

Abstract
Quantum computing (QC) has opened the door to advancements in machine learning (ML) tasks that are currently implemented in the classical domain. Convolutional neural networks (CNNs) are classical ML architectures that exploit data locality and possess a simpler structure than a fully connected multi-layer perceptrons (MLPs) without compromising the accuracy of classification. However, the concept of preserving data locality is usually overlooked in the existing quantum counterparts of CNNs, particularly for extracting multifeatures in multidimensional data. In this paper, we present an multidimensional quantum convolutional classifier (MQCC) that performs multidimensional and multifeature quantum convolution with average and Euclidean pooling, thus adapting the CNN structure to a variational quantum algorithm (VQA). The experimental work was conducted using multidimensional data to validate the correctness and demonstrate the scalability of the proposed method utilizing both noisy and noise-free quantum simulations. We evaluated the MQCC model with reference to reported work on state-of-the-art quantum simulators from IBM Quantum and Xanadu using a variety of standard ML datasets. The experimental results show the favorable characteristics of our proposed techniques compared with existing work with respect to a number of quantitative metrics, such as the number of training parameters, cross-entropy loss, classification accuracy, circuit depth, and quantum gate count.
Keywords: convolutional neural networks, quantum computing, variational quantum algorithms, quantum machine learning
1. Introduction
The choice of an appropriate machine learning model for specific applications requires consideration of the size of the model since it is linked to the performance [1]. Considering the aforementioned factor, convolutional neural networks (CNNs)s are preferable to multi-layer perceptrons (MLPs)s because of their smaller size and reduced training time while maintaining high accuracy [2,3]. Preserving the spatiotemporal locality of data allows CNNs to reduce unnecessary data connections and therefore reduces their memory requirements [2,3]. This phenomenon reduces the number of required training parameters and thus incurs less training time [2,3].
In the context of quantum computing, great emphasis has been given to quantum-based machine learning, and, in recent years, various techniques have been devised to develop this field [4]. The contemporary quantum machine learning (QML) techniques can be considered as hybrid quantum–classical variational algorithms [5,6,7,8,9]. Generally, variational quantum algorithms (VQAs) utilizes parameterized rotation gates in fixed quantum circuit structures, usually called ansatz, and is optimized using classical techniques like gradient descent [5,6,7,8,9]. However, like MLPs, preserving data locality is challenging for QML algorithms. For instance, the multidimensionality of input datasets is ignored in contemporary QML algorithms and are flattened into one-dimensional arrays [5,6,7,8,9]. Furthermore, the absence of a generalizable technique for quantum convolution limits the capability of QML algorithms to directly adapt CNN structures.
In this work, we present an multidimensional quantum convolutional classifier (MQCC) to address the shortcomings of the existing CNN implementations in reconciling the locality of multidimensional input data. The proposed VQA technique leverages quantum computing to reduce the number of training parameters and time complexity compared with classical CNN models. Similar to the CNN structures, MQCC contains a sequence of convolution and pooling layers for multifeature extraction from multidimensional input data and a fully connected layer for classification.
The subsequent sections of this paper are organized in the following structure. Section 2 discusses fundamental background information regarding different basic and complex quantum operations. Section 3 highlights existing works that are related to the proposed techniques. The proposed methodology is introduced in Section 4 with details given to the constituent parts. The experimental results and the explanation of the used verification metrics are presented in Section 5. Further discussion about the obtained results is provided in Section 6. Finally, Section 7 concludes this work with potential future directions.
2. Background
In this section, we present background information pertaining to quantum computing and quantum machine learning. Here, we present the quantum gates and operations that are utilized in the proposed multidimensional quantum convolutional classifier (MQCC). In addition, interested readers may find fundamental details related to quantum information and computing in Appendix A.
2.1. Quantum Measurement and Reset
The quantum measurement operation of a qubit is usually and informally referred to as a measurement “gate”. The measurement gate is a nonunitary operation that can project the quantum state of a qubit |〉 to the |0〉 or |1〉 basis states [10]. The likelihood of measuring any basis state can be obtained by taking the squared magnitude of their corresponding basis state coefficient. For an n-qubit register |〉 with possible basis states, the probability of measuring each qubit in any particular basis state |j〉, where is given by [11]. The classical output of n-qubit amplitude-encoded [12] data can be decoded as . This classical output vector can be reconstructed by the square root of the probability distribution , as shown in (1), (2), and Figure 1. When amplitude-encoding [12] is used for encoding positive real classical data, the coefficients of the corresponding quantum pure state [10]|〉 are also positive real, i.e., , where . Thus, the amplitudes of |〉 are numerically equal in values to the coefficients of , i.e., . Therefore, the quantum state |〉 can be completely determined from the measurement probability distribution such that only when the amplitudes of the quantum state are all of positive real values. Moreover, the probability distribution can be reconstructed by repeatedly measuring (sampling) the quantum state |〉. In general, an order of measurements is required to accurately reconstruct the probability distribution. In order to reduce the effects of quantum statistical noise, it is recommended to gather as many circuit samples (shots) [13] as possible.
| (1) |
| (2) |
Figure 1.

Full quantum state measurement diagram.
The reset operation sets the state of qubits to |0〉. This operation consists of a midcircuit measurement gate followed by a conditional X gate [14,15] such that the bit-flip operation is applied when the measured qubit is in state |1〉. The reset gate and its equivalent circuit are both shown in Figure 2 [15].
Figure 2.

Reset gate and equivalent circuit.
2.2. Classical-to-Quantum (C2Q)
There are a number of quantum data encoding techniques [12,16], each of which uses different methods to initialize quantum circuits from the ground state. Among the many methods, this work leverages the classical-to-quantum (C2Q) arbitrary state synthesis [12,16] operation to perform amplitude encoding and initialize an n-qubit state , see Figure 3. The C2Q operation employs a pyramidal structure of multiplexed and gates. It should be noted that the gates are only required for positive real data. Thus, for positive real data, the circuit depth is , while for complex data, the circuit depth is [12].
2.3. Convolutional Neural Networks (CNNs)
CNNs are one of the most widely used types of deep neural networks for image classification [17]. It consists of convolutional, pooling, and fully connected layers. The convolutional layer applies multiple filters to the input to create feature maps. The pooling layer reduces the dimensionality of each feature map but retains the most important information. Some of the most important pooling techniques include max-pooling, average pooling, and sum pooling. Fully connected layers are in the last layers of the CNN network, and their inputs correspond to the flattened one-dimensional matrix generated by the last pooling layer. Activation functions, which are essential for handling complex patterns, are used throughout the network. Finally, a softmax prediction layer is used to generate probability values for each of the possible output labels. The label with the highest probability is selected as the final prediction.
Figure 3.

