirus remained unidentified, while all other viruses were correctly identified with an accuracy score exceeding 95% (Supporting Information: Table S9). Subsequently, alternative cluster‐specific primers were selected for these two viruses. The primer set was subjected to re‐evaluation. Remarkably, both of these viruses were successfully identified during this subsequent assessment (Supporting Information: Table S7). These results demonstrated that multiPrime‐designed primers are reliable and precise in detecting viruses. In addition, we also assigned virus reads to their corresponding primers to evaluate the efficiency of each primer. Our analysis revealed that the number of mismatches remains the most significant factor affecting primer efficiency. Specifically, we found that positions adjacent to the 5′ end (while avoiding the 3′ end) had a relatively high impact compared to other positions (Supporting Information: Figure S10C).
DISCUSSION
The effectiveness and detection capabilities of tNGS rely heavily on the primer set used, making the enhancement of primer coverage a major focal point. The naive approach for tNGS primer sets candidate (PSC) would be the “divide and conquer” procedure. This approach involves dividing the input sequences into two groups, one containing primer and the other without, and repeating the procedure for the nonprimer‐containing group until all sequences are matched or no candidate primers can be found. However, it is challenging and time‐consuming to design primers and assess their compatibility at each iteration. It is crucial to ensure that newly designed primers do not interact with existing ones to prevent off‐target amplification and dimer formation. To address these challenges, an effective approach would be to group input sequences based on their identity, design primers for each group, and combine intergroup primers into a primer set. However, the success of this approach depends on achieving sufficiently high primer coverage for each group. If the primer coverage is insufficient or unsatisfactory, this approach would not be feasible. MultiPrime aims to design a degenerate primer that is similar to all input sequences and matches well with them by tolerating up to two mismatches instead of requiring a perfect matching. Compared to conventional primer design programs, multiPrime yields a higher number of candidate primers with higher coverage, resulting in a more efficient primer set with fewer primers. Furthermore, multiPrime uses a loss function to evaluate the likelihood of dimer formation, resulting in a reduced probability of dimer formation within the primer set and facilitating expansion of the primer set as needed. Overall, multiPrime offers an innovative and efficient approach for one‐step primer set design for tNGS.
PCR failure can be attributed to various factors, such as contamination level, poor template quality, inadequate operator proficiency, or suboptimal PCR conditions. Therefore, it is essential to validate all primer pairs in the primer set and monitor their amplification efficiency to ensure accuracy. Moreover, altering reagents or the reaction system for a specific primer pair may influence the amplification of other primers, thus requiring additional primer pair validation. MultiPrime offers a cluster‐specific set of candidate primer pairs that can complement or substitute existing primer pairs in the primer set, empowering researchers to design more effective panels to meet their research and development demands.
CONCLUSIONS
In our study, we have demonstrated that primers with specific mismatches can accurately amplify targets. MultiPrime incorporates a mismatch‐tolerant feature that simplifies the process of managing mismatches. It can design primers while avoiding mismatches at specific positions and automatically generate two minimal primer sets for tNGS. In a small cohort, direct sequencing using ONT identified all viruses while not detecting any nontarget virus reads in negative controls, proving the ability of primers with mismatch tolerance to identify target viruses. In a larger cohort, we achieved high identification accuracy, sensitivity, and specificity. Overall, multiPrime significantly expands the range of target sequences and enables ultra‐multiplex PCR. Incorporating multiPrime into tNGS is expected to simplify and enhance the effectiveness of the technique.
MATERIALS AND METHODS
Implementation
The workflow of multiPrime is illustrated in Figure 4 and the bioinformatic pipeline is illustrated in Supporting Information: Figure S1. The manual and software are freely accessible to all users at https://github.com/joybio/multiPrime. The installation video for multiPrime is available on Figshare (https://figshare.com/articles/media/Installation_video_of_multiPrime/23904159). All scripts in multiPrime are implemented as Python scripts, and the joint pipeline is written in Snakemake [64]. The input of multiPrime is a FASTA format file. It can be a set of CDSs, genes, genomes, or other kinds of sequences. MultiPrime has three main steps: First, multiPrime classifies the sequences by identity [65, 66]. Second, multiPrime randomly selects N (default: 500) sequences from each class to generate multi‐alignment results [67, 68] and design degenerate primers for them by allowing mismatches through the nearest‐neighbor (NN) model. Finally, a greedy algorithm is used to combine intercluster primer pairs into one primer set according to dimer examination and specificity evaluation.
Figure 4.
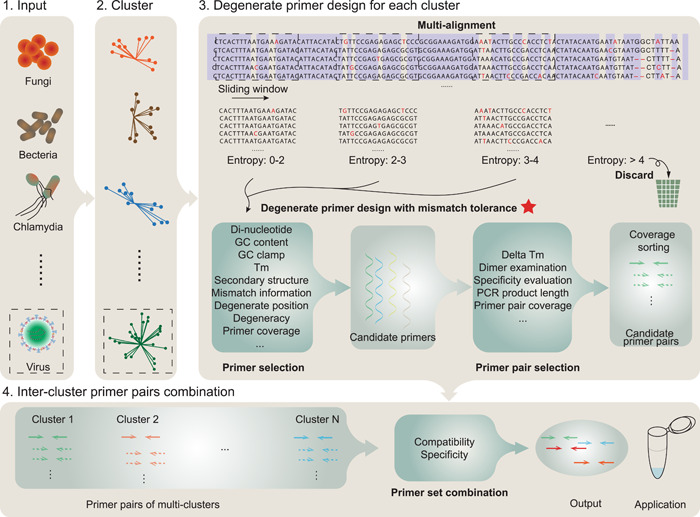
Schematic diagram depicting the one‐step targeted next‐generation sequencing (tNGS) primer set design method developed by using multiPrime. The red star indicates the step where the method is described in more detail. MultiPrime comprises four primary stages: (1) Input: In this initial phase, the collection of target sequences is required. (2) Cluster: Redundant sequences are eliminated and clusters are established based on sequence identity. (3) Degenerate Primer Design for Each Cluster: Utilizing MUSCLE or MAFFT, a multialignment procedure is conducted, followed by the design of candidate primers using the nearest‐neighbor model. (4) Intercluster Primer Pair Combination: Primer pairs are selected considering factors such as PCR product length, melting temperature, dimer formation assessment, coverage despite errors, and other pertinent criteria. Subsequently, a greedy algorithm is employed to merge primer pairs into an optimal minimal primer set, guided by dimer formation analysis.
