

Abstract
Purpose:
To develop deep learning models for detecting reticular pseudodrusen (RPD) using fundus autofluorescence (FAF) images or, alternatively, color fundus photographs (CFP) in the context of age-related macular degeneration (AMD).
Design:
Application of deep learning models to the Age-Related Eye Disease Study 2 (AREDS2) dataset.
Participants:
FAF and CFP images (n = 11 535) from 2450 AREDS2 participants. Gold standard labels from reading center grading of the FAF images were transferred to the corresponding CFP images.
Methods:
A deep learning model was trained to detect RPD in eyes with intermediate to late AMD using FAF images (FAF model). Using label transfer from FAF to CFP images, a deep learning model was trained to detect RPD from CFP (CFP model). Performance was compared with 4 ophthalmologists using a random subset from the full test set.
Main Outcome Measures:
Area under the receiver operating characteristic curve (AUC), κ value, accuracy, and F1 score.
Results:
The FAF model had an AUC of 0.939 (95% confidence interval [CI], 0.927–0.950), a κ value of 0.718 (95% CI, 0.685–0.751), and accuracy of 0.899 (95% CI, 0.887–0.911). The CFP model showed equivalent values of 0.832 (95% CI, 0.812–0.851), 0.470 (95% CI, 0.426–0.511), and 0.809 (95% CI, 0.793–0.825), respectively. The FAF model demonstrated superior performance to 4 ophthalmologists, showing a higher κ value of 0.789 (95% CI, 0.675–0.875) versus a range of 0.367 to 0.756 and higher accuracy of 0.937 (95% CI, 0.907–0.963) versus a range of 0.696 to 0.933. The CFP model demonstrated substantially superior performance to 4 ophthalmologists, showing a higher κ value of 0.471 (95% CI, 0.330–0.606) versus a range of 0.105 to 0.180 and higher accuracy of 0.844 (95% CI, 0.798–0.886) versus a range of 0.717 to 0.814.
Conclusions:
Deep learning-enabled automated detection of RPD presence from FAF images achieved a high level of accuracy, equal or superior to that of ophthalmologists. Automated RPD detection using CFP achieved a lower accuracy that still surpassed that of ophthalmologists. Deep learning models can assist, and even augment, the detection of this clinically important AMD-associated lesion.
Age-related macular degeneration (AMD) is the leading cause of legal blindness in developed countries.1,2 Late AMD, the stage of disease with the potential for severe vision loss, occurs in 2 forms: neovascular AMD and geographic atrophy (GA). Identifying eyes that have a high risk of progression to late AMD is important in clinical care, enabling the prescription of appropriate medical and lifestyle interventions,3–5 tailored home monitoring,6–8 and regular reimaging,9 which can reduce progression risk and optimize treatment. Identifying these eyes also can aid participant selection in AMD clinical trials.10
Reticular pseudodrusen (RPD), also known as subretinal drusenoid deposits, have been identified as a disease feature independently associated with increased risk of progression to late AMD.11 Unlike soft drusen, which are located in the sub–retinal pigment epithelial space, RPD are thought to represent aggregations of material in the subretinal space between the retinal pigment epithelium and photoreceptors.11,12 Compositional differences also have been found between soft drusen and RPD.12
The detection of eyes with RPD is important for multiple reasons. Not only is their presence associated with increased risk of late AMD, but the increased risk is weighted toward particular forms of late AMD, including the recently recognized phenotype of outer retinal atrophy.11,13,14 In recent analyses of Age-Related Eye Disease Study 2 (AREDS2) data, the risk of progression to GA was significantly higher with RPD presence, whereas the risk of neovascular AMD was not.15 Hence, RPD presence may be a powerfully discriminating feature that could be very useful in risk prediction algorithms for the detailed prognosis of AMD progression. The presence of RPD also has been associated with increased speed of GA enlargement,16 which is a key end point in ongoing clinical trials. Finally, in eyes with intermediate AMD, the presence of RPD seems to be a critical determinant of the efficacy of subthreshold nanosecond laser to slow progression to late AMD.17
However, owing to the poor visibility of RPD on clinical examination and on color fundus photography (CFP),15,18,19 these methods of assessment were not incorporated into the traditional AMD classification and risk stratification systems, such as the Beckman clinical classification scale20 or the Age-Related Eye Disease Study scales.21,22 With the advent of more recent imaging methods, including fundus autofluorescence (FAF), near-infrared reflectance (NIR), and OCT,11,12 the presence of RPD may be ascertained more accurately with careful grading at the reading center level.18,23,24 However, their detection by ophthalmologists (including retinal specialists) in a clinical setting may remain challenging.
For these reasons, we considered whether deep learning might be used in the automated detection of RPD from FAF and CFP images, which has not been studied before. Deep learning is a branch of machine learning that allows computers to learn by example. In the case of image analysis, it involves training algorithmic models on images with accompanying labels such that they can perform classification of novel images according to the same labels.25,26 The models typically are neural networks that are constructed of an input layer (which receives the image), followed by multiple layers of nonlinear transformations, to produce a classifier output (e.g., RPD present or absent).
In addition to investigating how deep learning models can detect RPD from FAF images, we wanted to explore their ability to perform detection from images obtained using CFP, an imaging method used much more widely than FAF. Importantly, the AREDS2 dataset contains corresponding FAF and CFP images that were obtained from the same participants at the same study visit, enabling the RPD assessment from reading center grading of FAF images to be transferred to corresponding CFP images. This represents a powerful technique called label transfer (between image methods)27 and enables the training of models on images containing features that are not consistently discernable by human viewers, such as RPD on CFP images.15,18,19
The first aim of this study was to assess the usefulness of deep learning for the detection of RPD using FAF images from a large population of more than 2000 individuals with AMD. An important additional aim was to examine the usefulness of deep learning for the detection of RPD from CFP images alone using the technique of label transfer from graded FAF images to corresponding CFP images.
Methods
An overview of the study approach and methodology is shown in Figure 1.
Figure 1.
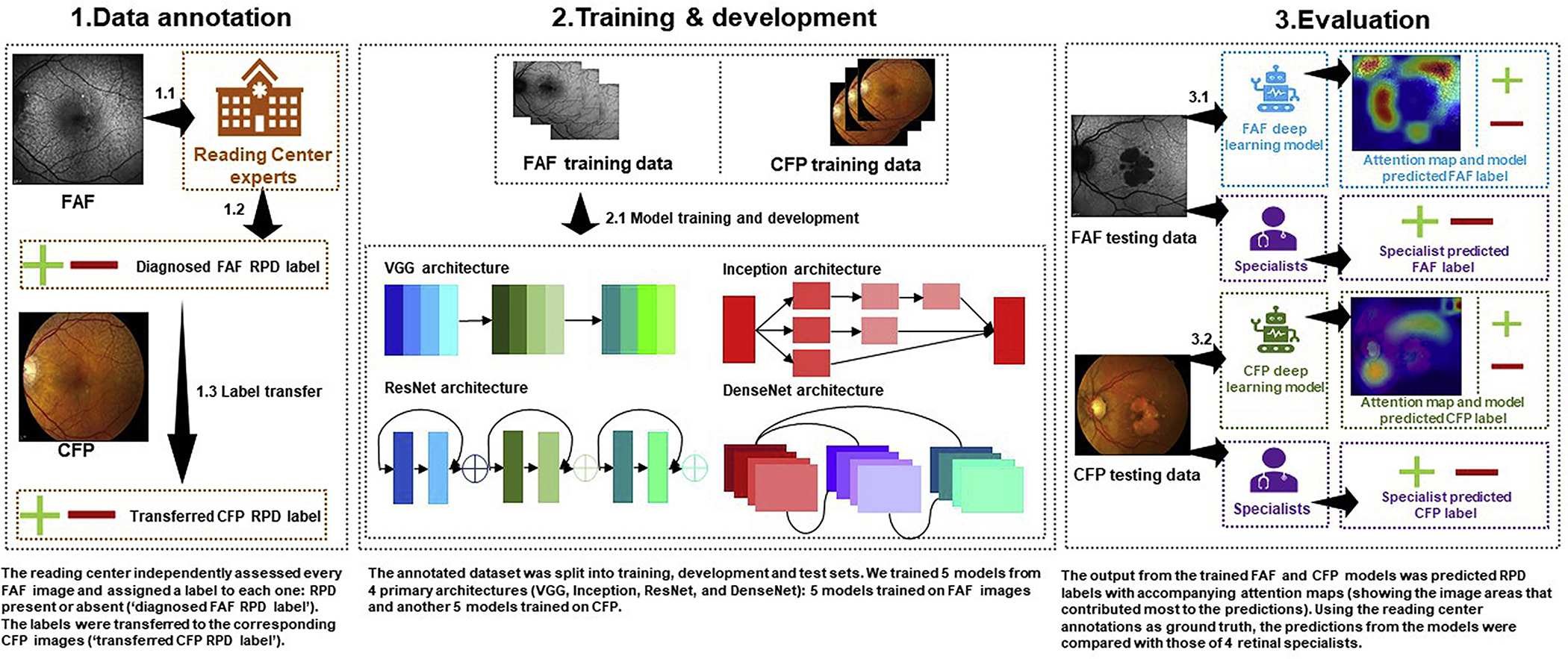
Study overview. First, the reading center experts graded the presence or absence of reticular pseudodrusen (RPD) on fundus autofluorescence (FAF) images (1.1 and 1.2). These labels were transferred to the corresponding color fundus photography (CFP) images (1.3). Then, the FAF and CFP images each were split into training, development, and test sets. Ten deep learning models were trained, 5 for the FAF detection task and 5 for the CFP detection task (2.1). Each model was evaluated on the holdout test sets (3.1 and 3.2). Four ophthalmologists also graded a subset of the test sets. Their grades were compared with those of the deep learning models, using the reading center grades as the ground truth.