The quantum circuit for classical-to-quantum (C2Q) arbitrary state synthesis [16].
2.4. Quantum Machine Learning with Variational Algorithms
Variational quantum algorithms are a type of quantum–classical technique that facilitates the implementations of machine learning on noisy intermediate-scale quantum (NISQ) machines [5,7]. Current quantum devices are not able to maintain coherent states for sufficient periods, preventing current algorithms from performing meaningful optimization on the machine learning model. Thus, VQAs combine classical optimization algorithms with parameterized quantum circuits, or ansatz. Here, the ansatz takes on the role of the model [5]. One specific type of VQA is the variational quantum classifier (VQC), which is used for classification problems. Existing VQCs [6,8,9] have been shown to be effective for classifying datasets with high accuracy and few training parameters in both simulation and current quantum processors.
3. Related Work
In this section, we discuss the existing related works with an emphasis on quantum machine learning. Our discussion focuses on commonly used data encoding techniques, existing implementations of the convolution and quantum convolution algorithms, and related quantum machine learning (QML) algorithms. Moreover, we also discuss existing quantum convolutional classification algorithms that leverage data locality.
3.1. Data Encoding
For encoding classical image data into the quantum domain, the commonly used methods are Flexible Representation of Quantum Images (FRQI) [18] and Novel Enhanced Quantum Representation (NEQR) [19]. In FRQI, positional and color information is encoded as amplitude encoding and angle encoding, respectively. In NEQR, positions of the pixels are encoded using amplitude encoding but color information is encoded using basis encoding, where q represents the number of bits/qubits allocated for color data. For data points, in terms of circuit width and depth, FRQI incurs and , respectively, while NEQR incurs and , respectively [20]. Although these techniques are employed in the existing quantum convolution techniques, their disadvantages are discussed below.
3.2. Convolution
We now discuss existing implementations of convolution and discuss their associated time complexity. These implementations consist of various classical and quantum techniques. In addition, we consider the shortcomings of existing quantum convolution methods.
3.2.1. Classical Convolution
Classical implementations of convolution are usually implemented directly, through general matrix multiplication (GEMM) or through the Fast Fourier transform (FFT). A data size N, running the direct implementation on CPUs, has complexity [21], while the complexity of an FFT-based implementation is [21]. On GPUs, FFT-based convolution incurs a similar complexity [22], while the direct approach requires FLOPS [23,24], where is the filter size.
3.2.2. Quantum Convolution
The existing quantum convolution techniques [25,26,27,28,29] rely on fixed filter sizes and support only specific filters at a time, e.g., edge detection. They do not contain methods for implementing a general filter. Additionally, these techniques have a quadratic circuit depth, i.e., , where is the number of qubits and N is the size of the input data. While these methods appear to show quantum advantage, these results do not include overhead incurred from data encoding. The related methods employ the FRQI and NEQR data encoding methods, leading to inferior performance compared with classical methods once the additional overhead is factored in. The authors in [30] propose an edge-detection technique based on quantum wavelet transform QWT and amplitude encoding, named quantum Hadamard edge detection (QHED), which is not generalizable for multiple convolution kernels or multidimensional data. Thus, their algorithm loses parallelism, increases circuit depth, and is difficult to generalize beyond capturing 1-D features. In [20], the authors have developed a quantum convolution algorithm that supports single feature/kernel and multidimensional data. In this work, we leverage the convolution method from [20] and generalize it to support multiple features/kernels in our proposed MQCC framework.
3.3. Quantum Machine Learning
There exist two primary techniques for quantum convolutional classification that may leverage data locality through convolution: quantum convolutional neural network (QCNN)s [31] and quanvolutional neural networks [32]. QCNNs are inspired by classical convolutional neural networks, employing quantum circuits to perform convolutions, and quanvolutional neural networks replace classical convolutional layers with quantum convolutional (or quanvolutional) layers.
3.3.1. Quantum Convolutional Neural Networks
The QCNN [31] and our proposed multidimensional quantum convolutional classifier (MQCC) are both VQAs models with structures inspired by CNNs. However, QCNNs borrow the superficial structure of CNNs without considering the underlying purpose. Specifically, the QCNN’s quantum ansatz is designed so that its “convolution” and “pooling” operations exploit the locality of qubits in the circuit (rather than the locality of data). However, unlike data locality, qubit locality does not have a practical purpose for machine learning in terms of isolating relevant input features. Moreover, by considering input data as 1-D, QCNNs do not leverage the dimensionality of datasets, which constitute a primary advantage of CNNs. MQCC, on the other hand, faithfully implements CNN operations in quantum circuits, offering performance improvements in circuit execution time (based on circuit depth) classification accuracy over contemporary implementations of QCNNs on classical computers.
3.3.2. Quanvolutional Neural Networks
Quanvolutional neural networks [32] are a hybrid quantum–classical algorithm named eponymously after the quanvolutional layer added to a conventional CNN. These quanvolutional layers serve to decimate a 2D image, which is then sequentially fed into a quantum device. In this manner, the quanvolutional layer effectively exploits data locality. Yet, the model’s dependency on classical operations, specifically the decimation of input data and the repeated serial data I/O transfer, vastly increases compute time. In contrast, the required convolution operation is incorporated into our proposed MQCC, reducing classical–quantum data transfer. Moreover, MQCC takes advantage of parallelism inherent to quantum computers, while quanvolutional neural networks do not. Together, this allows the MQCC to apply convolutional filters to window data in parallel.
4. Materials and Methods
In this section, we describe the materials and methods associated with the proposed multidimensional quantum convolutional classifier (MQCC). The proposed method mainly uses generalized quantum convolution, quantum pooling based on the quantum Haar transform (QHT) and partial measurement [11], and a quantum fully connected layer that is illustrated in this section. To the best of our knowledge, this work is the first to carry out the following:
Develop a generalizable quantum convolution algorithm for a quantum-convolution-based classifier that supports multiple features/kernels.
Design a scalable MQCC that uses multidimensional quantum convolution and pooling based on the QHT. This technique reduces training parameters and time complexity compared with other classical and quantum implementations.
Evaluate the MQCC model in a state-of-the-art QML simulator from Xanadu using a variety of datasets.
4.1. Quantum Fully Connected Layer
A fully connected classical neural network constitutes a collection of layers that each perform a linear transformation on input features to generate -feature output [2,3]. Each layer can be represented in terms of a multiply-and-accumulate (MAC) operation and an addition operation, as shown in (3), where and represent the trainable weight and bias parameters, respectively. Here, we use bold symbols to represent classical quantities, e.g., vectors, while the Dirac notation to represent their quantum counterparts.
| (3) |
The particular weights and biases that generate the feature of the output, , can be isolated by taking the column of , , and the term of , , as shown in (4), which can be directly implemented using quantum circuits. Section 4.1.1 discusses the quantum circuits for a single-feature output, and Section 4.1.2 generalizes the proposed technique for an arbitrary amount of features in the output.
| (4) |
4.1.1. Single-Feature Output
For a single-feature output neural network, the weight parameters can be represented as a vector . Here, can be expressed as a quantum state |w〉, as shown in (5), similar to the process of C2Q data encoding; see Section 2.2.
| (5) |
Similarly, for a single-feature output, Dirac notation of the MAC operation follows from (4), as shown in (6), where |〉 corresponds to the input data.
| (6) |
However, it is necessary to obtain a quantum operator to perform a parameterized unitary linear transformation from the weights vector |w〉 on the input data |〉 using an inverse C2Q operation as shown in Figure 4 and described by (7).
| (7) |
Figure 4.

Quantum multiply-and-accumulate (MAC) operation using inverse arbitrary state synthesis.
4.1.2. Multifeature Output
A multifeature output can be implemented in a naive approach using Single-Feature Output (7) for an -feature output, where , which can be obtained by encoding each weight vector as a normalized row in . However, the result might yield a nonunitary operator as the weight vectors can be arbitrary. is unitary when each row is orthogonal to all other rows in the matrix, mathematically, . As described in Appendix A.4, independently defined weights can be supported for each feature of the output by multiplexing . Now, the generic fully connected operation, , can be generated as shown in (8), where .
| (8) |
By generating replicas of the initial state, , the operation can be parallelized, i.e., transformations from (8).
Replication:
To replicate the initial state, qubits, which extends the state vector to a total size of , see (9) and Figure 5.
| (9) |
Figure 5.

Quantum fully connected layer with an -feature output.
By applying an -qubit Hadamard (see Appendix A.3) operation to the relevant qubits the replicas can be obtained through superposition (see (10) and Figure 5), which generates the desired replicas scaled by a factor of to maintain normalization .
| (10) |
Applying the Filter:
can perform the MAC operation for the entire -feature output in parallel with the set of replicas of ; see (11) and Figure 5.
| (11) |
Data Rearrangement:
The data rearrangement operation can be performed by applying perfect-shuffle gates; see Appendix A.6. It simplifies the output-feature extraction by gathering them into data points at the top of the state vector; see (12) and Figure 5.
| (12) |
It is worth mentioning that instead of applying the auxiliary qubits at the most significant position, as shown in the decomposed and simplified fully connected circuit in Figure 6, auxiliary qubits can be applied at the least significant position to avoid perfect-shuffle permutations.
4.1.3. Circuit Depth of the Quantum Fully Connected Layer
As discussed in Section 2.2, operation is implemented by applying the C2Q/arbitrary state synthesis operation with a depth of fundamental single-qubit and CNOT gates. The depth is expected to increase by a factor of when multiplexing to implement an -feature output [33], see (13).
| (13) |
Figure 6.

Decomposed and simplified quantum fully connected layer.
4.2. Generalized Quantum Convolution
The most significant part of the MQCC framework is the generalized quantum convolution operation with support for arbitrary, parameterized filters. Compared with the classical convolution operation, the convolution operation in the quantum domain achieves exponential improvement in time complexity due to its innate parallelism. The convolution operation consists of stride, data rearrangement, and multiply-and-accumulate (MAC) operations.
Stride:
The first step of quantum convolution is generating shifted replicas of the input data. Quantum decrementers controlled by additional qubits, called “filter” qubits are used for this purpose. The operator shown in Figure A8b shifts the replica by a single stride.
The stride operation, , is composed of controlled quantum decrementers, where each operation has a quadratic depth complexity; see (A15). Thus, the depth of the controlled quantum decrementer can be derived according to (14), where n corresponds to the number of qubits the decrementer is applied to and c reflects the number of control qubits.
| (14) |
Multiply-and-Accumulate (MAC):
Kernels are applied to the strided replicas of the input data in parallel using the MAC operation; see Figure 4. In the MAC operations, kernels are applied to the contiguous set of data with the help of the inverse arbitrary state synthesis operation. One benefit achieved by using this MAC operation is the superposition of multiple kernels. The superposition of the kernel can be helpful for the classification of multiple features.
Data Rearrangement:
Data rearrangement is required to coalesce the output pieces of the MAC steps and create one contiguous piece of output. This step is performed using perfect shuffle permutation (PSP) operations described in Appendix A.6.
4.2.1. One-Dimensional Multifeature Quantum Convolution
The one-dimensional quantum convolution operation, with a kernel of size terms, requires generating replicas of the input data in a range of possible strides between . Therefore, a total of terms need to be encoded into a quantum circuit, including the additional auxiliary qubits, denoted as “kernel” qubits, which are allocated the most significant qubits to maintain data contiguity.
Necessary replicas of the input vector are created by using Hadamard gates; see Figure 7. Convolution kernels can be implemented using multiply-and-accumulate (MAC) operations; as such, it is possible to leverage , as defined in Section 4.1, for implementing quantum convolution kernels. Given a kernel , the corresponding kernel operation can be constructed from the normalized kernel , as shown in (15).
| (15) |
When applied to the lower qubits of the state vector, applies the kernel K to all data windows in parallel. However, in CNNs, convolution layers typically must support multiple convolution kernels/features. Fortunately, one major advantage of the proposed quantum convolution technique is that multiple features can be supported by multiplexing only the MAC operations—the stride and data rearrangement operations do not need to be multiplexed; see Figure 7. Accordingly, for features, must be added to the circuit and placed in superposition using Hadamard gates, similar to the process in (9). Thus, the depth complexity of can be expressed in terms of , as described by (16), where for all ; see Figure 7. Similarly, the depth complexity of can be expressed by (17). Finally, The depth of the proposed multifeature 1D quantum convolution can be obtained as (18).
| (16) |
| (17) |
| (18) |
Figure 7.

