

Abstract
The case-crossover design of Maclure is widely used in epidemiology and other fields to study causal effects of transient treatments on acute outcomes. However, its validity and causal interpretation have only been justified under informal conditions. Here, we place the design in a formal counterfactual framework for the first time. Doing so helps to clarify its assumptions and interpretation. In particular, when the treatment effect is nonnull, we identify a previously unnoticed bias arising from strong common causes of the outcome at different person-times. We analyze this bias and demonstrate its potential importance with simulations. We also use our derivation of the limit of the case-crossover estimator to analyze its sensitivity to treatment effect heterogeneity, a violation of one of the informal criteria for validity. The upshot of this work for practitioners is that, while the case-crossover design can be useful for testing the causal null hypothesis in the presence of baseline confounders, extra caution is warranted when using the case-crossover design for point estimation of causal effects.
Keywords: case-crossover, causal inference, counterfactual framework
1. |. INTRODUCTION
The case-crossover design (Maclure, 1991) is used in epidemiology and other fields to study causal effects of transient treatments on acute outcomes. One of its major advantages is that it only requires information from individuals who experience the outcome of interest (the cases). Another appealing feature is that under certain circumstances (which we will discuss at length) the case-crossover estimator adjusts for unobserved time invariant confounding. In a seminal application of this design (Mittleman et al., 1993), researchers obtained data on the physical activity (a transient treatment) of individuals who experienced a myocardial infarction (MI, an acute outcome). They then defined any person-times less than 1 h after vigorous activity as “treated,” and all other person-times as “untreated.” Finally, they considered each person-time as an individual observation and computed a Mantel–Haenszel estimate of the corresponding hazard ratio (Greenland & Robins, 1985; Kleinbaum et al., 1982; Nurminen, 1981; Tarone et al., 1983). This hazard ratio estimate was interpreted as the causal effect of vigorous physical activity on MI. Some variants of the case-crossover design allow flexible control time selection strategies where control times can follow outcome occurrence (e.g., Levy et al., 2001), but in this paper we restrict attention to studies in which follow-up is terminated at the time of the first outcome occurrence as in the above MI example.
Past authors have extensively considered several threats to validity of the case-crossover design (Greenland, 1996; Janes et al., 2005; Levy et al., 2001; Maclure, 1991; Mittleman & Mostofsky, 2014; Vines & Farrington, 2001), and conditions for causal interpretation of the estimator have been informally stated in the literature. The usual criteria cited are that: (a) the outcome has acute onset; (b) the treatment effect on the outcome is transient; (c) there are no unobserved post-baseline common causes of treatment and outcome;(d)there are no time trends in treatment; and (e) the treatment effect is constant across subjects.
The Mantel–Haenszel estimator was originally applied to estimate the treatment-outcome odds ratio when subjects were classified in strata sharing values of confounders , and observed subjects in each stratum could be conceived of as independent draws from the (hypothetically) infinite stratum population. Under the assumptions that stratum-specific odds ratios are all equal and observations are independent within each stratum, the Mantel–Haenszel estimator was later proven consistent for the constant odds ratio as the number of strata approach infinity even if only a few subjects are observed in each stratum (Breslow, 1981). Since the values of the confounders are held constant within each stratum, the constant odds ratio can be endowed with a causal interpretation if includes all confounders. The same goes for the rate ratio (Greenland & Robins, 1985).
Maclure’s idea was to regard person-times (rather than subjects) as the units of analysis and subjects as the strata, then apply the Mantel–Haenszel estimator. As Maclure (1991) put it: “In the case-crossover design, the population base is considered to be stratified in the extreme, so there is only one individual per stratum... Use of subjects as their own controls eliminates confounding by subject characteristics that remain constant.” Analogy to past applications of the Mantel–Haenszel estimator would seem to imply that the case-crossover design eliminates baseline confounding as a source of bias assuming a constant treatment effect across subjects (informal condition (e)) and independent identically distributed observations across time within each subject. Of course, these two assumptions are unlikely to be satisfied in most research settings: the effect of treatment is rarely the same in all subjects, and variables at different person-times are typically not independent within subjects. Informal assumptions (a)–(d) can be viewed as a more plausible alternative to independent person-times, but to determine when the case-crossover estimator is asymptotically unbiased for causal effects in the presence of unobserved confounding requires a formal analysis.
Here we place the case-crossover design in a formal counterfactual causal inference framework (Rubin, 1978; Robins, 1986). Doing so helps to clarify its assumptions and interpretation. In Section 2, we introduce notation, describe the (possibly hypothetical) cohort that gives rise to the data in a case-crossover analysis, and summarize the MI study in more detail so that it can serve as a running example. In Section 3, we define a natural estimand motivated by a hypothetical randomized trial practitioners of the case-crossover design might wish to emulate. In Section 4, we state formal assumptions (mostly analogous to informal assumptions (a)–(e)) that allow us to causally interpret the limit of the case-crossover estimator and under which the limit approximates the trial estimand from Section 3. We identify and characterize a previously unnoticed bias present when there exist strong common causes of the outcomes at different times (as would seem likely in many instances) and the treatment effect is non-null. In Section 5, we discuss this bias and illustrate it with simulations. We also use our results from Section 4 to analyze sensitivity to effect heterogeneity, that is, violations of informal assumption (e). In Section 6, we conclude. Our general message to practitioners is that, while the case-crossover can be a clever way to test the null hypothesis of no causal effect in the presence of unobserved baseline confounding, its point estimates of nonnull effects can be sensitive to violations of unrealistic assumptions.
2 |. DATA-GENERATING PROCESS
2.1 |. Notation
While case-crossover studies only use data from subjects who experience the outcome, we will nonetheless describe a full cohort from which these subjects are drawn in order to facilitate the definition of certain concepts and quantities of interest. Consider a cohort of individuals followed from baseline(i.e.,study entry)—defined by calendar time, age, or time of some pre-defined index event—until they develop the outcome or the administrative end of follow-up, whichever occurs first. For simplicity, we assume no individual is lost to follow-up. Subjects are indexed by ,. Subject is followed for at most person-times (e.g., hours) indexed by . For simplicity, we take to be the same for all subjects. Let be a binary variable taking values 0 and 1 indicating whether subject was treated at time . Let be a binary variable taking values 0 and 1 indicating whether the outcome of interest occurred in subject before time . We assume that is a “time to event” outcome in the sense that if then for all . The above implies the temporal ordering , ,. Thus the outcome has an acute onset as required by informal condition (a). We define if the event has occurred by time .
