

Abstract
Background
In recent years, there has been an upwelling of artificial intelligence (AI) studies in the health care literature. During this period, there has been an increasing number of proposed standards to evaluate the quality of health care AI studies.
Objective
This rapid umbrella review examines the use of AI quality standards in a sample of health care AI systematic review articles published over a 36-month period.
Methods
We used a modified version of the Joanna Briggs Institute umbrella review method. Our rapid approach was informed by the practical guide by Tricco and colleagues for conducting rapid reviews. Our search was focused on the MEDLINE database supplemented with Google Scholar. The inclusion criteria were English-language systematic reviews regardless of review type, with mention of AI and health in the abstract, published during a 36-month period. For the synthesis, we summarized the AI quality standards used and issues noted in these reviews drawing on a set of published health care AI standards, harmonized the terms used, and offered guidance to improve the quality of future health care AI studies.
Results
We selected 33 review articles published between 2020 and 2022 in our synthesis. The reviews covered a wide range of objectives, topics, settings, designs, and results. Over 60 AI approaches across different domains were identified with varying levels of detail spanning different AI life cycle stages, making comparisons difficult. Health care AI quality standards were applied in only 39% (13/33) of the reviews and in 14% (25/178) of the original studies from the reviews examined, mostly to appraise their methodological or reporting quality. Only a handful mentioned the transparency, explainability, trustworthiness, ethics, and privacy aspects. A total of 23 AI quality standard–related issues were identified in the reviews. There was a recognized need to standardize the planning, conduct, and reporting of health care AI studies and address their broader societal, ethical, and regulatory implications.
Conclusions
Despite the growing number of AI standards to assess the quality of health care AI studies, they are seldom applied in practice. With increasing desire to adopt AI in different health topics, domains, and settings, practitioners and researchers must stay abreast of and adapt to the evolving landscape of health care AI quality standards and apply these standards to improve the quality of their AI studies.
Keywords: artificial intelligence, health care artificial intelligence, health care AI, rapid review, umbrella review, quality standard
Introduction
Growth of Health Care Artificial Intelligence
In recent years, there has been an upwelling of artificial intelligence (AI)–based studies in the health care literature. While there have been reported benefits, such as improved prediction accuracy and monitoring of diseases [1], health care organizations face potential patient safety, ethical, legal, social, and other risks from the adoption of AI approaches [2,3]. A search of the MEDLINE database for the terms “artificial intelligence” and “health” in the abstracts of articles published in 2022 alone returned >1000 results. Even by narrowing it down to systematic review articles, the same search returned dozens of results. These articles cover a wide range of AI approaches applied in different health care contexts, including such topics as the application of machine learning (ML) in skin cancer [4], use of natural language processing (NLP) to identify atrial fibrillation in electronic health records [5], image-based AI in inflammatory bowel disease [6], and predictive modeling of pressure injury in hospitalized patients [7]. The AI studies reported are also at different AI life cycle stages, from model development, validation, and deployment to evaluation [8]. Each of these AI life cycle stages can involve different contexts, questions, designs, measures, and outcomes [9]. With the number of health care AI studies rapidly on the rise, there is a need to evaluate the quality of these studies in different contexts. However, the means to examine the quality of health care AI studies have grown more complex, especially when considering their broader societal and ethical implications [10-13].
Coiera et al [14] described a “replication crisis” in health and biomedical informatics where issues regarding experimental design and reporting of results impede our ability to replicate existing research. Poor replication raises concerns about the quality of published studies as well as the ability to understand how context could impact replication across settings. The replication issue is prevalent in health care AI studies as many are single-setting approaches and we do not know the extent to which they can be translated to other settings or contexts. One solution to address the replication issue in AI studies has been the development of a growing number of AI quality standards. Most prominent are the reporting guidelines from the Enhancing the Quality and Transparency of Health Research (EQUATOR) network [15]. Examples include the CONSORT-AI (Consolidated Standards of Reporting Trials–Artificial Intelligence) extension for reporting AI clinical trials [16] and the SPIRIT-AI (Standard Protocol Items: Recommendations for Interventional Trials–Artificial Intelligence) extension for reporting AI clinical trial protocols [17]. Beyond the EQUATOR guidelines, there are also the Minimum Information for Medical AI Reporting standard [18] and the Minimum Information About Clinical Artificial Intelligence Modeling checklist [19] on the minimum information needed in published AI studies. These standards mainly focus on the methodological and reporting quality aspects of AI studies to ensure that the published information is rigorous, complete, and transparent.
Need for Health Care AI Standards
However, there is a shortcoming of standard-driven guidance that spans the entire AI life cycle spectrum of design, validation, implementation, and governance. The World Health Organization has published six ethical principles to guide the use of AI [20] that cover (1) protecting human autonomy; (2) promoting human well-being and safety and the public interest; (3) ensuring transparency, explainability, and intelligibility; (4) fostering responsibility and accountability; (5) ensuring inclusiveness and equity; and (6) promoting AI that is responsive and sustainable. In a scoping review, Solanki et al [21] operationalized health care AI ethics through a framework of 6 guidelines that spans the entire AI life cycle of data management, model development, deployment, and monitoring. The National Health Service England has published a best practice guide on health care AI on how to get it right that encompasses a governance framework, addressing data access and protection issues, spreading the good innovation, and monitoring uses over time [22]. To further promote the quality of health care AI, van de Sande et al [23] have proposed a step-by-step approach with specific AI quality criteria that span the entire AI life cycle from development and implementation to governance.
Despite the aforementioned principles, frameworks, and guidance, there is still widespread variation in the quality of published AI studies in the health care literature. For example, 2 systematic reviews of 152 prediction and 28 diagnosis studies have shown poor methodological and reporting quality that have made it difficult to replicate, assess, and interpret the study findings [24,25]. The recent shifts beyond study quality to broader ethical, equity, and regulatory issues have also raised additional challenges for AI practitioners and researchers on the impact, transparency, trustworthiness, and accountability of the AI studies involved [13,26-28]. Increasingly, we are also seeing reports of various types of AI implementation issues [2]. There is a growing gap between the expected quality and performance of health care AI that needs to be addressed. We suggest that the overall issue is a lack of awareness and of the use of principles, frameworks, and guidance in health care AI studies.
This rapid umbrella review addressed the aforementioned issues by focusing on the principles and frameworks for health care AI design, implementation, and governance. We analyzed and synthesized the use of AI quality standards as reported in a sample of published health care AI systematic review articles. In this paper, AI quality standards are defined as guidelines, criteria, checklists, statements, guiding principles, or framework components used to evaluate the quality of health care AI studies in different domains and life cycle stages. In this context, quality covers the trustworthiness, methodological, reporting, and technical aspects of health care AI studies. Domains refer to the disciplines, branches, or areas in which AI can be found or applied, such as computer science, medicine, and robotics. The findings from this review can help address the growing need for AI practitioners and researchers to navigate the increasingly complex landscape of AI quality standards to plan, conduct, evaluate, and report health care AI studies.
Methods
Overview
With the increasing volume of systematic review articles that appear in the health care literature each year, an umbrella review has become a popular and timely approach to synthesize knowledge from published systematic reviews on a given topic. For this paper, we drew on the umbrella review method in the typology of systematic reviews for synthesizing evidence in health care by MacEntee [29]. In this typology, umbrella reviews are used to synthesize multiple systematic reviews from different sources into a summarized form to address a specific topic. We used a modified version of the Joanna Briggs Institute (JBI) umbrella review method to tailor the process, including developing of an umbrella review protocol, applying a rapid approach, and eliminating duplicate original studies [30]. Our rapid approach was informed by the practical guide to conducting rapid reviews in the areas of database selection, topic refinement, searching, study selection, data extraction, and synthesis by Tricco et al [31]. A PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) flow diagram of our review process is shown in Figure 1 [32]. A PRISMA checklist is provided in Multimedia Appendix 1 [32].
Figure 1.

PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) flow diagram based on the work by Page et al [32]. JBI: Joanna Briggs Institute.
Objective and Questions
The objective of this rapid umbrella review was to examine the use of AI quality standards based on a sample of published health care AI systematic reviews. Specifically, our questions were as follows:
What AI quality standards have been applied to evaluate the quality of health care AI studies?
What key quality standard–related issues are noted in these reviews?
What guidance can be offered to improve the quality of health care AI studies through the incorporation of AI quality standards?
Search Strategy
Our search strategy focused on the MEDLINE database supplemented with Google Scholar. Our search terms consisted of “artificial intelligence” or “AI,” “health,” and “systematic review” mentioned in the abstract (refer to Multimedia Appendix 2 for the search strings used). We used the .TW search field tag as it searches on title and abstract as well as fields such as abstract, Medical Subject Heading terms, and Medical Subject Heading subheadings. Our rationale to limit the search to MEDLINE with simple terms was to keep the process manageable, recognizing the huge volume of health care AI–related literature reviews that have appeared in the last few years, especially on COVID-19. One author conducted the MEDLINE and Google Scholar searches with assistance from an academic librarian. For Google Scholar, we restricted the search to the first 100 citations returned.
Inclusion Criteria
We considered all English-language systematic review articles published over a 36-month period from January 1, 2020, to December 31, 2022. The review could be any type of systematic review, meta-analysis, narrative review, qualitative review, scoping review, meta-synthesis, realist review, or umbrella review as defined in the review typology by MacEntee [29]. The overarching inclusion criteria were AI and health as the focus. To be considered for inclusion, the review articles must meet the following criteria:
Each original study in the review is described, where an AI approach in the form of a model, method, algorithm, technique, or intervention is proposed, designed, implemented, or evaluated within a health care context to address a particular health care problem or topic area.
We define AI as a simulation of the approximation of human intelligence in machines that comprises learning, reasoning, and logic [33]. In that approximation, AI has different levels of adaptivity and autonomy. Weak AI requires supervision or reinforced learning with human intervention to adapt to the environment, with low autonomous interaction. Strong AI is highly adaptive and highly autonomous via unsupervised learning, with no human intervention.
We looked through all the articles, and our health care context categorization was informed by the stated settings (eg, hospital) and purpose (eg, diagnosis) mentioned in the included reviews.
The review can include all types of AI approaches, such as ML, NLP, speech recognition, prediction models, neural networks, intelligent robotics, and AI-assisted and automated medical devices.
The review must contain sufficient detail on the original AI studies, covering their objectives, contexts, study designs, AI approaches, measures, outcomes, and reference sources.
Exclusion Criteria
We excluded articles if any one of the following applied:
Review articles published before January 1, 2020; not accessible in web-based format; or containing only an abstract
Review articles in languages other than English
Earlier versions of the review article with the same title or topic by the same authors
Context not health care–related, such as electronic commerce or smart manufacturing
The AI studies not containing sufficient detail on their purpose, features, or reference sources
Studies including multiple forms of digital health technologies besides AI, such as telehealth, personal health records, or communication tools
Review Article Selection
One author conducted the literature searches and retrieved the citations after eliminating duplicates. The author then screened the citation titles and abstracts against the inclusion and exclusion criteria. Those that met the inclusion criteria were retrieved for full-text review independently by 2 other authors. Any disagreements in final article selection were resolved through consensus between the 2 authors or with a third author. The excluded articles and the reasons for their exclusion were logged.
