

ABSTRACT
Understanding the heterogeneous role of individuals in large-scale information spreading is essential to manage online behavior as well as its potential offline consequences. To this end, most existing studies from diverse research domains focus on the disproportionate role played by highly connected ‘hub’ individuals. However, we demonstrate here that information superspreaders in online social media are best understood and predicted by simultaneously considering two individual-level behavioral traits: influence and susceptibility. Specifically, we derive a nonlinear network-based algorithm to quantify individuals’ influence and susceptibility from multiple spreading event data. By applying the algorithm to large-scale data from Twitter and Weibo, we demonstrate that individuals’ estimated influence and susceptibility scores enable predictions of future superspreaders above and beyond network centrality, and reveal new insights into the network positions of the superspreaders.
Keywords: complex networks, social networks, social media, information spreading, superspreaders
While many works measured the role of social hubs for information spreading in social media, a new algorithm reveals that anticipating future superspreaders requires both individual characteristics and network structure.
INTRODUCTION
Modern communication technologies and online social media have radically transformed the way information propagates in human societies. Online information simultaneously influences and is influenced by offline behavior at an unprecedented pace, which offers both potential benefits and threats to mankind [1]. Potential benefits include accelerating human cooperation during emergencies [2], promoting community-minded [3] and healthy behavior [4], and increasing public trust in science [5]. On the other hand, uncontrolled online information flows can accelerate the spreading of dangerous misinformation [6–10], exacerbate polarization in society [11–14] and even trigger civil unrest [15,16].
Given the significant implications of online information spreading processes for global collective behavior, a major cross-disciplinary challenge is to provide mechanistic insights into the structure and dynamics of the spreading processes [17–24], which could be beneficial for predicting and managing their large-scale consequences [1]. In this respect, detecting superspreaders—individuals capable of triggering large-scale information cascades in social media—is crucial to diverse decision-makers, ranging from firms aiming to promote awareness for a new product [25,26] to policymakers and regulators seeking to design effective interventions to curb the large-scale diffusion of misinformation [7,8,27,28]. To shed light on the micro-level mechanisms behind information propagation in social media, we ask the following questions. To what extent can we predict future information superspreaders? Is an individual’s future spreading ability better predicted by her position in the social network or by her behavioral traits?
No consensus has been reached regarding the answers to these questions. Building on seminal opinion leadership and diffusion theories [29,30], researchers as diverse as sociologists, economists, physicists and computer scientists have tackled the problem by linking the micro-level properties of individuals and social ties with the large-scale spreading of information and behavior. Among them, many studies supported the hypothesis that a minority of influential individuals exert a disproportionately significant impact on online and offline information spreading, and that these ‘influentials’ can be detected via their centrality in the social networks they are embedded in. These works relied on diverse methods, ranging from observational data analysis [26,31], computational diffusion models [18,32–37] to field experiments [25,38].
Yet some works disagreed with the above conclusion [39–42], holding that centrality metrics alone do not reveal how information and behavior propagate from a given individual to her peers. Focusing on the diffusion of a single movie product, a seminal field experiment [43] found that peer-to-peer contagion in social media is jointly affected by two individual-level behavioral properties: influence, namely, how strongly people influence their neighbors; and susceptibility, how easily people are influenced by their neighbors [43]. They found that incorporating influence and susceptibility into agent-based diffusion models generates radically different predictions of information spreading processes than traditional diffusion models and centrality metrics [17]. However, when comparing these findings with those from the literature on social hubs, it remains unclear whether, compared to network-based characteristics such as centrality, individual-level behavioral traits are more accurate predictors of information superspreaders in empirical diffusion processes.
Here, we demonstrate that information superspreaders in social media are better predicted by individuals’ behavioral traits than by individuals’ centrality in the diffusion network. To this end, we first develop an algorithm that simultaneously quantifies individuals’ influence and susceptibility to influence from multiple spreading events. Based on an empirical influence model [17], we find that individual influence and susceptibility follow coupled non-linear, network-dependent equations. We also validate the algorithm’s ability to reconstruct individual influence and susceptibility in synthetic spreading data, even when the input data are incomplete. We further show that the algorithm’s scores in empirical data respect expected properties of the network positions of highly influential and susceptible individuals [43].
By applying the new algorithm to social media data collected from Twitter and Weibo, we reveal previously unknown assortativity properties of individual centrality, influence and susceptibility. Differently from recent results [23], our findings indicate that individuals’ influence and susceptibility are not necessarily correlated with their centrality. Crucially, we show that compared to network structural metrics (such as centrality [23]) and users’ past success [44], knowledge of both individuals’ influence and susceptibility can substantially improve the out-of-sample detection of superspreaders. Feature importance analysis reveals that beyond users’ past success, the most important predictors of being a future superspreader include the users’ influence as well as the influence and susceptibility of the influenced users. In particular, linear regression analysis suggests that the superspreaders are not disproportionately central in the social network, but they exhibit more high-contagion links (i.e. directed links that connect highly influential with highly susceptible users) and they tend to influence more influential users.
Compared to the many studies on the role of social networks in spreading processes, this collection of findings undermines the common assumption that network structural metrics are necessary to reliably predict future superspreaders. Our findings indicate that more accurate predictions are obtained by integrating individual-level behavioral traits and network properties. Future studies may seek to extend this conclusion from the online information spreading problem studied here to the complex diffusion of offline behaviors [4], which is highly relevant to societal challenges such as the promotion of sustainable consumption and vaccination.
