

Abstract
We utilize a Fourier transformation-based representation of Maxwell’s equations to develop physics-constrained neural networks for electrodynamics without gauge ambiguity, which we label the Fourier–Helmholtz–Maxwell neural operator method. In this approach, both of Gauss’s laws and Faraday’s law are built in as hard constraints, as well as the longitudinal component of Ampère–Maxwell in Fourier space, assuming the continuity equation. An encoder–decoder network acts as a solution operator for the transverse components of the Fourier transformed vector potential, , whose two degrees of freedom are used to predict the electromagnetic fields. This method was tested on two electron beam simulations. Among the models investigated, it was found that a U-Net architecture exhibited the best performance as it trained quicker, was more accurate and generalized better than the other architectures examined. We demonstrate that our approach is useful for solving Maxwell’s equations for the electromagnetic fields generated by intense relativistic charged particle beams and that it generalizes well to unseen test data, while being orders of magnitude quicker than conventional simulations. We show that the model can be re-trained to make highly accurate predictions in as few as 20 epochs on a previously unseen data set.
Subject terms: Applied physics, Computer science
Introduction
Electrodynamics govern a wide range of physical processes involving charged particle dynamics including universe expansion models, galactic disk formation, accelerator-based high energy X-ray light sources, achromatic metasurfaces, metasurfaces for dynamic holography, on-chip diffractive neural networks, and radiative damping of individual accelerated electrons1–21.
Despite widely available high performance computing, numerically calculating relativistic charged particle dynamics is still a challenge and an open area of research for large collections of particles undergoing collective effects in dynamics involving plasma turbulence22, space charge (SC) forces23,24, and coherent synchrotron radiation (CSR)25,26. For example, the photo-injectors of modern X-ray free electron lasers such as the LCLS, SwissFEL, and EuXFEL and plasma wakefield accelerators such as FACET-II can produce high quality intense bunches with few picosecond rms lengths of up to 2 nC charge per bunch that are accelerated and squeezed down to lengths of tens to hundreds of femtoseconds27–32. At low energy ( 5 MeV) the 6D phase space dynamics of such bunches are strongly coupled through collective SC forces. At high energy, when particle trajectories are curved through magnetic chicanes the dynamics are coupled by CSR.
For example, a 2 nC bunch contains electrons, for which calculating individual particle to particle SC or CSR interactions is a computationally expensive process. Conventional approaches can reduce the number of SC calculations by utilizing particle-in-cell methods, but state-of-the-art 3D CSR calculations still rely on point-to-point calculations33. Machine learning (ML) methods have demonstrated to be useful in non-invasive measurements and diagnostics of charged beams34 and in the simulations of magnetic fields through physics-informed neural networks35. They have also been found to speed up lattice quantum Monte Carlo simulations36, the design and simulation of fin field‑effect transistors37, the simulation of spin dynamical systems38 and finding the optimal ramp up for the production of Bose–Einstein condensates39.
Recently a new method was developed for enforcing hard physics constraints in ML, respecting physics and improving generalization40. In that work, 3D convolutional neural operators were used to generate the vector and scalar potential fields and , respectively, from which the electromagnetic fields were generated as , . Generating fields based on potentials as in40 enforces hard physics constraints, such as and , but it also adds gauge ambiguity. Building on this previous work, in this work we present a novel method for predicting electromagnetic fields, which utilizes a Fourier transformation-based representation of Maxwell’s equations and physics-constrained neural networks (PCNN) for electrodynamics without gauge ambiguity. In this approach, many of Maxwell’s equations are hard constraints: Gauss’s law for the electric and magnetic field, Faraday’s law and the longitudinal component (in Fourier space) of the Ampère–Maxwell’s law. We demonstrate this method for calculating the electromagnetic fields of intense relativistic charged particle beams.
Note: a hard constraint is one that is automatically satisfied. For example, using potentials, the condition automatically follows (up to numerical errors). This contrasts with a soft constraint, where one tries to guide the network to satisfy a condition by having a term in the loss function, such as .This term encourages the network to decrease the divergence at the specified locations and times during training but offers no guarantee the network’s output will be divergenceless.
Formalism
Maxwell’s equations in Fourier space
The formalism that will be employed here is also used in the canonical quantization of the electromagnetic field41, where distinguishing between the physical degrees of freedom and the gauge redundancies is important. In the context of our study, we use it to minimize the number of fields needed to be modeled, while also ensuring that a substantial number of Maxwell’s equations are automatically satisfied as hard constraints. We start with Maxwell’s equations in position space:
| 1 |
where , , , and are the time-varying electric field, magnetic field, current density, and charge density, respectively42. We perform a 3D spatial Fourier transform on Maxwell’s equations, which is defined for a vector field as
| 2 |
and rewrite Eq. (1) (assuming ; see “Appendix A” for a discussion of the zero case):
| 3 |
For each wave vector , a generic vector can be separated into components longitudinal and transverse to :
| 4 |
An inverse Fourier transformation of Eq. (4) will lead to a Helmholtz decomposition of . Gauss’s law for the electric and magnetic fields (Eq. (3)) can then be expressed as:
| 5 |
In Fourier space, the electric and magnetic fields’ dependence on the Fourier transformed scalar and vector potential, and , is given by . The transverse field components are:
| 6 |
Using Eq. (3), Faraday’s law trivially follows:
| 7 |
The transverse components of the Ampère–Maxwell equation become:
| 8 |
while using Eq. (5) it can be shown that the longitudinal components of the Ampère–Maxwell equation is equivalent to the continuity equation. The continuity equation also relates to , thus only and need be used.