IUPAC transition table
We implemented a hash table to simplify the NN model (Supporting Information: Figure S2A). In this table, degenerate base values are derived from normal bases, and the features of the IUPAC transition (trans) table are as follows:
The value of each normal base [A, G, C, T] is unique.
The value of a degenerate base is the sum of the contained normal bases.
The value of each degenerate base is unique.
The rounded down value of each base is equal to its degeneracy.
The value of a degenerate base minus the value of a contained normal base is present in the IUPAC trans table but it will not be when the value of a noncontained normal base is subtracted.
Nearest‐neighbor model
The nearest‐neighbor (NN) model's goal is to identify a degenerate primer that can match as many sequences as possible with up to X (0, 1, or 2) mismatches. It takes the multialignment result as input and identifies primer‐length windows as candidate primers. When a window begins or ends with a “‐” character, “‐” is removed, and the window shifts to the next base. The window is then extended to match the length of the primer being sought. However, not all windows are suitable for degenerate primer design (DPD). To filter out high‐entropy windows unlikely to yield effective primers, we employ entropy as a metric to quantify variation within the window. Only those windows with entropy values below 3.6 are selected for further processing in the DPD protocol (Supporting Information: Figure S2B).
Typically, the most frequent sequence or the most frequent bases in each position will be used as the primary primer (which can be called the optimal primer) to initialize DPD. However, the NN model assumes that both the base frequency at each position and the weight between NN bases contribute to optimal primer selection, and the Viterbi algorithm [69] (Supporting Information: Figure S2C) is employed to find the optimal primer. In certain instances, the most frequently occurring sequence may differ substantially from the most probable one. Therefore, we utilize both the most frequent sequence and the Viterbi result as the optimal primer to initiate DPD to select the best primer. A simplified version of our algorithm is outlined as follows: First, we compute the frequency and NN arrays of the input sequences (Supporting Information: Figure S3A,B). Second, we initialize DPD using the NN model until acceptable coverage is achieved with errors or degeneracy of the primer not exceeding the threshold (Supporting Information: Figure S3C,D). Third, we identify candidate primer pairs based on criteria, such as coverage with errors, evaluation of dimers, Tm difference between primers, and additional information. Finally, we obtain eligible candidate cluster‐specific primer pairs.
The efficiency of PCR with specific primer
We assigned all target reads to their primers and estimated the effectiveness of the primers by comparing them to primers that were perfectly annealed.
Efficiency (primer‐i) refers to the PCR efficiency specifically associated with primer‐i. Reads number (i) represents the count of reads that correspond to the target region of primer‐i. Similarly, reads number (c) denotes the quantity of reads attributed to the target region of the primer with a perfect match.
Evaluation of degenerate primer coverage with errors
We introduce a new metric, the Y‐distance, which is an extension of the Hamming distance (Supporting Information: Figure S4A), to measure the distance between degenerate primer and target sequence based on the number and positions of noncontained bases. For example, “G2SKR” is a common primer for Norovirus detection [70, 71, 72], and “Base” is a hypothetical target sequence. The Hamming distance between “G2SKR” and “Base” is 6, which is not sufficient for describing the difference because there is only a one‐nucleotide difference between “Base” and the closest sequence contained in “G2SKR.” However, there is only one value in the Y‐distance that is not in the IUPAC trans table (Supporting Information: Figure S4B,C), and 17 indicates that the 17th position in “G2SKR” is different than the 17th position in “Base.” The thresholds of the Y‐distance in multiPrime are as follows:
-
1)
The Y‐distance length, indicating the number of allowable mismatches, should be limited to fewer than 2.
-
2)
Certain positions (such as the 3′ end of the primer) should be avoided in the Y‐distance.
Dimer examination
The loss function used in multiPrime is an empirical formula that is modified from badness and is derived from SADDLE [73]. It aims to evaluate the compatibility between two primers. Primers are incompatible if the loss function between any two primers is greater than the threshold (high risk ≥ 3.96 and low risk ≤ 3).
Length is the length of the complementary sequence, distance1 and distance2 are the distances of the complementary sequence to the 3′ ends of primer, and GC content is the number of G/C nucleotides in the complementary sequence.
The threshold is determined by identifying the inflection point of the dimer ratio (Supporting Information: Figure S8) to balance the specificity and sensitivity of primer pairs, ensuring that the selected primer pairs have minimal dimer formation while achieving high coverage.
where, L is the value of the loss function, DNL is the dimer reads of primer‐primer with a loss function greater than L, and DNT is the total dimer reads.
Specificity evaluation
The burrows‐wheeler transform (BWT) algorithm [74] is employed to evaluate the specificity of the primer pairs. Primer pairs with 1 mismatch (at least 4 bp away from the 3′ end of the primer) having target regions in the host genome or transcriptome are considered potential nonspecific primer pairs. We use 9 bp of the 3′ terminus for mapping, which means that the 9 bp terminus of primer pairs with a target amplicon in the host should be considered 1 unit off‐target [21].
