

Abstract
We present a novel Bayesian-based optimization framework that addresses the challenge of generalization in overparameterized models when dealing with imbalanced subgroups and limited samples per subgroup. Our proposed tri-level optimization framework utilizes local predictors, which are trained on a small amount of data, as well as a fair and class-balanced predictor at the middle and lower levels. To effectively overcome saddle points for minority classes, our lower-level formulation incorporates sharpness-aware minimization. Meanwhile, at the upper level, the framework dynamically adjusts the loss function based on validation loss, ensuring a close alignment between the global predictor and local predictors. Theoretical analysis demonstrates the framework’s ability to enhance classification and fairness generalization, potentially resulting in improvements in the generalization bound. Empirical results validate the superior performance of our tri-level framework compared to existing state-of-the-art approaches. The source code can be found at https://github.com/PennShenLab/FACIMS.
1. INTRODUCTION
Machine learning has achieved exceptional performance through overparameterization and advanced techniques. This progress is supported by high-quality datasets with sufficient samples for each data class and subgroup. However, real-world datasets frequently exhibit imbalances of different types and magnitudes, reflecting the significance and diversity of the underlying domains [Barocas et al., 2023]. Two common imbalances are observed in label-imbalanced and group-sensitive classification scenarios.
Label-imbalanced classification (LIC) suffers from a significant discrepancy in the number of examples across classes, requiring the use of balanced accuracy as a more suitable metric than conventional misclassification error. To improve model performance and balanced accuracy, various methods have been developed, including [Buda et al., 2018] and loss re-weighting [He and Garcia, 2009]. Weighted cross-entropy (wCE) loss, a classical approach, amplifies the contribution of minority examples in proportion to the imbalance level. However, wCE may not effectively handle the imbalance in overparameterized models [Cao et al., 2019], which can result in poor generalization. Recent studies propose alternative loss functions, such as logit-adjusted loss [Menon et al., 2020, Cao et al., 2019], class-dependent temperature loss [Ye et al., 2020], and vector-scaling loss [Kini et al., 2021], aiming to address the challenges associated with overparameterization. Nonetheless, there is still a risk of overfitting on minority class samples despite these advancements [Rangwani et al., 2022].
In group-sensitive classification (GSC), the goal is to ensure fairness concerning protected attributes like gender or race, addressing the issue of stereotyping where certain target labels are more frequently associated with specific groups [Mehrabi et al., 2021]. For instance, the occupation of “nurse” being commonly associated with females. While there is no universal fairness metric [Kleinberg et al., 2016], one suggestion is group sufficiency, which aims to maintain identical conditional expectations of the ground-truth label across different subgroups given the predictor’s output . However, in overparameterized models with limited samples per subgroup, this control of group sufficiency may not always hold, despite its effectiveness under certain assumptions in unconstrained learning [Liu et al., 2019a, Shui et al., 2022c].
Given the aforementioned challenges regarding the performance of LIC and GSC in overparameterized models, we pose the following question:
Q: How can a classifier be designed to effectively generalize on imbalanced subgroups with limited samples?
To address , we establish a link between LIC and GSC and propose a novel Bayesian framework that maintains informative predictions for imbalanced data while minimizing generalization error. Our contributions can be summarized as follows.
• We design a Bayesian-based tri-level optimization framework called Fairness-Aware Class Imbalanced Learning on Multiple Subgroups (FACIMS). In FACIMS, local predictors are learned using a small amount of training data and a fair, class-balanced predictor. The lower-level formulation utilizes the sharpness-aware minimization [Foret et al., 2020] to encourage convergence to a flat minimum and effectively avoid saddle points for minority classes. The upper-level problem dynamically adjusts the loss function by monitoring the validation loss, following a similar approach to [Li et al., 2021], and updates the global predictor to align with all subgroup-specific predictors.
• We establish the convergence rate of our proposed three-level optimization framework, corresponding to a sample complexity with a fixed number of samples used per iteration.
• We quantify the generalization performance of the models trained using our proposed tri-level FACIMS approach. The generalization bound analysis demonstrates that our method can achieve superior generalization performance compared to bilevel variants, such as [Rangwani et al., 2022], for fair learning on multiple subgroups.
• We conduct experiments on synthetic and real-world datasets to evaluate the balanced accuracy, demographic parity, equalized odds, and group sufficiency. The results showcase the effectiveness of our proposed method.
2. PRELIMINARIES
We consider a joint random variable that follows an underlying distribution , where represents the input, represents the label, is a scalar discrete random variable that denotes the sensitive attribute or subgroup index. For instance, could represent gender or race. Throughout, denotes the conditional expectation of , which can be seen as a function of represents the expectation over the marginal distribution of .
Suppose we have a dataset sampled i.i.d. from a distribution with input space and classes. Let be a model that outputs a distribution over classes and let . The standard classification error is denoted by . For a loss function , we similarly denote
| (1a) |
| (1b) |
We denote the frequency of the ’th class via . Label/class-imbalance occurs when the class frequencies differ substantially, i.e., . We define
| (2a) |
| (2b) |
2.1. PARAMETRIC LOSSES
We review some of the SOTA re-weighting methods for training on imbalanced data with distribution shifts.
Label-Distribution-Aware Margin (LDAM) [Cao et al., 2019] determines optimal margins for each class by minimizing errors using a generalization bound. It utilizes as the margin for each class, defined as follows:
| (LDAM) |
LDAM prioritizes classes with low sample sizes over those with high frequencies. Deferred Re-Weighting (DRW) [Cao et al., 2019] involves training the model with an average loss until a certain epoch, then applying weights proportional to the inverse of the sample size to the loss term for each class. The loss function for DRW is as follows:
| (DRW) |
This way of re-weighting has been shown to be effective for improving generalization performance when combined with various losses.
