

Abstract
Goal: Deep learning techniques have made significant progress in medical image analysis. However, obtaining ground truth labels for unlabeled medical images is challenging as they often outnumber labeled images. Thus, training a high-performance model with limited labeled data has become a crucial challenge. Methods: This study introduces an underlying knowledge-based semi-supervised framework called UKSSL, consisting of two components: MedCLR extracts feature representations from the unlabeled dataset; UKMLP utilizes the representation and fine-tunes it with the limited labeled dataset to classify the medical images. Results: UKSSL evaluates on the LC25000 and BCCD datasets, using only 50% labeled data. It gets precision, recall, F1-score, and accuracy of 98.9% on LC25000 and 94.3%, 94.5%, 94.3%, and 94.1% on BCCD, respectively. These results outperform other supervised-learning methods using 100% labeled data. Conclusions: The UKSSL can efficiently extract underlying knowledge from the unlabeled dataset and perform better using limited labeled medical images.
Keywords: Deep learning, self-supervised learning, medical image analysis, semi-supervised learning, image classification
I. Introduction
Extracting underlying knowledge from limited labeled data is a challenging problem in machine learning, especially for medical image analysis, where annotation of medical images is costly and laborious. However, in medical image analysis, there are plenty of unlabeled or limited labeled images instead of all the images with ground-truth labels. Therefore, it is desirable to pay attention to the techniques with weak supervision or non-supervision, which can utilize unlabeled and limited labeled datasets in medical image analysis. In the last decade, machine learning has been developing a series of paradigms to deal with insufficient data annotation problems, such as semi-supervised learning [25], multi-instance learning [26], and self-supervised learning [27]. Within these paradigms, semi-supervised learning-based approaches are attractive because semi-supervised learning is able to achieve better performance than the self-supervised methods and it only needs a limited labeled dataset than the supervised methods.
Semi-supervised methods mainly consist of five types: generative methods [17], [18], consistency regularization methods [15], [16], graph-based methods [13], [14], pseudo-labeling methods [11], [12] and hybrid methods [9], [10]. One popular paradigm within the hybrid methods is combining self-supervised learning with supervised learning to construct a semi-supervised learning-based model. Our method is also based on this paradigm which constructs a contrastive learning-based model and then fine-tunes it with the limited labeled dataset.
Contrastive learning is one type of self-supervised learning, which aims to learn the fusion information of a dataset such that similar data instances are close and diverse data instances are far away from each other [8]. The most basic idea of contrastive learning is to learn semantic representations by constructing positive pairs (data points that should be similar) and negative pairs (data points that should be dissimilar). In recent years, there has been a surge of interest in contrastive learning. Some prior works like InstDisc [7], CPC [6], and CMC [5] attract lots of researchers to focus on this area. Later on, some significant works like SimCLR [28], MoCo [4], and SwAv [3] are proposed. These works introduce the momentum encoder and InfoNCE loss function, which accelerate the development of this area. Moreover, some works also focus on building the prediction task without negative pairs, such as BYOL [2] and SimSiam [1].
In this work, we employ a contrastive learning model to extract the feature map from unlabeled datasets. Subsequently, we construct a supervised learning model and fine-tune it using a limited labeled dataset. The proposed framework UKSSL achieves outstanding performance by using limited datasets compared with other state-of-the-art methods on the different medical image classification datasets: LC25000 and BCCD datasets. We observe that the self-supervised pre-training with an unlabeled dataset can get a meaningful underlying knowledge of the dataset, and fine-tuning this representation with a limited labeled dataset can achieve excellent performance on downstream tasks. We attribute this finding to exploring the robust contrastive model architectures and algorithms to enhance the performance of our framework.
The structure of the proposed framework is presented in Fig. 1, and our key findings and contributions are as follows:
-
•
The proposed framework UKSSL achieves excellent performance with partially labeled medical images, and it gets the best performance compared with other supervised methods.
-
•
We propose a MedCLR, which can efficiently extract the underlying knowledge from the unlabeled dataset. These extracted representations can be used in different proxy tasks.
-
•
We present a UKMLP, it improves the performance by using the underlying knowledge provided by the self-supervised model, which can be used with other self-supervised models.
Figure 1.

Our framework includes two components: (1) Training a knowledge extractor MedCLR on the unlabeled medical images based on the SimCLR [28]. (2) Using limited labeled medical images to fine-tune the UKMLP.
II. Materials and Methods
Our proposed UKSSL consists of two parts: MedCLR and UKMLP. MedCLR is inspired by SimCLR [28], which uses contrastive learning to extract underlying knowledge from unlabeled images. After pre-training the MedCLR, the second part UKMLP will utilize the underlying knowledge obtained by the MedCLR to fine-tune with limited labeled medical images. Then after finishing the entire process, the well-trained UKSSL can classify the medical images. In this section, we will introduce our MedCLR in Section II-A, then we will illustrate our UKMLP in Section II-B. Finally, the materials and experimental settings are shown in Section II-C.
A. Contrastive Learning of Medical Visual Representations (MedCLR)
To learn the medical images' visual representations, we design our MedCLR, which inspires by a contrastive learning method SimCLR [28]. MedCLR extracts the semantic information by maximizing agreement [29] between the different augmented images from the same image with contrastive loss function in the underlying semantic knowledge distributions. As Fig. 2 illustrates, there are four components of MedCLR: image augmentation module, deep learning-based encoder, projection head, and a contrastive loss function NT-Xent.
Figure 2.