Experimental validation
Input of multiprime
In the context of third‐generation sequencing, we employed a comprehensive data set consisting of a total of eight pandemic respiratory system viruses along with a combined count of 43,016 complete genomic and CDS (coding sequence) sequences. This data set was obtained from the National Center for Biotechnology Information (NCBI) and featured a diverse array of viral types, including 2522 enteroviruses (A and D, complete genome), 429 human coronaviruses (complete genome), 1155 human respiratory syncytial viruses (complete genome), 27,727 influenza A viruses (CDS), 9129 influenza B viruses (CDS), 166 influenza C viruses (CDS), 509 human parainfluenza viruses (HPIV; complete genome), and 1379 rhinoviruses (A, B, and C, complete genome), and were used as the input of multiPrime. All of these FASTA files were consolidated into a single file, which served as the input for the multiPrime. For the purposes of diversity and abundance analysis, a selection of 16 pandemic pathogens was chosen as the input for multiPrime. Furthermore, as part of our analysis using next‐generation sequencing, we extended our data set to include genomic and CDS sequences from a total of 30 distinct RNA viruses, encompassing various subtypes. This expanded data set was subsequently utilized as input for multiPrime.
Output of multiprime
The resulting output comprises a directory encompassing seven subdirectories along with over 40 individual files. A comprehensive elucidation of each file's particulars is available in the provided URL: https://github.com/joybio/multiPrime/README.md. Notably, the primary output encompasses two ultimate primer sets and the cluster‐specific primers.
Sample selection and preparation
Clinical specimens (sputum/bronchoalveolar lavage fluid [BALF]/cerebrospinal fluid [CSF]), virus stocks, and negative controls were used to evaluate multiPrime.
For third‐generation sequencing, a total of 19 clinical specimens (four sputum, 14 BALF, and one CSF), five virus stocks (three from Guangzhou BDS Biological Technology Co., Ltd. and two from the China Center for Type Culture Collection), and three negative controls were used for targeted ONT direct sequencing. The target virus sequences of clinical specimens (two influenza B viruses and one influenza C virus) were previously determined by mNGS.
For next‐generation sequencing (SE75), three influenza A BALF samples were used to assess mismatch effects; 63 clinical specimens with a positive RNA virus infection diagnosis with mNGS, 17 normal controls, and three negative controls were used to evaluate the performance of the 94‐plex multiPrime primer set.
RNA was extracted using a Quick DNA/RNA Miniprep Kit (200 Preps) (ZYMO) following the manufacturer's instructions, and the sample was eluted in RNase‐free water.
Library and sequencing
Amplicons for next‐generation sequencing were generated using AccurSTART U+ One Step RT‐qPCR Super PreMix (ONE TUBE) (Vazyme) and then purified using AMPure XP (Beckman). The purified amplicons were then amplified using KAPA HiFi HotStart Uracil+ ReadyMix (2X) (Roche) to complete library construction. A modified protocol for the NextSeq. 500/550 High Output Kit v2.5 was used for amplicon sequencing, and sequencing was performed on the Illumina NextSeq. 500 platform (75 cycles). Amplicons for third‐generation sequencing were generated by AccurSTART U+ One Step RT‐qPCR Super PreMix (Vazyme) and then purified using AMPure XP (Beckman). Second‐round PCR was performed with KOD‐Multi & Epi (TOYOBO) to complete library construction, and the library was sequenced on GridION X5.
Analysis of next‐generation sequencing data
The RCP pipeline (see Acknowledgments) is utilized for the analysis of next‐generation sequencing data. Briefly, sequencing reads were trimmed by BBMap (https://sourceforge.net/projects/bbmap). Seqkit [75] was employed to extract unique reads, and an R script was used to determine the duplication level. Unique reads were annotated with a simplified NT database (only viruses) by using BLAST (2.13.0+) [76, 77]. Dimer detection and counting were also performed using BLAST (2.13.0+).
Analysis of third‐generation sequencing data
Base calling of the raw fast5 files produced by sequencing was performed using Guppy v1.1. Adapters were trimmed off by Porechop (https://github.com/rrwick/Porechop). Clean reads were mapped to the Homo sapiens genome assembly T2T‐CHM13v2.0 and YH to remove the host genome with minimap2 [78]. The remaining reads were annotated with a simplified NT database (only viruses) by using BLAST (2.13.0+). “Confident on targets”: Reads annotated to viruses (BLAST). “High confidence on target”: “Confident on targets” reads with specific 5′/3′ primers.
AUTHOR CONTRIBUTIONS
The project was conceptualized and designed by Junbo Yang. All scripts were written by Junbo Yang. Experiments were conducted by Han Xia, Chen Luo, Junbo Yang, and Yuanlin Guan. The sequencing data were analyzed by Junbo Yang, Kangfei Wei, and Meilin Duan. Junbo Yang, Zhe Zhang, and David C. C. Lam wrote the manuscript. All authors contributed to the article and attested that they meet the current ICMJE criteria for authorship.
CONFLICT OF INTEREST STATEMENT
The authors declare no conflict of interest.
ETHICS STATEMENT
Our research was conducted in accordance with the principles of the Declaration of Helsinki. The study was approved by the Human and Artefacts Research Ethics Committee (HAREC) at The Hong Kong University of Science and Technology under the approval number HREP‐2023‐0221. Written informed consent was obtained from all participants before collecting clinical specimens for research purposes. All specimens were stored securely and handled using appropriate procedures to maintain their integrity. Deidentified data were used in all analyses to protect patient privacy.
Supporting information
Supporting information.
Supporting information.
ACKNOWLEDGMENTS
We thank all patients and their families. We also acknowledge Dr. Yulong Niu (niuyulong@hugobiotech.com) for the RCP pipeline of virus next‐generation sequencing data analysis. We also extend our acknowledgments to Dr. Biliang Zhang and M. D. Shengbin Peng for their valuable contributions to the analysis of bacteria and fungi data. This work was supported by the Shaanxi Qinchuangyuan “Scientists and Engineers” Team Construction Project (No. 2022KXJ‐82); Shaanxi Qinchuangyuan “Chief Scientist” project (2022‐SXKXJ‐005); Beijing Municipal Science and Technology Commission (No. Z211100002921063) and the Hong Kong Innovation and Technology Fund (MRP/039/18X).
