

Abstract
Background
As global populations age and become susceptible to neurodegenerative illnesses, new therapies for Alzheimer disease (AD) are urgently needed. Existing data resources for drug discovery and repurposing fail to capture relationships central to the disease’s etiology and response to drugs.
Objective
We designed the Alzheimer’s Knowledge Base (AlzKB) to alleviate this need by providing a comprehensive knowledge representation of AD etiology and candidate therapeutics.
Methods
We designed the AlzKB as a large, heterogeneous graph knowledge base assembled using 22 diverse external data sources describing biological and pharmaceutical entities at different levels of organization (eg, chemicals, genes, anatomy, and diseases). AlzKB uses a Web Ontology Language 2 ontology to enforce semantic consistency and allow for ontological inference. We provide a public version of AlzKB and allow users to run and modify local versions of the knowledge base.
Results
AlzKB is freely available on the web and currently contains 118,902 entities with 1,309,527 relationships between those entities. To demonstrate its value, we used graph data science and machine learning to (1) propose new therapeutic targets based on similarities of AD to Parkinson disease and (2) repurpose existing drugs that may treat AD. For each use case, AlzKB recovers known therapeutic associations while proposing biologically plausible new ones.
Conclusions
AlzKB is a new, publicly available knowledge resource that enables researchers to discover complex translational associations for AD drug discovery. Through 2 use cases, we show that it is a valuable tool for proposing novel therapeutic hypotheses based on public biomedical knowledge.
Keywords: Alzheimer disease, knowledge graph, knowledge base, artificial intelligence, drug repurposing, drug discovery, open source, Alzheimer, etiology, heterogeneous graph, therapeutic targets, machine learning, therapeutic discovery
Introduction
Background
Alzheimer disease (AD) is a progressive, neurodegenerative disease affecting an estimated 6.5 million Americans aged ≥65 years and represents a significant clinical, economic, and emotional burden worldwide [1]. AD is often cited as one of the greatest health care problems of the 21st century, particularly in high-income nations with an increasing proportion of older adults. Despite its societal impact, effective pharmaceutical treatments for AD remain notoriously elusive. The US Food and Drug Administration has approved 5 drugs for the treatment of AD, 4 of which (donepezil, rivastigmine, galantamine, and memantine) only temporarily treat symptoms but do not alter the overall progression of the disease [2], whereas the fifth (aducanumab) is highly controversial in terms of evidence of effectiveness and its safety profile [3]. AD researchers have prioritized the discovery and approval of new therapies for the disease both in terms of newly discovered compounds and by repurposing drugs that are already approved to treat other (non-AD) human diseases.
AD is associated with substantial changes in pathology, including the presence of neuritic plaques associated with the amyloid-β protein, extracellular deposition of amyloid-β, and neurofibrillary tangles. Previous research has shown that these neuropathological changes begin to occur years before clinical symptoms are apparent [4,5]. Despite decades of research, why this pathology begins to develop remains largely unknown [6]. Current consensus is that AD risk is multifactorial. The most well-established risk factors include age; family history; and certain genetic factors, especially the presence of the σ4 allele of the apolipoprotein E gene, which is involved in fat metabolism and cholesterol transport. However, the exact mechanism through which these factors—including APOE-σ4 presence—cause or contribute to AD risk is unknown [7].
Of the many techniques used in AD therapeutics research, there is a wealth of computer-aided approaches that leverage recent advances in bioinformatics, epidemiology, artificial intelligence (AI), and machine learning (ML). For example, Rodriguez et al [8] developed an ML framework to assess gene lists constructed by differential gene expression data in response to drug treatment to determine whether those drugs would be candidates for repurposing in AD. Tsuji et al [9] used an autoencoder neural network to perform dimensionality reduction of a high-density protein interaction network to identify new possible drug targets and then found drugs associated with those targets. Genome-wide association studies have long been used for the identification of genes that confer AD risk, particularly for rare genes or genes with small (but statistically significant) contributions to disease risk [10].
In this paper, we describe the design and deployment of a major new knowledge resource for computational AD research—named The Alzheimer’s Knowledge Base (AlzKB) [11]—with a particular focus on drug discovery and drug repurposing. The overall structure and contents of AlzKB are summarized in Figure 1. At its core, AlzKB consists of a large, heterogeneous graph database describing entities related to AD at multiple levels of biological organization, with rich semantic relationships describing how those entities are linked to one another. To demonstrate its value, we present two data-driven analyses involving ML on AlzKB’s knowledge graph: (1) predicting Parkinson disease (PD) genes that may also be associated with AD and (2) generating and explaining drug repurposing hypotheses for treating AD, both of which replicate existing knowledge while proposing entirely novel directions for future experimental validation. AlzKB is free, open source, and publicly available [11] and consists entirely of publicly sourced knowledge integrated from 22 diverse web-based biomedical databases. We hypothesized that the relationships and entities in AlzKB contain valuable knowledge that cannot be effectively captured in existing data resources, with the additional advantage of improving the explainability of new predictions.
Figure 1.
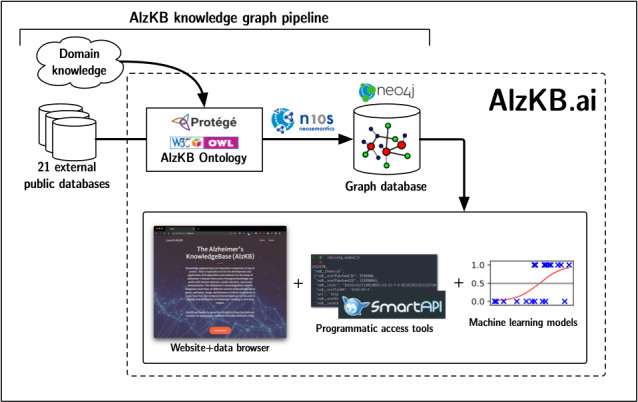
Schematic overview of the Alzheimer’s Knowledge Base (AlzKB).
Existing Graph-Based Approaches to AD Research
Due to the increased popularity and success of analyses using integrated knowledge, previous efforts have used knowledge graphs in AD research for a variety of purposes, including drug repurposing [12-14] and gene identification [15] and as general informational resources [16]. Similar to AlzKB, these bodies of work draw from a variety of sources to construct the underlying knowledge graphs, including scientific literature and formally structured biomedical databases. Some, including the Alzheimer Disease Knowledge Graph [14] and the Heterogeneous network-based data set for AD [16], have been released as publicly accessible resources similar to AlzKB. Other studies have used existing resources not specifically intended for AD research (such as the Semantic MEDLINE Database [13]) to answer questions related to AD. To our knowledge, AlzKB is the largest graph-based knowledge representation that focuses solely on AD and draws from the greatest number of source databases. For comparison, the next largest AD-specific knowledge graph that we are aware of is AD-KG, which contains 30,729 nodes and 398,544 edges (compared to AlzKB’s 118,902 nodes and 1,309,527 edges). Our emphasis on merging similar nodes or edges and cleaning the graph structure using an underlying biomedical ontology reduces the amount of noise that tends to be associated with many different node or edge types in a single graph, enabling more robust inference about relationships in AD, especially when used with emerging graph ML algorithms. Furthermore, AlzKB offers a public, web interface that allows for easy access and application to new research questions, whereas existing resources have either restricted access or are entirely unavailable for reuse. Given the challenge of identifying new or repurposed drugs for etiologically complex diseases such as AD, AlzKB represents a major step forward by improving both quantitatively and structurally on existing resources.
Methods
AlzKB Ontology
Graph databases are renowned for their flexibility in representing data that do not conform to a rigid, tabular structure, but this comes at the expense of implicitly enforcing consistency and semantic standardization [17]. To mitigate this issue, we designed a Web Ontology Language (OWL) 2 ontology—describing the types of entities relevant to AD and treatment of AD, as well as the types of relationships that link those entities—that serves as a template for nodes and edges in the knowledge graph. Ontologies (including OWL 2 ontologies) are formal representations of knowledge that are frequently used in biomedicine to computationally structure, retrieve, and make inferences about knowledge within a domain of interest [18]. Briefly, as many of the components of a graph database have a 1-to-1 correspondence with components of an OWL 2 ontology (eg, OWL 2 classes are equivalent to graph database node labels, and OWL 2 object properties are equivalent to edge types in a graph database), it is possible to populate the ontology using biomedical knowledge and translate the contents of the populated ontology into an equivalent graph database. Therefore, enforcing consistency in the ontology becomes equivalent to enforcing consistency in the graph database.
