

Abstract
Background
An early warning tool to predict attacks could enhance asthma management and reduce the likelihood of serious consequences. Electronic health records (EHRs) providing access to historical data about patients with asthma coupled with machine learning (ML) provide an opportunity to develop such a tool. Several studies have developed ML-based tools to predict asthma attacks.
Objective
This study aims to critically evaluate ML-based models derived using EHRs for the prediction of asthma attacks.
Methods
We systematically searched PubMed and Scopus (the search period was between January 1, 2012, and January 31, 2023) for papers meeting the following inclusion criteria: (1) used EHR data as the main data source, (2) used asthma attack as the outcome, and (3) compared ML-based prediction models’ performance. We excluded non-English papers and nonresearch papers, such as commentary and systematic review papers. In addition, we also excluded papers that did not provide any details about the respective ML approach and its result, including protocol papers. The selected studies were then summarized across multiple dimensions including data preprocessing methods, ML algorithms, model validation, model explainability, and model implementation.
Results
Overall, 17 papers were included at the end of the selection process. There was considerable heterogeneity in how asthma attacks were defined. Of the 17 studies, 8 (47%) studies used routinely collected data both from primary care and secondary care practices together. Extreme imbalanced data was a notable issue in most studies (13/17, 76%), but only 38% (5/13) of them explicitly dealt with it in their data preprocessing pipeline. The gradient boosting–based method was the best ML method in 59% (10/17) of the studies. Of the 17 studies, 14 (82%) studies used a model explanation method to identify the most important predictors. None of the studies followed the standard reporting guidelines, and none were prospectively validated.
Conclusions
Our review indicates that this research field is still underdeveloped, given the limited body of evidence, heterogeneity of methods, lack of external validation, and suboptimally reported models. We highlighted several technical challenges (class imbalance, external validation, model explanation, and adherence to reporting guidelines to aid reproducibility) that need to be addressed to make progress toward clinical adoption.
Keywords: asthma attack, exacerbation, prognosis, machine learning, electronic health record, review, EHR, asthma
Introduction
Background
Asthma is a chronic lung illness characterized by reversible airway blockage caused by inflammation and narrowing of the small airways in the lungs that can lead to cough, wheezing, chest tightness, and breathing difficulties [1]. It is a common noncommunicable disease that affects children and adults alike. In 2019, asthma affected an estimated 262 million individuals, resulting in 461,000 fatalities [1,2]. Asthma attacks occur particularly in those with poorly controlled diseases [3]. An asthma attack is a sudden or gradual deterioration of asthma symptoms that can have a major influence on a patient’s quality of life [4]. Such attacks can be life-threatening and necessitate rapid medical attention, such as an accident and emergency department visit or hospitalization, and can even lead to mortality [5]. Asthma attacks are prevalent, with >90,000 annual hospital admissions in the United Kingdom alone [6]. Early warning tools to predict asthma attacks offer the opportunity to provide timely treatments and, thereby, minimize the risk of serious outcomes [4].
Machine learning (ML) offers the potential to develop an early warning tool that takes different risk factors as input and then outputs the probability of an adverse outcome. So far, logistic regression (LR) has been the most common approach in building an asthma attack risk prediction tool [7-9]. However, the predictive performance of this method may be inferior to more advanced ML methods, especially for relatively high-dimensional data with complex and nonlinear relationships between the variables [10,11]. The use of ML has been investigated in a wide range of medical domains by using various data such as electronic health records (EHRs), medical images, genomics data, and wearables data [12-14]. However, to the best of our knowledge, there is still no widely used ML-based asthma attack risk prediction tool in clinical practice.
Objective
Previous recent systematic reviews have discussed the choice of models used for asthma prognosis [15,16]. An ML pipeline, however, has several components besides modeling choice (eg, feature engineering [17]), which can profoundly influence the performance of the algorithms. Owing to the lack of consensus about what constitutes best practices for the application of ML for predicting asthma attacks, there is considerable heterogeneity in previous studies [15,16], thereby making direct comparisons challenging. In this scoping review, we aimed to critically examine existing studies that used ML algorithms for the prediction of asthma attacks with routinely collected EHR data. Besides data type and choice of models, we have reviewed additional ML pipeline challenges. These include customizing off-the-shelf algorithms to account for domain-specific subtleties and the need for the model to be explainable, extensively validated (externally and prospectively), and transparently reported.
Methods
Overview
The scoping review was conducted based on the 5-stage framework by Arksey and O’Malley [18]. This framework includes identifying the research question; searching and collecting relevant studies; study filtering; data charting; and finally, collating, summarizing, and reporting the results. The research questions in this scoping review were the following:
What methods are commonly used in developing an asthma attack prediction model?
How did the authors process the features and outcome variables?
Are there any of these prediction models that have been implemented in a real-world clinical setting?
We then translated these 3 questions into the patient or population, intervention, comparison, and outcomes model [19,20], as shown in Table 1.
Table 1.
The patient or population, intervention, comparison, and outcomes structure.
| Item | Expansion | Keywords |
| P | Patient, population | People with asthma |
| I | Intervention, prognostic factor, or exposure | Machine learning |
| C | Comparison of intervention | N/Aa |
| O | Outcome | Asthma attack |
aN/A: not applicable.
Search Strategy
We used the patient or population, intervention, comparison, and outcomes model in Table 1 as our framework for defining relevant keywords. This approach led us to include clinical terms associated with asthma attacks, encompassing concepts such as asthma exacerbation, asthma control, asthma management, and hospitalization. In addition, we integrated technical terminology related to ML, incorporating terms such as artificial intelligence, supervised methods, and deep learning (DL). All the keywords that we used in the search strategy can be found in Multimedia Appendix 1 [4,11,21-35]. Overall, 2 databases, PubMed and Scopus, were chosen as the sources of papers. The search period was between January 1, 2012, and January 31, 2023, and the search was limited to the title, abstract, and keywords of each paper but without any language restriction. The complete query syntax for both databases is listed in Textbox 1.
Query syntax.
Scopus
((TITLE-ABS-KEY(“asthma”) AND (TITLE-ABS-KEY(“management”) OR TITLE-ABS-KEY(“control”) OR TITLE-ABS-KEY(“attack”) OR TITLE-ABS-KEY(“exacerbation”) OR TITLE-ABS-KEY(“risk stratification”) OR TITLE-ABS-KEY(“risk prediction”) OR TITLE-ABS-KEY(“risk classification”) OR TITLE-ABS-KEY (hospitalization”) OR TITLE-ABS-KEY (“hospitalisation”) OR TITLE-ABS-KEY (“prognosis”))) AND (TITLE-ABS-KEY(“machine learning”) OR TITLE-ABS-KEY(“artificial intelligence”) OR TITLE-ABS-KEY(“supervised method”) OR TITLE-ABS-KEY(“unsupervised method”) OR TITLE-ABS-KEY (“deep learning”) OR TITLE-ABS-KEY (“supervised learning”) OR TITLE-ABS-KEY (“unsupervised learning”))) AND PUBYEAR > 2011
PubMed
((asthma[Text Word]) AND ((Management[Text Word]) OR (Control[Text Word]) OR (Attack[Text Word]) OR (Exacerbation[Text Word]) OR (Risk Stratification[Text Word]) OR (Risk Prediction[Text Word]) OR (Risk Classification[Text Word]) OR (hospitalization[Text Word]) OR (hospitalisation[Text Word]) OR (prognosis[Text Word])) AND ((machine learning[Text Word]) OR (Artificial Intelligence[Text Word]) OR (supervised method[Text Word]) OR (unsupervised method[Text Word]) OR (deep learning[Text Word]) OR (supervised learning[Text Word]) OR (unsupervised learning[Text Word]))) AND (“2012/01/01”[Date - Publication] : “2023/01/31”[Date - Publication])
Eligibility Criteria and Study Selection
Overall, 2 authors (AB and KCHT) performed the 2-step study selection process. During the first selection step, we focused on the abstract. In the second step, we conducted a thorough reading of the full text of the manuscript. We only included papers that met our inclusion criteria: (1) used asthma attack as the outcome, (2) included an ML-based prediction model, and (3) used EHR data as the main data source. We defined the concept of EHR-derived data as structured, text-based, individual-level, and routinely collected data gathered within the health care system. In cases of unclear information extracted from the abstract, the reviewers decided to retain the studies for the next iteration (full-text review). We excluded nonresearch papers, such as commentary and systematic review papers because of the insufficient technical information. We also filtered out papers that did not provide sufficient details about the ML approach and the result, including protocol papers.
