

Abstract
The cognitive problems are prominent in the context of global aging, and the traditional Mendelian randomization method is not applicable to ordered multi-categorical exposures. Therefore, we aimed to address this issue through the development of a method and to investigate the causal inference of cognitive-related lifestyle factors. The study sample was derived from the Chinese Longitudinal Healthy Longevity Survey, which included 897 older adults aged 65 + . This study used genome-wide association analysis to screen genetic loci as instrumental variables and innovatively combined maximum likelihood estimation to infer causal associations between ordered multi-categorical exposures (diet, exercise, etc.) and continuous outcomes (cognitive level). The causal inference method for ordered multi-categorical exposures developed in this study was simple, easy to implement, and able to effectively and reliably discover the potential causal associations between variables. Through this method, we found a potential positive causal association between exercise status and cognitive level in Chinese older adults ( = 1.883, 95%CI 0.182–3.512), in which there was no horizontal pleiotropy (p = 0.370). The study provided a causal inference method applicable to ordered multi-categorical exposures, that addressed the limitations of the traditional Mendelian randomization method.
Keywords: Casual inference, Ordered multi-categorical exposures, Cognitive impairment, Mendelian randomization, Exercise
Subject terms: Cognitive ageing, Genetic association study, Risk factors, Statistics, Epidemiology, Genetics research
Introduction
Cognitive-related health issues are increasingly prominent against the backdrop of global aging. As of 2019, there were already more than 50 million people living with dementia worldwide, with an average of one new case of dementia every three seconds. More than 75 million people will suffer from dementia by 20301,2. China is a country with a huge aging population. Currently, the number of older adults aged 60 years and above in China has reached 264.02 million, accounting for 18.70% of the population3.
We have explored some factors (e.g., diet, activity status, etc.) associated with cognitive impairment in the Chinese older adults through our previous studies4,5. In order to better clarify whether there is some causal association, we therefore investigated the issue with the help of Mendelian randomization (MR). It is a method that uses genetic variation as the instrumental variable (IV) to make causal inferences about the effect of exposure on outcome6–8. However, this method has limitations when the exposure is ordered multi-categorical variables as such. Briefly, if an observed multi-level categorical exposure (i.e., intensities of exercise) is the manifestation of an underlying continuous exposure (i.e., motivation to exercise) passing certain cut-off points, the observed level of category may be stable even if the latent exposure has changed, because the latter haven’t crossed one of the cut-offs. This may violate the assumption of exclusivity of the instrumental variable9–11. In this scenario, disregarding the relationship between a latent, invisible continuous exposure and its external, visible categorical manifestation will bias the MR/IV estimation of effect size (if the latter is a strong stepwise mediator), or even confound the claim of casual association (if the latter is mostly a surrogate)12.
In view of the above issues, we aimed to develop and test an analytical pipeline of Mendelian randomization, tailed to ordered multi-categorical exposures and to further explore potential causal associations between cognitive levels and their influencing factors in the Chinese older adults.
Materials and methods
Data sources
Data for this study were obtained from the Chinese Longitudinal Healthy Longevity Survey (CLHLS) database (1998–2018)13,14. This was the largest and most extensive cohort of older adults in China, encompassing more than 40,000 older adults in total. The project mainly collected information on the socio-demographic characteristics, lifestyles, and health status of participants through a questionnaire (self-report). A total of 908 surviving older adults aged 65 years or older (based on the age of the participants when they first participated in the survey) were selected from individuals who participated in both the questionnaire and whole genome sequencing (WGS). Meanwhile, we collated their baseline information. After quality control (QC)15 of the genetic data, a total of 897 older adults aged 65–110 years were included (no missing data), with a male to female ratio of approximately 1:2.74.
Cognition
Individual cognitive data were collected and calculated by the Mini-mental State Examination (MMSE). This scale provides a comprehensive assessment of the individual's general ability, reactivity, attention and calculation, recall, language, comprehension and self-coordination. The total score is 30, with higher scores indicating a better cognitive status16.