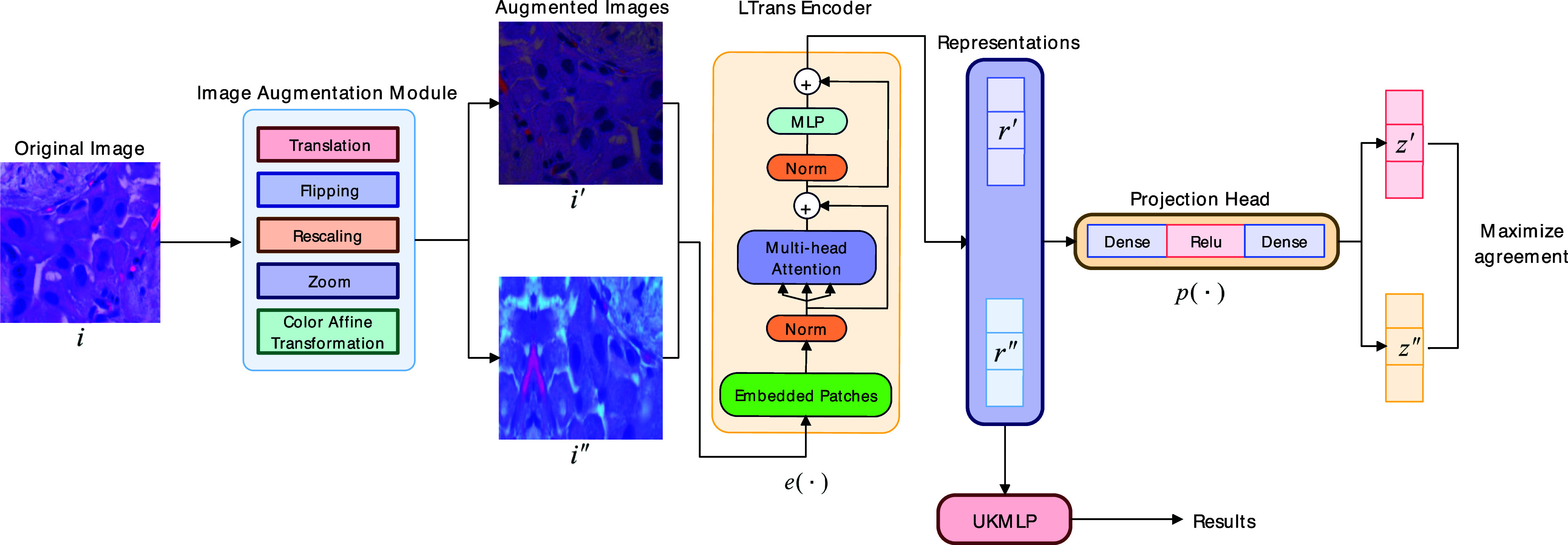
Architecture of the MedCLR. i denotes the original image,  and
and  denote two different augmented images from the original image i,
denote two different augmented images from the original image i, 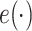 denotes the encoder, and there are two representations generated by the encoder called
denotes the encoder, and there are two representations generated by the encoder called 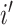 and
and 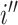 ,
, 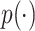 denotes for the projection head and
denotes for the projection head and 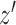 ,
, 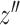 represents for the feature vectors from the projection head.
represents for the feature vectors from the projection head.
Image augmentation module applies multiple data augmentation techniques to transform the original image i to two augmented images 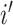 and
and 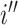 , the pair of
, the pair of 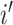 and
and 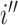 also called positive pair in one batch of the dataset, we denote the image augmentation module as
also called positive pair in one batch of the dataset, we denote the image augmentation module as 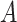 . In detail, there are five data augmentation techniques: rescaling the input data to the range of
. In detail, there are five data augmentation techniques: rescaling the input data to the range of 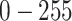 , random flipping of the images, random translation followed by the random zoom, and random color affine transformation.
, random flipping of the images, random translation followed by the random zoom, and random color affine transformation.
Encoder denotes by the 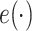 , which can extract the semantic knowledge from the augmented images to two representations
, which can extract the semantic knowledge from the augmented images to two representations 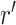 and
and 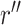 . In our framework, we inspire ideas from the Vision Transformer (ViT) [32] to design our light encoder architecture LTrans. It obtains representations
. In our framework, we inspire ideas from the Vision Transformer (ViT) [32] to design our light encoder architecture LTrans. It obtains representations 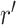 and
and 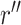 as (1) shows, where the output
as (1) shows, where the output 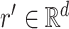 is generated by an average pooling layer.
is generated by an average pooling layer.
 |
The architecture of the encoder is shown in Fig. 3. Unlike the traditional Transformer, which will regard a 1D sequence of token embeddings as the input, we replace it by reshaping the image from the size 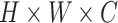 to a sequence of flattened 2D patches with size
to a sequence of flattened 2D patches with size 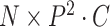 . Here, the
. Here, the 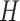 and
and 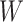 indicate the height and width of the original image. The
indicate the height and width of the original image. The 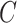 represents the number of channels. The
represents the number of channels. The 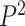 is the resolution of each image patch, and the number of patches is calculated by the (2).
is the resolution of each image patch, and the number of patches is calculated by the (2).
 |
Figure 3.