For a time-varying variable , we denote by the history of in subject up (i.e., prior) to time . We will often omit the subscript in the subsequent notation because we assume the data from different subjects are independent and identically distributed. Let denote a possibly multidimensional and unobserved baseline confounding variable that we assume has some population density . (For notational convenience, we shall write conditional probabilities given as . To avoid measure theoretic subtleties, we shall henceforth assume that when has continuous components, conditions sufficient to pick out a particular version of have been imposed as in Gill and Robins (2001).) Let denote common causes of outcomes (but not treatments) at different person-times not included in . For example, in the MI and exercise study, could denote formation of a blood clot by hour after baseline. We assume that the subjects are 𝑖𝑖𝑑 realizations of the random vector and that precedes and in the temporal ordering at each . Recall that in a case-crossover study the observed data on subject are as data on and are not available.
We assume that the causal directed acyclic graph (DAG) (Greenlandetal.,1999) in Figure 1 describes the data generating process within levels of baseline confounders . This DAG encodes aspects of informal assumptions (b) and (c). One salient feature of the DAG is that there are no directed paths from a current treatment to an outcome at a later time that do not first pass through the outcome at the time of the current treatment or through a later treatment. This can be considered a representation of informal assumption (b) that the treatment effect is transient. The DAG also excludes any common causes of treatments and outcomes other than not through past outcomes.(Since occurrence of the outcome at time determines the values of all variables at all later time points, outcome variable nodes in the DAG trivially must have arrows to all temporally subsequent variables.) This represents informal assumption (c) which bars nonbaseline confounding. This DAG also has fully forward connected treatments with arbitrary common causes of treatment at different times , indicating that we put no causal restrictions on the treatment assignment process. (We will, however, impose distributional assumptions.) We provide a fuller discussion of causal assumptions in Section 4, but we find it helpful to keep this DAG in mind.
FIGURE 1.
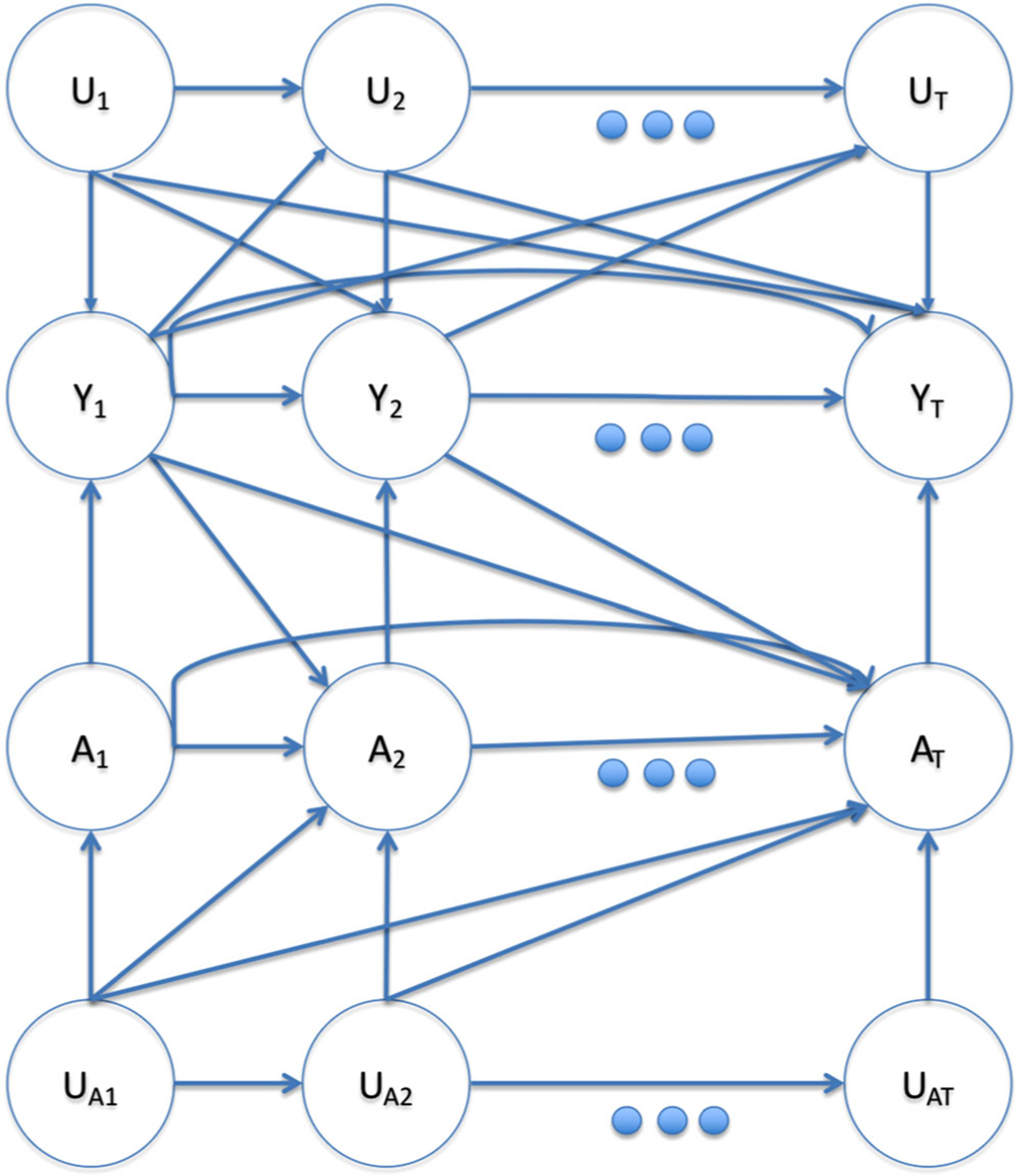
Causal DAG within levels of . A node with arrows pointing into every other node was omitted for visual clarity. This figure appears in color in the electronic version of this article, and any mention of color refers to that version
2.2 |. The case-crossover design
The outcome-censored case-crossover Mantel–Haenszel estimator requires data from subjects who experience the outcome on treatment status at the time of outcome occurrence and at designated “control” times preceding the outcome. It is computed as follows:
Select a random sample of person-times from the person times satisfying , , and where is a maximum “look back” time chosen by the investigator. We refer to these person-times when the outcome occurred for the first time and after time as the set of “case” person-times.