Dataset
The dataset used for this study was from the AREDS2. The AREDS2 was a multicenter phase 3 randomized controlled clinical trial designed to assess the effects of nutritional supplements on the course of AMD in people at moderate to high risk of progression to late AMD.28 Its primary outcome was the development of late AMD, defined as central GA or neovascular AMD. Institutional review board approval was obtained at the National Eye Institute, and written informed consent for the research was obtained from all study participants. The research complied with the tenets of the Declaration of Helsinki and the Health Portability and Accessibility Act.
The AREDS2 design has been described previously.28 In short, 4203 participants 50 to 85 years of age were recruited between 2006 and 2008 at 82 retinal specialty clinics in the United States. Inclusion criteria at enrollment were the presence of cither bilateral large drusen or late AMD in one eye and large drusen in the fellow eye. At baseline and annual study visits, comprehensive eye examinations were performed by certified study personnel using standardized protocols. The study visits included the capture of digital stereoscopic CFP images by certified technicians using standard imaging protocols. In the current study, the field 2 images (i.e., 30° imaging field centered at the fovea) were used.
In addition, as described previously,15 the AREDS2 ancillary study of FAF imaging was conducted at 66 selected clinic sites according to the availability of imaging equipment. Sites were permitted to join the ancillary study at any time after FAF imaging equipment became available during the 5-year study period. Hence, although patients at some sites underwent FAF imaging from the AREDS2 baseline visit onward, patients at other sites underwent FAF imaging from later study visits onward, and the remaining sites did not perform FAF imaging at any point. The FAF images were acquired from the Heidelberg Retinal Angiograph (Heidelberg Engineering, Heidelberg, Germany) and fundus cameras with autofluorescence capability by certified technicians using standard imaging protocols. For the Heidelberg images, a single image was acquired at 30° centered on the macula, captured in high-speed mode (768 × 768 pixels), using the automated real-time mean function set at 14. All images were sent to the University of Wisconsin Fundus Photograph Reading Center for analysis.
The ground truth labels used for both training and testing were the grades previously assigned to each FAF image by expert human graders at the University of Wisconsin Fundus Photograph Reading Center. The expert human grading team comprised 6 graders: 4 primary graders and 2 senior graders as adjudicators. The graders were certified technicians with more than 10 years of experience in the detailed evaluation of retinal images for AMD. (These graders did not overlap at all with the 4 ophthalmologists described next.) The protocol and grading definitions used to classify RPD presence or absence from the FAF images were described recently.15 In short, RPD were defined as clusters of discrete round or oval lesions of hypoautofluorescence, usually similar in size, or confluent ribbon-like patterns with intervening areas of normal or increased autofluorescence; a minimum of 0.5 disc areas (approximately 5 lesions) was required. Two primary graders at the reading center independently evaluated FAF images (from both initial and subsequent study visits) for the presence of RPD. In the case of disagreement between the 2 primary graders, a senior grader at the reading center adjudicated the final grade. Intergrader agreement for the presence or absence of RPD was 94%.15 Label transfer was used between the FAF images and their corresponding CFP images; this means that the ground truth label obtained from the reading center for each FAF image (RPD present or absent) also was applied to the corresponding CFP image (i.e., FAF-derived label, regardless of the reading center grade for the CFP image itself). Separately, all of the corresponding CFP images were graded independently at the reading center for RPD, defined on CFP as an ill-defined network of broad interlacing ribbons. However, these grades were not used as the ground truth.
All available AREDS2 FAF images were used in this study, that is, including those from all visits. The image datasets were split randomly into 3 sets: 70% for training, 10% for validation, and 20% for testing of the models. The split was made at the participant level, such that all images from a single participant were present in only 1 of the 3 sets. The details of the datasets and splits are shown in Table 1, including the demographic characteristics of the study participants and the distribution of AMD severity levels of the images.
Table 1.
Numbers of Study Participants and Fundus Autofluorescence and Color Fundus Photograph Image Pairs Used for Deep Learning Model Training
| Training Set | Validation Set | Test Set | Total | |
|---|---|---|---|---|
|
| ||||
| Participants (no.) | 1719 | 236 | 488 | 2443 |
| Female gender (%) | 57.7 | 57.6 | 56.8 | 57.5 |
| Mean age (yrs) | 72.7 | 73.0 | 73.4 | 72.9 |
| Images (no.)* | 7930 | 1096 | 2249 | 11275 |
| RPD present (%), gold-standard label, as determined by reading center grading of FAF images | 27.6 | 24.2 | 25.8 | 26.9 |
| AREDS 9-step AMD severity scale distribution (%) | ||||
| Steps 1–5 | 7.7 | 10.0 | 7.7 | 7.9 |
| Steps 6–8 | 53.0 | 52.0 | 50.6 | 52.4 |
| Geographic atrophy present | 14.1 | 14.1 | 16.0 | 14.5 |
| Neovascular AMD present | 25.1 | 23.5 | 25.4 | 25.0 |
| Not gradable | 0.2 | 0.4 | 0.3 | 0.2 |
AREDS = Age-Related Eye Disease Study; AMD = age-related macular degeneration; FAF = fundus autofluorescence; RPD = reticular pseudodrusen. The full set of image pairs was divided into the following subsets: training set (70%), validation set (10%), and test set (20%).
These refer to the total number of FAF and corresponding color fundus photograph image pairs, that is, 11 275 FAF images and the 11 275 corresponding color fundus photographs that were captured from the same eye at the same study visit.
The total number of images in all 3 datasets was 11 275. Of the 4724 study eyes, approximately half (51.5%) contributed only 1 image to the dataset: 51.4% (training set), 49.7% (validation set), and 52.6% (test set); the remaining eyes contributed more than 1 image. Overall, the mean number of images used per eye was 2.39: 2.39 (training set), 2.38 (validation set), and 2.39 (test set). The number of images in which multiple images were used from the same eye was 8983 images of 2432 eyes: 6316 images of 1708 eyes (training set), 864 images of 229 eyes (validation set), and 1803 images of 495 eyes (test set). Of these 8893 images, the proportion with RPD was 27.1%: 27.9% (training set), 25.2% (validation set), and 25.0% (test set). Of the 738 eyes that contributed multiple images in which at least 1 image showed RPD, the proportion that showed RPD from the first image used was 76.3%: 78.4% (training set), 71.2% (validation set), and 70.6% (test set).
Deep Learning Models
The convolutional neural network (CNN), a type of deep learning model designed for image classification, has become the state-of-the-art method for the automated identification of retinal diseases on CFP.25,26,29 In this study, the CNN DenseNet (version 152)30 was used to create both the FAF deep learning model and the CFP deep learning model for the binary detection of RPD presence or absence. This new CNN contains 601 layers, comprising a total of more than 14 million weights (learnable parameters) that are subject to training. Its main novel feature is that each layer passes on its output to all subsequent layers, such that every layer obtains inputs from all the preceding layers (not just the immediately preceding layer, as in previous CNNs).30 DenseNet has demonstrated superior performance to many other slightly older CNNs in a range of image classification applications.31 However, for comparison of performance according to the CNN used, we trained additional deep learning models using 4 different CNNs frequently used in image classification tasks: VGG version 16,32 VGG version 19,32 InccptionV3,33 and ResNet version 10134 (i.e., 8 additional deep learning models in total). These arc described in the Supplemental Material (available at www.aaojoumal.org).
All deep learning models were pretrained using ImageNet, an image database of more than 14 million natural images with corresponding labels, using methods described previously.25 (This very large dataset often is used in deep learning to pretrain models. Pretraining on ImageNet is used to initialize the layers or weights, leading to the recognition of primitive features, for example, edge detection, before subsequent training on the dataset of interest.) The models were trained with 2 commonly used libraries, Keras35 and TensorFlow.36 During the training process, each image was scaled to 512 × 512 pixels. Aside from this, no image preprocessing was performed for cither the FAF or CFP images. The model parameters were updated using the Adam optimizer (learning rate of 0.0001) for every minibatch of 16 images. Model convergence was measured when the loss on the training set began to increase. The training was stopped 5 epochs (passes of the entire training set) after the loss of the training set no longer decreased. All experiments were conducted on a server with 32 Intel Xeon CPUs (Intel Corporation, Santa Clara, CA), using 3 GeForce GTX 1080 Ti 11Gb GPUs (NVIDIA Corporation, Santa Clara, CA) for training and testing, with 512 Gb available in RAM memory. In addition, image augmentation procedures were used, as follows, to increase the dataset size and to strengthen model generalizability: (1) rotation (180°), (2) horizontal flip, and (3) vertical flip.
