

Abstract
Searching for a related article based on a reference article is an integral part of scientific research. PubMed, like many academic search engines, has a “similar articles” feature that recommends articles relevant to the current article viewed by a user. Explaining recommended items can be of great utility to users, particularly in the literature search process. With more than a million biomedical papers being published each year, explaining the recommended similar articles would facilitate researchers and clinicians in searching for related articles. Nonetheless, the majority of current literature recommendation systems lack explanations for their suggestions. We employ a post hoc approach to explaining recommendations by identifying relevant tokens in the titles of similar articles. Our major contribution is building PubCLogs by repurposing 5.6 million pairs of coclicked articles from PubMed’s user query logs. Using our PubCLogs dataset, we train the Highlight Similar Article Title (HSAT), a transformer-based model designed to select the most relevant parts of the title of a similar article, based on the title and abstract of a seed article. HSAT demonstrates strong performance in our empirical evaluations, achieving an F1 score of 91.72 percent on the PubCLogs test set, considerably outperforming several baselines including BM25 (70.62), MPNet (67.11), MedCPT (62.22), GPT-3.5 (46.00), and GPT-4 (64.89). Additional evaluations on a separate, manually annotated test set further verifies HSAT’s performance. Moreover, participants of our user study indicate a preference for HSAT, due to its superior balance between conciseness and comprehensiveness. Our study suggests that repurposing user query logs of academic search engines can be a promising way to train state-of-the-art models for explaining literature recommendation.
Keywords: Literature Search, Recommendation, Explainability, Query Logs
1. INTRODUCTION
Much of the knowledge gathered through biomedical research is solely accessible via literature [2]. Literature search, the process of finding scientific articles, is crucial in both patient care and biomedical research [11, 13, 18, 37]. However, millions of papers are published each year, making effective literature search increasingly challenging. For example, PubMed1, an academic search engine primarily for biomedical literature, indexes about 36 million articles and adds more than a million yearly.
There are numerous ways to conduct literature search. In addition to the usual query-based searches, a commonly employed approach in literature search is seeking “similar articles” based on a reference, or a “seed article.” On literature search engines such as PubMed, an article page might display a “similar articles” section, where titles and links to papers that the user might also be interested in are shown. Based on observations of PubMed user behavior, it is clear that similar articles play a major role in many researchers’ information seeking process [22]. Users often express a desire to explore other papers related to the same or closely related topics when they come across an article of interest. Essentially, they seek relevant related documents they might not have initially known to search for.
To meet this user need, for each retrieved article, PubMed displays the top five most closely related articles based on content similarity, with the option to see the full list of similar articles, which might be hundreds of articles long. By following links of the recommended similar articles, users can further explore the literature, based on their initial seed articles. This feature has not only demonstrated its effectiveness for information seeking but also stands as an integral part of how users interact with PubMed [22]. Furthermore, the same study reveals that once users initiate the exploration of related articles, they tend to persist in this activity, accounting for more than forty percent of their interactions. This surpasses the selection of new articles or the initiation of new queries, highlighting the significance of similar article recommendations [12].
Given the importance of similar articles in literature search, users naturally would want to see the explanations of similar article recommendations. Inevitably, users need to manually sort through each recommended similar article in order to find articles that fit their needs. Providing explanations as to the ways each particular similar article is relevant to the seed article would greatly facilitate this process, and thus speed up literature search. Articles are recommended for a variety of different reasons, and since users have diverse information needs – for example, one might only be interested in a certain topic, or type of similarity – explaining the recommendations becomes paramount for efficient literature search [17, 42].
One major barrier to providing explanations in academic search engines is data availability. Training a modern NLP model requires large-scale datasets, and to our knowledge, there has not been any such dataset for selecting relevant tokens in similar article titles. To tackle this issue, we utilize the user intelligence from PubMed search logs [9, 12] to build PubCLogs, a dataset for training and evaluating models for similar article recommendation explanations. We utilize article coclicks as summarized in Figure 2. We first obtain user coclick data spanning years from 2020 to 2023. The original search logs record a search of a user in a session. We pair up coclicked articles as seed and similar articles. Each pair of articles is linked to a list of corresponding queries that led to the coclicks, and each query’s click counts. Using the coclick counts, we select the top queried title tokens to act as the ground truth for each document pair. Our initial collection includes 5.6M such pairs. After filtering, we end up with 1.5M instances for the train set, 47k for the development set, and 47k for the test set.
Figure 2:

Overview of our novel method to utilize PubMed user query logs for building our dataset, PubCLogs. When a user issues a query and clicks on an article from the initial search results, then views the title and abstract of the clicked article, returns to the search page, and subsequently clicks on another article, we hypothesize that the coclicked articles are likely related, as the user chose the second article after reviewing the content of the first. Thus, pairs of coclicked articles form the foundation for constructing PubCLogs.
Given the importance and challenge of similar article recommendation explanation, in this work, we formulate the explanation task as selecting relevant tokens in the similar article title, given the title and abstract of a seed article. Figure 1 shows our model for the task. We train a transformer-based sequence tagging model, Highlight Similar Article Title (HSAT), using the PubCLogs dataset we construct with article coclicks from PubMed user query logs[36]. We show that it vastly outperforms common baselines such as BM25 [31] and SBERT [35], as well as GPT-3.5 [24] and GPT-4 [25] on independent holdout test set portion of PubCLogs.
Figure 1:

Outline of our model, Highlight Similar Article Title (HSAT). Given the title and abstract of a seed article, and the title of a “similar article,” HSAT selects the most relevant tokens in the similar article title to be highlighted.
On the test set, HSAT achieves a F1 of 91.72 percent, outperforming baselines such as BM25 (70.62), MPNet (67.11), MedCPT (62.22), GPT-3.5 (46.00), and GPT-4 (64.89). We also create a smaller, human-annotated test set to further verify our results. On the manually annotated test set, HSAT achieves a F1 of 80.62, again outscoring models such as BM25 (57.21), Word2Vec (54.81), GPT-3.5 (42.06), and GPT-4 (68.31). Our evaluation also includes case studies and user studies. Our A/B user studies show that our two annotators prefer HSAT outputs over GPT-4 outputs, 55 to 38 and 59 to 31. Our evaluations indicate the utility of our PubCLogs dataset, which we demonstrate by training HSAT with a binary sequence tagging objective that outperforms common baselines. HSAT performance suggests that utilizing user query logs is a promising approach to explaining article recommendations.
In summary, our contributions are three-fold:
We formulate the task of explaining similar article recommendations as selecting tokens in the similar article title that are the most relevant in relation to the seed article.
We construct a dataset, PubCLogs, using a novel method to repurpose the user search logs. We consider coclicked articles as seed and similar article pairs, and utilize queries that correspond to the coclicks to build the ground truth of relevant tokens in the similar article title.
Utilizing the PubCLogs dataset, we train Highlight Similar Article Title (HSAT), our transformer-based model, on a sequence tagging objective. HSAT outperforms baseline comparisons such as BM25, Word2Vec, GPT-3.5, and GPT-4 on our evaluations, which consist of the holdout test set of PubCLogs, a separate manually labeled test set, and a user preference study.