Let denote the person-time of the element of the set of sampled case person times. From the same subject , select times from the times prior to the time of subject first outcome event. We call these times the “control” person-times for subject . We discuss selection of “control” times below.
Let denote the treatment at the case time and denote treatments at the control times in subject . The Mantel–Haenszel case-crossover estimator is
| (1) |
Note that for subject the only data necessary to compute is .
Intuitively, the more subjects tend to be treated at the time of the outcome but not at earlier control times as opposed to vice versa, the stronger the estimated effect of treatment. To fix ideas, we consider an example of a case-crossover study from the literature. In a simplified version of Mittleman et al. (1993) study on the impact of exercise on MI mentioned in the introduction, suppose we collect data from a random sample of patients suffering MI on a particular Sunday. We record whether each patient exercised in the hour immediately preceding their MI and whether they exercised in the same hour the day before their MI. We compute the Mantel–Haenszel case-crossover estimator (1): in the numerator is the number of subjects who exercised immediately prior to their MI but not 24 h before, and in the denominator is the number of subjects who did not exercise immediately prior to their MI but did 24 h before. Mittleman et al. estimated a ratio of 5.9 (95% CI 4.6,7.7).
Many approaches to selecting control times might be acceptable. In the MI example, the lookback window is the 24 h before the MI and there is only one control time exactly 24 h before the outcome time. So , , and in the notation above.
3 |. A NATURAL ESTIMAND
Consider parallel group randomized trials in which, in trial , , treatment is randomly assigned at and only at time to all subjects who have yet to experience the outcome. Such a time -specific trial could estimate the immediate effect of treatment at time . To formalize, we adopt the counterfactual framework of Robins (1986). Let be the value of the outcome at time had, possibly contrary to fact, subject followed treatment regime through time . We refer to as a counterfactual or potential outcome. Since we will frequently consider treatment interventions at a single time point, we also introduce the notation as shorthand for , that is, the counterfactual value of random variable under observed treatment history through and treatment at time set to . The -specific trial would yield an estimate of 𝑗-specific risk ratio or discrete hazard ratio . Until Section 5.2, we assume
| (2) |
In the next section, we establish (strong) assumptions under which the case-crossover estimator approximately converges to .
4 |. DERIVATION OF THE COUNTERFACTUAL INTERPRETATION OF THE LIMIT OF THE CASE-CROSSOVER ESTIMATOR
4.1 |. Assumptions
Our goal is to specify natural and near minimal assumptions that allow us to causally interpret the limit of the case- crossover estimator. Counterfactuals and the observed data are linked by the following standard assumption:
| (3) |
Consistency states that the counterfactual outcomes corresponding to the observed treatment regimes are equal to the observed outcomes. Consistency is a technical assumption that has no counterpart in the informal assumptions (a)–(e) but is implicit in almost all analyses.
We assume that the causal graph in Figure 1 describes the data-generating process (Greenland et al., 1999). We will state some specific assumptions implied by the graph in counterfactual notation and also state additional assumptions. Figure 1 encodes informal assumption (c) that there are no post-baseline confounders not contained in , that is,
See Appendix B for further details. Assuming consistency, (4) can be read off the Single World Intervention Graph (Richardson & Robins, 2013) for the treatment associated with the causal graph of Figure 1. An example violation of (4) in the MI study would be if caffeine intake at hour both encouraged exercise and increased MI risk at . We might expect that confounders of this sort in the MI study (short-term encouragements to exercise that are associated with MI) are weak.
The DAG in Figure 1 also reflects informal assumption (b) that effects are transient by implying that has no direct effect on not through and for all . Graphically, this is the statement that the only treatment variable that is a parent of is . One might hope that the graphical definition of the transient effect assumption would be equivalent to the assumption that, conditional on , counterfactual hazards are independent of past treatment history, that is, that is the same for all , where the equalities all follow from (4) and (3). However, this is not generally true due to collider bias (Hernan et al., 2004) stemming from the presence of the common causes of the outcomes in Figure 1 since conditional on , for example, the path is open. Because of the collider bias, a formal counterfactual definition of the transient effect assumption requires conditioning on -histories. Specifically, let denote the conditional counterfactual hazard at time under treatment given past treatments , common causes of outcomes , and baseline confounders . As implied by Figure 1, we henceforth assume:
| (5) |
That is, conditional on and the history of , the current counterfactual hazard does not depend on past treatments. This assumption is consistent with the absence of any mention of such dependence in the case-crossover literature. Biological considerations determine the plausibility of (5). In the MI study, (5) would be violated if exercise can have delayed effects of more than one hour on MI. Maclure (1991) argued delayed effects would be weak in this setting.
Under (5), we can write the counterfactual hazard for any as . Define to be the counterfactual hazard at time given marginal over . Note is the treatment arm -specific conditional risk being estimated in the RCT conducted at time described in Section 3. Thus, is the -specific relative risk. Define .Then with weight is the parameter from the time -specific RCT in (2).
We make the constant effects assumption (e) that
| (6) |
which is stronger than assumption (2). Note under (6), is collapsible over at each so that the definition of does not depend on the specific variables comprising , which we leave unspecified. Although it is well known that hazard ratios are not collapsible (Greenland, 1999) in general, in our time -specific RCT, is just the conditional risk ratio in the follow up period from time to among those with , which is collapsible under (6).
(6) is a very strong assumption unlikely to ever hold exactly. Violations can be less extreme in subpopulations, for example, subjects who exercise regularly in the MI study. We examine sensitivity to violations of (6) in Section 5.2.