Data Extraction
From each of the eligible papers, we extracted data from the full text and web-based supplements. We then summarized these data under different categories such as data set (whether publicly available or not), population characteristics (source, size, age range, and region), year of data, outcome definition and how it was represented in the model, number of features, feature selection method, imbalance handling strategy, ML prediction methods, performance evaluation metric, evaluation result, external validation, explainability method, and real-world clinical setting implementation. The data extraction and summarization for each paper were conducted independently by 2 authors (AB and KCHT). In case of any discrepancies, the 2 authors discussed them in detail during face-to-face meetings to reach an agreement. If the 2 reviewers could not resolve the disagreement, we had a further discussion with the whole team. For each study, we have reported both the performance evaluation result of the prediction models and the most important predictors where available.
Results
Overview
In total, 458 nonduplicated, potentially eligible papers were identified. At the end of the selection process, 3.7% (17/458) of the papers were included based on the inclusion criteria (refer to the PRISMA [Preferred Reporting Items for Systematic Reviews and Meta-Analyses] diagram in Figure 1). The earliest study that was included in the full review was published in 2018. In the abstract filtering stage, most of the studies (353/458, 77.1%) were excluded because the prediction outcome was not an asthma attack. We included 10.5% (48/458) of the studies in the full-text filtering stage. Eventually, 3.1% (14/458) of the studies were excluded because they did not meet our inclusion criteria. Then, 2.6% (12/458) nonresearch papers were also excluded. In addition, we excluded 0.9% (4/458) of the studies, which were a follow-up for 2 main papers that we included in the extraction stage. All the summary points in these follow-up studies were identical to the ones in the main studies. We also excluded 0.2% (1/458) of the studies owing to insufficient information.
Figure 1.
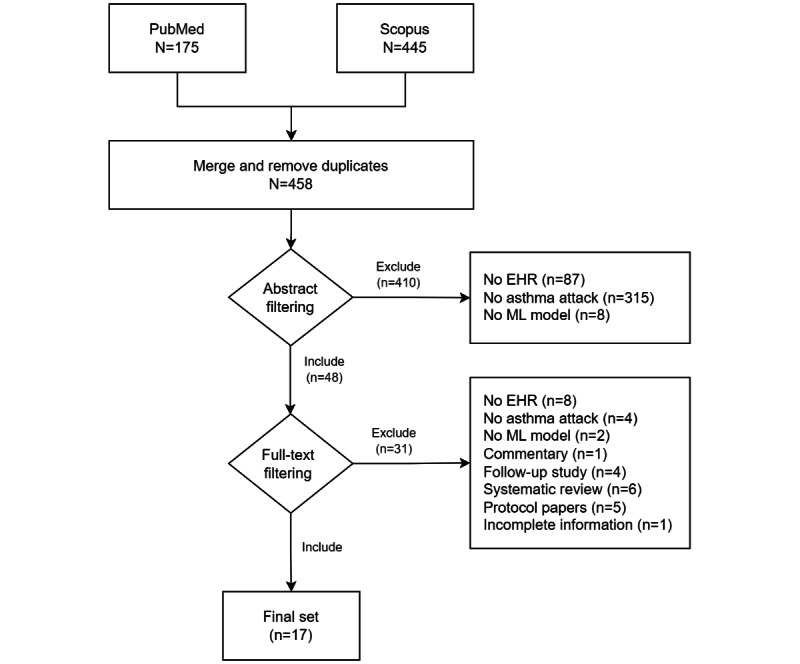
PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) diagram. EHR: electronic health record; ML: machine learning.
Asthma Data Sets
Table 2 summarizes the basic information about each included study. Only 6% (1/17) of the studies used routinely collected data from primary care alone [21]. Of the 17 studies, only 8 (47%) used data from secondary care, and the remaining 8 (47%) used routinely collected data from both primary and secondary care. All studies used data sets hosted either at the author’s institution or their collaborators’ institution, except a study [22] that used publicly available data (the Medical Information Mart for Intensive Care III data set [36]) as one of their data sets. Overall, 76% (13/17) of the studies used only EHR data to build the prediction model. Of the 17 studies, 4 (24%) studies integrated EHR data with additional modalities, including radiology images (chest computed tomography scans) [23] and environmental data [11,24,25], aiming to enhance predictive accuracy. The study populations varied across the studies, with most of them involving adults (8/17, 47%), followed by the general population, both children and adults (5/17, 29%), and children (4/17, 24%). Of the 17 studies, 14 (82%) had study populations from the United States. The other countries studied included Japan, Sweden, and the United Kingdom. All studies incorporated >1000 samples, except a study [23] that trained the prediction model on <200 samples. Among the studies, the biggest data set had data from 397,858 patients [26].
Table 2.
Summary of studies’ basic information.
| Study, year | Health care setting | Publicly available data set | Data source | Region | Data year | Sample size |
| Inselman et al [27], 2022 | Secondary care | No | Single modality | United States | 2003-2020 | 3057 |
| Hurst et al [25], 2022 | Both | No | Multimodality | United States | 2014-2019 | 5982 |
| Hogan et al [28], 2022 | Secondary care | No | Single modality | United States | 2013 | 18,489 |
| Zein et al [29], 2021 | Both | No | Single modality | United States | 2010-2018 | 60,302 |
| Sills et al [30], 2021 | Secondary care | No | Single modality | United States | 2009-2013 | 9069 |
| Hozawa et al [31], 2021 | Secondary care | No | Single modality | Japan | 2016-2017 | 42,685 |
| Lisspers et al [32], 2021 | Both | No | Single modality | Sweden | 2000-2013 | 29,396 |
| Ananth et al [23], 2021 | Secondary care | No | Multimodality | United Kingdom | 2018-2020 | 200 |
| Tong et al [33], 2021 | Both | No | Single modality | United States | 2011-2018 | 82,888 |
| Mehrish et al [24], 2021 | Secondary care | No | Multimodality | United States | 2013-2017 | 10,000 |
| Xiang et al [4], 2020 | Both | No | Single modality | United States | 1992-2015 | 31,433 |
| Cobian et al [34], 2020 | Both | No | Single modality | United States | 2007-2011 | 28,101 |
| Luo et al [35], 2020 | Both | No | Single modality | United States | 2005-2018 | 315,308 |
| Roe et al [22], 2020 | Secondary care | Yes | Single modality | United States | 2001-2012 | 38,597 |
| Luo et al [26], 2020 | Both | No | Single modality | United States | 2012-2018 | 397,858 |
| Wu et al [21], 2018 | Primary care | No | Single modality | United States | 1997-2002 | 4013 |
| Patel et al [11], 2018 | Secondary care | No | Multimodality | United States | 2012-2015 | 29,392 |
Data Preprocessing
There was considerable heterogeneity in the definition of the prediction outcome used in the models, including asthma exacerbation [4,25,27,29,31,32,34], asthma-related hospitalization [11,24,26,30,33,35], asthma readmission [28], asthma prevalence [24], asthma-related mortality [22], and asthma relapse [21].
The time horizon used to define the prediction outcome also varied across studies. Of the 17 studies, 6 (35%) studies defined the model task as a 1-year prediction [4,23,26,31,33,35]. Other variations in the time horizon for the outcome were 180 days [28], 90 days [34], 28 days [29], and 15 days [32]. A study compared the prediction model performances across 3 time horizons: 30, 90, and 180 days [25]. Of the 17 studies, 2 (12%) studies undertook a different approach, where the aim was to predict asthma attack–related hospitalization within 2 hours after an accident and emergency department visit [11,30]. Of the 17 studies, 3 (18%) studies did not report the prediction time horizon [21,22,24].