2. RELATED WORK
2.1. Post hoc model of explainability
There are two major approaches to recommendation explanation: one can seek explainability in the recommendation methods or the results [42]. The model-intrinsic approach aims to develop interpretable models that naturally lend themselves to enhanced transparency and explainability [43]. In contrast, the model-agnostic, or “post hoc,” approach aims to provide explanations independently from the model that created the recommendations [27, 34]. Since the explaining model and the recommending models are separate, the recommender system need not be interpretable, which offers more flexibility in model development given the black-box nature of many modern deep learning models [15]. Though explainability and interpretability are frequently conflated, the post hoc approach illustrates that interpretability is but an approach to explainability [1].
2.2. Production academic search engines
Despite the clear utility of explaining recommendations to users, most academic search engines are not sufficiently explainable. In its “related articles” section, Semantic Scholar2 provides short summary snippets of each article called “TLDR” [5]. However, as of January 2024, it does not highlight any key words in the title or TLDR of each recommended similar article, which means users have to read the entire TLDR, which can be relatively more time-consuming. Likewise, while Google Scholar3 does provide the first few lines of the abstract for its related articles, it does not do any highlighting or further annotations. Similarly, PubMed does not bold or highlight any part of the similar articles’ titles in its similar articles section [3]. We argue that highlighting relevant words in the similar article title is a practical and effective first step towards article recommendation explanations.
2.3. Sequence tagging
We initially considered training with an extractive QA task, where the “question” would be the context, i.e., the title and abstract of the seed article, and the “answer” would be the parts of the similar article title to be highlighted. But we ultimately choose sequence tagging because since the tokens to be highlighted would often not be contiguous, our task more closely resembles a multi-span extractive QA task. In most preexisting extractive QA benchmarks such as SQuAD [29], SQuAD2.0 [28], QuAC [6], and HotpotQA [40], models are to return a single, contiguous span of answer from each given context.
Multi-span extractive QA models can be more complicated to implement than their single-span counterparts, but as Setal et al. [33] show, a simple way to implement multi-span extraction is by treating it as a sequence tagging task. In the more recent MultiSpanQA benchmark [20], the sequence tagging approach vastly outperforms single span models as expected. Despite the simplicity, sequence tagging achieves SoTA results on span-extraction questions from DROP [10] and QuoREF [7]. The sequence tagging approach only requires finetuning one encoder model. Thus, we consider the sequence tagging approach a good balance between performance and simplicity in implementation.
3. METHOD
In this section, we will outline the preprocessing of user query logs and the construction of PubCLogs, our dataset, as well as the training process of our model, HSAT.
3.1. Building PubCLogs
Preprocessing.
Figure 3 summarizes our overall process for data collection and dataset construction. In building PubCLogs from PubMed user query logs, our key insight is in the interpretation of coclicked articles as pairs of seed and similar articles, a concept depicted in Figure 2. We start with user coclick data spanning the years 2020 to 2023. The data logs each user’s search within a session. Specifically, when a user executes a query and selects two or more articles from the results page, this action is recognized as a coclick instance for the article pair, e.g., the PMID of a seed article (PMID1) and the PMID of a similar article (PMID2), where PMID1 is the article that appears higher in the results page. PMID1 would be considered to be the “seed article” and PMID2 is treated as the “similar article.” In our starting material, each pair of articles, PMID1-PMID2, is linked to a dictionary of queries and their corresponding click counts, where the number of clicks is shown for each unique query. For each coclick instance, we then increment the coclick count corresponding to a unique query that retrieved the PMID pair.
Figure 3:

Overview of the PubCLogs dataset construction process: for each coclicked article pair, the initial article represents the seed article, and the related article clicked subsequently represents the similar article. For each token in the title of the similar article, we aggregate the number of coclicks from queries that included the title token. We apply a softmax function to these click counts and establish a predefined threshold, P, to identify the most frequently queried similar article title tokens, which are then used as the ground truth labels for the PMID pair.
From there, we tokenize the queries using the standard NLTK tokenizer [4]. Each token in the query is multiplied by the click count for the query. And we combine the coclick counts for each unique token in the list of queries to get a combined dictionary that links each unique token to the total coclick count, for each unique pair PMID1-PMID2. We apply softmax to the click counts and use a threshold to select the top queried title tokens to act as the ground truth for the document pair. The resulting PubCLogs entry is a set of unique tokens in the similar article title corresponding to each seed and similar article pairs. Our initial collection includes 5.6M article pair entries. We then filter out entries with less than 20 combined clicks, article titles less than seven tokens long, and less than 3 title tokens with nonzero click counts to reduce the noisy long tail.
Dataset analysis.
After preprocessing and filtering, 1.5M article pair entries remain for the train set, 47k for the development set, and 47k for the test set. The average title length is 17.5 tokens.
Our dataset before filtering for combined clicks is 4.3GB. When we filter for instances with over 20 combined clicks, it is 1.2GB, 300MB for 50 clicks, and 100MB for 100 clicks, so we see that click counts follow a power law.
3.2. Training HSAT
Setup.
We initialize a BERT-based model with PubMedBERT weights [14] and train it on a sequence tagging task using PubCLogs. We use Pytorch [26] and Hugging Face Transformer libraries [38] for training and inference, and train with Adam [19]. We use two labels for sequence tagging: 0 for nonrelevant title tokens and the context, i.e. the title and abstracts for the seed article; and 1 for relevant title tokens, i.e. tokens to be highlighted. After a grid search of and , we choose a learning rate of 5e-5 and of 0.9 for the Adam optimizer. We find that a cosine learning rate scheduler with warm up performs better than a linear one. We use a cosine learning rate scheduler with 20k warm up steps and train for 10 epochs without decay. The batch size 64. We otherwise use the Pytorch and Adam default hyperparameters for finetuning BERT. Training takes about 70 hours on two Nvidia Tesla V100-SXM2 32GB GPUs. On the development set, we find that the best performing checkpoint is one at 180,000 training steps. This checkpoint is the HSAT model that we refer to throughout this work, including in evaluations.
For inputs to our model, we use the abstract and title of the seed article, the title of the similar article, and similar article tokens to be highlighted. We tokenize all with the PubMedBERT tokenizer before concatenating them. HSAT inputs are formatted like so:
denotes the tokenized seed article title, denotes the tokenized seed article abstract, and denotes the tokenized similar article title. For the similar article, we choose to only use the title because of the length limit on BERT architectures, and to better simulate users’ behavior when they encounter similar articles, since only the titles are displayed on the search engine due to space constraints.
We noticed a more than a 10 percent points absolute increase in F1 after adding segment embeddings to better differentiate between the seed and similar articles in the concatenated inputs. Since we start with PubMedBERT, we also train a linear classifier in order to convert each token embedding into labels, relevant or nonrelevant. We take the last hidden state of HSAT, and use the trained linear classifier to label each similar title token.
Inference.
