

Abstract
As the volume of next generation sequencing data increases, an urgent need for algorithms to efficiently process the data arises. Universal hitting sets (UHS) were recently introduced as an alternative to the central idea of minimizers in sequence analysis with the hopes that they could more efficiently address common tasks such as computing hash functions for read overlap, sparse suffix arrays, and Bloom filters. A UHS is a set of -mers that hit every sequence of length , and can thus serve as indices to -long sequences. Unfortunately, methods for computing small UHSs are not yet practical for real-world sequencing instances due to their serial and deterministic nature, which leads to long runtimes and high memory demands when handling typical values of (e.g. ). To address this bottleneck, we present two algorithmic innovations to significantly decrease runtime while keeping memory usage low: (i) we leverage advanced theoretical and architectural techniques to parallelize and decrease memory usage in calculating -mer hitting numbers; and (ii) we build upon techniques from randomized Set Cover to select universal -mers much faster. We implemented these innovations in PASHA, the first randomized parallel algorithm for generating nearoptimal UHSs, which newly handles . We demonstrate empirically that PASHA produces sets only slightly larger than those of serial deterministic algorithms; moreover, the set size is provably guaranteed to be within a small constant factor of the optimal size. PASHA’s runtime and memory-usage improvements are orders of magnitude faster than the current best algorithms. We expect our newly-practical construction of UHSs to be adopted in many high-throughput sequence analysis pipelines.
Keywords: Universal hitting sets, Parallelization, Randomization
1. Introduction
The NIH Sequence Read Archive [8] currently contains over 26 petabases of sequence data. Increased use of sequence-based assays in research and clinical settings creates high computational processing burden; metagenomics studies generate even larger sequencing datasets [17, 19]. New computational ideas are essential to manage and analyze these data. To this end, researchers have turned to -mer-based approaches to more efficiently index datasets [7].
Minimizer techniques were introduced to select -mers from a sequence to allow efficient binning of sequences such that some information about the sequence’s identity is preserved [18]. Formally, given a sequence of length and an integer , its minimizer is the lexicographically smallest -mer in it. The method has two key advantages: selected -mers are close; and similar -mers are selected from similar sequences. Minimizers were adopted for biological sequence analysis to design more efficient algorithms, both in terms of memory usage and runtime, by reducing the amount of information processed, while not losing much or any information [12]. The minimizer method has been applied in a large number of settings [4, 6, 20].
Orenstein and Pellow et al. [14, 15] generalized and improved upon the minimizer idea by introducing the notion of a universal hitting set (UHS). For integers and , set is called a universal hitting set of -mers if every possible sequence of length contains at least one -mer from . Note that a UHS for any given and only needs to be computed once. Their heuristic DOCKS finds a small UHS in two steps: (i) remove a minimum-size set of vertices from a complete de Bruijn graph of order to make it acyclic; and (ii) remove additional vertices to eliminate all -long paths. The removed vertices comprise the UHS. The first step was solved optimally, while the second required a heuristic. The method is limited by runtime to , and thus applicable to only a small subset of minimizer scenarios. Recently, Marçais et al. [10] showed that there exists an algorithm to compute a set of -mers that covers every path of length in a de Bruijn graph of order . This algorithm gives an asymptotically optimal solution for a value of approaching . Yet this condition is rarely the case for real applications where and . The results of Marçais et al. show that for , the results are far from optimal for fixed . A more recent method by DeBlasio et al. [3] can handle larger values of , but with , which is impractical for real applications. Thus, it is still desirable to devise faster algorithms to generate small UHSs.
Here, we present PASHA (Parallel Algorithm for Small Hitting set Approximation), the first randomized parallel algorithm to efficiently generate nearoptimal UHSs. Our novel algorithmic contributions are twofold. First, we improve upon the process of calculating vertex hitting numbers, i.e. the number of -long paths they go through. Second, we build upon a randomized parallel algorithm for Set Cover to substantially speedup removal of -mers for the UHS—the major time-limiting step—with a guaranteed approximation ratio on the -mer set size. PASHA performs substantially better than current algorithms at finding a UHS in terms of runtime, with only a small increase in set size; it is consequently applicable to much larger values of . Software and computed sets are available at: pasha.csail.mit.edu and github.com/ekimb/pasha.