RESULTS
Algorithm derivation and validation
We consider a set of N individuals that form the nodes of a directed diffusion network represented by its adjacency matrix, A. We consider a recent diffusion model [17]—which we refer to as the empirical diffusion model—that assumes that the peer-to-peer propagation of a piece of information from individual i to j is driven by two properties: i’s influence and j’s susceptibility. This assumption is motivated by the findings of a large-scale field experiment on new product adoption in Facebook [43]. Specifically, the state of a given individual i is characterized by a binary variable: she has either reshared (‘retweeted’) a piece of information (ri = 1) or not (ri = 0). The probability pij that individual j reshares a piece of content after i reshares it (i.e. that the piece of information ‘propagates’ from i to j) is defined as 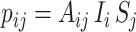 , where Ii and Sj represent individual i’s influence and individual j’s susceptibility, respectively, and Aij is equal to one if i and j are connected in the diffusion network where information propagates [35], and equal to zero otherwise. In this information diffusion network, a directed link from i to j exists if and only if at least one spreading event from i to j was recorded. This network might differ from the underlying structural network, where links exist based on the ‘follow’ relationship between users, and it is better suited to analyze the spreading dynamics [35]. Note that, according to the model’s terminology, a high-influence individual is effective at locally propagating information toward her social contacts, but might not be necessarily able to trigger large-scale propagation events. Using the model to generate synthetic data on diffusion processes reveals that the diffusion success outcomes are highly dependent on the assortativity properties of influence and susceptibility [17].
, where Ii and Sj represent individual i’s influence and individual j’s susceptibility, respectively, and Aij is equal to one if i and j are connected in the diffusion network where information propagates [35], and equal to zero otherwise. In this information diffusion network, a directed link from i to j exists if and only if at least one spreading event from i to j was recorded. This network might differ from the underlying structural network, where links exist based on the ‘follow’ relationship between users, and it is better suited to analyze the spreading dynamics [35]. Note that, according to the model’s terminology, a high-influence individual is effective at locally propagating information toward her social contacts, but might not be necessarily able to trigger large-scale propagation events. Using the model to generate synthetic data on diffusion processes reveals that the diffusion success outcomes are highly dependent on the assortativity properties of influence and susceptibility [17].
We consider here a different problem: given empirical data on multiple spreading events, can we reliably reconstruct individuals’ influence and susceptibility? Under the assumption of the diffusion model above, we derive two coupled non-linear equations that capture the relation between individual influence, individual susceptibility and network structure. Solving iteratively the derived equations leads to an algorithm to estimate individual influence and susceptibility from multiple spreading event data (see the Methods section below for the algorithm derivation). In the following, we refer to the scores determined by the algorithm as the reconstructed influence and susceptibility scores,  and
and  ; we refer to this derived algorithm through which to obtain
; we refer to this derived algorithm through which to obtain 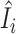 and
and 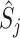 as the influence-susceptibility (IS) algorithm. The non-linear equations that define the algorithm indicate that, when estimating individual-level influence from multiple spreading data, one needs to consider both the rate at which a node influences her peers (the higher, the higher the node’s influence) and her peers’ average susceptibility (the higher, the lower the node’s influence; see Fig. 1a). Similarly, when estimating individual-level susceptibility from multiple spreading data, one needs to consider both the rate at which a node is influenced by her peers (the higher, the higher the node’s susceptibility) and her peers’ average influence (the higher, the lower the node’s susceptibility; see Fig. 1b).
as the influence-susceptibility (IS) algorithm. The non-linear equations that define the algorithm indicate that, when estimating individual-level influence from multiple spreading data, one needs to consider both the rate at which a node influences her peers (the higher, the higher the node’s influence) and her peers’ average susceptibility (the higher, the lower the node’s influence; see Fig. 1a). Similarly, when estimating individual-level susceptibility from multiple spreading data, one needs to consider both the rate at which a node is influenced by her peers (the higher, the higher the node’s susceptibility) and her peers’ average influence (the higher, the lower the node’s susceptibility; see Fig. 1b).
Figure 1.

Quantifying individual influence and susceptibility from observational data. To illustrate the intuition behind the proposed influence-susceptibility algorithm, in panel (a), we show how two nodes (A, B) with the same number of outgoing links and the same number of propagation events can achieve a widely different influence score I. The size of an orange (blue) node denotes its susceptibility score S (influence score I); the thickness of an arrow represents the number of propagation events. Both A and B have three outgoing links, meaning that they influence three nodes. However, A’s neighbors have a lower susceptibility than node B’s neighbors, because they are influenced fewer times by their other neighbors (the blue nodes in the outer-most shell). As A influences less susceptible individuals than B does, according to the IS algorithm, A is more influential than B. With a similar argument, in panel (b), node C is more susceptible than D.
We validate the IS algorithm’s outputs via two main findings. First, we find that in synthetic spreading data generated with the empirical diffusion model, the IS algorithm can reconstruct almost perfectly the latent ‘ground-truth’ influence and susceptibility scores of the nodes (see Note S1 within the online supplementary material). This finding is robust with respect to incomplete data: a high reconstruction accuracy can be maintained even when a substantial portion of the spreading events are removed (see Note S2). Second, we find that in empirical spreading data from Twitter and Weibo, the algorithm produces individual-level scores that respect the four stylized facts about influence and susceptibility identified in Aral and Walker’s experiment [43] (see Note S3). Specifically, our findings confirm the following four properties.
Highly influential individuals tend not to be susceptible, highly susceptible individuals tend not to be influential, and almost no one is both highly influential and highly susceptible to influence.
Both influential individuals and non-influential individuals have approximately the same distribution of susceptibility to influence among their peers.
There are more people with high influence scores than high susceptibility scores.
Influentials cluster in the network.