Living habits
Based on the results of our previous studies conducted on CLHLS4,5, we selected those factors that had some association with individual cognitive level for inclusion in this study. The variables in this section included individual drinking status, exercise status, dietary habits, and activity participation at their baseline. The drinking status were categorized by drinking (including abstainers) and never drinking. Exercise status was similarly divided into two categories according to exercise and never exercise. Diet and activity participation were recorded in terms of frequency, in descending order of "frequently", "occasionally" and "rarely/never", with higher values representing lower frequency. Other variables and detailed descriptions were given in Additional file 1.
Gene
Genetic data were obtained from the Longevity Study (CLHLS) conducted by Prof. Yi Zeng.17 The data were generated from whole genome sequencing and genotyped by Illumina humanomnizhhua-8 BeadChips. The chip was created by selecting optimally tagged single nucleotide polymorphisms (SNPs) from all three phases of the the International HapMap Project as well as from the Thousand Genomes Project. It covered 900 015 SNPs, including 600 000 common variants (Minor allele frequency, MAF ≥ 5%), 290 000 rare variants (MAF < 5%), and 10 000 SNPs present only in Chinese and other Asian populations. In addition to directly sequenced SNPs, the project also used IMPUTE software (version 2) to infer genotypes for SNPs with MAF ≥ 0.01 (The 1000 Genomes Project as a reference), representing approximately 85.38%17.
We performed quality control on the raw genetic data and examined the population stratification (multidimensional scaling, MDS)15. A total of 3 240 266 SNPs were included in this study with genotype data covering autosomes 1–22. The genotype of each SNP was recorded in the form of an additive model (i.e., 0, 1, 2). Chromosome location information was obtained from hg19.
Genome-wide association study
Genome-wide association study (GWAS)15 was conducted by plink 1.9 for individual cognitive level, living habits and potential confounders (e.g., educational status and stroke/CVD5). Among them, continuous variables were analyzed using linear regression, while categorical variables were performed through logistic regression. The covariates included were age, sex, ethnicity, and 10 dimensions representing stratified characteristics of the population obtained by multidimensional scaling. Subsequently, the Quantile–Quantile plot (Q-Q plot) and Manhattan plot were plotted based on the results obtained from GWAS.
Instrumental variables
Instrumental variables (IVs) were selected from independent loci that were significant in GWAS. In order to better validate the generalizability and stability of our method, we relaxed the selection criterion of p-value to "close to significance" when selecting instrumental variables. Based on the results of GWAS, independent and significant SNPs (p < 1 × 10–5) satisfying the three assumptions of instrumental variables8 were selected as IVs for each exposure after screening to exclude those loci that were associated with known confounders.
Specifically, the sub-routine groups significant SNPs into genome segments, that is, clumps, that are independently and significantly associated with the outcome, each indexed by one of the highly significant SNPs within. Each new clump is iteratively isolated by (1) greedily search the next most significant SNP with p-value no larger than 1e-5 (via –clump-p1 0.00001) but not yet enclosed in any existing clumps, that is, the so-called index variant of the soon to be new clump, then (2) adding variants within close proximity to the index, both in terms of physical units (+ /− 500 KB, via –clump-kb 500) and linkage disequilibrium (r2 > 0.2, via –clump-r2 0.2). The index SNPs are then taken as independent loci for an outcome of interest18.
Causal inference for ordered multi-categorical exposure
In order to better fit the CLHLS data while addressing the limitations in the traditional Mendelian randomization, a simple and reliable causal inference method was presented in this study. An ordered multi-categorical variable (exposure) can be regarded as an unknown continuous latent variable divided by the corresponding threshold. Thus, the model for causal inference with the instrumental variables can be expressed as (Fig. 1):
Figure 1.