Xia, Han , Zhang Zhe, Luo Chen, Wei Kangfei, Li Xuming, Mu Xiyu, Duan Meilin, et al. 2023. “MultiPrime: A Reliable and Efficient Tool for Targeted Next‐Generation Sequencing.” iMeta 2, e143. 10.1002/imt2.143
Han Xia, Zhe Zhang, Chen Luo and Kangfei Wei contributed equally to this study.
Contributor Information
Yuanlin Guan, Email: guanyuanlin@hugobiotech.com.
David C. C. Lam, Email: medcclam@ust.hk.
Junbo Yang, Email: 1806389316@pku.edu.cn.
DATA AVAILABILITY STATEMENT
All the necessary Python scripts and test data required for replicating our results can be found at https://github.com/joybio/multiPrime. The majority of the raw sequencing data presented in this paper have been deposited in the Genome Sequence Archive (Accession No. CRA009723) at the National Genomics Data Center, China National Center for Bioinformation/Beijing Institute of Genomics, Chinese Academy of Sciences, and are publicly available at https://ngdc.cncb.ac.cn/gsa. However, some data will not be made available in a public repository due to confidentiality concerns related to patient privacy. For further inquiries, please contact the corresponding author, Junbo Yang.
REFERENCES
- 1. Chen, Xiancheng , Cao Ke, Wei Yu, Qian Yajun, Liang Jing, Dong Danjiang, Tang Jian, Zhu Zhanghua, Gu Qin, and Yu Wenkui. 2020. “Metagenomic Next‐Generation Sequencing in the Diagnosis of Severe Pneumonias Caused by Chlamydia Psittaci.” Infection 48: 535–542. 10.1007/s15010-020-01429-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Gu, Wei , Miller Steve, and Chiu Charles Y.. 2019. “Clinical Metagenomic Next‐Generation Sequencing for Pathogen Detection.” Annual Review of Pathology: Mechanisms of Disease 14: 319–338. 10.1146/annurev-pathmechdis-012418-012751 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Wooley, John C. , and Ye Yuzhen. 2010. “Metagenomics: Facts and Artifacts, and Computational Challenges.” Journal of Computer Science and Technology 25: 71–81. 10.1007/s11390-010-9306-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Wu, Jieying , Gao Weimin, Zhang Weiwen, and Meldrum Deirdre R.. 2011. “Optimization of Whole‐Transcriptome Amplification From Low Cell Density Deep‐Sea Microbial Samples for Metatranscriptomic Analysis.” Journal of Microbiological Methods 84: 88–93. 10.1016/j.mimet.2010.10.018 [DOI] [PubMed] [Google Scholar]
- 5. Zhao, Na , Cao Jiabao, Xu Jiayue, Liu Beibei, Liu Bin, Chen Dingqiang, Xia Binbin, et al. 2021. “Targeting RNA With Next‐ and Third‐Generation Sequencing Improves Pathogen Identification in Clinical Samples.” Advanced Science 8: e2102593. 10.1002/advs.202102593 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Hansen, Wendy L. J. , Bruggeman Cathrien A., and Wolffs Petra F. G.. 2013. “Pre‐Analytical Sample Treatment and DNA Extraction Protocols for the Detection of Bacterial Pathogens from Whole Blood.” Methods in Molecular Biology 943: 81–90. 10.1007/978-1-60327-353-4_4 [DOI] [PubMed] [Google Scholar]
- 7. Marotz, Clarisse A. , Sanders Jon G., Zuniga Cristal, Zaramela Livia S., Knight Rob, and Zengler Karsten. 2018. “Improving Saliva Shotgun Metagenomics by Chemical Host DNA Depletion.” Microbiome 6: 42. 10.1186/s40168-018-0426-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. ElSharawy, Abdou , Warner Jason, Olson Jeff, Forster Michael, Schilhabel Markus B., Link Darren R., Rose‐John Stefan, et al. 2012. “Accurate Variant Detection Across Non‐Amplified and Whole Genome Amplified DNA Using Targeted Next Generation Sequencing.” BMC Genomics 13: 500. 10.1186/1471-2164-13-500 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Li, Shiying , Tong Jin, Liu Yi, Shen Wei, and Hu Peng. 2022. “Targeted Next Generation Sequencing is Comparable with Metagenomic Next Generation Sequencing in Adults with Pneumonia for Pathogenic Microorganism Detection.” Journal of Infection 85: e127–e129. 10.1016/j.jinf.2022.08.022 [DOI] [PubMed] [Google Scholar]
- 10. Gaston, David C , Miller Heather B., Fissel John A., Jacobs Emily, Gough Ethan, Wu Jiajun, Klein Eili Y., Carroll Karen C., and Simner Patricia J.. 2022. “Evaluation of Metagenomic and Targeted Next‐Generation Sequencing Workflows for Detection of Respiratory Pathogens from Bronchoalveolar Lavage Fluid Specimens.” Journal of Clinical Microbiology 60: e0052622. 10.1128/jcm.00526-22 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Cabibbe, Andrea M. , Spitaleri Andrea, Battaglia Simone, Colman Rebecca E., Suresh Anita, Suresh Anita, Uplekar Swapna, Rodwell Timothy C., and Cirillo Daniela M.. 2020. “Application of Targeted Next‐Generation Sequencing Assay on a Portable Sequencing Platform for Culture‐Free Detection of Drug‐Resistant Tuberculosis from Clinical Samples.” Journal of Clinical Microbiology 58: 10. 10.1128/jcm.00632-20 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Kambli, Priti , Ajbani Kanchan, Kazi Mubin, Sadani Meeta, Naik Swapna, Shetty Anjali, Tornheim Jeffrey A., Singh Harpreet, and Rodrigues Camilla. 2021. “Targeted Next Generation Sequencing Directly from Sputum for Comprehensive Genetic Information on Drug Resistant Mycobacterium tuberculosis .” Tuberculosis 127: 102051. 10.1016/j.tube.2021.102051 [DOI] [PubMed] [Google Scholar]
