

Abstract
We present a surface-accelerated string method (SASM) to efficiently optimize low-dimensional reaction pathways from the sampling performed with expensive quantum mechanical/molecular mechanical (QM/MM) Hamiltonians. The SASM accelerates the convergence of the path by using the aggregate sampling obtained from the current and previous string iterations, whereas approaches like the string method in collective variables (SMCV) or the modified string method in collective variables (MSMCV) update the path only from the sampling obtained from the current iteration. Furthermore, the SASM decouples the number of images used to perform sampling from the number of synthetic images used to represent the path. The path is optimized on the current best estimate of the free energy surface obtained from all available sampling, and the proposed set of new simulations are not restricted to be located along the optimized path. Instead, the umbrella potential placement is chosen to extend the range of the free energy surface and improve the quality of the free energy estimates near the path. In this manner, the SASM is shown to improve the exploration for a minimum free energy pathway in regions where the free energy surface is relatively flat. Furthermore, it improves the quality of the free energy profile when the string is discretized with too few images. We compare the SASM, SMCV, and MSMCV using 3 QM/MM applications: a ribozyme methyltransferase reaction using 2 reaction coordinates, the 2′-O-transphosphorylation reaction of Hammerhead ribozyme using 3 reaction coordinates, and a tautomeric reaction in B-DNA using 5 reaction coordinates. We show that SASM converges the paths using roughly 3 times less sampling than the SMCV and MSMCV methods. All three algorithms have been implemented in the FE-ToolKit package made freely available.
Graphical Abstract
1. Introduction
The ability to model chemical reactions in the condensed phase1 using molecular simulations has far-reaching implications to the study of catalysis in biological systems.2,3 Advances in fast, accurate quantum mechanical force fields4,5 and machine learning models6–11 have greatly extended the scope of applications that can be routinely addressed. Nonetheless, simulations of complex reaction pathways remain computationally intensive, and ongoing development of new methods to improve the robustness and computational cost are important.
Reaction mechanisms can be characterized by calculating a free energy surface in a set of relevant reaction coordinates, the determination of the minimum free energy profile (MFEP) through the surface, and identification of key stationary points along the MFEP. Many methods for calculating free energy surfaces have been developed. These approaches can be categorized as:12 methods which analyze equilibrium statistics obtained from umbrella sampling,13–16 methods which analyze nonequilibrium statistics17–20 based on the work of Jarzynski,21 and methods that integrate auxiliary degrees of freedom, such as λ-dynamics22–25 and metadynamics.26,27 Similarly, there are two general approaches for locating a minimum free energy path.28 The first approach is to sample the reaction over a wide range of reaction coordinate values to obtain a relatively complete picture of the free energy surface through which a path can be optimized. This approach can greatly benefit from enhanced sampling methods, such as replica exchange molecular dynamics29 and integrated tempering sampling.30 The second, and more cost-effective, approach is to use a chain-of-states method, such as nudged elastic band31 or the string method,32,33 to direct the sampling toward the MFEP, thereby reducing the amount of effort spent simulating irrelevant, high-energy regions of the free energy surface.
Many variations of the string method34–41 have been developed that are capable of being applied to large-scale problems, like protein folding.36,37 These applications often describe the path using a large number of reaction coordinates,42 direct comparison of Cartesian coordinates,32 path collective variables,28,43 the use of the hills method,26,44 or machine learning techniques.45 Although string method development was originally motivated by the desire to use many reaction coordinates,34,35,38 many examples can be found of their use in quantum mechanical/molecular mechanical (QM/MM) applications involving only a few reaction coordinates.46–52 String methods, such as the one presented in Ref. 38, are particularly appealing because it is performed with standard umbrella sampling with harmonic biasing potentials, which are widely supported across simulation packages. Because QM/MM sampling is very costly, the present work seeks to optimize the string method described in Ref. 38 specifically for cases involving QM/MM simulations with a few reaction coordinates. The new method reduces the number of string iterations required to reach convergence because it uses the current estimate of the unbiased free energy to accelerate the exploration of flat regions of the surface. In this respect, the new method draws inspiration from ideas behind the metadynamics approach;26,27 however, the new method only requires sampling obtained using standard harmonic biasing potentials.
We describe a new surface-accelerated string method (SASM) and compare it to two similar algorithms: the string method in collective variables34,35 (SMCV), and the modified string method in collective variables38 (MSMCV). We have implemented all 3 of these methods in the ndfes software49 freely distributed within the FE-ToolKit package.53 The FE-ToolKit package has also been incorporated in the open source AmberTools simulation suite.54 There are several key differences between the SASM and related string methods. First, the SASM is a hybrid of the two approaches for locating a MFEP (chain-of-states method versus calculation of a multidimensional free energy surface). Whereas the SMCV and MSMCV update the path from the sampling obtained in the most recent string iteration, the SASM optimizes the path on the current estimate of the multidimensional free energy surface calculated from the aggregate sampling of all string iterations. In this respect, the SASM is similar to some adaptive umbrella sampling strategies.55 Second, the SASM decouples the number of images used to represent the path from the number of simulated images. The SMCV and MSMCV methods construct a new path by fitting a curve that interpolates a set of discrete control points obtained from a corresponding number of simulated images; therefore, if there was an insufficient number of images, the path may cut corners. By decoupling the representation of the path from the number of simulated images, the level of detail used to describe the path is not limited by the number of simulations. Third, unlike the SMCV and MSMCV the SASM does not require the images to be simulated along the current estimate of the path. We take advantage of this by introducing alternating stages of “exploration” and “refinement” steps. The exploration steps propose new simulations offset from the path in the direction that the path is moving, and the refinement steps place simulations along the path in a manner that improves the phase space overlap.
We compare the progress of the string optimizations using the SMCV, MSMCV and SASM with respect to the number of simulations per string, the sampling per simulation, and the spline representation of the path (either piecewise linear or Akima spline paths) in 3 applications. The first application uses 2 reaction coordinates to describe a ribozyme undergoing a methyl transfer reaction (MTR1)56–58 (PDB ID 7V9E). The second application uses 3 reaction coordinates to model the 2′-O-transphosphorylation reaction of Hammerhead ribozyme (HHr)59 (PDB ID 2OEU). The third application uses 5 reaction coordinates to optimize a tautomeric reaction pathway in B-DNA (PDB ID 113D).60 Schematics of the 3 systems are shown in Figure 1. We demonstrate that the SASM converges the MFEP faster than the SMCV and MSMCV when we vary the amount of sampling. The SASM avoids artifacts that can occur in the path “reparametrization step” of the SMCV and MSMCV. Finally, we show that the SASM method will sample the path in an efficient manner that achieves good overlap between the biased simulations when the number of simulations is reduced.
Figure 1:
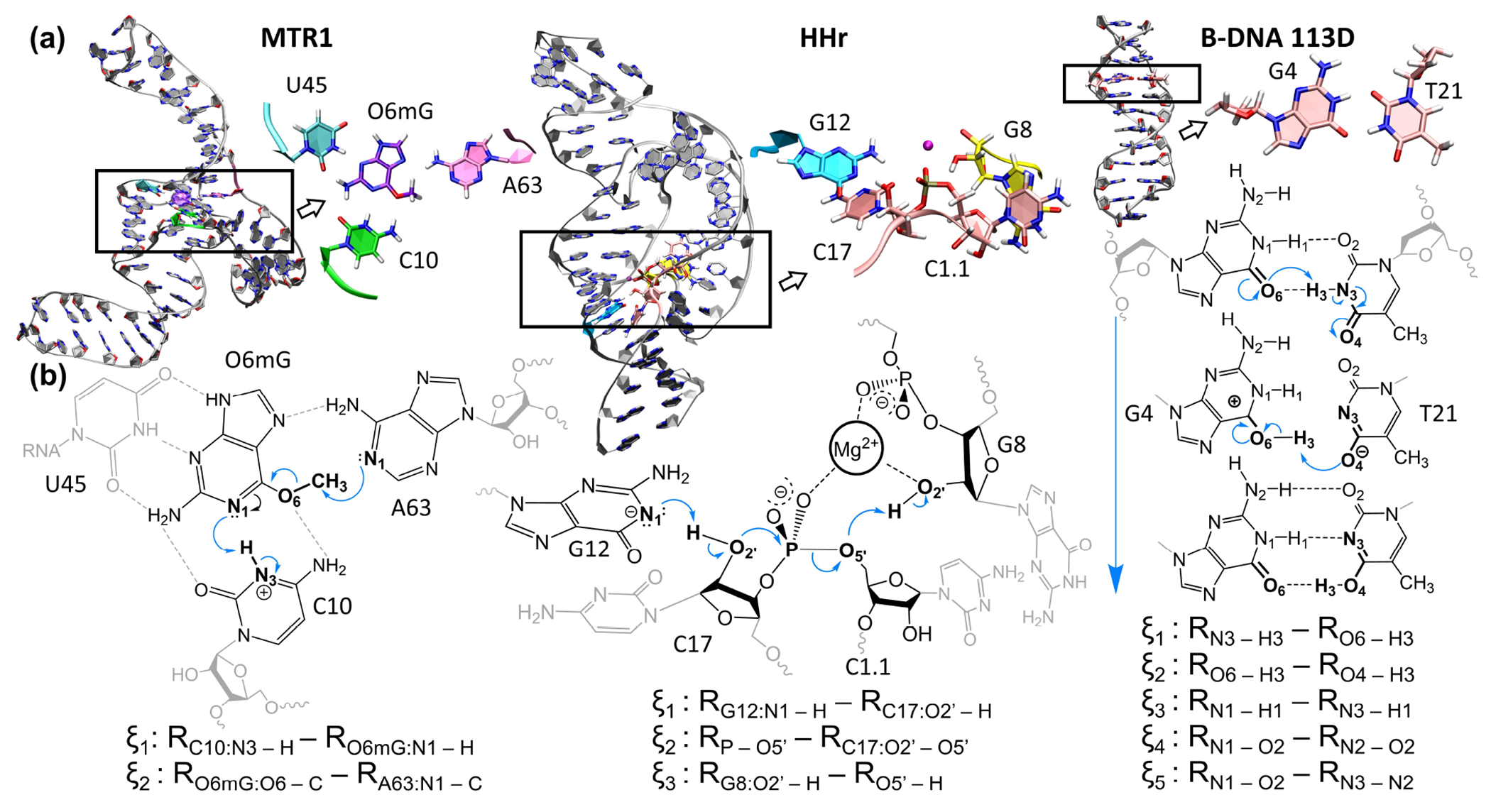
(a) The MTR1 ribozyme, HHr ribozyme, and a B-DNA with a GT wobble pair examined in this work. The rectangles highlight the active site region. (b) The reaction mechanisms and reaction coordinates. The B-DNA system is a tautomer reaction which transfers the T21 N3 proton to position O4 and reorganization of the G:T hydrogen bond network. The shown atomic configurations correspond to the reactant state. The black and gray atoms denote the QM region and nearby MM atoms, respectively.
2. Methods
2.1. String Method in Collective Variables
This section summarizes the SMCV method, which was originally described in Refs. 34 and 35. Let and be the 3N array of atomic positions and reaction coordinate values, respectively. Umbrella sampling is performed at images along the path using a biased potential energy function, .
| (1) |
Image is biased by a potential that is parametrized by harmonic force constants and equilibrium positions . In other words, is the size of the reduced dimensional space of reaction coordinates.
| (2) |
The algorithm for calculating the SMCV consists of the following steps.
Sample each of the images along the path for some amount of time, . The images differ by their biasing potentials, which center the harmonic potentials at discrete points along the current estimate of the path, .
Analyze the sampling to update (evolve) the reaction coordinate values, . The “control points”, are discrete estimates along the new path, but they do not necessarily uniformly discretize it. The calculation of the control points is sometimes called the “evolution step”.
Construct a parametric curve that interpolates the control points. The parametric curve is the new estimate of the path.
Uniformly discretize the parametric curve to obtain the biasing potential centers for the next iteration. The construction of a new curve and its discretization is sometimes called the “reparametrization step”.
The SMCV evolution step is given by eq. 3, where is the value of the reaction coordinate of image at string iteration , and is a control point used to define the parametric curve in string iteration , discussed in the next section. Each image is simulated for a length of time , and denotes a time average obtained from image .
| (3) |
approximates the free energy gradient about the point in dimension .
| (4) |
is closely related to a product of mass weighted Wilson B-matrices;61 that is to say, is the gradient of the reaction coordinate value with respect to the atomic positions of atom and is an atomic mass.
| (5) |
is a friction coefficient, a parameter of the method. The numerical stability of the SMCV critically depends on the ratio . In Ref. 35, it was found that the method was stable when choosing when fs. In the present work, we adjust to maintain this same ratio when is varied. The construction of parametric curves and their uniform discretization are described in the next section.