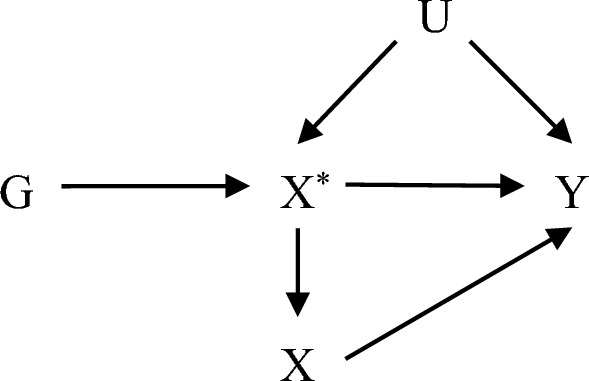
Directed acyclic graph (DAG) of instrumental variables in the causal inference of ordered multi-categorical variables. "G" denotes instrumental variables (genetic variation), "X" indicates exposure, "X*" denotes latent variables, "Y" and "U" represent outcome and confounders, respectively.
The association between variables can be represented by the following equation:
| 1 |
| 2 |
| 3 |
are the observable data. Without loss of generality, we assume that , , , , , and are mutual independent of each other. We want to estimate the causal effect () of on . Combining the above equation shows that the relationship between and can be expressed by the following equation:
| 4 |
, , and are independent of each other, so the parameter can be identified. Regression is performed on G utilizing Y. The regression coefficient is the estimate of the parameter . If non-zero can be identified, the parameter can be identified.
Note that
| 5 |
| 6 |
| 7 |
Since , , let , then
| 8 |
| 9 |
| 10 |
where is the cumulative distribution function of standard normal. From the above equation, it is clear that the parameter is not identifiable. Further we used Eq. (8), which after transformation yields
| 11 |
Subsequently, it is easy to know that can be identified by this equation. If one really wants to estimate the causal effect, they could try to estimate from a separate study. is connect to heritability of the continuous latent exposure . According to Eq. (1) and the definition of , , where is the remainder of variance of after accounting for non-confounding covariants (e.g., age, sex, and first few genotype principal components), and is variation in attributed to the genotype. If one knows the heritability , one could estimate , then —the part of variation in latent variable not attributed to genotype could be estimated, and thus one be able to estimate the true effect of the MR/IV model, and lastly, the true effect of on outcome Y.
For combining all observations, we used the maximum likelihood estimation (which produces smaller variance and mean squared error19) for the calculation. The log-likelihood function is given as:
| 12 |
where was defined by Eqs. (8–10), which is easily generalizable to exposures of more than 3 levels.
The above derivation still holds if there are multiple instrumental variables (i.e., is a vector). We can first use the observed data to get the estimate of by the maximum likelihood estimation, and then perform a regression on using (same as two-stage regression). The estimated of the causal effect (β) can be obtained by this process. Because the estimate of (i.e., the estimate of ) in this method differs from the true value by a constant multiple (), the result of this two-stage estimate also has a difference of a constant multiple () from the true value. If this estimate is significantly non-zero, then the true causal effect is significantly non-zero. Therefore, this method can be used to infer whether ordered multi-categorical exposures (commonly found in questionnaires) have a significant causal effect on outcome (IVs need to be found with genetic data). In this study, the confidence interval (CI) of the causal effect was estimated by the bootstrap (the "boot" package of R software).
We conducted simulations using ten data sets randomly generated (n = 1000, Group A–G in which was correlated with and the last three groups were uncorrelated) combined with repeated sampling (500 times per group), and the results validated the validity and reliability of this method for testing potential causal associations. The simulation results were shown in Table 1.
Table 1.
Simulation of causal inference for ordered multi-categorical exposure.