We make a rare outcome assumption that holds under all levels of , , and .
| (7) |
A consequence of the rare outcome assumption is that (to a good approximation) collider bias induced by conditioning on can be neglected. Because can be high dimensional and contain post-baseline information, it is unlikely this assumption holds in the MI study. For example, clot formation might cause a violation. But we will see that bias can be small even if this assumption fails as long as cases occurring under the violating levels do not account for a large proportion of total cases.
Mathematically, the final assumption we will need is
| (8) |
The left-hand side of (8) is a weighted average of time trends in treatment within levels of , with weights equal to . One way to satisfy (8) is if is almost always very small, but that is a very strong condition. We find it enlightening to consider a weaker trio of jointly sufficient conditions for (8).
The first of the three jointly sufficient conditions for (8) is
| (9) |
where is a control time for an outcome occurring at . A sufficient condition for (9) to hold is that, for each and the marginal correlation is near zero between the random functions and of . In fact, we require only that the sum over and of the -specific covariances for each control time is near zero. This condition prevents bias from so-called time modified baseline confounders (Platt et al., 2009) which, by definition, are baseline confounders that predict both (i) the hazard of an unexposed subject failing at various times and (ii) the difference in marginal probabilities of the events and . The case-crossover literature distinguishes between baseline and post-baseline confounders and says the former are allowed but not the latter. The more relevant distinction is whether a confounder has time-varying effects. To understand the issue, first consider a post-baseline confounder. We gave the example earlier of caffeine intake at time impacting probability of both exercise and MI at (more precisely, between and ). is temporally a post-baseline variable as its value is realized at time 𝑘, but in the causal ordering it could be equivalent to a baseline variable if it is not influenced by past treatments. For example, coffee at time could be equivalent to a 𝑘-hour delayed release caffeine pill at baseline. Suppose is a baseline variable (like the delayed release caffeine pill) such that causes and to be more likely. would induce bias just like , even though is a baseline confounder that (unlike ) would not lead to a violation of (4). However, whenever , and will both be large, inducing a correlation of the sort banned by (9). Thus, (9) serves to ban time modified confounding.
The second of the jointly sufficient conditions for (8) is a sort of positivity assumption that probability of outcome occurrences and probability of discordant exposure pairs are not so negatively correlated across levels of that they almost never co-occur.
| (10) |
for all , such that would be a control time if the outcome were to occur at.
The last of the jointly sufficient conditions for (8) formalizes the informal assumption (d) of no time trends in treatment.
| (11) |
for all such that would be a control time if the outcome were to occur at , is defined in (10), and is a small positive number. (11) is essentially the marginal pairwise exchangeability assumption previously derived by Vines and Farrington (2001). Note that the assumption is marginal over and so that it is empirically checkable (apart from being unknown). In Web Appendix A, we discuss bias inflation from small due to strong negative correlation between and and provide an example where the treatment time trend is very small (on an absolute scale, though not compared to ),and yet the estimator is significantly biased. Under (11), exposure can still exhibit arbitrarily complex temporal dependence as in the DAG in Figure 1. Whether (11) holds can depend in part on how control times are chosen. In the MI study, control times 12 h prior to the outcome could be much less likely to satisfy (11) than control times 24 h prior (e.g., 2 PM the previous day would be a better control time than 2 AM the morning of an MI that occurred at 2 PM).
4.2 |. The limit of the Mantel–Haenszel estimator
In the theorem below, we consider the probability limit of (1) in the outcome-censored case-crossover design under an asymptotic sequence in which the full cohort, the number of cases in the cohort, and the number of sampled cases grow at similar rates, that is, ,, and . We also assume subjects are iid.
Theorem 1.
Assume (3)–(8) or (3)–(7) and (9)–(11) hold for some and . Then, under the outcome-censored case-crossover design,.
The proof is in Appendix A, along with by product so of the derivation useful for bias analysis.
5 |. ANALYSIS OF SELECTED SOURCES OF BIAS
5.1 |. Bias due to strong common causes of the outcome
As discussed earlier, our rare outcome assumption within levels of (possibly post-baseline and high dimensional) common causes of the outcome is novel and unreasonably strong. In this subsection, we will examine analytically and through simulations the bias that arises when it fails even under a stronger constant effect assumption that does not depend on , , or . We first consider the special case in which, at each time , exposure is determined by an independent coin flip with success probability . In that case, as shown in Remark 1 in Appendix A, the multiplicative bias of the case-crossover estimator is well approximated by
| (12) |
where .
Disparities between the numerator and denominator of the bias term (12) will lead to bias of the estimator. Before examining disparities related to nonnegligible and -specific hazards, we note that the bias contribution of a disparity at a given level of and depends on the weight , which is large when both the probability of observing and the probability of an untreated event occurring at given and are large. Thus, the larger the proportion of total cases occurring at and , the more that failure of the rare outcome assumption at and biases the estimator.
The only difference between the numerator and denominator of (12) is that where appears in the numerator, appears in the denominator. The ratio of the term in the numerator to that in the demoninator is . When , this factor is equal to 1 and there is no bias. When , the bias is away from the null since if and only if and thus the MH estimator converges to a limit that is further from 1 than the true and in the same direction. For the mutiplicative bias to be nonnegligible requires a violation of the rare outcome assumption in which there exist histories , for which both and are nonnegligible.
We illustrate this bias with a simulation. For subjects, we simulated treatments and counterfactual outcomes for 24 time steps or until the first occurrence of the outcome according to the following data-generating process (DGP).
The DAG for this DGP is depicted in Figure 2. The true value of is 2. There are no common causes of treatments and outcomes, treatments are independent identically distributed and hence exhibit no time trends, and the outcome is rare when marginalized over . (Although the outcome is not rare when , it is rare that .) Yet the limit of the case-crossover estimator using the time prior to outcome occurrence as the control is approximately 2.8. The estimator fails because the outcome was common when or were 1 and a large proportion of total cases occurred when or were 1. The bias is away from the null, as predicted by our analysis above. The effect of on the outcome needed to be strong to produce the bias in this simulation. If instead of , then the case-crossover estimator is about 2.3 instead of 2.8. A recently formed blood clot could roughly play the role of in the MI example—a rare event that does not influence probability of exposure, greatly increases probability of the outcome at multiple time points after the clot forms, and without which the outcome is rare.