We constructed the ontology manually using the Protégé ontology editor (version 5.5.0; Stanford Center for Biomedical Informatics Research) [19] following an iterative process guided by expert domain knowledge. First, we prototyped a class hierarchy containing the types of nodes (eg, gene, disease, pathway, and drug) desired in the knowledge base. We then annotated these classes with data properties (eg, drugs can be assigned a property value corresponding to molecular weight) and object properties (relationship types that link 2 entities, such as “drug treats disease”). A thorough description of the components of OWL 2 ontologies is provided by Hitzler et al [20]. Finally, we placed restrictions on the ontology to reflect biology and clinical practice. For example, we specified restrictions stating that all pathways must contain one or more genes or that all drugs in the knowledge base must have a valid DrugBank ID. We repeated these steps several times, making revisions on previous iterations until several domain experts agreed that the semantic contents of the ontology were consistent with current AD knowledge and systems biology processes involved in AD etiology. After collecting the data sources used to populate the ontology (see the following section), we included additional data properties corresponding to identifiers in those source databases, enabling data provenance and facilitating both interoperability and validation. The final ontology structure consists of entity types involved in AD etiology (modeled as OWL 2 classes), types of semantic relationships that can link those entity types (modeled as OWL 2 object properties), and properties that can be annotated onto entities of specific types (modeled as OWL 2 data properties). Both before and after populating the ontology with individuals (see the Implementing AlzKB section), we validated its contents and structure by running FaCT++—an ontology inference engine that identifies errors by evaluating all assertions in the ontology against the ontology’s class or property hierarchy and other restrictions [21].
Collecting and Assembling Third-Party Data Sources
Using the AlzKB ontology’s class hierarchy as a starting point, we determined a set of the most important entity types to include in the first release of the knowledge base. For example, we prioritized inclusion of entities representing diseases (specifically AD and its various subtypes), genes, and drugs, among others. Similarly, we identified important relationship types (eg, “DRUG_BINDS_GENE” or “GENE_ASSOCIATED_WITH_DISEASE”) to include in the knowledge base. For each of these entity and relationship types, we identified a third-party, public data source that would serve as a collection of “ground truth knowledge” for that entity or relationship type. In the assembled knowledge base, there is roughly a 1-to-1 correspondence between a data record in the original “ground truth” data source and its corresponding entity or relationship in AlzKB, with some important exceptions. For example, we made the decision to only include neurological diseases in AlzKB rather than all diseases described in the “ground truth” data source (in this case, the Disease Ontology). We also identified instances in which properties from additional data sources could be used to augment the “ground truth” entities. For example, while DrugBank is used to specify the drugs described in AlzKB, we also used fields from Distributed Structure-Searchable Toxicity and PubChem to augment the properties annotated onto drugs (such as molecular weight, chemical fingerprint, and synonyms).
Implementing AlzKB
We populated the ontology by sequentially carrying out the following steps:
Import distinct entities from each data source corresponding to the corresponding ontology class and define those entities as ontology individuals (ie, instances of that class). For example, the drug memantine is defined as an instance of the ontology class Drug.
Populate data properties for all instances of each ontology class using data from relevant sources. For example, memantine is annotated with the Chemical Abstracts Service Registry number 19982-08-2.
Populate object properties as the semantic relationships linking pairs of entities using the appropriate data source. For example, an object property of type “DRUG_TREATS_DISEASE” links memantine to the instance of Disease named Alzheimer’s Disease.
After populating the AlzKB ontology with entities, relationships, and data properties, we serialized the ontology into the Resource Description Framework (RDF) or XML graph data format, which is compatible with modern graph database software as an input format. A complete list of the data sources used in AlzKB at the time of writing is provided in Table 1. We then populated a Neo4j graph database (version 4.4.5; Neo4j, Inc) [22] with the contents of the RDF or XML file using the neosemantics library [23], which parses the RDF data, inserting semantic triples into the graph database corresponding to each entity or relationship. Finally, we stripped the newly populated graph database of unnecessary artifacts that are components of the OWL 2 standard, leaving only nodes, relationships, and properties defined within the hierarchy. For the publicly hosted version of AlzKB, we created a web server that hosts both the static AlzKB website (containing information, documentation, and use details) and the Neo4j graph database, which is available by navigating to a subdomain [24] of the main website [11]. For reproducibility, this entire pipeline (including mappings to source databases) is provided as a single Python script available on GitHub (the most recent version) [25] or Zenodo (an archived version of the code at the time of publication) [26].
Table 1.
Third-party public data sources used in the Alzheimer’s Knowledge Base (AlzKB), which data elements were used from them, and total size of the data source (counts of entities of relevant data types only)a.
| Data source | Use in AlzKB | Size (number of entities) |
| AOP-DBb [27] | Adverse outcome pathways and chemical-gene associations | 1,207,456 |
| Bgeec [28] | Tissue-specific gene expression data; only human gene expression data were used in AlzKB | 9,093,494 |
| Disease Ontologyc [29] | Human diseases—only ADd, subtypes of AD, and related neurodegenerative diseases were included in AlzKB | 8043 |
| DisGeNET [30] | Diseases, genes, and disease-gene associations with scores representing levels of evidence; only AD and related neurodegenerative terms were used for diseases | 51,841 |
| DrugBank [31] | On-market and experimental pharmaceutical drugs | 15,550 |
| EPAe DSSToxf [32] | Chemical toxicity data—filtered in AlzKB to drugs contained in DrugBank | 1,200,059 |
| EPA ACToRg [33] | Chemical toxicity data—filtered in AlzKB to drugs contained in DrugBank | 504,871 |
| Gene Ontologyc [34,35] | Biological processes, molecular functions, and cellular components | 42,950 |
| GWASh Catalogc [36] | Gene-disease associations | 60,071 |
| Hetionet [37] | Graph modeling and entity resolution (for data sources marked with footnote indicator “c”) | 47,031 |
| Human Reference Protein Interactome Mapping Projectc [38] | Human protein-protein interactions (modeled as gene-gene interactions) | 9094 |
| LINCSi L1000c [39] | Human differential gene expression data | 7467 genes |
| NCBIj MeSHk [40] | Clinical and biomedical concepts (annotated to various node types) | Approximately 27,000 |
| NCBI Entrez Gene [41] | Human genes and gene synonyms | 62,407 |
| Pathway Interaction Databasec [42] | Pathways and gene-pathway membership | 223 |
| PharmacotherapyDBc [43] | Drug indications for human diseases | 698 |
| PubChem [44] | Chemical structures and identifiers—only chemicals in DrugBank were included in AlzKB | 115,067,800 |
| Reactome pathway databasec [45] | Pathways and gene-pathway membership | 1341 |
| SIDERc,l [46] | Drug side effects (modeled as diseases) | 5868 |
| TISSUESc [47] | Tissue-specific gene expression data | —m |
| Uberonc [48] | Human anatomical structures | 402 |
| WikiPathwaysc [49] | Pathways and gene-pathway membership | 298 |
aAs source data elements do not correspond in a 1-to-1 manner with entities in the graph (eg, entities may be merged, filtered, or used as edges rather than nodes), actual counts for entities in AlzKB stratified by source are not available. The sizes are the best available estimates at the time of publication. Table 2 and Table S1 in Multimedia Appendix 1 [50-56] provide actual node and edge type counts in AlzKB.
bAOP-DB: Adverse Outcome Pathway Database.
cThe derived data are structured in part using Hetionet.
dAD: Alzheimer disease.
eEPA: Environmental Protection Agency.
fDSSTox: Distributed Structure-Searchable Toxicity.
gACToR: Aggregated Computational Toxicology Resource.
hGWAS: genome-wide association studies.
iLINCS: Library of Integrated Network-Based Cellular Signatures.
jNCBI: National Center for Biotechnology Information.
kMeSH: Medical Subject Headings.
lSIDER: Side Effect Resource.
mCounts not applicable (TISSUES associations map to edges rather than nodes in the graph).
Validating AlzKB Using Real-World Use Cases
After building AlzKB’s knowledge graph, we designed two ML-based use cases that resemble real-world tasks for which AlzKB was originally designed: (1) proposing genetic targets for new drugs based on disease similarity and topological graph features and (2) predicting new edges in the knowledge graph linking AD to repurposed drugs via a graph completion model. These 2 use cases are intended to assess the external validity of AlzKB—for the ML models to perform well on tasks defined using real-world evaluation end points (eg, effective drugs or etiologically important genes), the informative patterns and phenomena underlying those end points need to be adequately captured in the knowledge graph.
In the first use case (identifying genetic targets via graph topology measures), we trained a random forest (RF) classifier (implemented in the scikit-learn library [Python Software Foundation] for the Python programming language) using the following topological graph features, which are computed for every node pair in the graph (regardless of whether an edge does or does not exist between them): common neighbors, total neighbors, preferential attachment, Adamic-Adar, and resource allocation [57-60]. Each feature gives a different measure of network “relatedness” for a pair of nodes, which are then used as predictive features in the RF model. For a given node pair (n1, n2), these metrics are defined as follows:
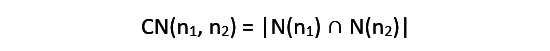 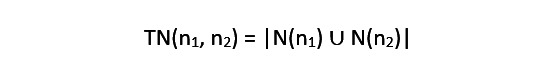 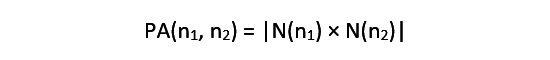 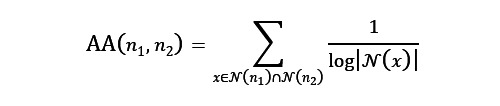 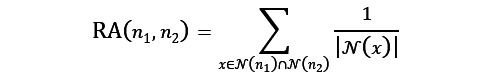
|
where N(n1) is the set of neighbor (adjacent) nodes of node i. Our training procedure for the RF model included 3-fold grid search cross-validation to optimize hyperparameters, an 80%/20% train/test split, and repeating the procedure 10 times with random sampling.