Quality Appraisal
In total, 2 authors applied the JBI critical appraisal checklist independently to appraise the quality of the selected reviews [30]. The checklist has 11 questions that allow for yes, no, unclear, or not applicable as the response. The questions cover the areas of review question, inclusion criteria, search strategy and sources, appraisal criteria used, use of multiple reviewers, methods of minimizing data extraction errors and combining studies, publication bias, and recommendations supported by data. The reviews were ranked as high, medium, and low quality based on their JBI critical appraisal score (≥0.75 was high quality, ≥0.5 and <0.75 was medium quality, and <0.5 was low quality). All low-quality reviews were excluded from the final synthesis.
Data Extraction
One author extracted data from selected review articles using a predefined template. A second author validated all the articles for correctness and completeness. As this review was focused on AI quality standards, we extracted data that were relevant to this topic. We created a spreadsheet template with the following data fields to guide data extraction:
Author, year, and reference: first author last name, publication year, and reference number
URL: the URL where the review article can be found
Objective or topic: objective or topic being addressed by the review article
Type: type of review reported (eg, systematic review, meta-analysis, or scoping review)
Sources: bibliographic databases used to find the primary studies reported in the review article
Years: period of the primary studies covered by the review article
Studies: total number of primary studies included in the review article
Countries: countries where the studies were conducted
Settings: study settings reported in the primary studies of the review article
Participants: number and types of individuals being studied as reported in the review article
AI approaches: the type of AI model, method, algorithm, technique, tool, or intervention described in the review article
Life cycle and design: the stage or design of the AI study in the AI life cycle in the primary studies being reported, such as requirements, design, implementation, monitoring, experimental, observational, training-test-validation, or controlled trial
Appraisal: quality assessment of the primary studies using predefined criteria (eg, risk of bias)
Rating: quality assessment results of the primary studies reported in the review article
Measures: performance criteria reported in the review article (eg, mortality, accuracy, and resource use)
Analysis: methods used to summarize the primary study results (eg, narrative or quantitative)
Results: aggregate findings from the primary studies in the review article
Standards: name of the quality standards mentioned in the review article
Comments: issues mentioned in the review article relevant to our synthesis
Removing Duplicate AI Studies
We identified all unique AI studies across the selected reviews after eliminating duplicates that appeared in them. We retrieved full-text articles for every tenth of these unique studies and searched for mention of AI quality standard–related terms in them. This was to ensure that all relevant AI quality standards were accounted for even if the reviews did not mention them.
Analysis and Synthesis
Our analysis was based on a set of recent publications on health care AI standards. These include (1) the AI life cycle step-by-step approach by van de Sande et al [23] with a list of AI quality standards as benchmarks, (2) the reporting guidelines by Shelmerdine et al [15] with specific standards for different AI-based clinical studies, (3) the international standards for evaluating health care AI by Wenzel and Wiegand [26], and (4) the broader requirements for trustworthy health care AI across the entire life cycle stages by the National Academy of Medicine (NAM) [8] and the European Union Commission (EUC) [34]. As part of the synthesis, we created a conceptual organizing scheme drawing on published literature on AI domains and approaches to visualize their relationships (via a Euler diagram) [35]. All analyses and syntheses were conducted by one author and then validated by another to resolve differences.
For the analysis, we (1) extracted key characteristics of the selected reviews based on our predefined template; (2) summarized the AI approaches, life cycle stages, and quality standards mentioned in the reviews; (3) extracted any additional AI quality standards mentioned in the 10% sample of unique AI studies from the selected reviews; and (4) identified AI quality standard–related issues reported.
For the synthesis, we (1) mapped the AI approaches to our conceptual organizing scheme, visualized their relationships with the AI domains and health topics found, and described the challenges in harmonizing these terms; (2) established key themes from the AI quality standard issues identified and mapped them to the NAM and EUC frameworks [8,34]; and (3) created a summary list of the AI quality standards found and mapped them to the life cycle phases by van de Sande et al [23].
Drawing on these findings, we proposed a set of guidelines that can enhance the quality of future health care AI studies and described its practice, policy, and research implications. Finally, we identified the limitations of this rapid umbrella review as caveats for the readers to consider. As health care, AI, and standards are replete with industry terminologies, we used the acronyms where they are mentioned in the paper and compiled an alphabetical acronym list with their spelled-out form at the end of the paper.
Results
Summary of Included Reviews
We found 69 health care AI systematic review articles published between 2020 and 2022, of which 35 (51%) met the inclusion criteria. The included articles covered different review types, topics, settings, numbers of studies, designs, participants, AI approaches, and performance measures (refer to Multimedia Appendix 3 [36-68] for the review characteristics). We excluded the remaining 49% (34/69) of the articles because they (1) covered multiple technologies (eg, telehealth), (2) had insufficient detail, (3) were not specific to health care, or (4) were not in English (refer to Multimedia Appendix 4 for the excluded reviews and reasons). The quality of these reviews ranged from JBI critical appraisal scores of 1.0 to 0.36, with 49% (17/35) rated as high quality, 40% (14/35) rated as moderate quality, and 6% (2/35) rated as poor quality (Multimedia Appendix 5 [36-68]). A total of 6% (2/35) of the reviews were excluded for their low JBI scores [69,70], leaving a sample of 33 reviews for the final synthesis.
Regarding review types, most (23/33, 70%) were systematic reviews [37-40,45-51,53-57,59-64,66,67], with the remaining being scoping reviews [36,41-44,52,58,65,68]. Only 3% (1/33) of the reviews were meta-analyses [38], and another was a rapid review [61]. Regarding health topics, the reviews spanned a wide range of specific health conditions, disciplines, areas, and practices. Examples of conditions were COVID-19 [36,37,49,51,56,62,66], mental health [48,65,68], infection [50,59,66], melanoma [57], and hypoglycemia [67]. Examples of disciplines were public health [36,37,56,66], nursing [42,43,61], rehabilitation [52,64], and dentistry [55,63]. Areas included mobile health and wearables [41,52,54,65], surveillance and remote monitoring [51,61,66], robotic surgeries [47], and biobanks [39]. Practices included diagnosis [37,47,49,58,59,62], prevention [47], prediction [36,38,49,50,57], disease management [41,46,47,58], and administration [42]. Regarding settings, less than half (12/33, 36%) were explicit in their health care settings, which included multiple sources [36,42,43,50,54,61], hospitals [45,49], communities [44,51,58], and social media groups [48]. The number of included studies ranged from 794 on COVID-19 [49] to 8 on hypoglycemia [67]. Regarding designs, most were performance assessment studies using secondary data sources such as intensive care unit [38], imaging [37,62,63], and biobank [39] databases. Regarding participants, they included patients, health care providers, educators, students, simulated cases, and those who use social media. Less than one-third of the reviews (8/33, 24%) mentioned sample sizes, which ranged from 11 adults [44] to 1,547,677 electronic medical records [40] (refer to Multimedia Appendix 3 for details).
Regarding AI approaches, there were >60 types of AI models, methods, algorithms, tools, and techniques mentioned in varying levels of detail across the broad AI domains of computer science, data science with and without NLP, and robotics. The main AI approaches were ML and deep learning (DL), with support vector machine, convolutional neural network, neural network, logistic regression, and random forest being mentioned the most (refer to the next section for details). The performance measures covered a wide range of metrics, such as diagnostic and prognostic accuracies (eg, sensitivity, specificity, accuracy, and area under the curve) [37-40,46-48,53,57,59,63,67], resource use (eg, whether an intensive care unit stay was necessary, length of stay, and cost) [37,58,62], and clinical outcomes (eg, COVID-19 severity, mortality, and behavior change) [36,37,49,56,62,65]. A few reviews (6/33, 18%) focused on the extent of the socioethical guidelines addressed [44,51,55,58,66,68]. Regarding life cycle stages, different schemes were applied, including preprocessing and classification [48,57], data preparation-preprocessing [37,38], different stages of adoption (eg, knowledge, persuasion, decision making, implementation) [44], conceptual research [42], model development [36,37,40,42,45,46,50-56,58-64,66,67], design [43], training and testing [38,42,45,50-53,58,61-64], validation [36-38,40,45,46,50,51,53,55,56,58-64,67], pilot trials [65], public engagement [68], implementation [42,44,60-62,66,68], confirmation [44], and evaluation [42,43,53,60-62,65] (refer to Multimedia Appendix 3 for details). It is worth noting that the period covered for our review did not include any studies on large language models (LLMs). LLM studies became more prevalent in the literature in the period just after our review.
Use of Quality Standards in Health Care AI Studies
To make sense of the different AI approaches mentioned, we used a Euler diagram [71] as a conceptual organizing scheme to visualize their relationships with AI domains and health topics (Figure 2 [36,41-43,47,48,51-54,56-58,60,62,65,67]). The Euler diagram shows that AI broadly comprised approaches in the domains of computer science, data science with and without NLP, and robotics that could be overlapping. The main AI approaches were ML and DL, with DL being a more advanced form of ML through the use of artificial neural networks [33]. The diagram also shows that AI can exist without ML and DL (eg, decision trees and expert systems). There are also outliers in these domains with borderline AI-like approaches mostly intended to enhance human-computer interactions, such as social robotics [42,43], robotic-assisted surgery [47], and exoskeletons [54]. The health topics in our reviews spanned the AI domains, with most falling within data science with or without NLP. This was followed by computer science mostly for communication or database and other functional support and robotics for enhanced social interactions that may or may not be AI driven. There were borderline AI approaches such as programmed social robotics [42,43] or AI-enhanced social robots [54]. These approaches focus on AI enabled social robotic programming and did not use ML or DL. Borderline AI approaches also included virtual reality [60] and wearable sensors [65,66,68].
Figure 2.
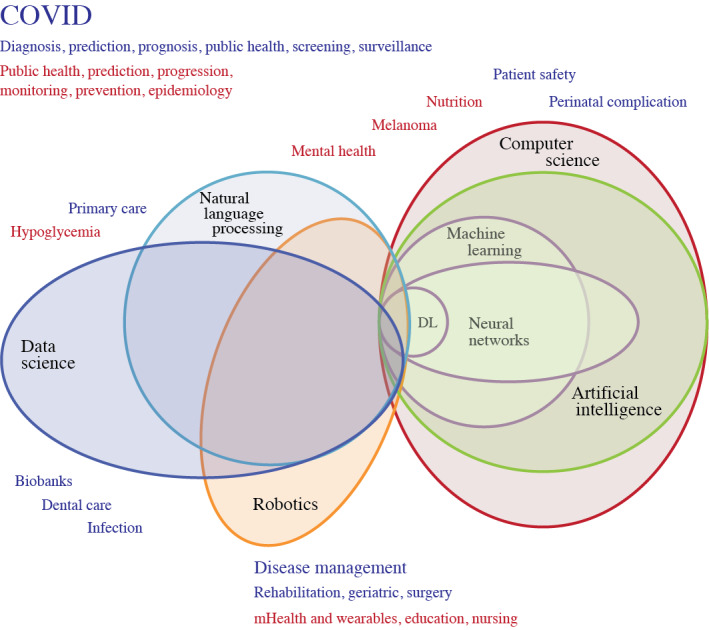
Euler diagram showing the overlapping artificial intelligence (AI) domains and health topics. Health topics in red are from reviews with no mention of specific AI quality standards. Health-related subjects in blue are from reviews with mention of AI quality standards. DL: deep learning; mHealth: mobile health.