There was an obvious class imbalance in 76% (13/17) of the studies (Table 3). Class imbalance is a problem where the distribution of samples across the classes is skewed [37]. Ignoring this problem during model development will produce a biased model. Among the selected studies, the smallest minority class ratio accounted for as little as 0.04% [32]. Among these 17 studies, only 5 (29%) [4,21,30,32,33] explicitly mentioned their strategies to appropriately handle imbalanced data. Synthetic minority oversampling technique [38], oversampling [39,40], and undersampling [39,40] were the methods reported in these studies. The objective of these 3 methods is to balance the proportion of samples in each class by either generating synthetic data from the minority class or omitting a certain number of samples in the majority class. Of the 17 studies, only 2 (12%) studies used a balanced data set [22,23], whereas 2 (12%) other studies did not report the class ratio of their data set [24,34]. Various feature selection methods were explicitly mentioned as part of the data preprocessing step, including backward stepwise variable selection [28], light gradient boosting method feature importance [32], and Pearson correlation [32]. Of the 17 studies, 5 (29%) studies [4,26,30,33,35] implemented the feature selection process as the built-in method in the model development phase, whereas the remaining studies did not mention the feature selection method in their report. The smallest feature set used in the study was 7 variables [24], and the biggest set was >500 variables [32]. The handling of missing values varied across the studies. In most cases (9/17, 53%), missing values were treated either as a distinct category or assigned a specific value [21,23,25-27,29,32,33,35]. However, some studies opted to exclude data containing missing values [4,11,28,30], whereas others did not specify their approach for addressing this issue [22,24,31,34]. Notably, more than half of the studies (11/17, 65%) did not describe their methods for data normalization. This step is particularly critical for certain ML algorithms such as LR and support vector machine to prevent uneven weighting of features in the model. In contrast, 35% (6/17) of the studies [11,22,23,26,33,35] used a standard mean normalization technique to standardize the continuous features, ensuring uniform scaling across the data set.
Table 3.
Summary of the data preprocessing step.
| Study, year | Outcomes | Prediction time horizon | Class imbalance ratio (%) | Data imbalance handling methods | Feature selection methods | Number of features |
| Inselman et al [27], 2022 | Asthma exacerbation | 180 d |
|
Unknown | Unknown | 21 |
| Hurst et al [25], 2022 | Asthma exacerbation | 30, 90, and 180 d |
|
Unknown | Unknown | 41 |
| Hogan et al [28], 2022 | Asthma readmission | 180 d |
|
Unknown | Backward stepwise variable selection | 21 |
| Zein et al [29], 2021 | Asthma exacerbation | 28 d |
|
Unknown | Unknown | 82 |
| Sills et al [30], 2021 | Asthma-related hospitalization | Admission after A&Ea department visit |
|
Oversampling | Automated feature selection | 13 |
| Hozawa et al [31], 2021 | Asthma exacerbation | 365 d |
|
Unknown | Unknown | 25 |
| Lisspers et al [32], 2021 | Asthma exacerbation | 15 d |
|
Undersampling and weighting method | Correlation and LGBMb model | >500 |
| Ananth et al [23], 2021 | Asthma exacerbation | 365 d |
|
Unknown | Unknown | 17 |
| Tong et al [33], 2021 | Asthma-related hospitalization or A&E department visit | 365 d |
|
WEKAc | Automated feature selection | 234 |
| Mehrish et al [24], 2021 | Asthma prevalence, asthma-related hospitalization, or hospital readmission | Unknown |
|
Unknown | Unknown | 7 |
| Xiang et al [4], 2020 | Asthma exacerbation | 365 d |
|
SMOTEd | Automated feature selection | Unknown |
| Cobian et al [34], 2020 | Asthma exacerbation | 90 d |
|
Unknown | Unknown | >25 |
| Luo et al [35], 2020 | Asthma-related hospitalization | 365 d |
|
Unknown | Automated feature selection | 235 |
| Roe et al [22], 2020 | Asthma-related mortality | Unknown |
|
Unknown | Unknown | 42 |
| Luo et al [26], 2020 | Asthma-related hospitalization | 365 d |
|
Unknown | Automated feature selection | 337 |
| Wu et al [21], 2018 | Asthma relapse | Unknown |
|
Random undersampling | Unknown | 60 |
| Patel et al [11], 2018 | Asthma-related hospitalization | Admission after EDe visit |
|
Unknown | Unknown | 100 |
aA&E: accident and emergency.
bLGBM: light gradient boosting method.
cWEKA: Waikato Environment for Knowledge Analysis.
dSMOTE: synthetic minority oversampling technique.
eED: emergency department.
ML Methods and Performance Evaluation
Table 4 describes the ML and performance evaluation methods used in the selected studies. We found a wide range of ML methods in the selected studies. Most (14/17, 82%) used conventional ML methods such as support vector machine [41], random forest [42], naïve Bayes [43], decision tree (DT) [44], K-nearest neighbor [45], and artificial neural network [46]. LR and its variations (ie, Ridge, Lasso, and Elastic Net) [47] were found to be the most common baseline model among the studies (10/15, 67%) [4,11,22-25,27-30,32,34]. Some studies developed the prediction model with more advanced ML algorithms such as gradient boosting DT (GBDT)–based methods [11,22,25-27,29,31-33,35] and DL-based methods [4,21,34]. A few studies [26,30,35] also used automated model selection tools, such as Waikato Environment for Knowledge Analysis [48] and autoML [49]. GBDT-based methods including extreme gradient boosting (XGBoost) [50] were the common best-performing models (area under the curve scores ranging from 0.6 to 0.9). The model performances in all studies were evaluated using the area under the receiver operating characteristic curve score, except in a study [21] that used F1-score as the only performance metric. Half of them (9/17, 53%) included additional evaluation metrics such as accuracy, precision, recall, sensitivity, specificity, positive predictive value, negative predictive value, F1-score, area under the precision-recall curve, and microaveraged accuracy [21,23,25-27,30,32,33,35]. Owing to different data sets and the heterogeneity in the definitions of the outcome, prediction time horizon, and preprocessing across the studies, we considered a direct comparison across studies based on the reported evaluation metric to be inappropriate. Only 18% (3/17) of the studies included external validation using retrospective studies in their analysis pipeline [21,26,33].
Table 4.
Summary of machine learning (ML) methods.
| Study, year | ML methods | Best models | Best performance metrics | External validation |
| Inselman et al [27], 2022 | GLMNeta, RFb, and GBMc | GBM |
|
No |
| Hurst et al [25], 2022 | Lasso, RF, and XGBooste | XGBoost |
|
No |
| Hogan et al [28], 2022 | Cox proportional hazard, LRf, and ANNg | ANN |
|
No |
| Zein et al [29], 2021 | LR, RF, and GBDTh | GBDT |
|
No |
| Sills et al [30], 2021 | AutoML, RF, and LR | AutoML |
|
No |
| Hozawa et al [31], 2021 | XGBoost | XGBoost |
|
No |
| Lisspers et al [32], 2021 | XGBoost, LGBMj, RNNk, and LR (Lasso, Ridge, and Elastic Net) | XGBoost |
|
No |
| Ananth et al [23], 2021 | LR, DTl, and ANN | LR |
|
No |
| Tong et al [33], 2021 | WEKAm and XGBoost | XGBoost |
|
Yes |
| Mehrish et al [24], 2021 | GLMn, correlation models, and LR | LR |
|
No |
| Xiang et al [4], 2020 | LR, MLPo, and LSTMp with an attention mechanism | LSTM with an attention mechanism |
|
No |
| Cobian et al [34], 2020 | LR, RF, and LSTM | LR with L1 (Ridge) |
|
No |
| Luo et al [35], 2020 | WEKA and XGBoost | XGBoost |
|
No |
| Roe et al [22], 2020 | XGBoost, NNq, LR, and KNNr | XGBoost |
|
No |
| Luo et al [26], 2020 | WEKA and XGBoost | XGBoost |
|
Yes |
| Wu et al [21], 2018 | LSTM | LSTM |
|
Yes |
| Patel et al [11], 2018 | DT, Lasso, RF, and GBDT | GBDT |
|
No |
aGLMNet: Lasso and Elastic-Net Regularized Generalized Linear Models.
bRF: Random Forest.
cGBM: gradient boosting method.
dAUC: area under the curve.
eXGBoost: extreme gradient boosting.
fLR: logistic regression.
gANN: artificial neural network.
hGBDT: gradient boosting decision tree.
iED: emergency department.
jLGBM: light gradient boosting method.
kRNN: recurrent neural network.
lDT: decision tree.
mWEKA: Waikato Environment for Knowledge Analysis.
nGLM: Generalized Linear Model.
oMLP: multilayers perceptron.
pLSTM: long short-term memory.
qNN: neural network.
rKNN: K-nearest neighbor.