One-dimensional quantum convolution circuit.
4.2.2. Multidimensional Multifeature Quantum Convolution
Multidimensional quantum convolution can be implemented by stacking multiple one-dimensional quantum circuits, as shown in Figure 8. A d-dimensional quantum convolution circuit can be constructed with a stacked kernel of 1-dimensional convolution circuits only when the multidimensional kernels are outer products of d instances of 1-dimensional kernels. The depth of d-D quantum convolution can be obtained as (19).
| (19) |
Figure 8.

Multidimensional quantum convolution circuit.
4.3. Quantum Pooling
A critical part of CNNs is the pooling operation or downsampling of the feature maps. One widely used method is average pooling, where only the average of the adjacent pixels in the feature map is preserved, creating a smoothing effect [34].
4.3.1. Quantum Average Pooling using Quantum Haar Transform
The average pooling operation can be implemented using the quantum wavelet transform (QWT) [11], which has the advantage of preserving data locality using wavelet transform decomposition. It is a commonly used technique for dimension reduction in image processing [11]. In this work, we utilize the simplest and first wavelet transform, quantum Haar transform (QHT) [11] to implement quantum pooling operation. This operation is executed in two steps: the Haar wavelet operation and data rearrangement.
Haar Wavelet Operation:
For separating the high- and low-frequency components from the input data, H gates are applied in parallel. The number of H gates applied in QHT is equal to the levels of decomposition.
Data Rearrangement:
After separating the high- and low-frequency components, quantum rotate-right (RoR) operations are applied to group them accordingly. As mentioned before, the proposed framework is highly parallelizable regardless of the dimensions of the data, as the QHT operation can be applied to multiple dimensions of data in parallel.
As shown in Figure 9a, for a single-level of decomposition, H gates are applied on one qubit (the least significant qubit) per dimension, and for ℓ-level decomposition, shown in Figure 9b, l number of H gates are applied per dimension. Each level of decomposition reduces the size of the corresponding dimension by a factor of 2.
Figure 9.

Quantum Haar transform circuits: (a) single-level One-dimensional (1-D) QHT circuit; (b) multilevel One-dimensional (1-D) QHT circuit.
4.3.2. Quantum Euclidean Pooling using Partial Measurement
In machine learning applications, the average and maximum (max) pooling [34] are the most commonly used pooling schemes for dimension reduction. The two schemes differ in the sharpness of data features. On one hand, max pooling yields a sharper definition of input features, which makes it preferable for edge detection and certain classification applications [34]. On the other hand, average pooling offers a smoother dimension reduction that may be preferred in other workloads [34]. Thus, to accompany our implementation of quantum averaging pooling using QHT (see Section 4.3.1), it would be beneficial to have an implementation of quantum max pooling. However, such an operation would be nonunitary, creating difficulty for the implementation of quantum max pooling [35]. Therefore, instead of max pooling, we utilize an alternative pooling technique we denote as quantum Euclidean pooling.
Mathematically, average and Euclidean pooling are special cases of the p-norm [36], where for a vector of size N elements, the p-norm or norm of a vector is given by (20) for [36]. The average pooling occurs for the 1-norm () and Euclidean pooling occurs for the 2-norm (). A notable benefit of the Euclidean pooling technique is its zero-depth circuit implementation by leveraging partial measurement [35].
| (20) |
This work leverages the multilevel, d-dimensional quantum Euclidean pooling circuit presented in [35]; see Figure 10. Here, for each dimension i, is the number of decomposition levels for dimension where [35].
4.4. Multidimensional Quantum Convolutional Classifier
The proposed multidimensional quantum convolution classifier framework, see Figure 11, resembles a CNN [2] structures. After a sequence of convolution pooling (CP) pairs, the model is finally connected to a fully connected layer, see Figure 6 and Figure 11. The total number of layers in the proposed model can be expressed in terms of CP pairs as , where is the number of CP pairs.
Figure 10.

Multilevel, d-D Euclidean pooling circuit.
Figure 11.

High-level overview of the MQCC architecture.
It is worth mentioning that there is no advantage in changing the number of features among convolution/pooling layers in the MQCC because of the implementation constraints. Therefore, the total number of kernel features can be estimated globally instead of layer-by-layer.
The circuit width of the MQCC (21) can be derived from the number of convolution layers, pooling layers, and the fully connected layer. Input data are encoded using n qubits, and each convolution operation adds qubits for features and qubits per layer for kernels. In addition, the fully connected operation contributes qubits to encode output features/classes. On the other hand, each Euclidean pooling layer frees ℓ qubits, which can then be reused by other layers.
| (21) |
The MQCC can be further parallelized in terms of circuit depth between the interlayer convolution/fully connected layers. This parallelism can be achieved by performing (multiplexed) MAC operations from the quantum convolution and fully connected layers in parallel with the stride operation from the previous layer(s) of quantum convolution. The circuit depth of MQCC can be derived as shown in (22).
| (22) |
4.5. Optimized MQCC
Figure 12 presents a width-optimized implementation of MQCC, which we refer to as Quantum-Optimized Multidimensional Quantum Convolutional Classifier (MQCC Optimized). To reduce the required number of qubits, the convolution and pooling operations are swapped, which allows kernel qubits to be trimmed for each convolution layer, see Section 4.2. To achieve higher processing efficiency, trimmed qubits are reassigned to later layers of dimension reduction and run in parallel. Furthermore, only Euclidean pooling with partial measurements is used because of the inherent circuit depth efficiency. The circuit width of MQCC Optimized is shown in (23), where n is the number of qubits corresponding to the data size, is the number of qubits corresponding to the features, and is the number of qubits corresponding to the classes. If necessary, additional pooling operations can be applied to keep the circuit width at or below the absolute minimum number of qubits n by excluding qubits dedicated to features and classes. It should be noted that reordering convolution and pooling operations reduces the maximum number of convolution operations by 1.
| (23) |
Accordingly, the depth of MQCC Optimized can be expressed as shown in (24).
| (24) |
To further reduce the depth of MQCC Optimized, we investigated replacing inverse-C2Q operations for MAC operations with different parameterized ansatz. More specifically, a common ansatz in QML, namely NLocal operation in Qiskit [37] or BasicEntanglerLayer in Pennylane [38], was utilized; see Figure 13. The depth of this ansatz is linear with respect to the data qubits (see (25)), which is a significant improvement over arbitrary state synthesis, which has a circuit depth of for an n-qubit state. Although the ansatz could potentially reduce circuit depth, its structure lacks theoretical motivation or guarantees for high fidelity when modeling convolution kernels.
| (25) |
Figure 12.

Quantum-Optimized Multidimensional Quantum Convolutional Classifier (MQCC Optimized).
Figure 13.

Alternate ansatz option, distinct from .
5. Experimental Work
In this section, we first detail our experimental setup, followed by the results for the proposed MQCC technique. Experiments were conducted using real-world, multidimensional image data to test both the individual and composite components of our techniques.
5.1. Experimental Setup
The MQCC methodology was validated by first evaluating its most important component, namely convolution using the metric of fidelity and then evaluating the complete technique, i.e., MQCC and MQCC optimized by conducting classifications experiments using 1D, 2D, and 3D datasets.
For the convolution experiments on 1D data, we used audio material published by the European Broadcasting Union for sound quality assessment [39]. Using a preprocessing step, the data were converted into a single channel, with the data size varying from data points to data points, sampled at a rate of kHz.
For conducting 2D convolution experiments, we used 2D images that are either black and white or color Jayhawks [40], as shown in Figure 14. These images range in size from pixels to pixels. For the 3D image experiments, we used hyperspectral images from the Kennedy Space Center (KSC) dataset [41]. The images were preprocessed and resized, with the sizes ranging from pixels to pixels. Simulations of quantum convolution operation were run using Qiskit SDK (v0.45.0) from IBM Quantum [13] over the given data. To demonstrate the effect of statistical noise on the fidelity (26), both noise-free and noisy (with 1,000,000 circuit samples/shots) simulation environments were evaluated.
| (26) |
Figure 14.