For inference, the model outputs binary labels, given concatenated tokens of PMID1 abstract and title and PMID2 title. We match the tokens with labels, and tokens with “1” are tokens to be predicted. Each model output is thus a subset of the tokenized title of the similar article. Moreover, because HSAT outputs are based on the PubMedBERT tokenizer, the tokenization of the same similar article titles will be different from the other baseline models, which is fed input tokenized by NLTK tokenizer [4]. Thus, we apply postprocessing to convert title tokens tokenized by BERT into NLTK-style tokens. We must also distinguish title and token level inference, which is shown well in Table 1. In token-level inference, we stop after the postprocessing. For title-level inference, we match all tokens in the similar article title that match each token in our predicted output set.
Table 1:
Results of evaluations on our test dataset. We compare standard baseline models versus our model, Highlight Similar Article Title (HSAT). We differentiate token-level and title-level metrics because titles can contain multiple instances of unique tokens. Best performances are bolded. L refers to the average length of predicted outputs, in terms of tokens.
| Model | PubCLogs Test Set | Manually Annotated Test Set | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||||||
| Token-level | Title-level | Token-level | Title-level | |||||||||||
|
| ||||||||||||||
| R | P | F1 | R | P | F1 | L | R | P | F1 | R | P | F1 | L | |
|
| ||||||||||||||
| HighlightAll | 100.0 | 21.45 | 35.32 | 100.0 | 21.45 | 35.05 | 17.5 | 100.0 | 21.49 | 35.35 | 100.0 | 21.49 | 35.10 | 17.5 |
| Overlapper | 61.91 | 24.71 | 35.32 | 59.43 | 24.27 | 34.47 | 9.2 | 67.75 | 25.04 | 36.57 | 65.01 | 24.27 | 35.35 | 9.8 |
| BM25 [31] | 67.28 | 74.30 | 70.62 | 64.56 | 71.29 | 67.76 | 3.2 | 55.53 | 59.00 | 57.21 | 53.43 | 56.13 | 54.75 | 3.2 |
|
| ||||||||||||||
| Word2Vec [23] | 48.57 | 52.26 | 50.35 | 46.51 | 50.09 | 48.23 | 3.2 | 55.65 | 54.00 | 54.81 | 53.33 | 51.08 | 52.18 | 3.2 |
| BioWord2Vec [41] | 39.06 | 41.78 | 40.37 | 37.45 | 40.10 | 38.73 | 3.2 | 50.50 | 49.00 | 49.74 | 48.68 | 47.08 | 47.87 | 3.2 |
| MPNet [35] | 64.83 | 69.56 | 67.11 | 62.27 | 66.76 | 64.43 | 3.2 | 73.78 | 74.33 | 74.06 | 70.90 | 70.48 | 70.69 | 3.2 |
| MedCPT [16] | 60.01 | 64.59 | 62.22 | 57.68 | 61.08 | 59.33 | 3.3 | 59.52 | 61.67 | 60.57 | 57.13 | 57.28 | 57.20 | 3.4 |
|
| ||||||||||||||
| GPT-3.5-turbo [24] | 51.75 | 41.40 | 46.00 | 49.50 | 42.43 | 45.69 | 3.8 | 47.08 | 38.00 | 42.06 | 45.26 | 41.05 | 43.05 | 3.5 |
| GPT-4 [25] | 75.68 | 56.79 | 64.89 | 72.59 | 58.25 | 64.63 | 4.4 | 80.47 | 60.49 | 69.06 | 77.05 | 59.57 | 67.19 | 4.3 |
|
| ||||||||||||||
| HSAT (ours) | 91.50 | 92.15 | 91.83 | 87.77 | 88.69 | 88.23 | 3.6 | 79.97 | 81.28 | 80.62 | 76.34 | 78.56 | 77.44 | 3.4 |
4. EVALUATION
We evaluate HSAT on the test set of PubCLogs and a manually annotated test set (“manual set”). We also conduct user studies to further confirm that users prefer HSAT outputs over those from GPT-4.
4.1. Baselines
We compare the performance of our HSAT model with the following baselines: HighlightAll, Overlapper, BM25, Word2Vec, BioWord2Vec, MPNet, and MedCPT. The results on the PubCLogs test set are shown in Table 1. HighlightAll and Overlapper are the trivial baselines. HighlightAll selects all possible tokens, hence the recall of 100% and low precision. Overlapper selects all similar article title tokens that are also in the seed article title. BM25 is implemented following the standard equation [31]. We opt not to use any single-span extractive QA models because as the MultiSpanQA evaluations [20] show, single-span models are greatly outperformed by the sequence tagging baseline, sometimes by over 40 F1 points.
Here we give more details on the implementations of our baselines. There were no straightforward ways to implement baselines. For the most “accurate” comparisons, we would ideally consider token binary classification models. However, most sequence tagging models follow the common <monospace>BIO</monospace> scheme, which is not suitable for our use case. For example, <monospace>biomedical-ner</monospace> is a BERT-based sequence tagging model that recognizes biomedical entities such as biological structures and symptoms [30]. Since our goal is to select tokens based on their relevance with respect to a span, rather than labeling each token, <monospace>biomedical-ner</monospace> would not be suitable to serve as a baseline for our task.
Thus, we end up implementing the following baselines – with the exception of HighlightAll and Overlapper – by calculating the relevance scores for each token in similar article title, ranking them by the relevance score, and choosing the top 3 similar article title tokens. Calculating the relevance score for each baseline depends on whether the model is more suited to process tokens or spans. We directly compute the relevance between a token and the entire span of seed article title when the model is designed to process a span, such as BM25, MPNet, and MedCPT. We denote the seed article title as , where . The similar article title is , where . We can represent the similarity score of a similar article token and the seed title as:
But for models that only work best at token-level, such as Word2Vec and BioWord2Vec, we can compute the relevance score of a similar article token by:
The metrics mentioned above are assuming token-level evaluation. Table 1 contains both token-level and title-level evaluations. The only difference between them is that title-level accounts for duplicate tokens in titles.
HighlightAll.
As the name indicates, this baseline simply selects every token of similar article title as relevant. As expected, it achieves a recall of 100 but has low precision.
Overlapper.
Here, we select all tokens in similar article title that are also in seed article title. We use a list of stopwords and an index of inverse document frequency to filter out some tokens. This is a decent commonsense baseline because any token that is also present in seed article title is bound to be relevant, but it inevitably cannot perform semantic matching.
BM25.
We implement BM25 using a standard formula [31], with a of 0.5 and of 0.3.
Word2Vec and BioWord2Vec.
The Word2Vec model is implemented using implementations from FastText [23]. The BioWord2Vec model [41] we use is from the NCBI and trained on PubMed and MIMIC-III clinical notes.
MPNet.
MPNet [35] is a model designed to overcome the drawbacks of BERT [8] and XLNet [39]. The masked language modeling objective has the drawback of the pretrain-finetune descrepancy, since the trained model will likely not encounter artificial tokens such as [MASK]. XLNet addresses these pitfalls with an autoregressive permutation language modeling objective. MPNet improves on both BERT and XLNet by introducing the masked and permuted language modeling objective. We use the MPNet model from the Sentence-Transformers library [35].