Vector Scaling (VS) [Kini et al., 2021] loss is a recently proposed loss function that unifies the idea of multiplicative shift [Ye et al., 2020], additive shift [Menon et al., 2020], and loss re-weighting. It has the following form:
| (VS) |
Here, , where are some hyperparameters.
Throughout, our main focus is on VS loss, but our framework can also accommodate other loss functions.
2.2. FAIRNESS NOTIONS
Next, we discuss fairness notions and their gaps.
Definition 1. Let f be a score function that maps the random variable X to a real number.
• Group Sufficiency (GS): We say that f is sufficient with respect to attribute A if .
• Demographic Parity (DP): f satisfies demographic parity with respect to A if .
• Equalized Odds (EO): f satisfies equalized odds with respect to A if .
GS means that the score function f captures all the information about the label Y that is relevant for prediction, regardless of the attribute A. DP ensures that the expected score remains constant, regardless of the attribute A. This principle guarantees that the distribution of scores remains unaffected by the sensitive attribute, thereby promoting fairness in the decision-making process. EO dictates that the expected score remains consistent across all combinations of labels Y and attributes A. It ensures that individuals sharing the same label but differing attributes are treated equally in terms of their predicted scores, irrespective of the sensitive attribute.
The impossibility theorem of fairness asserts that, in general cases, it is impossible to simultaneously achieve all common and intuitive definitions of fairness. Notably, [Barocas et al., 2019, Chouldechova, 2017] demonstrate that if , it is not feasible to achieve both group sufficiency and demographic parity. Moreover, [Barocas et al., 2019, Pleiss et al., 2017] reveal that when and , it is not possible for both group sufficiency and demographic parity to hold simultaneously.
Definition 1 leads to a notion of the group sufficiency gap, demographic parity gap, and equalized odds gap defined, respectively, as:
| (3a) |
| (3b) |
| (3c) |
measures the extent of group sufficiency violation, induced by the predictor f, which is taken by the expectation over . Hence, suggests that f satisfies group sufficiency and vice versa. For completeness, we also discuss computing these gaps in Appendix.
To conclude this section, we provide Group A-Bayes predictor and an upper bound for from [Shui et al., 2022c]. These findings serve as the foundation for our Bayesian-based tri-level optimization framework.
Definition 2 (A-group Bayes predictor). The A-group Bayes predictor associated with distribution is defined as: .
The following Theorem provides the upper bound of group sufficiency gap w.r.t. any predictor f:
Theorem 3. If A takes finite value, i.e. and follows uniform distribution with , then
| (4) |
Hence, depends on the discrepancy between the predictor f and the A-group Bayes predictor . In other words, when considering different subgroups , the optimal predictor f should closely align with all the group Bayes predictors , for all .
3. PROPOSED FRAMEWORK
In this section, we present the formulation of FACIMS, which is a framework designed to promote both classification accuracy and fairness through a randomized algorithm. FACIMS achieves this by learning a predictive distribution , which assigns higher scores to predictors that are favorable based on the available data. In the context of the Bayes framework, the predictor is sampled from the posterior distribution, represented as . During the inference stage, the predictor’s output is computed as the expectation of the learned predictive distribution .
In practical scenarios, it is infeasible to optimize over the entire space of possible distributions. Therefore, we constrain the predictive distribution to a specific distribution family , such as the Gaussian distribution. Additionally, we denote as the optimal prediction distribution with respect to the subgroup within the family :
In general, , since the distribution family is only the subset of all possible distributions.
Corollary 4 (Shui et al. [2022c]). The group sufficiency gap in a randomized algorithm w.r.t. the learned predictive distribution is bounded as follows:
| (5) |
where
Minimizing the Optim term ensures that the learned distribution is both fair and informative for making predictions. On the other hand, the Approx term represents the KL divergence between the optimal distribution and . If the distribution family has a rich expressive power, like that of a deep neural network, the Approx term will be small. See Figure 1 for a visual representation.
Figure 1:

An illustration of the FACIMS model defined in (7). and maximize the margin for minority classes for groups and in (7b). In the upper level problem (7a), FACIMS finds to achieve a small balanced accuracy while minimizing the discrepancy between . The approximation term is based on the distribution family (orange region). If the predefined has good expressive power, the approximation is treated as a small constant.
Now, we provide a framework for fairness-aware class imbalanced learning on multiple sub-groups with potentially improved generalization bound and . We begin with formulating the loss function design as a bilevel optimization over hyperparameters and a distribution . Assume each group has a fine-tuning training set and a separate validation set , where data are independently and identically distributed (i.i.d.) and drawn from the per-task data distribution . Following [Li et al., 2021], define the empirical risk and the balanced empirical risk over a finite-sample dataset as and . Here, can be manually adjusted using (DRW), (LDAM), and (VS).
Let stand for both fair and informative prediction. Building on [Kini et al., 2021, Li et al., 2021, Shui et al., 2022c], we design the following objective:
| (6a) |
| (6b) |
Here, the lower-level problem (6b) includes a regularization term as an informative prior for learning local predictor with a fixed predictive distribution . This optimization reduces the upper bound of the group-specific generalization error.
In the upper-level problem (6a), we update by minimizing the average KL-divergence between different , controlling the upper bound of according to (5), as well as the balanced empirical risk. However, directly minimizing (6b) in a single-level approach does not work well in our setting due to the limited number of samples in each subgroup. This leads to overfitting and large generalization error for each subgroup. To address this, we consider additional assumptions, such as the similarity in the data generation distribution for each subgroup. With these assumptions, we can learn shared and fair models that are informative and sufficient for a large number of subgroups.