Regarding AI life cycle stages, we harmonized the different terms used in the original studies by mapping them to the 5 life cycle phases by van de Sande et al [23]: 0 (preparation), I (model development), II (performance assessment), III (clinical testing), and IV (implementation). Most AI studies in the reviews mapped to the first 3 life cycle phases by van de Sande et al [23]. These studies would typically describe the development and performance of the AI approach on a given health topic in a specific domain and setting, including their validation, sometimes done using external data sets [36,38]. A small number of reviews reported AI studies that were at the clinical testing phase [60,61,66,68]. A total of 7 studies were described as being in the implementation phase [66,68]. On the basis of the descriptions provided, few of the AI approaches in the studies in the AI reviews had been adopted for routine use in clinical settings [66,68] with quantifiable improvements in health outcomes (refer to Multimedia Appendix 6 [36-68] for details).
Regarding AI quality standards, only 39% (13/33) of the reviews applied specific AI quality standards in their results [37-40,45,46,50,54,58,59,61,63,66], and 12% (4/33) mentioned the need for standards [55,63,68]. These included the Prediction Model Risk of Bias Assessment Tool [37,38,58,59], Newcastle-Ottawa Scale [39,50], Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modeling Studies [38,59], Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis–Machine Learning Extension [50], levels of evidence [61], Critical Appraisal Skills Program Clinical Prediction Rule Checklist [40], Mixed Methods Appraisal Tool [66], and CONSORT-AI [54]. Another review applied 7 design justice principles as the criteria to appraise the quality of their AI studies [68]. There were also broader-level standards mentioned. These included the European Union ethical guidelines for trustworthy AI [44]; international AI standards from the International Organization for Standardization (ISO); and AI policy guidelines from the United States, Russia, and China [46] (refer to Multimedia Appendix 6 for details). We updated the Euler diagram (Figure 2 [36,41-43,47,48,51-54,56-58,60,62,65,67]) to show in red the health topics in reviews with no mention of specific AI standards.
Of the 178 unique original AI studies from the selected reviews that were examined, only 25 (14%) mentioned the use of or need for specific AI quality standards (refer to Multimedia Appendix 7 [36-68] for details). They were of six types: (1) reporting—COREQ (Consolidated Criteria for Reporting Qualitative Research), Strengthening the Reporting of Observational Studies in Epidemiology, Standards for Reporting Diagnostic Accuracy Studies, PRISMA, and EQUATOR; (2) data—Unified Medical Language System, Food and Drug Administration (FDA) Adverse Event Reporting System, MedEx, RxNorm, Medical Dictionary for Regulatory Activities, and PCORnet; (3) technical—ISO-12207, FDA Software as a Medical Device, EU-Scholarly Publishing and Academic Resources Coalition, Sensor Web Enablement, Open Geospatial Consortium, Sensor Observation Service, and the American Medical Association AI recommendations; (4) robotics—ISO-13482 and ISO and TC-299; (5) ethics—Helsinki Declaration and European Union AI Watch; and (6) regulations—Health Insurance Portability and Accountability Act (HIPAA) and World Health Organization World Economic Forum. These standards were added to the list of AI quality standards mentioned by review in Multimedia Appendix 6.
A summary of the harmonized AI topics, approaches, domains, the life cycle phases by van de Sande et al [23], and quality standards derived from our 33 reviews and 10% of unique studies within them is shown in Table 1.
Table 1.
Summary of artificial intelligence (AI) approaches, domains, life cycle phases, and quality standards in the reviews.
| Review, year | Topics | Approaches; examples only (source from original review) | Domainsa | Life cycle phases | Quality standardsb |
| Abd-Alrazaq et al [36], 2020 | Public health, risk prediction, and COVID-19 | CNNc, SVMd, RFe, DTf, and LoRg | Data science with NLPh | Phase 0, I, and IIi | Not mentioned; Helsinki declarationb |
| Adamidi et al [37], 2021 | Public health, COVID-19, screening, diagnosis, and prognosis | ABj, ARMEDk, BEl, BNBm, and CNN | Data science | Phase 0, I, and II | PROBASTn, TRIPODb,o FDA-SaMDb,p, and STROBEb,q |
| Barboi et al [38], 2022 | Prediction, mortality, and ICUr | ANN-ELMs, DT, ELMt, ensemble LSTMu, and ESICULAv | Data science with NLP | Phase 0, I, and II | CHARMSw and PROBAST |
| Battineni et al [39], 2022 | Biobanks | CNN and SFCNx | Data science and computer science | Phase 0 and I, maybe II | NOSy |
| Bertini et al [40], 2022 | Perinatal and complications | AB, ANNz, DT, ENaa, and GAMab | Computer science | Phase 0, I, and II with need for phase-III clinical testing | CASPac |
| Bhatt et al [41], 2022 | mHealthad and disease management | DLae and FLaf | Data science | Phase 0 and I | Not mentioned |
| Buchanan et al [42], 2020 | Administration, clinical practice, policy, and research | MLag, SARah, CDSSai, and chatbots | Data science and robotics (x) | Phase 0, implied need for nurses to be involved in all phases | Not mentioned; COREQaj,b, ISO-13482ak,b, EU-SPARCal,b, and ISO and TC299, AMam,b |
| Buchanan et al [43], 2021 | Education | ML, virtual avatar applications, chatbots, wearable armband with ML, and predictive analysis | Data science and robotics (x) | Phase 0, implied need for nurses to be part of co-design at all stages | Not mentioned |
| Chew and Achananuparp [44], 2022 | General | Chatbots, weak AI, image recognition, AI diagnosis, and NLP | Data science with NLP and robotics | Implied phase 0 | Not mentioned |
| Choudhury et al [45], 2020 | Patient safety outcomes | ANN, BICMMan, BNCao, C4.5ap, and CPHaq | Data science | Phase 0 and I | ISO and IECar 23053, ISO 22100-5, Laskai, NISTas, and OECD-AIat |
| Choudhury and Asan [46], 2020 | Geriatrics and disease management | AUCau, AI, BCP-NNav, BCPNNaw, and BNMax | Data science with NLP | Phase 0 and I | TRIPOD, TRIPOD-MLay (cited but not used in AI studies; cited NIST standards), FAERSaz,b, MedExb, RxNormb, MedDRAba,b, PCORnetb, and MADE1.0bb,b |
| Eldaly et al [47], 2022 | Lymphedema, prevention, diagnosis, and disease management | ANN, ANFISbc, chatbots, DT, and EMLbd | Data science and robotics | Phase 0 and I | Not mentioned |
| Le Glaz et al [48], 2021 | Mental health | C4.5, CRAbe, CUIbf, DT, and KMbg | Data science with NLP and computer science | Phase 0 and I | Not mentioned; UMLSbh,b |
| Guo et al [49], 2021 | Prediction, diagnosis, prognosis, and COVID-19 | 3DQIbi, ACNNbj, AB, AI, and ANN | Data science | Phase 0 and I | Not mentioned |
| Hassan et al [50], 2021 | Prediction and sepsis | InSight, LASSObk, LR, MCRMbl, and MLRbm | Data science and computer science | Phase 0, I, and II | TRIPOD and NOS |
| Huang et al [51], 2022 | Telemedicine, monitoring, and COVID-19 | CNN-TFbn, IRRCNNbo, IoTbp-based wearable monitoring device, NVHODLbq, and SVM | Data science | Phase 0 and I | Not mentioned |
| Kaelin et al [52], 2021 | Pediatric and rehabilitation | NLP, ML, computer vision, and robotics | Data science, computer science, and robotics | Phase 0 and I | Not mentioned; HIPAAbr,b and COREQb |
| Kirk et al [53], 2021 | Nutrition | BCbs, CNN, DL, DT, and EMbt | Data science and computer science | Phase 0, I, and II; the mapping to these phases is questionable | Not mentioned (not even PRISMAbu) |
| Loveys et al [54], 2022 | Geriatrics and interventions | AI-enhanced robots, social robots, environmental sensors, and wearable sensors | Data science, computer science, and robotics (x) | Phase 0 and I | Revised Cochrane risk-of-bias tool for RCTsbv, cluster RCTs, and non-RCTs (ROBINS-Ibw) |
| Mörch et al [55], 2021 | Dentistry and ethics | DL, DSPbx, ML, and NNby | Data science | Phase 0 and I | Mentioned need for SPIRITbz and TRIPOD, used 2018 Montreal Declaration as AI ethical framework |
| Payedimarri et al [56], 2021 | Public health, interventions, and COVID-19 | ABSca, LiRcb, NN, and TOPSIScc | Data science | Phase 0 and I | Not mentioned |
| Popescu et al [57], 2022 | Cancer and prediction melanoma | ABCcd, autoencoder, CNN, combined networks, and DCNNce | Data science and computer science | Phase 0 and I | Not mentioned |
| Abbasgholizadeh Rahimi et al [58], 2021 | Primary care, diagnosis, and disease management | ALcf, ARcg, BNch, COBWEBci, and CHcj | Data science with NLP | Phase 0 and I | PROBAST |
| Sahu et al [59], 2022 | Detection, neonatal, and sepsis | AR-HMMck, LiR, LoR, MLoRcl, and NN | Data science | Phase 0 and I | CHARMS and PROBAST |
| Sapci and Sapci [60], 2020 | Education | AI, DL, ITScm, ML, and NLP | Data Science with NLP and computer science (x) | Phase 0 and I for AI education and training | Not mentioned; AMA –augmented intelligencecn,b |
| Seibert et al [61], 2021 | Ethics | APSco, ML, EScp, hybrid, and NLP | Data science, computer science, and robotics | Phase 0, I, II, and III | Risk of bias; levels of evidence from I to VII and not applicable; SWEcq,b, OGCcr,b, SOScs,b, COREQb, and STROBEb |
| Syeda et al [62], 2021 | Epidemiology, diagnosis, disease progression, and COVID-19 | ANN, BiGANct, CNN, DT, and DL | Data science | Phase 0, I, and II | Not mentioned |
| Talpur et al [63], 2022 | Dentistry and caries | ADA-NNcu, ANN, CNN, F-CNNcv, and FFBP-ANNcw | Data science | Phase 0, I, and II | Risk-of-bias assessment, no other standards mentioned |
| Vélez-Guerrero et al [64], 2021 | Rehabilitation | AL, ANN, AFMcx, ATCcy, and AFCcz | Data science, computer science, and robotics | Phase 0, I, and II | Need standardized protocol for clinical evaluation, FDAda regulatory standards |
| Welch et al [65], 2022 | Diagnosis, pediatrics, and psychiatry | ML and wearable biosensors | Data science with NLP and computer science (x) | Phase 0, I, and II | Not mentioned |
| Zhao et al [66], 2021 | Public health, surveillance, and COVID-19 | AI, AR, ML, physiological monitoring, and sensory technologies | Data science (x) | Phase 0, I, II, III, and IV; the mapping to these phases is questionable | MMATdb for study quality, Asadi framework for ethics, and STARDdc,b |
| Zheng et al [67], 2022 | Detection and hypoglycemia | ML or rule-based NLP | Data science with NLP (rule-based) | Phase 0, I, and II | Not mentioned |
| Zidaru et al [68], 2020 | Mental health | ML, NLP, sentiment analysis, VRdd, and wearable biosensors | Data science (x) | Phase 0, I, II, III, and IV; the mapping to these phases is questionable | Need standards for evaluating safety, outcomes, acceptability, explainability, and inclusive design; EU AI Watchde,b, FDA-SaMDb, EQUATORdf,b, WHO-WEF governancedg,b, CCC AI road mapdh,b, and ISO, IEC, or IEEE-12207di,b |
aBorderline AI approaches in the AI domains are identified with (x).