2.2. Parametric Curves and the Reparametrization Step
We represent a continuous path as a parametric curve of reaction coordinates, , where is a progress variable such that and denote two ends of the path. In other words, the path at string iteration is an array of one-dimensional splines that are chosen such that each spline interpolates the control points, located at a common set of progress control values, . Let and denote the arrays of progress control values and control points in dimension , respectively. The spline representation of the path in dimension is parametrized from these quantities.
| (6) |
In the context of the SMCV (or similar string methods), the control points are the new estimates of the reaction coordinates after the evolution step (eq. 3). In some cases, one may choose to reduce the numerical noise in the path by first applying a smoothing procedure, in which case the control points are the reaction coordinate values after smoothing. The results presented in this work use a smoothing algorithm implemented in the ndfes software when the parametric curve is modeled with Akima spline functions,62 but we do not apply smoothing to the control points when using piecewise linear paths. The details of the smoothing algorithm are described in the Supporting Information.
The parametric curve depends on the progress control values, which are interpreted as fractional arc lengths through the curve. If the path is a piecewise linear function connecting the control points, then the progress control values can be calculated from the Euclidean distance between adjacent points, as shown in eq. 7.
| (7) |
Alternatively, if the parametric curve is a set of Akima spline functions62 (or any smooth interpolating function), then eq. 7 is only an approximation of the fractional arc lengths. Accurate values of the progress control values can be found by iteratively solving eq. 8.
| (8) |
Equation 8 describes the iterative solution of by introducing a second, auxiliary index . The initial values, are the piecewise linear approximation shown in eq. 7, and we terminate the iterative solution when . We drop the auxiliary index to denote the converged progress control values.
Given the the parametric spline representation of the path, the uniformly discretized images for string iteration is shown in eq. 9, where .
| (9) |
2.3. Modified String Method in Collective Variables
The modified string method in collective variables (MSMCV) was originally presented in Ref. 38; it differs from the SMCV only by replacing the evolution step (eq. 3) with eq. 10.
| (10) |
In other words, the control points for the new path are the mean observed positions of the reaction coordinates from the simulations performed along the current path. Upon finding the control points, a new parametric curve is fit. The curve is uniformly discretized to define the new positions of the biasing potentials.
2.4. Surface-Accelerated String Method
The surface-accelerated string method (SASM) constructs a dimensional free energy surface from the available sampling and optimizes a path on that surface. A decision is then made to place a new set of simulations, which may or may not be along the optimized path. When the new simulations are placed along the path, we refer to it as a “refinement step”. Alternatively, we allow for “exploration steps” that offset the simulations from the path in the direction that the path is moving.
The algorithm for calculating the SASM consists of the following steps.
Sample each of the images for some amount of time.
Construct a dimensional unbiased free energy surface by analyzing the aggregate sampling produced from all simulations and string iterations. This is the best estimate of the free energy surface from the available sampling. The dimensional space is discretized into bins, and the free energy value and the number of observed samples in each bin are tabulated.
Create a smooth representation of the free energy surface, such that the free energy value and gradient can be readily computed at any point in the space of reaction coordinates.
Use the free energy surface to optimize a MFEP in the space of reaction coordinates. This optimization procedure does not involve the generation of additional sampling. Instead, the optimization is performed on a fixed free energy surface using a series of “synthetic string iterations”, described below.
If the current iteration is an even integer, then place the new simulations along the path. If the current iteration is an odd integer, then allow the new set of simulations to be displaced from the path by some amount in the direction that the path is moving.
The unbiased free energy can be calculated using established methods, such as the variational free energy profile method,49,63,64 the multistate Bennett acceptance ratio (MBAR) method,65 or the unbinned weighted histogram (UWHAM) method.66,67 As discussed in Ref. 49, a smooth representation of the free energy surface can be made using one of many methods, including the use of Cardinal B-Splines,68 radial basis functions,69,70 or Gaussian process regression.71 In the present work, we calculate the free energy surface by solving the MBAR/UWHAM equations to reweight the biased sampling. The samples are histogrammed, and the free energy of each bin is tabulated. We use fourth-order Cardinal B-splines to represent the surface as a smooth function. A mathematical description of the B-spline interpolation is provided in the Supporting Information for completeness. The free energy values are formally defined only in those regions whose histogram bins are occupied by at least one sample. In practice, we exclude all bins containing fewer than 10 samples because their free energy values are often unreliable.
To optimize a path on a fixed free energy surface, we adapt the MSMCV by replacing eq. 10 with eq. 11, where is the value of the unbiased free energy at .
| (11) |
| (12) |
The values are the control points of the synthetic images used to describe the path. Specifically, indexes the synthetic image, indexes the dimension, is the string iteration, and is the synthetic iteration. The number of synthetic images, , does not need to be the same as the number of images used to perform explicit simulations, . In the present work, we use to describe the path. The biasing potential appearing in eq. 11 requires a set of force constants for each synthetic image. If the number of simulated images was the same as the number of synthetic images, then the simulation force constants could be reused to define the synthetic image biasing potentials. The number of synthetic images is often much larger than the number of simulated images; therefore, one needs to transform the simulation force constants into a set of force constants. Our choice is to use a common set of force constants for each synthetic image by averaging the simulated force constants; that is, . Equation 11 is analogous to the MSMCV, but instead of performing a biased simulation of atomic coordinates to obtain the reaction coordinate distribution means, one performs a minimization directly on a biased free energy surface. In other words, eq. 11 is a synthetic iteration that allows us to repeatedly propagate the string without producing additional sampling. The path is optimized with iterations (or until convergence is sufficiently met), such that is the best estimate of the MFEP from the available sampling. The optimized synthetic control points also serve as the initial guess for the path in the next string iteration: .
By optimizing the MFEP on the current estimate of the free energy surface, the real images are no longer responsible for describing the path. Instead, their sole responsibility is to provide sampling to improve the the quality and range of the free energy surface. For this purpose, the SASM evolution step (eq. 13) includes two modifications relative to a simple uniform discretization.
| (13) |
The first modification is a shifting of the progress control points when discretizing the parametric curve,
| (14) |
where is a uniform discretization, and and shift the discretization by 1/3 of the distance to a neighboring image.
| (15) |
is the number of samples that have been observed at the point . In other words, the first 3 cases in eq. 14 check whether there are gaps in the sampling along the path. If there is a gap, then sampling at that position is prioritized. The last 3 cases in eq. 14 are a schedule that is followed when no gaps in the sampling are detected. The schedule alternates between these displacements during the course of the string optimization to help ensure that one obtains sufficient sampling along the path in the event that one underestimated an appropriate value of .
The second modification is the introduction of which displaces the image in the direction of the path’s movement.
| (16) |
We refer to as a refinement step that places the simulations along the path, and the other cases are exploration steps intended to better describe the free energy surface in the vicinity of path in the direction of its movement. The exploration steps accelerate the evolution of the string through flat areas of the free energy surface. The leading Kronecker delta function causes the exploration step to be skipped if a gap in the sampling was previously detected in eq. 14. The exploration direction is determined from the difference between the optimized paths of the current and previous iterations.
| (17) |
The value of is the point on the previous path that is closest to the point on the current path.
| (18) |
The values are the magnitude of the displacement, where is a width assigned to each dimension. In the present work, we use for all dimensions, which is also the width of the histogram bins used to construct the free energy surface.
| (19) |
If one imagines the point at as being located at the corner of a voxel, then eq. 19 can be interpreted as choosing the magnitude to be the maximum displacement that does not exceed the range of voxels.
The SASM method has several parameters that can be adjusted, including: the number of simulated images , the number of synthetic images , the simulation length , the biasing potential force constants , the cyclic schedules shown in eqs. 14 and 16, and the voxel width appearing in eq. 19. Unlike the SMCV and MSMCV, the SASM requires an estimate of the unbiased free energy surface to propagate the string. The calculation of an unbiased free energy surface from solution of the MBAR/UWHAM equations requires overlap between the biased distributions,65–67 so a suitably large value of is necessary. An optimal choice of depends on the length of the string, the gradient of the underlying free energy surface, and the values of and . In practice, one can validate their choice of by analyzing the sampling overlap produced from their initial guess pathway. In the event that the MFEP was significantly longer than the initial guess, may become too small during the course of the string method. We did not design the SASM to dynamically choose the value of based on the current string length because changes in may complicate resource allocation scheduling requests. Instead, the progress variable shifts (eq. 14) effectively increase over the course of several string iterations to minimize the consequences of having chosen an insufficiently small value. By using a cyclic schedule of length 3, eq. 14 acts to effectively increase by a factor of 3 over a series of string iterations. Alternatively, if the calculations were prepared with an excessive number of images, then the proposed shifts would be very small in relation to the length of the string, , rendering the shifts unnecessary.
The displacement schedule (eq. 16) alternates between refinement and exploration iterations to avoid introducing a bias to the exploration direction (eq. 17). In other words, if the exploration direction was chosen by optimizing a path on a surface that introduced new sampling in areas offset from the current path, then the new path is more likely to move in the direction of the added sampling. Our recommended displacement schedule cycles every 4 iterations rather than 2 iterations. We have explored the use of 2 iteration schedules that alternate between refinement and exploration iterations with or (eq. 19) using . In brief, the 2 iteration schedule involving was found to converge the MFEP faster than the 2 iteration schedule involving , and it performed about as well as the 4 iteration schedule. We recommend the 4 iteration schedule because it is less likely to produce gaps in the sampling. Appropriate values of are coupled to the value of . We use histogram bin widths of to construct the free energy surface because smaller bin widths are more likely to produce numerical noise in the free energy surface, which manifests as noise in the optimized path.49 Furthermore, if the displacements become too large, then extended simulations may be necessary to equilibrate the system after making a significant change to the biasing potential. Once the SASM has converged, further iterations will fluctuate around the MFEP. These random fluctuations, when coupled with the displacement schedule, causes the sampling to envelope a tube of nearby histogram bins surrounding the MFEP.
2.5. Computational Details
All QM/MM simulations in this work were performed with the sander molecular dynamics software54 using the default leapfrog integrator with a 1 fs integration time step. More efficient sampling with a longer integration time step may be obtained by using the recently developed “middle” thermostat scheme described in Refs. 72 and 73, which is already available in the Amber software. The SHAKE algorithm74 was used to fix MM bonds involving hydrogen, whereas all QM bonds were left unconstrained. The covalent bonds at the QM/MM boundary were capped with the hydrogen link-atom approach.75,76 Electrostatics were calculated with the particle mesh Ewald method77–79 adapted for use within semiempirical QM/MM simulations80,81 using tinfoil boundary conditions82,83 a 1 Å3 reciprocal space grid, and 10 Å real space cutoffs. The Lennard-Jones interactions were similarly calculated to 10 Å and a long-range tail correction was included to account for the interactions beyond the cutoff.84
The MTR1 ribozyme (PDB ID 7V9E58) consists of 2, 207 atoms with a net 66– charge. The ribozyme was solvated with 18, 250 TIP4P/Ew waters, 113 sodium ions, and 47 chlorine ions in a truncated octahedron with real space lattice vectors of length 90.2 Å resulting in 75, 367 particles and an ion concentration of 140 mM. The ff99OL3 RNA force field85 and Joung and Cheatham86 monovalent ion parameters have been used. Details regarding the preparation and equilibration of this system have already been reported elsewhere.87 In brief, the pressure and temperature were equilibrated for 50 ns with the MM force field potential to maintain 1 atm and 298 K in the isothermal-isobaric ensemble using the Berendsen barostat88 and Langevin thermostat89 with a collision frequency of 5 ps−1. At this point, the MM force field was replaced with the DFTB3 QM/MM potential using the “3ob” parameter set.90 The QM region consists of 48 atoms with net 1+ charge, as illustrated in Figure 1. A QM/MM simulation of the reactant state was equilibrated for 12.5 ps in the canonical ensemble at 298 K. The DFTB3 QM/MM umbrella production sampling was similarly performed at constant temperature with 200 kcal mol−1 Å−2 force constants on the two reaction coordinates describing the transfer of a proton, , and methyl group, as visualized in Figure 1.
The HHr ribozyme (PDB ID 2OEU59) consists of 2, 020 atoms with a net 62– charge. The ribozyme was solvated with 13, 319 TIP4P/Ew waters, 5 magnesium ions (replacing the crystal structure manganese ions), 86 sodium ions, and 34 chlorine ions in a truncated octahedron with real space lattice vectors of length 81.7 Å resulting in 55, 421 particles and an ion concentration of 140 mM. The ff99OL3 RNA force field,85 Joung and Cheatham86 monovalent ion, and Li-Merz91 12-6-4 divalent ion parameters with Panteva92,93 corrections, which ensure balanced interactions between metal ions and nucleic acids, have been used. Full details of the preparation and equilibration of this system has been reported elsewhere.94 In brief, the pressure and temperature were equilibrated for 100 ns with the MM force field potential to maintain 1 atm and 298 K in the isothermal-isobaric ensemble. The MM force field was replaced with the AM1/d QM/MM potential.95 The QM region consists of 85 atoms with net 1– charge. The QM region is illustrated in Figure 1; for clarity, the Mg2+ and the 4 waters directly coordinating the Mg2+ were including in the QM region. A QM/MM simulation of the reactant state was equilibrated for 50 ps in the canonical ensemble at 298 K. All AM1/d QM/MM umbrella production sampling was performed at constant temperature with 200 kcal mol−1 Å−2 force constants on the three reaction coordinates describing the proton transfer from the nucleophile to the general base, , and phosphoryl transfer, . and the proton transfer from the general acid to the leaving group, .