3.1. PARAMETRIC MODELS AND FACIMS
In this section, we propose a practical learning algorithm applicable to various differentiable and parametric models, including neural networks.
We utilize the Isotropic Gaussian distribution as to learn global informative with parameters . For each subgroup , we also learn group-specific parameters for in . The Isotropic Gaussian distribution is selected for computational efficiency in optimization, but other differentiable distributions can also be used for parameter density functions.
Given a training set, we learn parameterized by . Then is equivalent to sampling the model parameter from the predictive-distribution . Hence, learning the distribution is equivalent to learning parameter . Note that for each subgroup , can be modeled similarly. Both procedures can be formulated as follows:
To enhance the convergence to a flat minimum and effectively avoid saddle points for minority classes, we integrate the sharpness-aware minimization (SAM) algorithm [Foret et al., 2020] into (6b). SAM is a recently introduced technique that improves generalization performance by jointly minimizing the loss value and the loss sharpness, leveraging the geometry of the loss landscape. Given a perturbation parameter and the empirical risk , the goal of training is to choose having low population loss
| (7a) |
| (7b) |
Algorithm 1.
An Alternating Stochastic Gradient Method for FACIMS
| 1: | Input: VS loss hyperparameters ; distribution parameters and for all ; regularization parameters ; sharpness parameters ; and stepsizes . | ||
| 2: | for do | ||
| 3: | Sample dataset , where . | ||
| 4: | for do | ||
| 5: | Update in the lower level:
|
||
| 6: | Update using SGD (with step size ) in the middle level:
|
||
| 7: | end for | ||
| 8: | Update and using SGD (with step size ) in the upper level:
|
||
| 9: | end for | ||
| 10: | Return: . |
. SAM achieves this via the problem
| (SAM) |
Given , the maximization in (SAM) seeks to find the weight perturbation in the Euclidean ball that maximizes the empirical loss. If we define the sharpness as
then (SAM) essentially minimizes the sum of the sharpness and the empirical loss .
We incorporate (SAM) into (6b) and propose (7) by introducing a set of positive constants . The FACIMS framework, combined with SAM, promotes convergence to a flat minimum and aids in escaping saddle points for minority classes [Rangwani et al., 2022]. We empirically demonstrate the superiority of integrating SAM into FACIMS over popular baselines and provide theoretical evidence suggesting improved generalization bounds. Despite the tri-level problem formulation in (7), our algorithm design efficiently approximates the maximization step, making the computational cost comparable to that of (6).
Based on the analysis and (7), we provide an alternating optimization algorithm for solving (7) in Algorithm 1. Line 3 provides a partial group setting, i.e., for many subgroups, we can randomly sample a subset such that for memory saving.
4. THEORETICAL ANALYSIS OF FACIMS
Next, we analyze the performance of the FACIMS method.
To simplify, we assume for all and combine and into a single notation . We represent the stochastic gradients of as . Let and be the objective of (7a).
Assumption A (Lipschitz continuity). Assume that , , , , are Lipschitz continuous with constant , , , .
Assumption B (Stochastic derivatives). Assume that , , are unbiased estimator of , , respectively and their variances are bounded by .
Assumptions A–B also appear similarly in the convergence analysis of and bilevel optimization [Chen et al., 2021, Tarzanagh et al., 2022, Abbas et al., 2022]. With the above assumptions, we get the following theorem. The proof is deferred in Appendix.
Theorem 5. Under Assumptions , and choosing step-sizes and sharpness parameter , with some proper constants, we can get that the iterates generated by Algorithm 1 satisfy
| (11) |
Theorem 5 implies that under some standard assumption, Algorithm 1 can find stationary points for FACIMS objective (7) with iterations and samples.
Next, we establish the generalization performance.
Theorem 6. Assume the function is bounded for any . Let . Assume at the stationary point of (7) denoted by . Then, with probability over the choice of the training set , with , we have
| (12) |
Here, .
Theorem 6 shows that the difference between the population loss and the empirical loss of FACIMS is bounded by . Note that the bound in (12) is a function of . Hence, for a choice of , the bound (12) is not optimal. This suggests that tri-level FACIMS can have better generalization performance than that from bilevel variants such as [Li et al., 2021, Shui et al., 2022c].
5. EXPERIMENTS
5.1. EXPERIMENTAL SETUP
Datasets.
We applied our model to the Alzheimer’s disease (AD), credit card and drug consumption datasets, and the data information is summarized in Table 1.
Table 1:
Statistical summary of the datasets including class and sensitive feature information.
| Dataset | #Instance | #Features | Class | Class Distr. | Sensitive Feature | Sensitive Feature Distr. |
|---|---|---|---|---|---|---|
| Alzheimer’s Disease | 5137 | 17 | AD / MCI | 21% / 79% | Race | 93.75% / 3.20% / 1.88% / 1.17% |
| Credit Card | 30,000 | 22 | Credible / Not Credible | 22% / 77% | Education Level | 46.77% / 35.28% / 16.39% / 0.93% / 0.41% / 0.17% / 0.05% |
| Drug Consumption | 1885 | 9 | Never used / Not used in the past year / Used in the past year / Used in the past day | 1.81% / 5.41% / 65.98% / 26.80% | Education Level | 6.74% / 6.90% / 26.86% / 14.28% / 25.48% / 15.02% / 4.72% |
Alzheimer’s Disease dataset1 were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database [Weiner et al., 2017, Shen et al., 2014]. We included 5137 instances, including 4080 mild cognitive impairment (MCI, a prodromal stage of AD) and 1057 AD instances, to conduct the binary classification. Moreover, we chose race as the sensitive feature and divided the participants into four subgroups, where white subjects exceeding 90%. Our features included 17 AD-related biomarkers, including cognitive scores, volumes of brain regions extracted from the magnetic resonance imaging (MRI) scans, amyloid and tau measurements from positron emission tomography (PET) scans and cerebrospinal fluid (CSF), and risk factors like APOE4 carriers and age.