From Eqs. (5) and (6), the EM fields can then be determined by:
| 9 |
followed by inverse Fourier transforms.
Fourier–Helmholtz–Maxwell neural operator
Given the charge and current density distributions, the EM Fields can be by determined by , as per Eq. (9), and . can be found from via Eq. (8). From this, we propose finding the generated EM fields using the approach depicted in the diagram of Fig. 1, where the hard constraints (ones automatically obeyed) are listed. Since this approach incorporates Fourier transformations, Helmholtz decompositions, and Maxwell’s equations within a neural operator framework, we refer to it as the Fourier–Helmholtz–Maxwell neural operator (FoHM-NO) method.
Figure 1.

The FoHM-NO method and its built-in hard physics constraints. denotes Fourier transformation, is the projection of the vector field to components transverse to , NN a neural network, and is inverse Fourier transformation.
In this work, we attempt to estimate the EM fields from and using the FoHM-NO method, specifically with convolutional neural networks. When applying neural networks to physics problems, prior theoretical knowledge can be leveraged to model useful quantities already identified by physicists (i.e., ), rather than the direct observables (i.e., and ). This has been demonstrated previously through the use of neural networks to model the Hamiltonian of classical systems43, the scalar and vector potentials to estimate EM fields40 and the stream function of an incompressible fluid’s velocity flow field44.
Ultimately, the FoHM-NO method exploits that the EM fields have only 2 independent degrees of freedom, as can be seen from Eq. (9) in the source-less case. On a fundamental level though, this stems from the photon being a spin-1 massless particle. One benefit of the method is that it require fewer fields than the 6 that would be needed for directly estimating both the electric and magnetic field, or the 4 necessary by using the scalar potential and the entire vector potential. With more fields to fit, there comes increasing tension between fitting the data while also satisfying physical conditions. In contrast, with this procedure by construction three of the four Maxwell’s equations (Eqs. (5) and (7)) are built-in as hard constraints. This is also the case for the longitudinal component of Ampère–Maxwell’s Law, which follows from the continuity equation and Gauss’s law for the electric field (see “Appendix B”). Working in Fourier space, meanwhile, has the advantage that spatial derivatives are traded for multiplication by wave vectors. Thus, constraints like Eq. (4) can be easier to satisfy than their spatial derivative counterparts. For a fast Fourier transform (FFT), if N is the total number of spatial data points, then the FFT has a time complexity of . This, along with modern GPU computing, means that moving to and fro from Fourier space can be done extremely quickly, even for very large data sets. We did not perform a temporal Fourier transform as the time length of the simulations varied. This variation would pose challenges to the networks to learn in the frequency domain. Additionally, the adoption of a 4D CNN would present computational challenges and significantly increases the number of parameters in models.
Computational EM methods done in configuration space have a notable advantage: an easy, straight-forward incorporation of spatial boundary conditions, which can be useful in solving many real-world EM problems. Here, we don’t consider any special spatial boundary conditions. For one, the simulation was just started with the initial conditions of the particles. Secondly, neural networks have been found to be useful in solving inverse PDE problems, where the problem may be ill-posed. For example, insufficient boundary conditions, a case where classical methods struggle or cannot be used45–47. We wish to apply our approach to inverse problems in future works.
An additional benefit of FoHM-NO is that by focusing on just rather than all the potential fields, the issue of gauge redundancy is bypassed. To see this, note that under a gauge transformation,
| 10 |
for some scalar function . Since the vector potential change occurs in the direction then,
| 11 |
Hence, by using just there is no need to choose a particular gauge. The gauge invariance of is well known in works involving the quantization of the EM field41,48,49 and the spin-orbit decomposition of gauge fields50.
Care must be taken, though, if one were to change inertial reference frames as , unlike the gauge-dependent , is not a Lorentz 4-vector. For our purposes, which is finding efficient and accurate computational methods for accelerator physics, this is not a serious issue.
The rest of this article is a proof-of-concept application of FoHM-NO for predicting the EM fields generated by relativistically charged particle beams. However, it is applicable to any EM setting where and are given, although it can also be extended to include the matter density fields in the predictions if the equations of state are used. While FoHM-NO may generally not perform as accurately as mature, state-of-the-art EM codes, the use of neural networks here gives it the advantage of having a very fast runtime. This can be useful in cases where speed is essential, such as accelerator control and diagnostics settings, where beam time can be quite limited. Alternatively, it can be used for exploratory analyses to find approximate solutions before bringing in more accurate, but slower, methods for refinement.