We refer the reader to Note S3 for the results that demonstrate that the reconstructed IS scores respect these properties. Taken together, these properties suggest that the scores calculated by the IS algorithm are consistent with the influence and susceptibility traits as defined experimentally by Aral and Walker [43].
The relation between individual influence, susceptibility and degree
We apply the IS algorithm to empirical spreading data to determine the relation between an individual’s degree, influence and susceptibility. Specifically, we examine (i) the node-level correlation between an individual’s properties, i.e. influence, susceptibility and degree (see Fig. 2 and Fig. S15 for additional results with the PageRank and k-core centralities); (ii) the correlation between an individual’s properties (influence, susceptibility and degree) and her neighbors’ properties (see Fig. 3), which represents the assortativity of these node-level properties. Revealing these empirical correlations is important because numerical simulations have shown that they can dramatically alter the outcome of spreading processes and the effectiveness of seeding strategies [17]. To assess the statistical significance of the correlations between individuals’ properties, we measure the P values by comparing their empirical values against the values observed for randomized networks (see Note S4).
Figure 2.

Empirical correlations between individual-level properties. We divide the spreading events into six consecutive non-overlapping periods. The date on the x axis represents the starting date of each period. In each period, we reconstruct individual influence and susceptibility via the IS algorithm, and measure the Spearman’s correlation coefficients, ρ, between the indegree (kin), outdegree (kout), influence (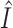 ) and susceptibility (
) and susceptibility ( ). Only those value pairs where both values are not equal to 0 are conserved. Filled markers denote correlation values that are significantly larger or smaller than the correlation values calculated on randomized networks (P < 0.05; see Note S4 for details); open markers denote correlation values that do not significantly differ from the correlation values calculated on randomized networks (P > 0.05). The strongest consistent empirical correlation is that between the outdegree (kout) and influence (
). Only those value pairs where both values are not equal to 0 are conserved. Filled markers denote correlation values that are significantly larger or smaller than the correlation values calculated on randomized networks (P < 0.05; see Note S4 for details); open markers denote correlation values that do not significantly differ from the correlation values calculated on randomized networks (P > 0.05). The strongest consistent empirical correlation is that between the outdegree (kout) and influence (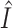 ); the other correlations are weak or non-significant.
); the other correlations are weak or non-significant.
Figure 3.

Empirical assortativity properties between degree, influence and susceptibility. We divide the spreading events into six consecutive non-overlapping periods. The date on the x axis represents the starting date of each period. In each period, we reconstruct individual influence and susceptibility via the IS algorithm, and we measure Spearman’s correlation coefficients, ρ, between an individual’s properties and her neighbors’ properties. The only consistent correlations are the positive one between an individual’s susceptibility (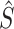 ) and the influence of the individuals she retweets (
) and the influence of the individuals she retweets ( ), and the negative one between an individual’s outdegree (kout) and the susceptibility of the individuals who retweet from her (
), and the negative one between an individual’s outdegree (kout) and the susceptibility of the individuals who retweet from her (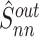 ).
).
When examining node-level correlations, we observe that an individual’s outdegree (kout) and influence (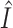 ) are the only pair of variables with a significant correlation across all four datasets. Aligning with previous arguments [39,44], the observed negative correlation suggests that individuals with many followers might not be the most effective ones at influencing their neighbors. At the same time, all other correlations are weak and dataset dependent, suggesting that influence, susceptibility and degree are orthogonal properties of individuals.
) are the only pair of variables with a significant correlation across all four datasets. Aligning with previous arguments [39,44], the observed negative correlation suggests that individuals with many followers might not be the most effective ones at influencing their neighbors. At the same time, all other correlations are weak and dataset dependent, suggesting that influence, susceptibility and degree are orthogonal properties of individuals.
As for assortativity properties, we focus on four correlations between an individual’s properties and her in- or out-neighbor properties: 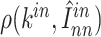 ,
, 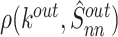 ,
, 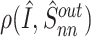 ,
,  ; in this notation, the subscript nn indicates that we average the property over an individual’s nearest neighbors, and the superscript in/out indicates the in or out neighbors, respectively. Here we find two consistent correlations: the positive one between an individual’s susceptibility (
; in this notation, the subscript nn indicates that we average the property over an individual’s nearest neighbors, and the superscript in/out indicates the in or out neighbors, respectively. Here we find two consistent correlations: the positive one between an individual’s susceptibility (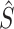 ) and the influence of the individuals she is influenced by (
) and the influence of the individuals she is influenced by ( ), and the negative one between an individual’s outdegree (kout) and the susceptibility of the individuals who retweet from her (
), and the negative one between an individual’s outdegree (kout) and the susceptibility of the individuals who retweet from her ( ). The other correlations are inconsistent, meaning that their sign switches from positive to negative depending on the dataset. These observed correlations and similar observations shed light on the assortativity properties of degree, influence and susceptibility, and they could serve as input for calibrated diffusion simulations to test the effectiveness of seeding programs [17].
). The other correlations are inconsistent, meaning that their sign switches from positive to negative depending on the dataset. These observed correlations and similar observations shed light on the assortativity properties of degree, influence and susceptibility, and they could serve as input for calibrated diffusion simulations to test the effectiveness of seeding programs [17].