Model Explainability and Implementation
We then compared how model explainability was handled across studies. Model explainability refers to the degree of transparency and the level of detail a model can provide to offer additional information about its output, facilitating a better understanding of how the model operates [51]. We grouped the studies into 2 categories based on their best model’s transparency. In the first group, we included 18% (3/17) of the studies in which the best-performing model can be considered as a transparent model [51], including LR [23,24,34]. However, only 67% (2/3) of them provided a report on this model explanation in the form of LR coefficient values for each variable [23,34]. We grouped the remaining studies into an opaque model category where a post hoc analysis was needed to explain the model prediction mechanism [51]. In this group, all studies [4,11,22,26,28-33,35] used a model-specific method for explaining the prediction mechanism, except for 14% (2/14) of the studies [27,29] that used a model-agnostic method called the shapely additive explanation (SHAP) method [29]. Overall, 14% (2/14) of the studies in this group did not include any model explanation approach [21,25]. Although model-specific explanation methods, such as those used in DT-based models, gauge the impact of each feature on a model’s decision through specific metrics developed during training, the SHAP method takes a more comprehensive approach. SHAP conducts a deductive assessment by exploring all the potential combinations of features to determine how each one influences the final prediction.
None of the studies followed any specific reporting guidelines. Furthermore, despite promising performances in some studies, none were implemented in a real-world clinical setting for prospective evaluation. In each of the studies reviewed, various limitations were identified, encompassing both clinical and nonclinical factors. One of the common limitations in these studies was the issue of generalizing their findings to different health care settings and patient groups [22,25,26,29,33,35]. This difficulty often arose because they lacked important information such as medication histories [35], environmental factors [25,30], and social determinants of health [28], which are known to play significant roles in health outcomes. Data-related limitations were also prevalent, with some studies dealing with the drawbacks of structured EHR data [4,26,33,35], potential of data misreporting [32], and missing data that could affect the reliability of their models [29,35]. In addition, from a clinical perspective, certain studies faced limitations owing to the lack of standardized definitions for specific outcomes [11,22,23,27,28], emphasizing the importance of consistent criteria in health care research such as in asthma management. The model explanation and implementation information are summarized in Table 5. All data extraction results can be found in Multimedia Appendix 1. We have also depicted some of the important principal findings in Multimedia Appendix 2.
Table 5.
Summary of model explainability and implementation.
| Study, year | Best model transparency | Model explanation methods | Follow reporting guidelines | Clinical implementation | Study limitations |
| Inselman, et al [27], 2022 | Opaque model | SHAPa | No | No |
|
| Hurst et al [25], 2022 | Opaque model | No model explanation | No | No |
|
| Hogan et al [28], 2022 | Opaque model | Estimated weights | No | No |
|
| Zein et al [29], 2021 | Opaque model | SHAP | No | No |
|
| Sills et al [30], 2021 | Opaque model | autoML method | No | No |
|
| Hozawa et al [31], 2021 | Opaque model | Extracted risk factors | No | No |
|
| Lisspers et al [32], 2021 | Opaque model | LGBMf gain score | No | No |
|
| Ananth et al [23], 2021 | Transparent model | LRg coefficients | No | No |
|
| Tong et al [33], 2021 | Opaque model | XGBoosth feature importance | No | No |
|
| Mehrish et al [24], 2021 | Transparent model | No model explanation | No | No |
|
| Xiang et al [4], 2020 | Opaque model | Attention mechanism | No | No |
|
| Cobian et al [34], 2020 | Transparent model | LR coefficients | No | No |
|
| Luo et al [35], 2020 | Opaque model | XGBoost feature importance | No | No |
|
| Roe et al [22], 2020 | Opaque model | XGBoost feature importance | No | No |
|
| Luo et al [26], 2020 | Opaque model | XGBoost feature importance | No | No |
|
| Wu et al [21], 2018 | Opaque model | No model explanation | No | No |
|
| Patel et al [11], 2018 | Opaque model | GBDTj feature importance | No | No |
|
aSHAP: shapely additive explanation.
bICD-9: International Classification of Diseases, Ninth Revision.
cIL-5: interleukin 5.
dPFT: Pulmonary Function Tests.
eFeNO: Fractional Exhaled Nitric Oxide.
fLGBM: light gradient boosting method.
gLR: logistic regression.
hXGBoost: extreme gradient boosting.
iEHR: electronic health record.
jGBDT: gradient boosting decision tree.
kCDC: Centers for Disease Control and Prevention.
Discussion
Principal Findings
Our review indicates that this research field is still underdeveloped, given the limited body of evidence, heterogeneity of methods, lack of external validation, and suboptimally reported models. There was considerable heterogeneity in the specific definition of asthma outcome and the associated time horizon used by studies that sought to develop asthma attack risk prediction models. Class imbalance was also common across studies, and there was also considerable heterogeneity in how it was handled. Consequently, it was challenging to directly compare the studies.
The GBDT-based methods were the most reported best-performing method. DL methods such as long short-term memory (LSTM), a relatively more complex and advanced method, were also found in a few studies [4,21,34]. However, none of the studies compared the performance of the DL-based models with that of GBDT-based models. Moreover, none of the studies was prospectively evaluated or followed any reporting guidelines, and most studies (3/17, 18%) were not externally validated.
Strengths and Limitations
The key strengths of our study include undertaking a systematic and transparent approach to ensure reproducibility. Overall, 2 independent reviewers followed a clear framework during the study selection and data extraction stage. Furthermore, the interpretation of the result was supported by a multidisciplinary team consisting of both technical and clinical experts.
A further strength is that most systematic reviews about the use of ML methods in asthma research have focused on either diagnosis or classifying asthma subtypes [52-56]. Although there have been 2 previous reviews about the use of ML in predicting asthma attacks [15,16], our review is the first to focus on several key considerations in an ML pipeline, from data preprocessing to model implementation for asthma attack predictions.
However, this review also has 3 key limitations. First, this scoping review provided broad coverage of various technical challenges, but it cannot ascertain how feasible and effective an ML-based intervention can be in supporting asthma management. Second, we were not able to directly compare studies owing to the heterogeneity across studies, and that prohibited us from identifying the best algorithm or approach for solving the technical challenges highlighted in this review. Finally, this review only focused on the technical challenges without taking into account additional, crucial, sociocultural and organizational barriers to the adoption of ML-based tools in health care [57-59].
Interpretation in the Light of the Published Literature
The heterogeneity of outcome definitions found in this paper was also uncovered in previous non-ML asthma attack prognosis studies [16,60]. This heterogeneity includes both the indicators they used to define asthma attacks and the prediction time resolution. Recent systematic reviews also highlighted the wide range of outcome variations in ML-based prognostic models for ischemic stroke [61] and brain injury [62].
GBDT methods, especially XGBoost, have become a state-of-the-art method, especially for large and structured data in several domains [63-65]. Among the DL methods, LSTM has also shown potential in several previous studies [66,67]. LSTM is one of the most popular methods for analyzing complex time series data. Its capability to learn the sequence pattern makes it very powerful to build a prediction model by representing the data as a sequence of events. EHR data consist of a sequence of historical clinical events, which represent the trajectory of each patient’s condition over time. Incorporating the temporal features into the model, rather than just summarizing the events, can potentially boost the model’s performance.
Most of the studies (14/17, 82%) in this review incorporated some form of model explainability that aimed to provide an accessible explanation of how the prediction is derived by the model to instill trust in the users [68]. Previous studies in various domains showed that an ML model can output a biased prediction caused by latent characteristics within the data [69]. Model explainability is therefore crucial to provide model transparency and enhance fairness [70], especially in high-stake tasks such as those in health care [71].
Model validation and standard reporting are some of the important challenges that can influence adoption into routine practices [72]. An ML model should be internally, externally, and prospectively validated to assess its robustness in predicting new data [73]. In addition, a standard guideline needs to be followed in reporting an ML model development [74] such as the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis [75] or the Developmental and Exploratory Clinical Investigations of Decision Support Systems Driven by Artificial Intelligence [76]. It will facilitate an improved and objective understanding and interpretation of model performance. However, our review found a lack of external validation and adherence to reporting guidelines among the selected studies. These points resonated with the findings in other reviews of different cases [77,78].