Credit Card dataset2 contains 22 attributes like clients’ basic information, history of payments, and bill statement amount to classify whether the clients are credible or not. We included 30000 instances with 6636 credible and 23365 not credible clients. We chose the education level as the sensitive feature where we observed more clients who graduated from university than other six levels.
Drug Consumption dataset3 contains demographic information such as age, gender, and education level, as well as measures of personality traits thought to influence drug use for 1885 respondents. The task is to predict alcohol use with categories (never used, not used in the past year, used in the past year, and used in the past day) for multi-class outcomes. The sensitive feature is education level (Left school before or at 16, Left school at 17-18, Some college, Certificate diploma, University degree, Masters, Doctorate ). The data information is summarized in Table 1 below. As can be seen, the class distribution shows that the dataset suffers from heavy label imbalance.
Baselines
To validate the effectiveness of our method, FACIMS, we compare it with seven baseline methods.
EIIL [Creager et al., 2021]: An Invariant Risk Minimization (IRM) based approach that promotes group sufficiency.
FSCS [Lee et al., 2021]: An approach that adopts the conditional mutual information constraint to improve group sufficiency.
FAMS [Shui et al., 2022c]: A bilevel framework that considers maintaining both the accuracy and group sufficiency gap for multiple subgroups.
ERM: Empirical Risk Minimization using a four-layer fully connected neural network trained with cross-entropy loss.
BERM: ERM with a balanced cross-entropy loss, incorporating class proportions as weights similar to [Cao et al., 2019].
FACIMS (, ): Our method without the lower level. Besides, in the upper level, we manually adjust the logits using the proportion of class [Menon et al., 2020, Kini et al., 2021] instead of learning the hyperparameter for logits adjustment.
FACIMS : Our method without the lower level which aims to flatten the sharp landscape of the objective in the middle level.
We set and to be 0.7. We use the grid of [0.1, 0.01, 0.001] to search the learning rate for global model and local models and report the results over five independent repeats.
5.2. EXPERIMENTAL RESULTS
In this section, we analyze Alzheimer’s disease and credit card datasets. The numerical results of the multi-class dataset drug consumption are included in the appendix due to page limits.
Balanced Accuracy and Sufficiency Gap
We primarily focus on balanced accuracy and group sufficiency gap as our main goals. Table 2 shows that on the Alzheimer’s disease dataset, our method FACIMS outperforms EIIL, FSCS, FAMS, and ERM in terms of balanced accuracy, with improvements of 2.6%, 4.0%, 5.3%, and 2.1% respectively. While BERM addresses the class imbalance issue and demonstrates a significant improvement over ERM by nearly 2%, our method still achieves a higher balanced accuracy than BERM. Our method significantly improves the group sufficiency gap by 6.5% and 4.0% respectively, compared to ERM and BERM which do not address this issue. Although EIIL, FSCS, and FAMS specifically target the group sufficiency problem and achieve lower sufficiency gaps than ERM and BERM, our method still outperforms these three baseline methods by improving the sufficiency gap by 1.4%, 2.0%, and 2.8% respectively.
Table 2:
Numerical results (mean ± standard deviation) for 5 repeats of different methods on Alzheimer’s disease (AD) and Credit Card (CC) datasets regarding six measurements. Time is in the format of “hours:minutes:seconds”. FACIMS-I means FACIMS , and FACIMS-II means FACIMS . “” indicates the larger the better while “” indicates the smaller the better. The best one in each column is bold.