Data
Two simulations of electrons beams entering a solenoid magnetic fields were generated (see Fig. 2) to develop the FoHM-NO method. The first, the complex beam, was generated to train the neural networks. This complex beam was initially composed of several Gaussian bunches with spreads differing both between bunches and along the x, y, and z axes (see Fig. 3). The second, the Gaussian Beam, was generated to test the networks on a completely new unseen distribution which was not used for model training (see Fig. 4). This test beam starts as a Gaussian bunch before entering the magnetic field. This enabled us to test the method under very different scenarios, with the more intricate complex beam having multiple length scales in order to train the networks over a wider range of inputs. The Gaussian beam, which is much more simple, was used as a test as it more closely resembles physical beams in accelerators. All the data was generated using general particle tracer (GPT)51,52.
Figure 2.
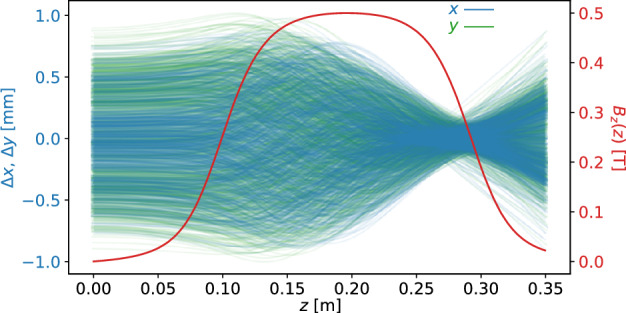
The (x, y) trajectories of 1000 random electrons within the beam are shown along with the z-component of the 0.5 Tesla magnetic field of the solenoid which over-compresses the beam.
Figure 3.

Cross-sections showing the spatial distribution of for the complex beam. The top row of plots shows x–y slices at z = 0 mm for different time steps. The bottom row shows x–z slices at y = 0 at the same time steps.
Figure 4.

Cross-sections showing the spatial distribution of for the Gaussian beam. The top row of plots shows x–y slices at z = 0 mm for different time steps. The bottom row shows x–z slices at y = 0 at the same time steps.
Considering the energy scales involved, GPT simulations only considered the space charge forces. For computational efficiency, GPT only registers EM fields where particles are present, creating artifacts where the EM field suddenly drop to where particles are absent. To address this issue, a large neutral group of particles co-moving with the beam was added to enable the registration of EM fields on the whole domain of interest without altering the motion of the electrons. Although the simulation took place on a spatial lattice, there were artifacts where the EM fields abruptly dropped to zero on the edges (not the matter fields, however). Therefore, the EM fields were cropped to for both beams.
Each simulations ran a 2 nC bunch of electrons with average energy 5.6 MeV moving through a 0.5 T solenoid magnetic field, first being compressed and then expanding (see Fig. 3). The space is a spatial grid. There were 201 time steps for the complex beam and 171 for the simple beam. The beam’s dynamics were simulated over a total time of 1.2 ns during which it traveled over a 0.35 m distance. The beam’s charge density and current density were binned as 3D histograms over cubes with 1.3 mm side lengths, as shown in Figs. 3 and 4. The physical spacing of grid were:
| 12 |
To improve convergence, we first scaled the data according to standard deviation. The data had a heavy tail, so in addition a log-like transform was performed , which has the property that larger values get greatly reduced, but smaller values stay about the same since for .
In this work, there were no special boundary condition considerations, an external magnetic field as generated by a cylindrically symmetric solenoid was provided as input. As charged particles moved through this field their dynamics were affected by the external solenoid field and by their own self-generated electric and magnetic fields which were calculated according to Maxwell’s equations based on the charge density and current density of the charged particle beam. In this setup the accelerator beam-pipe was assumed to be of large enough radius so that image charges and currents induced in the accelerator walls did not need to be considered. In future work, boundary conditions including image charges and Maxwell’s equations on the surfaces of conductors will be incorporated into the ML model as additional hard physics constraints.
Physics-constrained neural networks
Neural networks (NN’s) are powerful machine learning tools that, by the universal approximation theorem, can be used to approximate a function to arbitrary precision53,54. NN’s ability to approximate go even further by being universal approximators for operators55. This has been harnessed to produce approximate solutions to partial differential equations56,57, 3D electrodynamics40, and also two spatial dimensional magnetohydrodynamics simulations58,59.
The inclusion of physics information, constraints, or symmetries into NN be used to help guide training60. In some cases, these physics-incorporated NN’s can produce accurate predictions that are less computationally demanding than numerical simulations, while also being easier to develop and implement61. Here, we make use of a convolutional encoder–decoder architectures to make an NN that has as input and as output.
Models and fit
For a relativistic beam propagating along the z direction, we generally have and consequentially it is expected that the magnetic field is predominately in the x and y direction: . It was verified that this was indeed the case for both beam simulations used here. In fact, was both small and noisy, likely heavily corrupted by numerical errors. Thus, to make things more computationally efficient and increase training speed, the model was trained only using the z component of to predict the z component of :
| 13 |
From this the transverse components of the magnetic field, and , are obtained via . The models were trained on the first 85% of the complex beam run, which is the training set. The remainder, validation set, was used for hyperparameter tuning. The entire Gaussian Beam data was used as test data.
Architectures
Different architectures for the neural network were explored to optimize performance. The first models trained had a CNN encoder–decoder architecture design, which is depicted in Fig. 5 (once the skip connections are removed). This was chosen as the reduction and reconstruction from the small latent space acts as an effective regularizer. In addition, it was successful in a previous beam simulation task40. The encoder compresses the input to the latent space via various functional compositions, represented as layers. From there, two decoder arms are applied to the latent space, one producing and the other . Empirically, this bifurcated structure produced better results than having a single decoder that gave the both real and imaginary components of as output.