Predicting superspreaders
The above results indicate that the IS algorithm helps better understand the positions of influential and susceptible nodes in empirical networks. Here we show that it can be used to forecast who will be future superspreaders, namely, individuals who can trigger large-scale information cascades. To this end, we focus on the two large-scale datasets (Weibo COVID and Twitter COVID) for which the ID information of each spreading event is available, while we exclude the remaining datasets (Weibo 2012 and Twitter 2011) that do not include this essential information. We frame a predictive problem where, given data from a time window t, we seek to identify who will be the superspreaders in subsequent window t+1. More specifically, we split each of the two analyzed datasets (Weibo COVID and Twitter COVID) into a set of non-overlapping periods {d1, d2, …, dT} by the retweet time, and we use the IS scores and other metrics estimated in period dt to detect the superspreaders in period dt+1. Superspreaders are defined as the top 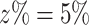 users by the average size of the cascades they initiate. To ensure the robustness of the results, we also implement additional selectivity thresholds of
users by the average size of the cascades they initiate. To ensure the robustness of the results, we also implement additional selectivity thresholds of 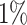 ,
, 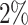 and
and 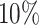 ; the corresponding results can be found in Figs S28–S30.
; the corresponding results can be found in Figs S28–S30.
In each training period dt, for a given individual i, we consider various classes of predictors. Specifically, we consider five new individual-level predictors based on the IS algorithm:
i’s influence,
 ;
;i’s susceptibility,
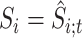 ;
;the total susceptibility of the individuals influenced by i,
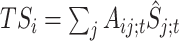 ;
;the total influence of the individuals influenced by i,
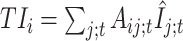 ;
;the IS total score that information spreads from i to her neighbors,
 , motivated by the empirical influence model.
, motivated by the empirical influence model.
To illustrate the advantage of the IS-based predictors compared to simpler behavior-based predictors, we also consider an individual’s total in-contagion rate and out-contagion rate. The contagion rate from i to j at period dt (i.e. the fraction of i’s reshared pieces of information that are also subsequently reshared by j within time window dt) is denoted as ωij; t. Individual j’s in-contagion rate is defined as 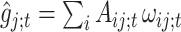 ; i’s out-contagion rate is defined as
; i’s out-contagion rate is defined as 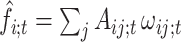 . Motivated by the vast literature on social hubs and superspreaders [19,31,35,36], we consider various network-based metrics as well: the outdegree,
. Motivated by the vast literature on social hubs and superspreaders [19,31,35,36], we consider various network-based metrics as well: the outdegree, 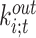 (reflecting the node’s total number of influenced neighbors); the indegree,
(reflecting the node’s total number of influenced neighbors); the indegree, 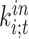 (reflecting the node’s total number of nodes that influenced i); the nodes’ PageRank and k-core centralities [35]. Given the previously documented effectiveness of past success in predicting future success for social media users [44,45], we also consider the average size of user i’s previously initiated cascades, which we refer to as past success.
(reflecting the node’s total number of nodes that influenced i); the nodes’ PageRank and k-core centralities [35]. Given the previously documented effectiveness of past success in predicting future success for social media users [44,45], we also consider the average size of user i’s previously initiated cascades, which we refer to as past success.
To understand the role of the above predictors in the superspreader prediction problem, we consider various classes of predictive models (see Note S8 for details), which differ in the types of features they include: two behavior-based models, with one based on the four IS-based features [behavior-based (IS) model], while the other is based on the contagion rate metrics [behavior-based (CR) model]; a structure-based model that includes the indegree, outdegree, PageRank and k-core centrality metrics extracted from the diffusion graph; a combined model that includes all the features in the behavior-based and structure-based models as well as the users’ past success. We consider a random classifier as a baseline model. Finally, in Twitter COVID, we are also able to consider a structure-based model based on the nodes’ indegrees and outdegrees in the follower-followee graph. We refer the reader to Table S4 within the online supplementary material for a summary of the features included in all the considered models.
We train different machine-learning algorithms: the random forest [46] (results shown in the main text), XGBoost algorithm [47] and multi-layer perceptron (MLP) [48]; the results for XGBoost and MLP are shown in Figs S31–S36. We evaluate the models according to two out-of-sample metrics: the area under the precision-recall curve (AUPRC), which is better suited than the popular area under the curve metric to evaluate classifier performance for imbalanced problems [49,50]; the precision of the metrics in identifying the superspreaders. We refer the reader to Note S8 for all the details of the models’ parameter settings and training.
We find that across all windows, the best-performing model is either the combined model or the behavior-based (IS) model (Fig. 4a, b, d and e). The behavior-based (IS) model outperforms the structural models, which points to the stronger predictive signals in the behavior-based features compared to structural ones. Performance differences between the combined model and the behavior-based (IS) model are only observed in Weibo but not in Twitter, and they tend to be relatively small. This indicates that adding the past success feature to the information already included in the behavior-based features brings no substantial accuracy gains. Finally, we note that the behavior-based (IS) model tends to substantially outperform the behavior-based (CR) model (Fig. 4a, b, d and e), which points to the superior predictive power of the IS algorithm scores compared to the contagion rates. While these conclusions were obtained through the random forest algorithm, to a large extent, they also hold for the XGBoost and MLP algorithms (Figs S31–S36), which indicates their robustness across different learning algorithms.
Figure 4.

Predicting superspreaders. We rely on the random forest classification algorithm and use different features as input to predict superspreaders, where the superspreaders are defined as individuals with top 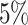 spreading capacity. Panels (a), (b), (d) and (e) show the superspreaders predicting performance on Weibo COVID and Twitter COVID. Two metrics, AUPRC and precision, are adopted to measure the performance of models. Panels (c) and (f) show the feature importance resulting from training the combined model. Across all windows, the best-performing model is either the combined model or the behavior-based (IS) model, which points to the essential role of the IS scores for the superspreader prediction. Panels (c) and (f) show the feature importance obtained from training the combined model. IS-based features tend to be more important than centrality-based features.
spreading capacity. Panels (a), (b), (d) and (e) show the superspreaders predicting performance on Weibo COVID and Twitter COVID. Two metrics, AUPRC and precision, are adopted to measure the performance of models. Panels (c) and (f) show the feature importance resulting from training the combined model. Across all windows, the best-performing model is either the combined model or the behavior-based (IS) model, which points to the essential role of the IS scores for the superspreader prediction. Panels (c) and (f) show the feature importance obtained from training the combined model. IS-based features tend to be more important than centrality-based features.