To accomplish the second use case (drug repurposing via graph completion models), we implemented and compared the performance of 5 graph completion algorithms applied to the entire AlzKB knowledge graph. These models learn low-dimensional representations of graph nodes as vector embeddings. The embeddings are then combined to propose all possible triples in the graph (source node, edge, and target node), and scores are generated to indicate the plausibility of the triple. The 5 models we evaluated are TransE, RotatE, DistMult, ComplEx, and ConvE [60].
We implemented the 5 models using PyKEEN—a Python library for knowledge graph embeddings [50]. We randomly split the data set of all triples into 80/10/10 training/validation/testing sets and used grid search to empirically set embedding dimensions to 256 and the number of epochs to 100 with early stopping allowed. All remaining hyperparameters were set to the PyKEEN defaults. We trained the models on Google Colab using a single Tesla T4 graphics processing unit and evaluated the results using the rank-based evaluation metrics hits@k (k=1, 3, and 10) and mean reciprocal rank (MRR) [61]. Ranking-based evaluation sorts the scores of triples in descending order and sets their rank as the index in the sorted list. In the case of multiple “true” triples having an equal score, we used the average of the most optimistic (best) and pessimistic (worst) ranks across the metrics. Briefly, hits@k is the ratio of true triples in the test set that have been ranked within the top k predictions of the model. Higher values indicate better performance. The MRR, also known as inverse harmonic mean rank, is the arithmetic mean of the inverse rank of the true triples. We performed evaluation on both left- and right-side predictions (ie, how well they can predict missing entities in partial triples without either the head [source] or tail [target] entities).
Ethical Considerations
No human participants were involved in this research. All data used to build and evaluate AlzKB were derived from publicly available biomedical knowledge retrieved from open access databases. None of the data included were derived from individual human participants. Similarly, AlzKB is entirely open source and publicly available and complies with the licensing terms of all 22 source databases used to build the knowledge base.
Results
Knowledge Base Description
The first release of AlzKB (version 1.0) [26] contains 118,902 distinct nodes (representing biomedical entities) and 1,309,527 relationships linking those nodes. A full summary of node and relationship types with counts, respectively, is provided in Table 2 and Table S1 in Multimedia Appendix 1. Users can interact with AlzKB in their web browser using the built-in Neo4j interface or programmatically by connecting to the graph database over the internet. We also provide instructions for installing a local copy of the graph database as well as how to build the database from its original data sources.
Table 2.
Node types and counts in the Alzheimer’s Knowledge Base listed in descending order by prevalence. Additional node types will be added over time, and counts will increase as new data sources are incorporated or existing sources are updated to newer versions.
| Node label | Total nodes, N |
| Gene | 62,407 |
| Drug | 35,063 |
| BiologicalProcess | 11,381 |
| Pathway | 4570 |
| MolecularFunction | 2884 |
| CellularComponent | 1391 |
| Symptom | 438 |
| BodyPart | 402 |
| DrugClass | 345 |
| Disease | 20 |
Proposing New Therapeutic Targets for AD
As a proof of concept, we performed an analysis to predict whether known PD genes are also linked to AD etiology. PD is a chronic, progressive neurological disorder characterized by uncontrollable movements and possible mental and behavioral changes. Similar to AD, the precise etiology of PD is not fully understood, but the disease is characterized by the death or dysfunction of basal ganglia neurons. A growing body of work has established physiological and genetic similarities between PD and AD [62], and it has been proposed that drugs targeting PD genes could potentially treat AD as well. To approach this hypothesis computationally, we defined a binary classification task to predict whether gene nodes in the AlzKB knowledge graph are or are not AD genes [63]. To assemble the data set, we considered all gene nodes adjacent to AD as positive (n=101) and all gene nodes not adjacent to AD as negative (n=62,306). The negative samples are assumed to contain a mixture of true negatives and false negatives; in link prediction tasks, the goal is to recover the false negatives. We further filtered the negative nodes to omit PD genes (n=73) and orphan gene nodes (n=43,032) and down sampled the remaining genes to 303 (ie, 3 times the number of positive samples). To evaluate the performance, we used accuracy, balanced accuracy, precision, recall, F1-score, area under the receiver operating characteristic curve, and area under the precision-recall curve, as shown in Figure 2.
Figure 2.
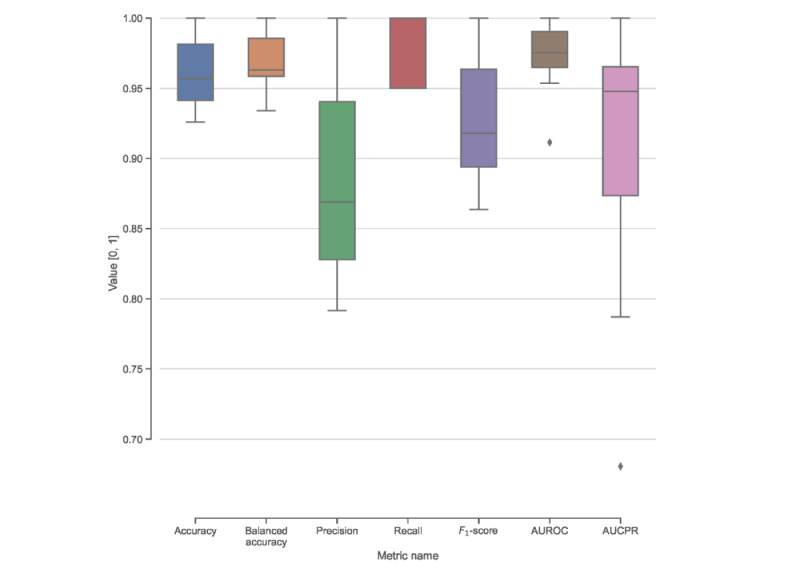
Random forest classifier performance (over 10 independent training runs) on the task of predicting whether Parkinson disease genes are also Alzheimer disease genes based on patterns of graph connectivity in the Alzheimer’s Knowledge Base’s heterogeneous knowledge graph. Across all metrics, a score of 1.00 represents the best possible performance. AUCPR: area under the precision-recall curve; AUROC: area under the receiver operating characteristic curve.
The RF model predicted gene-disease relationships with an average balanced accuracy of 96.2% (precision=0.88; recall=0.98). We applied the trained models to predict PD genes that are likely to also be AD genes. Of the 73 PD genes in AlzKB, 8 (11%; FYN, DCTN1, SNCA, SYNJ1, RSP12, ATXN2, KCNIP3, and CHRNB1; described in Table 3) were predicted to be AD genes. A total of 10% (7/73) of the genes were predicted to be AD genes in all 10 models, whereas CHRNB1 was predicted in 7 of the 10 models.
Table 3.
Parkinson disease genes predicted by a graph-augmented random forest model to also be associated with Alzheimer disease.
| Gene symbol | Gene name | Notes (from the Entrez Gene summary) |
| ATXN2 | Ataxin-2 | Modulates endocytosis, ribosomal translation, and mitochondrial function; aberrations are linked to diverse neurodegenerative diseases, diabetes, and obesity |
| CHRNB1 | Cholinergic receptor nicotinic β1 subunit | Beta subunit of muscle acetylcholine receptor involved in transmitting signals at neuromuscular junction |
| DCTN1 | Dynactin subunit 1 | Dynactin is a macromolecular complex involved in many cellular functions, including the formation of neuronal pathways |
| FYN | FYN proto-oncogene, Src tyrosine kinase family | Membrane-associated tyrosine kinase involved in control of cell growth; highly expressed in brain tissue |
| KCNIP3 | Potassium voltage-gated channel interacting protein 3 | Voltage-gated potassium channel–interacting protein that is critical to neuronal excitability |
Drug Repurposing via Graph Data Science
As a second use case, we considered the task of repurposing existing drugs—currently used to treat other diseases—based on patterns in the knowledge graph that suggest that they may also treat AD. To do this, we trained 5 state-of-the-art knowledge graph completion methods (TransE, RotatE, DistMult, ComplEx, and ConvE) [51] on AlzKB and selected the highest-performing one to predict links between drugs and AD. Additional details about the differences between these methods are provided in Multimedia Appendix 1.