MedCPT.
The MedCPT retriever is implemented using a bi-encoder architecture comprised of a query encoder and a document encoder. The bi-encoder was designed to calculate the relevance of a document to a query by computing the cosine similarity of embeddings from the respective encoders. Here, we adapt it to our use case by using the query encoder to encode and the document encoder to encode , since the query encoder is designed for shorter inputs and the document encoder is designed for longer inputs.
GPT-3.5 and GPT-4.
We use the OpenAI API to conduct experiments with GPT-3.5 (<monospace>gpt-3.5-turbo</monospace>) and GPT-4 (<monospace>gpt-4</monospace>), through Microsoft Azure’s OpenAI services. Inference temperature is set to 0 so that the outputs are as deterministic as possible. The GPT models are given the title and abstract of the seed article and the title of the similar article and asked to return the top 4 most relevant tokens from the similar article title, based on the seed article.
An interesting problem is deciding the cutoff point of the ranked list of to include as the relevant tokens to highlight. We experiment with two major methods: using softmax and threshold P, and selecting the top K tokens. Softmax yields slightly better results, but only after additional manually hardcoding. For example, if 7 tokens pass the threshold, and the length of similar article title is 10 tokens, then we only take the top 4 tokens. That is because even after the Softmax, the scores generated from baseline models are not sufficiently differentiable, so a threshold either selects too many or too few tokens most of the time. Thus, we opt to go with top K tokens to implement our baselines – top 3 for most baseline models and top 4 for GPT-3 and GPT-4.
4.2. Manually annotated test set
In order to further verify our evaluation results on PubCLogs, we create a separate manually annotated test set of 100 samples. From the top 1000 most highly clicked articles from our search logs, we randomly choose 20 articles to act as our seed articles. For each of those 20, we use NCBI Entrez Programming Utilities (E-Utilities) [32] to retrieve the top 20 similar articles, from which we randomly select five. Our annotator labels the 100 seed and similar article pairs by selecting the most relevant tokens from the similar article title. The righthand side of Table 1 shows our results on the manual set. The results, similarly to PubCLogs results, indicate that HSAT indeed outperforms all the baseline models evaluated.
4.3. Results
We choose standard metrics for evaluation: recall, precision, and F1. For each instance in the test set, i.e. the title and abstract of a seed article and the title of a corresponding similar article, there is a list of tokens to be highlighted (“true tokens”). Each baseline model and our model, HSAT, outputs a list of tokens to be highlighted (“predicted tokens”). When calculating our metrics, relevant elements are the true tokens and the retrieved elements are the predicted tokens.
Table 1 shows the main evaluation results on our test dataset, which is a holdout set from our dataset, PubCLogs, constructed from PubMed coclick user logs. Table 2 is our evaluation on a manually labeled test set. In Table 1, HighlightAll performs best on recall as expected. The precision is around 21, indicating that PubCLogs’s ground truth deems about one-fifth of all title tokens as relevant. The ideal percentage of relevant tokens is subjective, of course, but we choose a relatively lower number to focus users’ attention on the most important and relevant topics the recommendations represent. The Overlapper is our commonsense baseline, since we would naturally expect that words that appear in both seed and similar article titles would be the ones on the mutually shared topics. Both HighlightAll and Overlapper have a F1 of 35. BM25 [31] performs relatively well, at a precision of 74.30 and F1 of 70.62. As many recent studies continue to show, BM25 remains a strong baseline for many retrieval and NLP tasks, including article recommendation explanation [21].
Table 2:
Evaluations on subsets of the PubCLogs test set. Subsets are grouped by combined coclick counts of article pairs. We compare standard baseline models versus Highlight Similar Article Title (HSAT).
| Top 0.1% | Top third | Middle third | Bottom third | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
||||||||||||
| Model | R | P | F1 | R | P | F1 | R | P | F1 | R | P | F1 |
|
| ||||||||||||
| HighlightAll | 100.0 | 24.37 | 39.19 | 100.0 | 21.88 | 35.90 | 100.0 | 22.06 | 36.15 | 100.00 | 20.40 | 33.88 |
| Overlapper | 69.65 | 33.47 | 45.21 | 63.75 | 25.75 | 36.68 | 61.73 | 25.00 | 35.59 | 60.23 | 23.37 | 33.68 |
| BM25 [31] | 69.57 | 61.70 | 65.40 | 69.79 | 70.26 | 70.02 | 69.04 | 75.55 | 72.14 | 63.00 | 77.11 | 69.34 |
|
| ||||||||||||
| Word2Vec [23] | 67.84 | 56.03 | 61.37 | 54.56 | 53.56 | 54.06 | 50.39 | 54.27 | 52.26 | 40.72 | 48.94 | 44.45 |
| BioWord2Vec [41] | 62.09 | 51.77 | 56.47 | 43.88 | 42.67 | 43.27 | 40.28 | 43.07 | 41.63 | 32.99 | 39.60 | 36.00 |
| MPNet [35] | 83.16 | 68.09 | 74.87 | 71.62 | 69.56 | 70.58 | 66.18 | 70.90 | 68.46 | 56.68 | 68.20 | 61.91 |
| MedCPT [16] | 72.62 | 58.87 | 65.02 | 65.69 | 64.00 | 64.83 | 61.34 | 65.92 | 63.54 | 52.98 | 63.86 | 57.91 |
|
| ||||||||||||
| GPT-3.5 [24] | 51.38 | 35.46 | 41.96 | 56.71 | 41.53 | 47.95 | 53.73 | 42.89 | 47.70 | 44.80 | 39.76 | 42.13 |
| GPT-4 [25] | 87.13 | 55.11 | 67.51 | 80.05 | 56.27 | 66.08 | 77.44 | 58.62 | 66.73 | 69.54 | 55.48 | 61.72 |
|
| ||||||||||||
| HSAT (ours) | 97.62 | 97.48 | 97.55 | 92.57 | 93.12 | 92.84 | 92.18 | 93.09 | 92.64 | 89.38 | 90.34 | 89.86 |
Interestingly, for N-gram models such as Word2Vec [23], the general-purpose Word2Vec outperforms BioWord2Vec [41], at F1 of 50.35 versus 40.37. However, since these models were not explicitly trained for this task, we can expect some noise and variance in evaluation, especially since they both perform worse than BM25. The MPNet [35] and MedCPT [16] fare much better, at F1 of 67.11 and 62.22.
Our most sophisticated baselines are the two GPT models from OpenAI, GPT-3.5 [24] and GPT-4 [25]. Although over many magnitudes larger in size and inference cost compared to HSAT, GPT-3.5 does quite poorly, with a F1 of 46.00. GPT-4 does much better, at 64.89, but still underperforms BM25 by over 5.73 percentage points. Interestingly, although prompted to only return the top 4 most relevant tokens, GPT-4 sometimes returns over 5 tokens, which is why the recall is pretty high at 75.68. And due to the excessive number of selected tokens, the precision is lower at 56.79. Overall, the GPT models fare poorly, which is to be expected given the recent studies exposing the limits of LLMs, especially in more specialized domains such as science and medicine.
