

Abstract
Recent quantitative parameter mapping methods including MR fingerprinting (MRF) collect a time series of images that capture the evolution of magnetization. The focus of this work is to introduce a novel approach termed as Deep Factor Model(DFM), which offers an efficient representation of the multi-contrast image time series. The higher efficiency of the representation enables the acquisition of the images in a highly undersampled fashion, which translates to reduced scan time in 3D high-resolution multi-contrast applications. The approach integrates motion estimation and compensation, making the approach robust to subject motion during the scan.
Index Terms—: Multi-Contrast, Motion Correction
1. INTRODUCTION
The signal in MRI is sensitive to multiple physical properties of the tissue, which is exploited to observe organs with different contrast mechanisms. The classical MRI methods approach is to carefully choose the acquisition parameters to make the images sensitive to a specific physical property while being less sensitive to others. For example, the magnetization prepared rapid gradient echo (MPRAGE)[1] sequence uses inversion pulses and restricts the acquisition of the data at specific inversion times to obtain good contrast between the gray matter (GM) and white matter (WM) regions. However, a challenge with this approach is its low acquisition efficiency, resulting from the long waiting times and delay times to allow the magnetization to recover. The MPnRAGE[2] sequence was introduced recently, which relies on continuously acquiring the images using radial acquisitions after the inversion pulse; the radial data is binned depending on the inversion time and recovered using gridding. In addition to improving acquisition efficiency, this approach enables the acquisition of images at multiple inversion times.
The MPnRAGE approach has conceptual similarities to MRF [3] that continuously acquires the data using incoherent sampling patterns, while magnetization is continuously evolving. MRF attempts to estimate the physical parameters (e.g. ) directly from the undersampled k-t space data using pattern matching. These methods rely on large dictionaries of MRF derived using Bloch equation simulations, which correspond to different values of the physical parameters. Several constrained reconstruction algorithms were introduced to improve the reconstruction of the individual frames in MRF; the strategies include low-rank factor modeling of the reconstructed images [4].
The main focus of this paper is to introduce DFM for the joint recovery of inversion recovery data. The proposed DFM, illustrated in Fig. 1 (b), is a generalization of the low-rank model. It capitalizes on the benefits of convolutional neural networks (CNN) in representing images. While unrolled algorithms [5] were introduced to improve low-rank or subspace models, these methods need multiple copies of the subspace images at each unrolling step; the extremely high memory demand of these approaches makes them infeasible in our 3D setting.
Fig. 1.
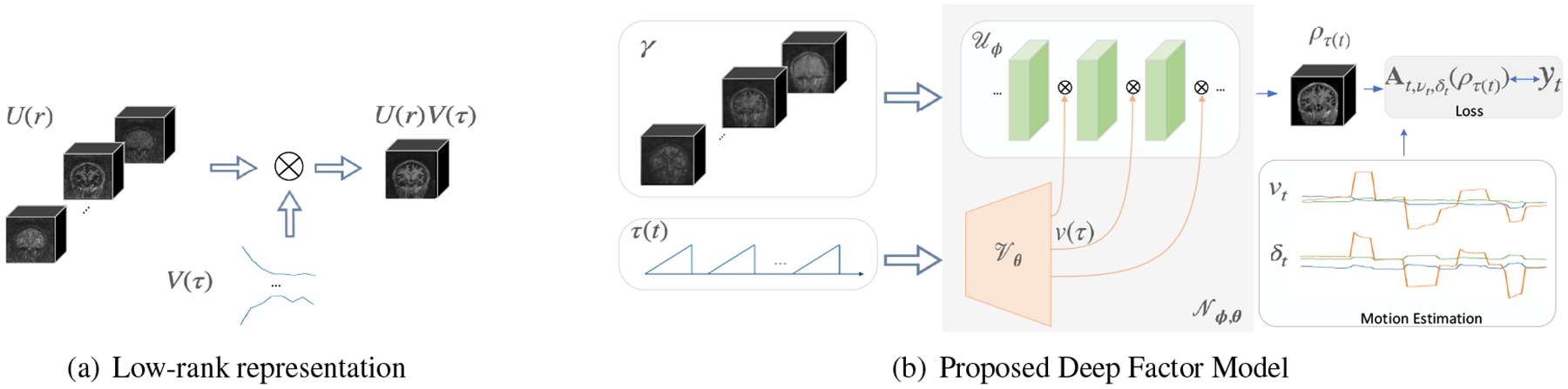
Illustration of the low-rank model and DFM. (a) The low-rank method represents the image corresponding to the delay as the weighted linear combination of the spatial basis functions based on weights ; (b) DFM models the signal as the output of a conditional network . The features of the CNN are modulated by generated by a dense network . The input to is , while that of the is an approximate initialization obtained from gridding.