| Data | Method | Balanced Accuracy ↑ | Demographic Parity ↓ | Equalized Odds ↓ | Sufficiency Gap ↓ | Recall 0 ↑ | Recall 1 ↑ | Time ↓ |
|---|---|---|---|---|---|---|---|---|
| AD | EIIL | .8639±.0199 | .0764±.0176 | .1015±.0529 | .1193±.0206 | .9288±.0119 | .7991±.0409 | 0:03:32 |
| FSCS | .8498±.0485 | .0711±.0287 | .1650±.1008 | .1254±.0528 | .9504±.0426 | .7493±.1018 | 0:08:05 | |
| FAMS | .8369±.0136 | .0431±.0210 | .1444±.0435 | .1328±.0273 | .7624±.0077 | .9114±.0096 | 0:09:51 | |
| ERM | .8687±.0136 | .0550±.0196 | .1143±.0390 | .1701±.0387 | .9883±.0053 | .7491±.0430 | 0:00:51 | |
| BERM | .8886±.0042 | .0869±.0204 | .0813±.0129 | .1456±.0330 | .9854±.0043 | .7918±.0520 | 0:02:24 | |
| FACIMS-II | .8839±.0079 | .0747±.0182 | .0868±.0130 | .1167±.0139 | .8456±.0148 | .9222±.0043 | 0:09:58 | |
| FACIMS-I | .8887±.0066 | .0893±.0080 | .0450±.0049 | .1059±.0060 | .8780±.0104 | .8994±.0148 | 0:13:38 | |
| FACIMS | .8897±.0098 | .0765±.0208 | .0616±.0142 | .1052±.0197 | .8832±.0072 | .8962±.0054 | 0:15:26 | |
| CC | EIIL | .6357±.0267 | .0834±.0200 | .1723±.0515 | .1266±.023 | .7897±.0176 | .4817±.0448 | 0:03:30 |
| FSCS | .5976±.0277 | .0850±.0137 | .2000±.0456 | .2007±.0039 | .8953±.0130 | .3000±.0685 | 0:42:10 | |
| FAMS | .6542±.0098 | .0746±.0066 | .1859±.0368 | .1352±.0106 | .8194±.0374 | .4890±.0270 | 0:10:21 | |
| ERM | .6104±.0111 | .0599±.0173 | .1577±.0175 | .2760±.0710 | .9919±.0233 | .2289±.0820 | 0:02:07 | |
| BERM | .6570±.0106 | .1060±.0125 | .1631±.0304 | .2315±.0623 | .8717±.0191 | .4423±.0146 | 0:02:09 | |
| FACIMS-II | .6446±.0163 | .0707±.0073 | .1973±.0358 | .1340±.0147 | .8002±.0374 | .4890±.0270 | 0:10:03 | |
| FACIMS-I | .6768±.0040 | .0750±.0105 | .1951±.0524 | .1396±.0081 | .8081±.0114 | .5455±.0098 | 0:14:07 | |
| FACIMS | .6799±.0374 | .0593±.0070 | .1567±.0230 | .1264±.0145 | .8136±.0054 | .5462±.0017 | 0:14:18 |
Removing the lower level leads to a slight decrease in balanced accuracy and group sufficiency gap as the objective landscape is not flattened in the middle level. Additionally, manually adjusting the logits instead of learning the hyperparameters (as in [Menon et al., 2020]) further decreases the balanced accuracy and group sufficiency gap. However, our bilevel structure for addressing fairness ensures that the group sufficiency gap remains good despite these drops.
On credit card dataset, we have similar results. As for balanced accuracy, our method FACIMS improves the performance by 4.4%, 8.2%, 2.6%, 7.0%, and 2.3% comapred to EIIL, FSCS, FAMS, ERM and BERM. When it comes to the group sufficiency gap, the performance of our method is improved by 0.2%, 7.4%, 0.8%, 15%, and 11% comapred to the same baseline methods as metioned above. The performances of FACIMS and FACIMS (, ) drop slightly regarding both measurements.
To provide a more intuitive visualization of the results, we present boxplots in Figure 2. Each axis represents a measurement, where the mean value is represented by the middle of the box and the box width corresponds to twice the length of the standard deviation. The model’s performance is reflected by the position of the box, with improved performance observed towards the bottom right corner, indicating higher balanced accuracy and lower group sufficiency gap. For clarity, we have excluded two variants of our method from Figure 2. The complete figures can be found in the appendix. Figure 2 highlights that our method is positioned towards the bottom right corner, indicating improved performance compared to other methods.
Figure 2:

Boxplot comparing balanced accuracy and group sufficiency gap for three real datasets with 5 repeats. The mean is represented by the middle of each box, while the box width represents twice the standard deviation. Better performance is indicated by boxes located towards the bottom right (higher balanced accuracy and lower group sufficiency). Two FACIMS variants are excluded for clarity, with complete results available in the appendix.
Results on Other Metrics
In addition to the result analysis on balanced accuracy and group sufficiency, we also report demographic parity, equalized odds, recall, and time in Table 2. The results show that our method achieves competitive results despite not outperforming all baselines in terms of demographic parity and equalized odds gaps. We emphasize that our method primarily addresses the group sufficiency gap for fairness, and it is challenging to optimize all three fairness measurements simultaneously, as discussed in Section 2. When assessing a classifier’s performance, it is important to achieve a high recall for each class. However, the average recall across all classes determines the balanced accuracy, highlighting the need for a balanced recall quantity across all classes. Our approach and its variations demonstrate a more balanced recall for each class, as illustrated in Table 2.
Comparing the time aspect, despite employing a complex tri-level optimization framework for training our model, the total runtime is not significantly longer than other fairness baselines. Indeed, utilizing differentiable bilevel methods in the large hyperparameter search provides substantial cost reduction and speedup compared to traditional approaches like grid search or random search. For instance, the first variant of our method, FACIMS (, ), runs in approximately 13 minutes. However, employing grid search or random search to tune the parametric loss would require significantly more time. For example, if we perform a search with five different settings to enhance the accuracy of FACIMS (, ), the total time would be , which is around four times longer than our differentiable tri-level FACIMS approach.
Influence of
In the middle level, the parameter determines the attention given to . A higher value of brings the local model closer to the global model, leading to improved group sufficiency gap but potentially worse balanced accuracy. We experimented with four different values of . Figure 3 illustrates the Accuracy- curve under varying on the Alzheimer’s disease dataset. The figure demonstrates a clear trend: as increases, both the balanced accuracy and group sufficiency gap decrease, aligning with our expectations. This analysis provides insight into how the KL divergence in the middle level influences the group sufficiency gap and balanced accuracy, enhancing our understanding of the framework’s mechanism.
