

Abstract
Objective:
There is a need for additional comprehensive and validated filters to find relevant references more efficiently in the growing body of research on immigrant populations. Our goal was to create reliable search filters that direct librarians and researchers to pertinent studies indexed in PubMed about health topics specific to immigrant populations.
Methods:
We applied a systematic and multi-step process that combined information from expert input, authoritative sources, automation, and manual review of sources. We established a focused scope and eligibility criteria, which we used to create the development and validation sets. We formed a term ranking system that resulted in the creation of two filters: an immigrant-specific and an immigrant-sensitive search filter.
Results:
When tested against the validation set, the specific filter sensitivity was 88.09%, specificity 97.26%, precision 97.88%, and the NNR 1.02. The sensitive filter sensitivity was 97.76%when tested against the development set. The sensitive filter had a sensitivity of 97.14%, specificity of 82.05%, precision of 88.59%, accuracy of 90.94%, and NNR [See Table 1] of 1.13 when tested against the validation set.
Conclusion:
We accomplished our goal of developing PubMed search filters to help researchers retrieve studies about immigrants. The specific and sensitive PubMed search filters give information professionals and researchers options to maximize the specificity and precision or increase the sensitivity of their search for relevant studies in PubMed. Both search filters generated strong performance measurements and can be used as-is, to capture a subset of immigrant-related literature, or adapted and revised to fit the unique research needs of specific project teams (e.g. remove US-centric language, add location-specific terminology, or expand the search strategy to include terms for the topic/s being investigated in the immigrant population identified by the filter). There is also a potential for teams to employ the search filter development process described here for their own topics and use.
Keywords: Filter, filters, immigrant health, search strategy, filter development, hedge, hedges
INTRODUCTION
Immigrants are individuals who, for various reasons, left their country of birth and reside or resided in a different country. The worldwide increase in immigration and individuals identified as immigrants corresponds to a rise in studies on immigrant health. As of November 2022, over 450 systematic reviews had been published in PubMed in the preceding five years on immigrant health. The topics included social determinants of health in immigrant populations, public health interventions for immigrants, health trajectories of immigrants, and the impact of migration on health status disparities [1–4]. As librarians and information professionals, we have experienced many challenges in searching for studies about immigrants. Existing filters including the “Immigrant Health Disparities” filter, which our project team developed in 2018 and 2019, vary in comprehensiveness and many have limited information on the methods used to generate the terms and the overall performance of these filters [5–10]. We launched the development and validation of PubMed search filters to meet our identified information needs, and those of our patrons, for retrieval of peer-reviewed literature on immigrant populations. Subsequently, our team embarked on a multi-year, multifaceted filter development process which allowed us to address a wide range of concepts and challenges.
To start, it was challenging but essential to define the population covered by our project scope due to the complexity of immigrant populations and how immigrants are studied and described in scholarly research. For example, immigrants and immigration may be key subjects in studies on language, culture, race, and ethnicity; however, these studies may never use immigrant-explicit terminology. Loetscher et al explore the influence of immigration on pregnancy outcomes in Switzerland [11]. The study conveys immigrant status using the phrase “mothers from” in conjunction with a foreign country. The record in PubMed uses no other explicit terms such as “immigrants” and “migrants” to describe the population. We also recognized that immigrant and immigration are evolving and sensitive topics, with nuances that influence term selection, the introduction or disuse of terms (e.g., “illegal immigrants”), and the overrepresentation of US-based research.
Perceptions of immigrants present their own set of challenges. Some groups identify “immigrants” as being residents from a different country [5]. However, the perception of foreignness is more nuanced due to internal migration as well as geopolitical and historical events. For example, “diaspora” can be associated with established populations such as Black Americans in the United States or more recent diasporic events such as Syrians immigrating to European countries. In response to these challenges, we dedicated substantial time and effort to defining immigrants during the project's scope and eligibility criteria phase.
Our examination of various term-generating strategies employed by teams developing comprehensive search filters revealed diverse strategies. Many teams generated terms using word frequency analysis and text analysis software such as PubReminer, Wordstat, Simstat, Concordance, and VOSViewer [12–20]. This approach often requires a manual review of the terms. A growing number of teams relied solely on automated processes, including data visualization tools and frequency analysis, to analyze user data with statistical modeling [17, 21]. Other teams relied on clinician, librarian, and expert opinions or recommendations to generate relevant terms [13, 20, 22]. Several teams undertook manual assessment or other unspecified approaches in reviewing relevant records and identifying relevant titles, abstracts, or controlled vocabulary terms [22–28]. Some teams combined manual review with automated processes, such as frequency analysis or applying an existing filter as a starting point to identify relevant articles [29, 30].
While we examined and used existing filter development processes as a foundation, the complexity of the topic led us to adapt our methodology. We initially aimed for a single filter for research on immigrants in PubMed, however, we realized the two-filter approach would give researchers the option to pull immigrant-related studies that use language and culture words to describe immigrants. Overall, the resulting sensitive and specific filters complement existing filters while providing reproducible methods and performance outcomes that are comparable with other comprehensive filters.
METHODS
Our methodologic approach relied primarily on the following four key phases (also illustrated in Figure 1):
Figure 1.