bItalicized entries are AI quality standards mentioned only in the original studies in the reviews.
cCNN: convolutional neural network.
dSVM: support vector machine.
eRF: random forest.
fDT: decision tree.
gLoR: logistic regression.
hNLP: natural language processing.
iPhase 0: preparation before model development; phase I: AI model development; phase II: assessment of AI performance and reliability; phase III: clinical testing of AI; and phase IV: implementing and governing AI.
jAB: adaptive boosting or adaboost.
kARMED: attribute reduction with multi-objective decomposition ensemble optimizer.
lBE: boost ensembling.
mBNB: Bernoulli naïve Bayes.
nPROBAST: Prediction Model Risk of Bias Assessment Tool.
oTRIPOD: Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis.
pFDA-SaMD: Food and Drug Administration–Software as a Medical Device.
qSTROBE: Strengthening the Reporting of Observational Studies in Epidemiology.
rICU: intensive care unit.
sANN-ELM: artificial neural network extreme learning machine.
tELM: ensemble machine learning.
uLSTM: long short-term memory.
vESICULA: super intensive care unit learner algorithm.
wCHARMS: Checklist for Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modeling Studies.
xSFCN: sparse fully convolutional network.
yNOS: Newcastle-Ottawa scale.
zANN: artificial neural network.
aaEN: elastic net.
abGAM: generalized additive model.
acCASP: Critical Appraisal Skills Programme.
admHealth: mobile health.
aeDL: deep learning.
afFL: federated learning.
agML: machine learning.
ahSAR: socially assistive robot.
aiCDSS: clinical decision support system.
ajCOREQ: Consolidated Criteria for Reporting Qualitative Research.
akISO: International Organization for Standardization.
alEU-SPARC: Scholarly Publishing and Academic Resources Coalition Europe.
amAMS: Associated Medical Services.
anBICMM: Bayesian independent component mixture model.
aoBNC: Bayesian network classifier.
apC4.5: a named algorithm for creating decision trees.
aqCPH: Cox proportional hazard regression.
arIEC: international electrotechnical commission.
asNIST: National Institute of Standards and Technology.
atOECD-AI: Organisation for Economic Co-operation and Development–artificial intelligence.
auAUC: area under the curve.
avBCP-NN: Bayesian classifier based on propagation neural network.
awBCPNN: Bayesian confidence propagation neural network.
axBNM: Bayesian network model.
ayTRIPOD-ML: Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis–Machine Learning.
azFAERS: Food and Drug Administration Adverse Event Reporting System.
baMedDRA: Medical Dictionary for Regulatory Activities.
bbMADE1.0: Medical Artificial Intelligence Data Set for Electronic Health Records 1.0.
bcANFIS: adaptive neuro fuzzy inference system.
bdEML: ensemble machine learning.
becTAKES: clinical Text Analysis and Knowledge Extraction System.
bfCUI: concept unique identifier.
bgKM: k-means clustering.
bhUMLS: Unified Medical Language System.
bi3DQI: 3D quantitative imaging.
bjACNN: attention-based convolutional neural network.
bkLASSO: least absolute shrinkage and selection operator.
blMCRM: multivariable Cox regression model.
bmMLR: multivariate linear regression.
bnCNN-TF: convolutional neural network using Tensorflow.
boIRRCN: inception residual recurrent convolutional neural network.
bpIoT: internet of things.
bqNVHDOL: notal vision home optical-based deep learning.
brHIPAA: Health Insurance Portability and Accountability Act.
bsBC: Bayesian classifier.
btEM: ensemble method.
buPRISMA: Preferred Reporting Items for Systematic Reviews and Meta-Analyses.
bvRCT: randomized controlled trial.
bwROBINS-I: Risk of Bias in Non-Randomised Studies of Interventions.
bxDSP: deep supervised learning.
byNN: neural network.
bzSPIRIT: Standard Protocol Items: Recommendations for Interventional Trials.
caABS: agent based simulation.
cbLiR: linear regression.
ccTOPSIS: technique for order of preference by similarity to ideal solution.
cdABC: artificial bee colony.
ceDCNN: deep convolutional neural network.
cfAL: abductive learning.
cgAR: automated reasoning.
chBN: Bayesian network.
ciCOBWEB: a conceptual clustering algorithm.
cjCH: computer heuristic.
ckAR-HMM: auto-regressive hidden Markov model.
clMLoR: multivariate logistic regression.
cmITS: intelligent tutoring system.
cnAMA: American Medical Association.
coAPS: automated planning and scheduling.
cpES: expert system.
cqSWE: software engineering.
crOGC: open geospatial consortium standard.
csSOS: start of sequence.
ctBiGAN: bidirectional generative adversarial network.
cuADA-NN: adaptive dragonfly algorithms with neural network.
cvF-CNN: fully convolutional neural network.
cwFFBP-ANN: feed-forward backpropagation artificial neural network.
cxAFM: adaptive finite state machine.
cyATC: anatomical therapeutic chemical.
czAFC: active force control.
daFDA: Food and Drug Administration.
dbMMAT: Mixed Methods Appraisal Tool.
dcSTARD: Standards for Reporting of Diagnostic Accuracy Study.
ddVR: virtual reality.
deEU: European Union.
dfEQUATOR: Enhancing the Quality and Transparency of Health Research.
dgWHO-WEF: World Health Organization World Economic Forum.
dhCCC: concordance correlation coefficient.
diIEEE: Institute of Electrical and Electronics Engineers.
There were also other AI quality standards not mentioned in the reviews or their unique studies. They included guidelines such as the do no harm road map, Factor Analysis of Information Risk, HIPAA, and the FDA regulatory framework mentioned by van de Sande et al [23]; AI clinical study reporting guidelines such as Clinical Artificial Intelligence Modeling and Minimum Information About Clinical Artificial Intelligence Modeling mentioned by Shelmerdine et al [15]; and the international technical AI standards such as ISO and International Electrotechnical Commission 22989, 23053, 23894, 24027, 24028, 24029, and 24030 mentioned by Wenzel and Wiegand [26].
With these additional findings, we updated the original table of AI standards in the study by van de Sande et al [23] showing crucial steps and key documents by life cycle phase (Table 2).
Table 2.
Use of health care standards in the reviews mapped to the life cycle phases by van de Sande et al [23].
|
|
Standards and corresponding reviewsa | ||
| Life cycle phase 0: preparation before AIb model development | |||
|
|
Define the problem and engage stakeholders |
|
|
|
|
Search for and evaluate available models |
|
|
|
|
Identify, collect data, and account for bias | ||
|
|
Handle privacy |
|
|
|
|
Ethical principles, frameworks, and guidelines |
|
|
| Life cycle phase I: AI model development | |||
|
|
Check applicable regulations |
|
|
|
|
Prepare data |
|
|
|
|
Train and validate |
|
|
|
|
Evaluate performance and report results |
|
|
| Life cycle phase II: assessment of AI performance and reliability | |||
|
|
Externally validate model or concept | ||
|
|
Simulate results and prepare for clinical study |
|
|
| Life cycle phase III: clinically testing AI | |||
|
|
Design and conduct clinical study | ||
| Life cycle phase IV: implementing and governing AI | |||
|
|
Legal approval |
|
|
|
|
Safely implement model |
|
|
|
|
Model and data governance | ||
|
|
Responsible model use |
|
|
| Standards in the reviews mapped to multiple phases | |||
|
|
Design justice principles |
|
|
|
|
Study quality |
|
|
|
|
Policy | ||
|
|
Technical and interoperability |
|
|
|
|
Terminology standards |
|
|
| Robotics | |||
|
|
Partnership for R&Dbe and innovation |
|
|
|
|
Robotic standardization and safety |
|
|
|
|
Robotic devices for personal care | ||
aItalicized references are original studies cited in the reviews, and references denoted with the footnote t are those cited in our paper but not present in any of the reviews.
bAI: artificial intelligence.
cFDA: Food and Drug Administration.
dECLAIR: Evaluate Commercial AI Solutions in Radiology.
eFHIR: Fast Healthcare Interoperability Resources.
fFAIR: Findability, Accessibility, Interoperability, and Reusability.
gPROBAST: Prediction Model Risk of Bias Assessment Tool.
hHIPAA: Health Insurance Portability and Accountability Act.
iOOTA: Office of The Assistant Secretary.
jGDPR: General Data Protection Regulation.
kEU: European Union.
lWMA: World Medical Association.
mWEF: World Economic Forum.
nSORMAS: Surveillance, Outbreak Response Management and Analysis System.
oWHO: World Health Organization.
pML: machine learning.
qTRIPOD: Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis.
rTRIPOD-ML: Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis—Machine Learning.
sCLAIM: Checklist for Artificial Intelligence in Medical Imaging.
tReferences denoted with the footnote t are those cited in our paper but not present in any of the reviews.
uCHARMS: Checklist for Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modeling Studies.
vPRISMA-DTA: Preferred Reporting Items for Systematic Reviews and Meta-Analyses of Diagnostic Test Accuracy.
wMI-CLAIM: Minimum Information About Clinical Artificial Intelligence Modeling.
xMINIMAR: Minimum Information for Medical AI Reporting.
yNOS: Newcastle-Ottawa Scale.
zLOE: level of evidence.
aaMMAT: Mixed Methods Appraisal Tool.
abCASP: Critical Appraisal Skills Programme.
acSTARD: Standards for Reporting of Diagnostic Accuracy Studies.
adCOREQ: Consolidated Criteria for Reporting Qualitative Research.
aeMADE1.0: Model Agnostic Diagnostic Engine 1.0.
afDECIDE-AI: Developmental and Exploratory Clinical Investigations of Decision-Support Systems Driven by Artificial Intelligence.
agSPIRIT-AI: Standard Protocol Items: Recommendations for Interventional Trials–Artificial Intelligence.
ahCONSORT-AI: Consolidated Standards of Reporting Trials–Artificial Intelligence.
aiRoB 2: Risk of Bias 2.
ajROBINS-I: Risk of Bias in Non-Randomised Studies of Interventions.
akRCT: randomized controlled trial.
alSTROBE: Strengthening the Reporting of Observational Studies in Epidemiology.
amAI-ML: artificial intelligence–machine learning.
anTAM: Technology Acceptance Model.
aoSaMD: Software as a Medical Device.
apIMDRF: International Medical Device Regulators Forum.
aqEQUATOR: Enhancing the Quality and Transparency of Health Research.
arNIST: National Institute of Standards and Technology.
asOECD: Organisation for Economic Co-operation and Development.
atAMA: American Medical Association.
auCCC: Computing Community Consortium.
avISO: International Organization for Standardization.
awIEEE: Institute of Electrical and Electronics Engineers.
axOGC: Open Geospatial Consortium.
aySWE: Sensor Web Enablement.
azSOS: Sensor Observation Service.
baIEC: International Electrotechnical Commission.
bbFAERS: Food and Drug Administration Adverse Event Reporting System.
bcMedDRA: Medical Dictionary for Regulatory Activities.
bdUMLS: Unified Medical Language System.
beR&D: research and development.
bfSPARC: Scholarly Publishing and Academic Resources Coalition.
bgTC: technical committee.