2. Background and Preliminaries
Preliminary Definitions
For and finite alphabet , directed graph is a de Bruijn graph of order if and represent - and ( + 1)-long strings over , respectively. An edge may exist from vertex to vertex if the -suffix of is the -prefix of . For any edge with label , labels of vertices and are the prefix and suffix of length of , respectively. If a de Bruijn graph contains all possible edges, it is complete, and the set of edges represents all possible -mers. An )-long path in the graph, i.e. a path of edges, represents an -long sequence over (for further details, see [1]).
For any -long string over , -mer set hits if there exists a -mer in that is a contiguous substring in . Consequently, universal hitting set (UHS) is a set of -mers that hits any -long string over . A trivial UHS is the set of all -mers, but due to its size , it does not reduce the computational expense for practical use. Note that a UHS for any given and does not depend on a dataset, but rather needs to be computed only once.
Although the problem of computing a universal hitting set has no known hardness results, there are several NP-hard problems related to it. In particular, the problem of computing a universal hitting set is highly similar, although not identical, to the -hitting set problem, which is the problem of finding a minimum-size -mer set that hits an input set of -long sequences. Orenstein and Pellow et al. [14, 15] proved that the -hitting set problem is NP-hard, and consequently developed the near-optimal DOCKS heuristic. DOCKS relies on the Set Cover problem, which is the problem of finding a minimum-size collection of subsets of finite set whose union is .
The DOCKS Heuristic
DOCKS first removes from a complete de Bruijn graph of order a decycling set, turning the graph into a directed acyclic graph (DAG). This set of vertices represent a set of -mers that hits all sequences of infinite length. A minimum-size decycling set can be found by Mykkelveit’s algorithm [13] in time. Even after all cycles, which represent sequences of infinite length, are removed from the graph, there may still be paths representing sequences of length , which also need to be hit by the UHS. DOCKS removes an additional set of -mers that hits all remaining sequences of length , so that no path representing an -long sequence, i.e. a path of length , remains in the graph.
However, finding a minimum-size set of vertices to cover all paths of length in a directed acyclic graph (DAG) is NP-hard [16]. In order to find a small, but not necessarily minimum-size, set of vertices to cover all -long paths, Orenstein and Pellow et al. [14, 15] introduced the notion of a hitting number, the number of -long paths containing vertex , denoted by . DOCKS uses the hitting number to prioritize removal of vertices that are likely to cover a large number of paths in the graph. This, in fact, is an application of the greedy method for the Set Cover problem, thus guaranteeing an approximation ratio of on the removal of additional -mers.
The hitting numbers for all vertices can be computed efficiently by dynamic programming: For any vertex and , DOCKS calculates the number of -long paths starting at , , and the number of -long paths ending at , . Then, the hitting number is directly computable by
| (1) |
and the dynamic programming calculation in graph is given by
| (2) |
Overall, DOCKS performs two main steps: First, it finds and removes a minimum-size decycling set, turning the graph into a DAG. Then, it iteratively removes vertex with the largest hitting number until there are no -long paths in the graph. DOCKS is sequential: In each iteration, one vertex with the largest hitting number is removed and added to the UHS output, and the hitting numbers are recalculated. Since the first phase of DOCKS is solved optimally in polynomial time, the bottleneck of the heuristic lies in the removal of the remaining set of -mers to cover all paths of length in the graph, which represent all remaining sequences of length .
As an additional heuristic, Orenstein and Pellow et al. [14, 15] developed DOCKSany with a similar structure as DOCKS, but instead of removing the vertex that hits the most -long paths, it removes a vertex that hits the most paths in each iteration. This reduces the runtime by a factor of , as calculating the hitting number for each vertex can be done in linear time with respect to the size of the graph. DOCKSanyX extends DOCKSany by removing vertices with the largest hitting numbers in each iteration. DOCKSany and DOCKSanyX run faster compared to DOCKS, but the resulting hitting sets are larger.
3. Methods
Overview of the Algorithm.
Similar to DOCKS, PASHA is run in two phases: First, a minimum-size decycling set is found and removed; then, an additional set of -mers that hits remaining -long sequences is removed. The removal of the decycling set is identical to that of DOCKS; however, in PASHA we introduce randomization and parallelization to efficiently remove the additional set of -mers. We present two novel contributions to efficiently parallelize and randomize the second phase of DOCKS. The first contribution leads to a faster calculation of hitting numbers, thus reducing the runtime of each iteration. The second contribution leads to selecting multiple vertices for removal at each iteration, thus reducing the number of iterations to obtain a graph with no -long paths. Together, the two contributions provide orthogonal improvements in runtime.