FIGURE 2.
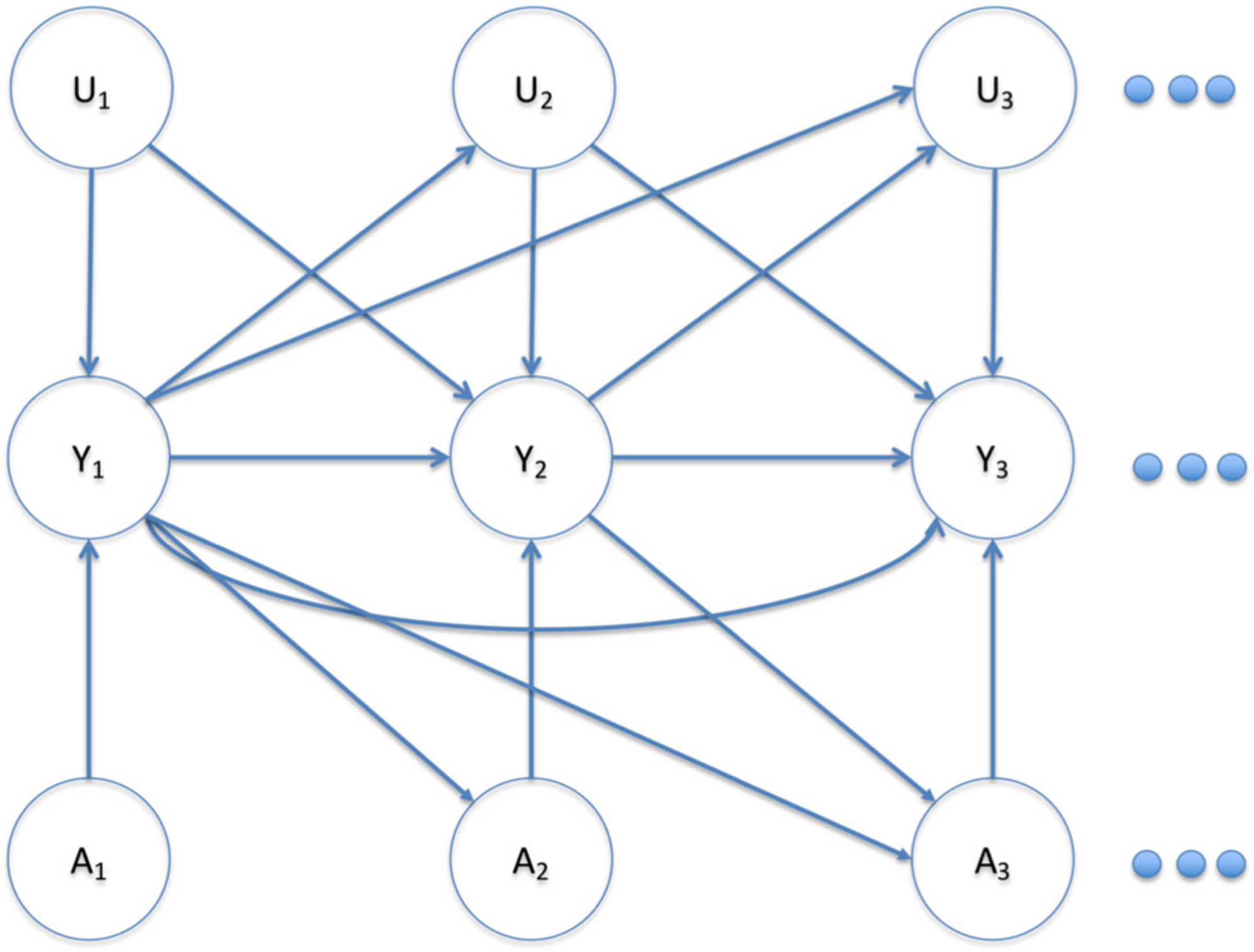
Causal DAG for simulation DGP with unobserved post-baseline common causes of outcomes at different times. This figure appears in color in the electronic version of this article, and any mention of color refers to that version
Now we consider bias in the more general scenario where treatments are correlated across time. In Appendix A, we expand the multiplicative bias term as
| (13) |
where denotes excluding and and (defined in Appendix A) roughly corresponds to the probability of observing treatment trajectory with , and treatment at the other time points equal to . When treatments are correlated, in the numerator might assign high weights to different treatment sequences than in the denominator, and under failure of the rare outcome assumption the highly weighted treatment sequences in the numerator might have significantly different survival probabilities for some values of and than the highly weighted treatment trajectories in the denominator. By the reasoning we applied to infer direction of bias in the case with uncorrelated exposures, strongly weighted untreated survival probabilities in the numerator combined with strongly weighted treated survival probabilities in the denominator would lead to bias away from the null, and vice versa. Depending on the treatment correlation pattern, treated or untreated survival probabilities might be more strongly weighted in the numerator or denominator. Thus, in the correlated treatment case the resulting bias can be either toward or away from the null. As in the case without correlated exposures, the magnitude of the bias contribution stemming from this dynamic for a given and depends on .
To illustrate, we modify our previous simulation example to add correlations in treatments over a time period much greater than the duration of the exposure’s transient effect. Specifically, we reduce the duration of the transient effect from 1 h to 1 s. Exposure and the unobserved common cause of the outcome are still independently assigned to 1 h intervals as in the previous simulation. This induces perfect correlation between treatments corresponding to 1 s time bins within the same hour. The untreated 1 s discrete hazards are set to preserve the hourly untreated survival probability from the previous simulation, and the multiplicative treatment effect within each one second bin is again set to 2. To formalize, we simulated data according to
where we have indexed “hours” by and seconds within hours by . The true value of in this DGP is again 2, but the case-crossover estimate using the time bin exactly one hour (3600 s) prior to the case as the control (as in the previous simulation) is 1.84. So decreasing the transient exposure effect to 1 s without changing either the case-crossover estimator or the treatment duration of 1 h made the bias switch direction. The two simulations taken together illustrate that bias from strong common causes of the outcome, when present, can be both sizable and unpredictable. (See Web Appendix B for analytic confirmation of simulation results from both DGPs using (A.4), discussion of what drives the discrepancy between the two simulations, and further analysis of bias in the correlated exposure setting.)