| Simulation | IVa | β | 95% Confidence interval (CI) | |||
|---|---|---|---|---|---|---|
| Normal | Basic | Percentile | ||||
| Group A | 8 | 1.5 | 2.503 | 2.314–2.783 | 2.315–2.784 | 2.221–2.690 |
| Group B | 6 | 1.5 | 2.395 | 2.067–2.817 | 2.003–2.781 | 2.010–2.787 |
| Group C | 5 | 1.5 | 2.227 | 1.913–2.577 | 1.907–2.556 | 1.898–2.547 |
| Group D | 4 | 2.7 | 4.419 | 3.912–5.054 | 3.848–5.014 | 3.823–4.990 |
| Group E | 6 | 2.7 | 4.419 | 4.022–4.938 | 4.005–4.916 | 3.922–4.833 |
| Group F | 6 | − 2.7 | − 4.068 | − 4.551–− 3.672 | − 4.525–− 3.580 | − 4.556–− 3.611 |
| Group G | 6 | − 1.5 | − 2.223 | − 2.495–− 2.014 | − 2.491–− 1.992 | − 2.453–− 1.954 |
| Group H | 5 | 0 | − 0.027 | − 0.112–0.063 | − 0.111–0.064 | − 0.118–0.057 |
| Group I | 8 | 0 | − 0.008 | − 0.073–0.062 | − 0.071–0.060 | − 0.075–0.056 |
| Group J | 3 | 0 | 0.048 | − 0.067–0.171 | − 0.064–0.180 | − 0.084–0.160 |
"a" represents the number of instrumental variables, "Normal" means the CI was calculated by the normal approximation method, "Basic" indicates the CI was calculated by the basic bootstrap method and "Percentile" stands for the CI was calculated by the bootstrap percentage method. The ten data sets were randomly generated with a preset of 1.5.
Furthermore, the factors () identified by previous studies as significantly associated with cognitive level () were used as exposures and analyzed in conjunction with our causal inference method. The exposures were drinking status, the intake frequency of fish, fruit, garlic, legume, meat, sugar, and vegetable, exercise status, and the participation in activities such as housework, mahjong, open-air activities, pet ownership, reading, and television/radio, respectively.
For the statistically significant results among them, we used the MR-Egger method to test the potential horizontal pleiotropy.
Role of the funding source
The funder of the study had no role in the study design, data collection, data analysis, data interpretation, or writing of the report. The corresponding authors had full access to all the data in the study and had final responsibility for the decision to submit for publication.
Ethics approval and consent to participate
The Research Ethics Committees of Peking University (number IRB00001052-13074) and Duke University granted approval for the CLHLS, including collections of questionnaire data with written informed consent before participation. The study was performed in accordance with the Declaration of Helsinki. This study only showed the secondary aggregated data, and we did not include any data of their personal information, including name, identity information, address, telephone number, etc. None of the authors in this study had access to identifying patient information during the analysis of the data.
Results
After quality control, a total of 897 older adults were included in the study. Their mean (SD) age was at 97.19 (6.70) years and their mean (SD) cognitive score was 21.42 (7.34). The genetic data covered 3 240 266 loci (autosomes 1–22). Meanwhile, the population distribution of our sample was highly homologous to the Asian population in the 1000 Genomes Project, and there was no population stratification in this study. The results were shown in Fig. 2.
Figure 2.
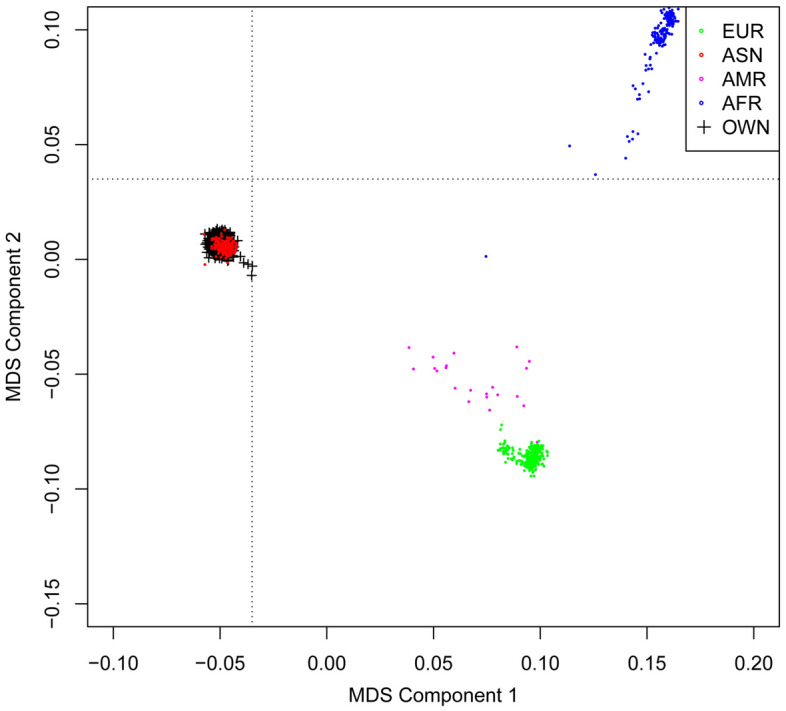
Population stratification of the sample (multidimensional scaling method). "EUR" stands for European, "ASN" for Asian, "AMR" for American, and "AFR" represents African origin (this part of the data was from the 1000 Genomes Project). "OWN" represents the data involved in this study.