Evaluation of the Deep Learning Models and Comparison with Human Clinical Practitioners
Each model was evaluated against the gold standard reading center grades of the test set. For each model, the following metrics were calculated: sensitivity (also known as recall), specificity, area under the receiver operating characteristic (ROC) curve (AUC), Cohen’s κ value, accuracy, precision, and F1 score. Sensitivity, specificity, AUC, and κ value are evaluation metrics commonly used in clinical research, whereas AUC and F1 score (which incorporates sensitivity and precision into a single metric) frequently are used in image classification research. For each performance metric, the metric and its 95% confidence interval (CI) were calculated by bootstrap analysis (i.e., by randomly resampling instances with replacement 2000 times to obtain a statistical distribution for each metric25).
First, using the full test set, the performance of the 5 different CNNs was compared (separately for the FAF and the CFP task), with AUC as the primary performance metric and κ value as the secondary performance metric. Second, the performance of the CNN with the highest AUC was compared (separately for the FAF and the CFP task) with the performance of 4 ophthalmologists with a special interest in RPD who manually graded the images by viewing them on a computer screen at full image resolution. The ophthalmologists comprised 2 retinal specialists (in practice as a retinal specialist for 35 years [E.Y.C.] and 2 years [T.D.K.]) and 2 postresidency retinal fellows (1 second-year fellow [C.K.H.] and 1 first-year fellow [A.T.T.]). Before grading, all 4 ophthalmologists were provided with the same RPD imaging definitions as those used by the reading center graders (see above). To capture the usual daily practice of RPD grading by the ophthalmologists, no standardization exercise was performed before grading by the 4 ophthalmologists. In addition, for the CFP task only, comparison also was made with the CFP-based reading center grades. In all cases, the ground truth for the CFP images was the reading center label from the corresponding FAF images. For these comparisons, the κ value was the primary performance metric, and the other metrics (particularly accuracy and F1 score) were the secondary performance metrics. The κ value was selected because it handles data with unbalanced classes well (as in this study, in which the number of negative instances outweighed the number of positive ones). These comparisons were conducted using a random sample (from the full test set) of 263 FAF images (from 50 participants) and the 263 corresponding CFP images; the 4 ophthalmologists each graded these images, independently of one another.
In secondary analyses, the performance of the CNN with the highest AUC was reanalyzed using the full test set but excluding eyes whose reading center grading changed over the study period from RPD absent to present. This secondary analysis was performed to explore scenarios in which performance might be higher or lower, specifically for the case of newly arising RPD. These RPD “in evolution” are thought to be localized and subtle,11,12 such that some disagreement between the deep learning models and the reading center determination might be expected, regarding the exact time points in successive images at which these early RPD arc judged as definitely present.
Finally, attention maps were generated to investigate the image locations that contributed most to decision making by the deep learning models. This was done by back-projecting the last layer of the neural network. The Python package “keras-vis” was used to generate the attention maps.37
Results
Performance of Deep Learning Models in Detecting Reticular Pseudodrusen from Fundus Autofluorescence Images and Color Fundus Photographs: Comparison of 5 Different Convolutional Neural Networks
Each of 5 CNNs was used to analyze the FAF images in the test set. Their accuracy in detecting RPD presence, relative to the gold standard (reading center grading of FAF images), was quantitated using multiple performance metrics. Separately, each of 5 CNNs was used to analyze CFP images in the test set. Their accuracy in detecting RPD presence, relative to the gold standard (labels transferred from reading center grading of the corresponding FAF images), was quantitated in a similar way. The results arc shown in Table 2 and in Figure 2.
Table 2.
Performance Results of 5 Different Deep Learning Convolutional Neural Networks for the Detection of Reticular Pseudodrusen from Fundus Autofluorescence Images and Their Corresponding Color Fundus Photographs Using the Full Test Set
| Performance Metric (95% Confidence Interval)* |
|||||||
|---|---|---|---|---|---|---|---|
| Convolutional Neural Network | Area under the Receiver Operating Characteristic Curve | Sensitivity (Recall) | Specificity | κ Value | Accuracy | Precision | F1 Score |
|
| |||||||
| Fundus autofluorescence images | |||||||
| VGG16 | 0.898 (0.881–0.913) | 0.574 (0.534–0.612) | 0.980 (0.972–0.986) | 0.628 (0.589–0.666) | 0.875 (0.861–0.889) | 0.907 (0.876–0.935) | 0.702 (0.669–0.733) |
| VGG19 | 0.806 (0.785–0.826) | 0.142 (0.115–0.170) | 0.983 (0.976–0.988) | 0.169 (0.133–0.207) | 0.766 (0.749–0.783) | 0.738 (0.658–0.816) | 0.238 (0.197–0.279) |
| InceptionV3 | 0.914 (0.898–0.929) | 0.686 (0.650–0.724) | 0.968 (0.959–0.976) | 0.706 (0.671–0.739) | 0.896 (0.883–0.908) | 0.882 (0.850–0.908) | 0.772 (0.744–0.799) |
| ResNet | 0.918 (0.904–0.931) | 0.618 (0.579–0.657) | 0.961 (0.951–0.970) | 0.635 (0.596–0.670) | 0.873 (0.859–0.886) | 0.846 (0.810–0.878) | 0.714 (0.682–0.744) |
| DenseNet | 0.939 (0.927–0.950) | 0.704 (0.667–0.741) | 0.967 (0.958–0.975) | 0.718 (0.685–0.751) | 0.899 (0.887–0.911) | 0.882 (0.851–0.909) | 0.783 (0.755–0.809) |
| Color fundus photographs | |||||||
| VGG16 | 0.759 (0.736–0.782) | 0.179 (0.150–0.212) | 0.968 (0.960–0.976) | 0.193 (0.154–0.235) | 0.764 (0.748–0.782) | 0.662 (0.588–0.736) | 0.281 (0.240–0.326) |
| VGG19 | 0.738 (0.716–0.761) | 0.256 (0.223–0.293) | 0.932 (0.919–0.943) | 0.229 (0.187–0.274) | 0.757 (0.739–0.775) | 0.566 (0.508–0.626) | 0.353 (0.312–0.394) |
| InceptionV3 | 0.787 (0.766–0.808) | 0.475 (0.436–0.517) | 0.891 (0.876–0.905) | 0.393 (0.350–0.437) | 0.783 (0.767–0.800) | 0.603 (0.558–0.647) | 0.531 (0.494–0.568) |
| ResNet | 0.779 (0.763–0.797) | 0.252 (0.217–0.288) | 0.963 (0.954–0.972) | 0.273 (0.230–0.316) | 0.779 (0.763–0.797) | 0.707 (0.645–0.766) | 0.372 (0.328–0.415) |
| DenseNet | 0.832 (0.812–0.851) | 0.538 (0.498–0.575) | 0.904 (0.889–0.918) | 0.470 (0.426–0.511) | 0.809 (0.793–0.825) | 0.660 (0.618–0.705) | 0.593 (0.557–0.627) |
For each metric, the highest result appears in boldface.
The performance metrics and their 95% confidence intervals were evaluated by bootstrap analysis.
Figure 2.
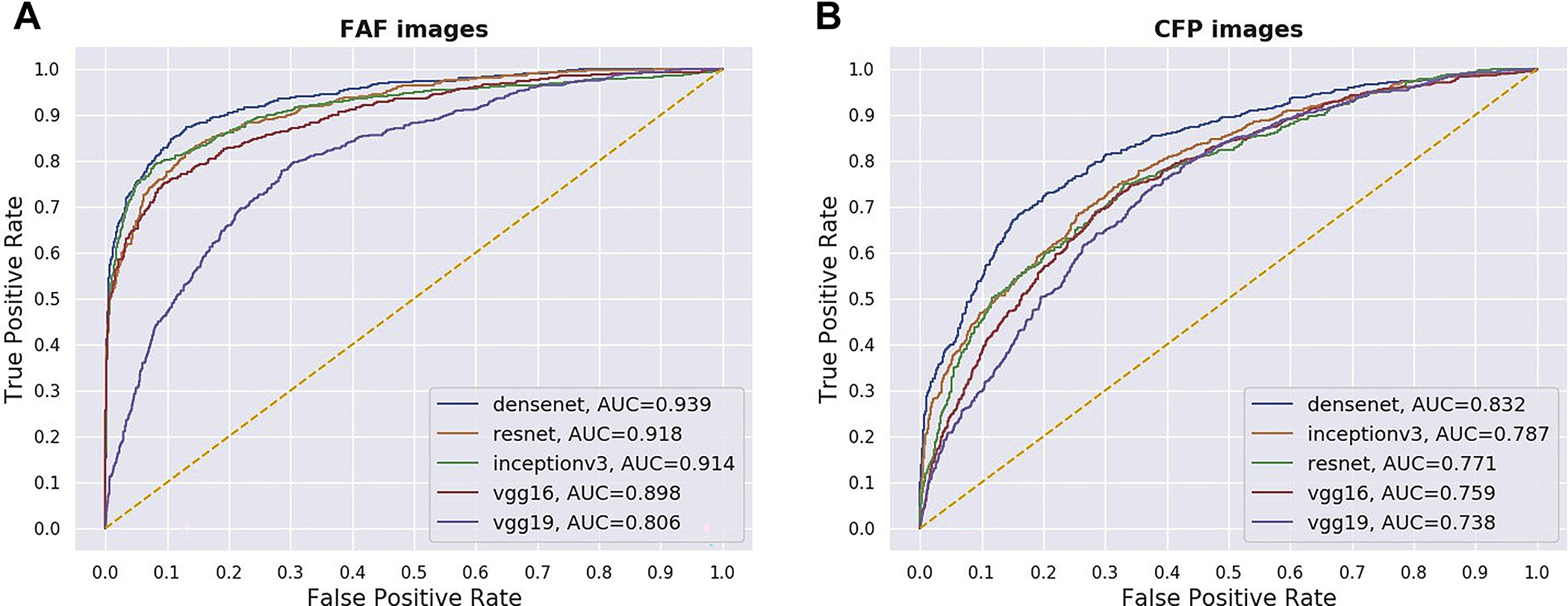
Receiver operating characteristic curves of 5 different deep learning convolutional neural networks for the detection of reticular pseudodrusen from (A) fundus autofluorescence (FAF) images and (B) their corresponding color fundus photography (CFP) images, using the full test set. AUC = area under the receiver operating characteristic curve.