5.2 |. Treatment effect heterogeneity
We now examine sensitivity to violations of the constant causal hazard ratio assumption if the rare outcome assumption holds. For simplicity, we consider a scenario where there are just two types of subjects and counterfactual hazard ratios are constant across time within types. For ,say subjects of type arise from the following data-generating process:
with data censored at the first occurrence of the outcome. So within each type , the constant causal hazard ratio is . Let denote the proportion of the population of type at baseline, which under the rare outcome assumption would also be approximately the proportion of type among surviving subjects at all subsequent follow-up times. According to Equation (A.6) from the proof of Theorem 1, if the rare outcome assumption holds, then the case-crossover estimator with (i.e., using just one control) will approach
| (14) |
(14) can be expressed as a weighted average of and , where and . Hence, the limit of the case-crossover estimator is bounded by the group-specific hazard ratios.
The relative risk computed from any of the RCTs described in Section 3 would approach
| (15) |
Like the case-crossover limit, the RCT estimand can be expressed as a weighted average of and :
| (16) |
Without loss of generality, assume . The ratio of the weight placed on the higher hazard ratio to the weight placed on the lower hazard ratio in the RCT estimand is
| (17) |
The corresponding case-crossover weight ratio is
| (18) |
(18) implies that bias of the case-crossover estimator due to treatment effect heterogeneity depends on the difference in treatment probability between groups with different effect sizes. If treatment probability does not vary across groups with different treatment effects, effect heterogeneity will not induce bias in the case-crossover estimator. When treatment probabilities do vary, whichever group has higher treatment variance , that is, whichever group has probability of treatment closer to 0.5, will be weighted too highly by the case-crossover estimator compared to the RCT estimand. Some intuition behind this behavior is that the closer the treatment probability within a group is to 0.5, the more subjects from that group will contribute discordant case-control pairs to the case-crossover estimator, weighting the estimator disproportionately toward the effect within that group.
For illustrative purposes, consider a numerical example where we set
Then , , and the RCT estimand (15) is equal to 4.67. converges to 5.5, while the naive cohort hazard ratio estimator that does not adjust for the confounder approaches 4.9. In this example, bias from effect heterogeneity overrides any benefits from control of unobserved confounding.
The specific numerical example above is a cautionary tale illustrating the potential significance of heterogeneity induced bias. But if both cohort and case-crossover analyses are feasible with available data, and unobserved baseline confounding and effect heterogeneity vary within realistic ranges, does one estimator tend to be more biased than the other? We addressed this question in the framework of our toy example by computing the limiting values of case-crossover and cohort estimators for a large grid of data-generating process parameter settings. We let and take values in , take values in , take values in , and and take values in . Figure 3 shows that neither estimator has a general advantage over the other across parameter settings.
FIGURE 3.
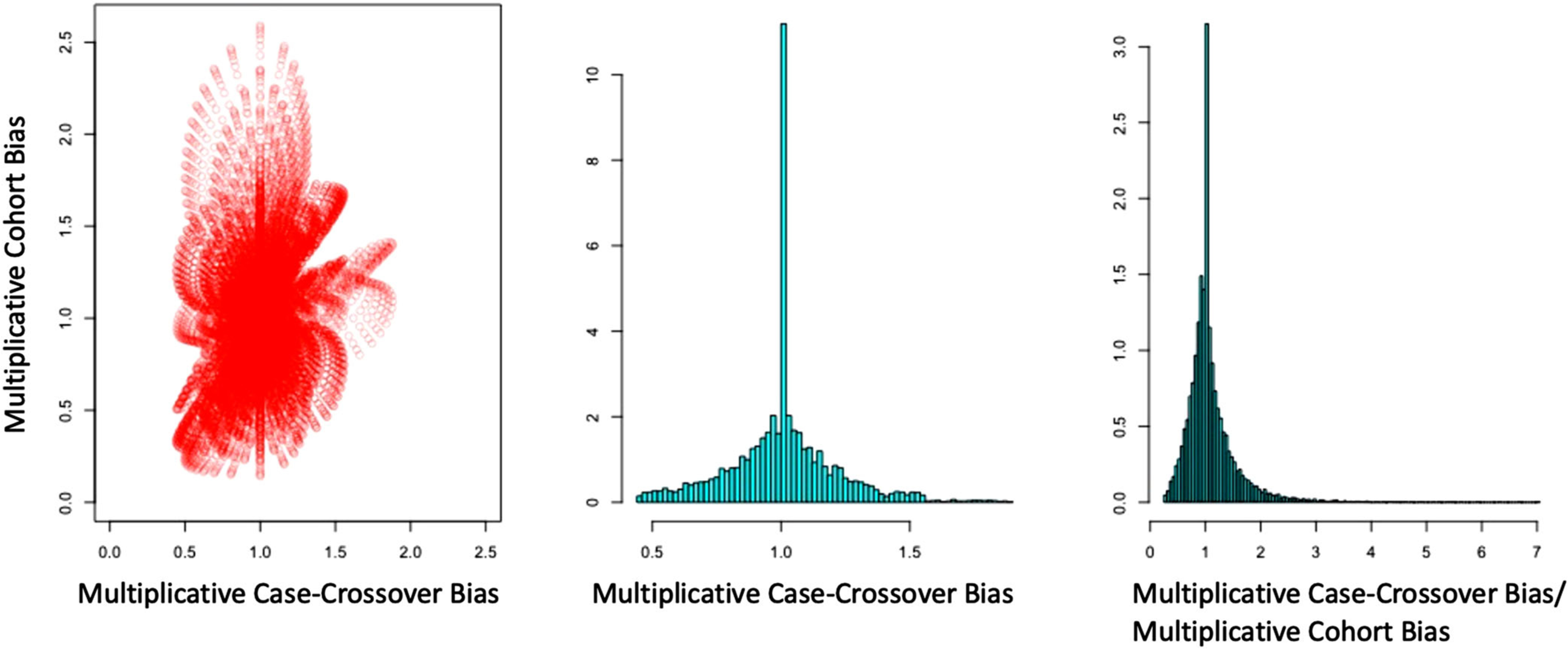
Left: Scatterplot of case-crossover versus cohort estimator multiplicative bias across a range of settings. Middle: Distribution of case-crossover estimator bias across settings. Right: Distribution of ratio of case-crossover bias to cohort bias across settings. This figure appears in color in the electronic version of this article, and any mention of color refers to that version
In the MI study, the effect of exercise appeared much greater in subjects who rarely exercised than in those who exercised regularly. Probability of treatment (i.e., exercise) clearly varied considerably between regular and rare exercise groups. Hence, we would expect an estimate of the marginal effect to be biased. The authors of the MI study reported separate effect estimates for the strata (exercise frequency prior to the study period) over which the effect was thought to vary. This is appropriate, as marginal effect estimates for the full population can be misleading.