Figure 3:
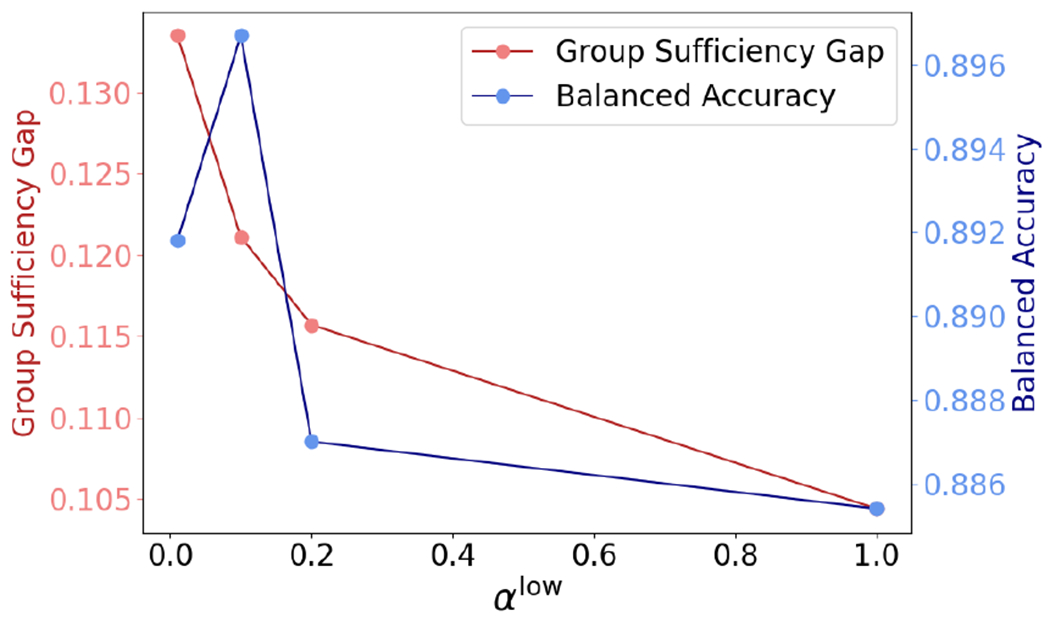
Accuracy-SGapf curve under different in Alzheimer’s disease dataset.
6. RELATED WORK
6.1. LONG-TAILED LEARNING
Re-sampling [Buda et al., 2018] and Re-weighting [He and Garcia, 2009] are commonly used methods for training on imbalanced datasets. Recent studies focus on optimizing loss landscapes for class-imbalanced datasets [Khan et al., 2017, Cao et al., 2019, Menon et al., 2020, Ye et al., 2020, Li et al., 2021, Kini et al., 2021, Behnia et al., 2023, Thrampoulidis et al., 2022]. Our work is related to the long-tail learning literature [Cao et al., 2019, Menon et al., 2020, Ye et al., 2020, Kini et al., 2021], where authors propose refined class-balanced loss functions that better adapt to training data. These include the logit-adjusted loss [Menon et al., 2020, Cao et al., 2019], the class-dependent temperature loss [Ye et al., 2020], and the VS loss [Kini et al., 2021], which unifies the concepts of multiplicative shift, additive shift, and loss re-weighting.
6.2. NESTED OPTIMZIATION
Nested optimization involves solving hierarchical problems with multiple levels of optimization [Colson et al., 2007, Tarzanagh et al., 2022, Chen et al., 2021, Ji et al., 2021, Tarzanagh and Balzano, 2022]. Min-max nested optimization is commonly used to learn fair representations in the context of demographic parity or equalized odds [Zemel et al., 2013, Song et al., 2019, Zhao et al., 2019]. Bi-level optimization and meta-learning algorithms have also been explored in the context of fair learning and classification [Shui et al., 2022b, Abbas et al., 2022]. Recent advancements in differentiable algorithms have led to faster bilevel algorithms for learning hyperparameters and classification [Li et al., 2021, Lorraine et al., 2020, Tarzanagh et al., 2022, Chen et al., 2021, Ji et al., 2021]. Building on [Li et al., 2021, Abbas et al., 2022], we propose a theoretically justified tri-level optimization perspective to control the group sufficiency gap and improve generalization performance across multiple subgroups with limited samples.
6.3. FAIRNESS
Group-sensitive learning aims to ensure fairness in the presence of under-represented groups [Lin et al., 2023, Zafar et al., 2017, Tarzanagh et al., 2021, Chierichetti et al., 2017]. Our work mainly focuses on the fair notion of group sufficiency. This notion has recently been studied in the health of populations [Obermeyer et al., 2019] and crime prediction [Chouldechova, 2017, Pleiss et al., 2017]. Liu et al. [2019b] show that under some assumptions, the group sufficiency can be controlled in unconstraint learning. On the other hand, Obermeyer et al. [2019], Shui et al. [2022a], Koh et al. [2021] claim that this conclusion may not always hold in the overparameterized models with limited samples per group. Subramanian et al. [2021] provided a method for fair and class-imbalanced learning.Lee et al. [2021] proposed a bilevel objective approach to achieve fairness in predictive models across all groups. In contrast, our tri-level algorithm incorporates a Bayesian framework for imbalanced learning, considering both class imbalance and subgroup distribution within each class, while also employing a nested optimization akin to SAM to overcome saddle points for minority classes.
7. CONCLUSIONS
We studied fairness-aware class imbalanced learning on multiple subgroups (FACIMS) using a Bayesian-based optimization framework. Through extensive empirical and theoretical analysis, we demonstrated that FACIMS enhances the generalization performance of overparameterized models when dealing with limited samples per subgroup.
Supplementary Material
ACKNOWLEDGEMENTS
This work was supported in part by the NIH grants U01 AG066833, RF1 AG063481, U01 AG068057, R01 LM013463 P30 AG073105, and U01 CA274576, and the NSF grant IIS 1837964. Data used in this study were obtained from the Alzheimer’s Disease Neuroimaging Initiative database (adni.loni.usc.edu), which was funded by NIH U01 AG024904. The authors Davoud Ataee Tarzanagh, Bojian Hou and Boning Tong have contributed equally to this paper.