Improved Hitting Number Calculation
Memory Usage Improvements.
We reduce memory usage through algorithmic and technical advances. Instead of storing the number of -long paths for in both and , we apply the following approach (Algorithm 1): We compute for all and . Then, while computing the hitting number, we calculate for iteration . For this aim, we define two arrays: and , to store only two instances of -long path counts for each vertex: The current and previous iterations. Then, for some , we compute based on , set , and add to the hitting number sum. Lastly, we increase , and repeat the procedure, adding the computed hitting numbers iteratively. This approach allows the reduction of matrix , since in each iteration we are storing only two arrays, and , instead of the original matrix consisting of arrays. Therefore, we are able to reduce memory usage by close to half, with no change in runtime.
To further reduce memory usage, we use float variable type (of size 4 bytes) instead of double variable type (of size 8 bytes). The number of paths kept in and increase exponentially with , the length of the paths. To be able to use the 8 bit exponent field, we initialize and to float minimum positive value. This does not disturb algorithm correctness, as path counting is only scaled to some arbitrary unit value, which may be 2−149, the smallest positive value that can be represented by float. This is done in order to account for the high numbers that path counts can reach. The remaining main memory bottleneck is matrix , whose size is bytes.
Lastly, we utilized the property of a complete de Bruijn graph of order being the line graph of a de Bruijn graph of order . While all -mers are represented as the set of vertices in the graph of order , they are represented as edges in the graph of order . If we remove edges of a de Bruijn graph of order , instead of vertices in a graph of order , we can reduce memory usage by another factor of . In our implementation we compute and for all vertices of a graph of order , and calculate hitting numbers for edges. Thus, the bottleneck of the memory usage is reduced to bytes.
Runtime Reduction by Parallelization.
We parallelize the calculation of the hitting numbers to achieve a constant factor reduction in runtime. The calculation of -long paths through vertex only depends on the previously calculated matrices for the -long paths through all vertices adjacent to (Eq. 2). Therefore, for some , we can compute and for all vertices in in parallel, where is the set of vertices left after the removal of the decycling set. In addition, we can calculate the hitting number for all vertices in parallel (similar to computing and ), since the calculation does not depend on the hitting number of any other vertex (we call this parallel variant PDOCKS for the purpose of comparison with PASHA). We note that for DOCKSany and DOCKSanyX, the calculations of hitting numbers for each vertex cannot be computed in parallel, since the number of paths starting and ending at each vertex both depend on those of the previous vertex in topological order.
Algorithm 1.
Improved hitting number calculation. Input:
| 1: | , with initialized to 1 |
| 2: | |
| 3: | initialized to 1 |
| 4: | initialized to 0 |
| 5: | for do: |
| 6: | for do: |
| 7: | for do: |
| 8: | |
| 9: | for do: |
| 10: | for do: |
| 11: | |
| 12: | for do: |
| 13: | |
| 14: | |
| 15: | |
| 16: | return |
Parallel Randomized -mer Selection
Our goal is to find a minimum-size set of vertices that covers all -long paths. We can represent the remaining graph as an instance of the Set Cover problem. While the greedy algorithm for the second phase of DOCKS is serial, we will show that we can devise a parallel algorithm, which is close to the greedy algorithm in terms of performance guarantees, by picking a large set of vertices that cover nearly as many paths as the vertices that the greedy algorithm picks one by one.
In PASHA, instead of removing the vertex with the maximum hitting number in each iteration, we consider a set of vertices for removal with hitting numbers within an interval, and pick vertices in this set independently with constant probability. Considering vertices within an interval allows us to efficiently introduce randomization while still emulating the deterministic algorithm. Picking vertices independently in each iteration enables parallelization of the procedure. Our randomized parallel algorithm for the second phase of the UHS problem adapts that of Berger et al. [2] for the original Set Cover problem.
The UHS Selection Procedure.
The input includes graph and randomization variables , (Algorithm 2). Let function calcHit() calculate the hitting numbers for all vertices, and return the maximum hitting number (line 2). We set (line 3), and run a series of steps from , iteratively decreasing by 1. In step , we first calculate the hitting numbers of all vertices (line 5); then, we define vertex set to contain vertices with a hitting number between and for potential removal (lines 8–9).