High-resolution, multidimensional, real-world input data used in experimental trials: (a) 2D B/W image [40]; (b) 3D RGB image [40]; (c) 3D hyperspectral image [41].
To evaluate the performance of the complete MQCC and the MQCC-optimized technique, they were tested against CNNs, QCNNs, and quanvolutional neural networks by their capabilities of binary classification on real-world datasets, such as MNIST [42], FashionMNIST [43], and CIFAR10 [44]. The classical components in these trials were run using PyTorch (v2.1.0) [45], while the quantum circuits used Pennylane (v0.32.0), a Xanadu QML-focused framework [46].
The experiments were performed on a cluster node at the University of Kansas [47]. The node consisted of a 48-Core Intel Xeon Gold 6342 CPU, three NVIDIA A100 80 GB GPUs (CUDA version 11.7) with PCIe 4.0 connectivity and 256 GB of 3200 MHz DDR4 RAM. To account for initial parameter variance in ML or noise in noisy simulations, experiments were repeated for 10 trials, with the median being displayed in graphs.
5.2. Configuration of ML Models
The different techniques fundamentally being ML models meant that they could share some parameters and metrics during their testing. For example, the log loss and the Adam optimizer [48] were shared by all the techniques, and the “feature-count” metric was shared between the CNN and MQCC, which have 4 features per convolution layer. The parameters that were unique to each model are discussed next.
Convolutional Neural Networks: In Figure 15, we show the classification accuracy of the CNN model on () and () FashionMNIST datasets, using average pooling, max pooling, and Euclidean pooling. The plots show the obtained accuracy with and without ReLU [49], which is an optional layer that can be appended to each pooling layer in a CNN. Based on the results, which show Max Pooling without ReLU to be the configuration with the best accuracy, we chose it to be the baseline configuration for CNN in our tests.
Figure 15.

Classification accuracy of convolutional neural network (CNN) configurations on the FashionMNIST dataset: (a) () dataset; (b) () dataset.
Quanvolutional Neural Networks: While quanvolutional neural networks were initially introduced without a trainable random quantum circuit in the quanvolutional layer, later work has suggested implementing parameterized and trainable quanvolutional layers. We, therefore, test both the trainable and nontrainable quanvolutional techniques, and Figure 16 demonstrates that the trainable variant outperforms the other method in the () FashionMNIST dataset, although the differences are negligible on the () dataset. This is used as evidence behind our decision to use the trainable variant of the quanvolutional neural network as the baseline for comparison with the other models.
Figure 16.

Classification accuracy of quanvolution neural network configurations on the FashionMNIST dataset: (a) () dataset; (b) () dataset.
Quantum Convolutional Neural Networks: We based our implementation of the QCNN on [50]; however, some modifications were made to the technique to work around limitations present in the data encoding method. When encoding data that are not of size in each dimension, the original method flattens (vectorizes) the input before padding with zeros, as opposed to padding each dimension. However, this sacrifices the advantage of multidimensional encoding, where each dimension is mapped to a region of qubits. To ensure a level field between QCNN and MQCC, the () and () FashionMNIST datasets were tested both for the original (1D) and a corrected (2D) data encoding configuration of the QCNN, the results of which are shown in Figure 17. As expected, we see a clear improvement on the () dataset, and based on this, we chose the corrected (2D) data encoding method as our baseline QCNN for comparison against other ML models.
Figure 17.

Classification accuracy of quantum convolutional neural network (QCNN) configurations on the FashionMNIST dataset: (a) () dataset; (b) () dataset.
5.3. Results and Analysis
We first present the results of the quantum convolution operations on data with varying dimensionalities. Then, we compare the fidelity results of the quantum convolution under a noisy simulation environment with reference to classical convolution implementation. Finally, we present the results for MQCC.
Quantum Convolution Results
The fidelity of the quantum convolution technique was tested in both a noise-free and noisy environment against a classical implementation using common and filter kernels. These kernels, as described in (27)–(33), include the Averaging , Gaussian blur , Sobel edge-detection /, and Laplacian of Gaussian blur (Laplacian) filters. To enable a quantum implementation of these kernels, a classical preprocessing step zero-padded each kernel until the dimensions were an integer power of two. As negative values may occur in classical convolution, the magnitudes of the output values were cast into a single-byte range in a classical postprocessing step.
| (27) |
| (28) |
| (29) |
| (30) |
| (31) |
| (32) |
| (33) |
| (34) |
A 1D averaging kernel of sizes () and () was applied to audio files after preprocessing, described in Section 5.1, with data size ranging from to data points. Table 1 presents the reconstructed output data of this operation, with Figure 18 displaying the associated calculated fidelity.
Table 1.
The 1D convolution (averaging) filters applied to 1D audio samples [39].
| Data Size (No. of Sample Points) |
(3) Averaging Classical/ Noise-Free |
(3) Averaging Noisy ( Shots) |
(5) Averaging Classical/ Noise-Free |
(5) Averaging Noisy ( Shots) |
|---|---|---|---|---|
| 256 |

|
|||
| 4096 |
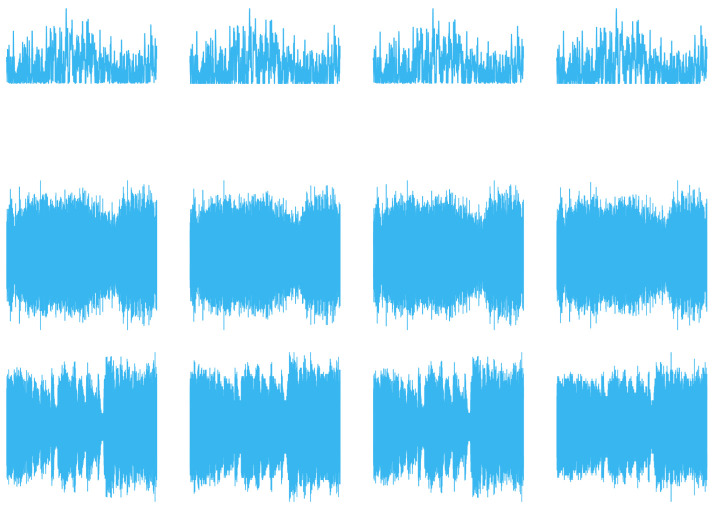
|
|||
| 65,536 | ||||
| 1,048,576 | ||||
Figure 18.

Fidelity of 1D convolution (averaging) filters with unity stride on 1D audio data (sampled with 1,000,000 shots).
The 2D averaging, Gaussian blur, Sobel edge-detection, and Laplacian kernels were applied to 2D black-and-white (B/W) and 3D RGB Jayhawk images, see Figure 14, ranging from () to () pixels and () pixels to () pixels, respectively.
The reconstruction from convolution operations in classical, noise-free, and noisy environments on ()- and ()-pixel input images can be seen in Table 2 and Table 3, respectively.
Table 2.
Two-dimensional convolution kernels applied to a () bw image [40].
| Kernel | () Kernel Classical/Noise-Free |
() Kernel Noisy ( Shots) |
() Kernel Classical/Noise-Free |
() Kernel Noisy ( Shots) |
|---|---|---|---|---|
| Average |
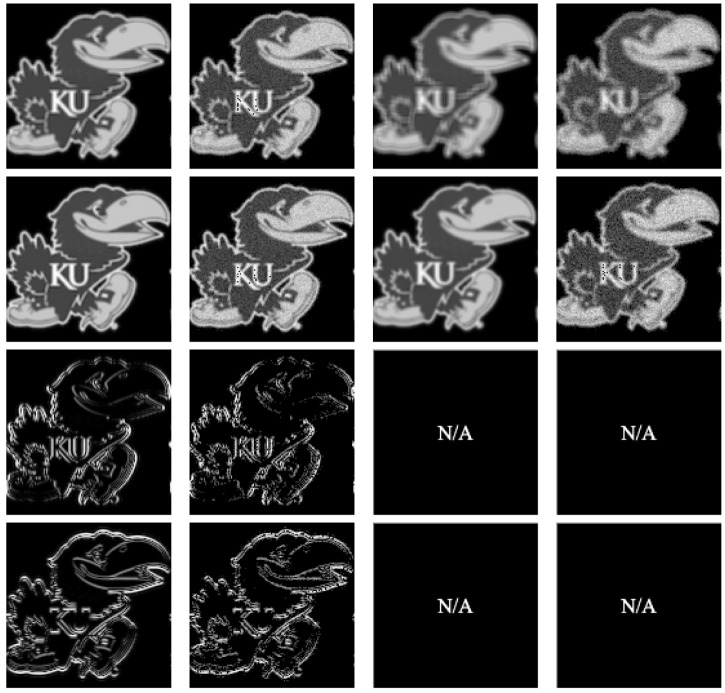
|
|||
| Gaussian | ||||
| Sobel-X | ||||
| Sobel-Y | ||||
| Laplacian |