HSAT holds the best precision at 92.29 and F1 at 91.72, outperforming GPT-4 by 26.83 percentage points. GPT-4 does perform better than GPT-3.5, but it still lags other baselines such as BM25 and MPNet. For example, on the PubCLogs test set, GPT-4 has a F1 of 64.89, which is lower than BM25’s 70.62 and MPNet’s 67.11.
Our main evaluations are in token-level, but we also show title-level metrics in Table 1. Performances on PubCLogs test set for title-level is slightly lower compared to token-level across the board, perhaps due to the added complexity of duplicate tokens in titles.
4.4. User studies
We conduct a user study with two annotators with graduate-level biomedical knowledge to determine whether users would prefer recommendation explanations from HSAT or GPT-4. We use HSAT and GPT-4 outputs from our manually annotated set, which has a size of 100. We randomize the order of the two outputs shown for each entry, and ask each study participant to rank the two. The manual set was ranked by the participants. Our user study shows that both users significantly favor HSAT outputs over GPT-4. Figure 5 shows our user study results. Annotator 1 preferred HSAT over GPT-4 55 to 38, while annotator 2 preferred HSAT by 59 to 31. The annotator agreement was 89%. The annotators agreed that HSAT tends to be more succinct in its answers, while highlighting topics that both seed and similar articles share.
Figure 5:
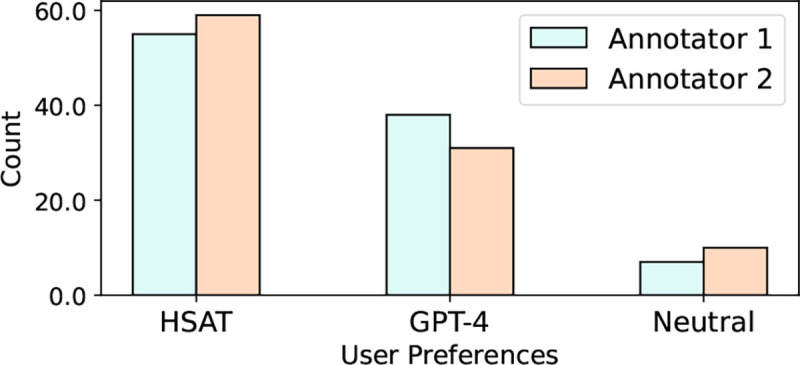
Results of our user preference studies of HSAT outputs versus GPT-4 outputs. The neutral column indicates that both outputs were similar in quality.
4.5. Case studies
We show three case studies in Table 3. Two entries are from the test set of PubCLogs and one is from our manually-annotated test set. The title and abstract for the seed article and the title of the similar article are shown on the leftmost column. Each row representing the model has a corresponding similar article title. Model names are in the middle column, and the similar article titles are shown in the rightmost column, where the predicted tokens are highlighted.
Table 3:
Case studies of outputs from Highlight Similar Article Title (HSAT) and baselines. The first two entries are from the PubCLogs test set, and the third one is from the manually annotated set. The leftmost column presents the PMIDs and the titles of the seed articles. In the middle column, rows are labelled as the similar article title, the ground truth, HSAT, and various baselines. In the third column, the similar article titles are shown, and ground truths and predicted outputs are highlighted.
|
Seed article PMID : 33332292 Similar article PMID: 33301246 Seed article title: The Advisory Committee on Immunization Practices’ Interim Recommendation for Use of Pfizer-BioNTech COVID-19 Vaccine - United States, December 2020. |
Similar article title | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine. |
| Ground truth | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine. | |
| HSAT (ours) | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine. | |
| HighlightAll | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine. | |
| Overlapper | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine. | |
| BM25 | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine. | |
| Word2Vec | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine. | |
| BioWord2Vec | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine. | |
| MPNet | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine. | |
| MedCPT | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine | |
| GPT-3.5-Turbo | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine | |
| GPT-4 | Safety and Efficacy of the BNT162b2 mRNA Covid-19 Vaccine | |
|
Seed article PMID : 23651522 Similar article PMID: 29361967 Seed article title: Very-low-carbohydrate ketogenic diet v. low-fat diet for long-term weight loss: a meta-analysis of randomized controlled trials. |
Similar article title | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … |
| Ground truth | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … | |
| HSAT (ours) | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … | |
| BM25 | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … | |
| Word2Vec | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … | |
| BioWord2Vec | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … | |
| MPNet | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … | |
| MedCPT | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … | |
| GPT-3.5-Turbo | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … | |
| GPT-4 | The effect of a ketogenic diet versus a high-carbohydrate, low-fat diet on sleep … and cardiovascular health independent of weight loss … | |
|
Seed article PMID: 27533649 Similar article PMID: 25650566 Seed article title: Efficacy of Turmeric Extracts and Curcumin for Alleviating the Symptoms of Joint Arthritis: A Systematic Review and Meta-Analysis of Randomized Clinical Trials. |
Similar article title | Mobile bearing vs fixed bearing prostheses for posterior cruciate retaining total knee arthroplasty … patients with osteoarthritis and rheumatoid arthritis. |
| Ground truth | Mobile bearing vs fixed bearing prostheses for posterior cruciate retaining total knee arthroplasty … patients with osteoarthritis and rheumatoid arthritis. | |
| HSAT (ours) | Mobile bearing vs fixed bearing prostheses for posterior cruciate retaining total knee arthroplasty … patients with osteoarthritis and rheumatoid arthritis. | |
| BM25 | Mobile bearing vs fixed bearing prostheses for posterior cruciate retaining total knee arthroplasty … patients with osteoarthritis and rheumatoid arthritis. | |
| Word2Vec | Mobile bearing vs fixed bearing prostheses for posterior cruciate retaining total knee arthroplasty … patients with osteoarthritis and rheumatoid arthritis. | |
| BioWord2Vec | Mobile bearing vs fixed bearing prostheses for posterior cruciate retaining total knee arthroplasty … patients with osteoarthritis and rheumatoid arthritis. | |
| MPNet | Mobile bearing vs fixed bearing prostheses for posterior cruciate retaining total knee arthroplasty … patients with osteoarthritis and rheumatoid arthritis. | |
| GPT-3.5-Turbo | Mobile bearing vs fixed bearing prostheses for posterior cruciate retaining total knee arthroplasty … patients with osteoarthritis and rheumatoid arthritis. | |
| GPT-4 | Mobile bearing vs fixed bearing prostheses for posterior cruciate retaining total knee arthroplasty … patients with osteoarthritis and rheumatoid arthritis. |
In the “Ground truth” rows, we show the ground truths from PubCLogs training set that we trained HSAT on. The ground truth tokens are selected by processing queries that led to coclicked article pairs. In the HSAT rows, outputs from the model are displayed. In the first entry, with PMID pair 33332292 and 33301246, HighlightAll highlights all tokens in the similar article title (“similar title”), which leads to perfect recall of 100.0 but low precision. Next is Overlapper, which selects tokens that are in both seed and similar titles. The Overlapper is a good, commonsense baseline. Intuitively, articles with titles that share many terms will tend to be similar. Overlapper works best when the similar title tokens lexically match tokens in the seed title. But due to its nature, it will inevitably also select tokens that are of low value to users, such as stopwords. And more importantly, it will miss tokens that are semantically, but not lexically matched with a seed title token.