Results of genome-wide association analysis
Genome-wide association analysis detected 512 significant loci with p < 1 × 10–5 adjusted for covariates. Among them, four independent loci were associated with cognition. Seventy-eight independent loci were detected for categorical exposures, distributed among drinking status (6), fish (7), fruit (3), garlic (5), legume (8), meat (8), sugar (2), vegetable (4), exercise status (7), housework (6), mahjong (3), open-air activities (5), pet ownership (6) read (4), and TV/radio (4). In addition, 11 and 3 independent loci were found in education and stroke/CVD, respectively. The results were shown in Additional file 2.
Among the above loci, one locus reached genome-wide significance (p < 5 × 10–8)—rs78069066 (p = 1.21 × 10–8, from drinking status). The Manhattan and Q-Q plots of GWAS results for each variable were detailed in Additional file 3.
Causal inference results for ordered multi-categorical exposures
We explored potential causal associations using a causal inference approach for ordered multi-categorical exposures. Instrumental variables were selected from independent loci that were significant in GWAS, and loci with known confounding were excluded. Finally, a total of 78 independent SNPs were selected as instrumental variables. The IVs included for each exposure were the same as the independent loci screened above, as detailed in additional file 2.
After multiple replicate calculations (500 replicates for each exposure), the results showed a positive causal association between individuals' exercise status and their own cognitive level ( = 1.883, 95%CI 0.182—3.512). In contrast, there was no causal association between diet, activity, and cognitive level of older adults. The specific results were shown in Table 2.
Table 2.
Causal inference results for ordered multi-categorical exposure.
| Variable | IVa | nb | 95% Cl (Basic) | pc | |
|---|---|---|---|---|---|
| Drink | 6 | 866 | − 1.127 | − 2.689–0.285 | 0.138 |
| Diet* | |||||
| Fish* | 7 | 882 | − 0.752 | − 2.551–1.151 | 0.426 |
| Fruit* | 3 | 874 | − 0.835 | − 3.427–1.612 | 0.516 |
| Garlic* | 5 | 877 | 0.710 | − 0.885–2.601 | 0.425 |
| Legume* | 8 | 858 | 0.830 | − 1.501–2.671 | 0.435 |
| Meat* | 8 | 827 | − 0.164 | − 2.299–1.835 | 0.877 |
| Sugar* | 2 | 892 | 1.126 | − 1.577–3.488 | 0.384 |
| Vegetable* | 4 | 869 | 0.291 | − 1.523–2.425 | 0.773 |
| Exercise status | 7 | 855 | 1.883 | 0.182–3.512 | 0.027 |
| Activity* | |||||
| Housework* | 6 | 884 | − 1.282 | − 3.676–1.175 | 0.300 |
| Mahjong* | 3 | 879 | − 1.075 | − 2.431–0.002 | 0.083 |
| Open-air* | 5 | 877 | − 1.438 | − 3.844–0.703 | 0.215 |
| Pet ownership* | 6 | 862 | − 1.080 | − 2.192–0.064 | 0.061 |
| Read* | 4 | 876 | − 0.516 | − 2.775–1.450 | 0.636 |
| TV/radio* | 4 | 885 | − 0.251 | − 2.435–1.726 | 0.813 |
“*” represents that the variable was reverse coded, with higher values indicating lower frequency, as described in detail in Additional file 1. "a" represents the number of instrumental variables, "b" represents the number of samples for each exposure (excluding individuals with missing information on the corresponding IVs), and "c" indicates that the p value is reverse derived from CI through a normal distribution.