|
|||
Table 3.
Two-dimensional convolution kernels applied to a () rgb image [40].
| Kernel | () Kernel Classical/Noise-Free |
() Kernel Noisy ( Shots) |
() Kernel Classical/Noise-Free |
() Kernel Noisy ( Shots) |
|---|---|---|---|---|
| Average |
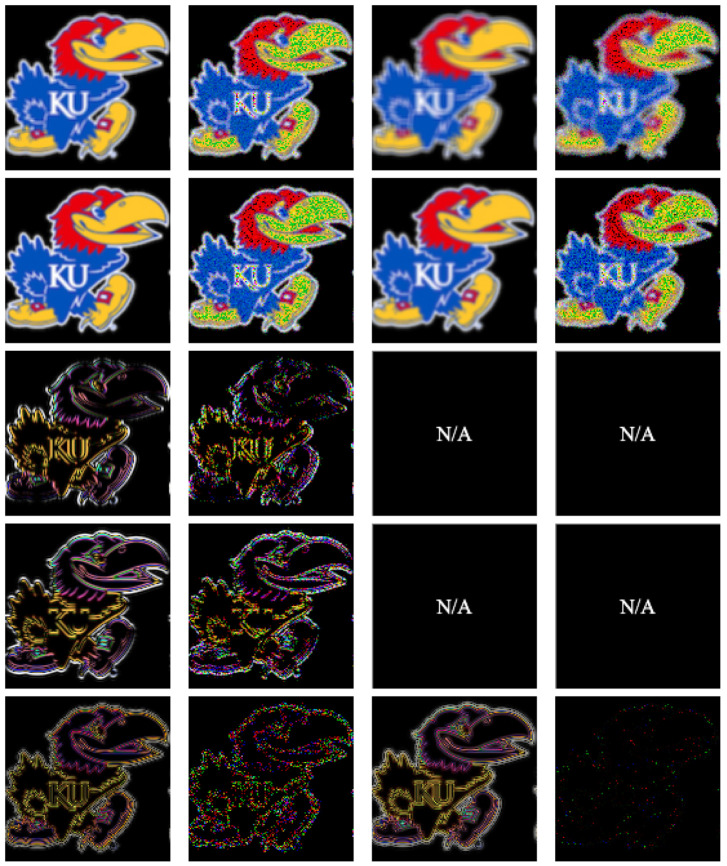
|
|||
| Gaussian | ||||
| Sobel-X | ||||
| Sobel-Y | ||||
| Laplacian | ||||
Finally, a 3D averaging kernel of sizes () and () was applied to hyperspectral images from the KSC dataset [41]. The images were preprocessed and resized to a power of two, ranging from () pixels to () pixels in size. Table 4 shows the reconstructed output images from convolution operations in classical, noise-free, and noisy environments.
Table 4.
The 3D convolution (averaging) filters applied to 3D hyperspectral images (bands 0, 1, and 2) [41].
| Data Size () |
() Averaging Classical/ Noise-Free |
() Averaging Noisy ( Shots) |
() Averaging Classical/ Noise-Free |
() Averaging Noisy ( Shots) |
|---|---|---|---|---|
| () |
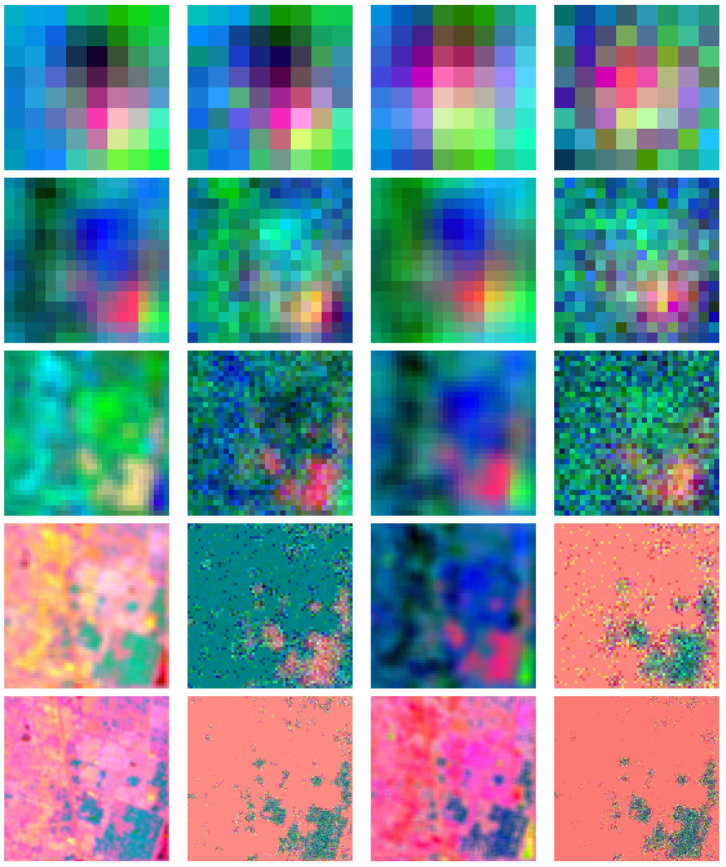
|
|||
| () | ||||
| () | ||||
| () | ||||
| () | ||||
Compared with the expected, classically generated results, the noise-free quantum results tested at 100% fidelity across all trials. Therefore, in a noise-free environment, given the same inputs, the proposed convolution techniques have no degradation compared with classical convolution. The fidelity of noisy simulations using 1D audio, 2D B/W, 2D RGB, and 3D hyperspectral data are presented in Figure 18, Figure 19, Figure 20, and Figure 21, respectively. The fidelity degradation in these figures is due to the statistical noise where the constant shot count (number of circuit samples) becomes less and less sufficient to describe the increasing data size. We could improve this reduction from noise by increasing the number of shots, but our experiments were limited to 1,000,000 shots in simulation, which is the maximum number of shots allowed by the simulator.
Figure 19.

Fidelity of 2D convolution filters with unity stride on 2D B/W data (sampled with 1,000,000 shots).
Figure 20.

Fidelity of 2D convolution filters with unity stride on 3D RGB data (sampled with 1,000,000 shots).
Figure 21.

Fidelity of 3D convolution (averaging) filters with unity stride on 3D hyperspectral data (sampled with 1,000,000 shots).
6. Discussion
In this section, we discuss the results of our experiments with MQCC and compare them against the other models in terms of the number of required training parameters, the accuracy of the model, and the circuit depth of the implemented model. The number of qubits required by MQCC can be easily calculated using (23). The number of qubits required for data encoding and filter implementation can be obtained from the dimensions of the data and filter respectively, i.e., for data, qubits for four features. Similarly, the number of qubits required for feature classes can be calculated as, for example, for 2 classes. All together, for input data encoded into n qubits, the optimized MQCC requires qubits.
6.1. Number of Parameters
Among the classical ML models evaluated, MQCC had the fewest trainable parameters; see Figure 22. This implies potential advantages such as reduced memory usage and faster performance when using classical gradient descent. Although the reduction in parameter decreases from (MLP to CNN) and then further from (CNN to MQCC), parameter reduction diminishes from (MLP to CNN) and further from (CNN to MQCC), and there is still a significant decrease in parameter count.
Figure 22.

Number of training parameters for ML models for tested data sizes.
6.2. Loss History and Accuracy
ML-based classifiers aim to maximize the accuracy of their classifications, measured by a loss function during training to estimate the accuracy that may be exhibited when deployed. Hence, Figure 23 and Figure 24 depict the performance of the ML models across the experimental datasets in their plotting of log-loss history and classification accuracy. The MNIST [42] dataset is not complex enough to effectively distinguish models; however, differences begin to emerge in the FashionMNIST [43] and CIFAR10 [44] datasets. MLP consistently achieves the highest accuracy across trials due to its larger parameter count, allowing for greater flexibility in adapting to nuances in input. The CNN showcases its ability to select relevant input features using convolution and data locality, demonstrating the second-highest accuracy. Among the tested models, QCNN generally performs the poorest, displaying its inability to properly leverage data locality. However, comparing the accuracy of MQCC and quanvolutional neural networks is inconclusive. Quanvolutional neural networks performed better on FashionMNIST, whereas MQCC performed better on CIFAR10.
Figure 23.

Loss history of ML models on various datasets: (a) MNIST (); (b) MNIST (); (c) FashionMNIST (); (d) FashionMNIST (); (e) CIFAR10 (); (f) CIFAR10 ().
Figure 24.


Classification accuracy of ML models on various datasets: (a) MNIST (); (b) MNIST (); (c) FashionMNIST (); (d) FashionMNIST (); (e) CIFAR10 (); (f) CIFAR10 ().
6.3. Gate Count and Circuit Depth
Although comparing MQCC, MQCC Optimized, and QCNN with quantum metrics like gate count and circuit depth is viable, see Figure 25, it is challenging to include quanvolutional neural networks in the comparison due to their significant differences from the other models. These differences are due to the quantum component within quanvolutional neural networks constituting a small fraction of the entire algorithm, bringing it closer to a classical algorithm than a quantum algorithm. Meanwhile, comparing the techniques of MQCC and QCNN in Figure 25 highlights the rationale behind developing MQCC Optimized. Initially, MQCC performed worse than QCNN in gate count and circuit depth. However, after optimizations, MQCC matched the performance of QCNN and even outperformed it in the best-case scenarios. While the QCNN architecture appears more suitable for shallower quantum circuits than MQCC, it is because the high parallelization of each QCNN layer halves the active qubits.
Despite QCNN using half the active qubits per layer than MQCC, MQCC utilizes the extra qubits for weights and features, with each pooling layer reducing the qubit count by a constant amount, . However, as QCNN structures are motivated by the classical convolution operation, they usually need more complex and deeper “convolution” and “pooling” ansatz to attain a higher accuracy.
Figure 25.