Figure 5.

The adapted U-Net architecture is shown. For the number of starting filters we took . The skip connection concatenates two feature maps of the same dimensions. The CNN architectures were very similar, with the skip connections removed and the number of filters in each layer changed with CNN-small-4 having filter numbers 16, 32, 64, 128, 64, 4, 64, 64, 32, 16 between the inputs and outputs. Having a double convolution layer before the in the input and output improved results. The output here is also cropped to (see text).
We made two models following Fig. 5 differing by the number of filters in the latent space, 4 and 6 filters, which we label CNN-small-4 and CNN-small-6, respectively. Also, we used an architecture similar to CNN-small-4, but with more filters in the hidden layers and thus more parameters, dubbed here CNN-large. We also investigated the adaption of an U-Net encoder–decoder architecture62, visually depicted in Fig. 5, which we call U-Net. U-Nets have found applications in scientific computation63,64 and computer vision. One limitation of the CNN encoder–decoder architecture in Fig. 5 is that information of the input gets ‘forgotten’ as it’s compressed to the latent space. The U-Net addresses this by adding ‘skipped connections’ between hidden layers of the encoder and decode that share the same dimensions. These connections concatenate the feature maps, allowing the decoder to pull information from the encoder and generally reproduce finer details more accurately than CNN architectures without skipped connections. The skipped connections are also useful during the training process by allowing for more gradient flow, thus can act as an effective tool against vanishing gradients and can speed up training.
Fits
An penalty for the weights and dropout with were used for regularization. All the NN’s were created, trained and tested using Tensorflow65, with training being done using the Adam optimizer66 with early stopping based on validation loss. All the machine learning training was done on a Dell Precision 7920 with two Nvidia RTX A6000 GPU’s with 48 GB VRAM each. A summary of the four architectures with a description can be found in Table 1.
Table 1.
Investigated architectures are arranged in descending order based on total number of parameters.
| Model | Description |
|---|---|
| CNN-small-4 | CNN encoder–decoder, with 4 filters in the latent space |
| CNN-small-6 | CNN encoder–decoder, with 6 filters in the latent space |
| U-Net | Encoder–decoder with skipped connection, with |
| CNN-large | The architecture is similar to CNN-small-4, but with more filters in the hidden layers |
Cost function and metric
NNs were trained to minimize mean squared error (MSE) in Fourier space summed over each time step in the training data:
| 14 |
where is the NN prediction for the Fourier transformed magnetic field. By the Plancherel theorem, this quantity is equivalent to the MSE in position space over the training data:
| 15 |
To evaluate the model performance at time step t we used the relative error of the magnetic field in position space:
| 16 |
Here, denotes a spatial integral over the domain. The time averaged was used to evaluate a model over a data set.
Results
The U-Net performed best across all data sets—the training, validation and test data (see Table 2). In addition, as seen in Fig. 6, at each time step for each data set it either had the lowest error or was virtually tied. Remarkably, the U-Net was able to accomplish this with approximately half the training epochs of the smaller CNN’s and a quarter that of CNN-large. Figure 7 shows predictions for at for the two models which performed best on the test data sets and how they compare to the true values. The results for were similar, and thus aren’t shown.
Table 2.
Summary of results.
| Model | Training error (%) | Validation error (%) | Test error (%) |
|---|---|---|---|
| CNN-small-4 | 8.2 | 13.3 | 12.6 |
| CNN-small-6 | 7.9 | 13.5 | 17.0 |
| U-Net | 4.5 | 6.7 | 8.6 |
| CNN-large | 5.0 | 12.4 | 15.9 |
Error over a data set is , defined by Eq. (16), averaged over time. Bold indicates best performing model according to column metric.
Figure 6.

Relative Error of the models on both the complex beam and the Gaussian beam.
Figure 7.

The top 5 rows show model predictions and absolute errors for the complex beam and the bottom 5 rows for the test Gaussian beam for at the mm slice at various time points. Only the 2 best performing models are shown. The scale of the absolute errors is zoomed in to 1/5 that of the true and model predictions.
The small CNN networks struggled to capture the complexity of the training data. As seen in Fig. 7, while they had a qualitatively correct picture, they struggled on getting many of the finer details correct. The large CNN model was able to capture the training data better, but its predictions quickly deteriorated on the validation set as it got further away from the training data, eventually surpassing the error of CNN-small-4, likely due to overfitting of the larger network. The U-Net captured the training data well and although its error also increases on the validation set, as seen in Fig. 6, it does so at a much smaller rate than any of the CNN models, indicating it learned to generalize better.
All the models struggled the most at the beginning of the Gaussian Beam, where the initial beam was most different from what they were trained on. Of the CNN models, CNN-small-4 did the best job generalizing, though it still lagged behind the U-Net. These results reinforce that the U-Net is doing the best at generalizing.
Transfer learning
Transfer learning is the process where a model trained on one set of data is retrained on another set. Since much of what was learned earlier can be helpful for the new data set, this cuts down on the training time and is quicker than if one started from scratch. It has been used in cases like Physics-Informed Neural Networks to learn beyond a single instance of a PDE67.