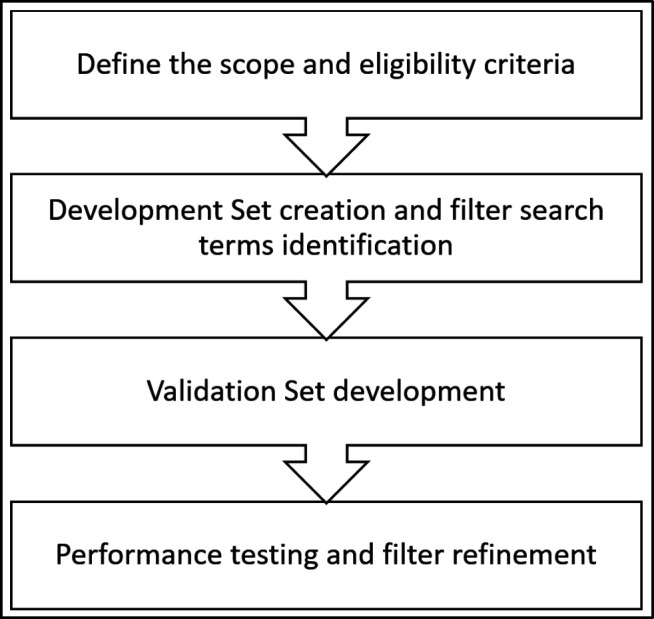
Filter Development Phases
Established a clear scope and eligibility criteria. This meant defining the population, establishing the inclusion and exclusion criteria for both studies and search terms, as well as compiling a list of known immigrant search terms from authoritative sources.
Created a development set or “gold standard” set comprised of references that meet the inclusion criteria, which the team reviewed, then extracted the immigrant-related term or terms to create the immigrant search filters for PubMed.
Created a validation set of references. These were separate sets of references that meet the inclusion criteria and were used to test the filters.
Conducted performance tests and revised the search filters as needed. We tested the filters against the validation set references and revised filters to optimize performance.
We compiled search terms for both filters by combining terms derived from authoritative sources (subject experts as well as academic and government publications), the development (gold standard) set references, and references identified from the validation set reference after we conducted the performance tests. As other filter development teams did, we applied manual review and automation to generate the filter terms.
We reviewed different approaches to validating or testing the filters. External validation is described by the UK InterTasc Information Specialists' Sub-Group (ISSG) as testing the filters against a set of records distinct from those used in the filter development [31]. We found that most filter development teams used external validation [13, 15–18, 21, 24, 26, 29, 30, 32–39]. Fewer teams opted for internal validation and tested the filter against the development set of records used to generate the filter [19, 27, 28, 40, 41]. We employed external validation by testing the specific and sensitive filters against the validation set. We selected external validation because we believed testing the final filter or filters against a separate set of references added a layer of objectivity because they were tested against a unique, yet relevant set of references.
We expand on our methodology in the subsequent text and highlight key methodological terms in Table 1.
Table 1.
Glossary of project methodological terms
| Term | Definition |
|---|---|
| Development set references | References that meet the inclusion criteria and are assessed to create the filter search terms. Also called the gold standard set. |
| Eligibility criteria | A predefined set of criteria applied to articles and terms during the screening process to determine whether they will be included or excluded for use in the search filter. |
| Exclusion criteria | A predefined set of criteria that disqualifies prospective articles or terms from the filter. |
| Inclusion criteria | A predefined set of criteria that must be present to be included in the search filter. |
| Indicator | Qualifier or companion word or words, usually non-immigrant specific, that must be combined with another term to indicate immigrant population and retrieve the relevant reference. |
| Sensitive filter | Search filter with the specific, language and culture terms. |
| Snowball set references | Studies from the reference lists of relevant systematic reviews identified from the initial topic search in PubMed. These references were randomly divided into two sets, one for the development set and the other for the validation set. |
| Specific filter | Search filter with specific terms that do not require an indicator. |
| Validation set references | References known to meet the inclusion criteria and used to test the performance of the search filter. |
Defining the Scope and Eligibility Criteria
During the development of the “Immigrant Health Disparities” search filter in 2019, we queried experts with research focused on immigrant health for recommendations on terms and definitions for immigrants. The experts' input guided us toward the definition by Diaz et. al, which describes immigrants as “persons who are moving or have moved across an international border away from their habitual place of residence, regardless of the causes for the movement or the voluntariness of their decision” [8]. This definition informed our discovery process and served as an essential point of reference in defining our scope. The eligibility criteria were applied during all phases of the project.
As part of our inclusion criteria, we included any study that used immigrant-explicit terminology such as “immigrant” or “refugee.” This includes individuals of foreign origin regardless of their immigration status (e.g., nonimmigrant workers). We included relevant studies regardless of geography. For example, studies about immigrants living in Sweden or China met the inclusion criteria. Language presented a unique challenge because many non-immigrants may speak a second language or multiple languages. Although individuals who do not identify as immigrants may speak a language different from the general population, many researchers use language phrases and concepts to communicate immigrant status. Consequently, we elected to include records with linguistic-related terms that conveyed a foreign or perceived non-native population such as “non-English speaking” or “language barriers.” We encountered a similar challenge with culture as many medical research studies equate cultural differences and acculturation with immigration. We marked references that used culturally specific terms and specific populations for inclusion in our filter and analysis.
Exclusion Criteria: Our exclusion criteria included studies that presented individuals and national, demographic, or administrative geographical units, without conveying international movement. We excluded studies that solely examined individuals' health based on race and ethnicity without taking into account their immigration status, as there are already comprehensive filters for race and ethnicity [42]. We did not restrict studies based on language or place of publication, but in the case of non-English references, relied on the translated title and English language abstract in PubMed.
Development Set (Gold Standard) References
The development set encompasses known references that meet the inclusion criteria [25]. To form the development set reference list, we ran a topic search in PubMed MEDLINE for systematic reviews on preventive health or pregnancy, both search topics were commonly requested by our patrons. This search resulted in 14,095 records, which we divided into two screening sets for two reviewer teams who then independently screened the titles and abstracts of their assigned set in Rayyan, the screening platform we used for the project. We resolved conflicts through discussion between all four reviewers, which resulted in 135 references meeting the inclusion criteria. From the reference lists of these systematic reviews, we then identified 4,531 unique records indexed in PubMed MEDLINE. This created the snowball set of references as highlighted in Table 1. The snowball set of references helped us populate the development and validation sets with potentially relevant references. We randomly selected half (2,266) of the references in the snowball set and assigned them to the development set for screening using the inclusion criteria. We set aside the other half of the snowball set references (2,265 records) to build the validation set references.