Quality Standard–Related Issues
We extracted a set of AI quality standard–related issues from the 33 reviews and assigned themes based on keywords used in the reviews (Multimedia Appendix 8 [36-68]). In total, we identified 23 issues, with the most frequently mentioned ones being clinical utility and economic benefits (n=10); ethics (n=10); benchmarks for data, model, and performance (n=9); privacy, security, data protection, and access (n=8); and federated learning and integration (n=8). Table 3 shows the quality standard issues by theme from the 33 reviews. To provide a framing and means of conceptualizing the quality-related issues, we did a high-level mapping of the issues to the AI requirements proposed by the NAM [8] and EUC [20]. The mapping was done by 2 of the authors, with the remaining authors validating the results. Final mapping was the result of consensus across the authors (Table 4).
Table 3.
Summary of quality standard–related issues in the reviews.
| Key themes | Quality issues | Reviews |
| Ethics | Guidelines needed, 10 issues—prudence, equity, privacy and intimacy, democratic participation, solidarity, responsibility, diversity inclusion, well-being, respect for autonomy, and sustainable development (Mörch et al [55]); the individual, organizational and society levels of the ethical framework by Asadi et al (Zhao et al [66]) | |
| Benefits, cost-effective, economic, external and clinical validation, and clinical utility | Need clinical validation and demonstration of economic benefits and clinical utility in real-world settings | |
| Benchmarks—models, data, and performance | Need standardized and comparable AIa models, parameters, evaluation measures, and gold standards | |
| Integration, federated learning, decision fusion, and ability to aggregate results | Need to integrate heterogeneous data from multiple sources and combine multiple classifier outputs into a common decision | |
| Privacy, security, open data, access, and protection | Need agreements and processes on privacy, security, access, open data, and data protection | |
| Education, web-based learning, learning experience, and competencies | Need education for the public, patients, students, and providers, including web-based learning and building competencies and as part of formal curricula | |
| Explainability | Enhance acceptability, understandability, and interpretability of solutions and ability to convey them to patients | |
| Reporting standards | Standardized reporting of study details to allow for comparison and replication | |
| Transparency | Need openness and being accountable through the entire AI life cycle | |
| Trust and trustworthiness | Need ethical guidelines to ensure confidence, truthfulness, and honesty with the design, use, and impact of AI systems | |
| Safety | Need to ensure patient safety from harm | |
| Bias—SDOHb and assessment | Need to consider sociodemographic variables and adequate sample sizes | |
| Co-design and engagement—user, provider, and public | Meaningful participation at all life cycle stages | |
| Technology maturity or feasibility, acceptance, and usability | Need user-friendly and mature AI systems with proven benefits to increase adoption | |
| Regulation and legal | Need legal framework and laws to ensure appropriate safe use and liability protection | |
| Context and time dependency | Purpose of AI models, health care context, and time lags have mediating effect | |
| Data integration and preprocessing | Need to integrate different variables and include multilevel data preprocessing to reduce dimensionality | |
| Design justice, equity, and fairness | Need design justice principles to engage the public and ensure a fair and equitable AI system | |
| Personalized care and targeted interventions | Select the best AI algorithms and outputs to customize care for specific individuals | |
| Quality—data and study | Need well-designed studies and quality data to conduct AI studies | |
| Social justice and social implications | Need to balance human caring needs with AI advances, understanding the societal impact of AI interventions |
|
| Governance | Need governance on the collection, storage, use, and transfer of data; being accountable and transparent with the process |
|
| Self-adaptability | Need adaptable and flexible AI systems that can improve over time |
|
aAI: artificial intelligence.
bSDOH: social determinants of health.
Table 4.
Quality standard–related issues by theme mapped to the National Academy of Medicine (NAM) and European Union Commission (EUC) requirements.
| Key themes | NAMa | EUCb | Reviews |
| Ethics | T6-2: ethics and fairness | 1—rights, agency, and oversight; 7—minimizing and reporting negative impact | |
| Benefits, cost-effective, economic, external and clinical validation, and clinical utility | B5-1: accuracy and outcome change; T6-2: cost, revenue and value, and safety and efficacy; and T6-3: improvement and assessments | 6—environmentally friendly and sustainable; 7—documenting trade-off and ability to redress | |
| Benchmarks—models, data, and performance | B5-1: accuracy and outcome change; T6-2: cost, revenue and value, and safety and efficacy; and T6-3: defining success and after-action assessments | 2—accuracy, reliability, and reproducibility; 3—data quality and integrity | |
| Integration, federated learning, decision fusion, and ability to aggregate results | T6-2: data environment and interoperability | 3—data governance; 4—traceability and explainability | |
| Privacy, security, open data, access, and protection | T6-2: cybersecurity and privacy | 2—resilience; 3—data privacy, protection, and access | |
| Education, web-based learning, learning experience, and competencies | T6-3: education and support | 7—minimizing and reporting negative impact | |
| Explainability | N/Ac | 4—explainability and communication | |
| Reporting standards | —d | 3—privacy and data protection; 7—auditability, documenting trade-offs, and ab | |
| Transparency | — | 4—traceability and communication | |
| Trust and trustworthiness | — | All 7 assessment list items | |
| Safety | T6-2: safety and efficacy | 2—resilience and safety | |
| Bias—SDOHe and assessment | B5-1: accuracy | 5—bias avoidance | |
| Co-design and engagement—user, provider, and public | B5-1: target users; T6-2: patient, family, and consumer engagement; and T6-3: stakeholder consensus | 1—rights, agency, and oversight; 5—participation | |
| Technology maturity or feasibility, acceptance, and usability | — | 5—accessibility and universal design | |
| Regulation and legal | T6-2: regulatory issues | 7—audibility and minimizing and reporting negative impact | |
| Context and time dependency | T6-3: problem identification | 2—accuracy, reliability, and reproducibility | |
| Data integration and preprocessing | — | 3—data quality and integrity | |
| Design justice, equity, and fairness | T6-2: ethics and fairness | 1—rights, agency, and oversight; 6—environmentally friendly and sustainable | |
| Personalized care and targeted interventions | B5-1: downstream interventions, target users, and capacity to intervene | 1—rights, agency, and oversight; 5—bias avoidance, universal design, and accessibility | |
| Quality—data and study | — | 3—data quality and integrity | |
| Social justice and social implications | B5-1: downstream interventions and desired outcome change | 1—rights, agency, and oversight; 6—social impact and society and democracy |
|
| Governance | T6-2: organizational capabilities, data environment, and personal capacity | 3—data quality and integrity; data access |
|
| Self-adaptability | — | 1—oversight |
|
aB5-1: key considerations in model development; T6-2: key considerations for institutional infrastructure and governance; and T6-3: key artificial intelligence tool implementation concepts, considerations, and tasks.
b1—human agency and oversight; 2—technical robustness and safety; 3—privacy and data governance; 4—transparency; 5—diversity, nondiscrimination, and fairness; 6—societal and environmental well-being; and 7—accountability.
cN/A: not applicable.
dThemes not addressed.
eSDOH: social determinants of health.
We found that all 23 quality standard issues were covered in the AI frameworks by the NAM and EUC. Both frameworks have a detailed set of guidelines and questions to be considered at different life cycle stages of the health care AI studies. While there was consistency in the mapping of the AI issues to the NAM and EUC frameworks, there were some differences across them. Regarding the NAM, the focus was on key aspects of AI model development, infrastructure and governance, and implementation tasks. Regarding the EUC, the emphasis was on achieving trustworthiness by addressing all 7 interconnected requirements of accountability; human agency and oversight; technical robustness and safety; privacy and data governance; transparency; diversity, nondiscrimination, and fairness; and societal and environmental well-being. The quality standard issues were based on our analysis of the review articles, and our mapping was at times more granular than the issues from the NAM and EUC frameworks. However, our results showed that the 2 frameworks do provide sufficient terminology for quality standard–related issues. By embracing these guidelines, one can enhance the buy-in and adoption of the AI interventions in the health care system.
Discussion
Principal Findings
Overall, we found that, despite the growing number of health care AI quality standards in the literature, they are seldom applied in practice, as is shown in a sample of recently published systematic reviews of health care AI studies. Of the reviews that mentioned AI quality standards, most were used to ensure the methodological and reporting quality of the AI studies involved. At the same time, the reviews identified many AI quality standard–related issues, including those broader in nature, such as ethics, regulations, transparency, interoperability, safety, and governance. Examples of broader standards mentioned in a handful of reviews or original studies are the ISO-12207, Unified Medical Language System, HIPAA, FDA Software as a Medical Device, World Health Organization AI governance, and American Medical Association augmented intelligence recommendations. These findings reflect the evolving nature of health care AI, which has not yet reached maturity or been widely adopted. There is a need to apply appropriate AI quality standards to demonstrate the transparency, robustness, and benefits of these AI approaches in different AI domains and health topics while protecting the privacy, safety, and rights of individuals and society from the potential unintended consequences of such innovations.
Another contribution of our study was a conceptual reframing for a systems-based perspective to harmonize health care AI. We did not look at AI studies solely as individual entities but rather as part of a bigger system that includes clinical, organizational, and societal aspects. Our findings complement those of recent publications, such as an FDA paper that advocates for a need to help people understand the broader system of AI in health care, including across different clinical settings [72]. Moving forward, we advocate for AI research that looks at how AI approaches will mature over time. AI approaches evolve through different phases of maturity as they move from development to validation to implementation. Each phase of maturity has different requirements [23] that must be assessed as part of evaluating AI approaches across domains as the number of health care applications rapidly increases [73]. However, comparing AI life cycle maturity across studies was challenging as there were a variety of life cycle terms used across the reviews, making it hard to compare life cycle maturity in and across studies. To address this issue, we provided a mapping of life cycle terms from the original studies but also used the system life cycle phases by van de Sande et al [23] as a common terminology for AI life cycle stages. A significant finding from the mapping was that most AI studies in our selected reviews were still at early stages of maturity (ie, model preparation, development, or validation), with very few studies progressing to later phases of maturity such as clinical testing and implementation. If AI research in health systems is to evolve, we need to move past single-case studies with external data validation to studies that achieve higher levels of life cycle maturity, such as clinical testing and implementation over a variety of routine health care settings (eg, hospitals, clinics, and patient homes and other community settings).
Our findings also highlighted that there are many AI approaches and quality standards used across domains in health care AI studies. To better understand their relationships and the overall construct of the approach, our applied conceptual organizing scheme for harmonized health care characterizes AI studies according to AI domains, approaches, health topics, life cycle phases, and quality standards. The health care AI landscape is complex. The Euler diagram shows multiple AI approaches in one or more AI domains for a given health topic. These domains can overlap, and the AI approaches can be driven by ML, DL, or other types (eg, decision trees, robotics). This complexity is expected to increase as the number of AI approaches and range of applications across all health topics and settings grows over time. For meaningful comparison, we need a harmonized scheme such as the one described in this paper to make sense of the multitude of AI terminology for the types of approaches reported in the health care AI literature. The systems-based perspective in this review provides the means for harmonizing AI life cycles and incorporating quality standards through different maturity stages, which could help advance health care AI research by scaling up to clinical validation and implementation in routine practice. Furthermore, we need to move toward explainable AI approaches where applications are based on clinical models if we are to move toward later stages of AI maturity in health care (eg, clinical validation, and implementation) [74].