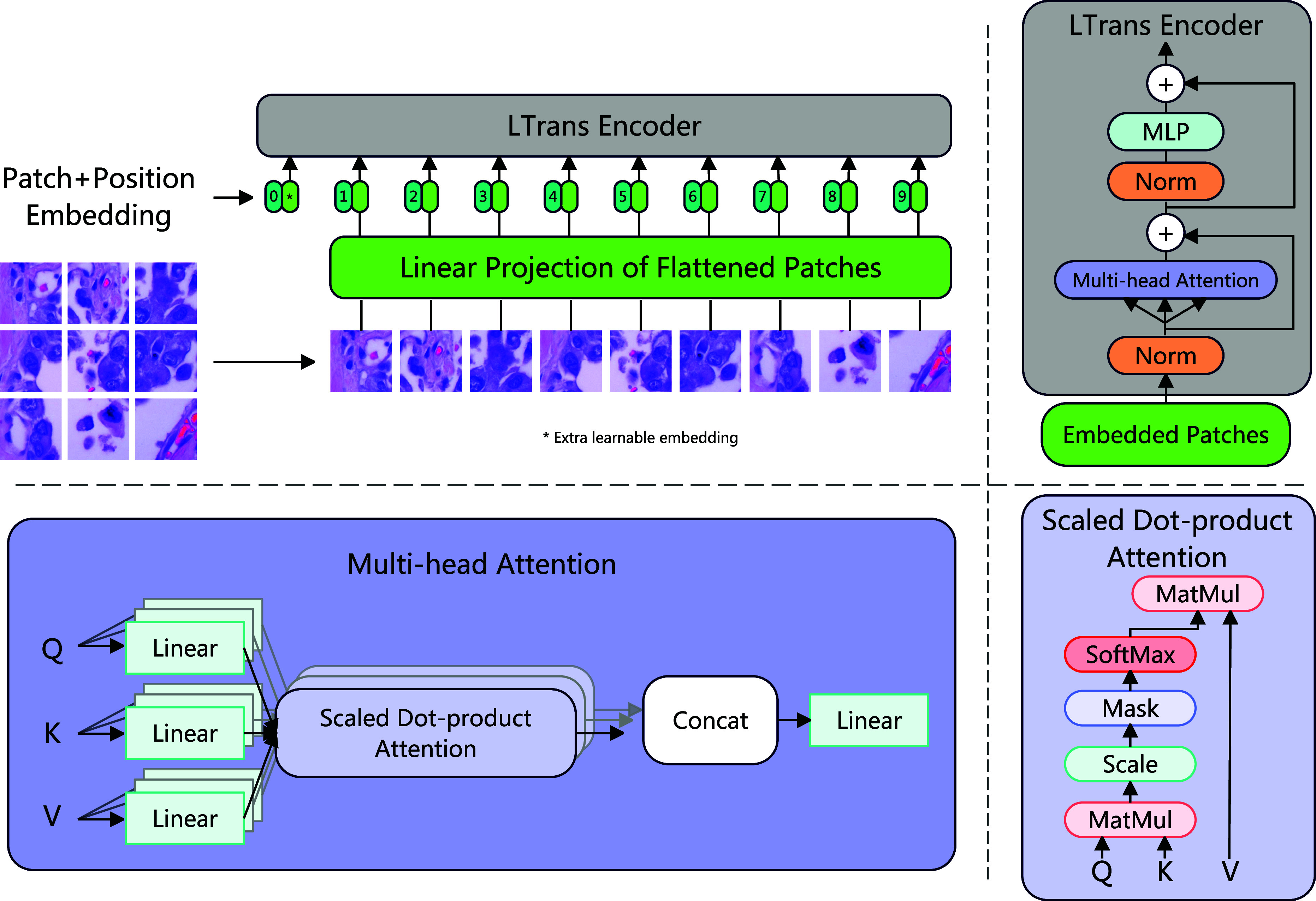
Architecture of the LTrans. Firstly, we reshape the original image into a sequence of flattened 2D patches and pass them into a linear projection with trainable parameters. Then the embedded patches pass the LTrans. The LTrans contains two normalization layers, two residual connections, a multi-head attention module, and an MLP. The details of the multi-head attention module are also provided in this figure.
After reshaping from original images to patches, we map flattened patches into 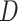 dimensions and pass them into a linear projection with trainable parameters. The linear projection is shown in (3), where
dimensions and pass them into a linear projection with trainable parameters. The linear projection is shown in (3), where 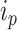 represents the flattened 2D patches from the original image
represents the flattened 2D patches from the original image 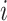 . The
. The 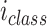 denotes a special classification token. This is similar to the
denotes a special classification token. This is similar to the 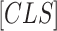 token in the BERT [33]. The output from this projection is called patch embeddings. We also use the position embeddings
token in the BERT [33]. The output from this projection is called patch embeddings. We also use the position embeddings 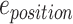 to keep the positional information. In detail, we use standard learnable 1D position embeddings, and after generating the position embeddings, we add the position embeddings with patch embeddings together to produce the final embedded patches
to keep the positional information. In detail, we use standard learnable 1D position embeddings, and after generating the position embeddings, we add the position embeddings with patch embeddings together to produce the final embedded patches 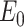 . Then passing embedded patches into the LTrans.
. Then passing embedded patches into the LTrans.
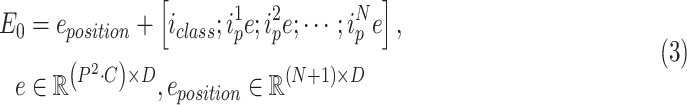 |
LTrans consists of multi-head self-attention (MSA) [32] and MLP blocks [34], and we add a normalization layer before each component, also a residual connection [35] after each component. Multi-head attention [31] attracts lots of researchers to use in their models. In detail, assuming we have an input sequence 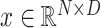 , we calculate a weighted sum over each value
, we calculate a weighted sum over each value 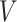 in the input sequence
in the input sequence 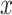 , as (4) shows. The weights of attention
, as (4) shows. The weights of attention 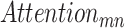 are determined by comparing the pairwise similarity of two elements within the sequence, along with their corresponding representations of query
are determined by comparing the pairwise similarity of two elements within the sequence, along with their corresponding representations of query 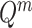 and key
and key 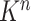 , as (5) shows. Finally, the self-attention
, as (5) shows. Finally, the self-attention 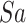 is calculated by the (6).
is calculated by the (6).
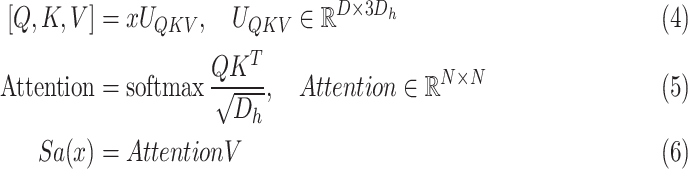 |
Multihead self-attention (MSA) runs 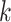 self-attention operations and projects their concatenated outputs, which is shown in (7).
self-attention operations and projects their concatenated outputs, which is shown in (7).
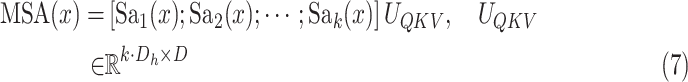 |
The MLP blocks in the LTrans have two fully connected layers with GELU non-linearity. The entire process of LTrans can be described in (8) and (9).