The performance of the 5 different knowledge graph completion models is shown in Table 4. Among them, RotatE performed best, with the highest MRR and hits@k values. Therefore, we used RotateE to make predictions on the test set to obtain missing head entities with the template ([drug], DRUG_TREATS_DISEASE, AD). The top 10 predicted drugs are listed in Table 5 along with their current approved use and relevant clinical trial status pertaining to AD efficacy. Of the top 10 predictions, 3 (30%) have been investigated in clinical trials to treat symptoms of AD. To further explore these predictions, we generated visualizations of a minimum spanning tree linking the 10 drugs to AD in AlzKB’s knowledge graph, as shown in Figure 3. The visualization shows that the shortest paths between the drugs and AD are mediated by a small set of AD-associated genes, each of which is associated with one or more of the proposed drugs. The visualization is suggestive of interpretable biological mechanisms through which the drugs could act on AD etiology and provides hypotheses to further explore their validity.
Table 4.
Ranking-based evaluation metrics of 5 embedding-based link prediction models on the Alzheimer’s Knowledge Base knowledge graph. Metrics are derived from the likelihood of existing (known) links being predicted by the models. Higher scores indicate better performance.
| Model name | Hits@1 | Hits@3 | Hits@10 | MRRa |
| RotatE | 0.126 b | 0.220 | 0.358 | 0.202 |
| TransE | 0.046 | 0.097 | 0.198 | 0.097 |
| DistMult | 0.027 | 0.056 | 0.126 | 0.061 |
| ComplEx | 0.074 | 0.142 | 0.263 | 0.136 |
| ConvE | 0.002 | 0.005 | 0.013 | 0.006 |
aMRR: mean reciprocal rank.
bItalicized values indicate maximum scores within a given column.
Table 5.
Drug repurposing predictions made by the best-performing topological link prediction model (RotatE). Also shown are current approved indications and (if available) clinical trials investigating the efficacy of the drug for treating Alzheimer disease (AD).
| Drug name | Approved indications | AD-related clinical trials |
| Sumatriptan | Migraines and cluster headaches | —a |
| Nicotine | Nicotine withdrawal symptoms | NCT00018278 (completed) |
| Pimozide | Tourette disorder | — |
| Risperidone | Schizophrenia, bipolar mania, and psychosis | NCT00034762 (completed) |
| Flurbiprofen | Osteoarthritis and rheumatoid arthritis | — |
| Sertraline | Depressive disorder and social anxiety disorder | NCT00086138 (completed); NCT00009191 (completed) |
| Clozapine | Schizophrenia | — |
| Tamoxifen | ER+b breast cancer | — |
| Amiodarone | Recurrent hemodynamically unstable ventricular tachycardia and recurrent ventricular fibrillation | — |
| Chlorpromazine | Nausea, vomiting, preoperative anxiety, schizophrenia, bipolar disorder, and severe behavioral problems in children | — |
aNo known AD-related clinical trials for the given drug.
bER+: estrogen-receptor positive.
Figure 3.
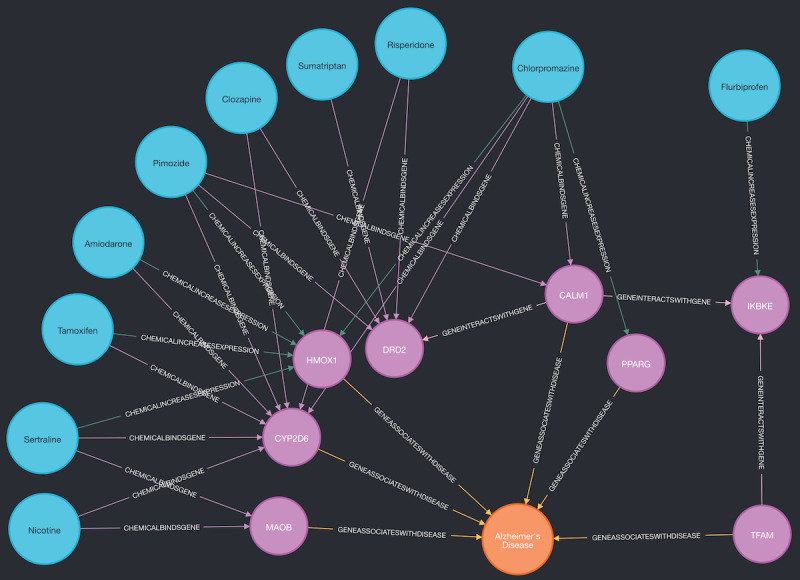
Spanning tree linking the 10 highest-scoring Alzheimer disease (AD) drug predictions (listed in Table 5) to AD. Blue nodes are drugs, pink nodes are genes, and the orange node is AD. Genes on the shortest path between a drug and AD can be considered putative mechanistic explanations for how the drug may act on AD etiology.
Discussion
Principal Findings
AlzKB is a freely available resource for the biomedical research community, with the primary goal of expanding the repertoire of therapies for AD via drug repurposing. In the previous sections, we described the current contents of AlzKB, the process of constructing it, and 2 specific data-driven use cases that illustrate how it can be applied to drug repurposing tasks. These use cases consisted of predicting the shared genetic architecture of AD and PD (potentially allowing for PD therapies to be repurposed for AD) and directly proposing drugs to repurpose for treating AD by predicting new links between drug and disease nodes in the knowledge graph. In both cases, the results are both biologically plausible and supported by quantitative metrics, yielding new hypotheses that merit experimental validation. AlzKB is a flexible resource that is not limited to these analyses, and we encourage other research teams to use it for different and complementary knowledge discovery tasks.
The Role of AlzKB in Biomedical Knowledge Discovery
AD and other neurodegenerative diseases present one of the greatest challenges in modern biomedicine. AD is by and large a disease of old age, and as improvements to health care continue to increase the overall global life expectancy, we can expect the number of people with various forms of dementia to also increase. As the etiology and pathophysiology of AD are highly multifactorial, there is likely no single “cure” for the disease. Instead, researchers and public health officials have shifted much of their focus toward finding therapies that reduce risk, slow the progression of the disease, or reverse neuronal damage. In addition, as there are various subtypes of AD with underlying mechanisms, any therapy might be effective for only some patients with AD. Therefore, an essential step for reducing global disease burden is to propose many new therapeutic agents that target various aspects of AD pathology. This is precisely the motivating use case for AlzKB. As we have demonstrated, AlzKB provides a rich representation of existing knowledge about AD and the biological context in which it acts. The 2 ML-based use cases we presented previously use real-world end points to demonstrate that the knowledge captured in AlzKB is meaningful and representative of the biological processes underlying the disease. AlzKB stands to become a major resource in the AD research community, where pattern analysis and integration with observational data can be used to propose a diverse array of new therapeutic hypotheses along with interpretable mechanistic explanations of how those therapies may act in the human body.
Building the initial release of AlzKB was a highly interdisciplinary effort involving contributions from experts in translational bioinformatics, data science, and clinical informatics as well as medical scientists. Although each of these domains was essential in delivering a knowledge base that reflects important biomedical patterns describing AD etiology and treatment, a key need during the design and implementation phases was data literacy. To support future work in this and related areas, we encourage the inclusion of informatics and data analysis techniques in all types of biomedical curricula. Beyond AlzKB, our approach for building the knowledge graph is generalizable to practically any domain and depends on (1) defining an ontology using expert knowledge that formally describes the domain of interest and (2) identifying source databases that provide the entities and relationships described in the ontology. We are directly involved in the ongoing development of other knowledge bases using this same approach, including ComptoxAI—a knowledge base that supports AI research in toxicology [64]. As both knowledge bases share many of the same “core” entities (genes, diseases, pathways, and anatomical structures), the knowledge graphs are already semantically harmonized and ready for integration in larger, cross-disciplinary biomedical knowledge applications.
Discovering Putative Therapies Through Graph Data Science
Of the PD genes predicted to also be AD genes (see the Proposing New Therapeutic Targets for AD section; Table 3), some are involved in neuronal signaling and structure, and some are known to be involved in a wide range of neurological disorders. FYN has seen recent attention and investigation into its possible link to AD due to its broad expression in brain tissue and known interactions with tau proteins [65,66]. Among the other identified genes, one (CHRNB1) is known to be involved in acetylcholine signaling [67,68], and another (KCNIP3) codes a protein that interacts with presenilin, and mutations in presenilin are causal for hereditary AD [69,70]. Some of these gene hits (ATXN2 and DCTN1) have limited or no current research directly linking them to AD but are biologically plausible. As such, they may represent novel therapeutic targets or targets for further research and investigation [71]. For example, DCTN1 encodes the dynactin-1 protein, and deficits in dynactin are connected to several neurodegenerative diseases; however, there is limited research linking this gene to AD [72,73].