The B-DNA sequence (PDB ID 113D)60 consists of 762 atoms with a net 22– charge. The ribozyme was solvated with 5, 151 TIP4P/Ew waters, 35 sodium ions, and 13 chlorine ions in a truncated octahedron with real space lattice vectors of length 59.3 Å resulting in 21, 414 particles and an ion concentration of 140 mM. The system was modeled with the OL5 DNA force field96 and Joung and Cheatham86 monovalent ion parameter set. The system was prepared by minimizing the solvent environment and hydrogen positions while restraining the DNA heavy atoms, followed by a gradual heating of the system from 0 to 298 K over the course of 300 ps in the NVT ensemble, and the system density was equilibrated at 1 atm for 8 ns in the NPT ensemble. The MM force field was replaced with the AM1/d QM/MM potential,95 where the QM region (the G4 and T21 nucleobases depicted in Figure 1) consists of 31 atoms with net neutral charge. A QM/MM simulation of the reactant state was equilibrated for 50 ps in the canonical ensemble at 298 K. All AM1/d QM/MM umbrella production sampling was performed at constant temperature with 200 kcal mol−1 Å−2 force constants for each of the reaction coordinates listed in Figure 1.
To start any string method, one must first construct a series of structures to be used as the initial guess. For the MTR1 reaction, we consider two initial guesses: a concerted guess that uniformly discretizes a line connecting the approximate position of the reactant state to the product state , and a stepwise guess that uniformly discretizes a piecewise linear path connecting the reactant state, approximate intermediate state , and the product state. For the HHR reaction, the initial guess discretizes a linear transformation between the approximate reactant state to the approximate product state . Similarly, the initial guess for the B-DNA tautomer reaction discretizes a linear transformation between the reactant , and product states . The atomic coordinates were generated from a sequence of short (200 fs) simulations that restart each image from the final structure of the previous image. After this scan was completed, each image was independently equilibrated for an additional 4 ps. The final coordinates from these equilibrations became the starting structures to initiate the string method.
The SMCV, MSMCV, and SASM were performed multiple times while varying the number of images and length of production sampling. The MTR1 simulations performed for 4 ps/image and 500 fs/image saved 400 samples/image and 250 samples/image, respectively. The HHr simulations performed for 625 fs/image and 312 fs/image saved 125 samples/image and 156 samples/image, respectively. The B-DNA simulations were performed for 1 ps/image and 200 samples/image were saved. In all cases, we analyze only the last 75% of saved samples when solving the MBAR/UWHAM equations.
3. Results and Discussion
Here we compare the SMCV, MSMCV, and SASM string methods using three reactive chemical systems having varying number of reaction coordinates. 1. A 2D example of an artificially engineered methyltransferase ribozyme (MTR1)56 that catalyzes the methylation of a target adenine. 2. A 3D example of a naturally occurring hammerhead ribozyme (HHr)59 that catalyzes site-specific RNA self-cleavage. 3. A 5D example of tautomerization in dG·dT wobble pairs that lead to misincorporation during replication.97
3.1. MTR1 catalytic mechanism
Evolutionary theories based on an RNA world98,99 presumably would require RNA molecules to catalyze C-C and C-N bond formation essential for nucleic acid synthesis and early metabolic transformations. There are no known naturally occurring examples of RNA enzymes that have this ability. Recently, a methyltransferase ribozyme (MTR1) has been evolved in vitro56 that binds O6-methylguanine and catalyzes the methylation of a target adenine (A63) at the N1 position57,100 (Figure 1a). Computational enzymology studies performed by our group,87 in collaboration with Huang, Lilley and co-workers,58 revealed a surprising sophisticated mechanism that involves a protonated cytosine residue that acts as an acid in order to facilitate site-specific C-N bond formation, broadening the range of known RNA-catalyzed chemistry and further demonstrating versatility of RNA catalysis.101 In the computational study, we employed an early version of the string method and found it to be slowly convergent, making it extremely costly to perform ab initio QM/MM simulations. Hence, we use this as our first test system for developing improved string methods with accelerated convergence.
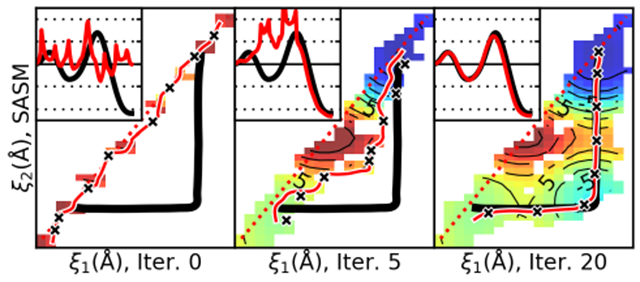
Figure 2 uses the MTR1 reaction to compare the progress of the SMCV, MSMCV, and SASM at string iterations 5, 15, 30, and 50. Each optimization was performed twice, starting from concerted and stepwise initial paths. Each string iteration samples 32 images for 4 ps/image (128 ps/iteration). The free energy surface is a best estimate made from the aggregate sampling of all iterations obtained from the 3 methods (38.4 ns of aggregate sampling). The black line is a reference MFEP, optimized on the aggregate free energy surface. The SMCV and MSMCV paths are Akima splines fit to the 32 evolved images, whereas the SASM paths are Akima splines fit to 100 synthetic images.
Figure 2:
Progress of the string methods at several iterations of the MTR1 reaction starting from concerted (red lines) and stepwise (green lines) initial guess paths. Parts a-d, e-h, and i-l illustrate the convergence of the SMCV, MSMCV, and SASM, respectively. Each string is composed of 32 images, and each image is sampled for 4 ps. The initial guesses are dashed lines. The colored areas are the best estimate of the free energy surface, calculated from the aggregate sampling produced by all string methods. The black line is the MFEP optimized on the best estimate of the surface. The insets are the reference free energy values along the paths (kcal/mol).
The three methods approach the MFEP at different rates. The SMCV and MSMCV make good progress during the first 15 iterations, but their progress stalls as they near the MFEP. This is due to the free energy surface becoming relatively flat near the MFEP. In contrast, the SASM gets closer to the MFEP at iteration 5 than the SMCV or MSMCV do at iteration 50. By placing the simulations around the path, the SASM is capable of exploring flat surfaces more efficiently.
To test whether the conclusions drawn from Figure 2 are sensitive to the simulation time scale (time/image), we re-performed the string methods using only 500 fs/image of sampling. The resulting comparison (Supporting Information Figure S1) is nearly indistinguishable from Figure 2.
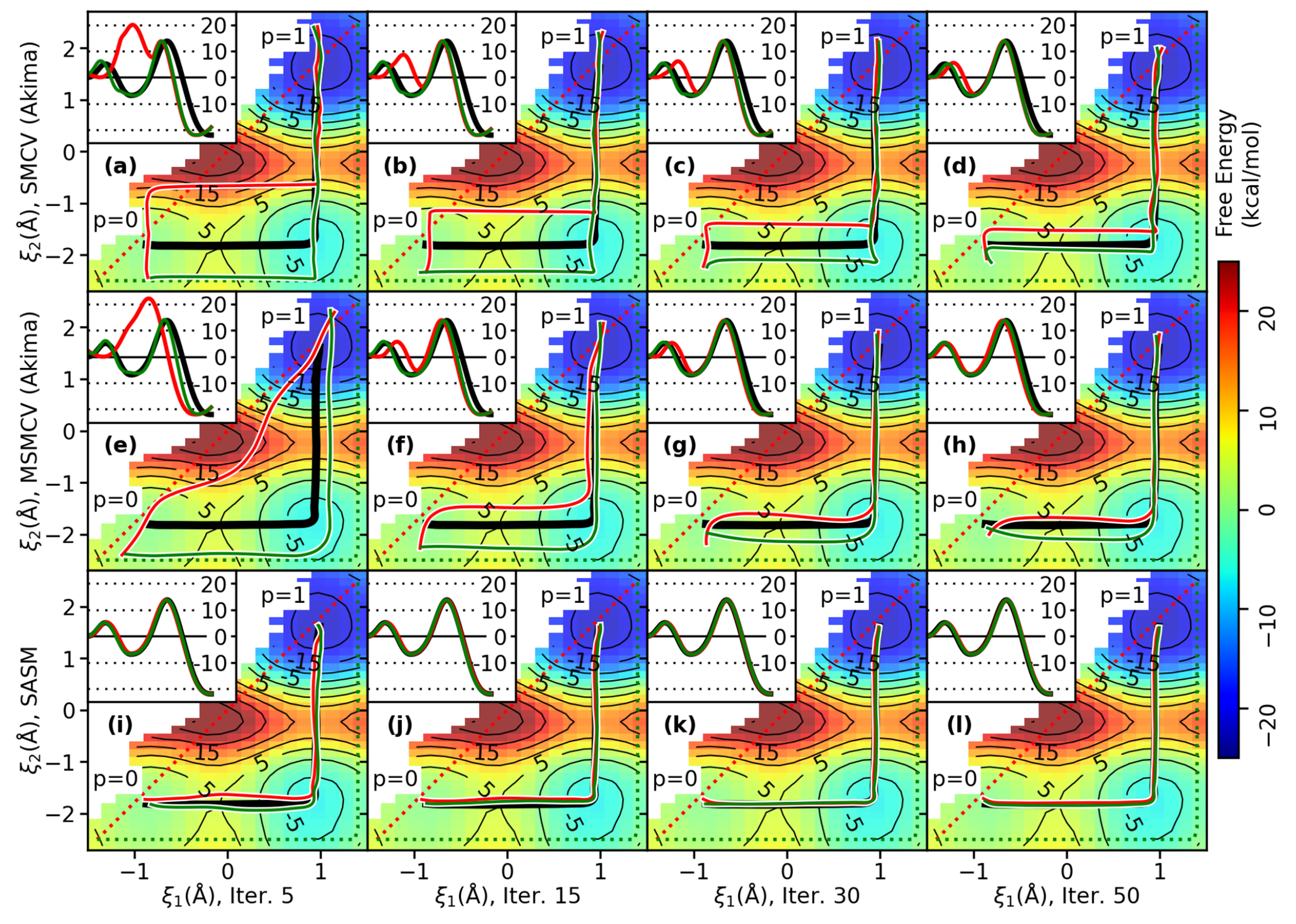
Figure 3 compares the string methods using fewer images and different spline representations of the path. The optimizations start from a concerted path, and each iteration samples 8 images for 4 ps/image. The colored areas are the current estimate of the free energy surface from the sampling produced by the current and previous iterations. The red line is the estimate of the path after the evolution step. The “x” marks are the proposed set of umbrella potential locations. The black line is the reference path shown in Figure 2. The insets display the free energy along the paths; the red line is the free energy of the current path from the available sampling, and the black line is the reference free energy along the reference path (made from 38.4 ns of aggregate sampling). The rows labeled “Akima” and “Linear” construct the parametric curve from Akima splines and piecewise linear functions, respectively. Whereas the SMCV and MSMCV paths are limited to 8 control points, the SASM path is constructed from Akima splines which interpolate 100 synthetic images optimized on the free energy surface.
Figure 3:
String iterations of MTR1 from a concerted (linear) initial guess (dashed red line). Each string is composed of 8 images, and each image is sampled for 4 ps. The solid red line is the current string, and the black “x” marks the next set of 8 simulations. The black line is a reference pathway, and the insets compare the current estimate of the free energy profile to the reference profile (kcal/mol). Parts a-d and e-h are the SMCV method using Akima and piecewise linear splines, respectively. Parts i-l and m-p similarly compare the MSMCV method. Parts q-t are the SASM method with 100 synthetic images.
Figure 3 illustrates that the SMCV and MSMCV methods are sensitive to the parametric form of the path when only a few (e.g., 8) images are simulated. Although the SMCV and MSMCV methods properly evolve the control points, both methods encounter artifacts within the reparametrization step when the path is modeled with Akima splines. The artifacts encountered by the SMCV are quite severe; reparametrization of the curve causes some images to be propagated in a direction away from the MFEP (Figure 3a–b), and the converged path differs significantly from the reference path (Figure 3d). The MSMCV similarly encounters artifacts between iterations 15 and 50, and it converges to an incorrect path (Figure 3l). The SMCV and MSMCV methods do approach the correct MFEP when using piecewise linear curves, however (see Figure 3h and p). The SASM does not exhibit artifacts using Akima splines because it is parametrized to 100 synthetic control points rather than 8 control points. By using more control points to define the path, the SASM also avoids corner cutting, which can be observed when using piecewise linear paths; for example, see the intermediate state in Figure 3p.
When only 8 images are simulated, the progress of the SASM is modestly better than SMCV (Linear) and MSMCV (Linear); however, the SASM does a much better job at producing samples to analyze the free energy surface. As can be seen in the insets of Figures 3a–p, the limited number of images causes the SMCV and MSMCV to produce sampling that does not well overlap, resulting in noisy free energy profiles. In contrast, the SASM evolution step shifts the progress values to improve the sampling between the set of uniformly discretized points, and the exploration steps provide sampling around the path. Consequently, the SASM free energy profile after 15 iterations reproduces the reference profile very well (Figure 3s). In fact, the SASM profile after 15 iterations is better than the SMCV and MSMCV profiles after 50 iterations. The SASM placement algorithm attempts to fill the gaps in the sampling, which is easiest to observe in Figure 3q. After sampling the initial guess, the optimized path remains similar to the initial guess because all areas of the surface which have not been sampled are assumed to have a high free energy. The first 3 cases in eq. 14 propose new simulations in the unoccupied regions along the path.