After screening titles and abstracts, we identified 894 of the 2,266 studies to include in the development set. We transferred the titles and available abstracts for each record in the development set to a spreadsheet. We separated those records into four groups, one for each team member to extract terms and phrases that met the inclusion criteria. The relevant terms or phrases were extracted and ranked based on the three-tiered system outlined in Table 2. Team members independently reviewed each term according to the inclusion criteria. We addressed conflicting rankings through discussion and consensus. We ensured that all included terms and phrases were in the PubMed Index [43].
Table 2.
Ranking system
| Rank | Description |
|---|---|
| 1 | Terms met inclusion criteria without the need for an indicator or indicators. |
| 2 | Terms met the inclusion criteria when paired with a single indicator. |
| 3 | Terms required multiple indicators to meet the inclusion criteria. |
Rank 1 terms met the inclusion criteria without the need for an additional indicator or indicators to describe immigrants or immigration. We combined Rank 1 terms with the words derived from the expert consensus and authoritative sources to produce the specific filter. As is the nature of certain terms, there are instances where Rank 1 terms, specific terms (e.g., migration, migrated), are commonly used in the literature to describe biomedical processes. Terms were considered and tested before inclusion. When the terms were tested alone against the validation set, the exclusion of “migrated” resulted in a 1% loss rate while the exclusion of “migration” resulted in an 12% loss rate. Further, when we tested the terms exclusion from the search filter when applied our validation set, the exclusion of “migrated” resulted in no change to the filter's recall, while the exclusion of “migration” resulted in a loss of recall. The term “migration,” therefore, was included in the final filter, while “migrated” was not included.
If a term needed a single indicator, we moved it to Rank 2. We placed terms requiring multiple indicators to communicate immigrant or immigration under Rank 3. The variability in Rank 3 words' indicators made it unfeasible to incorporate those words. As Rank 2 terms required clarification through the inclusion of an indicator, we tested each Rank 2 term or phrase against the specific search string. We assessed the number of unique results identified by that term and not by the specific search filter. We reviewed those unique records for relevant publications and determined inclusion if the term generated relevant records.
Indicators for Rank 2 terms fell under race and ethnicity, culture, language, and geographical location. Several records with Rank 2 terms had indicators from multiple categories. Given the complexity of immigrants and immigration and the use of language and culture to describe immigrants, we felt it necessary to incorporate both concepts by creating a sensitive search filter. The sensitive filter combines all the immigrant terms as well as terminology for language and culture terms. This produced a second filter with greater sensitivity or ability to retrieve all relevant studies because it is a broader search. The language and culture terms came from our term-extraction process and existing search strings [6, 7, 44–64].
To generate the Medical Subject Headings (MeSH) terms, we input the existing immigrant terms and PMIDs of the development set into the PubReminer software [65]. We also input terms into the MeSH browser for additional words [66]. We manually reviewed the results from the PubReminer and MeSH Browser queries for relevancy and inclusion. In 2022, we reran the search in PubReminer and scanned the MeSH browser for changes and new related headings. The specific and sensitive PubMed search filters are available in Appendix A.
Validation Set References
The validation set references are relevant studies the immigrant population filters should find in PubMed. We created the validation set by combining the 2,266 references from the snowball set with the 1,270 unique PubMed records from the Journal of Immigrant and Minority Health, a prominent peer-reviewed journal in the field, as well as its predecessor, the Journal of Immigrant Health. We performed the journal search on May 20, 2020, and an updated search on June 9, 2022, which produced 1,266 records. In all, we screened 4,802 unique records to determine inclusion in the validation set. We divided the records into two sets for an independent title and abstract screening by two pairs of team members. A total of 2,830 records met criteria for inclusion in the validation set after resolving conflicting decisions through discussion and consensus. Once completed, the validation set acted as a sample for testing both the full search filter and individual terms to determine various performance measures of the filter as a whole (e.g. how many of our validation set records were captured by our two filters) and individual terms (e.g. testing the recall of a specific term to determine inclusion).
Table 3.
Definitions of and formulas for performance measures
| Performance measure | Definition/Formula |
|---|---|
| Correct Inclusion | Relevant records retrieved by the filter, true positives. |
| Incorrect Inclusion | Irrelevant records retrieved, false positives. |
| Correct Exclusion | Irrelevant records not retrieved, true negatives. |
| Incorrect Exclusion | Relevant records not retrieved, false negatives. |
| Sensitivity | The number of relevant records retrieved determined by (correct inclusion) / the total number of relevant records (relevant records). |
| Specificity | The proportion of irrelevant records not retrieved calculated by (correct exclusion) / (irrelevant records). |
| Precision | The proportion of retrieved records that are relevant calculated by (correct inclusion) / (total records retrieved). |
| Accuracy | The proportion of all records correctly included or correctly excluded determined by (correct inclusion + correct exclusion) / (all records screened). |
| Number Needed to Read | The number of records that need to be read in order to identify a single relevant result calculated by 1 / (precision). |
RESULTS
We tested the performance of the specific and sensitive filters in PubMed on September 22, 2022.
The sensitive filter generated 1,674,705 results and captured 874 of the 894 references in the development set. This filter missed 20 relevant studies. Two missed studies used relevant phrases (e.g., “foreign in-home workers” and “born in a country with”) that were not in the PubMed Phrase Index. One study required the use of “generation” and variants of the terms. Nine records required a specific country or geographical name, five required a specific language, and two references had specific languages with specific ethnicities. The sensitivity of the sensitive filter was 97.76% when tested against the development set.