BM25 is a strong, standard baseline. In the first entry, however, we see that it selects “and” and “the,” which are stopwords that do not provide insight into the recommendations. This is likely due to the fact that the model was forced to return the top three tokens, even in entries where there were no clear top tokens.
Word2Vec and BioWord2Vec miss critical information in the first entry. Both the seed and similar article titles mention COVID-19, so it seems that both “COVID-19” and “vaccine” are relevant tokens. However, Word2Vec and BioWord2Vec fail to highlight “Covid-19” and select “safety” and “efficacy” instead, which are lower-value words. BioWord2Vec outputs show a similar pattern in the second entry, where it only selects “diet” but not “ketogenic,” which appears in both seed and similar titles. In the third entry, Word2Vec selects “arthroplasty,” which might be an important topic in the similar article on its own. However, the seed article seems to be about turmeric extracts and curcumin, and neither the title nor the abstract mentions arthroplasty at all. Since our goal is to select information that is relevant in relation to the seed article, ideal outputs should not include such words.
MPNet performs well despite being a general domain model. In the third entry, its outputs exactly match the ground truth, and produce acceptable results in the first two as well. It also shows relatively consistent performances in the PubCLogs test set and the manually annotated test set, showcasing its robustness. MedCPT retriever does not do as well, but still shows decent performance. It makes a critical mistake in the first entry by selecting “and” but not “Covid-19.” MedCPT’s lower performance may be due to the fact that the query encoder and document encoders of MedCPT were trained to encode text much longer than our usage.
As expected, GPT-4 does much better than GPT-3.5. GPT-3.5 makes trivial mistakes such as highlighting “safety” and “efficacy” but missing “Covid-19.” And although GPT-4 does better than GPT-3.5, it still underperforms other baselines such as BM25 and MPNet. For example, on the PubCLogs test set, GPT-4 has a F1 of 64.89, which is lower than BM25’s 70.62 and MPNet’s 67.11. Although we can argue that the lower performance is due to the fact that GPT models are general domain, so are BM25 and MPNet. Given the nonstellar performance and exorbitant training and inference cost of the GPT models, it seems for now that LLMs are not practical for large-scale usage in article recommendation explanation.
In the second entry, both the seed and similar articles are comparing ketogenic diets and low-fat diets for weight loss. Although almost all of our baselines correctly select “ketogenic diet” and “low-fat diet,” none of them highlight “weight,” which is arguably an important commonality between the articles. In this sense, HSAT correctly includes all three phrases in its output. In the third entry, “rheumatoid” is part of the similar title but is not mentioned in the seed article, yet is part of the PubCLogs ground truth and outputs from HSAT, and almost all baselines including Word2Vec, MPNet, GPT-3.5, and GPT-4. While this is a critical error, it is one made by most of the baselines as well. Interestingly, Overlapper and BM25 do not make this error, showing that each model has its strengths and weaknesses, and a fusion model that combines multiple model outputs is likely to be better than any one model on its own.
4.6. Analysis
We divide the test set of PubCLogs into five subgroups. The subgroups are divided with the total combined clicked counts of the article pair. A clear trend is that as that most models, including baseline models and HSAT, tend to perform worse on articles with fewer clicks. This trend could be explained by the fact that the bottom third contains more relatively obscure topics such as “autoimmune glial fibrillary acidic protein astrocytopathy,” whereas the top third contains proportionally more of popular topics such as COVID. For example, out of 15k instances each, COVID is mentioned more than 2000 times in the top third and about 900 times in the bottom third. We hypothesize that HSAT performs better on article pairs that are more highly clicked because they tend to be more popular topics that are widely read and researched. Because there are more articles in those areas, the recommendations are bound to be better. And since the pairs are more similar to each other, the quality of both the PubCLogs ground truths and HSAT outputs will be higher. To test this, we divide the test set into five subgroups based on semantic similarity. We use MedCPT article encoder to encode the seed and similar articles of each entry in the PubCLogs test set, and use cosine similarity to obtain the pairwise relevance. Based on the F1 scores of HSAT on each subgroup, we find that HSAT tends to do better when article pairs are more semantically similar, as described in Figure 4.
Figure 4:
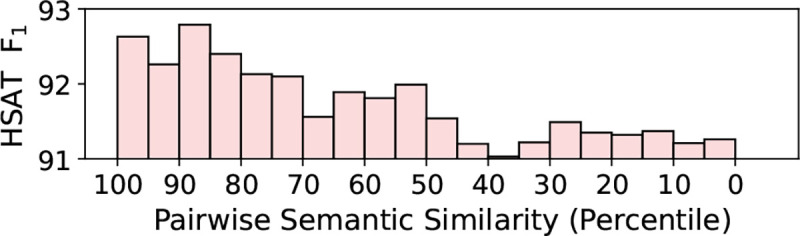
F1 scores of our model, Highlight Similar Article Title (HSAT) on subsets of the PubCLogs test set, divided based on article pair semantic similarity using MedCPT.
The performance of HSAT on the manual set is slightly lower at 80.62, compared to 91.72 on the test set. This may be due to the smaller size of the set, which contains 100 article pairs, compared to the PubCLogs test set’s 47,000. Also, to form the manual set, we randomly selected article pairs from the top 1000 most highly clicked articles, and chose from the top 20 similar articles actually recommended by PubMed. Because many highly clicked articles contain a higher percentage of types of titles that tend to be uninformative, such as “Methodology of a systematic review,” the semantic similarity between the pairs is bound to be lower, which would lead to lower HSAT performance as mentioned above.
Future work.
Since HSAT training depends on our collected dataset from user coclick logs, the prediction quality for PMIDs that do not get searched as often may not be as good. And since a substantial proportion of PubMed queries are long tail, we could find other ways to complement long tail instances. A source of noise in the training data might be simple article titles that do not provide much insight into their content, such as Report of the 49th annual meeting of the Pacific Association of Pediatric Surgeons, Kaua’i, Hawai’i, April 24th-28th, 2016 (PMID 27680595). In addition, because every user will have different prior knowledge and information seeking goals, personalized recommendation would be the ultimate goal for tasks such as highlighting similar article titles.
5. CONCLUSION
We approach the important problem of explaining literature recommendations by highlighting relevant tokens in the title of recommended articles. We utilize user query logs to construct the PubCLogs dataset by pairing coclicked articles into seed and similar articles, and using the respective queries to label relevant tokens in the similar article titles. To demonstrate the value of harnessing user intelligence, we train Highlight Similar Article Title (HSAT), a transformer-based model, on PubCLogs with a sequence tagging objective. HSAT outperforms strong common baselines, including BM25, Word2Vec, MPNet, and GPT-4. Our results on the PubCLogs test set, a separate manually annotated test set, and a user study confirm that user search logs can be effectively repurposed to provide explanations for article recommendations.