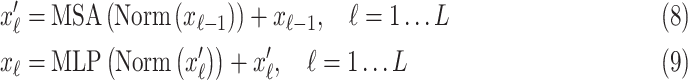 |
Projection head
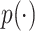 is a small non-linear MLP neural network that can project the representation
is a small non-linear MLP neural network that can project the representation 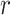 to another feature space
to another feature space 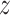 . As (10) shows, the
. As (10) shows, the 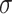 is a non-linear ReLU function, the
is a non-linear ReLU function, the 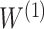 is the weight for the encoder
is the weight for the encoder 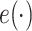 , and the
, and the 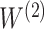 is the weight for the projection head
is the weight for the projection head 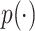 .
.
 |
Contrastive loss function NT-Xent is designed to optimize the performance of the prediction task, as (11) shows. This loss function is termed by Chen et al. [28] as NT-Xent (the normalized temperature-scaled cross-entropy loss), and it has been widely used in lots of works [6], [7], [30].
As Fig. 2 shows, given a minibatch with random 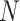 samples generated by the entire dataset, each image
samples generated by the entire dataset, each image 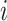 will produce two augmented images by the image augmentation module denoted by
will produce two augmented images by the image augmentation module denoted by 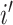 and
and 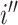 . This process results in
. This process results in 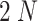 data samples. Within these
data samples. Within these 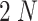 data samples, we regard two augmented images from the original image as positive pairs, and the remaining images
data samples, we regard two augmented images from the original image as positive pairs, and the remaining images 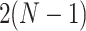 are negative pairs. Afterward, the two augmented images are passed into the encoder neural network
are negative pairs. Afterward, the two augmented images are passed into the encoder neural network 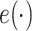 to produce the representations
to produce the representations 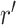 and
and 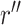 . Then representations are fed into the non-linear MLP projection head
. Then representations are fed into the non-linear MLP projection head 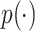 and yield feature space
and yield feature space 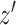 and
and 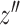 for calculations of contrastive loss.
for calculations of contrastive loss.
The loss function NT-Xent between a pair of positive examples 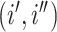 is defined as follows:
is defined as follows:
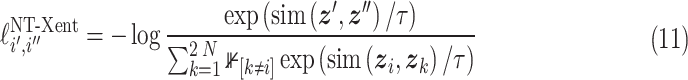 |
where 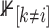 represents an indicator function, and iff
represents an indicator function, and iff 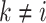 , the value of the function is equal to 1. The
, the value of the function is equal to 1. The 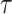 is called the temperature coefficient, which can control the strength of penalties on the hard negative samples. Finally, the loss is computed across all the positive pairs.
is called the temperature coefficient, which can control the strength of penalties on the hard negative samples. Finally, the loss is computed across all the positive pairs.
Combining the four components mentioned above, we build the completed MedCLR, and we provide the pseudo-code of MedCLR in Algorithm 1. In this algorithm, we have inputs such as a batch of data with size 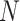 , constant
, constant 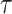 , encoder
, encoder 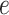 , projection head
, projection head 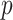 , and data augmentation module
, and data augmentation module 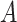 . Initially, we sample a mini-batch and do the two augmentations separately. After the data is augmented, we pass the augmented images into the encoder
. Initially, we sample a mini-batch and do the two augmentations separately. After the data is augmented, we pass the augmented images into the encoder 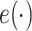 and projection head
and projection head 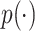 . After that, we do the pairwise similarity and calculate the loss function by updating the parameters of encoder
. After that, we do the pairwise similarity and calculate the loss function by updating the parameters of encoder 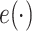 and projection head
and projection head 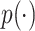 . Finally, we generate a well-trained encoder network
. Finally, we generate a well-trained encoder network 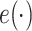 , then drop the projection head. We will use this well-trained encoder
, then drop the projection head. We will use this well-trained encoder 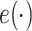 to generate the underlying data representations of the unlabeled dataset, then pass underlying knowledge into our UKMLP to do the proxy classification task. We will discuss the details of UKMLP in Section II-B.
to generate the underlying data representations of the unlabeled dataset, then pass underlying knowledge into our UKMLP to do the proxy classification task. We will discuss the details of UKMLP in Section II-B.
Algorithm 1: Algorithm of MedCLR.
INPUT: a batch of data with size
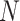 , constant
, constant 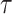 , encoder
, encoder 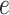 , projection head
, projection head 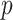 , data augmentation module
, data augmentation module 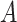
for sampled minibatch
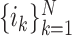 do
dofor all
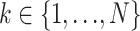 do
dodraw two augmentation functions
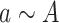 ,
, 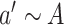
# the first augmentation
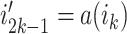 # augmentation
# augmentation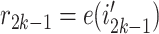 # representation
# representation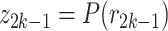 # projection
# projection# the second augmentation
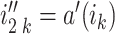 # augmentation
# augmentation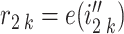 # representation
# representation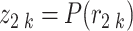 # projection
# projectionend for
for all
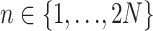 and
and 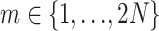 do
do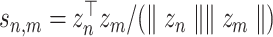 # pairwise similarity
# pairwise similarityend for
define
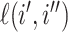 as
as 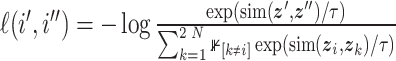
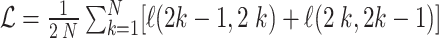
update networks
 and
and  to minimize
to minimize 
end for
return encoder network
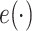 , and throw away projection head
, and throw away projection head 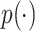
B. Underlying Knowledge Based Multi-Layer Perceptron Classifier (UKMLP)
The UKMLP aims to fine-tune the feature representation learned by the MedCLR by the limited labeled data. This process is similar to the transfer learning to fine-tune the last layer to obtain the results, but instead, we extend the traditional Multi-layer Perceptron classifier with deeper architecture, which includes 12 hidden layers, the first three layers contain 256 neurons, then connected with two layers with 512 neurons, followed by two layers with 1024 neurons, then the size of the two layers decreases to the 512, and finally, three layers with size 256 are connected. The overall architecture is described in Fig. 4. The architecture includes three parts, the input, hidden layers, and output layer. The input comes from well-trained MedCLR, then passing the underlying knowledge into the hidden layers. The number of neurons in the output layer varies to the classes of the dataset. For each hidden layer, it follows a rectified linear activation function (ReLU), as (12) shows. The output of the ReLU function is zero if the input 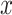 is lower than zero, and the value is the input value if the
is lower than zero, and the value is the input value if the 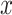 is larger than zero.
is larger than zero.
 |
Figure 4.