The U-Net model took 380 training epochs. We took that trained model and retrained it on the first 85% of Gaussian Beam. In only 20 epochs, the model’s relative error on the Gaussian beam dropped dramatically, and its performance was comparable to what it was on the complex beam (see Fig. 8). This demonstrates that our general approach can be useful for a wide range of new beam configurations which the model has not previously seen, so that it can be applied for the study of new different setups.
Figure 8.

The original U-Net that was trained on part of the complex beam (U-Net) and the model after 20 training epochs on 85% of the Gaussian beam (U-Net-TL(20)).
Improving generalization
To demonstrate the robustness and generalization capability of our approach when trained with more data, two new datasets were created, complex beam 2 and simple beam 2. Like the previous simulations, it consisted of an electron bunch entering a solenoid field, however now the initial distribution gradually dropped off in the z direction, as opposed to suddenly (see Figs. 3 and 4).
Using the pre-trained U-Net from earlier, the network was trained on both complex beam and complex beam 2. The network was tested on both the Gaussian Beam and Gaussian Beam 2, then its performance compared to the network trained on just the complex beam. The results can be seen in Fig. 9. For the Gaussian Beam, the average relative error of the new network on the Gaussian beam was 7.3, while the network trained exclusively on the complex beam was 8.6. Thus, the new network improved on predictions for the Gaussian beam with the inclusion of more data in the training set. For Gaussian Beam 2, the network trained on both complex beams consistently performed better, with an average relative error of 9.1 compared to 24.6. Thus, we see the inclusion of more data led to an improvement in the network”s ability to generalize.
Figure 9.

Relative Error of models on the on Gaussian beam and Gaussian beam 2.
Discussion
One reason for the great success of the U-Net could be simply, as mentioned, the skipped connections help with the optimization. Another possibility is that, given that local will correlate strongly with local , the network can start with a good first approximation by not altering the input that much. Indeed, one can compare, for example, at the mm slice for time step = 150 in the complex beam shown in Fig. 3 with the corresponding magnetic field in Fig. 7. The time of inputting and outputting for the entire test set was of the order of a few seconds. This is in contrast to the GPT simulation, which ran for a day. Of course, the GPT simulator is creating both the matter and electromagnetic fields, so this is not exactly a direct comparison. Nonetheless, it does illustrate some of the potential of the FoHMM-NO method to speed EM simulations greatly.
One way to improve our results would be exposing the model to many distinct simulations during the training phase. This would increase the duration of training, but our results in 5.2 suggests that this will make the model more accurate, robust and would generalize better. There are still some of Maxwell’s equations that are not built in as hard constraints, namely Eq. (8). One possible way to add this as an inductive bias would be to include in the cost function a penalty term that enforces Eq. (8), as is done with physics informed neural networks61. Such terms have also been used to enforce the Lorenz gauge for PCNN’s predicting electromagnetic potential fields40 and enforcing the mangetohydrodynamics equations with physics informed neural operators58. Although this is not a hard constraint, during training it would guide the model to predict more physical solutions. As mentioned, the approach here can be expanded to include and in the predictions. Alternatively, it can be incorporated into a conventional simulator to speed up it up.
Conclusions
Using Maxwell’s equation in Fourier space and modeling EM fields via , we have developed a novel approach to applying machine learning to EM problems. This method has the advantage of incorporating several of Maxwell’s equations as hard constraints, making the output more physically plausible. The FoHM-NO method can be beneficial in computational EM cases where speed is paramount. Here, we exchanged an error level of a few percent for a gain in speed of several orders of magnitude. We found that a U-Net architecture did best both at recreating the fields and generalizing beyond the training data. Given the exact and quantitative nature of physics constraints, domain knowledge can be incorporated into machine learning tools in unique ways. Integrating physics and machine learning in a synergistic way has great potential, but the approaches are still in their infancy. With the advent of powerful new machine learning algorithms, physicists have the opportunity to explore how these new tools can be used to complement or augment more traditional methods to solve previously intractable problems.
Acknowledgements
This work was supported by the U.S. Department of Energy (DOE), Office of Science High Energy Physics contract number 89233218CNA000001 and the Los Alamos National Laboratory LDRD Program Directed Research (DR) project 20220074DR.
Appendix A: k = 0 case
Taking the Fourier transform of Gauss’s Law for the electric field gives:
| 17 |
Integrating the left-hand side by parts:
| 18 |
where means a sphere of radius R.