Implications for Research, Policy, and Practice
This review highlighted several technical challenges that need to be addressed when developing asthma attack risk prediction algorithms. Further studies are required to develop a robust strategy for dealing with the class imbalance in asthma research. Class imbalance has been a common problem when working with EHR data [79,80]. However, there remains a notable gap in the literature regarding a systematic comparison of the effectiveness of existing methods, particularly in the context of asthma attack prediction. Several simple ML algorithms, such as linear regression, LR, and simple DTs, are easily interpretable [81]. In general, however, there is a trade-off between model interpretability and complexity, and most advanced methods are difficult to interpret, which then influences the users’ perception and understanding of the model [82]. We believe that the black box nature of the more complex methods, such as XGBoost and LSTM, is likely a technical barrier to implementing such models in a real-world clinical setting. Consequently, there is a need to continue exploring model explainability methods such as the attention mechanism approach recently developed for LSTM [83-85] that can augment complex “black box” algorithms.
There is a need for developing a global or at least a nationwide benchmark data set to facilitate external validation and to test the model’s generalizability [86]. Such validation is needed to ensure that the model will not only perform well under the data used in the model development but also can be reproduced to predict new data from different settings [87]. In addition, to maintain the transparency and reproducibility of the ML-based prediction model, adherence to a standard reporting guideline such as the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis [75] should be encouraged. Both good reproducibility and clear reporting are key points to facilitate critical assessment of the model before its implementation into routine practices. This effort is pivotal in addressing ethical concerns associated with data-driven prediction tools and in guaranteeing the safety and impartiality of the prediction [88]. Ensuring the ethical aspects of integrating a data-driven model into routine clinical practice is becoming a great challenge. This task demands substantial resources and relies on a collaborative effort involving experts from various disciplines [89].
Finally, to ensure that the ML-based model meets the requirements of the practices, a clear use case must be articulated. We found that almost all studies follow a clear clinical guideline to define asthma attacks, but there is a wide range of prediction time horizons across the studies. These variations are the result of distinct needs and goals from different practices. It is impossible to make a one-size-fits-all model. Therefore, a clear and specific clinical use case should be defined as the basis for developing an ML-based model.
Conclusions
ML model development for asthma attack prediction has been studied in recent years and includes the use of both traditional and DL methods. There is considerable heterogeneity in ML pipelines across existing studies that prohibits meaningful comparison. Our review indicates several key technical challenges that need to be tackled to make progress toward clinical implementation such as class imbalance problem, external validation, model explanation, and adherence to reporting guidelines for model reproducibility.
Acknowledgments
This paper presents independent research under the Asthma UK Centre for Applied Research (AUKCAR) funded by Asthma+Lung UK and Chief Scientist Office (CSO), Scotland (grant number: AUK-AC-2018-01). The views expressed are those of the authors and not necessarily those of Asthma+Lung UK or CSO, Scotland.
Abbreviations
- DL
deep learning
- DT
decision tree
- EHR
electronic health record
- GBDT
gradient boosting decision tree
- LR
logistic regression
- LSTM
long short-term memory
- ML
machine learning
- PRISMA
Preferred Reporting Items for Systematic Reviews and Meta-Analyses
- SHAP
shapely additive explanation
- XGBoost
extreme gradient boosting
List of the search keywords and full data extraction result.
Key findings.
Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR) checklist.
Footnotes
Conflicts of Interest: None declared.
References
- 1.Asthma. World Health Organization. 2023. May 04, [2023-11-28]. https://www.who.int/news-room/fact-sheets/detail/asthma .
- 2.GBD 2019 Diseases and Injuries Collaborators Global burden of 369 diseases and injuries in 204 countries and territories, 1990-2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet. 2020 Oct 17;396(10258):1204–22. doi: 10.1016/S0140-6736(20)30925-9. https://linkinghub.elsevier.com/retrieve/pii/S0140-6736(20)30925-9 .S0140-6736(20)30925-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Pocket guide for asthma management and prevention. Global Initiative for Asthma. [2023-11-20]. https://ginasthma.org/pocket-guide-for-asthma-management-and-prevention/
- 4.Xiang Y, Ji H, Zhou Y, Li F, Du J, Rasmy L, Wu S, Zheng WJ, Xu H, Zhi D, Zhang Y, Tao C. Asthma exacerbation prediction and risk factor analysis based on a time-sensitive, attentive neural network: retrospective cohort study. J Med Internet Res. 2020 Jul 31;22(7):e16981. doi: 10.2196/16981. https://www.jmir.org/2020/7/e16981/ v22i7e16981 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Wark PA, Gibson PG. Asthma exacerbations. 3: pathogenesis. Thorax. 2006 Oct;61(10):909–15. doi: 10.1136/thx.2005.045187. https://europepmc.org/abstract/MED/17008482 .61/10/909 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Martin MJ, Beasley R, Harrison TW. Towards a personalised treatment approach for asthma attacks. Thorax. 2020 Dec;75(12):1119–29. doi: 10.1136/thoraxjnl-2020-214692.thoraxjnl-2020-214692 [DOI] [PubMed] [Google Scholar]
- 7.Noble M, Burden A, Stirling S, Clark AB, Musgrave S, Alsallakh MA, Price D, Davies GA, Pinnock H, Pond M, Sheikh A, Sims EJ, Walker S, Wilson AM. Predicting asthma-related crisis events using routine electronic healthcare data: a quantitative database analysis study. Br J Gen Pract. 2021 Nov 25;71(713):e948–57. doi: 10.3399/BJGP.2020.1042. https://bjgp.org/lookup/pmidlookup?view=long&pmid=34133316 .BJGP.2020.1042 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Tibble H, Tsanas A, Horne E, Horne R, Mizani M, Simpson CR, Sheikh A. Predicting asthma attacks in primary care: protocol for developing a machine learning-based prediction model. BMJ Open. 2019 Jul 09;9(7):e028375. doi: 10.1136/bmjopen-2018-028375. https://bmjopen.bmj.com/lookup/pmidlookup?view=long&pmid=31292179 .bmjopen-2018-028375 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Hussain Z, Shah SA, Mukherjee M, Sheikh A. Predicting the risk of asthma attacks in children, adolescents and adults: protocol for a machine learning algorithm derived from a primary care-based retrospective cohort. BMJ Open. 2020 Jul 23;10(7):e036099. doi: 10.1136/bmjopen-2019-036099. https://bmjopen.bmj.com/lookup/pmidlookup?view=long&pmid=32709646 .bmjopen-2019-036099 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Bose S, Kenyon CC, Masino AJ. Personalized prediction of early childhood asthma persistence: a machine learning approach. PLoS One. 2021 Mar 1;16(3):e0247784. doi: 10.1371/journal.pone.0247784. https://dx.plos.org/10.1371/journal.pone.0247784 .PONE-D-20-24744 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Patel SJ, Chamberlain DB, Chamberlain JM. A machine learning approach to predicting need for hospitalization for pediatric asthma exacerbation at the time of emergency department triage. Acad Emerg Med. 2018 Dec;25(12):1463–70. doi: 10.1111/acem.13655. https://onlinelibrary.wiley.com/doi/10.1111/acem.13655 . [DOI] [PubMed] [Google Scholar]