Gate count and circuit depth of MQCC vs. QCNN: (a) gate count; (b) circuit depth.
6.4. Complexity Comparison with Classical Models
The proposed method can also be compared with the classical models in terms of temporal complexity. The temporal/depth complexity of MQCC Optimized can be easily derived using Figure 11 and Figure 12, as well as (24), as shown in (35), where and are combined to obtain .
| (35) |
For a MAC-based fully connected layer, we can consider to obtain the complexity using (13) and (35), as shown in (36). Similarly, for an ansatz-based fully connected layer, we can consider to obtain the complexity using (25) and (35), as shown in (37).
| (36) |
| (37) |
The general expression for calculating the temporal complexity of classical CNNs is shown in (38). It can be broadly divided into three parts: the complexity of the convolutional layers, the complexity of the pooling layers, and the complexity of the fully connected layers. The complexity of the combined layers of convolution and pooling is primarily determined by the number of filters, the size of the filters, and the dimensions of the input feature maps, while the complexity of fully connected layers depends on the number of neurons in the layers. It is worth mentioning that in classical CNNs, convolutional layers dominate both the pooling and fully connected layers in the overall execution time, as expressed by (38).
| (38) |
A comparison of the depth/temporal complexity of MQCC Optimized against the classical method is shown in Table 5. It details the depth complexities of C2Q data encoding (I/O overhead), two variants of MQCC Optimized, i.e., MAC-based fully connected layer and ansatz-based fully connected layer, and three variants of classical CNN implementation. Among the classical CNN variants, i.e., Direct (CPU), FFT (CPU/GPU), and GEMM (GPU), we consider the Direct (CPU) case as the worst case and GEMM (GPU) as the best case. The MQCC-optimized algorithm with a MAC-based fully connected layer matches the best case. Considering the depth of the I/O circuit, which, in this case, is the depth of the C2Q method, the overall complexity of MQCC is still better than the worst case in classical methods. The MQCC-optimized algorithm, with an ansatz-based fully connected layer, has the least complexity among all the compared models. Although the I/O overhead represents the worst-case scenario for our proposed technique (see Table 5), the complexity of our proposed MQCC technique, including the I/O overhead, matches the best case in classical methods. It is worth emphasizing that the I/O overhead is not intrinsic to our proposed technique; rather, it is a general consideration for any data-intensive quantum application like quantum machine learning (QML) classification. Moreover, our proposed MQCC method provides two additional advantages over classical CNNs, being highly parallelizable and requiring fewer training parameters, see Figure 22, which ultimately leads to fewer resource requirements than classical CNNs.
Table 5.
Comparison of depth/time complexity of proposed MQCC-optimized against classical CNN.
| a Depth complexity of C2Q [12] data encoding (I/O) technique | ||||
| b Complexity of proposed technique compared with classical convolutional neural network | ||||
| MQCC Optimized with MAC-based fully connected layer | MQCC Optimized with ansatz-based fully connected layer | Direct (CPU) [21] | FFT (CPU/GPU) [21,22] | GEMM (GPU) [23,24] |
7. Conclusions
In this paper, we presented a multidimensional quantum convolutional classifier (MQCC) that consists of quantum convolution, quantum pooling, and a quantum fully connected layer. We leveraged existing convolution techniques to support multiple features/kernels and utilized them in our proposed method. Furthermore, we proposed a novel width-optimized quantum circuit that reuses freed-up qubits from the pooling layer in the subsequent convolutional layer. The proposed MQCC additionally preserves data locality in the input data which has shown to improve data classification in convolutional classifiers. The MQCC methodology is generalizable for any arbitrary multidimensional filter operation and pertinent for multifeature extraction. The proposed method can also support data of arbitrary dimensionality since the underlying quantum pooling and convolution operations are generalizable across data dimensions. We experimentally evaluated the proposed MQCC on various real-world multidimensional images, utilizing several filters through simulations on state-of-the-art quantum simulators from IBM Quantum and Xanadu. In our experiments, MQCC achieved higher classification accuracy over contemporary QML methods while having a reduced circuit depth and gate count. In our future work, we are planning on expanding MQCC with additional convolution capabilities, such as arbitrary striding and dilation, and further optimizing it for deployment on real-world quantum processors. In addition, we will investigate using our proposed quantum techniques for real-life applications such as medical imaging and classification.
Acknowledgments
This research used resources of the Oak Ridge Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC05-00OR22725.
Appendix A
In this section, we briefly discuss fundamental quantum topics including various quantum operations that are relevant to the proposed MQCC. These operations are generally applicable to quantum computing and quantum machine learning.
Appendix A.1. Quantum Bits and States
A single quantum bit, or qubit, can be represented by a normalized vector |〉 with elements, called a state vector; see (A1). The state of a qubit is represented as a point on the surface of the Bloch sphere [51], as shown in Figure A1. To preserve the normalization property of a state vector, a qubit’s state can only be expressed as a point on the sphere’s surface [10].
| (A1) |
Figure A1.

The Bloch sphere.
For n qubits, the state vector |〉 has elements. As shown in (A2), each element of |〉 represents the amplitude/coefficient of the entry in |〉, or the basis state |j〉 [10].
| (A2) |
Appendix A.2. Rotation Gates
The rotation gates, , , and , are parameterized versions of the Pauli single-qubit gates, shown in (A3), (A4) and (A5), respectively [33]. In QML, rotation gate parameters are trained to produce better models [5,7].
| (A3) |
| (A4) |
| (A5) |
Appendix A.3. Hadamard Gate
The Hadamard gate is a fundamental quantum gate that puts the qubit into a superposition of two basis states, the |0〉 and |1〉 states; see (A6) and Figure A2 [10]. Similarly, by applying Hadamard gates on n qubits independently, an n-qubit superposition can be created that comprises of basis states, as shown in (A7).
| (A6) |
Figure A2.
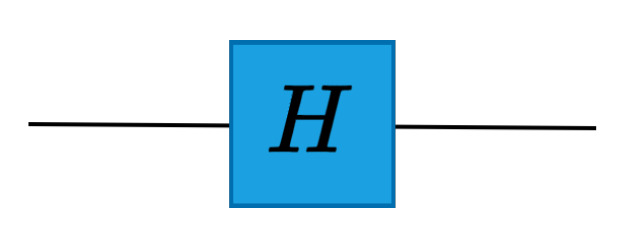
Hadamard gate diagram.
| (A7) |
Appendix A.4. Controlled-NOT (CNOT) Gate
CNOT gates can form a fundamental set of basis gates in conjunction with single-qubit rotation gates [33]; see (A8) and Figure A3. CNOT gates can be used to entangle two qubits, where a measurement of one qubit can provide information about the second qubit [33].
| (A8) |
Figure A3.
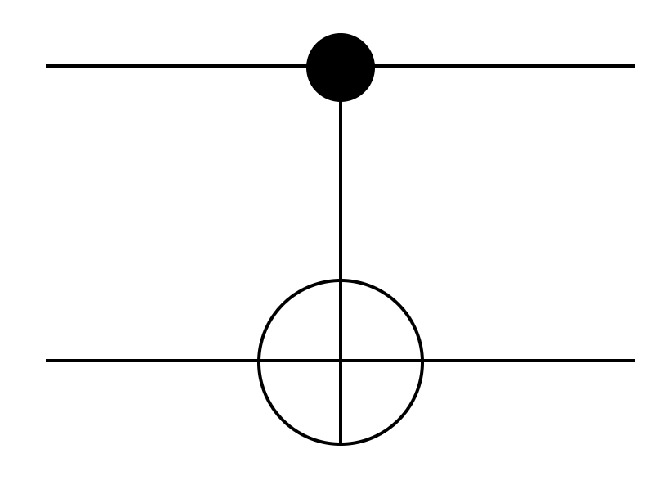
Controlled-NOT gate diagram.
All gates, single- or multiqubit, can be extended to have control qubit(s), as shown for a general U in (A9) and Figure A4 [33].
| (A9) |
Figure A4.
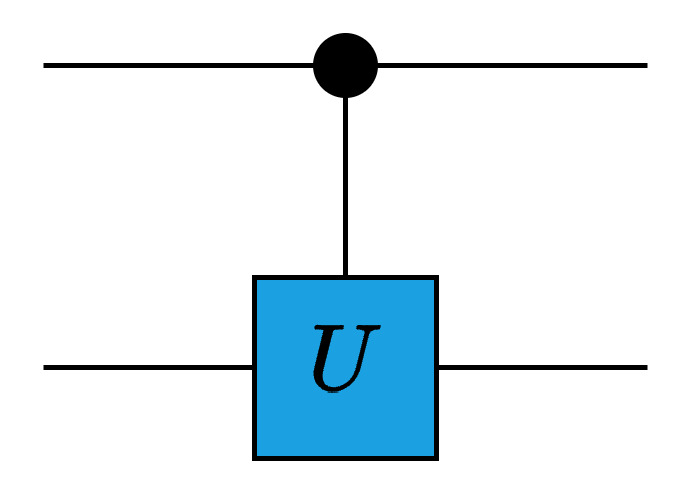
Controlled-U gate diagram.
When a general multiqubit gate is extended to have more control qubits, it becomes an n-qubit multiple-controlled U (MCU) gate. In the context of CNOT gates, the operation becomes a multiple-controlled-not (MCX) gate [52]. For an n-qubit MCX gate with control qubits and 1 target qubit (see (A10)), the depth of an MCX gate with the addition of a single extra qubit can be found in (A11) [52].
| (A10) |
| (A11) |
The most general controlled gate is the multiplexer, see (A12), which defines a quantum operation to be applied on qubits for each state permutation of some control qubit(s), [33]. In quantum circuits, the square box notation is used to denote a multiplexer operation, as shown in Figure A5 [33].
| (A12) |
Figure A5.