Let be the sum of all hitting numbers of the vertices in , i.e. (line 10). In each step, if the hitting number for vertex is more than a fraction of , i.e. , we add to the picked vertex set (lines 11–13). For vertices with a hitting number smaller than , we pairwise independently pick them with probability . We test the vertices in pairs to impose pairwise independence: If an unpicked vertex satisfies the probability , we choose another unpicked vertex and test the same probability . If both are satisfied, we add both vertices to the picked vertex set ; if not, neither of them are added to the set (lines 14–16). This serves as a bound on the probability of picking a vertex. If the sum of hitting numbers of the vertices in set is at least , we add the vertices to the output set, remove them from the graph, and decrease by 1 (lines 17–20). The next iteration runs with decreased . Otherwise, we rerun the selection procedure without decreasing .
Algorithm 2.
The selection procedure. Input: , ,
| 1: | |
| 2: | |
| 3: | |
| 4: | while do |
| 5: | if then break |
| 6: | |
| 7: | |
| 8: | for do: |
| 9: | if then |
| 10: | |
| 11: | for do: |
| 12: | if then |
| 13: | |
| 14: | for do: |
| 15: | if and and and then |
| 16: | |
| 17: | if then |
| 18: | |
| 19: | |
| 20: | |
| 21: | return |
Performance Guarantees.
At step , we add the selected vertex set to the output set if . Otherwise, we rerun the selection procedure with the same value of . We show in Appendix A that with high probability, . We also show that PASHA produces a cover times the optimal size, where . In Appendix B, we give the asymptotic number of the selection steps and prove the average runtime complexity of the algorithm. Performance summaries in terms of theoretical runtime and approximation ratio are in Table 1.
Table 1.
Summary of theoretical results for the second phase of different algorithms for generating a set of -mers hitting all -long sequences. PDOCKS is DOCKS with the improved hitting number calculation, i.e. greedy removal of one vertex at each iteration. , denote the total number of picked vertices for DOCKS/PDOCKS and DOCKSany, respectively. denotes the number of parallel threads used, the maximum vertex hitting number, and and PASHA’s randomization parameters.
| Algorithm | DOCKS | PDOCKS | DOCKSany | PASHA |
|---|---|---|---|---|
| Theoretical runtime | ||||
| Approximation ratio | N/A |
4. Results
PASHA Outperforms Extant Algorithms for
We compared PASHA and PDOCKS to extant methods on several combinations of and . We ran DOCKS, DOCKSany, PDOCKS, and PASHA over , DOCKSanyX, PDOCKS, and PASHA for and , and PASHA and DOCKSanyX for , 1000 for respectively, for . We say that an algorithm is limited by runtime if for some value of and for , its runtime exceeds 1 day (86400 s), in which case we stopped the operation and excluded the method from the results for the corresponding value of . While running PASHA, we set , and to set an emulation ratio (see Sect. 3 and Appendix A). The methods were benchmarked on a 24-CPU Intel Xeon Gold (2.10 GHz) with 754 GB of RAM. We ran all tests using all available cores ( in Table 1).
Comparing Runtimes and UHS Sizes.
We ran DOCKS, PDOCKS, DOCKSany, and PASHA for and . As seen in Fig. 1A, DOCKS has a significantly higher runtime than the parallel variant PDOCKS, while producing identical sets (Fig. 1B). For small values of , DOCKSany produces the largest UHSs compared to other methods, and as increases, the differences in both runtime and UHS size for all methods decrease, since there are fewer -mers to add to the removed decycling set to produce a UHS.
Fig. 1.