3.2. HHr Mechanism
The hammerhead ribozyme (HHr)59,102–104 is a metal-dependent small endonucleolytic self-cleaving RNA that has been extensively studied experimentally105–107,107,108 and computationally,109–115 and is an archetype model for RNA catalysis. The active site adopts an L-platform/L-scaffold architecture116 with an L-pocket guanine residue that forms a divalent metal ion binding site enabling electrostatic interactions94 to facilitate the reaction. The 2′O-transphosphorylation mechanism can be described by three reaction coordinates, illustrated in Figure 1b.
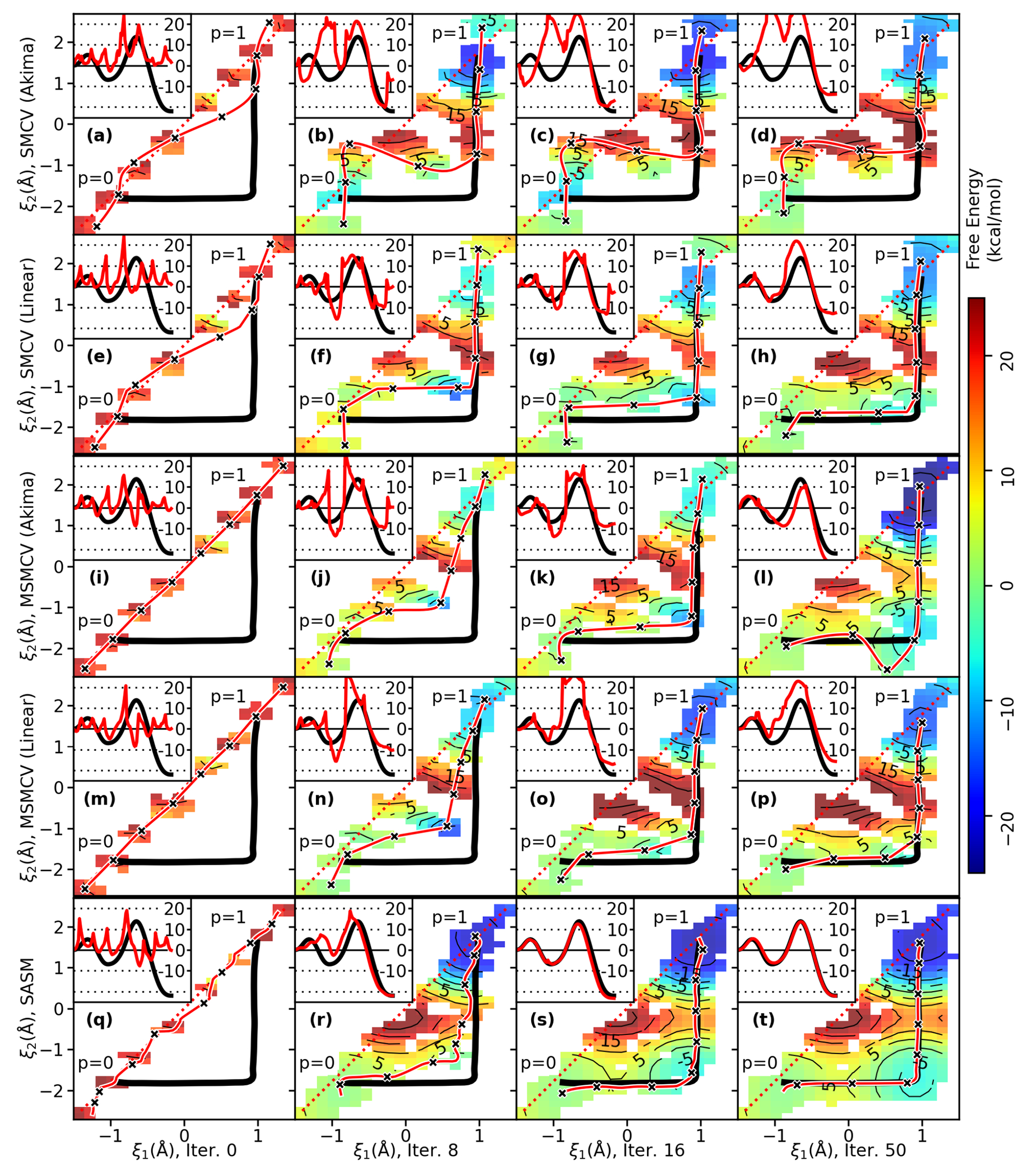
Figure 4 extends the comparisons to the 3 dimensional HHr transphosphorylation reaction profiles. The dashed line is the concerted initial guess, and the remaining lines are the paths at a series of string iterations. The reference path shown in each image is provided as a visual aid. The reference path is the SASM MFEP after 300 iterations using 32 images and 625 fs/image of sampling. In other words, it is the MFEP optimized on the 3 dimensional surface produced from the analysis of 6 ns of aggregate sampling. The string methods were performed multiple times by varying the number of images and the amount of sampling. Each column of Figure 4 successively halves the amount of sampling per string.
Figure 4:
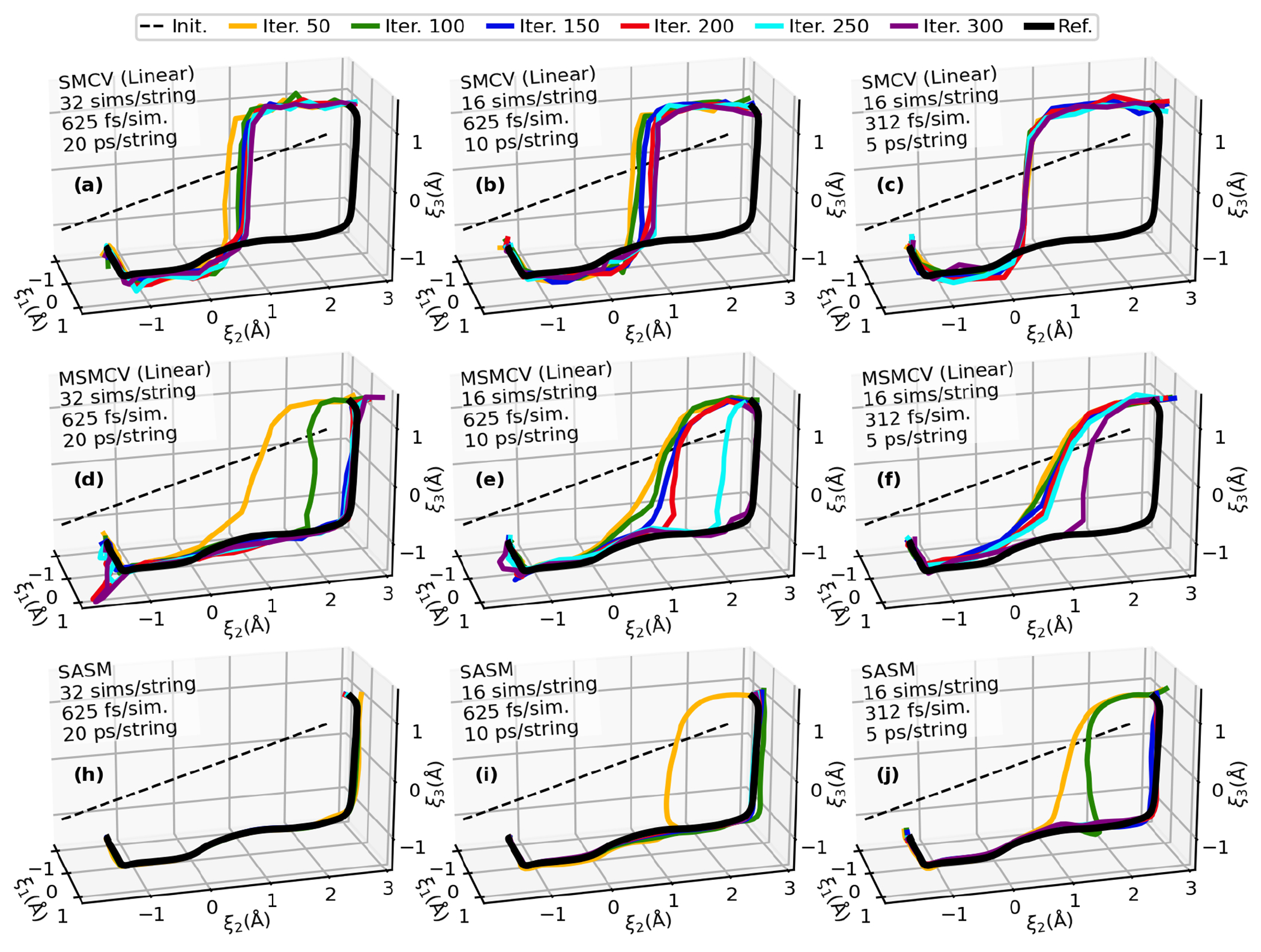
String iterations of HHr from a linear initial guess (dashed black line). Parts a-c, d-f, and h-j illustrate the convergence of the SMCV, MSMCV, and SASM, respectively, with several simulation protocols.
All of the string methods predict that the first stage of the reaction transfers a proton (the coordinate) from the O2′ to the N1 position of the G12 general base (Figure 1b). The more interesting part of the comparison is the behavior of the paths in the plane, where is the phosphoryl transfer coordinate, and measures the proton transfer between the O5′ and the G8 general acid. The SMCV fails to locate the MFEP after 300 iterations, although it is possible that it may find the MFEP if iterated further.
The MSMCV locates the MFEP, but it requires many iterations. The MSMCV requires 150 iterations to locate the MFEP when performed with 32 images and sampled for 625 fs/image (Figure 4d). This corresponds to 3 ns of aggregate sampling. When the number of images is reduced to 16 (Figure 4e), the amount of sampling per iteration is reduced, but the MSMCV now requires 300 iterations (3 ns of aggregate sampling) to locate the MFEP. Further reduction in the amount of sampling requires more than 300 MSMCV iterations (Figure 4f). Notice that the progress of the MSMCV in Figures 4e–f does not significantly change from iterations 50 to 150, which would likely cause one to incorrectly believe that the path has converged. In fact, previous application of the MSMCV to the HHr reaction incorrectly concluded that the mechanism was concerted because of this behavior,49 whereas the extended iterations presented in Figure 4 suggest that the MFEP is stepwise. The fundamental reason why MSMCV progress stalls is because the free energy gradient in the directions perpendicular to the path are quite small (Figure 5). The qualitative similarity between the MSMCV path at iteration 50 to the paths produced by SMCV is suggestive that the SMCV fails for a similar reason.
Figure 5:
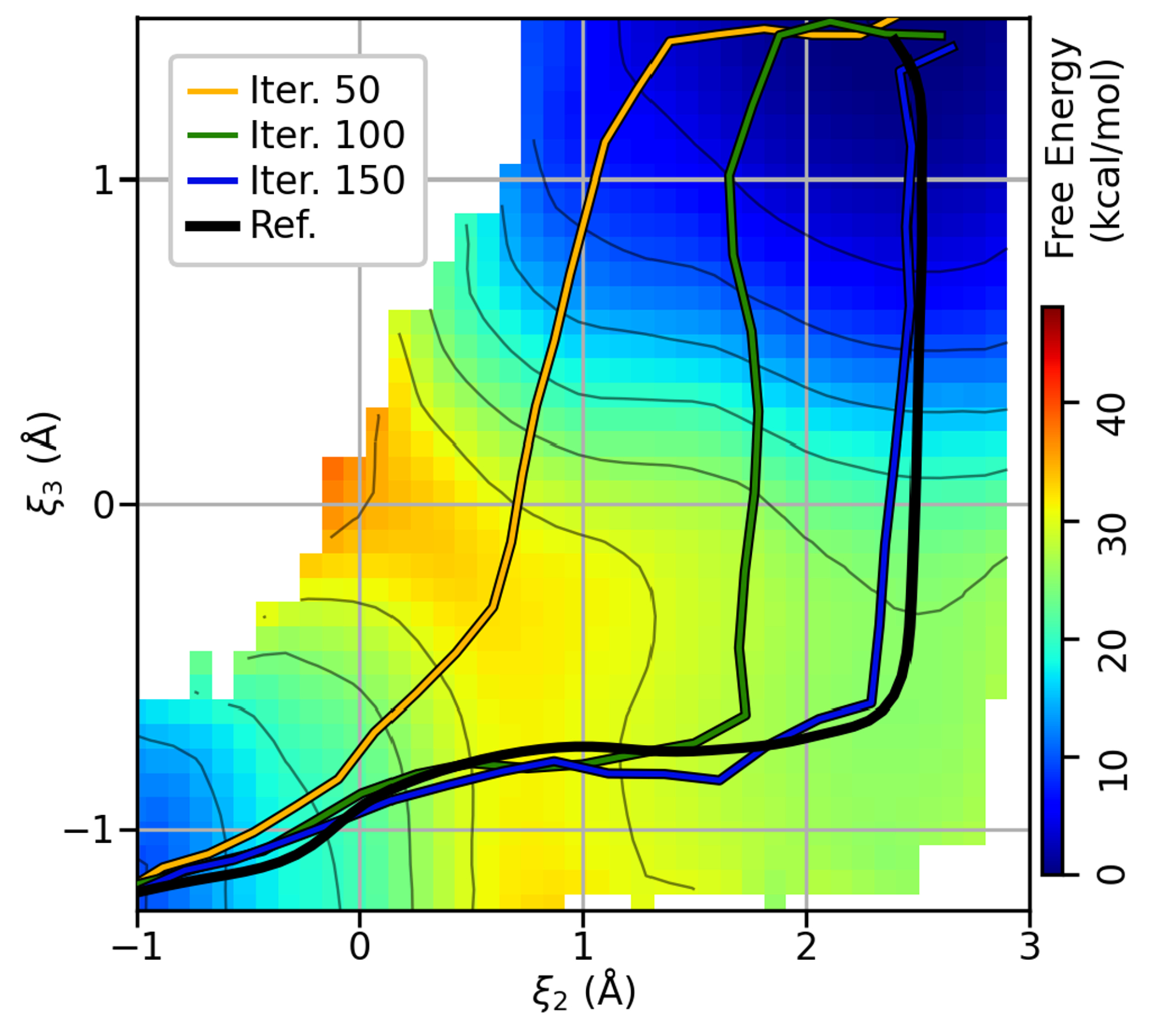
Two dimensional projection of the HHr free energy surface defined by the plane. The colored lines are the MSMCV paths at iterations 50, 100, and 150, and the black line is the SASM reference curve after 300 iterations, as shown in Figure 4d. The colored areas are the free energy values calculated from the aggregate sampling produced from 300 MSMCV and 300 SASM iterations (12 ns of sampling).