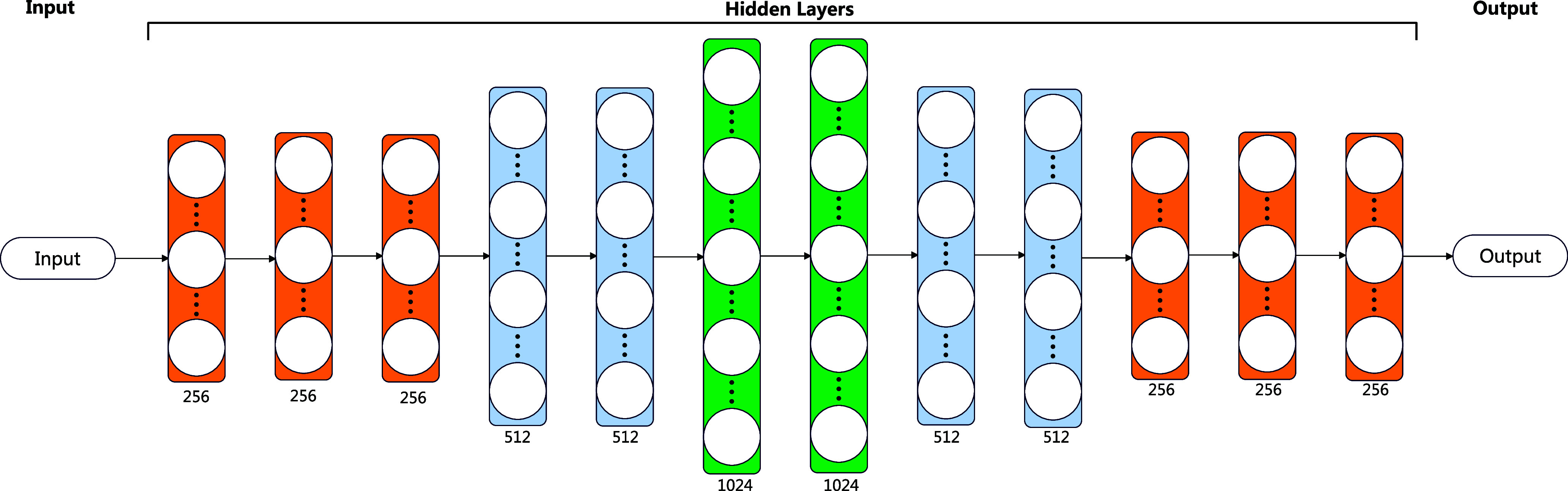
Architecture of the UKMLP. The input of UKMLP is the feature representation learned by the MedCLR, and the output is the classification result. As the figure shows, the layers with different colors represent different sizes of the layer: the orange layer contains 256 neurons, the blue layer contains 512 neurons, and the green layer contains 1024 neurons.
The loss function of UKMLP is multi-class entropy which is shown in (13), where 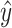 is a vector of predicted class probabilities for each of the
is a vector of predicted class probabilities for each of the 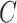 classes,
classes, 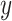 is a one-hot encoded vector of the true class label, and the
is a one-hot encoded vector of the true class label, and the 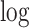 is the natural logarithm.
is the natural logarithm.
 |
C. Materials and Experimental Settings
We evaluate our framework on two different medical datasets: LC25000 (https://www.kaggle.com/datasets/andrewmvd/lung-and-colon-cancer-histopathological-images), and BCCD Dataset (https://github.com/Shenggan/BCCD_Dataset). The LC25000 dataset includes five types of lung and colon cancers: Lung benign tissue, Lung adenocarcinoma, Lung squamous cell carcinoma, Colon adenocarcinoma, and Colon benign tissue, in a total of 25000 images. The BCCD dataset contains four different types of blood cell, which are Eosinophil, Lymphocyte, Monocyte and Neutrophil, in total, 12500 images. To avoid data leakage, we initially split the entire dataset with 80% of the training dataset and 20% of the test dataset. Then the training dataset splits with different labeled ratios into two datasets: unlabeled training dataset and labeled training dataset. All the images on the test dataset have ground-truth labels. So the test dataset is yet to be seen by the UKSSL before evaluating the performance of UKSSL at the last stage.
We list the hyper-parameters of our experiments in Table 1, and we run our experiments with an NVIDIA TESLA P100 16 GB RAM GPU and a Xeon CPU with 13 GB RAM. The code is implemented in Keras [36] with scikit-learn [37].
TABLE 1. Hyper-Parameters of Experiment.
| Name | Value |
|---|---|
| image size |
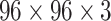
|
| epochs | 200 |
| batch size | 500 |
| temperature | 0.1 |
| patch size | 6 |
| projection dimension | 64 |
| input width of projection head | 128 |
III. Results and Discussion
The overall performance of our UKSSL is shown in Tables 2 and 3. In these tables, we present the performances of different datasets regarding different labeled ratios: 10%, 25%, and 50%. As Tables 2 and 3 show that our UKSSL gets a precision of 91.5%, a recall of 90.8%, an F1-score of 90.7%, and an accuracy of 90.6% if we only use 10% of the LC25000 dataset. By increasing the labeled ratio to 25%, the precision, recall, F1-score, and accuracy are 96.3%, 96.3%, 96.3%, and 96.3%, respectively. If the labeled ratio is 50%, the precision, recall, F1-score, and accuracy are 98.9%, 98.9%, 98.9%, and 98.9%, separately. We also test the performance of our method on the BCCD dataset, and it also gets good performance which shows in Table 3.