- 13. Quick, Joshua , Grubaugh Nathan D., Pullan Steven T., Claro Ingra M., Smith Andrew D., Gangavarapu Karthik, Oliveira Glenn, et al. 2017. “Multiplex PCR Method for MinION and Illumina Sequencing of Zika and Other Virus Genomes Directly From Clinical Samples.” Nature Protocols 12: 1261–1276. 10.1038/nprot.2017.066 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Wu, Sheng‐Han , Xiao Yu‐Xin, Hsiao Hseuh‐Chien, and Jou Ruwen. 2022. “Development and Assessment of a Novel Whole‐Gene‐Based Targeted Next‐Generation Sequencing Assay for Detecting the Susceptibility of Mycobacterium Tuberculosis to 14 Drugs.” Microbiology Spectrum 10: e0260522. 10.1128/spectrum.02605-22 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Cesar ignacio‐Espinoza, J , Solonenko Sergei A., and Sullivan Matthew B.. 2013. “The Global Virome: Not as Big as we Thought?” Current Opinion in Virology 3: 566–571. 10.1016/j.coviro.2013.07.004 [DOI] [PubMed] [Google Scholar]
- 16. Paez‐Espino, David , Eloe‐Fadrosh Emiley A., Pavlopoulos Georgios A., Thomas Alex D., Huntemann Marcel, Mikhailova Natalia, Rubin Edward, Ivanova Natalia N., and Kyrpides Nikos C.. 2016. “Uncovering Earth's Virome.” Nature 536: 425–430. 10.1038/nature19094 [DOI] [PubMed] [Google Scholar]
- 17. Andreson, Reidar , Möls Tõnu, and Remm Maido. 2008. “Predicting Failure Rate of PCR In Large Genomes.” Nucleic Acids Research 36: e66. 10.1093/nar/gkn290 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Bustin, Stephen A , Mueller Reinhold, and Nolan Tania. 2020. “Parameters for Successful PCR Primer Design.” Methods in Molecular Biology 2065: 5–22. 10.1007/978-1-4939-9833-3_2 [DOI] [PubMed] [Google Scholar]
- 19. Leggate, Johanna , and Blais Burton W. 2006. “An Internal Amplification Control System Based on Primer‐Dimer Formation for PCR Product Detection By DNA Hybridization.” Journal of Food Protection 69: 2280–2284. 10.4315/0362-028x-69.9.2280 [DOI] [PubMed] [Google Scholar]
- 20. Vallone, Peter M. , and Butler John M.. 2004. “AutoDimer: A Screening Tool for Primer‐Dimer and Hairpin Structures.” BioTechniques 37: 226–231. 10.2144/04372ST03 [DOI] [PubMed] [Google Scholar]
- 21. Wang, Kun , Li Haiwei, Xu Yue, Shao Qianzhi, Yi Jianming, Wang Ruichao, Cai Wanshi, Hang Xingyi, Zhang Chenggang, Cai Haoyang et al. 2019. “MFEprimer‐3.0: Quality Control for PCR Primers.” Nucleic Acids Research 47: W610–W613. 10.1093/nar/gkz351 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Ye, Jian , Coulouris George, Zaretskaya Irena, Cutcutache Ioana, Rozen Steve, and Madden Thomas L. 2012. “Primer‐BLAST: A Tool to Design Target‐Specific Primers for Polymerase Chain Reaction.” BMC Bioinformatics 13: 134. 10.1186/1471-2105-13-134 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Guo, Jingwen , Starr David, and Guo Huazhang. 2021. “Classification and Review of Free PCR Primer Design Software.” Bioinformatics 36: 5263–5268. 10.1093/bioinformatics/btaa910 [DOI] [PubMed] [Google Scholar]
- 24. Kechin, Andrey , Borobova Viktoria, Boyarskikh Ulyana, Khrapov Evgeniy, Subbotin Sergey, and Filipenko Maxim. 2020. “NGS‐PrimerPlex: High‐Throughput Primer Design for Multiplex Polymerase Chain Reactions.” PLoS Computational Biology 16: e1008468. 10.1371/journal.pcbi.1008468 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Shen, Zhiyong , Qu Wubin, Wang Wen, Lu Yiming, Wu Yonghong, Li Zhifeng, Hang Xingyi, Wang Xiaolei, Zhao Dongsheng, and Zhang Chenggang. 2010. “MPprimer: A Program for Reliable Multiplex PCR Primer Design.” BMC Bioinformatics 11: 143. 10.1186/1471-2105-11-143 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Untergasser, Andreas , Cutcutache Ioana, Koressaar Triinu, Ye Jian, Faircloth Brant C, Remm Maido, and Rozen Steven G. 2012. “Primer3‐‐New Capabilities and Interfaces.” Nucleic Acids Research 40: e115. 10.1093/nar/gks596 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Bekaert, Michaël , and Teeling Emma C. 2008. “UniPrime: A Workflow‐Based Platform for Improved Universal Primer Design.” Nucleic Acids Research 36: e56. 10.1093/nar/gkn191 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Collatz, Maximilian , Braun Sascha D., Monecke Stefan, and Ehricht Ralf. 2022. “ConsensusPrime—A Bioinformatic Pipeline for Ideal Consensus Primer Design.” BioMedInformatics 2: 637–642. 10.3390/biomedinformatics2040041 [DOI] [Google Scholar]