Additional insights into the positions of superspreaders can be gained by looking at feature importance in the combined model trained with the random forest algorithm (Fig. 4c and f). The features based on the IS scores tend to be more important than the structure-based features. The IS total score of a node is consistently among the two most important predictors; only the past success is a more important feature in Weibo. These findings are robust with respect to different thresholds for the superspreader detection (e.g. top 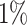 , top
, top 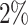 and top
and top  ; Figs S28–S30).
; Figs S28–S30).
To better characterize the superspreaders’ network positions, we perform a linear regression analysis with a linear mixed-effect model. After removing a multicollinearity issue (see Note S7 for details), we find that the IS total score, the total influence and the k-core centrality [35] are the only variables with a significant association with the users’ spreading success in both Twitter and Weibo COVID (see Note S7 and Table S16 for details). The found positive effect of the IS total score suggests that the superspreaders are characterized by more high-contagion links (i.e. directed links with high  ); the positive effect of the total influence suggests that they tend to influence more influential users. Taken together, these results indicate that behavior-based variables based on the IS algorithm can substantially improve the accuracy of superspreader predictions above and beyond model network centrality, and reveal new insights into the network positions of the superspreaders.
); the positive effect of the total influence suggests that they tend to influence more influential users. Taken together, these results indicate that behavior-based variables based on the IS algorithm can substantially improve the accuracy of superspreader predictions above and beyond model network centrality, and reveal new insights into the network positions of the superspreaders.
CONCLUSION
Prior works on the role of individuals in online information diffusion focused either on individuals’ network centrality or their behavioral traits such as influence and susceptibility. However, these studies did not clarify whether individuals’ network centrality or behavioral traits are better predictors of diffusion success. In this work, we propose an iterative algorithm that can reliably infer influence and susceptibility from empirical data on multiple spreading events in social media. Therefore, unlike previous studies that merely relied on parsimonious assumptions to explore the micro-level mechanism behind the spreading process, our algorithm provides reliable empirical scores of network individuals, allowing for a more precise understanding of the information diffusion process. In general, the proposed approach offers more accurate predictions of future superspreaders compared to methods that only rely on network-based structural characteristics. Notably, the proposed algorithm simultaneously incorporates information on the global network structure and peer-to-peer propagation events. Differently from previous studies that emphasized the role of highly connected social hubs [19,31,35,36] or highly influential individuals [19], our results indicate that to understand and accurately predict information spreading in social media, inferring both individuals’ influence and susceptibility is necessary.
Our work opens exciting research directions. First, we have focused on social platforms (Twitter and Weibo) where users reshare content from other users by explicitly mentioning them. When such an explicit mention is absent, it is challenging to distinguish between content propagation from user to user and other possible reasons for sharing, like advertising and general media influence [35]. Besides, generalizing our algorithm to quantify individual influence and susceptibility from generic adoption time series would require careful consideration to factor out potential homophily effects, which notoriously lead to an overestimation of social contagion estimates [51]. Furthermore, beyond social contagion, our method may prove useful in identifying influential and susceptible individuals in epidemic spreading processes, where ‘superspreaders’ can disproportionately infect many other individuals [52], whereas some individual groups might be significantly more vulnerable to the severe consequences of a disease [53]. In general, our algorithm may prove useful wherever there is peer-to-peer contagion, and there is heterogeneity in individual units’ influence and susceptibility; it can also shed some light on the network dismantling and population immunization problems [36,54].
To conclude, our findings could have implications for behavioral-change campaigns, such as viral marketing campaigns or community-minded behavioral nudging. These programs traditionally focus on the most central individuals in a given social network [25,26,36,38]. However, our results suggest that better strategies might involve identifying the network connections between highly influential and highly susceptible individuals. Given that our findings rely on predictive insights, additional research is needed in order to generalize them and develop intervention strategies. For instance, future studies may leverage observational data and field experiments, exploring how to best integrate network and behavioral information to design policies aimed at large-scale behavioral change.