Among the drug repurposing predictions (see the Drug Repurposing via Graph Data Science section; Table 5) are some agents that have previously been proposed for the treatment of AD (risperidone and sertraline) or for symptoms associated with AD (nicotine). Sumatriptan has been the subject of several studies focused on AD [74] and is connected to a strong comorbidity of migraine headaches and dementia in women [75]. Pimozide has been shown to reduce the aggregation of tau protein in mice [76] and is linked to AD in a number of unrelated in silico models [77]. The inclusion of nicotine is also noteworthy as it has seen recent interest among AD researchers and is the subject of an ongoing clinical trial to improve memory [78]. Other drugs listed in Table 5 have not yet been identified as AD treatments and represent novel repurposing candidates. Each can be considered a testable hypothesis meriting further investigation, giving credence to the increased detective power of AlzKB’s knowledge graph approach over existing AD data resources. It should be noted that this approach can only propose new indications for existing drugs and is based on existing knowledge and derived from known biological associations with those drugs. Other approaches (including emerging techniques in graph ML) could be used to propose entirely new drugs that could treat AD.
Future Directions With AlzKB
AlzKB is a growing resource, and we have plans for adding new features and data types that are in various stages of implementation. As a central hypothesis of AD pathogenesis revolves around the atypical accumulation of proteins within and around brain cells, an important step will be to adequately distinguish and differentiate genes from the proteins that those genes code for. Existing data resources available for inclusion in AlzKB largely fail to make this distinction in a way that is accepted by the scientific community, so we are currently evaluating options to use either postprocessing of existing knowledge sources or synthesis of new knowledge to achieve a good representation of genes, proteins, and functional or structural variants that are key to understanding AD.
Current ML models often do not generalize well to heterogeneous graphs such as the one that constitutes AlzKB’s knowledge graph. This is largely because traditional models cannot use the network structure and heterogeneous nature of different entity types. Several promising algorithms can be used for prediction on heterogeneous graphs—including GraphSAGE [79] and metapath2vec [80]—but most fail to scale effectively when the number of node or edge types increases. As any effective therapy must be accompanied by a mechanistic understanding of how it functions, we also need to ensure that new heterogeneous graph ML models are explainable. With this in mind, we are using AlzKB as a motivating resource for designing new, cutting-edge algorithms that produce interpretable predictions from highly heterogeneous knowledge graphs. Furthermore, the increasing popularity of large language models (LLMs; such as GPT-4) presents a wealth of opportunities for incorporating knowledge graphs such as AlzKB into diverse AI applications [81]. One application we are considering is using AlzKB to provide LLMs with formalized knowledge about AD that allows them to more effectively produce informative outputs about AD etiology. Currently, LLMs can perform poorly on technically complex or poorly understood domains due to a scarcity of relevant content in their training corpora, and augmenting their performance using domain-specific knowledge graphs is an emerging strategy for fixing that issue. As we do so, these will be released alongside AlzKB with educational resources that facilitate ease of use and adoptability by various stakeholders.
Knowledge graphs—including AlzKB—come with several important limitations that will be crucial to address in coming years. One of these is the subjective nature of determining what does and does not constitute “knowledge,” implying broad acceptance by the scientific community (as opposed to “data,” which consist of individual observations). Currently, we use expert domain knowledge and careful screening of source databases to accomplish this, but with the advent of broadly accessible generative AI tools, there may be emerging strategies that minimize sources of human bias [82]. Furthermore, new predictions made using knowledge graphs still necessitate costly and time-consuming experimental or observational follow-up studies to validate those predictions. This is due in part to the absence of negative samples for training predictive models. While the presence of an edge between 2 nodes in a knowledge graph is interpreted as a “positive sample” for model training, the absence of an edge simply means that we do not know whether a relationship does or does not exist, and therefore, it may not in fact be a negative sample. New methods, including self-supervised contrastive learning, show promise in alleviating this issue [83], but further work is needed to determine whether these generalize well to AlzKB and similar highly heterogeneous biomedical knowledge graphs. Nonetheless, these are active areas of research in the AI, informatics, and computer science communities, and in spite of them, our results are still robust enough to provide compelling evidence demonstrating AlzKB’s scientific value.
Ultimately, we aim to provide AlzKB as a robust resource that helps unravel the etiology of AD. It is already a large, high-quality knowledge base from which graph-based AI or ML approaches can be developed for drug repurposing and drug discovery. As we and the rest of the biomedical research community make these discoveries in the coming years, they will be included and publicized on the AlzKB website as a public resource to drive innovation and scientific progress.
Obtaining AlzKB for Local Use and Extending the Knowledge Graph
As it is a public and open-source resource for scientific discovery, we provide AlzKB through a variety of interfaces with distinct advantages for different use cases and user types. Casual users who wish to browse the knowledge base or perform simple analyses can do so directly through the Neo4j browser interface [24]. However, for more advanced use cases (or when computational needs exceed those available on the public version of the knowledge base), AlzKB can be either downloaded and populated locally into a Neo4j installation or built from the original source data files via the tools included on the AlzKB GitHub repository [25]. The latter of these options also allows users to extend the knowledge base to include additional data sources, entity types, or relationships beyond those provided in the official knowledge base distribution. We also encourage users who make modifications to the knowledge base to submit their changes for review to be included in the main code distribution. Instructions for how to contribute to AlzKB are also available on the GitHub repository.
As the data sources included in AlzKB are all, themselves, from open-source databases, we urge users to ensure that any new data sources they merge into AlzKB similarly comply with open-source standards. In brief, AlzKB can only be maintained under the most restrictive license terms of its included third-party sources, so restrictive license terms in a database being considered decrease that database’s suitability for inclusion. We hope for AlzKB to be recognized as a community effort for aggregating and democratizing the discovery of new AD therapeutics and, therefore, encourage public discussion of new methods and data sources to be included.
Conclusions
In this work, we introduced AlzKB as a free, publicly available toolkit and data resource for novel discoveries in AD research, with a particular focus on therapeutic approaches to treating AD. AlzKB is both new and continually growing, and we aim to cultivate a community of researchers to collaboratively increase the impact, speed, and throughput of AD research, along with rapid dissemination to health care, academia, and the pharmaceutical industry. In the future, we will develop new AI and data science methods to continually extract knowledge from AlzKB, but in this study, we already demonstrate through graph data science that AlzKB can both replicate existing AD knowledge and generate entirely new, testable hypotheses to drive the future of drug repurposing and drug discovery.
Acknowledgments
The Alzheimer’s Knowledge Base is supported by US National Institutes of Health grants U01-AG066833, R01-LM010098, R01-LM013463 (principal investigator [PI]: JHM), and R00-LM013646 (PI: JDR).
Abbreviations
- AD
Alzheimer disease
- AI
artificial intelligence
- AlzKB
Alzheimer’s Knowledge Base
- LLM
large language model
- ML
machine learning
- MRR
mean reciprocal rank
- OWL
Web Ontology Language
- PD
Parkinson disease
- RDF
Resource Description Framework
- RF
random forest
Supplemental information providing expanded details on the knowledge graph completion methods used to validate Alzheimer’s Knowledge Base, as well as counts for relationship types in the knowledge graph.
Data Availability
The data sets generated during and analyzed during this study are available in the GitHub and Zenodo repositories [25,26].
Footnotes
Conflicts of Interest: None declared.