Footnotes
References
- Abbas Momin, Xiao Quan, Chen Lisha, Chen Pin-Yu, and Chen Tianyi. Sharp-maml: Sharpness-aware modelagnostic meta learning. In International Conference on Machine Learning, pages 10–32. PMLR, 2022. [Google Scholar]
- Barocas Solon, Hardt Moritz, and Narayanan Arvind. Fairness and Machine Learning. fairmlbook.org, 2019. http://www.fairmlbook.org.
- Barocas Solon, Hardt Moritz, and Narayanan Arvind. Fairness and machine learning: Limitations and opportunities. MIT Press, 2023. [Google Scholar]
- Behnia Tina, Kini Ganesh Ramachandra, Vakilian Vala, and Thrampoulidis Christos. On the implicit geometry of cross-entropy parameterizations for label-imbalanced data. In International Conference on Artificial Intelligence and Statistics, pages 10815–10838. PMLR, 2023. [Google Scholar]
- Buda Mateusz, Maki Atsuto, and Mazurowski Maciej A. A systematic study of the class imbalance problem in convolutional neural networks. Neural networks, 106: 249–259, 2018. [DOI] [PubMed] [Google Scholar]
- Cao Kaidi, Wei Colin, Gaidon Adrien, Arechiga Nikos, and Ma Tengyu. Learning imbalanced datasets with label-distribution-aware margin loss. Advances in neural information processing systems, 32, 2019. [Google Scholar]
- Chen Tianyi, Sun Yuejiao, and Yin Wotao. Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems. Advances in Neural Information Processing Systems, 34:25294–25307, 2021. [Google Scholar]
- Chierichetti Flavio, Kumar Ravi, Lattanzi Silvio, and Vassilvitskii Sergei. Fair clustering through fairlets. Advances in neural information processing systems, 30, 2017. [Google Scholar]
- Chouldechova Alexandra. Fair prediction with disparate impact: A study of bias in recidivism prediction instruments. Big data, 5(2):153–163, 2017. [DOI] [PubMed] [Google Scholar]
- Colson Benoît, Marcotte Patrice, and Savard Gilles. An overview of bilevel optimization. Annals of operations research, 153:235–256, 2007. [Google Scholar]
- Creager Elliot, Jacobsen Jörn-Henrik, and Zemel Richard. Environment inference for invariant learning. In International Conference on Machine Learning, pages 2189–2200. PMLR, 2021. [Google Scholar]
- Foret Pierre, Kleiner Ariel, Mobahi Hossein, and Neyshabur Behnam. Sharpness-aware minimization for efficiently improving generalization. arXiv preprint arXiv:2010.01412, 2020. [Google Scholar]
- He Haibo and Garcia Edwardo A. Learning from imbalanced data. IEEE Transactions on knowledge and data engineering, 21(9):1263–1284, 2009. [Google Scholar]
- Ji Kaiyi, Yang Junjie, and Liang Yingbin. Bilevel optimization: Convergence analysis and enhanced design. In International conference on machine learning, pages 4882–4892. PMLR, 2021. [Google Scholar]
- Khan Salman H, Hayat Munawar, Bennamoun Mohammed, Sohel Ferdous A, and Togneri Roberto. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE transactions on neural networks and learning systems, 29(8):3573–3587, 2017. [DOI] [PubMed] [Google Scholar]
- Kini Ganesh Ramachandra, Paraskevas Orestis, Oymak Samet, and Thrampoulidis Christos. Label-imbalanced and group-sensitive classification under overparameterization. Advances in Neural Information Processing Systems, 34: 18970–18983, 2021. [Google Scholar]
- Kleinberg Jon, Mullainathan Sendhil, and Raghavan Manish. Inherent trade-offs in the fair determination of risk scores. arXiv preprint arXiv:1609.05807, 2016. [Google Scholar]
- Koh Pang Wei, Sagawa Shiori, Marklund Henrik, Xie Sang Michael, Zhang Marvin, Balsubramani Akshay, Hu Weihua, Yasunaga Michihiro, Phillips Richard Lanas, Gao Irena, et al. Wilds: A benchmark of in-the-wild distribution shifts. In International Conference on Machine Learning, pages 5637–5664. PMLR, 2021. [Google Scholar]
- Lee Joshua K, Bu Yuheng, Rajan Deepta, Sattigeri Prasanna, Panda Rameswar, Das Subhro, and Wornell Gregory W. Fair selective classification via sufficiency. In International Conference on Machine Learning, pages 6076–6086. PMLR, 2021. [Google Scholar]
- Li Mingchen, Zhang Xuechen, Thrampoulidis Christos, Chen Jiasi, and Oymak Samet. Autobalance: Optimized loss functions for imbalanced data. Advances in Neural Information Processing Systems, 34:3163–3177, 2021. [Google Scholar]
- Lin Mingquan, Xiao Yuyun, Hou Bojian, Wanyan Tingyi, Sharma Mohit Manoj, Wang Zhangyang, Wang Fei, Van Tassel Sarah, and Peng Yifan. Evaluate underdiagnosis and overdiagnosis bias of deep learning model on primary open-angle glaucoma diagnosis in under-served patient populations. arXiv preprint arXiv:2301.11315, 2023. [PMC free article] [PubMed] [Google Scholar]
- Liu Lydia T, Simchowitz Max, and Hardt Moritz. The implicit fairness criterion of unconstrained learning. In International Conference on Machine Learning, pages 4051–4060. PMLR, 2019a. [Google Scholar]