For the FAF image analyses, DenseNet, relative to the other 4 CNNs, achieved the highest AUC, the primary performance metric, at 0.939 (95% CI, 0.927–0.950), and the highest κ value, the secondary performance metric, at 0.718 (95% CI, 0.685–0.751). Of the 5 other performance metrics, DenseNet was highest for 3 (sensitivity, accuracy, and F1 score) relative to the other CNNs. It achieved sensitivity of 0.704 (95% CI, 0.667–0.741) and specificity of 0.967 (95% CI, 0.958–0.975).
For the CFP image analyses, DenseNet achieved the highest AUC, at 0.832 (95% CI, 0.812–0.851), and the highest κ value, at 0.470 (95% CI, 0.426–0.511). Of the 5 other performance metrics, DenseNet was highest for 4 (sensitivity, accuracy, precision, and F1 score) relative to the other CNNs. It achieved sensitivity of 0.538 (95% CI, 0.498–0.575) and specificity of 0.904 (95% CI, 0.889–0.918).
Performance of Automated Deep Learning Models versus Human Practitioners in Detecting Reticular Pseudodrusen
The highest-performing CNN, DenseNet, was used to analyze images from a random subset of the test set (263 FAF and CFP corresponding image pairs). For both FAF and CFP images in this test set, the performance metrics for the detection of RPD presence were compared with those obtained by each of 4 ophthalmologists who manually graded the images (when viewed on a computer screen at full image resolution). For the CFP images only, the performance metrics also were compared with CFP-derived labels (i.e., reading center grading of the CFP images) using the FAF-derived labels as the ground truth. The results arc shown in Table 3. In addition, the ROC curves for the 2 DenseNet deep learning models are shown in Figure 3. For comparison, the performance of the 4 ophthalmologists is shown as 4 single points; for the CFP task, the performance of the reading center grading also is shown as a single point.
Table 3.
Performance Results of the Most Accurate Deep Learning Convolutional Neural Networks (DenseNet) and 4 Ophthalmologists for the Detection of Reticular Pseudodrusen from Fundus Autofluorescence Images and Their Corresponding Color Fundus Photographs Using a Sample of the Test Set Containing the Images from 50 Randomly Selected Participants
| Performance Metric (95% Confidence Interval)* |
|||||||
|---|---|---|---|---|---|---|---|
| Area under the Receiver Operating Characteristic Curve | Sensitivity (Recall) | Specificity | κ Value | Accuracy | Precision | F1 Score | |
|
| |||||||
| Fundus autofluorescence images | |||||||
| Ophthalmologist 1 (second-year fellow) | — | 0.929 (0.854–0.984) | 0.641 (0.577–0.704) | 0.367 (0.277–0.462) | 0.696 (0.641–0.752) | 0.380 (0.303–0.471) | 0.539 (0.452–0.629) |
| Ophthalmologist 2 (first-year fellow) | — | 0.712 (0.583–0.833) | 0.834 (0.781–0.883) | 0.472 (0.346–0.602) | 0.811 (0.759–0.856) | 0.508 (0.389–0.640) | 0.591 (0.482–0.698) |
| Ophthalmologist 3 (retinal specialist for 35 yrs) | — | 0.498 (0.367–0.632) | 0.995 (0.986–1.000) | 0.601 (0.464–0.723) | 0.899 (0.863–0.933) | 0.961 (0.870–1.000) | 0.653 (0.532–0.766) |
| Ophthalmologist 4 (retinal specialist for 2 yrs) | — | 0.673 (0.544–0.800) | 0.995 (0.986–1.000) | 0.756 (0.641–0.855) | 0.933 (0.900–0.961) | 0.973 (0.906–1.000) | 0.795 (0.693–0.883) |
| DenseNet | 0.962 | 0.776 (0.646–0.874) | 0.977 (0.955–0.995) | 0.789 (0.675–0.875) | 0.937 (0.907–0.963) | 0.894 (0.787–0.977) | 0.828 (0.725–0.898) |
| Color fundus photographs | |||||||
| Ophthalmologist 1 (second-year fellow) | — | 0.217 (0.109–0.345) | 0.878 (0.832–0.920) | 0.105 (0.000–0.802) | 0.750 (0.700–0.802) | 0.299 (0.151–0.447) | 0.249 (0.129–0.358) |
| Ophthalmologist 2 (first-year fellow) | — | 0.337 (0.214–0.459) | 0.808 (0.751–0.856) | 0.138 (0.019–0.267) | 0.717 (0.662–0.768) | 0.297 (0.194–0.414) | 0.314 (0.210–0.425) |
| Ophthalmologist 3 (retinal specialist for 35 yrs) | — | 0.137 (0.053–0.226) | 0.976 (0.952–0.995) | 0.159 (0.040–0.279) | 0.814 (0.768–0.855) | 0.589 (0.300–0.882) | 0.217 (0.089–0.341) |
| Ophthalmologist 4 (retinal specialist for 2 yrs) | — | 0.232 (0.125–0.345) | 0.919 (0.882–0.954) | 0.180 (0.052–0.308) | 0.787 (0.741–0.833) | 0.410 (0.227–0.575) | 0.293 (0.168–0.410) |
| Reading center† | — | 0.193 (0.096–0.296) | 0.991 (0.976–1.000) | 0.258 (0.130–0.387) | 0.836 (0.791–0.875) | 0.837 (0.581–1.000) | 0.311 (0.173–0.444) |
| DenseNet | 0.817 | 0.527 (0.398–0.670) | 0.920 (0.885–0.954) | 0.471 (0.330–0.606) | 0.844 (0.798–0.886) | 0.614 (0.473–0.756) | 0.565 (0.434–0.674) |
— = not applicable.
For the color fundus photographs, the performance results are also shown for the reading center. For each metric, the highest result appears in boldface.
The performance metrics and their 95% confidence intervals were evaluated by bootstrap analysis.
Reading center evaluation of color fundus photographs, assessed by the ground truth of reading center independent evaluation of the corresponding fundus autofluorescence images.
Figure 3.