References
- 1.2022 Alzheimer's disease facts and figures. Alzheimers Dement. 2022 Apr;18(4):700–89. doi: 10.1002/alz.12638. [DOI] [PubMed] [Google Scholar]
- 2.Yiannopoulou KG, Papageorgiou SG. Current and future treatments in Alzheimer disease: an update. J Cent Nerv Syst Dis. 2020 Feb 29;12:1179573520907397. doi: 10.1177/1179573520907397. https://journals.sagepub.com/doi/10.1177/1179573520907397?url_ver=Z39.88-2003&rfr_id=ori:rid:crossref.org&rfr_dat=cr_pub0pubmed .10.1177_1179573520907397 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Rabinovici GD. Controversy and progress in Alzheimer's disease - FDA approval of aducanumab. N Engl J Med. 2021 Aug 26;385(9):771–4. doi: 10.1056/NEJMp2111320. [DOI] [PubMed] [Google Scholar]
- 4.DeTure MA, Dickson DW. The neuropathological diagnosis of Alzheimer's disease. Mol Neurodegener. 2019 Aug 02;14(1):32. doi: 10.1186/s13024-019-0333-5. https://molecularneurodegeneration.biomedcentral.com/articles/10.1186/s13024-019-0333-5 .10.1186/s13024-019-0333-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Aisen PS, Cummings J, Jack CR Jr, Morris JC, Sperling R, Frölich L, Jones RW, Dowsett SA, Matthews BR, Raskin J, Scheltens P, Dubois B. On the path to 2025: understanding the Alzheimer's disease continuum. Alzheimers Res Ther. 2017 Aug 09;9(1):60. doi: 10.1186/s13195-017-0283-5. https://alzres.biomedcentral.com/articles/10.1186/s13195-017-0283-5 .10.1186/s13195-017-0283-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Fan L, Mao C, Hu X, Zhang S, Yang Z, Hu Z, Sun H, Fan Y, Dong Y, Yang J, Shi C, Xu Y. New insights into the pathogenesis of Alzheimer's disease. Front Neurol. 2019;10:1312. doi: 10.3389/fneur.2019.01312. https://europepmc.org/abstract/MED/31998208 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Silva MV, de Mello Gomide Loures C, Alves LC, de Souza LC, Borges KB, Carvalho MD. Alzheimer's disease: risk factors and potentially protective measures. J Biomed Sci. 2019 May 09;26(1):33. doi: 10.1186/s12929-019-0524-y. https://jbiomedsci.biomedcentral.com/articles/10.1186/s12929-019-0524-y .10.1186/s12929-019-0524-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Rodriguez S, Hug C, Todorov P, Moret N, Boswell SA, Evans K, Zhou G, Johnson NT, Hyman BT, Sorger PK, Albers MW, Sokolov A. Machine learning identifies candidates for drug repurposing in Alzheimer's disease. Nat Commun. 2021 Feb 15;12(1):1033. doi: 10.1038/s41467-021-21330-0. doi: 10.1038/s41467-021-21330-0.10.1038/s41467-021-21330-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Tsuji S, Hase T, Yachie-Kinoshita A, Nishino T, Ghosh S, Kikuchi M, Shimokawa K, Aburatani H, Kitano H, Tanaka H. Artificial intelligence-based computational framework for drug-target prioritization and inference of novel repositionable drugs for Alzheimer's disease. Alzheimers Res Ther. 2021 May 03;13(1):92. doi: 10.1186/s13195-021-00826-3. https://alzres.biomedcentral.com/articles/10.1186/s13195-021-00826-3 .10.1186/s13195-021-00826-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Grupe A, Abraham R, Li Y, Rowland C, Hollingworth P, Morgan A, Jehu L, Segurado R, Stone D, Schadt E, Karnoub M, Nowotny P, Tacey K, Catanese J, Sninsky J, Brayne C, Rubinsztein D, Gill M, Lawlor B, Lovestone S, Holmans P, O'Donovan M, Morris JC, Thal L, Goate A, Owen MJ, Williams J. Evidence for novel susceptibility genes for late-onset Alzheimer's disease from a genome-wide association study of putative functional variants. Hum Mol Genet. 2007 Apr 15;16(8):865–73. doi: 10.1093/hmg/ddm031.ddm031 [DOI] [PubMed] [Google Scholar]
- 11.The Alzheimer's KnowledgeBase (AlzKB) AlzKB. [2023-02-24]. https://alzkb.ai/
- 12.Daluwatumulle G, Wijesinghe R, Weerasinghe R. In silico drug repurposing using knowledge graph embeddings for Alzheimer's disease. Proceedings of the 9th International Conference on Bioinformatics Research and Applications; ICBRA '22; September 18-20, 2022; Berlin, Germany. 2022. [DOI] [Google Scholar]
- 13.Nian Y, Hu X, Zhang R, Feng J, Du J, Li F, Bu L, Zhang Y, Chen Y, Tao C. Mining on Alzheimer's diseases related knowledge graph to identity potential AD-related semantic triples for drug repurposing. BMC Bioinformatics. 2022 Sep 30;23(Suppl 6):407. doi: 10.1186/s12859-022-04934-1. https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-022-04934-1 .10.1186/s12859-022-04934-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Hsieh KL, Plascencia-Villa G, Lin KH, Perry G, Jiang X, Kim Y. Synthesize heterogeneous biological knowledge via representation learning for Alzheimer's disease drug repurposing. iScience. 2022 Nov 26;26(1):105678. doi: 10.1016/j.isci.2022.105678. https://linkinghub.elsevier.com/retrieve/pii/S2589-0042(22)01950-2 .S2589-0042(22)01950-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Binder J, Ursu O, Bologa C, Jiang S, Maphis N, Dadras S, Chisholm D, Weick J, Myers O, Kumar P, Yang JJ, Bhaskar K, Oprea TI. Machine learning prediction and tau-based screening identifies potential Alzheimer's disease genes relevant to immunity. Commun Biol. 2022 Feb 11;5(1):125. doi: 10.1038/s42003-022-03068-7. doi: 10.1038/s42003-022-03068-7.10.1038/s42003-022-03068-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Sügis E, Dauvillier J, Leontjeva A, Adler P, Hindie V, Moncion T, Collura V, Daudin R, Loe-Mie Y, Herault Y, Lambert JC, Hermjakob H, Pupko T, Rain JC, Xenarios I, Vilo J, Simonneau M, Peterson H. HENA, heterogeneous network-based data set for Alzheimer's disease. Sci Data. 2019 Aug 14;6(1):151. doi: 10.1038/s41597-019-0152-0.10.1038/s41597-019-0152-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Robinson I, Webber J, Eifrem E. Graph Databases: New Opportunities for Connected Data. Sebastopol, CA: O'Reilly Media; 2015. [Google Scholar]
- 18.Davis R, Shrobe H, Szolovits P. What is a knowledge representation? AI Mag. 1993;14(1):17. doi: 10.1609/aimag.v14i1.1029. [DOI] [Google Scholar]
- 19.Musen MA, Protégé Team The Protégé project: a look back and a look forward. AI Matters. 2015 Jun;1(4):4–12. doi: 10.1145/2757001.2757003. https://europepmc.org/abstract/MED/27239556 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hitzler P, Krötzsch M, Parsia B, Patel-Schneider PF, Rudolph S. OWL 2 Web ontology language primer. World Wide Web Consortium. 2009. Apr 21, [2024-03-25]. https://www.w3.org/TR/2009/WD-owl2-primer-20090421/
- 21.Tsarkov D, Horrocks I. FaCT++ description logic reasoner: system description. Proceedings of the International Joint Conference on Automated Reasoning; IJCAR 2006; August 17-20, 2006; Seattle, WA. 2006. [DOI] [Google Scholar]
- 22.Neo4j. [2022-10-25]. https://neo4j.com/
- 23.Barrasa J, Cowley A. neosemantics (n10s): Neo4j RDF and semantics toolkit. Neo4j. [2022-10-25]. https://neo4j.com/labs/neosemantics/
- 24.Neo4j browser. Neo4j. [2023-02-24]. http://neo4j.alzkb.ai/browser/
- 25.EpistasisLab/AlzKB. GitHub. [2023-02-24]. https://github.com/EpistasisLab/AlzKB .
- 26.Romano J, Wang P. EpistasisLab/AlzKB: AlzKB first DOI release. Zenodo. 2022. Aug 22, [2024-03-27]. https://zenodo.org/records/7015728 .