- Liu Lydia T., Simchowitz Max, and Hardt Moritz. The implicit fairness criterion of unconstrained learning. In Chaudhuri Kamalika and Salakhutdinov Ruslan, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 4051–4060. PMLR, 09–15 Jun 2019b. URL https://proceedings.mlr.press/v97/liu19f.html. [Google Scholar]
- Lorraine Jonathan, Vicol Paul, and Duvenaud David. Optimizing millions of hyperparameters by implicit differentiation. In International Conference on Artificial Intelligence and Statistics, pages 1540–1552. PMLR, 2020. [Google Scholar]
- Mehrabi Ninareh, Morstatter Fred, Saxena Nripsuta, Lerman Kristina, and Galstyan Aram. A survey on bias and fairness in machine learning. ACM Computing Surveys (CSUR), 54(6):1–35, 2021. [Google Scholar]
- Menon Aditya Krishna, Jayasumana Sadeep, Rawat Ankit Singh, Jain Himanshu, Veit Andreas, and Kumar Sanjiv. Long-tail learning via logit adjustment. arXiv preprint arXiv:2007.07314, 2020. [Google Scholar]
- Obermeyer Ziad, Powers Brian, Vogeli Christine, and Mullainathan Sendhil. Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464):447–453, 2019. doi: 10.1126/science.aax2342. URL 10.1126/science.aax2342. [DOI] [PubMed] [Google Scholar]
- Pleiss Geoff, Raghavan Manish, Wu Felix, Kleinberg Jon, and Weinberger Kilian Q. On fairness and calibration. arXiv preprint arXiv:1709.02012, 2017. [Google Scholar]
- Rangwani Harsh, Aithal Sumukh K, Mishra Mayank, and Babu R Venkatesh. Escaping saddle points for effective generalization on class-imbalanced data. arXiv preprint arXiv:2212.13827, 2022. [Google Scholar]
- Shen Li, Thompson Paul M, Potkin Steven G, et al. Genetic analysis of quantitative phenotypes in AD and MCI: imaging, cognition and biomarkers. Brain Imaging Behav, 8 (2):183–207, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shui Changjian, Chen Qi, Li Jiaqi, Wang Boyu, and Gagné Christian. Fair representation learning through implicit path alignment. In ICML, 2022a. [Google Scholar]
- Shui Changjian, Chen Qi, Li Jiaqi, Wang Boyu, and Gagné Christian. Fair representation learning through implicit path alignment. arXiv preprint arXiv:2205.13316, 2022b. [Google Scholar]
- Shui Changjian, Xu Gezheng, Chen Qi, Li Jiaqi, Ling Charles, Arbel Tal, Wang Boyu, and Gagné Christian. On learning fairness and accuracy on multiple subgroups. arXiv preprint arXiv:2210.10837, 2022c. [Google Scholar]
- Song Jiaming, Kalluri Pratyusha, Grover Aditya, Zhao Shengjia, and Ermon Stefano. Learning controllable fair representations. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 2164–2173. PMLR, 2019. [Google Scholar]
- Subramanian Shivashankar, Rahimi Afshin, Baldwin Timothy, Cohn Trevor, and Frermann Lea. Fairness-aware class imbalanced learning. arXiv preprint arXiv:2109.10444, 2021. [Google Scholar]
- Tarzanagh Davoud Ataee and Balzano Laura. Online bilevel optimization: Regret analysis of online alternating gradient methods. arXiv preprint arXiv:2207.02829, 2022. [Google Scholar]
- Tarzanagh Davoud Ataee, Balzano Laura, and Hero Alfred O. Fair structure learning in heterogeneous graphical models. arXiv preprint arXiv:2112.05128, 2021. [Google Scholar]
- Tarzanagh Davoud Ataee, Li Mingchen, Thrampoulidis Christos, and Oymak Samet. Fednest: Federated bilevel, minimax, and compositional optimization. In International Conference on Machine Learning, pages 21146–21179. PMLR, 2022. [Google Scholar]
- Thrampoulidis Christos, Kini Ganesh Ramachandra, Vakilian Vala, and Behnia Tina. Imbalance trouble: Revisiting neural-collapse geometry. Advances in Neural Information Processing Systems, 35:27225–27238, 2022. [Google Scholar]
- Weiner Michael W, Veitch Dallas P, Aisen Paul S, et al. Recent publications from the Alzheimer’s Disease Neuroimaging Initiative: Reviewing progress toward improved AD clinical trials. Alzheimer’s & Dementia, 13 (4):e1–e85, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ye Han-Jia, Chen Hong-You, Zhan De-Chuan, and Chao Wei-Lun. Identifying and compensating for feature deviation in imbalanced deep learning. arXiv preprint arXiv:2001.01385, 2020. [Google Scholar]
- Zafar Muhammad Bilal, Valera Isabel, Rogriguez Manuel Gomez, and Gummadi Krishna P. Fairness constraints: Mechanisms for fair classification. In Artificial intelligence and statistics, pages 962–970. PMLR, 2017. [Google Scholar]
- Zemel Rich, Wu Yu, Swersky Kevin, Pitassi Toni, and Dwork Cynthia. Learning fair representations. In International conference on machine learning, pages 325–333. PMLR, 2013. [Google Scholar]
- Zhao Han, Coston Amanda, Adel Tameem, and Gordon Geoffrey J. Conditional learning of fair representations. arXiv preprint arXiv:1910.07162, 2019. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.