The sensitive filter correctly captured 2,749 references (correct inclusion) from the validation set and missed 81 references (incorrect exclusion) that met the inclusion criteria. This contributed to a sensitivity of 97.14%. Records were missed because they used terms for geographic locations (e.g., “born in Mexico”), specific language terms (e.g., “Spanish”), specific race and ethnicity terms (e.g., “Korean American”), or terms related to travel medicine. The number of records missed for each reason is shown in Figure 2.
Figure 2.
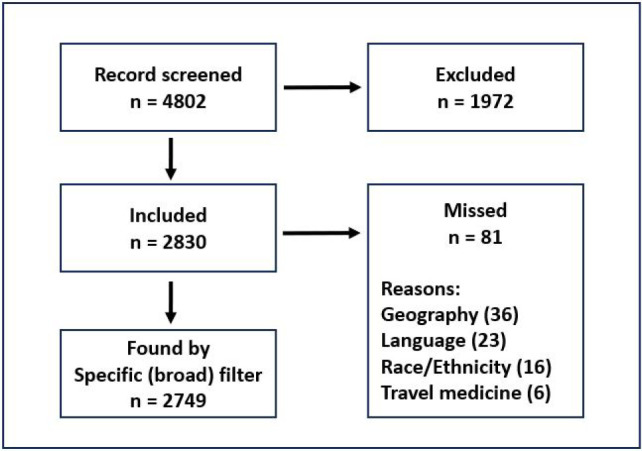
Flowchart for the creation of the validation set
The sensitive filter pulled 354 references that did not meet the inclusion criteria (incorrect inclusion), and it correctly excluded 1,618 irrelevant references (correct exclusion) contributing to a specificity of 82.05%. The sensitive filter performed with a precision of 88.59%, accuracy of 90.94%, and NNR of 1.13.
The specific filter yielded a total of 460,584 results. When tested against the 894 references in the development set, the specific filter correctly identified (correct inclusion) 779 of the 894 references. It excluded 115 relevant references (incorrect exclusion). Overall, the sensitivity of the specific filter when tested against the development set was 87.14%.
When tested against the validation set, the specific filter correctly found 2,493 references of the 2,830 references in the validation set (correct inclusion). It failed to include 337 references that met the inclusion criteria (incorrect exclusion). This resulted in a sensitivity of 88.09%. The filter incorrectly included 54 references that did not meet the inclusion criteria (incorrect inclusion). It correctly excluded 1,918 references that did not meet the inclusion criteria (correct exclusion), which resulted in a specificity of 97.26%. In all, the specific filter produced a precision of 97.88%and an accuracy of 91.86%. Accuracy was determined by the records correctly included or correctly excluded. The number needed to read (NNR) was 1.02.
Table 4.
Performance of the search filters
| Filter | Correct Inclusion | Incorrect Inclusion | Correct Exclusion | Incorrect Exclusion | Sensitivity (%) | Specificity (%) | Precision (%) | Accuracy (%) | NNR |
|---|---|---|---|---|---|---|---|---|---|
| Sensitive (broad) vs Validation Set | 2749 | 354 | 1618 | 81 | 97.14 | 82.05 | 88.59 | 90.94 | 1.13 |
| Specific (focused) vs Validation Set | 2493 | 54 | 1918 | 337 | 88.09 | 97.26 | 97.88 | 91.86 | 1.02 |
While we did not have a baseline or separate comprehensive immigrant population filter to compare performance measurements against, the sensitivity and specificity of the Immigrant Population filters closely resemble numbers generated by the Clinical Study Categories search filters to identify therapy studies and randomized controlled trials in PubMed [22]. PubMed's Therapy filter optimized for sensitive/broad search has a sensitivity of 99% compared to our sensitive filter sensitivity of 97%. The specificity for the sensitive filter was 70% for PubMed and 82% for the sensitive filter. The Haynes team's' Therapy filter optimized for specific/focused or narrower searching resulted in a sensitivity of 93% and specificity of 97%. The specific filter produced a sensitivity of 88% and specificity of 97%. We believe we found a balance between sensitivity and specificity because higher sensitivity indicates less likelihood of missing relevant literature. Higher specificity means less likelihood of retrieving irrelevant records and is inversely related to sensitivity.
DISCUSSION
A comprehensive filter to find studies related to immigrant populations is essential for both healthcare providers working with immigrant and refugee populations, and for researchers seeking to learn more about the topic [67]. Initially, we set out to address the lack of comprehensive search filters for immigrant populations in a health-related database by developing a robust search filter. However, the complexity of the topic lead us to create two filters to allow for a stronger capture of immigrant-related articles [68]. This approach provides searchers with the option to apply a desired level of specificity, precision, and sensitivity to their search. Searchers can select the specific filter, which maximizes specificity and precision, or increase sensitivity by adopting the sensitive filter. As with any comprehensive filter, our filters pulled many irrelevant studies or “noise” because of the inclusion of terms like “migration” which meets our inclusion criteria but also is used in non-immigrant related research.
Screening for the development set revealed that we could optimize sensitivity by adding language and cultural terms, which we opted to include as a sensitive filter. The need for supplemental filters further shows searching for studies on immigrant populations requires a multifaceted approach. Searchers must strategically build their search with filters such as the Immigrant Health search filters, the MEDLINE®/PubMed® Health Disparities and Minority Health Search Strategy while including other terms and concepts unique to their research questions [69]. In the future, we hope to see more systematic approaches to developing language and culture filters to enhance the sensitive filter to further optimize performance and improve search results.
As with any topic related to health, immigrant populations in health-related research are a nuanced subject leaving considerable room for subjectivity in the selection and relevance ranking of terms. We mitigated this as much as possible by creating clear eligibility criteria and a system for term identification and ranking. The exclusion of Rank 3 terms because they require multiple indicators means our filters missed relevant studies. Likewise, the filters did not find references with long phrases, such as “time living in the United States” that have countless iterations and are not recognized by PubMed's phrase index. Additional enhancements to PubMed, particularly the introduction of proximity searching, may make it more feasible to find records that use more complex word-phase combinations [43].