The square box notation for a quantum multiplexer [33].
Here, is a matrix of size defining the unitary operations/gates applied on each data qubit for the corresponding values i, where, .
Appendix A.5. SWAP Gate
In a quantum circuit, SWAP gates are applied to interchange the position of two qubits, as shown in (A13) and Figure A6. The SWAP gate can be decomposed into three CNOT gates [10]; see Figure A6.
| (A13) |
Figure A6.
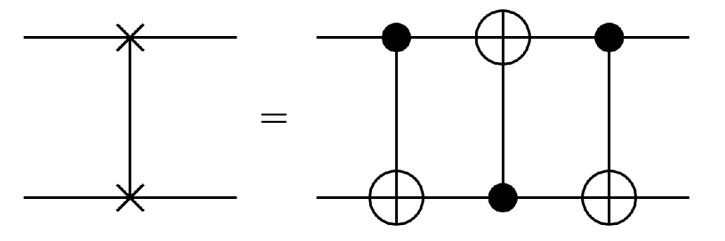
Swap gate diagram and decomposition.
Appendix A.6. Quantum Perfect-Shuffle Permutation (PSP)
The quantum perfect-shuffle permutations (PSPs) are operations that perform a cyclical rotation of given input qubits and can be implemented using SWAP gates. Figure A7 shows the rotate-left (RoL) and rotate-right (RoR) PSP operations [11] with SWAP operations, or equivalent CNOT operations. More information about CNOT and SWAP gates can be found in Appendix A.4 and Appendix A.5, respectively.
Figure A7.

Quantum Perfect-Shuffle Permutations [11]. (a) RoL: ; (b) RoR: .
Appendix A.7. Quantum Shift Operation
The quantum shift operation also performs a cyclic rotation of the basis states [20] similar to the quantum perfect-shuffle operations. Here, the basis states of the n-qubit state |〉 are shifted by or positions by applying a shift operation ; see (A14). Here, the value of k determines the type of operation such that when , and the corresponding shift operation is denoted as a quantum incrementer, as shown in Figure A8a [30,53], and when , the corresponding shift operation is denoted as a quantum decrementer [30,53], as shown in Figure A8b. The quantum shift operation plays a vital role in convolution operation by striding the filter operation over data windows [25].
| (A14) |
Figure A8.