TABLE 2. Comparison With State-of-the-Art Methods on the LC25000 Dataset.
| Author | Method | labeled ratio | Precision | Recall | F1-score | Accuracy |
|---|---|---|---|---|---|---|
| Bukhari et al. [46] | RESNET50 | 100% | 95.74% | 81.82% | 96.26% | 93.91% |
| RESNET18 | 100% | 93.04% | 84.21% | 95.79% | 93.04% | |
| RESNET34 | 100% | 93.04% | 80.95% | 95.74% | 93.04% | |
| Phankokkruad [45] | Ensemble | 100% | 92% | 91% | 91% | 91% |
| ResNet50V2 | 100% | 91% | 90% | 90% | 90% | |
| Hlavcheva et al. [44] | CNN-D | 100% | - | - | - | 94.6% |
| Hatuwal and Thapa [43] | CNN | 100% | 97.33% | 97.33% | 97.33% | 97.2% |
| Mangal et al. [42] | Shallow-CNN | 100% | - | - | - | 97.89% |
| Masud et al. [47] | DL-based CNN | 100% | 96.39% | 96.37% | 96.38% | 96.33% |
| Ours | UKSSL | 10% | 91.5% | 90.8% | 90.7% | 90.6% |
| 25% | 96.3% | 96.3% | 96.3% | 96.3% | ||
| 50% | 98.9% | 98.9% | 98.9% | 98.9% |
TABLE 3. Comparison With State-of-the-Art Methods on the BCCD Dataset.
| Author | Method | labeled ratio | Precision | Recall | F1-score | Accuracy |
|---|---|---|---|---|---|---|
| Yao et al. [41] | TWO-DCNN | 100% | 91.6% | 91.6% | 91.6% | - |
| Edi Jaya et al. [40] | NM-BPNN | 100% | - | - | - | 73.4% |
| Li and Chen [39] | RF | 100% | - | - | 78% | 74.3% |
| Şengür et al. [38] | LSTM-based method | 100% | 62.36% | 68.25% | 64.74% | 92.89% |
| Ours | UKSSL | 10% | 70.1% | 67.7% | 66.3% | 69.1% |
| 25% | 87.3% | 86.8% | 86.5% | 86.2% | ||
| 50% | 94.3% | 94.5% | 94.3% | 94.1% |
We compare the performance of our methods with other state-of-the-art methods in Tables 2 and 3. As shown in Table 2, our method improves at least 1.57% of precision, recall, F1-score, and 1.01% of accuracy when compared with other state-of-the-art methods on the LC25000 dataset, and we only use 50% labeled data to achieve the best performance. If we only use 25% labeled data, it also gets a great performance with 96.3% of precision, recall, F1-score, and accuracy, respectively. In Table 3, we show the performance of our method on the BCCD dataset, and our method improves by at least 2.7% in precision, F1-score, 2.9% in recall, 1.21% in accuracy, and we only use 50% of labeled data to get the best performance compared with other existing methods.
Table 4 shows the ablation study of our UKSSL, the ablation study uses 50% labeled datasets, and there are significant improvements in accuracy after adding the UKMLP in our UKSSL, the accuracy improves by 5.34% on the LC25000 and 30.76% on the BCCD dataset. Compared with other state-of-the-art methods, we found that UKSSL-MedCLR trained with 50% labeled LC25000 gets an accuracy of 93.56%, which means that the feature obtained by the MedCLR without fine-tuning also can achieve great performance. In this setting, the accuracy is better than the RESNET18 and RESNET34 proposed by Bukhari et al. [46], also it is better than the Ensemble and ResNet50V2 designed by the Phankokkruad [45], although all these methods use 100% labeled data. If we add UKMLP, we find that the performance is better than all the methods mentioned in Table 2. For the BCCD dataset, the UKSSL-MedCLR trained with 50% labeled data does not get a great performance, but if we add the UKMLP, the overall performance also can achieve the best accuracy compared with other methods, as Table 3 shows. The different performances trained on these two datasets are related to the complexity of the feature map in each dataset, we can easily find that the overall performance of using the LC25000 dataset is better than the BCCD dataset, as demonstrated in Tables 2 and 3, respectively. So it is acceptable that the feature map extracted by the MedCLR on the BCCD dataset is not good as LC25000 dataset. But on the other hand, we find that the UKMLP indeed helps UKSSL to get better performance.
TABLE 4. Ablation Study of UKSSL.
| Dataset (50%) | UKSSL-MedCLR | UKSSL-UKMLP | Accuracy |
|---|---|---|---|
| LC25000 | ✓ | ✗ | 93.56% |
| ✓ | ✓ | 98.9% | |
| BCCD | ✓ | ✗ | 63.34% |
| ✓ | ✓ | 94.1% |
Although we reached outstanding performance on the different medical datasets compared with other state-of-the-art methods, there are still some challenges that need to solve. Firstly, since the data augmentation techniques are essential in both supervised and unsupervised representation learning methods [23], [24], most works consider them to define the contrastive prediction task by implementing the traditional augmented techniques. For example, our experiments use rescaling, random flipping, random translation, random zoom, and random color affine transformation. However, some traditional data augmentation techniques might not help models extract underlying knowledge from medical images. For example, some flipped medical images still look the same because the entire image with the same patterns. It is unlike the natural image, and flipping it will make huge differences compared with the original image. So it is important to use different data augmentation techniques, especially for medical images, such as contrast enhancement [22] and gamma correction [21]. Secondly, our methods highly rely on the effectiveness of data augmentation methods. Apart from designing contrastive prediction tasks by different augmented views, some works focus on modifying the model architecture, such as DIM [20] and AMDIM [19]. In the future, if the performance of our method is limited to the effectiveness of data augmentation methods, we can also try designing contrastive prediction tasks with model architectures. The last limitation of our method is computational power. Due to the limited computational power, our LTrans can only have one transformer layer, although it also can achieve good performance. At the same time, our batch size is limited to 500. We believe our framework can reach higher performance by simply expanding the size of the LTrans and other related parameters.
Our proposed UKSSL has the potential to make a significant impact in the clinical and healthcare domain. On the one hand, our method can involve different categorizations of medical images such as X-rays, CT scans, MRI scans, and histopathological slides into different classes, aiding in the diagnosis, prognosis, and treatment of different diseases. On the other hand, the proposed method can efficiently solve the annotation problems for medical images. Moreover, our method also applies to rare disease detection. Rare diseases only have limited data, making it much more difficult to train an accurate classifier. Our method applies to this situation by combining labeled data from common diseases and unlabeled data that may contain rare disease data. Then our proposed method can learn shared features across different diseases, enabling better detection of rare diseases.