We also recognize a bias towards United States immigration in our selected terminology because of the heavy representation of U.S.-based researchers and publications in PubMed. To reduce the impact of geography bias, future development and review should incorporate collaborators from outside the U.S. to bring more global perspectives. Our commitment to the methodology and sourcing terms from pre-determined sources and building our reference and validation sets from topics based on local requests may have introduced selection bias and led to the omission of relevant word variants and terms. We hope to address this limitation in future versions of the filters by broadening the scope of authoritative sources and actively seeking input from researchers and fellow librarians. Likewise, publication of the filters paves the way for enhancements and refinements guided by input from peers, which will help rectify possible limitations stemming from the absence of peer review.
There is a need for collective consensus on reproducible search methodologies that can best help researchers to retrieve relevant literature about immigrants. Community search consortia in library professional groups, especially in countries that have national health systems, may also provide models for centralization and more international collaboration for the development, validation, and sharing of search filters, including those for immigrant populations. We await further developments in this area that will address not only the centralization aspects, but also the additional challenges of ensuring that search filter options can be discoverable not only by librarians but by researchers as well.
Developing the immigrant population filters was a three-year process. During that time, no other similarly focused search filters came to the forefront. The challenges we encountered, from trying to reduce bias and identify all relevant terms, to accommodating more nuanced concepts like language and culture, made us realize why comprehensive filters for immigrant populations have either not been developed or have not been widely shared. These factors motivated us to complete the project. Based on validation in two topic areas, we accomplished our goal to develop comprehensive search filters for immigrant populations to help find subsets of evidence in PubMed. Since the completion of the project, there have been notable advancements in Generative Artificial Intelligence and its associated tools with implications for search filter developments [70]. Further discussion on this subject exceeds the scope of this paper, as the report focuses on tools and approaches under consideration during the development and testing of the immigrant search filters. Nevertheless, we acknowledge the potential of generative AI for future iterations of the search filters. We look forward to future use, external testing, the possible expansion to other databases, and revisions using tools such as generative AI that would build upon our work and continue to improve the performance measurements thus making the specific and sensitive filters even more valuable to librarians and researchers.
ACKNOWLEDGMENTS
The project team thanks Emma Wilson and Molly Beestrum for their review and manuscript edits.
DATA AVAILABILITY STATEMENT
Associated data for this article are available at https://doi.org/10.18131/g3-163n-n075.
AUTHOR CONTRIBUTIONS STATEMENT:
Q. Eileen Wafford: conceptualization; data curation; formal analysis; investigation; methodology; project administration; supervision; validation; visualization; writing – original draft; writing – review & editing. Ramune K. Kubilius: data curation; formal analysis; investigation; methodology; validation; visualization; writing – original draft; writing – review & editing. Corinne H. Miller: data curation; formal analysis; investigation; methodology; validation; visualization; writing – original draft; writing – review & editing. Annie B. Wescott: data curation; formal analysis; investigation; methodology; validation; visualization; writing – original draft; writing – review & editing.
SUPPLEMENTAL FILES
Appendix A: Immigrant Populations PubMed Search Filters
REFERENCES
- 1.Shommu NS, Ahmed S, Rumana N, Barron GR, McBrien KA, Turin TC. What is the scope of improving immigrant and ethnic minority healthcare using community navigators: A systematic scoping review. Int J Equity Health. 2016. Jan 15;15:6. https://www.ncbi.nlm.nih.gov/pubmed/26768130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Chang CD. Social Determinants of Health and Health Disparities Among Immigrants and their Children. Curr Probl Pediatr Adolesc Health Care. 2019. Jan;49(1):23–30. https://www.ncbi.nlm.nih.gov/pubmed/30595524. [DOI] [PubMed] [Google Scholar]
- 3.Lu Y, Denier N, Wang JS, Kaushal N. Unhealthy assimilation or persistent health advantage? A longitudinal analysis of immigrant health in the United States. Soc Sci Med. 2017. Dec;195:105–14. https://www.ncbi.nlm.nih.gov/pubmed/29172047. [DOI] [PubMed] [Google Scholar]
- 4.Shishehgar S, Gholizadeh L, DiGiacomo M, Davidson PM. The impact of migration on the health status of Iranians: an integrative literature review. BMC Int Health Hum Rights. 2015. Aug 15;15:20. https://www.ncbi.nlm.nih.gov/pubmed/26275716. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Dropp K, Nyhan B. Nearly half of Americans don't know Puerto Ricans are fellow citizens. The New York Times. 2017. 26. [Google Scholar]
- 6.Campbell SM. A Filter to Retrieve Studies Related to Refugees/Immigrants from the OVID MEDLINE Database. John W. Scott Health Sciences Library, University of Alberta; 2020. [Google Scholar]
- 7.Ziegler D. Emigrant. Search Strategy Concepts Canadian Health Libraries Association, Quebec Chapter [Sept 11, 2014 cited]. https://extranet.santecom.qc.ca/wiki/!biblio3s/doku.php?id=concepts:emigrant.
- 8.Diaz E, Ortiz-Barreda G, Ben-Shlomo Y, Holdsworth M, Salami B, Rammohan A, Chung RY, Padmadas SS, Krafft T. Interventions to improve immigrant health. A scoping review. Eur J Public Health. 2017. Jun 1;27(3):433–9. https://www.ncbi.nlm.nih.gov/pubmed/28339883. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Roth S, Orozco R. MLA Latinx Caucus Latinx/Hispanic US Population Search Hedges [2021-07 cited]. https://scholarshare.temple.edu/handle/20.500.12613/6949.