6 |. DISCUSSION
We have put the case-crossover estimator on more solid theoretical footing by providing a proof of its approximate convergence to a formal counterfactual causal estimand, , under certain assumptions. This result alone may not be of much utility, but it was overdue for such a widely used method. And the derivation yielded some practical insights as by products.
First, we discovered a new source of potential bias when the treatment effect is not null–strong common causes of the outcome across time. We analyzed this bias and illustrated its potential significance and unpredictability with simulations. The effect of the common cause needs to be quite strong to induce sizable bias, but the fact that can be high dimensional and temporally postbaseline increases the likelihood of this in a real analysis. Formation of a blood clot might induce a bias of this sort in the MI example, but it is difficult to speculate about how often meaningful bias of this type appears in practice.
Second, expression (A.6) characterizing the limit of the case-crossover estimator allowed us to quantify sensitivity to violations of the constant treatment effect assumption. We analyzed a simple scenario with two groups of subjects having potentially different baseline risks, exposure rates, and treatment effects. The limit of the case-crossover estimator was a weighted average of the group-specific hazard ratios. The bias relative to the estimand (2) that would be targeted by an RCT depends on the exposure rates in the groups. If the groups have the same exposure rate, effect heterogeneity would not induce any bias. Otherwise, whichever group had exposure rate closer to 0.5 would be overweighted. We provided a numerical example in which significant unobserved baseline confounding (which could be controlled by the case-crossover estimator) and effect heterogeneity were both present. In this example,the effect heterogeneity bias in the case-crossover estimator was greater than the confounding bias in a standard cohort hazard ratio estimator, illustrating that effect heterogeneity can sometimes override benefits from control of unobserved baseline confounding in the case-crossover estimator. More extensive numerical analyses showed that neither the cohort estimator nor the case-crossover had a general advantage across a range of settings in which the levels of unobserved confounding and effect heterogeneity varied. An analyst concerned about bias from effect heterogeneity could employ the general framework of our numerical studies to conduct a quantitative bias analysis (Lash et al., 2014).
Overall, the formal assumptions required for consistency mostly mapped onto informal assumptions (a)–(e). Unsurprisingly for a method that has been used for 30 years, our contributions do not drastically alter its recommended use. As an illustrative exercise, we assess our simplified version of Mittleman et al. (1993) study of the effect of exercise on MI assumption by assumption through the lens of our analysis in Web Appendix C.
We might summarize our general guidance to practitioners and consumers of case-crossover analyses as follows. If unobserved baseline confounding is thought to be serious and/or data collection for a cohort study is unfeasible, the case-crossover should be considered as an option. If interest lies only in testing the null hypothesis of no effect, fewer assumptions are necessary. Under the null: the transient treatment effects assumption automatically holds; common causes of the outcome do not induce bias; the rare outcome assumption is not necessary; and there is no treatment effect heterogeneity. Hence, the case-crossover design remains a clever method for causal null hypothesis testing in the presence of unmeasured baseline confounders under the exchangeability (4), no time trends in treatment (11), and no time-modified confounding (9) assumptions. If interest lies in obtaining a point estimate, results should be interpreted with considerable additional caution as effect heterogeneity, delayed treatment effects, and common causes of outcomes will all be present to some degree, and as we have shown can have a large impact on results.
There are many variants of the case-crossover design, of which we have here only analyzed arguably the simplest one. One important extension of the MH estimator adjusts for post-baseline confounders through matching. Another variant employs conditional logistic regression in place of the MH estimator. Inthiscase, Vines and Farrington(2001) showed that joint exchangeability is required among all control times and the case time as opposed to just pairwise exchangeability. Additionally, in situations where time trends in treatment are present, the case-time-control method (Suissa, 1995) is often utilized and requires alternative assumptions (Greenland, 1996). The case-crossover design is also frequently applied in air pollution epidemiology. In this setting, the treatment regime is shared among all subjects and later values of treatment are not influenced by past values of subjects’ outcomes, allowing more flexible control time selection strategies, including using control times following outcome occurrence (Janes et al., 2005; Levy et al., 2001; Navidi, 1998). It would be interesting to investigate these variants in a similar counterfactual framework.
Supplementary Material
ACKNOWLEDGMENTS
This research was partly funded by NIH grant R37 AI102634. We also wish to thank Sonia Hernandez-Diaz and Anke Neumann for guidance and helpful discussions.
Funding information
National Institutes of Health, Grant/Award Number: R37 AI102634
APPENDIX A: PROOF OF THEOREM 1
From the definition of , it is clear that under the case-crossover design
| (A.1) |
where is the outcome occurrence time random variable set to if the outcome occurs after end of followup (i.e.,). For simplicity, we present the proof for the case where and, if the outcome occurs at time , there is one control time (so ). Letting denote excluding and , we can express (A.1) as
| (A.2) |
| (A.3) |
| (A.4) |
We get (A.2) by basic probability rules; (A.3) by consistency (3), Sequential Exchangeability (4), and UV-transient hazards (5); and (A.4) by total probability. Under rare outcome assumption (7), as collider paths| conditional on are effectively closed. So we can approximate (A.4)
| (A.5) |
| (A.6) |
| (A.7) |
where the first equality in (A.7) follows from the constant hazard ratio assumption (6). We can rewrite as
| (A.8) |
Thus under (3)–(8). Alternatively, under (9)–(11) we can write as
| (A.9) |
| (A.10) |
| (A.11) |
| (A.12) |
where (A.9) and (A.10) are algebra, (A.11) follows from (9), and (A.12) follows from applying (10) to the denominator of the quotient in (A.11) and then (11) to the numerator, proving that under (3)–(7) and (9)–(11).