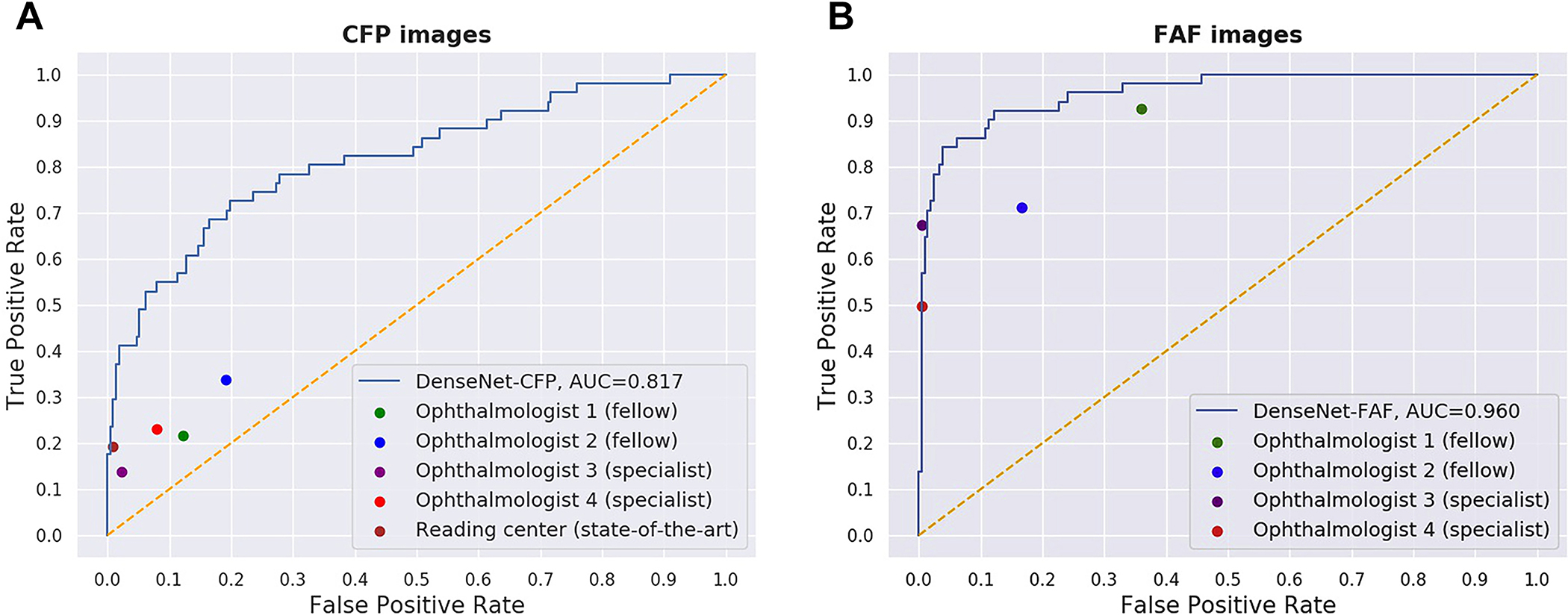
Receiver operating characteristic curves for the detection of reticular pseudodrusen by the convolutional neural network DenseNet from (A) fundus autofluorescence (FAF) images and (B) their corresponding color fundus photography (CFP) images. The performance of the 4 ophthalmologists on the same test sets is shown by 4 single points. In (B), the performance of the reading center grading of the CFP images also is shown as a single point. In all cases, the ground truth is the reading center grading of the FAF images. AUC = area under the receiver operating characteristic curve. Ophthalmologist 1 was a second-year retinal fellow, ophthalmologist 2 was a first-year retinal fellow, ophthalmologist 3 had been a retinal specialist for 35 years, and ophthalmologist 4 had been a retinal specialist for 2 years.
For the FAF image analyses, DenseNet, relative to the 4 ophthalmologists, achieved the highest κ value, the primary performance metric, at 0.789 (95% CI, 0.675–0.875). This was numerically higher than the κ value of 1 retinal specialist, substantially higher than that of the other retinal specialist, and very substantially higher than that of the 2 retinal fellows. Regarding accuracy and F1 score, DenseNet achieved the highest performance, at 0.937 (95% CI, 0.907–0.963) and 0.828 (95% CI, 0.725–0.898), respectively. The 2 retinal specialists demonstrated high levels of specificity (0.995 [95% CI, 0.986–1.0001 for both) and precision (0.961 [95% CI, 0.870–1.0001 and 0.973 [95% CI, 0.906–1.000]) but at the expense of decreased sensitivity (0.498 [95% CI, 0.367–0.6321 and 0.673 T95% CI, 0.544–0.8001). Regarding the ROC curves (Fig 3A), the performance of the 2 retinal specialists was similar or very slightly superior to that of DenseNet (AUC, 0.962), whereas the performance of the 2 fellows was cither moderately or substantially inferior.
For the CFP image analyses, DenseNet, relative to the 4 ophthalmologists, achieved the highest κ value, at 0.471 (95% CI, 0.330–0.606), the primary performance metric. This was very substantially higher than the κ value of all 4 ophthalmologists (range, 0.105–0.180). It was also substantially higher than the reading center grading of CFP, at 0.258 (95% CI, 0.130–0.387). Regarding accuracy and F1 score, DenseNet achieved the highest performance, at 0.844 (95% CI, 0.798–0.886) and 0.565 (95% CI, 0.434–0.674), respectively. Both the 4 ophthalmologists and the reading center grading demonstrated relatively high levels of specificity but extremely low levels of sensitivity, consistent with the idea that RPD arc not consistently discernable from CFP by human viewers.15,18,19 Regarding the ROC curves (Fig 3B), the performance of DenseNet (AUC, 0.817) was substantially superior to that of all 4 ophthalmologists and very substantially superior to that of 3 of them.
Secondary Analyses
To explore scenarios in which the DenseNet deep learning models may perform more or less accurately, prespecified secondary analyses were performed, considering eyes with RPD “in evolution” (i.e., in which the reading center grading for RPD on FAF images changed from absent to present over the course of the AREDS2 follow-up period). From previous natural history studies, newly arisen RPD are thought to be localized (rather than widespread across the macula) and may be subtle, even on FAF imaging.11,12 Hence, the test set was divided (at the eye level) into 2 subgroups, for both the FAF and CFP images: (1) images from eyes whose RPD grading changed from absent to present during follow-up, and (2) all other images. The performance of the 2 DenseNet deep learning models was tested separately on the 2 subgroups of images. The performance metrics are shown in Table 4.
Table 4.
Secondary Analyses: Performance Results of the DenseNet Deep Learning Models for the Detection of Reticular Pseudodrusen Presence from Fundus Autofluorescence Images and Their Corresponding Color Fundus Photographs Using the Full Test Set with and without Excluding Images from Eyes Whose Grading Changed over the Study Period from Absent to Present (i.e., Converting Eyes)
| Performance Metric |
|||||||
|---|---|---|---|---|---|---|---|
| Area under the Receiver Operating Characteristic Curve | Sensitivity (Recall) | Specificity | κ Value | Accuracy | Precision | F1 Score | |
|
| |||||||
| Fundus autofluorescence images | |||||||
| All images (n = 2249) | 0.941 | 0.707 | 0.967 | 0.721 | 0.900 | 0.882 | 0.785 |
| Images from converting eyes only (n = 197) | 0.827 | 0.482 | 0.929 | 0.383 | 0.675 | 0.900 | 0.628 |
| All images except those from converting eyes (n = 2052) | 0.960 | 0.761 | 0.969 | 0.766 | 0.922 | 0.879 | 0.816 |
| Color fundus photographs | |||||||
| All images (n = 2249) | 0.832 | 0.537 | 0.903 | 0.469 | 0.809 | 0.660 | 0.592 |
| Images from converting eyes only (n = 197) | 0.636 | 0.348 | 0.847 | 0.180 | 0.563 | 0.750 | 0.476 |
| All images except those from converting eyes (n = 2052) | 0.863 | 0.582 | 0.907 | 0.507 | 0.832 | 0.649 | 0.613 |
For both the FAF and the CFP analyses, as hypothesized, the performance metrics generally were inferior for the first subgroup (i.e., eyes with RPD in evolution) and superior for the second subgroup. For example, for the FAF image analyses, the AUC was 0.827 versus 0.960, respectively, and the κ value was 0.383 versus 0.766, respectively. Similarly, for the CFP analyses, the AUC was 0.636 and 0.863, respectively, and the κ value was 0.180 and 0.507, respectively.
In addition, post hoc analyses were performed to explore whether the performance of the 2 DenseNet models was affected by AMD severity, specifically the presence or absence of late AMD. The results are described in the Supplemental Materials (available at www.aaojoumal.org).
Attention Maps Generated on Fundus Autofluorescence Images and Color Fundus Photographs by Deep Learning Model Evaluation
Consequent to the evaluation of FAF and CFP images using the DenseNet models, attention maps were generated and superimposed on the fundus images to represent in a quantitative manner the relative contributions that different areas in each image made to the ascertainment decision. Examples of these attention maps arc shown for 3 separate FAF and CFP image pairs from different study participants in Figure 4. As seen in these examples, the areas of the fundus images that contributed most consequentially to RPD detection were located in the outer areas of the central macula within the vascular arcades, approximately 3 to 4 mm from the foveal center. Although the algorithms were not subject to any spatial guidance with respect to the location of RPD, these “high-attention” areas correspond well to the typical localization of clinically observable RPD within fundus images.11,12 In the specific examples shown in Figure 4, clinically observable RPD can be located within these high-attention areas. Hence, through these attention maps, the outputs of the deep learning models display a degree of face validity and interpretability for the detection of RPD. Qualitatively, a moderate degree of correspondence was found between the attention maps of corresponding FAF and CFP pairs, with each showing a similar macular distribution.
Figure 4.