IV. Conclusion
Supervised pre-training on the large dataset and fine-tuning medical image analysis has achieved great success. Our research investigates an alternative way that uses contrastive learning to pre-train on the unlabeled medical dataset and fine-tune it with the limited labeled dataset, which constructs a semi-supervised paradigm. The proposed UKSSL includes two components: MedCLR and UKMLP. The MedCLR can extract the underlying knowledge from the unlabeled dataset, and UKMLP will fine-tune with the limited labeled dataset to achieve excellent classification performance. We get the best performance by comparing it with other state-of-the-art methods when using a limited labeled dataset, and our performance is possibly further improved by increasing the number of parameters or the size of our UKSSL. In the future, we will evaluate our method with powerful computational power and apply different contrastive learning-based methods to extract underlying knowledge from the unlabeled dataset.
Funding Statement
This work was supported in part by MRC, U.K. under Grant MC_PC_17171, in part by Royal Society, U.K. under Grant RP202G0230, in part by BHF, U.K. under Grant AA/18/3/34220, in part by the Hope Foundation for Cancer Research, U.K. under Grant RM60G0680, in part by GCRF, U.K. under Grant P202PF11, in part by Sino-U.K. Industrial Fund, U.K. under Grant RP202G0289, in part by LIAS, U.K. under Grants P202ED10 and P202RE969, in part by Data Science Enhancement Fund, U.K. under Grant P202RE237, in part by Fight for Sight, U.K. under Grant 24NN201, in part by Sino-U.K. Education Fund, U.K. under Grant OP202006, and in part by BBSRC, U.K. under Grant RM32G0178B8.
Contributor Information
Zeyu Ren, Email: zr41@leicester.ac.uk.
Xiangyu Kong, Email: xk18@leicester.ac.uk.
Yudong Zhang, Email: yudong-zhang@ieee.org.
Shuihua Wang, Email: shuihuawang@ieee.org.
References
- [1].Chen X. and He K., “Exploring simple siamese representation learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 15750–15758. [Google Scholar]
- [2].Grill J. et al. , “Others bootstrap your own latent-a new approach to self-supervised learning,” in Proc. Annu. Conf. Neural Inf. Process. Syst., 2020, pp. 21271–21284. [Google Scholar]
- [3].Caron M., Misra I., Mairal J., Goyal P., Bojanowski P., and Joulin A., “Unsupervised learning of visual features by contrasting cluster assignments,” in Proc. Annu. Conf. Neural Inf. Process. Syst., 2020, pp. 9912–9924. [Google Scholar]
- [4].He K., Fan H., Wu Y., Xie S., and Girshick R., “Momentum contrast for unsupervised visual representation learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. 9729–9738. [Google Scholar]
- [5].Tian Y., Krishnan D., and Isola P., “Contrastive multiview coding,” in Proc. 16th Eur. Conf., 2020, pp. 776–794. [Google Scholar]
- [6].Oord A., Li Y., and Vinyals O., “Representation learning with contrastive predictive coding,” 2018, arXiv:1807.03748.
- [7].Wu Z., Xiong Y., Yu S., and Lin D., “Unsupervised feature learning via non-parametric instance discrimination,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 3733–3742. [Google Scholar]
- [8].Jaiswal A., Babu A., Zadeh M., Banerjee D., and Makedon F., “A survey on contrastive self-supervised learning,” Technologies, vol. 9, 2021, Art. no. 2. [Google Scholar]
- [9].Li J., Socher R., and Hoi S., “Dividemix: Learning with noisy labels as semi-supervised learning,” in Proc. Int. Conf. Learn. Representations, 2020. [Google Scholar]
- [10].Sohn K. et al. , “Fixmatch: Simplifying semi-supervised learning with consistency and confidence,” in Proc. Annu. Conf. Neural Inf. Process. Syst., 2020, pp. 596–608. [Google Scholar]
- [11].Xie Q., Luong M., Hovy E., and Le Q., “Self-training with noisy student improves imagenet classification,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. 10687–10698. [Google Scholar]
- [12].Li W., Meng W., and Au M., “Enhancing collaborative intrusion detection via disagreement-based semi-supervised learning in IoT environments,” J. Netw. Comput. Appl., vol. 161, 2020, Art. no. 102631. [Google Scholar]
- [13].Guan Y., Jahan T., and Kaick O., “Generalized autoencoder for volumetric shape generation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops, 2020, pp. 268–269. [Google Scholar]
- [14].Wang D., Cui P., and Zhu W., “Structural deep network embedding,” in Proc. 22nd ACM SIGKDD Int. Conf. Knowl. Discov. Data Mining, 2016, pp. 1225–1234. [Google Scholar]
- [15].Miyato T., Maeda S. I., Koyama M., and Ishii S., “Virtual adversarial training: A regularization method for supervised and semi-supervised learning,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 8, pp. 1979–1993, Aug. 2019. [DOI] [PubMed] [Google Scholar]
- [16].Tarvainen A. and Valpola H., “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,” in Proc. Annu. Conf. Neural Inf. Process. Syst., 2017, pp. 1195–1204. [Google Scholar]
- [17].Ren Z., Zhang Y., and Wang S., “LCDAE: Data augmented ensemble framework for lung cancer classification,” Technol. Cancer Res. Treat., vol. 21, 2022, Art. no. 15330338221124372. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Ren Z., Zhang Y., and Wang S. A., “Hybrid framework for lung cancer classification,” Electronics, vol. 11, 2022, Art. no. 1614. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Bachman P., Hjelm R., and Buchwalter W., “Learning representations by maximizing mutual information across views,” in Proc. Annu. Conf. Neural Inf. Process. Syst., 2019, pp. 15509–15519. [Google Scholar]