Proposed Guidance
To improve the quality of future health care AI studies, we urge AI practitioners and researchers to draw on published health care AI quality standard literature, such as those identified in this review. The type of quality standards to be considered should cover the trustworthiness, methodological, reporting, and technical aspects. Examples include the NAM and EUC AI frameworks that address trustworthiness and the EQUATOR network with its catalog of methodological and reporting guidelines identified in this review. Also included are the Minimum Information for Medical AI Reporting guidelines and technical ISO standards (eg, robotics) that are not in the EQUATOR. Components that should be standardized are the AI ethics, approaches, life cycle stages, and performance measures used in AI studies to facilitate their meaningful comparison and aggregation. The technical standards should address such key design features as data, interoperability, and robotics. Given the complexities of the different AI approaches involved, rather than focusing on the underlying model or algorithm design, one should compare their actual performance based on life cycle stages (eg, degree of accuracy in model development or assessment vs outcome improvement in implementation). The summary list of the AI quality standards described in this paper is provided in Multimedia Appendix 9 for those wishing to apply them in future studies.
Implications
Our review has practice, policy, and research implications. For practice, better application of health care AI quality standards could help AI practitioners and researchers become more confident regarding the rigor and transparency of their health care AI studies. Developers adhering to standards may help make AI approaches in domains less of a black box and reduce unintended consequences such as systemic bias or threats to patient safety. AI standards may help health care providers better understand, trust, and apply the study findings in relevant clinical settings. For policy, these standards can provide the necessary guidance to address the broader impacts of health care AI, such as the issues of data governance, privacy, patient safety, and ethics. For research, AI quality standards can help advance the field by improving the rigor, reproducibility, and transparency in the planning, design, conduct, reporting, and appraisal of health care AI studies. Standardization would also allow for the meaningful comparison and aggregation of different health care AI studies to expand the evidence base in terms of their performance impacts, such as cost-effectiveness, and clinical outcomes.
Limitations
Despite our best effort, this umbrella review has limitations. First, we only searched for peer-reviewed English articles with “health” and “AI” as the keywords in MEDLINE and Google Scholar covering a 36-month period. It is possible to have missed relevant or important reviews that did not meet our inclusion criteria. Second, some of the AI quality standards were only published in the last few years, at approximately the same time when the AI reviews were conducted. As such, it is possible for AI review and study authors to have been unaware of these standards or the need to apply them. Third, the AI standard landscape is still evolving; thus, there are likely standards that we missed in this review (eg, Digital Imaging and Communications in Medicine in pattern recognition with convolutional neural networks [75]). Fourth, the broader socioethical guidelines are still in the early stages of being refined, operationalized, and adopted. They may not yet be in a form that can be easily applied when compared with the more established methodological and reporting standards with explicit checklists and criteria. Fifth, our literature review did not include any literature reviews on LLMs [76], and we know there are reviews of LLMs published in 2023 and beyond. Nevertheless, our categorization of NLP could coincide with NLP and DL in our Euler diagram, and furthermore, LLMs could be used in health care via approved chatbot applications at an early life cycle phase, for example, using decision trees first to prototype the chatbot as clinical decision support [77] before advancing it in the mature phase toward a more robust AI solution in health care with LLMs. Finally, only one author was involved in screening citation titles and abstracts (although 2 were later involved in full-text review of all articles that were screened in), and there is the possibility that we erroneously excluded an article on the basis of title and abstract. Despite these limitations, this umbrella review provided a snapshot of the current state of knowledge and gaps that exist with respect to the use of and need for AI quality standards in health care AI studies.
Conclusions
Despite the growing number of AI standards to assess the quality of health care AI studies, they are seldom applied in practice. With the recent unveiling of broader ethical guidelines such as those of the NAM and EUC, more transparency and guidance in health care AI use are needed. The key contribution of this review was the harmonization of different AI quality standards that could help practitioners, developers, and users understand the relationships among AI domains, approaches, life cycles, and standards. Specifically, we advocate for common terminology on AI life cycles to enable comparison of AI maturity across stages and settings and ensure that AI research scales up to clinical validation and implementation.
Acknowledgments
CK acknowledges funding support from a Discovery Grant from the Natural Sciences and Engineering Research Council of Canada (RGPIN/04884-2019). The authors affirm that no generative artificial intelligence tools were used in the writing of this manuscript.
Abbreviations
- AI
artificial intelligence
- CONSORT-AI
Consolidated Standards of Reporting Trials–Artificial Intelligence
- COREQ
Consolidated Criteria for Reporting Qualitative Research
- DL
deep learning
- EQUATOR
Enhancing the Quality and Transparency of Health Research
- EUC
European Union Commission
- FDA
Food and Drug Administration
- HIPAA
Health Insurance Portability and Accountability Act
- ISO
International Organization for Standardization
- JBI
Joanna Briggs Institute
- LLM
large language model
- ML
machine learning
- NAM
National Academy of Medicine
- NLP
natural language processing
- PRISMA
Preferred Reporting Items for Systematic Reviews and Meta-Analyses
- SPIRIT-AI
Standard Protocol Items: Recommendations for Interventional Trials–Artificial Intelligence
PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) checklist.
PubMed search strings.
Characteristics of the included reviews.
List of excluded reviews and reasons.
Quality of the included reviews using Joanna Briggs Institute scores.
Health care artificial intelligence reviews by life cycle stage.
Quality standards found in 10% of unique studies in the selected reviews.
Quality standard–related issues mentioned in the artificial intelligence reviews.
Summary list of artificial intelligence quality standards.
Footnotes
Authors' Contributions: CK contributed to conceptualization (equal), methodology (equal), data curation (equal), formal analysis (equal), investigation (equal), and writing—original draft (lead). DC contributed to conceptualization (equal), methodology (equal), data curation (equal), formal analysis (equal), investigation (equal), and visualization (equal). SM contributed to conceptualization (equal), methodology (equal), data curation (equal), formal analysis (equal), investigation (equal), and visualization (equal). MM contributed to conceptualization (equal), methodology (equal), data curation (equal), formal analysis (equal), and investigation (equal). FL contributed to conceptualization (equal), methodology (lead), data curation (lead), formal analysis (lead), investigation (equal), writing—original draft (equal), visualization (equal), project administration (lead), and supervision (lead).
Conflicts of Interest: None declared.
References
- 1.Saleh L, Mcheick H, Ajami H, Mili H, Dargham J. Comparison of machine learning algorithms to increase prediction accuracy of COPD domain. Proceedings of the 15th International Conference on Enhanced Quality of Life and Smart Living; ICOST '17; August 29-31, 2017; Paris, France. 2017. pp. 247–54. [DOI] [Google Scholar]
- 2.Gerke S, Minssen T, Cohen IG. Ethical and legal challenges of artificial intelligence-driven healthcare. Artif Intell Healthc. 2020:295–336. doi: 10.2139/ssrn.3570129. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7332220/ [DOI] [Google Scholar]
- 3.Čartolovni A, Tomičić A, Lazić Mosler E. Ethical, legal, and social considerations of AI-based medical decision-support tools: a scoping review. Int J Med Inform. 2022 May;161:104738. doi: 10.1016/j.ijmedinf.2022.104738.S1386-5056(22)00052-1 [DOI] [PubMed] [Google Scholar]
- 4.Das K, Cockerell CJ, Patil A, Pietkiewicz P, Giulini M, Grabbe S, Goldust M. Machine learning and its application in skin cancer. Int J Environ Res Public Health. 2021 Dec 20;18(24):13409. doi: 10.3390/ijerph182413409. https://www.mdpi.com/resolver?pii=ijerph182413409 .ijerph182413409 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Elkin P, Mullin S, Mardekian J, Crowner C, Sakilay S, Sinha S, Brady G, Wright M, Nolen K, Trainer J, Koppel R, Schlegel D, Kaushik S, Zhao J, Song B, Anand E. Using artificial intelligence with natural language processing to combine electronic health record's structured and free text data to identify nonvalvular atrial fibrillation to decrease strokes and death: evaluation and case-control study. J Med Internet Res. 2021 Nov 09;23(11):e28946. doi: 10.2196/28946. https://www.jmir.org/2021/11/e28946/ v23i11e28946 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Kawamoto A, Takenaka K, Okamoto R, Watanabe M, Ohtsuka K. Systematic review of artificial intelligence-based image diagnosis for inflammatory bowel disease. Dig Endosc. 2022 Nov;34(7):1311–9. doi: 10.1111/den.14334. https://onlinelibrary.wiley.com/doi/10.1111/den.14334 . [DOI] [PubMed] [Google Scholar]
- 7.Anderson C, Bekele Z, Qiu Y, Tschannen D, Dinov ID. Modeling and prediction of pressure injury in hospitalized patients using artificial intelligence. BMC Med Inform Decis Mak. 2021 Aug 30;21(1):253. doi: 10.1186/s12911-021-01608-5. https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-021-01608-5 .10.1186/s12911-021-01608-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Matheny M, Israni ST, Ahmed M, Whicher D. Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril. Washington, DC: National Academy of Medicine; 2019. [Google Scholar]
- 9.Park Y, Jackson GP, Foreman MA, Gruen D, Hu J, Das AK. Evaluating artificial intelligence in medicine: phases of clinical research. JAMIA Open. 2020 Oct;3(3):326–31. doi: 10.1093/jamiaopen/ooaa033. https://europepmc.org/abstract/MED/33215066 .ooaa033 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Yang C, Kors JA, Ioannou S, John LH, Markus AF, Rekkas A, de Ridder MA, Seinen TM, Williams RD, Rijnbeek PR. Trends in the conduct and reporting of clinical prediction model development and validation: a systematic review. J Am Med Inform Assoc. 2022 Apr 13;29(5):983–9. doi: 10.1093/jamia/ocac002. https://europepmc.org/abstract/MED/35045179 .6511611 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Van Calster B, Wynants L, Timmerman D, Steyerberg EW, Collins GS. Predictive analytics in health care: how can we know it works? J Am Med Inform Assoc. 2019 Dec 01;26(12):1651–4. doi: 10.1093/jamia/ocz130. https://europepmc.org/abstract/MED/31373357 .5542900 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Kelly CJ, Karthikesalingam A, Suleyman M, Corrado G, King D. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 2019 Oct 29;17(1):195. doi: 10.1186/s12916-019-1426-2. https://bmcmedicine.biomedcentral.com/articles/10.1186/s12916-019-1426-2 .10.1186/s12916-019-1426-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Yin J, Ngiam KY, Teo HH. Role of artificial intelligence applications in real-life clinical practice: systematic review. J Med Internet Res. 2021 Apr 22;23(4):e25759. doi: 10.2196/25759. https://www.jmir.org/2021/4/e25759/ v23i4e25759 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Coiera E, Ammenwerth E, Georgiou A, Magrabi F. Does health informatics have a replication crisis? J Am Med Inform Assoc. 2018 Aug 01;25(8):963–8. doi: 10.1093/jamia/ocy028. https://europepmc.org/abstract/MED/29669066 .4970161 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Shelmerdine SC, Arthurs OJ, Denniston A, Sebire NJ. Review of study reporting guidelines for clinical studies using artificial intelligence in healthcare. BMJ Health Care Inform. 2021 Aug 23;28(1):e100385. doi: 10.1136/bmjhci-2021-100385. https://informatics.bmj.com/lookup/pmidlookup?view=long&pmid=34426417 .bmjhci-2021-100385 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Liu X, Rivera SC, Moher D, Calvert MJ, Denniston AK, SPIRIT-AI and CONSORT-AI Working Group Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: the CONSORT-AI extension. BMJ. 2020 Sep 09;370:m3164–48. doi: 10.1136/bmj.m3164. http://www.bmj.com/lookup/pmidlookup?view=long&pmid=32909959 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Rivera SC, Liu X, Chan AW, Denniston AK, Calvert MJ, SPIRIT-AI and CONSORT-AI Working Group Guidelines for clinical trial protocols for interventions involving artificial intelligence: the SPIRIT-AI extension. BMJ. 2020 Sep 09;370:m3210. doi: 10.1136/bmj.m3210. http://www.bmj.com/lookup/pmidlookup?view=long&pmid=32907797 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Hernandez-Boussard T, Bozkurt S, Ioannidis JP, Shah NH. MINIMAR (MINimum information for medical AI reporting): developing reporting standards for artificial intelligence in health care. J Am Med Inform Assoc. 2020 Dec 09;27(12):2011–5. doi: 10.1093/jamia/ocaa088. https://europepmc.org/abstract/MED/32594179 .5864179 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Norgeot B, Quer G, Beaulieu-Jones BK, Torkamani A, Dias R, Gianfrancesco M, Arnaout R, Kohane IS, Saria S, Topol E, Obermeyer Z, Yu B, Butte AJ. Minimum information about clinical artificial intelligence modeling: the MI-CLAIM checklist. Nat Med. 2020 Sep;26(9):1320–4. doi: 10.1038/s41591-020-1041-y. https://europepmc.org/abstract/MED/32908275 .10.1038/s41591-020-1041-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Ethics and governance of artificial intelligence for health: WHO guidance. Licence: CC BY-NC-SA 3.0 IGO. World Health Organization. [2024-04-05]. https://apps.who.int/iris/bitstream/handle/10665/341996/9789240029200-eng.pdf .