Remark 1.
In the absence of rare disease and under the stronger constant effects assumption that does not depend on , , or , it follows from (A.4) that we can expand the multiplicative bias as
| (A.13) |
where and . If at each time , , the bias is approximately .
APPENDIX B: FURTHER DETAILS ON SEQUENTIAL EXCHANGEABILITY ASSUMPTION
More precisely, Equation (4) holds under the assumption (which we assume is true) that the causal DAG in Figure 1 represents an underlying FFRCISTG counterfactual causal model (Robins, 1986) and thus also under Pearl’s NPSEM with independent errors. See Richardson and Robins (2013) and Shpitser, Richardson, and Robins (2020).
Footnotes
SUPPORTING INFORMATION
Web Appendices referenced in Sections 4, 5, and 6 and R code for simulations in Section 5 are available with this paper at the Biometrics website on Wiley Online Library.
DATA AVAILABILITY STATEMENT
Data sharing is not applicable as no new data were created or analyzed in this paper.
REFERENCES
- Breslow N. (1981) Odds ratio estimators when the data are sparse. Biometrika, 68(1), 73–84. [Google Scholar]
- Gill RD & Robins JM (2001) Causal inference for complex longitudinal data: the continuous case. Annals of Statistics, 29, 1785–1811. [Google Scholar]
- Greenland S. (1996) Confounding and exposure trends in case-crossover and case-time-control designs. Epidemiology, 7(3), 231–239. [DOI] [PubMed] [Google Scholar]
- Greenland S. & Robins JM (1985) Estimation of a common effect parameter from sparse follow-up data. Biometrics, 41, 55–68. [PubMed] [Google Scholar]
- Greenland S, Pearl J. & Robins JM (1999) Causal diagrams for epidemiologic research. Epidemiology, 10, 37–48. [PubMed] [Google Scholar]
- Hernan MA, Hernandez-Díaz S. & Robins JM (2004) A structural approach to selection bias. Epidemiology, 15, 615–625. [DOI] [PubMed] [Google Scholar]
- Janes H, Sheppard L. & Lumley T. (2005) Case-crossover analyses of air pollution exposure data: referent selection strategies and their implications for bias. Epidemiology, 16(6), 717–726. [DOI] [PubMed] [Google Scholar]
- Kleinbaum D, Kupper L. & Chambless L. (1982) Logistic regression analysis of epidemiologic data: theory and practice. Communications in Statistics-Theory and Methods, 11(5), 485–547. [Google Scholar]
- Lash TL, Fox MP, MacLehose RF, Maldonado G, McCandless LC & Greenland S. (2014) Good practices for quantitative bias analysis. International Journal of Epidemiology, 43(6), 1969–1985. [DOI] [PubMed] [Google Scholar]
- Levy D, Lumley T, Sheppard L, Kaufman J. & Checkoway H. (2001) Referent selection in case-crossover analyses of acute health effects of air pollution. Epidemiology, 12(2), 186–192. [DOI] [PubMed] [Google Scholar]
- Maclure M. (1991) The case-crossover design: a method for studying transient effects on the risk of acute events. American Journal of Epidemiology, 133(2), 144–153. [DOI] [PubMed] [Google Scholar]
- Mittleman MA, Maclure M, Tofler GH, Sherwood JB, Goldberg RJ & Muller JE (1993) Triggering of acute myocardial infarction by heavy physical exertion–protection against triggering by regular exertion. New England Journal of Medicine, 329(23), 1677–1683. [DOI] [PubMed] [Google Scholar]
- Mittleman MA & Mostofsky E. (2014) Exchangeability in the case-crossover design. International Journal of Epidemiology, 43, 1645–1655. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Navidi W. (1998) Bidirectional case-crossover designs for exposures with time trends. Biometrics, 54, 596–605. [PubMed] [Google Scholar]
- Nurminen M. (1981) Asymptotic efficiency of general noniterative estimators of common relative risk. Biometrika, 68(2), 525–530. [Google Scholar]
- Platt RW, Schisterman EF & Cole SR. (2009) Time-modified confounding. American Journal of Epidemiology, 170(6), 687–694. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Richardson TS & Robins JM (2013) Single world intervention graphs (SWIGs): A unification of the counterfactual and graphical approaches to causality. Center for the Statistics and the Social Sciences, University of Washington Series. Working Paper 128. [Google Scholar]
- Robins JM (1986) A new approach to causal inference in mortality studies with a sustained treatment period–application to control of the healthy worker survivor effect. Mathematical Modelling, 7(9–12), 1393–1512. [Google Scholar]
- Robins JM & Hernan MA (2009) Estimation of the causal effects of time-varying treatments. New York, NY: Chapman and Hall/CRC Press. [Google Scholar]
- Rubin DB (1978) Bayesian inference for causal effects: the role of randomization. The Annals of Statistics, 6, 34–58. [Google Scholar]
- Shpitser I, Richardson TS & Robins JM (2020) Multivariate counterfactual systems and causal graphical models. Preprint, arXiv:2008.06017. [Google Scholar]
- Suissa S. (1995) The case-time-control design. Epidemiology, 6(3), 248–53. [DOI] [PubMed] [Google Scholar]
- Tarone RE, Gart J. & Hauck W. (1983) On the asymptotic inefficiency of certain noniterative estimators of a common relative risk or odds ratio. Biometrika, 70(2), 519–522. [Google Scholar]
- Vines SK & Farrington CP (2001) Within-subject treatment dependency in case-crossover studies. Statistics in Medicine, 20(20), 3039–3049. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Data sharing is not applicable as no new data were created or analyzed in this paper.