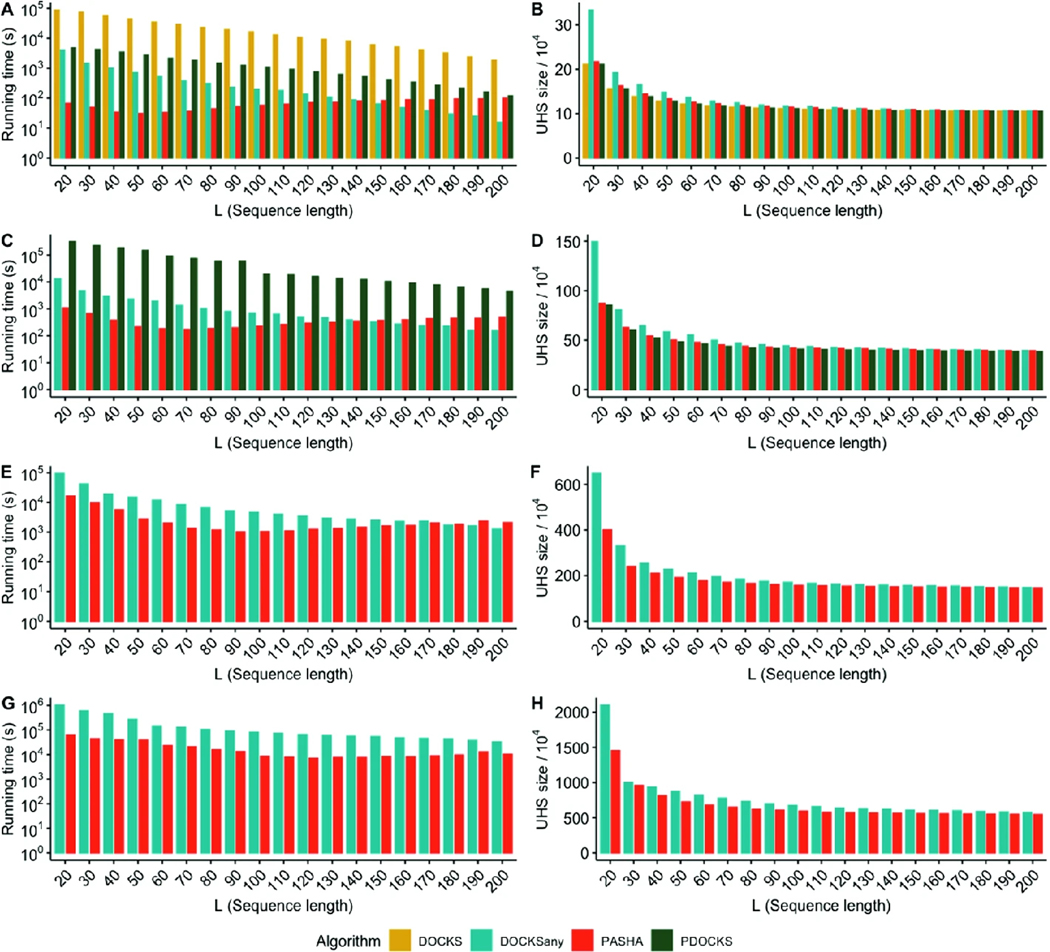
Runtimes (left) and UHS sizes (divided by 104, right) for values of (A, B), 11 (C, D), 12 (E, F), and 13 (G, H) and for the different methods. Note that the y-axes for runtimes are in logarithmic scale.
We ran PDOCKS, DOCKSany10, and PASHA for and . As seen in Fig. 1C, for small values of , both PDOCKS and DOCKSany10 have significantly higher runtimes than PASHA; while for larger , DOCKSany10 and PASHA are comparable in their runtimes (with PASHA being negligibly slower). In Fig. 1D, we observe that PDOCKS computes the smallest sets for all values of . Indeed, its guaranteed approximation ratio is the smallest among all three benchmarked methods. While the set sizes for all methods converge to the same value for larger , DOCKSany10 produces the largest UHSs for small values of , in which case PASHA and PDOCKS are preferable.
PASHA’s runtime behaves differently than that of other methods. For all methods but PASHA, runtime decreases as increases. Instead of gradually decreasing with , PASHA’s runtime gradually decreases up to , at which it starts to increase at a much slower rate. This is explained by the asymptotic complexity of PASHA (Table 1). Since computing a UHS for small requires a larger number of vertices to be removed, the decrease in runtime with increasing up to is significant; however, due to PASHA’s asymptotic complexity being quadratic with respect to , we see a small increase from to . All other methods depend linearly on the number of removed vertices, which decreases as increases.
Despite the significant decrease in runtime in PDOCKS compared to DOCKS, PDOCKS was still limited by runtime to . Therefore, we ran DOCKSany100 and PASHA for and . As seen in Figs. 1E and F, both methods follow a similar trend as in , with DOCKSany100 being significantly slower and generating significantly larger UHSs for small values of . For larger values of , DOCKSany100 is slightly faster, while PASHA produces sets that are slightly smaller.