Deep learning attention maps overlaid on fundus autofluorescence (FAF) images and color fundus photography (CFP) images. For each of the 3 representative eyes, the FAF images (left column) and CFP images (right column) are shown in the top row, with the corresponding attention maps overlaid in the bottom row. The heatmap scale for the attention maps also is shown: signal range from −1.00 (purple) to +1.00 (brown). A, (Top left) Original FAF image. Reticular pseudodrusen (RPD) are observed as ribbon-like patterns of round and oval hypoautofluorescent lesions with intervening areas of normal and increased autofluorescence in the following locations: (1) in an arcuate band across the superior macula (black arrows), extending across the vascular arcade to the area superior to the optic disc, and less prominently and affecting a smaller area, and (2) in the inferior macula (broken black arrows), extending across the vascular arcade to the area inferior to the optic disc. (Bottom left) Fundus autofluorescence image with deep learning attention map overlaid. The areas of highest signal correspond very well with the retinal locations observed to contain RPD in the original FAF image. The superior arcuate band, extending to the area superior to the optic disc, is demonstrated clearly (black arrows), as are the 2 inferior locations (broken black arrows). The predominance of superior over inferior macular involvement also is captured in the attention map. (Top right) Original CFP image. Reticular pseudodrusen are not observed in most retinal locations known to be affected from the corresponding FAF image. However, an area of possible involvement may be present on the CFP image at the superonasal macula (broken gray arrow). (Bottom right) Color fundus photography image with deep learning attention map overlaid. The areas of highest signal correspond very well with both (1) the retinal locations observed to contain RPD in the original FAF image (although the deep learning model never received the FAF image as input) and (2) the areas of highest signal in the FAF image attention map. Hence, the CFP attention map has areas of high signal in both (1) the area (superonasal macula) with RPD possibly visible to humans on the CFP image (broken gray arrow) and (2) other areas where RPD appear invisible on the CFP image, but visible on the corresponding FAF image. B, (Top left) Original FAF image. Reticular pseudodrusen are observed clearly as widespread ribbon-like patterns of round and oval hypoautofluorescent lesions with intervening areas of normal and increased autofluorescence. The area affected is large, affecting almost the entire macula, but sparing the central macula, that is, in a doughnut configuration. (Bottom left) Fundus autofluorescence image with deep learning attention map overlaid. The doughnut configuration is captured well on the attention map, that is, the areas of highest signal correspond very well with the retinal locations observed to contain RPD in the FAF image. (Top right) Original CFP image. Reticular pseudodrusen are observed in some, but not all, of the retinal locations known from the corresponding FAF image to contain RPD: the superior peripheral macula seems to contain RPD (broken gray arrow), but they are not visible clearly in the inferior peripheral macula. (Bottom right) Color fundus photography image with deep learning attention map overlaid. The CFP attention map has areas of high signal in both (1) the area (superior macula) with RPD visible to humans on the CFP image (broken gray arrow), and (2) other areas (inferior macula) where RPD seem invisible on the CFP image but visible on the corresponding FAF image (although the deep learning model never received the FAF image as input). C, (Top left) Original FAF image. Reticular pseudodrusen are observed as ribbon-like patterns of round and oval hypoautofluorescent lesions with intervening areas of normal and increased autofluorescence. These are relatively widespread across the macula (black arrows; corresponding almost to a doughnut configuration), as well as the area superior to the optic disc (black arrow), but are less apparent in the inferior and inferotemporal macula (broken black arrows). (Bottom left) Fundus autofluorescence image with deep learning attention map overlaid. The areas of highest signal correspond very well with the retinal locations observed to contain RPD in the original FAF image (black arrows). The doughnut configuration, with partial sparing of the inferotemporal macula (broken black arrows), complete sparing of the central macula (affected by geographic atrophy), and additional involvement of the area superior to the optic disc, is captured well. (Top right) Original CFP image. Reticular pseudodrusen are not observed in most retinal locations known from the corresponding FAF image to be affected. However, an area of possible involvement may be present on the CFP image at the superotemporal macula (broken gray arrow). (Bottom right) Color fundus photography image with deep learning attention map overlaid. The CFP attention map shows areas of high signal in both (1) the area (superotemporal macula) with RPD potentially visible to humans on the CFP image (broken gray arrow), and (2) another area (inferior to the optic disc) that potentially may contain additional signatures of RPD presence.
Discussion
Main Findings
The DenseNet deep learning model was able to identify RPD presence from FAF images with a relatively high level of accuracy during internal validation on the AREDS2 test set. The AUC was high at 0.94, driven principally by high specificity of 0.97 (and lower sensitivity of 0.70). The performance was superior to that of the 4 ophthalmologists, although they had a specialized interest in RPD (with a greater than typical experience in viewing RPD-containing images) and substantially higher than that of the 2 ophthalmologists at the fellowship level. Hence, depending strongly on the results of external validation, the performance of the deep learning model might be expected to exceed that of nonspecialized ophthalmologists in routine clinical practice. This level of performance was achieved by the deep learning model without any preprocessing of the test images before analysis, nor were test images prescreened for high image quality.
The performance of the deep learning model seemed to be stratified according to how recently RPD had evolved during study follow-up. Its performance was higher on a prespecified subset that excluded eyes in which RPD grades changed from absent to present during follow-up relative to its performance on the overall test set. These eyes contained RPD that had newly arisen during study follow-up, which often are subtle and localized to a smaller area and thus challenging to detect. For the subset of eyes with established RPD presence, the AUC increased to 0.96, which may approach the limit of the ability of trained human graders to detect RPD from FAF images (i.e., the gold standard method used to label RPD presence). For context, the reading center grading for this complete dataset (including the training, validation, and test sets considered together) had an intergrader agreement value of 94%.15
The important next step in this study was to analyze the ability of deep learning models to detect RPD from CFP images. Reticular pseudodrusen typically are considered to be very difficult to detect from CFP images, even by retinal specialists or trained human graders. (Indeed, in this same dataset, among eyes with RPD graded as present on FAF imaging, the equivalent feature was graded positive on the corresponding CFP images in only 21% of eyes.15) Label transfer from graded corresponding FAF images served as the gold standard for these CFP images for the purposes of model training and testing. We found that the model identified RPD presence from CFP images with an AUC of 0.83, including a relatively high specificity of 0.90. This performance substantially exceeded not only that of the 4 ophthalmologists (across a range of experience and specialized expertise) but also that of grading at the reading center level. Depending on the results of external validation, this highlights the potential for deep learning models like this to ascertain RPD presence from CFP in a practical way, that is, without requiring access to FAF images. This approach would be particularly attractive if the sensitivity could be improved by further training on additional datasets.
Implications and Importance
The ability to perform accurate detection of RPD presence in an efficient and accessible manner is of practical importance for multiple reasons. It enables a more detailed AMD classification and phenotyping that provides important diagnostic and prognostic information relevant to medical decision making. Accurate RPD ascertainment can lead to more precise patient risk stratification for late AMD that can guide the institution of risk-reduction treatments (e.g., Age-Related Eye Disease Study supplementation) and appropriate patient follow-up frequency. Given that RPD presence increases the likelihood of progression to late AMD and preferentially to specific forms of late AMD,11 its inclusion in progression prediction algorithms can enable more accurate overall and subtype-specific predictions. Similarly, predictions of GA enlargement rates are likely to be improved,16 which is important for patient recruitment, stratification, and data analysis in future clinical trials for GA intervention. Another example is experimental subthreshold nanosecond laser treatment of intermediate AMD, in which RPD presence highly influences the effect of treatment on decreasing or conversely increasing progression risk to late AMD.17
Using automated algorithms to ascertain RPD presence also has advantages over ascertainment by human graders and clinicians. Deep learning models can perform grading of large numbers of images very quickly, with complete consistency, and can provide a confidence value associated with each binary prediction. Attention maps can be generated for each graded image to verify that the models are behaving with face validity. By contrast, human grading of RPD presence, particularly from CFP, is difficult to perform accurately, even by trained graders at the reading center level. This form of grading is operationally time consuming and is associated with lower rates of intergrader agreement relative to other AMD-associated features.18,23,24 Human grading of RPD presence from FAF images has higher accuracy than from CFP imaging, but additional FAF imaging in clinical care involves added time and expense, and grading expertise for FAF images currently is limited to a small number of specialist centers in developed countries.
With label transfer, we have the potential for deep learning models to be capable of ascertaining RPD presence from CFP images. This capability could unlock an additional dimension in CFP image datasets from established historical studies of AMD that are unaccompanied by corresponding images captured with other methods and impractical to replicate with multimodal imaging. These include the Age-Related Eye Disease Study, Beaver Dam Eye Study, Blue Mountains Eye Study, and other population-based and AMD-based longitudinal datasets that have provided a wealth of information on AMD epidemiologic characteristics and genetics.
It is possible that the deep learning models presented here also may be applicable to 45° images (i.e., in addition to the standard 30° images that this dataset comprised), either directly or after additional training. This would entail brief additional training using a sample of 45° images with accompanying labels for the presence and absence of RPD. However, these ideas have not been tested in the current work.
Exploratory Error Analyses
Exploratory error analyses were performed to investigate the possibility that poor image quality may be a factor that limits deep learning model performance and to observe potential patterns of findings in images that were associated with errors. These analyses were performed by examining random samples of 20 images in each of the 4 following categories of images misclassified by the 2 DenseNet deep learning models: FAF image false-negative and false-positive results and CFP image false-negative and false-positive results; representative examples for each of the error categories are shown in the Supplemental Material. The images were analyzed qualitatively by one of the authors (T.D.K., a National Eye Institute faculty retinal specialist). Regarding the FAF images, 10 of the false-negative and 2 of the false-positive cases had poor or very poor image quality. For 3 of the false-positive cases, the reading center label was negative for those particular images but positive for subsequent images acquired 1 to 2 years later. Regarding the CFP images, 7 of the false-positive and 5 of the false-negative cases had poor or very poor image quality. These error analyses suggest that overall model accuracy may be impacted negatively by a subset of images of poor quality. Although we did not filter images by quality criteria in the current study, the institution of such measurements may be used to increase model performance.