In this application, the SASM requires 3 times fewer iterations than MSMCV to reach convergence when using the same amount of sampling. Only 50 SASM iterations are required to converge the path using 32 images (Figure 4h) in comparison to 150 MSMCV iterations. When the number of images is reduced to 16 (Figure 4i), convergence is reached after 100 SASM iterations in comparison to 300 MSMCV iterations. The SASM requires fewer iterations because the synthetic string optimizations performed within the SASM can evolve the path to the fringes of the aggregate sampling, and the exploration steps increase the range of the free energy surface that can be used.
3.3. B-DNA G·T Wobble Tautomer Reaction
Rare tautomeric forms of nucleobases can cause Watson-Crick-like (WC-like) mispairs in DNA, and in turn lead to disease.117 In the WC model, nucleobase pairs are in their “keto” form,118 rather then “imino” or “enol” form. Recently, tautomerization has been reported for a G-T wobble pair () in B-DNA detected by NMR97,119,120 and subsequently studied computationally.121 This tautomerization reaction can be described by 5 reaction coordinates (Figure 1b).
A pathway in 5D cannot be visualized in the same way as the 2D and 3D systems, hence Figure 6a illustrates the convergence of the MFEP for the B-DNA tautomer reaction by calculating the root mean square deviation (RMSD) between the current estimate of the path and the initial guess using the 5 reaction coordinates. The SASM RMSD values plateau at 50 iterations, whereas the MSMCV requires 150 iterations to reach a similar RMSD. Although both methods seek to locate the nearest MFEP, they use different representations of the path, so one would not expect the RMSD values to exactly agree. Specifically, the MSMCV path is a piecewise linear spline constructed from 32 images, whereas the SASM path is an Akima spline constructed from 100 synthetic images. After 150 iterations, the SASM and MSMCV paths fluctuate about the MFEP; however, the fluctuations in the SASM RMSD values are significantly dampened because the additional sampling introduced by each iteration represents a smaller percentage of the aggregate. Figure 6b shows the initial and final profiles of the and reaction coordinates. The other 3 reaction coordinates are excluded from the figure to improve legibility. The initial path directly transfers the proton from N3 to the O4 position. The optimized paths instead transfer the proton from the N3 to O6 while shifting the hydrogen bond pattern of the G:T basepair. This is followed by the transfer of the proton from O6 to the O4 position. The SASM and MSMCV produce very similar paths after 150 iterations. In summary, this application shows that the SASM can be extended to 5 dimensions and it can converge the path in fewer iterations than the MSMCV.
Figure 6:
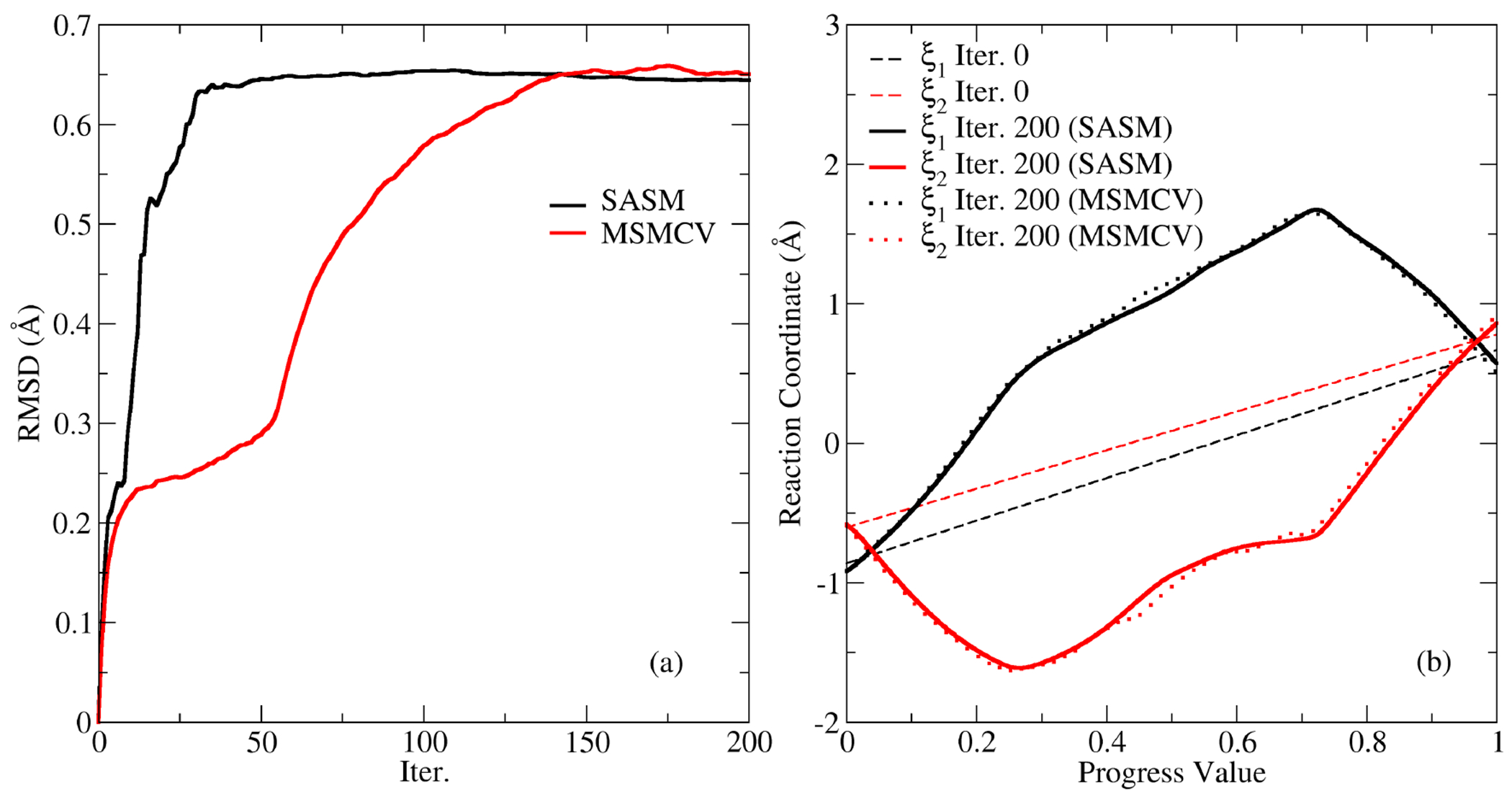
Convergence of the path describing the tautomeric reaction in B-DNA. (a) The root mean square deviation of the 5 reaction coordinates relative to the concerted (linear) initial guess. (b) The and reaction coordinates along the initial and final pathways produced by the MSMCV and SASM. These two coordinates describe the proton transfer between N3-O6 and O6-O4, respectively.
3.4. Computational Cost
Table 1 compares the CPU resources needed to perform the string methods on the HHr system with 32 images and 625 fs/image of sampling and the B-DNA system with 32 images and 1 ps/image of sampling. The measurements were performed on a single core of an Intel Xeon E5-2630 v3 processor, and the software was compiled with GCC 9.2.1. The timings can be decomposed into two components: the resources used to perform the QM/MM simulations , and the resources used to perform the evolution step .
Table 1:
The number of CPU days required to perform MSMCV and SASM on the HHr and B-DNA systems for the specified number of iterations. Iteration 0 is the simulation and analysis of the initial path. Bold entries denote converged paths.
| HHr |
B-DNA |
|||||
|---|---|---|---|---|---|---|
| Iter. | ||||||
| 0 | 0.51 | 0.51 | 1.00 | 0.19 | 0.19 | 1.00 |
| 10 | 5.56 | 5.56 | 1.00 | 2.07 | 2.08 | 1.00 |
| 25 | 13.14 | 13.16 | 1.00 | 4.89 | 4.96 | 1.01 |
| 50 | 25.77 | 25.96 | 1.01 | 9.60 | 10.07 | 1.05 |
| 100 | 51.03 | 52.48 | 1.03 | 19.01 | 22.57 | 1.19 |
| 150 | 76.30 | 81.12 | 1.06 | 28.42 | 40.20 | 1.41 |
| (20) |
The MSMCV times only include the resources used to perform the QM/MM simulations; the string evolution step (eq. 10) requires a negligible amount of effort, . The cost of performing MSMCV for the HHr and B-DNA systems are given by eqs. 21 and 22, respectively.
| (21) |
| (22) |
The SASM timings also include the cost of the evolution step, which is further decomposed into the resources used to solve the MBAR/UWHAM equations, , and the cost of performing an optimization on the resulting free energy surface, .
| (23) |
The solution of the MBAR/UWHAM equations formally scales , where is the number of samples to be reweighted and is the number of states. The dimensionality does not vary with string iteration, and and are both proportional to the number of iterations, leading to , where is coefficient fit to the observed times. This coefficient is and for the HHr and B-DNA systems, respectively. The quadratic dependence of means that the aggregate cost for performing string iterations scales cubically. The cost of performing the optimization formally scales , where is the order of the Cardinal B-spline, is the number of synthetic iterations, and is the number of synthetic images used to describe the path. These quantities are independent of string iteration, so , where is and for the HHr and B-DNA systems, respectively.
The timings listed in Table 1 suggest that the SASM increases the computational cost by 1%-5% relative to the MSMCV for the first 50 iterations. This small increase is reflected in the high computational cost of performing QM/MM sampling. Although the SASM is more expensive, it converges in fewer iterations. The SASM reduces the resources needed to converge the path by factors of 2.9 and 2.8 for the HHr and B-DNA systems, respectively. The SASM becomes increasingly expensive with respect to the number of iterations because the MBAR/UWHAM equations are solved using the aggregate sampling. To prevent the method from becoming too costly at high iterations, one could limit the analysis to the samples produced from the most recent 50 iterations, for example.
Figure 7 uses the first 50 SASM iterations of the B-DNA system to illustrate the cost of and as the number of reaction coordinates is varied. Although the sampling was performed with 5 reaction coordinates, we can measure and by ignoring 1-or-more of the reaction coordinates during the analysis. As previously discussed, the solution of the MBAR/UWHAM equations has a linear dependence on , and B-spline evaluations of the free energy surface has an exponential dependence on . The dashed lines are linear and exponential fits to the observed times. Figure 7 demonstrates that the SASM quickly becomes impractical when using more than 6 reaction coordinates due to high cost of evaluating the free energy of a high-dimensional surface. Another aspect to consider is that each added dimension further subdivides the samples into different histogram bins. For a fixed amount of sampling, each subdivision reduces the average number of samples per occupied bin and thus increases the uncertainty of the free energy in that region. For these reasons, we do not view the SASM as a replacement for the MSMCV when a large number of reaction coordinates is needed. Instead, the SASM is a complimentary tool specifically tailored to accelerate the convergence of low-dimensional pathways frequently encountered in QM/MM applications. In these situations, the added expense of generating free energy surfaces and optimizing paths from the available sampling is worthwhile to reduce the number of QM/MM evaluations.