In response to the statistically significant results, a further sensitivity analysis confirmed that there was no horizontal pleiotropy between cognitive level and exercise status (p > 0.05, Table 3). This proved that the causal effect described above was valid and reliable.
Table 3.
Results of the horizontal pleiotropy test.
| Variable | Egger intercept | S.E | p value |
|---|---|---|---|
| Exercise status | 1.203 | 1.221 | 0.370 |
Discussion
Currently, Mendelian randomization is the mostly commonly accepted method of causal inference in medical field. The traditional MR, however, has a relatively limited field of application and usually prefers causal inference of exposure and outcome in the form of continuous variables. If categorical variables were directly analyzed as exposures, the estimated causal effects would be inaccurate10,20. Although the methodology in this field has been expanded somewhat in recent years, causal inference involving categorical variables has focused more on cases where the outcome is a categorical variable21–23, and studies of categorical exposures are still lacking.
Causal inference with exposure in the form of categorical variables such as binary categories was highly sensitive to the choice of thresholds. Since categorical exposures typically only contain effects associated with boundary points and category changes and do not adequately capture subtle changes (failure to change category) in its original variables (continuous exposures), true causal effect are often difficult to explore. In addition, the causal estimates calculated by MR can sometimes be difficult to interpret. Therefore, it has been suggested that MR should focus more on testing for potential causal effects rather than trying to compute estimates of causal effects24,25.
The innovative method in this study treats ordered multi-categorical variables as divided from continuous variables by specific boundary points, and on this basis, the causal association between ordered multi-categorical exposures and continuous outcomes was inferred and uncovered through maximum likelihood estimation. This method can easily and effectively explore the causal associations between exposures and outcomes. Meanwhile, this added a new theoretical basis to the field and provided evidence to support the development of subsequent methods. In addition, this method estimated causal effects that differed from the true effects by a constant multiple. This situation was consistent with the idea mentioned in previous studies that using coarsened measures (categorical exposures) as exposures for estimation leads to bias, which would amplify or reduce their effect estimates without inverting their sign10.
In addition, the study confirmed a potential causal association between exercise status and individual cognitive level through our method. The results suggested that exercise could delay the cognitive decline. A recent international study that analyzed the brains of hundreds of deceased older adults found that individuals who participated more in daily exercise had higher levels of presynaptic proteins and better synaptic integrity in their brains during old age26 This is the first time that the positive effects of exercise on synaptic function have been demonstrated in humans. Earlier studies have shown that only 10 min of moderate intensity running per day can improve mood and cognitive performance27. Exercise such as running increases blood flow to five cortical areas: l-DLPFC, l-FPA, r-DLPFC, r-VLPF and r-FPA. The stimulation received by these areas played a very important role in improving mood and cognition. Regardless of the activity, high-frequency exercise invariably increases the cognitive load of older adults. After exercise with high cognitive load, it enhanced functional connectivity in the superior frontal gyrus and prefrontal cortex and reduced functional connectivity in the middle occipital gyrus and postcentral gyrus at rest, which in turn delayed cognitive decline28.
On the other hand, the positive effects from exercise were not really lasting26. This also demonstrated to some extent the importance of maintaining a long-term, healthy exercise habit in the older adults. The adoption of measures such as appropriate physical activity was necessary no matter what age. As Dr. Robert S. Wilson said29, "It's never too late to start participating in such activities. Even in your 80 s, cognitive stimulation activities can delay the onset of Alzheimer's disease.
Conclusion
The causal inference method developed in this study combined with the maximum likelihood estimation addressed the problem of difficult causal inference for ordered multi-categorical exposures and compensated for the limitations of traditional MR methods. This not only provides us a practical tool, but also a different way of developing methodologies in this field. In addition, we uncovered a potential positive causal association between exercise and cognition through a more in-depth analysis based on previous studies. This result further confirmed the positive effect of exercise on cognitive health in Chinese older adults and added stronger evidence for delaying cognitive decline in the older individuals.