- 29. Fredslund, Jakob , Schauser Leif, Madsen Lene H., Sandal Niels, and Stougaard Jens. 2005. “PriFi: Using a Multiple Alignment of Related Sequences to Find Primers for Amplification of Homologs.” Nucleic Acids Research 33: W516–W520. 10.1093/nar/gki425 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Gadberry, Michael D. , Malcomber Simon T., Doust Andrew N., and Kellogg Elizabeth A.. 2005. “Primaclade—A Flexible Tool to Find Conserved PCR Primers Across Multiple Species.” Bioinformatics 21: 1263–1264. 10.1093/bioinformatics/bti134 [DOI] [PubMed] [Google Scholar]
- 31. Hugerth, Luisa W. , Wefer Hugo A., Lundin Sverker, Jakobsson Hedvig E., Lindberg Mathilda, Rodin Sandra, Engstrand Lars, and Andersson Anders F.. 2014. “DegePrime, a Program for Degenerate Primer Design for Broad‐Taxonomic‐Range PCR in Microbial Ecology Studies.” Applied and Environmental Microbiology 80: 5116–5123. 10.1128/aem.01403-14 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Jabado, Omar J. , Palacios Gustavo, Kapoor Vishal, Hui Jeffrey, Renwick Neil, Zhai Junhui, Briese Thomas, and Lipkin W. Ian. 2006. “Greene SCPrimer: A Rapid Comprehensive Tool for Designing Degenerate Primers from Multiple Sequence Alignments.” Nucleic Acids Research 34: 6605–6611. 10.1093/nar/gkl966 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Kreer, Christoph , Döring Matthias, Lehnen Nathalie, Ercanoglu Meryem S., Gieselmann Lutz, Luca Domnica, Jain Kanika, Schommers Philipp, Pfeifer Nico, and Klein Florian. 2020. “openPrimeR for Multiplex Amplification of Highly Diverse Templates.” Journal of Immunological Methods 480: 112752. 10.1016/j.jim.2020.112752 [DOI] [PubMed] [Google Scholar]
- 34. Lamprecht, Anna‐Lena , Margaria Tiziana, Steffen Bernhard, Sczyrba Alexander, Hartmeier Sven, and Giegerich Robert. 2008. “GeneFisher‐P: Variations of GeneFisher as Processes in Bio‐jETI.” BMC Bioinformatics 9: S13. 10.1186/1471-2105-9-S4-S13 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Lane, Courtney E. , Hulgan Daniel, O'Quinn Kelly, and Benton Michael G.. 2015. “CEMAsuite: Open Source Degenerate PCR Primer Design.” Bioinformatics 31: 3688–3690. 10.1093/bioinformatics/btv420 [DOI] [PubMed] [Google Scholar]
- 36. Linhart, Chaim , and Shamir Ron. 2002. “The Degenerate Primer Design Problem.” Bioinformatics 18: S172–S181. 10.1093/bioinformatics/18.suppl_1.S172 [DOI] [PubMed] [Google Scholar]
- 37. Rose, Timothy M. , Henikoff Jorja G., and Henikoff Steven. 2003. “CODEHOP (COnsensus‐DEgenerate Hybrid Oligonucleotide Primer) PCR Primer Design.” Nucleic Acids Research 31: 3763–3766. 10.1093/nar/gkg524 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. Yoon, Hyejin , and Leitner Thomas. 2015. “PrimerDesign‐M: A Multiple‐Alignment Based Multiple‐Primer Design Tool for Walking Across Variable Genomes.” Bioinformatics 31: 1472–1474. 10.1093/bioinformatics/btu832 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. You, Frank M. , Huo Naxin, Gu Yong Q., Lazo Gerard R., Dvorak Jan, and Anderson Olin D.. 2009. “ConservedPrimers 2.0: A High‐Throughput Pipeline for Comparative Genome Referenced Intron‐Flanking PCR Primer Design and Its Application in Wheat SNP Discovery.” BMC Bioinformatics 10: 331. 10.1186/1471-2105-10-331 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Clarke, Erik L. , Sundararaman Sesh A., Seifert Stephanie N., Bushman Frederic D., Hahn Beatrice H., and Brisson Dustin. 2017. “Swga: A Primer Design Toolkit for Selective Whole Genome Amplification.” Bioinformatics 33: 2071–2077. 10.1093/bioinformatics/btx118 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Gardner, Shea N. , Hiddessen Amy L., Williams Peter L., Hara Christine, Wagner Mark C., and Colston Bill W.. 2009. “Multiplex Primer Prediction Software for Divergent Targets.” Nucleic Acids Research 37: 6291–6304. 10.1093/nar/gkp659 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Hendling, Michaela , Pabinger Stephan, Peters Konrad, Wolff Noa, Conzemius Rick, and Barišić Ivan. 2018. “Oli2go: An Automated Multiplex Oligonucleotide Design Tool.” Nucleic Acids Research 46: W252–W256. 10.1093/nar/gky319 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Wu, Yueni , Feng Kai, Wei Ziyan, Wang Zhujun, and Deng Ye. 2020. “ARDEP, a Rapid Degenerate Primer Design Pipeline Based on K‐Mers for Amplicon Microbiome Studies.” International Journal of Environmental Research and Public Health 17: 5958. 10.3390/ijerph17165958 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Hysom, David A. , Naraghi‐Arani Pejman, Elsheikh Maher, Carrillo A. Celena, Williams Peter L., and Gardner Shea N.. 2012. “Skip the Alignment: Degenerate, Multiplex Primer and Probe Design Using K‐Mer Matching Instead of Alignments.” PLoS One 7: e34560. 10.1371/journal.pone.0034560 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Dwivedi‐Yu, Jane A. , Oppler Zachary J., Mitchell Matthew W., Song Yun S., and Brisson Dustin. 2023. “A Fast Machine‐Learning‐Guided Primer Design Pipeline for Selective Whole Genome Amplification.” PLoS Computational Biology 19: e1010137. 10.1371/journal.pcbi.1010137 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46. Huang, Yu‐Cheng , Chang Chun‐Fan, Chan Chen‐Hsiung, Yeh Tze‐Jung, Chang Ya‐Chun, Chen Chaur‐Chin, and Kao Cheng‐Yan. 2005. “Integrated Minimum‐Set Primers and Unique Probe Design Algorithms for Differential Detection on Symptom‐Related Pathogens.” Bioinformatics 21: 4330–4337. 10.1093/bioinformatics/bti730 [DOI] [PubMed] [Google Scholar]