At we observed the superior performance of PASHA over DOCKSany1000 in both runtime and set size for all values of . We ran DOCKSany1000 and PASHA for and . As seen in Figs. 1G and H, DOCKSany1000 produces larger sets and is significantly slower compared to PASHA for all values of . This result demonstrates that the slow increase in runtime for PASHA compared to other algorithms for does not have a significant effect on runtime for larger values of .
PASHA Enables UHS for , 15, 16
Since all existing algorithms and PDOCKS are limited by runtime to , we report the first UHSs for and computed using PASHA, run on a 24-CPU Intel Xeon Gold (2.10 GHz) with 754 GB of RAM using all 24 cores. Figure 2 shows runtimes and sizes of the sets computed by PASHA.
Fig. 2.

Runtimes (A) and UHS sizes (divided by 106) (B) for and for PASHA. Note that the y-axis for runtime is in logarithmic scale.
Density Comparisons for the Different Methods
In addition to runtimes and UHS sizes, we report values of another measure of UHS performance known as density. The density of the minimizers scheme is the fraction of selected -mers’ positions over the number of -mers in the sequence. Formally, the density of scheme over sequence is defined
as
| (3) |
where is the set of positions of the -mers selected over sequence .
We calculate densities for a UHS by selecting the lexicographically smallest -mer that is in the UHS within each window of consecutive -mers, since at least one -mer is guaranteed to be in each such window. Marçais et al. [11] showed that using UHSs for -mer selection in this manner yields smaller densities than lexicographic or random minimizer selection schemes. Therefore, we do not report comparisons between UHSs and minimizer schemes, but rather comparisons among UHSs constructed by different methods.
Marçais et al. [11] also showed that the expected density of a minimizers scheme for any and window size is equal to the density of the minimizers scheme on a de Bruijn sequence of order . This allows for exact calculation of expected density for any -mer selection procedure. However, for we calculated UHSs only for , and iterating over a de Bruijn sequence of order 100 is infeasible. Therefore, we computed the approximate expected density on long random sequences, since the computed expected density on these sequences converges to the expected density [11]. In addition, we computed the density of different methods on the entire human reference genome (GRCh38).
We computed the density values of UHSs generated by PDOCKS, DOCKSany, and PASHA over 10 random sequences of length 106, and the entire human reference genome (GRCh38), for and , when a UHS was available for such combination.
As seen in Fig. 3, the differences in both approximate expected density and density computed on the human reference genome are negligible when comparing UHSs generated by the different methods. For most values of , DOCKS yields the smallest approximate expected density and human genome density values, while DOCKSany generally yields lower human genome density values, but higher expected density values than PASHA. For , the UHS is only the decycling set; therefore, density values for these values of are identical for the different methods.
Fig. 3.

Mean approximate expected density (A), and density on the human reference genome (B) for different methods, for and . Error bars represent one standard deviation from the mean across 10 random sequences of length 106. Density is the fraction of selected -mer positions over the number of -mers in the sequence.
Since there is no significant difference in the density of the UHSs generated by the different methods, other criteria, such as runtime and set size, are relevant when evaluating the performance of the methods: As increases, PASHA produces sets that are only slightly smaller or larger in density, but significantly smaller in size and significantly faster than extant methods.
5. Discussion
We presented an efficient randomized parallel algorithm for generating a small set of -mers that hits every possible sequence of length and produces a set that is a small guaranteed factor away from the optimal set size. Since the runtime of DOCKS variants and PASHA depend exponentially on , these greedy heuristics are eventually limited by runtime. However, using these heuristics in conjunction with parallelization, we are newly able to compute UHSs for values of and large enough for most biological applications.
The improvements in runtime for the hitting number calculation are due to parallelization of the dynamic programming phase, which is the bottleneck in sequential DOCKS variants. A minimum-size set that hits all infinite-length sequences is optimally and rapidly removed; however, the remaining sequences of length are calculated and removed in time polynomial in the output size. We show that a constant factor reduction is beneficial in mitigating this bottleneck for practical use. In addition, we reduce the memory usage of this phase by theoretical and technical advancements. Last, we build on a randomized parallel algorithm for Set Cover to significantly speed up vertex selection. The randomized algorithm can be derandomized, while preserving the same approximation ratio, since it requires only pairwise independence of the random variables [2].