- 10.Miller CH, Wescott A, Kubilius RK, Wafford QE. Development and Validation of a Search Filter in PubMed MEDLINE for Immigrant Health Disparities. Medical Library Association 119th Annual Meeting; May 3-8, 2019; Chicago, IL. [Google Scholar]
- 11.Loetscher KCQ, Selvin S, Zimmermann R, Abrams B. Ethnic-cultural background, maternal body size and pregnancy outcomes in a diverse Swiss cohort. Women & Health. 2007. 45(2):25–40. [DOI] [PubMed] [Google Scholar]
- 12.Boynton J, Glanville J, McDaid D, Lefebvre C. Identifying systematic reviews in MEDLINE: developing an objective approach to search strategy design. Journal of information science. 1998. 24(3):137–54. [Google Scholar]
- 13.Damarell RA, Tieman J, Sladek RM, Davidson PM. Development of a heart failure filter for Medline: an objective approach using evidence-based clinical practice guidelines as an alternative to hand searching. BMC Med Res Methodol. 2011. Jan 28;11:12. https://www.ncbi.nlm.nih.gov/pubmed/21272371. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Golder S, Wright K, Loke YK. The development of search filters for adverse effects of surgical interventions in medline and Embase. Health Info Libr J. 2018. Jun;35(2):121–9. https://www.ncbi.nlm.nih.gov/pubmed/29603850. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Gosch F, Lux B, Buchberger B, editors. Development and validation of a search filter to retrieve publications on eHealth-project description. HEC 2016; 2016 28 August-2 September 2016; Munich, Germany PMC7088195. [Google Scholar]
- 16.Hausner E, Waffenschmidt S, Kaiser T, Simon M. Routine development of objectively derived search strategies. Syst Rev. 2012. Feb 29;1:19. https://www.ncbi.nlm.nih.gov/pubmed/22587829. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Neilson C, Lê ML. A failed attempt at developing a search filter for systematic review methodology articles in Ovid Embase. J Med Libr Assoc. 2019. Apr;107(2):203–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Rietjens JA, Bramer WM, Geijteman EC, van der Heide A, Oldenmenger WH. Development and validation of search filters to find articles on palliative care in bibliographic databases. Palliat Med. 2019. Apr;33(4):470–4. https://www.ncbi.nlm.nih.gov/pubmed/30688143. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.White VJ, Glanville JM, Lefebvre C, Sheldon TA. A statistical approach to designing search filters to find systematic reviews: objectivity enhances accuracy. Journal of information science. 2001. 27(6):357–70. [Google Scholar]
- 20.Wilczynski NL, Lokker C, McKibbon KA, Hobson N, Haynes RB. Limits of search filter development. J Med Libr Assoc. 2016. Jan;104(1):42–6. https://www.ncbi.nlm.nih.gov/pubmed/26807051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Li J, Lu Z. Developing topic-specific search filters for PubMed with click-through data. Methods Inf Med. 2013. 52(5):395–402. https://www.ncbi.nlm.nih.gov/pubmed/23666447. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Haynes RB, Wilczynski NL. Optimal search strategies for retrieving scientifically strong studies of diagnosis from Medline: analytical survey. BMJ. 2004. May 1;328(7447):1040. https://www.ncbi.nlm.nih.gov/pubmed/15073027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Brown L, Carne A, Bywood P, McIntyre E, Damarell R, Lawrence M, Tieman J. Facilitating access to evidence: Primary Health Care Search Filter. Health Info Libr J. 2014. Dec;31(4):293–302. https://www.ncbi.nlm.nih.gov/pubmed/25411047. [DOI] [PubMed] [Google Scholar]
- 24.Glanville J, Dooley G, Wisniewski S, Foxlee R, Noel-Storr A. Development of a search filter to identify reports of controlled clinical trials within CINAHL Plus. Health Info Libr J. 2019. Mar;36(1):73–90. [DOI] [PubMed] [Google Scholar]
- 25.Jenkins M. Evaluation of methodological search filters–a review. Health Info Libr J. 2004. Sep;21(3):148–63. https://www.ncbi.nlm.nih.gov/pubmed/15318913. [DOI] [PubMed] [Google Scholar]
- 26.Rogers M, Bethel A, Boddy K. Development and testing of a medline search filter for identifying patient and public involvement in health research. Health Info Libr J. 2017. Jun;34(2):125–33. https://www.ncbi.nlm.nih.gov/pubmed/28042699. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Sladek R, Tieman J, Fazekas BS, Abernethy AP, Currow DC. Development of a subject search filter to find information relevant to palliative care in the general medical literature. J Med Libr Assoc. 2006. Oct;94(4):394–401. https://www.ncbi.nlm.nih.gov/pubmed/17082830. [PMC free article] [PubMed] [Google Scholar]
- 28.Stewart F, Fraser C, Robertson C, Avenell A, Archibald D, Douglas F, Hoddinott P, van Teijlingen E, Boyers D. Are men difficult to find? Identifying male-specific studies in MEDLINE and Embase. Syst Rev. 2014. Jul 18;3:78. https://www.ncbi.nlm.nih.gov/pubmed/25033713. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Terwee CB, Jansma EP, Riphagen, II, de Vet HC. Development of a methodological PubMed search filter for finding studies on measurement properties of measurement instruments. Qual Life Res. 2009. Oct;18(8):1115–23. https://www.ncbi.nlm.nih.gov/pubmed/19711195. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Prady SL, Uphoff EP, Power M, Golder S. Development and validation of a search filter to identify equity-focused studies: reducing the number needed to screen. BMC Med Res Methodol. 2018. Oct 12;18(1):106. https://www.ncbi.nlm.nih.gov/pubmed/30314471. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Glanville J, Bayliss S, Booth A, Dundar Y, Fernandes H, Fleeman ND, Foster L, Fraser C, Fry-Smith A, Golder S, Lefebvre C, Miller C, Paisley S, Payne L, Price A, Welch K. So many filters, so little time: the development of a search filter appraisal checklist. J Med Libr Assoc. 2008. Oct;96(4):356–61. https://www.ncbi.nlm.nih.gov/pubmed/18974813. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Leclercq E, Leeflang MM, van Dalen EC, Kremer LC. Validation of search filters for identifying pediatric studies in PubMed. J Pediatr. 2013. Mar;162(3):629–34 e2. https://www.ncbi.nlm.nih.gov/pubmed/23084708. [DOI] [PubMed] [Google Scholar]