For , . The boundary term on the left-hand side of Eq. (18) is a flux, the second term disappears and we get the integral form of Gauss’s law for a large sphere:
| 19 |
For , the phase inside the boundary term on the left-hand side of Eq. (18) oscillates rapidly because of the large R. The boundary term thus disappears and we get the expected expression:
| 20 |
Appendix B: Longitudinal Ampère–Maxwell
The longitudinal component of Ampère–Maxwell’s equation in Fourier space follows from the continuity equation and Gauss”s law for .
| 21 |
Since then:
| 22 |
Author contributions
C.L.: Conceptualization (equal); data curation (equal); formal analysis (equal); investigation (equal); writing—original draft (equal); writing—review and editing (equal). A.S.: Conceptualization (equal); data curation (equal); formal analysis (equal); funding acquisition (lead); investigation (equal); methodology (lead); supervision (equal); writing—original draft (supporting); writing—review and editing (equal)
Data availibility
Datasets used and analyzed during the current study are available from the corresponding author upon reasonable request.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.De Lorenci V, Klippert R, Novello M, Salim J. Nonlinear electrodynamics and FRW cosmology. Phys. Rev. D. 2002;65:063501. doi: 10.1103/PhysRevD.65.063501. [DOI] [Google Scholar]
- 2.Novello M, Bergliaffa SP, Salim J. Nonlinear electrodynamics and the acceleration of the universe. Phys. Rev. D. 2004;69:127301. doi: 10.1103/PhysRevD.69.127301. [DOI] [Google Scholar]
- 3.Kruglov S. Universe acceleration and nonlinear electrodynamics. Phys. Rev. D. 2015;92:123523. doi: 10.1103/PhysRevD.92.123523. [DOI] [Google Scholar]
- 4.Bandos I, Lechner K, Sorokin D, Townsend PK. Nonlinear duality-invariant conformal extension of Maxwell’s equations. Phys. Rev. D. 2020;102:121703. doi: 10.1103/PhysRevD.102.121703. [DOI] [Google Scholar]
- 5.Li J, et al. Addressable metasurfaces for dynamic holography and optical information encryption. Sci. Adv. 2018;4:eaar6768. doi: 10.1126/sciadv.aar6768. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Evoli C, Blasi P, Morlino G, Aloisio R. Origin of the cosmic ray galactic halo driven by advected turbulence and self-generated waves. Phys. Rev. Lett. 2018;121:021102. doi: 10.1103/PhysRevLett.121.021102. [DOI] [PubMed] [Google Scholar]
- 7.Nättilä J, Beloborodov AM. Heating of magnetically dominated plasma by Alfvén-wave turbulence. Phys. Rev. Lett. 2022;128:075101. doi: 10.1103/PhysRevLett.128.075101. [DOI] [PubMed] [Google Scholar]
- 8.Luo X, et al. Metasurface-enabled on-chip multiplexed diffractive neural networks in the visible. Light Sci. Appl. 2022;11:1–11. doi: 10.1038/s41377-022-00844-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Aieta F, Kats MA, Genevet P, Capasso F. Multiwavelength achromatic metasurfaces by dispersive phase compensation. Science. 2015;347:1342–1345. doi: 10.1126/science.aaa2494. [DOI] [PubMed] [Google Scholar]
- 10.Miao J, Ishikawa T, Robinson IK, Murnane MM. Beyond crystallography: Diffractive imaging using coherent X-ray light sources. Science. 2015;348:530–535. doi: 10.1126/science.aaa1394. [DOI] [PubMed] [Google Scholar]
- 11.Bacchini F, Pucci F, Malara F, Lapenta G. Kinetic heating by Alfvén waves in magnetic shears. Phys. Rev. Lett. 2022;128:025101. doi: 10.1103/PhysRevLett.128.025101. [DOI] [PubMed] [Google Scholar]
- 12.Chaston C, Carlson C, Peria W, Ergun R, McFadden J. Fast observations of inertial Alfvén waves in the dayside aurora. Geophys. Res. Lett. 1999;26:647–650. doi: 10.1029/1998GL900246. [DOI] [Google Scholar]
- 13.Deng J, et al. Correlative 3D X-ray fluorescence and ptychographic tomography of frozen-hydrated green algae. Sci. Adv. 2018;4:eaau4548. doi: 10.1126/sciadv.aau4548. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Gurram H, Egedal J, Daughton W. Shear Alfvén waves driven by magnetic reconnection as an energy source for the aurora borealis. Geophys. Res. Lett. 2021;48:e2021GL094201. doi: 10.1029/2021GL094201. [DOI] [Google Scholar]
- 15.Tang S, et al. Stabilization of Alfvén eigenmodes in DIII-D via controlled energetic ion density ramp and validation of theory and simulations. Phys. Rev. Lett. 2021;126:155001. doi: 10.1103/PhysRevLett.126.155001. [DOI] [PubMed] [Google Scholar]
- 16.Tang H, et al. Stable and scalable multistage terahertz-driven particle accelerator. Phys. Rev. Lett. 2021;127:074801. doi: 10.1103/PhysRevLett.127.074801. [DOI] [PubMed] [Google Scholar]
- 17.Zhang Z, Satpathy S. Electromagnetic wave propagation in periodic structures: Bloch wave solution of Maxwell’s equations. Phys. Rev. Lett. 1990;65:2650. doi: 10.1103/PhysRevLett.65.2650. [DOI] [PubMed] [Google Scholar]
- 18.Zachariasen W. A general theory of X-ray diffraction in crystals. Acta Crystallograph. 1967;23:558–564. doi: 10.1107/S0365110X67003202. [DOI] [Google Scholar]