Comparison with Literature
We are not aware of any previous reports exploring the use of deep learning to detect RPD from en face imaging. One prior report described a traditional machine learning approach to the identification of RPD from CFP, FAF, and NIR images (alone and in combination).23 In this study, the dataset contained 278 eyes from the Rotterdam Study, including 72 with RPD. Importantly, the eyes with RPD were selected by identification from CFP, with confirmation on FAF and NIR imaging. Hence, unusually, all 72 positive cases showed RPD apparent on CFP. Therefore, it is possible that these RPD cases are not representative of the full spectrum of eyes with RPD. The machine learning approach comprised 3 steps: preprocessing, feature extraction, and classification. The preprocessing step required the manual specification of landmarks for every image, for registration, followed by vessel removal. The feature extraction step involved the application of Gaussian filters followed by the calculation of multiple feature values for each pixel. The final prediction was performed by a random forest classifier and the generation of a probability map. This method requires labeled training examples produced by human experts.
The authors of the prior study reported an AUC of 0.844 (sensitivity, 0.806; specificity, 0.747) for identification from FAF images alone, that is, a much lower AUC than our deep learning model, with substantially lower specificity. Interestingly, the AUC was higher for identification from CFP images alone (AUC, 0.942); however, this presumably relates to the fact that the cases were selected from CFP examples of RPD. The AUC for detection from multimodal images was 0.941, that is, similar to that for CFP alone. Regarding comparison with 2 human retinal specialists, the AUC of 0.844 for detection from FAF alone by the machine learning approach was lower than that of one of the retinal specialists (AUC, 0.793) and higher than that of the other (AUC, 0.881).
Although direct comparison between the prior study and our study is only partially meaningful, the AUC of 0.939 from deep learning identification on FAF images compares favorably with the AUC of 0.844 from machine learning. Indeed, deep learning has clear advantages over traditional machine learning. The accuracy of deep learning models usually is substantially higher than that of machine learning approaches and has less tendency to reach a plateau with increasing training data. Although machine learning normally requires a task to be broken down into multiple steps and may require some manual input, deep learning does not; our deep learning approach is completely automated and involves minimal preprocessing. In addition, deep learning models also are considered more adaptable and transferable; for example, our deep learning models are likely to be transferable to other en face imaging methods, such as NIR or confocal blue reflectance.
Strengths and Limitations
The strengths of this study include the large size of the FAF image dataset (one of the largest currently available) in a well-characterized cohort of participants with AMD followed up longitudinally. With regard to the ground truth used for image labels, the availability of reading center-level annotation for all images by at least 2 certified graders, using a single grading definition under a standardized protocol, is a major strength. Because the FAF images had accompanying CFP images captured at the same visit, we were able to use the powerful technique of label transfer. Other strengths include the use of multiple CNNs (i.e., to select the one with optimum performance) and the comparison of performance with that of ophthalmologists at 2 different levels of experience. Importantly, the models are likely to be highly generalizable, given the breadth of training data from many retinal specialty clinics across the United States, together with the variety of FAF and CFP cameras and operators used. Indeed, we did not exclude any images on the basis of quality, unlike in many studies of RPD; had we done so, our accuracy likely would have been higher, but we preferred to aim as far as possible for real-world generalizability. Finally, the attention maps provide a degree of interpretability and face validity.
The limitations of the study include the use of 1 imaging method (FAF) for the ground truth classification of RPD presence, rather than another imaging method (e.g., NIR or OCT) or multimodal assessment. Some previous studies have reported that NIR imaging has slightly higher sensitivity than FAF imaging for RPD detection (e.g., 95% vs. 87% in a small Japanese study24); however, the disadvantages of NIR include lower specificity than FAF24 and low sensitivity in detecting ribbon-type RPD.38 Similarly, spectral-domain OCT imaging generally is considered to have slightly higher sensitivity and specificity than FAF imaging, but this may be dependent on the instrument used11; in addition, RPD are found most commonly in and near the superior and inferior arcades, so that standard macular cube scans may miss some cases.11 With regard to multimodal imaging, adding a second imaging method has the potential to increase either the sensitivity or the specificity but not both.11 Indeed, in the Rotterdam Study described previously, the AUC values for the identification of RPD presence from good-quality images by 2 retinal specialists actually were similar for FAF alone versus multimodal imaging (comprising CFP, FAF, and NIR).23
Additional training data to fine-tune model performance would be helpful, particularly for the CFP model, which had lower sensitivity than the FAF model. To maximize the size of the training data, multiple images were used from approximately half of the study eyes (i.e., from both the baseline study visit and follow-up visits). However, this increases the chance of overfitting to the dataset, with the possibility that performance will be inferior during external validation. Hence, as with any novel diagnostic aid or test, we strongly recommend external validation of these models on different datasets, ideally on a variety of datasets including both clinic-based cohorts (with a high prevalence of AMD) and population-based cohorts (with a lower prevalence of AMD). For these reasons, we are planning external validation studies using well-chosen population-based studies from different continents.
Additional steps are required before deployment of deep learning models like this in clinical practice. In addition to external validation, prospective validation would be ideal, for example, comparing the performance of ophthalmologists versus deep learning for detecting RPD in a prospective clinical trial setting (as carried out recently for diabetic retinopathy,39 leading to the first Food and Drug Administration approval of an autonomous artificial intelligence system in clinical care) or a cross-over clinical trial comparing the performance of physicians aided versus unaided by a deep learning software tool for RPD detection. Although detecting RPD is likely to be very useful for refined diagnostic and prognostic purposes, as described previously, further progress elsewhere in the field may be required to show that systems like this may decrease vision loss from AMD. For example, understanding the differential effect of treatments like experimental subthreshold nanosecond laser, according to RPD presence or absence,17 will be vital.
In conclusion, our highest-performing deep learning model, selected from the quantitative assessment of 5 separate CNNs, achieved a high level of accuracy in the detection of RPD presence from FAF images during internal validation. This level was equal or superior to that of ophthalmologists tested in our clinic and likely to that of non-specialized ophthalmologists in clinical practice. The model is rapid and consistent and capable of handling large numbers of images and can generate ancillary attention maps that help to provide face validity and interpretability. The application of label transfer as a technique further enabled the training of deep learning models for detecting RPD presence from CFP images, a task that is performed suboptimally by human graders. The highest performing model for this task achieved an accuracy substantially higher than that of all ophthalmologists tested in our clinic, across different levels of experience, and even that of grading at the level of the reading center. This CFP-based model may find potential use in identifying RPD from historical image datasets comprising solely CFP images, enabling analyses regarding AMD risk and progression not previously possible owing to suboptimal human grading for RPD. Depending on external validation, these models potentially could lead to efficient and accessible real-world ascertainment of RPD presence in ways helpful to the diagnosis and prognosis of AMD patients.
Supplementary Material
Acknowledgments
Supported by the National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, and the National Eye Institute, National Institutes of Health, Bethesda, Maryland (grant nos.: HHS-N-260-2005-00007-C, N01-EY-5-0007, and K99LM013001). Funds were generously contributed to these contracts by the following National Institutes of Health institutes: Office of Dietary Supplements; National Center for Complementary and Alternative Medicine; National Institute on Aging; National Heart, Lung, and Blood Institute; and National Institute of Neurological Disorders and Stroke. The sponsor and funding organization participated in the design and conduct of the study; data collection, management, analysis, and interpretation; and the preparation, review and approval of the manuscript. Supported by the Heed Ophthalmic Foundation (C.K.H.); and the NIH Medical Research Scholars Program (D.H.L), a public-private partnership supported jointly by the National Institutes of Health and by contributions to the Foundation for the National Institutes of Health from the Doris Duke Charitable Foundation (grant no.: 2014194), the American Association for Dental Research, the Colgate-Palmolive Company, Genentech, Elsevier, and other private donors.
Abbreviations and Acronyms:
- AMD
age-related macular degeneration
- AREDS2
Age-Related Eye Disease Study 2
- AUC
area under the receiver operating characteristic curve
- CFP
color fundus photograph
- CI
confidence interval
- CNN
convolutional neural network
- FAF
fundus autofluorescence
- GA
geographic atrophy
- NIR
near-infrared reflectance
- OCT
optical coherence tomography
- ROC
receiver operating characteristic
- RPD
reticular pseudodrusen
Footnotes
Financial Disclosure(s):
The author(s) have made the following disclosure(s): T.D.K.: Patent pending – “Methods and Systems for Predicting Rates of Progression of Age-Related Macular Degeneration”; Financial support – Bayer
Q.C.: Patent pending – “Methods and Systems for Predicting Rates of Progression of Age-Related Macular Degeneration”
Y.P.: Patent pending – “Methods and Systems for Predicting Rates of Progression of Age-Related Macular Degeneration”
E.A.: Patent pending – “Methods and Systems for Predicting Rates of Progression of Age-Related Macular Degeneration”
Z.L.: Patent pending – “Methods and Systems for Predicting Rates of Progression of Age-Related Macular Degeneration”
E.Y.C.: Patent pending – “Methods and Systems for Predicting Rates of Progression of Age-Related Macular Degeneration”
HUMAN SUBJECTS: Human subjects were included in this study. Institutional review board approval was obtained at the National Eye Institute (the Combined NeuroScience Institutional Review Board [CNS IRB]-Blue Panel). All research complied with the Health Insurance Portability and Accountability (HIPAA) Act of 1996 and adhered to the tenets of the Declaration of Helsinki. All participants provided informed consent.