- [20].Hjelm R. et al. , “Learning deep representations by mutual information estimation and maximization,” in Proc. Int. Conf. Learn. Representations, 2019. [Google Scholar]
- [21].Anwar S., Majid M., Qayyum A., Awais M., Alnowami M., and Khan M., “Medical image analysis using convolutional neural networks: A review,” J. Med. Syst., vol. 42, 2018, Art. no. 226. [DOI] [PubMed] [Google Scholar]
- [22].Patel P. and Bhandari A. A., “Review on image contrast enhancement techniques,” Int. J. Online Sci., vol. 5, pp. 14–18, 2019. [Google Scholar]
- [23].Henaff O., “Data-efficient image recognition with contrastive predictive coding,” in Proc. Int. Conf. Mach. Learn., 2020, pp. 4182–4192. [Google Scholar]
- [24].Krizhevsky A., Sutskever I., and Hinton G., “ImageNet classification with deep convolutional neural networks,” Commun. ACM, vol. 60, pp. 84–90, 2017. [Google Scholar]
- [25].Chapelle O., Scholkopf B., and Zien A., “Semi-supervised learning (Chapelle, O. et al., Eds.; 2006) [Book reviews],” IEEE Trans. Neural Netw., vol. 20, no. 3, pp. 542–542, Mar. 2009. [Google Scholar]
- [26].Dietterich T., Lathrop R., and Lozano-Pérez T., “Solving the multiple instance problem with axis-parallel rectangles,” Artif. Intell., vol. 89, pp. 31–71, 1997. [Google Scholar]
- [27].Chen T., Kornblith S., Swersky K., Norouzi M., and Hinton G., “Big self-supervised models are strong semi-supervised learners,” in Proc. Annu. Conf. Neural Inf. Process. Syst., 2020, pp. 22243–22255. [Google Scholar]
- [28].Chen T., Kornblith S., Norouzi M., and Hinton G., “A simple framework for contrastive learning of visual representations,” in Proc. Int. Conf. Mach. Learn., 2020, pp. 1597–1607. [Google Scholar]
- [29].Becker S. and Hinton G., “Self-organizing neural network that discovers surfaces in random-dot stereograms,” Nature, vol. 355, pp. 161–163, 1992. [DOI] [PubMed] [Google Scholar]
- [30].Sohn K., “Improved deep metric learning with multi-class N-pair loss objective,” in Proc. Annu. Conf. Neural Inf. Process. Syst., 2016, pp. 1849–1857. [Google Scholar]
- [31].Vaswani A. et al. , “Attention is all you need,” in Proc. Annu. Conf. Neural Inf. Process. Syst., 2017, pp. 5998–6008. [Google Scholar]
- [32].Dosovitskiy A. et al. , “An image is worth 16x16 words: Transformers for image recognition at scale,” in Proc. Int. Conf. Learn. Representations, 2021. [Google Scholar]
- [33].Devlin J., Chang M., Lee K., and Toutanova K., “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. Conf. North Amer. Chapter Assoc. Comput. Linguistics-Hum. Lang. Technol., 2019, pp. 4171–4186. [Google Scholar]
- [34].Rumelhart D., Hinton G., and Williams R., “Learning internal representations by error propagation,” DTIC Document, Tech. Rep, 1985.
- [35].He K., Zhang X., Ren S., and Sun J., “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778. [Google Scholar]
- [36].Chollet F. et al. , “Keras,” GitHub, 2015. [Online]. Available: https://github.com/fchollet/keras
- [37].Pedregosa F. et al. , “Scikit-learn: Machine learning in Python,” J. Mach. Learn. Res., vol. 12 pp. 2825–2830, 2011. [Google Scholar]
- [38].Şengür A., Akbulut Y., Budak Ü., and Cömert Z., “White blood cell classification based on shape and deep features,” in Proc. IEEE Int. Artif. Intell. Data Process. Symp., 2019, pp. 1–4. [Google Scholar]
- [39].Li Y. and Chen Z., “Performance evaluation of machine learning methods for breast cancer prediction,” Appl. Comput. Math., vol. 7, pp. 212–216, 2018. [Google Scholar]
- [40].Kusuma E., Shidik G., and Pramunendar R., “Optimization of neural network using Nelder Mead in breast cancer classification,” Int. J. Intell. Eng. Syst., vol. 13, pp. 330–337, 2020. [Google Scholar]
- [41].Yao X., Sun K., Bu X., Zhao C., and Jin Y., “Classification of white blood cells using weighted optimized deformable convolutional neural networks,” Artif. Cells Nanomedicine, Biotechnol., vol. 49, pp. 147–155, 2021. [DOI] [PubMed] [Google Scholar]
- [42].Mangal S., Chaurasia A., and Khajanchi A., “Convolution neural networks for diagnosing colon and lung cancer histopathological images,” 2020, arXiv:2009.03878.
- [43].Hatuwal B. and Thapa H., “Lung cancer detection using convolutional neural network on histopathological images,” Int. J. Comput. Trends Technol., vol. 68, pp. 21–24, 2020. [Google Scholar]
- [44].Hlavcheva D., Yaloveha V., Podorozhniak A., and Kuchuk H., “Comparison of CNNs for lung biopsy images classification,” in Proc. IEEE 3rd Ukraine Conf. Elect. Comput. Eng., 2021, pp. 1–5. [Google Scholar]
- [45].Phankokkruad M., “Ensemble transfer learning for lung cancer detection,” in Proc. 4th Int. Conf. Data Sci. Inf. Technol., 2021, pp. 438–442. [Google Scholar]
- [46].Bukhari S., Asmara S., Bokhari S., Hussain S., Armaghan S., and Shah S., “The histological diagnosis of colonic adenocarcinoma by applying partial self supervised learning,” MedRxiv, vol. 2020, pp. 1–11, 2020. [Google Scholar]
- [47].Masud M., Sikder N., Nahid A., Bairagi A., and AlZain M., “A machine learning approach to diagnosing lung and colon cancer using a deep learning-based classification framework,” Sensors, vol. 21, 2021, Art. no. 748. [DOI] [PMC free article] [PubMed] [Google Scholar]