METHODS
Influence-susceptibility algorithm derivation and convergence
The main idea of the derivation is to obtain an equation for the individual-level scores by summing pij over all possible source nodes i (to derive an equation for j’s susceptibility) and over all possible target nodes j (to derive an equation for i’s influence). For each individual i, we sum the contagion probability pij over all i’s neighbors:
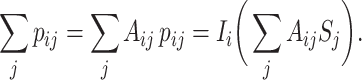 |
(1) |
Similarly, for each individual j, we sum the contagion probability pij over all her neighbors that can influence her:
 |
(2) |
For convenience, we define 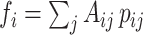 and
and 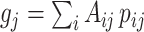 ; these two variables can be respectively interpreted as i’s outgoing contagion rate (i.e. how frequently i’s neighbors reshare the pieces of information shared by i) and j’s incoming contagion rate (i.e. how frequently j reshares the pieces of information shared by her neighbors). The rates fi and gj can be interpreted as rough estimates of i’s influence on her neighbors and j’s susceptibility to her neighbors, respectively. We can rewrite equation (1) as
; these two variables can be respectively interpreted as i’s outgoing contagion rate (i.e. how frequently i’s neighbors reshare the pieces of information shared by i) and j’s incoming contagion rate (i.e. how frequently j reshares the pieces of information shared by her neighbors). The rates fi and gj can be interpreted as rough estimates of i’s influence on her neighbors and j’s susceptibility to her neighbors, respectively. We can rewrite equation (1) as
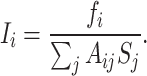 |
(3) |
Similarly, from equation (2), we obtain
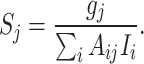 |
(4) |
The set of equations (3) and (4) indicate that to infer influence and susceptibility from observational data, a nonlinear algorithm is needed. The nonlinearity of equation (3) stems from the fact that, given data on multiple spreading events, an individual i is ‘highly influential’ (large Ii) if she has a large outgoing contagion rate fi, and low 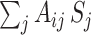 , indicating that, overall, individuals who are influenced by i are not highly susceptible. Similarly, from equation (4), an individual j is ‘highly susceptible’ (large Sj) if she has a large incoming contagion rate gj, and low
, indicating that, overall, individuals who are influenced by i are not highly susceptible. Similarly, from equation (4), an individual j is ‘highly susceptible’ (large Sj) if she has a large incoming contagion rate gj, and low 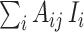 , indicating that, overall, individuals who influence j are not highly influential. In Fig. 1, we provide an illustration of the interpretation of the influence I and susceptibility S using equations (3) and (4).
, indicating that, overall, individuals who influence j are not highly influential. In Fig. 1, we provide an illustration of the interpretation of the influence I and susceptibility S using equations (3) and (4).
Leveraging these two equations to estimate individual influence and susceptibility faces two potential obstacles. First, to estimate f and g, we need to know the contagion probability pij, which is unknown a priori. Second, estimating the scores Ii and Sj of individual i requires knowledge of her neighbors’ susceptibility and influence scores, respectively.
To estimate f and g, we infer pij from the spreading data by measuring the fraction of i’s reshared pieces of information that are also subsequently reshared by j, ωij, and thus produce estimates  and
and 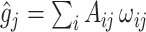 of the outgoing and incoming contagion rates, respectively. To overcome the second obstacle, inspired by state-of-the-art economic complexity algorithms [55], we estimate the scores iteratively through the nonlinear map
of the outgoing and incoming contagion rates, respectively. To overcome the second obstacle, inspired by state-of-the-art economic complexity algorithms [55], we estimate the scores iteratively through the nonlinear map
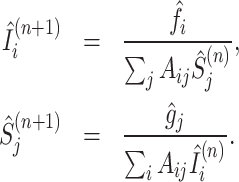 |
(5) |
By appropriately setting the initial condition, the convergence of the algorithm is guaranteed. We refer the reader to Note S5 for the detailed proofs and conclusions. For further discussions and extensions of the IS algorithm, see Note S10.
Supplementary Material
Contributor Information
Fang Zhou, Institute of Fundamental and Frontier Sciences, University of Electronic Science and Technology of China, Chengdu 610054, China; Yangtze Delta Region Institute (Huzhou), University of Electronic Science and Technology of China, Huzhou 313001, China.
Linyuan Lü, Institute of Fundamental and Frontier Sciences, University of Electronic Science and Technology of China, Chengdu 610054, China; School of Cyber Science and Technology, University of Science and Technology of China, Hefei 230026, China.
Jianguo Liu, Department of Digital Economics, Shanghai University of Finance and Economics, Shanghai 200433, China.
Manuel Sebastian Mariani, Institute of Fundamental and Frontier Sciences, University of Electronic Science and Technology of China, Chengdu 610054, China; URPP Social Networks, Universität Zürich, Zürich 8006, Switzerland.
DATA AVAILABILITY
The data collection, sampling and partition for the four large-scale empirical datasets are described in Note S9. The source code of the IS algorithm is available at https://github.com/zervel3/IS-algorithm.
FUNDING
L.L. acknowledges support from the National Natural Science Foundation of China (T2293771), the STI 2030–Major Projects (2022ZD0211400), the Sichuan Province Outstanding Young Scientists Foundation (2023NSFSC1919) and the New Cornerstone Science Foundation through the XPLORER PRIZE. J.G.L. acknowledges support from the National Natural Science Foundation of China (72371150 and 72032003) and the Fundamental Research Funds for the Central Universities in funding ‘High-Quality Development 23 of Digital Economy: An Investigation of Characteristics and Driving Strategies’ (2023110139). M.S.M. acknowledges financial support from the Swiss National Science Foundation (100013-207888) and the URPP Social Networks at the University of Zurich.
AUTHOR CONTRIBUTIONS
L.L. and M.S.M. conceived and designed the experiments; F.Z. and J.G.L. collected the empirical datasets; F.Z. performed the numeric analysis; F.Z. and M.S.M. developed the new algorithm and wrote the first draft of the manuscript; all the authors analyzed the data and revised the manuscript.
Conflict of interest statement . None declared.