- 19.Monico L, et al. Probing the chemistry of CdS paints in the scream by in situ noninvasive spectroscopies and synchrotron radiation X-ray techniques. Sci. Adv. 2020;6:eaay3514. doi: 10.1126/sciadv.aay3514. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Mehrabi P, et al. Serial femtosecond and serial synchrotron crystallography can yield data of equivalent quality: A systematic comparison. Sci. Adv. 2021;7:eabf1380. doi: 10.1126/sciadv.abf1380. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Hartemann F, Luhmann N., Jr Classical electrodynamical derivation of the radiation damping force. Phys. Rev. Lett. 1995;74:1107. doi: 10.1103/PhysRevLett.74.1107. [DOI] [PubMed] [Google Scholar]
- 22.Grošelj D, Mallet A, Loureiro NF, Jenko F. Fully kinetic simulation of 3D kinetic Alfvén turbulence. Phys. Rev. Lett. 2018;120:105101. doi: 10.1103/PhysRevLett.120.105101. [DOI] [PubMed] [Google Scholar]
- 23.Franchetti G, Hofmann I, Jeon D. Anisotropic free-energy limit of halos in high-intensity accelerators. Phys. Rev. Lett. 2002;88:254802. doi: 10.1103/PhysRevLett.88.254802. [DOI] [PubMed] [Google Scholar]
- 24.Franchetti G, Hofmann I, Aslaninejad M. Collective emittance exchange with linear space charge forces and linear coupling. Phys. Rev. Lett. 2005;94:194801. doi: 10.1103/PhysRevLett.94.194801. [DOI] [PubMed] [Google Scholar]
- 25.Cai Y. Coherent synchrotron radiation by electrons moving on circular orbits. Phys. Rev. Accel. Beams. 2017;20:064402. doi: 10.1103/PhysRevAccelBeams.20.064402. [DOI] [Google Scholar]
- 26.Zagorodnov I, Tomin S, Chen Y, Brinker F. Experimental validation of collective effects modeling at injector section of X-ray free-electron laser. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrom. Detect. Assoc. Equip. 2021;995:165111. doi: 10.1016/j.nima.2021.165111. [DOI] [Google Scholar]
- 27.Emma P, et al. First lasing and operation of an Rangström-wavelength free-electron laser. Nat. Photon. 2010;4:641. doi: 10.1038/nphoton.2010.176. [DOI] [Google Scholar]
- 28.Milne C, et al. Swissfel: The Swiss X-ray free electron laser. Appl. Sci. 2017;7:720. doi: 10.3390/app7070720. [DOI] [Google Scholar]
- 29.Decking W, et al. A MHz-repetition-rate hard X-ray free-electron laser driven by a superconducting linear accelerator. Nat. Photon. 2020;14:391–397. doi: 10.1038/s41566-020-0607-z. [DOI] [Google Scholar]
- 30.Gessner S, et al. Demonstration of a positron beam-driven hollow channel plasma wakefield accelerator. Nat. Commun. 2016;7:1–6. doi: 10.1038/ncomms11785. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Yakimenko V, et al. Facet-ii facility for advanced accelerator experimental tests. Phys. Rev. Accel. Beams. 2019;22:101301. doi: 10.1103/PhysRevAccelBeams.22.101301. [DOI] [Google Scholar]
- 32.Chen Y, Zagorodnov I, Dohlus M. Beam dynamics of realistic bunches at the injector section of the European X-ray free-electron laser. Phys. Rev. Accel. Beams. 2020;23:044201. doi: 10.1103/PhysRevAccelBeams.23.044201. [DOI] [Google Scholar]
- 33.Dohlus, M., Limberg, T. et al. Csrtrack: Faster calculation of 3D CSR effects. In Proceedings of the 2004 FEL Conference, 18–21 (2004).
- 34.Scheinker A, Cropp F, Paiagua S, Filippetto D. An adaptive approach to machine learning for compact particle accelerators. Sci. Rep. 2021;11:1–11. doi: 10.1038/s41598-021-98785-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Coskun UH, Sel B, Plaster B. Magnetic field mapping of inaccessible regions using physics-informed neural networks. Sci. Rep. 2022;12:12858. doi: 10.1038/s41598-022-15777-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Li S, Dee PM, Khatami E, Johnston S. Accelerating lattice quantum Monte Carlo simulations using artificial neural networks: Application to the Holstein model. Phys. Rev. B. 2019;100:020302. doi: 10.1103/PhysRevB.100.020302. [DOI] [Google Scholar]
- 37.Kim I, et al. Simulator acceleration and inverse design of fin field-effect transistors using machine learning. Sci. Rep. 2022;12:1140. doi: 10.1038/s41598-022-05111-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Park S, Kwak W, Lee HK. Accelerated spin dynamics using deep learning corrections. Sci. Rep. 2020;10:13772. doi: 10.1038/s41598-020-70558-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Wigley PB, et al. Fast machine-learning online optimization of ultra-cold-atom experiments. Sci. Rep. 2016;6:25890. doi: 10.1038/srep25890. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Scheinker A, Pokharel R. Physics-constrained 3D convolutional neural networks for electrodynamics. APL Mach. Learn. 2023;1:026109. doi: 10.1063/5.0132433. [DOI] [Google Scholar]
- 41.Cohen-Tannoudji C, Dupont-Roc J, Grynberg G. Atom-Photon Interactions: Basic Processes and Applications. Wiley; 1998. [Google Scholar]
- 42.Jackson JD. Classical Electrodynamics. Wiley; 1999. [Google Scholar]
- 43.Greydanus, S., Dzamba, M. & Yosinski, J. Hamiltonian neural networks. In Advances in Neural Information Processing Systems, vol. 32 (2019).