Figure 7:
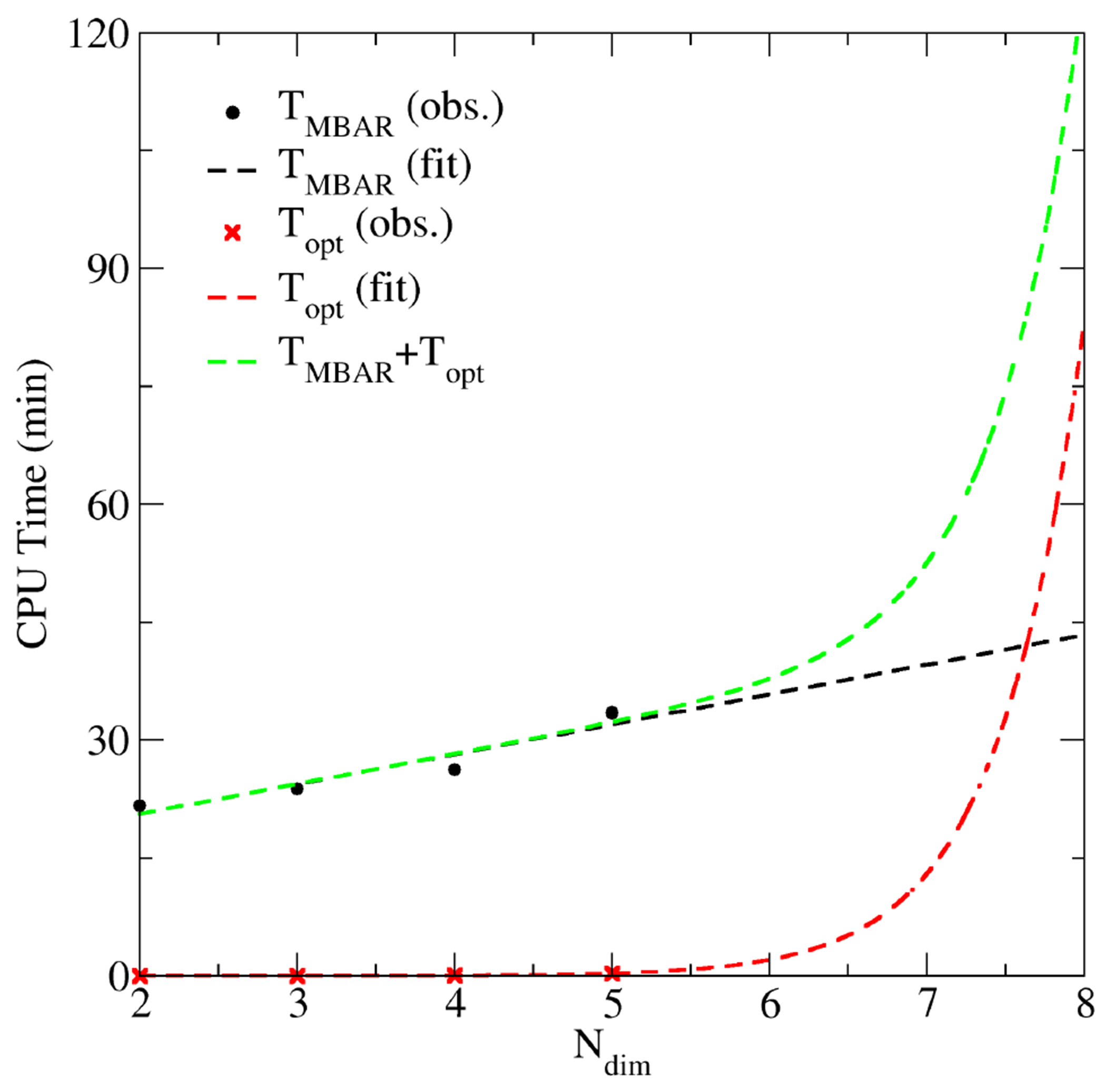
CPU time required to perform MBAR analysis and path optimization on the resulting free energy surface. The observed times were measured using the B-DNA sampling at iteration 50. The black and red dashed lines are linear and exponential fits to and , respectively.
The bond forming and breaking events of many biological mechanisms can be described with 6-or-fewer dimensions; however, this limitation may become problematic when the chemical events are coupled with conformational changes. As a specific example, a previous investigation of nucleobase tautomerization reactions used 13 interatomic distances to describe the change in hydrogen bond patterns.121 A compromise solution may be to explicitly model the bond forming and breaking coordinates with distances (or distance differences) and describe the conformational changes with path collective variables28,43 or other strategies developed to reduce the dimensionality.122–128 Alternatively, the SASM approach could greatly benefit from new methods that are exploring the use of deep neural networks to efficiently represent high-dimensional free energy surfaces.129,130
The reader may question if there are ideas introduced in the SASM that can be directly used to improve the convergence of the SMCV and MSMCV methods when a high-dimensional free energy surface is too expensive to evaluate. Unfortunately, if the free energy surface is not available, then the synthetic optimizations (eq. 11) are clearly not possible. Furthermore, the SASM progress value shifting (eq. 14) and exploration (eq. 16) modifications rely on the fact that the simulated images are not responsible for describing the path, which is not the situation when using the SMCV or MSMCV methods. Nevertheless, the SASM approach is an enabling technology that allows one to explore new strategies that are not readily possible within the SMCV and MSMCV frameworks, as described below.
The reaction coordinates describing the chemical events are often assigned from chemical intuition, and one typically performs the string method several times starting from different initial guess pathways to compare a limited number of plausible mechanistic scenarios; for example, the associative versus dissociative mechanisms of phosphoryl transfer reactions. From a given initial guess, the SASM seeks to find the nearest MFEP. It is unlikely that that the SASM will discover an alternate pathway unless it was separated by a small barrier that could be leapfrogged by the exploration stage. We have investigated the idea of using the SASM to simultaneously propagate multiple strings, each starting from a different initial guess. Each image from every string is sampled, the sampling is aggregated to form a single free energy surface, and the MFEP of each string is obtained from independent synthetic optimizations on the unified surface. In other words, the SASM is performed for each string, but their progress is synchronized at each iteration to form a single, global view of the free energy surface. The present work did not elaborate on this strategy because we remain unconvinced that it offers a meaningful computational advantage in the few test cases we have performed, which involved pathways that did not significantly overlap with each other in areas other than the reactant and product states. In these situations, it is sufficient to independently converge each string and aggregate the sampling in a post-processing step. Furthermore, we note that the SASM formally provides the capability to sample with an inexpensive reference semiempirical Hamiltonian while propagating the string with a high-level target Hamiltonian by using the weighted thermodynamic perturbation method to construct the free energy surface.71,131,132 We suspect, however, that a better strategy would be to converge the path with the reference potential, perform production sampling on the final path, and reweight the production sampling to estimate the target free energy surface only in the immediate vicinity of the MFEP.
4. Conclusions
We applied the SMCV, MSMCV and SASM methods to QM/MM sampling of the MTR1, HHr, and B-DNA G·T mispair systems. These applications served to compare the behavior and performance of the string methods using 2, 3, and 5 reaction coordinates. The SASM is a new method developed in this work that is robust and has performance advantages for systems up to approximately 6-dimensions . Rather than propagating the path from the sampling produced by the most recent set of images, the SASM uses the aggregate sampling from all string iterations. The sampling is used to construct the current best-estimate of a multidimensional free energy surface, and a MFEP is optimized on the surface. Consequently, the simulated images are no longer responsible for describing the parametric form of the path; their sole responsibility is to improve the quality and range of the sampling used to estimate the surface. The SASM exploits this freedom by alternating between “exploration” and “refinement” steps to rapidly traverse flat regions of the free energy surface.
Overall, the SMCV, MSMCV, and SASM methods are capable of converging to the correct MFEP if the right control parameters are found. In some cases, spline artifacts can be observed with the SMCV and MSMCV when only a few images (e.g., 8) are used. The SASM is found to be more robust, and it often requires approximately 1/3 of the string iterations to converge the MFEP. Analysis of computational timings indicate that the SASM increases the computational cost per string iteration by 5% or less relative to the MSMCV, but this is more than offset by requiring fewer iterations to reach convergence. The computational cost of representing a free energy surface with more than 6 reaction coordinates quickly becomes prohibitive; therefore, the SASM is not a blanket replacement for the MSMCV. Rather, it is a valuable tool that can be used to considerably accelerate convergence in QM/MM applications using a modest number of reaction coordinates.
Supplementary Material
Acknowledgments
The authors are grateful for financial support provided by the National Institutes of Health (No. GM62248) and the National Science Foundation (CSSI Frameworks Grant No. 2209718). Computational resources were provided by the Office of Advanced Research Computing (OARC) at Rutgers, The State University of New Jersey; the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation grants #2138259, #2138286, #2138307, #2137603, and #2138296 (supercomputer Expanse at SDSC through allocation CHE190067); and the Texas Advanced Computing Center (TACC) at the University of Texas at Austin, URL: http://www.tacc.utexas.edu (supercomputer Frontera through allocation CHE20002). .
Footnotes
Supporting Information Available
Descriptions of the procedures used to smooth the control points and Cardinal B-spline evaluation of the free energy, and a comparison of MTR1 profiles generated from reduced sampling. This material is available free of charge via the Internet at http://pubs.acs.org/.
References
- (1).Giese TJ; York DM Quantum mechanical force fields for condensed phase molecular simulations. J. Phys. Condens. Matter 2017, 29, 383002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (2).Gao J; Truhlar DG Quantum Mechanical Methods for Enzyme Kinetics. Annu. Rev. Phys. Chem 2002, 53, 467–505. [DOI] [PubMed] [Google Scholar]
- (3).Garcia-Viloca M; Gao J; Karplus M; Truhlar DG How enzymes work: Analysis by modern rate theory and computer simulations. Science 2004, 303, 186–195. [DOI] [PubMed] [Google Scholar]
- (4).Giese TJ; Huang M; Chen H; York DM Recent Advances toward a General Purpose Linear-Scaling Quantum Force Field. Acc. Chem. Res 2014, 47, 2812–20. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (5).Gao J; Truhlar DG; Wang Y; Mazack MJ; Löffler P; Provorse MR; Rehak P Explicit polarization: A quantum mechanical framework for developing next generation force fields. Acc. Chem. Res 2014, 47, 2837–2845. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (6).Behler J First Principles Neural Network Potentials for Reactive Simulations of Large Molecular and Condensed Systems. Angew. Chem. Engl 2017, 56, 12828–12840. [DOI] [PubMed] [Google Scholar]
- (7).Meuwly M Machine Learning for Chemical Reactions. Chem. Rev 2021, 121, 10218–10239. [DOI] [PubMed] [Google Scholar]
- (8).Zeng J; Giese TJ; Ekesan Ş; York DM Development of Range-Corrected Deep Learning Potentials for Fast, Accurate Quantum Mechanical/Molecular Mechanical Simulations of Chemical Reactions in Solution. J. Chem. Theory Comput 2021, 17, 6993–7009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (9).Giese TJ; Zeng J; Ekesan Ş; York DM Combined QM/MM, Machine Learning Path Integral Approach to Compute Free Energy Profiles and Kinetic Isotope Effects in RNA Cleavage Reactions. J. Chem. Theory Comput 2022, 18, 4304–4317. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (10).Pan X; Yang J; Van R; Epifanovsky E; Ho J; Huang J; Pu J; Mei Y; Nam K; Shao Y Machine-Learning-Assisted Free Energy Simulation of Solution-Phase and Enzyme Reactions. J. Chem. Theory Comput 2021, 17, 5745–5758. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (11).Snyder R; Kim B; Pan X; Shao Y; Pu J Bridging semiempirical and ab initio QM/MM potentials by Gaussian process regression and its sparse variants for free energy simulation. J. Chem. Phys 2023, 159, 054107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (12).Kästner J Umbrella sampling. WIREs Comput. Mol. Sci 2011, 1, 932–942. [Google Scholar]
- (13).Torrie GM; Valleau JP Monte Carlo free energy estimates using non-Boltzmann sampling: Application to the sub-critical Lennard-Jones fluid. Chem. Phys. Lett 1974, 28, 578–581. [Google Scholar]
- (14).Torrie GM; Valleau JP Nonphysical sampling distributions in Monte Carlo free-energy estimation: Umbrella sampling. J. Comput. Phys 1977, 23, 187–199. [Google Scholar]
- (15).McDonald IR; Singer K Machine Calculation of Thermodynamic Properties of a Simple Fluid at Supercritical Temperatures. J. Chem. Phys 1967, 47, 4766–4772. [Google Scholar]
- (16).McDonald IR; Singer K Examination of the Adequacy of the 12–6 Potential for Liquid Argon by Means of Monte Carlo Calculations. J. Chem. Phys 1969, 50, 2308–2315. [Google Scholar]
- (17).Adib AB Free energy surfaces from nonequilibrium processes without work measurement. J. Chem. Phys 2006, 124, 144111. [DOI] [PubMed] [Google Scholar]
- (18).Hummer G Fast-growth thermodynamic integration: Error and efficiency analysis. J. Chem. Phys 2001, 114, 7330–7337. [Google Scholar]
- (19).Zuckerman DM; Woolf TB Theory of a Systematic Computational Error in Free Energy Differences. Phys. Rev. Lett 2002, 89, 180602. [DOI] [PubMed] [Google Scholar]
- (20).Ozer G; Valeev EF; Quirk S; Hernandez R Adaptive Steered Molecular Dynamics of the Long-Distance Unfolding of Neuropeptide Y. J. Chem. Theory Comput 2010, 6, 3026–38. [DOI] [PubMed] [Google Scholar]
- (21).Jarzynski C Nonequilibrium equality for free energy differences. Phys. Rev. Lett 1997, 78, 2690–2693. [Google Scholar]
- (22).Knight JL; Brooks CL 3rd Lambda-dynamics free energy simulation methods. J. Comput. Chem 2009, 30, 1692–1700. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (23).Kong X; Brooks CL III: λ-dynamics: A new approach to free energy calculations. J. Chem. Phys 1996, 105, 2414–2423. [Google Scholar]
- (24).Liu Z; Berne BJ Method for accelerating chain folding and mixing. J. Chem. Phys 1993, 99, 6071–6077. [Google Scholar]
- (25).Tidor B Simulated annealing on free energy surfaces by a combined molecular dynamics and Monte Carlo approach. J. Phys. Chem 1993, 97, 1069–1073. [Google Scholar]