One main open problem still remains from this work. Although the randomized approximation algorithm enables us to generate a UHS more efficiently, the hitting numbers still need to be calculated at each iteration. The task of computing hitting numbers remains as the bottleneck in computing a UHS. Is there a more efficient way of calculating hitting numbers than the dynamic programming calculation done in DOCKS and PASHA? A more efficient calculation of hitting numbers will enable PASHA to run over in a reasonable time.
As for long reads, which are becoming more popular for genome assembly tasks, a -mer set that hits all infinite long sequences, as computed optimally by Mykkelveit’s algorithm [13], is enough due to the length of these long read sequences. Still, due to the inaccuracies and high cost of long read sequencing compared to short read sequencing, the latter is still the prevailing method to produce sequencing data, and is expected to remain so for the near future.
We expect the efficient calculation of UHSs to lead to improvements in sequence analysis and construction of space-efficient data structures. Unfortunately, previous methods were limited to small values of , thus allowing application to only a small subset of sequence analysis tasks. As there is an inherent exponential dependency on in terms of both runtime and memory, efficiency in calculating these sets is crucial. We expect that the UHSs newly-enabled by PASHA for will be useful in improving various applications in genomics.
6. Conclusion
We developed a novel randomized parallel algorithm PASHA to compute a small set of -mers which together hit every sequence of length . It is based on two algorithmic innovations: (i) improved calculation of hitting numbers through paralleization and memory reduction; and (ii) randomized parallel selection of additional -mers to remove. We demonstrated the scalability of PASHA to larger values of up to 16. Notably, the universal hitting sets need to be computed only once, and can then be used in many sequence analysis applications. We expect our algorithms to be an essential part of the sequence analysis toolkit.
Supplementary Material
Acknowledgments.
This work was supported by NIH grant R01GM081871 to B.B. B.E. was supported by the MISTI MIT-Israel program at MIT and Ben-Gurion University of the Negev. We gratefully acknowledge the support of Intel Corporation for giving access to the Intel®AI DevCloud platform used for part of this work.
A. Emulating the Greedy Algorithm
The greedy Set Cover algorithm was developed independently by Johnson and Lovász for unweighted vertices [5, 9]. Lovász [9] proved:
Theorem 1.
The greedy algorithm for Set Cover outputs cover with , where is the maximum cardinality of a set.
We adapt a definition for an algorithm emulating the greedy algorithm for the Set Cover problem to the second phase of DOCKS [2]. We say that an algorithm for the second phase of DOCKS -emulates the greedy algorithm if it outputs a set of vertices serially, during which it selects a vertex set such that
where is the set of -long paths covered by . Using this definition, we come up with a near-optimal approximation by the following theorem:
Theorem 2.
An algorithm for the second phase of DOCKS that -emulates the greedy algorithm produces cover with , where OPT is the optimal cover.
Proof. We define the cost of covering path as , where is the set of vertices selected in the selection step in which was covered, and the set of -long paths covered by . Then, .
Let be the set of all -long paths in . A fractional cover of graph is function s.t. for all , . The optimal cover has minimum .
Let be such an optimal fractional cover. The size of the cover produced is
where is the set of all -long paths through vertex .
Lemma 1.
There are at most paths such that for any , .
Proof. Assume the contrary: Before such a path is covered, . Thus,
contradicting the definition.
Suppose we rank the paths by decreasing order of . From the above remark, if the path has cost , then . Then, we can write
Then,
and finally
In PASHA, we ensure that in step , the sum of vertex hitting numbers of selected vertex set is at least . We now show that this is satisfied with high probability in each step.
Theorem 3.
With probability at least 1/2, the sum of vertex hitting numbers of selected vertex set at step is at least .
Proof. For any vertex in selected vertex set at step , let be an indicator variable for the random event that vertex is picked, and .
Note that , and , since we are given that no vertex covers a fraction of the -long paths covered by the vertices in . By Chebyshev’s inequality, for any ,
and with probability 3/4,
and
Let denote the set of -long paths covered by vertex set . Then,
We know that , which is bounded below by . Let . Then,
Hence, with probability at least 3/4,
Both events hold with probability at least 1/2, and the sum of vertex hitting numbers is at least
B. Runtime Analysis
Here, we show the number of the selection steps and the average-time asymptotic complexity of PASHA.
Lemma 2.
The number of selection steps is .