The DFM represents each image in the time series as the output of a conditional CNN. The input of the CNN is a series of representative image volumes corresponding to a few inversion delays obtained from gridding. The inversion time-dependent network derives each image in the time series as a denoised non-linear function of the gridded images. The temporal factors derived from a dense network are used to modulate the features of the CNN. Unlike supervised deep learning models, DFM is an unsupervised learning approach that directly learns the subject-specific representation from the measured k-t space data. This approach of learning the network parameters from the undersampled measurements is motivated by [6], which learns an image or an ensemble of images from undersampled measurements. We hypothesize that non-linear deep representation is more efficient that the linear low-rank factor models, and offers implicit spatial regularization due to the implicit bias of CNN blocks towards images.
We also capitalize on the unsupervised learning strategy to compensate for subject motion. In particular, we model the subject motion during the scan as a rigid body. We use the relation between rigid body motions and corresponding transformations in the Fourier domain to absorb them into the forward model. These time-varying parameters are assumed to be unknowns and are solved during signal recovery.
The data is acquired using a radial ultrashort echo time (UTE) sequence with intermittent inversion pulses and a delay time for magnetization recovery. We acquire the data from 3T scanners, with and without motion.
2. PROPOSED APPROACH
2.1. Signal Acquisition and Modeling
The acquisition of data is illustrated in Fig. 2. We assume that the evolution of magnetization during each inversion block is identical, and one initial inversion and segmented UTE scheme is performed to reduce steady-state effects. We consider the image volume to be dependent on the delay from the previous inversion pulse.
Fig. 2.
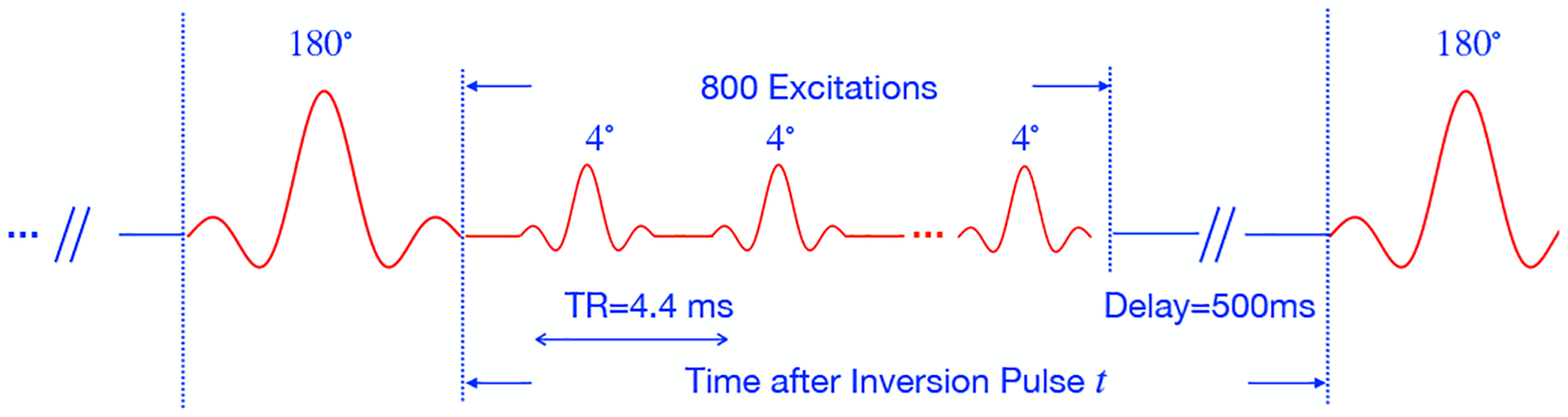
Illustration of the pulse sequence. The data is acquired using an inversion recovery with a segmented readout consisting of a train of UTE 3D radial acquisitions with ms. Intermittent adiabatic inversion pulses are applied after 800 UTE radial lines, with a delay of 500 ms after each segmented acquisition block to allow for signal recovery to a steady state. The total acquisition time was 4.3 minutes to acquire 50K spokes with a matrix size of 2563. The radial spokes are ordered according to the tiny golden angle view order. The field of view was 24cm3.