Quantum incrementer, decrementer, and construction of quantum shift operation: (a) quantum incrementer by 1; (b) quantum decrementer by 1; (c) quantum shift operation by , where .
Each quantum shift operation acting on an n-qubit state can be decomposed into a pyramidal structure of n× MCX gates in a series pattern [20], as shown in Figure A8a,b. In terms of fundamental single-qubit and CNOT gates, the depth of a quantum shift operation with can be demonstrated as quadratic [52]; see (A15). Generalized quantum shift operations can be derived using operations, from the expression in (A14), and the corresponding circuit depth can be derived as shown in (A16).
| (A15) |
| (A16) |
Now, can be expressed as a sequence of controlled shift operations, as shown in (A17). Such operations can be denoted as , where and indicates that the shift operation is applied to an n-qubit state, as shown in (A18). Instead of applying sequential operations, each operation can be performed using a single operation; see (A18). Therefore, a more depth-efficient decomposition is shown in Figure A8, and the corresponding depth is provided in (A19).
| (A17) |
| (A18) |
| (A19) |
Author Contributions
Conceptualization: E.E.-A., M.J., D.K., and V.J.; methodology: E.E.-A., M.J., D.K., and V.J.; software: E.E.-A., M.J., D.K., and D.L.; validation: E.E.-A., M.J., V.J., A.N., D.K., and D.L.; formal analysis: E.E.-A., M.J., D.L., D.K., and V.J.; investigation: E.E.-A., M.J., V.J., A.N., D.K., D.L., I.I., M.C., A.F., E.V., M.S., A.A., and E.B.; resources: E.E.-A., M.J., A.N., D.L., V.J., M.C., D.K., A.F., I.I., E.B., M.S., A.A., and E.V.; data curation: E.E.-A., M.J., V.J., A.N., D.K., D.L., I.I., M.C., A.F., E.V., M.S., E.B., and A.A.; writing—original draft preparation: E.E.-A., A.N., M.J., V.J., D.K., D.L., I.I., and M.C.; writing—review and editing: E.E.-A., M.J., V.J., A.N., D.K., D.L., I.I., M.C., A.F., E.V., M.S., E.B., and A.A.; visualization: E.E.-A., M.J., V.J., A.N., D.K., D.L., I.I., M.C., A.F., E.V., M.S., E.B., and A.A.; supervision: E.E.-A.; project administration: E.E.-A.; funding acquisition: E.E.-A. All authors have read and agreed to the published version of the manuscript.
Data Availability Statement
The audio samples used in this work are publicly available from the European Broadcasting Union at https://tech.ebu.ch/publications/sqamcd (accessed on 23 February 2024) as file 64.flac [39]. The hyperspectral data used in this work are publicly available from the Grupo de Inteligencia Computacional (GIC) at https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes#Kennedy_Space_Center_(KSC) (accessed on 23 February 2024) under the heading Kennedy Space Center (KSC) [41].
Conflicts of Interest
The authors declare no conflicts of interest.
Funding Statement
This research received no external funding.
Footnotes
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
References
- 1.Villalobos P., Sevilla J., Besiroglu T., Heim L., Ho A., Hobbhahn M. Machine learning model sizes and the parameter gap. arXiv. 20222207.02852 [Google Scholar]
- 2.LeCun Y., Kavukcuoglu K., Farabet C. Convolutional networks and applications in vision; Proceedings of the 2010 IEEE International Symposium on Circuits and Systems; Paris, France. 30 May–2 June 2010; New York, NY, USA: IEEE; 2010. pp. 253–256. [Google Scholar]
- 3.Lecun Y., Bengio Y., Hinton G. Deep learning. Nature. 2015;521:436–444. doi: 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- 4.Chakraborty S., Dey L. Computing for Data Analysis: Theory and Practices. Springer; Singapore: 2023. pp. 161–178. [Google Scholar]
- 5.Peruzzo A., McClean J., Shadbolt P., Yung M.H., Zhou X.Q., Love P.J., Aspuru-Guzik A., O’Brien J.L. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 2014;5:4213. doi: 10.1038/ncomms5213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Havlíček V., Córcoles D., Temme K., Harrow W., Kandala A., Chow J., Gambetta M. Supervised learning with quantum-enhanced feature spaces. Nature. 2019;567:209–212. doi: 10.1038/s41586-019-0980-2. [DOI] [PubMed] [Google Scholar]
- 7.Farhi E., Goldstone J., Gutmann S. A quantum approximate optimization algorithm. arXiv. 20141411.4028 [Google Scholar]
- 8.Farhi E., Neven H. Classification with quantum neural networks on near term processors. arXiv. 20181802.06002 [Google Scholar]
- 9.Schuld M., Bocharov A., Svore M., Wiebe N. Circuit-centric quantum classifiers. Phys. Rev. A. 2020;101:032308. doi: 10.1103/PhysRevA.101.032308. [DOI] [Google Scholar]
- 10.Williams C.P. Explorations in Quantum Computing. 2nd ed. Springer; London, UK: 2011. [Google Scholar]
- 11.Jeng M., Islam S.I.U., Levy D., Riachi A., Chaudhary M., Nobel M.A.I., Kneidel D., Jha V., Bauer J., Maurya A., et al. Improving quantum-to-classical data decoding using optimized quantum wavelet transform. J. Supercomput. 2023;79:20532–20561. doi: 10.1007/s11227-023-05433-7. [DOI] [Google Scholar]
- 12.El-Araby E., Mahmud N., Jeng M.J., MacGillivray A., Chaudhary M., Nobel M.A.I., Islam S.I.U., Levy D., Kneidel D., Watson M.R., et al. Towards Complete and Scalable Emulation of Quantum Algorithms on High-Performance Reconfigurable Computers. IEEE Trans. Comput. 2023;72:2350–2364. doi: 10.1109/TC.2023.3248276. [DOI] [Google Scholar]
- 13.IBM Quantum. Qiskit: An Open-Source Framework for Quantum Computing. Zenodo. [(accessed on 28 February 2024)]. Available online: [DOI]
- 14.Nation P. How to Measure and Reset a Qubit in the Middle of a Circuit Execution. 2021. [(accessed on 26 February 2024)]. Available online: https://www.ibm.com/quantum/blog/quantum-mid-circuit-measurement.
- 15.Mi A., Deng S., Szefer J. Securing Reset Operations in NISQ Quantum Computers; Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security; Los Angeles, CA, USA. 7–11 November 2022; pp. 2279–2293. [Google Scholar]
- 16.Mahmud N., Jeng M., Nobel M.A.I., Chaudhary M., Ul Islam S.M.I., Levy D., El-Araby E. Efficient Data Encoding and Decoding for Quantum Computing; Proceedings of the 2022 IEEE International Conference on Quantum Computing and Engineering (QCE); Broomfield, CO, USA. 18–23 September 2022; pp. 765–768. [DOI] [Google Scholar]
- 17.Albawi S., Mohammed T.A., Al-Zawi S. Understanding of a convolutional neural network; Proceedings of the 2017 International Conference on Engineering and Technology (ICET); Antalya, Turkey. 21–23 August 2017; Piscataway, NJ, USA: IEEE; 2017. pp. 1–6. [Google Scholar]
- 18.Le Q., Dong F., Hirota K. A flexible representation of quantum images for polynomial preparation, image compression, and processing operations. Quantum Inf. Process. 2011;10:63–84. doi: 10.1007/s11128-010-0177-y. [DOI] [Google Scholar]
- 19.Zhang Y., Lu K., Gao Y., Wang M. NEQR: A novel enhanced quantum representation of digital images. Quantum Inf. Process. 2013;12:2833–2860. doi: 10.1007/s11128-013-0567-z. [DOI] [Google Scholar]
- 20.Jeng M., Nobel A., Jha V., Levy D., Kneidel D., Chaudhary M., Islam I., Rahman M., El-Araby E. Generalized Quantum Convolution for Multidimensional Data. Entropy. 2023;25:11. doi: 10.3390/e25111503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Burrus C.S.S., Parks T.W. DFT/FFT and Convolution Algorithms: Theory and Implementation. John Wiley & Sons, Inc.; Hoboken, NJ, USA: 1991. [Google Scholar]
- 22.Podlozhnyuk V. FFT-Based 2D Convolution. NVIDIA. 2007. [(accessed on 18 February 2024)]. Available online: https://developer.download.nvidia.com/compute/cuda/1.1-Beta/x86_64_website/projects/convolutionFFT2D/doc/convolutionFFT2D.pdf.
- 23.NVIDIA CUTLASS Convolution. Github. 2023. [(accessed on 18 February 2024)]. Available online: https://github.com/NVIDIA/cutlass/blob/main/media/docs/implicit_gemm_convolution.md.
- 24.NVIDIA Convolution Algorithms. Github. 2023. [(accessed on 18 February 2024)]. Available online: https://docs.nvidia.com/deeplearning/performance/dl-performance-convolutional/index.html#conv-algo.
- 25.Fan P., Zhou R., Hu W., Jing N. Quantum image edge extraction based on classical Sobel operator for NEQR. Quantum Inf. Process. 2018;18:24. doi: 10.1007/s11128-018-2131-3. [DOI] [Google Scholar]
- 26.Ma Y., Ma H., Chu P. Demonstration of Quantum Image Edge Extration Enhancement through Improved Sobel Operator. IEEE Access. 2020;8:210277–210285. doi: 10.1109/ACCESS.2020.3038891. [DOI] [Google Scholar]
- 27.Zhang Y., Lu K., Gao Y. QSobel: A novel quantum image edge extraction algorithm. Sci. China Inf. Sci. 2015;58:1–13. doi: 10.1007/s11432-014-5158-9. [DOI] [Google Scholar]
- 28.Zhou R., Yu H., Cheng Y., Li F. Quantum image edge extraction based on improved Prewitt operator. Quantum Inf. Process. 2019;18:261. doi: 10.1007/s11128-019-2376-5. [DOI] [Google Scholar]
- 29.Li P. Quantum implementation of the classical Canny edge detector. Multimed. Tools Appl. 2022;81:11665–116941. doi: 10.1007/s11042-022-12337-w. [DOI] [Google Scholar]
- 30.Yao X., Wang H., Liao Z., Chen M., Pan J., Li J., Zhang K., Lin X., Wang Z., Luo Z., et al. Quantum Image Processing and Its Application to Edge Detection: Theory and Experiment. Phys. Rev. X. 2017;7:031041. doi: 10.1103/PhysRevX.7.031041. [DOI] [Google Scholar]
- 31.Cong I., Choi S., Lukin M.D. Quantum convolutional neural networks. Nat. Phys. 2019;15:1273–1278. doi: 10.1038/s41567-019-0648-8. [DOI] [Google Scholar]
- 32.Henderson M., Shakya S., Pradhan S., Cook T. Quanvolutional neural networks: Powering image recognition with quantum circuits. Quantum Mach. Intell. 2020;2:2. doi: 10.1007/s42484-020-00012-y. [DOI] [Google Scholar]
- 33.Shende V., Bullock S., Markov I. Synthesis of quantum-logic circuits. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2006;25:1000–1010. doi: 10.1109/TCAD.2005.855930. [DOI] [Google Scholar]
- 34.Bieder F., Sandkühler R., Cattin P. Comparison of methods generalizing max-and average-pooling. arXiv. 2021 doi: 10.48550/arXiv.2103.01746.2103.01746 [DOI] [Google Scholar]
- 35.Jeng M., Nobel A., Jha V., Levy D., Kneidel D., Chaudhary M., Islam I., Baumgartner E., Vanderhoof E., Facer A., et al. Optimizing Multidimensional Pooling for Variational Quantum Algorithms. Algorithms. 2024;17:82. doi: 10.3390/a17020082. [DOI] [Google Scholar]
- 36.PyTorch. torch.nn.LPPool1d [Computer Software] 2023. [(accessed on 18 February 2024)]. Available online: https://pytorch.org/docs/stable/generated/torch.nn.LPPool1d.html.
- 37.IBM Quantum. qiskit.circuit.library.NLocal [Computer Software] 2023. [(accessed on 18 February 2024)]. Available online: https://qiskit.org/documentation/stubs/qiskit.circuit.library.NLocal.html.
- 38.Xanadu. qml.BasicEntanglerLayers [Computer Software] 2023. [(accessed on 18 February 2024)]. Available online: https://docs.pennylane.ai/en/stable/code/api/pennylane.BasicEntanglerLayers.html.
- 39.Geneva, Switzerland. Sound Quality Assessment Material: Recordings for Subjective Tests. 1988. [(accessed on 18 February 2024)]. Available online: https://tech.ebu.ch/publications/sqamcd.
- 40.Brand Center, University of Kansas. Jayhawk Images. [(accessed on 18 February 2024)]. Available online: https://brand.ku.edu/
- 41.Graña M., Veganzons M.A., Ayerdi B. Hyperspectral Remote Sensing Scenes. [(accessed on 18 February 2024)]. Available online: https://www.ehu.eus/115ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes#Kennedy_Space_Center_(KSC)
- 42.Deng L. The MNIST database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012;29:141–142. doi: 10.1109/MSP.2012.2211477. [DOI] [Google Scholar]
- 43.Xiao H., Rasul K., Vollgraf R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv. 20171708.07747 [Google Scholar]
- 44.Krizhevsky A. Learning Multiple Layers of Features from Tiny Images. 2009. [(accessed on 18 February 2024)]. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf.
- 45.Paszke A., Gross S., Massa F., Lerer A., Bradbury J., Chanan G., Killeen T., Lin Z., Gimelshein N., Antiga L., et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019;32:8026–8037. [Google Scholar]
- 46.Bergholm V., Izaac J., Schuld M., Gogolin C., Ahmed S., Ajith V., Alam M.S., Alonso-Linaje G., AkashNarayanan B., Asadi A., et al. PennyLane: Automatic differentiation of hybrid quantum-classical computations. [(accessed on 18 February 2024)];arXiv. 2022 Available online: https://pennylane.ai/1811.04968 [Google Scholar]
- 47.KU Community Cluster, Center for Research Computing, University of Kansas. [(accessed on 18 February 2024)]. Available online: https://crc.ku.edu/systems-services/ku-community-cluster.
- 48.Kingma D.P., Ba J. Adam: A method for stochastic optimization. arxiv. 20141412.6980 [Google Scholar]
- 49.Arora R., Basu A., Mianjy P., Mukherjee A. Understanding deep neural networks with rectified linear units. arxiv. 20141611.01491 [Google Scholar]
- 50.Hur T., Kim L., Park D. Quantum convolutional neural network for classical data classification. Quantum Mach. Intell. 2022;4:3. doi: 10.1007/s42484-021-00061-x. [DOI] [Google Scholar]
- 51.Anton F.K., Franco N. Quantum Bits with Josephson Junctions. Springer; Cham, Switzerland: 2019. [Google Scholar]
- 52.Balauca S., Arusoaie A. Efficient Constructions for Simulating Multi Controlled Quantum Gates; Proceedings of the Computational Science—ICCS, 22nd International Conference; London, UK. 21–23 June 2022; Cham, Switzerland: Springer International Publishing; 2022. pp. 179–194. [DOI] [Google Scholar]
- 53.Li X., Yang G., Torres M., Zheng D., Wang L. A Class of Efficient Quantum Incrementer Gates for Quantum Circuit Synthesis. Int. J. Mod. Phys. B. 2014;28:1350191. doi: 10.1142/S0217979213501919. (Preprint) [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The audio samples used in this work are publicly available from the European Broadcasting Union at https://tech.ebu.ch/publications/sqamcd (accessed on 23 February 2024) as file 64.flac [39]. The hyperspectral data used in this work are publicly available from the Grupo de Inteligencia Computacional (GIC) at https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes#Kennedy_Space_Center_(KSC) (accessed on 23 February 2024) under the heading Kennedy Space Center (KSC) [41].