Proof. The number of steps is , and within each step, there are selection steps (where is the sum of vertex hitting numbers of the vertex set for that step and the number of threads used), since we are guaranteed to remove at least fraction of the paths during that step. Overall, there are selection steps.
Theorem 4.
For , there is an approximation algorithm for the second phase of DOCKS that runs in average time, where m is the number of threads used, and produces a cover of size at most times the optimal size, where .
References
- 1.Berger B, Peng J, Singh M: Computational solutions for omics data. Nat. Rev. Genet 14(5), 333 (2013) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Berger B, Rompel J, Shor PW: Efficient NC algorithms for set cover with applications to learning and geometry. J. Comput. Syst. Sci 49(3), 454–477 (1994) [Google Scholar]
- 3.DeBlasio D, Gbosibo F, Kingsford C, Marçais G.: Practical universal k-mer sets for minimizer schemes. In: Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, pp. 167–176. ACM (2019) [Google Scholar]
- 4.Deorowicz S, Kokot M, Grabowski S, Debudaj-Grabysz A: KMC 2: fast and resource-frugal k-mer counting. Bioinformatics 31(10), 1569–1576 (2015) [DOI] [PubMed] [Google Scholar]
- 5.Johnson DS: Approximation algorithms for combinatorial problems. J. Comput. Syst. Sci 9(3), 256–278 (1974) [Google Scholar]
- 6.Kawulok J, Deorowicz S: CoMeta: classification of metagenomes using k-mers. PLoS ONE 10(4), e0121453 (2015) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Kucherov G: Evolution of biosequence search algorithms: a brief survey. Bioinformatics 35(19), 3547–3552 (2019) [DOI] [PubMed] [Google Scholar]
- 8.Leinonen R, Sugawara H, Shumway M, Collaboration INSD: The sequence read archive. Nucleic Acids Res. 39, D19–D21 (2010) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Lovász L: On the ratio of optimal integral and fractional covers. Discret. Math 13(4), 383–390 (1975) [Google Scholar]
- 10.Marçais G, DeBlasio D, Kingsford C: Asymptotically optimal minimizers schemes. Bioinformatics 34(13), i13–i22 (2018) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Marçais G, Pellow D, Bork D, Orenstein Y, Shamir R, Kingsford C: Improving the performance of minimizers and winnowing schemes. Bioinformatics 33(14), i110–i117 (2017) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Marçais G, Solomon B, Patro R, Kingsford C: Sketching and sublinear data structures in genomics. Ann. Rev. Biomed. Data Sci 2, 93–118 (2019) [Google Scholar]
- 13.Mykkeltveit J: A proof of Golomb’s conjecture for the de Bruijn graph. J. Comb. Theory 13(1), 40–45 (1972) [Google Scholar]
- 14.Orenstein Y, Pellow D, Marçais G, Shamir R, Kingsford C: Compact universal k-mer hitting sets. In: Frith M, Storm Pedersen CN (eds.) WABI 2016. LNCS, vol. 9838, pp. 257–268. Springer, Cham: (2016). 10.1007/978-3-319-43681-4_21 [DOI] [Google Scholar]
- 15.Orenstein Y, Pellow D, Marçais G, Shamir R, Kingsford C: Designing small universal k-mer hitting sets for improved analysis of high-throughput sequencing. PLoS Comput. Biol 13(10), e1005777 (2017) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Paindavoine M, Vialla B: Minimizing the number of bootstrappings in fully homomorphic encryption. In: Dunkelman O,Keliher L (eds.) SAC 2015. LNCS, vol. 9566, pp. 25–43. Springer, Cham: (2016). 10.1007/978-3-319-31301-6_2 [DOI] [Google Scholar]
- 17.Qin J, et al. : A human gut microbial gene catalogue established by metagenomic sequencing. Nature 464(7285), 59 (2010) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Roberts M, Hayes W, Hunt BR, Mount SM, Yorke JA: Reducing storage requirements for biological sequence comparison. Bioinformatics 20(18), 3363–3369 (2004) [DOI] [PubMed] [Google Scholar]
- 19.Turnbaugh PJ, Ley RE, Hamady M, Fraser-Liggett CM, Knight R, Gordon JI: The human microbiome project. Nature 449(7164), 804 (2007) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Ye C, Ma ZS, Cannon CH, Pop M, Douglas WY: Exploiting sparseness in de novo genome assembly. BMC Bioinform. 13(6), S1 (2012) [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.