REFERENCES
- 1. Bak-Coleman JB, Alfano M, Barfuss W et al. Stewardship of global collective behavior. Proc Natl Acad Sci USA 2021; 118: e2025764118. 10.1073/pnas.2025764118 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Lacassin R, Devès M, Hicks SP et al. Rapid collaborative knowledge building via twitter after significant geohazard events. Geosci Lett 2020; 3: 129–46. 10.5194/gc-3-129-2020 [DOI] [Google Scholar]
- 3. Chen Y, Harper FM, Konstan J et al. Social comparisons and contributions to online communities: a field experiment on movielens. Am Econ Rev 2010; 100: 1358–98. 10.1257/aer.100.4.1358 [DOI] [Google Scholar]
- 4. Centola D. How Behavior Spreads. Princeton: Princeton University Press, 2018. [Google Scholar]
- 5. Huber B, Barnidge M, Gil de Zúñiga H et al. Fostering public trust in science: the role of social media. Public Underst Sci 2019; 28: 759–77. 10.1177/0963662519869097 [DOI] [PubMed] [Google Scholar]
- 6. Lazer DM, Baum MA, Benkler Y et al. The science of fake news. Science 2018; 359: 1094–6. 10.1126/science.aao2998 [DOI] [PubMed] [Google Scholar]
- 7. Shao C, Ciampaglia GL, Varol O et al. The spread of low-credibility content by social bots. Nat Commun 2018; 9: 4787. 10.1038/s41467-018-06930-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Bovet A, Makse HA. Influence of fake news in Twitter during the 2016 US presidential election. Nat Commun 2019; 10: 7. 10.1038/s41467-018-07761-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Guess AM, Nyhan B, Reifler J. Exposure to untrustworthy websites in the 2016 US election. Nat Hum Behav 2020; 4: 472–80. 10.1038/s41562-020-0833-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Gallotti R, Valle F, Castaldo N et al. Assessing the risks of ‘infodemics’ in response to COVID-19 epidemics. Nat Hum Behav 2020; 4: 1285–93. 10.1038/s41562-020-00994-6 [DOI] [PubMed] [Google Scholar]
- 11. Stella M, Ferrara E, De Domenico M. Bots increase exposure to negative and inflammatory content in online social systems. Proc Natl Acad Sci USA 2018; 115: 12435–40. 10.1073/pnas.1803470115 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Johnson NF, Velásquez N, Restrepo NJ et al. The online competition between pro-and anti-vaccination views. Nature 2020; 582: 230–3. 10.1038/s41586-020-2281-1 [DOI] [PubMed] [Google Scholar]
- 13. Baumann F, Lorenz-Spreen P, Sokolov IM et al. Modeling echo chambers and polarization dynamics in social networks. Phys Rev Lett 2020; 124: 048301. 10.1103/PhysRevLett.124.048301 [DOI] [PubMed] [Google Scholar]
- 14. Medo M, Mariani MS, Lü L. The fragility of opinion formation in a complex world. Commun Phys 2021; 4: 75. 10.1038/s42005-021-00579-3 [DOI] [Google Scholar]
- 15. González-Bailón S, Borge-Holthoefer J, Rivero A et al. The dynamics of protest recruitment through an online network. Sci Rep 2011; 1: 197. 10.1038/srep00197 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Mooijman M, Hoover J, Lin Y et al. Moralization in social networks and the emergence of violence during protests. Nat Hum Behav 2018; 2: 389–96. 10.1038/s41562-018-0353-0 [DOI] [PubMed] [Google Scholar]
- 17. Aral S, Dhillon PS. Social influence maximization under empirical influence models. Nat Hum Behav 2018; 2: 375–82. 10.1038/s41562-018-0346-z [DOI] [PubMed] [Google Scholar]
- 18. Hu Y, Ji S, Jin Y et al. Local structure can identify and quantify influential global spreaders in large scale social networks. Proc Natl Acad Sci USA 2018; 115: 7468–72. 10.1073/pnas.1710547115 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Wang X, Lan Y, Xiao J. Anomalous structure and dynamics in news diffusion among heterogeneous individuals. Nat Hum Behav 2019; 3: 709–18. 10.1038/s41562-019-0605-7 [DOI] [PubMed] [Google Scholar]
- 20. Shi D, Lü L, Chen G. Totally homogeneous networks. Natl Sci Rev 2019; 6: 962–9. 10.1093/nsr/nwz050 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Tang D, Du W, Shekhtman L et al. Predictability of real temporal networks. Natl Sci Rev 2020; 7: 929–37. 10.1093/nsr/nwaa015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Xie J, Meng F, Sun J et al. Detecting and modelling real percolation and phase transitions of information on social media. Nat Hum Behav 2021; 5: 1161–8. 10.1038/s41562-021-01090-z [DOI] [PubMed] [Google Scholar]
- 23. Zhou B, Pei S, Muchnik L et al. Realistic modelling of information spread using peer-to-peer diffusion patterns. Nat Hum Behav 2020; 4: 1198–207. 10.1038/s41562-020-00945-1 [DOI] [PubMed] [Google Scholar]
- 24. Juul JL, Ugander J. Comparing information diffusion mechanisms by matching on cascade size. Proc Natl Acad Sci USA 2021; 118: e2100786118. 10.1073/pnas.2100786118 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Hinz O, Skiera B, Barrot C et al. Seeding strategies for viral marketing: an empirical comparison. J Mark 2011; 75: 55–71. 10.1509/jm.10.0088 [DOI] [Google Scholar]
- 26. Muller E, Peres R. The effect of social networks structure on innovation performance: a review and directions for research. Int J Res Mark 2019; 36: 3–19. 10.1016/j.ijresmar.2018.05.003 [DOI] [Google Scholar]
- 27. Budak C, Agrawal D, El Abbadi A. Limiting the spread of misinformation in social networks. In: Proceedings of the 20th International Conference on World Wide Web. New York: Association for Computing Machinery, 2011, 665–74. 10.1145/1963405.1963499 [DOI] [Google Scholar]
- 28. Grinberg N, Joseph K, Friedland L et al. Fake news on Twitter during the 2016 US presidential election. Science 2019; 363: 374–8. 10.1126/science.aau2706 [DOI] [PubMed] [Google Scholar]