- 33.Sladek RM, Tieman J, Currow DC. Improving search filter development: a study of palliative care literature. BMC Med Inform Decis Mak. 2007. Jun 28;7:18. https://www.ncbi.nlm.nih.gov/pubmed/17597549. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Ayiku L, Levay P, Hudson T, Craven J, Barrett E, Finnegan A, Adams R. The medline UK filter: development and validation of a geographic search filter to retrieve research about the UK from OVID medline. Health Info Libr J. 2017. Sep;34(3):200–16. https://www.ncbi.nlm.nih.gov/pubmed/28703418. [DOI] [PubMed] [Google Scholar]
- 35.Davies BM, Goh S, Yi K, Kuhn I, Kotter MRN. Development and validation of a MEDLINE search filter/hedge for degenerative cervical myelopathy. BMC Med Res Methodol. 2018. Jul 6;18(1):73. https://www.ncbi.nlm.nih.gov/pubmed/29976134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Gill PJ, Roberts NW, Wang KY, Heneghan C. Development of a search filter for identifying studies completed in primary care. Fam Pract. 2014. Dec;31(6):739-45. https://www.ncbi.nlm.nih.gov/pubmed/25326923. [DOI] [PubMed] [Google Scholar]
- 37.Pols DH, Bramer WM, Bindels PJ, van de Laar FA, Bohnen AM. Development and Validation of Search Filters to Identify Articles on Family Medicine in Online Medical Databases. Ann Fam Med. 2015. Jul-Aug;13(4):364–6. https://www.ncbi.nlm.nih.gov/pubmed/26195683. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.van Hoorn R, Kievit W, Booth A, Mozygemba K, Lysdahl KB, Refolo P, Sacchini D, Gerhardus A, van der Wilt GJ, Tummers M. The development of PubMed search strategies for patient preferences for treatment outcomes. BMC Med Res Methodol. 2016. Jul 29;16:88. https://www.ncbi.nlm.nih.gov/pubmed/27473226. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Wessels M, Hielkema L, van der Weijden T. How to identify existing literature on patients' knowledge, views, and values: the development of a validated search filter. J Med Libr Assoc. 2016. Oct;104(4):320–4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Johnson N, Tongbram V, Ndirangu K, Ogden K, Bay C. Development of a systematic review search filter to identify medication adherence studies. Value in Health. 2016. 19(3):A72. [Google Scholar]
- 41.Pienaar E, Grobler L, Busgeeth K, Eisinga A, Siegfried N. Developing a geographic search filter to identify randomised controlled trials in Africa: finding the optimal balance between sensitivity and precision. Health Info Libr J. 2011. Sep;28(3):210–5. [DOI] [PubMed] [Google Scholar]
- 42.Wafford QE, Miller CH, O'Dwyer LC. Validating the MEDLINE®/PubMed® Health Disparities and Minority Health Search Strategy. Spotlight: Race and Ethnicity. Medical Library Association 118th Annual Meeting; May 18-23, 2018; Atlanta, GA2018. [Google Scholar]
- 43. PubMed User Guide National Library of Medicine [cited]. https://pubmed.ncbi.nlm.nih.gov/help/#phrase-index.
- 44.Ahmed S, Shammu N, Rumana N, Turin TC. Scoping study of communication barriers between physicians and immigrant patients. Canadian Family Physician. 2016. 62(2):S51. https://www.embase.com/search/results?subaction=viewrecord&id=L617600685&from=export. [Google Scholar]
- 45.Aival-Naveh E, Rothschild-Yakar L, Kurman J. Keeping culture in mind: A systematic review and initial conceptualization of mentalizing from a cross-cultural perspective. Clinical Psychology: Science and Practice. 2019. 26(4):e12300. https://onlinelibrary.wiley.com/doi/abs/10.1111/cpsp.12300. [Google Scholar]
- 46.Al Shamsi H, Almutairi AG, Al Mashrafi S, Al Kalbani T. Implications of Language Barriers for Healthcare: A Systematic Review. Oman Med J. 2020. Mar;35(2):e122. https://www.ncbi.nlm.nih.gov/pubmed/32411417. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Boylen S, Cherian S, Gill FJ, Leslie GD, Wilson S. Impact of professional interpreters on outcomes for hospitalized children from migrant and refugee families with limited English proficiency: a systematic review. JBI Evid Synth. 2020. Jul;18(7):1360–88. https://www.ncbi.nlm.nih.gov/pubmed/32813387. [DOI] [PubMed] [Google Scholar]
- 48.Chu X, Luo X, Chen Y. A systematic review on cross-cultural information systems research: Evidence from the last decade. Information & Management. 2019. 2019/April/01/;56(3):403–17. https://www.sciencedirect.com/science/article/pii/S0378720618303422. [Google Scholar]
- 49.Degrie L, Gastmans C, Mahieu L, Dierckx de Casterle B, Denier Y. “How do ethnic minority patients experience the intercultural care encounter in hospitals? a systematic review of qualitative research”. BMC Med Ethics. 2017. Jan 19;18(1):2. https://www.ncbi.nlm.nih.gov/pubmed/28103849. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Fernandez-Gutierrez M, Bas-Sarmiento P, Albar-Marin MJ, Paloma-Castro O, Romero-Sanchez JM. Health literacy interventions for immigrant populations: a systematic review. Int Nurs Rev. 2018. Mar;65(1):54–64. https://www.ncbi.nlm.nih.gov/pubmed/28449363. [DOI] [PubMed] [Google Scholar]