CCS CONCEPTS.
• Information systems → Language models; Information retrieval.
ACKNOWLEDGMENTS
This research was supported by the Intramural Research Program of the National Library of Medicine (NLM), National Institutes of Health.
Footnotes
Contributor Information
Ashley Shin, National Library of Medicine, National Institutes of Health, Bethesda, MD, USA.
James Anibal, Clinical Center, National Institutes of Health, Bethesda, MD, USA.
Qiao Jin, National Library of Medicine, National Institutes of Health, Bethesda, MD, USA.
Zhiyong Lu, National Library of Medicine, National Institutes of Health, Bethesda, MD, USA.
REFERENCES
- [1].Ai Qingyao and Lakshmi Narayanan.R. 2021. Model-Agnostic vs. Model-Intrinsic Interpretability for Explainable Product Search. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (Virtual Event, Queensland, Australia) (CIKM ‘21). Association for Computing Machinery, New York, NY, USA, 5–15. 10.1145/3459637.3482276 [DOI] [Google Scholar]
- [2].Baumgartner William A Jr, Cohen K Bretonnel, Fox Lynne M, Acquaah-Mensah George, and Hunter Lawrence. 2007. Manual curation is not sufficient for annotation of genomic databases. Bioinformatics 23, 13 (2007), i41–i48. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Bioinformatics Bmc, Lin Jimmy J., Wilbur John, and Email. 2007. PubMed related articles: a probabilistic topic-based model for content similarity. BMC Bioinformatics 8 (2007), 423–423. https://api.semanticscholar.org/CorpusID:3201001 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Bird Steven, Klein Ewan, and Loper Edward. 2009. Natural Language Processing with Python (1st ed.). O’Reilly Media, Inc. [Google Scholar]
- [5].Cachola Isabel, Lo Kyle, Cohan Arman, and Weld Daniel S.. 2020. TLDR: Extreme Summarization of Scientific Documents. ArXiv abs/2004.15011 (2020). https://api.semanticscholar.org/CorpusID:216867622 [Google Scholar]
- [6].Choi Eunsol, He He, Iyyer Mohit, Yatskar Mark, Wen tau Yih Yejin Choi, Liang Percy, and Zettlemoyer Luke. 2018. QuAC: Question Answering in Context. In Conference on Empirical Methods in Natural Language Processing. https://api.semanticscholar.org/CorpusID:52057510 [Google Scholar]
- [7].Dasigi Pradeep, Liu Nelson F., Marasović Ana, Smith Noah A., and Gardner Matt. 2019. Quoref: A Reading Comprehension Dataset with Questions Requiring Coreferential Reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Inui Kentaro, Jiang Jing, Ng Vincent, and Wan Xiaojun (Eds.). Association for Computational Linguistics, Hong Kong, China, 5925–5932. 10.18653/v1/D19-1606 [DOI] [Google Scholar]
- [8].Devlin Jacob, Chang Ming-Wei, Lee Kenton, and Toutanova Kristina. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Burstein Jill, Doran Christy, and Solorio Thamar (Eds.). Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186. 10.18653/v1/N19-1423 [DOI] [Google Scholar]
- [9].Dogan Rezarta Islamaj, Murray G. Craig, Névéol Aurélie, and Lu Zhiyong. 2009. Understanding PubMed® user search behavior through log analysis. Database: The Journal of Biological Databases and Curation 2009 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Dua Dheeru, Wang Yizhong, Dasigi Pradeep, Stanovsky Gabriel, Singh Sameer, and Gardner Matt. 2019. DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Burstein Jill, Doran Christy, and Solorio Thamar (Eds.). Association for Computational Linguistics, Minneapolis, Minnesota, 2368–2378. 10.18653/v1/N19-1246 [DOI] [Google Scholar]
- [11].Ely John W, Osheroff Jerome A, Chambliss M Lee, Ebell Mark H, and Rosenbaum Marcy E. 2005. Answering physicians’ clinical questions: obstacles and potential solutions. Journal of the American Medical Informatics Association 12, 2 (2005), 217–224. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Fiorini Nicolas, Leaman Robert, Lipman David J., and Lu Zhiyong. 2018. How user intelligence is improving PubMed. Nature Biotechnology 36 (2018), 937–945. https://api.semanticscholar.org/CorpusID:52892576 [DOI] [PubMed] [Google Scholar]
- [13].Gopalakrishnan Vishrawas, Jha Kishlay, Jin Wei, and Zhang Aidong. 2019. A survey on literature based discovery approaches in biomedical domain. Journal of biomedical informatics 93 (2019), 103141. [DOI] [PubMed] [Google Scholar]
- [14].Gu Yu, Tinn Robert, Cheng Hao, Lucas Michael, Usuyama Naoto, Liu Xiaodong, Naumann Tristan, Gao Jianfeng, and Poon Hoifung. 2021. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH) 3, 1 (2021), 1–23. [Google Scholar]
- [15].Jain Sarthak and Wallace Byron C.. 2019. Attention is not Explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Burstein Jill, Doran Christy, and Solorio Thamar (Eds.). Association for Computational Linguistics, Minneapolis, Minnesota, 3543–3556. 10.18653/v1/N19-1357 [DOI] [Google Scholar]
- [16].Jin Qiao, Kim Won, Chen Qingyu, Comeau Donald C, Yeganova Lana, Wilbur W John, and Lu Zhiyong. 2023. MedCPT: Contrastive Pre-trained Transformers with large-scale PubMed search logs for zero-shot biomedical information retrieval. Bioinformatics 39, 11 (2023), btad651. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Jin Qiao, Leaman Robert, and Lu Zhiyong. 2023. PubMed and Beyond: Biomedical Literature Search in the Age of Artificial Intelligence. arXiv:2307.09683 [cs.IR] [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Jin Qiao, Tan Chuanqi, Chen Mosha, Yan Ming, Zhang Ningyu, Huang Songfang, Liu Xiaozhong, et al. 2022. State-of-the-Art Evidence Retriever for Precision Medicine: Algorithm Development and Validation. JMIR Medical Informatics 10, 12 (2022), e40743. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Kingma Diederik P. and Ba Jimmy. 2014. Adam: A Method for Stochastic Optimization. CoRR abs/1412.6980 (2014). [Google Scholar]
- [20].Li Haonan, Tomko Martin, Vasardani Maria, and Baldwin Timothy. 2022. MultiSpanQA: A Dataset for Multi-Span Question Answering. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Carpuat Marine, de Marneffe Marie-Catherine, and Ruiz Ivan Vladimir Meza (Eds.). Association for Computational Linguistics, Seattle, United States, 1250–1260. 10.18653/v1/2022.naacl-main.90 [DOI] [Google Scholar]
- [21].Lin Jimmy. 2019. The Neural Hype and Comparisons Against Weak Baselines. SIGIR Forum 52, 2 (jan 2019), 40–51. 10.1145/3308774.3308781 [DOI] [Google Scholar]
- [22].Lin Jimmy and Wilbur W John. 2009. Modeling actions of PubMed users with n-gram language models. Information retrieval 12 (2009), 487–503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Mikolov Tomas, Sutskever Ilya, Chen Kai, Corrado Gregory S., and Dean Jeffrey. 2013. Distributed Representations of Words and Phrases and their Compositionality. In Neural Information Processing Systems. https://api.semanticscholar.org/CorpusID:16447573 [Google Scholar]
- [24].OpenAI. 2022. Introducing ChatGPT. https://openai.com/blog/chatgpt, Last accessed on 2024-01-11.