- 47. Wu, Jain‐Shing , Lee Chungnan, Wu Chien‐Chang, and Shiue Yow‐Ling. 2004. “Primer Design Using Genetic Algorithm.” Bioinformatics 20: 1710–1717. 10.1093/bioinformatics/bth147 [DOI] [PubMed] [Google Scholar]
- 48. Wu, Jingli , Wang Jianxin, and Chen Jian'er. 2009. “A Practical Algorithm for Multiplex PCR Primer Set Selection.” International Journal of Bioinformatics Research and Applications 5: 38–49. 10.1504/ijbra.2009.022462 [DOI] [PubMed] [Google Scholar]
- 49. Haas, Stefan , Vingron Martin, Poustka A., and Wiemann Stefan. 1998. “Primer Design for Large Scale Sequencing.” Nucleic Acids Research 26: 3006–3012. 10.1093/nar/26.12.3006 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Riaz, Tiayyba , Shehzad Wasim, Viari Alain, Pompanon François, Taberlet Pierre, and Coissac Eric. 2011. “Ecoprimers: Inference of New DNA Barcode Markers from Whole Genome Sequence Analysis.” Nucleic Acids Research 39: e145. 10.1093/nar/gkr732 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. Smolander, Niina , Julian Timothy R., and Tamminen Manu. 2022. “Prider: Multiplexed Primer Design Using Linearly Scaling Approximation of Set Coverage.” BMC Bioinformatics 23: 174. 10.1186/s12859-022-04710-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Zhang, David Yu , Chen Sherry Xi, and Yin Peng. 2012. “Optimizing the Specificity of Nucleic Acid Hybridization.” Nature Chemistry 4: 208–214. 10.1038/nchem.1246 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53. Banos, Stefanos , Lentendu Guillaume, Kopf Anna, Wubet Tesfaye, Glöckner Frank Oliver, and Reich Marlis. 2018. “A Comprehensive Fungi‐Specific 18S rRNA Gene Sequence Primer Toolkit Suited for Diverse Research Issues and Sequencing Platforms.” BMC Microbiology 18: 190. 10.1186/s12866-018-1331-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54. Frech, Christian , Breuer Karin, Ronacher Bernhard, Kern Thomas, Sohn Christof, and Gebauer Gerhard. 2009. “Hybseek: Pathogen Primer Design Tool for Diagnostic Multi‐Analyte Assays.” Computer Methods and Programs in Biomedicine 94: 152–160. 10.1016/j.cmpb.2008.12.007 [DOI] [PubMed] [Google Scholar]
- 55. Ghedira, Rim , Papazova Nina, Vuylsteke Marnik, Ruttink Tom, Taverniers Isabel, and De Loose Marc. 2009. “Assessment of Primer/Template Mismatch Effects on Real‐Time PCR Amplification of Target Taxa for GMO Quantification.” Journal of Agricultural and Food Chemistry 57: 9370–9377. 10.1021/jf901976a [DOI] [PubMed] [Google Scholar]
- 56. Rejali, Nick A. , Moric Endi, and Wittwer Carl T.. 2018. “The Effect of Single Mismatches on Primer Extension.” Clinical Chemisty 64: 801–809. 10.1373/clinchem.2017.282285 [DOI] [PubMed] [Google Scholar]
- 57. Stadhouders, Ralph , Pas Suzan D., Anber Jeer, Voermans Jolanda, Mes Ted H. M., and Schutten Martin. 2010. “The Effect of Primer‐Template Mismatches on the Detection and Quantification of Nucleic Acids Using the 5′ Nuclease Assay.” The Journal of Molecular Diagnostics 12: 109–117. 10.2353/jmoldx.2010.090035 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58. Zhao, Sheng , Zhang Cuicui, Wang Liqun, Luo Minxuan, Zhang Peng, Wang Yue, Malik Waqar Afzal, et al. 2023. “A Prolific and Robust Whole‐Genome Genotyping Method Using PCR Amplification Via Primer‐Template Mismatched Annealing.” Journal of Integrative Plant Biology 65: 633–645. 10.1111/jipb.13395 [DOI] [PubMed] [Google Scholar]
- 59. Krausa, Peter , Bodmer Julia G., and Browning Michael J.. 1993. “Defining the Common Subtypes of HLA A9, A10, A28 and A19 By Use of ARMS/PCR.” Tissue Antigens 42: 91–99. 10.1111/j.1399-0039.1993.tb02243.x [DOI] [PubMed] [Google Scholar]
- 60. Sint, Daniela , Raso Lorna, and Traugott Michael. 2012. “Advances in Multiplex PCR: Balancing Primer Efficiencies and Improving Detection Success.” Methods in Ecology and Evolution 3: 898–905. 10.1111/j.2041-210X.2012.00215.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61. Linhart, Chaim , and Shamir Ron. 2005. “The Degenerate Primer Design Problem: Theory and Applications.” Journal of Computational Biology 12: 431–456. 10.1089/cmb.2005.12.431 [DOI] [PubMed] [Google Scholar]