- 51.Garcia ME, Ochoa-Frongia L, Moise N, Aguilera A, Fernandez A. Collaborative Care for Depression among Patients with Limited English Proficiency: a Systematic Review. J Gen Intern Med. 2018. Mar;33(3):347–57. https://www.ncbi.nlm.nih.gov/pubmed/29256085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Genoff MC, Zaballa A, Gany F, Gonzalez J, Ramirez J, Jewell ST, Diamond LC. Navigating Language Barriers: A Systematic Review of Patient Navigators' Impact on Cancer Screening for Limited English Proficient Patients. J Gen Intern Med. 2016. Apr;31(4):426–34. https://www.ncbi.nlm.nih.gov/pubmed/26786875. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Gerchow L, Burka LR, Miner S, Squires A. Language barriers between nurses and patients: A scoping review. Patient Educ Couns. 2021. Mar;104(3):534–53. https://www.ncbi.nlm.nih.gov/pubmed/32994104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Govere L, Govere EM. How Effective is Cultural Competence Training of Healthcare Providers on Improving Patient Satisfaction of Minority Groups? A Systematic Review of Literature. Worldviews Evid Based Nurs. 2016. Dec;13(6):402–10. https://www.ncbi.nlm.nih.gov/pubmed/27779817. [DOI] [PubMed] [Google Scholar]
- 55.Horvat L, Horey D, Romios P, Kis-Rigo J. Cultural competence education for health professionals. Cochrane Database Syst Rev. 2014. May 5;(5):CD009405. https://www.ncbi.nlm.nih.gov/pubmed/24793445. [DOI] [PMC free article] [PubMed]
- 56.Iwelunmor J, Newsome V, Airhihenbuwa CO. Framing the impact of culture on health: a systematic review of the PEN-3 cultural model and its application in public health research and interventions. Ethn Health. 2014. Feb;19(1):20–46. https://www.ncbi.nlm.nih.gov/pubmed/24266638. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Karliner LS, Jacobs EA, Chen AH, Mutha S. Do professional interpreters improve clinical care for patients with limited English proficiency? A systematic review of the literature. Health Serv Res. 2007. Apr;42(2):727–54. https://www.ncbi.nlm.nih.gov/pubmed/17362215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.McCallum GB, Morris PS, Brown N, Chang AB. Culture-specific programs for children and adults from minority groups who have asthma. Cochrane Database Syst Rev. 2017. Aug 22;8(8):CD006580. https://www.ncbi.nlm.nih.gov/pubmed/28828760. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Ohtani A, Suzuki T, Takeuchi H, Uchida H. Language Barriers and Access to Psychiatric Care: A Systematic Review. Psychiatr Serv. 2015. Aug 1;66(8):798–805. https://www.ncbi.nlm.nih.gov/pubmed/25930043. [DOI] [PubMed] [Google Scholar]
- 60.Taira BR, Kim K, Mody N. Hospital and Health System-Level Interventions to Improve Care for Limited English Proficiency Patients: A Systematic Review. Jt Comm J Qual Patient Saf. 2019. Jun;45(6):446–58. https://www.ncbi.nlm.nih.gov/pubmed/30910471. [DOI] [PubMed] [Google Scholar]
- 61.Tay AK, Riley A, Islam R, Welton-Mitchell C, Duchesne B, Waters V, Varner A, Moussa B, Mahmudul Alam ANM, Elshazly MA, Silove D, Ventevogel P. The culture, mental health and psychosocial wellbeing of Rohingya refugees: a systematic review. Epidemiol Psychiatr Sci. 2019. Oct;28(5):489–94. https://www.ncbi.nlm.nih.gov/pubmed/31006421. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Thonon F, Perrot S, Yergolkar AV, Rousset-Torrente O, Griffith JW, Chassany O, Duracinsky M. Electronic Tools to Bridge the Language Gap in Health Care for People Who Have Migrated: Systematic Review. J Med Internet Res. 2021. May 6;23(5):e25131. https://www.ncbi.nlm.nih.gov/pubmed/33955837. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Truong M, Paradies Y, Priest N. Interventions to improve cultural competency in healthcare: a systematic review of reviews. BMC Health Serv Res. 2014. Mar 3;14:99. https://www.ncbi.nlm.nih.gov/pubmed/24589335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Schmidt C. PubMed Search Strategies [Internet]2009. Available from: http://pubmedsearches.blogspot.com/2009/07/underserved-keyword.html.
- 65.Koster J. PubMed PubReMiner [cited]. https://hgserver2.amc.nl/cgi-bin/miner/miner2.cgi.
- 66. Medicine NLo. MeSH Browser. [Google Scholar]
- 67.Carlock DM. Finding information on immigrant and refugee health. J Transcult Nurs. 2007. Oct;18(4):373–9. https://www.ncbi.nlm.nih.gov/pubmed/17977111. [DOI] [PubMed] [Google Scholar]
- 68.Wafford QE, Miller CH, Wescott AB, Kubilius R. Immigrant Health PubMed Search Filters. DigitalHub. Galter Health Sciences Library & Learning Center; 2022. [Google Scholar]
- 69. MEDLINE®/PubMed® Health Disparities and Minority Health Search Strategy. PubMed Special Queries [May 9, 2019 cited]. https://www.nlm.nih.gov/services/queries/health_disparities_details.html.
- 70.Qureshi R, Shaughnessy D, Gill KA, Robinson KA, Li T, Agai E. Are ChatGPT and large language models “the answer” to bringing us closer to systematic review automation? Systematic Reviews. 2023. 12(1):72. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Appendix A: Immigrant Populations PubMed Search Filters
Data Availability Statement
Associated data for this article are available at https://doi.org/10.18131/g3-163n-n075.