- [25].OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] [Google Scholar]
- [26].Paszke Adam, Gross Sam, Massa Francisco, Lerer Adam, Bradbury James, Chanan Gregory, Killeen Trevor, Lin Zeming, Gimelshein Natalia, Antiga Luca, Desmaison Alban, Köpf Andreas, Yang Edward Z., DeVito Zach, Raison Martin, Tejani Alykhan, Chilamkurthy Sasank, Steiner Benoit, Fang Lu, Bai Junjie, and Chintala Soumith. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. CoRR abs/1912.01703 (2019). arXiv:1912.01703 http://arxiv.org/abs/1912.01703 [Google Scholar]
- [27].Peake Georgina and Wang Jun. 2018. Explanation mining: Post hoc interpretability of latent factor models for recommendation systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2060–2069. [Google Scholar]
- [28].Rajpurkar Pranav, Jia Robin, and Liang Percy. 2018. Know What You Don’t Know: Unanswerable Questions for SQuAD. ArXiv abs/1806.03822 (2018). https://api.semanticscholar.org/CorpusID:47018994 [Google Scholar]
- [29].Rajpurkar Pranav, Zhang Jian, Lopyrev Konstantin, and Liang Percy. 2016. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Conference on Empirical Methods in Natural Language Processing. https://api.semanticscholar.org/CorpusID:11816014 [Google Scholar]
- [30].Raza Shaina, Reji Deepak John, Shajan Femi, and Bashir Syed Raza. 2022. Large-scale application of named entity recognition to biomedicine and epidemiology. PLOS Digital Health 1, 12 (2022), e0000152. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Robertson Stephen E. and Zaragoza Hugo. 2009. The Probabilistic Relevance Framework: BM25 and Beyond. Found. Trends Inf. Retr. 3, 4 (2009), 333–389. 10.1561/1500000019 [DOI] [Google Scholar]
- [32].Sayers Eric. 2018. Entrez Programming Utilities Help. https://www.ncbi.nlm.nih.gov/books/NBK25501/. National Center for Biotechnology Information (NCBI). [Google Scholar]
- [33].Segal Elad, Efrat Avia, Shoham Mor, Globerson Amir, and Berant Jonathan. 2020. A Simple and Effective Model for Answering Multi-span Questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Webber Bonnie, Cohn Trevor, He Yulan, and Liu Yang (Eds.). Association for Computational Linguistics, 3074–3080. 10.18653/v1/2020.emnlp-main.248 [DOI] [Google Scholar]
- [34].Singh Jaspreet and Anand Avishek. 2019. EXS: Explainable Search Using Local Model Agnostic Interpretability. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining (Melbourne VIC, Australia) (WSDM ‘19). Association for Computing Machinery, New York, NY, USA, 770–773. 10.1145/3289600.3290620 [DOI] [Google Scholar]
- [35].Song Kaitao, Tan Xu, Qin Tao, Lu Jianfeng, and Liu Tie-Yan. 2020. MPNet: Masked and Permuted Pre-training for Language Understanding. In Advances in Neural Information Processing Systems, Larochelle H., Ranzato M., Hadsell R., Balcan M.F., and Lin H.(Eds.), Vol. 33. Curran Associates, Inc., 16857–16867. https://proceedings.neurips.cc/paper_files/paper/2020/file/c3a690be93aa602ee2dc0ccab5b7b67e-Paper.pdf [Google Scholar]
- [36].Vaswani Ashish, Shazeer Noam, Parmar Niki, Uszkoreit Jakob, Jones Llion, Gomez Aidan N, Kaiser Ł ukasz, and Polosukhin Illia. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems, Guyon I., Von Luxburg U., Bengio S., Wallach H., Fergus R., Vishwanathan S., and Garnett R. (Eds.), Vol. 30. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf [Google Scholar]
- [37].Wang Shuai, Scells Harrisen, Koopman Bevan, and Zuccon Guido. 2023. Neural Rankers for Effective Screening Prioritisation in Medical Systematic Review Literature Search. In Proceedings of the 26th Australasian Document Computing Symposium (Adelaide, Australia) (ADCS ‘22). Association for Computing Machinery, New York, NY, USA, Article 4, 10 pages. 10.1145/3572960.3572980 [DOI] [Google Scholar]
- [38].Wolf Thomas, Debut Lysandre, Sanh Victor, Chaumond Julien, Delangue Clement, Moi Anthony, Cistac Pierric, Rault Tim, Louf Remi, Funtowicz Morgan, Davison Joe, Shleifer Sam, Patrick von Platen Clara Ma, Jernite Yacine, Plu Julien, Xu Canwen, Teven Le Scao Sylvain Gugger, Drame Mariama, Lhoest Quentin, and Rush Alexander. 2020. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Computational Linguistics, Online, 38–45. 10.18653/v1/2020.emnlp-demos.6 [DOI] [Google Scholar]
- [39].Yang Zhilin, Dai Zihang, Yang Yiming, Carbonell Jaime, Salakhutdinov Ruslan, and Le Quoc V.. 2019. XLNet: generalized autoregressive pretraining for language understanding. [Google Scholar]
- [40].Yang Zhilin, Qi Peng, Zhang Saizheng, Bengio Yoshua, Cohen William W., Salakhutdinov Ruslan, and Manning Christopher D.. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Conference on Empirical Methods in Natural Language Processing. https://api.semanticscholar.org/CorpusID:52822214 [Google Scholar]
- [41].Zhang Yijia, Chen Qingyu, Yang Zhihao, Lin Hongfei, and Lu Zhiyong. 2019. BioWordVec, improving biomedical word embeddings with subword information and MeSH. Scientific Data 6 (2019). https://api.semanticscholar.org/CorpusID:149445302 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [42].Zhang Yongfeng, Chen Xu, et al. 2020. Explainable recommendation: A survey and new perspectives. Foundations and Trends® in Information Retrieval 14, 1 (2020), 1–101. [Google Scholar]
- [43].Zhang Yongfeng, Lai Guokun, Zhang Min, Zhang Yi, Liu Yiqun, and Ma Shaoping. 2014. Explicit factor models for explainable recommendation based on phrase-level sentiment analysis. In Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval. 83–92. [Google Scholar]