- 12.Shickel B, Tighe PJ, Bihorac A, Rashidi P. Deep EHR: a survey of recent advances in deep learning techniques for electronic health record (EHR) analysis. IEEE J Biomed Health Inform. 2018 Sep;22(5):1589–604. doi: 10.1109/JBHI.2017.2767063. https://europepmc.org/abstract/MED/29989977 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Giger ML. Machine learning in medical imaging. J Am Coll Radiol. 2018 Mar;15(3 Pt B):512–20. doi: 10.1016/j.jacr.2017.12.028.S1546-1440(17)31673-3 [DOI] [PubMed] [Google Scholar]
- 14.Yu K-H, Beam AL, Kohane IS. Artificial intelligence in healthcare. Nat Biomed Eng. 2018 Oct;2(10):719–31. doi: 10.1038/s41551-018-0305-z.10.1038/s41551-018-0305-z [DOI] [PubMed] [Google Scholar]
- 15.Alharbi ET, Nadeem F, Cherif A. Predictive models for personalized asthma attacks based on patient's biosignals and environmental factors: a systematic review. BMC Med Inform Decis Mak. 2021 Dec 09;21(1):345. doi: 10.1186/s12911-021-01704-6. https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-021-01704-6 .10.1186/s12911-021-01704-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Bridge J, Blakey JD, Bonnett LJ. A systematic review of methodology used in the development of prediction models for future asthma exacerbation. BMC Med Res Methodol. 2020 Feb 05;20(1):22. doi: 10.1186/s12874-020-0913-7. https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-020-0913-7 .10.1186/s12874-020-0913-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Duboue P. The Art of Feature Engineering: Essentials for Machine Learning. Cambridge, United Kingdom: Cambridge University Press; 2020. [Google Scholar]
- 18.Arksey H, O'Malley L. Scoping studies: towards a methodological framework. Int J Soc Res Methodol. 2005;8(1):19–32. doi: 10.1080/1364557032000119616. [DOI] [Google Scholar]
- 19.Eriksen MB, Frandsen TF. The impact of patient, intervention, comparison, outcome (PICO) as a search strategy tool on literature search quality: a systematic review. J Med Libr Assoc. 2018 Oct;106(4):420–31. doi: 10.5195/jmla.2018.345. https://europepmc.org/abstract/MED/30271283 .jmla-106-420 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Leonardo R. PICO: model for clinical questions. Evid Based Med. 2018;4(1):1–2. doi: 10.4172/2471-9919.1000115. [DOI] [Google Scholar]
- 21.Wu S, Liu S, Sohn S, Moon S, Wi C-I, Juhn Y, Liu H. Modeling asynchronous event sequences with RNNs. J Biomed Inform. 2018 Jul;83:167–77. doi: 10.1016/j.jbi.2018.05.016. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(18)30099-6 .S1532-0464(18)30099-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Roe KD, Jawa V, Zhang X, Chute CG, Epstein JA, Matelsky J, Shpitser I, Taylor CO. Feature engineering with clinical expert knowledge: a case study assessment of machine learning model complexity and performance. PLoS One. 2020 Apr 23;15(4):e0231300. doi: 10.1371/journal.pone.0231300. https://dx.plos.org/10.1371/journal.pone.0231300 .PONE-D-18-17232 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Ananth S, Navarra A, Vancheeswaran R. S1 obese, non-eosinophilic asthma: frequent exacerbators in a real-world setting. Thorax. 2021;76:A5–6. doi: 10.1136/thorax-2021-BTSabstracts.7. [DOI] [PubMed] [Google Scholar]
- 24.Mehrish D, Sairamesh J, Hasson L, Sharma M. Combining weather and pollution indicators with insurance claims for identifying and predicting asthma prevalence and hospitalizations. 4th International Conference on Human Interaction and Emerging Technologies: Future Applications (IHIET – AI 2021); April 28-30, 2021; Strasbourg, France. 2021. [DOI] [Google Scholar]
- 25.Hurst JH, Zhao C, Hostetler HP, Ghiasi Gorveh M, Lang JE, Goldstein BA. Environmental and clinical data utility in pediatric asthma exacerbation risk prediction models. BMC Med Inform Decis Mak. 2022 Apr 22;22(1):108. doi: 10.1186/s12911-022-01847-0. https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-022-01847-0 .10.1186/s12911-022-01847-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Luo G, Nau CL, Crawford WW, Schatz M, Zeiger RS, Rozema E, Koebnick C. Developing a predictive model for asthma-related hospital encounters in patients with asthma in a large, integrated health care system: secondary analysis. JMIR Med Inform. 2020 Nov 09;8(11):e22689. doi: 10.2196/22689. https://medinform.jmir.org/2020/11/e22689/ v8i11e22689 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Inselman JW, Jeffery MM, Maddux JT, Lam RW, Shah ND, Rank MA, Ngufor CG. A prediction model for asthma exacerbations after stopping asthma biologics. Ann Allergy Asthma Immunol. 2023 Mar;130(3):305–11. doi: 10.1016/j.anai.2022.11.025.S1081-1206(22)01972-X [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Hogan AH, Brimacombe M, Mosha M, Flores G. Comparing artificial intelligence and traditional methods to identify factors associated with pediatric asthma readmission. Acad Pediatr. 2022;22(1):55–61. doi: 10.1016/j.acap.2021.07.015.S1876-2859(21)00378-8 [DOI] [PubMed] [Google Scholar]
- 29.Zein JG, Wu C-P, Attaway AH, Zhang P, Nazha A. Novel machine learning can predict acute asthma exacerbation. Chest. 2021 May;159(5):1747–57. doi: 10.1016/j.chest.2020.12.051. https://europepmc.org/abstract/MED/33440184 .S0012-3692(21)00031-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Sills MR, Ozkaynak M, Jang H. Predicting hospitalization of pediatric asthma patients in emergency departments using machine learning. Int J Med Inform. 2021 Jul;151:104468. doi: 10.1016/j.ijmedinf.2021.104468.S1386-5056(21)00094-0 [DOI] [PubMed] [Google Scholar]
- 31.Hozawa S, Maeda S, Kikuchi A, Koinuma M. Exploratory research on asthma exacerbation risk factors using the Japanese claims database and machine learning: a retrospective cohort study. J Asthma. 2022 Jul;59(7):1328–37. doi: 10.1080/02770903.2021.1923740. [DOI] [PubMed] [Google Scholar]
- 32.Lisspers K, Ställberg B, Larsson K, Janson C, Müller M, Łuczko M, Bjerregaard BK, Bacher G, Holzhauer B, Goyal P, Johansson G. Developing a short-term prediction model for asthma exacerbations from Swedish primary care patients' data using machine learning - based on the ARCTIC study. Respir Med. 2021;185:106483. doi: 10.1016/j.rmed.2021.106483. https://linkinghub.elsevier.com/retrieve/pii/S0954-6111(21)00189-X .S0954-6111(21)00189-X [DOI] [PubMed] [Google Scholar]
- 33.Tong Y, Messinger AI, Wilcox AB, Mooney SD, Davidson GH, Suri P, Luo G. Forecasting future asthma hospital encounters of patients with asthma in an academic health care system: predictive model development and secondary analysis study. J Med Internet Res. 2021 Apr 16;23(4):e22796. doi: 10.2196/22796. https://www.jmir.org/2021/4/e22796/ v23i4e22796 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Cobian A, Abbott M, Sood A, Sverchkov Y, Hanrahan L, Guilbert T, Craven M. Modeling asthma exacerbations from electronic health records. AMIA Jt Summits Transl Sci Proc. 2020 May 30;2020:98–107. https://europepmc.org/abstract/MED/32477628 . [PMC free article] [PubMed] [Google Scholar]
- 35.Luo G, He S, Stone BL, Nkoy FL, Johnson MD. Developing a model to predict hospital encounters for asthma in asthmatic patients: secondary analysis. JMIR Med Inform. 2020 Jan 21;8(1):e16080. doi: 10.2196/16080. https://medinform.jmir.org/2020/1/e16080/ v8i1e16080 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Johnson AE, Pollard TJ, Shen L, Lehman L-W, Feng M, Ghassemi M, Moody B, Szolovits P, Celi LA, Mark RG. MIMIC-III, a freely accessible critical care database. Sci Data. 2016 May 24;3:160035. doi: 10.1038/sdata.2016.35. doi: 10.1038/sdata.2016.35.sdata201635 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Sun Y, Wong AK, Kamel MS. Classification of imbalanced data: a review. Int J Pattern Recognit Artif Intell. 2009;23(04):687–719. doi: 10.1142/S0218001409007326. [DOI] [Google Scholar]