We model the signal measurements at the time instant
| (1) |
Here, denotes the forward model that accounts for multichannel Fourier measurements and the k-space trajectory at time , which is measured from the start of the acquisition. In the absence of motion, the measurements corresponding to a specific value can be pooled together.
2.2. Deep Factor Model
We note that low-rank factor models represent the signal as
| (2) |
where the columns of are the spatial factors and the rows of are the temporal factors. The spatial basis functions are modulated by the temporal basis functions to generate the image at a specific time . Note that low-rank factor models do not use any spatial regularization on the spatial basis functions .
We model the image as the output of a deep conditional network
| (3) |
and denote the parameters of , while denotes the inversion delay. is a coarse initial reconstruction.
We use a deep factor architecture to realize the conditional model as shown in Fig. 1 In particular, we feed delay time to a dense network , which provides the temporal factors
| (4) |
We apply channel-wise multiplication between the feature maps and corresponding temporal factors to modulate the feature maps of and obtain
| (5) |
One may view this approach as selectively activating and suppressing specific channels, based on the delay . If the network . only consists of a single hidden layer, this approach reduces to the traditional low-rank model. We expect the deep factorization at different layers to offer improved representation power. The unknowns of (3) are and . In the absence of motion, we pose the reconstction as
| (6) |
2.3. Deep Factor Model with Motion Compensation
We assume the brain to be a rigid body and model any subject motion using 3 rotations and 3 translations. The object at time instant is assumed to be a rotated and translated version of . We denote the transformation operator as , where and are the rotation and translation parameters at time . In particular,
| (7) |
where is the coordinate in the image domain. With this assumption, (1) changes as
| (8) |
We note that a rotation in the image domain by an angle corresponds to a rotation by the same angle in the Fourier domain. This amounts to rotating the k-space trajectory by the same angle. Similarly, a translation in the image domain corresponds to a phase modulation in the Fourier domain. Using these Fourier properties, we rewrite the above relation as
| (9) |
This reformulation allows us to absorb the impact of motion into the forward model and further extend the proposed method to DFM with motion compensation(DFM-MC). In the presence of motion, we use (9) to minimize the cost function
| (10) |
with respect to the network parameters as well as the motion parameters .
3. IMPLEMENTATION DETAILS
The data were acquired from two human volunteers on a 3.0T GE Premier scanner with 48 channel head coil. From each subject, we acquired two datasets. During the first acquisition, the subjects were instructed to stay still during the 4.3-minute acquisition. During the second acquisition, the subject was instructed to move the head multiple times during the scan. We implemented using a multichannel NUFFT operator, which was differentiable with respect to the input image as well as the trajectory parameters. Post recovery, we fed the network with different delays to generate the images. We used principal component analysis (PCA) to reduce the 48 coils to 10 virtual coils.
3.1. Deep Factor Model
We implemented using three 3D convolutional blocks, each with a 3D convolutional layer, a channel-wise multiplication layer, and a non-linear activation layer. Each block has 16 channels, except the last layer which has 2 channels representing the real and imaginary parts of the output image. contains two 2D convolutional blocks with kernel size 1 and 32 channels. The first block of is activated by tanh function. Other blocks are activated by the Leaky ReLU function. and are randomly initialized.
We binned the data into eight subsets according to and gridding was applied to each subset to obtain 8 volumes, denoted by . While these approximate reconstructions are very noisy and exhibit significant alias artifacts, they capture the contrasts reasonably well. In this work, we considered the recovery of images with 32 different inversion times; was linearly sampled from 0 to 1 with 32 steps. We jointly optimized and based on Eq. 6 In this section, we assume the acquisition was collected without motion.