- (26).Laio A; Parrinello M Escaping free-energy minima. Proc. Natl. Acad. Sci. USA 2002, 99, 12562–12566. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (27).White AD; Dama JF; Voth GA Designing Free Energy Surfaces That Match Experimental Data with Metadynamics. J. Chem. Theory Comput 2015, 11, 2451–2460. [DOI] [PubMed] [Google Scholar]
- (28).Branduardi D; Gervasio FL; Parrinello M From to A to B in free energy space. J. Chem. Phys 2007, 126, 054103–054112. [DOI] [PubMed] [Google Scholar]
- (29).Sugita Y; Okamoto Y Replica-exchange molecular dynamics method for protein folding. Chem. Phys. Lett 1999, 314, 141–151. [Google Scholar]
- (30).Yang L; Shao Q; Gao Y Comparison between integrated and parallel tempering methods in enhanced sampling simulations. J. Chem. Phys 2009, 130, 124111. [DOI] [PubMed] [Google Scholar]
- (31).Jónsson H; Mills G; Jacobsen KW Classical And Quantum Dynamics In Condensed Phase Simulations; World Scientific, 1998; Chapter Nudged elastic band method for finding minimum energy paths of transitions, pp 385–404. [Google Scholar]
- (32).E W; Ren W; Vanden-Eijnden E String method for the study of rare events. Phys. Rev. B 2002, 66, 052301. [DOI] [PubMed] [Google Scholar]
- (33).E W; Ren W; Vanden-Eijnden E Simplified and improved string method for computing the minimum energy paths in barrier-crossing events. J. Chem. Phys 2007, 126, 164103. [DOI] [PubMed] [Google Scholar]
- (34).Maragliano L; Fischer A; Vanden-Eijnden E; Ciccotti G String method in collective variables: minimum free energy paths and isocommittor surfaces. J. Chem. Phys 2006, 125, 024106. [DOI] [PubMed] [Google Scholar]
- (35).Ovchinnikov V; Karplus M; Vanden-Eijnden E Free energy of conformational transition paths in biomolecules: The string method and its application to myosin VI. J. Chem. Phys 2011, 134, 085103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (36).Ovchinnikov V; Karplus M Investigations of α-helix ↔ β-sheet transition pathways in a miniprotein using the finite-temperature string method. J. Chem. Phys 2014, 140, 175103–175121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (37).Vanden-Eijnden E; Venturoli M Revisiting the finite temperature string method for the calculation of reaction tubes and free energies. J. Chem. Phys 2009, 130, 194103. [DOI] [PubMed] [Google Scholar]
- (38).Rosta E; Nowotny M; Yang W; Hummer G Catalytic Mechanism of RNA Backbone Cleavage by Ribonuclease H from Quantum Mechanics/Molecular mechanics simulations. J. Am. Chem. Soc 2011, 133, 8934–8941. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (39).Khavrutskii IV; Arora K; Brooks CL 3rd, Harmonic Fourier beads method for studying rare events on rugged energy surfaces. J. Chem. Phys 2006, 125, 174108. [DOI] [PubMed] [Google Scholar]
- (40).Peters B; Heyden A; Bell AT; Chakraborty A A growing string method for determining transition states: comparison to the nudged elastic band and string methods. J. Chem. Phys 2004, 120, 7877–7886. [DOI] [PubMed] [Google Scholar]
- (41).Pan AC; Sezer D; Roux B Finding transition pathways using the string method with swarms of trajectories. J. Phys. Chem. B 2008, 112, 3432–3440. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (42).Matsunaga Y; Komuro Y; Kobayashi C; Jung J; Mori T; Sugita Y Dimensionality of Collective Variables for Describing Conformational Changes of a Multi-Domain Protein. J. Phys. Chem. Lett 2016, 7, 1446–1451. [DOI] [PubMed] [Google Scholar]
- (43).Kulshrestha A; Punnathanam SN; Ayappa KG Finite temperature string method with umbrella sampling using path collective variables: application to secondary structure change in a protein. Soft Matter 2022, 18, 7593–7603. [DOI] [PubMed] [Google Scholar]
- (44).Ensing B; Laio A; Parrinello M; Klein ML A Recipe for the Computation of the Free Energy Barrier and the Lowest Free Energy Path of Concerted Reactions. J. Phys. Chem. B 2005, 109, 6676–6687. [DOI] [PubMed] [Google Scholar]
- (45).Badaoui M; Buigues PJ; Berta D; Mandana GM; Gu H; Földes T; Dickson CJ; Hornak V; Kato M; Molteni C; Parsons S; Rosta E Combined Free-Energy Calculation and Machine Learning Methods for Understanding Ligand Unbinding Kinetics. J. Chem. Theory Comput 2022, 18, 2543–2555. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (46).Ganguly A; Thaplyal P; Rosta E; Bevilacqua PC; Hammes-Schiffer S Quantum Mechanical/Molecular Mechanical Free Energy Simulations of the Self-Cleavage Reaction in the Hepatitis Delta Virus Ribozyme. J. Am. Chem. Soc 2014, 136, 1483–1496. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (47).Zhong J; Reinhardt CR; Hammes-Schiffer S Role of Water in Proton-Coupled Electron Transfer between Tyrosine and Cysteine in Ribonucleotide Reductase. J. Am. Chem. Soc 2022, 144, 7208–7214. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (48).Zhong J; Reinhardt CR; Hammes-Schiffer S Direct Proton-Coupled Electron Transfer between Interfacial Tyrosines in Ribonucleotide Reductase. J. Am. Chem. Soc 2023, 145, 4784–4790. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (49).Giese TJ; Ekesan Ş; York DM Extension of the Variational Free Energy Profile and Multistate Bennett Acceptance Ratio Methods for High-Dimensional Potential of Mean Force Profile Analysis. J. Phys. Chem. A 2021, 125, 4216–4232. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (50).Reinhardt CR; Sayfutyarova ER; Zhong J; Hammes-Schiffer S Glutamate Mediates Proton-Coupled Electron Transfer Between Tyrosines 730 and 731 in Escherichia coli Ribonucleotide Reductase. J. Am. Chem. Soc 2021, 143, 6054–6059. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (51).Li P; Soudackov AV; Hammes-Schiffer S Fundamental Insights into Proton-Coupled Electron Transfer in Soybean Lipoxygenase from Quantum Mechanical/Molecular Mechanical Free Energy Simulations. J. Am. Chem. Soc 2018, 140, 3068–3076. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (52).Ganguly A; Boulanger E; Thiel W Importance of MM Polarization in QM/MM Studies of Enzymatic Reactions: Assessment of the QM/MM Drude Oscillator Model. J. Chem. Theory Comput 2017, 13, 2954–2961. [DOI] [PubMed] [Google Scholar]
- (53).Giese TJ; York DM FE-ToolKit: The free energy analysis toolkit. https://gitlab.com/RutgersLBSR/fe-toolkit.
- (54).Case DA; Aktulga HM; Belfon K; Cerutti DS; Cisneros GA; Cruzeiro VWD; Forouzesh N; Giese TJ; Götz AW; Gohlke H; Izadi S; Kasavajhala K; Kaymak MC; King E; Kurtzman T; Lee T-S; Li P; Liu J; Luchko T; Luo R; Manathunga M; Machado MR; Nguyen HM; O’Hearn KA; Onufriev AV; Pan F; Pantano S; Qi R; Rahnamoun A; Risheh A; Schott-Verdugo S; Shajan A; Swails J; Wang J; Wei H; Wu X; Wu Y; Zhang S; Zhao S; Zhu Q; Cheatham TE 3rd; Roe DR; Roitberg A; Simmerling C; York DM; Nagan MC; Merz KM Jr, AmberTools. J. Chem. Inf. Model 2023, 63, 6183–6191. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (55).Wojtas-Niziurski W; Meng Y; Roux B; Bernèche S Self-learning adaptive umbrella sampling method for the determination of free energy landscapes in multiple dimensions. J. Chem. Theory Comput 2013, 9, 1885–1895. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (56).Scheitl CPM; Ghaem Maghami M; Lenz A-K; Höbartner C Site-specific RNA methylation by a methyltransferase ribozyme. Nature 2020, 587, 663–667. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (57).Scheitl CPM; Mieczkowski M; Schindelin H; Höbartner C Structure and mechanism of the methyltransferase ribozyme MTR1. Nat. Chem. Biol 2022, 18, 547–555. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (58).Deng J; Wilson TJ; Wang J; Peng X; Li M; Lin X; Liao W; Lilley DMJ; Huang L Structure and mechanism of a methyltransferase ribozyme. Nat. Chem. Biol 2022, 18, 556–564. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (59).Martick M; Lee T-S; York DM; Scott WG Solvent structure and hammerhead ribozyme catalysis. Chem. Biol 2008, 15, 332–342. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (60).Hunter WN; Brown T; Kneale G; Anand NN; Rabinovich D; Kennard O The structure of guanosine-thymidine mismatches in B-DNA at 2.5-A resolution. J. Biol. Chem 1987, 262, 9962–9970. [DOI] [PubMed] [Google Scholar]
- (61).Wilson EB Jr., Decius JC; Cross PC Molecular Vibrations; Dover Publications, Inc.: New York, 1980. [Google Scholar]
- (62).Akima H A New Method of Interpolation and Smooth Curve Fitting Based on Local Procedures. J. ACM 1970, 17, 589–602. [Google Scholar]
- (63).Lee T-S; Radak BK; Pabis A; York DM A new maximum likelihood approach for free energy profile construction from molecular simulations. J. Chem. Theory Comput 2013, 9, 153–164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (64).Lee T-S; Radak BK; Huang M; Wong K-Y; York DM Roadmaps through free energy landscapes calculated using the multidimensional vFEP approach. J. Chem. Theory Comput 2014, 10, 24–34. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (65).Shirts MR; Chodera JD Statistically optimal analysis of samples from multiple equilibrium states. J. Chem. Phys 2008, 129, 124105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (66).Tan Z; Gallicchio E; Lapelosa M; Levy RM Theory of binless multi-state free energy estimation with applications to protein-ligand binding. J. Chem. Phys 2012, 136, 144102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (67).Zhang BW; Xia J; Tan Z; Levy RM A Stochastic Solution to the Unbinned WHAM Equations. J. Phys. Chem. Lett 2015, 6, 3834–3840. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (68).Milovanović GV; Udovičić Z Calculation of coefficients of a cardinal B-spline. Applied Mathematics Letters 2010, 23, 1346–1350. [Google Scholar]
- (69).Hardy RL Multiquadric equations of topography and other irregular surfaces. J. Geophys. Res 1971, 76, 1905–1915. [Google Scholar]
- (70).Fornberg B; Wright G Stable computation of multiquadric interpolants for all values of the shape parameter. Comput. Math. with Appl 2004, 48, 853–867. [Google Scholar]
- (71).Li P; Jia X; Pan X; Shao Y; Mei Y Accelerated Computation of Free Energy Profile at ab Initio Quantum Mechanical/Molecular Mechanics Accuracy via a Semi-Empirical Reference Potential. I. Weighted Thermodynamics Perturbation. J. Chem. Theory Comput 2018, 14, 5583–5596. [DOI] [PubMed] [Google Scholar]
- (72).Zhang Z; Liu X; Chen Z; Zheng H; Yan K; Liu J A unified thermostat scheme for efficient configurational sampling for classical/quantum canonical ensembles via molecular dynamics. J. Chem. Phys 2017, 147, 034109. [DOI] [PubMed] [Google Scholar]
- (73).Zhang Z; Liu X; Yan K; Tuckerman ME; Liu J Unified Efficient Thermostat Scheme for the Canonical Ensemble with Holonomic or Isokinetic Constraints via Molecular Dynamics. J. Phys. Chem. A 2019, 123, 6056–6079. [DOI] [PubMed] [Google Scholar]
- (74).Ryckaert JP; Ciccotti G; Berendsen HJC Numerical Integration of the Cartesian Equations of Motion of a System with Constraints: Molecular Dynamics of n-Alkanes. J. Comput. Phys 1977, 23, 327–341. [Google Scholar]
- (75).Warshel A; Levitt M Theoretical studies of enzymic reactions: Dielectric, electrostatic and steric stabilization of the carbonium ion in the reaction of lysozyme. J. Mol. Biol 1976, 103, 227–249. [DOI] [PubMed] [Google Scholar]
- (76).Singh UC; Kollman PA A combined ab initio quantum mechanical and molecular mechanical method for carrying out simulations on complex molecular systems: Applications to the CH3Cl+Cl− exchange reaction and gas phase protonation of polyethers. J. Comput. Chem 1986, 7, 718–730. [Google Scholar]
- (77).Essmann U; Perera L; Berkowitz ML; Darden T; Lee H; Pedersen LG A smooth particle mesh Ewald method. J. Chem. Phys 1995, 103, 8577–8593. [Google Scholar]