- 27.Mortensen HM, Senn J, Levey T, Langley P, Williams AJ. The 2021 update of the EPA's adverse outcome pathway database. Sci Data. 2021 Jul 12;8(1):169. doi: 10.1038/s41597-021-00962-3. doi: 10.1038/s41597-021-00962-3.10.1038/s41597-021-00962-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Bastian F, Parmentier G, Roux J, Moretti S, Laudet V, Robinson-Rechavi M. Bgee: integrating and comparing heterogeneous transcriptome data among species. Proceedings of the Data Integration in the Life Sciences; DILS 2008; June 25-27, 2008; Evry, France. 2008. [DOI] [Google Scholar]
- 29.Schriml LM, Mitraka E, Munro J, Tauber B, Schor M, Nickle L, Felix V, Jeng L, Bearer C, Lichenstein R, Bisordi K, Campion N, Hyman B, Kurland D, Oates CP, Kibbey S, Sreekumar P, Le C, Giglio M, Greene C. Human Disease Ontology 2018 update: classification, content and workflow expansion. Nucleic Acids Res. 2019 Jan 08;47(D1):D955–62. doi: 10.1093/nar/gky1032. https://europepmc.org/abstract/MED/30407550 .5165342 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Piñero J, Queralt-Rosinach N, Bravo A, Deu-Pons J, Bauer-Mehren A, Baron M, Sanz F, Furlong LI. DisGeNET: a discovery platform for the dynamical exploration of human diseases and their genes. Database (Oxford) 2015;2015:bav028. doi: 10.1093/database/bav028. https://europepmc.org/abstract/MED/25877637 .bav028 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Wishart DS, Knox C, Guo AC, Cheng D, Shrivastava S, Tzur D, Gautam B, Hassanali M. DrugBank: a knowledgebase for drugs, drug actions and drug targets. Nucleic Acids Res. 2008 Jan;36(Database issue):D901–6. doi: 10.1093/nar/gkm958. https://europepmc.org/abstract/MED/18048412 .gkm958 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Grulke CM, Williams AJ, Thillanadarajah I, Richard AM. EPA's DSSTox database: history of development of a curated chemistry resource supporting computational toxicology research. Comput Toxicol. 2019 Nov 01;12:100096. doi: 10.1016/j.comtox.2019.100096. https://europepmc.org/abstract/MED/33426407 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Judson R, Richard A, Dix D, Houck K, Elloumi F, Martin M, Cathey T, Transue TR, Spencer R, Wolf M. ACToR--Aggregated computational toxicology resource. Toxicol Appl Pharmacol. 2008 Nov 15;233(1):7–13. doi: 10.1016/j.taap.2007.12.037.S0041-008X(08)00281-0 [DOI] [PubMed] [Google Scholar]
- 34.Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, Davis AP, Dolinski K, Dwight SS, Eppig JT, Harris MA, Hill DP, Issel-Tarver L, Kasarskis A, Lewis S, Matese JC, Richardson JE, Ringwald M, Rubin GM, Sherlock G. Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat Genet. 2000 May;25(1):25–9. doi: 10.1038/75556. https://europepmc.org/abstract/MED/10802651 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Gene Ontology Consortium The Gene Ontology resource: enriching a GOld mine. Nucleic Acids Res. 2021 Jan 08;49(D1):D325–34. doi: 10.1093/nar/gkaa1113. https://europepmc.org/abstract/MED/33290552 .6027811 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Buniello A, MacArthur JA, Cerezo M, Harris LW, Hayhurst J, Malangone C, McMahon A, Morales J, Mountjoy E, Sollis E, Suveges D, Vrousgou O, Whetzel PL, Amode R, Guillen JA, Riat HS, Trevanion SJ, Hall P, Junkins H, Flicek P, Burdett T, Hindorff LA, Cunningham F, Parkinson H. The NHGRI-EBI GWAS Catalog of published genome-wide association studies, targeted arrays and summary statistics 2019. Nucleic Acids Res. 2019 Jan 08;47(D1):D1005–12. doi: 10.1093/nar/gky1120. https://europepmc.org/abstract/MED/30445434 .5184712 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Himmelstein DS, Lizee A, Hessler C, Brueggeman L, Chen SL, Hadley D, Green A, Khankhanian P, Baranzini SE. Systematic integration of biomedical knowledge prioritizes drugs for repurposing. Elife. 2017 Sep 22;6:e26726. doi: 10.7554/eLife.26726. https://europepmc.org/abstract/MED/28936969 .26726 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.The human reference protein interactome mapping project. The Human Reference Interactome. [2023-02-24]. http://www.interactome-atlas.org/
- 39.Duan Q, Reid SP, Clark NR, Wang Z, Fernandez NF, Rouillard AD, Readhead B, Tritsch SR, Hodos R, Hafner M, Niepel M, Sorger PK, Dudley JT, Bavari S, Panchal RG, Ma'ayan A. L1000CDS: LINCS L1000 characteristic direction signatures search engine. NPJ Syst Biol Appl. 2016 Aug 04;2(1):16015. doi: 10.1038/npjsba.2016.15. doi: 10.1038/npjsba.2016.15.16015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Lipscomb CE. Medical Subject Headings (MeSH) Bull Med Libr Assoc. 2000 Jul;88(3):265–6. https://europepmc.org/abstract/MED/10928714 . [PMC free article] [PubMed] [Google Scholar]
- 41.Maglott D, Ostell J, Pruitt KD, Tatusova T. Entrez Gene: gene-centered information at NCBI. Nucleic Acids Res. 2011 Jan;39(Database issue):D52–7. doi: 10.1093/nar/gkq1237. https://europepmc.org/abstract/MED/21115458 .gkq1237 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Schaefer C, Anthony K, Krupa S, Buchoff J, Day M, Hannay T, Buetow K. PID: the pathway interaction database. Nat Prec. 2008 Aug 29; doi: 10.1038/npre.2008.2243.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Himmelstein D, Pouya K, Hessler CS, Green AJ, Baranzini S. PharmacotherapyDB 1.0: the open catalog of drug therapies for disease. Figshare. 2016. [2024-03-25]. https://tinyurl.com/mv8k46em .
- 44.Kim S, Chen J, Cheng T, Gindulyte A, He J, He S, Li Q, Shoemaker BA, Thiessen PA, Yu B, Zaslavsky L, Zhang J, Bolton EE. PubChem in 2021: new data content and improved web interfaces. Nucleic Acids Res. 2021 Jan 08;49(D1):D1388–95. doi: 10.1093/nar/gkaa971. https://europepmc.org/abstract/MED/33151290 .5957164 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Wu G, Haw R. Functional interaction network construction and analysis for disease discovery. Methods Mol Biol. 2017;1558:235–53. doi: 10.1007/978-1-4939-6783-4_11. [DOI] [PubMed] [Google Scholar]
- 46.Kuhn M, Letunic I, Jensen LJ, Bork P. The SIDER database of drugs and side effects. Nucleic Acids Res. 2016 Jan 04;44(D1):D1075–9. doi: 10.1093/nar/gkv1075. https://europepmc.org/abstract/MED/26481350 .gkv1075 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Palasca O, Santos A, Stolte C, Gorodkin J, Jensen LJ. TISSUES 2.0: an integrative web resource on mammalian tissue expression. Database (Oxford) 2018 Jan 01;2018:2. doi: 10.1093/database/bay028. https://europepmc.org/abstract/MED/30403794 .4939216 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Mungall CJ, Torniai C, Gkoutos GV, Lewis SE, Haendel MA. Uberon, an integrative multi-species anatomy ontology. Genome Biol. 2012 Jan 31;13(1):R5. doi: 10.1186/gb-2012-13-1-r5. https://genomebiology.biomedcentral.com/articles/10.1186/gb-2012-13-1-r5 .gb-2012-13-1-r5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Martens M, Ammar A, Riutta A, Waagmeester A, Slenter DN, Hanspers KA, A Miller R, Digles D, Lopes EN, Ehrhart F, Dupuis LJ, Winckers LA, Coort SL, Willighagen EL, Evelo CT, Pico AR, Kutmon M. WikiPathways: connecting communities. Nucleic Acids Res. 2021 Jan 08;49(D1):D613–21. doi: 10.1093/nar/gkaa1024. https://europepmc.org/abstract/MED/33211851 .5992285 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Ali M, Berrendorf M, Hoyt CT, Vermue L, Sharifzadeh S, Tresp V, Lehmann J. PyKEEN 1.0: a python library for training and evaluating knowledge graph embeddings. J Mach Learn Res. 2021;22(82):1–6. https://jmlr.org/papers/v22/20-825.html . [Google Scholar]
- 51.Zamini M, Reza H, Rabiei M. A review of knowledge graph completion. Information. 2022 Aug 21;13(8):396. doi: 10.3390/info13080396. [DOI] [Google Scholar]
- 52.Bordes A, Usunier N, Garcia-Duran A, Weston J, Yakhnenko O. Translating embeddings for modeling multi-relational data. Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2; NIPS'13; December 5-10, 2013; Lake Tahoe, Nevada. 2013. [Google Scholar]
- 53.Sun Z, Deng ZH, Nie JY, Tang J. RotatE: knowledge graph embedding by relational rotation in complex space. arXiv. Preprint posted online February 26, 2019. http://arxiv.org/abs/1902.10197 . [Google Scholar]
- 54.Yang B, Yih WT, He X, Gao J, Deng L. Embedding entities and relations for learning and inference in knowledge bases. arXiv. Preprint posted online December 20, 2014. https://arxiv.org/abs/1412.6575 . [Google Scholar]
- 55.Trouillon T, Welbl J, Riedel S, Gaussier E, Bouchard G. Complex embeddings for simple link prediction. arXiv. Preprint posted online June 20, 2016. https://arxiv.org/abs/1606.06357 . [Google Scholar]
- 56.Dettmers T, Minervini P, Stenetorp P, Riedel S. Convolutional 2D knowledge graph embeddings. arXiv. doi: 10.1609/aaai.v32i1.11573. Preprint posted online July 5, 2017. http://arxiv.org/abs/1707.01476 . [DOI] [Google Scholar]