- 62. Mallona, Izaskun , Weiss Julia, and Egea‐Cortines Marcos. 2011. “PcrEfficiency: A Web Tool for PCR Amplification Efficiency Prediction.” BMC Bioinformatics 12: 404. 10.1186/1471-2105-12-404 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63. Eisfeld, Amie J. , Neumann Gabriele, and Kawaoka Yoshihiro. 2014. “Influenza A Virus Isolation, Culture and Identification.” Nature Protocols 9: 2663–2681. 10.1038/nprot.2014.180 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64. Köster, Johannes , and Rahmann Sven. 2012. “Snakemake‐‐A Scalable Bioinformatics Workflow Engine.” Bioinformatics 28: 2520–2522. 10.1093/bioinformatics/bts480 [DOI] [PubMed] [Google Scholar]
- 65. Li, Weizhong , and Godzik Adam. 2006. “Cd‐Hit: A Fast Program for Clustering and Comparing Large Sets of Protein or Nucleotide Sequences.” Bioinformatics 22: 1658–1659. 10.1093/bioinformatics/btl158 [DOI] [PubMed] [Google Scholar]
- 66. Hernández‐Salmerón, Julie E , and Moreno‐Hagelsieb Gabriel. 2022. “FastANI, Mash and Dashing Equally Differentiate Between Klebsiella Species.” PeerJ 10: e13784. 10.7717/peerj.13784 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67. Edgar, Robert C . 2004. “MUSCLE: Multiple Sequence Alignment With High Accuracy and High Throughput.” Nucleic Acids Research 32: 1792–1797. 10.1093/nar/gkh340 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68. Katoh, Kazutaka , and Standley Daron M.. 2013. “MAFFT Multiple Sequence Alignment Software Version 7: Improvements in Performance and Usability.” Molecular Biology and Evolution 30: 772–780. 10.1093/molbev/mst010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69. Viterbi, A . 1967. “Error Bounds for Convolutional Codes and an Asymptotically Optimum Decoding Algorithm.” IEEE Transactions on Information Theory 13: 260–269. 10.1109/TIT.1967.1054010 [DOI] [Google Scholar]
- 70. Kojima, Shigeyuki , Kageyama Tsutomu, Fukushi Shuetsu, Hoshino Fuminori B., Shinohara Michiyo, Uchida Kazue, Natori Katsuro, Takeda Naokazu, and Katayama Kazuhiko. 2002. “Genogroup‐Specific PCR Primers for Detection of Norwalk‐Like Viruses.” Journal of Virological Methods 100: 107–114. 10.1016/s0166-0934(01)00404-9 [DOI] [PubMed] [Google Scholar]
- 71. Nishida, Tomoko , Nishio Osamu, Kato Masahiko, Chuma Takehisa, Kato Hirotomo, Iwata Hiroyuki, and Kimura Hirokazu. 2007. “Genotyping and Quantitation of Noroviruses in Oysters from Two Distinct Sea Areas in Japan.” Microbiology and Immunology 51: 177–184. 10.1111/j.1348-0421.2007.tb03899.x [DOI] [PubMed] [Google Scholar]
- 72. Schultz, Anna Charlotte , Saadbye Peter, Hoorfar Jeffrey, and Nørrung Birgit. 2007. “Comparison of Methods for Detection of Norovirus in Oysters.” International Journal of Food Microbiology 114: 352–356. 10.1016/j.ijfoodmicro.2006.09.028 [DOI] [PubMed] [Google Scholar]
- 73. Xie, Nina G. , Wang Michael X., Song Ping, Mao Shiqi, Wang Yifan, Yang Yuxia, Luo Junfeng, Ren Shengxiang, and Zhang David Yu. 2022. “Designing Highly Multiplex PCR Primer Sets with Simulated Annealing Design Using Dimer Likelihood Estimation (SADDLE.” Nature Communications 13: 1881. 10.1038/s41467-022-29500-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74. Langmead, Ben , and Salzberg Steven L.. 2012. “Fast Gapped‐Read Alignment with Bowtie 2.” Nature Methods 9: 357–359. 10.1038/nmeth.1923 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75. Shen, Wei , Le Shuai, Li Yan, and Hu Fuquan. 2016. “SeqKit: A Cross‐Platform and Ultrafast Toolkit for FASTA/Q File Manipulation.” PLoS One 11: e0163962. 10.1371/journal.pone.0163962 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76. Altschul, Stephen F. , Gish Warren, Miller Webb, Myers Eugene W., and Lipman David J.. 1990. “Basic Local Alignment Search Tool.” Journal of Molecular Biology 215: 403–410. 10.1016/s0022-2836(05)80360-2 [DOI] [PubMed] [Google Scholar]
- 77. Altschul, Stephen F. , Madden Thomas L., Schaffer Alejandro A., Zhang Jinghui, Zhang Zheng, Miller Webb, and Lipman David J.. 1997. “Gapped BLAST and PSI‐BLAST: A New Generation of Protein Database Search Programs.” Nucleic Acids Research 25: 3389–3402. 10.1093/nar/25.17.3389 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78. Li, Heng . 2018. “Minimap2: Pairwise Alignment for Nucleotide Sequences.” Bioinformatics 34: 3094–3100. 10.1093/bioinformatics/bty191 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supporting information.
Supporting information.
Data Availability Statement
All the necessary Python scripts and test data required for replicating our results can be found at https://github.com/joybio/multiPrime. The majority of the raw sequencing data presented in this paper have been deposited in the Genome Sequence Archive (Accession No. CRA009723) at the National Genomics Data Center, China National Center for Bioinformation/Beijing Institute of Genomics, Chinese Academy of Sciences, and are publicly available at https://ngdc.cncb.ac.cn/gsa. However, some data will not be made available in a public repository due to confidentiality concerns related to patient privacy. For further inquiries, please contact the corresponding author, Junbo Yang.