- 38.Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-sampling technique. J Artif Intell Res. 2002;16:321–57. doi: 10.1613/JAIR.953. [DOI] [Google Scholar]
- 39.Spelmen VS, Porkodi R. A review on handling imbalanced data. 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT); March 1-3, 2018; Coimbatore, India. 2018. [DOI] [Google Scholar]
- 40.Mohammed R, Rawashdeh J, Abdullah M. Machine learning with oversampling and undersampling techniques: overview study and experimental results. 11th International Conference on Information and Communication Systems (ICICS); April 7-9, 2020; Irbid, Jordan. 2020. [DOI] [Google Scholar]
- 41.Brereton RG, Lloyd GR. Support vector machines for classification and regression. Analyst. 2010 Feb;135(2):230–67. doi: 10.1039/b918972f. [DOI] [PubMed] [Google Scholar]
- 42.Xu M, Tantisira KG, Wu A, Litonjua AA, Chu J-H, Himes BE, Damask A, Weiss ST. Genome wide association study to predict severe asthma exacerbations in children using random forests classifiers. BMC Med Genet. 2011 Jun 30;12:90. doi: 10.1186/1471-2350-12-90. https://bmcmedgenet.biomedcentral.com/articles/10.1186/1471-2350-12-90 .1471-2350-12-90 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Ren J, Lee SD, Chen X, Kao B, Cheng R, Cheung D. Naive Bayes classification of uncertain data. 2009 Ninth IEEE International Conference on Data Mining; December 6-9, 2009; Miami Beach, FL. 2009. [DOI] [Google Scholar]
- 44.Song Y-Y, Lu Y. Decision tree methods: applications for classification and prediction. Shanghai Arch Psychiatry. 2015 Apr 25;27(2):130–5. doi: 10.11919/j.issn.1002-0829.215044. https://europepmc.org/abstract/MED/26120265 .sap-27-02-130 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Guo G, Wang H, Bell D, Bi Y, Greer K. KNN model-based approach in classification. OTM Confederated International Conferences CoopIS, DOA, and ODBASE 2003; November 3-7, 2003; Sicily, Italy. 2003. [DOI] [Google Scholar]
- 46.Wu Y-C, Feng J-W. Development and application of artificial neural network. Wireless Pers Commun. 2017 Dec 30;102:1645–56. doi: 10.1007/s11277-017-5224-x. [DOI] [Google Scholar]
- 47.Liang X, Jacobucci R. Regularized structural equation modeling to detect measurement bias: evaluation of lasso, adaptive lasso, and elastic net. Struct Equ Modeling Multidiscip J. 2019 Dec 12;27(5):722–34. doi: 10.1080/10705511.2019.1693273. https://doi.org/101080/1070551120191693273 . [DOI] [Google Scholar]
- 48.Holmes G, Donkin A, Witten IH. WEKA: a machine learning workbench. ANZIIS '94 - Australian New Zealand Intelligent Information Systems Conference; November 29-December 2, 1994; Brisbane, Australia. 1994. [DOI] [Google Scholar]
- 49.He X, Zhao K, Chu X. AutoML: a survey of the state-of-the-art. Knowl Based Syst. 2021 Jan 05;212:106622. doi: 10.1016/j.knosys.2020.106622. [DOI] [Google Scholar]
- 50.Chen T, Guestrin C. XGBoost: a scalable tree boosting system. 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; August 13-17, 2016; San Francisco, CA. 2016. [DOI] [Google Scholar]
- 51.Barredo Arrieta A, Díaz-Rodríguez N, Del Ser J, Bennetot A, Tabik S, Barbado A, Garcia S, Gil-Lopez S, Molina D, Benjamins R, Chatila R, Herrera F. Explainable artificial intelligence (XAI): concepts, taxonomies, opportunities and challenges toward responsible AI. Inf Fusion. 2020 Jun;58:82–115. doi: 10.1016/j.inffus.2019.12.012. [DOI] [Google Scholar]
- 52.Daines L, McLean S, Buelo A, Lewis S, Sheikh A, Pinnock H. Systematic review of clinical prediction models to support the diagnosis of asthma in primary care. NPJ Prim Care Respir Med. 2019 May 09;29(1):19. doi: 10.1038/s41533-019-0132-z. doi: 10.1038/s41533-019-0132-z.10.1038/s41533-019-0132-z [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Loymans RJ, Debray TP, Honkoop PJ, Termeer EH, Snoeck-Stroband JB, Schermer TR, Assendelft WJ, Timp M, Chung KF, Sousa AR, Sont JK, Sterk PJ, Reddel HK, Ter Riet G. Exacerbations in adults with asthma: a systematic review and external validation of prediction models. J Allergy Clin Immunol Pract. 2018;6(6):1942–52.e15. doi: 10.1016/j.jaip.2018.02.004. http://hdl.handle.net/10044/1/58802 .S2213-2198(18)30096-5 [DOI] [PubMed] [Google Scholar]
- 54.Luo G, Nkoy FL, Stone BL, Schmick D, Johnson MD. A systematic review of predictive models for asthma development in children. BMC Med Inform Decis Mak. 2015 Nov 28;15:99. doi: 10.1186/s12911-015-0224-9. https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-015-0224-9 .10.1186/s12911-015-0224-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Smit HA, Pinart M, Antó JM, Keil T, Bousquet J, Carlsen KH, Moons KG, Hooft L, Carlsen KC. Childhood asthma prediction models: a systematic review. Lancet Respir Med. 2015 Dec;3(12):973–84. doi: 10.1016/S2213-2600(15)00428-2.S2213-2600(15)00428-2 [DOI] [PubMed] [Google Scholar]
- 56.Exarchos KP, Beltsiou M, Votti C-A, Kostikas K. Artificial intelligence techniques in asthma: a systematic review and critical appraisal of the existing literature. Eur Respir J. 2020 Sep 3;56(3):2000521. doi: 10.1183/13993003.00521-2020. http://erj.ersjournals.com/cgi/pmidlookup?view=long&pmid=32381498 .13993003.00521-2020 [DOI] [PubMed] [Google Scholar]
- 57.Watson J, Hutyra CA, Clancy SM, Chandiramani A, Bedoya A, Ilangovan K, Nderitu N, Poon EG. Overcoming barriers to the adoption and implementation of predictive modeling and machine learning in clinical care: what can we learn from US academic medical centers? JAMIA Open. 2020 Jul;3(2):167–72. doi: 10.1093/jamiaopen/ooz046. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Morrison K. Artificial intelligence and the NHS: a qualitative exploration of the factors influencing adoption. Future Healthc J. 2021 Sep 02;8(3):e648–54. doi: 10.7861/fhj.2020-0258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Pumplun L, Fecho M, Wahl N, Peters F, Buxmann P. Adoption of machine learning systems for medical diagnostics in clinics: qualitative interview study. J Med Internet Res. 2021 Oct 15;23(10):e29301. doi: 10.2196/29301. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Alharbi F, Atkins A, Stanier C. Understanding the determinants of cloud computing adoption in Saudi healthcare organisations. Complex Intell Syst. 2016 Jul 13;2(3):155–71. doi: 10.1007/s40747-016-0021-9. [DOI] [Google Scholar]
- 61.Zeng M, Oakden-Rayner L, Bird A, Smith L, Wu Z, Scroop R, Kleinig T, Jannes J, Jenkinson M, Palmer LJ. Pre-thrombectomy prognostic prediction of large-vessel ischemic stroke using machine learning: a systematic review and meta-analysis. Front Neurol. 2022 Sep 8;13:945813. doi: 10.3389/fneur.2022.945813. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Cerasa A, Tartarisco G, Bruschetta R, Ciancarelli I, Morone G, Calabrò RS, Pioggia G, Tonin P, Iosa M. Predicting outcome in patients with brain injury: differences between machine learning versus conventional statistics. Biomedicines. 2022 Sep 13;10(9):2267. doi: 10.3390/biomedicines10092267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Stemerman R, Arguello J, Brice J, Krishnamurthy A, Houston M, Kitzmiller R. Identification of social determinants of health using multi-label classification of electronic health record clinical notes. JAMIA Open. 2021 Feb 9;4(3):ooaa069. doi: 10.1093/jamiaopen/ooaa069. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Pan P, Li Y, Xiao Y, Han B, Su L, Su M, Li Y, Zhang S, Jiang D, Chen X, Zhou F, Ma L, Bao P, Xie L. Prognostic assessment of COVID-19 in the intensive care unit by machine learning methods: model development and validation. J Med Internet Res. 2020 Nov 11;22(11):e23128. doi: 10.2196/23128. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Muro S, Ishida M, Horie Y, Takeuchi W, Nakagawa S, Ban H, Nakagawa T, Kitamura T. Machine learning methods for the diagnosis of chronic obstructive pulmonary disease in healthy subjects: retrospective observational cohort study. JMIR Med Inform. 2021 Jul 6;9(7):e24796. doi: 10.2196/24796. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Dong X, Deng J, Rashidian S, Abell-Hart K, Hou W, Rosenthal RN, Saltz M, Saltz JH, Wang F. Identifying risk of opioid use disorder for patients taking opioid medications with deep learning. J Am Med Inform Assoc. 2021 Jul 30;28(8):1683–93. doi: 10.1093/jamia/ocab043. https://europepmc.org/abstract/MED/33930132 .6261158 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Zhao J, Feng Q, Wu P, Lupu RA, Wilke RA, Wells QS, Denny JC, Wei W-Q. Learning from longitudinal data in electronic health record and genetic data to improve cardiovascular event prediction. Sci Rep. 2019 Jan 24;9:717. doi: 10.1038/s41598-018-36745-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Petch J, Di S, Nelson W. Opening the black box: the promise and limitations of explainable machine learning in cardiology. Can J Cardiol. 2022 Feb;38(2):204–13. doi: 10.1016/j.cjca.2021.09.004. [DOI] [PubMed] [Google Scholar]
- 69.Rudin C, Radin J. Why are we using black box models in AI when we don’t need to? A lesson from an explainable AI competition. Harvard Data Sci Rev. 2019 Nov 01;1(2) doi: 10.1162/99608f92.5a8a3a3d. [DOI] [Google Scholar]
- 70.Rasheed K, Qayyum A, Ghaly M, Al-Fuqaha A, Razi A, Qadir J. Explainable, trustworthy, and ethical machine learning for healthcare: a survey. Comput Biol Med. 2022 Oct;149:106043. doi: 10.1016/j.compbiomed.2022.106043. [DOI] [PubMed] [Google Scholar]
- 71.Rudin C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat Mach Intell. 2019 May 13;1(5):206–15. doi: 10.1038/s42256-019-0048-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Verma AA, Murray J, Greiner R, Cohen JP, Shojania KG, Ghassemi M, Straus SE, Pou-Prom C, Mamdani M. Implementing machine learning in medicine. Can Med Assoc J. 2021 Aug 29;193(34):E1351–7. doi: 10.1503/cmaj.202434. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Cabitza F, Campagner A, Soares F, García de Guadiana-Romualdo L, Challa F, Sulejmani A, Seghezzi M, Carobene A. The importance of being external. methodological insights for the external validation of machine learning models in medicine. Comput Methods Programs Biomed. 2021 Sep;208:106288. doi: 10.1016/j.cmpb.2021.106288. [DOI] [PubMed] [Google Scholar]
- 74.Stevens LM, Mortazavi BJ, Deo RC, Curtis L, Kao DP. Recommendations for reporting machine learning analyses in clinical research. Circ Cardiovasc Qual Outcomes. 2020 Oct 14;13(10) doi: 10.1161/circoutcomes.120.006556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD Statement. BMC Med. 2015;13(1):1. doi: 10.1186/s12916-014-0241-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Vasey B, Nagendran M, Campbell B, Clifton DA, Collins GS, Denaxas S, Denniston AK, Faes L, Geerts B, Ibrahim M, Liu X, Mateen BA, Mathur P, McCradden MD, Morgan L, Ordish J, Rogers C, Saria S, Ting DS, Watkinson P, Weber W, Wheatstone P, McCulloch P. Reporting guideline for the early stage clinical evaluation of decision support systems driven by artificial intelligence: DECIDE-AI. BMJ. 2022 May 18;377:e070904. doi: 10.1136/bmj-2022-070904. http://www.bmj.com/lookup/pmidlookup?view=long&pmid=35584845 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Wynants L, Van Calster B, Collins GS, Riley RD, Heinze G, Schuit E, Albu E, Arshi B, Bellou V, Bonten MM, Dahly DL, Damen JA, Debray TP, de Jong VM, De Vos M, Dhiman P, Ensor J, Gao S, Haller MC, Harhay MO, Henckaerts L, Heus P, Hoogland J, Hudda M, Jenniskens K, Kammer M, Kreuzberger N, Lohmann A, Levis B, Luijken K, Ma J, Martin GP, McLernon DJ, Navarro CL, Reitsma JB, Sergeant JC, Shi C, Skoetz N, Smits LJ, Snell KI, Sperrin M, Spijker R, Steyerberg EW, Takada T, Tzoulaki I, van Kuijk SM, van Bussel BC, van der Horst IC, Reeve K, van Royen FS, Verbakel Jy, Wallisch C, Wilkinson J, Wolff R, Hooft L, Moons KG, van Smeden M. Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal. BMJ. 2020 Apr 07;369:m1328. doi: 10.1136/bmj.m1328. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Tsang KC, Pinnock H, Wilson AM, Shah SA. Application of machine learning algorithms for asthma management with mHealth: a clinical review. J Asthma Allergy. 2022 Jun;Volume 15:855–73. doi: 10.2147/jaa.s285742. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Santiso S, Casillas A, Pérez A. The class imbalance problem detecting adverse drug reactions in electronic health records. Health Informatics J. 2018 Sep 19;25(4):1768–78. doi: 10.1177/1460458218799470. [DOI] [PubMed] [Google Scholar]
- 80.Tasci E, Zhuge Y, Camphausen K, Krauze AV. Bias and class imbalance in oncologic data—towards inclusive and transferrable AI in large scale oncology data sets. Cancers. 2022 Jun 12;14(12):2897. doi: 10.3390/cancers14122897. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Molnar C, Casalicchio G, Bischl B. Interpretable machine learning – a brief history, state-of-the-art and challenges. ECML PKDD 2020 Workshops; September 14-18, 2020; Ghent, Belgium. 2020. [DOI] [Google Scholar]
- 82.Lauritsen SM, Kristensen M, Olsen MV, Larsen MS, Lauritsen KM, Jørgensen MJ, Lange J, Thiesson B. Explainable artificial intelligence model to predict acute critical illness from electronic health records. Nat Commun. 2020 Jul 31;11(1):3852. doi: 10.1038/s41467-020-17431-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I. Attention is all you need. arXiv. doi: 10.5860/choice.189890. Preprint posted online June 12, 2017. https://arxiv.org/abs/1706.03762 . [DOI] [Google Scholar]
- 84.Shen L, Zheng J, Lee EH, Shpanskaya K, McKenna ES, Atluri MG, Plasto D, Mitchell C, Lai LM, Guimaraes CV, Dahmoush H, Chueh J, Halabi SS, Pauly JM, Xing L, Lu Q, Oztekin O, Kline-Fath BM, Yeom KW. Attention-guided deep learning for gestational age prediction using fetal brain MRI. Sci Rep. 2022 Jan 26;12(1):1408. doi: 10.1038/s41598-022-05468-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Nguyen-Duc T, Mulligan N, Mannu GS, Bettencourt-Silva JH. Deep EHR spotlight: a framework and mechanism to highlight events in electronic health records for explainable predictions. AMIA Jt Summits Transl Sci Proc. 2021 May 17;2021:475–84. [PMC free article] [PubMed] [Google Scholar]
- 86.Futoma J, Simons M, Panch T, Doshi-Velez F, Celi LA. The myth of generalisability in clinical research and machine learning in health care. Lancet Digit Health. 2020 Sep;2(9):e489–92. doi: 10.1016/S2589-7500(20)30186-2. https://linkinghub.elsevier.com/retrieve/pii/S2589-7500(20)30186-2 .S2589-7500(20)30186-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Bates DW, Auerbach A, Schulam P, Wright A, Saria S. Reporting and implementing interventions involving machine learning and artificial intelligence. Ann Intern Med. 2020 Jun 02;172(11_Supplement):S137–44. doi: 10.7326/m19-0872. [DOI] [PubMed] [Google Scholar]
- 88.Angerschmid A, Zhou J, Theuermann K, Chen F, Holzinger A. Fairness and explanation in AI-informed decision making. Mach Learn Knowl Extr. 2022 Jun 16;4(2):556–79. doi: 10.3390/make4020026. [DOI] [Google Scholar]
- 89.Obafemi-Ajayi T, Perkins A, Nanduri B, Wunsch DC II, Foster JA, Peckham J. No-boundary thinking: a viable solution to ethical data-driven AI in precision medicine. AI Ethics. 2021 Nov 29;2(4):635–43. doi: 10.1007/s43681-021-00118-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
List of the search keywords and full data extraction result.
Key findings.
Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR) checklist.