- 57.Newman ME. Clustering and preferential attachment in growing networks. Phys Rev E. 2001 Jul 26;64(2):025102. doi: 10.1103/physreve.64.025102. [DOI] [PubMed] [Google Scholar]
- 58.Barabasi AL, Albert R. Emergence of scaling in random networks. Science. 1999 Oct 15;286(5439):509–12. doi: 10.1126/science.286.5439.509.7898 [DOI] [PubMed] [Google Scholar]
- 59.Adamic LA, Adar E. Friends and neighbors on the web. Soc Netw. 2003 Jul;25(3):211–30. doi: 10.1016/s0378-8733(03)00009-1. [DOI] [Google Scholar]
- 60.Zhou T, Lü L, Zhang YC. Predicting missing links via local information. Eur Phys J B. 2009 Oct 10;71(4):623–30. doi: 10.1140/epjb/e2009-00335-8. [DOI] [Google Scholar]
- 61.Gao Z, Ding P, Xu R. KG-Predict: a knowledge graph computational framework for drug repurposing. J Biomed Inform. 2022 Aug;132:104133. doi: 10.1016/j.jbi.2022.104133. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(22)00149-6 .S1532-0464(22)00149-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Nussbaum RL, Ellis CE. Alzheimer's disease and Parkinson's disease. N Engl J Med. 2003 Apr 03;348(14):1356–64. doi: 10.1056/NEJM2003ra020003.348/14/1356 [DOI] [PubMed] [Google Scholar]
- 63.Abbas K, Abbasi A, Dong S, Niu L, Yu L, Chen B, Cai SM, Hasan Q. Application of network link prediction in drug discovery. BMC Bioinformatics. 2021 Apr 12;22(1):187. doi: 10.1186/s12859-021-04082-y. https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04082-y .10.1186/s12859-021-04082-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Romano JD, Hao Y, Moore JH, Penning TM. Automating predictive toxicology using ComptoxAI. Chem Res Toxicol. 2022 Aug 15;35(8):1370–82. doi: 10.1021/acs.chemrestox.2c00074. https://europepmc.org/abstract/MED/35819939 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Iannuzzi F, Sirabella R, Canu N, Maier TJ, Annunziato L, Matrone C. Fyn tyrosine kinase elicits amyloid precursor protein Tyr682 phosphorylation in neurons from Alzheimer's disease patients. Cells. 2020 Jul 30;9(8):1807. doi: 10.3390/cells9081807. https://www.mdpi.com/resolver?pii=cells9081807 .cells9081807 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Nygaard HB, van Dyck CH, Strittmatter SM. Fyn kinase inhibition as a novel therapy for Alzheimer's disease. Alzheimers Res Ther. 2014 Feb 5;6(1):8. doi: 10.1186/alzrt238. https://alzres.biomedcentral.com/articles/10.1186/alzrt238 .alzrt238 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Lardenoije R, Roubroeks JA, Pishva E, Leber M, Wagner H, Iatrou A, Smith AR, Smith RG, Eijssen LM, Kleineidam L, Kawalia A, Hoffmann P, Luck T, Riedel-Heller S, Jessen F, Maier W, Wagner M, Hurlemann R, Kenis G, Ali M, Del Sol A, Mastroeni D, Delvaux E, Coleman PD, Mill J, Rutten BP, Lunnon K, Ramirez A, van den Hove DL. Alzheimer's disease-associated (hydroxy)methylomic changes in the brain and blood. Clin Epigenetics. 2019 Nov 27;11(1):164. doi: 10.1186/s13148-019-0755-5. https://clinicalepigeneticsjournal.biomedcentral.com/articles/10.1186/s13148-019-0755-5 .10.1186/s13148-019-0755-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Lombardo S, Maskos U. Role of the nicotinic acetylcholine receptor in Alzheimer's disease pathology and treatment. Neuropharmacology. 2015 Sep;96(Pt B):255–62. doi: 10.1016/j.neuropharm.2014.11.018. https://hal.archives-ouvertes.fr/pasteur-01197130 .S0028-3908(14)00434-1 [DOI] [PubMed] [Google Scholar]
- 69.Jo DG, Lee JY, Hong YM, Song S, Mook-Jung I, Koh JY, Jung YK. Induction of pro-apoptotic calsenilin/DREAM/KChIP3 in Alzheimer's disease and cultured neurons after amyloid-beta exposure. J Neurochem. 2004 Feb;88(3):604–11. doi: 10.1111/j.1471-4159.2004.02159.x. https://onlinelibrary.wiley.com/resolve/openurl?genre=article&sid=nlm:pubmed&issn=0022-3042&date=2004&volume=88&issue=3&spage=604 .2159 [DOI] [PubMed] [Google Scholar]
- 70.Jin JK, Choi JK, Wasco W, Buxbaum JD, Kozlowski PB, Carp RI, Kim YS, Choi EK. Expression of calsenilin in neurons and astrocytes in the Alzheimer's disease brain. Neuroreport. 2005 Apr 04;16(5):451–5. doi: 10.1097/00001756-200504040-00007.00001756-200504040-00007 [DOI] [PubMed] [Google Scholar]
- 71.Rosas I, Martínez C, Clarimón J, Lleó A, Illán-Gala I, Dols-Icardo O, Borroni B, Almeida MR, van der Zee J, Van Broeckhoven C, Bruni AC, Anfossi M, Bernardi L, Maletta R, Serpente M, Galimberti D, Scarpini E, Rossi G, Caroppo P, Benussi L, Ghidoni R, Binetti G, Nacmias B, Sorbi S, Piaceri I, Bagnoli S, Antonell A, Sánchez-Valle R, De la Casa-Fages B, Grandas F, Diez-Fairen M, Pastor P, Ferrari R, Álvarez V, Menéndez-González M. Role for ATXN1, ATXN2, and HTT intermediate repeats in frontotemporal dementia and Alzheimer's disease. Neurobiol Aging. 2020 Mar;87:139.e1–.e7. doi: 10.1016/j.neurobiolaging.2019.10.017.S0197-4580(19)30381-1 [DOI] [PubMed] [Google Scholar]
- 72.Aboud O, Parcon PA, DeWall KM, Liu L, Mrak RE, Griffin WS. Aging, Alzheimer's, and APOE genotype influence the expression and neuronal distribution patterns of microtubule motor protein dynactin-P50. Front Cell Neurosci. 2015 Mar 25;9:103. doi: 10.3389/fncel.2015.00103. https://europepmc.org/abstract/MED/25859183 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Caroppo P, Le Ber I, Clot F, Rivaud-Péchoux S, Camuzat A, De Septenville A, Boutoleau-Bretonnière C, Mourlon V, Sauvée M, Lebouvier T, Bonnet A, Levy R, Vercelletto M, Brice A. DCTN1 mutation analysis in families with progressive supranuclear palsy-like phenotypes. JAMA Neurol. 2014 Feb;71(2):208–15. doi: 10.1001/jamaneurol.2013.5100. https://europepmc.org/abstract/MED/24343258 .1788742 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Zochodne DW, Ho LT. Sumatriptan blocks neurogenic inflammation in the peripheral nerve trunk. Neurology. 1994 Jan;44(1):161–3. doi: 10.1212/wnl.44.1.161. [DOI] [PubMed] [Google Scholar]
- 75.Liu CT, Wu BY, Hung YC, Wang LY, Lee YY, Lin TK, Lin PY, Chen WF, Chiang JH, Hsu SF, Hu WL. Decreased risk of dementia in migraine patients with traditional Chinese medicine use: a population-based cohort study. Oncotarget. 2017 Oct 03;8(45):79680–92. doi: 10.18632/oncotarget.19094. https://www.oncotarget.com/lookup/doi/10.18632/oncotarget.19094 .19094 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Kim YD, Jeong EI, Nah J, Yoo SM, Lee WJ, Kim Y, Moon S, Hong SH, Jung YK. Pimozide reduces toxic forms of tau in TauC3 mice via 5' adenosine monophosphate-activated protein kinase-mediated autophagy. J Neurochem. 2017 Sep 11;142(5):734–46. doi: 10.1111/jnc.14109. https://onlinelibrary.wiley.com/doi/10.1111/jnc.14109 . [DOI] [PubMed] [Google Scholar]
- 77.Kumar S, Chowdhury S, Kumar S. In silico repurposing of antipsychotic drugs for Alzheimer's disease. BMC Neurosci. 2017 Oct 27;18(1):76. doi: 10.1186/s12868-017-0394-8. https://bmcneurosci.biomedcentral.com/articles/10.1186/s12868-017-0394-8 .10.1186/s12868-017-0394-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.van Duijn CM, Hofman A. Relation between nicotine intake and Alzheimer's disease. BMJ. 1991 Jun 22;302(6791):1491–4. doi: 10.1136/bmj.302.6791.1491. https://europepmc.org/abstract/MED/1855016 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Hamilton WL, Ying R, Leskovec J. Inductive representation learning on large graphs. arXiv. Preprint posted online June 7, 2017. https://arxiv.org/abs/1706.02216 . [Google Scholar]
- 80.Dong Y, Chawla NV, Swami A. metapath2vec: scalable representation learning for heterogeneous networks. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; KDD '17; August 13-17, 2017; Halifax, NS. 2017. https://dl.acm.org/doi/10.1145/3097983.3098036 . [Google Scholar]
- 81.Pan S, Luo L, Wang Y, Chen C, Wang J, Wu X. Unifying large language models and knowledge graphs: a roadmap. arXiv. doi: 10.48550/arXiv.2306.08302. Preprint posted online June 14, 2023. https://arxiv.org/abs/2306.08302 . [DOI] [Google Scholar]
- 82.Zhu Y, Wang X, Chen J, Qiao S, Ou Y, Yao Y, Deng S, Chen H, Zhang N. LLMs for knowledge graph construction and reasoning: recent capabilities and future opportunities. arXiv. Preprint posted online May 22, 2023. https://arxiv.org/abs/2305.13168v1 . [Google Scholar]
- 83.Kefato ZT, Girdzijauskas S. Self-supervised Graph Neural Networks without explicit negative sampling. arXiv. Preprint posted online March 27, 2021. https://arxiv.org/abs/2103.14958v4 . [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplemental information providing expanded details on the knowledge graph completion methods used to validate Alzheimer’s Knowledge Base, as well as counts for relationship types in the knowledge graph.
Data Availability Statement
The data sets generated during and analyzed during this study are available in the GitHub and Zenodo repositories [25,26].