- 29. Katz E, Lazarsfeld PF. Personal Influence. Piscataway: Transaction Publishers, 1955. [Google Scholar]
- 30. Rogers EM. Diffusion of Innovations. New York: Simon and Schuster, 2010. [Google Scholar]
- 31. Goldenberg J, Han S, Lehmann DR et al. The role of hubs in the adoption process. J Mark 2009; 73: 1–13. 10.1509/jmkg.73.2.1 [DOI] [Google Scholar]
- 32. Domingos P, Richardson M. Mining the network value of customers. In: Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: Association for Computing Machinery, 2001, 57–66. 10.1145/502512.502525 [DOI] [Google Scholar]
- 33. Kempe D, Kleinberg J, Tardos É. Maximizing the spread of influence through a social network. In: Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: Association for Computing Machinery, 2003, 137–46. 10.1145/956750.956769 [DOI] [Google Scholar]
- 34. Kitsak M, Gallos LK, Havlin S et al. Identification of influential spreaders in complex networks. Nat Phys 2010; 6: 888–93. 10.1038/nphys1746 [DOI] [Google Scholar]
- 35. Pei S, Muchnik L, Andrade JS Jr et al. Searching for superspreaders of information in real-world social media. Sci Rep 2014; 4: 5547. 10.1038/srep05547 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Lü L, Chen D, Ren XL et al. Vital nodes identification in complex networks. Phys Rep 2016; 650: 1–63. 10.1016/j.physrep.2016.06.007 [DOI] [Google Scholar]
- 37. Zhou F, Lü L and Mariani MS. Fast influencers in complex networks. Commun Nonlinear Sci Numer Simul 2019; 74: 69–83. 10.1016/j.cnsns.2019.01.032 [DOI] [Google Scholar]
- 38. Banerjee A, Chandrasekhar AG, Duflo E et al. The diffusion of microfinance. Science 2013; 341: 1236498. 10.1126/science.1236498 [DOI] [PubMed] [Google Scholar]
- 39. Watts DJ, Dodds PS. Influentials, networks, and public opinion formation. J Consum Res 2007; 34: 441–58. 10.1086/518527 [DOI] [Google Scholar]
- 40. Galeotti A, Goyal S. Influencing the influencers: a theory of strategic diffusion. RAND J Econ 2009; 40: 509–32. 10.1111/j.1756-2171.2009.00075.x [DOI] [Google Scholar]
- 41. Mariani MS, Gimenez Y, Brea J et al. The wisdom of the few: predicting collective success from individual behavior. arXiv: 2001.04777.
- 42. Rossman G, Fisher JC. Network hubs cease to be influential in the presence of low levels of advertising. Proc Natl Acad Sci USA 2021; 118: e2013391118. 10.1073/pnas.2013391118 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Aral S, Walker D. Identifying influential and susceptible members of social networks. Science 2012; 337: 337–41. 10.1126/science.1215842 [DOI] [PubMed] [Google Scholar]
- 44. Bakshy E, Hofman JM, Mason WA et al. Everyone’s an influencer: quantifying influence on Twitter. In: Proceedings of the Fourth ACM International Conference on Web Search and Data Mining. New York: Association for Computing Machinery, 2011, 65–74. 10.1145/1935826.1935845 [DOI] [Google Scholar]
- 45. Martin T, Hofman JM, Sharma A et al. Exploring limits to prediction in complex social systems. In: Proceedings of the 25th International Conference on World Wide Web. Geneva: International World Wide Web Conferences Steering Committee, 2016, 683–94. 10.1145/2872427.2883001 [DOI] [Google Scholar]
- 46. Breiman L. Random forests. Mach Learn 2001; 45: 5–32. 10.1023/A:1010933404324 [DOI] [Google Scholar]
- 47. Chen T, Guestrin C. XGBoost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: Association for Computing Machinery, 2016, 785–94. 10.1145/2939672.2939785 [DOI] [Google Scholar]
- 48. Gardner MW, Dorling S. Artificial neural networks (the multilayer perceptron)—a review of applications in the atmospheric sciences. Atmos Environ 1998; 32: 2627–36. 10.1016/S1352-2310(97)00447-0 [DOI] [Google Scholar]
- 49. Davis J, Goadrich M. The relationship between precision-recall and ROC curves. In: Proceedings of the 23rd International Conference on Machine Learning. New York: Association for Computing Machinery, 2006, 233–40. 10.1145/1143844.1143874 [DOI] [Google Scholar]
- 50. Saito T, Rehmsmeier M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS One 2015; 10: e0118432. 10.1371/journal.pone.0118432 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. Aral S, Muchnik L, Sundararajan A. Distinguishing influence-based contagion from homophily-driven diffusion in dynamic networks. Proc Natl Acad Sci USA 2009; 106: 21544–9. 10.1073/pnas.0908800106 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Lloyd-Smith JO, Schreiber SJ, Kopp PE et al. Superspreading and the effect of individual variation on disease emergence. Nature 2005; 438: 355–9. 10.1038/nature04153 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53. Godri Pollitt KJ, Peccia J, Ko AI et al. COVID-19 vulnerability: the potential impact of genetic susceptibility and airborne transmission. Hum Genomics 2020; 14: 17. 10.1186/s40246-020-00267-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54. Liu Y, Sanhedrai H, Dong G et al. Efficient network immunization under limited knowledge. Natl Sci Rev 2021; 8: nwaa229. 10.1093/nsr/nwaa229 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Tacchella A, Cristelli M, Caldarelli G et al. A new metrics for countries’ fitness and products’ complexity. Sci Rep 2012; 2: 723. 10.1038/srep00723 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The data collection, sampling and partition for the four large-scale empirical datasets are described in Note S9. The source code of the IS algorithm is available at https://github.com/zervel3/IS-algorithm.