- 44.Mohan AT, Lubbers N, Chertkov M, Livescu D. Embedding hard physical constraints in neural network coarse-graining of three-dimensional turbulence. Phys. Rev. Fluids. 2023;8:014604. doi: 10.1103/PhysRevFluids.8.014604. [DOI] [Google Scholar]
- 45.Lin, B., Mao, Z., Wang, Z. & Karniadakis, G. E. Operator learning enhanced physics-informed neural networks for solving partial differential equations characterized by sharp solutions. arXiv preprint arXiv:2310.19590 (2023).
- 46.Adler J, Öktem O. Solving ill-posed inverse problems using iterative deep neural networks. Inverse Probl. 2017;33:124007. doi: 10.1088/1361-6420/aa9581. [DOI] [Google Scholar]
- 47.Zhao, Q., Lindell, D. B. & Wetzstein, G. Learning to solve PDE-constrained inverse problems with graph networks (2022).
- 48.Vukics A, Kónya G, Domokos P. The gauge-invariant Lagrangian, the Power–Zienau–Woolley picture, and the choices of field momenta in nonrelativistic quantum electrodynamics. Sci. Rep. 2021;11:16337. doi: 10.1038/s41598-021-94405-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Gustin C, Franke S, Hughes S. Gauge-invariant theory of truncated quantum light-matter interactions in arbitrary media. Phys. Rev. A. 2023;107:013722. doi: 10.1103/PhysRevA.107.013722. [DOI] [Google Scholar]
- 50.Chen X-S, Lü X-F, Sun W-M, Wang F, Goldman T. Spin and orbital angular momentum in gauge theories: Nucleon spin structure and multipole radiation revisited. Phys. Rev. Lett. 2008;100:232002. doi: 10.1103/PhysRevLett.100.232002. [DOI] [PubMed] [Google Scholar]
- 51.Van Der Geer S, Luiten O, De Loos M, Pöplau G, Van Rienen U. 3D space-charge model for GPT simulations of high brightness electron bunches. Inst. Phys. Conf. Ser. 2005;175:101. [Google Scholar]
- 52.Brynes A, et al. Beyond the limits of 1D coherent synchrotron radiation. New J. Phys. 2018;20:073035. doi: 10.1088/1367-2630/aad21d. [DOI] [Google Scholar]
- 53.Hornik K, Stinchcombe M, White H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989;2:359–366. doi: 10.1016/0893-6080(89)90020-8. [DOI] [Google Scholar]
- 54.Park, S., Yun, C., Lee, J. & Shin, J. Minimum width for universal approximation. arXiv preprint arXiv:2006.08859 (2020).
- 55.Chen T, Chen H. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Trans. Neural Netw. 1995;6:911–917. doi: 10.1109/72.392253. [DOI] [PubMed] [Google Scholar]
- 56.Lu L, Jin P, Pang G, Zhang Z, Karniadakis GE. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nat. Mach. Intell. 2021;3:218–229. doi: 10.1038/s42256-021-00302-5. [DOI] [Google Scholar]
- 57.Li, Z. et al. Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895 (2020).
- 58.Rosofsky, S. G. & Huerta, E. Magnetohydrodynamics with physics informed neural operators. arXiv preprint arXiv:2302.08332(2023).
- 59.Bormanis A, Leon CA, Scheinker A. Solving the Orszag–Tang vortex magnetohydrodynamics problem with physics-constrained convolutional neural networks. Phys. Plasmas. 2024;31:012101. doi: 10.1063/5.0172075. [DOI] [Google Scholar]
- 60.Karniadakis GE, et al. Physics-informed machine learning. Nat. Rev. Phys. 2021;3:422–440. doi: 10.1038/s42254-021-00314-5. [DOI] [Google Scholar]
- 61.Raissi M, Perdikaris P, Karniadakis GE. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019;378:686–707. doi: 10.1016/j.jcp.2018.10.045. [DOI] [Google Scholar]
- 62.Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18, 234–241 (Springer, 2015).
- 63.Rahman MA, Ross ZE, Azizzadenesheli K. U-shaped neural operators (U-NO) Trans. Mach. Learn. Res. 2023;2023:1–17. [Google Scholar]
- 64.Wen G, Li Z, Azizzadenesheli K, Anandkumar A, Benson SM. U-FNO–An enhanced Fourier neural operator-based deep-learning model for multiphase flow. Adv. Water Resour. 2022;163:104180. doi: 10.1016/j.advwatres.2022.104180. [DOI] [Google Scholar]
- 65.Abadi, M. et al. TensorFlow: Large-scale machine learning on heterogeneous systems. Software available from tensorflow.org (2015).
- 66.Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- 67.Desai, S., Mattheakis, M., Joy, H., Protopapas, P. & Roberts, S. One-shot transfer learning of physics-informed neural networks. arXiv preprint arXiv:2110.11286 (2021).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Datasets used and analyzed during the current study are available from the corresponding author upon reasonable request.