- 21.Solanki P, Grundy J, Hussain W. Operationalising ethics in artificial intelligence for healthcare: a framework for AI developers. AI Ethics. 2022 Jul 19;3(1):223–40. doi: 10.1007/s43681-022-00195-z. doi: 10.1007/s43681-022-00195-z. [DOI] [Google Scholar]
- 22.Joshi I, Morley J. Artificial intelligence: how to get it right: putting policy into practice for safe data-driven innovation in health and care. National Health Service. 2019. [2024-04-05]. https://transform.england.nhs.uk/media/documents/NHSX_AI_report.pdf .
- 23.van de Sande D, Van Genderen ME, Smit JM, Huiskens J, Visser JJ, Veen RE, van Unen E, Ba OH, Gommers D, Bommel JV. Developing, implementing and governing artificial intelligence in medicine: a step-by-step approach to prevent an artificial intelligence winter. BMJ Health Care Inform. 2022 Feb 19;29(1):e100495. doi: 10.1136/bmjhci-2021-100495. https://informatics.bmj.com/lookup/pmidlookup?view=long&pmid=35185012 .bmjhci-2021-100495 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Andaur Navarro CL, Damen JA, Takada T, Nijman SW, Dhiman P, Ma J, Collins GS, Bajpai R, Riley RD, Moons KG, Hooft L. Completeness of reporting of clinical prediction models developed using supervised machine learning: a systematic review. BMC Med Res Methodol. 2022 Jan 13;22(1):12. doi: 10.1186/s12874-021-01469-6. https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-021-01469-6 .10.1186/s12874-021-01469-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Yusuf M, Atal I, Li J, Smith P, Ravaud P, Fergie M, Callaghan M, Selfe J. Reporting quality of studies using machine learning models for medical diagnosis: a systematic review. BMJ Open. 2020 Mar 23;10(3):e034568. doi: 10.1136/bmjopen-2019-034568. https://bmjopen.bmj.com/lookup/pmidlookup?view=long&pmid=32205374 .bmjopen-2019-034568 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Wenzel MA, Wiegand T. Towards international standards for the evaluation of artificial intelligence for health. Proceedings of the 2019 ITU Kaleidoscope: ICT for Health: Networks, Standards and Innovation; ITU K '19; December 4-6, 2019; Atlanta, GA. 2019. pp. 1–10. https://ieeexplore.ieee.org/abstract/document/8996131 . [DOI] [Google Scholar]
- 27.Varghese J. Artificial intelligence in medicine: chances and challenges for wide clinical adoption. Visc Med. 2020 Dec;36(6):443–9. doi: 10.1159/000511930. doi: 10.1159/000511930.vis-0036-0443 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Nyarairo M, Emami E, Abbasgholizadeh S. Integrating equity, diversity and inclusion throughout the lifecycle of artificial intelligence in health. Proceedings of the 13th Augmented Human International Conference; AH '22; May 26-27, 2022; Winnipeg, MB. 2022. pp. 1–4. https://dl.acm.org/doi/abs/10.1145/3532530.3539565 . [DOI] [Google Scholar]
- 29.MacEntee MI. A typology of systematic reviews for synthesising evidence on health care. Gerodontology. 2019 Dec 06;36(4):303–12. doi: 10.1111/ger.12439. [DOI] [PubMed] [Google Scholar]
- 30.Aromataris E, Fernandez R, Godfrey C, Holly C, Khalil H, Tungpunkom P. Umbrella reviews. In: Aromataris E, Lockwood C, Porritt K, Pilla B, Jordan Z, editors. JBI Manual for Evidence Synthesis. Adelaide, South Australia: Joanna Briggs Institute; 2020. [Google Scholar]
- 31.Tricco AC, Langlois EV, Straus SE. Rapid reviews to strengthen health policy and systems: a practical guide. Licence CC BY-NC-SA 3.0 IGO. World Health Organization. 2017. [2024-04-05]. https://apps.who.int/iris/handle/10665/258698 .
- 32.Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, Shamseer L, Tetzlaff JM, Akl EA, Brennan SE, Chou R, Glanville J, Grimshaw JM, Hróbjartsson A, Lalu MM, Li T, Loder EW, Mayo-Wilson E, McDonald S, McGuinness LA, Stewart LA, Thomas J, Tricco AC, Welch VA, Whiting P, Moher D. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. 2021 Mar 29;372:n71. doi: 10.1136/bmj.n71. http://www.bmj.com/lookup/pmidlookup?view=long&pmid=33782057 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Russell S, Norvig P. Artificial Intelligence: A Modern Approach. 4th edition. London, UK: Pearson Education; 2021. [Google Scholar]
- 34.Ethics guidelines for trustworthy AI. European Commission, Directorate-General for Communications Networks, Content and Technology. [2024-04-05]. https://data.europa.eu/doi/10.2759/346720 .
- 35.Lloyd N, Khuman AS. AI in healthcare: malignant or benign? In: Chen T, Carter J, Mahmud M, Khuman AS, editors. Artificial Intelligence in Healthcare: Recent Applications and Developments. Singapore, Singapore: Springer; 2022. pp. 1–46. [Google Scholar]
- 36.Abd-Alrazaq A, Alajlani M, Alhuwail D, Schneider J, Al-Kuwari S, Shah Z, Hamdi M, Househ M. Artificial intelligence in the fight against COVID-19: scoping review. J Med Internet Res. 2020 Dec 15;22(12):e20756. doi: 10.2196/20756. https://www.jmir.org/2020/12/e20756/ v22i12e20756 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Adamidi ES, Mitsis K, Nikita KS. Artificial intelligence in clinical care amidst COVID-19 pandemic: a systematic review. Comput Struct Biotechnol J. 2021;19:2833–50. doi: 10.1016/j.csbj.2021.05.010. https://linkinghub.elsevier.com/retrieve/pii/S2001-0370(21)00191-4 .S2001-0370(21)00191-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Barboi C, Tzavelis A, Muhammad LN. Comparison of severity of illness scores and artificial intelligence models that are predictive of intensive care unit mortality: meta-analysis and review of the literature. JMIR Med Inform. 2022 May 31;10(5):e35293. doi: 10.2196/35293. https://medinform.jmir.org/2022/5/e35293/ v10i5e35293 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Battineni G, Hossain MA, Chintalapudi N, Amenta F. A survey on the role of artificial intelligence in biobanking studies: a systematic review. Diagnostics (Basel) 2022 May 09;12(5):1179. doi: 10.3390/diagnostics12051179. https://www.mdpi.com/resolver?pii=diagnostics12051179 .diagnostics12051179 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Bertini A, Salas R, Chabert S, Sobrevia L, Pardo F. Using machine learning to predict complications in pregnancy: a systematic review. Front Bioeng Biotechnol. 2021 Jan 19;9:780389. doi: 10.3389/fbioe.2021.780389. https://europepmc.org/abstract/MED/35127665 .780389 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Bhatt P, Liu J, Gong Y, Wang J, Guo Y. Emerging artificial intelligence-empowered mHealth: scoping review. JMIR Mhealth Uhealth. 2022 Jun 09;10(6):e35053. doi: 10.2196/35053. https://mhealth.jmir.org/2022/6/e35053/ v10i6e35053 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Buchanan C, Howitt ML, Wilson R, Booth RG, Risling T, Bamford M. Predicted influences of artificial intelligence on the domains of nursing: scoping review. JMIR Nurs. 2020 Dec 17;3(1):e23939. doi: 10.2196/23939. https://nursing.jmir.org/2020/1/e23939/ v3i1e23939 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Buchanan C, Howitt ML, Wilson R, Booth RG, Risling T, Bamford M. Predicted influences of artificial intelligence on nursing education: scoping review. JMIR Nurs. 2021 Jan 28;4(1):e23933. doi: 10.2196/23933. https://nursing.jmir.org/2021/1/e23933/ v4i1e23933 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Chew HS, Achananuparp P. Perceptions and needs of artificial intelligence in health care to increase adoption: scoping review. J Med Internet Res. 2022 Jan 14;24(1):e32939. doi: 10.2196/32939. https://www.jmir.org/2022/1/e32939/ v24i1e32939 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Choudhury A, Renjilian E, Asan O. Use of machine learning in geriatric clinical care for chronic diseases: a systematic literature review. JAMIA Open. 2020 Oct;3(3):459–71. doi: 10.1093/jamiaopen/ooaa034. https://europepmc.org/abstract/MED/33215079 .ooaa034 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Choudhury A, Asan O. Role of artificial intelligence in patient safety outcomes: systematic literature review. JMIR Med Inform. 2020 Jul 24;8(7):e18599. doi: 10.2196/18599. https://medinform.jmir.org/2020/7/e18599/ v8i7e18599 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Eldaly AS, Avila FR, Torres-Guzman RA, Maita K, Garcia JP, Serrano LP, Forte AJ. Artificial intelligence and lymphedema: state of the art. J Clin Transl Res. 2022 Jun 29;8(3):234–42. https://europepmc.org/abstract/MED/35813896 .jctres.08.202203.010 [PMC free article] [PubMed] [Google Scholar]
- 48.Le Glaz A, Haralambous Y, Kim-Dufor DH, Lenca P, Billot R, Ryan TC, Marsh J, DeVylder J, Walter M, Berrouiguet S, Lemey C. Machine learning and natural language processing in mental health: systematic review. J Med Internet Res. 2021 May 04;23(5):e15708. doi: 10.2196/15708. https://www.jmir.org/2021/5/e15708/ v23i5e15708 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Guo Y, Zhang Y, Lyu T, Prosperi M, Wang F, Xu H, Bian J. The application of artificial intelligence and data integration in COVID-19 studies: a scoping review. J Am Med Inform Assoc. 2021 Aug 13;28(9):2050–67. doi: 10.1093/jamia/ocab098. https://europepmc.org/abstract/MED/34151987 .6307183 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Hassan N, Slight R, Weiand D, Vellinga A, Morgan G, Aboushareb F, Slight SP. Preventing sepsis; how can artificial intelligence inform the clinical decision-making process? A systematic review. Int J Med Inform. 2021 Jun;150:104457. doi: 10.1016/j.ijmedinf.2021.104457.S1386-5056(21)00083-6 [DOI] [PubMed] [Google Scholar]