Supplementary Information
Acknowledgements
Collections of the Chinese Longitudinal Healthy Longevity Surveys (CLHLS) datasets analyzed in this paper were jointly supported by Beijing TaiKang YiCai Public Welfare Foundation, National Natural Sciences Foundation of China (72061137004) and the National Key R&D Program of China (2018YFC2000400). The authors would like to express their gratitude for the support as well as the Peking University Start-up Grant.
Author contributions
L.H. and J.J. conceived and designed the study. Y.Z. and T.H. collected and provided the source data of the study. L.H. and J.J. prepared software and performed the statistical analysis. L.H. prepared the manuscript and interpreted the data. J.J. and T.H. assisted with the editing of the paper and provided critical comments. J.J., Y.Z. and T.H. revised it critically for important intellectual content. All authors read and approved the final manuscript.
Funding
The study was supported by grants from the Peking University Start-up Grant. Collections of the Chinese Longitudinal Healthy Longevity Surveys (CLHLS) datasets analyzed in this paper were jointly supported by the National Key R&D Program of China (2018YFC2000400) and National Natural Sciences Foundation of China (72061137004).
Data availability
The datasets generated and/or analyzed during the current study are available in the Peking University Open Research Data repository. The code can be obtained by contacting the corresponding author. [https://opendata.pku.edu.cn/dataset.xhtml?persistentId=doi%3A10.18170%2FDVN%2FWBO7LK].
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Tao Huang, Email: huang.tao@pku.edu.cn.
Jinzhu Jia, Email: jzjia@math.pku.edu.cn.
Supplementary Information
The online version contains supplementary material available at 10.1038/s41598-024-59326-7.
References
- 1.WHO. World report on ageing and health. (World Health Organization, 2016).
- 2.ADI. The World Alzheimer Report 2019: Attitudes to dementia. (Alzheimer’s Disease International, London, 2019).
- 3.Department of Aging Health, N. H. C., PRC. National aging development report 2020, <http://www.nhc.gov.cn/lljks/pqt/202110/c794a6b1a2084964a7ef45f69bef5423.shtml> (2021).
- 4.Han LZ, Jia JZ. Long-term effects of alcohol consumption on cognitive function in seniors: a cohort study in China. BMC Geriatr. 2021 doi: 10.1186/s12877-021-02606-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Han LZ, Jia JZ. Alcohol consumption, poor lifestyle choices, and air pollution worsen cognitive function in seniors: A cohort study in China. Environ. Sci. Pollut. Res. 2022;29:26877–26888. doi: 10.1007/s11356-021-17891-8. [DOI] [PubMed] [Google Scholar]
- 6.Little M. Mendelian randomization: methods for using genetic variants in causal estimation. J. R. Stat. Soc. Stat. 2018;181:549–550. doi: 10.1111/rssa.12343. [DOI] [Google Scholar]
- 7.Smith GD, Ebrahim S. 'Mendelian randomization': can genetic epidemiology contribute to understanding environmental determinants of disease? Int. J. Epidemiol. 2003;32:1–22. doi: 10.1093/ije/dyg070. [DOI] [PubMed] [Google Scholar]
- 8.Lawlor DA, Harbord RM, Sterne JA, Timpson N, Davey Smith G. Mendelian randomization: using genes as instruments for making causal inferences in epidemiology. Stat. Med. 2008;27:1133–1163. doi: 10.1002/sim.3034. [DOI] [PubMed] [Google Scholar]
- 9.Burgess S, Labrecque JA. Mendelian randomization with a binary exposure variable: Interpretation and presentation of causal estimates. Eur. J. Epidemiol. 2018;33:947–952. doi: 10.1007/s10654-018-0424-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Tudball MJ, et al. Mendelian randomisation with coarsened exposures. Genet. Epidemiol. 2021;45:338–350. doi: 10.1002/gepi.22376. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Angrist JD, Imbens GW. Two-stage least squares estimation of average causal effects in models with variable treatment intensity. J. Am. Stat. Ass. 1995;90:431–442. doi: 10.1080/01621459.1995.10476535. [DOI] [Google Scholar]
- 12.Howe LJ, Tudball M, Smith GD, Davies NM. Interpreting Mendelian-randomization estimates of the effects of categorical exposures such as disease status and educational attainment. Int. J. Epidemiol. 2021 doi: 10.1093/ije/dyab208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Center, D. A. Chinese Longitudinal Healthy Longevity Survey (CLHLS)-Duke University School of Medicine, <https://sites.duke.edu/centerforaging/programs/chinese-longitudinal-healthy-longevity-survey-clhls/> (2021).