No animal subjects were included in this study.
Supplemental material available at www.aaojournal.org.
References
- 1.Quartilho A, Simkiss P, Zekite A, et al. Leading causes of certifiable visual loss in England and Wales during the year ending 31 March 2013. Eye (Lond). 2016;30(4):602–607. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Congdon N, O’Colmain B, Klaver CC, et al. Causes and prevalence of visual impairment among adults in the United States. Arch Ophthalmol. 2004;122(4):477–485. [DOI] [PubMed] [Google Scholar]
- 3.Age-Related Eye Disease Study Research Group. A randomized, placebo-controlled, clinical trial of high-dose supplementation with vitamins C and E, beta carotene, and zinc for age-related macular degeneration and vision loss: AREDS report no. 8. Arch Ophthalmol. 2001;119(10):1417–1436. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Age-Related Eye Disease Study 2 Research Group. Lutein + zeaxanthin and omega-3 fatty acids for age-related macular degeneration: the Age-Related Eye Disease Study 2 (AREDS2) randomized clinical trial. JAMA. 2013;309(19):2005–2015. [DOI] [PubMed] [Google Scholar]
- 5.Lawrenson JG, Evans JR. Advice about diet and smoking for people with or at risk of age-related macular degeneration: a cross-sectional survey of eye care professionals in the UK. BMC Public Health. 2013;13:564. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Domalpally A, Clemons TE, Bressler SB, et al. Imaging characteristics of choroidal neovascular lesions in the AREDS2-HOME study: report number 4. Ophthalmol Retina. 2019;3(4):326–335. [DOI] [PubMed] [Google Scholar]
- 7.Group AHSR Chew EY, Clemons TE, et al. Randomized trial of a home monitoring system for early detection of choroidal neovascularization home monitoring of the Eye (HOME) study. Ophthalmology. 2014;121(2):535–544. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Wittcnbom JS, Clemons T, Regillo C, et al. Economic evaluation of a home-based age-Related macular degeneration monitoring system. JAMA Ophthalmol. 2017;135(5):452–459. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.American Academy of Ophthalmology. Age-related macular degeneration Preferred Practice Patterns. Accessed 25.04.19 https://www.aao.org/preferred-practice-pattern/age-related-macular-degeneration-ppp-2015. Accessed 25.04.19.
- 10.Calaprice-Whitty D, Galil K, Salloum W, et al. Improving clinical trial participant prescreening with artificial intelligence (AI): a comparison of the results of AI-assisted vs standard methods in 3 oncology trials. Ther Innov Regul Sci. 2020;54(1):69–74. [DOI] [PubMed] [Google Scholar]
- 11.Spaide RF, Ooto S, Curcio CA. Subretinal drusenoid deposits AKA pseudodrusen. Surv Ophthalmol. 2018;63(6):782–815. [DOI] [PubMed] [Google Scholar]
- 12.Wightman AJ, Guymer RH. Reticular pseudodrusen: current understanding. Clin Exp Optom. 2019;102(5):455–462. [DOI] [PubMed] [Google Scholar]
- 13.Sadda SR, Guymer R, Holz FG, et al. Consensus definition for atrophy associated with age-related macular degeneration on OCT: Classification of Atrophy report 3. Ophthalmology. 2018;125(4):537–548. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Spaide RF. Outer retinal atrophy after regression of subretinal drusenoid deposits as a newly recognized form of late age-related macular degeneration. Retina. 2013;33(9):1800–1808. [DOI] [PubMed] [Google Scholar]
- 15.Domalpally A, Agrón E, Pak JW, et al. Prevalence, risk, and genetic association of reticular pseudodrusen in age-related macular degeneration: Age-Related Eye Disease Study 2 report 21. Ophthalmology. 2019;126(12):1659–1666. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Fleckenstein M, Mitchell P, Freund KB, et al. The progression of geographic atrophy secondary to age-related macular degeneration. Ophthalmology. 2018;125(3):369–390. [DOI] [PubMed] [Google Scholar]
- 17.Guymer RH, Wu Z, Hodgson LAB, et al. Subthreshold nanosecond laser intervention in age-related macular degeneration: the LEAD randomized controlled clinical trial. Ophthalmology. 2019;126(6):829–838. [DOI] [PubMed] [Google Scholar]
- 18.Schmitz-Valckenberg S, Altcn F, Steinberg JS, et al. Reticular drusen associated with geographic atrophy in age-related macular degeneration. Invest Ophthalmol Vis Sci. 2011;52(9):5009–5015. [DOI] [PubMed] [Google Scholar]
- 19.Alten F, Clemens CR, Heiduschka P, Eter N. Characterisation of reticular pseudodrusen and their central target aspect in multi-spectral, confocal scanning laser ophthalmoscopy. Graefes Arch Clin Exp Ophthalmol. 2014;252(5):715–721. [DOI] [PubMed] [Google Scholar]
- 20.Ferris FL 3rd, Wilkinson CP, Bird A, et al. Clinical classification of age-related macular degeneration. Ophthalmology. 2013;120(4):844–851. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Davis MD, Gangnon RE, Lee LY, et al. The Age-Related Eye Disease Study severity scale for age-related macular degeneration: AREDS report no. 17. Arch Ophthalmol. 2005;123(11):1484–1498. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Ferris FL, Davis MD, Clemons TE, et al. A simplified severity scale for age-related macular degeneration: AREDS report no. 18. Arch Ophthalmol. 2005;123(11):1570–1574. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.van Grinsven MJ, Buitendijk GH, Brussee C, et al. Automatic identification of reticular pseudodrusen using multimodal retinal image analysis. Invest Ophthalmol Vis Sci. 2015;56(1):633–639. [DOI] [PubMed] [Google Scholar]
- 24.Ueda-Arakawa N, Ooto S, Tsujikawa A, et al. Sensitivity and specificity of detecting reticular pseudodrusen in multimodal imaging in Japanese patients. Retina. 2013;33(3):490–497. [DOI] [PubMed] [Google Scholar]
- 25.Peng Y, Dharssi S, Chen Q, et al. DeepSeeNet: a deep learning model for automated classification of patient-based age-related macular degeneration severity from color fundus photographs. Ophthalmology. 2019;126(4):565–575. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Keenan TD, Dharssi S, Peng Y, et al. A deep learning approach for automated detection of geographic atrophy from color fundus photographs. Ophthalmology. 2019;126(11):1533–1540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Varadarajan AV, Bavishi P, Ruamviboonsuk P, et al. Predicting optical coherence tomography-derived diabetic macular edema grades from fundus photographs using deep learning. Nat Commun. 2020;11(1):130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.AREDS2 Research Group, Chew EY, Clemons T, et al. The Age-Related Eye Disease Study 2 (AREDS2): study design and baseline characteristics (AREDS2 report number 1). Ophthalmology. 2012;119(11):2282–2289. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Chen Q, Peng Y, Keenan T, et al. A multi-task deep learning model for the classification of age-related macular degeneration. AMIA Jt Summits Transl Sci Proc. 2019;2019:505–514. [PMC free article] [PubMed] [Google Scholar]
- 30.Huang G, Liu Z, Pleiss G, et al. Convolutional Networks With Dense Connectivity. IEEE Trans Pattern Anal Mach Intell. 2019. May 23. 10.1109/TPAMI.2019.2918284. Online ahead of print. [DOI] [PubMed] [Google Scholar]
- 31.Rawat W, Wang Z. Deep convolutional neural networks for image classification: a comprehensive review. Neural Comput. 2017;29(9):2352–2449. [DOI] [PubMed] [Google Scholar]
- 32.Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. ICLR. 2015. [Google Scholar]
- 33.Szegedy C, Vanhouckc V, Ioffe S, et al. Rethinking the inception architecture for computer vision. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015. [Google Scholar]
- 34.He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition; 2016. Available at: arxiv.org/abs/1512.03385. Accessed 11/13/2019. [Google Scholar]
- 35.Keras Chollet F.. https://github.com/keras-team/keras; 2015. Accessed 11/13/2019.
- 36.Abadi M, Agarwal A, Brevdo E, et al. TensorFlow: large-scale machine learning on heterogeneous distributed systems, https://arxiv.org/abs/1603.04467; 2015. Accessed 11/13/2019.
- 37.Simonyan K, Vcdaldi A, Zisserman A. Deep inside convolutional networks: visualising image classification models and saliency maps. https://arxiv.org/abs/1312.6034; 2013. Accessed 11/13/2019. [Google Scholar]
- 38.Suzuki M, Sato T, Spaide RF. Pseudodrusen subtypes as delineated by multimodal imaging of the fundus. Am J Ophthalmol. 2014;157(5):1005–1012. [DOI] [PubMed] [Google Scholar]
- 39.Abramoff MD, Lavin PT, Birch M, et al. Pivotal trial of an autonomous AI-based diagnostic system for detection of diabetic retinopathy in primary care offices. NPJ Digit Med. 2018; 1:39. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.