- 51.Huang JA, Hartanti IR, Colin MN, Pitaloka DA. Telemedicine and artificial intelligence to support self-isolation of COVID-19 patients: recent updates and challenges. Digit Health. 2022 May 15;8:20552076221100634. doi: 10.1177/20552076221100634. https://journals.sagepub.com/doi/abs/10.1177/20552076221100634?url_ver=Z39.88-2003&rfr_id=ori:rid:crossref.org&rfr_dat=cr_pub0pubmed .10.1177_20552076221100634 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Kaelin VC, Valizadeh M, Salgado Z, Parde N, Khetani MA. Artificial intelligence in rehabilitation targeting the participation of children and youth with disabilities: scoping review. J Med Internet Res. 2021 Nov 04;23(11):e25745. doi: 10.2196/25745. https://www.jmir.org/2021/11/e25745/ v23i11e25745 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Kirk D, Catal C, Tekinerdogan B. Precision nutrition: a systematic literature review. Comput Biol Med. 2021 Jun;133:104365. doi: 10.1016/j.compbiomed.2021.104365. https://linkinghub.elsevier.com/retrieve/pii/S0010-4825(21)00159-1 .S0010-4825(21)00159-1 [DOI] [PubMed] [Google Scholar]
- 54.Loveys K, Prina M, Axford C, Domènec ÒR, Weng W, Broadbent E, Pujari S, Jang H, Han ZA, Thiyagarajan JA. Artificial intelligence for older people receiving long-term care: a systematic review of acceptability and effectiveness studies. Lancet Healthy Longev. 2022 Apr;3(4):e286–97. doi: 10.1016/S2666-7568(22)00034-4. https://linkinghub.elsevier.com/retrieve/pii/S2666-7568(22)00034-4 .S2666-7568(22)00034-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Mörch CM, Atsu S, Cai W, Li X, Madathil SA, Liu X, Mai V, Tamimi F, Dilhac MA, Ducret M. Artificial intelligence and ethics in dentistry: a scoping review. J Dent Res. 2021 Dec 01;100(13):1452–60. doi: 10.1177/00220345211013808. [DOI] [PubMed] [Google Scholar]
- 56.Payedimarri AB, Concina D, Portinale L, Canonico M, Seys D, Vanhaecht K, Panella M. Prediction models for public health containment measures on COVID-19 using artificial intelligence and machine learning: a systematic review. Int J Environ Res Public Health. 2021 Apr 23;18(9):4499. doi: 10.3390/ijerph18094499. https://www.mdpi.com/resolver?pii=ijerph18094499 .ijerph18094499 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Popescu D, El-Khatib M, El-Khatib H, Ichim L. New trends in melanoma detection using neural networks: a systematic review. Sensors (Basel) 2022 Jan 10;22(2):496. doi: 10.3390/s22020496. https://www.mdpi.com/resolver?pii=s22020496 .s22020496 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Abbasgholizadeh Rahimi S, Légaré F, Sharma G, Archambault P, Zomahoun HT, Chandavong S, Rheault N, T Wong S, Langlois L, Couturier Y, Salmeron JL, Gagnon MP, Légaré J. Application of artificial intelligence in community-based primary health care: systematic scoping review and critical appraisal. J Med Internet Res. 2021 Sep 03;23(9):e29839. doi: 10.2196/29839. https://www.jmir.org/2021/9/e29839/ v23i9e29839 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Sahu P, Raj Stanly EA, Simon Lewis LE, Prabhu K, Rao M, Kunhikatta V. Prediction modelling in the early detection of neonatal sepsis. World J Pediatr. 2022 Mar 05;18(3):160–75. doi: 10.1007/s12519-021-00505-1. https://europepmc.org/abstract/MED/34984642 .10.1007/s12519-021-00505-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Sapci AH, Sapci HA. Artificial intelligence education and tools for medical and health informatics students: systematic review. JMIR Med Educ. 2020 Jun 30;6(1):e19285. doi: 10.2196/19285. https://mededu.jmir.org/2020/1/e19285/ v6i1e19285 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Seibert K, Domhoff D, Bruch D, Schulte-Althoff M, Fürstenau D, Biessmann F, Wolf-Ostermann K. Application scenarios for artificial intelligence in nursing care: rapid review. J Med Internet Res. 2021 Nov 29;23(11):e26522. doi: 10.2196/26522. https://www.jmir.org/2021/11/e26522/ v23i11e26522 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Syeda HB, Syed M, Sexton KW, Syed S, Begum S, Syed F, Prior F, Yu Jr F. Role of machine learning techniques to tackle the COVID-19 crisis: systematic review. JMIR Med Inform. 2021 Jan 11;9(1):e23811. doi: 10.2196/23811. https://medinform.jmir.org/2021/1/e23811/ v9i1e23811 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Talpur S, Azim F, Rashid M, Syed SA, Talpur BA, Khan SJ. Uses of different machine learning algorithms for diagnosis of dental caries. J Healthc Eng. 2022 Mar 31;2022:5032435–13. doi: 10.1155/2022/5032435. doi: 10.1155/2022/5032435. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Vélez-Guerrero MA, Callejas-Cuervo M, Mazzoleni S. Artificial intelligence-based wearable robotic exoskeletons for upper limb rehabilitation: a review. Sensors (Basel) 2021 Mar 18;21(6):2146. doi: 10.3390/s21062146. https://www.mdpi.com/resolver?pii=s21062146 .s21062146 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Welch V, Wy TJ, Ligezka A, Hassett LC, Croarkin PE, Athreya AP, Romanowicz M. Use of mobile and wearable artificial intelligence in child and adolescent psychiatry: scoping review. J Med Internet Res. 2022 Mar 14;24(3):e33560. doi: 10.2196/33560. https://www.jmir.org/2022/3/e33560/ v24i3e33560 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Zhao IY, Ma YX, Yu MW, Liu J, Dong WN, Pang Q, Lu XQ, Molassiotis A, Holroyd E, Wong CW. Ethics, integrity, and retributions of digital detection surveillance systems for infectious diseases: systematic literature review. J Med Internet Res. 2021 Oct 20;23(10):e32328. doi: 10.2196/32328. https://www.jmir.org/2021/10/e32328/ v23i10e32328 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Zheng Y, Dickson VV, Blecker S, Ng JM, Rice BC, Melkus GD, Shenkar L, Mortejo MC, Johnson SB. Identifying patients with hypoglycemia using natural language processing: systematic literature review. JMIR Diabetes. 2022 May 16;7(2):e34681. doi: 10.2196/34681. https://diabetes.jmir.org/2022/2/e34681/ v7i2e34681 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Zidaru T, Morrow EM, Stockley R. Ensuring patient and public involvement in the transition to AI-assisted mental health care: a systematic scoping review and agenda for design justice. Health Expect. 2021 Aug 12;24(4):1072–124. doi: 10.1111/hex.13299. https://europepmc.org/abstract/MED/34118185 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Khan ZF, Alotaibi SR. Applications of artificial intelligence and big data analytics in m-Health: a healthcare system perspective. J Healthc Eng. 2020;2020:8894694. doi: 10.1155/2020/8894694. doi: 10.1155/2020/8894694. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Sarker S, Jamal L, Ahmed SF, Irtisam N. Robotics and artificial intelligence in healthcare during COVID-19 pandemic: a systematic review. Rob Auton Syst. 2021 Dec;146:103902. doi: 10.1016/j.robot.2021.103902. https://europepmc.org/abstract/MED/34629751 .S0921-8890(21)00187-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Herrmann H. The arcanum of artificial intelligence in enterprise applications: toward a unified framework. J Eng Technol Manag. 2022 Oct;66:101716. doi: 10.1016/j.jengtecman.2022.101716. [DOI] [Google Scholar]
- 72.Wu E, Wu K, Daneshjou R, Ouyang D, Ho DE, Zou J. How medical AI devices are evaluated: limitations and recommendations from an analysis of FDA approvals. Nat Med. 2021 Apr 05;27(4):582–4. doi: 10.1038/s41591-021-01312-x.10.1038/s41591-021-01312-x [DOI] [PubMed] [Google Scholar]
- 73.Bohr A, Memarzadeh K. The rise of artificial intelligence in healthcare applications. In: Bohr A, Memarzadeh K, editors. Artificial Intelligence in Healthcare. New York, NY: Academic Press; 2020. pp. 25–57. [Google Scholar]
- 74.Jacobson FL, Krupinski EA. Clinical validation is the key to adopting AI in clinical practice. Radiol Artif Intell. 2021 Jul 01;3(4):e210104. doi: 10.1148/ryai.2021210104. https://europepmc.org/abstract/MED/34350416 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Tran K, Bøtker JP, Aframian A, Memarzadeh K. Artificial intelligence for medical imaging. In: Bohr A, Memarzadeh K, editors. Artificial Intelligence in Healthcare. New York, NY: Academic Press; 2020. pp. 143–61. [Google Scholar]
- 76.Hassija V, Chamola V, Mahapatra A, Singal A, Goel D, Huang K, Scardapane S, Spinelli I, Mahmud M, Hussain A. Interpreting black-box models: a review on explainable artificial intelligence. Cogn Comput. 2023 Aug 24;16(1):45–74. doi: 10.1007/s12559-023-10179-8. doi: 10.1007/s12559-023-10179-8. [DOI] [Google Scholar]
- 77.Chrimes D. Using decision trees as an expert system for clinical decision support for COVID-19. Interact J Med Res. 2023 Jan 30;12:e42540. doi: 10.2196/42540. https://www.i-jmr.org/2023//e42540/ v12i1e42540 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) checklist.
PubMed search strings.
Characteristics of the included reviews.
List of excluded reviews and reasons.
Quality of the included reviews using Joanna Briggs Institute scores.
Health care artificial intelligence reviews by life cycle stage.
Quality standards found in 10% of unique studies in the selected reviews.
Quality standard–related issues mentioned in the artificial intelligence reviews.
Summary list of artificial intelligence quality standards.