- 14.Studies, C. F. H. A. A. D. Chinese Longitudinal Healthy Longevity Survey (CLHLS)-Peking University, <https://opendata.pku.edu.cn/dataverse/CHADS> (2021).
- 15.Marees, A. GWA tutorial, <https://github.com/MareesAT/GWA_tutorial> (2020).
- 16.Folstein MF, Folstein SE, McHugh PR. Mini-mental state. A practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 1975;12:189–198. doi: 10.1016/0022-3956(75)90026-6. [DOI] [PubMed] [Google Scholar]
- 17.Zeng Y, et al. Novel loci and pathways significantly associated with longevity. Sci. Rep. 2016;6:21243. doi: 10.1038/srep21243. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Chang CC, et al. Second-generation PLINK: rising to the challenge of larger and richer datasets. Gigascience. 2015 doi: 10.1186/s13742-015-0047-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Dai JY, Zhang XC. Mendelian randomization studies for a continuous exposure under case-control sampling. Am. J. Epidemiol. 2015;181:440–449. doi: 10.1093/aje/kwu291. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Palmer TM, Thompson JR, Tobin MD, Sheehan NA, Burton PR. Adjusting for bias and unmeasured confounding in Mendelian randomization studies with binary responses. Int. J. Epidemiol. 2008;37:1161–1168. doi: 10.1093/ije/dyn080. [DOI] [PubMed] [Google Scholar]
- 21.Clarke PS, Windmeijer F. Instrumental variable estimators for binary outcomes. J. Am. Stat. Ass. 2012;107:1638–1652. doi: 10.1080/01621459.2012.734171. [DOI] [Google Scholar]
- 22.Burgess S. Sample size and power calculations in Mendelian randomization with a single instrumental variable and a binary outcome. Int. J. Epidemiol. 2014;43:922–929. doi: 10.1093/ije/dyu005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Burgess S, Thompson SG. Improving bias and coverage in instrumental variable analysis with weak instruments for continuous and binary outcomes. Stat. Med. 2012;31:1582–1600. doi: 10.1002/sim.4498. [DOI] [PubMed] [Google Scholar]
- 24.Didelez V, Sheehan N. Mendelian randomization as an instrumental variable approach to causal inference. Stat. Methods Med. Res. 2007;16:309–330. doi: 10.1177/0962280206077743. [DOI] [PubMed] [Google Scholar]
- 25.VanderWeele TJ, Tchetgen EJT, Cornelis M, Kraft P. Methodological challenges in mendelian randomization. Epidemiology. 2014;25:427–435. doi: 10.1097/Ede.0000000000000081. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Casaletto K, et al. Late-life physical activity relates to brain tissue synaptic integrity markers in older adults. Alzheimers Dement. 2022 doi: 10.1002/alz.12530. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Damrongthai C, et al. Benefit of human moderate running boosting mood and executive function coinciding with bilateral prefrontal activation. Sci. Rep. 2021;11:22657. doi: 10.1038/s41598-021-01654-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Chao Y-P, et al. Cognitive load of exercise influences cognition and neuroplasticity of healthy elderly: An exploratory investigation. J. Med. Biol. Eng. 2020;40:391–399. doi: 10.1007/s40846-020-00522-x. [DOI] [Google Scholar]
- 29.Rivas, K. Puzzles, card games later in life may delay Alzheimer’s onset by five years, study finds, <https://www.foxnews.com/health/delay-alzheimers-onset-five-years-cognitive-activity-study> (2021).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The datasets generated and/or analyzed during the current study are available in the Peking University Open Research Data repository. The code can be obtained by contacting the corresponding author. [https://opendata.pku.edu.cn/dataset.xhtml?persistentId=doi%3A10.18170%2FDVN%2FWBO7LK].