- (78).Darden T; York D; Pedersen L Particle mesh Ewald: An N log (N) method for Ewald sums in large systems. J. Chem. Phys 1993, 98, 10089–10092. [Google Scholar]
- (79).Petersen HG Accuracy and efficiency of the particle mesh Ewald method. J. Chem. Phys 1995, 103, 3668–3679. [Google Scholar]
- (80).Nam K; Gao J; York DM An efficient linear-scaling Ewald method for long-range electrostatic interactions in combined QM/MM calculations. J. Chem. Theory Comput 2005, 1, 2–13. [DOI] [PubMed] [Google Scholar]
- (81).Walker RC; Crowley MF; Case DA The implementation of a fast and accurate QM/MM potential method in Amber. J. Comput. Chem 2008, 29, 1019–1031. [DOI] [PubMed] [Google Scholar]
- (82).Figueirido F; Del Buono GS; Levy RM On finite-size effects in computer simulations using the Ewald potential. J. Chem. Phys 1995, 103, 6133–6142. [Google Scholar]
- (83).de Leeuw SW; Perram JW; Smith ER Simulation of electrostatic systems in periodic boundary conditions. I. Lattice sums and dielectric constants. Proc. R. Soc. London, Ser. A 1980, 373, 27–56. [Google Scholar]
- (84).Giese TJ; York DM A GPU-Accelerated Parameter Interpolation Thermodynamic Integration Free Energy Method. J. Chem. Theory Comput 2018, 14, 1564–1582. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (85).Zgarbová M; Otyepka M; Šponer J; Mládek A; Banáš P; Cheatham TE III; Jurečka P Refinement of the Cornell et al. nucleic acids force field based on reference quantum chemical calculations of glycosidic torsion profiles. J. Chem. Theory Comput 2011, 7, 2886–2902. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (86).Joung IS; Cheatham TE III Determination of alkali and halide monovalent ion parameters for use in explicitly solvated biomolecular simulations. J. Phys. Chem. B 2008, 112, 9020–9041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (87).McCarthy E; Ekesan Ş; Giese TJ; Wilson TJ; Deng J; Huang L; Lilley DMJ; York DM Catalytic mechanism and pH dependence of a methyltransferase ribozyme (MTR1) from computational enzymology. Nucleic Acids Res. 2023, 51, 4508–4518. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (88).Berendsen HJC; Postma JPM; van Gunsteren WF; Dinola A; Haak JR Molecular dynamics with coupling to an external bath. J. Chem. Phys 1984, 81, 3684–3690. [Google Scholar]
- (89).Loncharich RJ; Brooks BR; Pastor RW Langevin dynamics of peptides: the frictional dependence of isomerization rates of N-acetylalanyl-N’-methylamide. Biopolymers 1992, 32, 523–535. [DOI] [PubMed] [Google Scholar]
- (90).Gaus M; Cui Q; Elstner M DFTB3: Extension of the seld-consistent-charge densityfunctional tight-binding method (SCC-DFTB). J. Chem. Theory Comput 2011, 7, 931–948. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (91).Li P; Roberts BP; Chakravorty DK; Merz KM Jr.. Rational design of Particle Mesh Ewald compatible Lennard-Jones parameters for +2 metal cations in explicit solvent. J. Chem. Theory Comput 2013, 9, 2733–2748. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (92).Panteva MT; Giambaşu GM; York DM Comparison of structural, thermodynamic, kinetic and mass transport properties of Mg2+ ion models commonly used in biomolecular simulations. J. Comput. Chem 2015, 36, 970–982. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (93).Panteva MT; Giambasu GM; York DM Force Field for Mg2+, Mn2+, Zn2+, and Cd2+ Ions that have Balanced Interactions with Nucleic Acids. J. Phys. Chem. B 2015, 119, 15460–15470. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (94).Ekesan Ş; McCarthy E; Case DA; York DM RNA Electrostatics: How Ribozymes Engineer Active Sites to Enable Catalysis. J. Phys. Chem. B 2022, 126, 5982–5990. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (95).Lopez X; York DM Parameterization of semiempirical methods to treat nucleophilic attacks to biological phosphates: AM1/d parameters for phosphorus. Theor. Chem. Acc 2003, 109, 149–159. [Google Scholar]
- (96).Zgarbova M; Sponer J; Otyepka M; Cheatham TE III; Galindo-Murillo R; Jurecka P Refinement of the sugar-phosphate backbone torsion beta for AMBER Force Fields improves the description of Z- and B-DNA. J. Chem. Theory Comput 2015, 11, 5723–5736. [DOI] [PubMed] [Google Scholar]
- (97).Kimsey IJ; Szymanski ES; Zahurancik WJ; Shakya A; Xue Y; Chu C-C; Sathyamoorthy BJ; Suo Z; Al-Hashimi HM Dynamic basis for dG.dT misincorporation via tautomerization and ionization. Nature 2018, 554, 195–201. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (98).Kruger K; Grabowski P; Zaug A; Sands J; Gottschling D; Cech T Self-splicing RNA: autoexcision and autocyclisation of the ribosomal RNA intervening sequence of Tetrahymena. Cell 1982, 31, 147–157. [DOI] [PubMed] [Google Scholar]
- (99).Gilbert W The RNA World. Nature 1986, 319, 618. [Google Scholar]
- (100).Deng J; Shi Y; Peng X; He Y; Chen X; Li M; Lin X; Liao W; Huang Y; Jiang T; Lilley DMJ; Miao Z; Huang L Ribocentre: a database of ribozymes. Nucleic Acids Res. 2023, 51, D262–D268. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (101).Wilson TJ; Lilley DMJ The potential versatility of RNA catalysis. Wiley Interdiscip. Rev. RNA 2021, 12, 1651. [DOI] [PubMed] [Google Scholar]
- (102).Scott WG Biophysical and biochemical investigations of RNA catalysis in the hammerhead ribozyme. Q. Rev. Biophys 1999, 32, 241–294. [DOI] [PubMed] [Google Scholar]
- (103).Martick M; Scott WG Tertiary contacts distant from the active site prime a ribozyme for catalysis. Cell 2006, 126, 309–320. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (104).Leclerc F Hammerhead Ribozymes: True Metal or Nucleobase Catalysis? Where Is the Catalytic Power from? Molecules 2010, 15, 5389–5407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (105).Blount KF; Uhlenbeck OC The Structure-Function Dilemma of the Hammerhead Ribozyme. Annu. Rev. Biophys. Biomol. Struct 2005, 34, 415–440. [DOI] [PubMed] [Google Scholar]
- (106).Nelson JA; Uhlenbeck OC Hammerhead redux: does the new structure fit the old biochemical data? RNA 2008, 14, 605–615. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (107).Thomas JM; Perrin DM Probing general acid catalysis in the hammerhead ribozyme. J Am Chem Soc 2009, 131, 1135–1143. [DOI] [PubMed] [Google Scholar]
- (108).Ward WL; Plakos K; DeRose VJ Nucleic acid catalysis: metals, nucleobases, and other cofactors. Chem. Rev 2014, 114, 4318–4342. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (109).Lee T-S; Silva-Lopez C; Martick M; Scott WG; York DM Insight into the role of Mg2+ in hammerhead ribozyme catalysis from x-ray crystallography and molecular dynamics simulation. J. Chem. Theory Comput 2007, 3, 325–327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (110).Lee T-S; Silva Lopez C; Giambaşu GM; Martick M; Scott WG; York DM Role of Mg2+ in hammerhead ribozyme catalysis from molecular simulation. J. Am. Chem. Soc 2008, 130, 3053–3064. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (111).Lee T-S; Giambaşu GM; Sosa CP; Martick M; Scott WG; York DM Threshold Occupancy and Specific Cation Binding Modes in the Hammerhead Ribozyme Active Site are Required for Active Conformation. J. Mol. Biol 2009, 388, 195–206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (112).Lee T-S; York DM Computational mutagenesis studies of hammerhead ribozyme catalysis. J. Am. Chem. Soc 2010, 132, 13505–13518. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (113).Wong K-Y; Lee T-S; York DM Active participation of the Mg2+ ion in the reaction coordinate of RNA self-cleavage catalyzed by the hammerhead ribozyme. J. Chem. Theory Comput 2011, 7, 1–3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (114).Chen H; Giese TJ; Golden BL; York DM Divalent Metal Ion Activation of a Guanine General Base in the Hammerhead Ribozyme: Insights from Molecular Simulations. Biochemistry 2017, 56, 2985–2994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (115).Ganguly A; Weissman BP; Piccirilli JA; York DM Evidence for a Catalytic Strategy to Promote Nucleophile Activation in Metal-Dependent RNA-Cleaving Ribozymes and 8-17 DNAzyme. ACS Catal. 2019, 9, 10612–10617. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (116).Gaines CS; Piccirilli JA; York DM The L-platform/L-scaffold framework: a blueprint for RNA-cleaving nucleic acid enzyme design. RNA 2020, 26, 111–125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (117).Mendiratta G; Ke E; Aziz M; Liarakos D; Tong M; Stites EC Cancer gene mutation frequencies for the U.S. population. Nat. Commun 2021, 12, 5961. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (118).Watson JD; Crick FHC Molecular structure of nucleic acids. Nature 1953, 171, 737–738. [DOI] [PubMed] [Google Scholar]
- (119).Kimsey IJ; Petzold K; Sathyamoorthy B; Stein ZW; Al-Hashimi HM Visualizing transient Watson-Crick-like mispairs in DNA and RNA duplexes. Nature 2015, 519, 315–320. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (120).Szymanski ES; Kimsey IJ; Al-Hashimi HM Direct NMR Evidence that Transient Tautomeric and Anionic States in dG·dT Form Watson–Crick-like Base Pairs. J. Am. Chem. Soc 2017, 139, 4326–4329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (121).Li P; Rangadurai A; Al-Hashimi HM; Hammes-Schiffer S Environmental Effects on Guanine-Thymine Mispair Tautomerization Explored with Quantum Mechanical/Molecular Mechanical Free Energy Simulations. J. Am. Chem. Soc 2020, 142, 11183–11191. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (122).Ceriotti M; Tribello GA; Parrinello M Simplifying the representation of complex free-energy landscapes using sketch-map. Proc. Natl. Acad. Sci. USA 2011, 108, 13023–13028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (123).Ferguson AL; Panagiotopoulos AZ; Debenedetti PG; Kevrekidis IG Integrating diffusion maps with umbrella sampling: Application to alanine dipeptide. J. Chem. Phys 2011, 134, 135103. [DOI] [PubMed] [Google Scholar]
- (124).Noé F; Clementi C Kinetic Distance and Kinetic Maps from Molecular Dynamics Simulation. J. Chem. Theory Comput 2015, 11, 5002–5011. [DOI] [PubMed] [Google Scholar]
- (125).Tiwary P; Berne BJ Spectral gap optimization of order parameters for sampling complex molecular systems. Proc. Natl. Acad. Sci. USA 2016, 113, 2839–2844. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (126).Das P; Moll M; Stamati H; Kavraki LE; Clementi C Low-dimensional, free-energy landscapes of protein-folding reactions by nonlinear dimensionality reduction. Proc. Natl. Acad. Sci. USA 2006, 103, 9885–9890. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (127).Mendels D; Piccini G; Parrinello M Collective Variables from Local Fluctuations. J. Phys. Chem. Lett 2018, 9, 2776–2781. [DOI] [PubMed] [Google Scholar]
- (128).Rohrdanz MA; Zheng W; Maggioni M; Clementi C Determination of reaction coordinates via locally scaled diffusion map. J. Chem. Phys 2011, 134, 124116. [DOI] [PubMed] [Google Scholar]
- (129).Zhang L; Wang H; E W Reinforced dynamics for enhanced sampling in large atomic and molecular systems. J. Chem. Phys 2018, 148, 124113. [DOI] [PubMed] [Google Scholar]
- (130).Schneider E; Dai L; Topper RQ; Drechsel-Grau C; Tuckerman ME Stochastic Neural Network Approach for Learning High-Dimensional Free Energy Surfaces. Phys. Rev. Lett 2017, 119, 150601. [DOI] [PubMed] [Google Scholar]
- (131).Giese TJ; Zeng J; York DM Multireference Generalization of the Weighted Thermodynamic Perturbation Method. J. Phys. Chem. A 2022, 126, 8519–8533. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (132).Wang J-N; Xue Y; Li P; Pan X; Wang M; Shao Y; Mo Y; Mei Y Perspective: Reference-Potential Methods for the Study of Thermodynamic Properties in Chemical Processes: Theory, Applications, and Pitfalls. J. Phys. Chem. Lett 2023, 14, 4866–4875. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.