3.2. Deep Factor Model with Motion Compensation
We assume the motion after one inversion pulse remains to be the same and hence estimate the motion of the subject with temporal resolution=4s. The parameters and were initialized as zeros in (10) and solved with and .
4. RESULTS
4.1. Validation of Deep factor model
We first validate DFM in the absence of motion in Fig. 3. We compare DFM against the low-rank approach with two ranks. We observed that the lower rank translated to a poor fit to the magnetization recovery curve. In particular, we note that GM does not appear fully inverted in low-rank reconstructions at ms. By contrast, the DFM and low-rank reconstructions show nulled GM as expected.
Fig. 3.
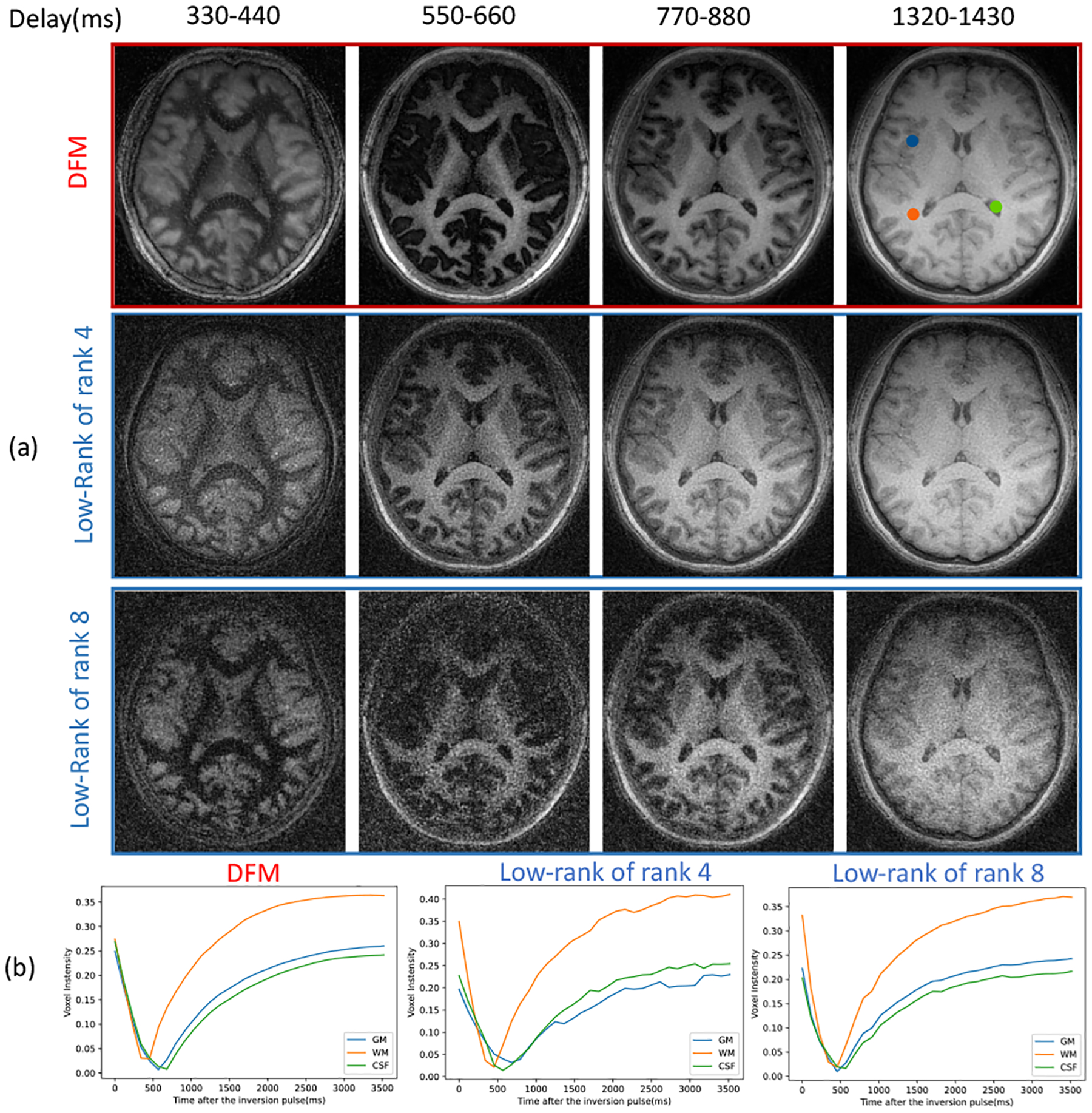
Validation of DFM in the absence of motion. (a) The four columns correspond to four delay times after one inversion pulse; (b) Magnetization recovery curve of GM, WM, and CSF voxels indicated in the top image, estimated by different approaches.
The reconstructed images demonstrate that the DFM can offer less noisy reconstructions, especially the bins corresponding to ms and ms, where WM and GM are nulled. We note that low-rank reconstructions exhibit significant noise, while the DFM reconstructions are relatively less noisy. The plots of the voxel intensity profiles, shown in Fig. 3 (b), show that the DFM curves are closer to the expected magnetization recovery. While the accuracy of the low-rank curves would improve with rank, this will come with increased sensitivity to noise.
4.2. Validation of motion compensation
The results in Fig. 4 show the motion-compensated recovery using DFM-MC. The results demonstrate that the proposed DFM-MC can compensate for motion effects and offer reconstructions that are comparable to DFM reconstructions of the dataset without motion.
Fig. 4.
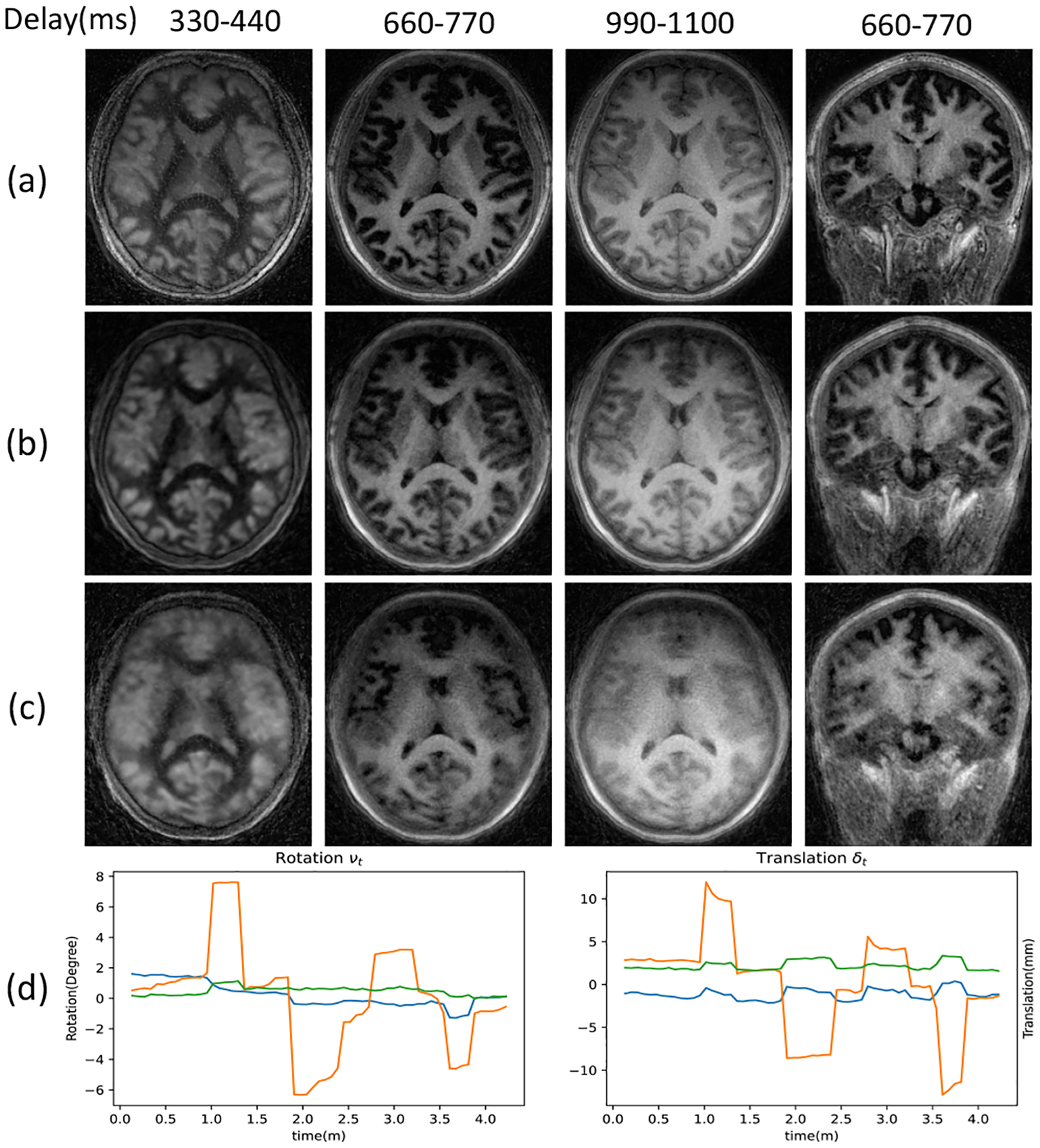
Validation of DFM-MC. (a)(c) DFM reconstructions of the acquisitions with or without motion, respectively; (b) DFM-MC reconstructions of the acquisition with motion; (d) Motion parameters estimated by DFM-MC including rotation and translation to correct (b) from (c).
5. CONCLUSION
We introduced DFM to jointly recover multi-contrast images from inversion recovery MRI data. The proposed approach further extended and generalized the low-rank method and recovered a series of images. Our experiments demonstrate that the improved representation translated to higher-quality reconstructions than low-rank models. In particular, the DFM reconstructions are less noisy and offer a more faithful representation of the magnetization recovery. The reconstructions also show the great potential of modeling and correcting for motion during the acquisition, which would be beneficial while imaging older subjects.
6. COMPLIANCE WITH ETHICAL STANDARDS
This research study was conducted using human subject data. The institutional review board at the local institution approved the acquisition of the data, and written consent was obtained from all participants.
Acknowledgments
This work is supported by NIH R01AG067078 and 3R43MH122028-02S1, and was conducted on an instrument funded by 1S10OD025025-01.
REFERENCES
- [1].Brant-Zawadzki Michael, Gillan Gary D, and Nitz Wolf-gang R, “Mp rage: a three-dimensional, t1-weighted, gradient-echo sequence-initial experience in the brain.,” Radiology, vol. 182, no. 3, pp. 769–775, 1992. [DOI] [PubMed] [Google Scholar]
- [2].Kecskemeti Steven, Samsonov Alexey, Hurley Samuel A, Dean Douglas C, Field Aaron, and Alexander Andrew L, “Mpnrage: A technique to simultaneously acquire hundreds of differently contrasted mprage images with applications to quantitative t1 mapping,” Magnetic resonance in medicine, vol. 75, no. 3, pp. 1040–1053, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Ma Dan, Gulani Vikas, Seiberlich Nicole, Liu Kecheng, Sunshine Jeffrey L, Duerk Jeffrey L, and Griswold Mark A, “Magnetic resonance fingerprinting,” Nature, vol. 495, no. 7440, pp. 187–192, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Zhao Bo, Setsompop Kawin, Adalsteinsson Elfar, Gagoski Borjan, Ye Huihui, Ma Dan, Jiang Yun, Grant P Ellen, Griswold Mark A, and Wald Lawrence L, “Improved magnetic resonance fingerprinting reconstruction with low-rank and subspace modeling,” Magnetic resonance in medicine, vol. 79, no. 2, pp. 933–942, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Sandino Christopher Michael, Ong Frank, Iyer Siddharth Srinivasan, Bush Adam, and Vasanawala Shreyas, “Deep subspace learning for efficient reconstruction of spatiotemporal imaging data,” in NeurIPS 2021 Workshop on Deep Learning and Inverse Problems, 2021. [Google Scholar]
- [6].Zou Qing, Ahmed Abdul Haseeb, Nagpal Prashant, Kruger Stanley, and Jacob Mathews, “Dynamic imaging using a deep generative storm (gen-storm) model,” IEEE transactions on medical imaging, vol. 40, no. 11, pp. 3102–3112, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]